
Abstract
Keywords
Introduction
In the current healthcare landscape, the importance of effective blood pressure (BP) management is increasingly critical, especially considering its direct link to major health concerns such as cardiovascular diseases (CVDs), stroke, kidney failure, and peripheral arterial disease. 1 High BP, commonly known as hypertension, is a silent yet widespread health concern. 2 This urgency is underscored by striking global statistics. According to the World Health Organization (WHO), hypertension—a key risk factor for these conditions—affects approximately 1.28 billion adults aged 30–79 years worldwide. 3 Alarmingly, about 46% of adults with hypertension are unaware of their condition. 3 This contributes to increasing CVDs mortality rates, 2 projected to rise from 246 to 264 per one million from 2015 to 2030,4,5 These figures highlight the imperative need for consistent and effective BP monitoring and management strategies. Such strategies are essential, not only for individual health but also for alleviating the broader public health burden posed by hypertension and its associated diseases. Despite the imperative need for consistent and effective BP monitoring, the prevalent methods for measuring BP, ranging from invasive procedures to noninvasive cuff-based techniques, present considerable challenges for continuous monitoring.
The invasive methods, involving the insertion of a thin tube into a vein, pose significant risks such as infection, localized bleeding, vein blockage, and potential damage to vein walls. 6 This procedure demands a specialized medical team, expensive equipment, and may cause discomfort for patients. 6 On the other hand, noninvasive cuff-based methods for BP measurement, while more accessible, are not without drawbacks. These techniques typically involve arterial occlusion, rendering them impractical for continuous monitoring purposes. Furthermore, the pressure exerted by these cuff-based methods can cause discomfort for some individuals. To overcome these challenges and usher in a new era of continuous and noninvasive BP measurement, innovative approaches have emerged, including wearable devices, mobile health applications, ultrasound technology, and hybrid approaches.7–9 Specifically, mobile health applications have gained significant attention for their potential to enable continuous monitoring of BP using smartphones and wearable devices. These applications can collect real-time data, analyze it using cloud-based systems, and provide immediate feedback to users, fostering better adherence to BP management strategies and promoting long-term health monitoring outside of clinical environments. One promising method that has gained significant attention in the scientific community involves signal processing techniques based on photoplethysmography (PPG).10–22
Plethysmography encompasses different types, each employing specific transducers to measure blood volume changes, which may vary across devices. 23 These include air plethysmography, strain-gauge plethysmography, electrical impedance plethysmography, and optical plethysmography, among others. Optical plethysmograms, categorized as PPG signals, provide volumetric measurements. 23 PPG signals provide a wealth of cardiovascular information, including blood oxygen levels, heart rate, blood volume changes, arterial stiffness, and valuable data for BP estimation,24,25 Given their intricate nature and susceptibility to artifacts, a meticulous analysis is imperative for ensuring precise interpretation. 23
Typically, obtaining PPG signals involves the use of uncomplicated optical sensors equipped with both a light emitting diode (LED) and a corresponding photodetector. There are two distinct modes for PPG devices: transmission mode and reflection mode. 23 In transmission mode, the photodetector and LED are positioned on opposite sides of the tissue, allowing light to pass through. On the other hand, reflection mode involves installing the LED and photodetector on the same side of the tissue, enabling signal recording from backscattered light. 26 In extracting PPG waveforms, red, green, and infrared light are frequently employed. While red and infrared light have the ability to penetrate tissues to a depth of approximately 2.5 mm, green light has a lower penetration capacity of less than 1 mm,27,28 Specifically, red light falls within the 600–750 nm wavelength range, while infrared light occupies the 850–950 nm wavelength range. 23 As a result, infrared light is commonly employed for acquiring PPG signals in BP measurement. 24 PPG has demonstrated its efficacy as a highly viable alternative for BP measurement methods. 23
As detailed in,
29
Martinez et al. investigated the correlation of arterial blood pressure (ABP) and PPG signals in both temporal and spectral domains. Their findings revealed that PPG possesses informational features consistent with ABP, with a waveform closely resembling that of ABP, suggesting PPG as a viable alternative to ABP. For understanding of PPG waveforms and their clinical relevance, refer to Figure 1. This figure illustrates a typical PPG waveform, emphasizing its three critical components: the systolic peak (indicating maximum arterial pressure during the cardiac cycle), the dicrotic notch (a minor dip post-systolic peak signifying aortic valve closure), and the diastolic peak (representing the minimal arterial pressure during cardiac relaxation).
30
Notably, these key points correspond to those observed in invasive BP measurement methods. Therefore, this correlation between the PPG waveform components and the key indicators in invasive BP measurement underscores the potential of PPG as a clinically significant, non-invasive tool for accurate BP monitoring. This alignment not only validates the effectiveness of PPG in capturing essential BP data but also highlights its advantage in offering a more patient-friendly and less cumbersome alternative to traditional methods. Illustration of a typical PPG waveform highlighting the systolic peak, dicrotic notch, and diastolic peak.
Recent research has introduced various methodologies for estimating BP from PPG signals. As detailed in, 31 some of these algorithms employ waveform analysis combined with PPG-derived biometrics for BP estimation. Their efficacy has been assessed across a diverse population, varying in age, height, and weight. Upon calibration, PPG demonstrates considerable potential for monitoring BP fluctuations, presenting notable health and economic benefits. As detailed in, 32 a bio-inspired mathematical model is introduced that employs comprehensive mathematical analysis of PPG signals for the estimation of systolic blood pressure (SBP) and diastolic blood pressure (DBP). This model marks a significant advancement in the domain of non-invasive BP monitoring, illustrating the potential of integrating mathematical precision with biomedical applications. Its emphasis on a bio-inspired approach offers a novel perspective in understanding and interpreting cardiovascular dynamics, potentially leading to more accurate and patient-friendly BP monitoring techniques.
Machine learning (ML) algorithms can be instrumental in analyzing PPG signals for BP estimation. A critical aspect of applying these ML techniques is feature engineering. PPG signals offer a diverse range of extractable features, including temporal characteristics, frequency-domain attributes, and morphological aspects,28,33,34 Extensive research has explored a broad spectrum of features in this context. For instance, the study referenced in 35 extracted a total of 46 distinct features, whereas another investigation 36 employed 35 features. Furthermore, a separate study 37 utilized a composite set of features, encompassing time-domain, frequency-domain, and morphological characteristics, to enhance the model’s predictive accuracy. BP estimation can also be effectively achieved through models based on electrocardiogram (ECG) and PPG signals. These models leverage the combined data from ECG and PPG to enhance the accuracy of BP measurements. In the domain of BP estimation utilizing models based on ECG and PPG, these models predominantly rely on key features like Pulse Arrival Time (PAT) and Pulse Transit Time (PTT). 38
PTT has been a focal point in studies,39,40 for predicting SBP and DBP levels. Research in 41 expanded the scope by incorporating a combination of PAT and heart rate for BP prediction. This approach demonstrated superior predictive capabilities for SBP and DBP compared to using PTT alone, indicating the potential of integrating multiple physiological parameters for more accurate estimations. Further advancing the field, the beat-to-beat optical BP measurement technique, as detailed in, 42 represents a significant leap. This method was exclusively developed using PPG signals obtained from fingertips. It involved extracting key features such as amplitudes and cardiac phase components through fast Fourier transformation (FFT). These features were then employed in training an artificial neural network (ANN), highlighting the evolving complexity and precision of non-invasive BP monitoring techniques and their potential in continuous and real-time health monitoring scenarios.
In the realm of BP monitoring through non-invasive methods, ML algorithms have shown promising results. A study outlined in 43 particularly highlights the efficacy of the support vector machine (SVM) algorithm, which exhibited superior accuracy in BP estimation compared to both linear regression and ANN methods. This finding underscores the potential of advanced ML techniques in the precise analysis of BP data. Building on this understanding, Chowdhury et al. 28 conducted a comprehensive analysis of PPG signals. In their study, a variety of features extracted from these signals were used to train and evaluate different ML algorithms. Notably, the integration of Gaussian process regression (GPR) with the ReliefF feature selection method demonstrated remarkable effectiveness, outperforming other algorithms in the accurate estimation of both SBP and DBP. This progression in research highlights the continuous evolution and refinement of ML applications in non-invasive cardiovascular monitoring.
The burgeoning field of deep learning (DL) 44 has recently catalyzed significant advancements in various medical applications. Among these, the study by Su et al. 45 addresses a critical issue in current BP estimation models derived from PPG signals—the challenge of accuracy degradation due to frequent calibration needs. To tackle this, they introduced a deep recurrent neural network (RNN) model, incorporating long short-term memory (LSTM) algorithms, tailored for time-series analysis of BP data. This model utilized both PPG and ECG data as inputs, showcasing the integration of multiple physiological signals in enhancing model accuracy. Complementing this approach, Gotlibovych et al. 46 explored the potential of using raw PPG data in detecting arrhythmias, achieving considerable success. This accomplishment not only reinforces the utility of PPG data in cardiovascular monitoring but also suggests the feasibility of employing raw PPG signals directly as inputs for DL models. Further extending the application of DL in this realm, a study by Slapničar et al. 47 developed a novel spectro-temporal deep neural network. This network was unique in its approach, taking not only the PPG signal but also its first and second derivatives as inputs, thus providing a more comprehensive analysis of the signal’s properties. Collectively, these studies highlight the progressive integration of DL techniques in the analysis of PPG signals, opening new avenues for accurate, non-invasive cardiovascular monitoring.
One of the significant challenges in applying DL techniques is the extensive time and computational resources required for model training. To address this limitation and explore more efficient alternatives, we focused on ML regression algorithms that are less computationally demanding while still offering strong predictive performance. Specifically, we investigated and compared five ensemble and tree-based ML regressors—Decision Tree (DT), Random Forest (RF), Extra Trees (ET), Gradient Boosting (GB), and CatBoost (CB). Among these, ensemble methods like ET and RF help reduce overfitting and enhance generalization by aggregating multiple decision trees. This comparative approach enabled us to systematically evaluate the trade-offs between training efficiency and estimation accuracy across different models.
In our research, we aimed to overcome several limitations identified in previous studies, employing strategies that reinforce the strengths of our approach: • Sole Utilization of PPG Signals: Diverging from some previous studies that incorporated both PPG and ECG data, our methodology exclusively relies on PPG signals. This focus not only simplifies the computational requirements but also enhances the efficiency and applicability of our approach in practical scenarios. • Larger Sample Size: We expanded our research to include a more extensive number of subjects compared to some past studies, enhancing the robustness and generalizability of our findings. • Employing ML Algorithms: Rather than relying on a single technique, our study systematically compares distinct ML algorithms. This comparative approach allows us to assess the trade-offs between computational efficiency and predictive accuracy, providing a more balanced perspective on model performance.
As a result of implementing these strategies, our study achieved improved outcomes in the separate estimation of SBP and DBP, reflecting the efficacy of our chosen methodologies and algorithm. Thus, our research demonstrates the potential of utilizing PPG signals and ML techniques for BP estimation. Furthermore, it successfully overcomes prior constraints observed in previous studies, such as limited sample sizes, reliance on both PPG and ECG signals, and the high training time associated with DL models, presenting a hopeful trajectory for practical implementation in cardiovascular monitoring and assessment.
The article is organized as follows: Section 2 offers an overview of the methodology, Section 3 discusses the results, Section 4 provides the discussion, and Section 5 provides the conclusion.
Material and methods
This section provides a comprehensive overview of the steps used to estimate BP, including the data used, signal preprocessing techniques, feature extraction methods, as well as feature selection techniques and the ML algorithms employed. Figure 2 illustrates the initial phase of our methodology, which entailed a rigorous assessment of PPG signals quality to confirm their reliability for further analysis. The PPG signals were then subjected to a series of preprocessing steps to prepare them for feature extraction. Subsequent to the extraction process, feature selection techniques were applied to both reduce computational complexity and minimize the risk of overfitting. The resulting dataset was shuffled and randomly divided into two subsets: 80% was dedicated to training the ML algorithms, and the remaining 20% was reserved for evaluating algorithmic performance. The training and evaluation of the ML algorithms were conducted using a 10-fold cross-validation approach to ensure robustness and generalizability of our model. Methodological flowchart: From PPG signals quality assessment to ML algorithms evaluation.
Database description and collection protocol
The dataset underpinning our investigation, procured from Liang et al., 24 is a publicly accessible compendium of data from 219 adults, ranging in age from 21 to 86 years, with a near-equal gender distribution of 48% male and 52% female participants. These individuals were involved in experimental sessions lasting about 15 min each, during which they were first acclimatized to the environment for 10 min to ensure a stabilized physiological state. Comfortably seated and with minimal interference, participants then underwent the data collection phase. In this phase, raw PPG signals were directly recorded from the participants. Each subject had three separate non-overlapping PPG recordings, each lasting 2.1 s (2100 samples at a sampling rate of 1 kHz with 12-bit resolution). 24 Immediately after the three PPG acquisitions, blood pressure was measured using a sphygmomanometer by a trained nurse. The entire PPG acquisition and BP measurement process lasted approximately 3 min. The PPG signal was sourced from the left index finger’s tip, and BP measurement were meticulously taken from the right forearm. In total, the database therefore contains 657 raw PPG segments (3 segments × 219 participants). Of these, 282 high-quality segments were selected and used in the present study; additional details of the selection procedure are provided in later sections.
In addition to the rich demographic spectrum, the breadth of health statuses among the participants—ranging from healthy to various pathological conditions—was a decisive factor in selecting this database. This diversity is critical for our research on physiological variations, as it allows for a nuanced analysis of PPG signals across a broad spectrum of the population. Figure 3 exemplifies this by showcasing PPG waveforms from four distinct individuals of varying ages and health conditions, with Table 1 elaborating on the database specifics. Younger, healthy subjects with normal BP present PPG waveforms with all characteristic features, such as the dicrotic notch and diastolic peak, visibly intact. In contrast, PPG waveforms from older or ailing subjects exhibit discernible deviations, with these features becoming increasingly subdued or altered—a testament to the physiological impacts of aging and health deterioration.
23
Such variations underscore the necessity for advanced analytical techniques, which our study seeks to address. Illustrative PPG signal variability across different health profiles: This figure is pivotal in demonstrating the diversity of PPG signals across a spectrum of ages and health conditions, underscoring the relevance and necessity of our study. Panel (a) shows the PPG signal of a 25-year-old healthy woman with normal BP, serving as a baseline reference. Panel (b) presents the signal from a 59-year-old man with prehypertension and cerebrovascular disease, illustrating the alterations in the PPG signal due to cardiovascular changes. Panel (c) depicts the signal of a 63-year-old woman with stage 1 hypertension and type 2 diabetes, further highlighting the PPG signal’s sensitivity to varying health states. Lastly, panel (d) exhibits the signal from a 78-year-old man with stage 2 hypertension and a history of cerebral infarction, showcasing the pronounced signal differences in advanced cardiovascular conditions. Demographic and health characteristics of the study population
48
.

However, a challenge arose when assessing the quality of PPG signals in the dataset. Out of the total 657 signals, a considerable number exhibited low quality and were deemed unsuitable for feature extraction. To address this issue, Liang et al.
48
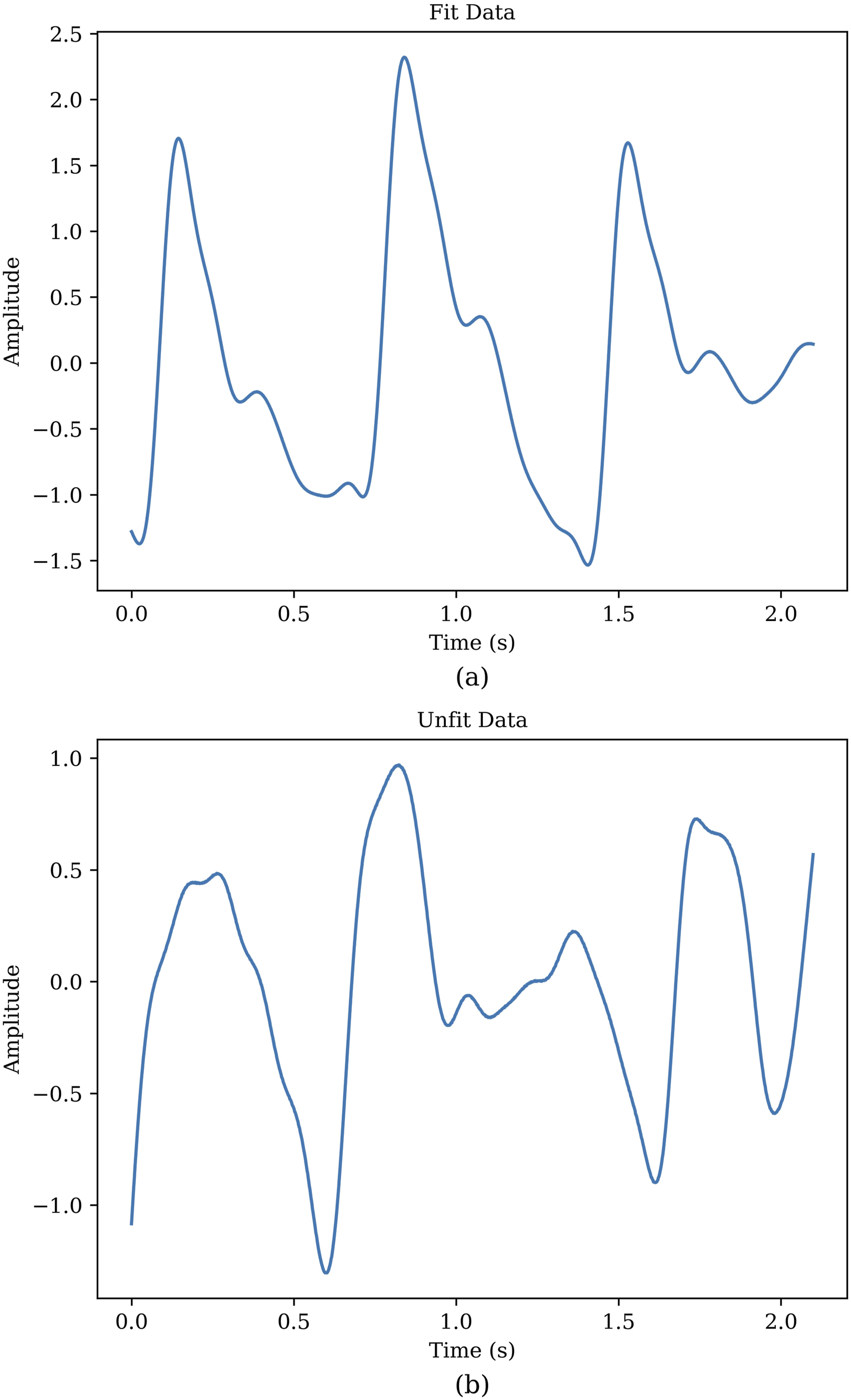
employed a signal quality index (SQI) based on skewness, the formula for which is presented in equation (1), to identify suitable signals. The results of their research are documented in a separate file accompanying the database. The application of this SQI, followed by a rigorous quality assurance process that filtered the data based on skewness, led to the retention of 282 signals for our analysis. Signals with aberrant or non-standard PPG waveforms, or those lacking distinct features necessary for accurate interpretation, were systematically excluded. It is worth noting that the retained subset covers the same age range and diversity of health conditions as the original dataset. This meticulous selection process, while reducing the number of usable signals, significantly enhanced the reliability and validity of the subsequent analyses, ensuring that only high-quality data were utilized in our study. Figure 4 provides a comparative visualization, delineating both the exemplar and the disqualified signals, thereby illustrating the stringent selection criteria employed to ensure the integrity of our study’s data pool. • S represents the Skewness of the PPG signal. • N is the number of samples in the PPG signal. • xi refers to the i-th sample value in the PPG signal. • μ denotes the mean value of the PPG signal. • σ signifies the standard deviation of the PPG signal. Comparative analysis of fit and unfit PPG waveforms. Panel (a) displays a fit waveform exhibiting clear diastolic and systolic peaks with distinct features. Panel (b) depicts an unfit waveform where the key features are less pronounced or absent, indicating lower signal quality.
Preprocessing of PPG signals
Before feature extraction, the raw PPG signals went through various preprocessing steps including normalization, filtering and baseline correction, which are as follows:
Normalization
In order to derive valuable insights from the signals, it was imperative to normalize the signal data. This study employed the Z-score technique for signal normalization, which involved transforming the signals into amplitude-limited data by centering them around their mean and scaling them by their standard deviation. This normalization process ensures that the signals have a consistent scale and facilitates meaningful comparisons and analysis across different data points. It was noticed that the implementation of other preprocessing techniques became more straightforward following the normalization process. • Z is the normalized PPG signal value. • x is the raw PPG signal value to be normalized. • μ is the mean of the PPG signal values. • σ is the standard deviation of the PPG signal values.
Filtering
In our analysis, we observed the presence of high-frequency and low-frequency noise components in the signals obtained from the database.
24
To address the occurrence of noise components, various filters were tested for filtering PPG signals48–52 and removing unwanted noise (including moving average filter, Butterworth filter, wavelet de-noising filter, and Chebyshev filter
48
). Ultimately, we applied a Chebyshev II filter to the signals, designed with a filter order of four and a cutoff frequency of 12 Hz. This was implemented in Python 3.9.13 using the SciPy library (v1.9.3). Figure 5 illustrates both the normalized raw signal and the filtered signal, highlighting the effectiveness of this filtering process. Comparison of normalized raw PPG signal with the filtered signal over time.
Baseline correction
The PPG waveform often exhibits baseline wandering as a result of respiratory activity, occurring within a frequency range of 0.15 to 0.5 Hz.53–55 Consequently, it is crucial to effectively filter the signal to eliminate this baseline wandering while retaining essential information. To achieve this, we employed a polynomial fit to identify the signal’s underlying trend. Subsequently, we subtracted this trend from the signal to obtain the baseline-corrected signal,
28
as depicted in Figure 6. We experimented with polynomial degrees ranging from 3 to 6, and found that a degree of 5 provided the best result. This was implemented in Python 3.9.13 using the NumPy library (v1.23.5). Comparison of the filtered PPG signal with baseline wandering and the signal after detrending process.
Feature extraction
The feature extraction process was conducted in three distinct parts. Firstly, a comprehensive set of features was extracted using the BIOBSS 56 library in Python. BIOBSS, a Python package created on Feb 2, 2023, can be succinctly described as a biological signal processing and feature extraction library. Features extracted in this phase are reported in Tables 3–5, which focus on time-domain, morphological, frequency-domain, and statistical characteristics of the PPG signals.
Signal key points as feature set (12 features) 23 .

Time domain/Morphological features (25 features) 56 .

Frequency domain features (8 features) 56 .

Statistical features (9 features) 56 .

Derived features (8 features) 23 .

Demographic features (9 features).

Feature selection
In this study, we utilized five feature selection techniques: SelectFromModel, 57 SelectKBest, 57 Recursive Feature Elimination (RFE), 57 Sequential Feature Selection (SFS), 57 and Correlation-Based Feature Selection (CFS). 58 These techniques were implemented leveraging Python’s built-in functions. Their primary role was to identify the most relevant features for our analysis. Below, we provide a brief description of each of these feature selection techniques.
SelectFromModel
SelectFromModel is a feature selection technique commonly used in ML. It works by training a ML model (e.g., a DT or a linear model) and then selecting the most important features based on the model’s internal feature importance scores 57 This method allows you to choose features that contribute the most to the model’s estimation performance, thus reducing the dimensionality of the data while preserving relevant information.
SelectKBest
SelectKBest is a simple and straightforward feature selection technique. It evaluates each feature’s individual statistical significance with respect to the target variable using statistical tests like mutual information regression. 57 Then, it selects the top K features with the highest scores. This method is particularly useful when you want to specify a fixed number (K) of features to retain.
Recursive Feature Elimination
RFE is an iterative feature selection technique. It starts with all features and recursively removes the least important ones. The importance of features is determined by training a model and examining feature weights or coefficients. RFE continues to eliminate features until the desired number or a predetermined threshold is reached 57 This method is effective for selecting a subset of features while maintaining model performance.
Sequential Feature Selection
SFS is an iterative technique that systematically adds or removes features from the model. It works by selecting or excluding features one at a time based on their contribution to model performance. The process involves evaluating different feature subsets to identify the most informative combination. During each iteration, SFS considers the influence of each feature on the predictive power of the model. This method is valuable for finding the optimal subset of features that maximizes model accuracy while minimizing dimensionality. 57
Correlation-based Feature Selection
CFS functions as a feature selection technique, assessing the correlation between features and the target variable. It measures how well each feature is related to the outcome of interest. Additionally, CFS assesses the intercorrelations among features to avoid redundancy. Features that have high correlations with the target variable and low correlations with each other are selected, resulting in a subset of relevant and non-redundant features. 58
These feature selection techniques are crucial for improving the performance and interpretability of ML algorithms by identifying and retaining the most informative features while reducing the risk of overfitting, where models become too specialized to the training data and perform poorly on new, unseen data.
Machine learning algorithms
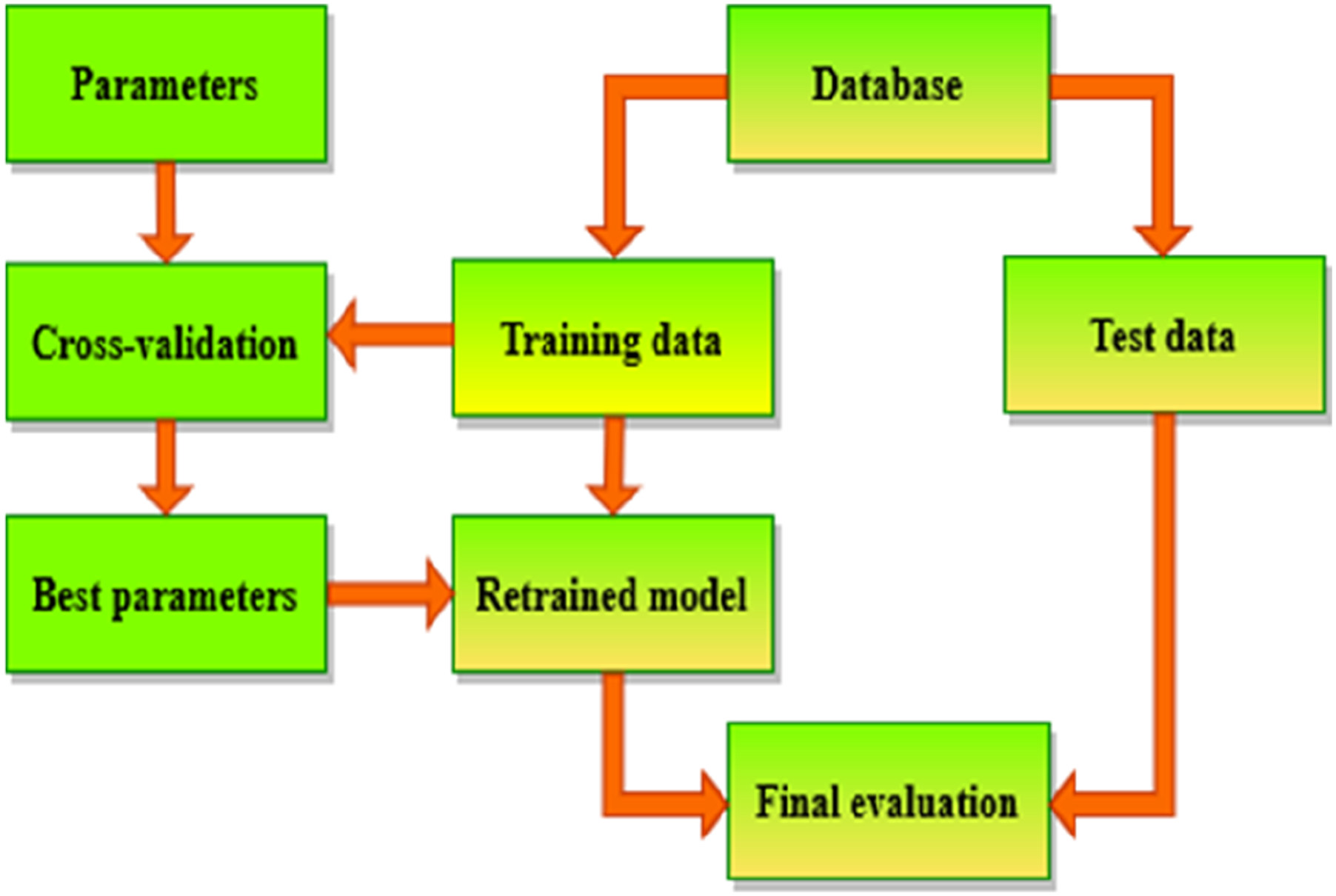
After extracting features and using feature selection methods, we trained and evaluated 10 different algorithms using 10-fold cross-validation, and in the following, we report the results of five of the best ones. The obtained data were shuffled and then randomly divided into two subsets: 80% for training, and 20% for evaluating algorithm performance. Here’s an explanation of the 10-fold cross-validation method,
59
and the whole process is shown in Figure 7: (1) Train data Splitting: -The train dataset is divided into 10 equal-sized folds. (2) Training and Validation: - The model is trained and evaluated 10 times, each time using a different fold as the validation set and the remaining 9 folds as the training set. - In the first iteration, the first fold is used as the validation set, and the model is trained on the remaining 9 folds. In the second iteration, the second fold is used as the validation set, and so on. (3) Performance Metrics: - Performance metrics are recorded for each iteration. (4) Average Performance: - The performance metrics from all 10 iterations are averaged to obtain a more reliable estimate of the model’s performance. (5) Parameter Tuning: - If the model has hyperparameters that need to be tuned, this process is repeated for different combinations of hyperparameters. (6) Best Parameters Selection: - The hyperparameters that result in the best average performance across the 10 folds are selected. (7) Final Model Training: -The final model is trained on the entire dataset using the selected hyperparameters. (8) Model Evaluation: -The performance of the final model is evaluated on a test set that was not used during training or cross-validation. Flowchart of cross-validation workflow in model training.
We evaluated the performance of ML algorithms in BP estimation using five criteria,28,60 In this context, ‘ŷ’ represents the predicted data, ‘y’ represents the actual data, and ‘n’ represents the number of samples.
Mean absolute error
Mean absolute error (MAE) is a valuable metric, particularly in the context of regression analysis. It serves as a straightforward and intuitive measure for evaluating the overall accuracy of a predictive model. Specifically, MAE measures the average absolute difference between the predicted values and the actual target values in the dataset. Lower MAE values indicate a higher level of accuracy, implying that the model’s predictions closely align with the true values. MAE is less sensitive to outliers compared to other metrics like Mean squared error (MSE).
Mean squared error
MSE is another metric used in regression analysis, and it differs from MAE in how it measures the accuracy of a predictive model. While MAE calculates the average absolute differences between the predicted and actual values, MSE takes the average of the squared differences. This squaring of differences has two primary effects: it emphasizes larger errors due to the square operation, and it penalizes outliers more significantly. Consequently, MSE tends to be more sensitive to outliers compared to MAE.
Root mean squared error
Root mean squared error (RMSE) is the square root of the MSE and provides a measure of the average magnitude of the errors in the same units as the target variable. It is a more interpretable metric than MSE because it is on the same scale as the original data. RMSE is widely used for evaluating the overall accuracy of a regression model.
R-squared
R-squared (R2) is a useful metric for evaluating the goodness of fit of a regression model. It provides insights into how well the model explains the variance in the data. R2 ranges from 0 to 1, with 1 indicating that the model explains all the variance, and 0 indicating that the model provides no improvement over a simple mean prediction. It is a measure of goodness-of-fit and helps assess how well the model fits the data.
Mean absolute percentage error
Mean absolute percentage error (MAPE) is a relative error metric that calculates the average percentage difference between the predicted values and the actual values. It measures the accuracy of the model in terms of a percentage error, which can be helpful for understanding the magnitude of errors relative to the actual values.
These evaluation criteria can be implemented using Python functions. 60 Assessing ML algorithms yields valuable insights regarding their capability to accurately estimate BP, assisting in the identification of the top performing model for the given task.
The explanation of the five selected algorithms is as follows:
Decision tree Regressor
The DT Regressor is a simple, tree-based model used for regression tasks. It recursively splits the data into subsets based on the features to predict a continuous target variable. 61 While DTs can be prone to overfitting and may not capture complex relationships in the data, they are highly interpretable and easy to understand. In the context of ensemble methods like RF or gradient boosting (GB), DTs are often used as base learners to improve predictive performance. 62
Random forest Regressor
The RF Regressor is an ensemble learning method that builds multiple DTs and combines their predictions to make more accurate and stable predictions. It reduces overfitting and provides an unbiased estimate of the target variable. 63 RF regressors are less prone to overfitting compared to individual DTs and can handle high-dimensional data well. They work well for various regression tasks and are relatively easy to use and tune. 64
Extra trees Regressor
The ET Regressor is an ensemble ML model that belongs to the family of DT-based algorithms. It is an extension of the RF algorithm. This model builds multiple DTs using bootstrapped samples and random feature subsets. It takes a random subset of features at each split, which adds an extra layer of randomness compared to RF. The model combines the predictions of these individual trees to make a final prediction. 65 ET is known for its high level of randomness and often provides robust and accurate predictions. It is suitable for a wide range of regression problems. 66
Gradient boosting Regressor
The GB Regressor is another ensemble learning method that builds an ensemble of DTs in a sequential manner. It aims to minimize the error of the previous tree by adding a new tree that focuses on the residual errors. GB is a powerful algorithm for regression tasks, as it can capture complex relationships in the data and achieve high predictive accuracy. However, it may be more computationally expensive and require careful tuning of hyperparameters. 67
CatBoost Regressor
The CB Regressor is a specific type of GB algorithm. Functioning as a boosting ensemble algorithm, it iteratively constructs DTs, each time correcting the errors made by the previous trees. CB is particularly proficient in managing categorical variables, obviating the need for extensive preprocessing. It excels in handling high-cardinality categorical features as well. The model is designed to automatically manage missing data and consistently provides robust performance across a variety of regression tasks. 68
In this study, hyperparameters were carefully selected and tested for each algorithm to optimize performance. Below, we describe the key hyperparameters for each algorithm. criterion: This hyperparameter determines the function used to measure the quality of a split in a node. It determines how the algorithm chooses the best feature and threshold to divide the data at each node to improve the model’s predictive accuracy. max_depth: It controls the maximum depth of the individual trees. Setting it to ‘None’ means there is no restriction on the depth, and the trees can grow until they contain a minimum number of samples per leaf (controlled by ‘min_samples_leaf’) or until all leaves are pure. max_features: It determines the maximum number of features to consider for splitting a node. When set to ‘1.0’, it means all features are considered for each split. min_samples_leaf: It sets the minimum number of samples required to be at a leaf node. In this case, it’s set to ‘1’, meaning that a leaf node must have at least one sample. min_samples_split: It sets the minimum number of samples required to split an internal node. In this case, it’s set to ‘2’, meaning that a node must have at least two samples to be split. n_estimators: This value determines how many decision trees the model will create during the training process. In ensemble methods, multiple trees are trained on different subsets of the data and then their predictions are combined to produce the final output. By using more trees, the model can reduce the variance of predictions and improve generalization, often leading to more accurate results. loss_function: It defines the objective function used during the training process. border_count: It determines the number of splits for the categorical feature handling. This parameter helps control how the algorithm handles the data when it encounters categorical variables, which can affect the model’s performance and complexity.
These hyperparameters control various aspects of algorithms, 69 and their values can be adjusted based on the characteristics of the data and the desired behavior of the model. Fine-tuning these hyperparameters can often improve the performance of the model on specific tasks.
Results
Performance comparison of algorithms for SBP using test data.

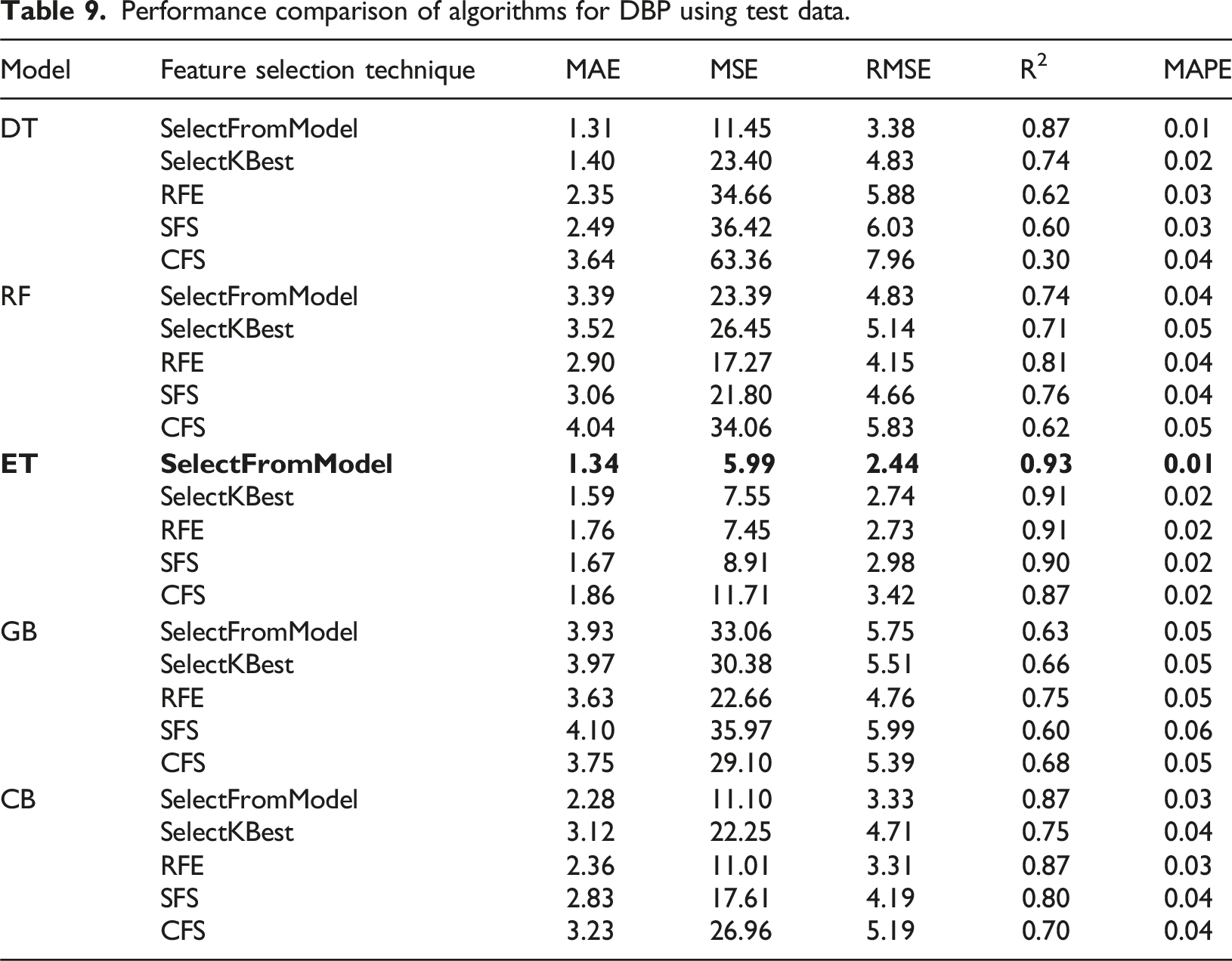
Performance comparison of algorithms for DBP using test data.
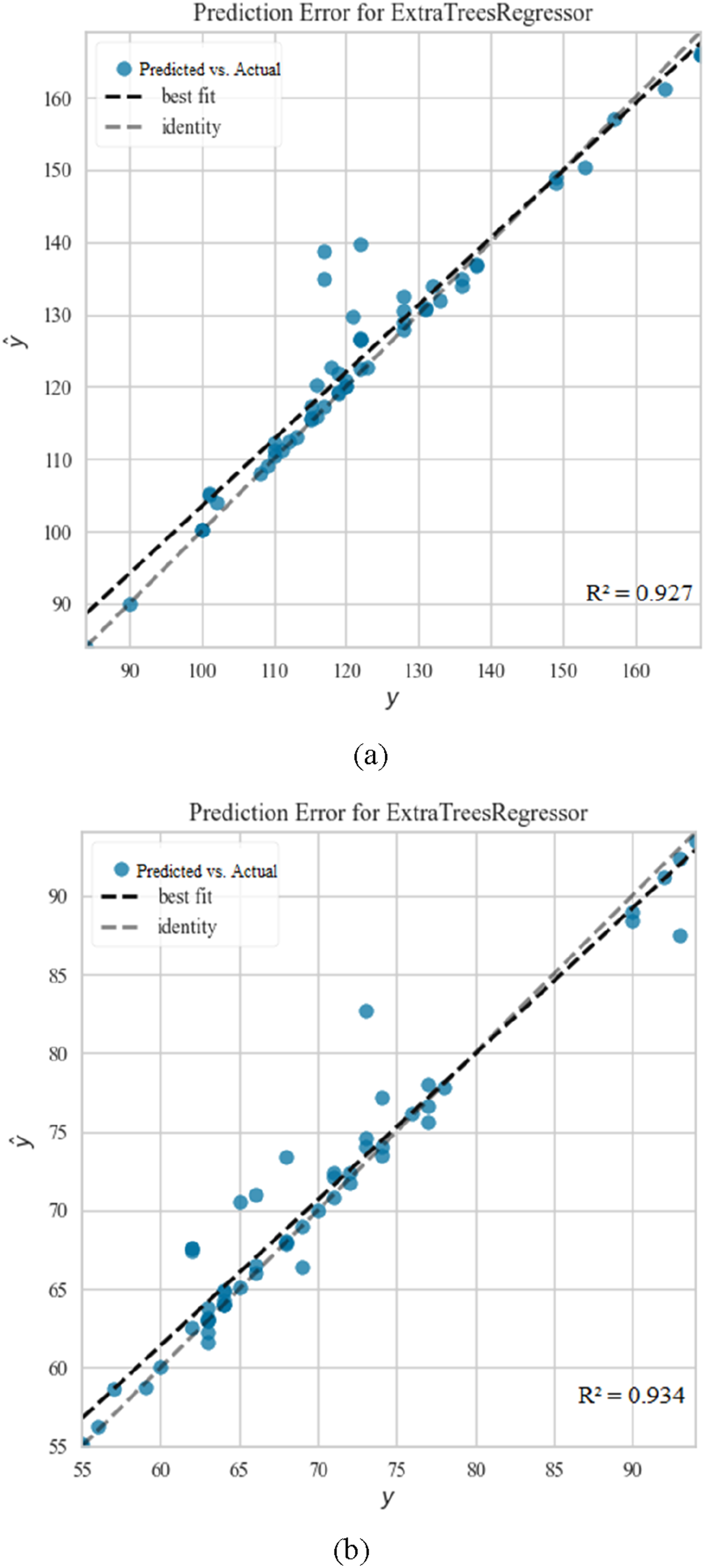
Comparative analysis of predicted (ŷ) Versus actual (y) values for BP estimation using ET: (a) illustrates the best result obtained for Systolic BP prediction, while (b) depicts the best result for Diastolic BP prediction.
Selected hyperparameters and their explored ranges for algorithms.

Performance comparison of algorithms for SBP using test data.

Performance comparison of algorithms for DBP using test data.


Comparative analysis of predicted (ŷ) Versus Actual (y) Values for BP Estimation Using ET: (a) illustrates the best result obtained for Systolic BP prediction, while (b) depicts the best result for Diastolic BP prediction.
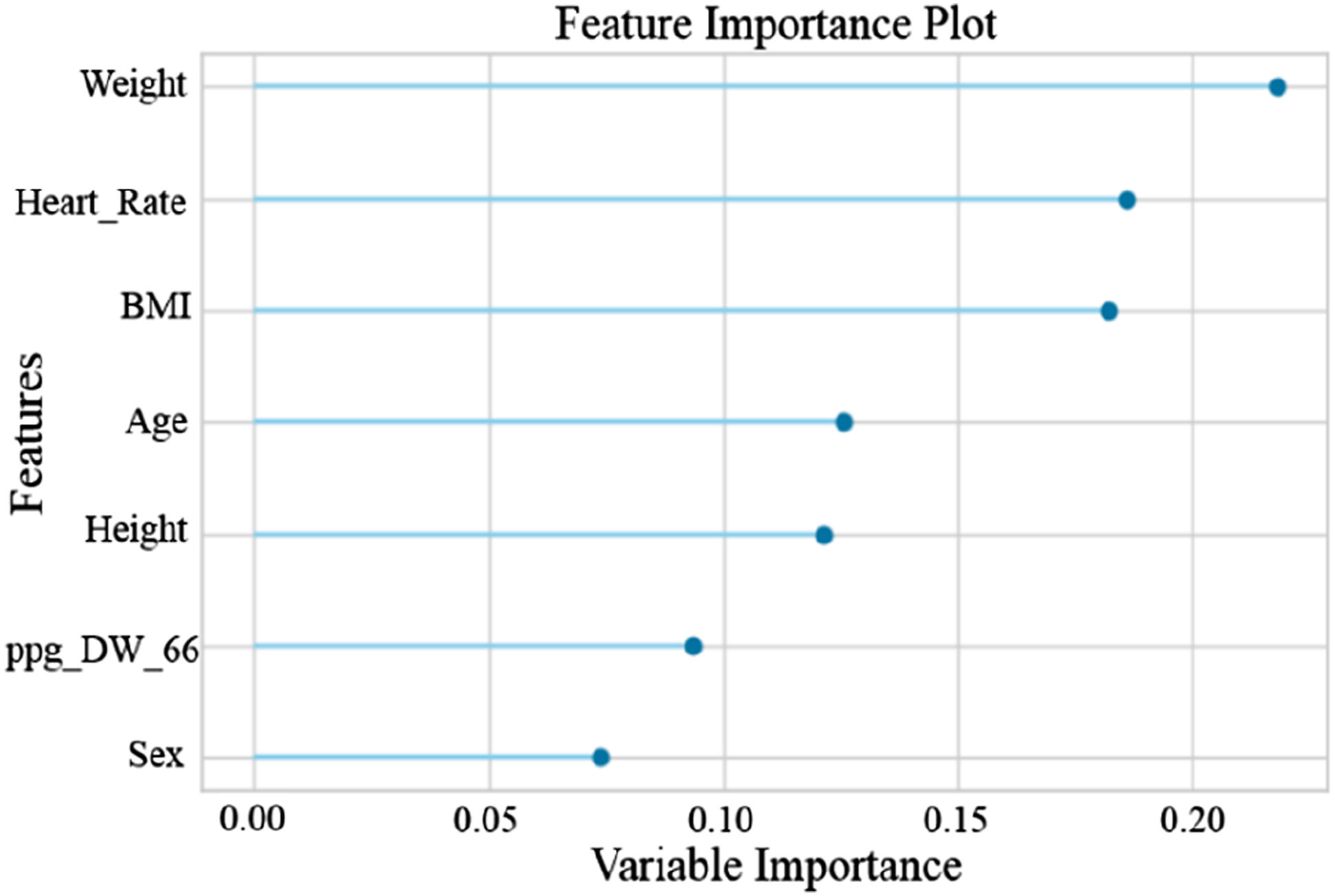
The findings of the experiments emphasize the effectiveness of the ET algorithm in BP estimation. The SelectFromModel feature selection technique focuses on the most relevant and distinct aspects of the data, and by identifying 10 key features for SBP and seven critical features for DBP from the set of extracted features, it results in the ET algorithm achieving the resultant outcomes. The 10 features selected by the SelectFromModel feature selection method for SBP include Age, Heart rate, BMI, Weight, Sex, Height, ppg_DW_SW_75, ppg_DW_SW_50, Cerebrovascular disease, and Diabetes. Additionally, seven features selected by this method for DBP include Weight, Heart Rate, BMI, Age, Height, ppg_DW_66, and Sex.
By employing the recursive feature elimination with cross validation (RFECV) method, we assessed the significance of each feature for SBP and DBP, and their corresponding graphs are depicted in Figures 10 and 11. As evident, Age is the most critical feature in estimating SBP,70–74 while Weight plays a significant role in DB75–79 estimation. These results align with the findings of several mentioned studies. It should be noted that the scale of variable importance in Figures 10 and 11 is normalized between 0 and 1, where a value of 1 indicates the most important feature relative to the others in the model. This does not imply that the feature is perfect or flawless, but rather that it contributes the most to the prediction accuracy compared with other features. Values closer to 0 indicate features with less relative impact, though they may still carry useful information. Importance of ten features for estimating SBP – A graphical representation highlighting the significance of various features in the accurate estimation of SBP. Importance of seven features for estimating DBP – A graphical representation highlighting the significance of various features in the accurate estimation of DBP.
Discussion
Comparing the performance with prior research.

Su et al. 45 used DL, in their work they used both PPG and ECG signals of a small database and obtained low error due to the small number of subjects. Slapničar et al. 47 worked with the MIMIC III dataset and achieved reasonable estimation accuracy using DL spectro-temporal ResNet algorithm. Zadi et al. 80 used a very small dataset (only 15 people) to calculate SBP and DBP, and estimates were obtained from the PPG signal as input to fifth-order autoregressive moving average (ARMA) models. Chowdhury et al. 28 used our selected dataset but considered fewer people and signals. They achieved their results by extracting features from signals and using the GPR algorithm, while we were able to achieve better results with more people and signals and different and fewer inputs and a distinct algorithm.
As far as we know, no work has extracted all of our features and achieved such a low error rate using the SelectFromModel feature selection method and the ET machine learning algorithm. Table 13 provides a comparative summary of the mentioned works with our study based on evaluation parameters: MAE, MSE, RMSE, R2, and MAPE (The results reported in Table 13 are the average results of two phases of our study).
Comparison of study results with the AAMI standard for BP measurements.

In general, in this research, in addition to achieving better results, our goal was to eliminate the limitations of previous studies. Compared to some studies, we examined a larger number of participants and the selected data set shows a good representation of people in different age groups, including healthy and unhealthy people of both sexes. Furthermore, we used only PPG signals, simplifying the complexities encountered in a series of studies. Finally, we used ML algorithms, which require less training time compared to DL models.
Our research effectively learned the underlying algorithms and infrastructures in the dataset using the selected features as input to the ET algorithm. The success of the ET algorithm can be attributed to several factors, including: (1) ET is an ensemble learning method that builds several DTs and combines their predictions. This helps reduce overfitting and improve generalization to new and unseen data. (2) The algorithm uses a random subset of features for each DT, which increases diversity among trees and can improve performance. (3) PPG signals can still have noise despite the pre-processing steps, and this affects the extracted features. Ensemble methods such as ET are generally robust against noisy data because they consider multiple models and can effectively deal with outliers. (4) PPG signals often show complex and non-linear patterns. DT-based algorithms, including ET, are able to capture nonlinear relationships between features and the target variable, making them suitable for such data.
Additionally, SelectFromModel helped enhance the performance by selecting only the most relevant features from the dataset, eliminating irrelevant or less impactful ones. This further optimized the model by ensuring that it focuses on the most important features, improving both its efficiency and accuracy.
This study demonstrates promising results in BP estimation using PPG signals. However, there are several aspects that can be explored in future research to further enhance the model’s applicability and generalizability.
First, this study primarily utilizes the Figshare database as the primary data source. While the dataset provides a reasonable level of diversity, it may not fully encompass all demographic groups or rare clinical conditions. Although the proposed model has shown strong performance under the given conditions, future work could benefit from the inclusion of larger, more representative datasets that capture a broader range of demographic and clinical characteristics. Incorporating datasets that represent diverse populations, including various age groups, ethnicities, and patients with rare conditions, would help assess the model’s robustness and improve its performance across different clinical scenarios.
Additionally, this study focuses on BP estimation using PPG signals in controlled environments, where factors such as sensor calibration and signal quality are optimized. In real-world applications, however, challenges such as sensor quality, motion artifacts, noise levels, and skin-tone variability can impact signal accuracy and lead to less reliable measurements. For instance, poor sensor calibration or suboptimal skin contact can introduce inaccuracies, while noise from environmental factors, such as ambient light or electrical interference, can degrade signal fidelity. Furthermore, variations in skin tone can affect the absorption and reflection of light, especially in devices using light-based sensors, which could result in significant variations in signal strength and quality across different individuals.
To further improve the model’s performance, it is crucial to evaluate the system’s effectiveness in real-world, less controlled settings. This includes addressing challenges related to motion artifacts, sensor calibration, and noise interference, which are inherent in everyday usage. Moreover, future work will focus on incorporating datasets annotated for skin tone and ethnicity to systematically investigate the impact of optical and physiological diversity on PPG signal quality and BP estimation accuracy. External validation using diverse datasets that capture real-world variability could help affirm the model’s translational value and demonstrate its effectiveness across various populations and environmental conditions.
While the limitations mentioned above do not impact the validity of our current findings, addressing these challenges in future studies could significantly enhance the generalizability, robustness, and practical utility of the proposed approach.
Conclusions
In this research, the authors have proposed and implemented a methodology for estimating SBP and DBP using features extracted from the PPG signal and ML algorithms. The research effectively demonstrates the estimation of patients’ BP without resorting to cuff-based pressure measurement or invasive techniques, thereby overcoming the drawbacks associated with both invasive and non-invasive cuff-based measurements.
The entire process, encompassing the preprocessing of PPG fingertip signals, feature extraction, feature reduction, and the training and evaluation of algorithms, was comprehensively discussed. Various preprocessing techniques were applied to the raw signals. This system used time-domain, frequency-domain and statistical features along with demographic data and features obtained from different formulas. To address computational complexity, different feature selection methods were utilized. The SBP and DBP were trained separately because they often had different key properties. Ten different ML algorithms were trained and evaluated for SBP and DBP. The combination of the SelectFromModel feature selection method and the ET machine learning algorithm yielded the most favorable outcomes. The ET algorithm achieved a noteworthy R2 score of 0.93 for both SBP and DBP.
In future work, DL algorithms can be used with larger datasets to generate a better prediction model. The trained model can be used in the development of prototypes for wearable or portable BP monitoring devices based on commercial light-based sensors, such as PPG, to estimate blood pressure. Such a system can contribute to continuous BP monitoring and help prevent critical health conditions due to sudden changes.
Footnotes
Ethical considerations
Given the nature of this research, which involved the analysis of existing, publicly available data without direct involvement of human or animal subjects, formal ethical approval was not required.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.