
Abstract
Algorithmic curation of social media platforms is considered to create a clickbait media environment. Although clickbait practices can be risky especially for legacy news outlets, clickbait is widely applied. We conceptualize clickbait content supply as a revision game with an unknown threshold. Combining supervised machine learning with time series analysis of Facebook posts and Twitter messages of 37 German legacy news outlets over 54 months, we observe outlets’ behavior following algorithm changes. Results reveal (1) an infrequent use of clickbait with few heavier-using outlets and (2) turning points of clickbait performance as clickbait supply and user interaction form a reversed U-shaped relationship. News outlets (3) collectively adjust toward an industry clickbait standard. While we (4) cannot prove that algorithmic curation increases clickbait, (5) Facebook’s regulative intervention to decrease clickbait disperses heterogeneous tendencies in clickbait supply. We contribute to an understanding of editorial decision-making in competitive environments facing platforms’ regulative intervention.
Keywords
Introduction
Social media platforms provide an infinitely scrollable and personalized news feed intending to tie users in. To be part of the feed, Caplan and boyd (2018) argue that news outlets must construct their content with algorithmic curation in mind. Therefore, social interaction metrics such as likes or shares denote an online currency (Myllylahti, 2020) and serve as popularity cues for editors and users alike (Haim et al., 2018; Munger, 2020). By rewarding popularity, algorithmic curation can lead to conformity in the news industry (Caplan and boyd, 2018). News outlets collectively design “addictive distractions” (Naughton, 2018: 387) to grab user attention, maximize popularity, and ultimately profits (Sismeiro and Mahmood, 2018).
Clickbait headlines signify one example of such addictive distractions created to succeed in a high-choice algorithmic-curation environment of social media. Clickbait represents a linguistic strategy to articulate a message in a curiosity-arousing way that entices readers to click on the referring article (Potthast et al., 2018). Clickbait headlines originate from new entrants to journalism such as Upworthy or BuzzFeed (Tandoc, 2018). Meanwhile, they are used by tabloids (Blom and Hansen, 2015), broadsheets (Potthast et al., 2018; Rony et al., 2017), and by hoax outlets to spread disinformation (Braun and Eklund, 2019). Particularly, legacy news outlets find themselves in a dilemma of jeopardizing their reputation and user trust when providing too much clickbait (Molyneux and Coddington, 2020; Zhang et al., 2020).
Against the background of algorithmic curation and competition for user attention, we ask, what are determinants of legacy news outlets’ clickbait headline supply on social media platforms over time? Going beyond previous research focusing on clickbait performance, this study sheds light on the collective clickbait provision behavior of legacy news outlets facing algorithmic curation. Our goals are (a) to contribute to an understanding of journalistic decision-making in competitive social media environments and (b) to empirically assess “how algorithms and data-driven technologies, enacted by an organization like Facebook, can induce similarity across an industry” (Caplan and boyd, 2018: 1).
Empirically, we focus on the news industry level and analyze 856,252 Facebook posts and 1,305,297 tweets of n = 37 national and regional legacy news outlets in Germany, a country with a strong ethical-professional news industry (Hanitzsch et al., 2011) and comparatively modest social media use for news (Newman et al., 2018), representing a conservative example for the present research goals. The observation period begins in 2013, when the German news industry was widely active on social media and ends in 2017, when social media use for news had stagnated in Germany (Newman et al., 2018). During this period, Facebook provided an algorithmic-curation environment and intended to reduce clickbait supply twice. Twitter shifted from non-curation to algorithmic curation, potentially inviting clickbait.
Literature review
Clickbait news making
Journalists consider various aspects for news selection and editing, including audience metrics (Fürst, 2020; Lamot and van Aelst, 2020), competitor content (Boczkowski, 2010), social media content (Cagé et al., 2020), and outlet reputation (Andina-Díaz and García-Martínez, 2020; Siegert et al., 2011). Social media editors or members of the editorial team are involved in editing news for social media (Cornia et al., 2018). These editors develop conceptions of social media algorithms and “feel the need to optimize their content” (Peterson-Salahuddin and Diakopoulos, 2020: 27) for platforms. Consequently, social media editors recognize that certain topics, for example, health, work better on Facebook than foreign politics (Lischka, 2021). On social media, editors depart from the traditional text norms and add subjective views (Hågvar, 2019) or highlight surprise and emotions (Peterson-Salahuddin and Diakopoulos, 2020). Therefore, news outlet’s social media teasers are more tabloid-like (Magin et al., 2021) and include emojis and more question marks (Haim et al., 2021) than news on their websites. Peterson-Salahuddin and Diakopoulos (2020) conclude that social media editors constantly negotiate newsworthiness with interaction worthiness to be promoted through curation algorithms.
Clickbait represents one way to edit clickworthy teasers. Clickbait headlines highlight gossip, sensational, or provoking aspects or create curiosity gaps by withholding information, which includes listicle, forward-referencing, and question-based headlines (Scacco and Muddiman, 2020). Traditional (summary) headlines also intend to attract readers’ attention by giving more weight to certain aspects of a story while remaining precise (Andrew, 2007). In contrast, clickbait headlines exaggerate arousal and lack precision (Scacco and Muddiman, 2020). Clickbait is regarded as deviating from professional traditions (Hågvar, 2019), and journalists employ clickbait even if they do not favor it (Potthast et al., 2018). Since clickbait originates from digital-native news outlets (Tandoc, 2018), especially legacy news editors may face a dilemma when writing clickbait headlines.
Game-theoretic framework to clickbait news making
Clickbait headlines could be conceptualized resulting from heteronomous market forces in journalism based on field theory (Bourdieu, 1983), which deviate from the dominant view, the journalistic “doxa.” Field theory is applied to explain new entrances in journalism (Tandoc, 2018) and changes in journalistic culture and practices (Schultz, 2007). Moreover, to explain institutional pressures and homogeneity within journalism facing algorithmic curation, the institutionalist perspective of isomorphism (DiMaggio and Powell, 1983) is useful, as adopted in Caplan and boyd (2018). The strength of field theory and isomorphism lies in connecting actors to their environment. Game theory focuses on decision-making while considering the environment of actors. Game theory provides a suitable framework for describing clickbait news supply, acknowledging the interests and actions of editors, competitors, users, and platforms.
A game is an abstract, usually mathematical, description of possible choices that players can make given their information about available actions and consequences in a given setting (Osborne and Rubinstein, 1994). Players can be cooperative or may not exchange information (Nash, 1951; Neumann and Morgenstern, 1944). Game-theoretic approaches are rarely applied to journalism. One exception demonstrates a leader–follower game, in which reputational news outlets withhold questionable scoops fearing reputation loss, while less reputable outlets cover such scoops (Andina-Díaz and García-Martínez, 2020). We describe the roles of journalists, users, competitors, and social media platforms for clickbait news supply in four scenes that can occur subsequently or simultaneously.
Scene 1: game invitation
The online environment of “clickbait media” (Munger, 2020), enabled by interaction-rewarding algorithmic curation (Caplan and boyd, 2018), signals cues to news outlets, civic users, and hoax publishers alike to join an attention maximization game on social media platforms (Braun and Eklund, 2019; Myllylahti, 2020). Previous research describes platforms as powerful intermediaries (Nielsen and Ganter, 2017), while placing journalism into dilemmas with professional standards (Peterson-Salahuddin and Diakopoulos, 2020). Journalists regard Facebook as a central distributer they invest resources into and depend on (Meese and Hurcombe, 2020). Nielsen and Ganter (2017) argue that “digital intermediaries act, leaving news media organizations to react” (p. 1613). If social media platforms efficiently initiate an attention maximization game by algorithmic curation, clickbait supply of news outlets should increase.
H1. Clickbait supply increases in algorithmic curation but not in a non-curative setting.
Scene 2: collective outcomes through stigmergy
While competing news organizations rarely coordinate news supply, news outlets observe each other’s news coverage leading to greater news homogeneity online (Boczkowski, 2010). Through mutual monitoring, news formats, and style collectively adopt over time across the news industry, especially under fierce competition (Arbaouit al., 2020), and even if individual journalists disapprove (Potthast et al., 2018). Accordingly, Haim et al. (2021) show that news outlets’ language is more homogeneous on social media than across their websites. Collective outcomes in journalism thus may involve coordination through environmental cues, which can also explain the universal usage of clickbait.
The concept of stigmergy describes this kind of coordination. Originally proposed to explain collective behavior of termites (Grassé, 1959), stigmergy is a way of indirect communication to coordinate actions through changes to the environment, which actors mutually perceive and respond to (Vrancx et al., 2010). While termites leave pheromone trails that coordinate nest building, human actors’ communicative cues within networks of users instigate stigmergy (Cimino et al., 2018). If clickbait dissemination in journalism is stigmergic, the following should hold:
H2. Outlets adjust their clickbait supply to an industry standard.
Scene 3: playing against an unknown threshold
Whether clickbait effectively maximizes interaction is questioned by studies showing that clickbait may either receive more (Rony et al., 2017) or less clicks (Kuiken et al., 2017; Mourão and Robertson, 2019; Scacco and Muddiman, 2020) than non-clickbait posts. Zhang et al. (2020) find an inverted U-shaped relationship between the number of clickbait headlines and page views. That is, traffic increases up to certain level of clickbait, but decreases if used too extensively.
An inverted U-shape can be justified with regret game theories (Starmer, 2000). Accordingly, the decision of whether to click on a piece of content depends on users’ expected utility. If users frequently experience disappointment with clickbait from any source, because of the lower quality these articles have than summary headlines (Scacco and Muddiman, 2020), regretful users may avoid the type of content or source for future decisions. In this regard, Molyneux and Coddington (2020) argue that negative perceptions of clickbait headlines may aggregate over time, whenever a clickbait headline disappoints users, and ultimately, risks losing their trust. Interaction with clickbait may decrease considerably, which is reflected in popularity cues including likes and shares (Haim et al., 2018). Disappointment follows a steep convex negative function (little disappointment is related to strong utility loss), whereas exceeding expected utility is characterized by a flatter concave positive utility function (a lot more utility than expected is required for extra utility gain; Starmer, 2000). The combination of concave and convex utility functions provides an explanation for the reverse U-shaped relation between clickbait and clicks.
To learn about the optimal amount of clickbait, editors need to experiment. Chen’s (2020) revision game of experimentation on an unknown threshold represents a risk-control game to explore an optimum. Chen (2020) uses the example of a food maker that tries to find out how much of a cheaper substance can be added to a food product without decreasing its quality or, worse, causing health issues. Similarly, news organizations may post clickbait headlines to increase traffic. But if a news outlet adds too many clickbait headlines over time, users’ utility and the outlet’s reputation may be compromised (Molyneux and Coddington, 2020). However, news outlets do not exactly know how much of their own and other clickbait is too much for users. By revising their own actions while observing user behavior, news outlets can incrementally approach the unknown clickbait threshold. Meese and Hurcombe (2020) describe such behavior as “riding the waves of engagement” (p. 5). We propose,
H3. The more user interaction with past clickbait, the more clickbait is supplied at present.
Scene 4: interfering in the game
Outlets benefit from platforms with audience traffic (Sismeiro and Mahmood, 2018) and platforms from engaging content with user loyalty (Chen and Pain, 2019), suggesting a strategic alliance relationship between platforms and outlets. In an alliance, the threat of opportunistic behavior of each party is small (Hansen et al., 2008). Yet, a downward slope of utility initiated by user regret can be harmful for social media platforms due to decreasing user loyalty. Platforms will be interested to maximize utility for users and punish outlets for crossing users’ clickbait threshold. Being providers for the outlet-user interaction, platforms can transform from an ally to a regulator. Their curation algorithms serve as bureaucratic mechanisms (Caplan and boyd, 2018) to enforce regulation. Facebook has intended to penalize clickbait in 2014 and 2016 due to displeased users (Peysakhovich and Hendrix, 2016), revealing a form of responsive regulator interference (Etienne, 2013). To outlets, regulation implies opportunistic behavior of the outlet’s former ally and increases uncertainty toward the future behavior of the platform. Since journalistic routines are used to adapt to frequent algorithm shifts (dos Santos et al., 2018), news outlets may adhere to platform’s algorithm changes, as shown for increases in ideological news diversity (Garz and Szucs, 2021) and social video supply (Tandoc and Maitra, 2018). Alternatively, outlets may not comply facing unpredictable algorithm changes (Cornia et al., 2018; Meese and Hurcombe, 2020). We ask,
RQ1. How does clickbait supply change after a platform’s regulative algorithm change?
Method
Sample
Platform selection
Facebook and Twitter were selected as information-rich cases stratified regarding news outlets’ dependency (high vs low), algorithmic curation (permanent vs incremental), intention to reduce clickbait (twice vs none), and a rather general versus information-elitist audience, respectively (Cornia et al., 2018; Myllylahti, 2020; Newman et al., 2018). Given Facebook’s and Twitter’s accessibility, the platform selection strategy combines stratified purposeful and convenience sampling (Suri, 2011).
Regarding Facebook’s News Feed, two algorithm updates explicitly targeted clickbait. In August 2014, Facebook announced that its news feed would “weed out” clickbait (El-Arini and Tang, 2014). In August 2016, Facebook refined its clickbait detection using supervised learning techniques to curb the distribution of “misleading and spammy” clickbait more effectively (Peysakhovich and Hendrix, 2016).
Twitter users were exposed to tweets in reverse chronological order until 2016. In January 2015, Twitter announced to start testing features of algorithmic content selection to “surface a few of the best Tweets” (Rosiana, 2015). These features were gradually rolled out on an opt-in basis. In March 2016, Twitter switched to algorithmic curation as users’ default option (Kamen, 2016).
Country and news outlet selection
Germany is a country with a strong ethical-professional conduct in journalism (Hanitzsch et al., 2011), strong in print revenues compared to slowly growing online revenues (Newman, 2016), comparatively low social media use for news but increasing mobile news use during the observation period (Newman et al., 2018). Facebook was used for news by 25% and Twitter by 4% of users (Newman et al., 2018).
The sample of news outlets comprises 10 national and 27 regional news outlets with a legacy in print following a traditional, two-sided model of advertising and audience revenue, which had a Facebook and Twitter account during the study’s observation period (see Figures 3 and 4). The sample thus stands for a potentially maximized tension between following traditional professional standards and adopting to algorithmic curation—while news outlets’ revenue dependency on platforms is comparatively low.
Data collection
We collected 856,252 posts and 1,305,297 tweets published between January 2013 and June 2017 by the official Facebook Pages and Twitter accounts of 37 German news outlets, which comprises the total posting activity of these outlets. The data include the date and time of publication, the post message, and the number of likes and shares. The dataset was compiled using the Facebook graph application programming interface (API) combined with the mining application Netvizz. For Twitter, we used the Python library “GetOldTweets3.” This library offers an automated approach to access and parse the browser-based Twitter search. We recovered each tweet’s date, time, message, and number of likes and retweets.
Supervised machine learning approach
We used supervised learning to obtain clickbait classifications of all content in our dataset, based on the characteristics of the posts and tweets rated by human coders.
Human coding
We drew random samples of 20,000 posts and 20,000 tweets and had humans evaluate whether these messages classify as clickbait. German-speaking coders were recruited through Fiverr.com, an online platform for freelance services. To verify the coding quality, we had each potential coder evaluate a test batch of 500 messages, which we had coded ourselves. We paid potential coders 20 Euros for rating these 500 messages and offered further work if their coding “fulfilled our quality standards.” That is, we compared their evaluation of the test batch with our own coding and selected only coders whose kappa-statistic (Landis and Koch, 1977) indicated that the ratings are systematically related to the gold standard (at the 1% level). The employed coders achieved inter-rater agreement rates between 94.8% and 98.0%, corresponding to kappa-statistics between 0.61 and 0.77. The coders received further batches of randomly selected post messages, each batch for 20 Euros incentive. We assured ongoing coding quality by spot checking the results. Importantly, we kept repeating our offer to ask for more work “as long as our quality standards were met,” which arguably created a strong incentive for the coders to take the task seriously. Each batch included a nondescript identifier, the post or tweet message, and one blank column for the evaluation. The files did not include date and outlet, to avoid priming the coders.
The coding instructions asked to evaluate whether a given post message qualifies as clickbait (“yes,” “no,” and “maybe”), considering the following instructions: Clickbait refers to headlines designed to maximize clicks, often for commercial interests such as ad revenues. For instance, clickbait exaggerates or withholds information to arouse the attention and curiosity of the reader, so that the reader clicks on the headline and opens the linked story.
The instructions included specific examples of non-clickbait and clickbait, including forward-references, questions, listicles, and sensationalization (see Table 1).
Examples of non-clickbait and clickbait headlines.

Clickbait classification
The classification was implemented using the R package “caret—Classification And REgression Training” (Kuhn, 2008). To evaluate the power of different classification methods, we randomly divided the samples of coded messages into training (70%) and testing observations (30%). Given the potential differences between formats, content, and outlets’ social media strategies across platforms, we used separate classifiers for each platform (see Appendix 1).
Following the literature on automated clickbait classification (Biyani et al., 2016; Chakraborty et al., 2016; Rony et al., 2017), we considered the following predictors to train the models. First, we created count variables for each 1-, 2-, and 3-gram in the messages. For that purpose, we removed punctuation and numeric characters and tokenized the texts. We did not remove stop words and refrained from stemming words to their root because differences between clickbait and non-clickbait could be subtle. The messages consist of ca. 540,000 n-grams, all of which were considered as potential predictors of clickbait. In addition, we constructed various variables based on quantifiable characteristics of the messages, including the number of words, the mean word length, as well as the number of periods, question marks, exclamation marks, colons, and numerical characters. We also constructed binary variables indicating if a message starts with a number or a 5W1H word (i.e. what, why, when, who, which, and how), contains a third person personal pronoun (i.e. he, she, his, her, him), or includes a demonstrative (this, that, those, these). Finally, we evaluated the predictive power of meta-level characteristics, including outlet, day of the week, day of the month, and hour of publication, and whether the post or tweet included a link embedded in the text.
Given the large number of potential predictors, we pre-screened the variables based on their bivariate correlation with the observed clickbait status of a post or tweet to speed up training. We retained the 500 predictors with the largest correlation coefficients to train various classification models, including (boosted) logistic regression, (penalized) discriminant analysis, generalized linear models, gradient boosting, and random forests. All models were trained using 20-fold cross validation. We used penalized discriminant analysis, because this approach outperformed the other approaches. 1 We also compared the performance for a 3-point (i.e. “yes,” “maybe,” “no”) versus a 2-point clickbait scale (i.e. “yes” and “no”; combining initial “yes” and “maybe” into one category). We decided to proceed with the 2-point scale because the coding instructions induced conservative ratings and the classification models performed better.
Analysis
Data preparation
Model-based classification does not involve a “hard” assessment of whether a headline is clickbait or not. Instead, for each post and tweet in our dataset, we obtained the probability that the corresponding headline classifies as clickbait. 2 For the regression analyses, the individual probabilities were then aggregated at the outlet-month level. We created two panel datasets (one for each platform), consisting of 37 outlets and 54 months. We follow Zhang et al. (2020) and use a monthly frequency because quarterly or yearly observations would imply an unnecessary loss of information, whereas a higher frequency (e.g. weekly or daily) would make the analyses vulnerable to the influence of posts or tweets with extreme interaction metrics.
Estimation
To test the hypotheses, we estimated regression models of the following form:
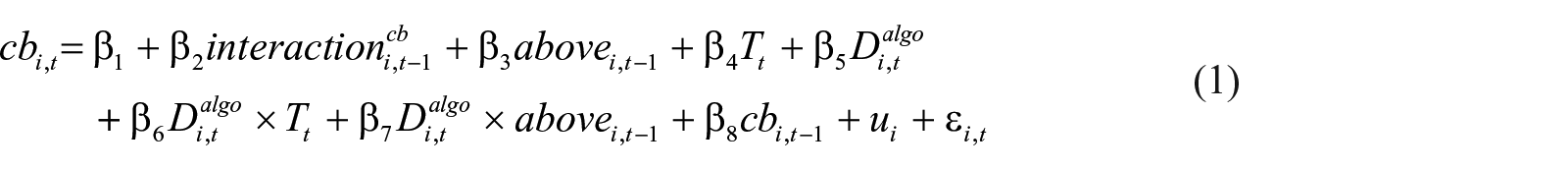
where
We estimated Equation (1) as a fixed effects panel model through ordinary least squares, using
Results
Clickbait probability
The average probability that a post or tweet is clickbait was 5.9% (SD = 4.6, Min = 0, Max = 33.5) on Facebook during our observation period and 2.8% (SD = 2.0, Min = 0, Max = 33.3) on Twitter. On average, the monthly like and share interaction with clickbait summed up to 4712 likes and shares on Facebook and 133 on Twitter per outlet. On Facebook, the clickbait probability followed an upward trend, starting at around 5% in 2013 and reaching a peak of about 7% toward the end of 2016. Afterwards, the use of clickbait seems to have stagnated or even declined (Figure 1). The clickbait probability on Twitter appears quite stable over time (Figure 2). On Facebook, news outlets ranged in their average clickbait probability between 2% (Freie Presse) and 28% (Focus; see Figure 3). On Twitter, the clickbait probability ranged between 1% and 3% for most outlets; but four outlets stand out, with probabilities around 6% (Figure 4).
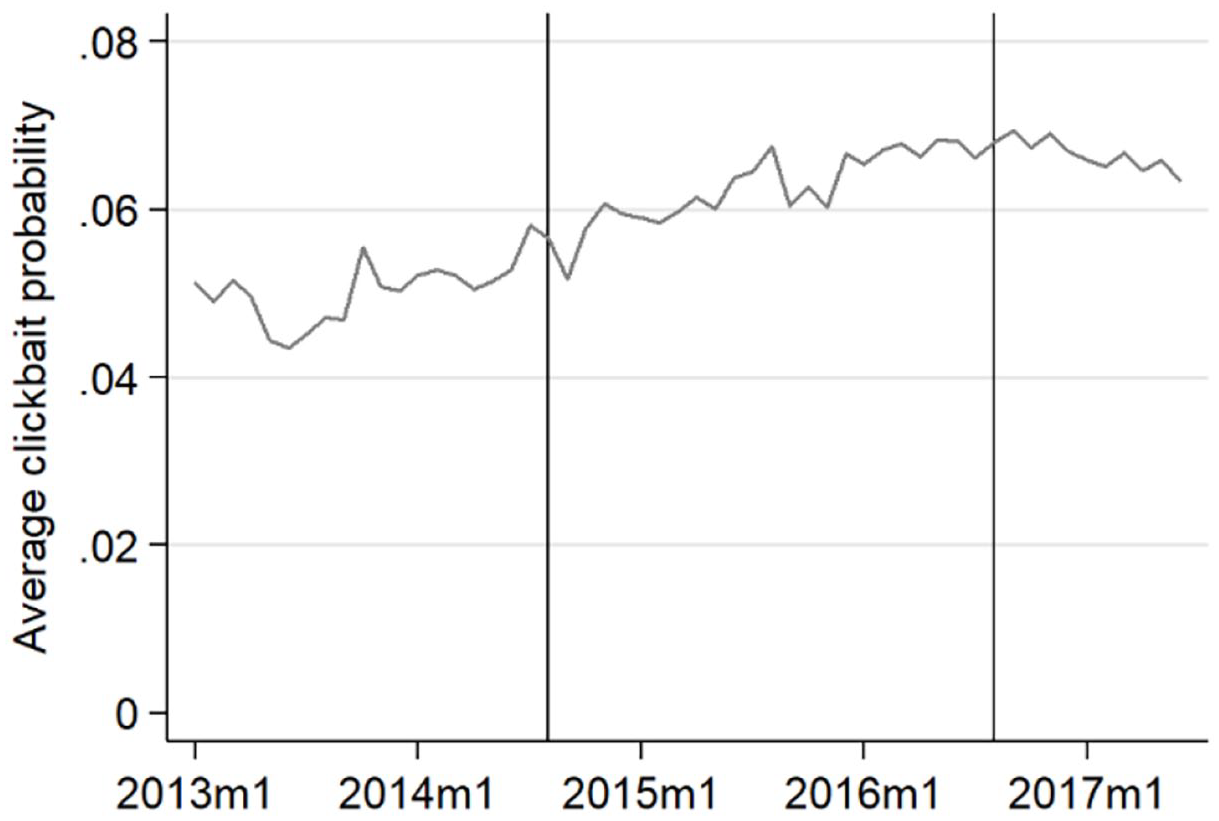
Use of clickbait over time, Facebook.
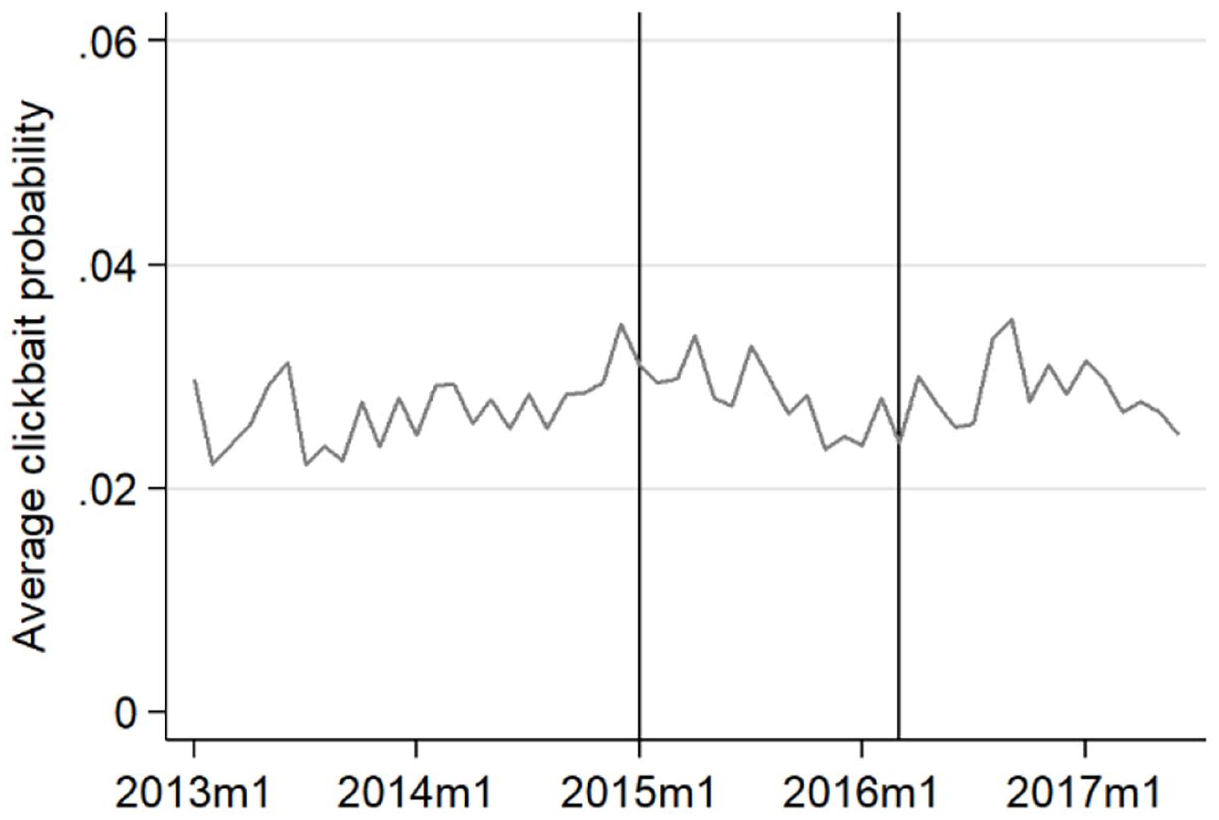
Use of clickbait over time, Twitter.
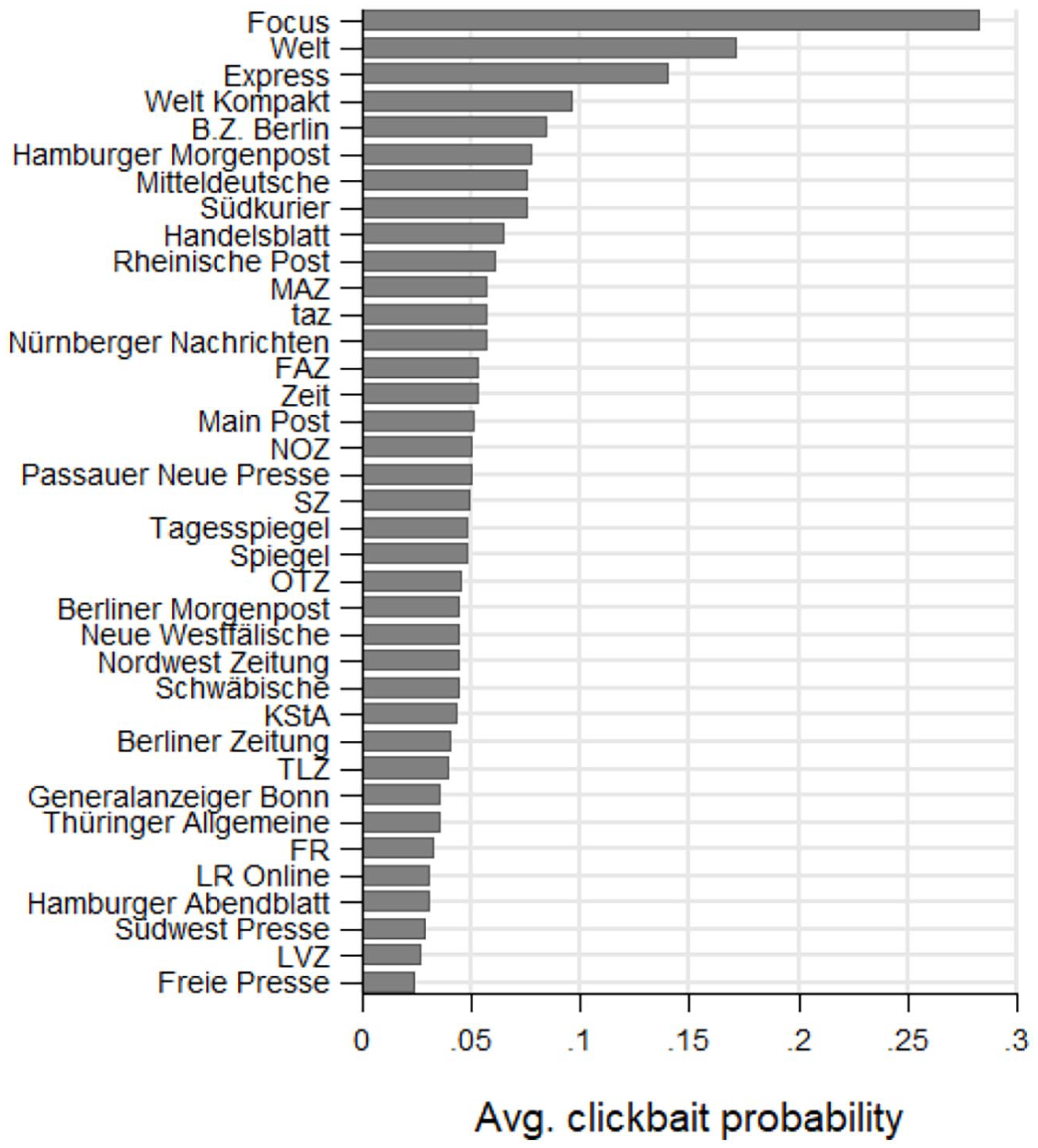
Use of clickbait across outlets, Facebook.
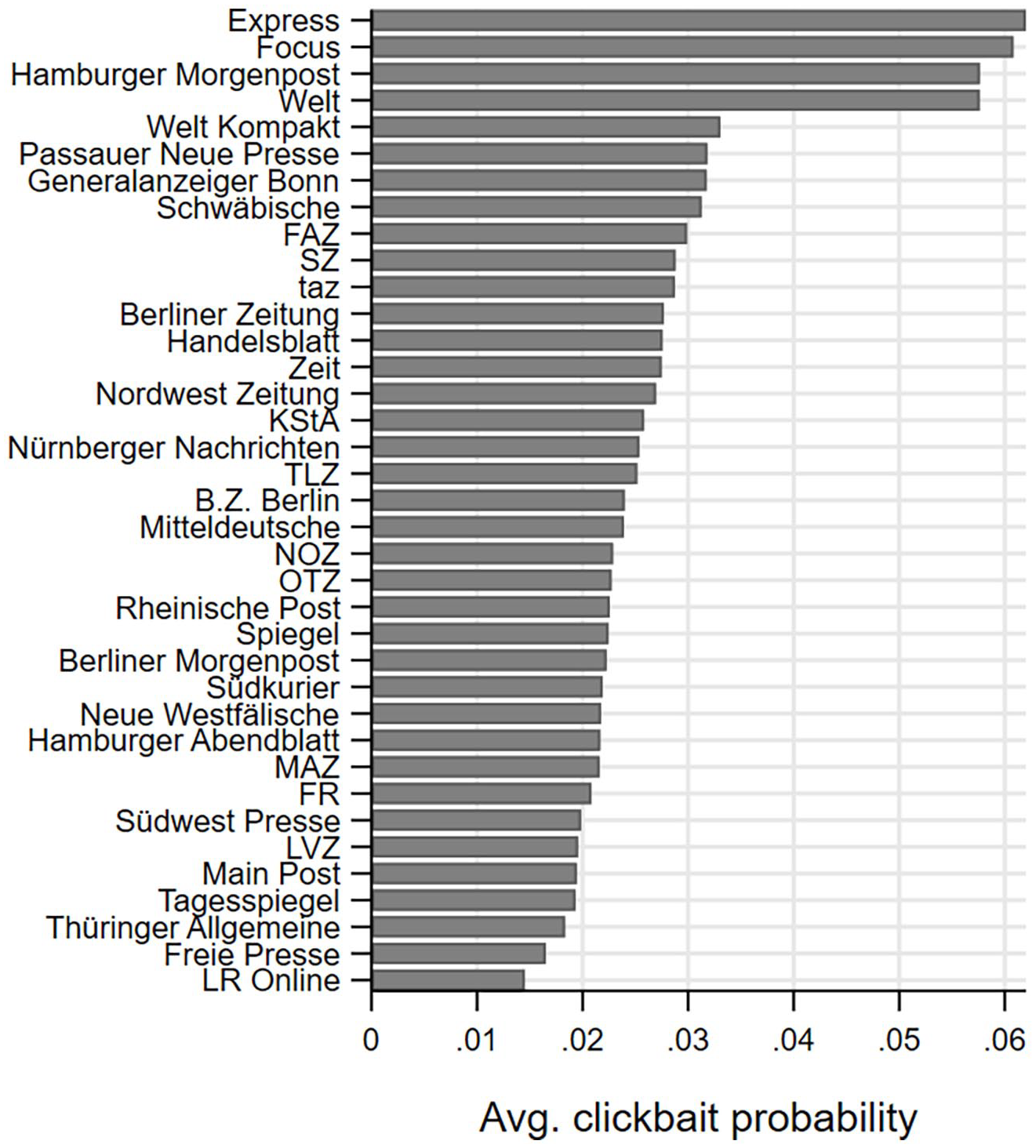
Use of clickbait across outlets, Twitter.
Reverse U-shape
We assume a threshold of clickbait that news outlets can supply before users grow tired. Our data reveal a reverse U-shaped relationship between clickbait supply and subsequent user interaction (see Figures 5 and 6). That is, user interaction increases when the outlets provide more clickbait—but only until a certain point, after which more clickbait results in decreasing interaction. We calculate this point at 21% clickbait probability on Facebook and 6% on Twitter.
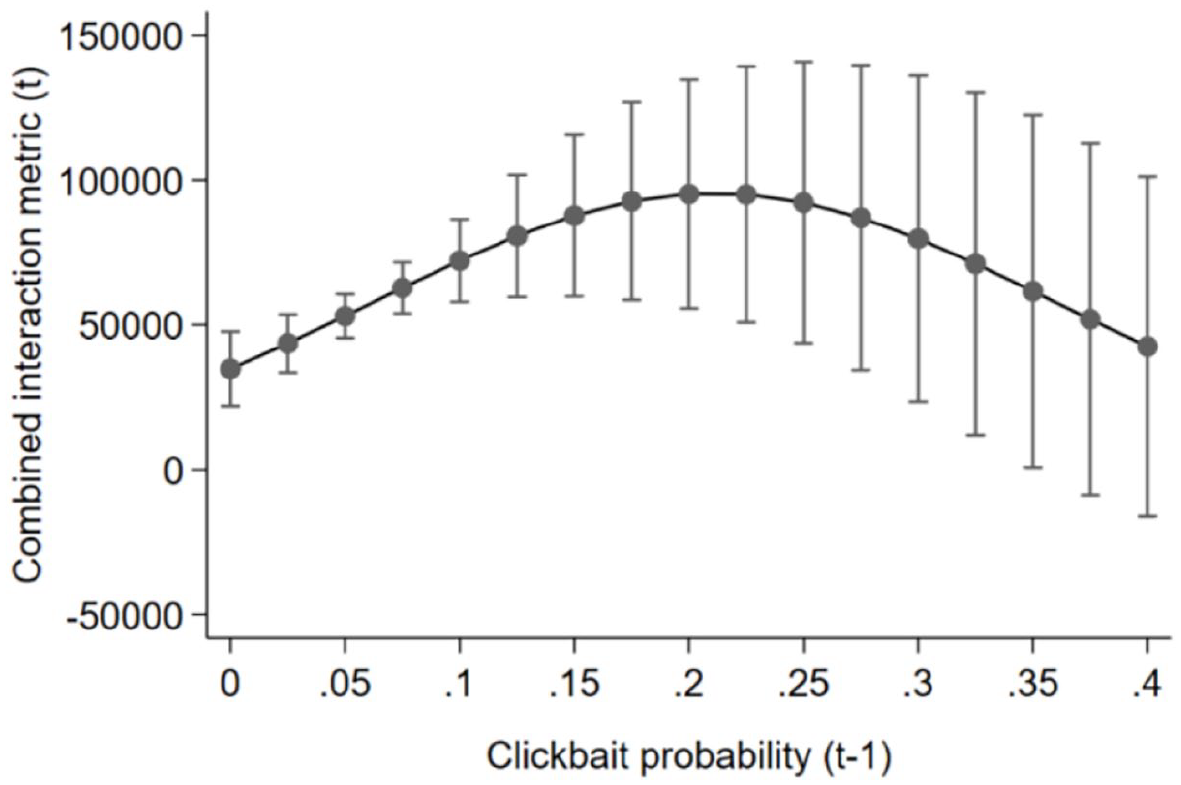
Clickbait and Facebook user interaction.
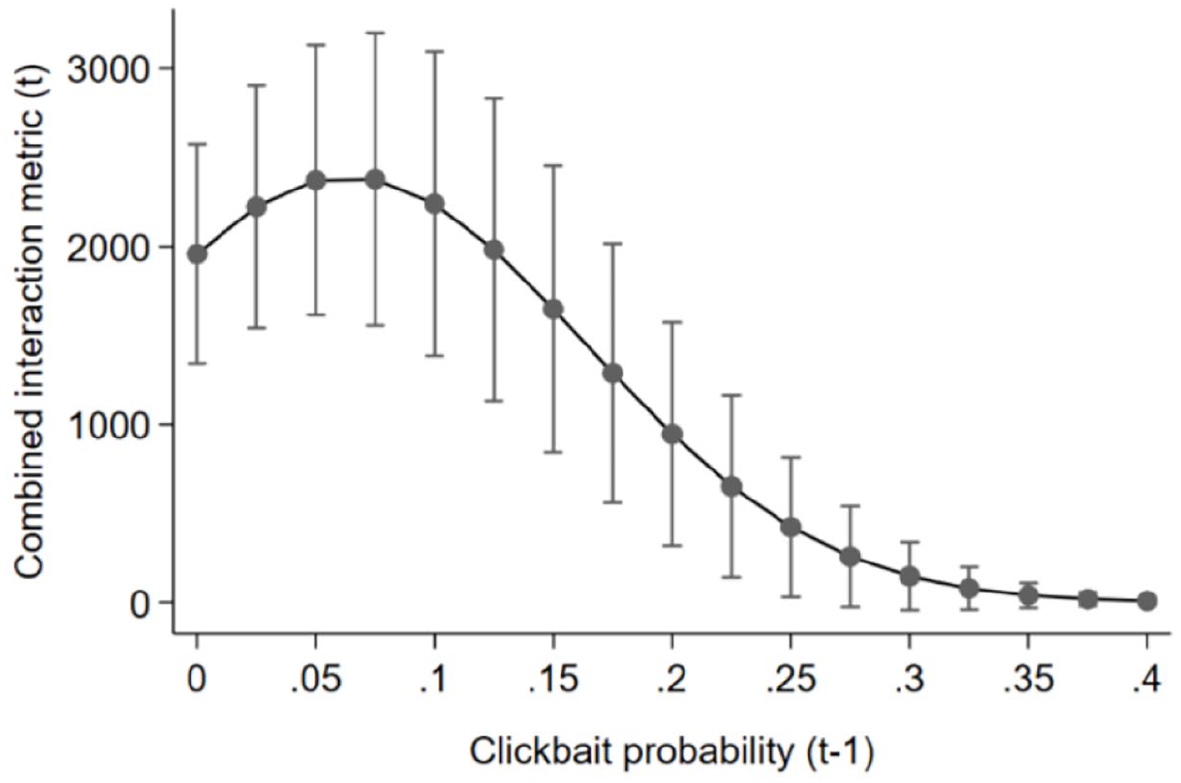
Clickbait and Twitter user interaction.
Scene 1: game invitation
To evaluate if clickbait supply increases in algorithmic curation but not in a non-curative setting (H1), we compare the development of the clickbait probability on Twitter for the time before and after the platform rolled out its algorithm. The raw probability plotted in Figure 2 did not change visibly when Twitter started testing its algorithm in 2015, and there does not seem to be any increase after the global roll-out in 2016 either. To evaluate H1 formally, we consult the regression results in Table 2, Column (2), especially the coefficients on the interaction terms between the algorithm dummies and the time trend variable. The coefficient on Jan 2015 to Feb 2016 × time trend captures the development of the clickbait probability after the start of Twitter’s testing phase (relative to the pre-algorithm period from Jan 2013 to Dec 2014), whereas after Feb 2016 × time trend measures the development after the global roll-out. As the estimates show, neither the testing phase nor the implementation phase was associated with increases in clickbait probability. In contrast, we find that this probability decreased during the testing phase between Jan 2015 and Feb 2016—the corresponding coefficient is negative and significant at the 10% level. In addition, the Time trend variable—which captures the development between Jan 2013 and Dec 2014—indicates that clickbait had been growing in a non-curative setting, before Twitter started testing its algorithm. Hence, we reject H1.
Determinants of clickbait supply.

Notes: Estimates based on fixed effects panel data models. Robust standard errors (clustered by outlet) in parentheses.
p < .10; **p < .05; ***p < .01.
Scene 2: stigmergy
H2 is evaluated by consulting the coefficient on Above industry level, t–1 in Table 2. For Facebook, we obtain a negative significant value (Column 1). The estimate thus implies that those outlets that have a higher clickbait probability than the median outlet adjust their clickbait supply downward in the following month. The coefficient also implies that outlets below the industry level increase their clickbait supply. Thus, the monthly adjustment process can be described as one of convergence between outlets. For Twitter, the coefficient is also negative, but not significant at conventional levels. Hence, we confirm H2 for Facebook but reject it for Twitter.
Scene 3: playing against a threshold
Results in Table 2 confirm that higher amounts of past user interaction with clickbait are associated with greater levels of current clickbait supply (H3). On Facebook, this relationship is statistically significant at the 5% level. According to the point estimate of 0.0141, a one-unit increase in Combined interaction with clickbait (= 100,000 additional likes/shares) results in an increase in clickbait probability by 1.4 percentage points in the next month. To put this effect size in perspective, the combined interaction with clickbait on Facebook averaged 4712 likes/shares per month. If this number was doubled, the outlets’ clickbait probability would increase by
Scene 4: interfering in the game
To answer RQ1, we first test if Facebook’s modifications of the news feed algorithm to curb the proliferation of clickbait worked as intended. The interaction terms Aug 2014 to Jul 2016 × time trend and after Jul 2016 × time trend allow us to compare the development of clickbait supply over time after each modification of the algorithm in comparison to the period from Jan 2013 to Jul 2014. Accordingly, the time after the platform’s first algorithm update (Aug 2014 to Jul 2016) was not characterized by a different trend in clickbait supply. However, the coefficient on after Jul 2016 × time trend is negative and significant at the 1% level, which implies that Facebook’s second modification initiated a downward trend in clickbait. Yet, this development did not (immediately) result in a lower level of clickbait. As the coefficient on the After Jul 2016 dummy indicates, the overall clickbait supply remained on a higher level than between Jan 2013 to Jul 2014 despite the initiation of a downward trend.
Second, the interaction terms Aug 2014 to Jul 2016 × above industry and after Jul 2016 × above industry have a significantly positive sign. Thus, after Facebook’s modification, the news outlets were less inclined to revert to the industry standard, compared to the time before the platform tried to lessen the distribution of clickbait. Hence, the algorithm updates also reduced the outlets’ tendency to align their behavior with their competitors.
Discussion
This study explores the clickbait posting behavior of legacy news outlets in the German news industry. Overall, we observe a low level of clickbait during the observation period (about 6% on Facebook and 3% on Twitter). The variations in the use of clickbait across platforms as well as between news outlets could be driven by differences in audiences’ news consumption preferences. That is, Twitter’s information-elitist audience of “politicians, journalists, and news lovers” (Cornia et al., 2018: 7) could be generally less attracted to clickbait because of a greater demand for quality news. Since social media use is related to an incidental news consumption during leisure time (Boczkowski et al., 2018), consuming sensational news on Facebook may be more valued than on Twitter. Moreover, the outlets with the highest clickbait probabilities in our sample tend to be tabloids (e.g. Express, B. Z. Berlin, and Hamburger Morgenpost), whose readers may have a higher degree of acceptance of sensational content.
Beyond these structural differences, news outlets appear to play a stigmergic revision game for finding the optimal amount of clickbait. Clickbait supply reveals characteristics of collective behavior that is coordinated through environmental cues. With clickbait headlines, news outlets leave each other communicative trails that explain an industry-wide diffusion of clickbait as shown in previous research (Blom and Hansen, 2015; Rony et al., 2017). News outlets adopt toward an industry-wide clickbait supply standard as predicted by stigmergy games (Vrancx et al., 2010).
However, although platforms represent a powerful force for journalism (Caplan and boyd, 2018; Nielsen and Ganter, 2017), we cannot prove that introducing algorithmic curation increases clickbait—at least not on Twitter. In contrast, the clickbait game was already being played before Twitter introduced algorithmic curation, as we find a slight upward trend in clickbait during that period. Thus, we observe a stigmergic tendency toward interaction-cumulating content within the news industry across platforms, which may reflect a universal appeal of clickbait in an environment of competing for fleeting user attention. In addition, our results show that Facebook’s attempts to reduce clickbait were not initially successful. The platform’s first modification of its algorithm used reading time and interaction with a piece of content and thus focused on indicators for user regret. This approach may not have been sophisticated enough to identify clickbait and outlets may not have experienced lower visibility. Only the second update in 2016, in which Facebook used a supervised approach with humans identifying clickbait to train a classifier, resulted in a sustainable decrease in clickbait growth. That is, news outlets adjusted to this algorithm change but did not reduce clickbait to the lower 2013 level. Hence, the universal appeal of clickbait represents a sustainable sway in the news industry whose effect is hardly reversible.
Still, regulative intervention has an indirect effect on news outlets’ clickbait supply. Outlets’ tendency to adjust to the average industry clickbait supply declined after both algorithm changes of Facebook. That is, the news outlets’ clickbait supply deviated from each other, which indicates a replacement of stigmergic orientation with opportunistic behavior. This result complements the findings of Meese and Hurcombe (2020) and Cornia et al. (2018), who show that algorithm changes induced outlets to turn away from Facebook as a central distributer. Thus, algorithm changes may have unintended consequences leading to a decrease of news homogeneity online.
User behavior determines clickbait supply as well, and perhaps, more so than algorithm changes. We show that likes and shares of clickbait predict subsequent clickbait supply on Facebook and Twitter. However, the outlets’ reactions to user interaction are relatively small, which implies cautious supply adjustment in every step. News outlets continue their upward search for a threshold as long as the user interaction with clickbait content grows—or else, they decrease their supply accordingly, indicating a careful ride of the waves of interaction.
Regarding a fatigue threshold, our results show that a moderate level of clickbait performs better than low or high levels. This result is in line with previous research pointing at an inverted U-shaped relationship between clickbait and user interaction (Zhang et al., 2020) and suggesting a wear-out effect of these headlines (Molyneux and Coddington, 2020). We specify a wear-out threshold of clickbait at 21% probability on Facebook and 6% on Twitter over all observed news outlets, with a flat increase and a steeper decrease of clickbait performance for Twitter. The lower threshold, flat increase, and steeper decrease on Twitter may be due to an information-elitist audience whose experienced utility of clickbait news barely excels their expected utility but is easily disappointed. Moreover, the steepness of the interaction decline on Twitter may be fueled by decreasing popularity cues signaling low utility to users and lowering stigmergic user behavior as suggested by Dipple et al. (2012).
Regarding limitations, first, our data capture social media news and thus ignore a larger news environment that editors may consider. Future research on clickbait provision outside social platforms could reveal whether clickbait supply collectively changes as found here. Also, our data do not include non-journalistic content suppliers, which are however relevant as clickbait fatigue is related to users’ total clickbait exposure. Second, our sample period ends in 2017 due to Facebook’s restrictions, not including Facebook’s 2018 algorithm changes that broadly address news content. More recent data could also reveal whether legacy news outlets abstain from using clickbait since the rise of hoax outlets, as predicted by reputation games. Third, our investigation is limited to legacy media in Germany, implying a conservative context with relatively low online advertising revenue growth and modest social media news use. Future research could evaluate if our results hold in countries with more strongly growing online revenues and larger social media audiences, possibly exhibiting greater responsiveness to platforms’ regulative intentions. Fourth, likes and shares are certainly of interest to social media editors—although these popularity cues cannot be equated with engagement with journalism (Haim et al., 2018). User interaction in the form of referral traffic might have an even larger impact on media outlets’ decisions because this traffic can be directly monetized. Sismeiro and Mahmood (2018) show that social media interaction with news stories is a strong predictor of news outlets’ website traffic, which gives us confidence that the likes and shares considered here are relevant metrics. Fifth, supervised machine learning makes it possible to detect clickbait in a large corpus of text. The automated classification may not reach the same accuracy as human coding though. As shown in Appendix 1, our clickbait classifiers achieved a satisfactory performance—especially in comparison to previous clickbait detection studies (Biyani et al., 2016; Chakraborty et al., 2016; Potthast et al., 2018)—but methodological advances are desirable to improve the accuracy of automated text classification. Finally, as our data include only the editorial output of the news organizations under study, it remains unclear to what extent players consciously follow an established strategy. While audience metrics seem to gamify journalism to some extent (Ferrer-Conill, 2017), follow-up research is required to understand whether social media editors make decisions with a revision game on an unknown threshold in mind.
Conclusion
We explore the clickbait supply trends and patterns of legacy news outlets in an altering algorithmic-curation platform environment with utility-seeking users. This study is the first to determine the relation between news outlets and platforms by observing collective long-term news supply behavior during several curation algorithm changes.
Legacy outlets collectively supply interaction-inducing content on social media platforms following a revision game. They tend to underuse clickbait, except for a few heavier-using outlets with a tabloid focus, suggesting that professional norms endure on social media. An adjustment toward the optimal clickbait threshold takes place in small steps, which implies uncertainty despite the availability of detailed audience metrics. This uncertainty may lead to sharing audience metrics across outlets—potentially enhancing audience datafication in journalism (Livingstone, 2019).
Results endorse an increasing audience focus in online environments. Audience interaction serves as utility cues for users, revision cues for news outlets, and loyalty cues for platforms. Present results indicate that news outlets embrace a universal and almost irreversible focus on audience attention and popularity cues as suggested previously (Fürst, 2020; Lamot and van Aelst, 2020; Myllylahti, 2020). In a competitive environment, even legacy news outlets become “clickbait media” (Munger, 2020) that design “addictive distractions” (Naughton, 2018: 387), at least on a low level.
Finally, our findings contribute to an understanding of the relationship between social platforms and legacy media, especially concerning implications of platform policy for editorial decisions. News outlets can adhere to (Garz and Szucs, 2021; Tandoc and Maitra, 2018) and, as in our study, be indirectly responsive to changes in algorithmic curation. Both reactions acknowledge the central role of platforms not only in news distribution but also for news supply. Hence, curation algorithms serve as bureaucratic mechanisms (Caplan and boyd, 2018) that can enforce news similarity (Boczkowski, 2010; Haim et al., 2021). Our results advance these findings suggesting that algorithm changes reverse heterogeneity tendencies and unintendedly may increase news diversity online.
Footnotes
Appendix 1
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.