
Abstract
We utilize deep neural networks to develop prediction models for patient survival and conditional survival of colon cancer. Our models are trained and validated on data obtained from the Surveillance, Epidemiology, and End Results Program. We provide an online outcome calculator for 1, 2, and 5 years survival periods. We experimented with multiple neural network structures and found that a network with five hidden layers produces the best results for these data. Moreover, the online outcome calculator provides conditional survival of 1, 2, and 5 years after surviving the mentioned survival periods. In this article, we report an approximate 0.87 area under the receiver operating characteristic curve measurements, higher than the 0.85 reported by Stojadinovic et al.
Introduction
Colon and rectum cancers rank among the top cancer types worldwide. The chances of survival increase with early diagnosis, and treatment can greatly increase the chances of eliminating the disease. 1 Colon cancer is common among men than women. The Surveillance, Epidemiology, and End Results (SEER) Program is a good source of domestic statistics of cancer. SEER approximately covers 30 percent of the US population representing different races and across several geographic regions. The data are publicly available through the SEER website upon submission and approval of a SEER limited-use data agreement form.
In this article, we analyze data obtained from the SEER program, in particular, the colon cancer data. Our goal is to develop accurate survival and conditional survival prediction models for colon cancer and making these models publicly available via an outcome calculator. The data analyzed in our study are from SEER’s colon and rectum cancer incidence between 1973 and 2010. The follow-up cutoff date of the data set is 31 December 2010. 2 These incidences are collected from four different regions in the United States.
Neural networks are considered deep when they have more than two hidden layers. 3 Deep neural networks (DNNs) have been successfully used to solve image,4–6 speech recognition, 7 and text classification 8 problems. In this work, we used DNNs to predict survival of colon cancer patients, at the end of 1, 2, and 5 years of diagnosis. We also predict conditional survival given survival of 1, 2, and 5 years. We built models to predict outcomes of colon cancer based on a set of patient attributes. We experimented with multiple neural network structures and found that a network with five hidden layers produces the best results for these data. Moreover, we developed a front end to effectively provide a tool to facilitate user interaction with the developed models. This tool can be used to provide insight from the historical data that SEER provides.
Background
The increase in availability of electronic medical records leads to interest in mining medical data. Data mining research has been published on private hospital data9,10 and publicly available data such as American College of Surgeons National Surgical Quality Improvement Program (ACS NSIQP)11,12 and United Network for Organ Sharing (UNOS).13,14 Since SEER data are publicly available, there have been many studies conducted on its data. SEER provides a tool, SEER*Stat, to assist in generating statistics about their data. Data mining applications have been developed on various types of cancer. Zhou and Jiang 15 explored decision trees and artificial neural networks for survivability analysis of breast cancer. Also, using the breast cancer data, Delen et al. 16 studied neural networks, decision trees, and logistic regression for survivability prediction. Survival of lung cancer on SEER data has been studied by Chen et al. 17 Agrawal et al.18,19 analyzed SEER lung cancer patients and provided an outcome calculator for survival and conditional survival using ensemble voting techniques.
Data mining applications and studies of colorectal cancer are not covered as much as breast or lung cancers. Fathy 20 studied colorectal cancer survival prediction rates versus the number of hidden nodes in the artificial neural networks (ANNs). Stojadinovic et al. 21 developed a clinical decision support model using Bayesian belief network (ml-BBN). Wang et al. 22 analyzed colorectal cancer survival based on different parameters such as stage, age, gender, and race.
The continuous success of deep learning in the fields of computer vision and speech recognition and the increase in availability of electronic health records (EHRs) helped the surge of research of different types of neural networks on EHR. Cheng et al. 23 proposed a convolutional neural network (CNN) to extract phenotypes and perform prediction of chronic diseases on patient EHR. Lipton et al. 24 used intensive care unit (ICU) data and evaluated the ability of recurrent neural networks (RNNs) using long short-term memory (LSTM) units to classify 128 diagnoses given in 13 clinical measurements.
Data
We had earlier analyzed colon cancer data from SEER, 25 since then new submission has been made by SEER. 26 The new data enabled us to experiment with a newer set of features and get better predictive accuracy using deep learning methods, as presented in this article. The cutoff date for the new SEER data was 31 December 2010. The cutoff date is to determine the status of the patient at the time of data release by SEER. If a patient had survived past the cutoff date, but passed away afterward, their status at the cutoff date is the one reported, that is, the patient is reported alive. If a patient was diagnosed after the cutoff date, their record is excluded from the data release. We analyze different periods in our study; as a result, each period has a different end date. For example, if we are to build a model for 1-year survival, we consider patients diagnosed up to the year of 2009. This is to guarantee that all patients had a full year before the cutoff date of 2010. The same logic applies to patients analyzed for 3 years of survival; we consider patients diagnosed up to the year of 2007 (see Table 1) for class distributions.
There is clear imbalance in the two classes of colon survival across most of the years we studied.
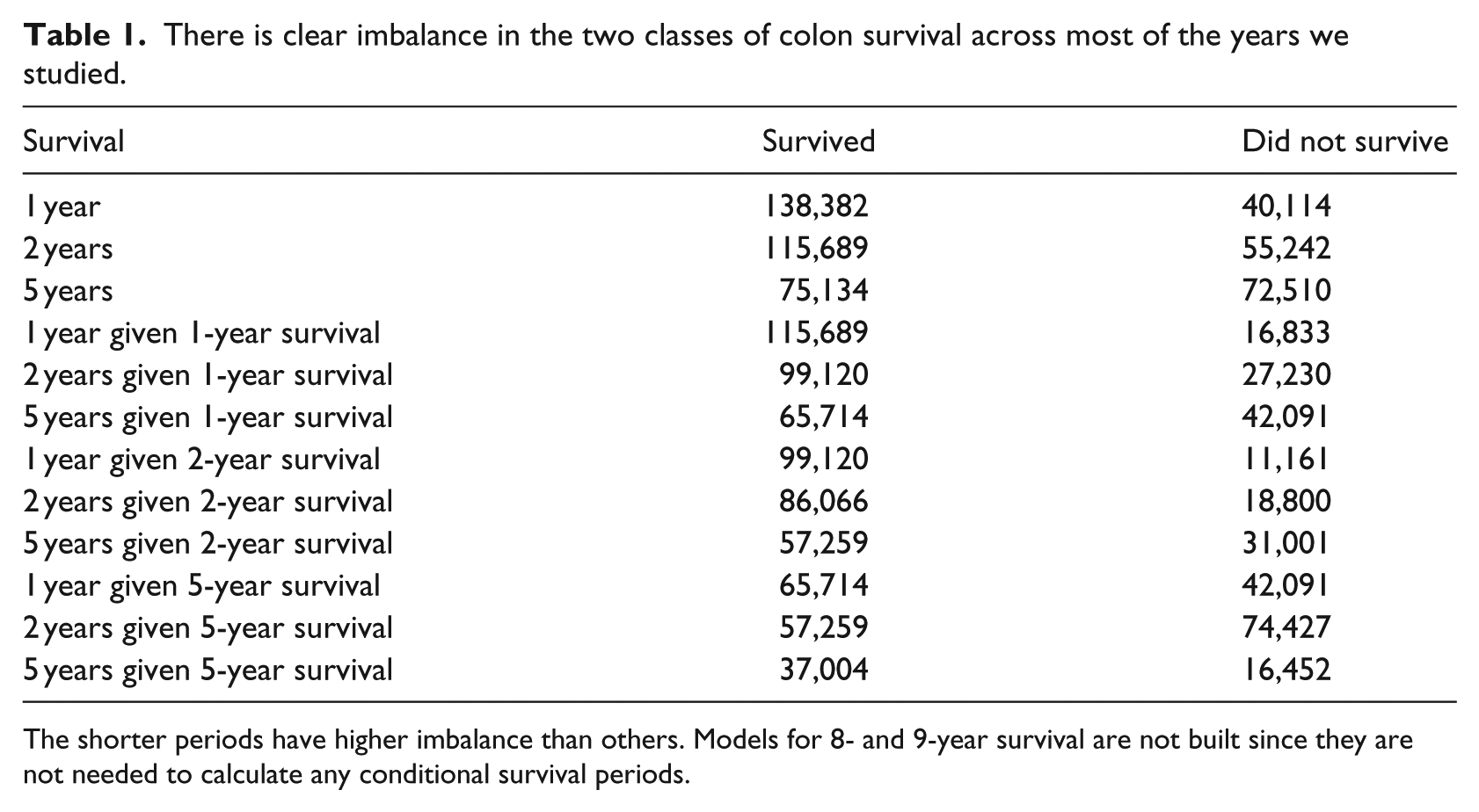
The shorter periods have higher imbalance than others. Models for 8- and 9-year survival are not built since they are not needed to calculate any conditional survival periods.
The majority of features in the data set are categorical features such as sex, birthplace, and stage. A few features are numerical such as tumor size and number of nodes. To overcome this, categorical features were transformed using a one-hot scheme. Each categorical feature was transformed to integers and mapped to sparse matrices where each column corresponds to a category of a feature (see Table 2).
Categorical feature transformation.

Numerical features were normalized to improve performance of estimators. Standard normalization was applied to numerical features to make such features look more like normal distributions

The rest of the article is organized as follows: section “Background” summarizes related work, followed by a description of the data used in this study in section “Data.” A description of the methods used in this work is described in section “Methodology.” Results are presented in section “Results.” In section “Outcome calculator,” a brief description of the outcome calculator is provided, and a conclusion and future work in section “Conclusion and future work.”
Methodology
The SEER data contain attributes that have been collected for specific periods and attributes that contain patient vital status. First, any attributes that contain vital status indication are removed. We combine some attributes such as tumor size. Collaborative Stage (CS) tumor size was collected for years 2004 onward and for years 1988 to 2003 the tumor size was collected under the Extent of Disease (EOD) 10-size feature. A new feature is engineered to cover both periods. After the data are cleaned, they are split into training, validation, and testing (50/30/20). Feature selection is done only from the training set, and the best features are selected from the validation and testing sets based on how their rank was in the training set. DNN models are built using the training and validation sets and then checked against the testing set. Figure 1 gives an overview of the architecture. The following sections describe the components of the system.
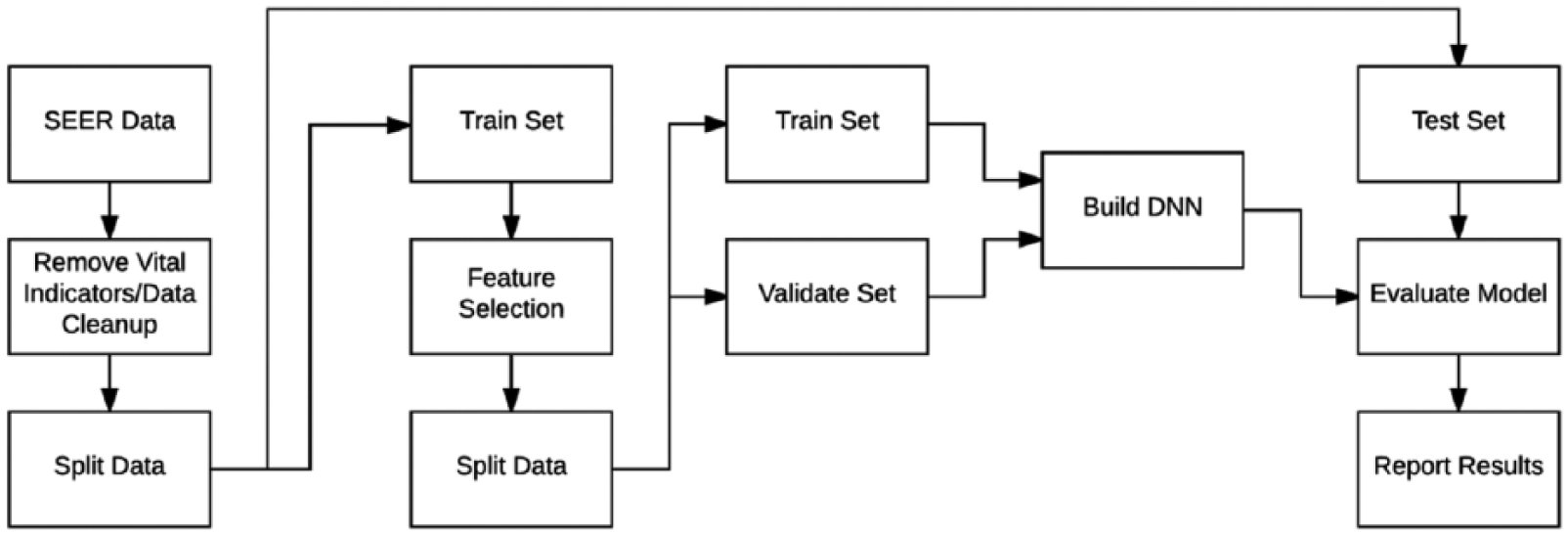
An overview of the steps in our experiment. After the removal of vital status indicators and data cleanup, the data are split into training, validation, and testing sets. Feature selection is performed on the training set and the same features are then selected from the validation and testing sets. Neural network models are built using the training and validation sets and results are reported after running the testing set against the learned models.
Feature selection
The SEER data set have 143 features. In order to build a user-friendly outcome calculator, we need to have a smaller set of features that represents the whole set of features. Any feature that directly indicates the vital status of the patient is manually removed before running feature selection. Using scikit-learn, we select the best performing features on the training set. We use a meta-transformer with a base algorithm of extra-trees. Extra-trees are a set of randomized decision trees on multiple sub-samples of the training data set. The use of randomization and multiple subsets improves accuracy and avoids overfitting. After running the feature selection algorithm, we select features having importance value greater than 0.01. Also, after removing any redundant features, we obtain the features in Table 3.
Features used in building prediction models.

EOD: Extent of Disease.
Neural network building blocks
Rectified linear unit is an activation function that is strictly non-negative and its output has a lower bound of 0 with no upper bound (see equation (2) and Figure 2)

Softmax function is used to transform the outputs of the network into probabilities. It takes an input vector z of length K and outputs a probability vector of the same length that sums to 1 27
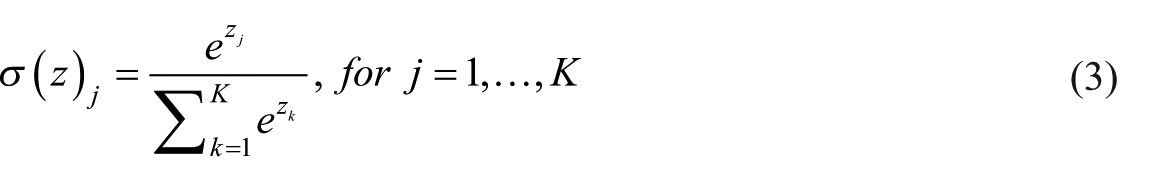
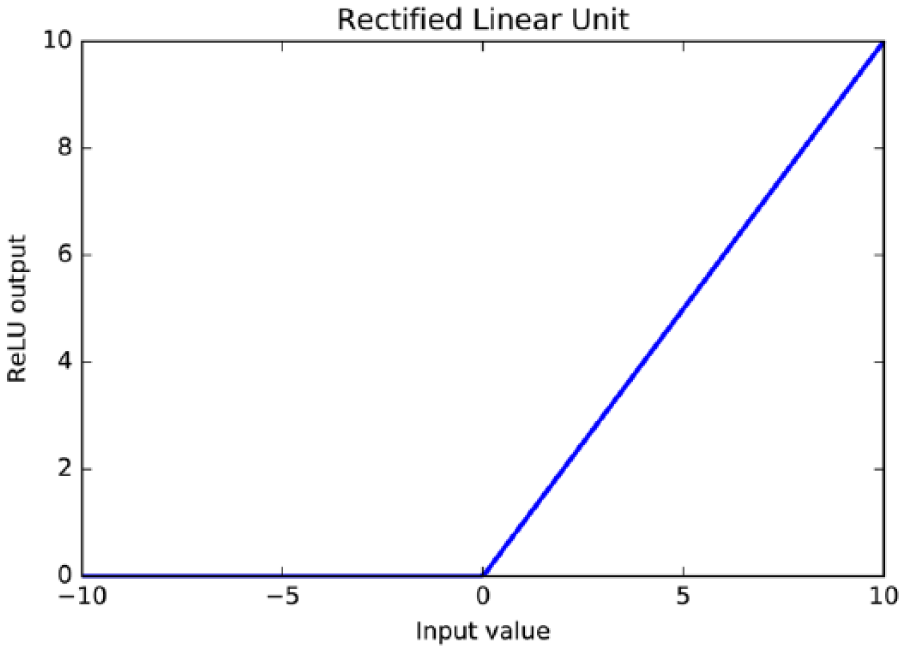
The rectified linear unit activation function is strictly non-negative and its output has a lower bound of 0, but no upper bound. It yields neurons with exactly 0 activation, that is, inputs to the activation function that are below 0 will always output an activation of 0.
DNN
Neural networks are inspired by biological neural networks. They are used to estimate functions based on inputs and weight adjustments for hidden layer nodes “neurons.” These adjustments enable these networks to learn. 28 Each node “neuron” has an activation function that defines the nodes output given an input (see Figure 3 for a full connected neural network structure example). All activation functions in the experiments were rectified linear units. A neural network is considered deep if it has more than two hidden layers. 3
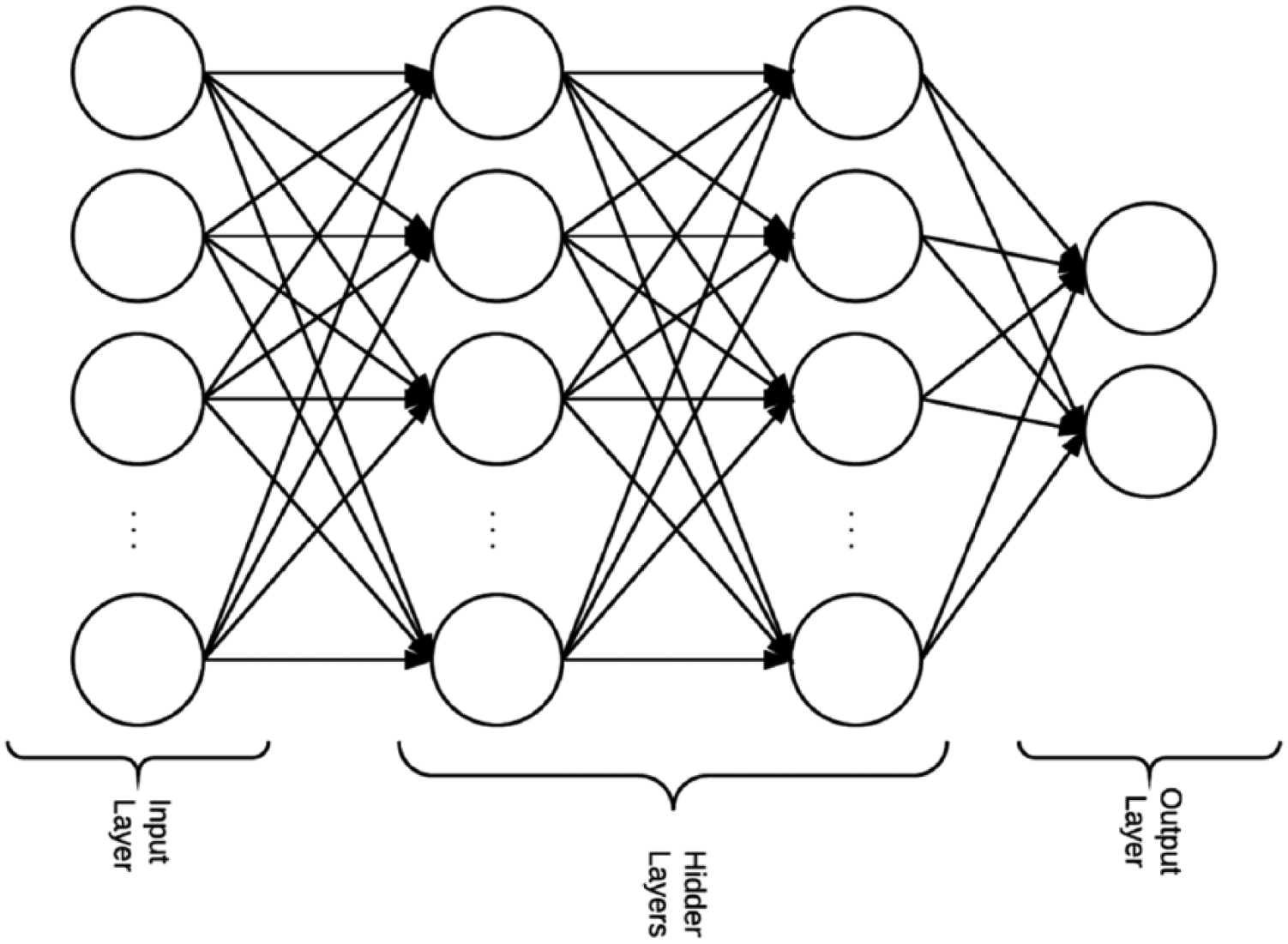
An example of a neural network structure with two hidden layers.
The neural network is trained by performing a forward pass. Then, the error is calculated by comparing the actual class and predicted class. Based on the error, a backward pass is done (backpropagation) to adjust the weights of the network. The neural network is trained on mini-batches randomly sampled inputs from the training set.
Baseline models
We compare the performance of our neural networks approach against two baseline classifiers: random forests and logistic regression:
Random forest. The random forest 29 classifier consists of multiple decision trees. The final class of an instance in a random forest is assigned by outputting the class that is the mode of the outputs of individual trees, which can produce robust and accurate classification and ability to handle a very large number of input variables.
Logistic regression. Logistic regression 30 is used for prediction of the probability of occurrence of an event by fitting data to a sigmoidal S-shaped logistic curve. Logistic regression is often used with ridge estimators to improve the parameter estimates and to reduce the error made by further predictions.
Conditional survival
Conditional survival is the probability of a patient surviving an additional y number of years after surviving x number of years. We create different data sets to build conditional survival models. For example, to calculate conditional survival of 5 years given that the patient already survived 2 years, we first select patients that have survived 2 years. Then, we mark a patient to be alive if they satisfy surviving a total of 7 years; otherwise, they are marked no alive. The Colon Cancer Outcome Calculator presented here calculates patient-specific survival and conditional survival probabilities.
Artificial neural network structure
Developments packages
The DNNs used in our experiments were developed using TensorFlow 31 an open-source software library for numerical computation and, Keras 32 a minimalist, neural networks library, written in Python. Keras was used to enable fast experimentation with different network structures.
Selecting the network structure
In our experiments, we trained fully connected neural networks. We started by training a single-layer network and captured the performance measures of the network on a test data set. By iteratively adding layers to expand the network, we collected performance measures of networks of depths ranging from a single layer to eight layers. We trained models with depths between one and eight hidden layers. We selected the network consisting of five hidden layers, and our selection was based on the five measures we used to evaluate our models. As shown in Figure 4, the collective set of measures performs best for the neural network with five hidden layers. The DNN structure that we used was selected based on training on 1-year survival data. The same network structure was used on the remaining periods.
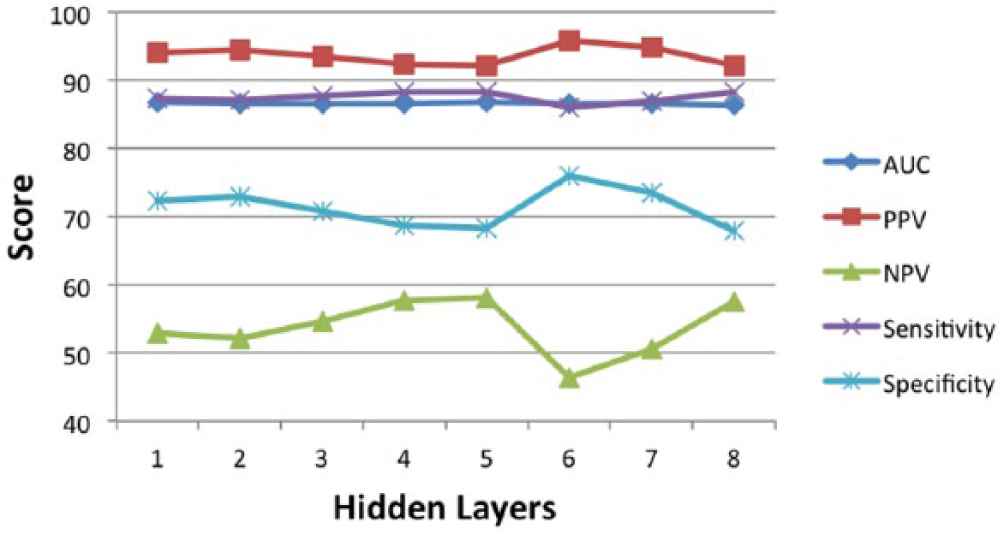
Comparison of all performance measures at different network depths was made to select the best network structure. A network with five hidden layers was selected and used for all survival periods.
Final structure
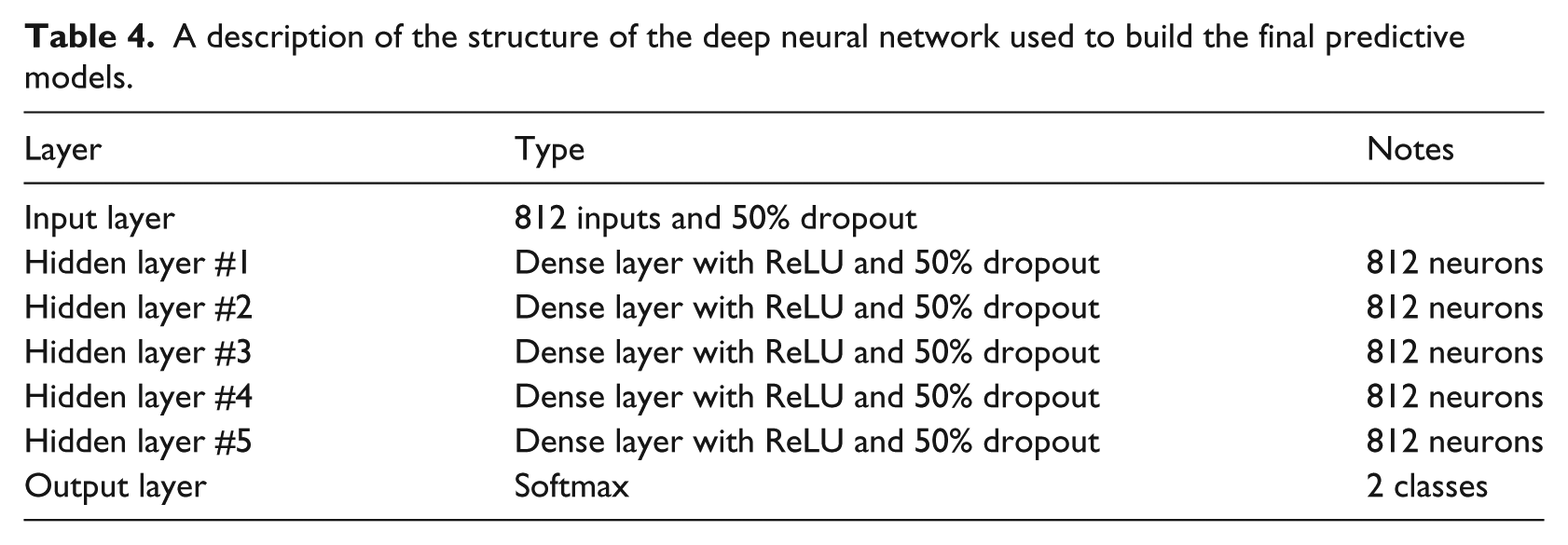
A description of our network is presented in Table 4. Our proposed neural network consists of an input layer, five hidden layers, and a softmax output layer. All of the layers are fully connected dense layers with rectified linear units.
A description of the structure of the deep neural network used to build the final predictive models.
Neural network regularization
Two of the useful techniques to regularize the network during training are examining the validation set error after each epoch and dropout implementation.
Early termination
It prevents overfitting of the network by looking at the performance on the validation set and stopping the training of the neural network as soon as the loss stops improving, that is, decreasing in value. Early termination prevents over optimizing on the training set and takes in consideration the validation set. In our experiments, we monitor the validation loss and stop the training when the loss does not decrease over two consecutive epochs.
Dropout
Different layers of the network are connected using activation functions. Dropout is randomly setting a percentage of the activations to 0 during the training of the network (see Figure 5). Dropping out activations enables the network to not rely on specific activations to be present forcing the network to learn redundant representations. These redundant representations make the network robust and avoid overfitting. 33 Moreover, the network acts as an ensemble of networks. In our experiments, we tried training without dropout and dropout out of 25 and 50 percent and found that dropping out 50 percent of the activations gave the best results.
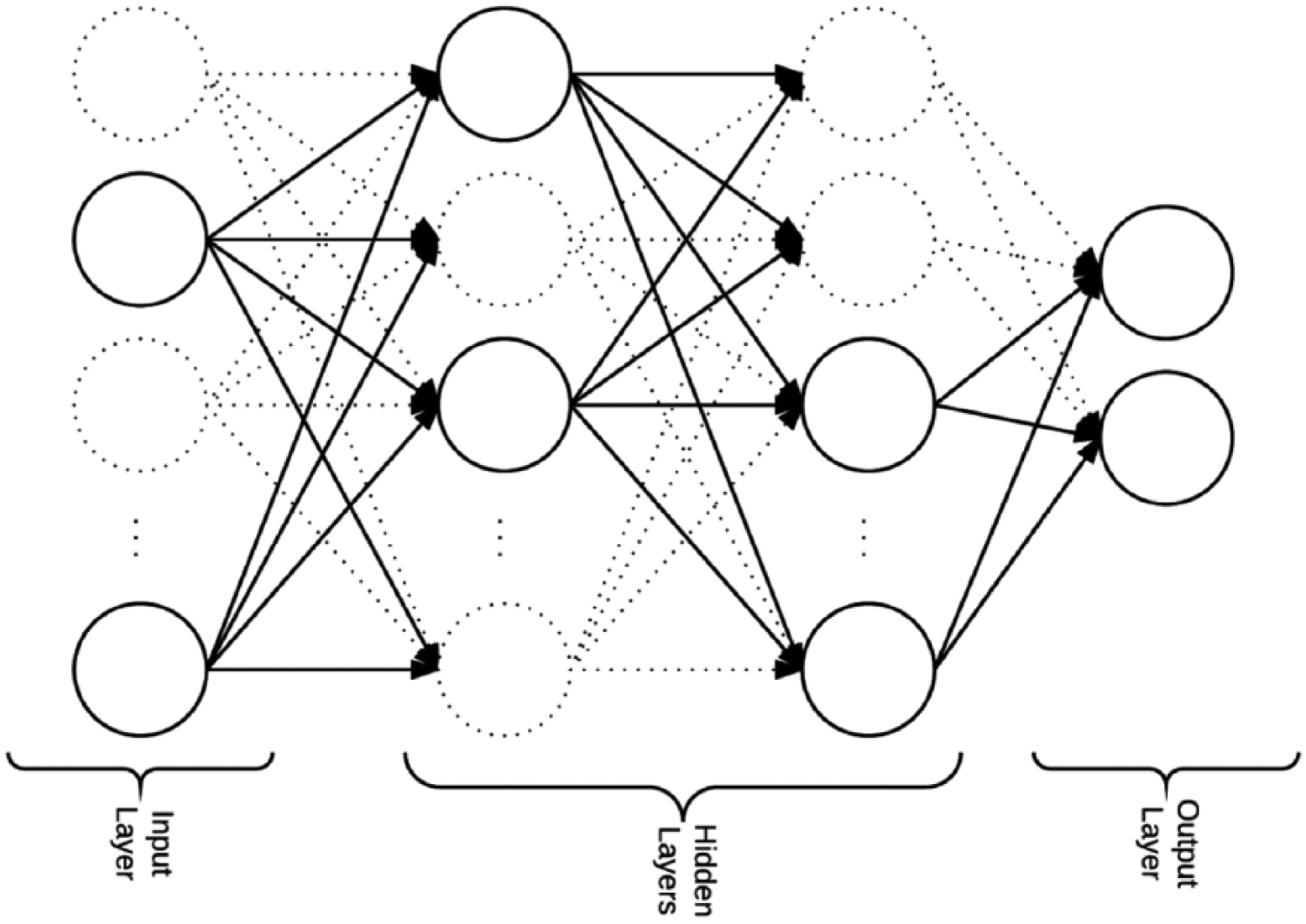
Randomly dropping out activations enables the network to learn redundant representations. This helps building robust networks and less overfitting.
Performance measures
We use the following performance measures in our experiments to evaluate the DNNs:
Area under ROC curve is a calculation of the area under a curve after plotting the true-positive rate versus the false-positive rate. Since this metric is independent of the classification probability cutoff and truly measures the discriminative power of the model in distinguishing cases from non-cases, it is considered a more reliable evaluation metric than other cutoff-based metrics as described below.
Positive predictive value also known as precision is the ratio of true positives to both true positives and false positives combined and is calculated as follows

Negative predictive value is the ratio of true negative to both true negative and false negative combined and is calculated as follows

Sensitivity is the portion of positive labeled examples in the data set that are classified as positive

Specificity is the portion of negative labeled examples in the data set that are classified as negative

Results
We trained multiple models on subset of the SEER data set. The data set of colon cancer patients consists of 188,336 records between the years of 1988 and 2009. All these models were of the same structure presented in Table 4. We compare our results against the results from Stojadinovic et al. 21 We also show results for conditional survival models in Table 5 and compare the results against the two baseline models we described earlier (random forests and logistic regression).
Result comparison between Bayesian belief network (ml-BBN) model reported by Stojadinovic et al. 21 and the neural networks (NNs) we developed.
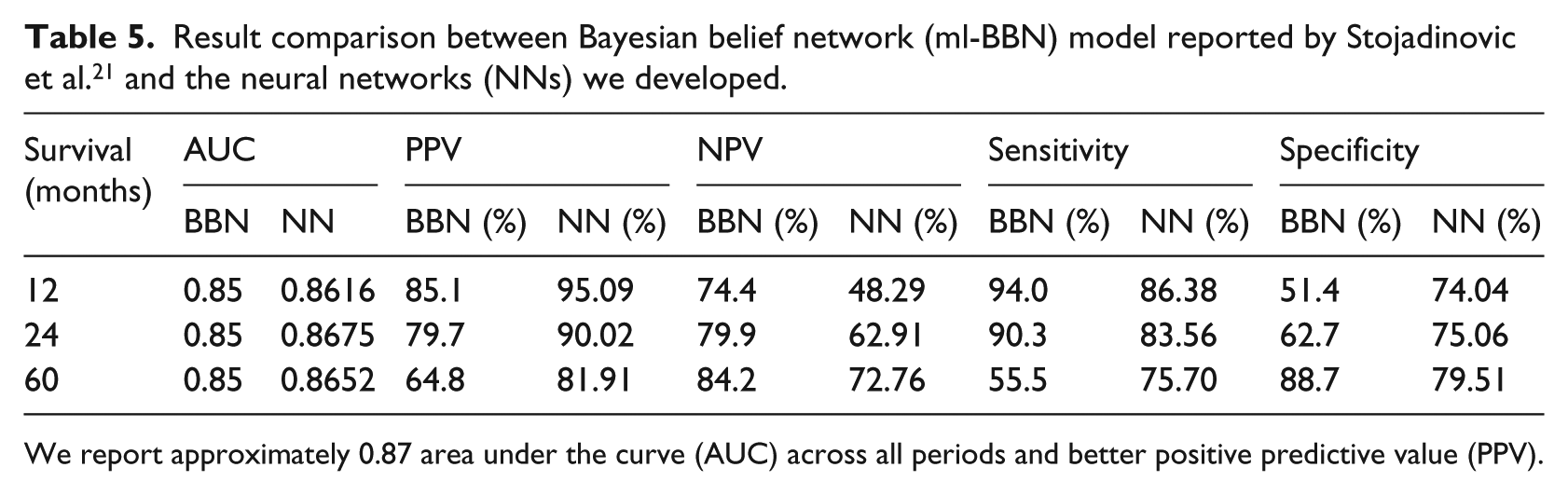
We report approximately 0.87 area under the curve (AUC) across all periods and better positive predictive value (PPV).
Stojadinovic et al. present their results for mortality, whereas our study is for survival. The results are organized accordingly to compare the metrics (see Table 5). Sensitivity measures the proportion of correctly identified positive instances. Our models yield better area under ROC numbers and positive predictive values. Moreover, our models have better specificity percentages for predicting survival for 1, 2, and 3 years. The sensitivity percentages are low due to the imbalance in the two classes (see Table 1 for class distributions). The conditional survival patient distribution is imbalanced and smaller compared to 1, 2, and 5 years data sets, which explains the lower values, specifically area under ROC (Table 6).
Results for the conditional survival models.
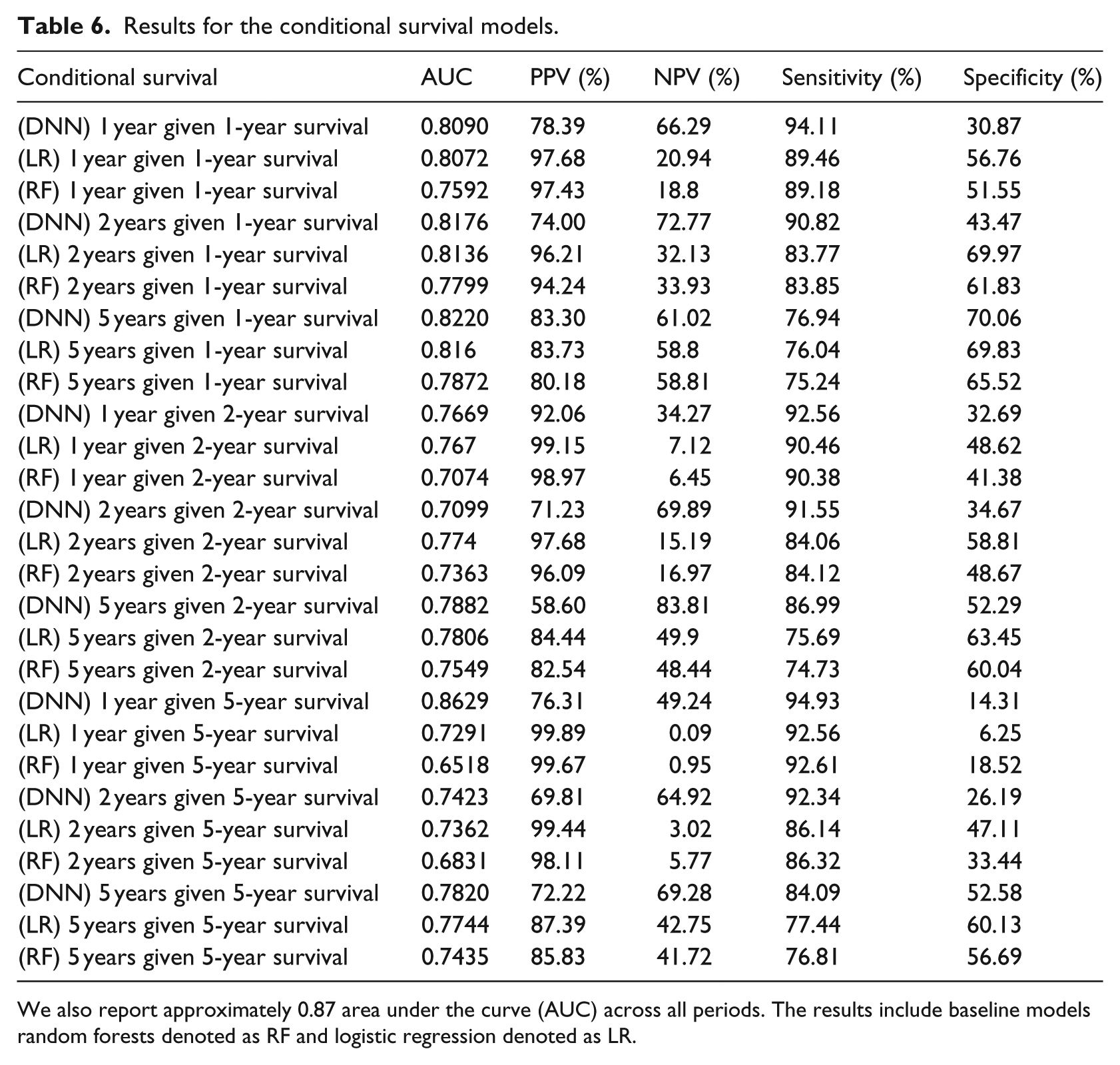
We also report approximately 0.87 area under the curve (AUC) across all periods. The results include baseline models random forests denoted as RF and logistic regression denoted as LR.
Outcome calculator
The purpose of developing an outcome calculator for colon cancer is survival estimation. We used attribute selection techniques to reduce the attribute set. The goal was to have only a few of the attributes to be used in the outcome calculator yet retain comparable production power to the original attribute set. We used 15 attributes in our calculator. Figure 6 shows a screenshot of the outcome calculator.
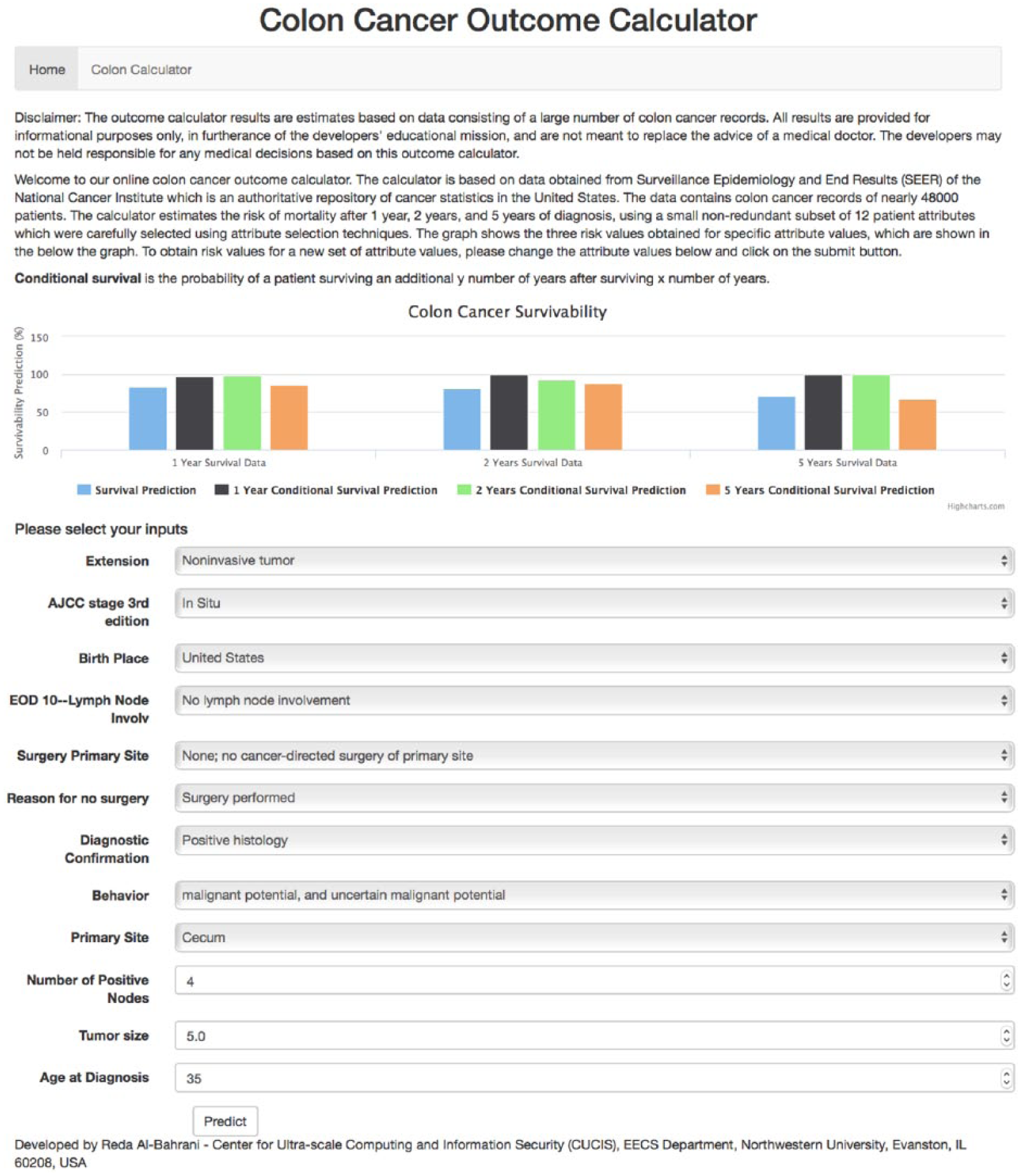
Colon Cancer Outcome Calculator (http://info.eecs.northwestern.edu:5001/).
The outcome calculator was built using several tools: Python, 34 Flask, 35 Tornado, 36 and Apache web server:
Python is a general-purpose programming language. Its strong aspects are code readability and ease of use. It enables concept expression in fewer lines of code than would be possible lower level languages.
Flask is a micro web framework for Python. Applications that use Flask include Pinterest, LinkedIn, and the Flask page.
Tornado is a scalable, non-blocking web server and web application framework written in Python.
Conclusion and future work
In this article, we utilize DNNs to make survival predictions on the SEER program colon cancer data. We look at different depths of neural networks and compare the performance metrics to come up with the best network depth for this problem. We compared our results with a previous study and outperformed in some of the predictive measures. Our models yield better area under ROC numbers and positive predictive values. Our area under ROC numbers for 1, 2, and 5 years of survival were 0.87 compared to 0.85 in the other study. Moreover, our models have better specificity percentages for predicting survival for 1, 2, and 5 years. We compare our models against two baseline machine learning methods: random forests and logistic regression. Although our models have good sensitivity percentages, these could be improved by training on more patient records. Finally, we present our models as a web application for Colon Cancer Outcome Calculator.
For future work, we would like to focus on further improving the neural network architecture, the time it takes to train it, and performance. We could also represent the data with less sparsity and examine whether that helps to improve results. Also, we would like to improve accuracy by training the neural networks on larger data sets. The data set size would be increased by obtaining more data or grouping patients’ records from multiple types of cancer.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported in part by the following grants: NSF award CCF-1409601, DOE awards DE-SC0007456, DE-SC0014330, and Northwestern Data Science Initiative.