
Abstract
Surgery cancellations waste scarce operative resources and hinder patients’ access to operative services. In this study, the Wilcoxon and chi-square tests were used for predictor selection, and three machine learning models – random forest, support vector machine, and XGBoost – were used for the identification of surgeries with high risks of cancellation. The optimal performances of the identification models were as follows: sensitivity − 0.615; specificity − 0.957; positive predictive value − 0.454; negative predictive value − 0.904; accuracy − 0.647; and area under the receiver operating characteristic curve − 0.682. Of the three models, the random forest model achieved the best performance. Thus, the effective identification of surgeries with high risks of cancellation is feasible with stable performance. Models and sampling methods significantly affect the performance of identification. This study is a new application of machine learning for the identification of surgeries with high risks of cancellation and facilitation of surgery resource management.
Keywords
Introduction
Surgery cancellation is a universal problem that results in many wasted healthcare resources and thus has a considerable negative impact on the efficiency of healthcare resource management. It forces scarce operative resources to remain idle and hinders patients’ access to operative services. In addition, the costs of cancellations are high.1–4 According to our review, the global cancellation rate (CR) generally ranges from 4.65 to 30.3 per cent,1,5–21 a high proportion that increases the wastage of resources. The CR of different types of surgery varies even in the same hospital.7,12,18,19 In previous studies, the highest CR has been reported for general surgery;7,12 however, other studies present a contrary situation, in which general surgery does not have the highest CR. 18 Such inconsistency between the CRs reported in different studies impedes the development of effective surgery resource management methods. Given this prevailing problem, research has been conducted to investigate the main risk factors of surgery cancellation to reduce CRs. Previous studies have validated the relationship between certain risk factors (e.g. increasing medical admission and preoperative clinic visits) and surgery cancellation.5,22–24 In addition, studies have been conducted to explore a feasible method of lowering the general surgery CR in certain contexts.25–30
The previously mentioned studies have focused on hospital-level management. However, specific patient-level preventive actions, which refer to specific and effective services according to patients’ situations, must also be investigated. Allocating a specific service to each patient may not be feasible because of limited healthcare resources. Hence, identifying surgeries with high risks of cancellation is the superior solution. If such surgeries are marked, preventive actions can be performed to avoid cancellation. Since the CR ranges from 4.65 to 30.3 per cent, identifying even only a fraction of these cancelled surgeries in advance will significantly enhance the efficiency of surgery resource allocation. If precise identification is achieved, surgery resources can be prevented from becoming idle and the latent surgery CR can be decreased. This is the motivation for this study.
A hospital information system (HIS) records information about patients’ healthcare processes and thus includes abundant data on aspects such as admission and surgery schedule information. Numerous healthcare management-related studies on HISs have been conducted, including on the identification of patients with high risks of hospital-acquired infection, 31 time length estimation, 32 identification of critical factors in patient falls, 33 prediction for the risk of death, 34 assessment of fractures after falls at the hospital, 35 and other important fields.36–38 In our view, applying HIS data to identifying surgeries with high and low risks of cancellation is feasible. 39
Machine learning (ML) is a powerful and effective tool for healthcare management. Izad Shenas et al. 40 used ML to build predictive models for identifying patients in the top five percentile of cost among the general population; the results of their study can be used to improve the delivery of health services. Liu et al. 41 considered ensemble-of-trees methods as an alternative for risk adjustment in evaluating a hospital’s performance, and the results showed that ML is superior to logistic regression for investigating risk adjustment. Furthermore, there were similar applications in the fields of healthcare cost prediction, 42 readmission and hospitalization,43–46 and healthcare insurance. 47
This study aims to identify surgeries with high risks of cancellation based on ML techniques and an HIS to facilitate surgery management. Routine risk factors and newly proposed predictors are considered; these are sourced from the HIS. This study experimentally validates the performance of a combination of ML techniques and HIS data in identifying surgeries with high risks of cancellation. Based on the results of this study, a surgery manager can identify surgeries with high risks of cancellation and therefore alert the healthcare system and adopt preventive actions to achieve a lower CR.
Data and methods
Data source and description
This study was based on data sourced from West China Hospital (WCH), which is the largest hospital in southeast China. It focused on elective urologic surgeries from 1 January 2013 to 31 December 2014. Overall, the data contained 5125 cases, of which 810 were cancelled (positive) and 4315 were not, providing a CR of 15.80 per cent. All surgeries were scheduled one day in advance, and all cancellations were institutional resource- and capacity-related cancellations. All the considered predictors are listed in Table 1. The statistics of several predictors are shown in Appendix 1 (Table 6 and Figure 1).
Predictors considered in this study.
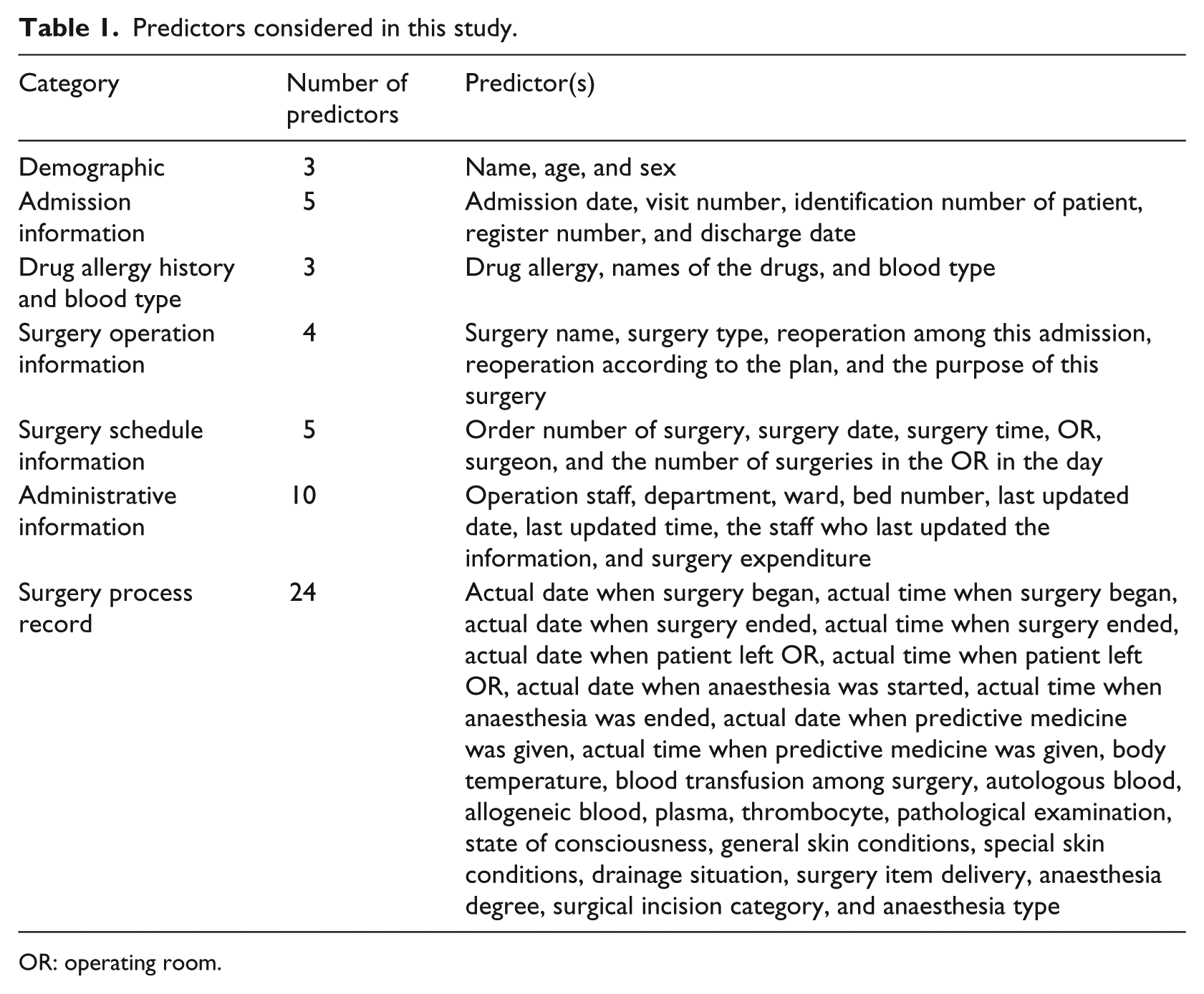
OR: operating room.
Yan et al. 48 analysed the data of WCH and reported that patient age, surgeon, and type of surgery had important impacts on surgery cancellation. Moreover, according to our survey in WCH, there were several predictors related to surgery cancellation in addition to routine risk factors. These newly proposed predictors are selected and provided below.
Cancellation record
Generally, surgeries with an existing cancellation record were less likely to be cancelled owing to the exposure of their latent causes for cancellation, and a remedial solution was likely to be implemented.
First surgery of a surgeon
Several surgeries were cancelled because the surgeon was occupied in a previous surgery. Hence, if a surgeon does not have a surgery immediately before another surgery, the probability of cancellation may be diminished, assuming that other risk factors are fixed.
First surgery in an operating room (OR)
Several surgeries were cancelled because the surgery scheduled before them in the same OR exceeded its planned schedule. In this case, if there is no surgery scheduled immediately before another surgery, the occurrence of cancellation may be diminished, assuming that other risk factors are fixed.
Holiday
This predictor is related to hospital preparation, as we assumed that when there is a holiday, medical resources, particularly staff resources, are scarcer. Hence, holidays may be more likely to lead to surgery cancellation.
Number of days in admission
Because all surgeries in our data are elective surgeries, the number of days in admission is strongly related to surgery preparation. More preparation is required if the duration is longer.
Predictor selection
We used the Wilcoxon and chi-square tests to assess the significance of continuous and discrete predictors on surgery cancellation for routine predictors, respectively. We set the significance level as 0.95 and selected the predictors, the p-values of which were less than 0.05. As shown in Table 2, among all continuous predictors, the number of days in admission and the sequence in the waiting list show significant impacts on surgery cancellation. Regarding discrete predictors (including binary predictors), only the type of surgery, surgeon, OR, and the total number of surgeries in the OR show significant impacts on surgery cancellation. According to Yan et al., 48 patient age is a significant factor of CR; however, it did not prove significant in our data. This may be because we focused on elective urologic surgery, while Yan et al. 48 focused on general surgery.
Statistical tests for routine predictor selection (significant only).
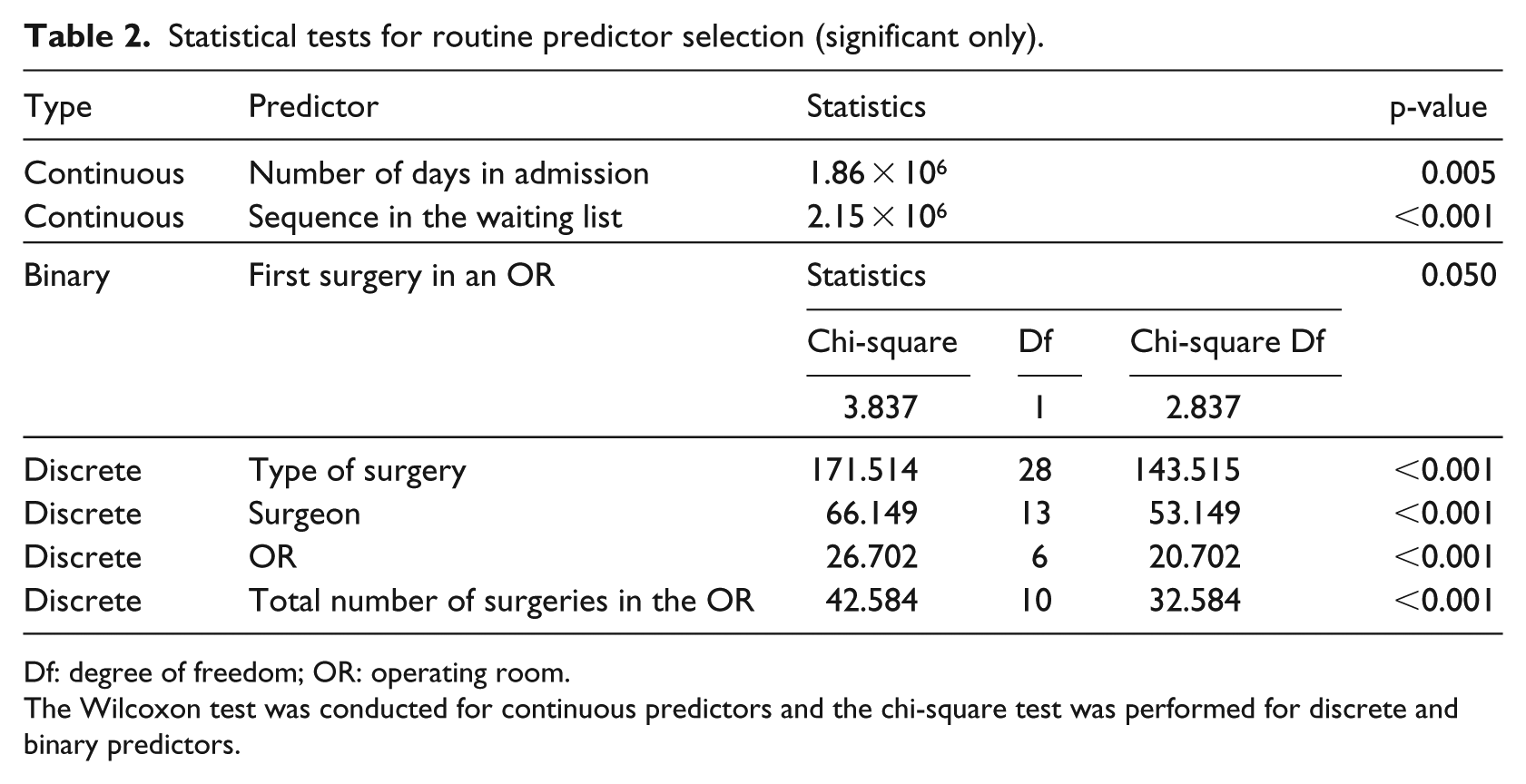
Df: degree of freedom; OR: operating room.
The Wilcoxon test was conducted for continuous predictors and the chi-square test was performed for discrete and binary predictors.
Applied models and experimental setup
The ML techniques used in this study were random forest (RF), support vector machine (SVM), and XGBoost algorithms. The RF classifier, which was first proposed by Breiman, 49 combines a number of trees for training and prediction, and it is widely used in healthcare management with satisfactory results.28,43,46 An SVM is a supervised learning method with an associated learning algorithm that analyses the data used for classification and regression analysis. 50 In this study, two versions of SVMs were employed, SVM-linear and SVM-radial, which use different kernel functions. Boosting is an ensemble algorithm in ML used primarily to reduce the bias and variance of learners; thus, a family of boosting algorithms was proposed to combine a series of weak learners into a strong learner. 51 XGBoost is the most widely used and powerful variation of boosting, with different components. XGBoost-linear is XGBoost with a linear kernel function, and XGBoost-tree is XGBoost with a tree kernel function. 52 Over- and under-sampling have been employed because of the extreme imbalance in the positive–negative ratio (2:11) to achieve better performance, except for the original dataset, in which no changes were made. This method has performed well in several fields, such as customer churn prediction 53 and customer classification 54 with imbalanced class distributions (for more details, please refer to Chawla et al. 55 ). All cases were divided into two sets, the train and test sets, with a ratio of 8:2. The train set was used to fit the ML models, and the test set was employed to validate the performance of the ML models.
In this study, we designed 15 schemes (i.e. three sampling methods) and 5 ML models, as mentioned above. Each scheme was run independently 10 times to find and validate the optimal pattern of best performance.
Evaluation criteria
The performance was measured according to six metrics: sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), accuracy, and area under the receiver operating characteristic curve (AUC). Among them, sensitivity, specificity, PPV, NPV, and accuracy are the basic criteria for algorithm evaluation. For a binary classification system, the performance evaluation is typically illustrated using the receiver operating characteristic (ROC) curve and AUC (which is the area under the ROC curve) to enable comprehensive consideration of the sensitivity and specificity. In this study, AUC was considered the key criterion.
Results
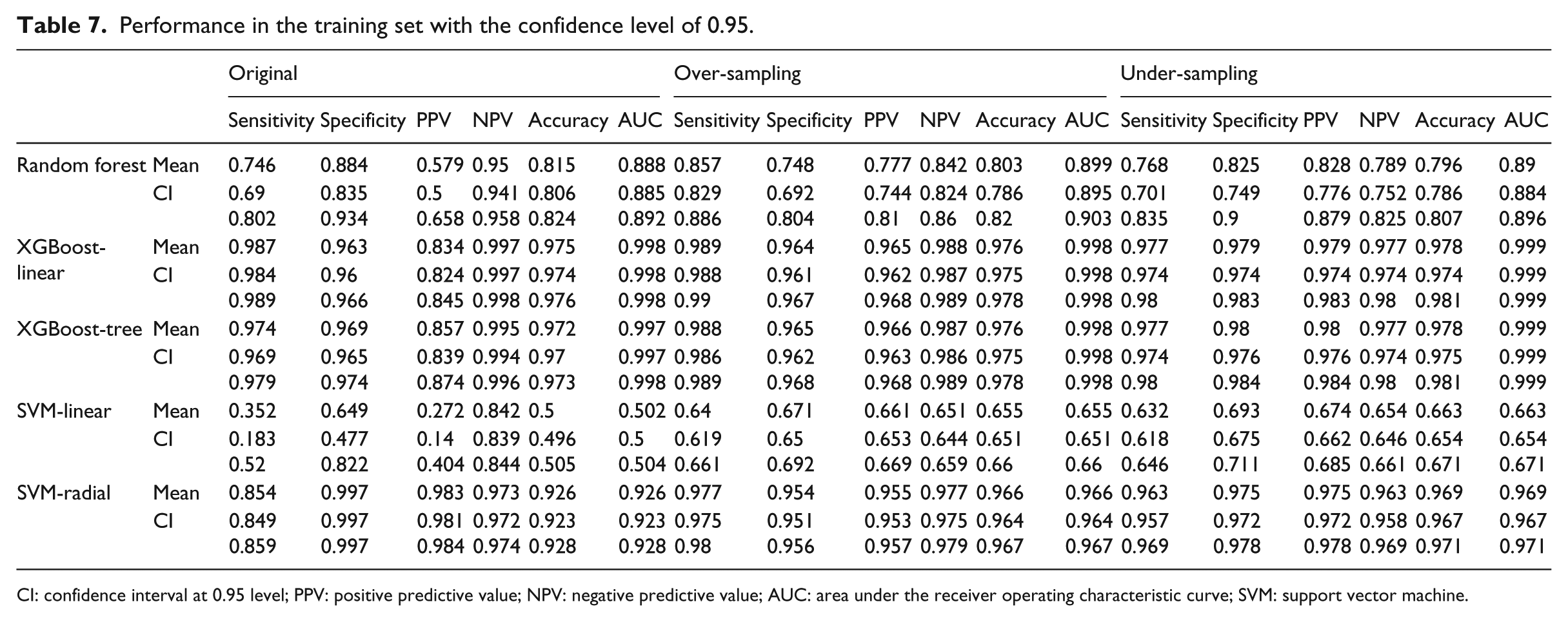
The performances of each scheme in the train and test sets are shown in Tables 3 and 7, respectively. For the scheme performance in the test set, the following conclusions can be drawn: (1) the RF model with over-sampling achieved the best performance according to NPV, accuracy, and AUC, whereas the one with under-sampling achieved the best sensitivity. Furthermore, the best values of specificity and PPV were achieved by the original SVM-radial model; (2) for all the 15 schemes, the mean NPV showed a stable performance, and all the obtained NPVs were approximately 0.9; (3) the 95 per cent confidence intervals of AUCs were very narrow, and the gaps between the upper and lower bounds were all less than 0.04; (4) the AUCs of the RF, XGBoost-linear, and XGBoost-tree models were all greater than 0.6, with the maximum being 0.682, whereas those of the SVM-linear and SVM-radial models ranged from 0.501 to 0.612; (5) regardless of the sampling method, the RF model achieved the highest performance in sensitivity, NPV, accuracy, and AUC, whereas the SVM-radial model achieved the lowest sensitivity and highest specificity and PPV; (6) when we changed the sampling method from original to over- or under-sampling, sensitivity increased and specificity decreased, while the AUCs nearly remained unchanged, for all ML models.
Performance in the test set with the confidence level of 0.95.
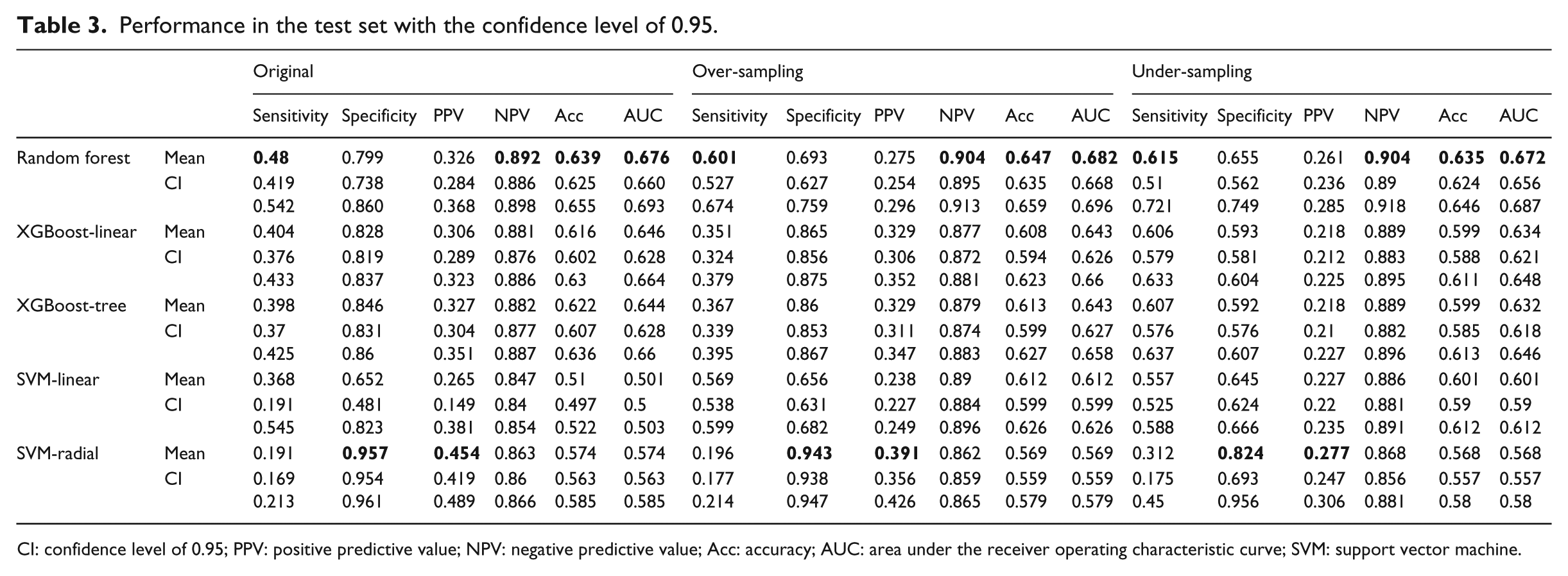
CI: confidence level of 0.95; PPV: positive predictive value; NPV: negative predictive value; Acc: accuracy; AUC: area under the receiver operating characteristic curve; SVM: support vector machine.
Table 4 shows the comparison of AUCs between the schemes by the one-sided t-test. According to the table, the following conclusions can be drawn: (1) the RF model outperformed other ML models for all sampling methods; (2) the XGBoost models (XGBoost-linear and XGBoost-tree) were superior to the SVM models (SVM-linear and SVM-radial); (3) no difference was observed between the models belonging to the same category (SVM or XGBoost); (4) different sampling methods showed similar performances; however, slight differences still existed at the significant level, where models with over-sampling achieved the highest significant level, and the original model was superior to the model with under-sampling.
The p-values of t-test for the areas under the receiver operating characteristic curve (AUCs) in the test set.
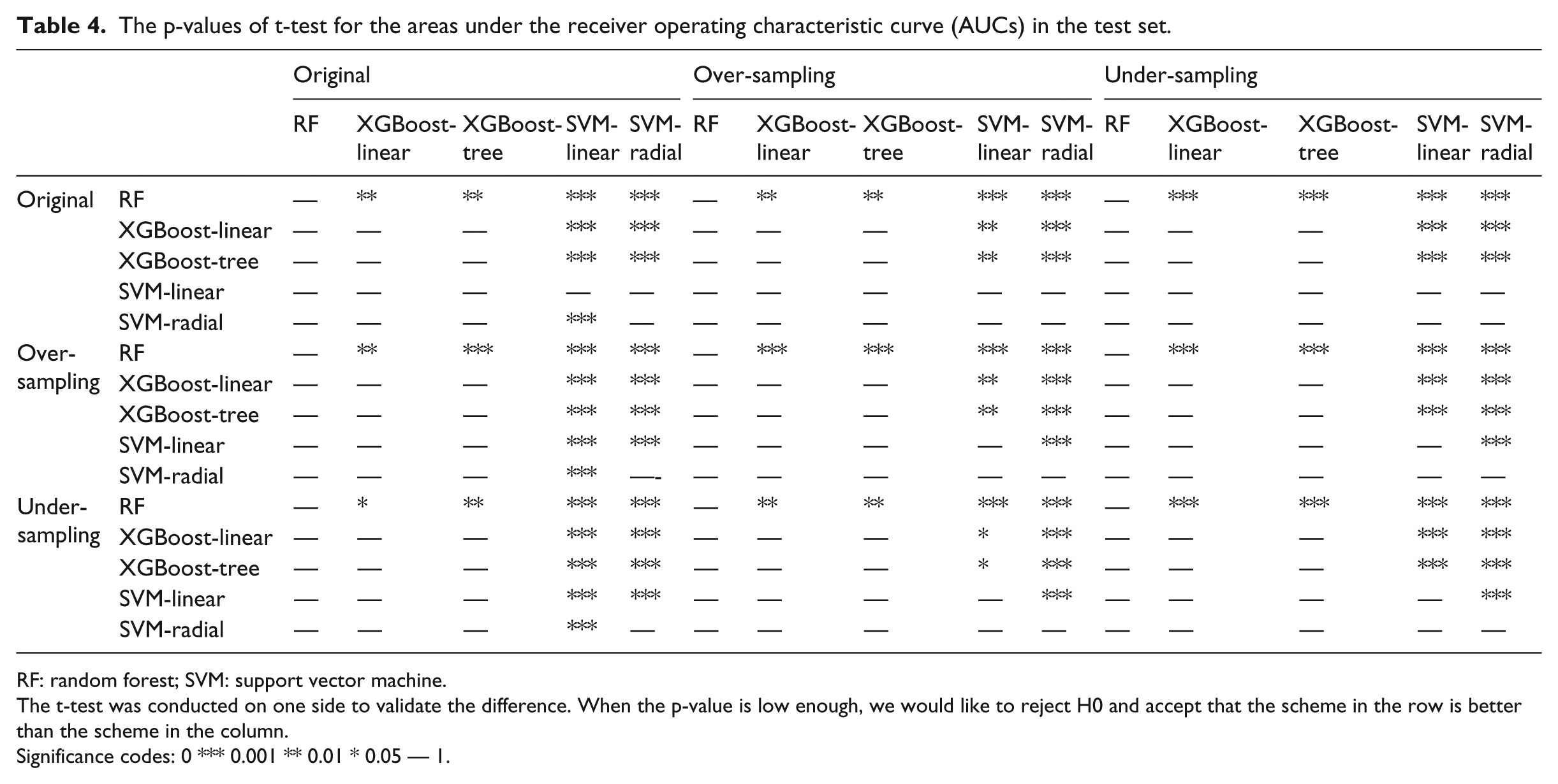
RF: random forest; SVM: support vector machine.
The t-test was conducted on one side to validate the difference. When the p-value is low enough, we would like to reject H0 and accept that the scheme in the row is better than the scheme in the column.
Significance codes: 0 *** 0.001 ** 0.01 * 0.05 — 1.
The results of this study indicate that a model or a sampling method influences the AUC; however, scientific validation is still needed. To determine whether these two factors have a significant impact on AUCs, an analysis of variance (ANOVA) was performed to validate the data. Table 5 shows the ANOVA results of AUCs based on models and sampling methods. According to the results, all p-values were less than 0.001, indicating that the model type, sampling method, and their interaction can significantly influence AUCs.
ANOVA for the areas under the receiver operating characteristic curve (AUCs) in the test set.
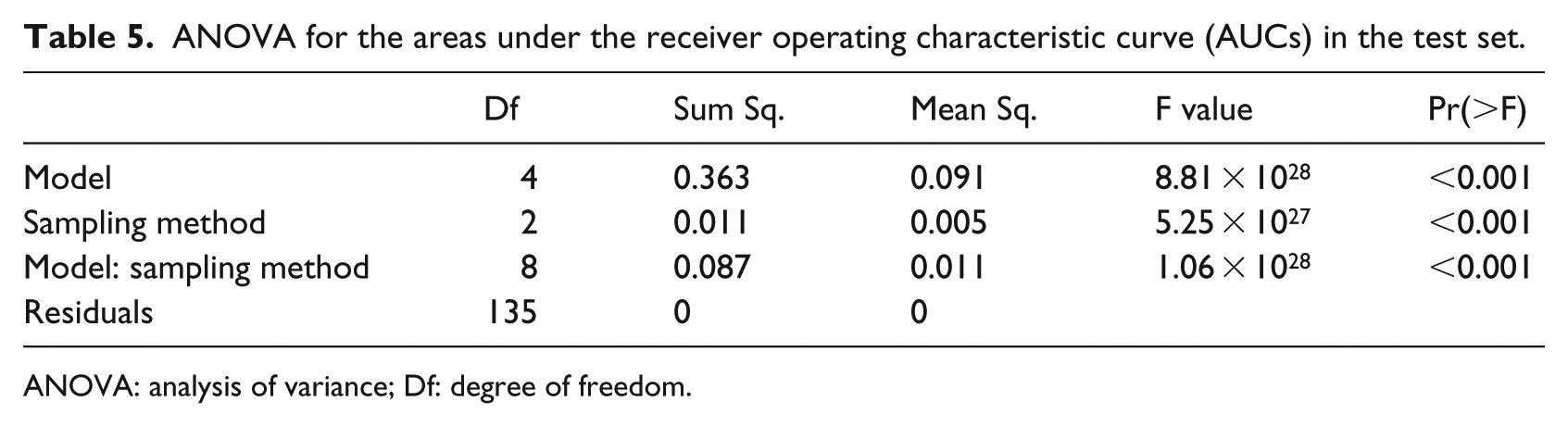
ANOVA: analysis of variance; Df: degree of freedom.
Discussion
This study indicates the feasibility of identifying surgeries with high risks of pre-cancellations. The general AUCs in the test set are above 0.6, with the maximum being 0.682 for the RF with over-sampling. Moreover, the ML models show stable performance with a difference of less than 0.04 between the upper and lower bounds. All ML models achieved a high NPV (approximately 0.9), meaning that 90 per cent of the surgeries labelled as low risks were not cancelled. In this case, almost all negative cases can be determined, thereby narrowing the sets of suspicious surgeries. Considering the extreme imbalance between positive and negative cases (2:11), the ML models can still effectively identify the considerably high-risk patients, even though PPV was slightly lower.
Different sampling methods can effectively adjust the performance of the ML models. According to this study, over- and under-sampling would lead to the increase of sensitivity and the decrease of specificity compared to the original method. As expected, practitioners’ concerns greatly affect their preference on model performance. This study’s findings help the practitioners adjust the ML models according to their needs.
The models and sampling methods significantly affect the performance of identification. Currently, no existing fixed omnipotent scheme exists for achieving the best performance in the identification of surgeries with high risks of cancellation, owing to the different datasets involving diverse features. Using various ML models and sampling methods, optimal identification results can be appropriately achieved.
Although independent repeated experiments and over/under-sampling were used to guarantee a rigorous work, limitations still exist. First, surgeries of other diseases in other hospitals and countries must be considered in future studies. Second, this research only focused on institutional resource- and capacity-related cancellations. Further comparison is required on other kinds of cancellations, as well as on the cancellations in other medical institutions. The obtained comparison results might provide more details on surgery cancellations.
Conclusion
This study pioneered the identification of surgeries with high risks of cancellation through ML techniques. The results of the study indicate that with a stable performance the effective identification of surgeries with high risks of cancellation is feasible. Moreover, we validated that model types and sampling methods have significant effects on the performance of identification. This study is a new application of ML for identifying surgeries with high risks of cancellation, thereby facilitating surgery scheduling and resource management. Based on this research, a surgery manager can identify surgeries with high risks of cancellation, alert the healthcare system, and adopt preventive actions, leading to a lowered CR. As mentioned earlier, a lowered CR will lead to a higher utility rate of institutional resources, such as ORs, resulting in improved cost efficiency of the healthcare system. Further studies on simulations to optimize surgery scheduling considering CRs are required.
Footnotes
Appendix 1
Performance in the training set with the confidence level of 0.95.
| Original | Over-sampling | Under-sampling | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sensitivity | Specificity | PPV | NPV | Accuracy | AUC | Sensitivity | Specificity | PPV | NPV | Accuracy | AUC | Sensitivity | Specificity | PPV | NPV | Accuracy | AUC | ||
| Random forest | Mean | 0.746 | 0.884 | 0.579 | 0.95 | 0.815 | 0.888 | 0.857 | 0.748 | 0.777 | 0.842 | 0.803 | 0.899 | 0.768 | 0.825 | 0.828 | 0.789 | 0.796 | 0.89 |
| CI | 0.69 0.802 |
0.835 0.934 |
0.5 0.658 |
0.941 0.958 |
0.806 0.824 |
0.885 0.892 |
0.829 0.886 |
0.692 0.804 |
0.744 0.81 |
0.824 0.86 |
0.786 0.82 |
0.895 0.903 |
0.701 0.835 |
0.749 0.9 |
0.776 0.879 |
0.752 0.825 |
0.786 0.807 |
0.884 0.896 |
|
| XGBoost-linear | Mean | 0.987 | 0.963 | 0.834 | 0.997 | 0.975 | 0.998 | 0.989 | 0.964 | 0.965 | 0.988 | 0.976 | 0.998 | 0.977 | 0.979 | 0.979 | 0.977 | 0.978 | 0.999 |
| CI | 0.984 0.989 |
0.96 0.966 |
0.824 0.845 |
0.997 0.998 |
0.974 0.976 |
0.998 0.998 |
0.988 0.99 |
0.961 0.967 |
0.962 0.968 |
0.987 0.989 |
0.975 0.978 |
0.998 0.998 |
0.974 0.98 |
0.974 0.983 |
0.974 0.983 |
0.974 0.98 |
0.974 0.981 |
0.999 0.999 |
|
| XGBoost-tree | Mean | 0.974 | 0.969 | 0.857 | 0.995 | 0.972 | 0.997 | 0.988 | 0.965 | 0.966 | 0.987 | 0.976 | 0.998 | 0.977 | 0.98 | 0.98 | 0.977 | 0.978 | 0.999 |
| CI | 0.969 0.979 |
0.965 0.974 |
0.839 0.874 |
0.994 0.996 |
0.97 0.973 |
0.997 0.998 |
0.986 0.989 |
0.962 0.968 |
0.963 0.968 |
0.986 0.989 |
0.975 0.978 |
0.998 0.998 |
0.974 0.98 |
0.976 0.984 |
0.976 0.984 |
0.974 0.98 |
0.975 0.981 |
0.999 0.999 |
|
| SVM-linear | Mean | 0.352 | 0.649 | 0.272 | 0.842 | 0.5 | 0.502 | 0.64 | 0.671 | 0.661 | 0.651 | 0.655 | 0.655 | 0.632 | 0.693 | 0.674 | 0.654 | 0.663 | 0.663 |
| CI | 0.183 0.52 |
0.477 0.822 |
0.14 0.404 |
0.839 0.844 |
0.496 0.505 |
0.5 0.504 |
0.619 0.661 |
0.65 0.692 |
0.653 0.669 |
0.644 0.659 |
0.651 0.66 |
0.651 0.66 |
0.618 0.646 |
0.675 0.711 |
0.662 0.685 |
0.646 0.661 |
0.654 0.671 |
0.654 0.671 |
|
| SVM-radial | Mean | 0.854 | 0.997 | 0.983 | 0.973 | 0.926 | 0.926 | 0.977 | 0.954 | 0.955 | 0.977 | 0.966 | 0.966 | 0.963 | 0.975 | 0.975 | 0.963 | 0.969 | 0.969 |
| CI | 0.849 0.859 |
0.997 0.997 |
0.981 0.984 |
0.972 0.974 |
0.923 0.928 |
0.923 0.928 |
0.975 0.98 |
0.951 0.956 |
0.953 0.957 |
0.975 0.979 |
0.964 0.967 |
0.964 0.967 |
0.957 0.969 |
0.972 0.978 |
0.972 0.978 |
0.958 0.969 |
0.967 0.971 |
0.967 0.971 |
|
CI: confidence interval at 0.95 level; PPV: positive predictive value; NPV: negative predictive value; AUC: area under the receiver operating characteristic curve; SVM: support vector machine.
Acknowledgements
The authors would like to thank Dr Yingkang Shi for his support and guidance and anonymous reviewers for their advice and comments.
Authors’ note
Li Luo, Fengyi Zhang, Yao Yao and RenRong Gong are also affilated with West China Hospital, Sichuan University, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported in part by the National Natural Science Foundation of China (grant nos 71532007, 71501135, 71471124, 71131006, and 7117219), Major Project of the National Social Science Foundation of China (grant no 18VZL006) and the Excellent Youth Fund of Sichuan University (grant nos skqy201607, skzx2016-rcrw14, and sksyl201709).