
Abstract
Due to the accessibility and economy of human speech, speaker verification has become the research hotspot in the field of biometric authentication. A novel normalization sequence kernel based on Bhattacharyya distance clustering and within class covariance normalization was proposed in this paper. In this kernel, the high computation complexity and channel interference susceptibility that commonly exist in speaker verification could be restrained. In our method, we calculated the Bhattacharyya distance between pairs of Gaussian mixture models first. And then, a clustering algorithm was designed according to Gaussian mixture model’s Bhattacharyya distance to obtain clustering center models. Maximum a posteriori was applied on these clustering center models to generate super-vectors immediately following. The sequence kernel was generated based on Bhattacharyya distance transformation and super-vectors. Finally, within class covariance normalization was utilized to restrain the channel distortion in kernel space. We adopted support vector machine as classifier to decide the target speaker. The experiment results on TIMIT corpus and NIST 2008 SRE showed that our proposed kernel has superior recognition accuracy and better robustness.
Keywords
Introduction
Speaker recognition 1 has played an important role in biometric authentication field, which includes speaker identification and speaker verification. It has broad application prospect in the fields of military, E-bank, information security, 2 and so on. Speaker verification is usually formulated as a hypothesis test that verifies an identity claim by estimating the similarity of the claimant’s speech and the enrolled utterance(s). The effective feature extraction and high-efficiency recognition model design have important effect on speaker verification system performance.
The speaker personality characteristics are largely reflected in the speaker’s pronunciation channel variation, that is the channel frequency characteristics. 3 Features that can characterize speaker personality are short-term energy, short-term average amplitude, short-term zero-crossing rate, short-time pitch period, pitch frequency, linear prediction coefficient, line-spectrum pair features, short-term spectrum, formant frequency and bandwidth, cepstrum features, Mel frequency cepstral coefficient (MFCC), and so on. MFCC can reflect the spectrum amplitude of speech and describe sound channel more accurately. And it is also easy to calculate. Therefore, it is more widely and effectively applied in the field of speaker recognition. In this paper, we adopt MFCC as the speech parameters.
In text-independent speaker verification, support vector machine (SVM) has been proven to be effective classifier and most popularly used for many years. 4 It has many desirable properties inherently, including the ability to classify patterns with least expected risk principle, to classify sparse data 5 without over-training problem, and to make non-linear decisions via kernel function. Sloin and Burshtein 6 presented a discriminative training algorithm based on SVM to improve the classification of hidden Markov models. Good experimental results had been obtained. Chu and Wang 7 used SVM for cancer classification with microarray data. Khandoker et al. 8 applied SVM for automated recognition of obstructive sleep apnea syndrome types from their nocturnal electrocardiograph recordings.
The key issue of SVM is kernel function. It is used primarily as an alternative to the complicated inner product operation. In this way, the dimension disaster could be avoided because of the complexity reduction. Nevertheless, SVM has its own inherent limitations in dealing with fixed-length vectors. 9 Spectral features 10 cannot be used directly for SVM, since the spectral features are extracted from utterances of various lengths. In order to overcome this defect of SVM, many new kernels based on fixed vectors were proposed. 11 Longworth and Gales 12 called these SVM kernels as sequence kernel, which could convert variable length feature vectors into fixed length. Campbell 13 proposed Gaussian mixture model (GMM) super-vector based on the in-depth study of GMM parameters and maximum a posteriori (MAP) algorithm. He computed Kullback–Leibler (KL) divergence between pairs of GMM super-vectors to generate KL divergence sequence kernel. You CH, Lee KA and Li H. 14 proposed a novel kernel based on GMM super-vector and Bhattacharyya distance. However, the computing complexity of this kernel increased sharply with the increase of speech data. This problem also would enhance the modeling complexity of SVM. And then, it would affect the recognition speed of system. In addition, speaker voice would be affected by noise and channel distortion inevitably that make the dynamic range of dimension value in SVM become large. 15 Simultaneously, cross-channel degradation is one of the important challenges facing speaker recognition. 16 So, the channel variations between training voice and testing voice have affected and inhibited the performance of the recognition system largely in the practical application of speaker recognition. Kanagasundaram et al. 17 investigated advanced channel compensation techniques such as linear discriminant analysis (LDA), within class covariance normalization (WCCN), and weighted LDA (WLDA) for speaker verification. The experiments based on NIST 2008 and NIST 2010 speaker recognition evaluation (SRE) corpora demonstrated the effectiveness of each channel compensation method. And the experimental results also showed that WCCN performs better than LDA and WLDA as channel variations mainly depended on the within-speaker variation than between-speaker variation.
For the sake of solving the problems of high computing complexity and channel interference susceptibility of GMM super-vectors, we proposed a novel SVM kernel based on Bhattacharyya distance and WCCN smoothing technique inspired by above related research. In our algorithm, we clustered GMMs of all registered speaker according to their Bhattacharyya distance first. By doing so, we expected that the computing complexity of GMM super-vectors would be reduced. And then, the sequence kernel was generated based on the super-vectors of the clustering center models. In order to relieve the influence of noise and channel distortion, WCCN was adopted to restrain the cross-channel interference for this sequence kernel. The main goal of our method is to improve robustness and performance of speaker verification system. The novelty of our method mainly includes as follows. First, we use Bhattacharyya distance instead of the Euclidean distance in K-means clustering. This gives full play to the effective similarity measure between GMMs of Bhattacharyya distance. Second, the Bhattacharyya sequence kernel function is generated by computing Bhattacharyya distance between clustering center model super-vectors and testing speech model super-vectors. Third, WCCN is used to suppress channel interference in the sequence kernel function space.
The remainder of this paper is organized as follows. In the next section, we give a detailed description of our new sequence kernel based on Bhattacharyya distance clustering and WCCN. Experimental evaluation and results discussion based on TIMIT corpus and NIST 2008 SRE are presented in the “Experiments and discussion” section. Finally, conclusions are drawn in the “Conclusions” section.
SVM kernel based on Bhattacharyya distance clustering and WCCN
With the increase of system registered speakers, the speech data of speaker verification system will enhance amazingly. It is a serious problem in speaker verification, since that it will lead to huge amount of input samples for training and testing in subsequent process. And it will also slower the classifier training speed. In addition, the input speech data are vulnerable to variable-length speech sequence and noise interference. Because of the above factors, the good performance could not be achieved in SVM speaker verification. The key problems in SVM speaker verification are how to get SVM to classify on whole sequence and how to remove channel interference. In order to solve these problems, we propose a novel sequence kernel based on in-depth study of Bhattacharyya distance and WCCN. The system framework is shown in Figure 1.
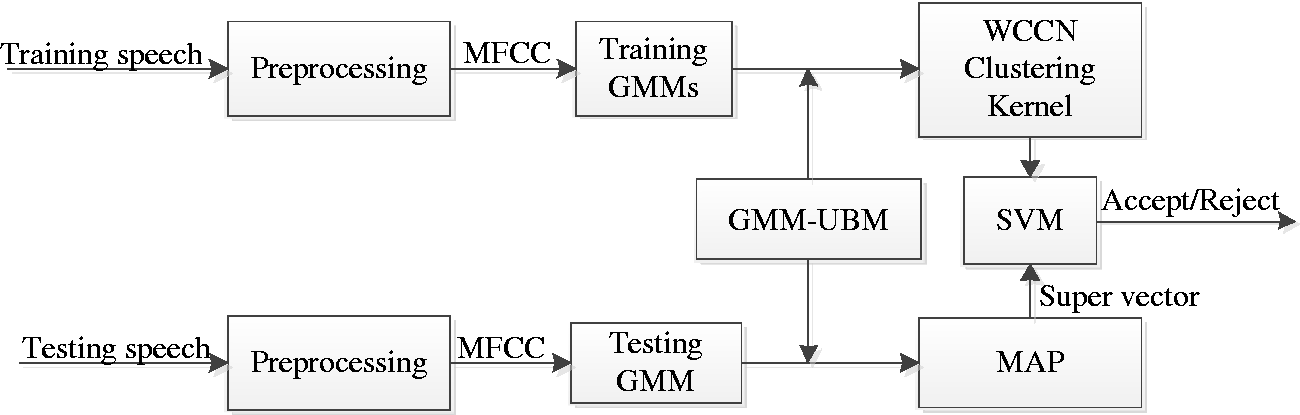
The framework of speaker verification based on WCCN clustering sequence kernel.
Figure 2 shows the generation diagram of our proposed sequence kernel based on Bhattacharya distance cluster and WCCN. From Figures 1 and 2, we can easily see that the training process of our proposed speaker verification can be divided into four phases. The first phase was GMM clustering, in which Bhattacharya distance of GMMs was adopted as clustering measure. The generation of GMM super-vectors was immediately followed by this phase, called the second phase. In order to generate the GMM mean super-vector, a GMM must first be trained from GMM-UBM using MAP adaptation. And the third phase was the generation of our new sequence kernel based on Bhattacharyya distance transformation and WCCN. Finally, we trained SVM using new kernel. In the testing process, we extract the super-vector of testing speech first after SVM was trained successfully, which has the same preprocessing as training speech based on GMM-UBM and MAP. Finally, this testing super-vector is regarded as input of SVM directly to verify the identity of the speaker.

The generation diagram of WCCN clustering kernel.
Speaker GMM clustering based on Bhattacharyya distance
As previously mentioned, the increase of the enrollment amount will lead to the size of the input data rapidly increase. This will be time-consuming in GMM and then will affect the system performance. In order to reduce the size of input data, we considered to cluster speaker GMM models. Speaker clustering based on distance between models is the most widely used means. Bhattacharyya distance is a common distance measure of Gaussian distributions. Gomathy et al. 18 analyzed the clustering performance of Euclidean distance, Mahalanobis distance, Manhattan distance, and Bhattacharyya distance in speech processing gender clustering and classification. The better performance was achieved in Bhattacharyya distance. Therefore, Bhattacharyya distance has the advantages of simple form and stability in model similarity measurement. Prasanth and Chandra Mouli 19 proposed a robust blind watermarking method using Bhattacharyya distance and exponential function to preserve the copyright protection and identify the ownership of digital data. Inspired by K-means clustering algorithm,20 we used the Bhattacharyya distance instead of the Euclidean distance to measure the similarity of GMM models. So, we clustered speaker GMMs according to the Bhattacharyya distance between models. The purpose of this was to reduce the number of input models.
In our clustering algorithm, we utilized Bhattacharyya distance to replace Euclidean distance in conventional K-means clustering algorithm. The Bhattacharyya distance between speaker GMM
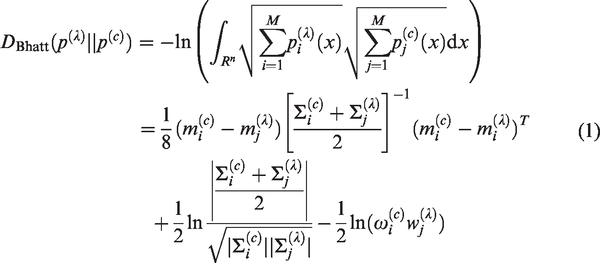
Since we only adapted the means of GMM according to the generation principle of GMM super-vector, all speakers had same weights and covariance matrix. The upper bound of equation (1) can be achieved as equation (2)
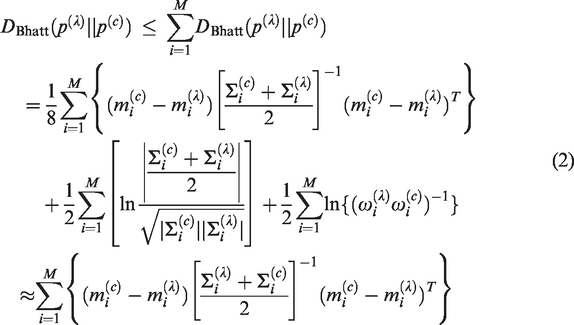
In order to present our proposed clustering algorithm clearly, we described its procedure as follows.
Super-vector extraction of GMM clustering center model
After speaker GMMs have been clustered into
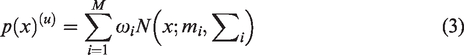
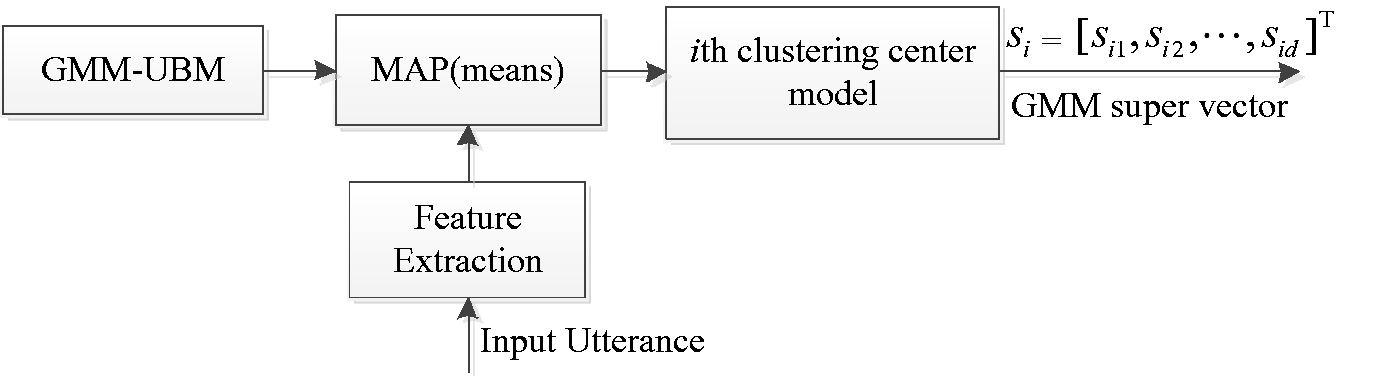
The generation diagram of GMM super-vector.
From Figure 3, we can see that GMM super-vectors have fixed length. Therefore, we can use the GMM super-vectors as the input vectors for SVM learning. However, the dimensions of GMM super-vectors are high. It will slow down the SVM training speed. In order to reduce the computing complexity, covariance matrix usually is adopted in diagonalization form.
The generation of sequence kernel
The defect of classification running on the whole speech sequence has become a big obstacle to develop good classification performance on SVM in speaker verification system. For the sake of overcoming this problem, we proposed a novel sequence kernel on the basis of above speaker clustered models and super-vectors.
Sequence kernel based on Bhattacharyya distance transformation
We denoted the mean distance
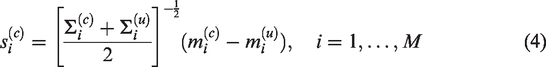
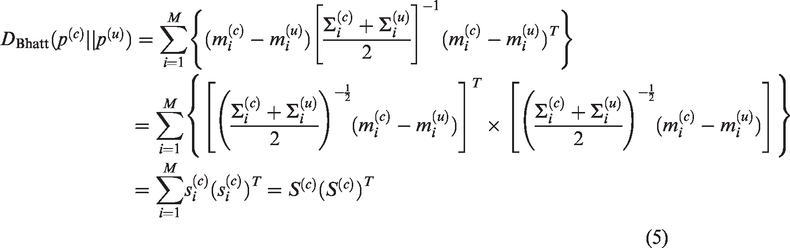
Suppose that the GMM of testing speech is defined as
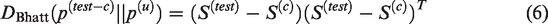
Therefore, we define our Bhattacharyya sequence kernel as follows
Obviously, equation (7) satisfies the Mercer condition. It could be regarded as the inner product of GMM-UBM mean distance super-vectors. This is a novel clustering sequence kernel. It could make SVM classify on whole speech sequence.
Channel compensation using WCCN for new kernel
In speaker verification system, speech is vulnerable to noise and channel distortion. This will lead to the decline of system performance. In order to solve this problem, we utilized WCCN 23 to restrain noise and channel distortion in kernel function space. The covariance matrix of single speaker only reflects the influence of noise. It does not reflect the channel characteristic yet. Therefore, we use more than one speaker’s average covariance matrix.
We denote
SVM based on new kernel for speaker verification
SVM, invented by Vapnik, 25 is a powerful tool for data classification. According to the principle of structural risk minimization, SVM could find the optimal decision boundary in two classes of input samples. It is one of the most robust binary classifier in speaker verification. The basic idea of SVM is illustrated in Figure 4.
The principle presentation drawing of SVM.
In our method, the new feature vectors of target speaker and imposters are used to train SVM, so the class decision function for each speaker can be obtained as follows
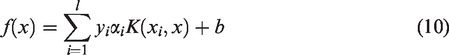
We define the Lagrange function of SVM as
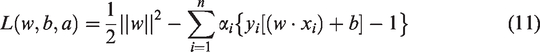
We will refer to the
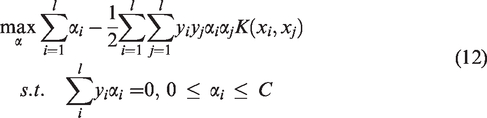
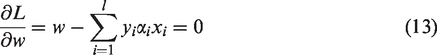

The separation equation can be determined by using bound SV
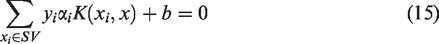
Where
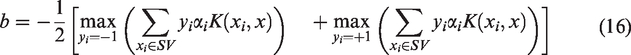
Experiments and discussion
Speech database and preprocessing
Speaker recognition experiments were carried out based on TIMI database and NIST 2008 SRE dataset. We employed TIMI database to test new kernel performance. And NIST 2008 SRE was utilized to test the robustness of new kernel.
In our experiments, two speech databases had the same speech preprocessing. The first-order digital filter was


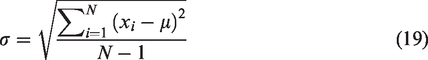
Experiments based on TIMI corpus
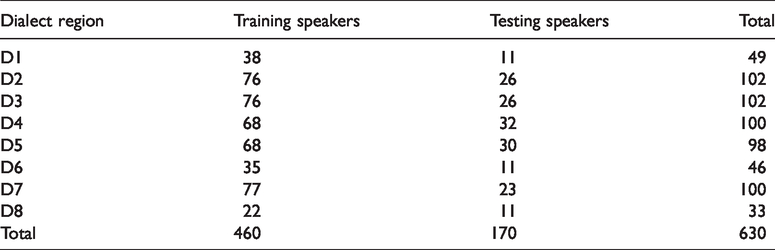
TIMIT speech database contains broadband recordings of 630 speakers including 438 male and 192 females. And all speakers had eight major dialects of American English labeled from D1 to D8. Each speaker was asked for reading 10 different phonetically rich sentences. The total sentences are 6300. The sample information distribution is listed in Table 1. Two of these sessions were dialect uttering by every speaker, and other eight sessions were different for each speaker. The speech signal was recorded through a high-quality microphone in quiet environment, with a 0–8 kHz bandwidth. The signal was sampled at 16 kHz, on 16 bits, on a linear amplitude scale. In our experiments, the training set contains five utterances of each speaker, randomly chosen from the 10 sessions, and the testing set contains the rest of five utterances of each speakers.
The distribution of training and testing sample information.
The clustering performance testing of new kernel
In this experiment, we placed emphasis on the clustering performance testing of our proposed kernel. In order to compare the clustering performance of our proposed kernel, we set the values of K as 630, 460, 300, 200, 150, 100, and 50 in the clustering algorithm, respectively. The experimental results are shown in Table 2.
The clustering performance comparison of our proposed new kernel.
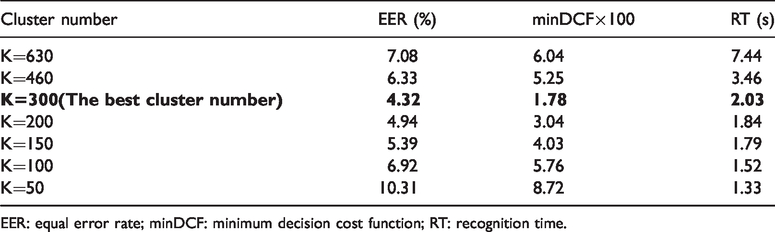
EER: equal error rate; minDCF: minimum decision cost function; RT: recognition time.
K is the number of clusters. If there are too many clusters, there is no clustering effect. The number of registered speakers is not effectively reduced, and the amount of data is large, which affects the computational complexity of subsequent processing. The system RT will be longer. In Table 2, when K = 630, the RT is 7.44 s. With the slow reduction of value of K, a large number of similar models are gathered together to generate a new model. It effectively reduces the amount of data. However, when the value of K becomes smaller, the system EER has become larger. This indicates that the number of training data is too small to improve the recognition performance. However, the RT of the system is very short due to the small amount of data, such as when K = 50, the RT is only 1.33 s. From Table 2, the condition of K = 300 obtained the best performance in our proposed kernel. So, we selected K = 300 in subsequent experiment and reduction ratio of training GMM size reached 56.52%. The RT comparison in different clustering number is shown in Figure 5.
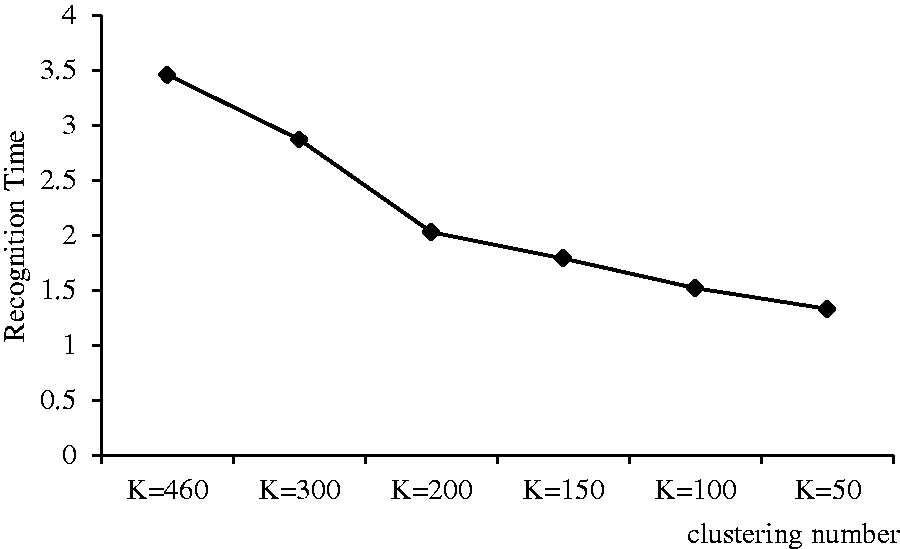
The RT comparison in different clustering number.
The performance comparison between our kernel and other different kernels
In our experiments, we selected linear kernel, polynomial kernels (
EER and minDCF comparison of different kernels.
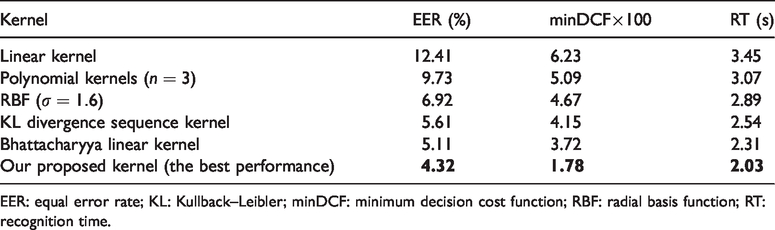
EER: equal error rate; KL: Kullback–Leibler; minDCF: minimum decision cost function; RBF: radial basis function; RT: recognition time.
Obviously, from Table 3 we could see as follows:
The performance of Bhattacharyya linear kernel improved significantly compared to linear kernel, of which EER decreased by 7.3% and minDCF decreased by 0.0251. Compared to polynomial kernels (
Our proposed kernel was superior to Bhattacharyya linear kernel in EER, minDCF, and RT. The EER of our proposed kernel decreased by 0.79%, minDCF fell by 0.0194, and RT shortened 0.28 s. The experimental results showed that our proposed kernel not only had the advantages of the Bhattacharyya linear kernel, but also had a shorter recognition time. The superiority of our proposed kernel is attributed to the speaker models clustering first. By doing so, it could reduce the computational complexity of GMM-UBM model and shorten the RT. Second, the use of WCCN could restrain the influence of noise and channel distortion to kernel, and improve the system performance effectively. The EER comparison of different kernels is shown in Figure 6.
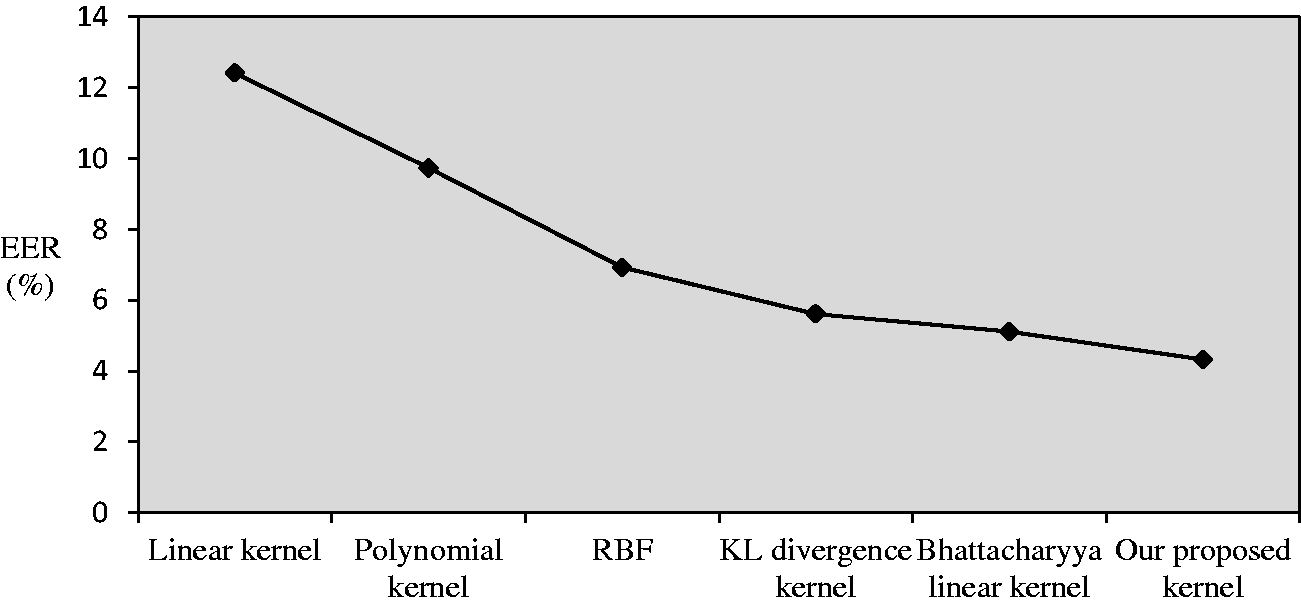
The EER comparison of different kernels.
Experiments based on NIST 2008
The robustness test of new kernel
In order to test the robustness of new kernel, we carried out our testing experiment on NIST 2008 SRE database. We denoted our kernel without WCCN channel compensation as clustering kernel. NIST 2008 evaluation was performed using the telephone–telephone, interview–interview, telephone–microphone, and interview–telephone enrolment-verification conditions. The voice parameter extraction was the same as TIMI corpus. Performance measurement also was EER and minDCF. The experimental results are shown in Table 4.
Speaker verification performance of new kernel.

EER: equal error rate; minDCF: minimum decision cost function; WCCN: within class covariance normalization.
Form Table 4, it was seen that the performance of clustering kernel based on WCCN was completely superior to kernel without channel compensation in telephone–telephone, interview–interview, telephone–microphone, and interview–telephone enrolment-verification conditions. In telephone–telephone condition, EER decreased by 0.54% and minDCF fell by 0.0072. In other conditions, EER and minDCF of our proposed kernel had obvious reduction. Therefore, the proposed new kernel had better robustness.
The performance comparison between our speaker verification system and other systems
In this experiment, we mainly focus on comparing the performance of our proposed speaker verification system with the state-of-the-art system such as GMM-SVM and SVM. The number of GMM-UBM mixtures was 1024. We selected EER and minDCF as performance measurement. The experimental results are showed in Table 5.
Performance comparison of different systems.
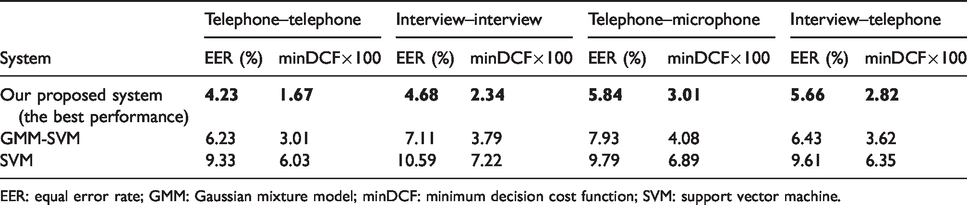
EER: equal error rate; GMM: Gaussian mixture model; minDCF: minimum decision cost function; SVM: support vector machine.
From Table 5, we could easily see that our proposed system has superior performance compared with GMM-SVM and SVM. In the telephone–telephone condition, the EER of our system decreased by 2%, minDCF fell by 0.0134 compared to GMM-SVM. Compared with SVM, the EER of our system decreased by 5.1% and minDCF fell by 0.0436. In the same way, our system also showed superior performance in other enrolment-verification conditions. Our system has shown its effectiveness.
Conclusions
On the in-depth study of k-means clustering algorithm and GMM super-vector, a novel sequence kernel based on Bhattacharyya distance clustering and WCCN was proposed in this paper. With the aid of WCCN smoothing technique, the noise and channel distortion were eliminated in kernel space. This improved the system recognition accuracy effectively. At the same time, our proposed clustering algorithm based on the Bhattacharyya distance could effectively reduce the computational complexity of speaker models and speed up the system RT. Our proposed kernel was proven to be an effective and feasible sequence kernel on the corpus of TIMIT and NIST 2008 SRE database in SVM speaker verification. However, there are large numbers of matrix operations in the process of our kernel generation and WCCN smooth normalization. These will enhance the computing complexity of kernel. Therefore, how to simplify the solving process of our kernel is our focus in the follow-up work.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This paper is supported by National Natural Science Foundation of China (NSFC) (61841203), China.