
Abstract
This article contends that the attention economy of social media reflects a shift toward soundscapes where networked sound objects – whether popular music or ambient sound, remixed speech or glitched audio – play a central role in amplifying user engagement. The analysis centers on audiovisual communities that operate as contra points to common TikTok trends, with particular attention to the Alt genre and niche phenomenon of Deep TikTok or DeepTok. Sound-linking and hashtagging practices within DeepTok reveal a dual dynamic: To survive the algorithmic visibility contest, DeepTokers creatively repurpose TikToknative sharing features, playing by the platform’s communicative rules. Meanwhile, glitch techniques deployed in the service of attention capture constitute engaging spaces that simultaneously incorporate and reject mainstream content. We inquire into these relations by exploring video and platform metadata attached to a curated collection of 497 #deeptiktok posts, arguing for a contextual understanding of memetic soundscapes that reenact noise.
Introduction
This article contends that the attention economy of social media reflects a shift toward soundscapes or resonant environments designed to keep users engaged. On TikTok, a platform known for its creative approach to short video remixing (Abidin and Kaye, 2021; Kaye et al., 2021), sounds have become key network designers. With a single click on the “use this sound” button, creators can effortlessly incorporate other users’ audio into new videos, contributing to a vast database of memetic content. Earlier studies of sonic phenomena have shown how sounds, once tied to specific temporal and spatial contexts, become dislocated, repeatable, and portable in ways that prefigure the logic of audio memeification (Rogers, 2023; Schafer, 1977; Thompson, 2017: 93–95). Sonic concepts – such as rhythm and resonance – have helped explain how platforms organize the micro-temporal fluctuations of user attention (Lupinacci, 2024; Paasonen, 2019; Venturini, 2022). Yet, while memes and metrics fuel the algorithmic regimes of social media broadly, sonic social media call for a new vocabulary attuned to more ambient dynamics of audiovisual circulation, noise, and attention hijacking.
In the following, we build on ongoing discussions in meme, platform, and sound studies to propose that TikTok soundscapes give rise to a mutable acoustic ecology where sounds not only capture and amplify affective engagement but also interrupt one another and overlap. We demonstrate how, in the process of circulation, familiar sounds “become muddled” (Rogers, 2023: 115) through video-crafting techniques that foreground noise as the main “memetic stratifier” (Geboers and Pilipets, 2024: 93). By analyzing metadata attached to digitally altered content within the Alt genre and niche phenomenon of Deep TikTok, we ask: What linkages between niche communities and established trends arise from replicating warped sounds across contexts? Which practices sustain memetic rhythms and which introduce dissonance?
Deep TikTok, also abbreviated as DeepTok, is known for its “deep-fried aesthetic” and deliberately “ugly” (Douglas, 2014) appearance achieved through audiovisual glitch effects in combination with elements of bizarre, surreal humor (Chateau, 2024; Galip, 2021; Tanni, 2024). Sound-linking and hash-tagging practices that hold DeepTok spaces together operate in a two-fold manner. To survive the algorithmic visibility contest (Abidin, 2021), DeepTokers creatively repurpose TikTok-native sharing features, subverting the platform’s communicative rules. Meanwhile, glitch techniques deployed in the service of attention capture constitute vernacular environments that simultaneously incorporate and reject mainstream content (De Zeeuw and Tuters, 2020; Menkman, 2011). Whether it is visually or sonically, deep-fried TikToks create an engaging space where user communities focus on mutual disorientation and diversion, rather than straightforward amplification. Navigating this space requires approaching TikTok sounds in their materiality as objects of “networked resonance” (Paasonen, 2019). Furthermore, it requires recognizing how noise can also resonate, acting as a catalyst for memetic circulation.
Starting from the premise that TikTok navigation via sound linkages renders visible “imitation publics” (Zulli and Zulli, 2022), the article extends the study of sound memes beyond easily traceable templates. Unlike the follower- and friendship-based content flows of Instagram and Facebook, TikTok relies on its infrastructural design features – such as sounds, duets, stitches, and video effects – to drive content circulation (Rogers and Giorgi, 2023; Geboers and Bösch, 2025). TikTok performances, formatted as short videos, can be networked through “licensed” sounds from the commercial sound library or published with the polyvocal “original sound.” The latter is of particular interest as it affords disguised circulation of trending songs, speech elements, and audio spin-offs (Kaye et al., 2021). As DeepTokers compose, remix, glitch, and modify “original sound” content, memetic soundscapes evolve through networked reenactment and cross-user riffing. Noise – understood not merely as a disturbance or unwanted deviation, but as a dynamic pool of discordant information (Menkman, 2011; Salvaggio, 2024; Thompson, 2017) – is what animates these dynamics, calling for methods that foreground the interplay between dominant memetic patterns and more fractured audiovisual rhythms (Hagen et al., in press; Han and Zappavigna, 2023).
In the next sections, the article first introduces concepts relevant to the platform-specific understanding of soundscapes on TikTok. It then outlines the main subcultural characteristics of Deep TikTok along with the methods for navigating users’ tactics of audiovisual sabotage. Combining walkthrough and digital methods for platform navigation and metadata analysis (Caliandro et al., 2024; Duguay and Gold-Apel, 2023; Peeters, 2022; Pilipets and Chao, 2025), we trace how #deeptiktok sounds align with other memetic components, focusing on the speech fragments embedded in the original sounds. A situated exploration of sound-co-hashtag relations then concentrates on the ability of DeepToks to resist full assimilation within the platform’s dominant traits. The focus on deep-fried aesthetics puts forward the flexibility of the “original sound” along with its capacity to subvert linear recording and content replication techniques. Throughout, TikTok’s engaging mechanisms and data assemblies (Parry, 2022; 2023) remain at the center of critical reflection, with particular attention to the ambient interplay of sounds, visual content, and hashtags. The analysis attends to these mechanisms through multimodal data from a curated collection of 497 #deeptiktok videos, arguing for a contextual understanding of memetic soundscapes that reenact noise.
Memetic soundscapes: noise and networked resonance
To understand the engaging potential of noise within memetic soundscapes on TikTok, it is essential to approach sounds in their materiality. Popularized by R. Murray Schafer (1977), the notion of soundscapes suggests that sounds can be conceptualized both temporally and spatially – as a sonic environment unfolding in the moment of perception. What defines the perception of the audible, and what is considered a soundscape or an acoustic landscape, is subject to our transient relations with “the place where all the sounds occur” (p. 152). On TikTok, a soundscape unfolds by assembling video flows via clickable, searchable, and templatable sound objects—“licensed” and “original” sounds open for sharing and adaptation. The composition of videos linked through licensed sounds from the sound library is closely interwoven with the platform’s logic of trend amplification (Abidin, 2021; Bainotti et al., 2022). However, not all videos utilize sounds from the library, and some are not easily found through song titles. Most TikToks feature the so-called “original sound,” allowing for interventions in the platform’s automated content attribution system.
Open to both algorithmic amplification and subcultural manipulation, TikTok soundscapes assemble multimodal content into collectively shared and traceable “compositional material” (Rogers, 2023: 115). Like reaction buttons (Gerlitz and Helmond, 2013; Geboers et al., 2020), TikTok sounds invite recurrent interaction, allowing the platform to capture engagement as relational data and metrics. When a sound is integrated via the sound button or sound library, the newly created video automatically displays the audio source along with the account name and sound title linked to all other videos using the same sound. Very often, though, such attribution paths remain unclear and become an uneasy subject to TikTok’s fingerprinting system, as users can also share their audio or republish sounds previously recorded from other users’ videos under the default title “original sound” or a custom title (Kaye et al., 2021). When a sound meme goes viral, multiple identical “original sounds” take off under new names published by different authors. As users remix and share, memetic communities overlap and noise accumulates, disrupting the linear logic of source and adaptation.
As a vital means of vernacular expression within these communities, noise comes into play as a soundscape’s ambient component that “infests every medium, modifies every sound-signal, takes part in every musical event” (Thompson, 2017: 175). Across networked acoustic ecologies of Instagram, YouTube, and TikTok that both archive and disseminate sonic content, noise registers as a “cacophony of data” (Salvaggio, 2024), emerging where sounds have been “stretched, abstracted, augmented, heightened, or otherwise manipulated” (Rogers, 2023: 133). In subcultural networks not limited to the digital realm, noise is a tactic of “semantic disorder” and a “temporary blockage in the system of representation” (Hebdige, 1979: 90–91). In new media art, noise is often referred to as a “glitch” and considered “a break from the protocolized data flows” (Menkman, 2011: 26). According to Rosa Menkman (2011: 28–31), noise cannot be singularly codified as it rejects categorical boundaries, inevitably raising questions of affect, perception, and aesthetics.
For fringe memetic communities populating sonic social media, noise can be both an attention-grabbing technique and a temporary means of disconnection from the dominant regimes of “visibility moderation” (Zeng and Kaye, 2022). While mainstream TikTok content typically engages the platform’s multimodal design elements (Han and Zappavigna, 2023) – such as linking to trending sounds or applying searchable video effects—DeepTok videos often operate outside this logic. By reposting content with externally added distortions and filters, users intentionally subvert TikTok’s indexing structures, pushing their videos outside the platform’s algorithmically optimized flows. To navigate noise in this context means exploring how oral cultures become reassembled through excessive vernacular content-crafting techniques. Within Deep TikTok, such techniques animate resonant networked exchanges, both internal and external to the platform’s engaging infrastructure designed to elicit affective feedback (Brown et al., 2022; Hautea et al., 2021).
Affect, in this aesthetic constellation, operates as a volatile, engaging force that drives online interactions in spaces where user attention is manipulated for data extraction (Paasonen, 2018). Writing about social media, Susanna Paasonen (2019) defines resonance as instances of being affected in online encounters “the intensities of which grow, linger, and fade away at varying speeds as user attention and interest perpetually circulate, move, shift, and relocate” (p. 60). In the continuous, rhythmic flow of TikTok’s For You Page, sound linkages operate as affective shortcuts, bridging diffuse cultural communities with emergent trends (Haberer, 2024). Through a process of “sensorial orchestration” (Highmore, 2011: 166; Lupinacci, 2024: 4085–4089) within this flow, algorithmic systems control what is visible and hidden, audible and inaudible. At the same time, ongoing subcultural interventions into platform-modulated sound ecologies point toward more opaque ways in which networked audiovisual content is crafted and circulated. The “noise” produced by DeepTokers cannot be attributed to a single sound, video effect, hashtag, account, or any other platform object; rather, it arises from network disturbances across different layers of affective engagement.
Navigating DeepTok: fringe subcultures and ethics of circulation
Deep TikTok, or DeepTok, is a subgenre within Alt/Elite TikTok that gained popularity in 2020 and 2021 by circulating surreal, artistically distorted content (Aesthetics Wiki, 2024a). Unlike mainstream or “Straight TikTok” known for its comedy performances, lip-syncs, and dance challenges (Merrilees, 2020), Alt TikTok, and Deep TikTok in particular, thrive on absurdity and excessive “vernacular editing” (Menkman, 2011: 17–25). The vernacular component is especially evident in the circulation of “deep-fried” videos – a fringe genre of the “purposefully poor” (Chateau, 2024; Steyerl, 2009) or “ugly aesthetic” (Douglas, 2014; Galip, 2021) featuring heavily pixelated, washed-out visuals and manipulated audio. DeepTokers skillfully adapt these techniques across subcultural communities by applying eerie audio effects, altering music tempos, distorting voices, and using “original sounds.” The latter allow users to circulate trending audio under new, usually glitched, sound titles, pairing music from popular artists with bizarre audiovisual elements (Figure 1).
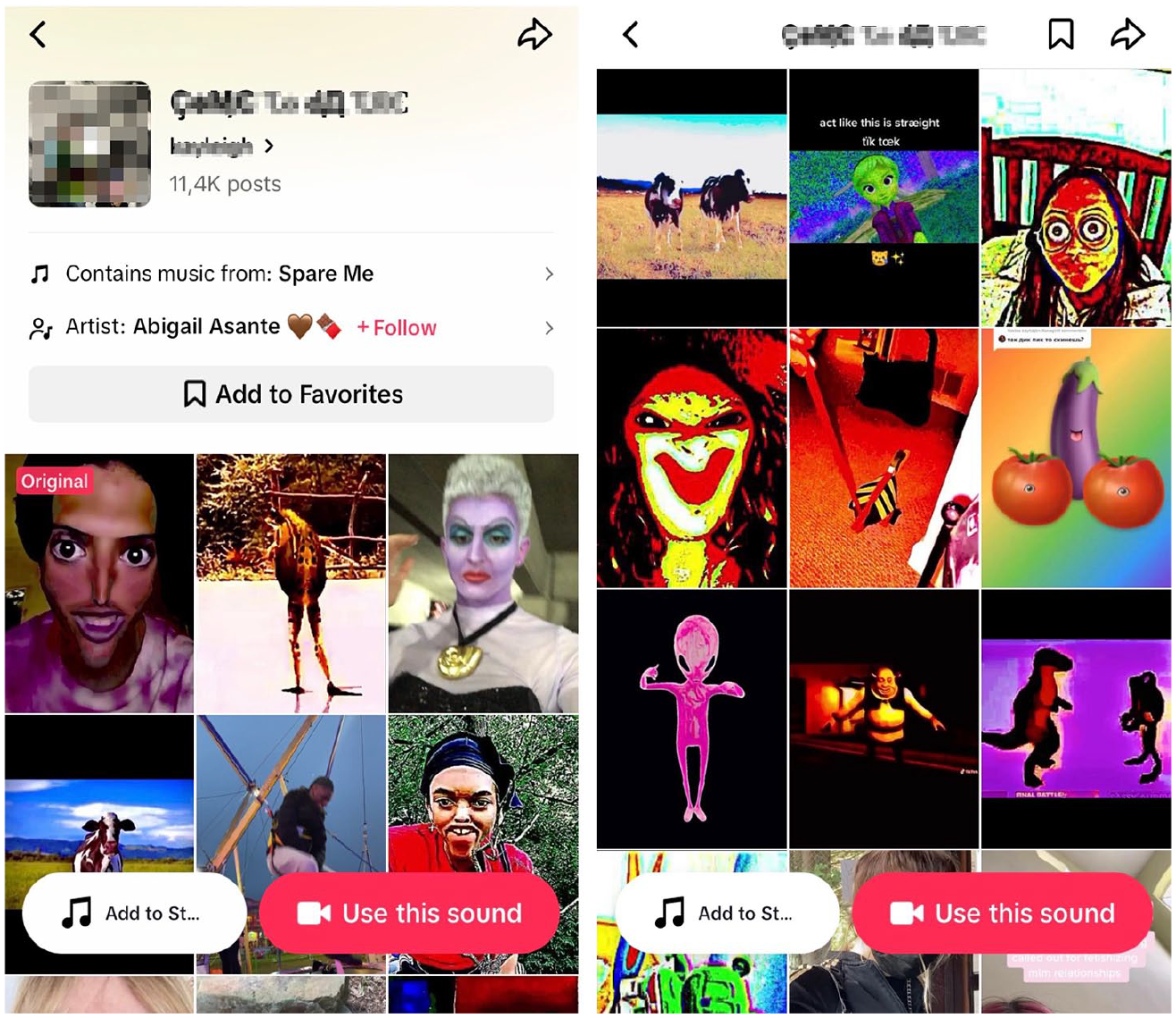
An example of a sound page for DeepTok Videos linked through a glitched original sound hijacking the trending song “Spare me” by Abigail Asante (screengrabbed via TikTok app, deidentified, June 2024).
Revealing glitched visual, auditory, and textual elements, the #deeptiktok hashtag page incorporates deliberately distorted low-resolution content characteristic of deep-fried memes (Merrilees, 2020; Yalcinkaya, 2022): Imagine a cacophony of warped sounds – pitch-shifted pop songs mixed with distorted vocals – alongside glitched appearances of Shrek, Spider-Man, Elsa, Barbie, and Peppa Pig. Add to this pixelated, eerie faces, dancing cows, and floating quotes about anxiety, and you arrive at the full DeepTok experience – “out of sync” yet strangely embedded within the platform’s “expressive assembly” (Parry, 2022: 27–31, 2023: 19) surrounded by hashtags, comments, captions, and likes. Much like the paradoxical appeal of the “ugly” (Douglas, 2014; Galip, 2021), the resonances these elements evoke register as “disturbing, unpleasant, and revolting kinds of dissonances” (Paasonen, 2019: 51). The affective intensities involved blur lines between fun and unease, prompting “ambiguous amalgamations of mixed feeling that both titillate and repel” (p. 51).
Noise, in many of these instances, comes to act explicitly as both an “unwanted” and “unmusical sound” (Schafer, 1977: 182–183), manifested through layers of background audio that disrupt the rhythm of the main sound in the foreground. Simply navigating to the sound pages of #deeptiktok posts reveals how fringe content creators strategically employ noise to disrupt the neat audiovisual experience favored by the platform. Some contributions integrate already established sounds via the sound button, adding glitched components while still crediting original music authors. A popular example in this context is the comedic song Buttholes Are Nothing to Be Laughed At by Laura Clery branching out across 7,525 videos – many of which adapt the template to circulate intentionally distorted audio remixes with “creepy face” videos (Figure 2). Other DeepTok strands, however, ignore the platform’s sound indexing system entirely, resharing untraceable sound copies.

A selection of 60 “Buttholes Are Nothing to Be Laughed At” videos arranged by color similarity. These videos employ audiovisual deep-frying techniques to create a grotesque aesthetic, deliberately leveraging surreal exaggeration for humorous effect.
Previous research shows that practices of glitching, masking, borrowing, or otherwise hijacking audiovisual content are common on different platforms, including YouTube and TikTok, presenting an attributional challenge for both user communities and automated content recognition systems (Kaye and Gray, 2020). “Mask cultures” at the fringes of increasingly centralized platform economies, characterized by ephemerality and anonymity, have been discussed in their capacity to undermine the “face cultures” of mainstream platforms like Facebook and Instagram (De Zeeuw and Tuters, 2020). Similarly, with their layered low-res images and glitched audio, deep-fried videos circulate as disguised objects of play beyond singular platforms’ constraints. Such play combines TikTok’s “play-based affordances” (Cervi and Divon, 2023) with external content crafting tools, subverting TikTok’s more “circumscribed” (Kaye et al., 2021) understandings of creativity. At its most extreme, deep-frying removes all traceable audiovisual cues, resembling a mask that renders content imperceptible to both algorithmic recommendation and platform moderation.
The amalgamation of all this into practices of video remix paves the way for approaching DeepTok soundscapes as noisy spaces that derail audio-based memetic templates (Abidin and Kaye, 2021). In analyzing these spaces, the platform environment plays a crucial role (Geboers and Bösch, 2025; Rogers and Giorgi, 2023), necessitating ethical methods for interpreting multimodal data generated through subcultural engagement. Focusing on the emergence of noise in a collection of #deeptiktok videos, we account for the “ethics of circulation” (Dieterle et al., 2019) to emphasize context as essential for reflecting on the cultural ambiguities such content entails. On the one hand, DeepToks are an obvious example of content misattribution, presenting issues for creators who strive to monetize their posts through TikTok’s sharing and crediting features (Kaye et al., 2021). On the other hand, DeepToks testify to the vernacular legacy of pseudonymous users who seek to (at least partially) evade platform-centric mechanisms of “visibility moderation” (Zeng and Kaye, 2022).
To ethically attune our methods to these tensions, we focus on networked practices and aesthetic patterns, rather than individual creators or posts. In our visualizations, we de-identify account names and avoid referencing specific captions to prevent post-based searchability. Analyzing sound-co-hashtag relations, we focus on the hashtags attached to multiple contributions, which enables us to explore questions of resonance without compromising specific users. Although each sound assembles multiple videos, we added minor deviations to potentially sensitive titles, adapting DeepTokers’ vernacular techniques for scattering the search results through glitched text and imitation. For popular references disguised by original sounds and reproduced in videos, we provide context and credit the initial authors. Together, these techniques allow us to engage meaningfully with the material and associated metadata, while maintaining careful consideration of the (sub)cultural environments from which these data emerge.
Methods: from navigation to “metadating”
As a hub for memetic content, TikTok is known for its networked design features, but it is also, above all, a metadata machine. Each time a sound is applied to a new performance along with a string of hashtags, stickers, and video effects, it feeds replicable components into a dynamic formation of platform-distributed content. Yet platform affordances do not solely dictate creativity (Caliandro et al., 2024: 219–221)—creators regularly sidestep TikTok’s native editing tools, relying on external software to craft their videos before uploading. Especially “original sound” videos pose methodological limitations, as the platform does not always efficiently recognize audio similarities unless explicitly indicated by users. Another limitation comes with the number of videos displayed on a TikTok page, particularly when browsing outside the mobile app. TikTok pages let users load more content by clicking a “Load More” button. However, both automated and manual scrolling reveal that while more videos are available, the browser page currently hits its limit at approximately 1,000 videos, preventing further loading.
For our exploration, we used Zeeschuimer – a browser extension that “looks over your shoulder” and automatically collects metadata from posts as you browse (Peeters, 2022). Collecting relevant data with this tool requires purposeful navigation of the platform. TikTok hashtag pages situate audiovisual content in interactions with other platform-native design elements, revealing a variety of acoustic, visual, and textual linkages that users can follow and that shape the content they encounter. Inspecting a TikTok hashtag page with Zeeschuimer reenacts the paths of the platform’s expected use. Much like the walkthrough method outlined by Light et al. (2018), this approach involves engaging directly with the app’s interface “to examine its technological mechanisms and embedded cultural references (p. 882)” (see also Duguay and Gold-Apel, 2023). At the same time, it repurposes TikTok’s data infrastructure itself as an analytical lens (Bainotti and Rogers, 2022; Rogers and Giorgi, 2023), enabling a situated study of how use cultures emerge through platform design.
Scrolling down the #deeptiktok hashtag page, we collected metadata from a total of 951 out of 9255.9 posted contributions. To analytically contextualize these metadata with a focus on the resonant qualities of noise, we further reduced the dataset to 497 videos, selecting those that used “original sounds” – both default and custom-titled – featured in at least five posts. The range of distribution techniques, aesthetic modalities, and metadata involved makes it possible to trace how the alteration of sounds in a collection of #deeptiktok videos plays out in a series of networked reenactments. Some videos follow a template, such as applying similar video effects, while others lack visual or textual similarities but still use cropped or distorted versions of the same song. In light of these entanglements, we treat associated metadata as “data assemblies” (Parry, 2022, 2023) – or composite records of user-platform exchange. Rather than approaching metadata as static descriptors that merely “connect data with other data” (Manovich, 2002), we propose “metadating” as an interpretive practice: one that invites researchers to spend time with data, prompting methods for ethical and contextual data remix.
In an analytical process that blends platform navigation and metadating, multimodal data records offer various interpretative paths, opening up new perspectives on the same video sample (Pilipets and Chao, 2025). Temporal metadata like time of publication and video length point to the rhythms of sharing and appropriation, ranging in their intensities and impact. Engagement metrics such as like, view, and comment counts offer insights into varying qualities of attention concentrated on certain contributions. Co-hashtags, stickers, and video captions delineate DeepTokers’ audiovisual interventions, prolonging the resonance of sounds through text. A sound button affords action by allowing TikTok creators to use it contextually as part of a scalable environment or soundscape where it simultaneously assembles and intensifies engagement. In this sense, data assembled through user actions become dynamic instances of recording and re-enactment (Parry, 2023). A significant part of these data derives its value from appearing next to and in relation with other data (Acker, 2021; Gerlitz, 2017). Metadating makes these platform-mediated relations explicit in their “multivalent, multiformat, multimotivated” (Parry, 2022: 206) nature and invites interpretative techniques that defy unifying readings.
We explore two such techniques to perform a mixed audio-visual analysis of 497 DeepToks. The first technique dedicated to network analysis of sound-co-hashtag relations presents a distant reading of soundscapes driven by DeepToker’s original sound appropriations. Hashtags, as searchable networked artifacts, territorialize sound memes and make trends perceptible to targeted audiences that “invite affective attunement” (Papacharissi, 2015: 308). Associated data records – including sounds – not only help researchers identify relevant patterns in the dataset but also enable the creation of sub-samples through sorting, filtering, and re-arranging (Bainotti and Rogers, 2022). Resonant sharing patterns manifest in repetitions within data, while dissonances arise through diverting intensities of engagement, forming outliers. Given the challenges inherent in automatically detecting mashed-up and distorted audio samples without lyrics (Hou et al., 2023; Kaye et al., 2021), we employed common hashtag combinations as entry points for systematically listening to the original sound videos lacking discernible speech.
To trace audio patterns in videos containing speech or song lyrics, AI tools such as Speech-to-Text Converter (Chao, 2023a) proved more effective, revealing the dynamics of “repetition-with-variation” or memetic rhythms enacted by oral cultures (Hagen and Venturini, 2024; Hagen et al., in press). The tool converts speech in audio files to text using Google Cloud (2024) Speech-to-Text API and saves the transcriptions in a spreadsheet file (Figure 3). When applied to the entire dataset, disguised speech templates emerge, enabling the sampling of content formations that use the same (or modified) song under different titles, across different accounts, and tied to various subcultural trends.

A filtered spreadsheet view fragment highlights a disguised speech template from Gabbie Hanna’s “Roast Yourself Harder,” showcasing the 10 most-liked variations across both custom-titled and default original sounds.
The second technique builds on this analysis, focusing on a collection of the 10 most liked #deeptiktok videos that repurpose Gabbie Hanna’s 2018 diss track “Roast Yourself Harder” under new and default sound titles. This is where additional data enrichment comes into play, including automated video frame extraction (Chao, 2023b) to make sense of the video’s multimodal expressive layers. To arrive at the “Roast Yorself Harder” videos that adapt both the sound and the lyrics, we first used the Speech-to-Text Converter (Figure 3). We then visualized the frames extracted from the videos in a montage to reconstruct the sound-driven choreography of imitation through qualitative means. The resulting mix of methods and perspectives foregrounds the background or the environment co-constituting DeepTok soundscapes, including their networked and rhythmic (hashtags and sounds) as well as embodied and embedded (speech and images) characteristics.
Original sound memes: does noise have patterns?
Focusing on the resonances and dissonances within a soundscape, this section explores the affective alignments of #deeptiktok sounds with other memetic components—hashtags and video content. Video metadata collected with Zeeschuimer and saved in a spreadsheet file for systematic analysis are attached to posts made visible by TikTok. However, this does not imply that this view is the only one possible. The network analysis in Figure 4 situates associated content formations by mapping sound-co-hashtag relations of 497 curated #deeptiktok videos shared with the original sounds. Original sounds – or audio files not included in the TikTok library and subject to user modification, removal, or reporting – carry associated metadata for “music title.” When deliberately renamed, original music titles can be specific, but they more often default to “original sound” or its linguistic variations, which change based on users’ app settings – for example, “sonido original” (Spanish), “Originalton” (German), “son original” (French), or “ оригинальный звук” (Russian).
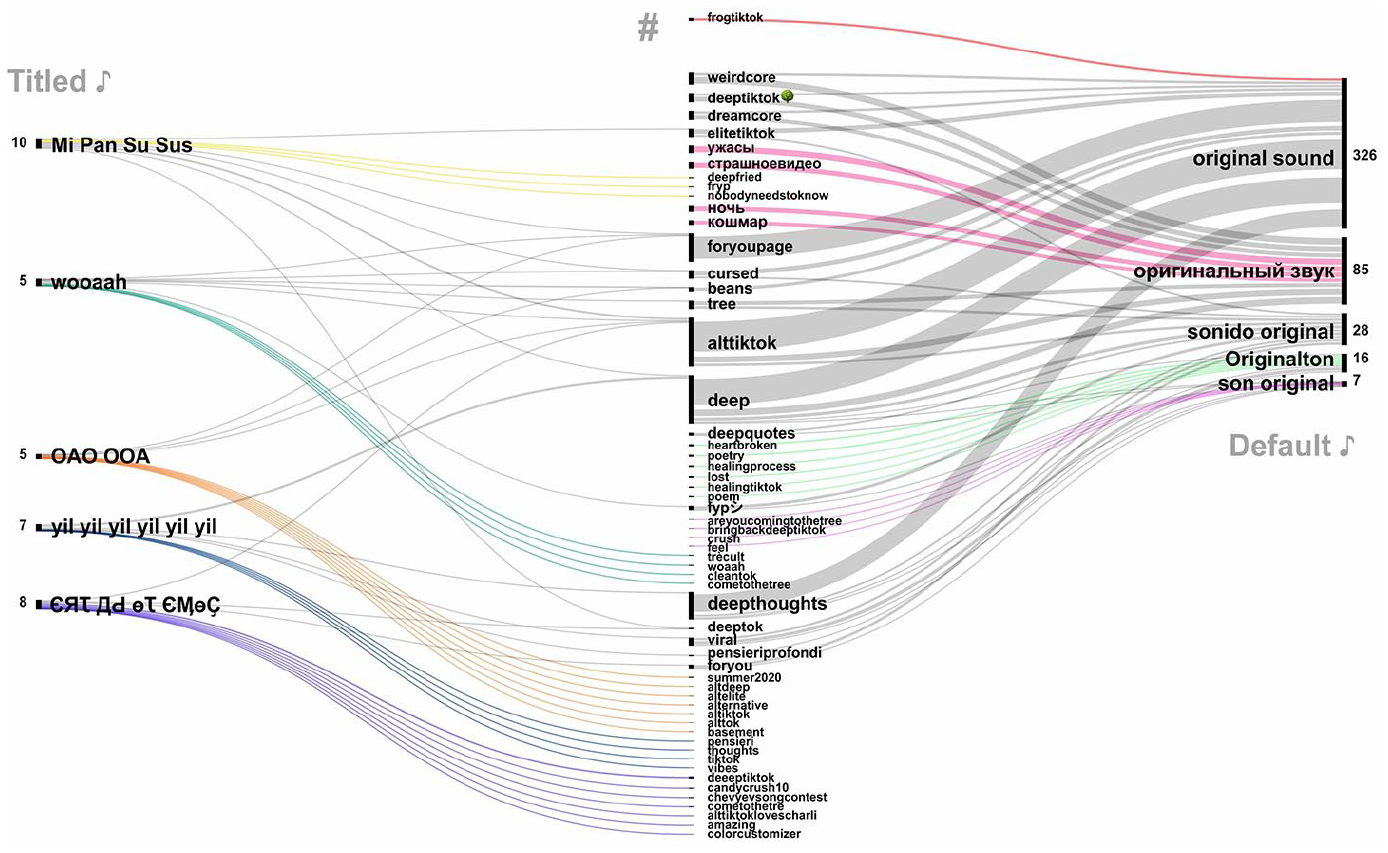
A sound-co-hashtag analysis of 497 #deeptok posts, displaying titled and default original sounds, the number of videos linked to each sound, and their associated co-hashtags. Sound-specific hashtag formations are colored, hashtags shared across different sounds appear in gray. Visualized with RawGraphs.
The thickness of edges and the size of nodes in the network represent the extent to which hashtags and sounds are attuned to one another based on the number of videos they assemble. Videos published with titled sounds (left) deploy unique and shared co-hashtag-associations visible in the center of the diagram. Default “original sound” videos blend and distribute these associations across different linguistic spheres (right), positioning DeepTok as an intercultural fringe vernacular—pseudonymized, eclectic, multilingual, and masked through layers of collective editing (De Zeeuw and Tuters, 2020). Corresponding audio tracks range from unauthorized recordings of existing sounds to plain speech, to mashed-up songs, to even random noises. This means that original sounds associated with different accounts and cultural settings can contain identical audio, concealing memetic communities.
The multimodal network in Figure 4 captures varying intensities of noise and imitation across memetic formations within DeepTok’s soundscape. Sound-based glitch techniques are most evident in the prevalence of multilingual original sounds spanning different language communities. Bringing together original sounds from Russian- and English-speaking user groups, 46 out of 497 posts reference #deeptiktok and the associated tré-Cult that features a (no longer accessible) distorted mashup of Jennifer Lawrence’s “Hanging Tree” from The Hunger Games mixed with high-pitched K-Pop tracks and trending songs like Doja Cat’s “Say So.” The mismatched song rhythms create an uncanny effect, amplified by deep-fried filters and eerie visuals. A notable exception within this mashed-up arrangement is ЄЯꚌ ДԀ өꚌ ЄӍөҪ (Come to the Tree)—a niche meme drawn from the tré-Cult that entirely consists of a republished and renamed excerpt from Abigail Asante’s “Spare Me.” Reiterating Asante’s line “Have you ever been snaked by a friend then just for the clout, they’ll do it again?,” the sound showcases TikTok’s fingerprinting system in action, ensuring credit to the original artist through automated means (Figure 1).
and the associated tré-Cult that features a (no longer accessible) distorted mashup of Jennifer Lawrence’s “Hanging Tree” from The Hunger Games mixed with high-pitched K-Pop tracks and trending songs like Doja Cat’s “Say So.” The mismatched song rhythms create an uncanny effect, amplified by deep-fried filters and eerie visuals. A notable exception within this mashed-up arrangement is ЄЯꚌ ДԀ өꚌ ЄӍөҪ (Come to the Tree)—a niche meme drawn from the tré-Cult that entirely consists of a republished and renamed excerpt from Abigail Asante’s “Spare Me.” Reiterating Asante’s line “Have you ever been snaked by a friend then just for the clout, they’ll do it again?,” the sound showcases TikTok’s fingerprinting system in action, ensuring credit to the original artist through automated means (Figure 1).
In Russian-speaking #weirdcore (23 posts), “tré-Cult typically accompanies a reference to a tree, paired with co-hashtags like #ужасы (#horror), #страшноевидео (#scaryvideo), #ночь (#night), and #кошмар (#nightmare). The aesthetic draws on “Hanging Tree” song remixes combined with distorted face filters and cryptic invitations like “come to the tree” or “sacrifice 2 the tré.” Videos often adopt a low-color palette—sepia tones, faded green or brown—evoking abandoned spaces, nostalgia, and dreamlike decay. In contrast, English-language videos using the same or slightly altered soundtrack lean more into softer interpretations of the #weirdcore and #dreamcore aesthetics (18 posts), which, like #frogtiktok videos (nine posts), are considered surreal but “pleasantly creepy” within Elite TikTok (Aesthetics Wiki, 2024b). Many of these aesthetic references, while they vary in terms of content, share what Valentina Tanni (2024) has described as a vibe or an atmosphere: The lighting is dim or all wrong, spoiled by too much flash. The images, often found online, are edited, the contrasts accentuated, and text, marks, and holes added to boost the sense of strangeness [. . .] The weird effect is intentionally created in three main ways: the vagueness of the places and objects pictured, the contrasts between odd assortments of elements, and the addition of cryptic or nonsensical messages (p. 131).
Spanish- and French-speaking #deepquotes creators combine X-Files-like music with melancholic quotes and panorama shots of dark highways, using audio tracks with mysterious titles like “yil yil yil yil yil yil” (seven posts), while German #deepthoughts posts blend in colorful video effects accompanied by hashtags #heartbroken or #lost. The hashtag #deep often signals a desire for profound content, though it frequently veers into the bizarre, incorporating a range of distorted sounds and voices, from grotesque screams and repetitive chants to soft whispers (98 videos). Some videos give off a creepy vibe, reminiscent of disturbing yet captivating cursed images (Pilipets and Paasonen, 2024; Tanni, 2024: 93)—a reference echoed in #cursed DeepToks tagged with “sonido original” (eight posts)—while others lean toward absurd humor involving popular cartoon characters.
Three other renamed original sounds in our dataset – Mi Pan Su Sus, wooaah, and OAO OOA circulate both unchanged and slightly modified as default “original sound,” “Originalton” and “оригинальный звук,” further blurring the soundscape’s memetic and cultural boundaries. Mi Pan Su Sus—a nod to a 2010 Russian Kellogg’s jingle promoting honey cereal Miel Pops with animated bees—has appeared in multiple variations, with altered speed and pitch turning “Miel Pops” into “Mi Pan” and the bees’ zooming into “Su Sus.” Memetic re-enactments of OAO OOA and wooaah, detected through speech recognition, vary in duration and style but consistently reference DeepTok’s anti-trends in hashtags, video stickers, and post captions. Despite rich layers of vernacular references, most posts avoid direct crediting of the songs’ creators—American YouTubers Shane Dawson (“Check Me Out,” republished as OAO OOA) and Gabbie Hanna (“Roast Myself Harder,” republished as wooaah). What comes to the fore instead are altered reiterations of song lyrics and audiovisual glitch techniques that take center stage in DeepTokers’ attempts at attention hijacking. Fast-paced but monotonous, OAO OOA memes have gained traction within TikTok’s “Subway Surfers” niche, featuring random quotes in video stickers alongside snippets of endless runner gameplay set to Dawson’s bass-boosted remix of “Check Me Out.” Gabbie Hanna’s “Roast Yourself Harder,” reiterated through sound snippets such as “wooaah” and renamed multiple times, aligns closely with DeepTok’s fascination with the glitch aesthetics explored in the next section.
Roast Yourself Harder: deep-fried animal dance
Despite the artist’s official presence on TikTok, Gabbie Hanna’s “Roast Yourself Harder” currently circulates under different republished original sound titles. Much like Mi Pan Su Sus memes (Ainsworth, 2020) but with a stark audio contrast, these DeepToks center around an anti-trend of dancing animals and cartoon figures accompanied by emoji-distorted video captions and comments. The tonal clash is striking: a lighthearted ad jingle competes with the aggressive beats of Hanna’s controversial diss track. “Roast Yourself Harder,” published in 2018 on YouTube and documented by KnowYourMeme (2024a), has resurfaced as a DeepTok phenomenon 2 years after its release, driven by parodies focused on the singers’ a capella outro and intense lyrics, including the lines People love that I hate myself. I climbed out of my head and watched myself implode A thought without a body ought to be a shot to take a load off My brain is poisoned and I’m searching for the antidote But every time I find it, my defenses scream, “Oh, no you don’t!” Woah.
To analyze the rhythms of videos overlaid with fragments of “Roast Yourself Harder,” Figure 5 combines different visualization techniques. Preparing material for qualitative cross-reading, it arranges 10 most-liked videos with the same disguised sound pattern in a montage with the aid of automated video frame extraction (Chao, 2023b). By extracting static video frames per second and reassembling them in their original sequence, the montage method – as adapted from Lev Manovich (2013)—effectively captures the videos’ sequential narrative, showcasing deep-fried gestures and movements accelerated to match the song’s rhythmic structure.

A montage of “original sound” videos using Gabbie Hanna’s “Roast Yourself Harder” arranged by publication date. Only hashtags used in three or more videos are displayed. Visualized with ImageJ’s image montage macro.
A horizontal reading renders visible the videos’ storylines, highlighting variations in content, shot length, and pacing. A vertical reading tracks the evolution of memetic components in a chronologically arranged timeline of 10 videos, from the oldest at the top to the most recent at the bottom. By combining visual metadata with publication time, the analysis reveals the persistence of “deep-fried animal dance” as a dissonant form of memetic riffing. The appearance of video stickers like “We nearly lost you to straight tiktok, interact to stay on deep tiktok” underscores ongoing subcultural tensions within the platform. The videos’ grainy, oversaturated look indicates that noise extends beyond platform boundaries. Deep-frying techniques, including pixelation and saturation filters, rarely rely on TikTok’s built-in design features. Of the 10 analyzed videos, only one contains metadata for video effects. Instead, users turn to external formatting tools, assembling disparate animations of pre-existing cultural material into an unruly yet recognizable flow.
The juxtaposition of glitched aggressive rap with fast, deep-fried animations of llamas, turkeys, and cows, either dancing or twerking both solo and in groups, blurs the line between awkward offbeat humor and vernacular editing (Menkman, 2011: 17–25). Visually, “wooaah” DeepToks combine deep-frying effects, assembling video footage run through external filter software until it changes color and becomes pixelated. Sonically, these videos distort the original sound through repeated recording, echoing Rosa Menkman’s (2011) notion of glitch as an aesthetic of failure where intentional breaks in the audio-visual flow create dissonance. Producing copypasta derivatives like, “ climbed
climbed  out
out  of
of  my
my  head
head  and
and  watched
watched  myself
myself  implode
implode  a
a  thought
thought  without
without  a
a  body
body  oughta
oughta  be
be  the
the  shot
shot  ,” the song lyrics expand into the comment sections. The soundscape spills over, each word paired with an emoji for a surreal, attention-grabbing effect. Similar to hashtag emojis in terms of semiotic versatility (Highfield, 2018; Zappavigna and Logi, 2024) but with a bizarre and disorienting spin, these textual reverberations mimic the musical rhythms of Roast Yourself Harder, amplifying the resonance between users and deep-fried animal dance memes.
,” the song lyrics expand into the comment sections. The soundscape spills over, each word paired with an emoji for a surreal, attention-grabbing effect. Similar to hashtag emojis in terms of semiotic versatility (Highfield, 2018; Zappavigna and Logi, 2024) but with a bizarre and disorienting spin, these textual reverberations mimic the musical rhythms of Roast Yourself Harder, amplifying the resonance between users and deep-fried animal dance memes.
In sound adaptations, a cross-reading of audiovisual metadata points to another interesting detail: varying video lengths align with distinct audio cropping and alteration methods, as revealed through speech-to-text conversion (Figure 3). Such methods can be used both for creative expression and to bypass TikTok’s automatic sound identification system (Kaye et al., 2021). As a means of (de)contextualization, this vernacular approach co-exists with the engaging logic according to which DeepTokers repurpose the platform infrastructure for various affective ends. Like other TikTok creators, DeepTokers engage in platform-specific “visibility labor” (Abidin, 2021) by combining subcultural references such as #trécult with common platform vernaculars, which includes frequently tagging their posts with #foryoupage, #foryou, and #fyp (Figures 4 and 5).
While these hashtags on “Straight TikTok” signal users’ desire to appear on the algorithmically curated For You Page, DeepTok creators pursue a slightly different path to “post-based virality” (79): When their content does make it to the FYP, it is met with humor in the comments, featuring absurd variations of the phrase, “
 with
with this
this because
because I
I don’t
don’t want
want to
to be
be on
on straight
straight TikTok
TikTok .” Along with the emoji-laden song lyrics posted on repeat, such interactions form a sub-genre of “memetic commenting” (Pilipets and Paasonen, 2024) that reflects DeepTok’s affinity with diversion tactics and cryptic subcultural references. Yet, despite their use of obfuscation techniques, layered meanings, and glitch effects, the affective pull of DeepTok videos remains platform-bound. While DeepTokers disrupt conventional engagement patterns, they ultimately rely on TikTok’s interactive features to ensure that “the noise” stands out amid algorithmically pushed trends.
.” Along with the emoji-laden song lyrics posted on repeat, such interactions form a sub-genre of “memetic commenting” (Pilipets and Paasonen, 2024) that reflects DeepTok’s affinity with diversion tactics and cryptic subcultural references. Yet, despite their use of obfuscation techniques, layered meanings, and glitch effects, the affective pull of DeepTok videos remains platform-bound. While DeepTokers disrupt conventional engagement patterns, they ultimately rely on TikTok’s interactive features to ensure that “the noise” stands out amid algorithmically pushed trends.
Conclusion: toward sonic social media
In describing DeepTok soundscapes as resonant spaces that reenact noise, this article contributes to a broader understanding of sonic social media – where networked sound objects – whether popular music or ambient sound, remixed speech or glitched audio – play a central role in distributing content and capturing user engagement as data. Rather than focusing solely on the algorithmically favored “earworms” (Abidin and Kaye, 2021; Geboers and Bösch, 2025), our approach foregrounds fringe sonic vernaculars that animate the fuzzier edges of TikTok. Our exploration of Deep TikTok underscores how, within sonic social media, sound operates as a network designer while noise emerges as an ambient tactic of attention-hijacking.
DeepTok formations driven by “original sounds” are particularly intriguing but difficult to study, as they encourage unconventional recording and distribution techniques that challenge one-dimensional conceptions of resonance as mere visibility. As we have suggested elsewhere (Pilipets, 2023: 126–127), with everyday practices of audio-remix available in the “use this sound” feature, the “aural turn” (Abidin and Kaye, 2021) of TikTok plays out both on the infrastructural level that encourages scale and on the basis of social micro-events that involve drift and displacement. Even though less visible in terms of metrics, the latter, more flexible foundation is central in terms of understanding mundane memetic exchanges resembling the eclectic vernacular languages of oral cultures (De Zeeuw and Tuters, 2020; Venturini, 2022).
Premised on repetition and contextual variation, DeepTok interventions are contained in neither of these dimensions but aggregate into blended and partially contested amalgamations thereof. In the soundscapes assembled through #deeptiktok, the “ugly” aesthetic (Douglas, 2014) of deep-fried video memes highlights users’ vernacular attempts to reattune mainstream content to alternative engagement venues. DeepToker’s appropriations of “original sounds” often hijack already established content formations, injecting the same sound into new memetic communities under a different sound title. The soundscape emerging through these intersecting trajectories activates resonant networks with varying engaging potential. Combining audiovisual glitch techniques, DeepToks capture attention as noise – or what Menkman (2011) has described as the vernacular interplay of formats in “the absence of a message” (p. 28).
Broad enough to evade targeted searchability yet specific enough to signal subcultural belonging, associated co-hashtags – like #beanz, #trè, #trècult, #elitesideoftiktok, and #alt – illustrate the fluidity of DeepTok content and its ability to incorporate both niche and mainstream cultural elements. Most visual material associated with “Roast Yourself Harder” and depicted in Figure 5—including Joel Erkkinen’s infamous twerking turkey (or “Twurkey”), first published on YouTube in 2016 (KnowYourMeme, 2024b)—reappears multiple times in our dataset. Each recurrence is associated with a different original sound meme and music author—variations of the dancing cows, to give another example, have been republished with “Min Pan Su Sus,” “wooaah,” and multiple default original sounds.
From a methodological perspective, navigating such unruly online environments requires a nuanced understanding of how sounds and images are re-enacted along both infrastructural (Rogers and Giorgi, 2023) and vernacular (Menkman, 2011) trajectories. Like metadata they generate, sonic social media facilitate hierarchies between user (sub)cultures – communities playing the visibility game (Zeng and Kaye, 2022) and communities whose interventions become “heard” through tactical disruptions. Formalized into clickable sound objects and embedded in the infrastructure that rewards imitation, even ambient noise can be replicated, creating resonant relational patterns. DeepTok noise, as we have shown, feeds into these dynamics, animating memetic ensembles that are purposefully “out of sync.” This opens up new possibilities for approaching memes in their dissonance and “potential for reassembly” (Parry, 2022: 220–225), expanding contextual care to online interactions that defy conventional visibility regimes.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Deutsche Forschungsgemeinschaft [Grant Number Project-ID 262513311 SFB 1187].