
Abstract
Keywords
Introduction
Large language models (LLMs), advanced artificial intelligence (AI) systems pretrained on vast text datasets, are fine-tuned with human feedback to process natural language, enabling them to generate accurate text responses to medical inquiries, offering a convenient way for patients and physicians to access health information.1,2 OpenAI’s ChatGPT became the fastest-growing consumer application in human history, amassing ore than 400 million weekly active users by February 2025, 3 allowing it to cater to a broad audience and handle diverse linguistic needs. In contrast, Gemini is optimized primarily for English, with a corpus that focuses on English-language data for greater contextual precision, limiting its ability to handle other languages like Chinese effectively. Kimi, on the other hand, is designed for Chinese language users, with a specialized dataset tailored to Chinese discourse and cultural nuances. This monolingual focus ensures better performance in Chinese-speaking populations. Google’s Gemini and Moonshot AI’s Kimi are gaining popularity for their exceptional information retrieval capabilities. As people increasingly turn to LLMs to seek information, generate ideas, and enhance productivity,4,5 our research focused on assessing these three models—ChatGPT, Gemini, and Kimi.
Mild cognitive impairment (MCI) is characterized by cognitive decline that surpasses normal aging but is not severe enough for a dementia diagnosis, representing an intermediate stage between normal aging and dementia. 6 The prevalence of MCI increases with age, affecting 15%–20% of individuals aged 65 or older. 7 Although not all MCI cases progress to dementia, MCI increases the risk of developing Alzheimer’s disease. 8 Early identification and management are crucial for delaying progression and improving quality of life. 9 However, many older adults—particularly those in community or primary care settings—encounter barriers to timely diagnosis and intervention. Nonspecialist healthcare professionals (HPs) and care partners (CPs), often the first point of contact, frequently face challenges due to insufficient training, fragmented resources, and time constraints, contributing to delayed diagnoses and increased CP burden.10,11 In China, these challenges are compounded by a lack of routine cognitive screening, limited access to formal care, and inadequate CP education. 12 Most individuals with MCI or dementia rely on informal home-based care, with formal services concentrated among higher-income groups or those with milder symptoms.13–15 The dementia care continuum framework advocates early detection, targeted intervention, and sustained support tailored to patients’ evolving cognitive, emotional, and social needs. 16 In this context, LLMs present a promising, scalable solution. By providing accessible, evidence-based, and linguistically appropriate information, LLMs can enhance CP education, 17 support nonspecialist healthcare providers, and reduce system burden—particularly in resource-constrained environments such as community-based aging care in China.
LLMs have rapidly expanded in medicine, enhancing insights into MCI and dementia care. Recent research showed that LLMs have predominantly concentrated on leveraging spontaneous speech and clinical notes for diagnosis and symptom monitoring.18,19 MCI research has emphasized early detection and progression prediction to prevent or delay dementia onset.20–22 However, concerns about hallucination and reliability remain, emphasizing the need for careful validation in clinical contexts. 23 Although early studies highlighted the potential of LLMs in areas like diagnosis and speech-based detection,24,25 most research has focused on narrow tasks or single-user evaluations,20,26–28 limiting understanding of their broader applicability across diverse patient populations. Furthermore, the current evidence is largely confined to English-language settings, with limited assessments in Chinese, Dutch, or Korean.29–32 This underscores the need for multilingual and multiperspective evaluations to ensure equitable and effective deployment in global healthcare.
Therefore, we had three aims for this study: (a) to evaluate the potential of LLMs to respond to questions related to MCI management for older adults; (b) to explore how the needs of nonspecialist HPs and CPs might be more effectively met by LLMs; and (c) to compare and assess differences between English and Chinese responses to MCI care queries. Based on this systematic and comprehensive evaluation, our study can catalyze further research into this underexplored yet critical area at the intersection of generative AI and MCI management (see Figure 1). Overview of LLM model pipeline.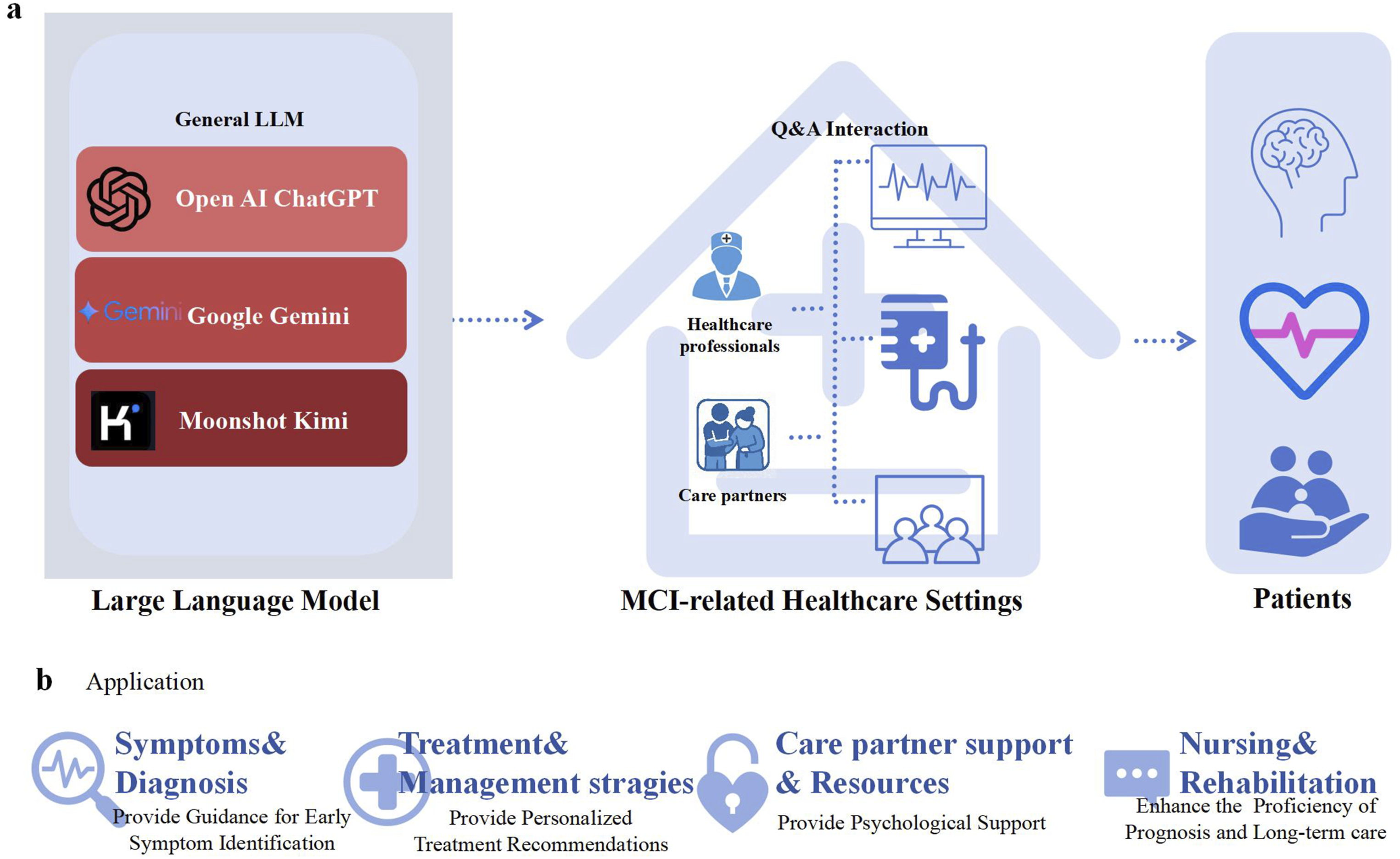
Methods
Ethical statement
This study received approval from the Tsinghua University Institutional Review Board (Protocol: THU01KS2025035). All participants provided informed consent through procedures reviewed and approved by the ethics committee. Data collection was strictly anonymous, with no personally identifiable information retained during analysis or storage.
Participant selection
The recruitment of nonspecialist HPs and CPs occurred between November 28 and December 3, 2024. All participants voluntarily participated and provided informed consent.
The recruitment of nonspecialist HPs was designed to ensure diversity in hospital types (tertiary hospitals and primary care facilities), clinical expertise, and work experience. Inclusion criteria were: (a) at least 2 years of clinical experience providing care or performing related duties in a relevant linguistic environment, specifically involving patients with cognitive decline or dementia symptoms; (b) current employment at a tertiary hospital or primary care facility; and (c) voluntary participation. This approach aimed to capture a wide range of perspectives from practitioners with direct clinical exposure to MCI or dementia, ensuring the findings reflect real-world challenges in managing cognitive impairments.
CPs were recruited to ensure diversity in age, gender, cultural background, and educational level, with all participants having direct caregiving experience. Inclusion criteria were: (a) at least 1 year of hands-on experience providing daily care for an individual with MCI; (b) sufficient language proficiency to understand and contribute to the study; (c) 18 years old or older, representing diverse caregiving contexts; and (d) voluntary participation. This approach aimed to capture a wide range of caregiving experiences relevant to MCI management. All characteristics are listed in Multimedia Appendix 2.
Question pool development
In this study, four primary domains related to MCI were identified for evaluation: (a) symptoms and diagnosis, (b) treatment and management strategies, (c) CP support and resources and (d) nursing and rehabilitation. For each domain, 18 open-ended questions were carefully developed, spanning three levels of difficulty to ensure a comprehensive assessment—from basic knowledge to complex scenarios (see Multimedia Appendix 1 for the complete question set). During the initial design phase, extensive reference was made to authoritative publications from esteemed professional associations and organizations and established medical guidelines from China, the United Kingdom, and the United States, ensuring the relevance and accuracy of the question pool.33–39 These questions did not involve real case data.
LLMs and response generation
This study evaluated the effectiveness of three LLMs in responding to MCI-related questions: ChatGPT-4o (OpenAI), Gemini 2.0 Flash (Google DeepMind), and Kimi 1.18.1 (Moonshot AI). These LLMs were selected based on their prominence and availability in November 2024.
To ensure fair evaluation aligned with each model’s primary use case, ChatGPT-4o was tested in both Chinese and English, reflecting its multilingual adaptability. In contrast, Kimi and Gemini were tested in their specialized languages—Chinese and English, respectively—due to their focus on excelling in specific linguistic domains. All responses are listed in Multimedia Appendix 3.
Evaluation response
To minimize evaluator bias in assessing responses from LLMs, a partially repeated evaluation design was implemented. For each language, three HPs and two CPs independently evaluated the responses. These HPs and CPs had clinical and care experience in regions where the respective languages are predominantly spoken, ensuring familiarity with the cultural and linguistic nuances of the responses. Prior to the evaluation, the evaluation criteria and requirements were emphasized on the assessment homepage.
Using a random number generator, unique identifiers were assigned to 144 responses to maintain a double-blind design, ensuring that evaluators were unaware of the source LLM for each response. All evaluations were completed through an online scoring system. To ensure consistency, each question was submitted twice consecutively. If the LLM did not answer either submission, the question was excluded from further evaluation. The coded responses were scored based on a 5-point Likert scale (1 = strongly disagree to 5 = strongly agree) across four criteria: accuracy,40,41 comprehensibility, 28 specificity, 42 and actionability. 43 Accuracy reflected the factual correctness of the response, ensuring that the information aligned with established clinical guidelines, evidence-based practices, or authoritative sources. Comprehensibility assessed how clear and understandable the response was for the target audience, including both HPs and lay CPs. Specificity evaluated the degree of detail and context specificity in the response, avoiding vague or generalized answers. Finally, actionability determined whether the response provided practical, clear, and implementable recommendations or guidance (Figure 2).
Before starting, all evaluators received a briefing and opportunity for clarification from a single research team member Y.X., and the scoring criteria were reiterated on the evaluation homepage to ensure standardization. Methodological framework for evaluating LLMs in MCI research.
Statistical analysis
Descriptive statistics, including means and standard deviations, were calculated for Likert scale ratings across all response categories. The reliability of evaluators was assessed using intraclass correlation coefficients (ICCs), calculated with a two-way mixed-effects model for the k rater type. ICC values and 95% confidence intervals (CIs) were interpreted as follows: less than .50 indicated low reliability, .50–.74 indicated moderate reliability, .75–.90 indicated good reliability, and more than .90 indicated excellent reliability. 44
The Kruskal-Wallis H test was used to analyze the performance of LLMs in the four domains of MCI management. For bilingual analysis and comparisons between HPs and CPs, we conducted Mann-Whitney U tests. A Shapiro-Wilk test confirmed that the data did not follow a normal distribution. A significance level of p < .05 was applied for all statistical tests. Statistical analysis was performed using R version 4.3.1, and Bonferroni correction was applied to account for multiple comparisons.
Results
General findings
Figure 3 displays the response consistency rates of four LLMs when responding to 72 questions, assessed through duplicate submissions. All LLMs demonstrated high consistency, with response consistency rates exceeding 80%. To ensure the accuracy of the analysis, inconsistent responses were excluded from the data, as indicated by the Figure 3 note. The ICC values for HPs and CPs both exceeded .75, indicating good consistency in their ratings (see Table 1 and Table 2). Evaluation of LLMs in MCI Management. (a) LLM performance across categories; (b) consistency across Four LLMs; (c) comparison of Chinese versus English responses by evaluation criteria; and (d) comparison of HP and CP evaluations based on evaluation criteria. Abbreviations: ChatGPT-CN, Chinese version of ChatGPT; ChatGPT-EN, English version of ChatGPT; CP, care partner; HP, healthcare professional. ICCs for HPs. ICCs for CPs.


Descriptive statistics of evaluation scores across domains.
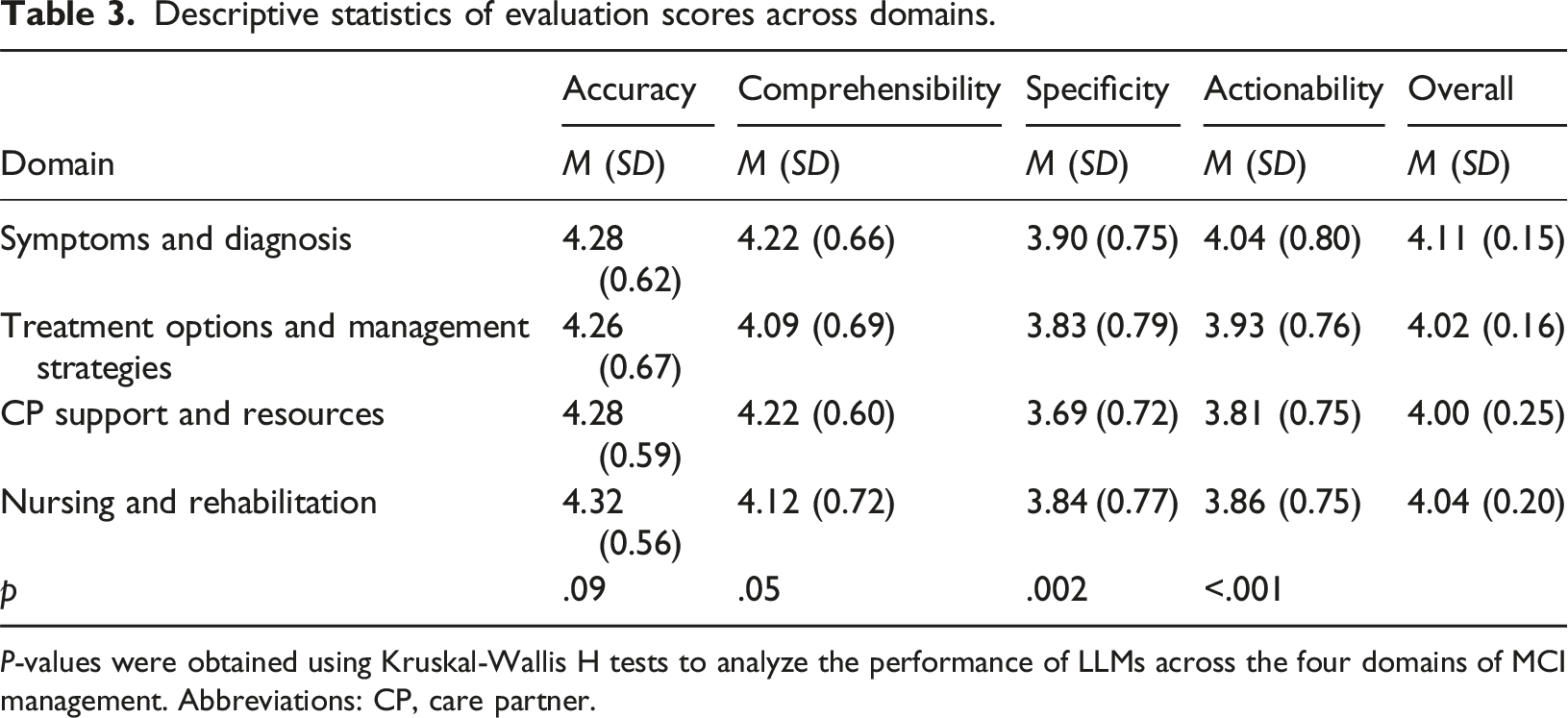
P-values were obtained using Kruskal-Wallis H tests to analyze the performance of LLMs across the four domains of MCI management. Abbreviations: CP, care partner.
Overview of LLM performance across key evaluation criteria.

P-values were obtained using Kruskal–Wallis H tests for comparisons across LLMs. Mann–Whitney U tests were used for bilingual comparisons and HP–CP group differences. Abbreviations: ChatGPT-CN, Chinese version of ChatGPT; ChatGPT-EN, English version of ChatGPT; CP, care partner; HP, healthcare professional.
Symptoms and diagnosis
LLM performance across key evaluation criteria in symptoms and diagnosis.

P-values were obtained using Kruskal–Wallis H tests for comparisons across LLMs. Mann–Whitney U tests were used for bilingual comparisons and HP–CP group differences. Abbreviations: ChatGPT-CN, Chinese version of ChatGPT; ChatGPT-EN, English version of ChatGPT; CP, care partner; HP, healthcare professional.
For example, responses varied across LLMs to the question, “What are the causes of mild cognitive impairment?” ChatGPT provided a detailed and structured answer, covering neurological, vascular, psychiatric, lifestyle, and genetic factors. Gemini focused on treatable causes and risk factors but lacked detail on neurological and vascular factors. Kimi emphasized Alzheimer’s disease, vascular issues, and psychiatric conditions, but missed lifestyle and genetic factors. ChatGPT-CN mirrored ChatGPT’s response in Chinese, offering a similar level of detail. Overall, ChatGPT-EN performed best, providing the most comprehensive and multifactorial explanation of MCI causes.
Treatment options and management strategies
LLM performance across key evaluation criteria in treatment options and management strategies.

P-values were obtained using Kruskal–Wallis H tests for comparisons across LLMs. Mann–Whitney U tests were used for bilingual comparisons and HP–CP group differences. Abbreviations: ChatGPT-CN, Chinese version of ChatGPT; ChatGPT-EN, English version of ChatGPT; CP, care partner; HP, healthcare professional.
In response to a patient reporting severe headaches on donanemab, a treatment for early stage Alzheimer’s disease, ChatGPT-EN provided the most comprehensive guidance, detailing symptom evaluation, timing relative to treatment, management strategies, and the importance of consulting the clinical trial team. ChatGPT-CN offered a similar but less detailed response, particularly lacking nuanced recommendations on imaging and follow-up. Kimi provided a more basic symptom assessment, omitting references to trial protocols and complications associated with donanemab. Gemini also suggested general evaluations such as medical history review and imaging but did not address critical concerns like amyloid-related imaging abnormalities or infusion-related reactions.
CP support and resources
The lower scores in this domain (Table 1) can be attributed to several key factors. Responses were often too general, lacking depth and specificity in addressing the unique needs of CPs. Many suggestions were broad and did not provide clear, actionable steps. Additionally, the emotional and psychological challenges of caregiving were not fully acknowledged, leading to responses that may have felt impersonal or insufficient. More personalized, practical advice and greater empathy would improve the relevance and effectiveness of these responses.
LLM performance across key evaluation criteria in CP support and resources.

P-values were obtained using Kruskal–Wallis H tests for comparisons across LLMs. Mann–Whitney U tests were used for bilingual comparisons and HP–CP group differences. Abbreviations: ChatGPT-CN, Chinese version of ChatGPT; ChatGPT-EN, English version of ChatGPT; CP, care partner; HP, healthcare professional.
Nursing and rehabilitation
LLM performance across key evaluation criteria in nursing and rehabilitation.

P-values were obtained using Kruskal–Wallis H tests for comparisons across LLMs. Mann–Whitney U tests were used for bilingual comparisons and HP–CP group differences. Abbreviations: ChatGPT-CN, Chinese version of ChatGPT; ChatGPT-EN, English version of ChatGPT; CP, care partner; HP, healthcare professional.
Discussion
Principal results
We evaluated the performance of three LLMs (ChatGPT, Gemini, and Kimi) by analyzing their responses to MCI-related questions in both Chinese and English, as assessed by nonspecialist HPs and CPs. A rigorous study design incorporating appropriate masking, randomization, and dual independent reviews helped ensure the robustness and integrity of our evaluation process. Our findings suggest that LLMs—particularly ChatGPT-4o—have strong potential to generate accurate and comprehensive responses to MCI-related queries.
Notably, the inclusion of CPs as evaluators provided a distinctive contribution. As individuals who engage extensively with patients on a daily basis, CPs offer unique, experience-based insights that complement those of HPs. Their close observation and firsthand knowledge of patients’ behavioral and emotional changes bring an essential real-world perspective to the assessment of LLMs in chronic disease management. By incorporating CPs into our evaluation design, we aimed to not only reflect the real-world complexity of MCI care but also inform the development of vertical, user-sensitive LLMs tailored to the diverse needs of stakeholders in long-term, community-based care settings. English responses outperformed Chinese in comprehensibility and specificity, highlighting the need for language-tailored optimization as an important direction for LLM development.
LLM performance in MCI healthcare pathways
LLMs showed significant potential, particularly in the symptoms and diagnosis domain of the MCI healthcare pathway, due to their comprehensive and specialized training in clinical and diagnostic content, which aligns with the current medical emphasis on clinical care. 45 Our study found that LLMs provided accurate, detailed, and actionable information about MCI symptoms, causes, and diagnostic processes, effectively supporting HPs. However, their performance was weaker in the CP support and resources domain, because CPs need not only factual information but also emotional support and practical guidance. 46 This supports prior research that highlighted the lack of focus on CP support. 47 LLM responses tended to be too general, 48 lacking the personalized depth necessary to address the unique challenges of CPs. As noted in previous studies, lack of comprehensiveness was prevalent in nearly 90% of the research analyzed, with LLM outputs often being incomplete or overly general, particularly regarding medical tasks. 49 This gap in LLM performance may inadvertently amplify issues in healthcare—such as an overemphasis on treatment at the expense of prevention and CP support 50 —by providing users with seemingly accurate but ultimately imprecise or generalized insights. Therefore, caution is needed when relying on LLMs in these domains.
This study highlights how LLMs can strengthen the dementia care continuum, particularly in managing MCI among older adults. By delivering timely, accessible, and accurate information, LLMs can support early detection and intervention—key pillars often challenged by low diagnosis rates and limited professional training among nonspecialist CPs. 51 Beyond initial diagnosis, LLMs also can offer ongoing guidance on cognitive monitoring, lifestyle adjustments, and CP education, helping sustain the well-being of aging individuals. 52 By improving the efficiency and reach of care, LLMs could ease healthcare burdens and make the continuum more inclusive and sustainable for an aging population. 53 Our findings reinforce the value of integrating LLMs into dementia care to enhance quality and optimize processes for older adults with MCI (Figure 4).
In addition to their clinical strengths, LLMs may face limitations in nonmedical domains related to MCI care, particularly in providing emotional support for caregivers. The complexity of human emotions and caregiving dynamics makes it difficult for LLMs to offer truly empathetic and personalized responses.
54
Our study found that CPs perceived LLMs as less effective in providing actionable and empathetic support, which is crucial in managing the emotional and practical challenges of caregiving. This highlights a critical gap in LLM performance, because CPs need not only factual information but also emotional support and tailored guidance. Development of LLMs could benefit from incorporating personalization features, such as adapting responses to the unique caregiving situations and emotional needs of individuals, ensuring more empathetic and contextually appropriate interactions.
17
Pathways for patients in MCI healthcare system empowered by LLMs.
Diverging perceptions between HPs and CPs
An interesting pattern emerged in this study: CPs—who typically lack formal medical training—assigned slightly higher scores for accuracy than HPs. However, HPs rated responses significantly higher than CPs in comprehensibility and actionability, with notably lower scores by CPs in these areas. In contrast, specificity ratings were higher for CPs, though this difference was not statistically significant. These findings suggest that CPs prioritize accuracy but may face challenges in understanding and applying detailed information, whereas HPs, despite their more extensive clinical knowledge, value comprehensibility, specificity, and actionability more due to their professional experience and training.
This suggests that CPs, who are generally focused on practical relevance and everyday caregiving tasks, prioritize accuracy based on how well the information aligns with their experience, rather than technical precision. Meanwhile, due to their clinical background, HPs emphasize the clarity, detail, and applicability of the information provided. These findings indicate that users evaluate LLM-generated content through the lens of their knowledge and caregiving role. This is consistent with previous research showing that CPs may prioritize relevance over technical accuracy, particularly in nonmedical domains.55,56
These differences underscore the necessity for LLMs to be designed with audience-specific customization. CPs and patients require content that is not only factually accurate but also accessible and relevant to their caregiving needs. In contrast, HPs would benefit from LLM outputs that emphasize clinical precision, specificity, and actionability. Therefore, when integrating LLMs into healthcare contexts, it is crucial that model development involves tailored outputs by user type. Moreover, the use of LLMs in medical decision-making must be closely supervised by healthcare providers to ensure ethical standards and patient safety. LLMs should serve as supplementary tools, not replacements for professional judgment. Healthcare providers remain responsible for patient care, because LLM hallucination may generate incorrect or misleading information, risking misdiagnosis or inappropriate treatment. Therefore, robust monitoring frameworks are essential to detect and correct inaccuracies, especially in high-stakes settings.
Therefore, HPs must be trained to recognize the limitations of AI-generated content to prevent overreliance. Clear guidelines are needed for integrating AI into clinical workflows without compromising patient safety. 57 Research should focus on best practices for LLM integration, addressing both benefits and ethical concerns to minimize errors and improve human–AI collaboration in healthcare.
Impact of linguistic and cultural contexts on LLM performance
This study’s innovation lies in its comparative evaluation of LLM performance in English and Chinese, revealing the significant influence of linguistic and cultural contexts on the effectiveness of AI tools in healthcare. Notably, the most pronounced differences between the two languages occurred in comprehensibility and specificity, reflecting not only technical discrepancies but also deeper cultural and communicative distinctions, which aligns with the latest research. 58 Previous research has primarily used language-specific knowledge bases, which may have overlooked the nuanced contextual processing capabilities of LLMs across linguistic environments.30,32
High-quality medical literature is predominantly published in English, contributing to more structured, standardized, and clinically annotated training corpora. In contrast, Chinese medical corpora are often less formalized and lower in domain-specific consistency, which may adversely affect the performance of LLMs in clinical reasoning and content generation. Furthermore, the Chinese language often favors indirect or general expressions, especially in the context of stigmatized conditions such as MCI and dementia, for which cultural norms may discourage open discussion.
These findings highlight the need for linguistic and cultural alignment in LLM development, particularly in languages other than English. Linguistic structure, semantic conventions, and cultural communication norms shape not only how models interpret and present information but also how users perceive its accuracy and relevance. 59 To realize the potential of LLMs in global healthcare delivery, particularly for aging populations, developers must integrate culturally appropriate language patterns, clinical norms, and user expectations into model design. Building on these insights, we propose that integrating LLMs with socialized knowledge bases, region-specific clinical guidelines, and population-level patient profiles can substantially improve performance in both specificity and actionability. Such integration would enable LLMs to deliver more precise, context-aware content to HPs while also offering clear, accessible, and culturally sensitive guidance to CPs. Addressing language-based disparities could not only enhance clinical applicability but also bridge knowledge gaps, reduce inequities, and advance equitable, evidence-based MCI care across diverse healthcare systems.
Limitations
The study’s findings should be interpreted with caution for several reasons. First, the sample size of CPs and HPs was relatively small, which may limit the robustness and generalizability of the results. In addition, the question pool used for evaluation was not pretested or validated prior to deployment, which may have affected the reliability and interpretability of the scoring outcomes. Second, the evaluation relied on single-turn, standardized prompts rather than dynamic, multiturn clinical dialogues, potentially overstating model performance in real-world use. Third, filtering out incomplete or inconsistent responses, although improving methodological rigor, may have introduced selection bias by omitting prompts that could expose model limitations. Fourth, language coverage was asymmetric: ChatGPT-4o was evaluated in both English and Chinese, whereas Gemini and Kimi were tested in one language each, constraining direct model-to-model comparisons. Fifth, subjective 5-point Likert ratings may be prone to evaluator bias; incorporating objective endpoints in future assessments would improve validity. Sixth, model performance may evolve over time, and our evaluation reflects only the version status as of November and December 2024. Finally, only three general-purpose LLMs were tested using a single MCI-related question set, limiting the applicability of findings to other models or specialized clinical scenarios in MCI care. These limitations suggest that researchers should prioritize larger and more diverse samples, validated question sets, real-world dialogue formats, balanced multilingual designs, and objective clinical outcomes.
These considerations underscore the need for research in broader and more varied contexts, incorporating patient-facing dialogues and real-time clinical workflows. Studies should include larger samples and more sociodemographically diverse groups of CPs and HPs to ensure greater representativeness. In addition, evaluating LLM performance across a wider range of input languages would better simulate real-world scenarios and provide a more comprehensive understanding of model robustness in multilingual healthcare environments.
Conclusions
This study provided an early role-sensitive evaluation of LLMs in the context of MCI management. By assessing ChatGPT, Gemini, and Kimi across four core domains—symptoms and diagnosis, treatment strategies, CP support, and rehabilitation—we demonstrated the potential of LLMs to deliver accurate, actionable, and comprehensible information, particularly in diagnostic areas. However, notable differences emerged based on language, user group, and model, with English responses generally outperforming Chinese responses in specificity and comprehensibility and HPs and CPs showing distinct evaluative patterns shaped by their expertise and experience.
These findings highlight the promise of LLMs in supporting dementia care pathways while also emphasizing the need for culturally and linguistically tailored development. Future research should include expanded evaluation populations, incorporate more realistic interaction settings, and ensure model outputs align with the practical needs of both professional and nonprofessional users. With thoughtful refinement, LLMs can be positioned as accessible, scalable tools to support early detection and ongoing management of cognitive impairment in aging populations.
Supplemental Material
Supplemental Material - Evaluating large language models for mild cognitive impairment among older adults: A bilingual comparison of ChatGPT, Gemini, and Kimi
Supplemental Material for Evaluating large language models for mild cognitive impairment among older adults: A bilingual comparison of ChatGPT, Gemini, and Kimi by Yexuan Xiao, Qianhui Pan, Haoyuan Liu, Yilin He, Yuhe Zhang, Nan Jiang in Health Informatics Journal
Supplemental Material
Supplemental Material - Evaluating large language models for mild cognitive impairment among older adults: A bilingual comparison of ChatGPT, Gemini, and Kimi
Supplemental Material for Evaluating large language models for mild cognitive impairment among older adults: A bilingual comparison of ChatGPT, Gemini, and Kimi by Yexuan Xiao, Qianhui Pan, Haoyuan Liu, Yilin He, Yuhe Zhang, Nan Jiang in Health Informatics Journal
Supplemental Material
Supplemental Material - Evaluating large language models for mild cognitive impairment among older adults: A bilingual comparison of ChatGPT, Gemini, and Kimi
Supplemental Material for Evaluating large language models for mild cognitive impairment among older adults: A bilingual comparison of ChatGPT, Gemini, and Kimi by Yexuan Xiao, Qianhui Pan, Haoyuan Liu, Yilin He, Yuhe Zhang, Nan Jiang in Health Informatics Journal
Footnotes
Ethical considerations
This study received approval from Tsinghua University Institutional Review Board (Protocol: THU01KS2025035). All participants provided informed consent through procedures reviewed and approved by the ethics committee. Data collection was strictly anonymous, with no personally identifiable information retained during analysis or storage.
Authors’ contributions
Y.X. and Q.H. contributed to the conceptualization, literature review, data analysis, and wrote the original manuscript. N.J. is the corresponding author, contributed to the conception and suggestions of this study, and supervised the entire research process. H.Y. contributed to the literature review, LLM evaluation, and data analysis. Y.L. participated in the LLM evaluation and data analysis. Y.H. contributed to the creation of figures and tables. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The National Natural Science Foundation of China (72495135), Ministry of Education, PRC (171-BHZX) and Tsinghua University Seed Grant (53331100125). The funder has no role in study design, data collection and analysis, preparation of manuscript, or decision to submit for publication.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Supplemental Material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.