
Abstract
Keywords
Introduction
Over the past decade, healthcare initiatives to collect information about patients’ social risks, also known as adverse social determinants of health (SDH; e.g., food insecurity and housing instability) have expanded.1,2 In theory, these efforts can inform work to intervene on social risks to improve health outcomes.3–9 Despite growing efforts to collect and document social risk data in electronic health records (EHRs), there is significant variability in data collection and documentation.10,11 This raises the possibility that research using EHR-sourced social risk data may operationalize the same social risk domain using different concepts, or operationalize the same domain using the same concept but vary on what data are used to support that concept. These both may impact researchers’ ability to conduct population comparisons and intervention comparative effectiveness studies across settings and populations.
Existing measures for social risk domains can track distinct concepts related to an individual domain. 12 For instance, some housing stability tools assess patients’ current housing status; others ask about lifetime experiences of homelessness; still others ask about overcrowding or housing quality concerns. 13 Differences in how social risk domains are defined can present challenges to interpreting and comparing social risk data across settings.
Social risk domains can also be defined using the same concept but be based on different data with variable validity. Some healthcare settings ask patients about social risks using screening tools with standardized survey questions. Even among these screening tools, however, questions related to any one social risk domain are not standardized. As one example, food insecurity measures used in Kaiser Permanente’s Your Current Life Situation (YCLS) and the Centers for Medicare & Medicaid Innovation’s (CMS) Accountable Health Communities (AHC) Health-Related Social Needs (HRSN) Screening tools differ in the look-back timeframe (3-months vs 12-months, respectively) and in assessment of severity of risk (YCLS includes response options for “very often” and “often” worrying about food running out, whereas the AHC tool does not distinguish beyond “often”). 14 Though a brief, validated (compared to gold standard measure) food insecurity screening measure exists,12,15 many other social risk domains lack validated measures and measures are often adapted without additional validity testing. 12 Beyond screening tools, some researchers may depend on social risk data from unstructured free-text data collected more informally in the course of clinician verbal history-taking. If one study classifies patients as food insecure using a proxy of documented use of a food bank in a clinician note whereas another uses self-report of food insecurity in a patient screening tool, the reported data will be different: one tells you about whether a patient is using a food resource whereas the other the prevalence of patient food insecurity disclosure. These differences can influence conclusions evaluating how food insecurity is associated with patient health outcomes (e.g., patients who use a food resource may have a higher level of food insecurity than patients who report experiencing food insecurity, or vice versa if the patient using the resource is having their need addressed while the other patient is not).
In parallel, the way social risk data are documented also impacts how readily they can be extracted and evaluated. These differences in social risk content and documentation have implications for the usability and representativeness of social risk data, especially in cases where researchers aim to compare rates of social risk or the efficacy of an intervention across settings and populations. Data documented in structured fields (e.g., socio-demographic fields, screening tools with select answer options that are directly embedded in the EHR or integrated into the EHR after completion on a paper form) or in other standardized data (e.g., billing codes, International Classification of Disease (ICD) diagnosis codes) can be more readily extracted from EHRs. Identifying data from unstructured and non-standardized data is more challenging and has historically required manual review of free-text notes.16–18 The emergence of advanced data analytic techniques such as natural language processing (NLP) offers alternatives to manual chart reviews, though their sensitivity, specificity, and scalability across settings has not yet been well-established.19–21 Research studies that rely on structured versus unstructured data—or a combination of the two—are likely to calculate different levels of social risk based on methodological differences rather than actual differences between populations.
This review builds on two prior systematic reviews that explore SDH data captured in EHRs.21,22 These reviews (Chen et al. and Patra et al.) evaluated the use of EHR-based SDH data in risk prediction modeling (including area/neighborhood-level data (i.e., social risks at the level of the community)) and NLP techniques used for social risks data extraction, respectively. This scoping review explores both the kinds of patient-level social risk data (i.e., experiences of social risk at the level of the individual patient) that are being extracted from EHRs for research purposes and the EHR locations where the data are found. We focused on six social risk domains that have been most commonly included in national healthcare sector discussions about social risk data collection and interventions: housing, food, transportation, utilities, personal safety, and social support/isolation. Due to the expansive and evolving nature of social risk screening and data extraction and lack of existing literature on the review topic, a systematic scoping review was appropriate for broadly synthesizing the literature and identifying knowledge gaps. 23 The goal was to better understand the comparability and generalizability of social risk data pulled from EHRs. A better understanding of the state of social risk data being used in research should inform future data collection efforts as well as subsequent design of social risk-related interventions. To our knowledge, this review is the first to examine a range of ways that researchers have extracted patient-level social risk data from EHRs and explored how these data are used to define specific social risk domains.
Methods
In collaboration with an experienced medical librarian, two study team members (E.H.D., N.V.S.) developed a search strategy to identify studies that included EHR-based social risk data. We further refined the search to maximize yield based on previously identified articles deemed relevant by expert referral.24,25 This resulted in a three-concept search that included terms for 1) EHRs, 2) social risks, and 3) data extraction.
The social risks concept included both broad terms for the social determinants of health (SDH), as well as terms related to six specific social risk domains. Five of these domains—housing, food, transportation, utilities, and personal safety—are the core domains included in CMS’s AHC HRSN screening tool. 26 The AHC tool has been adopted by healthcare settings even outside the CMS Innovation Center’s demonstration as well as included in new quality measure designs by both the National Commission for Quality Assurance (NCQA) and CMS.27,28 We added a sixth domain by also searching for terms related to social support/isolation given the recognition that social isolation is a significant driver of health and mortality.29–31 Data extraction terms included the different techniques used to extract both structured (e.g., ICD codes or templated social risk fields) and unstructured data (e.g., social risk information included in free-text notes). See Appendix 1 for more information about the search strategy and a complete list of search terms.
We limited our review to the peer-reviewed literature. Databases searched included: PubMed, EMBASE, CINAHL, and Web of Science. We adapted the search strategy for each included database. To be included in our review, research studies had to analyze patient-level social risk data, defined as information on patients’ individual experiences of social risks, for at least one of six social risk domains (housing, food, transportation, utilities, personal safety, and social support/isolation). We did not include articles evaluating proxies for patient-level social risk data, such as area/neighborhood-level data pulled from publicly available sources. Studies that relied on social risk data from sources outside the EHR, such as the U.S. Census Bureau data, were excluded from our study. Our study focus was on evaluating data stored in the EHR and prior research has shown that individual-level social risk factors do not correlate highly with area-level measures. 32 Articles had to be available in English and published in the peer-reviewed literature from 1/1/2009 to 7/20/2020. Our search was limited to articles published after 2009, based on the reasoning that the 2009 Health Information Technology for Economic and Clinical Health (HITECH) Act spurred widespread EHR adoption.33,34 We did not distinguish between type of evidence included in our review; studies could include both quantitative and/or qualitative information.
Search results were uploaded to, and duplicates removed from, a group library in Zotero 5.0.96.2 reference manager. Title and abstract screening, followed by full-text review, were completed independently by three study team members (G.H.L., S.P., H.K.). Following full-text review, every study recommended by one of the reviewers was reviewed by an additional study team reviewer, such that the full-text of each article was reviewed by at least two study authors. Differences of opinion between reviewers at both the title/abstract and full-text level were resolved through group discussion and with additional input from a fourth study team member (E.H.D.).
Data extracted from each article included study design, setting, patient population, social risk factor(s) documented in the EHR, documentation location in the EHR, domain definition, method of data extraction, and outcomes evaluated (e.g., prevalence of social risks, patient health, healthcare utilization). The review was registered with the International Prospective Register of Systematic Reviews (CRD42020180539) and followed the Preferred Reporting Items for Systematic reviews and Meta-Analyses extension for Scoping Reviews. 35
Results
General characteristics
Our initial search yielded 9022 unique articles. Following an initial title/abstract screen, 133 articles underwent full-text review. (Figure 1). After full text review, 111 articles met inclusion criteria (Appendix Table 1). Most studies (N = 88/111, 79%) were from the United States (see Appendix Figure 1 for information on country of origin). Thirty percent of the studies (N = 33/111) extracted information for multiple social risk domains; the sum of the studies within each domain is therefore greater than the total number of included studies. The most frequently included social risk domain was social support/isolation (N = 68/111, 61%), followed by housing-related social risks (N = 49/111, 44%), personal safety concerns (N = 26/111, 23%), food insecurity (N = 10/111, 9%), transportation barriers (N = 9/111, 8%), and utilities insecurity (N = 5/111, 5%). (Appendix Table 2). PRISMA flow sheet.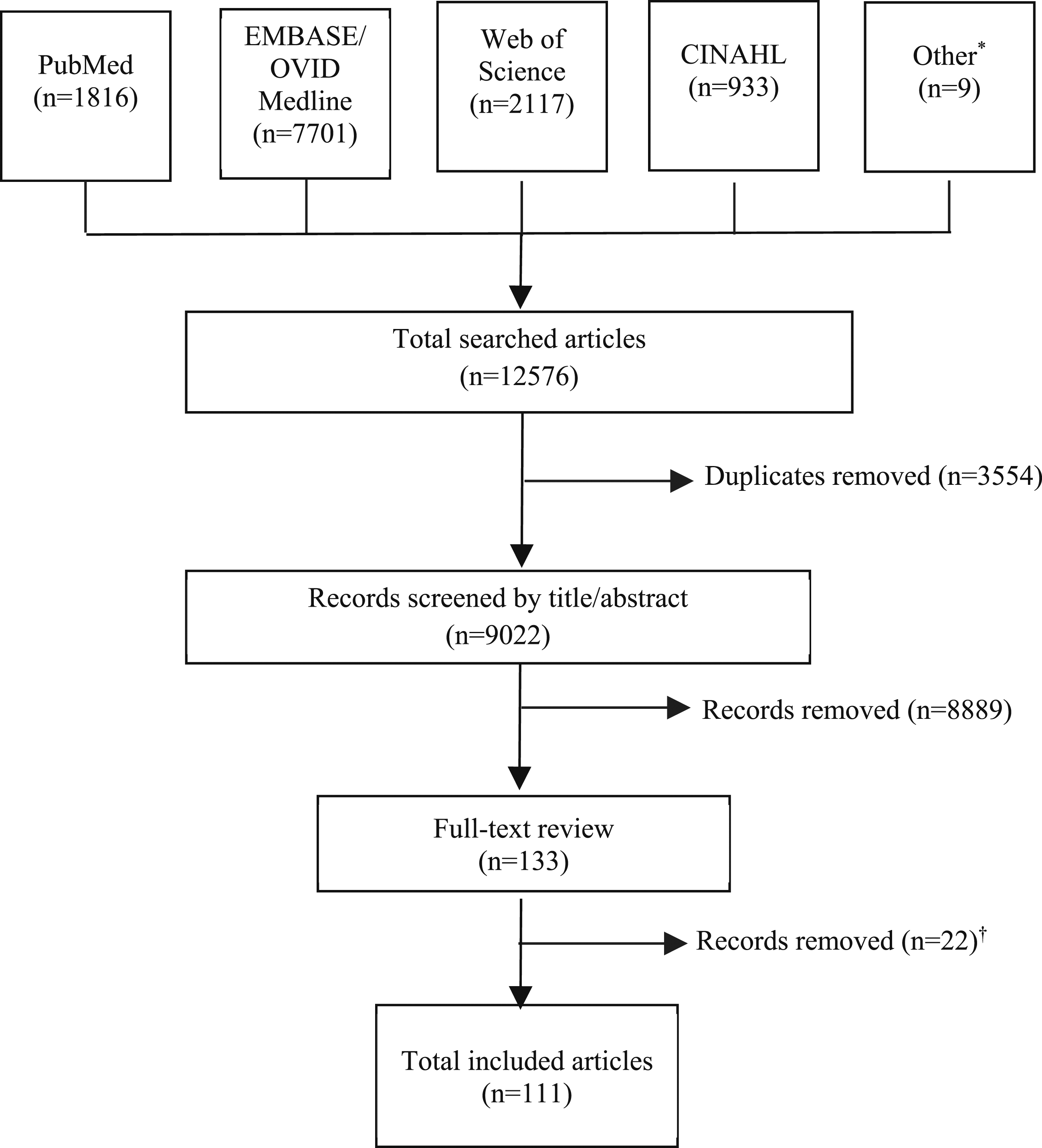
The purpose for using patient-level social risk data differed across studies. The majority (N = 71/111, 64%) extracted social risk data to evaluate whether social risk factors were predictors for health or healthcare utilization outcomes. A smaller number of articles characterized social risks in the patient population (N = 16/111, 14%) or evaluated the performance of machine learning for extracting social risk factors from EHRs (N = 13/111, 12%). (Appendix Table 3).
Social risk domain definitions
Social risk domain breakdown across included studies (N = 111).
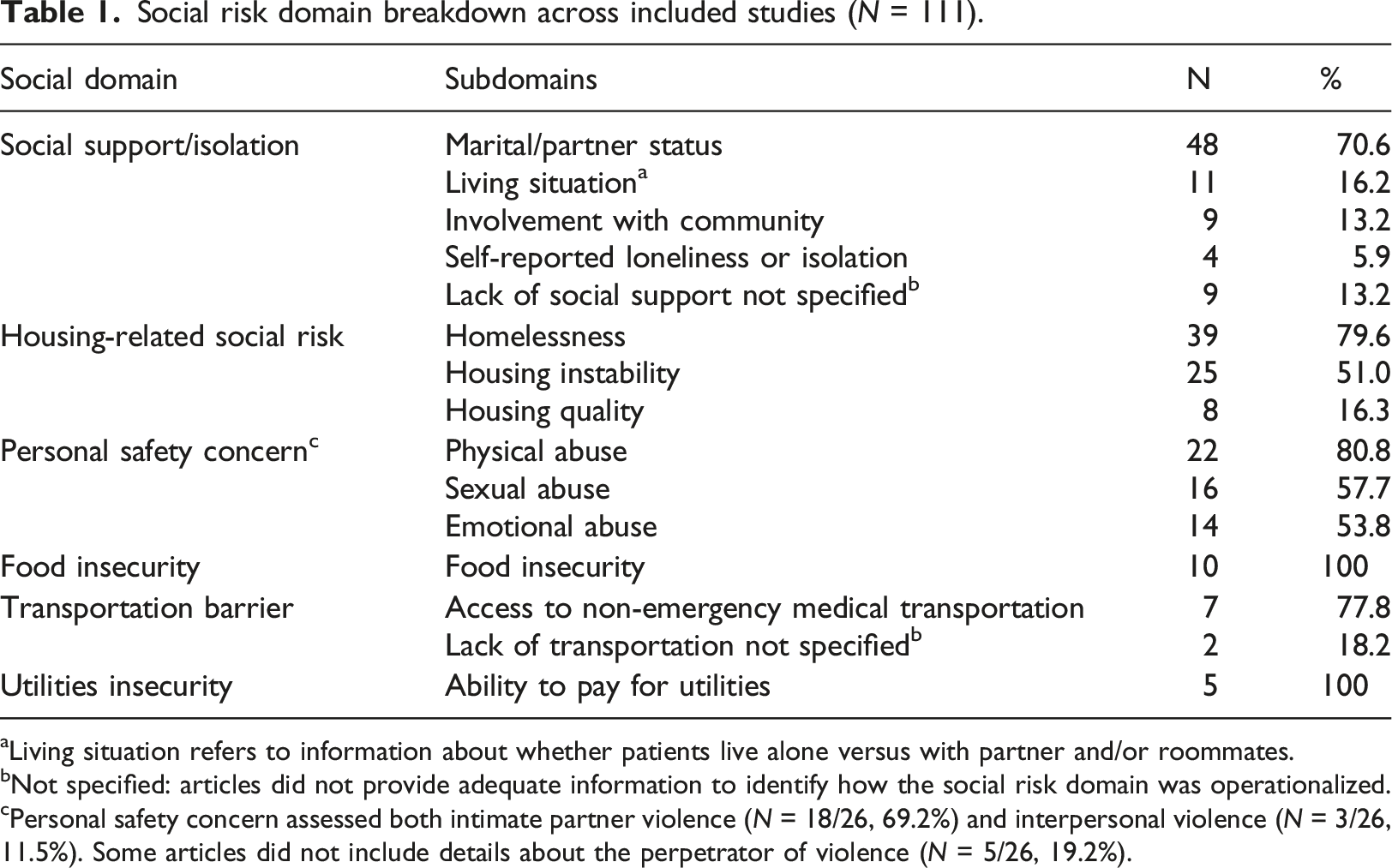
aLiving situation refers to information about whether patients live alone versus with partner and/or roommates.
bNot specified: articles did not provide adequate information to identify how the social risk domain was operationalized.
cPersonal safety concern assessed both intimate partner violence (N = 18/26, 69.2%) and interpersonal violence (N = 3/26, 11.5%). Some articles did not include details about the perpetrator of violence (N = 5/26, 19.2%).
Data extraction methods
Across domains (e.g., housing) and subdomains (e.g., housing quality), different types of data were used to capture risks. Eighty percent of studies (N = 89/111) analyzed structured data whereas 29% (N = 32/111) analyzed unstructured data. These categories were not mutually exclusive; 17% studies (N = 19/111) analyzed both structured and unstructured data (Appendix Table 5). See Figure 2 and Appendix Table 6 for breakdown of data extraction method by social risk domain. Study use of structured versus unstructured data, by social risk domain*.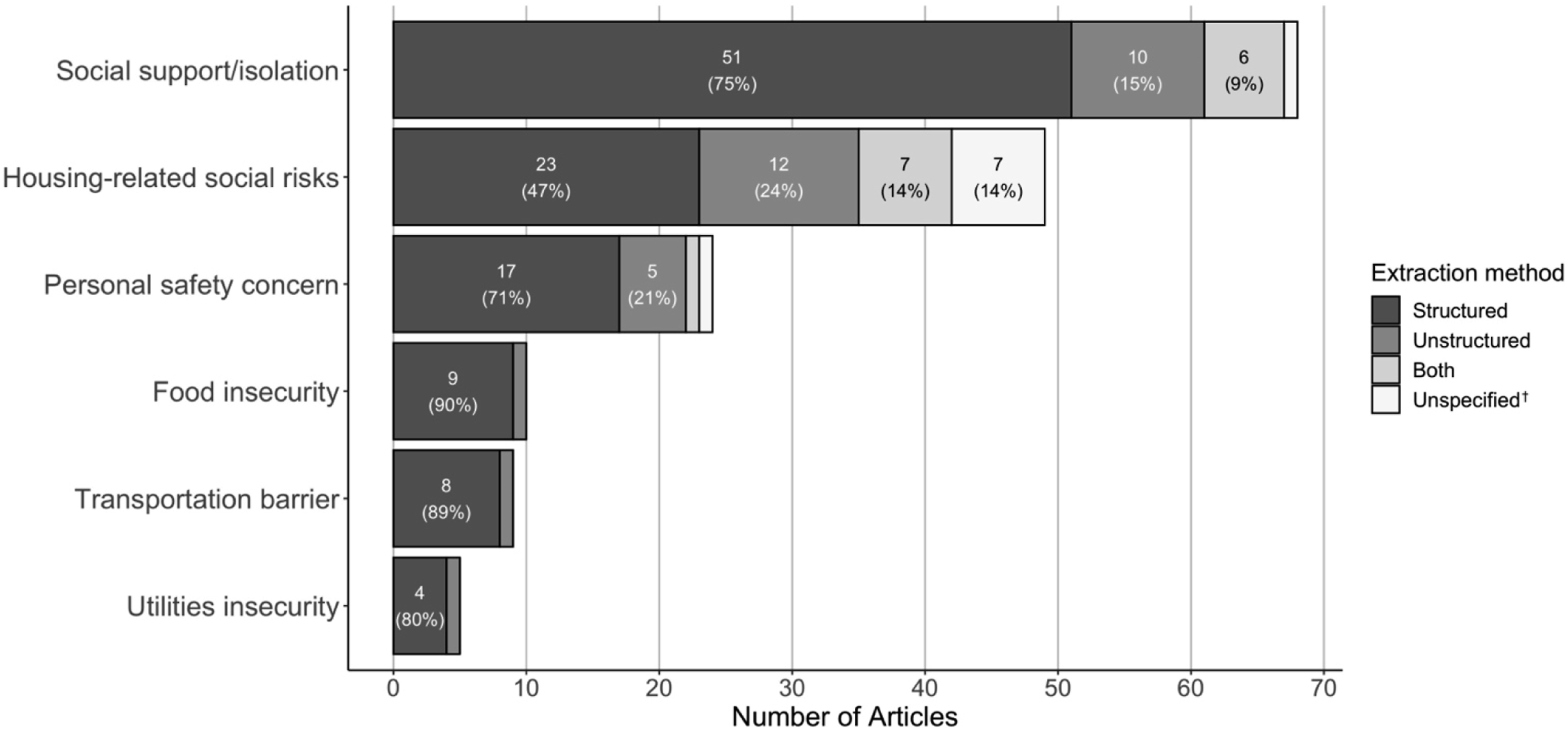
Structured data
Of the 89 studies that relied on structured data for analysis, 53% (N = 47) used sociodemographic fields, 32% (N = 28) used billing codes, and 30% (N = 27) used social risk screening tools integrated into the EHR (which included screenings that were done on a paper form and manually entered into the EHR at a later time) (Appendix Table 5). By domain, 50% of the articles on housing-related social risks and personal safety concerns used information from billing codes (N = 15/30; N = 10/20; respectively). Screening tools were used in at least 50% of articles on food insecurity (N = 7/9, 78%), utilities insecurity (N = 3/4, 75%), personal safety concerns (N = 11/20, 55%), and transportation barriers (N = 4/8, 50%). Eighty-four percent (N = 47/57) of articles examining structured data on social support/isolation used sociodemographic data, 96% (N = 45/47) of which were used to determine marital status. (Figure 3(a); Appendix Table 7). Study data extraction methods, by social risk domain. (a) Sources of structured data, by social risk domain. (b) Sources of unstructured data, by social risk domain.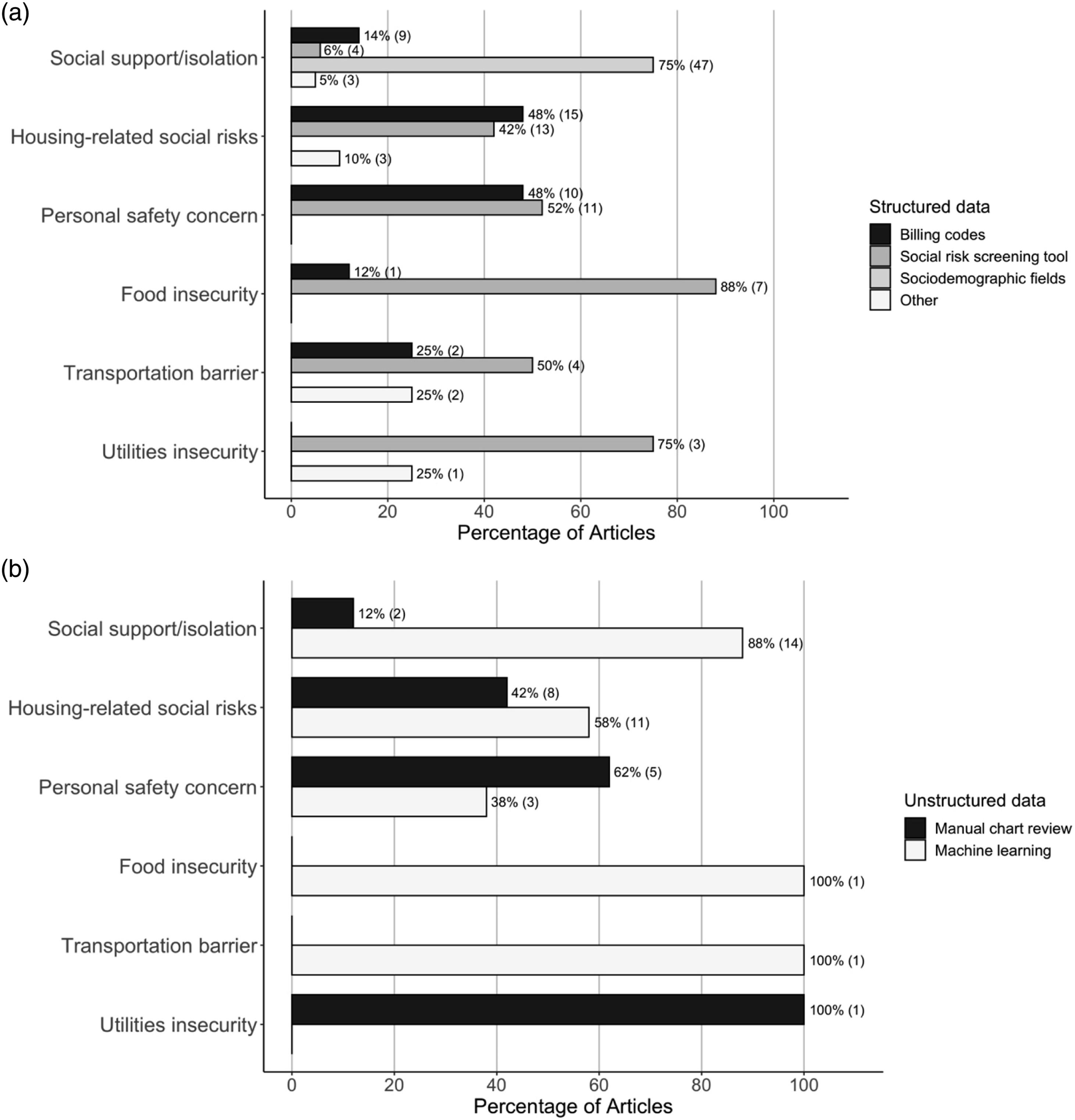
Unstructured data
Of the studies that used unstructured EHR data, 44% (N = 14/32) extracted the data from free-text notes using manual chart review and 66% (N = 21/32) used machine learning techniques (Appendix Table 5). By domain, machine learning techniques were used in 88% of the articles on social support/isolation (N = 14/16), 58% of the articles on housing-related social risks (N = 11/19), and 38% of the articles on personal safety (N = 3/8). Only one article pulled unstructured data on food insecurity and one on transportation barriers; both utilized machine learning. (Figure 3(b); Appendix Table 8).
Both structured and unstructured data
Of the studies that examined both structured and unstructured data, 37% (N = 7/19) compared the performance of structured and unstructured data for identifying social risk information.19,20,36–40 The remainder used both structured and unstructured data to increase the yield of social risk detection (N = 12/19, 63%).41–52 Articles in this category extracted data pertaining to social support/isolation (N = 11/19, 58%),19,20,36,37,39,40,47–49,51,52 housing-related social risks (N = 10/19, 53%)19,20,38,41,44–46,49,51,52 and/or personal safety concerns (N = 5/19, 26%).42,43,48,50,52
Discussion
This is a novel review that examines the techniques by which researchers are capturing patient-level social risk information from the EHR, along with the ways that data are defined into specific social risk domains. Our study is relevant and timely as many healthcare systems stand to benefit from a new crop of federal, state, and private payer incentives designed to increase screening and documentation of patients’ social risks.27,28,53,54 These measures will likely increase the prevalence of standardized social risk screening and subsequent data availability to researchers.
We found only 27% of articles identified in this scoping review relied on data from integrated patient social risk screening tools. Although many common social risk screening tools include questions about transportation, food, and utilities, these domains were less represented than social support/isolation, housing-related risks, and personal safety in the patient-level data extracted from EHRs.26,55 While screening tools are increasingly embedded into EHRs,56,57 studies of screening programs frequently report using paper collection tools, which may not be consistently transferred to the EHR.23,34–38 It is possible that data on food, transportation, and utilities securities are less frequently documented in the EHR than other domains, which is consistent with a previous study reporting low rates of food and utilities securities screening by healthcare providers, 64 the reasons for which are unclear. As multi-domain screening for social risks increases, we would expect an increase in documentation for food insecurity, transportation barriers, and utilities insecurity, provided integration of these tools within EHRs also increases.
Our findings also highlight how a lack of standardization in social risks definitions can influence social risk research outcomes and comparability of findings across studies. Many studies had differences in how they operationalized the same social risk domain or used very different data to support/refute the presence of a social risk. Others lacked detailed methodology explaining what social risk data were used to represent domains. For instance, several studies did not specify how or what data they used to define the term “social support” (e.g., it was unclear if they relied solely on martial/partner status from demographic screening, or if they used more robust information on interpersonal relationships and involvement with the community). Without this information, it is not possible to compare study results. The inconsistency of social risk domain definitions across studies limits the interpretation and synthesis of research findings, given that different studies may utilize very different representations of individual social risks. Further standardizing definitions of social risk domains or reporting requirements for social risk data would improve the ability to pool data and/or compare results across settings and populations. Organizations like the Gravity Project, which is trying to develop standards for social risk data for healthcare settings, can serve as a resource for researchers interested in capturing social risk data. 72
The method of extracting social risk data from the EHR also impacts the generalizability and comparability of research studies. Social support/isolation and housing-related risks were commonly extracted from both structured and unstructured fields, whereas food security and personal safety were primarily extracted from structured fields. While a growing number of studies are utilizing machine learning tools to extract free-text data from the EHR, these technologies are still in the research stage and limited by the quality of the written text.21,73 Heterogeneity in where social risk data is documented and can be extracted from limits the accessibility of that data to both clinicians and researchers, even if shared definitions were to be used. The inadequate standardization in social risk data documentation and extraction limits the comparability of data across clinical settings and institutions and provides technological barriers to efficiently access social risk data. Until there are standards on how/where to document social risks within EHRs, researchers will likely need to mine EHRs for multiple types of data to achieve a more complete picture of patients’ social risks. We believe it is therefore important for researchers to be transparent and explicit about their extraction methods, as well as domain definitions, so that study results can be contextualized and compared only when appropriate.
Health systems face substantial barriers to implementing comprehensive social risk screening tools and standardized documentation of social risk factors. Barriers to screening described in the existing literature include workforce and time constraints. 74 These barriers likely contribute to both inconsistent documentation and under-documentation of social risk data, 75 which then impacts the availability and reliability of these data for both individual- and public health-level interventions, and research. It is also important to acknowledge the challenges and potential pitfalls of standardized documentation. Condensing a nuanced conversation about social risks between a patient and provider into a structured field could inappropriately oversimplify patients’ experiences.73,76 Standardized documentation of social risks, however, may in fact facilitate more involved discussions between patients and providers about how patients’ experiences impact health and wellness. Moving forward, diverse stakeholder involvement (including patients, caregivers, and frontline healthcare team members), training and education of personnel, and necessary resources/infrastructure are vital to overcome the barriers of integrating social risk data into the EHR.77,78
This scoping review builds on two prior systematic reviews. In contrast to a review from Chen et al, in this study we focus on six social risk domains that have been prioritized in recent government and private payer programs, rather than including any SDH used in risk prediction models. Furthermore, Chen et al. largely drew from studies that relied on neighborhood-level SDH data that were used in risk-prediction models. 22 In contrast, in this study we explored the many ways researchers use patient-level social risk data from EHRs, including how individual social risks are both defined and extracted. We believe this study’s findings are especially relevant in the context of new government and private payer incentives (e.g., quality measures) that focus on patient-reported data. The review from Patra et al. synthesized studies that specifically used NLP to extract patient social risk data from unstructured EHR fields. 21 While Patra et al. report on NLP methods used to identify social risk, 19 our review examined a wider range of ways researchers have extracted social risks from both structured and unstructured EHR fields. In fact, NLP is currently only used to identify select social risk domains; given persistent EHR documentation barriers, we believe that efforts to identify social risks using a combination of structured and unstructured data may provide a more comprehensive picture of patients’ social risks.
Limitations
The review has several limitations that should be considered when interpreting findings. First, our academic database search was not designed to capture initiatives underway outside of research. Social risk data available outside of academia (e.g., healthcare systems or EHR vendors) may be more standardized than those used for research purposes due to data sharing policies and organization research priorities. Second, this is a rapidly evolving field, which means new articles have been published since the search was conducted. Since no new standards for social risk data in the EHR have been developed, however, we believe the findings are still relevant and should be used to prompt more standardization efforts. Third, we had low search specificity. In developing our search terms, we were unable to add or remove terms to reduce our yield without unacceptably reducing search sensitivity. As a scoping review, our priority was to broadly evaluate the literature 23 and therefore prioritize sensitivity. Lastly, we did not critically appraise each manuscript for risk of bias or other measure of quality. As a scoping review with a high volume of articles, our priority was to focus on the comparability of data based on how it was documented and extracted.
Conclusion
In this systematic scoping review, we explored how and what types of social risk data are extracted from EHRs for research. Evaluating how social risks are documented at the patient-level in the research literature is important and timely given the increased impetus and incentives to screen for and document patient social risk factors. Our findings highlight that current data documentation and extraction approaches have meant social risk data are not consistently comparable across populations and settings. Consensus on definitions and more standardized documentation practices cannot be achieved overnight. But as consensus emerges and implementation improves, social risk data will be both more reliable and generalizable. Standardization of efforts can improve both patient- and population-level activities to integrate social and medical care, by providing more consistent, reliable, and ideally complete information. Attention will need to focus on what data needs to be collected and where those data can and should be stored to ensure they meaningfully influence interventions, payment, and research that improve patient and population health.
Supplemental Material
Supplemental Material - Evaluating the comparability of patient-level social risk data extracted from electronic health records: A systematic scoping review
Supplemental Material for Evaluating the comparability of patient-level social risk data extracted from electronic health records: A systematic scoping review by Gaia H Linfield, Shyam Patel, Hee Joo Ko, Benjamin Lacar, Laura M Gottlieb, Julia Adler-Milstein, Nina V Singh, Matthew S Pantell and Emilia H De Marchis in Health Informatics Journal
Supplemental Material
Supplemental Material - Evaluating the comparability of patient-level social risk data extracted from electronic health records: A systematic scoping review
Supplemental Material for Evaluating the comparability of patient-level social risk data extracted from electronic health records: A systematic scoping review by Gaia H Linfield, Shyam Patel, Hee Joo Ko, Benjamin Lacar, Laura M Gottlieb, Julia Adler-Milstein, Nina V Singh, Matthew S Pantell and Emilia H De Marchis in Health Informatics Journal
Footnotes
Acknowledgements
We would like to thank our medical librarian, Evans M. Whitaker, MD, MLIS, for his expert guidance on generating a search strategy for our scoping review. We would also like to thank the Robert Wood Johnson Foundation (RWJF) and Kaiser Permanente (KP) for their support of the UCSF Social Interventions Research & Evaluation Network (SIREN). L.M.G. is the founding co-director at SIREN and E.H.D. and M.P. are affiliate faculty.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the G.H.L. was supported by The David Vanderryn Memorial Fund Preceptorship/Project Program during summer 2020. S.P. was supported by the University of California, San Francisco Summer Explore Research Fellowship during summer 2020. B.L.’s work was supported by the Innovate for Health program, including the UC Berkeley Institute for Data Science, the UCSF Bakar Computational Health Sciences Institute, and Johnson & Johnson. M.P.’s work was funded by the NIH (Loan Repayment Program award 9L40-HD-106442-02A1), the Agency for Healthcare Research and Quality (award K12-HS-026383), and the National Center for Advancing Translational Sciences (award KL2-TR-001870).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.