
Abstract
Current suicide risk assessments for predicting suicide attempts are time consuming, of low predictive value and have inadequate reliability. This paper aims to develop a predictive model for suicide attempts among patients with depression using machine learning algorithms as well as presents a comparative study on single predictive models with ensemble predictive models for differentiating depressed patients with suicide attempts from non-suicide attempters. We applied and trained eight different machine learning algorithms using a dataset that consists of 75 patients diagnosed with a depressive disorder. A recursive feature elimination was used to reduce the features via three-fold cross validation. An ensemble predictive models outperformed the single predictive models. Voting and bagging revealed the highest accuracy of 92% compared to other machine learning algorithms. Our findings indicate that history of suicide attempt, religion, race, suicide ideation and severity of clinical depression are useful factors for prediction of suicide attempts.
Introduction
Suicide prevention is a global health priority that has critical socio-economic implications, as highlighted by the United Nations’ third Sustainable and Development Goal (UN SDG) that has included suicide mortality as the mental health indicator to promote mental health and well-being worldwide. Almost one million people die by suicide every year, and the suicidal rates have increased significantly worldwide during recent years. 1 The phenomena of suicidal behaviour are highly complex and dynamic involving different variables such as biological, psychological and clinical variables. 2
Younger age, childhood abuse, substance use disorder, parent history of suicide attempt, personal history of suicide attempt and has mental illness are common risk factors for suicidal behaviour in the world.2,3 Most of the risk factors have been studied globally to display and understand the relationship towards suicidal behaviour. 3 Suicidal behaviour are mostly related to a suicide death, suicide attempt and suicide ideation. A nonfatal and self-inflicted destructive act with explicit or inferred intent to die was generally referred to as a suicide attempt. 4 The studies showed that people who attempted suicide were the most prominent with depressive disorders.5,6
In the context of Malaysia, rates of suicidal behaviour among the youth have increased recently.7,8 The statistics from Malaysia National Health and Morbidity Survey 2017 showed every 3 in 10 adults aged 16 years and above are suffering from mental health issues that may lead to the rising level of suicidal tendency in Malaysia. Malaysia has a moderately high suicide rate, which is approximately 12 deaths per 100,000 population,7,9 although this figure is an estimate that remains underreported because suicide is illegal in Malaysia. Suicide attempts in Malaysia have been associated with various factors such as depression, poverty, substance use disorder, stressful life and economic problems.7,9
Classifying and identifying which patients are at risk of suicide for preventive measures can potentially reduce suicide rates. 10 However, a major challenge in clinical psychiatry is able to predict who at risk for future suicide attempts accurately. Chan et al.9,11 highlighted that the accurate identification of those who are at the highest risk of suicidal acts is one of the key processes in suicide prevention. Suicide risk assessment scales have been widely used in identifying and detecting individuals for suicidal behaviour. However, the conventional risk assessment scales such as The Columbia-Suicide Severity Rating Scale (C-SSRS), Beck Suicidal Ideation Scale (BSI) and SAD person scale have inadequate reliability, are time-consuming and suffer from low predictive values. 12 Therefore, more rapid and reliable approaches are needed for predicting suicide attempts.
Machine learning in psychiatric research is growing as a valuable tool to integrate many predictors and improve classification capabilities among unseen observations such as diagnosis and behaviour of the patients.12,13 Machine learning is an approach where the complex relationships in data are modelled to build optimal predictive models. In the context of predicting future suicide attempts, the models classify patients into suicide attempters and non-attempters. Numerous machine learning algorithms have been studied to predict future suicide attempts such as Decision Tree, Support Vector Machine, Random Forest, Naïve Bayes and Artificial Neural Network.14 –16 Predictive model is constructed by providing historical data from patients that did or did not attempt to suicide.17,18 The data contain the risk factors that are associated with suicide which are also known as the features in machine learning to predict suicide attempts.
Numerous risk factors such as a family history of suicide attempt, child abuse, substance abuse, alcohol addiction, the severity of life stressor, younger age and severity of mental illness have been studied and presented to clarify why some individuals may be focused to attempt suicide in general population 3 but the studies mainly describe the differences between suicide attempters and non-attempters without attempting to improve predictive power. In order to improve the predictive accuracy of these risk factors, it is imperative and essential that the most relevant risk factors are determined and used to build a predictive model. 15 It is because the risk factors that are associated with suicide are different from one country to another since the population is varied due to socio-cultural and geographical differences.
In the context of Malaysia, religion and race are significant risk factors influencing suicide attempts. Sinniah et al. 7 has highlighted that suicidal behaviour in Malaysia should be explored in greater depth using its own risk factors for detecting individuals with a suicide attempt. The cultural differences in the Malaysian context need to be considered in measuring suicidal behaviour in comparison with Western and other Asian studies. Malaysia consists of a multiracial society with Malays, Chinese, Indians and other ethnicities, 9 therefore, cultural heterogeneity remains a challenge in predicting which individuals within a defined population will attempt suicide. Depression is a psychiatric disorder with one of the highest risk of suicide. 11 Therefore, it is of the utmost importance to develop predictive models for predicting suicide attempts among this group of patients in Malaysia.
Machine learning-based models have the potential to be used and deployed into clinical settings to assist psychiatrists in clinical suicide assessment. However, the existing predictive models that have been developed globally are not suited and cannot be applied to the Malaysian context. The differences in culture, economic status and geographical factors may influence and affect the performance of the predictive models. The risk factors used as the features for development of the predictive model using machine learning algorithms previously cannot be applied as one-size-fits-all to classify the suicide attempters with non-attempters. 14 This is because the previous predictive models were developed from a Western perspective of investigation and population which give a different interpretation in the Malaysian context. Therefore, the main objective of this work is to build an effective and reliable predictive model that can accurately classify suicide attempters and non-attempters among a Malaysian sample with clinical depression. Furthermore, this work presents a comparative study on single predictive models with ensemble predictive models for differentiating suicide attempters from non-suicide attempters.
Related works
Numerous machine learning algorithms have been proposed for suicide attempt prediction. Delgado-Gomez et al., 10 have used machine learning techniques such as stepwise linear regression, linear regression, decision tree, Elastic Net and Support Vector Machine (SVM) to differentiate suicide attempters from non-attempters. Two types of self-report questionnaires which are the presence of life events and personality disorder were used on both data to detect suicide attempts. It is reported that the Elastic Net achieved the highest accuracy of 84.00%. The result also showed marital separation and emotional difficulties were the best discriminative risk factors that influenced suicide attempts.
The study by Passos et al. 19 showed that Relevance Vector Machine has higher accuracy with 77% compared to other algorithms in predicting and identifying an individual’s probability of attempting suicide among patients with mood disorder using clinical and demographic variables. The results revealed that previous hospitalization for depression, cocaine dependence, history of psychosis and post-traumatic stress disorder comorbidity are the most relevant predictive variables in distinguishing suicide attempters from non-suicide attempters. Furthermore, the study by Hettige et al. 16 used four different algorithms on clinical, demographic, illness-related and comorbid variables based on the Columbia Suicide Severity Rating Scale (C-SSRS) and Beck Suicide Ideation Scale (BSS). LASSO, Support Vector Machine (SVM), Random Forest and Elastic Net have been used to build the classification models. The results show that LASSO can classify suicide attempters among schizophrenia patients with an accuracy of 72%. Drug and substance abuse are the predictive variables which influenced in predicting suicide attempters.
Decision tree has been applied to identify and discriminate high-risk suicide attempts by Bae et al. 17 among Korean adolescents. The study uses sociodemographic (sex, school level, socioeconomic status and family structure), intrapersonal and extrapersonal variables (delinquency, depression, stress, self-esteem and intimacy with family) to develop the predictive model for a suicide attempt. The severity of depression is identified as the strongest variable to predict suicide attempts among school students. The study shows that an accuracy of 93% has been achieved in classifying suicide attempters using the proposed model. Recently, a study by Oh et al. 18 has proposed a predictive model using Artificial Neural Network in classifying suicide attempts based on multiple systemic psychiatric scales such as Beck Depression Inventory (BDI), Strait-Trait Anxiety Inventory (SAI) and Emotion Regulation Questionnaire (ERQ). The results show that an accuracy of 92% has been achieved with the Emotion Regulation Questionnaire has the highest contribution for predicting suicide attempts. The study also highlighted that religious belief, marriage status and status of employment plays important predictive risk factors in identifying suicide attempters with non-suicide attempters. However, most of the prediction model developed does not consider race and religion as their features in the studies. 4
Although the predictive models from previous studies have shown to achieve high accuracy in classifying suicide attempts and non-attempts, the predictive models are built only for a specific population and risk factors. This has been highlighted by Ryu et al. 20 which it is mentioned that the performance of predictive models are differed and depends on the group of interest. Religious beliefs and race are closely interrelated in the Malaysia context. 7 However, most of the predictive models that have been developed do not consider race and religion as their features in the studies. Therefore, the risk factors that have been used in constructing the previous prediction models are not suitable for Malaysia due to cultural differences. Hence, this paper attempts to develop a predictive model for suicide attempts among Malaysian population with clinical depression. Also, the research attempts to determine the most relevant and reliable features using feature selection algorithms as well as provides a valuable comparative study on single predictive models with ensemble predictive models for classifying the suicide attempters from non-suicide attempters.
Methods
Study population
This work was performed with clinical research data from Universiti Kebangsaan Malaysia Medical Centre (UKMMC) which was conducted to describe the interactions of clinical and psychosocial risk factors influencing suicide attempt in Malaysian depressed inpatients, further information on the data can be referred to the paper by Chan et al. 9 The dataset was based on psychiatric inpatients in UKMMC with a depressive disorder study from May 2007 to October 2008. The institutional review board of the UKM ethics approved the protocol of the study. The study focuses on the specific group of psychiatric inpatients in Malaysia involves 75 people between the ages of 18–76 years consists of 33 males and 42 females who have been treated for a depressive disorder. The dataset was used in this study are limited due to patient privacy and confidential issue. Also, the dataset was a bit old due to suicidal sources are scarce in Malaysia context, and the latest available dataset is not complete with the same features in this study.
Data pre-processing and feature selection
The original dataset consists of 100 features including assessment scales, demographics and clinical information of the patients. We selected and used 36 features manually based on the suggestion from a psychiatrist, which commonly available in identifying and predicting suicide attempters. The criteria used to choose 36 features out of 100 features are based on the meta-analysis conducted and studied by Franklin et al. 21 and Ribeiro et al. 3 which present valuable information on the risk factors for suicidal thoughts and behaviours. The original 36 features were used to train the machine learning algorithms as shown in Table 1. Subsequently, no missing values in the dataset and the numeric data were normalized to the range of 0–1.
Set of features after psychiatrist evaluation.

Feature selection has been used to reduce the complexity of the predictive models, facilitates better visualization of data and improves the performance of prediction.22,23 This work performed Recursive Feature Elimination with a Random Forest on the training set in order to select the minimum subset of features that most accurately classify suicide attempters. Recursive feature elimination (RFE) is a backward selection of the features which begins by building a model on the entire set of predictors and calculating an importance score for each predictor. The least important features are then removed, the model is re-built and importance scores are calculated again. 22 The Random Forest model is used with RFE because it is a well-known and recognized internal method for measuring feature importance. 20 The features that have been selected using RFE shown in Table 2 before they are used to train the predictive models.
The features used in building predictive model.

Machine learning algorithms
In this work, we utilized eight machine learning algorithms which are logistic regression, decision tree, support vector machine, naïve Bayes, k-nearest neighbours, random forest, bagging and voting. The eight machine learning algorithms have been broadly accepted to solve binary classification problems between suicide attempters with non-suicide attempters due to the performance in ease of interpretation, implementation, accuracy and robustness. 24 Each of the algorithms was used to classify individuals between suicide attempter and non-suicide attempter. In this study, machine learning algorithms have been classified into two categories which are single model (logistic regression, decision tree, support vector machine, naïve Bayes and k-Nearest Neighbours) and ensemble model (random forest, bagging and voting). Generally, the ensemble model contains several (single) base learners which usually generated from training data. 25 The ensemble model has been applied recently to increase the performance of the single model classification. However, this work is focusing on the three single models only which are logistic regression, decision tree and support vector machine while naïve Bayes and k-Nearest Neighbours are used in the ensemble model. The eight models have been presented in the results and discussion section.
Logistic regression
Logistic regression is a classification model used to give observations to a discrete set of classes such as suicide attempters or non-attempters.16,26 Logistic regression converts its output using the more complex cost function known as logistic sigmoid function to return a probability value. Logistic regression has a sigmoid function that helps in reducing real-valued continuous inputs into a range of (0, 1).
Decision tree
The decision tree is a classification model which uses a tree structure to classify data. Recursive splitting of random subsets of predictors to form ‘parent’ and ‘child’ nodes are constructed from decision trees. 17 ‘Splits’ in the decision trees replicate binary classification with respect to predictors. Generally, each node represents decision values based on a certain condition of an attribute of the dataset. The outcome of the test is represented by a branch with leaf nodes that represent the class labels. The decision tree criterion of ‘gini’, minimum sample split of two and a maximum number of the depth of four has been used as the parameter in building the model.
Support vector machine
Support vector machine (SVM) is a method to find optimal hyperplanes that separate two classes (suicide attempters and non-attempters) of input space. 27 The best hyperplanes has a maximum margin obtained from discriminant boundaries (dividing lines). The regularization parameter used in SVM classifier is 1.0 and the Radial basis function kernel (RBF) which also known as Gaussian kernel has been applied to represent the similarity between the distance vectors.
Random forest
Random Forest works by constructing a multitude of decision trees and providing an output class. The random forest is one of the ensemble learning methods that consist of a set of decision trees that are generated by the recursive sampling of bootstrapped samples of predictor data. 14 Each branching node is equivalent to one of the input variables. The subset of input variables selected by random forest to construct a tree, the most likely class is decided by each tree for the given inputs and selected the most frequent class among all the trees. The number of estimators in the random forest used for building the model is 20, with the maximum number of tree depth is 4.
Bagging
Bagging is shorthand for the combination of bootstrapping and aggregating. 28 Bagging combines the base learners in parallel on different bootstrap samples and then aggregated the individual prediction in average weight to form a final prediction. Bagging method is helping to decrease the variance of the classifier and reduce overfitting by resampling data with replacement from the original training set. 25 The decision tree (criterion is ’gini’, maximum depth is 4) has been used as the base classifier for the bagging method in building the predictive model. The difference between bagging and random forest is the features splitting by a node in the base learner (decision tree). The random forest considered only a subset of the features which are sampled randomly for each node for splitting while bagging considered all the features for each node based on bootstrapping sampling.
Voting
Voting is the simplest way of combining classifiers in machine learning applications. 25 In voting, several predictive models diverse characteristics are trained and ensemble to produce the final prediction. 26 There are two types of voting which are hard voting and soft voting. Hard voting is based on the majority vote while soft voting based on the averaging sum of predicted probabilities in the class label. In this study, the decision tree, naïve Bayes and k-nearest neighbour (k-NN) are used to train the predictive models and their outputs are combined to produce the final prediction using hard voting.
For the evaluation of the above classification models, the three-fold cross-validation was used to increase the generalization of the model as well as to avoid overfitting. We randomly partitioned the data into a training set (75%) and test set (25%). The three-fold cross-validation was implemented as the number of samples is limited. The analysis was completely performed in the Python Programming Language (version 3.0, Supplemental Material) for the development of the predictive models.
Performance measurement
The three classification fitted models were used to predict the classes (non-attempter and suicide attempter) in the test set, and the predicted classes were compared with the actual classes. The performance of three models in predicting the classes was evaluated by using the area under receiver operating characteristic (ROC) curve (AUC). We also calculated the accuracy, specificity, sensitivity, positive predictive value and negative predictive value from the confusion matrix. Classification accuracy is the ratio of correct predictions to the total number of predictions which are normally known as how often the classifier is correct. The result where the model correctly predicts the positive class is known as true positive,
The sensitivity is known as recall, or true positive rate is the proportion of people who test positive among all those who are actually attempting suicide.

The specificity of a test is the proportion of individuals who negative among all those who actually do not attempt suicide.

Positive predictive value is the probability that following positively classified cases, that individual will truly positive attempting suicide.
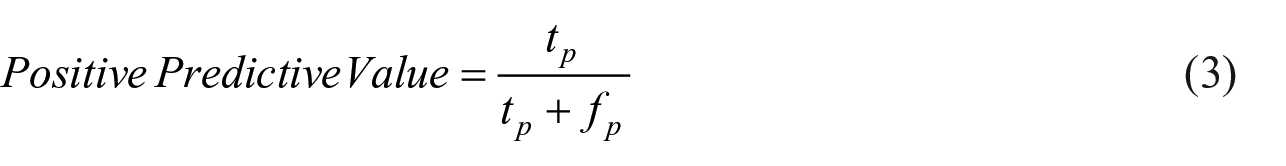
Negative predictive value is the probability that following negatively classified cases, that individual will truly not attempting suicide.
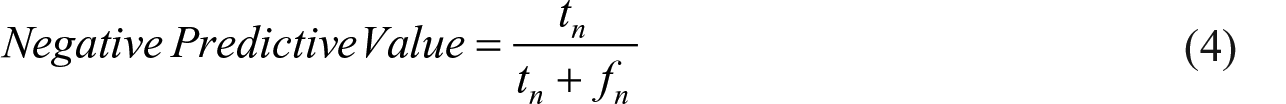
Results and discussion
A total of 75 patients have been used to develop predictive models using machine learning algorithms. A class distribution is shown in Figure 1 as non-suicide attempters and suicide attempters. Although the data is showing unbalanced, the number of attempters are more than one-fifth the number of non-attempters, therefore, it is considered adequate for trained the model without balancing the dataset. This statement is based on the distribution of the sample of psychiatric inpatients, and the data splitting methods conducted are based on random sample selection. 29
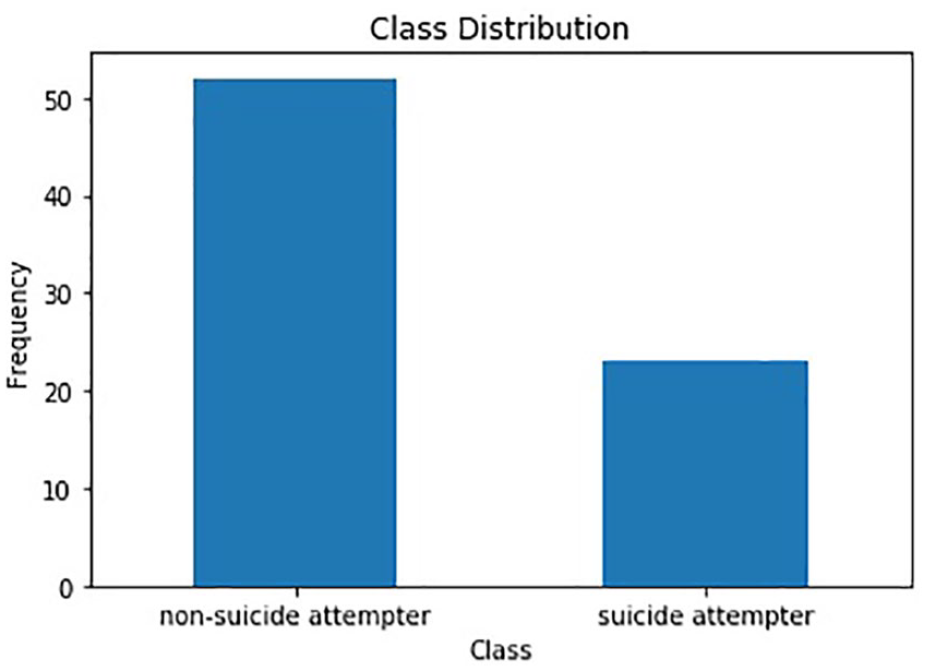
A distribution of class label in predictive model.
After data pre-processing and feature selection, a model trained with 15 features achieved the highest value with three-fold cross-validation (Figure 2). The three-fold cross-validation 75% of the data are used for training, 25% for validation and in the next iteration another 25% of data is chosen as a testing data which makes this process is repeated three times until all data have served as validation data. In three-fold cross-validation, the dataset is first partitioned into three equally sized segments. Subsequently, three iterations of training and validation are performed such that within each iteration a different segment of the data is held-out for validation while the remaining k (3)–1 folds are used for learning. Then, average the overall error estimate across all three trials was computed as shown in Figure 2.30,31 The 15 features were as follows: ‘race’, ‘religion ’, ‘class social ’, ‘marital status’, ‘medical problem’, ‘suicidal ideation’, ‘history of suicide attempt’, ‘Personality disorder’, ‘Anxiety disorder’, ‘Clinical depression severity’, ‘Nicotine dependence’, ‘Polysubstance dependence’, ‘previous alcohol abuse’, ‘substance abuse’ and ‘lifetime psychotic’.
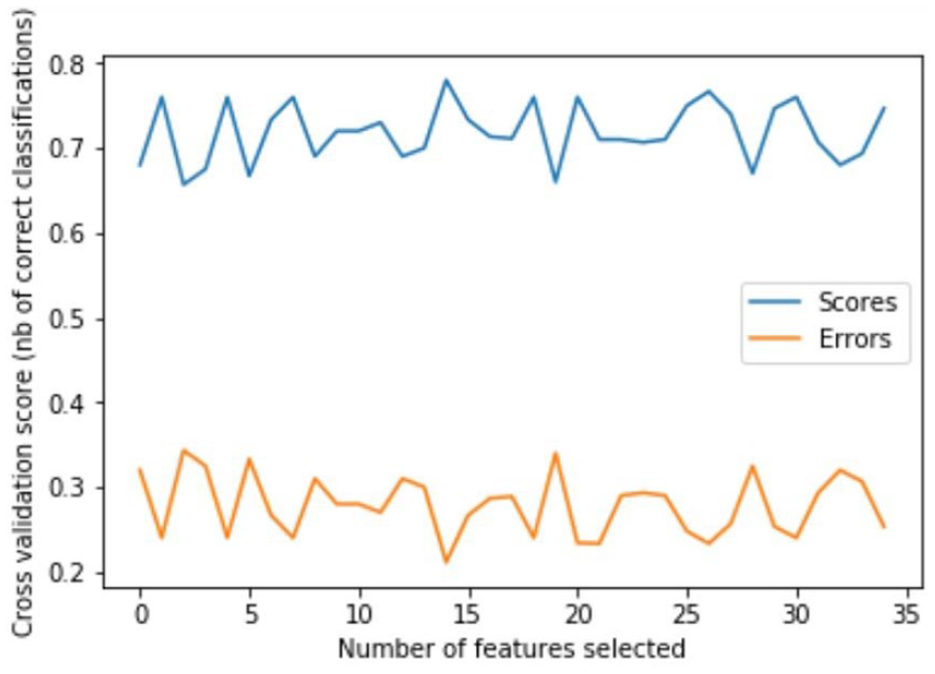
A graph of feature selection using recursive feature elimination.
Feature selection is important in the predictive model for dimensionality reduction in the machine learning algorithms. Recursive Feature Elimination (RFE) has been used in the study using a random forest classifier which is to select the more important variables that have higher accuracy for building the predictive model. The optimal number of features selected by RFE presented in Figure 2 which has the highest classification accuracy with 0.78 for 15 features. The three-fold cross-validation score has been applied in order to validate the recursive feature elimination using the random forest classifier. Therefore, the 15 important features selected automatically by the algorithm has been used to build the predictive model.
Figure 3 shows the features importance based on the value of the features using RFE in classifying suicide attempters from non-suicide attempters. RFE has assigned a score for the feature ranking based on how useful they are in the model. The highest value of the feature important in Figure 3 is the history of suicide attempts with 0.40. It means that the history of suicide attempts is the strong predictor in classifying suicide attempter with non-suicide attempters. This result portrayed that the risk factor of past suicide attempts should be taken seriously in preventing future suicide attempts. Besides that, the other features ranking is followed by 2) Suicide ideation, 3) Race, 4) Religion, 5) Clinical depression severity and 6) Medical problem.
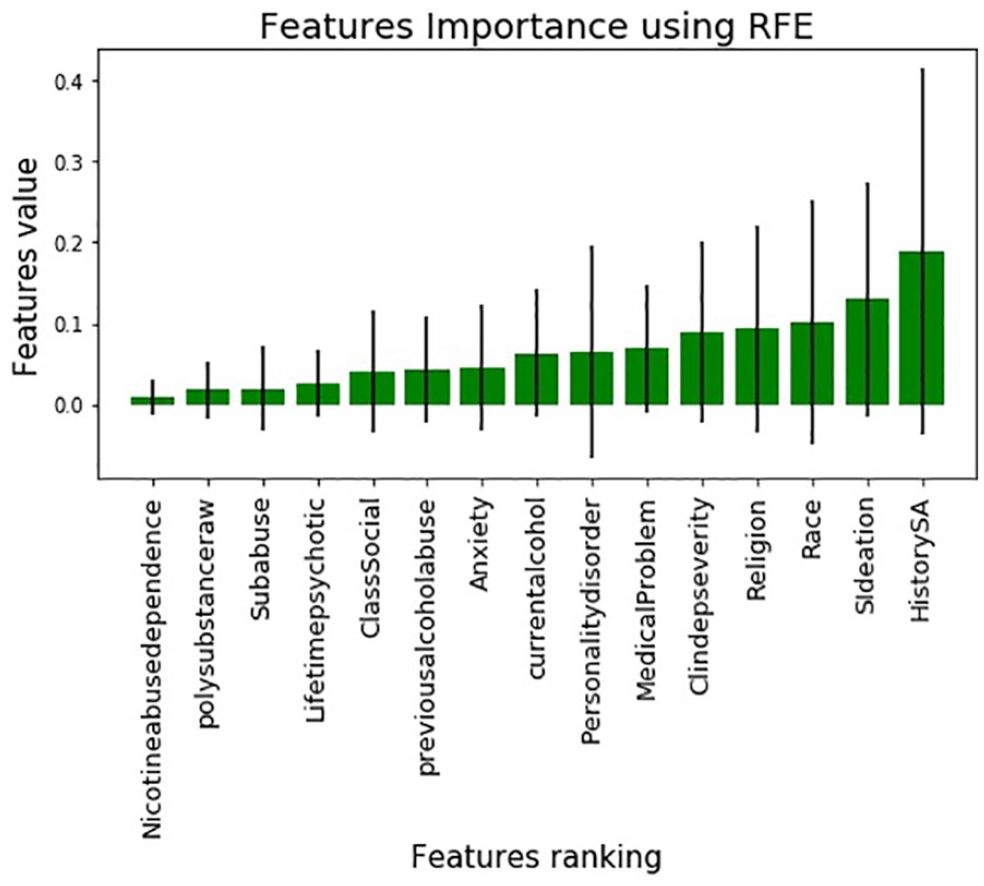
Ranking of features importance.
This study categorized the machine learning algorithms into a single model and ensemble model to predict the suicide attempters in the Malaysian sample with clinical depression. The logistic regression, decision tree, support vector machine, naïve Bayes and k-nearest neighbour algorithms have been used for the single predictive models while random forest, bagging and voting algorithms have been used for ensemble predictive models. All predictive models are trained using the selected 15 features. Overall, machine learning algorithms presented a good performance (AUC = 0.65–0.87) in predicting suicide attempters in Malaysian samples with clinical depression.
As shown in Table 3, among the single predictive models, support vector machine achieved the best performance with an accuracy of 0.84 followed by logistic regression model (accuracy = 0.83), decision tree (accuracy = 0.82), naïve Bayes (accuracy = 0.82) and k-Nearest Neighbours (accuracy = 0.79). The support vector machine shows relatively higher sensitivity with 0.92 and specificity with 0.60 compared to other single predictive models. The sensitivity of the test indicates that the proportion of people who attempted suicide will have a positive result which means that the support vector machine algorithm is good for identifying suicide attempters when the suicide attempters have a positive test. The range of specificity value from single predictive models is 0.50 to 0.60. Despite having low specificity, the models are able to classify non-suicide attempters who will have a test negative result. This is because a test with a high sensitivity value will lead to low specificity value due to negative test results. 32 The 92% sensitivity means that the test will detect nearly every person who has attempted suicide, but its relatively low specificity means that false positives are few. A high sensitivity test will be helpful to the clinician when the test result is negative. 31
Comparison of predictive models’ performance.
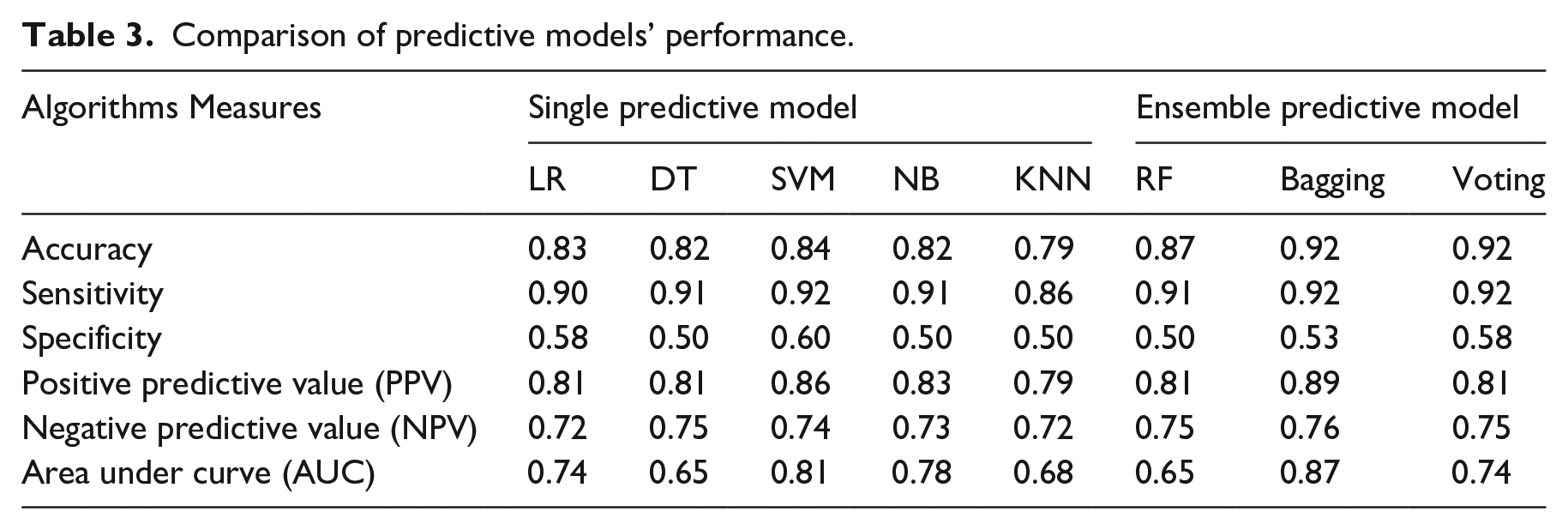
Positive predictive value in each of the single predictive models shows a good performance in which support vector machine achieved the highest PPV with 0.86 followed by naïve Bayes (0.83), logistic regression (0.81), decision tree (0.81) and k-Nearest Neighbours (0.79). The PPV indicates the ability of the models correctly identified the patients who have a positive result or having attempt suicide. This means that the support vector machine has correctly identified the 86% of suicide attempters were among those with a positive screening test. Therefore, based on the overall performance, it shows that the support vector machine is a suitable model for predicting suicide attempters in single predictive model.
As for ensemble predictive models, bagging and voting achieved the highest accuracy of 0.92 while random forest slightly lower accuracy of 0.87. The accuracy of voting is similar to bagging due to the combination of several base learners (decision tree, naïve Bayes, k-Nearest Neighbours) that complement each other to produce more accurate predictions. The result of single-base learners has been presented in Table 3. Voting achieved relatively higher sensitivity (0.92) and specificity (0.58) compared to other ensemble predictive models. However, bagging achieved the highest PPV with 0.89 followed by voting and random forest with 0.81 respectively. In this study, bagging is the best ensemble predictive model due to the high positive predictive value which indicates the likelihood of patients actually attempted suicide among those with a positive result. As shown in Table 2, the ensemble predictive models outperformed all single predictive models in predicting suicide attempters.
A ROC curve plots the False Positive Rate and True Positive Rate to visualize the performance of classifying two output classes (suicide attempters and non-attempters) using single predictive models and ensemble predictive models across varying cut-offs. The percentage of the ROC plot underneath the curve is known as AUC. As shown in Figure 4, support vector machine demonstrated the highest AUC with 0.81 followed by naïve Bayes (0.78), logistic regression (0.74), k-Nearest Neighbours (0.68) and decision tree (0.65). As for ensemble predictive models, bagging showed the highest AUC with 0.87, followed by voting (0.74) and random forest (0.65) as shown in Figure 5. A ROC curve lying on the diagonal line reflects the performance of a diagnostic test, the slope of ROC curve at any point is equal to the ratio of the density function which describes the distribution of the separator variable in the suicide attempters and non-suicide attempters. 33 The corresponding AUC in Figure 4 shows that support vector machine has predictive ability to discriminate suicide attempters from non-suicide attempters in single predictive model. In the ensemble model, bagging model has the highest AUC, which means it able to discriminate suicide attempters from the non-suicide attempters. Therefore, this study found that the samples of non-suicide attempters have been well separated from the suicide attempters using support vector machine and bagging.
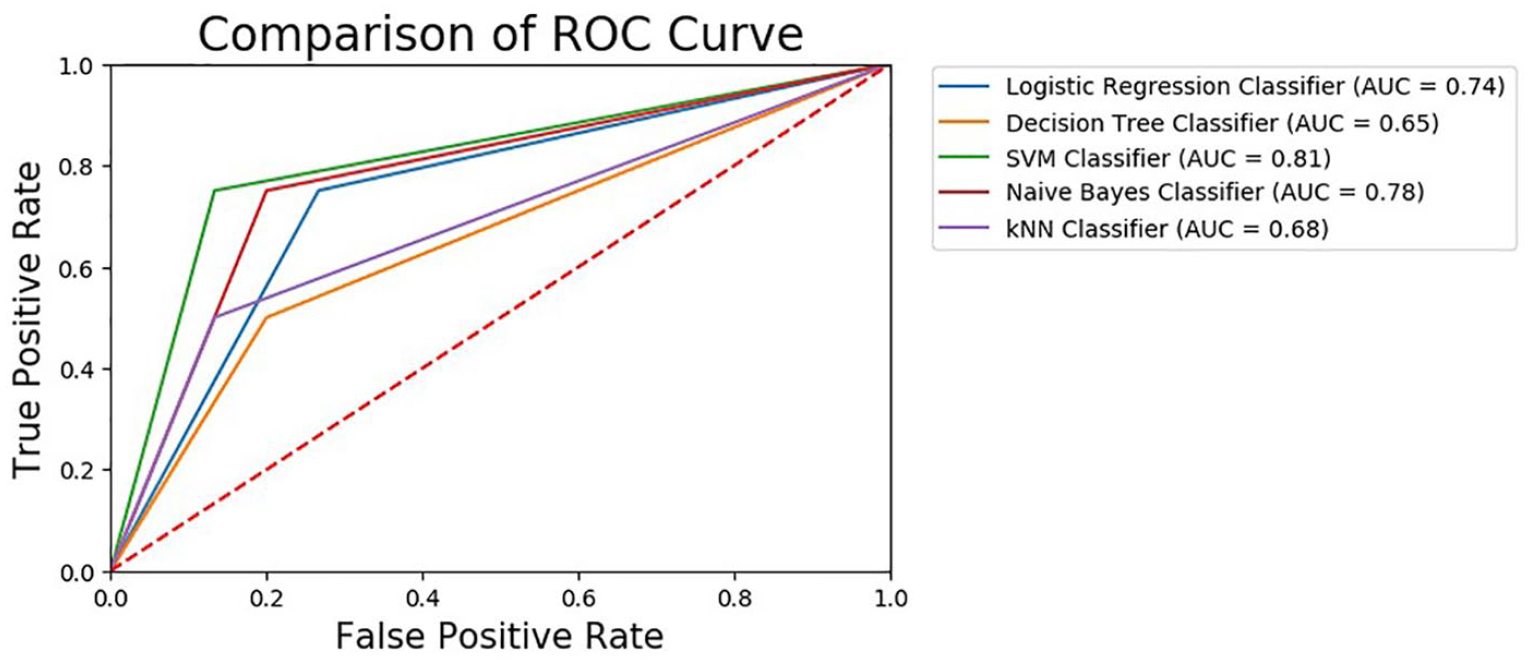
Comparison of AUC values for single model.
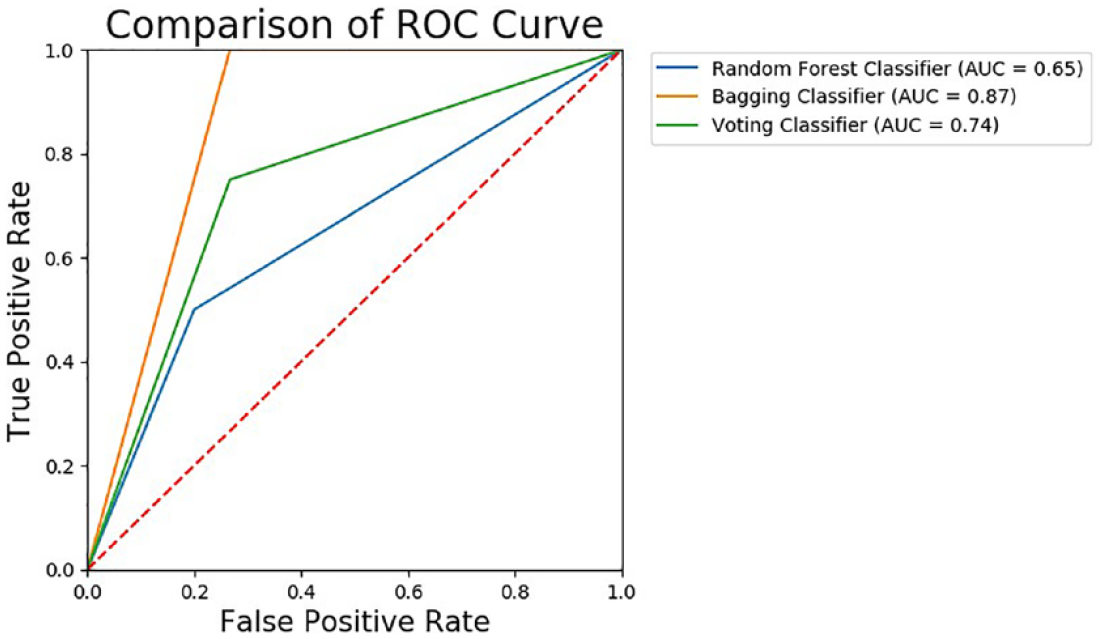
Comparison of AUC values for ensemble model.
From 75 patients with depression, we developed predictive models with moderate sensitivity, specificity and a modest AUC. With a limited dataset, this work showed that machine learning algorithms could perform and achieve good accuracy in predicting suicide attempters. Although the performance of each algorithm is good, a larger sample could be used to increase the accuracy of the model. In addition, none of the work has been done using machine learning algorithms on clinical research data in Malaysia. The approach demonstrates how clinical research data enriched with clinically relevant information for suicide attempters which can be used to identify the patient with a history of suicidal behaviour including suicidal ideation and suicide attempt for future attempts which can aid inpatient treatment management during a vulnerable time for a high-risk population.
This work showed that machine learning-based predictive models are successful in predicting suicide attempters among depressed patients in Malaysia by using simple information on the psychosocial and clinical risk factors as well as demographic characteristics. The ensemble model achieved more accurate prediction compared to a single model in distinguishing suicide attempters. This work has demonstrated that ensemble models can be used to improve the accuracy of single predictive models. Other studies have only focused on applying single predictive models in classifying and predicting suicidal behaviour.17–19 Therefore, this work provides a valuable comparative study on single predictive models with ensemble predictive model for classifying the suicide attempters from non-suicide attempters.
The issue that has been continuously arising in the classification model is the dimension of the features. To avoid the ‘curse of dimensionality’ as the number of features grows which may overfit the classification models, we identify and select 15 most relevant features using Recursive Feature Elimination. Then, the selected features are used to train the predictive models, as well as to increase the generalization of the models. 23 A wrapper method of feature selection has been chosen to find optimal features due to feature dependencies and better generalization than the filter method. In this study, we used variables that are related to psychosocial and clinical factors including demographic characteristics as the features for classifying suicide attempters. Based on the predictive model, it is found that the history of suicide attempts, religion, race, lifetime psychotic and suicide ideation are the most important features for distinguishing suicide attempters from non-suicide attempters. The study by Chan et al. 9 also demonstrated that race and religion were significant factors for suicide attempts in Malaysia. Therefore, race and religion have shown to be important features in predicting suicide attempts with non-attempters in the Malaysian context. However, the history of suicide attempts and having lifetime psychotic has not been recognized by clinicians as a possible clinical variable for suicide attempters based on previous research. The present study by Walsh et al. 14 also does not found that the history of suicide attempts may affect the patient with depressive disorder of having suicidal behaviour. With the capability of machine learning algorithms, the feature selection techniques have been demonstrated to select the most important features in classifying the suicide attempters with non-suicide attempters.
The current work has some limitations. First, this work uses a limited clinical research dataset which may limit the generalizability of the findings. The eight models tested do no differ because of the small sample size affected the comparison test among different models. The accuracy of the classification models may be improved by using a dataset with a large number of samples. Therefore, future research may utilize a similar approach to differentiate suicide attempters with non-attempters using a larger dataset. Third, this study compared only eight different machine learning algorithms which are decision tree, logistic regression, support vector machine, naïve Bayes, k-nearest neighbours, random forest, bagging and voting model. Additional analyses using different machine learning algorithms such as Artificial Neural Network and Boosting may be applied to compare the performance of predictive models. Fourth, this work uses only the wrapper feature selection technique (recursive feature elimination), which may limit the performance of each of the features. In future work, the embedded feature selection technique will be implemented to select the best features in classifying and predicting suicide attempters with non-suicide attempters. In addition, the larger sample size with the same clinical variables will be explored to recognize the importance of feature selection technique as well as to identify possible clinical variables that could be added for diagnostic value in suicide attempt studies.
Conclusion
In conclusion, this study indicates that machine learning-based predictive models can successfully predict individuals with suicide attempts in Malaysia using clinical research data. The ensemble model has demonstrated the capability of achieving higher accuracy than the single model classifiers. The machine learning models have clinical utility in classifying suicide attempters based on their risk for suicidal behaviour. With the increasing prevalence of suicidal behaviour among Malaysian adolescents as demonstrated by the Malaysian National Health and Morbidity Survey 2017, the binary classification algorithms for machine learning models may complement and improve the diagnostic reliability of clinicians in classifying and predicting suicide attempters. Advanced probabilistic algorithms on a larger clinical data set may be utilized and employed in order to develop highly predictive models that support clinical decisions related to the risk of suicidal behaviour.
Supplemental Material
sj-py-1-jhi-10.1177_1460458221989395 – Supplemental material for A comparative study of machine learning techniques for suicide attempts predictive model
Supplemental material, sj-py-1-jhi-10.1177_1460458221989395 for A comparative study of machine learning techniques for suicide attempts predictive model by Noratikah Nordin, Zurinahni Zainol, Mohd Halim Mohd Noor and Chan Lai Fong in Health Informatics Journal
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.