
Abstract
Introduction
Oral squamous cell carcinoma (OSCC) is a prevalent and aggressive malignant tumor in the head and neck, known for its high metastatic rate and recurrence, posing serious threats to patients’ lives. Relying solely on pathologists for diagnosis is time-consuming, labor-intensive, and prone to subjective bias. Therefore, developing artificial intelligence methods for automated detection is of significant clinical value and urgently needed.
Methods
We have developed a novel deep learning model based on an improved lightweight EfficientNetSwift, a lightweight deep learning framework designed to achieve precise and automated detection of pathological images of oral squamous cell carcinoma (OSCC). By comparing our model with mainstream models such as ResNet, MobileNet, and VIT, our model achieved superior performance in terms of precision, accuracy, and other metrics.
Results
In this study, EfficientNetSwift achieved the best results for detecting OSCC from pathological images, with 95.3% accuracy and an AUC of 0.99 using 20,180,050 parameters. This is half of ResNet's parameters and significantly fewer than VGG's, while only slightly more than MobileNet's but with better performance. The Swin Transformer performed the worst.
Conclusion
The automatic detection of OSCC using deep learning can significantly reduce labor costs and decrease the workload of clinicians. Additionally, it can assist doctors in diagnosing the disease more efficiently and accurately, providing precise prognostic predictions. This lays a solid foundation for the formulation of personalized treatment plans.
Keywords
Introduction
Oral squamous cell carcinoma is one of the most common malignant tumors of the head and neck. It originates from a series of atypical hyperplasia of oral epithelial cells. According to statistics, there are about 355,000 new cases of patients worldwide every year, accounting for about 90% of oral malignancies. Oral squamous cell carcinoma usually occurs in the lips, buccal mucosa, floor of the mouth, soft and hard palate, tongue and gums. 1 Seriously affect the patient's speech, swallowing, expression and other functions. 2 The biological characteristics of oral squamous cell carcinoma make it highly invasive, with high lymph node metastasis rate and easy recurrence after operation. Therefore, the prognosis is poor, seriously affecting the life and health of patients, and the five-year survival rate after surgery is only 50%. 3 Due to slow progress in early screening and diagnosis of oral squamous cell carcinoma, the overall death rate from oral squamous cell carcinoma has not decreased significantly since the 1980s. In fact, the 5-year survival rate of OCSCC decreases significantly with the progression of the disease, from 84% in the early stage (stages I and II) to 39% in the late stage (stages III and IV). 4 Patients with advanced oral squamous cell carcinoma not only suffer great physical pain, but also face a heavy financial burden and poor quality of life after surgery. 5
The traditional method for detecting OSCC is the pathological examination of histological tissue samples from the oral area under a microscope. Whole tissues and lesions are identified at low magnification, while cell morphology is identified at high magnification. However, the accuracy of this traditional pathological detection depends not only on the location, area, depth and quality of the biopsy, but also on the subjective judgment and technical level of the pathologist. It has the disadvantages of misdiagnosis, time consuming, late treatment, etc, so that patients are often already in serious condition when they receive treatment. Especially for patients with asymptomatic lesions, the best time for early intervention is often missed. 6 In addition, there are certain errors in the process of collecting, transporting and storing biopsy samples. Therefore, the traditional pathological diagnosis has considerable limitations in the standardized diagnosis and treatment of oral squamous cell carcinoma.
In recent years, a number of studies have shown that the application of deep learning in the clinical diagnosis of oral squamous cell carcinoma can significantly improve the accuracy of diagnosis, reduce the workload of doctors, and greatly improve the early detection rate. 7 Research has shown that advanced deep learning algorithms can help in the early identification and precise diagnosis of such lesions by using large data sets to identify tiny details that may indicate malignancy. 8 In addition, deep learning has been shown to overcome the shortcomings of traditional diagnostic strategies with higher sensitivity and specificity in detecting OC and its progenitor cells. 9 Improving the diagnostic accuracy can greatly improve the prognosis of patients, which allows us to conduct timely intervention and develop personalized treatment plans according to the individual conditions of each patient in clinical work. 10 In addition, applying deep learning to the diagnosis and treatment of OC can further simplify the diagnostic procedure and maximize the use of resources. On this basis, it is hoped that health care services will be simplified. 7 Currently, the lack of high-quality data required for the training and validation of efficient deep learning models is one of the major obstacles, and to ensure the robustness and generalization of models, extensive data sets covering many symptoms of oral cancer need to be collated. 11 In addition, a major challenge is the need to ensure that deep learning algorithms are interpretable and transparent, especially in clinical situations where the reasoning behind treatment or diagnostic decisions needs to be easily understood. 10 To overcome these barriers, interdisciplinary collaboration between researchers, physicians, and regulators is needed to create deep learning frameworks that are both clinically and ethically sound. It is believed that by integrating multiple data sources, such as genomic, proteomic and imaging data, it is possible to better understand the biological background of OC and create tailored treatments. 9 Deep learning algorithms, combined with advances in imaging technology, can contribute to improving prognosis after surgery and guiding real-time decision making during surgery. 8 Some scholars advocate that encouraging equitable access to deep learning technologies through collaborative projects and open source platforms could spur innovation and advance the discipline. 12 Overall, despite the obstacles, the integration of deep machine learning in oral cancer treatment offers revolutionary prospects for improving diagnostic accuracy, prognostic accuracy, and treatment customization.
In this paper, we propose the EfficientNetSwift model, focusing on the precise and automated detection of oral squamous cell carcinoma (OSCC) through pathological images. Our approach innovatively combines three key techniques: Firstly, we incorporate a large number of batch normalization layers and optimize image size processing to accelerate convergence and enhance generalization capability. Secondly, we replace the original depthwise separable convolution modules with more straightforward 3 × 3 convolutions, effectively reducing the model's parameter count. Finally, we introduce regularization methods such as Dropout, L1, and Mixup, further improving the model's adaptation and generalization to new data. These innovations collectively ensure that our model remains lightweight while efficiently and accurately detecting oral cancer. Figure 1 illustrates our workflow.

Working Flow Chart of This Study.
Methods
Data Acquisition
This study utilizes a publicly available dataset from the Kaggle platform(https://www.kaggle.com/datasets/mangalmanan/oscc-normal), which includes two types of images: normal oral images and oral squamous cell carcinoma (OSCC) images. The dataset comprises a total of 5200 images, with 2500 normal oral images and 2700 OSCC images. For ease of processing and analysis, the images are organized into two subfolders: the “Normal” folder contains all normal oral images, while the “OSCC” folder stores all OSCC images. The pathological classification of all images is based on clinical diagnosis and histopathological evaluation to ensure high accuracy and reliability of the data. Normal oral images are sourced from healthy individuals showing no signs of cancer, whereas OSCC images come from patients pathologically confirmed to have oral squamous cell carcinoma. This rigorous classification method aims to enhance the accuracy of model training and ensure that the model can effectively learn the key features distinguishing the two pathological states. Figure 2 shows a portion of our dataset.
Part of the Data Set is Shown.
Data Preprocessing
In this study, we implemented a series of comprehensive image preprocessing steps to enhance the quality of input data for the oral cancer detection model. First, we performed image cleaning to remove irrelevant background information and potential interfering elements, allowing for more accurate highlighting of cancerous tissues. Additionally, we employed denoising and filtering techniques to reduce random noise in the images and enhance their detailed features, thereby improving the recognizability of cancerous tissues. We also adjusted the image contrast to enhance visual clarity and strengthen the contrast between normal and abnormal tissues, making it easier for the model to distinguish these subtle differences. These meticulously designed preprocessing steps ensure that the deep learning model receives high-quality and consistent input data, thereby improving the model's accuracy and generalization capability in the task of automated oral cancer detection.
In addition, to improve the generalization ability and performance of the model, we implement data augmentation strategies on the training set and validation set images. In the training set, we first crop the image to 224 × 224 pixels using random cropping, and then increase the diversity of the data using random horizontal flipping. The image is then converted into a PyTorch tensor and normalized by applying the mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5) to ensure a consistent data distribution. For the validation set, we resize the image to 224 × 224 pixels and perform the same tensor conversion and normalization steps. To improve the model's generalization, we applied data augmentation strategies such as random cropping and horizontal flipping only to the training set. The validation set underwent standard preprocessing, including resizing and normalization, to ensure consistent evaluation conditions. These preprocessing and data augmentation measures are designed to optimize the training efficiency and evaluation accuracy of the model, ensuring its optimal performance in the task of oral cancer detection.
Construction of Auxiliary Diagnostic Model
Proposal of a Deep Learning-Based Model
In the field of oral cancer detection, deep learning technology has shown significant application potential. A classic reference model is EfficientNet, developed by Google. 13 The model achieves state-of-the-art performance at the time while maintaining a low computational cost through a systematic model scaling approach. EfficientNet improves model accuracy and efficiency by balancing the network's width, depth, and resolution, introducing a new compound scaling method. Although EfficientNet has achieved excellent results on several standard datasets, it still has some limitations in specific applications such as medical image analysis and oral cancer detection: Firstly, while EfficientNet is designed for efficiency, its model size and the computational resources required still pose a challenge when processing large volumes of high-resolution medical images. Secondly, EfficientNet is not optimized for specific types of medical images, such as oral pathology images, which may prevent it from fully utilizing the unique features of these images. Lastly, despite its good performance across various tasks, the relatively large model size and computational resource demands of EfficientNet indicate that its lightweight nature still needs improvement for tasks involving specific medical images like oral cancer pathology. In view of these limitations, we propose a lightweight improved model based on EfficientNet, specifically optimized for oral cancer pathology images.
Our model is optimized and lightweight, based on the EfficientNet architecture, aiming to provide an efficient and accurate automatic cancer detection solution. The core advantages of this model lie in its innovative architectural design, meticulous parameter tuning, and specialized optimization for medical image analysis tasks. By adjusting the convolutional layers, batch normalization layers, SiLU activation function (Swish), and the distinctive Squeeze-and-Excite blocks, we have constructed a network that is both efficient and capable of effectively handling complex image tasks. To reduce model complexity, we employed standard 3 × 3 convolutions instead of depthwise separable convolutions in the convolutional blocks, and we achieved model simplification by adjusting the expansion ratio and the number of filters. Additionally, we integrated regularization techniques such as DropPath (stochastic depth), Dropout, RandAugment, and Mixup, which effectively prevent overfitting and enhance the model's generalization ability to unseen data. Through these meticulous parameter adjustments, the entire model achieves an optimized balance between high performance and computational cost. Figures 3a and 3b illustrate our model architecture.
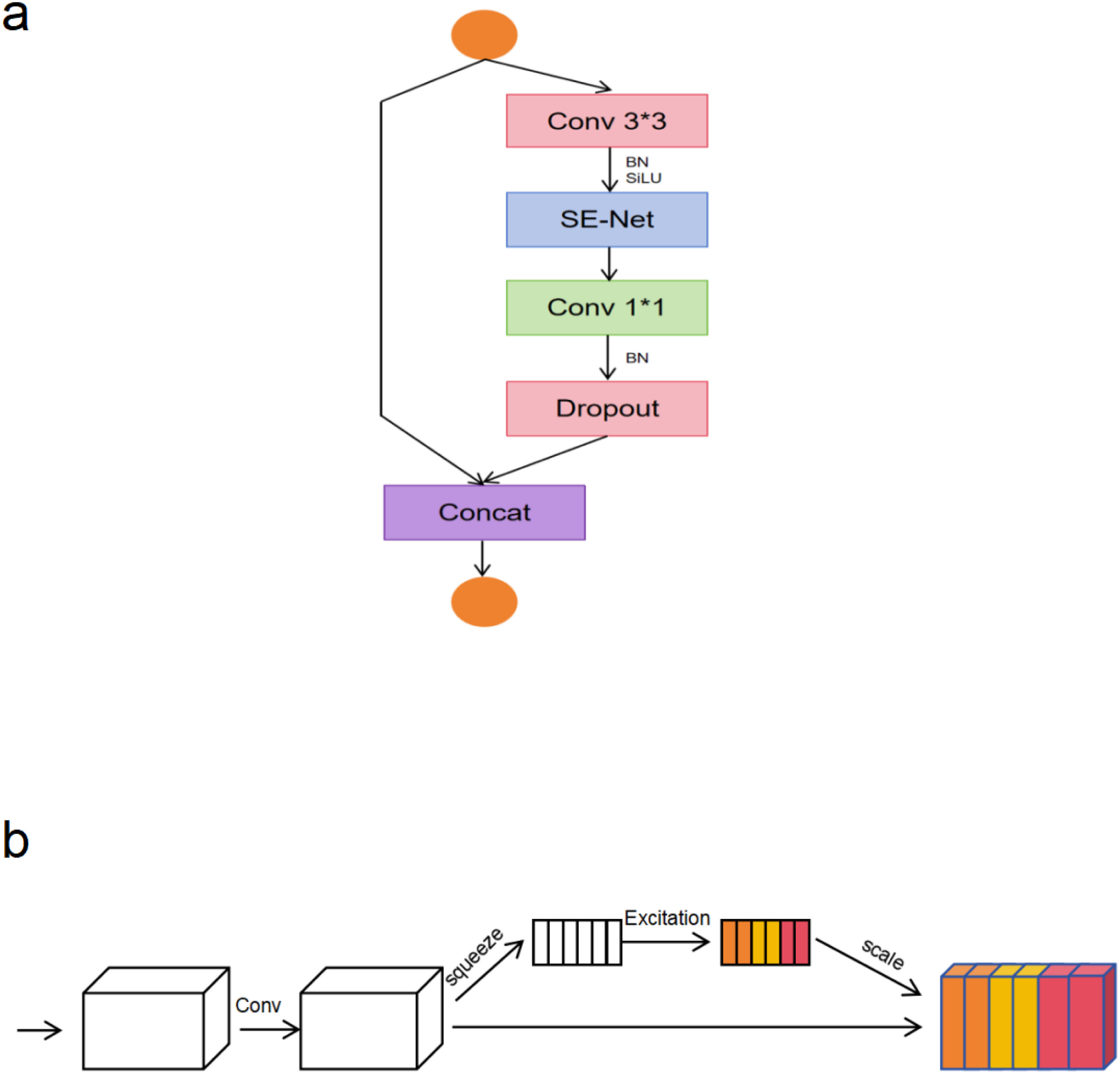
(a) The Architecture of the Proposed EfficientNetSwift Model, Illustrating the Overall Network Design. the Model Incorporates Standard 3 × 3 Convolutional Layers to Replace the Original Depthwise Separable Convolutions, Reducing Computational Complexity While Maintaining Strong Representational Capacity. (b) The Structure of the Integrated Squeeze-and-Excite (SE) Block, Which Enables Dynamic Channel-Wise Feature Recalibration by Modeling inter-Channel Dependencies.
Our model provides an efficient and accurate solution for the recognition and detection of oral squamous cell carcinoma (OSCC). This model integrates best practices in deep learning with targeted technological innovations, aiming to overcome common challenges in medical image analysis. Firstly, it reduces the model's parameter count and computational demands, enabling deployment in resource-constrained environments such as mobile devices and edge computing platforms. This is particularly important for extending advanced diagnostic tools to low-resource settings. Secondly, the model retains sufficient feature extraction capability while simplifying computation, which is crucial for accurately identifying subtle differences in OSCC. Additionally, the integration of DropPath, Dropout, RandAugment, and Mixup technologies enhances the model's generalization ability and reduces the risk of overfitting. This ensures that the model can make stable and accurate predictions when faced with the high variability of oral pathology images. Finally, the introduction of Squeeze-and-Excite blocks allows the model to dynamically adjust the importance of feature channels, focusing more on the regions of the image that are most significant for diagnosis. This attention mechanism is critical for improving the sensitivity and specificity of OSCC detection.
Comparative Models
AlexNet marked a significant early success in deep learning, with its outstanding performance in the ImageNet competition leading to subsequent technological developments. Although AlexNet was initially used for natural image classification, its success also inspired the exploration of deep learning applications in medical image analysis, such as using it as a feature extractor to assist in diagnosing diseases like oral cancer. 14 The VGG network deepened the network by repeatedly using simple 3 × 3 convolutional layers, demonstrating the critical role of network depth in enhancing image recognition performance. Its excellent feature extraction capability has led to its widespread application in the classification and recognition of medical images, aiding in identifying cancer-related image features. 15 ResNet addressed the vanishing gradient problem in deeper networks by introducing residual connections, significantly improving the performance of image classification and recognition tasks. In the field of medical image analysis, ResNet is used for the automatic identification and classification of various types of cancer images, including oral cancer, due to its ability to capture complex pathological features. 16 MobileNet was designed for mobile and embedded devices, achieving model lightweight and efficient computation through depthwise separable convolutions. It is suitable for quick diagnosis and real-time image analysis. 17 ShuffleNet further enhanced network lightweight and computational efficiency through channel shuffling and group convolution techniques, making it an ideal choice for medical image analysis on resource-constrained devices. 18 ViT introduced the Transformer architecture to the field of image classification by segmenting images into multiple patches and processing them using self-attention mechanisms, showing performance comparable to traditional CNN models. With its excellent performance in image classification, ViT's potential in medical image analysis, especially in fine pathological image classification like oral cancer detection, is being further explored. 19 The Swin Transformer improved efficiency and performance in handling large-scale images by introducing a strategy of window partitioning and cross-window connections, 20 providing new possibilities for medical image analysis.
Experimental Setup
In this study, to ensure the accuracy and reliability of model performance, we conducted internal evaluations followed by testing and validation using an independent external dataset. Specifically, for the division of the dataset, we adhered to an 8:1:1 ratio, splitting it into training, validation, and testing sets to validate the model's generalization ability on unseen data. To achieve optimal model performance, all model parameters were finely tuned. The tuning process employed a combination of grid search and random search strategies to efficiently find the optimal parameter combinations within the parameter space. Additionally, we used early stopping and monitored the loss values on the validation set to prevent overfitting, ensuring the model's convergence and generalization ability. The experimental environment was set up as follows: all experiments were conducted on a high-performance computing platform equipped with an NVIDIA 4060Ti GPU with 32GB of memory and an Intel Xeon CPU. Our experimental software environment was based on the PyTorch deep learning framework, version 1.7.1, running on the Ubuntu 18.04 operating system. To ensure the reproducibility of the experiments, we also fixed all random seeds that could affect the experimental results, including those for PyTorch, NumPy, and Python itself.
Model Evalution
In order to evaluate the effectiveness of the model, common classification indexes such as precision, recall, accuracy, F1 score, roc curve and confusion matrix were adopted. Accuracy is the most intuitive performance measure, representing the percentage of the total sample that the model correctly predicts. The accuracy rate is the proportion of the predicted positive examples that are actually positive. The recall rate is the proportion of samples that are actually positive cases that are correctly predicted to be positive cases. The F1 score is a harmonic average of accuracy and recall and is used to measure the balance between the two. The ROC curve shows the relationship between the model's true rate (TPR) and false positive rate (FPR) at different thresholds. Used to measure the overall performance of the model. The confusion matrix is a table that describes the relationship between model predictions and actual labels, including true cases (TP), false negative cases (FN), true negative cases (TN), and false positive cases (FP). Through the evaluation of the above indicators, we can comprehensively measure the performance of the model, and effectively evaluate and compare the model. The use of these indicators not only makes the evaluation results more objective and accurate, but also increases people's trust in the validity of the model. The relevant formula can be expressed as follows:




Results
The Proposed Model Verification Results
During the training of the model, selecting appropriate hyperparameters, optimizers, learning rates, and batch sizes is crucial for the model's performance. Here is a detailed explanation of these key factors involved in the training process of our oral cancer detection model: We employed an adaptive learning rate adjustment strategy, setting the initial learning rate to 0.001. This initial value provides a good starting point for the model, being neither too large to cause unstable training nor too small to slow down the training process. To balance training efficiency and hardware resource constraints, we chose 64 as our batch size. This size is feasible on most modern GPUs and ensures sufficient data mixing and update efficiency. We selected the Adam optimizer for training the model. The Adam optimizer combines the advantages of both the momentum method and RMSProp, capable of automatically adjusting the learning rate, making it suitable for optimizing large-scale data and parameters. Since our task is a binary classification problem, we used Binary Cross-Entropy Loss as the loss function, which directly optimizes the probability outputs. Figure 4 shows the training iteration process of our model.

Improved Model Performance Display Diagram. (a) Training and Validation Loss and Accuracy, Showing Convergence; (b) ROC Curve and Confusion Matrix, Demonstrating Classification Accuracy.
In our task of detecting oral cancer from pathological images, the proposed new model has demonstrated exceptional performance. Through rigorous evaluation, the model achieved impressive results across multiple key performance metrics. Specifically, the model reached a precision of 97.5%, indicating that it is extremely accurate in identifying oral cancer images, with very few healthy samples being misclassified as cancerous. The recall was 97.4%, showing that the model effectively identifies the vast majority of oral cancer cases, avoiding missed diagnoses. The accuracy reached 95.3%, indicating high overall diagnostic consistency and reliability. Additionally, the F1 score was 95.4%, reflecting a good balance between precision and recall, ensuring robust performance in identifying both positive and negative samples. Through ROC curve analysis, the model's AUC (Area Under the Curve) value reached 0.99, demonstrating the model's outstanding ability to distinguish between oral cancer and normal images, maintaining high performance across different threshold settings. The confusion matrix results further confirmed the model's accuracy in the classification task, showing the specific performance of the model in predicting different categories, including the number of true positives, false positives, true negatives, and false negatives, further substantiating the model's diagnostic efficiency and accuracy.
To further validate the contribution of each architectural modification in EfficientNetSwift, we conducted an ablation study focusing on two key components: (1) the replacement of depthwise separable convolutions with standard 3 × 3 convolutions, and (2) the introduction of advanced regularization strategies, including DropPath, Mixup, and Dropout. We constructed three model variants for this analysis: a baseline EfficientNet variant retaining the original depthwise convolution blocks (denoted as Baseline-EffNet), a version incorporating 3 × 3 convolutions but excluding regularization (Swift-noReg), and the final proposed EfficientNetSwift with both enhancements. The results, summarized in Table S1, show that replacing depthwise convolutions with 3 × 3 convolutions alone led to improvements in both F1-score (0.948 → 0.951) and accuracy (0.946 → 0.949), suggesting better spatial feature modeling and learning capacity. Further integration of regularization techniques yielded additional performance gains, pushing the F1-score to 0.954 and accuracy to 0.953. Notably, the combination of these two enhancements consistently outperformed each single component in isolation, indicating their synergistic effect on both robustness and generalizability. These findings justify our architectural design decisions and demonstrate the importance of combining structural simplification with effective regularization for pathological image classification tasks.
Comparison Validation Results
In our study, in addition to the proposed new model, we also compared the performance of several classic and advanced deep learning models in the task of detecting oral cancer from pathological images. These comparison models include AlexNet, VGG, ResNet, MobileNet, ShuffleNet, Vision Transformer (ViT), and Swin Transformer. Compared to these models, our proposed new model outperformed all key metrics. Table 1 presents the results of the comparison models. The evaluation indicators include Precision, Recall, F1-score, Accuracy and Parameters. The EfficientNetSwift model showed excellent performance in all performance indicators, especially in Precision and Recall of 0.975 and 0.974, and F1-score and Accuracy of 0.954 and 0.953, respectively. It also has relatively low Parameters (20180050). Figure 5 and Figure 6 show the roc curve and confusion matrix of the comparison model, respectively.
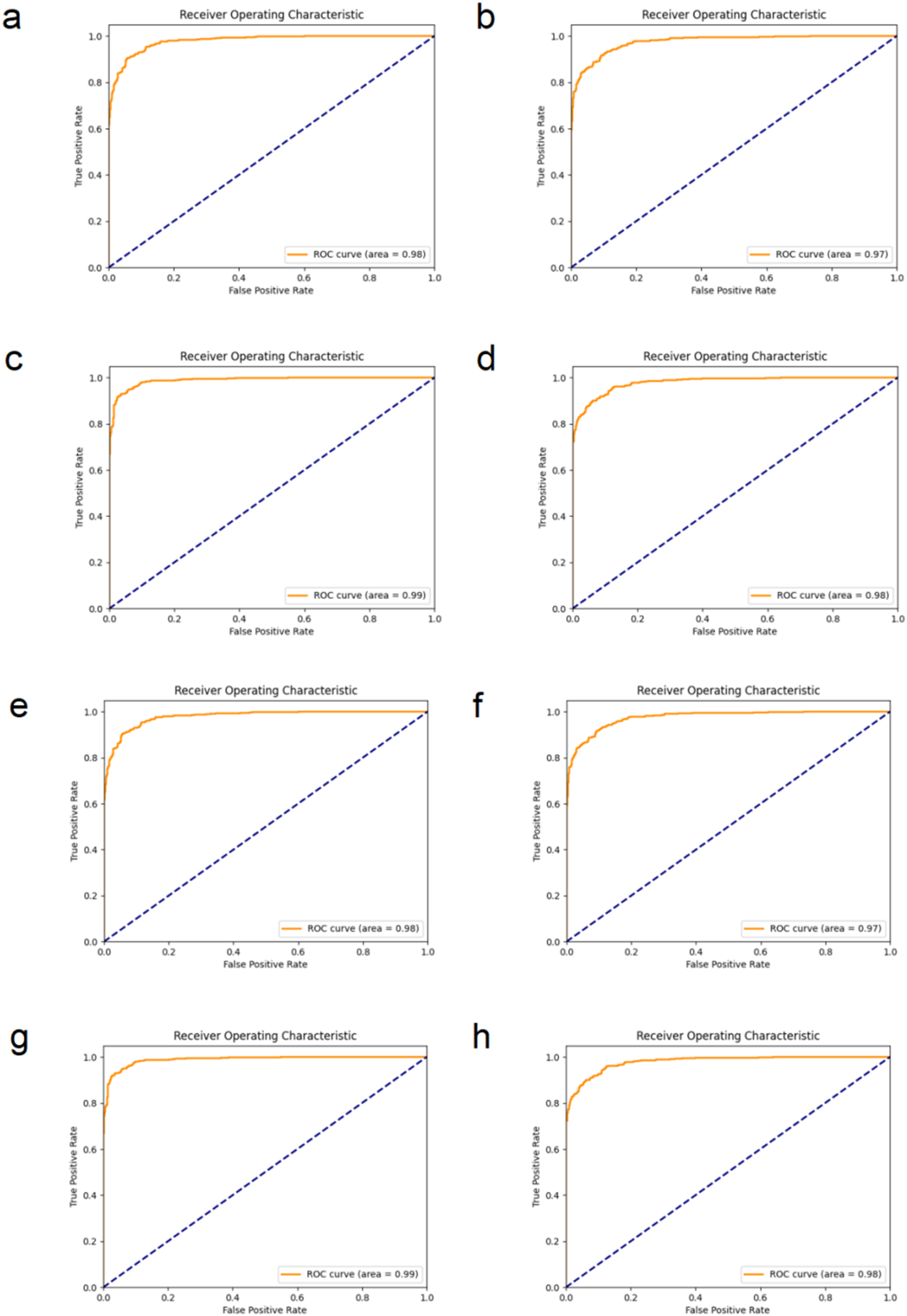
Comparison of Model roc Curves. The ROC Curves of Eight Different Models for Oral Cancer Classification Were Presented. Where (a) is AlexNet, (b) is VGG, (c) is ResNet, (d) is MobileNet, (e) is ShuffleNet, (f) is VIT, (g) is Swin Transformer, and (h) is EfficientNet.

Model Confusion Matrix Comparison Diagram. The Confusion Matrix of Eight Different Models in the Oral Cancer Classification Task is Shown. Where (a) is AlexNet, (b) is VGG, (c) is ResNet, (d) is MobileNet, (e) is ShuffleNet, (f) is VIT, (g) is Swin Transformer, and (h) is EfficientNet.
Summarizes the Performance Comparison of major Deep Learning Models on the Oral Cancer Image Classification Task.

External Test Result
To further validate the generalization ability of our model, we used external tests with data at different magnifications from publicly available datasets (https://data.mendeley.com/datasets/ftmp4cvtmb/1). Table 2 shows the results of the external test. The EfficientNetSwift model maintained high performance, achieving a precision of 0.967, recall of 0.951, F1-score of 0.959, and accuracy of 0.977. These results indicate that EfficientNetSwift outperformed other models, further demonstrating its robustness and reliability in detecting oral squamous cell carcinoma across varied conditions. Figure 7 shows the external test performance process of our model.

External Test Performance Chart. The External Test Results of the Model Under Different Magnifications are Presented, Including the ROC Curve and Confusion Matrix. the ROC Curve (Left) Shows an AUC Value, and the Confusion Matrix (Right) Shows the Model's Performance on the Test Data, Including True Positives, True Negatives, False Positives, and False Negatives.
Shows the Performance of Each Model in External Tests.

Clinical Interpretability
The pathological diagnosis of oral squamous cell carcinoma (OSCC) primarily relies on the identification of characteristic cytological features, such as increased nuclear-cytoplasmic ratio, nuclear pleomorphism, hyperchromatism, keratin pearls, and abnormal mitotic figures. Pathologists are trained to examine these features across multiple fields of view under various magnifications, often requiring manual screening of over 100 high-power fields per case, depending on lesion complexity. This process is not only labor-intensive and time-consuming, but also subject to intra- and inter-observer variability, especially in borderline or poorly differentiated lesions.
To support interpretability, our model incorporates Gradient-weighted Class Activation Mapping (Grad-CAM) to generate activation heatmaps, which visualize the spatial regions that contribute most strongly to the classification output. These heatmaps are overlaid on the original histopathological images, highlighting the tissue zones the model “attends to” when predicting malignancy. In our analysis, we compared model-generated heatmaps with expert annotations on 50 randomly sampled OSCC test patches. Approximately 88% of the model's high-attention regions (>0.7 activation intensity) overlapped with regions identified by senior pathologists as diagnostically relevant, such as areas containing dysplastic epithelial cells or invasive fronts.
This high degree of spatial alignment supports the model's clinical interpretability and its potential utility as an assistive tool. For example, in Figure 8, the model accurately focuses on a peritumoral region with irregular nuclei and cell crowding, corresponding to areas marked as high-risk by human experts. Such interpretability allows clinicians to rapidly validate AI-generated predictions, localize suspect zones, and cross-reference with their own diagnostic criteria. Ultimately, heatmap-based visualization bridges the gap between black-box AI models and the evidence-based workflow of diagnostic pathology, enabling a synergistic approach that can reduce diagnostic latency and increase reproducibility across cases.

Activation Heatmap Visualization of Oral Squamous Cell Carcinoma (OSCC) Detection. Each Pair of Images Presents the Original Pathological Image on the Left and the Corresponding Grad-CAM-based Activation Heatmap on the Right. Warm-colored Areas (eg, Red and Yellow) Indicate Regions with High Model Attention, Often Corresponding to Histological Features Typical of Malignancy Such as Irregular Nuclei, Increased Mitotic Figures, and Disordered Epithelial Architecture.
Discussion
In this study, we present a deep learning model for the automated and accurate detection of oral squamous cell carcinoma (OSCC) from pathological images. By incorporating lightweight architecture, advanced regularization, and medical-specific data augmentation, our model achieved strong performance: 97.5% precision, 97.4% recall, 95.3% accuracy, 95.4% F1 score, and an AUC of 0.99. It outperformed established models including AlexNet, VGG, ResNet, and Swin Transformer. External validation at varying magnifications confirmed its robustness, while activation heatmaps enhanced interpretability by highlighting clinically relevant regions, supporting faster and more accurate diagnosis.
The exceptional performance of our model in the detection of oral squamous cell carcinoma (OSCC) stems from its lightweight design and deep adaptation to the task's characteristics. By simplifying the network architecture and applying efficient convolutions, the model ensures low computational consumption while capturing detailed features, making it suitable for various computing environments. Additionally, the customized design of the model architecture, particularly tailored for the subtle and complex features in OSCC pathological images, enhances diagnostic accuracy. The training strategy includes specialized data augmentation and regularization techniques, which improve the model's ability to learn the unique cellular structures and morphological patterns of OSCC, thus boosting its robustness when faced with real-world medical image variability.
This work not only significantly saves time and effort, reduces costs, simplifies processes, and alleviates the workload of clinical doctors, but also overcomes the limitations of traditional diagnostic methods. It reduces the likelihood of missed diagnoses and misdiagnoses caused by doctor fatigue, subjectivity, and errors. Additionally, the powerful computational capabilities and use of big data help identify minute details that the human eye can easily overlook, greatly improving the early detection rate of OSCC. This truly enables “early detection, early diagnosis, and early treatment,” significantly improving patient prognosis and enhancing their quality of life.
In light of emerging advancements in robust medical AI design, our study aligns with a broader trend of developing lightweight yet diagnostically powerful deep learning models for image-based detection tasks. Similar to the approach taken by Batool et al (2025), 21 who demonstrated the utility of deep learning in forensic radiology through robust model structures for bone profile estimation, our EfficientNetSwift model emphasizes compact architecture without compromising diagnostic performance, particularly in resource-limited clinical scenarios. Moreover, future iterations of our framework may benefit from incorporating architectural innovations aimed at enhancing data security and model resilience. For instance, the work by Gabr et al (2024) 22 on memristive neural networks offers promising directions for integrating secure computation and real-time protection into medical AI systems. Additionally, as highlighted in the systematic review by Yee et al (2024), 23 generalizability and adaptability remain key challenges in AI-based detection tasks, especially under conditions of data drift or rare case presentation. These concerns are directly relevant to OSCC diagnosis, and we plan to address them by expanding dataset diversity and exploring domain-adaptive learning strategies in future work.
Currently, this work is limited to the preliminary diagnosis and identification of OSCC. In the future, we aim to achieve more precise diagnosis and personalized treatment by differentiating between various subtypes and stages of OSCC based on an enriched database and clinical data. This study primarily relies on open-source OSCC pathological images, and future work may need to incorporate imaging examinations and clinical tests, utilizing multi-center data to further refine the algorithm model. At this stage, the work is still in the research and development phase and requires further validation and refinement. It needs to be integrated with clinical practice to ultimately develop related systems that can be translated into clinical applications, truly implementing them into clinical practice.
In addition to the quantitative performance of our model, we recognize the importance of assessing its clinical applicability in real-world settings. While the current study focuses on publicly available histopathological datasets with expert-confirmed labels, the actual clinical utility of the model requires further validation through physician involvement. To address this, we plan to initiate a pilot clinical study in collaboration with certified oral pathologists. This small-scale trial will involve blind testing of the model on newly collected biopsy slides from routine clinical practice, followed by comparative evaluation between model predictions and pathologist diagnoses. Furthermore, we will gather qualitative feedback from participating physicians regarding interpretability, diagnostic confidence, and integration feasibility into existing workflows. Such a validation process will not only enhance the practical credibility of our model but also provide valuable insights for refining its interface, explainability modules (eg, heatmaps), and real-time deployment potential. We believe this step is essential for bridging the gap between algorithmic performance and clinical translation.
To address the need for concrete future work, we have formulated three clear research directions. First, we plan to integrate multi-modal data sources—such as proteomic signatures and radiographic imaging—to enrich the feature space and improve model robustness. Second, we will initiate prospective clinical trials across three geographically distinct medical centers to evaluate the model's diagnostic performance in real-world settings. Third, we aim to develop an interactive visual explanation dashboard tailored for OSCC subtype-specific detection, enabling clinicians to interpret model decisions with greater clarity and confidence. These steps are critical to advancing the model toward clinical integration.
Conclusion
This study demonstrates that using deep learning to detect OSCC can accelerate the diagnostic process and facilitate timely treatment. The precise diagnostic process reduces human error and alleviates the workload of clinical doctors. It also helps address the issue of uneven distribution of clinical experts across different regions and hospitals, alleviating the real-world challenges posed by uneven medical resources for patients. Additionally, it can assist in evaluating the grading, staging, and prognosis of tumors, providing more information for clinical decision-making. Although this study currently has many limitations, future improvements are expected by incorporating multi-center data and integrating clinical data such as imaging, medical examinations, and patient treatment follow-ups. This will further refine the deep learning model, enhancing the accurate diagnosis of OSCC subtypes and achieving early detection, early diagnosis, early treatment, and personalized therapy.
Supplemental Material
sj-docx-1-tct-10.1177_15330338251380966 - Supplemental material for EfficientNetSwift: A Lightweight and Precise Deep Learning Model for Detecting Oral Squamous Cell Carcinoma Using Pathological Images
Supplemental material, sj-docx-1-tct-10.1177_15330338251380966 for EfficientNetSwift: A Lightweight and Precise Deep Learning Model for Detecting Oral Squamous Cell Carcinoma Using Pathological Images by Min Wu, MS, Yue Hu, PhD, Fa Tian, PhD, and Huiping Lin, PhD in Clinical Rehabilitation
Footnotes
Acknowledgements
The authors thank all the participating patients and doctors.
Ethical Considerations
Ethical approval and patient consent are not required for scoping review because the data are collected from publicly available publications.
Author Contributions
Min Wu: conceptualization, writing—original draft. Yue Hu: data curation, writing—original draft. Fa Tian: formal analysis, supervision, funding acquisition, writing—review editing. Huiping Lin: project administration, writing—review editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Natural Science Foundation of Zhejiang Province (grant numbers LQ20H140007).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data and Materials Accessibility
In line with the criteria,the research datasets used in the study were supplied by the participating authors.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.