
Abstract
Progress in understanding students’ development of psychological literacy is critical. However, generative AI represents an emerging threat to higher education which may dramatically impact on student learning and how this learning transfers to their practice. This research investigated whether ChatGPT responded in ways that demonstrated psychological literacy and whether it matched the responses of subject matter experts (SMEs) on a measure of psychological literacy. We tasked ChatGPT with providing responses to 13 psychology research methods scenarios as well as to rate each of the five response options that were already developed for each scenario by the research team. ChatGPT responded in ways that would typically be regarded as displaying a high level of psychological literacy. The response options which were previously rated by two groups of SMEs were then compared with ratings provided by ChatGPT. The Pearson's correlations were very high (r's = .73 and .80, respectively), as were the Spearman's rhos (rho's = .81 and .82, respectively). Kendall's tau were also quite high (tau's = .67 and .68, respectively). We conclude that ChatGPT may generate responses that match SME psychological literacy in research methods, which could also generalise across multiple domains of psychological literacy.
Psychological literacy is regarded as one of the primary outcomes for all undergraduate psychology degrees (Hulme & Cranney, 2021). Recently, Cranney et al. (2022) proposed a framework for undergraduate psychology capabilities that includes both discipline-specific knowledge and skills, as well as generic capabilities that are applied in personal, professional, and community settings. Psychology is a diverse discipline, with approximately 20% of undergraduate students pursuing professional psychology careers (Hulme & Cranney, 2021). Because psychological literacy is relevant to many different pathways beyond a career as a psychologist, possessing psychological literacy can contribute to the work readiness and employable skills self-efficacy in a broad range of careers (Machin & Gasson, 2022). For students who have completed an undergraduate psychology degree, we would expect to see a moderate to advanced level of psychological literacy which supports their practice across different contexts.
Psychological literacy is not a new concept, and although the understanding of psychological literacy is still being debated, there is some convergence emerging. For instance, McGovern et al. (2010) provided nine components of psychological literacy that undergraduate students might demonstrate. However, Newell et al. (2021) concluded that there is substantial lack of agreement about what elements to include in the conceptual definition of psychological literacy, as well as whether psychological literacy has single or multiple dimensions. The same authors subsequently proposed that the key dimensions of psychological literacy included understanding, investigating, and communicating psychological knowledge (Newell et al., 2022). We accept that psychological literacy is a multidimensional construct which may therefore require a range of assessment strategies to fully capture these multiple dimensions. For the current study, we began with the assumption that psychological literacy involves the application of psychological knowledge across different contexts (e.g., personal, professional, and community as per Cranney et al., 2022).
More recently, we note that there is a disruptive influence which can potentially compromise assessment of learning in higher education, that is, generative AI tools such as ChatGPT (one example of a large language model or LLM). Ray (2023) explains that ChatGPT has the potential to revolutionise scientific research, impacting on virtually all aspects of the research process. According to OpenAI (2023), ‘While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers’ (p. 1). Therefore, it is now possible to use a generative language model to generate human-like responses to an unlimited range of scenarios. Thus ChatGPT (and other generative AI) have impacted on some of the core business of higher education and have generated debate about the appropriate role for generative AI in assessment of student learning, and this has become a major (if not the key) concern for academics across the higher education sector.
There are a number of studies which have already evaluated the performance of ChatGPT on standardised exams. For example, Choi et al. (2023) used ChatGPT to answer questions on University of Minnesota law exams and found that, while ChatGPT could pass the exams and thus be eligible for a law degree, the answers lacked deep comprehension with the materials (i.e., just at a pass level). Further, Gilson et al. (2023) discovered that ChatGPT achieved a passing score equivalent to a third-year medical student on the National Board of Medical Examiners (NBME) free 120 questions. It was able to logically justify its responses for most of the questions, although extraneous information was often included. More recently, van Dis et al. (2023) demonstrated that ChatGPT provided false information and errors in responses to summarising a systematic review, suggesting that those who use ChatGPT need to be aware of its limitations. With ChatGPT 4 more readily available (e.g., free through Bing), there is an immediate need to evaluate the capacity of LLMs to provide the kind of responses that would exemplify psychological literacy.
Research Aims and Overview of the Two Studies
In this paper, we were interested in understanding whether ChatGPT (3.5) could provide responses that are regarded as psychologically literate. Uludag and Zhao (2023) have already demonstrated that ChatGPT can respond well to multiple choice questions used in the Graduate Record Examination (GRE) in psychology, suggesting that ChatGPT may be useful as a tutor or a study aid. Thus, we would anticipate that ChatGPT (3.5) would be able to provide basic psychological information when prompted, however, based on van Dis et al. (2023), we also were cautious as to whether this information may be incorrect or only partially true (and potentially misleading). We were also uncertain how ChatGPT (3.5) would respond to critical thinking challenges and demonstration of reflective skills, particularly in applying psychological concepts to everyday scenarios beyond multiple choice questions.
We approached the research in two different ways. That is, we were interested in how ChatGPT (3.5) would respond to scenarios used to assess psychological literacy and, subsequently, how ChatGPT's (3.5 and 4) responses compared to that of subject matter experts (SMEs) in psychology. In Study 1, we used ChatGPT (3.5) to respond to 13 open-ended research methods scenarios used to assess psychological literacy (which is the original format for the Test of Psychological Literacy (TOPL), also called the TOPL-Free Response), and in Study 2 we compared ChatGPT (3.5 and 4) to SMEs’ ratings used in the development of the Revised Test of Psychological Literacy (TOPL-R). The value of comparing ChatGPT's (3.5 and 4) responses to those obtained from SMEs is that it would support the potential use of this agent (and other LLMs) in the initial training of psychology students as an enhanced, personalised tutor, which ultimately may impact on the transfer of learning to practice contexts.
Study 1
Materials
Test of Psychological Literacy (TOPL - Free Response; Roberts & Gasson, 2018). The original TOPL (Free Response) utilised 86 realistic scenarios and asked students to provide an open-ended response to the scenario along with a justification for that response. Respondents are required to answer two questions for each scenario: In response to the scenario, first, what would you say (or do/suggest/recommend), and second, what have you learned in your psychology studies that might be of relevance? In this article, we chose the research methods subscale (comprising 13 items) of the TOPL (Free Response) for both Studies 1 and 2, which has been the focus of validation efforts to date (Machin & Gasson, 2022). The 13 scenarios in this subscale are provided in Appendix 1 and focus on the application of psychological science to various research methods situations.
Method
To answer the research aim, in January 2023, we asked ChatGPT (3.5) to provide responses to 13 open-ended scenarios that demonstrate differing domains of psychological literacy. The first author inserted the actual item and the two stimulus questions (see Appendix 1) as the prompts used to task ChatGPT (3.5), and all authors discussed the corresponding output provided by ChatGPT (3.5). It should be noted that all authors are considered experts in the field of Psychology learning and teaching and are proficient in marking student responses to the types of questions found in the TOPL (Free Response). The original TOPL (Free Response) scoring manual was also used to evaluate the responses and the scoring criteria are listed for each item in Appendix 1.
The first two scenarios that we used differed from the rest of the scenarios as there was no explicit request to identify learnings from the respondents’ (in this case, ChatGPT 3.5) psychology studies that might be of relevance, however the second question still focused on providing a justification for the response. The first scenario focuses on survey responses while the second scenario focuses on designing basic research. These questions are more straightforward than other scenarios. The third scenario focused on the use of a psychic medium for a grieving friend. The fourth scenario asked about the use of alternative health treatments for a health problem. The fifth scenario asked about an organisation that wishes to use a correlation between conscientiousness and productivity as the basis for making hiring decisions. The sixth scenario referred to a negative correlation between carbohydrate consumption and cognitive performance, and how a friend has decided to remove carbohydrates from their diet. A similar situation exists for the seventh scenario, where a negative association is reported between time spent in front of screens and grades in class, and the person is asked what advice should they offer to parents? The eighth scenario describes someone who is experiencing increased stress before an exam and a friend recommends a stress reduction technique. The ninth scenario asks for advice about the mindfulness meditation diet. Our tenth scenario is a situation where a person is asked to advise a parent who has a child with autism, about a potential treatment. The eleventh scenario asks about a medical appointment with an older relative who feels overwhelmed. Scenario 12 features a sports club that wishes to recruit new members and a request to provide a recommendation about an effective recruitment strategy. Finally, scenario 13 described a relative who is new to their university and who relies on Wikipedia for all their assignment references.
Results
The results from tasking ChatGPT (3.5) with the scenario and two prompts are shown in Table 1. The 13 scenarios are listed in Appendix 1 as well as the scoring criteria developed by the authors. Our scoring (out of 2) of each response is also in Table 1.
ChatGPT Response to Each Scenario and the Score from the Scoring Guide.

Apart from the response for the second scenario, the ChatGPT (3.5) responses were all scored as 2 out of 2. In the second scenario, the required answer was an experimental research design that ensured tasters were unaware of the coffee brand being tasted. ChatGPT (3.5) offered four suggestions which involved customers being surveyed about their preferred brands or providing feedback after tasting samples. These responses would probably assist the manager but failed to meet the required criteria for that response.
Discussion
The range of scenarios is sufficiently broad to ensure a reliable assessment of ChatGPT's (3.5) capacity to provide responses that are psychologically literate. Apart from scenario 2 (where the response was deemed inadequate), we rated the ChatGPT (3.5) responses as receiving full marks. Many of the responses contain extremely useful advice that falls outside of the scope of our definition of psychological literacy but would still be helpful. For example, in scenario three (consulting a psychic medium), the ChatGPT (3.5) response suggests that ‘It might also be helpful to consider your own beliefs and feelings about the afterlife and whether you believe that it is possible to communicate with the deceased. Additionally, you may want to consider any potential risks or drawbacks of working with a psychic medium, such as the possibility of being scammed or being given false hope’.
We also examined the responses for any misleading information or ‘hallucinations’. The latter is a phenomenon that appears to occur when a LLM creates a fact out of nothing. We identified several statements that may be misleading such as ‘Some research suggests that certain nutrients, such as omega-3 fatty acids and antioxidants, may be beneficial for cognitive function’. This statement sits along with a disclaimer ‘However, it is also important to note that the relationship between diet and cognitive performance is complex, and more research is needed to understand the specific ways in which different nutrients and dietary patterns may influence cognitive function’. Therefore, we did not regard this as misleading. Another potentially misleading statement was ‘Some research suggests that mindfulness meditation may be associated with a number of health benefits, including stress reduction and improved physical health’. It also is accompanied by a disclaimer ‘However, it is important to note that mindfulness meditation is just one aspect of a healthy lifestyle and should not be used as a sole means of weight loss. A healthy diet and regular physical activity are also important for maintaining a healthy weight’.
We concluded that ChatGPT's (3.5) responses demonstrated high levels of psychological literacy for the items focused on psychology research methods scenarios. ChatGPT (3.5) provided answers that were cautious, but clearly outlined risks and benefits based on psychological knowledge. It may be less capable in providing responses to the other subscales of the TOPL (Free Response) (e.g., psychopathology, cross-cultural psychology, and ethics) where there are more complex issues and nuanced ethical scenarios. It seems to include advice that undergraduate psychology students should be able to generate from their psychology studies. The degree of sophistication of the responses was quite high.
The second study compared ChatGPT's (3.5 and 4) ratings of various responses to the same items from Study 1 with the SMEs’ ratings from two expert reference groups used in the TOPL-R.
Study 2
Materials
Revised Test of Psychological Literacy (TOPL-R; Machin & Gasson, 2022). The TOPL-R presents five response options for each of the 13 research methods scenarios and respondents are asked to rate the degree to which these responses reflect their own understanding and application of psychological science.
Method
Ethical approval for the collection of data for the TOPL (Free Response) and TOPL-R was provided by Curtin University Human Research Ethics Committee (HRE2017-0480-15) and the UniSQ Human Research Ethics Committee (H19REA085v5). No additional ethical approval was sought for the AI responses.
This study was a comparison of the SMEs’ ratings which were obtained as part of Machin and Gasson (2022) and Gasson et al. (2023), with those provided by ChatGPT (3.5) and ChatGPT (4). The improvement in the language model for ChatGPT (4) meant that there may be slightly different ratings and therefore we included both language models. ChatGPT (3.5) was tasked in January 2023, whilst ChatGPT (4) was tasked in November 2023. The process of collecting ratings from SMEs is critical for weighting the responses to the scenarios in Situational Judgement Tasks (SJT). Once the SME ratings are collected, individual respondent's scores are assigned which reflect the proportion of SMEs who selected that specific rating (from 1 to 5) for that response option. There were five responses that were created for each of the 13 scenarios in the research methods subscale, and these were independently judged by two groups of SMEs (N = 7 and 8).
The first group of SMEs (N = 7) were members of a national psychology associations’ interest group for psychology education. These seven respondents included four previous recipients of the award for distinguished contribution to psychology education and all were experienced psychology academics with PhDs. Their responses were collected in 2021. The second group of SMEs (N = 8) were either psychology academics with an APAC accredited psychology program at an Australian university or currently practising registered psychologists, representing a more diverse range of views than the first group. Their responses were collected in 2022.
Average ratings were calculated across the two groups to evaluate how similar they were with Mean of Group1 = 2.90 (SD = 1.09) and Mean of Group2 = 3.39 (SD = 1.13). To assess the degree of similarity in the two groups’ ratings, the Pearson's r correlation was calculated (r = .87, p < .001), as well as the Spearman's rho (rho = .91, p < .001). These indicate almost identical profiles in the average ratings of the SME groups. The Kendall's tau (a measure reflecting rater agreement when the metric is an ordinal scale) was also excellent (tau = .76, p < .001). The SMEs’ ratings were compared ChatGPT's ratings for each response across the 13 research methods scenarios.
The prompt used to task ChatGPT (3.5) and ChatGPT (4) was as follows: Consider the following scenario [insert scenario]. Please rate each Response below from 1 to 5 where: 1 = No application of psychological science and 5 = Completely appropriate application of psychological science. The SME ratings and ChatGPT's (3.5) and ChatGPT's (4) ratings for one of the TOPL-R scenarios (RM1) and its five response options is shown in Table 2. Additional Tables 3–14 are contained in Appendix 2 showing the TOPL-R stem and ratings from SMEs and ChatGPT (3.5 and 4) for research methods scenarios two to 13.
TOPL-R Stem and Ratings from SMEs and ChatGPT for RM1 (Machin & Gasson, 2022).
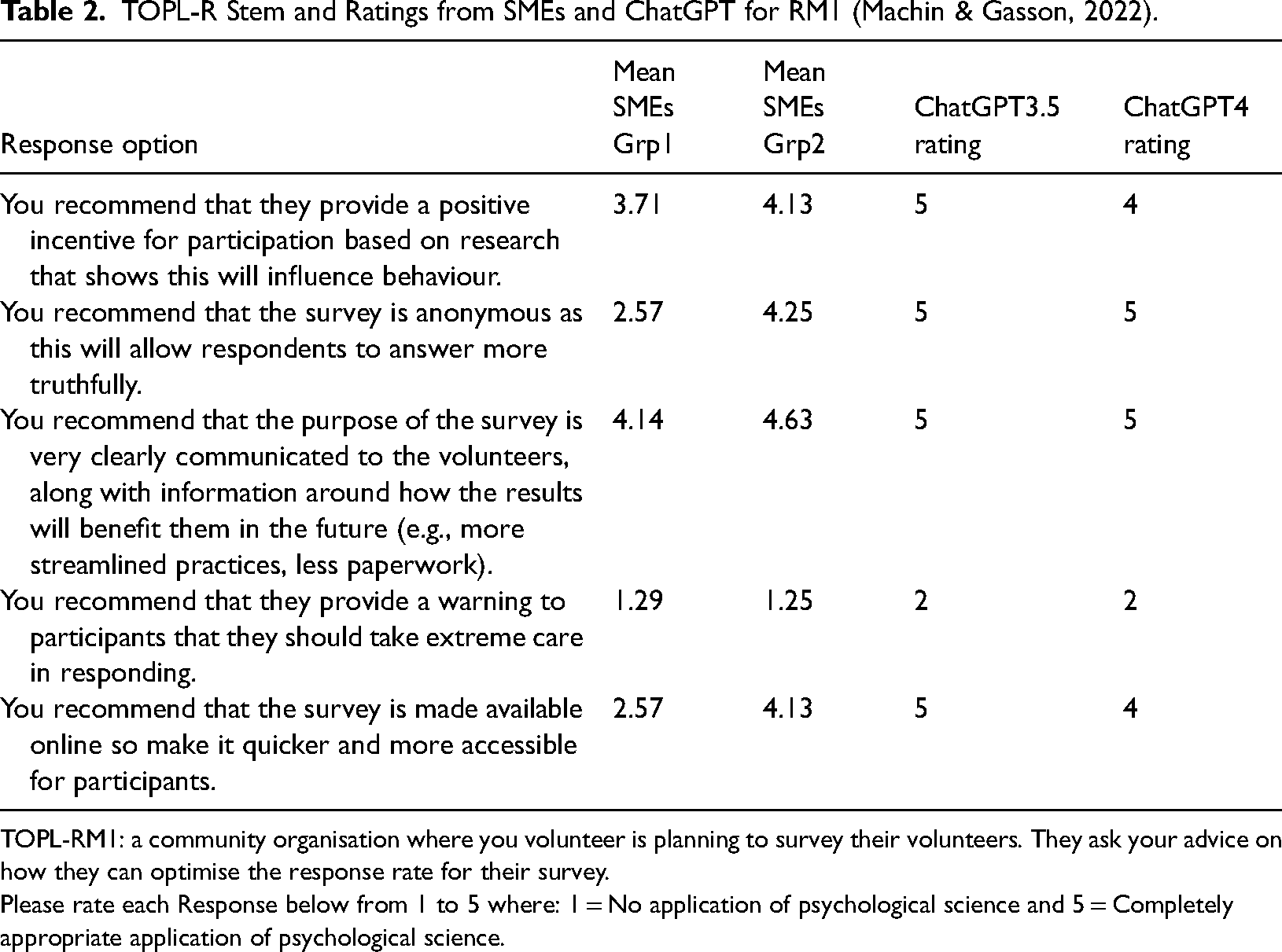
TOPL-RM1: a community organisation where you volunteer is planning to survey their volunteers. They ask your advice on how they can optimise the response rate for their survey.
Please rate each Response below from 1 to 5 where: 1 = No application of psychological science and 5 = Completely appropriate application of psychological science.
Results
The ChatGPT ratings for the responses were considerable higher than both of the SME groups’ ratings with a Mean (ChatGPT3.5) = 3.97 (SD = 1.17) while Mean (ChatGPT4) = 3.80 (SD = 1.21). Group1's mean rating was 2.90 (SD = 1.09) while Group2's mean rating was 3.39 (SD = 1.13). There were many more responses that ChatGPT (both 3.5 and 4) rated as 5 (out of 5) and almost none were rated 1. We calculated the Pearson correlations with Group1 and Group2 and these were very high (r's = .73 and .80, respectively, for ChatGPT3.5 and r's = .77 and .84, respectively, for ChatGPT4), whilst the Spearman's rhos were also very high (rho's = .81 and .82, respectively, for ChatGPT3.5 and rho's = .81 and .85, respectively, for ChatGPT4). The Kendall's tau was also calculated for both rater groups with ChatGPT (both 3.5 and 4) to indicate the level of rater agreement where the metric is an ordinal scale. These were also quite high (tau's = .67 and .68 for Group1 and tau's = .69 and .71 for Group 2). These statistics were all significant at p < .001.
Discussion
We concluded that ChatGPT does provide a reasonable guide as to the degree of psychological literacy being required in the responses to the 13 scenarios we submitted. There may be some additional value in using the ChatGPT (4) language model as these ratings were more similar to both SME groups. The ChatGPT ratings for both version 3.5 and 4 showed a tendency towards being more lenient than the SME's ratings which needs to be re-evaluated with further developments of the language model. We are yet to investigate whether the type of category item would impact on the quality of the ChatGPT response; that is, ChatGPT may provide poorer responses to the more complex scenarios and ethical dilemmas that are part of the larger TOPL (Free Response) and TOPL-R (with 86 scenarios across 13 categories).
ChatGPT (3.5) was first trained on information which was produced before 2021. This means that the responses provided are limited to information available before that date. However, ChatGPT (4) was trained using data available until January 2022 (see OpenAI Developer Forum (2023): What is the actual cutoff date for GPT-4?). ChatGPT and other generative AI tools are predictive models that create responses based on the prompts that are entered. While we used the prompts that students would be asked in the TOPL (Free Response) and TOPL-R, more refined prompts may produce different responses which may result in better of poorer responses from the AI. We initially used the free version of ChatGPT (i.e., 3.5) for this research, but during revisions to the paper, we repeated the analysis in Study 2 with the paid version (4). The main limitation of LLMs is that the responses are based on the strength of associations that the LLM has developed at that time, and so can vary over time.
Conclusions
In conclusion, our results demonstrate that ChatGPT's responses display moderate to high levels of psychological literacy in psychology research methods. While its responses do not yet match the rigour of a SME when rating response options, it can provide free response answers that are sufficient to receive the maximum score. Given that ChatGPT provides promising responses which demonstrate psychological literacy in one domain, psychology educators may find ChatGPT helpful in generating assessments or providing examples for students, although caution should be applied given that ChatGPT may offer responses which contain misleading or false information (van Dis et al., 2023). Psychology educators are therefore encouraged to continue to exercise their academic judgement and expertise, and not rely solely on ChatGPT to generate assessments, particularly for important outcomes such as psychological literacy. Students who engage in utilising ChatGPT for help with assessments should also approach ChatGPT with a healthy dose of caution. While ChatGPT did provide responses that demonstrated moderate to high psychological literacy in research methods, it is too early to suggest that ChatGPT will provide similar responses in all 13 TOPL categories. Our prediction is that there may be similar levels of psychological literacy displayed across multiple domains of psychology.
When it comes to test development and the use of SMEs, ChatGPT responses are encouraging. Given that access to SMEs and other resources that were previously required to develop and test scenarios is a serious limitation for all Situational Judgement Tests, the use of ChatGPT to generate ratings in SJT is promising, especially as researchers have immediate access to the responses that can evaluated and modified iteratively. Where there are several responses to a scenario receiving very low (indicating poor understanding) or very high ratings, these could be revised and resubmitted to ChatGPT to ensure that a wide range of response options are available. For future test development in psychological literacy, generative AI may provide a novel strategy for developing scenarios across multiple domains as well as creating examples of better and poorer responses to further provide insight into psychological literacy levels.
Supplemental Material
sj-docx-1-plj-10.1177_14757257241241592 - Supplemental material for Comparing ChatGPT With Experts’ Responses to Scenarios that Assess Psychological Literacy
Supplemental material, sj-docx-1-plj-10.1177_14757257241241592 for Comparing ChatGPT With Experts’ Responses to Scenarios that Assess Psychological Literacy by M. Anthony Machin, Tanya M. Machin and Natalie Gasson in Psychology Learning & Teaching
Supplemental Material
sj-docx-2-plj-10.1177_14757257241241592 - Supplemental material for Comparing ChatGPT With Experts’ Responses to Scenarios that Assess Psychological Literacy
Supplemental material, sj-docx-2-plj-10.1177_14757257241241592 for Comparing ChatGPT With Experts’ Responses to Scenarios that Assess Psychological Literacy by M. Anthony Machin, Tanya M. Machin and Natalie Gasson in Psychology Learning & Teaching
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.