
Abstract
Background
With the arrival of generative artificial intelligence (genAI) tools, psychology educators are rethinking their assessment practices.
Objective
This paper describes one approach to integrating genAI into an assessment designed to promote psychological literacy.
Method
Students used ChatGPT to generate a media release about a published article and then wrote a critique. We evaluated whether students were able to use the marking rubric to assess the ChatGPT output, and whether working with the rubric early in the assessment process had benefits for their grades on subsequent tasks.
Results
The results show that students accurately assessed the ChatGPT output against the marking rubric, judging the output to be stylistically good but lacking in accurate coverage of the aims, methods, and results of the research. Working with genAI and the marking rubric early in the assessment process had benefits for performance, relative to cohorts that had engaged in peer review.
Conclusion
By allowing students to use genAI and scaffolding the process of critiquing and revising, students gained competencies in psychological, feedback, and AI literacies.
Teaching implications
Integrating genAI presents opportunities for learning, if educators can think beyond the artifact and design assessment that allows our students to showcase their learning process.
Educators in psychology are shifting focus. While traditional approaches have emphasized students mastering foundational knowledge, many programs now focus on students acquiring competencies that allow them to use that knowledge upon graduation (Nolan & Cranney, 2023). Coined by McGovern et al. (2010), “psychological literacy” refers to students’ ability to apply psychological knowledge and skills to achieve personal, work, and community goals (Cranney et al., 2022). To be psychologically literate, students need to assess the quality of evidence they encounter and translate it for people who do not have training in psychology.
Feedback is key to developing psychological literacy. Students often think of feedback as the information that educators give them to justify a grade on a piece of work, however, Carless and Boud (2018) argue that comments cannot be termed “feedback” unless learners are given the opportunity to make sense of and use them to enhance the quality of their work. Feedback literacy refers to the understandings, capacities, and dispositions needed for students to use feedback to enhance their work (Carless & Boud, 2018).
Assessment in psychology can be built with both psychological and feedback literacy in mind. In a large lower level, social, and developmental psychology course, we have students engage with a science communication project, coined the “Media Assignment.” Students are assigned a recent Psychological Science paper and are tasked with producing a 3–4 min video abstract that showcases the research for a lay audience. The task is to translate the research for teachers, parents, or professionals who are interested in children or social behavior but who do not have a background in psychology. Students work on the Media Assignment in three phases. First, students write a 500-word media release and submit it for peer review. Second, students revise their initial draft, integrating peer feedback and improving their script before submitting for feedback from their tutorial instructor. While instructors mark the submitted revisions, students design graphics to support the story they plan to talk about the research. Third, students integrate feedback from their instructor and have the option to write a rejoinder, outlining for their instructor how they have used the feedback. Finally, they combine their graphics and script and record their final video submission (Richmond, 2024).
There are several strengths of this assessment approach. First, students are tasked with writing with a particular audience in mind. To do this, they need to think about how the research relates to issues in the real world and select the details that are most relevant to their intended audience. Second, the task builds science communication skills. Students need to adopt a writing style that is engaging to a lay audience and design graphics to support their story. Third, the assessment emulates how writing works in the professional world. Students receive feedback on their work from both peers and instructors. As in the workplace, advice from different sources is often not consistent, so students must engage in self-evaluation to decide which pieces of feedback are valid and useful. In addition, the rejoinder writing task scaffolds the process of leveraging feedback to improve their work, building feedback literacy skills.
Although this assessment targets psychological and feedback literacy skills, it does not address the need for artificial intelligence (AI) literacy (Gado et al., 2022). With the rapid development of genAI tools like ChatGPT, students also need to understand, work with, and critically evaluate AI and its applications (Laupichler et al., 2022). This assessment may be particularly at risk in the age of genAI because it requires students to engage in processes that ChatGPT appears to be good at, that is, summarizing and writing in a particular style. With this in mind, in Term 1 2023, we integrated genAI into the three-phase assessment process (see Table 1).
Assessment Activities Associated With Each Phase of the Media Assignment in Social and Developmental Psychology.

Note: The assessment guidelines, templates, and rubrics are available on Open Science Framework https://osf.io/n5pks/, Richmond (2024).
We decided to modify Phase 1 to require students to use ChatGPT (or another genAI tool) to write the first draft of their media release. Instead of providing feedback to their peers in Phase 1, students were tasked with critiquing the output from ChatGPT using a template (Richmond, 2024). First, they were asked to use the script revision marking rubric to give ChatGPT a grade (High Distinction, Distinction, Credit, Pass, Fail) on each of the criteria. Then they were asked to write about three strengths and three weaknesses of the ChatGPT output and three priorities for revision. In Phase 2, students put their revision plan into action, documenting changes to the ChatGPT output using tracked changes in Microsoft Word and submitting their revision for instructor feedback. Phase 3 of the assessment process remained unchanged.
In evaluating this new assessment approach, we were particularly interested in students’ ability to identify the strengths and weaknesses of the ChatGPT output and to use the script revision marking rubric to identify priorities for revision. We evaluated this by comparing the rubric grades that students allocated to ChatGPT for the “Style” criterion to those that students allocated to ChatGPT for the “Aims/Methods/Results” criterion. Given that large language models like ChatGPT are trained on massive volumes of text from the internet, we predicted that the ChatGPT output would be judged highly against the “Style” criterion, which emphasized the importance of language that was free of jargon and technical terms and a writing style that was well-structured, clear, and concise. In contrast, given that large language models do not have access to the details from current published papers and are prone to “hallucination,” we predicted that the model output would contain many inaccuracies when it came to representing the details of the paper. Thus, we hypothesized that students would rate the ChatGPT output more highly on the “Style” criterion than the “Aims/Methods/Results” criterion. We were also interested in the potential benefits of working with genAI and the marking rubric early in the assessment process. We anticipated that the process of applying the marking rubric to grade the ChatGPT output may lead students to use the marking rubrics more actively as they revised their scripts in Phase 2 and produced their final videos in Phase 3, leading to improved grades at these later stages of the assessment. To determine whether working with genAI and the marking rubric had benefits for script and/or final video quality, we compared the grade distributions from T1 2023 to those from the previous year, in which students had written drafts and engaged in a peer feedback exercise, rather than writing an AI critique.
Method
Participants
The participants were 363 undergraduates enrolled in a second-year undergraduate Social and Developmental Psychology course in Term 1 2023 (February–May). The project was approved by the UNSW Human Ethics Advisory Panel C (File #3785) and involved an opt-out consent procedure. Participants were made aware of the purpose of the research and how data from the learning management system would be used via an email from a school administrative officer which was sent 4 weeks after the term had finished. If students preferred that their data were not included, they could opt out by completing a linked form within 2 weeks. There were no students who chose to opt out of the research and data analysis was conducted in July–September 2023. Ethics approval allowed for the access and deidentification of data from the learning management system, which does not include sex or age variables, however, research with UNSW psychology students would suggest a sex distribution 60% female 40% male and an average age of 19.
Additional ethics approval was sought in 2024 to access the gradebook data from the Term 1 2022 course (N = 397) to allow comparison of assessment grades with the previous cohort. Given that much time had elapsed and many students in that cohort had already graduated, seeking consent was deemed impractical. In addition, the gradebook data could be accessed in a nonidentifiable state, so a waiver of consent was approved for the use of this data for research purposes.
Materials and Procedure
The gradebook and AI critique submissions from the T1 2023 cohort were downloaded from the learning management system and deidentified by assigning each student a random participant ID. A research assistant coded each AI critique, recording the grades (High Distinction, Distinction, Credit, Pass, Fail) that students had given the ChatGPT output for each of the six marking criteria. The gradebook items for the script revision and final video submission were downloaded from the T1 2022 cohort without accompanying identifying information. Gradebook items were analyzed to gain insight into student performance on the critique task (T1 2023) and potential differences in script revision and final video performance across cohorts.
Results
In Phase 1, students used the script revision marking rubric to grade the output generated by ChatGPT (Richmond, 2024). For this paper, we present the data for two of the six marking criteria that we expected ChatGPT would do particularly well (“Style”) and particularly poorly (“Aims/Methods/Results”). The “Style” criterion required students to judge whether the ChatGPT output was clear and concise, free from jargon and technical terms, and written in an engaging style that would be suitable for a lay audience. The distribution of grades illustrated in Figure 1 shows that students recognized style as a strength of the output generated by ChatGPT. Most students (92%) gave ChatGPT grades higher than pass.
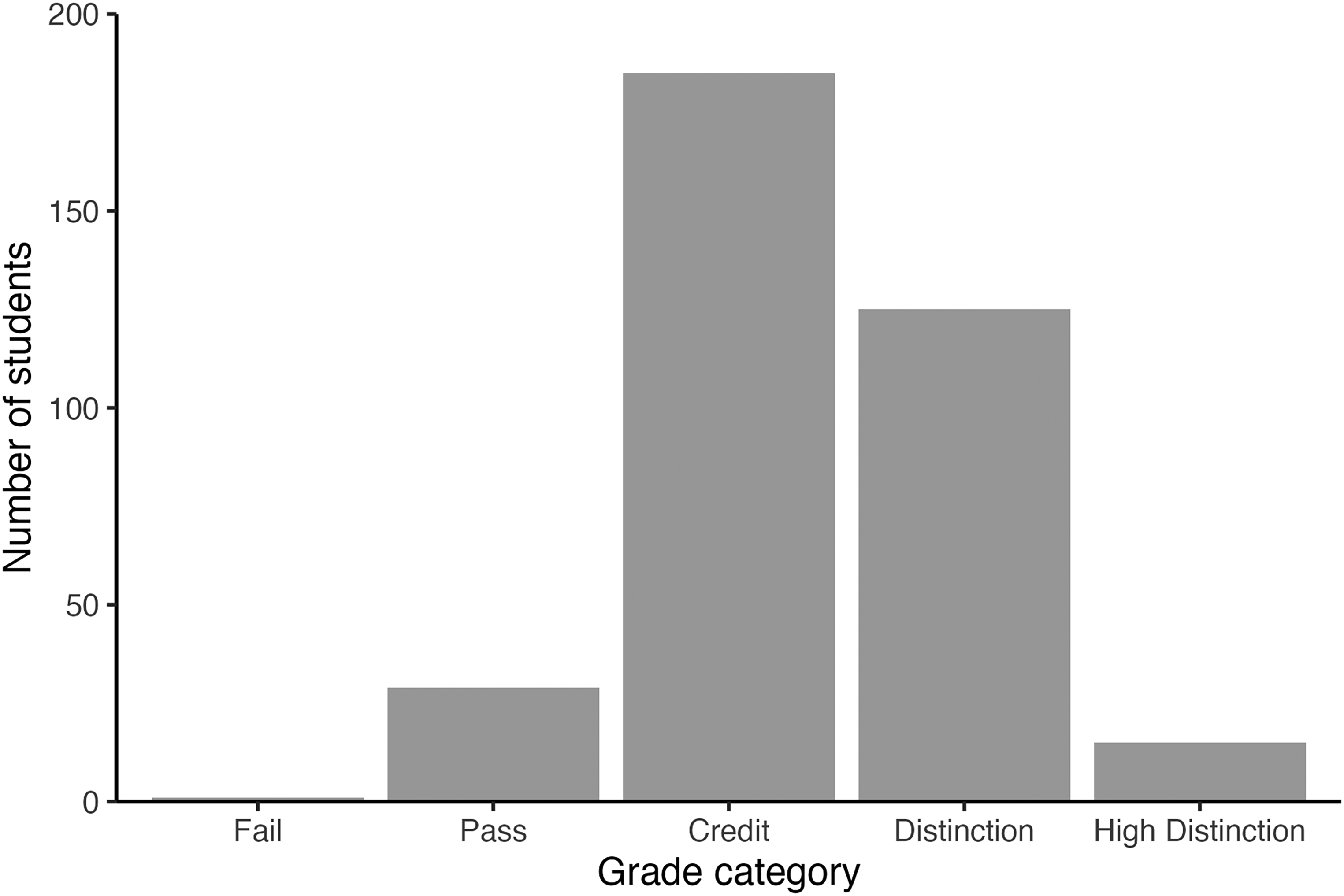
The distribution of grades that students allocated to ChatGPT drafts for the “style” criterion.
In contrast, students were less impressed with how ChatGPT met the requirements of the “Aims/Methods/Results” criterion (see Figure 2). This criterion related to comprehensively and accurately covering what the goal of the research was, what the researchers did and what they found. Here, most students recognized the limitations of what ChatGPT was capable of and rated ChatGPT poorly against the “Aims/Methods/Results” criterion; 94% of students gave ChatGPT marks at credit level or lower.
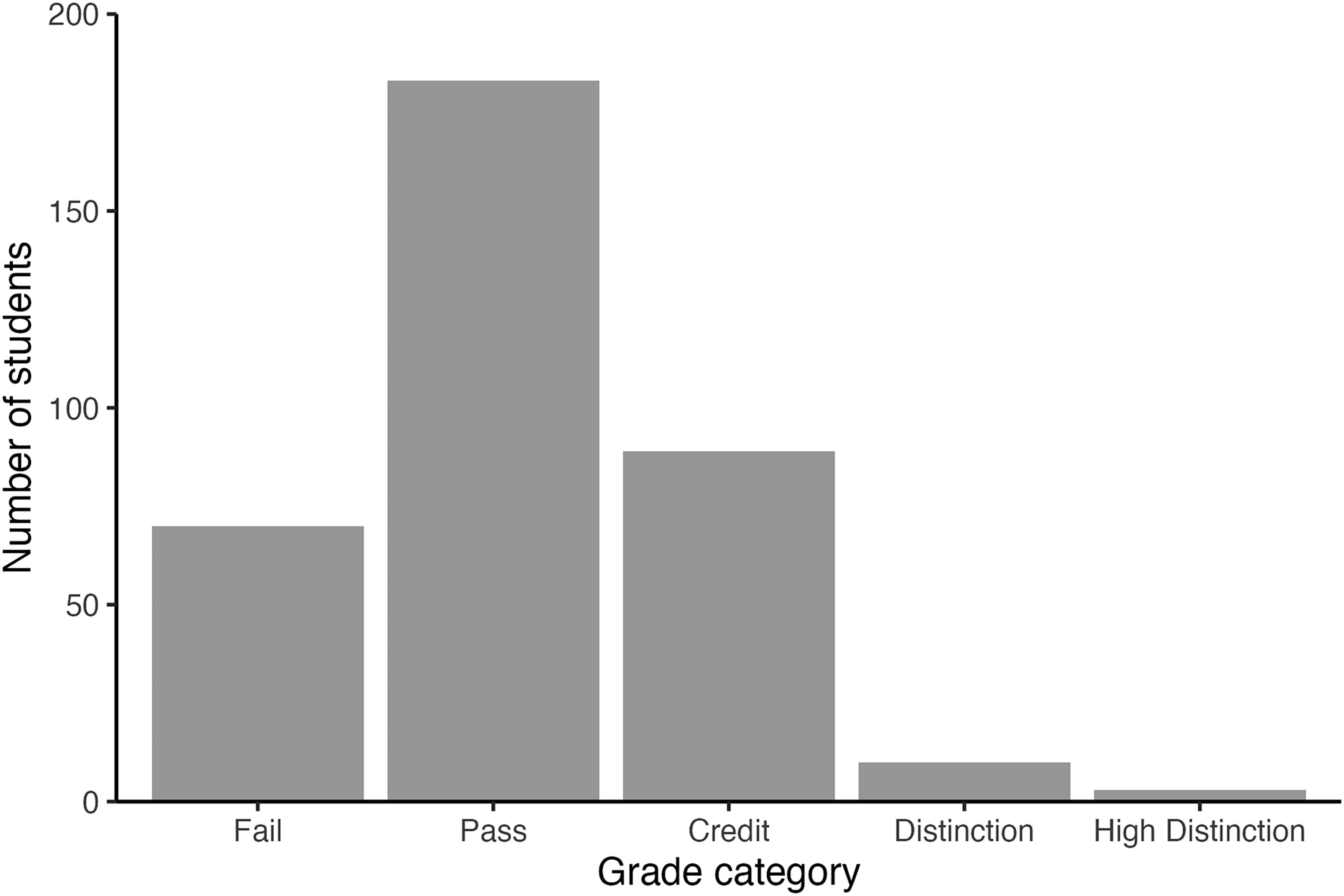
The distribution of grades that students allocated to ChatGPT drafts for the “aims/methods/results” criterion.
To determine whether the allocation of grades differed for each rubric criterion (“Style” and “Aims/Method/Results”), we conducted a Chi-Square Test of Independence. For the “Style” criterion, observed frequencies indicated that 1 student rated the output as Fail, 30 rated as Pass, 185 rated as Credit, 125 rated as Distinction, and 15 rated as High Distinction (Expected frequencies: Fail = 36, Pass = 107, Credit = 137, Distinction = 68, High Distinction = 9). For the “Aims/Methods/Results” criterion, observed frequencies indicated that 70 students rated the output as Fail, 184 rated as Pass, 89 rated as Credit, 10 rated as Distinction, and 3 rated as High Distinction. The Chi-Square test was statistically significant, and large, χ2 (4 = 317.48, p < .001; Adjusted Cramer's V = 0.66, 95% CI [0.60, 1.00]), indicating an association between rubric criterion and grade category. This analysis shows that high rubric scores were overrepresented within the “Style” criterion and low rubric scores were overrepresented in the “Aims/Methods/Results” criterion.
Instructors graded students’ ability to identify strengths and weaknesses of the ChatGPT output and priorities for revision using the AI critique rubric (Richmond, 2024). Students performed well on the AI critique task (see Figure 3). The average grade was 72.7, with 44% of the cohort achieving Distinction and High Distinction grades.
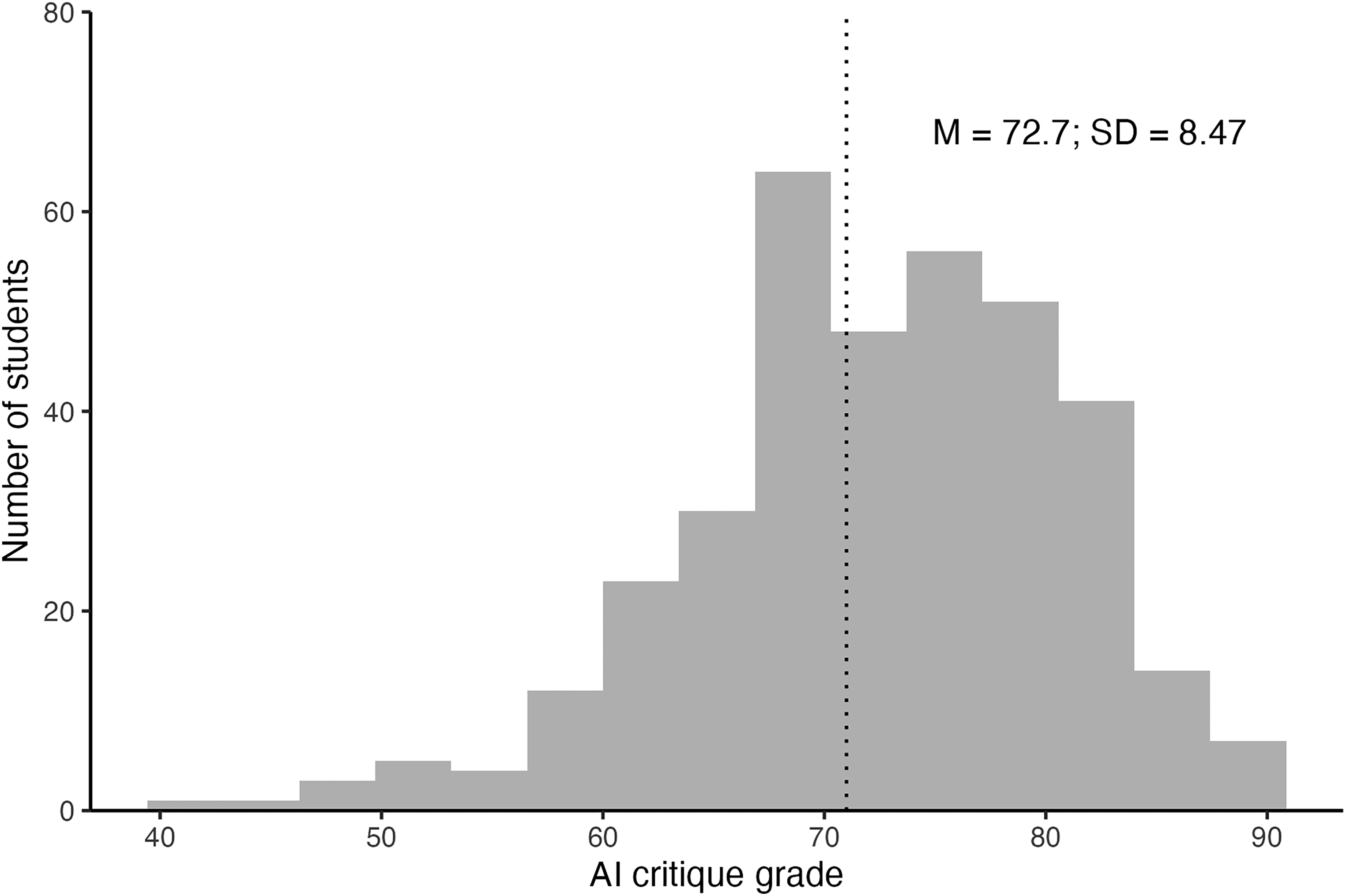
The distribution of grades that instructors allocated to students for the AI critique task.
We were also interested in whether the opportunity to work with genAI and apply the marking rubric to ChatGPT output early in the assessment process had benefits for students’ ability to use the marking criteria to inform their work in Phase 2 (script revision) and Phase 3 (final video). To test this possibility, we compared grades allocated by instructors for these phases of the assessment to grades allocated in the previous year, when students had written drafts and engaged in peer review. The descriptive results are illustrated in Table 2. Our analysis showed that there was a small but significant difference in script revision grades across cohorts. Students who had completed the AI critique task in 2023 performed better on the script revision task than did students who had completed the peer review task in 2022, t(733.05) = 4.93, p < .001, d = 0.36, 95% CI [−0.51, −0.22]. However, there was no significant difference in performance on the final video task, t(732.48) = 1.52, p = .129, d = 0.11, 95% CI [−0.26, 0.03].
Mean Grades for the Script Revision (Phase 2) and the Final Video (Phase 3) in 2022 and 2023.

Discussion
Students used the marking rubric to evaluate a media release draft generated by ChatGPT and were able to identify that the genAI output was stylistically strong but did not comprehensively and accurately reflect the details of the experimental study. Student grades for the AI critique task were high; however, there were a small number of students who failed to recognize inaccuracies in the coverage, giving ChatGPT High Distinction/Distinction grades for the “Aims/Methods/Results” criterion. This suggests that some students may benefit from more scaffolding of the critical thinking process required to evaluate the veracity of output from ChatGPT. When compared to the previous year, in which students had written script drafts and engaged in peer feedback, we saw a significant improvement in performance on the script revision component of the Media Assignment task, however, we are cautious about the source of this benefit.
By allowing students to use genAI to generate a first draft and then scaffolding the process of critiquing and revising, we saw evidence of several key learning benefits. In terms of feedback literacy, the AI critique task required that students engage with the marking rubric early in the term and had some advantages over our previous peer review process. First, ChatGPT produced drafts of a consistent quality, which made the review process more equitable. Second, students were able to be candid in their critique of the output without concern about the reaction that their feedback might produce in the “person” who wrote the draft. In addition, students were asked to implement the revision plan that they had produced, rather than needing to integrate feedback from a peer.
In terms of psychological literacy, the goal of this assessment was to challenge students to write about psychological research for a lay audience and in doing so develop critical thinking, problem-solving, communication, and personal and professional development skills (Nolan et al., n.d.). Removing the technical language that is common in published research and writing about experimental work with a particular audience in mind is a key challenge of this assessment. In rating the ChatGPT output against the marking criteria, students identified the stylistic strengths of AI-generated text, as well as the detail-related weaknesses. In Phase 2, students needed to correct inaccuracies while maintaining the writing style that in some cases, may have been stronger than they could produce themselves. This process highlighted to the instructor team that revising requires quite different competencies than writing. It is possible that this part of the assessment may have been less confronting if we had asked students to reflect on what ChatGPT had done well and poorly, and to use those insights when writing their own media release draft in Phase 2. We are considering trialing this approach in our next implementation.
The process of working with the marking rubric and using it to evaluate output from ChatGPT early in the assessment process may have prompted additional self-evaluation and had benefits for students’ feedback literacy. There were small but statistically significant improvements in grades at the script revision stage relative to the previous year, in which students had written their own draft and received feedback from their peers, before revising their script for grading. While it is possible that these gains resulted from early engagement with the marking rubric, we cannot rule out the possibility that these gains were due to students working from ChatGPT output that was stylistically good. The fact that final video grades were not significantly different between the two cohorts would seem to rule out the possibility that inherent differences between cohorts or instructor teams can account for the benefit. Future research should focus on whether improvements in self-evaluation and feedback literacy can account for the benefits in writing performance that this kind of assessment approach may produce.
Researchers in higher education are pointing to the urgent need to shift the assessment emphasis away from the product and toward the process of learning (Boud, 2020; Lodge et al., 2023). In a world where genAI can produce an artifact (e.g., essay, report, media release, video) that mimics what a human could do, educators need to assess the process that human learners engage in to get to the artifact, rather than the artifact itself. In moving toward an assessment system that emphasizes process, educators will need to scaffold and showcase what the learning process looks like for students whose educational journey has until now, focussed on the output. Learning management systems will also need to evolve to embed version control and tools that make it easy for students to document their learning process.
Bloom's taxonomy is often used to design assessment in higher education (Anderson et al., 2001; Bloom, 1956). The taxonomy is pyramid-shaped; students typically begin with tasks that require them to remember or understand, before engaging with tasks that allow them to apply or analyze their knowledge. While learning outcomes often refer to the highest order processes on the pyramid (i.e., evaluate, create), it is less common for assessment tasks to tap into the top levels of the taxonomy (Halupa, 2017). The idea that good assessment should prioritize the highest levels of the taxonomy is not new (Wright, 2012), however, the idea that genAI can help educators with this is novel (Rivers & Holland, 2023). Assessments like those described here outsource the initial creation process to ChatGPT and give students the opportunity to learn how to evaluate and analyze by working with output that has been created by genAI. By giving students the opportunity to work with artifacts that are in some ways much higher quality than they could have produced themselves, and in other ways much lower quality, we can promote the higher-order cognitive skills that will be required from psychologically literate citizens (Cranney et al., 2022; McGovern et al., 2010).
In summary, the arrival of genAI into the higher education assessment space will likely push educators to make changes to how we think about assessment in higher education (Lodge et al., 2023). The shift away from foundational knowledge towards skills is underway (Nolan & Cranney, 2023), and competencies related to working with genAI productively and ethically will be essential skills for psychology graduates. GenAI presents opportunities to enhance student learning (Rivers & Holland, 2023; Wright, 2012), provided we can think beyond the artifact and design assessment that allows our students to showcase their learning process (Boud, 2020).
Footnotes
Acknowledgments
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.