
Abstract
Strain-load is a critical aspect of high-performance textile composites, and testing and application of these materials require significant time, numerous samples, as well as extensive physical experimentation. To address these challenges, this study proposes the construction of machine learning prediction models as an alternative to traditional methods for assessing the strain-load performance of 3D woven fabrics. Four algorithms of Random Forest, Ridge Regressor, K-Nearest Neighbor, and Multi-layer Perceptron were investigated with different feature extraction strategies to predict the strain-load curves of 3D woven fabrics for both warp and weft directions as a whole. A total of 62 datasets sourced from the literature were investigated with 5-fold cross validation in model construction. The results indicate that the strain-load curves can be effectively simulated by different machine learning models basically, and more data with better feature extraction is expected to promote the prediction performance of constructed models in more application cases in future work.
Introduction
Weaving is one of the most common techniques for manufacturing textile preforms. To overcome many shortcomings associated with the manufacturing, moulding, and application of the two-dimensional (2D) laminates, three-dimensional (3D) fabrics have attracted tremendous attention as reinforcement in composites over the past years. 1 These 3D fabrics represent a new class of lightweight materials for composite reinforcements in applications of military, navy, automotive, civil infrastructure, wind energy, aircraft, automobile, aerospace, medical devices, etc. 2 Laminated composite plates, which offer good in-plane properties, are prone to delamination due to their poor mechanical properties in the thickness direction. To address these issues, 3D woven fabrics have been developed, offering improvements in both manufacturing and mechanical properties compared to traditional laminated composites. 3 Different architectures of 3D woven fabrics, such as through-thickness angle interlock, through-thickness orthogonal interlock, layer-to-layer angle interlock, and layer-to-layer orthogonal interlock, have been studied experimentally and modeled analytically and numerically,4,5 These architectures, characterized by a multilayer integral structure with strong design ability and outstanding mechanical properties in composite materials, 6 represent specific arrangements of different interlaced yarns: orthogonal warp and weft yarns with through-thickness binder yarns. The advantage of this manufacturing approach lies in its ability to tailor the mechanical properties and through-thickness reinforcement of a textile material to meet specific design requirements. 7 The mechanical characterization of fabrics has been a growing scientific field in recent years.1,8 The mechanical properties of a textile composite are strongly influenced by the initial arrangement of yarns and fibers in their as-manufactured state for selecting application scenarios, determining engineering design parameters and guiding material development. 9 Moreover, understanding the relationship between the composition, structure and properties is the fundamental to the development of new textile materials.10,11 Material properties are closely linked to and highly affected by the process parameters and the resulting microstructure.
However, the design process and experimental analysis of 3D fabrics are time-consuming, inefficient, and costly. In the design process of a 3D fabric, it is highly unclear the interrelated effects of layer, structure, yarn, material on the performance of strength, endurance, etc. To reduce the number of labor-intensive physical experimental and manufacturing trials, it is essential to predict the mechanical properties of a manufactured textile-reinforced composite based on its initial geometry and yarns architecture. 7 Issues related to fiber architecture, matrix properties, and fiber properties, which affect the mechanical characteristics of composites, are highly complex, making the modeling of textile composites challenging. Various assumptions have been made by researchers in the past to address this challenge. Techniques such as the rule of mixtures, composite cylinder models, and boundary variation methods provide approximate estimates of the mechanical properties of composites but are limited to simple geometries and cannot be applied to complex fiber architectures. 3 In recent decades, two main methods, used to predict the mechanical properties of 3D woven fabrics, were the analytical and numerical methods. Conventional finite element approach to simulate the mechanical properties of 3D textile fabric is extremely time-consuming.3,12 It can take days or weeks of computational time to produce a reliable deformed model. Moreover, finite element simulations of this type of material typically model only a single unit cell representative of the entire material to obtain faster simulations. However, due to the complexity of 3D woven fibre architecture, it is hard to avoid distorted elements when traditional meshing methods are employed. 9 During the weaving process, different types of yarns are mechanically interlocked to form a compact woven architecture of the textile. Zhang et al. 13 and Duan et al. 14 carried out detailed 3D continuum finite element analyses, proving to be effective tools for capturing and elucidating the detailed dynamic response of single-layer fabrics with the disadvantages of demanding expense in computation when applied to practical armor systems, which typically contain 30-50 fabric layers/plies. A model is needed in this field to depict the interrelationship among factors and features of 3D fabrics so that designers can reduce the time and resource required for experimental effort and physics-based process simulation to optimize the design. However, this is not a straightforward task due to the complexity of the problem and the exotic properties of the material.
Researchers have achieved promising results in predicting materials’ performance by using machine learning and deep learning with the development of artificial intelligence and material informatics.15,16 Intelligent techniques, such as artificial neural networks (ANNs), can simplify the nonlinear modeling process by learning from data, particularly in cases where relationships among variables (e.g., load, stress, displacement, and strains) are established. This approach can eliminate the necessity of physical modelling by learning through examples. Deep learning techniques are widely used in the field of woven composites offering computational efficiency over conventional modeling methods. The application of intelligent techniques is strongly associated with the nature of the present problems for intelligent product design, especially when understanding interrelationship between the designing parameters and their behavioural patterns. 17 Various researchers have successfully employed intelligent techniques to study the dynamic and quasi-static behaviour of composites.18,19 They were shown to be able to predict the load-displacement relationship of composite fibre reinforced concrete 20 and cotton fibre filler content in Polyvinyl Chloride (PVC) composite. 17 Whereas, the investigation and implication of machine learning in the field of textile composites is still in its infancy.
Based on the preeminence in related fields, a feasible solution to the aforementioned issue could be intelligent modeling of woven composite’s properties using textile data provided by a manufacturer for conducting rapid assessments. An example of such a predictive framework, which aims to replace time-consuming micromechanical finite element analysis, was proposed by. 21 Kostelac et al. 7 trained deep neural networks to predict the architecture of complex 3D textile composites, and the designed system was able to operate within a 10% error margin for stiffness property predictions. However, the use of intelligent models for predicting the strain-load curves of 3D fabrics has not been addressed in the literature. The promotion of machine learning methods will help to expedite the solution of many challenges currently faced in the mechanical analysis of textile composites. Therefore, it is crucial to develop convenient approaches based on intelligent data-driven algorithms to accelerate the design and analysis of 3D fabrics.
In this study, a series of data-driven models are developed to predict the strain-load curves, enhancing the understanding of the behavior of 3D fabrics. Firstly, the experimental data on 3D fabrics needs to be collected from literature. This data will serve as the input for developing models to predict the strain-load curves corresponding to the exact experimental data points. 22 Based on the literature, the designed 3D fabrics were analyzed with their tensile strength, and their strain-load curves to construct models. Accurate predictions of these curves will significantly assist researchers in anticipating the responses of such engineering materials, thereby reducing the number of materials and time required to expedite the characterization process. More concretely, the machine learning models could be integrated into the design and development process of high-performance 3D fabric from the very beginning by replacing the design-and-test cycles and reducing the material production wastes and the experimental endeavors from simulated results. It is worth mentioning that only strain-load curves in warp direction and weft direction of high-performance 3D woven fabrics are studied in the modeling process in this study. It is due to the fact that most of the existed research generally focused on this performance with enough data to support the present investigation. It is not only hard to find sufficient literatures with data that work with the studied performance coupled with other performances, such as strain-load in bias direction. It is also difficult to develop models in current situation to investigate multiple targets.
In the rest paragraphs of this paper, the section of Methodology and experimental indicates the methodology of the study, Section 3 presents the research results and findings, as well as analysis and discussion, and Section 4 concludes the study and discusses the future perspectives.
Methodology and experimental
Workflow
The workflow of this study is illustrated in Figure 1. Initially, feature data and performance testing data were collected, observed, and preprocessed. After data processing, feature engineering was conducted to formulate the input variables. The prediction targets of the study, namely the strain-load performances of various textile composites, were abstracted as the model outputs via specific designing and selecting the most important features, with two different strategies being investigated. In the experimental section, four multivariable machine learning approaches including Random Forest (RF), Ridge regressor, K-Nearest Neighbor (KNN), and Multi-Layer Perceptron (MLP) were explored to develop the prediction models. During the development process, the loss function of machine learning models was defined and the hyperparameters of various machine learning methods were explored in detailed. To evaluate the developed machine learning-based strain-load prediction models for high-performance textile composites, it is visualized, compared, and analyzed the training effects and prediction closeness of developed machine learning models with diverse strategies, machine learning algorithms, and hyperparameters. Workflow of this study.
Datasets
The basic factor-level information of the collected data.

As shown in Table 1, the dataset includes both categorical variables (e.g., material, structure) and numerical variables (e.g., layers, density). These variables impact the strain-load curves of a composite dramatically as a whole. In order to enable the machine learning models to learn from their unknown effects on the composite physical performance simultaneously, the categorical variables were converted into dummy variables, allowing them to be used alongside the numerical variables as model inputs. Consequently, six variables of material (Aramid, E-glass, Flax, Carbon, Sisal, HMWPE), four structures (O-L, O-T, A-L, A-T), weft layer, linear density, thickness, and areal density were taken into account as inputs to develop the machine learning prediction models. Flax and sisal yarns are the most popular ones developed in recent studies of the high-performance 3D woven fabrics. We consider them with other high-performance fibers together in this study as they are the most applied materials and always comparatively studied in many literatures about high-performance 3D woven fabrics.
For training and validating, the dataset was divided into two sections with ratio of 8: 2 in a 5-fold cross validation. Cross-validation is an effective way to assist the machine learning algorithm to learn from the data in general to formulate the model. It can avoid the models to local optimality or overfitting situation. The reason of the division of data into 8:2 ratio during 5-fold cross-validation is due to the fact that the study was conducted on a small group of data, the 8:2 ratio during 5-fold cross-validation can make sure the model can at least learn the tendencies from the data with enough samples and compare the performances of different machine learning tools.
Model and algorithm
The primary output of the developed models in this study is the predicted strain-load curves of high-performance textile composite in both warp and weft directions. However, it is worth noting that including more points on a curve in the model may lead to decreased accuracy, as insignificant features can waste computational power. Therefore, the most valuable information from a strain-load cures, such as initial modulus, elastic modulus, strain and load break, and strain and load at break, etc., can be extracted. Two designed strategies were coming up with in this study, where the output feature in terms of strain-load curves were abstracted into seven and five specific points, respectively. Figure 2(a) illustrates the difference between these two strategies in selecting featured points from a strain-load curve. Samples of (a) points selection for machine learning in different strategies and (b) loss function calculation.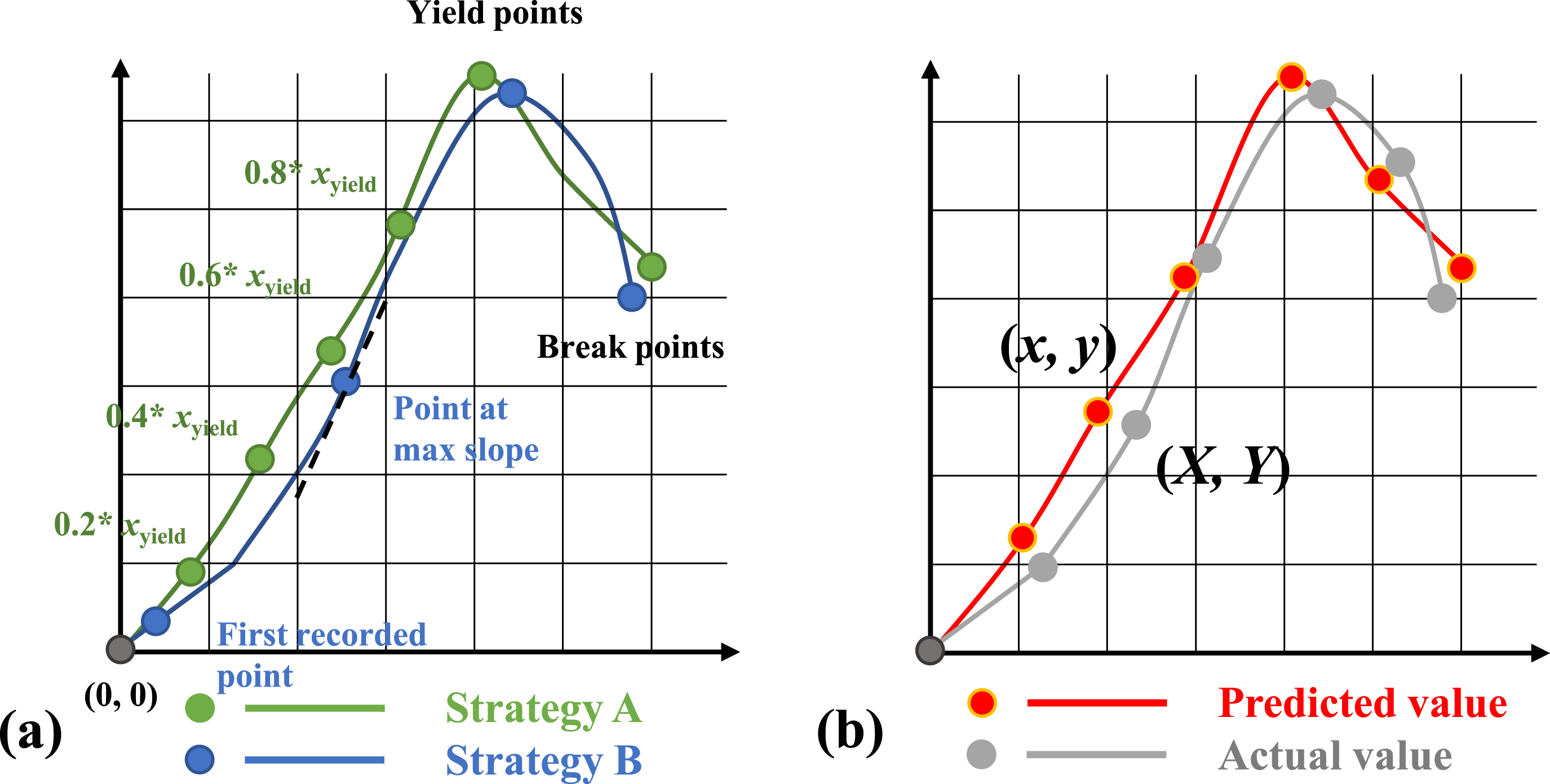
Specifically, in Strategy A, seven points were selected as the output features composed by original point, yield point, break point, and points of 0.2, 0.4, 0.6, 0.8 times the yield point at X axis respectively. In Strategy B, five points are selected including origin, max slope point, yield point, and break point. These two strategies extract features from strain-load curve from both data and mechanism perspectives respectively that can well support the prediction model to depict the curves. The different number of outputs considered in these two strategies is also worth to be observed in the model development though they are both formulated as multi-output modelling problems.
The basic characteristics of the four applied algorithms.

All machine learning models researched in this study were developed on the basis of Python language and Scikit-learn library.
The RF is a predictive model that consists of a weighted combination of multiple regression trees, designed to map inputs and targets by learning from data. 39 Each tree is constructed using a different bootstrap sample of the dataset. Unlike a traditional decision tree, determining the best split at each node by considering all variables, the RF selects the best split from a randomly chosen subset of predictors at that node. In general, combining multiple regression trees enhances predictive performance. The RF model achieves accurate predictions by taking advantage of the interactions among variables and assessing the significance of each variable.
The RF regressor is an ensemble learning algorithm that utilizes a bagging method to combine multiple independently constructed decision tree predictors for the purpose of classifying or predicting specific output variables. This ensemble algorithm that averages randomized decision trees using perturb-and-combine techniques specifically designed for trees. By introducing randomness during the construction of regressors, diverse set of regressors models created generated. The final of the ensemble is given determined by averaging averaged predictions the individual regressors.
Ridge regression addresses some of the issues associated with Ordinary Least Squares by imposing a penalty on the size of the coefficients.
40
The ridge coefficients minimize a penalized residual sum of squares:
The KNN algorithm is a simple and easy-to-implement supervised machine learning method. 35 The principle behind nearest neighbor methods is of identifying a predefined number of training samples that are closest in distance to a new data point, and predict the label based on these samples. The number of samples can be a user-defined constant (k-nearest neighbor learning), or can vary according to the local density of points (radius-based neighbor learning). The distance can, in general, be any metric measure: standard Euclidean distance is the most commonly used choice. Neighbors-based methods are known as non-generalizing machine learning methods, as they simply “remember” all of its training data (possibly transformed into a fast indexing structure such as a Ball Tree or KD Tree).
MLP is the simplest type of feed-forward neural network. In a network structure of MLP, the units are arranged into a set of layers, and each layer contains some number of identical units. 41 Every unit in one layer is connected to every unit in the subsequent layer; we say that the network is fully connected. The first layer is the input layer, where the units receive the values of the input features. The last layer is the output layer, and it has one unit for each value the network outputs (i.e., a single unit in the case of regression or binary classification, or K units in the case of K-class classification). All the layers in between these are known as hidden layers, because we don’t know ahead of time what these units should compute, and this needs to be discovered during learning. The units in these layers are known as input units, output units, and hidden units, respectively. The number of layers is known as the depth, and the number of units in a layer is known as the width. As widely known, “deep learning” refers to training neural nets with many layers in such methodology.
Loss function and hyperparameter
In Figure 2(b), it is depicted the predicted curve in orange and the actual curve in gray respectively. The points of predicted curve and the actual curve are given by 
The investigated machine learning algorithm, hyperparameters, and grid search ranges.

Results and discussion
Data processing
It is depicted the box chart of data collected from the literature to showcase their distribution in Figure 3. It can be found that for material and structure, the data distributes generally from the similar ranges and levels. In order to avoid the negative influence of imbalanced dataset, Synthetic Minority Over-Sampling Technique (SMOT) was used to over-sample the minorities of samples. Since the strain-load performance is illustrated separately in warp and weft directions, the modeling process was independently conducted for warp and weft direction respectively. Distribution of the collected data in regard to material and structure.
Model development
Warp direction
Due to the significant difference in strain-load performance of textile composite in warp direction and weft direction, experiments were conducted separately on the two directions of the model development. In the warp direction, four machine learning approaches and two different feature selection strategies were investigated to develop the optimal prediction model of strain-load for high-performance textile composite. Figure 4 shows the losses of four machine learning algorithms during the training process with different hyperparameter combinations, aiming at predict the strain-load performance of the textile composite in the warp direction. It is worth mentioning that the losses are average cross validation results of five folds by different divisions of datasets to evenly mine the data and the behind hidden interrelationship of features. The color goes deeper to purple indicating the better prediction performance of the trained model, vice versa, yellow implies the poorer of model for predicting strain-load curves of textile composite. It is observed that different strategies have apparently varied effects on hyperparameter tunning process, reflecting the different features of strategies extracted from the curves. Training process with differernt hyperparameters through grid search of machine learning warp model (a) RF, (b) Ridge regressor, (c) KNN, (d) MLP (left: strategy A, right: strategy B).
For random forest in Figure 4(a), three hyperparameters were considered during the training process, which include n_estimators, min_samples_leaf, and min_samples_split. It was observed that min_samples_leaf impact the RF training process at most, and decreasingly by the amount of it. By contrast, min_samples_split played an insignificant role in this training process and has limited influence to be observed from its variation. In the case of the Ridge regressor, as shown in Figure 4(b), the gap of strategies was more obvious, and both of fit_interrept and alpha influence the model performance clearly, that True fit_interrept with alpha = 0.02 for strategy A, and False fit_interrept with alpha = 0.1 are the utmost ones trained in this study. In terms of KNN, exhibited in Figure 4(c), weights, n_neighbors affect the model performance clearer than the hyperparameter p, and the optimal ones for strategy A and B are of n_neighbors = 13, p = 1, weights set to distance, and n_neighbors = 2, p = 2, weights set to distance, respectively. Regarding the MLP models trained in Figure 4(d), it was found that ReLu activation function had a more dramatic impact in strategy A than that in strategy B, and most optimal at Logistic for both. Different combinations of hidden_layer_sizes had similar functions in the models training with strategies A and B that optimized roughly concentrated on the hidden layer sizes of (5), (5, 5, 5), and (10, 10, 5). Upon grid search of hyperparameters of these machine learning models; the optimal model was selected for investigating the stain-load curve prediction in subsequent steps.
Weft direction
The development of machine learning-based model for predicting strain-load curves in weft direction, the development of it in hyperparameter tunning is depicted in Figure 5. It was observed that in weft direction, the model training process with identical setting of hyperparameters does not perform identically. At the same time, the difference of RF, KNN, and MLP from strategies A to B is also not as significant as that in Figure 4. After optimizing the hyperparameters via grid search, the results of the model development for strain-load curve prediction are listed in Table 4. These 16 developed machines learning based models will be further explored and verified in the case study of section 3.3. Training process with differernt hyperparameters through grid search of machine learning weft model (a) RF, (b) Ridge regressor, (c) KNN, (d) MLP (left: strategy A, right: strategy B). The optimized hyperparameters of developed machine learning models.

Case verification
To verify the built machine learning models, their performance in the case study with the rest 20% datasets, which have not been studied in training process, is concluded in Figure 6 by 5 case studies for warp direction prediction (Figure 6(a) and (b)). Similarly, 5 case studies for weft direction prediction are concluded as a whole (Figure 6(a) and (c) for Strategy A). It is worth noting that the axis of these figures denotes the strain-loads of different samples with units of % and N as a whole. For both strategies A and B, the selected seven points and five points were predicted first, and then a regression would be applied to approximate to the points to simulate the strain-load curves of textile composites. In Figure 6, the dash line represents the actual curve, while the yellow, red, green, and blue solid lines represent the predicted results of RF, Ridge regressor, KNN, MLP models, respectively. Each row is composed of five different cases, and each column compares the results of different models in the cases, which vary between warp and weft predictions. Case verification of trained models for two different directions of textile composite with two different strategies: (a) Warp, strategy A; (b) Warp, strategy B; (c) Weft, strategy A; (d) Weft, strategy B.
One of the most dramatic effects observed from Figure 6 is that the MLP models are far away from normality of strain-load curves prediction, for no matter which direction and strategy. The probably reason may involve to the dependency of MLP algorithm on normalization. However, the range of datasets in this study is not fixed and is expected to expand to other better textile composites in the future application, so that it is regarded not feasible to develop the models with normalized datasets. Data was fed without normalization also taking into account for the robustness and accuracy of the developed models. On the other hand, this experiment also is helpful for observing the different effects of the normalization functions in varied machine learning algorithms. The poor performance of MLP revealed the different function of normalization on it from other machine learning algorithms. The former applies normalization to accelerate the learning efficiency of MLP to convergence, while KNN, Ridge, as algorithms also need normalization to evade the interruption of varied data scale of feature to discriminate similar samples. The latter two need to avoid skewing the prediction results toward features with large numbers, meanwhile Ridge without normalization may also lead the regular term to invalid. Though the effects of normalization on these machine learning algorithms can hardly be observed in quantitative, this experimental result provides qualitative support for the above analysis that MLP relies heavier than the others on normalization process in model development.
To provide a clearer comparison, MLP was removed from the observation, and Figure 7 shows the detailed prediction effects of other models developed by RF, Rideg regressor, and KNN algorithms. Overall, it can be found that basically RF performed better than the KNN and Ridge regressor sequentially. As discussed above, KNN and Ridge regressor require normalization to avoid the influence of different data scale, and their performance varies from non-linear to linear perspectives, complicating the comparative analysis of their prediction results. In contrast, RF regression is a classical non-linear ensemble machine learning algorithm without dependence on normalization process, allowing it to perform better in this comparison. Case verification of trained models without MLP for two different directions of textile composite with two different strategies: (a) Warp, strategy A; (b) Warp, strategy B; (c) Weft, strategy A; (d) Weft, strategy B.
In the detailed comparison of Figure 7, it is worth noting that different strategies did not make a significant difference from the model performance of RF. The axis of these figures denotes the strain-loads of different samples with units of % and N as a whole. However, strategy A can assist Ridge regressor and KNN to decrease their loss and get closer to the actual results, while the strategy B led to unexpected results for Ridge and KNN in weft direction case 1 and case 5. Ridge is more of linear regressor, the comparison of RF and KNN could release more details. Both RF and KNN performed well in warp direction cases 1 and 2, but their predictions struggled in cases 3 and 4, which featured two peaks in the curves. These phenomena could be attributed to the feature engineering process, where only one peak was considered as seven-points in strategy A and five-points in strategy B, and seven-points allowed the algorithm to learn more effectively from the datasets. The results from cases 1 to 4 in Figure 7(a) and (b) suggest that strain-load curve prediction should be divided into multiple scenarios when multiple peaks are present. Currently, only cases with a single peak can be predicted. The gap in model performance in warp and weft directions is very minimal, indicating the consistent application of built models in these two directions.
On the basis of random forest, it is calculated the relative importance of the model input variables on the model performance as illustrated in Figure 8. It is found that areal density, linear density, and material type are the most important features that affect the model prediction in terms of 32%, 26%, and 23%. Other than that, weft layer and thickness can also affect the model performances significantly by around 10%. However, structure is less important comparing with other variables in this study, which could be very meaningful to validate in the future work with more investigated samples. Relative importance of the model input variables on the model performance.
The specific performance metrics of the developed models.

Conclusion and future works
High-performance 3D fabrics are widely applied in the industry and related areas, but testing their strain-load performance consumes significant materials, time, and physical experimental efforts. In order to support the associate research on high-performance 3D fabrics, efficiently discover their strain-load performance, and reduce physical experimental effort and wastes, this study explored machine learning approaches, including Random Forest, Ridge regressor, K-Nearest Neighbor, Multi-layer perceptron to model the strain-load performance of 3D fabrics from a collection of datasets based on literature. The potential applicability of these models for modeling textile composite strain-load performance modeling was estimated. The key findings are summarized below: • Strain-load performance of high-performance textile composite can be approximated by machine leaning tools by learning from data. • Random Forest and K-Nearest Neighbor performed better than the other explored algorithms in the model development in this study. • The number of datasets and strategy of strain-curve feature extraction are important to develop the machine learning-based prediction models. • MLP, due to its dependency on normalization of datasets, is not recommended to be applied in this issue.
Despite these findings, several shortcomings should be addressed to strengthen future work. It is recommended to enlarge the datasets to enhance the robustness of the constructed models and to extract more features from the curves, including those with multiple peaks. Nevertheless, the ability to provide a rapid estimation of a woven composite’s mechanical properties opens new horizons in textile modelling. It is suggested to work with other performances, such as strain-load curves of the 3D textile in bias direction and so on, in the future study to promote the textile design process as a whole.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was funded by the National Social Science Foundation General Project in Art (No. 23BG127), The Philosophy and Social Science Planning Project of Guangdong Province (No. GD23XYS037), The Philosophy and Social Science Planning Basic Theoretical Research Major Project of Guangdong Province in 2021 (No. GD21ZDZYS01), Ordinary University Youth Innovative Talent Project of Guangdong Province (No. 2023WQNCX056), and National Local Joint Laboratory for Advanced Textile Processing and Clean Production, Wuhan Textile University (No. FX20240008).