
Abstract
Background
AI-based chatbots are increasingly used as sources of health information. However, their reliability in delivering accurate and scientifically sound responses to patient questions remains uncertain, especially in chronic diseases such as chronic obstructive pulmonary disease (COPD). This study aims to compare the reliability of ChatGPT-4o and Gemini 2.5 Flash in providing patient-centered medical information on COPD.
Methods
A total of 34 common public questions about COPD were submitted to ChatGPT-4o and Gemini 2.5 Flash. Responses were evaluated blindly by four pulmonologists across three domains: accuracy, clarity, and scientific adequacy. The mean scores and word counts were analyzed and compared via nonparametric tests.
Results
Gemini 2.5 Flash outperforms ChatGPT-4o in terms of scientific adequacy (mean score: 4.69 ± 0.31 vs. 4.34 ± 0.45, p<0.001). No significant difference was found in accuracy or clarity. The Gemini 2.5 Flash also generated significantly longer responses, particularly in the treatment and prognosis domains (p<0.001). Both models provided generally acceptable answers, but ChatGPT-4o′s responses were shorter and occasionally less complete.
Conclusions
While both models delivered largely accurate and understandable content, Gemini 2.5 Flash tended to produce more detailed responses and received higher scientific adequacy ratings; however, this difference should be interpreted in light of the substantial imbalance in response length. These tools may support patient education however, the findings reflect a comparison between AI systems only and should be interpreted within this scope.
Keywords
1. Introduction
Chronic obstructive pulmonary disease (COPD) remains an important public health problem worldwide because of its high rates of morbidity and mortality. In low- and middle-income countries, it ranks among the top three causes of death.1,2 Ongoing exposure to risk factors and the aging global population continue to increase the prevalence and burden of the disease each year. 3 As a result, access to healthcare becomes more difficult for patients and creates additional pressure on health systems. Shatto et al. emphasized inequalities in access to care for COPD patients, reporting that people living in rural areas and those with lower socioeconomic status face disadvantages both in receiving care and in health outcomes. 4
Access to accurate, current and reliable information is critically important for recognizing COPD and managing it successfully. Accurate information increases patient awareness, helps patients better understand their symptoms, and supports more effective management of the treatment process. In the past, this information was delivered mainly by physicians. However, the growing demand for health information has made it difficult for physicians to meet this need alone, leading patients to seek out online sources. These resources play a key role in increasing disease awareness, helping patients interpret their symptoms correctly, and improving adherence to treatment plans. Social media platforms, search engines, health-focused websites, and AI-based chatbots are among the most commonly used sources.5,6
In recent years, the rapid development of artificial intelligence technologies has transformed AI-based chatbots into systems capable of scanning large volumes of scientific information within seconds, answering questions without the need for additional research, and even citing sources. Advances in digital infrastructure and mobile technologies have made access to information through these tools faster and more convenient. As a result, AI-based chatbots such as ChatGPT-4o and Gemini have gained prominence over other online information sources. 7 However, despite their potential benefits in accessing medical information, concerns about the reliability of these models persist. Experts note that chatbots may occasionally provide incomplete or inaccurate information and may cite questionable sources.8,9 Such errors can lead to misinterpretation of symptoms, incorrect associations with risk factors, and inappropriate treatment decisions in patients with COPD.
In this study, 34 frequently asked questions about COPD were submitted to ChatGPT-4o and Gemini 2.5 Flash. ChatGPT-4o and Gemini 2.5 Flash were selected as the most widely accessible and frequently used AI-based chatbots available to the public at the time of the study, thus reflecting real-world patient behavior in seeking medical information. The responses generated by both models were blindly evaluated by four experienced pulmonologists in terms of accuracy, clarity, and scientific adequacy. The aim of this study was to assess the reliability of these two AI-based chatbots in providing patient-oriented medical information related to COPD.
2. Methods
2.1. Development of the question set
The most frequently asked questions about COPD were identified through various publicly accessible online sources, including social media platforms, search engines, and health-related forums. Although these platforms are commonly used by patients seeking health information, the exact identity of users cannot be verified, and the questions may also reflect queries from caregivers, students, or members of the general public. In addition, the research team added commonly encountered questions on the basis of clinical experience. The final list of questions was independently reviewed by two pulmonologists, and 34 questions were selected by mutual agreement. Therefore, the question set was designed to reflect commonly encountered public queries related to COPD rather than strictly patient-verified questions. The questions were grouped into four categories on the basis of their content:
1. General information about COPD (n=4).
2. Diagnosis of COPD (n=8).
3. Treatment of COPD (n=18).
4. Follow-up and prognosis in COPD patients (n=4).
Each question-and-answer pair was treated as an independent unit of analysis (see Supplemental Table 1).
2.2. Acquisition of responses
On August 1, 2025, each of the 34 questions was submitted individually as separate prompts to ChatGPT®-4o (OpenAI, Microsoft Corporation) and Gemini®-2.5 Flash (Google AI, Google LLC). The questions were entered exactly as written, without any contextual preprocessing. To prevent the inclusion of unnecessary or off-topic content, the following instructions were used as prompts: • “Answer the following questions by focusing only on the question itself. You may explain your reasoning but do not include information unrelated to the question.”
This instruction was provided once at the beginning of the session and applied to all subsequent questions. No role-based instructions (e.g., “respond as a patient” or “respond as a doctor”) were used. ChatGPT was accessed via https://chat.openai.com, and Gemini was accessed via https://gemini.google.com/app. To avoid influence from prior interactions, browser history and model memory were removed, and new sessions were initiated for both platforms. For each model, all 34 questions were entered sequentially within the same session to simulate a continuous user interaction. However, before initiating each model session, browser history and prior interactions were cleared to minimize potential bias from previous prompts. This instruction was intentionally designed to simulate a typical patient-oriented interaction, where users often seek brief and focused answers rather than extensive academic explanations. However, it was anticipated that different platforms might interpret this instruction differently, potentially resulting in systematic variations in response length across models.
This instruction was not intended to restrict the length of the responses but to simulate a typical patient-oriented query, where users generally seek focused and relevant answers. The same prompt was applied identically to both models to maintain methodological consistency. However, the models may have operationalized this instruction differently, which likely contributed to the observed differences in response length. Although longer responses could be elicited from ChatGPT through additional instructions or multi-step prompting, such strategies were intentionally avoided in this study. Our aim was to simulate a typical first-step patient interaction using a single, neutral prompt applied equally to both models. No attempt was made to standardize or equalize response length between the models, as the primary objective was to simulate a real-world, single-step patient interaction. In everyday use, patients typically ask a single question without specifying length constraints, and the resulting response style reflects each model’s inherent communication behavior. The study design was intentionally based on a single-step question format to reflect a common real-world scenario in which patients ask an initial question without follow-up prompts. Multi-step or conversational prompting strategies were not included, as the primary objective was to evaluate the quality of first-response patient-oriented information.
2.3. Assessment procedure
The responses generated by the models were blindly evaluated by four pulmonologists, each with a minimum of five years of clinical experience. The answers were compiled into two separate anonymized booklets with all model identifiers removed and were presented to the reviewers without any indication of their origin. Only the data analyst was aware of which response belonged to which model. To maintain the integrity of the blinding protocol, the analyst did not participate in the evaluation process.
The assessments were based on three main criteria: • • • Scoring was performed via a 5-point Likert scale, which is consistent with similar studies in the literature10,11: • 1 point: Strongly disagree/unacceptable inaccuracies • 2 points: Disagree/minor but potentially harmful inaccuracies • 3 points: Neutral/potentially misleading or ambiguous inaccuracies • 4 points: Agree/only minor, harmless inaccuracies • 5 points: Strongly agree/no inaccuracies
Each reviewer independently scored the responses. For each question, the final score was calculated by taking the arithmetic mean of the four individual scores. No predefined answer key or model response was used during the evaluation process. Each response was assessed independently based on current clinical guidelines, standard medical knowledge, and the reviewers’ professional judgement.
2.4. Ethical approval
As the study involved only the evaluation of responses generated by AI-based chatbots and did not include patient data, ethical approval was not needed.
2.5. Statistical analysis
The data were analyzed via SPSS® version 25.0 (IBM Corp., Armonk, NY, USA). Descriptive statistics are presented as the mean ± standard deviation (SD) and median (minimum–maximum) values. The normality of continuous variables was assessed via the Shapiro–Wilk test, which indicated that none of the criteria met the assumption of a normal distribution (p<0.05). Therefore, nonparametric tests were used for comparisons.
The Wilcoxon signed-rank test was applied to compare the ChatGPT-4o and Gemini 2.5 Flash responses across the three criteria (accuracy, scientific adequacy, and clarity) as paired groups. The Friedman test was used to assess differences between criteria. When significant results were found, Bonferroni correction was applied, and pairwise comparisons were conducted via the Wilcoxon test.
ICC values are reported with 95% confidence intervals. A p value <0.05 was considered to indicate statistical significance.
In addition to the scoring domains, the total word count of each response was recorded and compared between the two models, as response length may influence perceived comprehensiveness and adequacy.
3. Results
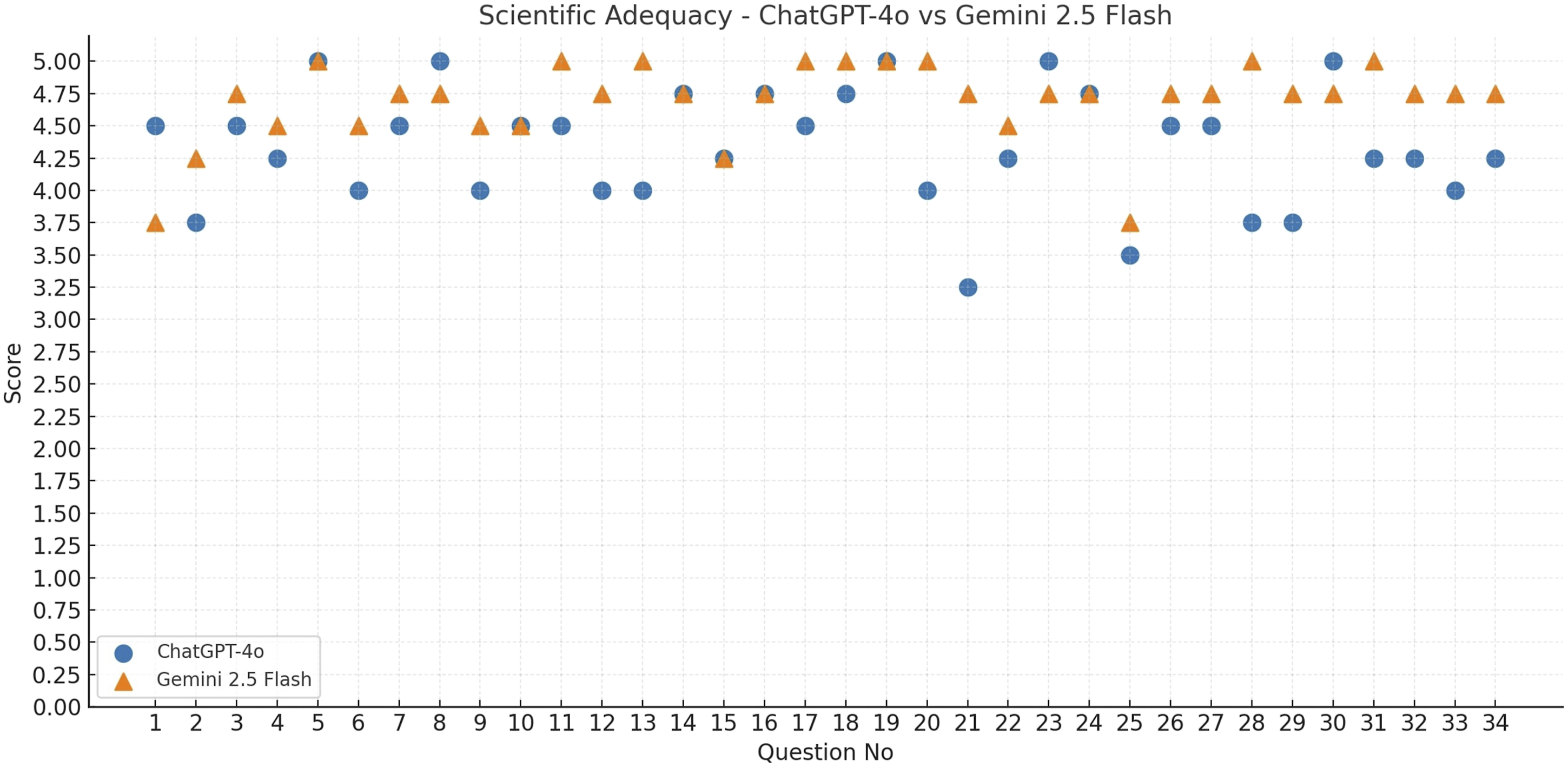
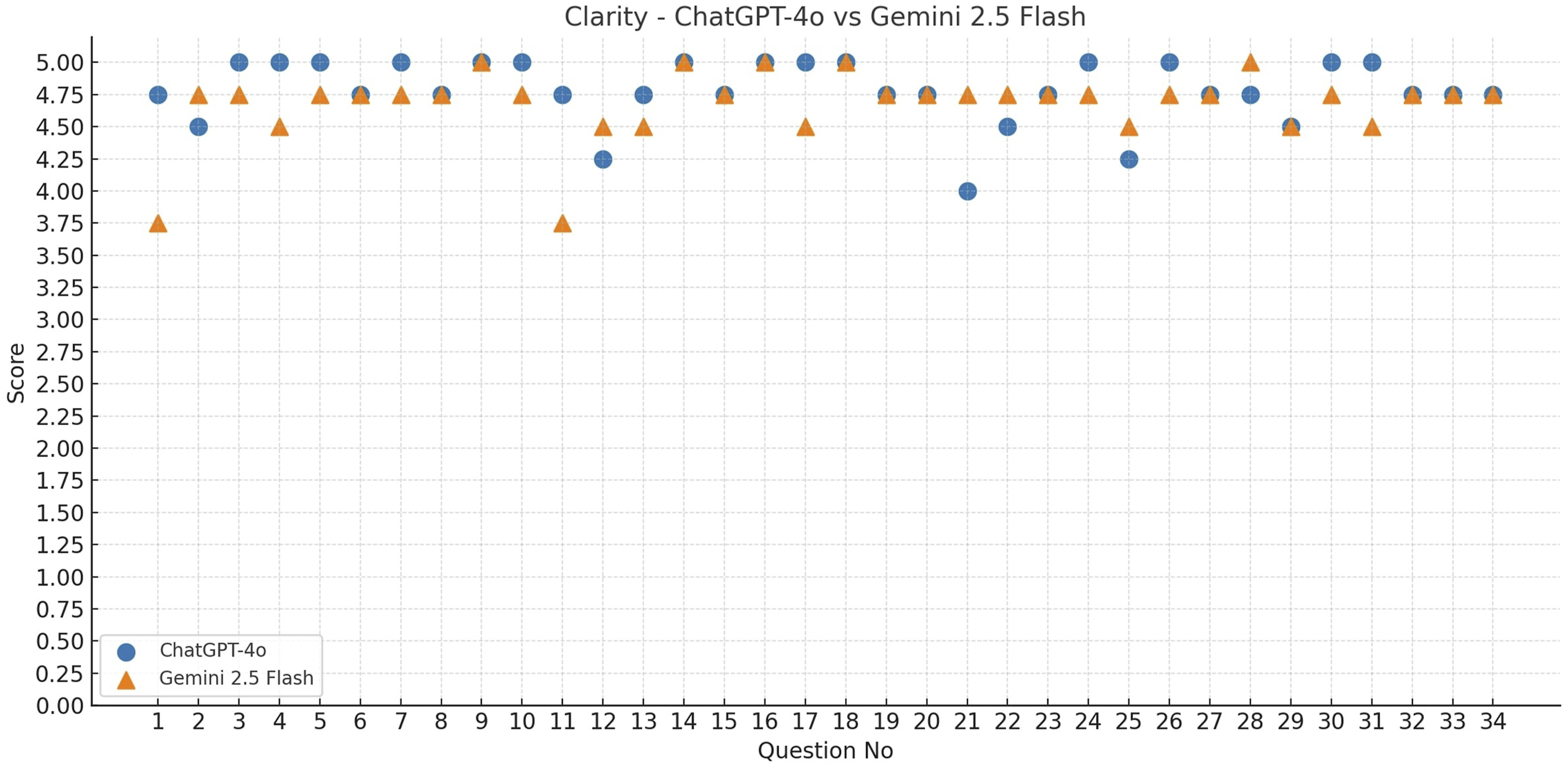
The accuracy, scientific adequacy, and clarity scores of ChatGPT-4o and Gemini 2.5 Flash were evaluated for a total of 34 questions. The accuracy (Figure 1), scientific adequacy (Figure 2), and clarity scores (Figure 3) for each question are presented in the corresponding figures. According to descriptive statistics, ChatGPT-4o received a mean accuracy score of 4.73 ± 0.33, a scientific adequacy score of 4.34 ± 0.45, and a clarity score of 4.78 ± 0.25. Gemini 2.5 Flash’s corresponding scores were 4.79 ± 0.22 for accuracy, 4.69 ± 0.31 for scientific adequacy, and 4.68 ± 0.28 for clarity. A comparison of the responses from both AI-based chatbots in terms of mean reviewer scores and word counts is presented in Table 1. Notably, Gemini 2.5 Flash generated substantially longer responses than ChatGPT-4o across most question categories, resulting in a marked imbalance in response length between the two models. This difference in response length may partly explain the higher scientific adequacy scores observed for Gemini 2.5 Flash. The comparison of ChatGPT-4o and Gemini 2.5 Flash in terms of the mean accuracy scores for each question. The comparison of ChatGPT-4o and Gemini 2.5 Flash in terms of the mean scientific adequacy scores for each question. The comparison of ChatGPT-4o and Gemini 2.5 Flash in terms of the mean clarity scores for each question. Comparison of ChatGPT-4o and Gemini 2.5 flash responses in terms of mean reviewer scores and word counts.

Comparison of ChatGPT-4o and Gemini 2.5 flash responses by question categories.

Inter-rater agreement analysis.

ICC: Intraclass Correlation Coefficient, CI: Confidence interval.
The Friedman test revealed significant differences between the evaluation criteria for both models (ChatGPT-4o: p<0.001; Gemini 2.5 Flash: p=0.030). In ChatGPT-4o, the scientific adequacy scores were significantly lower than both the accuracy and the clarity scores were (both p<0.001). In Gemini 2.5 Flash, a significant difference was observed only between accuracy and scientific adequacy (p=0.004); however, significance was lost in other pairwise comparisons after Bonferroni correction. These findings indicate that ChatGPT-4o performed relatively poorly in terms of the scientific adequacy criterion, whereas Gemini 2.5 Flash exhibited only a limited difference between accuracy and adequacy.
4. Discussion
In recent years, interest among researchers in exploring the use of AI-based chatbots in healthcare has increased. This increasing attention is largely driven by the digitalization of patient data, improved access to health information, and the growing emphasis on patient-centered communication strategies.6,12,13 Studies on AI-based chatbots in the medical field often focus on evaluating the models’ knowledge of diseases and their performance in diagnostic and treatment-related decision-making.14,15 In the field of pulmonary medicine, previous research has assessed the performance of these models in diseases such as asthma, pneumonia, and lung cancer, showing that they can provide clinically relevant responses.11,13,16 However, the limited number of studies that systematically compare the responses of AI-based chatbots specifically in COPD patients via expert evaluation highlights a clear gap in the literature.
COPD is one of the most common diseases encountered in pulmonary medicine. Owing to its high morbidity and mortality, it remains a major public health concern. 1 Patients require reliable guidance to manage their condition effectively. In our study, two AI-based chatbots- ChatGPT-4o and Gemini 2.5 Flash-were compared using a set of questions covering general information, diagnosis, treatment, and follow-up related to COPD. Our findings show that both models generally received “agree” or “strongly agree” ratings from experts in terms of scientific adequacy, clarity, and factual accuracy. This finding indicates that both models were able to provide responses that were largely accurate, adequate, and understandable. However, when scientific adequacy was considered, the Gemini 2.5 Flash demonstrated a notable advantage over ChatGPT-4o. In addition, Gemini 2.5 Flash provided significantly more accurate and detailed answers, particularly in the treatment and follow-up/prognosis categories. These results are consistent with comparative analyses in the literature. In such reports, ChatGPT is often described as more suitable for general research, search engine optimization, and summarization tasks, with responses that are short, concise, and engaging. In contrast, Gemini is characterized as a model capable of delivering in-depth answers with verifiable sources, especially in academic and complex research contexts. 17 It should also be noted that most of the questions included in this study were knowledge-based and focused on commonly asked informational topics. Large language models are generally strong in such factual queries, which may limit the ability of the question set to clearly discriminate performance differences between models. However, the primary aim of this study was to evaluate the quality of responses to commonly encountered public questions rather than to construct a technically challenging benchmark.
We believe that the internet-connected structure of Gemini, which enables it to draw on a broad dataset including Google’s internal resources and web pages-particularly Google Scholar-contributes to its superior performance. A key methodological consideration is the substantial difference in response length between the two models. Longer responses may be perceived as more comprehensive, thereby inflating scientific adequacy ratings. Our additional analyses examining the relationship between word count and adequacy suggest that response length may have contributed to the observed advantage of Gemini in scientific adequacy. Therefore, our findings should be interpreted as reflecting differences in response style (conciseness vs. expansiveness) as much as differences in factual quality.
Although studies in the literature have reported positive outcomes regarding the use of AI-based chatbots in healthcare, the accuracy and adequacy of the information they generate remain subjects of debate. 12 In particular, for AI-based chatbots to deliver up-to-date medical knowledge, they must be trained on a sufficient volume of well-labeled and reliable data. Until this process is fully achieved, these models may continue to provide users with outdated or obsolete information. 18 Moreover, previous studies have shown that chatbots have the potential to generate hallucinated content-that is, inaccurate or fabricated information generated by AI.19,20 In our study, both models responded to a question about pneumococcal vaccination in COPD patients (Question 25) using outdated information from older literature, without referencing the 20-valent conjugate pneumococcal vaccine approved by the Food and Drug Administration (FDA) in 2023. In another case (Question 21), both models provided a response lacking scientific support. These examples demonstrate that, despite their broad access to data, AI-based chatbot models still pose risks in medical communication because of their tendency to present outdated or hallucinated information, which may threaten patient safety. The present study compared two AI-based chatbots rather than benchmarking them against human experts. Therefore, the findings should not be interpreted as evidence that these models perform at the level of specialist physicians. Future studies incorporating expert-generated reference answers or a third comparison arm would provide a more direct assessment of whether LLMs can match specialist-level guidance across the full scope of COPD-related information.
In our analysis, the interrater agreement across the evaluation criteria ranged from low to moderate. The highest level of consistency was observed in the scientific adequacy criterion. The lower ICCs in the other domains may be attributed to individual differences in how the reviewers interpreted the evaluation criteria. The relatively low intraclass correlation coefficients should also be interpreted with caution, as most responses received uniformly high scores. Limited variability in the ratings may have artificially reduced the correlation estimates, despite overall agreement among reviewers regarding the high quality of the responses. As this variability may have influenced the final scoring, it should be considered a limitation of the study. In future research, conducting a brief calibration session prior to the assessment process may help improve agreement among reviewers.
ChatGPT-4o was found to provide significantly shorter responses than Gemini 2.5 Flash. While ChatGPT-4o received higher scores for clarity, its accuracy and scientific adequacy scores were lower than those of the Gemini 2.5 Flash, suggesting that response length may have influenced expert evaluations. In addition, the scoring system did not include a specific domain to evaluate the presence of unnecessary or overly detailed information. From a patient-centered perspective, excessively long answers may reduce clarity by introducing information that is not directly relevant to the original question. Future studies may benefit from incorporating additional scoring categories that assess response conciseness or the presence of irrelevant content.
The ability of ChatGPT to simplify complex information and deliver more understandable answers is especially valuable for patients who are not familiar with medical terminology. However, this tendency to offer simpler responses may, in some cases, result in content gaps and thus should be interpreted with caution in clinical settings. This difference may also be partly related to how each model interpreted the instruction to focus strictly on the question. While this instruction was designed to reduce irrelevant content and reflect patient-style queries, it may have encouraged more concise responses from ChatGPT compared with Gemini. It should also be noted that longer responses could “technically” be elicited from ChatGPT through additional prompting strategies. However, such approaches were deliberately avoided in order to reflect a typical single-step patient query, where users often enter a single question without further instructions. It is also possible that equalizing response length between the models might have resulted in a fairer comparison, particularly for the scientific adequacy domain. Longer responses inherently allow for more detailed explanations, which may have contributed to the higher adequacy scores observed for Gemini. The substantial difference in response length observed in this study may have influenced expert ratings, particularly in the scientific adequacy domain, as longer responses naturally allow more detailed explanations. Consequently, the comparison between the two models should not be interpreted as a strict like-for-like evaluation, but rather as a comparison of their natural response styles under identical prompting conditions.
It should also be acknowledged that, in real-world use, patients may ask follow-up questions to obtain more detailed information. Therefore, a multi-step or conversational evaluation might yield different results. However, the present study was designed to assess the quality of the initial, single-response output, which represents a common first point of interaction between patients and AI-based systems. Another methodological consideration is that the questions were derived from publicly available online sources rather than from verified patient interviews or patient involvement groups. Although such sources are widely used by patients seeking health information, the exact identity of users cannot be confirmed. Therefore, the question set may also reflect queries from caregivers, students, or members of the general public.
Another important consideration is the rapid evolution of AI models. The two models evaluated in this study belong to different release generations, and newer versions may demonstrate improved performance. Therefore, the findings should be interpreted as a snapshot of model performance at a specific point in time rather than a definitive ranking of available systems. However, an important contribution of this study is the development of a structured, expert-based evaluation framework that can be applied to future models. This benchmark-style protocol may facilitate standardized comparisons across different AI systems and help track improvements in patient-oriented medical responses over time.
5. Conclusion
In this study, a systematic expert-level evaluation was conducted to assess the responses of ChatGPT-4o and Gemini 2.5 Flash to publicly asked questions about COPD. To our knowledge, this is the first study to provide a comparative assessment of these two models, specifically in the context of COPD-related patient information. Although both models generally delivered accurate and understandable responses across content areas, the observed differences between the models should be interpreted cautiously, particularly given the imbalance in response length. Importantly, diagnostic, treatment, and follow-up strategies for COPD must also be tailored to individual patients.
The present findings reflect a comparative evaluation between two AI-based systems and should not be interpreted as a benchmark against specialist physician performance. Future studies incorporating expert responses or clinical comparison arms may provide a more comprehensive perspective on the clinical role of large language models.
6. Limitations
This study has several limitations. The primary limitation of this study is the substantial imbalance in response length between the models, which may have influenced expert ratings-particularly scientific adequacy-by favoring more detailed responses. Equalizing response length might have enabled a more direct comparison, particularly for the scientific adequacy domain, where longer responses may naturally appear more comprehensive. Future studies should standardize output length (e.g., token/word-limited prompts, matched-length post-processing, or multi-shot patient-like prompting) to enable fairer like-for-like comparisons. In addition, no formal sample size or power calculation was performed prior to the study. The number of questions and evaluators was determined pragmatically, in line with similar exploratory studies in the literature, which may limit the statistical power and generalizability of the findings. In particular, some comparisons approached statistical significance (e.g., clarity scores), and it is possible that a larger number of questions or evaluators could have resulted in statistically significant differences. Therefore, the findings should be interpreted as exploratory rather than definitive. Second, all the questions were submitted to the models in English only. Given the wide range of languages spoken globally, responses may vary across different languages. However, evaluating multiple languages within a single study introduces analytical complexity. Another limitation is that the pulmonologists evaluated the responses of each model in the same order, reviewing one model entirely before moving to the other. This may have led to rater fatigue or order-related bias. Future studies may consider randomizing the order of responses to minimize such risks.
In addition, the adequacy of the responses in this study was assessed solely by expert physicians. In particular, the clarity domain was evaluated by pulmonologists rather than by patients or laypersons, which may limit the ability of the study to fully reflect real-world patient perceptions of understandability. The understandability and practical usefulness of the answers from the perspective of the general public were not evaluated. Future research could incorporate patient input to better reflect the real-world applicability of chatbot models. Another limitation is the imbalance in the number and complexity of questions across content categories, which may have limited direct comparability between groups. These limitations may have affected the generalizability of the findings. Therefore, future studies that incorporate multiple languages and patient perspectives will be valuable in addressing these gaps. Additionally, most of the questions were knowledge-based and focused on basic informational topics. Such questions may be less effective in differentiating performance between large language models, which are typically strong in factual knowledge retrieval. Furthermore, the scoring system did not include a dedicated domain to assess the presence of unnecessary or overly detailed information, which may have limited the evaluation of response conciseness from a patient-centered perspective. Moreover, objective readability metrics were not assessed in this study. In addition, the evaluation process did not include a free-text comment section for reviewers to explain the reasons behind their scores, which may limit the interpretability of individual rating decisions. Furthermore, the study relied primarily on quantitative scoring domains, and no formal qualitative content analysis of the responses was performed. Such analyses could provide deeper insights into response structure, tone, and clinical reasoning, and may enhance the scientific value of future comparative studies. The inclusion of standardized readability analyses could provide additional insight into how understandable the responses are for the average patient and should be considered in future research.
The other limitation is the study was limited to single-step prompts and did not evaluate multi-turn or conversational interactions. In real-world settings, patients may ask follow-up questions to obtain more detailed explanations, and future studies should investigate such multi-step interaction models. Furthermore, the questions were not generated through direct patient interviews or patient involvement groups. Although they were derived from commonly accessed public sources, this approach may not fully represent the typical information needs of COPD patients.
Supplemental material
Supplemental material - Comparative assessment of ChatGPT and gemini answers to common chronic obstructive pulmonary disease questions: An expert panel evaluation by pulmonologists
Supplemental material for Comparative assessment of ChatGPT and gemini answers to common chronic obstructive pulmonary disease questions: An expert panel evaluation by pulmonologists by Mutlu Onur Güçsav, Damla Serçe Unat, Onur Akçay, Ömer Selim Unat, Aysu Ayrancı and Ahmet Emin Erbaycu in Chronic Respiratory Disease.
Footnotes
ORCID iDs
Ethical considerations
As the study involved only the evaluation of responses generated by AI-based chatbots and did not include any patient data, ethical approval was not required.
Consent to participate
This study did not involve human participants, patient data, or identifiable personal information requiring consent.
Consent for publication
Not applicable. No individual person’s data, images, or other identifiable information are included in this article.
Authors’ contributions
Güçsav, Akçay, and Serçe Unat contributed to the conception and design of the study. Data collection was performed by Güçsav, Serçe Unat, Unat, Ayrancı, and Erbaycu. Data analysis was carried out by Güçsav and Akçay. The first draft of the manuscript was written by Güçsav, and all authors provided comments on previous versions of the manuscript. All authors read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All review data are publicly available. Our article has not been published previously except in the form of a preprint, an abstract, a published lecture, academic thesis or registered report. Our article is not under consideration for publication elsewhere.
Declaration of generative AI tools
ChatGPT-4o (OpenAI, Microsoft Corporation, San Francisco, CA, USA) and Gemini 2.5 Flash (Google AI, Google LLC) are AI-based chatbots, and in this study, they were used to generate responses to patient questions related to COPD. Additionally, ChatGPT-4o was used during the writing process solely to improve the readability and language of the manuscript. The final content was critically reviewed and approved by the human authors, who are fully responsible for the integrity and accuracy of the work. The models were not involved in authorship or editorial decision-making processes.
Supplemental material
Supplemental material for this article is available online.