
Abstract
Psychometric scales are foundational to market research, yet their development is traditionally resource-intensive, slow, and prone to cognitive and cultural bias. Item generation, the stage where abstract constructs are translated into candidate measures, is especially demanding. This paper introduces a methodological framework for integrating generative artificial intelligence (AI) into item generation, illustrated through a proof-of-concept study on the entrepreneurial mindset. We outline a structured human–AI workflow that combines large language model outputs with critical researcher oversight at key decision points. The process demonstrates how AI can rapidly expand item pools, reduce redundancy, and surface alternative phrasings, while expert validation safeguards theoretical fidelity and conceptual clarity. Our framework is both rigorous and adaptable. It provides detailed replication guidance, highlights ethical and practical considerations, and identifies how researchers can transparently document AI use. By showing how AI-assisted item generation can enhance efficiency without compromising validity, this paper rethinks scale development methods for an era where market research must be both conceptually robust and responsive to fast-changing contexts.
Keywords
Introduction
Psychometric scales, once authored exclusively by researchers, can now be co-developed with generative AI. Generative artificial intelligence (AI), particularly large language models (LLMs), is reshaping how knowledge is produced and validated across disciplines. For management and marketing scholars, the implications are transformative. Psychometric scales have long been recognised as essential tools for measuring latent constructs in marketing and management research (Gerbing & Anderson, 1988; Morgado et al., 2018; Nunnally & Bernstein, 1994). Today, these instruments can also be developed using generative algorithms to augment traditional researcher-led approaches.
Psychometric scale development has always been central to advancing theory, however it remains slow, resource-intensive, and vulnerable to conceptual and methodological biases (DeVellis & Thorpe, 2016; Hinkin, 1998; Morgado et al., 2018). Traditional methods safeguard rigour, but at the cost of agility (DeVellis & Thorpe, 2016). In contemporary market research, where consumer preferences and cultural trends evolve rapidly, these constraints sharpen the longstanding paradox between conceptual robustness and adaptability. Recent studies indicate that generative AI offers tools to navigate, though not eliminate, this challenge (DeVellis & Thorpe, 2016; Grassini, 2023; Hoffmann et al., 2024).
Generative AI brings this methodological tension into sharper focus. LLMs can rapidly produce diverse and theoretically anchored item pools, refine phrasing for clarity, and detect redundancies (Beghetto et al., 2025; Hoffmann et al., 2024; Russell-Lasalandra et al., 2024). Early evidence suggests that AI-generated items approach the quality of human-authored ones (e.g. Görgülü et al., 2025), with development timelines reduced from weeks to days. However, these gains risk being offset by challenges of transparency, inclusivity, and researcher agency.
Despite growing interest in AI for research methods, detailed methodological guidance remains scarce (Behrend & Landers, 2025; Grassini, 2023; Hoffmann et al., 2024). While some studies outline AI’s potential across the entire scale development process, the item generation stage, widely recognised as the most cognitively demanding and consequential for translating theory into measurement (Hinkin, 1998; Morgado et al., 2018), remains underexplored. This paper does not seek to publish a fully validated scale; rather, it offers a methodological deep dive into AI-assisted item generation, illustrated through the entrepreneurial mindset as a proof-of-concept. Full validation analyses, including factor structure, reliability, and cross-cultural replication, will be reported separately.
This paper makes both a practical and a theoretical contribution. Practically, it offers researchers a replicable workflow for embedding AI responsibly into item generation. Theoretically, it reconceptualises item generation, not as a traditionally opaque process reliant on expert judgement, but as one that can be rendered transparent, auditable, and open to scrutiny. Together, these contributions highlight how psychometrics may evolve in an AI era, where efficiency gains are balanced with the preservation of conceptual integrity.
Psychometric Scale Development and AI in Market Research
Psychometric scales are indispensable in market research, providing the foundation for measuring latent constructs (Gerbing & Anderson, 1988; Nunnally & Bernstein, 1994), such as consumer trust (Morgan & Hunt, 1994), brand loyalty (Chaudhuri & Holbrook, 2001), customer engagement (Hollebeek et al., 2014), and service quality (Parasuraman et al., 1988). By rendering complex psychological and behavioural phenomena measurable, scales enable researchers to generate insights that inform marketing strategies and organisational decision-making.
Comparison of Traditional and AI-Assisted Psychometric Scale Development
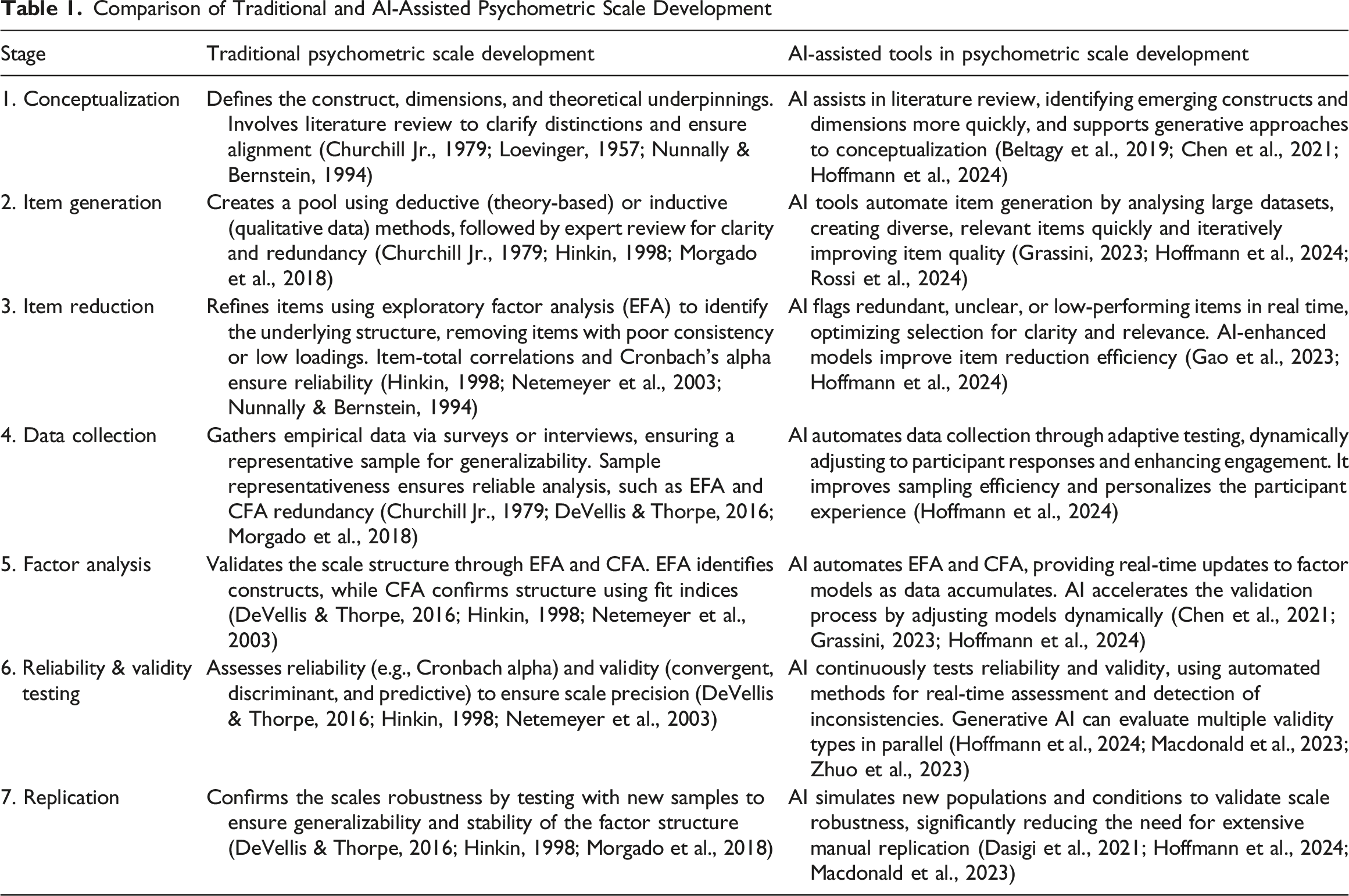
These frameworks were conceived in a slower-paced research environment, where constructs such as brand loyalty or service quality were relatively stable, and multi-year scale development projects were feasible. In contemporary market research, however, consumer preferences, digital platforms, and cultural trends shift rapidly. Traditional processes, with their cycles of literature review, expert evaluation, and repeated empirical testing, are increasingly out of step with practice. They are resource-intensive, slow, and vulnerable to incomplete reporting, especially at the item generation stage, where methodological opacity often limits replication and adaptation across studies (DeVellis & Thorpe, 2016; Morgado et al., 2018). At the same time, construct definitions and item wording are shaped by human cognitive and cultural biases, which can compromise clarity, inclusivity, and reliability (Hinkin, 1998; Morgado et al., 2018).
This creates a paradox at the heart of psychometric research. The very rigour that ensures validity often undermines timeliness, while the responsiveness required in practice threatens conceptual precision. For market researchers facing globalised, digitised, and rapidly shifting consumer environments, the challenge is not simply to accelerate scale development but to reimagine its methodological foundations.
Generative AI enters precisely at this juncture. By streamlining item generation and expanding conceptual coverage, it offers tools to manage, though not eliminate, the tension between methodological rigour and practical responsiveness (Beghetto et al., 2025; Hoffmann et al., 2024; Russell-Lasalandra et al., 2024). Its role is not merely to accelerate existing methods. If candidate items are produced by machines rather than human theorists, questions of validity, originality, and researcher agency must be reopened. Equally, transparency becomes critical. Researchers need to show how prompts, models, and iterations influence the resulting item sets, so that processes remain auditable and replicable. The opportunity, therefore, is not only to improve efficiency but also to reconsider how constructs are operationalised, validated, and adapted in an AI era.
Transforming Scale Development with AI
Table 1 juxtaposes the seven traditional stages of scale development with the ways AI-driven methodologies diverge from them. At each stage, AI promises not only to reduce time and resource requirements but also to challenge assumptions about how theoretical constructs are operationalised. Tools such as OpenAI’s ChatGPT, Anthropic’s Claude, Google’s Gemini, and Meta’s LLaMA now leverage neural networks and natural language processing (NLP) to automate tasks once seen as the exclusive domain of expert judgement, including literature synthesis, item generation, and refinement (Beghetto et al., 2025; Grassini, 2023; Hoffmann et al., 2024; Russell-Lasalandra et al., 2024).
The impact begins with conceptualisation. Traditionally, this stage depends on manual literature reviews and expert consensus to define and structure constructs (Churchill Jr., 1979; Loevinger, 1957; Nunnally & Bernstein, 1994). Recent AI-enabled approaches extend this capacity by scanning large corpora to identify emerging constructs, map theoretical clusters, and flag contradictions (Grassini, 2023; Hoffmann et al., 2024; Russell-Lasalandra et al., 2024). Dedicated research assistants such as Elicit, Consensus, and ResearchRabbit further enable thematic clustering and cross-study comparisons, opening possibilities for more comprehensive and transparent conceptualisation. This shifts the epistemic balance. Conceptual clarity is no longer solely the product of expert synthesis but becomes partially machine-mediated, raising questions about authority, originality, and researcher agency.
Currently, AI’s most significant contribution lies in item generation, historically the most resource-intensive and opaque stage. Traditional approaches combine deductive and inductive logics, producing items from theory and qualitative data before subjecting them to expert review (Churchill Jr., 1979; Hinkin, 1998; Morgado et al., 2018). Cognitive limitations often result in redundancy and uneven construct coverage, and reporting of this stage is often incomplete, limiting transparency and replication across studies (DeVellis & Thorpe, 2016; Morgado et al., 2018). Generative AI, by contrast, can rapidly produce large, diverse, and theoretically anchored item pools (Beghetto et al., 2025; Russell-Lasalandra et al., 2024). It can refine language for clarity, flag redundancies, anticipate response patterns, and support translation across cultural contexts (Grassini, 2023). This automation broadens both the scale and inclusivity of item generation, but it also shifts the researcher’s role from originator to curator. Validity becomes a hybrid achievement of human–AI collaboration, demanding new norms of disclosure about prompt design, model selection, and filtering procedures.
Beyond item generation, AI also has potential to reshape validation and analysis. At the questionnaire design stage, adaptive logic can tailor question paths to respondents, reducing fatigue and enhancing data quality (Clickup, 2024; Hoffmann et al., 2024; infodesk, 2024). Synthetic datasets are already being used in market research practice to pre-test scales and identify weaknesses before field deployment (e.g., NielsenIQ, 2024; Parmar, 2024), suggesting a methodological opportunity for academic psychometrics. During administration, AI-enabled platforms dynamically manage recruitment and stratification, ensuring representation and higher response rates (e.g., SurveySensum, 2024). In analysis, AI can support statistical routines such as factor analysis and reliability testing, offering efficiency gains while raising questions of transparency and researcher agency (Beghetto et al., 2025; Hoffmann et al., 2024; Russell-Lasalandra et al., 2024). The result is not simply a faster pipeline but a methodological environment where simulation, automation, and adaptation become integral to scale development practice.
Taken together, these innovations point to a paradigm shift. Traditional frameworks privileged rigour and transparency, often at the cost of speed. AI introduces the prospect of combining rigour with agility, but it also embeds new dependencies, including opacity of algorithms, risks of homogenisation, and the amplification of bias. For psychometricians and marketing researchers alike, AI should not be viewed merely as a technical supplement but as a catalyst for rethinking what it means to build, test, and validate scales. The ethical and practical consequences of this transformation are considered later in this paper, where we outline safeguards for responsible adoption.
Methodological Framework for AI-Assisted Item Generation
Item generation has long been regarded as the most cognitively demanding stage of psychometric scale development. It requires balancing theoretical precision with linguistic nuance, ensuring construct coverage without redundancy, and anticipating how items will be interpreted across diverse respondents and contexts. Traditional methods rely heavily on human expertise, iterative consensus-building, and qualitative input. While robust, these approaches are resource-intensive, shaped by researcher bias, and often under-reported in ways that undermine replication and adaptation across studies (Hinkin, 1998; Morgado et al., 2018).
Generative AI alters this methodological terrain. Its ability to rapidly generate large, diverse, and theoretically anchored item sets allows researchers to break through long-standing constraints of time, cost, and cognitive limits (Beghetto et al., 2025; Hoffmann et al., 2024; Russell-Lasalandra et al., 2024). AI does not simply accelerate an existing process. It redefines the locus of creativity, shifting the researcher’s role from sole author to collaborative curator of machine-generated possibilities, consistent with typologies that frame LLMs as research assistants rather than autonomous authors (Behrend & Landers, 2025). This reframing raises both opportunities for rigour, by expanding item pools, surfacing overlooked dimensions, and reducing blind spots, and risks of opacity, homogenisation, or misplaced trust in algorithmic outputs. Any framework for AI-assisted item generation must therefore grapple explicitly with this methodological tension, namely the simultaneous pursuit of efficiency and conceptual integrity (Grassini, 2023). To address this challenge, we propose a five-component framework for embedding generative AI into scale development while maintaining transparency and replicability. 1. Establishing conceptual foundations: Item generation must remain anchored in clear theoretical definitions and construct boundaries. AI prompts should be theory-driven rather than ad hoc, ensuring that breadth does not come at the expense of construct validity. 2. Outlining a step-by-step workflow: Researchers should specify how AI outputs are generated, filtered, and refined through human oversight. Documenting iterations and decision rules creates an auditable trail and mitigates the opacity that often surrounds both human and machine processes. 3. Specifying prompts and parameters: Transparency requires that the precise inputs, model type, temperature settings, prompt structures, are disclosed. Such reporting reduces hidden variation, enhances replicability, and allows future researchers to evaluate how modelling choices influenced item outputs. 4. Comparing AI-assisted and traditional approaches: To assess methodological value, AI-generated items should be systematically evaluated against those produced through conventional methods. This includes coverage of construct dimensions, redundancy levels, and downstream psychometric quality. 5. Addressing ethical and practical considerations: Responsible adoption requires explicit attention to risks of bias, opacity, and over-reliance. Safeguards include cross-validation across models, cultural adaptation, disclosure of AI involvement, and training researchers to critically interrogate outputs.
Although illustrated here through the entrepreneurial mindset scale as a proof-of-concept, the framework is designed for broader application. Constructs central to market research, including customer trust, brand loyalty, and service quality, can be operationalised through this workflow. In this way, the framework does not merely automate item generation; it offers a replicable, transferable model that demonstrates how psychometric practice itself is evolving in the age of AI.
Conceptual Foundations
Establishing robust conceptual foundations is the first step in psychometric scale development. For this proof-of-concept, we selected the entrepreneurial mindset, a construct widely invoked across entrepreneurship, management, and education but inconsistently defined (Kuratko et al., 2020; Naumann, 2017; Zappe, 2018). Its fragmented conceptualisation illustrates a broader challenge in market research, where core constructs such as consumer trust or brand engagement are similarly diffuse, contested, and operationalised in divergent ways. Demonstrating how generative AI can advance conceptual alignment in such contexts underscores its broader methodological significance.
To ground the construct, we conducted a systematic literature review following established protocols (e.g., Denyer & Tranfield, 2009; Macpherson & Jones, 2010; Tranfield et al., 2003). Searches across EBSCO Host, ProQuest, and Scopus identified 2,370 publications, of which 427 peer-reviewed articles were retained after screening (see Figure 1). Using NVivo, we coded definitions and conceptualisations of entrepreneurial mindset, extending Hruby’s et al. (2016) thematic analysis of global mindset definitions and related frameworks (Davis et al., 2016; Kuratko et al., 2020; London et al., 2018; Naumann, 2017; Robinson & Gough, 2020; Shekhar et al., 2019). Four recurrent themes emerged: cognition, competence (knowledge, skills, and attributes), personality, and predisposition (attitudes and behaviours). Summary of the Systematic Literature Review Methodology (Adapted From Zahoor et al., 2020)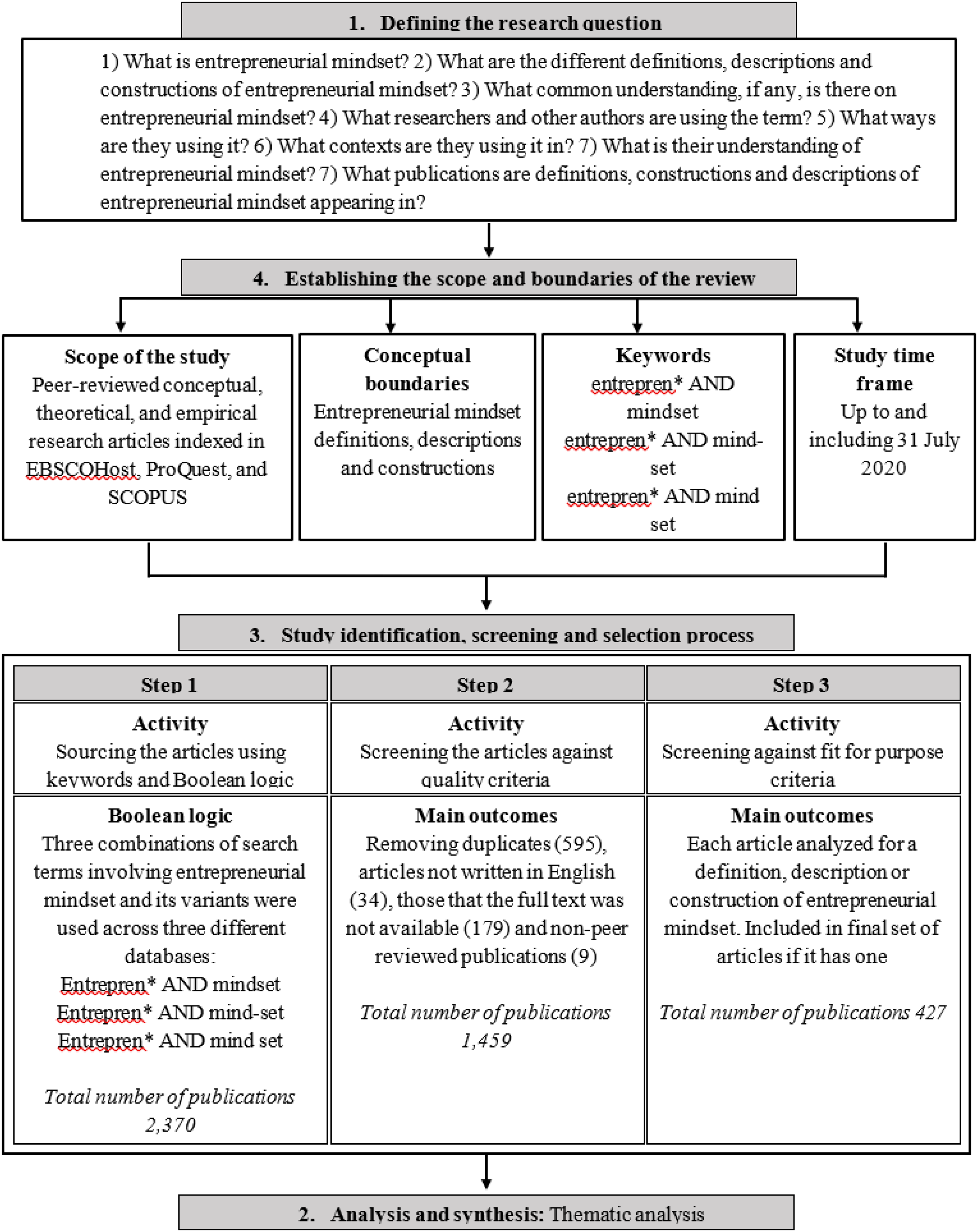
A critical insight from this review is that the entrepreneurial mindset has deep but underexplored roots in cognitive psychology. Early research by the Würzburg School emphasised how tasks (“Aufgaben”) activate cognitive processes that orient individuals toward particular responses (French II, 2016; Gibson, 1941; Gollwitzer, 1990, 2012; Mathisen & Arnulf, 2014). Despite this lineage, contemporary treatments often neglect cognition, resulting in conceptual drift (Buchanan & Kern, 2017; Mathisen & Arnulf, 2014). Re-grounding the entrepreneurial mindset in cognitive psychology not only strengthens its theoretical coherence but also parallels the development of widely used marketing constructs (e.g., brand attitudes, service quality), which are similarly anchored in cognitive–behavioural theory.
ChatGPT Prompts

The resulting definition was: An entrepreneurial mindset refers to a mental framework or lens through which an individual selectively perceives and interprets information, guiding their understanding, actions, and responses in the context of entrepreneurship. It is shaped by past experiences and evolves through interaction. The mindset filters and biases information processing, reinforcing existing beliefs and behaviours, but remains open to change and adaptation when confronted with inconsistent information. Individuals with such a mindset are self-aware of their cognitive filters, enabling them to navigate complexity, ambiguity, and dynamism in entrepreneurial contexts.
This definition anchored subsequent item generation and highlights a broader methodological insight. AI-assisted synthesis can clarify contested constructs by generating candidate formulations that are then refined through human expertise. In market research, where constructs such as consumer trust and brand engagement are equally fragmented, such a workflow offers a replicable pathway toward conceptual consolidation.
Step-by-Step Workflow for AI-Assisted Item Generation
Item generation is one of the most consequential stages in psychometric development because the breadth, clarity, and theoretical fidelity of the initial pool determine all subsequent testing (Churchill Jr., 1979; Hinkin, 1998; Morgado et al., 2018). Traditional approaches combine deductive theory and inductive qualitative insights but are resource-intensive and constrained by human cognition, often yielding pools that are narrow, redundant, or biased (DeVellis & Thorpe, 2016; Netemeyer et al., 2003).
AI-Supported Item Generation Process

Dimensions and Example Items for the Entrepreneurial Mindset Scale

Each tool contributed in different ways. ChatGPT produced broad and semantically diverse item pools, Bard (Gemini) assisted with redundancy detection and semantic clustering, and Grammarly aided in linguistic refinement. Human researchers remained central throughout, removing vague or leading items, checking reverse-coded items, eliminating potential construct contamination (for example, drift toward entrepreneurial orientation), and verifying cultural neutrality. While redundancy reduction was partly automated through cross-model comparison and similarity clustering, final decisions rested with expert reviewers.
This hybrid AI–human workflow accelerated development while maintaining theoretical alignment. Just as importantly, it established a replicable process. Prompts, parameters, and decision criteria were documented so that future researchers can reproduce or adapt the workflow. In addition to the procedures applied in this study, the methodological framework also outlines several advanced techniques, such as semantic similarity clustering with vector embeddings (Russell-Lasalandra et al., 2024), persona-based simulated respondent testing, and adaptive logic, as prospective enhancements to AI-assisted item generation. Overall, the workflow illustrates how generative AI can be embedded into item generation in ways that increase efficiency without undermining conceptual integrity. It signals a methodological shift in which researchers move from sole authorship to critical curation and auditing of machine-generated outputs, ensuring that psychometric rigour remains grounded in human judgement.
Comparative Analysis
Comparison of Traditional vs. AI-Assisted Item Generation

The chief advantage of AI-assisted item generation lies in efficiency and breadth. Generative models such as ChatGPT or Gemini can produce hundreds of candidate items in a fraction of the time required for traditional approaches, while redundancy detection and semantic clustering help to minimise conceptual blind spots. However, these advantages come with caveats. Commercial LLMs function with limited transparency, leaving researchers little insight into their internal processes (Dwivedi et al., 2023; Zhuo et al., 2023) whose inner workings are inaccessible to researchers. They also reflect cultural and linguistic asymmetries present in the corpora on which they are trained (Bender et al., 2021; Ferrara, 2023; Weidinger et al., 2021), which can compromise inclusivity and construct validity if not actively mitigated.
Equity presents another challenge. Uneven access to premium AI platforms across institutions and geographies may widen methodological divides between well-resourced and less-resourced scholars. In the absence of deliberate safeguards, such disparities risk reinforcing structural inequities in opportunities to innovate within psychometric practice.
For these reasons, AI should be understood not as a replacement for traditional methods but as a complement to them. Where traditional approaches emphasise rigour, transparency, and theoretical fidelity, AI contributes speed, scalability, and semantic variation. The methodological opportunity lies in integration. Developing hybrid workflows that retains the strengths of both while mitigating their respective weaknesses.
AI Prompts and Parameters
Prompt design is central to both transparency and replicability. Poorly structured prompts risk conceptual drift, whereas well-designed prompts anchor item generation in theoretical definitions (Beghetto et al., 2025; Gao et al., 2023; Russell-Lasalandra et al., 2024).In this study, prompts were anchored in established definitions, constrained for psychometric suitability (DeVellis & Thorpe, 2016; Hinkin, 1998), and designed to balance semantic breadth with conceptual precision. Different tools were employed in complementary ways, with ChatGPT providing creative breadth, Bard assisting with redundancy detection, and Grammarly refining language. Cross-model triangulation further enhanced robustness by reducing the likelihood of overfitting to any single model’s idiosyncrasies (Chen et al., 2021; Dwivedi et al., 2023).
The deliberate documentation of prompt structures, parameter settings, and workflow decisions was not ancillary but central to methodological rigour. Full prompt sets and configurations are provided in Appendix A, enabling replication and critical evaluation. In doing so, the study offers a template for transparent reporting in AI-assisted psychometrics.
Ethical and Practical Considerations
Generative AI introduces methodological opportunities but also a new layer of risk. Transparency is a longstanding weakness in psychometric item generation, which has often been described as a “black box” process (Morgado et al., 2018). Researchers seldom disclose how candidate items were produced, or which ones were discarded and why. AI threatens to compound this opacity unless prompts, model parameters, and workflow decisions are disclosed in sufficient detail (Görgülü et al., 2025; Russell-Lasalandra et al., 2024).To counter this, our framework embeds replication readiness by publishing the full set of prompts and configurations, making explicit processes that have traditionally remained opaque.
Bias represents another systemic challenge. LLMs inherit cultural, gendered, and linguistic asymmetries from their training corpora (Bender et al., 2021; Ferrara, 2023). In our outputs, we observed gendered phrasing and culturally narrow examples, patterns that were mitigated through cross-model triangulation and human auditing but not fully eliminated (Grassini, 2023; Macdonald et al., 2023). Long-term mitigation will require domain-specific architectures, including fine-tuned models or retrieval-augmented generation, trained on corpora that are diverse, representative, and context-sensitive (Lewis et al., 2021; Russell-Lasalandra et al., 2024).
Privacy and deployment risks further complicate adoption. Commercial LLMs raise unresolved concerns about data ownership, security, and model retraining (Dwivedi et al., 2023; Zhuo et al., 2023). These risks are especially pertinent in market research, where psychometric instruments routinely capture sensitive attitudinal and behavioural data. Addressing them requires privacy-by-design principles (Dasigi et al., 2021), and movement toward locally hosted or RAG-enhanced models that minimise dependence on proprietary platforms (Hoffmann et al., 2024).
Together, these concerns underline a key point. AI-assisted psychometrics is not only a technical innovation but also an ethical practice. Without robust safeguards, efficiency gains may be offset by hidden risks to validity, inclusivity, and trust, reinforcing the need for structured human oversight of LLM use in research (Behrend & Landers, 2025).
Case Study: Entrepreneurial Mindset Scale – Proof of Concept
The AI-assisted workflow (Table 3) was applied to the entrepreneurial mindset construct as a proof of concept. The aim was not to provide an exhaustive procedural account but to illustrate what changes when generative AI is embedded into the most cognitively demanding stage of psychometric scale development. Specifically, the case illustrates the accelerated production of a pilot-ready scale, alongside the design of test samples and initial psychometric evidence. The methodological framework outlines advanced options such as semantic similarity clustering, simulated respondents, and adaptive logic as potential extensions to the workflow. These were not applied in this proof-of-concept study, which focused solely on item generation and refinement.
Application of the workflow generated a 33-item pool mapped onto six cognitive dimensions of entrepreneurial mindset. What would normally require weeks of expert consultation and iterative drafting was achieved in fewer than three days. This acceleration proved decisive. It enabled inclusion of the scale in the 2023–24 Global University Entrepreneurial Spirit Students’ Survey (GUESSS). Without AI, the development timeline would almost certainly have precluded participation. The case, therefore, demonstrates how AI expands the time horizons of psychometric development, enabling bespoke scale design under severe time and resource constraints.
Acceleration did not eliminate the need for oversight. Generative AI produced diverse candidate items, but human intervention remained indispensable. For example, a generic item such as “I can adapt to changes in my environment” was sharpened into “I can quickly adjust my strategies when encountering unexpected challenges.” Items drifting toward entrepreneurial orientation, a related but distinct construct, were excluded, and reviewers flagged ambiguous or culturally biased phrasing. This illustrates the central tension of AI-assisted methods: the very tools that expand item breadth simultaneously increase the risk of construct drift and bias, thereby amplifying the importance of researcher judgement.
Feasibility testing of the AI-generated items was conducted with two university student samples, reflecting the scale’s intended application in entrepreneurship education contexts. The first dataset came from the 2023–24 Global University Entrepreneurial Spirit Students’ Survey (GUESSS) at the University of Auckland (n = 1,319). The second dataset was collected in the United Kingdom via Prolific Academic’s student panel (n = 510). Prolific’s pre-screening ensured that only currently enrolled higher-education students were recruited. This dual-sample design strengthens the initial feasibility test and demonstrates the applicability of AI-generated items within entrepreneurship education contexts.
Preliminary psychometric checks were promising. Internal consistency exceeded conventional thresholds for most dimensions (Nunnally & Bernstein, 1994), although heuristics fell slightly below. Exploratory factor analysis suggested a two-factor higher-order structure, with entrepreneurial alertness loading strongly on one factor. Reverse-coded items proved unstable and were removed, consistent with prior cautionary notes on their reliability (DeVellis & Thorpe, 2016). These findings are presented as evidence of feasibility, with full validation to follow in subsequent work.
The case, therefore, illustrates both the promise and limits of automation. AI reduced development time, broadened semantic coverage, and enabled participation in an international survey under compressed timelines. Human oversight was vital in refining items, clarifying ambiguities, and preserving theoretical integrity. AI altered, rather than displaced, researcher involvement. It redirected effort from drafting to the critical tasks of evaluation, curation, and ethical governance.
Rather than substituting for human expertise, it reconciles speed with rigour by redistributing expertise to the points where it is most valuable. The lessons extend well beyond entrepreneurship. Constructs such as brand loyalty, consumer trust, and perceived service quality also require measures that are both theoretically robust and adaptable to fast-changing contexts. In this process, generative AI delivers acceleration and semantic breadth, while human researchers safeguard conceptual clarity, cultural sensitivity, and ethical integrity. To support replication, the study provides full prompt sets, model parameters, and decision criteria in Appendix A.
Implications for Psychometric Scale Development in Market Research
This study carries significant implications for market research, highlighting new ways to enhance the efficiency, adaptability, and transparency of psychometric scale development (Russell-Lasalandra et al., 2024). Generative AI enables faster development while supporting precision in construct operationalisation. Constructs central to marketing practice, like brand loyalty, customer engagement, trust, and perceived service quality, demand instruments that are theoretically robust yet agile enough to adapt to fast-changing contexts.
One implication lies in rapid contextual customisation. Traditional development cycles require lengthy iterations between literature reviews, expert panels, and focus groups, delaying actionable insights. By contrast, generative AI can analyse real-time consumer data, linguistic usage, and cultural nuance to propose items attuned to specific cohorts or industries (Hoffmann et al., 2024). A loyalty scale could be adapted for younger versus older consumers, or a trust measure fine-tuned for financial services versus social media, without restarting the entire development process. This yields instruments that are contextually specific while remaining timely, thereby enhancing their managerial relevance (Gao et al., 2023).
A second implication concerns scalability across markets and populations. Global studies often require substantial manual effort to adapt instruments while retaining comparability. Generative AI can produce parallel item pools tailored to local contexts yet linked to a common measurement framework (Russell-Lasalandra et al., 2024). For multinational firms tracking brand engagement, this allows instruments to be simultaneously localised and standardised. Such scalability accelerates timelines and enables more granular segmentation, strengthening responsiveness to diverse consumer environments.
A third implication is the capacity to move beyond static measurement. AI tools can generate items responsive to emerging discourse, such as consumer reactions during a viral campaign (Rossi et al., 2024). Adaptive questionnaires, which dynamically adjust items based on prior responses, reduce redundancy and fatigue while improving psychometric quality (Grassini, 2023). This signals a shift toward more adaptive, respondent-centred measurement, fulfilling a long-standing aspiration in market research for instruments that evolve alongside consumer behaviour.
The study also underscores the value of hybrid workflows. In practice, different tools proved complementary, with ChatGPT generating semantically rich items, Bard resolving redundancies, and Grammarly refining linguistic clarity. Coupled with expert judgement, this ensemble yielded a more diverse and precise item pool. The implication for practitioners is clear. AI does not replace expertise but redistributes it. Researchers become curators and auditors of item pools rather than sole originators, shifting attention toward construct integrity, theoretical alignment, and ethical safeguards (Dwivedi et al., 2023).
Looking ahead, three domains require particular attention. 1. Cross-cultural and multilingual adaptation. Generative AI can accelerate translation, detect idiomatic mismatches, and flag culturally loaded phrasing, lowering the cost of international studies. Systematic testing of equivalence remains essential to guard against false comparability. 2. Respondent experience. While AI can streamline surveys, little is known about how respondents perceive AI-generated items. Do they appear clearer and more engaging, or less trustworthy because of their perceived artificiality? Comparative studies of data quality and engagement will determine whether efficiency gains translate into authentic insight. 3. Safeguards against automation complacency. The speed of AI risks premature adoption of unvalidated scales in commercial contexts. Protocols must therefore be institutionalised. These include expert panels for construct definition, mandatory reliability and validity testing, and training for critical interrogation of AI outputs. Without such safeguards, efficiency could erode conceptual clarity and ethical integrity.
In sum, the implications extend well beyond the entrepreneurial mindset. Generative AI can accelerate conceptualisation, broaden item diversity, enable adaptive and cross-cultural measurement, and provide scales that are both timely and psychometrically rigorous. However, these benefits are realised only if researchers resist over-reliance, attend to inclusivity and respondent trust, and maintain institutional safeguards. Under such conditions, AI functions not only as a tool for efficiency but as a catalyst for re-examining psychometric practice, recasting scale development as a more agile, transparent, and participant-centred process at the heart of market research. Recent work has outlined general frameworks for how large language models can be incorporated into organisational research (Behrend & Landers, 2025). Building on this foundation, the present study demonstrates how those principles can be operationalised within market research through a replicable, construct-focused workflow for psychometric scale development.
Limitations
Several limitations of this study should be acknowledged. First, it does not present a fully validated scale. The entrepreneurial mindset instrument is offered as a proof of concept, with full validation, including confirmatory factor analysis, reliability testing, and assessments of convergent and discriminant validity, to be reported separately. Accordingly, this study is positioned as a methodological contribution on AI-assisted item generation rather than as the presentation of a finalised instrument.
Second, the study relies on commercial large language models (LLMs). While these platforms offer accessibility and replicability, they are constrained by opaque “black-box” architectures and by the cultural and linguistic biases embedded in their training data (Dwivedi et al., 2023; Hoffmann et al., 2024). Their use illustrates both the potential and the tension of AI in scale development. Models accelerate item generation but at the cost of transparency and interpretability. Domain-specific alternatives such as fine-tuned open-source models or retrieval-augmented generation (RAG) architectures may offer greater control, bias mitigation, and theoretical traceability (Grassini, 2023; Russell-Lasalandra et al., 2024). Comparative evaluations of these architectures remain an important next step.
Third, the case study is narrow in scope. Entrepreneurial mindset is a useful illustrative construct but remains peripheral to the central concerns of market research, and the initial testing relied on Western-educated student samples. As a result, the generalisability of AI-generated items across constructs, industries, and cultural settings is unproven. Establishing robustness through cross-cultural, multilingual, and industry-specific validation is therefore a critical research priority (Beghetto et al., 2025; Görgülü et al., 2025). This limitation highlights the need for work that positions AI not only as a technical aid but also as a tool for inclusive and globally relevant measurement.
Finally, this study concentrated on the technical workflow of item generation rather than respondent experience or longer-term researcher practices. Risks such as automation complacency where researchers over-trust AI outputs require careful management through explicit validation protocols, ethical safeguards, and training in human–AI collaboration (Dwivedi et al., 2023; Hoffmann et al., 2024). Equally, little is known about how respondents perceive AI-generated items. Whether they view them as clearer, more engaging, or less trustworthy than human-authored items, remains an open question with direct implications for data quality and instrument legitimacy.
Taken together, these limitations suggest three priority directions for future research: (1) advancing beyond commercial LLMs to domain-specific and transparent architectures, (2) extending validation across cultures, languages, and industries to establish generalisability, and (3) examining the behavioural dynamics of human–AI collaboration from both researcher and respondent perspectives. Addressing these gaps will be essential for establishing AI as a rigorous, transparent, and globally relevant tool for psychometric scale development.
Conclusions
This paper advances methodological practice in market research by demonstrating how generative AI can be systematically integrated into psychometric scale development. Focusing on the pivotal stage of item generation, we outlined a replicable framework that translates theoretical constructs into candidate items through prompt engineering, accelerates production without compromising conceptual rigour, and embeds safeguards through structured human oversight (Russell-Lasalandra et al., 2024). The entrepreneurial mindset case served as a proof of concept, showing how constructs that typically require weeks of expert iteration can be operationalised within days and incorporated into international surveys under real-world constraints.
The central contribution lies in reframing item generation as a methodological contradiction where acceleration and opacity coexist. Generative AI compresses timelines dramatically (Beghetto et al., 2025), but its “black-box” nature threatens transparency and introduces bias (Dwivedi et al., 2023; Hoffmann et al., 2024). The hybrid human–AI process demonstrated here shows that this tension can be managed productively. Automation broadens the semantic and conceptual scope of item pools, while expert oversight safeguards validity, alignment, and ethical integrity. Efficiency is therefore best understood not as an end in itself but as a redistribution of researcher effort from routine drafting to higher-order judgement and curation (Görgülü et al., 2025).
The study also underscores the need to extend inquiry beyond a single case. Entrepreneurial mindset is peripheral to the core concerns of market research, and reliance on Western student samples limits generalisability. Constructs central to marketing practice, such as brand loyalty, consumer trust, engagement, and perceived service quality, provide vital testbeds for assessing whether AI-assisted methods can deliver scalable, context-sensitive, and globally relevant instruments. Systematic replication across industries, populations, and cultural contexts will be essential if AI is to be consolidated as a robust methodological resource.
More broadly, the findings point toward a re-examination of psychometric practice in an AI era. Item generation has long been a labour-intensive yet opaque preliminary step (Morgado et al., 2018). Generative AI transforms it into an auditable and replicable process in which prompts, parameters, and decision rules can be documented in ways rarely possible in human-only workflows. This shift signals a future in which psychometrics evolves from descriptive tool-making to an adaptive, dynamic, and accountable science of measurement.
In conclusion, generative AI should not be understood as a substitute for established psychometric practice but as a catalyst for its renewal. By formalising a transparent, replicable, and human-centred approach to item generation, this study provides a methodological foundation upon which future scholarship can build (Rossi et al., 2024). As AI reshapes research practices, psychometrics and market research can benefit from approaches that couple computational power with scholarly oversight, contributing to higher standards of methodological rigour, inclusivity, and innovation.
Footnotes
Ethical Approval
The research stage described in the paper did not require ethics approval.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The manuscript does not report the results of data analysis.
Practical Guide for AI-Assisted Item Generation
This appendix provides a detailed account of the workflow we used for AI-assisted item generation. While the main text outlines the conceptual rationale, here we document the full stepwise process, including prompts, model parameters, and decision points requiring human oversight. The objective is to maximise transparency and replicability, enabling other researchers to adapt this workflow to their own constructs. The workflow described below includes both the steps applied in our proof-of-concept study and additional exploratory options (e.g., persona-based simulated respondents, adaptive logic). These latter steps are included to illustrate potential enhancements for future applications of AI-assisted item generation but were not implemented in the entrepreneurial mindset case study.