
Abstract
This article describes the development and evaluation of a set of knowledge patterns that provide guidelines and implications of design for developers of mental health portals. The knowledge patterns were based on three foundations: (1) knowledge integration of language technology approaches; (2) experiments with language technology applications and (3) user studies of portal interaction. A mixed-methods approach was employed for the evaluation of the knowledge patterns: formative workshops with knowledge pattern experts and summative surveys with experts in specific domains. The formative evaluation improved the cohesion of the patterns. The results of the summative evaluation showed that the problems discussed in the patterns were relevant for the domain, and that the knowledge embedded was useful to solve them. Ten patterns out of thirteen achieved an average score above 4.0, which is a positive result that leads us to conclude that they can be used as guidelines for developing health portals.
Keywords
Introduction
Online resources are increasingly used for meeting information needs related to health and well-being.1–3 Online health portals provide specialized medical knowledge and are developed to address such needs in a user-friendly manner.
4
Moreover, ideally, users should be able to find relevant information in their own native language. Online health portals are formally defined by Bamidis et al.
5
as … an interactive service or entry point site to the Web, offering information resources related to health subjects like hospital and doctor information, nutrition, health guide, daily care, health tests, latest published research work, health articles on nearly every subject, health electronic libraries and athletics. Services offered include search engines, links to health portals around the world, e-mail, chatting, news about the pharmaceutical industry and a part with medical information for the people that practice medicine …
The development of online portals involves several foundational aspects that cover technical methods and solutions for language technologies and graphical user interfaces (GUIs). This article describes the evaluation of a set of knowledge patterns (a knowledge pattern is a format for describing a solution to a design problem) that provide design guidelines and implications for future developers of online health portals that support searching in more than one language, in the field of psychology and psychotherapy.
The patterns are based on three foundational aspects: (1) knowledge integration of language technology approaches within cross-language information retrieval (CLIR), question answering (QA) systems and their distinctive features; (2) experiments with language technology applications within CLIR on a mental health portal and (3) user studies of portal interaction, that is, studies of how psychological information seekers utilize and experience mental health portals. A multilingual collection of frequently asked questions (FAQs) from an online portal about mental health (Web4health (http://web4health.info)) was also utilized as a test bed, with a focus on Swedish and English. Previous research on health portals has mainly focused on each foundation separately: reviews of existing knowledge; 6 experiments and evaluation of techniques and applications available on the portals;7,8 user studies and user search behaviour.5,9 An enterprise knowledge pattern (EKP) approach was used for the knowledge pattern development.10,11 The aim of this research is to provide a more holistic view that covers all these three foundations, producing guidelines for the implementation of health portals for users without medical expertise. To our knowledge, these are the first knowledge patterns that explicitly cover health portals in the field of psychology and psychotherapy.
Mental health is one of medical areas where online health portals are increasingly being utilized to help users with in-depth medical information, 12 psychological counselling, 13 monitoring of health condition 14 and adherence to medication plans. 15 Online portals have proved to be very useful for reaching citizens that cannot visit specialist centres at scheduled hours, that is, users living in rural areas 13 or suffering from physical impairments 16 or mental impairments. 17 The development of national online portals for access to mental health services is considered a priority in some countries with large rural areas (e.g. Australia). 18
Three foundational aspects for online health portals
A survey from 2014 reported that over 50 per cent of the studied population with psychiatric problems utilize online resources to search for information concerning their mental health condition. 19 Previous research studies have shown that health information seekers prefer to submit their information needs in their own native language.20,21 This has also been confirmed in studies of multilingual mental health portals. 22 Moreover, studies of monolingual mental health portals 15 have shown that users consider multilingual content an important property for a mental health portal, since negative feedback was given due to the lack of multilingual services and multilingual content.
CLIR is the information retrieval (IR) process where the user’s information requests and the retrieved documents/answers are in different languages. The implementation of CLIR functionality requires specific knowledge in language technology techniques. In this research, previous knowledge has been integrated23,24 and new experiments with language technology applications on a mental health portal within this field have been performed.25–27 Since health information seekers have different backgrounds, search goals and information needs,28,29 the mediated information should be tailored to fit their needs and profiles. In our research, we have performed user studies of portal interaction, evaluating the acceptance of online medical information, 22 different GUIs and user tailored search services in the field of psychology and psychotherapy. 30
Knowledge patterns and guidelines for e-health
Knowledge patterns were originally created for architecture by Alexander 31 as individual pieces of knowledge that applied solutions to recurring design problems. They discovered that recurring design problems could be solved with similar solutions and developed a formal design documentation language where each pattern unit included a statement and a discussion of (1) the problem; (2) the context where the problem occurs; (3) the competing forces and constraints involved and (4) the solution to the problem, that is, a generic list of instructions to solve the problem in different situations. Borchers 32 stated that since the ultimate goal of the pattern language was to help common citizens to form and design their own cities and environments, it can be compared to participatory design in software development, where the end users are involved in all stages of the development cycles.
This design documentation methodology was later applied in software engineering33,34 in order to support software and source code reuse. Patterns were later utilized by interaction designers in order to solve recurring user interface (UI) problems in human–computer interaction (HCI). UI designers also noted that certain design problems re-occurred, and that these problems could be solved generally by known solutions. However, there has been a problem communicating them. Guidelines represent a possible solution, but they are generally seen as hard to interpret and as requiring excessive effort to find relevant material. 35 For this reason, there has been an increasing interest in patterns to document UI design solutions. Mahemoff and Johnston 35 produced patterns for users and UI elements. Nilsson 36 provided a set of UI design patterns for mobile applications. The focus was to provide indications for developing more user-friendly applications on mobile devices. Three main problems were individualized (‘screen space utilization’, ‘interaction mechanisms’ and ‘design at large’) and the patterns were evaluated with questionnaires in tutorials and workshops.
Tidwell 37 summarized UI best practices and reusable ideas into design patterns that provided solutions to common design problems for mobile apps, web applications, desktop software and even social media applications. Her design patterns are widely used (http://designinginterfaces.com/) and are distinctive in that they are limited to a few essential sections.
The EKP approach and format10,11 are well established tools for documenting design solutions and best practice in healthcare. 11 Knowledge patterns are easily understood by readers without technical skills and also provide background reasoning behind the proposed solution, the so-called rationale. 38 Knowledge patterns have also been utilized in e-health for presenting business models,39,40 guiding e-health providers for commercializing e-health services.
The content of the knowledge patterns
Since natural language (NL) interfaces are also utilized when searching for medical information on health portals, the studied knowledge patterns integrate previous knowledge in the main research approaches within CLIR and QA, pinpointing the advantages and disadvantages of each approach, the context and the applications that best fit each approach in the medical domain. IR systems are traditionally seen as document retrieval systems, that is, systems that return documents matching user queries. A step towards the QA paradigm is the development of document retrieval systems into passage retrieval systems, where the focus is on retrieving text passages or text chunks rather than entire text documents. 23
There are several available CLIR techniques that can be implemented in order to support input from users with different native languages. These techniques support translation of information requests or documents from source to target language or translate both into an intermediate language and a semantic representation (interlingua translation 41 ). The information request translation is the most common translation approach since it is less computationally costly and easier to maintain. 41 There are three main types of methods for translating information requests or user queries: approaches based on (1) bilingual dictionary search; (2) machine translation (MT) and (3) parallel corpora.41,42 Earlier research in this field21,43 has neither focused specifically on the domain of psychology and psychotherapy, nor considered both single-word units (SWUs) and multi-word units (MWUs). To fill this gap, experiments were carried out and the quality of available query translation methods (bilingual dictionary search and MT) was assessed on the test bed from Web4health.info. The source language was Swedish and the target language was English.
Three dictionaries and two MT approaches were employed and compared when applied on two different search engines (Google Site Search (https://www.google.com/work/search/products/gss.html)), that is, a custom search engine for specific websites, and Quick Ask. 44 Experiments were also conducted with the extraction of bilingual lexicons from parallel corpora from the same portal in order to study the quality of the lexicons extracted from differently pre-processed versions of the corpus: lemmatized (words normalized to their base form), part-of-speech tagged (automatically assigning the part-of-speech of each word), syntactically parsed (automatically assigning the syntactic role of a word) and chunked (automatically assigning a word to a phrase).
Earlier user studies of portal interaction in the field of mental health 15 has focused mainly on the practitioners’ point of view. Our portal interaction studies were instead conducted focusing on the layman’s point of view: information was collected about how lay users interacted with the above mentioned mental health portal and evaluated the acceptance of the mediated information. Factors that information seekers characterized as good and informative for a health portal were also studied.
According to Sainfort et al., 45 two of the specific qualities that UIs must embrace in order to be optimal for the medical personnel and the patient are: (1) first they have to be multimodal, that is, with multiple interaction modalities, and (2) adaptive, that is, adapts to users’ background and skills. However, health portal technologies are rather limited since they do not typically allow personalized search facilities. 8 The ranking algorithms of search engines and QA-systems on health portals generally do not consider users’ different backgrounds and profiles and implement a ‘one-size fits all’ information delivery approach. A multimodal and adaptive tool that tailored the retrieval of information on the test portal to users’ characteristics and information needs was developed. The tool was utilized to conduct user studies that investigated the contexts that better fit personalization of IR and the contexts that did not. Two different techniques were implemented to capture user profiles and a discussion about which technique was more successful and why was conducted. We also studied how health portal users experienced different interfaces and modalities that help users to express their information needs: menu-based forms and NL panels.
The EKP approach
To develop and document the knowledge patterns, we used the EKP approach and format. 10 This approach has been successfully utilized for design and best practice solutions in healthcare.11 The knowledge embedded in the patterns is aimed for developers, researchers and health care providers, that is, people who are responsible for mediating medical information on health portals for users without medical expertise. When several solutions are presented, a discussion about the advantages and disadvantages of each solution is also included. Table 1 shows the outline of the template that was utilized in order to formalize the knowledge patterns, including an example in the rightmost column. The template was modified to also include relevant references and pattern classification information.
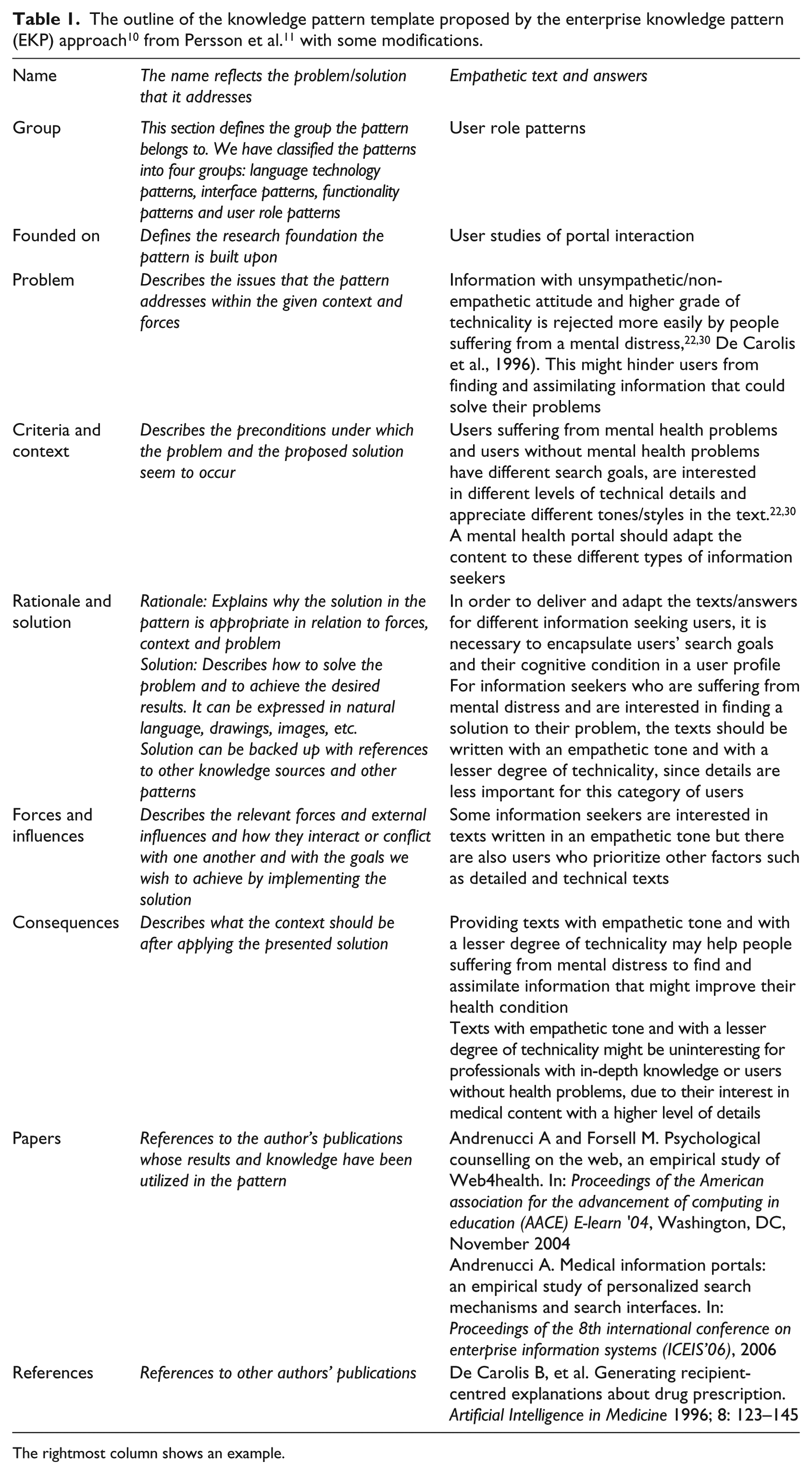
The rightmost column shows an example.
Methods
Figure 1 shows the overall workflow of this study, where the grey boxes are the outcome in each phase. The two first phases constitute the background material for this study. The results of the first phase (foundations: knowledge integration of language technology approaches, experiments with language technology applications and user studies of portal interaction) led to the creation of 20 knowledge pattern drafts (phase 2).
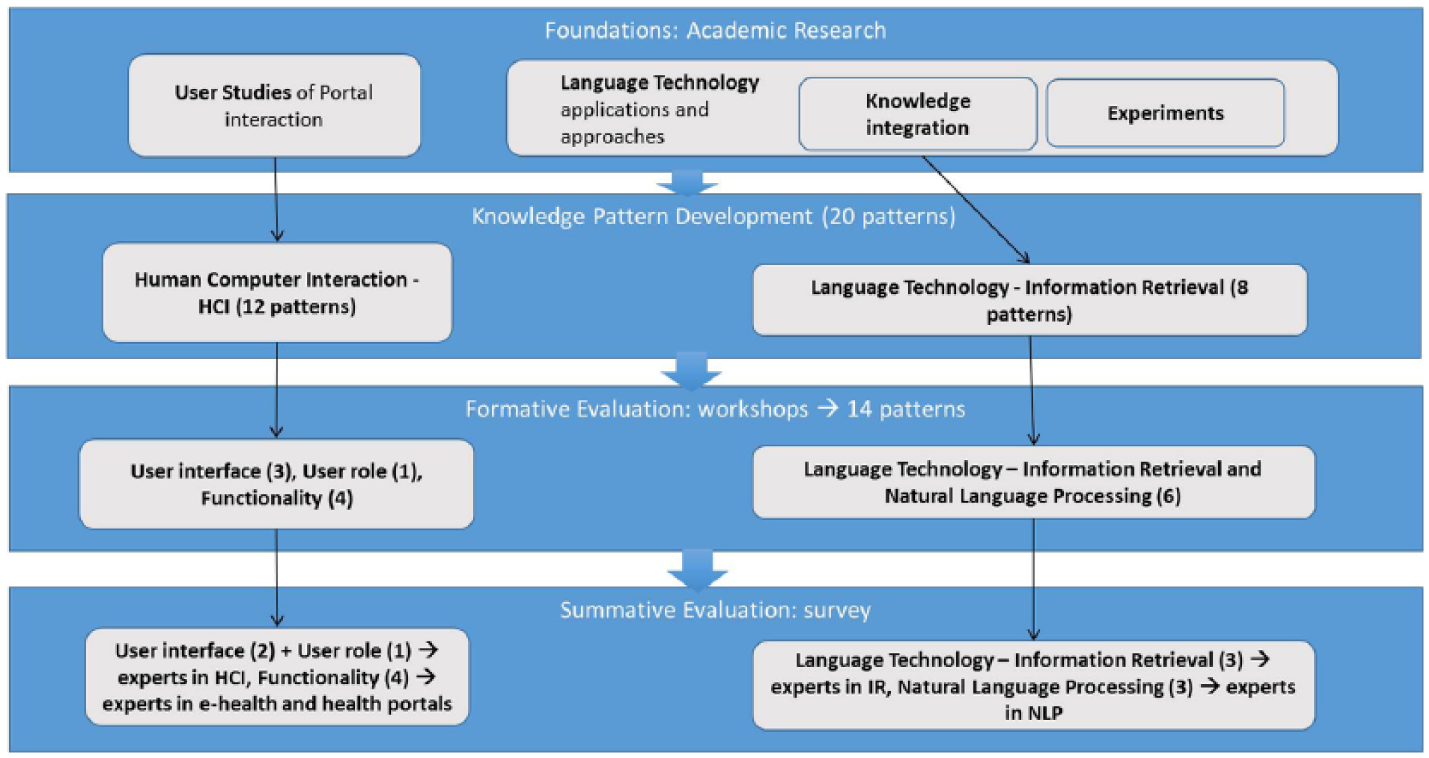
Overall workflow of this study outlining the phases for the development and evaluation of the knowledge patterns. The first two phases constitute the background material and the two last phases constitute the evaluation phases.
A sequential mixed-methods approach was then employed in the third and fourth phases for further development and evaluation of the knowledge patterns. First, a formative evaluation (a formative evaluation implies that an artefact is evaluated while it is still being designed/developed) 46 was employed with the purpose of improving with iterative steps the patterns during the design process (phase 3). Then, a summative evaluation (a summative evaluation produces a final assessment of an artefact after it has been finally designed/developed) 46 was employed, in order to get a final assessment of the patterns (phase 4). The main rationale behind this choice of a sequential mixed-methods approach was to obtain complementarity – to increase the validity of the overall results as well as to minimize the risk of method bias in the end result. This approach also allowed the possibility to refine the material and possibly gain unexpected insights 47 prior to employing a final assessment phase.
Semi-structured participatory workshops were utilized in the formative evaluation in order to clarify misunderstandings or ambiguities through a dialogue with domain and knowledge pattern experts. Online surveys with both closed questions and open-ended commentary fields were utilized in the summative phase. This latter approach was chosen in order to (1) involve a greater number of evaluators than in the workshops, avoiding locational or logistic constraints; (2) allow evaluators to respond in their own time to improve the quality of their responses.
Formative evaluation
Phase 3 involved evaluating the content and language in the knowledge patterns that were developed in phase 2. In this step, four semi-structured participatory workshops48–50 were organized with invited knowledge pattern experts (N = 3) as well as with domain experts (N = 3) in the field of language technology, e-health and HCI. To prepare for the workshops, the participants received in advance an email with the following parts: an introduction about the objectives and approach of the evaluation, the patterns and a presentation of their format, and a brief description of the research work that led to their development. This information was also repeated as an introduction to the workshops.
The workshop discussions were documented through note-taking, including action points for edits and improvements. These notes were used as a base for editing all patterns. A subset of the edited patterns was circulated to workshop participants in order to reach a consensus on the appropriateness of the edits. The outcome of the formative evaluation was (1) a more precise use of the template sections, (2) a more fine-grained classification of the patterns, (3) an initial ex-ante evaluation (an ex-ante evaluation implies that an artefact is evaluated before its implementation or before it is fully developed) 46 of the content and (4) an improvement of the knowledge and language embedded in the patterns.
Summative evaluation
Phase 4 involved a summative evaluation of the knowledge patterns based on an online survey that was sent to a non-randomized set of international domain experts (see section ‘Results’) in the areas of natural language processing (NLP), IR, HCI and e-health. The domain experts were selected from a list of experienced professionals from both industry and academia and are active in research communities in different countries (Sweden, Finland and Australia).
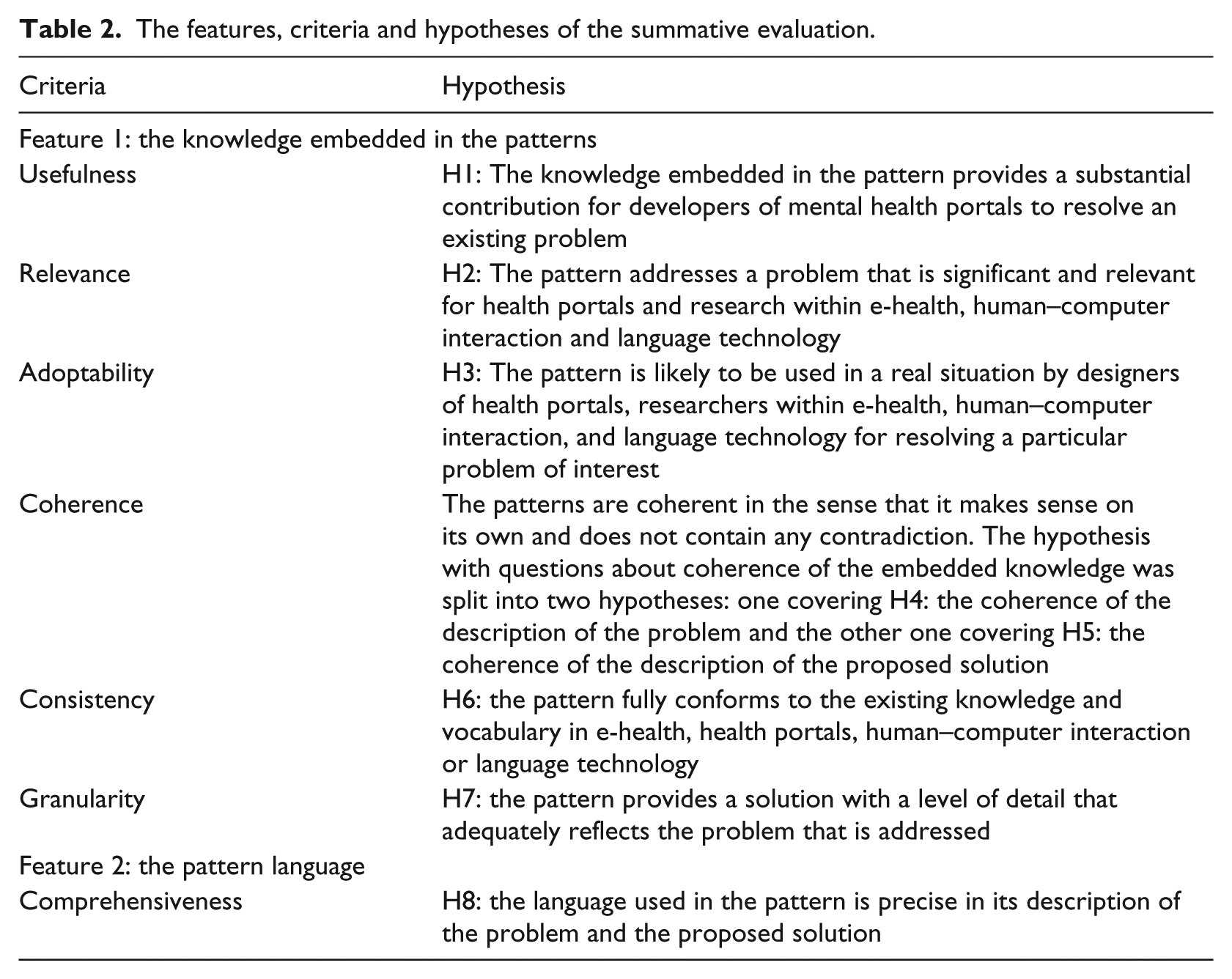
The summative evaluation approach of Rolland et al. 48 was employed, since it has successfully been used to assess knowledge patterns with the help of domain experts in previous studies. The evaluation focused on two distinctive features in the knowledge patterns: (1) the knowledge embedded in the patterns and (2) the language utilized to mediate the knowledge in the patterns to the users. For each feature, eight hypotheses were specified to be evaluated against given evaluation criteria and metrics (Table 2). The online surveys were divided into four categories and sent to experts with different domain expertise according to the following partition: (1) UIs and user roles (expertise in HCI); (2) functionality (expertise in e-health and health portals) and (3, 4) language technologies (expertise in NLP and IR respectively). The language technology patterns that focused more on word processing were submitted to experts in NLP, while the language technology patterns that focused on search and retrieval were submitted to IR experts (Figure 1).
The features, criteria and hypotheses of the summative evaluation.
The respondents received by email: (1) the patterns to assess (which were also available on the online survey); (2) information about the background of this study; (3) information about the pattern notation and format; (4) the goal of the evaluation as well as instructions about how to fill the survey and (5) a web link to the online survey.
The evaluation concerned the following criteria: 48
Usefulness, that is, the degree to which the usage of the pattern would provide a substantial contribution in the context of a real problem-solving application.
Relevance, that is, the degree to which a pattern addresses a significant problem for health portals and the research areas of language technology and HCI.
Adoptability, that is, the degree of acceptance of the pattern to be used by domain experts for resolving a particular problem of interest.
Coherence, that is, the degree to which the pattern constitutes a coherent unit including correct relationships with other patterns.
Consistency, that is, the degree to which the pattern conforms to existing knowledge and vocabulary used in the fields of health portals/e-health, language technology and HCI.
Granularity, that is, the level of detail at which the pattern addresses a problem.
Comprehensiveness, that is, the degree to which the language used in the pattern is precise in its description of the problem and the proposed solution.
Each question in the survey allowed to evaluate a given hypothesis against a given criterion. Each criterion could be graded from 1 to 5, where 1 was lowest and 5 highest. The respondent was also offered the possibility to choose ‘I can’t answer’, in case the evaluator considered herself unable to answer for some reason. The option to write open comments was also included, to enable the possibility of getting more detailed feedback. For each knowledge pattern, evaluation tuples in the following form were generated: <knowledge pattern name, feature, hypothesis, criterion, metric>. Table 3 illustrates an example of an average result for an evaluation tuple.
Results for the tuple <‘Choice of QA approaches’, ‘The knowledge embedded in the pattern’, ‘The patterns is coherent in the sense that it makes sense on its own and does not contain any contradiction’, ‘Coherence of the problem’, ‘1–5’>, where ‘1 to 5’ is the coherence grading.

QA: question answering.
To consider a hypothesis verified, we used a threshold of 4, since in a 5-point Likert scale, the value of 3 has more of a neutral value, 51 that is, an evaluator does not agree nor disagree with a statement, while 4 is generally equal to ‘agree’. Scores between 3 and 4 were considered to only partially verify the hypotheses. A similar approach was applied in earlier research. Rolland et al. 48 evaluated knowledge patterns that modelled business processes and business changes in organizations, achieving average scores equal or above 4 which was considered to verify the hypotheses and scores between 3 and 4 only partially verified the hypotheses. Nilsson 36 evaluated design patterns for GUI for mobile applications with the help of a 6-point scale questionnaires, where the average scores around 5 were considered to validate the hypothesis.
As a complement to the quantitative results, a qualitative analysis of the open comments was also performed to allow for a better understanding of the statistical results. The open comments were read in detail and analysed by one of the authors, and summarized and exemplified in conjunction with the quantitative results.
Results
Formative evaluation
The feedback from the knowledge pattern experts was important in order to gain a deeper understanding of each section in the knowledge patterns template, in particular the specific differences between ‘forces’ and ‘criteria’. The sections ‘problem’, ‘solution’ and ‘consequences’ were also discussed in-depth and reformulated to be more effective, for example, clarifying that ‘actors’ have a problem and ‘actors’ embrace both positive and negative ‘consequences’ with the proposed ‘solution’. The pattern names were also improved: shortened and more informative, with the usage of noun phrases or verb phrases. The name should focus either on the problem, the activity in which the problem arises, or the solution. The experts also suggested to move the ‘rationale’ section before the ‘solution’, in order to better understand the reasoning process behind the proposed solution. The classification process of the knowledge patterns was also revised, categorizing them in the following groups: (1) functionality of the portals; (2) UIs that give access to the functionality; (3) user role, that is, the user behaviour when interacting with the portal; (4) language technology that makes the functionality possible. The new categorization of the patterns is an example of an unexpected insight that was gained as a result of the workshop discussions. The patterns were also ‘tagged’ with the research foundation they referred to. The workshops functioned as an ex-ante evaluation of the knowledge in the patterns. The participants’ domain knowledge helped to merge together patterns with related or similar content, thus reducing the total number of patterns from 20 to 14 (Table 4 and Figure 1).
Reduction and merging of 20 patterns to 14 (phases 2–3).

HCI: human–computer interaction; GUI: graphical user interface; QA: question answering; NLP: natural language processing; QT: query translation.
The original pattern names and their groups from phase 2 are on the left side, on the right side the pattern names and groups resulting from phase 3 are presented. The bracket shows a merge between two or more original patterns.
① evaluated by NLP experts, ② evaluated by IR experts, ③ evaluated by HCI experts, ④ evaluated by e-health experts.
One pattern was discarded (‘Implement different layout metaphors’), since it was considered too vague. The participants’ feedback led to improvements in the knowledge embedded in the rationale and solution sections, and to an updated vocabulary. The evaluators also suggested to add more specific details in the solution sections, for instance adding examples with screenshots in order to illustrate the solution. This was particularly recurrent for patterns covering the portal UI. Additional related research was also recommended. Overall, the feedback improved the content in the individual patterns, turning them into self-contained knowledge units and reducing the coupling to other patterns. The goal was to make it possible for the reader to view and understand the content in any knowledge pattern, without having to read the patterns in a certain sequence.
Summative evaluation
For each pattern, eight hypotheses were evaluated. Out of the 14 patterns, one was excluded (‘Exhaustive help’), because it was deemed to need further work during the workshops in phase 3. Table 4 outlines the final knowledge patterns, including their titles and categories, as well as information about which domain expert group each pattern was sent to for evaluation. Eighty-one potential evaluators were contacted and 25 responses were received. The average response rate was slightly over 30 per cent, with the following rates per pattern group: NLP patterns 40 per cent, IR 23.8 per cent, interface/user role 27.7 per cent and functionality 29.4 per cent.
Overall results per hypothesis
The total average result for each hypothesis was 4.23 (see Figure 2), which indicates the overall quality of the knowledge patterns. The hypotheses with the highest overall scores regarded usefulness (4.32 for H1), relevance (4.54 for H2), and coherence of the problem (4.51 for H4). These results indicate that in general, the issues/problems discussed in the knowledge patterns are relevant for the domain, and that the knowledge embedded is useful to solve them. The fact that coherence of the problem achieved such an overall score also indicates that the revisions resulting from the workshops (phase 3) were impactful, since cohesion was discussed extensively and employed in the revisions.
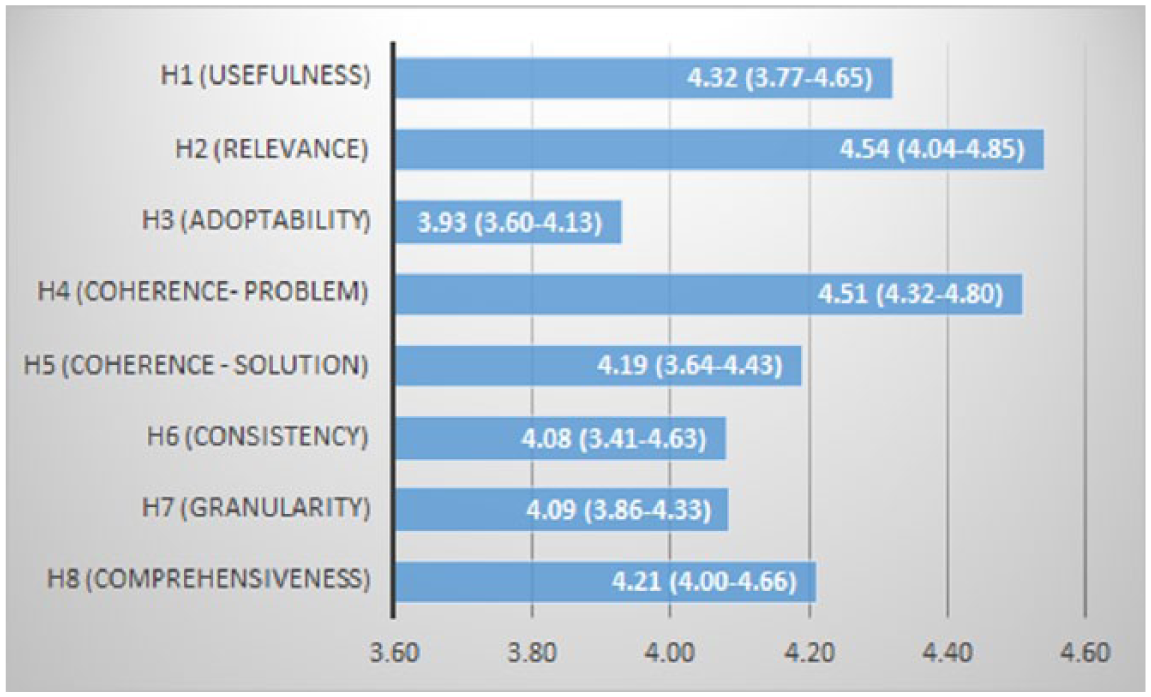
Total average values per hypothesis (min–max averages in parenthesis).
The hypothesis covering comprehensiveness (H8) also scored good overall results (4.21), indicating that even the language utilized to describe the knowledge in the patterns was appropriate and precise. The open comments provided useful feedback to understand the results (see next section for more details) and revealed three interesting issues: (1) the evaluators suggested for some patterns an addition of more alternatives or alternative methods in the proposed solutions, (2) the evaluators considered few of the solutions vague and suggested the addition of more detailed and concrete examples, (3) some patterns could be potentially adopted in other domains where similar problems arise, that is, they were not specific for the mental health portal domain only.
Results per pattern group
All patterns resulted in an average score above 3 and 10 patterns out of 13 have an average above 4 (Figure 3). The lowest average values are among the NLP patterns (3.85 overall average), specifically the questions concerning adoptability (3.60 for H3), consistency (3.41 for H6) and coherence with the solution (3.64 for H5) resulted in lower scores (Figure 4). The average scores for relevance (H2), coherence of the problem (H4) and comprehensiveness (H8) are higher than 4. We expected probably a higher value for consistency (H6) with existing knowledge and vocabulary in the domain of NLP, considering that the patterns were processed with domain experts during the formative evaluation phase, and the proposed solutions are based on highly cited research results. Usefulness (H1) scored 3.77 and coherence of the solution (H5) scored 3.64, which does not indicate that the knowledge embedded in the patterns (in their current form) would provide a substantial contribution. These results were also confirmed by some open comments pinpointing a high level of technicality in terms, such as part of speech tagging, lemmatization and parsing, which needs further explanations in ‘layman’ words in order to allow non-experts to fully take part of the embedded knowledge. One evaluator pointed out that the information provided for instance in the pattern ‘Choice of QA approaches’ was useful, but perhaps not fully explanatory on its own. The NLP patterns’ proposed solutions are on a higher level of abstraction, compared for instance to interface patterns, which provide more immediate solutions, enhanced with ‘visual’ examples. This might be one reason behind the lower overall scores in this group. Some evaluators suggested to enrich the proposed solutions with alternative methods. For instance, in the pattern ‘Choice of query translation approaches’, solutions with pivot languages were recommended for dictionary look-ups where no cross-language dictionaries nor parallel texts were available. One evaluator suggested to expand the solution with alternatives for people with visual incapability. Another evaluator requested additional examples of what was considered as ‘compound words’ and how they differ from MWUs.
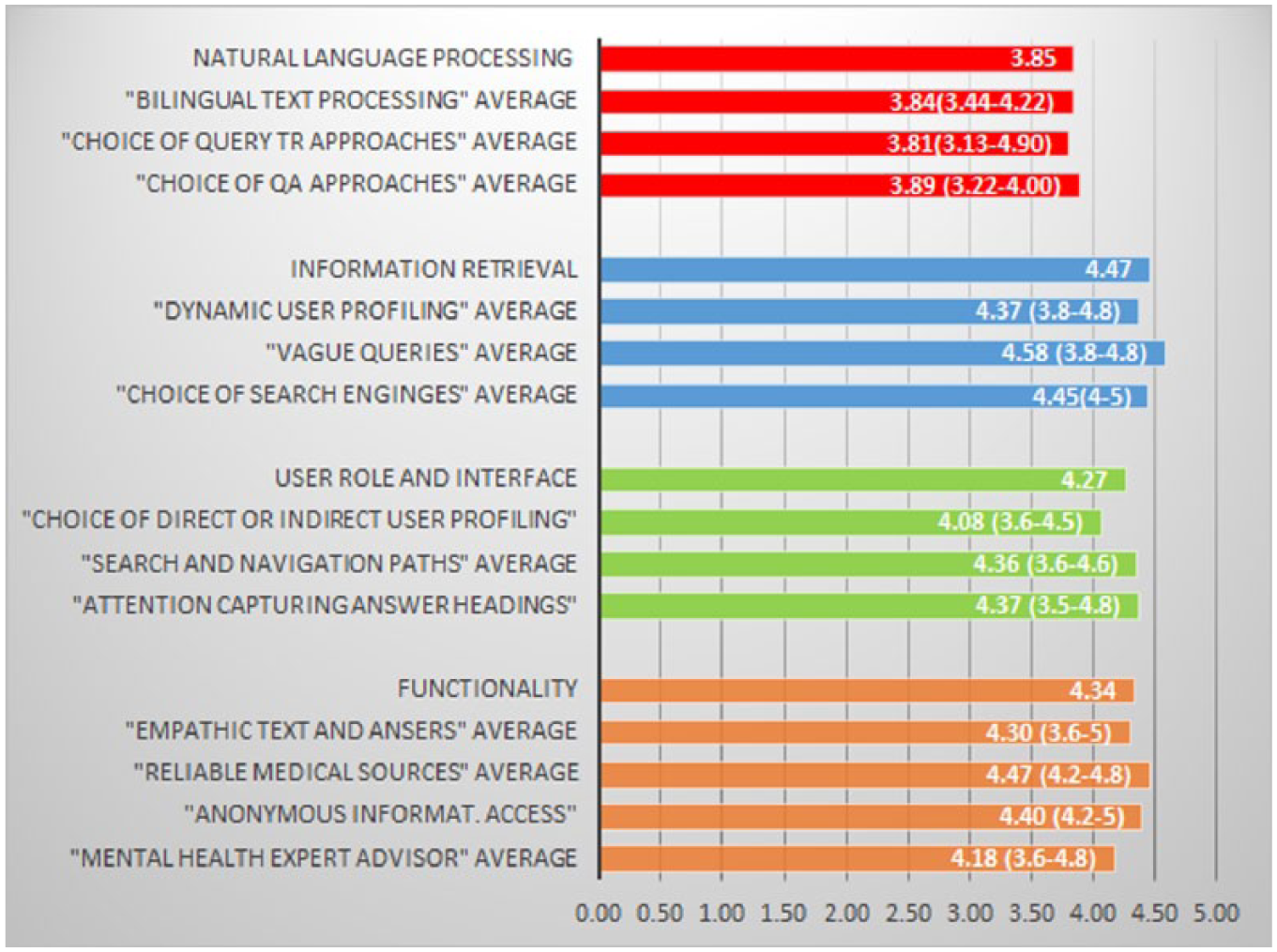
Average values for each knowledge pattern and for each pattern group (min–max averages in parenthesis).
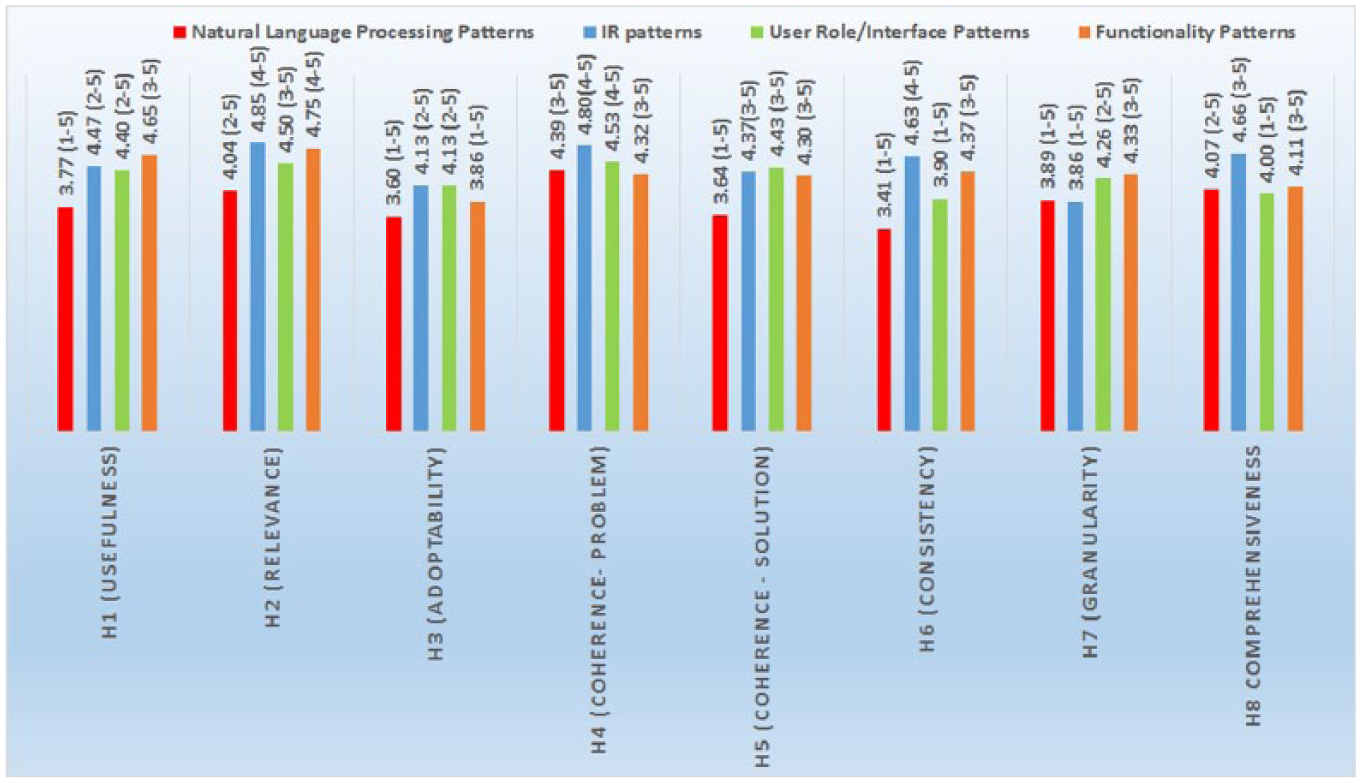
Average values per hypothesis in each pattern group (min–max in parenthesis).
Two evaluators chose the response ‘I can’t answer’. This was in the question about granularity and the levels of details for the pattern ‘Choice of QA approaches’.
IR patterns received their highest average scores for relevance (4.85 for H2), coherence of the problem (4.80 for H4) and comprehensiveness (4.66 for H8) (4), which indicates that the problems described in the patterns were deemed as very relevant, the descriptions of the problems self-contained and free of contradictions; and the language in the problem and solution sections was considered precise. One evaluator chose the response ‘I can’t answer’. This was a question about consistency with the existing knowledge and vocabulary in the domain of e-health, HCI or NLP for the pattern ‘Choice of search engines’. The granularity results were slightly lower (3.86 for H7); the open comments concerning the solution sections and their level of details gave us useful hints. One evaluator suggested to implement guidelines about ‘how-to’ evaluate/choose a search engine when designing a health portal, instead of providing a specific comparison between search engines. The pattern should provide a guidance based on cost/benefit outcomes. Another evaluator suggested to expand the comparison to other search engines than Google Site Search (https://www.google.com/work/search/products/gss.html) and Quick Ask, 44 an aspect which was, however, listed as a limitation. In the pattern about the solution of vagues queries, alternative techniques were suggested as well as more explicit explanations, since the solution is at a fairly abstract level. One evaluator argued that the text was not clear in describing the type of information included in the user profile.
Interface patterns
The highest scores in this group were for usefulness (4.40 for H1), relevance (4.50 for H2), coherence of the problem (4.53 for H4) and coherence of the solution (4.43 for H5). This indicates that the patterns contained significant and relevant problems, and the knowledge was considered a significant contribution for research. The patterns were also considered coherent in their description of the problems and the proposed solutions, that is, they formed self-contained knowledge units. The average scores per hypothesis in this group were above or equal to 4, with only one score slightly under (3.90 for H6 consistency). The open comments helped with some useful feedback regarding consistency. Two evaluators suggested the inclusion of related literature (e.g. Tidwell 2000) in the pattern ‘Search and navigation paths’, since some of the knowledge of the pattern can be enriched by Tidwell’s work. One evaluator also pinpointed that the embedded knowledge in the pattern was design practice that could be utilized in several domains and not only in e-health. We also received more content-specific comments about the proposed solutions: the solution in the pattern ‘Choice of direct or indirect user profiling’ was for example defined a little bit too abstract by an evaluator. The evaluator recommended the implementation of more ‘concrete’ examples, even if the pattern was relevant overall. Some terms were not considered precise enough, as another evaluator suggested for the ‘Reliable medical sources’ pattern, where the solution part advised the utilization of content originating from reliable medical experts/sources. According to the evaluator, it was not clear what was meant by the word ‘utilize’ and its meaning should be specified. The name of the pattern ‘Attention capturing answer headings’ should be changed to ‘Include search terms in answer headings lists’ according to another comment.
Only one evaluator chose ‘I can’t answer’ as an option. It was in the question about consistency for the pattern ‘Attention capturing answer headings’.
Functionality patterns
Usefulness and Relevance achieved the highest scores (4.75 for H1 and 4.65 for H2). This indicates that the patterns addressed significant and relevant problems and the embedded knowledge was considered a significant contribution for developers of mental health portals. All average scores per hypothesis were higher than 4 (except for adoptability, 3.86 for H3). Some interesting issues were discovered in the open comments concerning adoptability. In the pattern ‘Mental health expert advisor’ that suggests developers to offer the possibility for mental health portal users to consult a human expert, the financing issues were raised by two evaluators: How much would such a service cost? Could such a service be subsidized by the state where the portal is implemented? One evaluator also suggested to enhance the pattern with a description about how to organize the financing in detail. This was something we did not think about during the development process.
In the pattern that suggest ‘Anonymous information access’ an evaluator commented that a mental health expert’s advice in Sweden is subject to revision by various authorities (e.g. the National Board of Health and Welfare and The Swedish Psychological Association), which may cause hinders to the anonymity factor, in cases where a patient requires that the text of a written question should not be revealed to ‘outsiders’. This type of anonymity might thus not be feasible in all countries, which hinders its adoptability.
The pattern ‘Empathetic text and answers’ discusses the adaptation of the information provided to the background of the information seekers, suggesting empathetic tone and a lesser degree of technicality for people suffering from mental distress. One of the evaluators argued that this was vague and suggested to explicitly define where to draw the line between empathetic and technical in terms of text quality and text composition.
Other comments included to let external mental experts sign and attest the quality of the knowledge available on the portals. This would work as a ‘certificate’ of quality and should be included as part of the solution for the pattern ‘Reliable medical sources’. Two evaluators chose the response ‘I can’t answer’, in the question about consistency for the pattern ‘Empathetic text and answers’.
Result summary
The summative evaluation results of the patterns’ content show that the following apply for the content of all patterns: all questions related to relevance (average 4.54 for H2) and coherence of the problem (average 4.51 for H4) scored above 4.0. This indicates that the following hypotheses are verified for all pattern groups: H2: The patterns address a problem that is significant and relevant for health portals and research within e-health, HCI and language technology; H4: the description of the problem is coherent in the sense that it makes sense on its own and does not contain any contradiction. The questions related to usefulness (H1) and coherence of the solution (H5) scored average marks above 4.0 for IR patterns (average 4.47 for H1, 4.37 for H5), interface patterns (4.40 for H1, 4.43 for H5) and functionality patterns (4.65 for H1, 4.30 for H5), but average marks below 4.0 for NLP patterns (3.77 for H1, 3.64 for H5). These results indicate that the following hypotheses are verified for three pattern groups but only partially verified for NLP patterns: H1) the knowledge embedded in the patterns provides a substantial contribution for developers of mental health portals to resolve an existing problem; H5) the description of the solution is coherent in the sense that it makes sense on its own and does not contain any contradiction. Adoptability (H3) scored average marks above 4.0 for IR patterns (4.13), interface patterns (4.13) but lower average marks for functionality patterns (3.86) and NLP patterns (3.60). This indicate that the following hypothesis is verified for IR patterns and interface patterns, but partially verified for NLP patterns and functionality patterns: H3) the patterns are likely to be used in real situations by designers of health portals and domain experts.
The questions related to consistency (H6) scored above 4 for IR patterns (average 4.63) and functionality patterns (average 4.37). The following hypothesis is thus verified for these pattern groups but only partially verified for NLP patterns (average 3.41) and interface patterns (3.90): H6: The patterns conform to the existing knowledge and vocabulary in e-health, health portals, HCI or language technology. Similarly, the hypothesis related to granularity (H7) – the patterns provide a solution with a level of detail that adequately reflects the problem that is addressed – is verified for interface patterns (average 4.28) and functionality patterns (4.33), but only partially verified for NLP patterns (3.89) and IR patterns (3.86). The NLP patterns group seems to be the group that needs more development with the knowledge part, since the questions related to hypotheses H1, H3, H4, H5, H6 and H7 scored average marks below 4.0. Comments from the evaluators about the proposed solutions and the level of details confirm these indications. Evaluation results of the pattern language show that the hypothesis concerning the language of the patterns (H8) is verified for all pattern groups (all averages equal to or above 4.0), so we can argue that the language utilized in the patterns was precise in its description of the problem and the proposed solution.
The open comments indicate three interesting fine-tuning points: (1) the evaluators suggested for some patterns an addition of more alternatives or alternative methods in the proposed solutions, (2) the evaluators considered some of the solutions vague and suggested the addition of more detailed and concrete examples and (3) some patterns could be potentially adopted in other domains where similar problems arise, that is, they were not specific for the mental health portal domain only.
Comparison with related research
Response rate and sample size
To our knowledge, there is currently no consensus in the research community on what constitutes an acceptable response rate. Some authors claim that 20 per cent is acceptable 52 while others claim that 50 per cent should be the minimum. 53 Previous research about response rates and surveys 54 has shown that surveys with lower response rates generally have lower demographic representativeness, but in this study, demographic representativeness is not a relevant factor, since the participants’ expertise and knowledge are of greater importance. Several research studies 52 showed that surveys with response rate near 20 per cent provided more accurate answers than surveys with higher response rates (e.g. 60% or higher), which demonstrated more dedication by the informants that provided the feedback. Previous research 55 has also shown that the higher the respondents are on an organizational hierarchy, the harder it is to get their involvement in answering online or mail surveys. Hence, we consider the resulting response rate in this study to be acceptable.
There is no clear consensus on what is considered an acceptable sample size. The size should be ‘large enough’ to be representative of the population; 56 however, the sample size is always an arbitrary judgement 57 that also depends on time and budgetary constraints. 58 Some researchers claim that smaller sample groups fit better research with complex or large qualitative information coming from individual respondents. 58 In this case, relevant data might be missed if large sample groups are used. 57 Although the response rate of our study is deemed acceptable, a larger number of evaluators would provide more substantial material for the quantitative evaluation. However, the approach to include a set of non-randomized domain experts ensures that the respondents who completed the survey were more likely to be motivated and engaged, as evidenced by the valuable feedback in the open comments. Their qualitative information was very useful to understand the quantitative results and to identify future improvements of the patterns.
Evaluation of knowledge patterns
The average scores of the quantitative results of our research are comparable with Nilsson36 and Rolland et al.,48 but are higher than Chung et al. 50 Nilsson 36 evaluated design patterns for GUI for mobile applications with the help of a 6-point scale questionnaire with 48 participants, where the average scores were around 5.0. The evaluation focused only on two parameters (relevance and usefulness) while this research covers eight parameters/hypotheses. Rolland et al. 48 evaluated knowledge patterns that modelled business processes and business changes in organizations. We have utilized their approach in the summative evaluation of the content and language of our patterns; however, their research utilizes 21 parameters/hypotheses and – in addition to the patterns’ content and language – they also assessed the methodology for developing their patterns. The data collection was also performed with the help of a questionnaire that 26 evaluators compiled interactively at a workshop. Most of their patterns achieved average scores per hypothesis equal or above 4.0.
Chung et al. 50 evaluated design patterns for ubiquitous computing. The researchers performed an iterative evaluation based on two-rounds with 16 evaluators working in pairs. The patterns were improved after each evaluation round depending on the feedback received. Their quantitative results were also based on a 5-point scale but their data collection was performed through interactive workshops instead of questionnaires. Their three pattern groups scored average scores of 3.1, 3.6 and 3.8, respectively.
Kohler and Kerkow 59 also utilized several criteria in the evaluation process of patterns in the domain of workflow modelling. Among others, they assessed: usefulness, understandability (i.e. our comprehensiveness), consistency and applicability (i.e. our adoptability). For the evaluation, they applied interviews with three domain experts in the field of workflow applications. Their results are not directly comparable to ours since they did not utilize a point scale but gathered ‘yes/no’ answers to research questions such ‘does the solution proposed in the pattern description solve the problem stated in the pattern description?’ or ‘can the solution proposed in the pattern description be transferred to a concrete solution in a software system?’. For eight of their nine patterns, the results were positive. But due to the different data collection approach, the results are not comparable.
Discussion and conclusion
To our knowledge, this is the first study that describes the development and evaluation of knowledge patterns for online mental health portal development. This is also the first study that presents results that cover three foundational aspects: knowledge integration of language technology approaches, experiments with language technology applications and user studies of portal interaction. The knowledge patterns were the results of previous research which resulted in scientific publications. The results were used as input to create the knowledge patterns. This process to create the knowledge patterns included different stages of expert validations, from formative workshops with knowledge pattern experts to summative surveys with experts in specific domains. This should provide scientific validity of the knowledge contained in the patterns.
Our study has some limitations, for instance the sample size as mentioned in section ‘Comparison with related research’. Although the response rate is deemed acceptable, a larger number of evaluators would provide more substantial material for the evaluation. Our evaluation mixed-methods approach could have been extended or complemented by for example interviews or interactive workshops. This was, however, not feasible in this study. All our experiments with CLIR techniques were performed utilizing Swedish as a source language and English as target language. No further studies were performed with other languages.
In summary, the lessons learned and future directions of this study are as follows:
The involvement of domain experts and knowledge patterns experts in the formative evaluation improved the cohesion of the patterns as self-contained units of knowledge. This type of involvement is advisable when developing knowledge patterns in this domain.
The results of the summative evaluation indicate that overall the issues/problems discussed in the knowledge patterns are relevant for the domain, and that the knowledge embedded in the pattern was useful to solve them. The language utilized was considered precise in the description of the problems and the solution.
The evaluators suggested the addition of more details in the solution parts that were considered vague and also suggested the utilization of graphic examples in order to illustrate the solution. If online health portal developers better understand appropriate design solutions, they can develop interfaces and search services that improve the information search experience and relevance of retrieved results.
The content of mental health expert’s advice in Sweden is subject to revision by various authorities (e.g. the National Board of Health and Welfare and The Swedish Psychological Association) in order to ensure its quality, as one evaluator pointed out. This may cause conflicts with anonymity in cases where a patient requires that the content of a written question should not be revealed to ‘outsiders’. This problem could be relevant even in other countries with similar regulations.
Two evaluators raised important points regarding financing issues of portal services, such as human expert consultation. Could such a service be subsidized by the state where the portal is implemented? This was something we did not consider in our patterns, but could be included in the future to help health portal developers.
In one pattern, there is a proposition to adapt the information to the background of the information seekers, with an empathetic tone and a lesser degree of technicality. One evaluator suggested to explicitly define where to draw the line between empathetic and technical in terms of text quality and text composition.
Some evaluators commented that a couple of patterns could be potentially adopted for development of portals in other domains than mental health, which means that the resulting knowledge patterns may be more widely adoptable.
Further work is needed to finalize the NLP patterns, in particular the solution sections. We leave this as a future work.
Ten patterns out of thirteen achieved an average score above 4.0, which is a positive and encouraging result that indicates the quality of the patterns, and leads us to conclude that they can be used as guidelines for developing mental health portals.
Online health portals are important resources for providing relevant, accurate and supportive information, especially in the domain of mental health. Developing such portals with multilingual support and tailored interfaces has the potential of reaching a larger group of citizens globally without requiring visits to specialist centres. The findings from this study provide important directions in further advances in this area.
Footnotes
Acknowledgements
The authors would like to thank the experts and the evaluators for their vital help and also thank the anonymous reviewers for valuable comments. S.V. is supported by the Swedish Research Council (2015-00359) and the Marie Skłodowska Curie Actions, Cofund, Project INCA 600398.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.