
Abstract
Assistive technologies can improve the quality of life of people diagnosed with different forms of social communication disorders. We report on the design and evaluation of an affective avatar aimed at engaging the user in a social interaction with the purpose of assisting in communication therapies. A human–avatar taxonomy is proposed to assist the design of affective avatars aimed at addressing social communication disorder. The avatar was evaluated with 30 subjects to assess how effectively it conveys the desired emotion and elicits empathy from the user. Results provide evidence that users become used to the avatar after a number of interactions, and they perceive the defined behavior as being logical. The users’ interactions with the avatar entail affective reactions, including the mimic emotions that users felt, and establish a preliminary ground truth about prototypic empathic interactions with avatars that is being used to train learning algorithms to support social communication disorder evaluation.
Keywords
Introduction
Social communication disorder (SCD) typically encompasses problems with social interaction, social understanding, and pragmatics. 1 Assistive technologies have the potential to assist individuals who suffer from the ailment to live more independent lives, facing less difficulties and socialization issues. 2 In particular, affective avatars can engage users in conversations that can lead to effective therapies that contribute to improve their social skills, the management of their emotions and empathy, and the understanding of themselves (introspection). In this article, we report on the design and evaluation of an affective avatar that interacts with people. The avatar evaluation involved interactions with normotypical users, who tried to interpret the emotion exhibited by the avatar and whether its behavior seemed like a logical response to the interaction.
SCDs entail multiple kinds of issues, and each of them can be faced through different treatments. Therefore, we defined a taxonomy of human–avatar interactions to support seven cognitive processes. Then, we used the taxonomy to instantiate this prototype, by adapting it to support a particular cognitive process related to communication: emotional states and empathic behavior, a singular area of intervention in SCDs.
Related work
Human–avatar interaction has been the subject of research for several years. It has been applied to assist older adults in conducting activities of daily living (ADLs), 3 assisting people with severe motor disabilities, 4 and supporting elderly people with mental disorders and/or physical disabilities. 5 Additional uses include a three-dimensional (3D) avatar as an assistant in interactive TV 6 and for engagement in videogames. 7 These previous works have helped us in the process of understanding what possible needs and technologies have been used in terms of assistance to people with or without disabilities.
Some studies have assessed user preferences with different types of avatars. Some were directed at specific populations such as older adults 3 or children. 8 In some cases, questionnaires are used to conduct these evaluations, and the avatar is not necessarily fully functional; a few images of the avatar might be sufficient.8,9 Some of the findings of these studies include that the design of avatars needs to consider the needs and interests of children 8 and that a human-like appearance and a friendly attitude were preferred by older adults. A recent study explored how older adults perceived the emotion expressed in the facial expression of virtual avatars in three emotional dimensions—Evaluation (valance), Potency (power/dominance), and Activity—with significant consensus reached in the first two dimensions. 10 Of those avatars implemented, natural interaction has been achieved using gestures 5 as well as verbal communication. 7 Other studies have explored how to enact intelligent reactive behavior in avatars. 11 With regard to avatar, realism studies have found that visual realism associated with low kinematic conformity scored low in perception of social presence, 12 while Kang and Watt 13 found evidence that satisfaction with communication was associated with high anthropomorphic avatars. All these studies have helped shape the design of the avatar, as well as an awareness of what has been previously done with avatars in general.
When comparing with our work, previous research has placed no special emphasis on the affective reaction of the avatar and the emphatic response of the user. More importantly, we are not aware of previous research on the use of avatars to assist in dealing with communication disorders, generally having seen proposals with very specific goals of guiding people (either elderly or disabled) with certain activities, centered on improving the quality of life through simplifying daily tasks. The main novelty of this work is the quantitative analysis of interactions of neurotypical people with affective avatars that state the ground truth to develop future assistive avatars.
Design of the avatar-based interactions
In Ref. 14, the authors presented a conceptual prototype of the avatar designed to interact with SCD patients. Figure 1 shows the interactions supported by the avatar, indicated by arrows, which point both ways indicating bilateral communication between the human and the avatar. Particularly, voice-based communication and video- and audio-based emotion interactions refer to the audio, verbal, ocular, and facial interactions that will be explained in the taxonomy presented below.
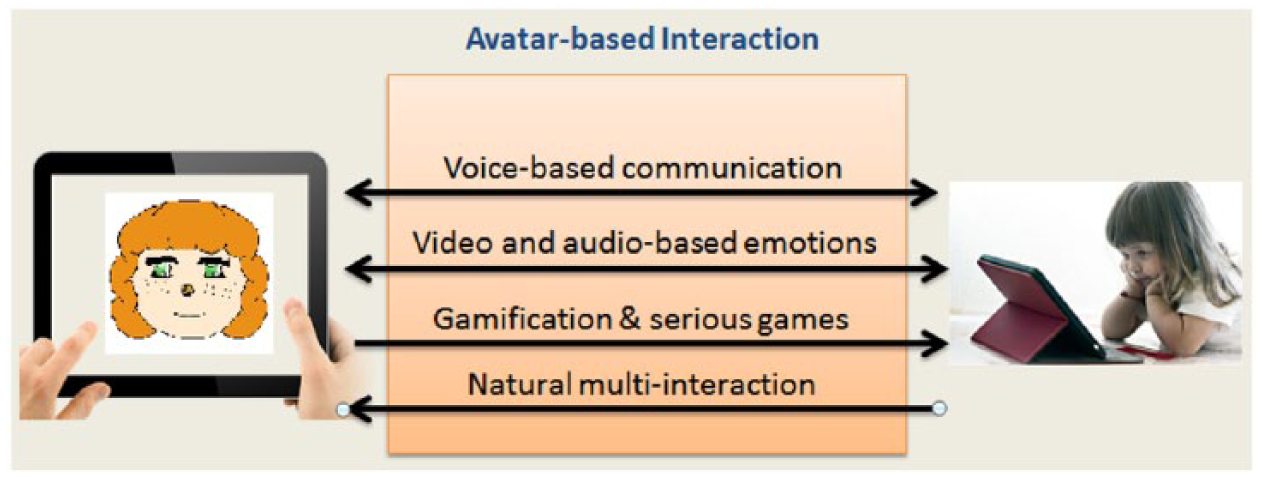
Avatar-based interactions included in the system and draft of the avatar.
Gamification and serious games15,16 refer to the narrative role playing games that the avatar will play with the human, although in this case it is unilateral as it is something that the avatar sends to the human (as the user does not propose games to the avatar). Natural multi-interaction comes from the human and they are the user’s reactions to emotions, messages, and games that the avatar shows. So although it seems like the multi-interaction is unilateral, the whole interaction is bilateral between the human and the avatar, but they perform their interaction in different ways and with different understandings; therefore, the terminology changes when the avatar interacts with the human and when the human interacts with the avatar.
The interactions were implemented through gestures in a tablet-PC; therefore, the peripherals used as sensors are those available in this device type: a camera for ocular and facial interaction, microphone for verbal interaction, and headphones/speakers for audio interaction. Both the accelerometer and the tactile screen supported the tactile interaction.
Taxonomy of human–avatar interactions
The interactions that a person can have with an avatar can be classified into different categories. Each interaction type can be used to treat particular communicative and cognitive skills. For instance, treatments to improve communication skills in children with SCD involve verbal and non-verbal communication skills.
In order to help developers identify which interaction type can be used to enhance and improve particular communication skills, we defined a taxonomy that takes into account seven cognitive processes (Table 1): joint attention (J) is the shared focus of two individuals on a same point or object and also the action of looking at each other’s eyes; focused attention (F) is the cognitive process of selectively concentrating on a discrete aspect of the communication; emotional states (E) are the feeling that we see during the communication; intonation (I) is the variations in spoken pitch that indicate the attitudes of the speaker; self-control (S) is the ability to control ones behavior and desires in communication demands; proprioception (P) represents the sense of body position (e.g. hands, arms, face) related to body language; and understanding (U) is the general comprehension of matters in the conversation.
Taxonomy of interaction types.
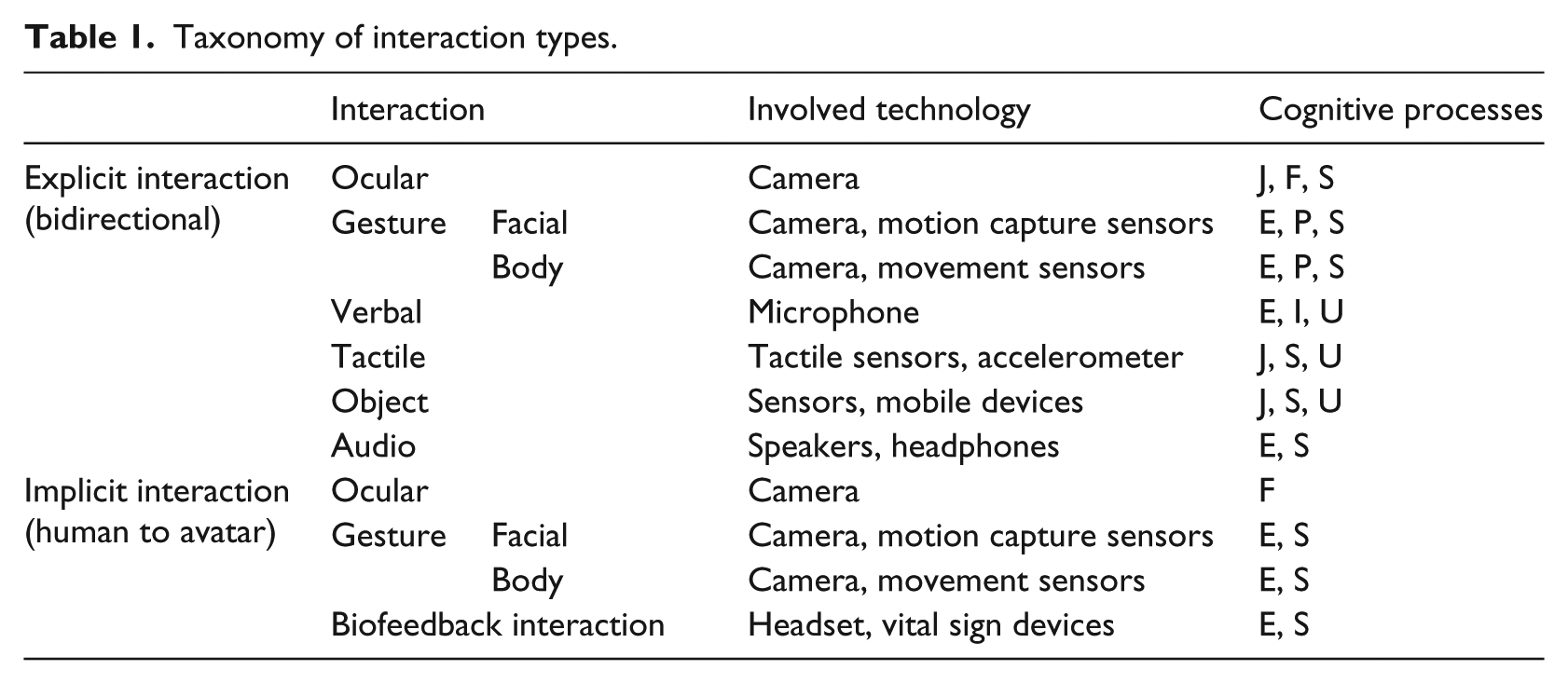
The taxonomy considers implicit and explicit interactions. Implicit interactions are related to involuntary communication elements, that is, cues such as laughing, sweating, and body postures that can reveal the inner emotional state to others.
Table 1 presents the taxonomy of interactions, including the communicative and cognitive skills that can be treated with each kind of interaction. In terms of explicit interactions using gestures, we refer to them as voluntary interactions, as they are consciously performed by the user with full intention. Because of this way to understand explicit interactions, we have classified them into the following types: Ocular, Gestural (Facial and Body-language), Verbal, Tactile, Object, and Audio Interaction.
This taxonomy, which is described in more detail in Ref. 14, aims to understand the human–avatar interactions and the way in which they affect different cognitive processes. It will also help establish reference models that guide the development of the multi-interactive avatar for SCD. Considering the conceptual prototype described in section “Design of the avatar-based interactions,” we used this taxonomy as a roadmap to develop our assistive avatar that is described in the next section.
Avatar for recognizing and managing emotions
This avatar was designed with a focus on the cognitive process Emotional State (E), and it intends to assist people in the management of their emotions. This allows supporting the undertaking of cognitive function and the theory of the mind that are important research lines in SCD. 1 The avatar design is partially based on the neurological function, particularly on mirror neurons. These neurons play an important role in the acquirement of knowledge and building empathy, which is particularly useful in the case of people with SCD.
We also work with the theory of the mind as that is the capacity we have to deduce the mental state of another person. The avatar makes this information more accessible and offers an individualized training to add to the users’ mental maps.
Avatar implementation
One of the implementation premises was that interacting with the avatar aids the user in better facing social communications in real life. For this reason, the avatar has a humanoid look, resembling reality as much as possible, and its emotional expressivity should be subtle, as it often occurs in reality. The implementation was done with Blender (https://www.blender.org/). By considering the importance of the empathy between users and the avatar gender, 8 we designed an androgynous avatar. Thus, the users themselves would decide the gender of their avatar, as to draw a more positive interaction.
After starting the design in Blender, the androgynous look has been somewhat diminished, but we have attempted to mimic it as much as possible. The design was done by extending a two-dimensional plane (in accordance with Figure 1) to a 3D model. The avatar hair was created with spheres and half-spheres to achieve the “curly” aspect. The mouth was given more attention with the design of teeth, gums, and a tongue since it has to maximize the expressivity and likeness to a human mouth. After the avatar design, we applied to it texture paint and details, finalizing with the setting of bones, which enable us to control the mesh of the avatar into moving or deforming as we wish, in this case, the expressions. Figure 2 shows the position of the bones in the avatar, as well as the end design.

Final design of the avatar and the bones that control it.
As mentioned before, those bones are what enable the expressions on the avatar’s face and general movement. The biggest bone controls the movement of the head (rotation and movement), the horizontal bone that is furthest from the face controls the wandering of the eyes, and the smallest bone in the bottom is the Bone Master, which is the root of the bone hierarchy and moves all the other bones if it is moved. The other bones, from top to bottom, control the eyebrows, eyelids, and mouth.
To achieve the different expressions, we modeled shape keys, which modify the position of the vertices of the object in relation to the basis. We created a shape key for each possible movement of the face, which included three different types of movement for the eyebrows (rise, frown and sad), a blinking motion, and several movements for the mouth which included the smile, frown, and two types of open mouth. This, together with the bones, allowed for the creation and movement of the expressions we deemed necessary for this model to show.
The expressions that we have included in the avatar are Happiness, Sadness, Anger, Surprise, Fear, an idle state that would consist on blinking, and a Neutral state (Figure 3). These expressions are the named universal emotion categories proposed by Paul Ekman in 1972, from which one was removed (disgust) due to it not being relevant to the conducted work.

(Top to bottom, left to right): Anger, Fear, Surprise, Happiness, Sadness, and Neutral.
The avatar transitions between these emotions and the idle animation depending on the actions of the user, as well as the inactions. This means that if the user is in a determined state, not doing anything will also mean changing states, as it can be seen in the state machine depicted in Figure 4.
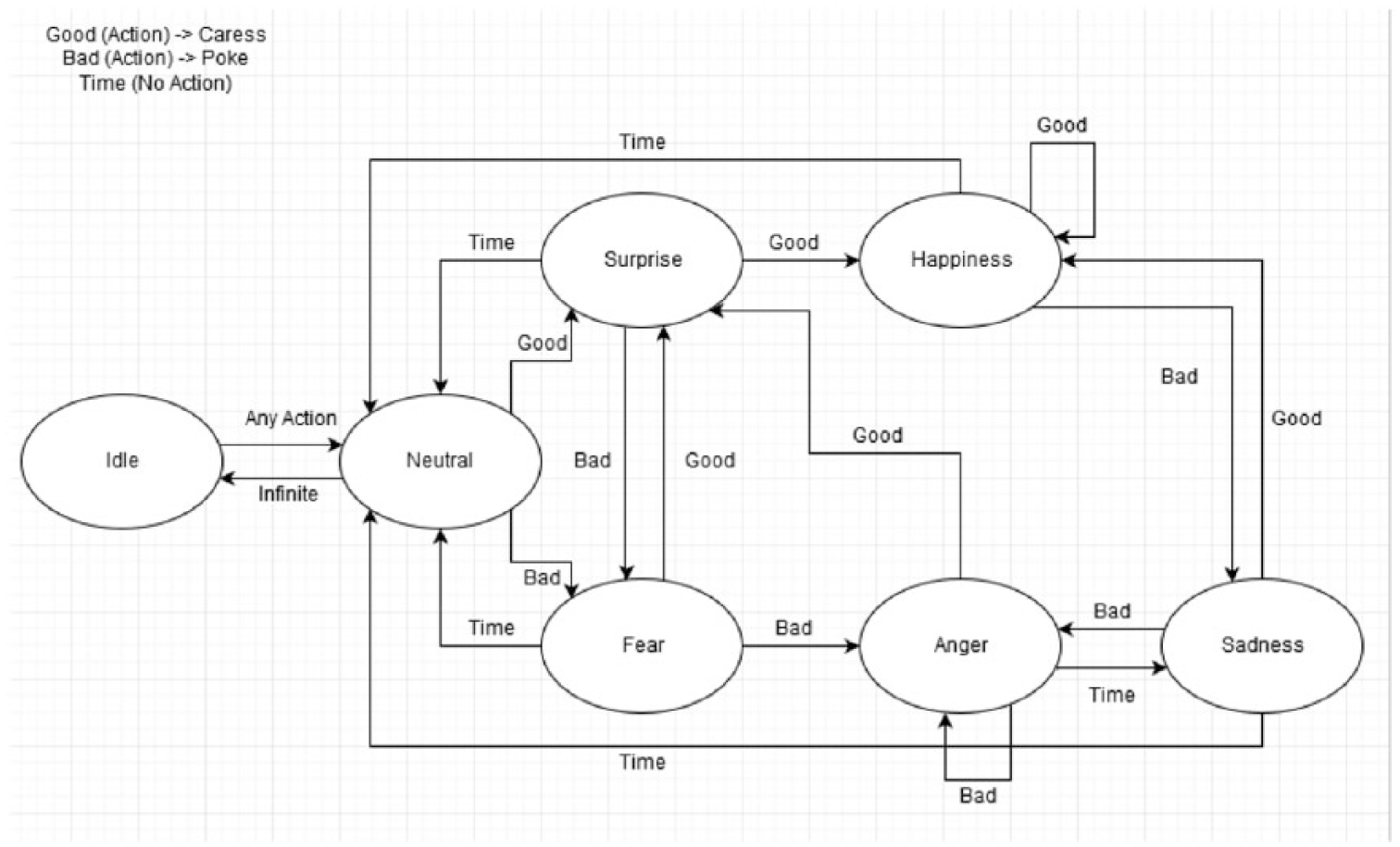
State machine that represents the changes in avatar emotions after certain actions.
In this state machine, sliding the finger on a touch screen is considered the “Good (Action)” since in the real world this action seems to be a caress. A “Bad (Action)” is poking the touch screen since in real life it can be translated to a poke, which is more unpleasant than the caress. The term “Time (No Action)” refers to those transitions that would happen when the avatar is in certain states without receiving any user interaction, as in real life one does not stay in certain emotional states indefinitely, and this was the simplest way to mimic it. The amount of time depends on the level of arousal of the current emotion (the greater the arousal level, the smaller the timeframe to stay in that emotional state); for example, going from Surprise to Neutral would take a lot less than going from Sadness to Neutral.
Experiment to assess the emotional state of the avatar
The purpose of the experiment was to validate the 3D model of the avatar and determine whether users exhibited empathy with it. The avatar was tested by showing users the avatar going through different emotional states and asking users to report the emotional state they perceived from the avatar.
In all, 30 subjects participated in the study. They were grouped by age (C1: under 12 years; C2: 12–21 years; C3: 22–30 years, 10 people for each age group) (13 males (V) and 17 females (M)). This age range and cohorts have been determined taking into account the typical ages to diagnose and treat SCDs, 1 although none of them have any diagnosed SCDs. The experimental protocol was as follows: (1) participants were informed about the purpose of the experiment and the information to be collected; (2) the avatar in its neutral emotional state was shown to participants and the different possible interactions were explained; and (3) participants perform 20 interactions with the avatar (collecting 600 interactions during the whole experiment), and the following data were collected: initial emotion of the avatar, final emotion of the avatar after the interaction, reflected emotion in the user (if any), and the opinion of the user about whether the emotion of the avatar is logical or not.
Regarding the avatar emotion recognition, although the users performed 20 interactions, we distinguished results on identification accuracy both using the 20 interactions and the last 10 since we used the first 10 for them to get familiar with the facial expressions.
Evaluation results
We describe the results obtained from the experiment, including accuracy, F-scores, and a confusion matrix. The mean accuracy in the correct identification of emotions during the whole test was 73.69 percent, while the mean accuracy of the correct identification of emotions only taking into account the last 10 interactions was 79.33 percent, indicating the overall improvement of correct identification overtime. Table 2 shows the recognition accuracy with all 20 interactions and the last 10. The last 10 are used since we consider the first interactions as a training period, when the user is getting familiar with the task and the avatar reactions; the Neutral emotion (59.88%; 65.15%) was the least successfully recognized mood, followed by Anger (61.90%; 64.10%) and Fear (65.26%; 75.56%). Happiness (94.16%; 94.27%) and Surprise (82.05%; 92.00%) were the most successful ones. There is a clear increase in accuracy when only the last 10 interactions are considered, indicating that the user gets familiar with the avatar.
Accuracy in the recognition of the avatar emotions by the user (global (top) and for the 10 last interactions (bottom)).
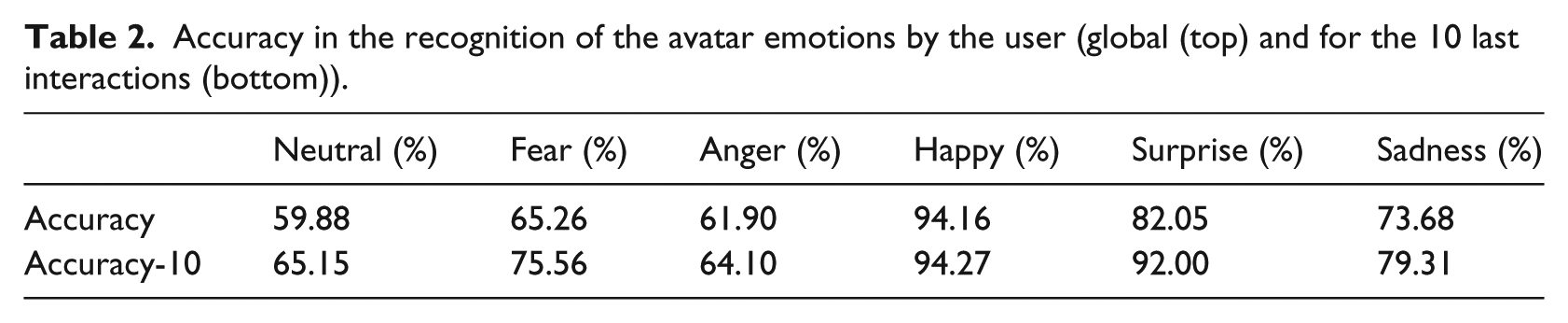
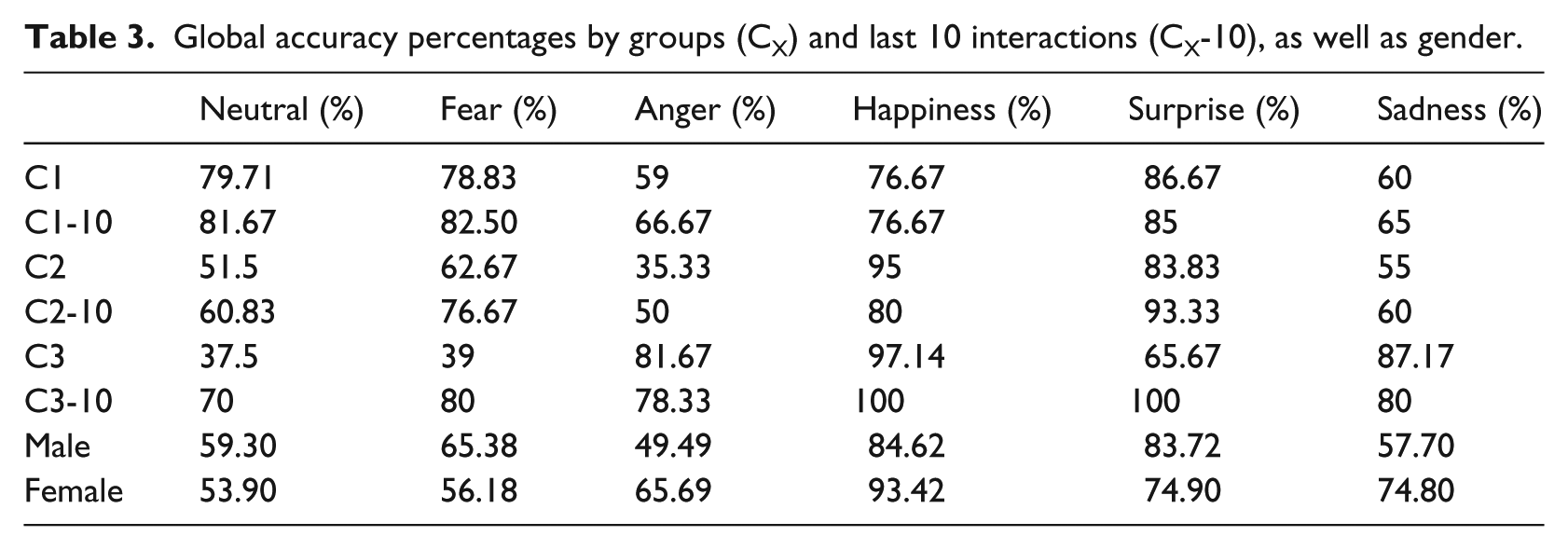
Table 3 shows the percentages indicated in Table 2, but separated by age groups and gender.
Global accuracy percentages by groups (CX) and last 10 interactions (CX-10), as well as gender.
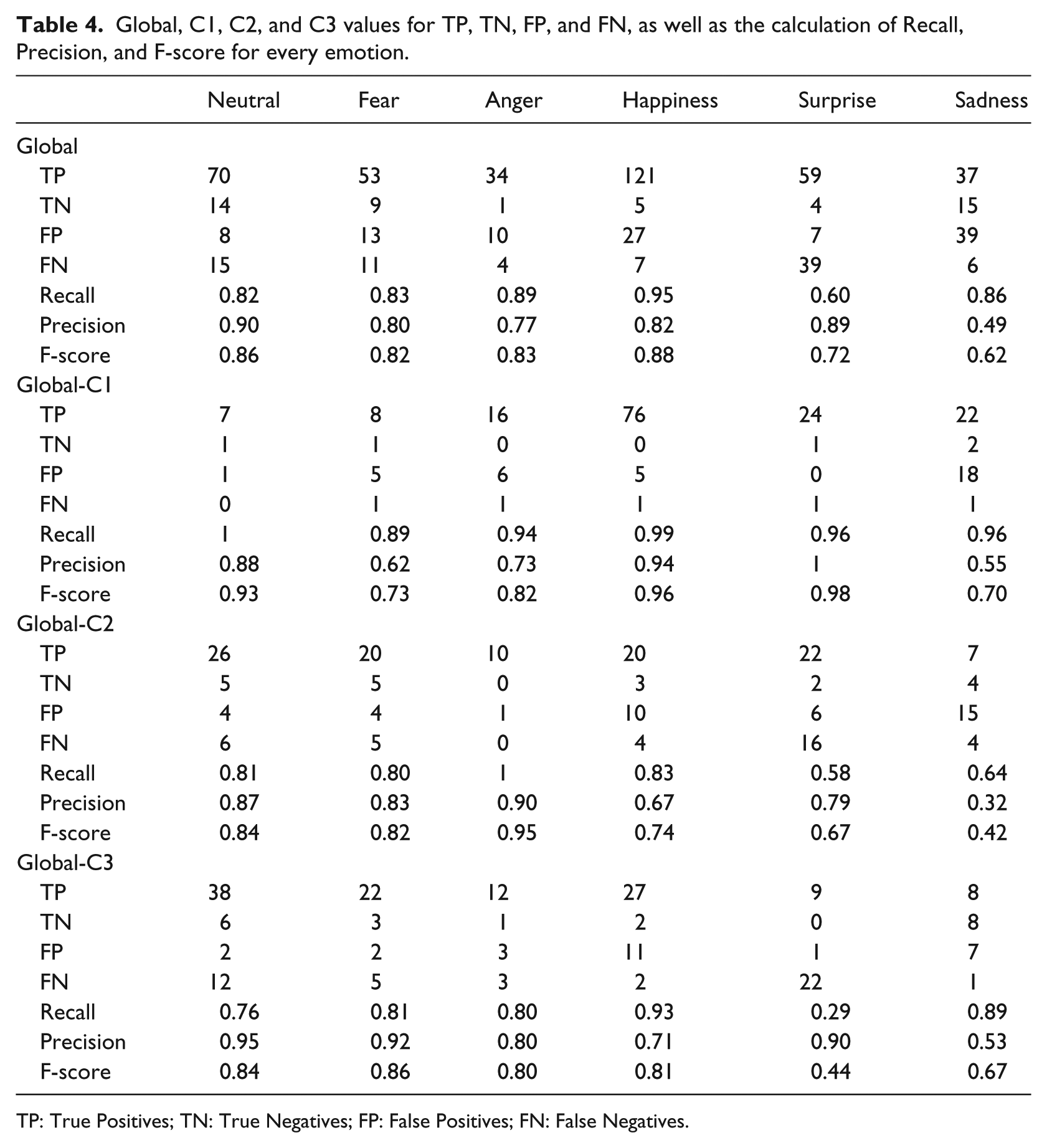
With these numbers, we set out to calculate Recall, Precision, and F-score, which will be obtained by calculating True Positives (correct emotion identification and logical behavior), True Negatives (incorrect emotion identification and not logical behavior), False Positives (incorrect emotion identification and logical behavior), and False Negatives (correct emotion identification and not logical emotion). By logical/not logical emotion, we refer to the user’s perception of the avatar’s emotion being a logical/expected one or not. After gathering all this information from the tests, we have obtained the results shown in Table 4.
Global, C1, C2, and C3 values for TP, TN, FP, and FN, as well as the calculation of Recall, Precision, and F-score for every emotion.
TP: True Positives; TN: True Negatives; FP: False Positives; FN: False Negatives.
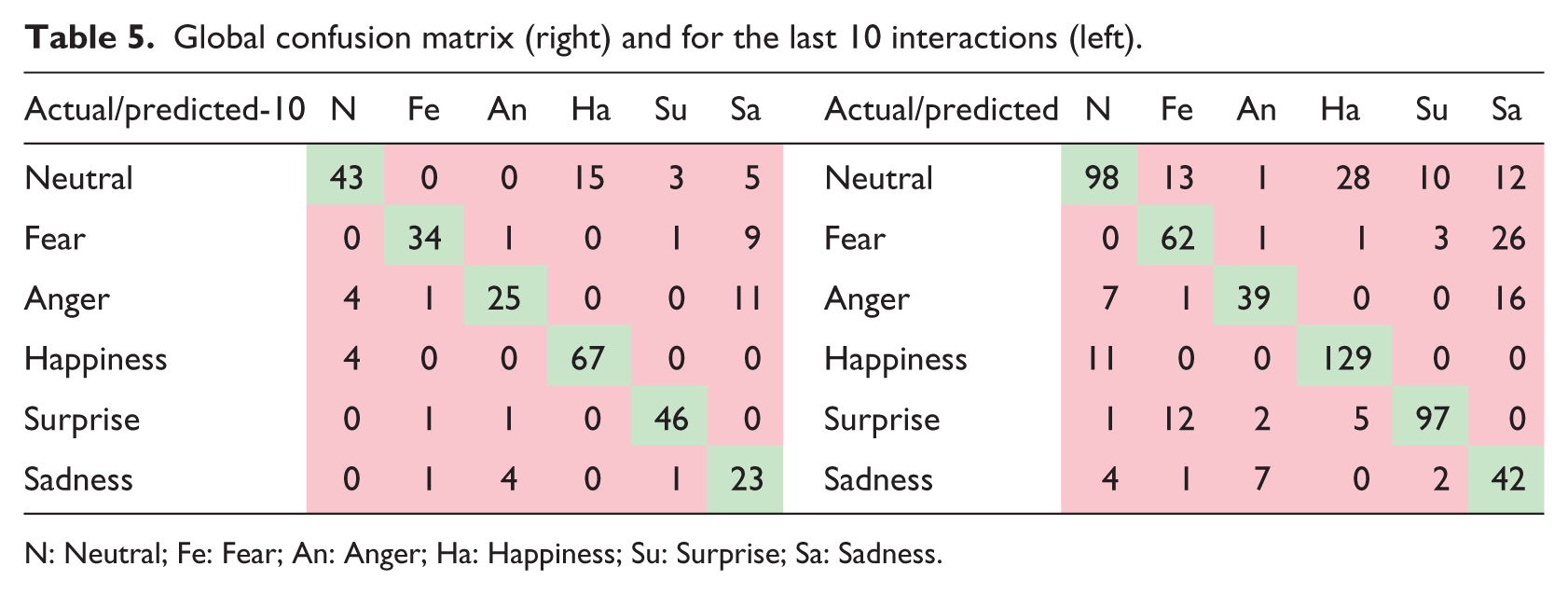
We can observe that the recall for Surprise of C3 is rather low, alongside the Precision of Sadness, which coincides with C2, although only the low Precision of Sadness occurs in C1, along with a low Precision for Fear. On a global level, the low Precision and Accuracy that occur in C3 and C2 are reflected in a similar manner. The confusion matrix below (Table 5) shows us the amount of mix-up when identifying an emotion, for which emotion it is confused, and whether the problem persists after the user has become more accustomed to the avatar.
Global confusion matrix (right) and for the last 10 interactions (left).
N: Neutral; Fe: Fear; An: Anger; Ha: Happiness; Su: Surprise; Sa: Sadness.
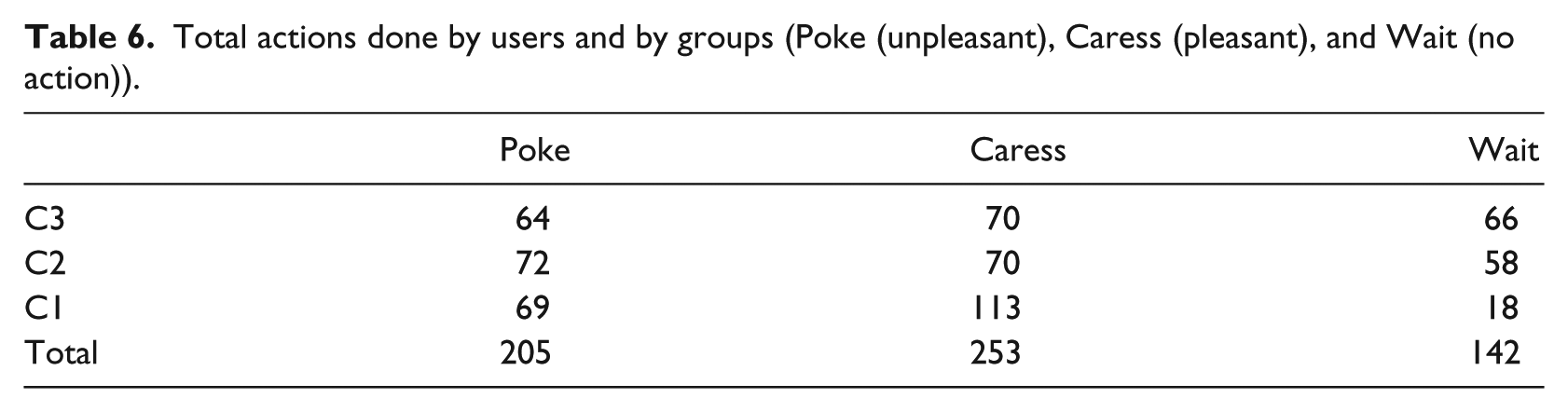
We can see that most of the errors arise with the Neutral emotion, followed by confusing Fear with Sadness, Happiness with Neutral, and Sadness with Fear. Even after becoming used to the avatar, the users continue having some issues confusing Neutral and Happiness, as well as Fear and Sadness and Anger and Sadness. The likely reason for this is the similarity between Neutral and Happiness expressions, in which both look happy and welcoming, with the idea of inspiring happier emotions, but it should be rectified so that these issues do not occur again. Sadness and Anger have a similar issue, with the difference being a subtle change in the eyebrows and mouth, for which we will strive to make them clearly different. The mix for Fear confused for Sadness is very possibly the frowns on both faces, and we will seek to rectify this as well. Finally, the interactions themselves and the feelings that have appeared the most are shown in Tables 6 and 7.
Total actions done by users and by groups (Poke (unpleasant), Caress (pleasant), and Wait (no action)).
Total number of emotions the avatar has shown, divided by groups.
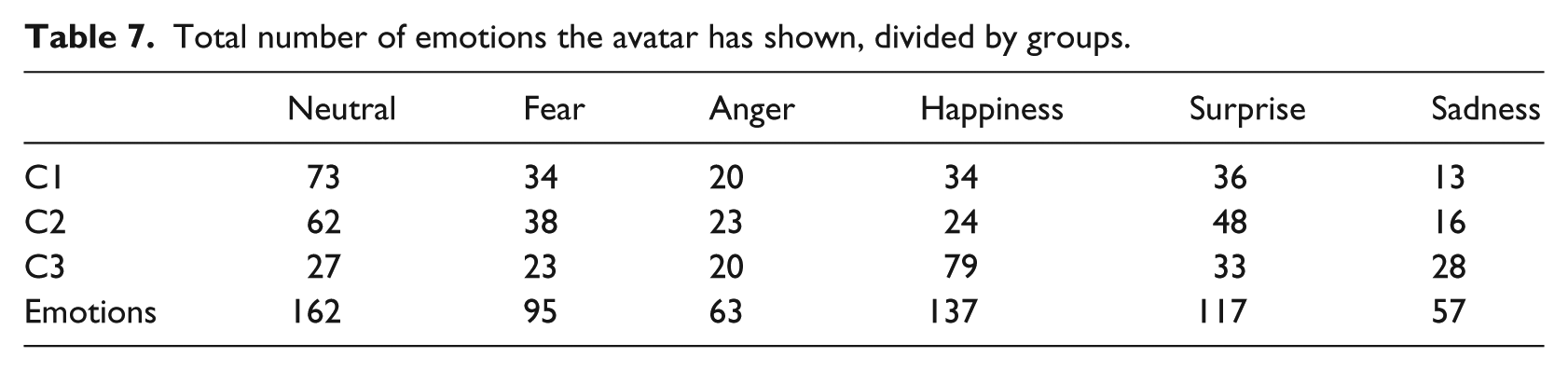
As it can be seen, most users chose to caress the avatar, followed by poking and then waiting. Younger users (group C1) engaged more in general, forgoing the wait most of the time and choosing to caress. This was because after observing the avatar behavior, they figured out that caressing made the avatar happy, and they seemed to have preferred seeing the avatar in this emotional state, even choosing not to do anything other than this action in the later part of the experiment. Groups C2 and C3, aged 12–30 years, have a much more even distribution of the actions, with an overall small difference among the three groups.
The most visited state was “Happiness” and “Neutral,” although the latter is due to the fact that it is the initial emotion. For all groups, happiness was the emotion more frequently elicited, while Sadness is the least visited emotion in the two youngest groups, whereas Anger is the least visited emotion for the older group, followed closely by Fear.
Not counting Neutral, the users had overall a more positive than negative stream of emotions (56.05% were positive, 43.95% were negative, although the split for the youngest age group was more: 59.14%–41.86%). This is a positive result, and the likelihood of the small difference is due to the older age groups commenting on the fact that feelings such as “Surprised” on the avatar annoyed them when they wanted to make the avatar happy.
Overall, most users had a positive response to the avatar, and they commented that the feeling of “Surprise” puzzled them after a certain amount of interactions, citing that “it shouldn’t feel surprised after a while.” Another reason for the small difference is that we are not accounting for Neutral, which was a fairly common feeling for older age groups. Upon observing the given answers, most children were fairly polarizing, and if the avatar was happy or surprised, they were as well, whereas negative emotions made them feel Sadness more than Fear or Anger. Sadness also had a high incidence of erroneous identifications; therefore, we will strive to fix these issues on the model.
Conclusion and future work
This work contributes to the field of health-related affective systems, particularly to help design avatar-based interactive applications to evaluate and assist people with SCD. First, the taxonomy presented in section “Taxonomy of human–avatar interactions” can aid the research community when developing interactive systems using avatars, providing a better understanding of both the interactions and the way in which they affect particular cognitive processes. Second, being the main contribution of this article, we have evaluated interactions with affective avatars, and we have learnt the following lessons:
Since the design objective of the avatar was to show emotions in a very subtle way, as they occur in real life, the evaluation highlighted the need to redesign some of them, due to low recognition accuracy by the normotypical users.
We identified a significant improvement in emotion identification after the first 10 interactions; thus, it is important to give the user certain time to get used to the avatar and distinguish its emotions and behavior.
We obtained evidence that the current state machine of affective behavior makes sense for the users when they successfully identify the avatar’s emotions.
Results evidence that users have a mimic response of emotions; they generally react with positive emotions (mainly happiness) to positive states of the avatar and also feel sad when the avatar exhibits a negative emotion.
Some differences among age cohorts have been identified. For example, we observed that C1 (less than 12-year-old users) forgoes wait without doing any interaction and performs more pleasant interactions than unpleasant.
In terms of discussion, the learnt lessons seem to evidence characteristic interaction patterns that show empathic behavior of users, for example, to avoid repetitive negative interaction in order to avoid unpleasant avatar responses and a mimic response to emotions. These findings are more evident in C2 and C3 cohorts. These patterns can enhance future assistive avatars in terms of SCD diagnosis and treatment, mainly with children over 12 years old. Currently, and after redesigning some of the avatar emotions, we are collecting more evaluation data with normotypical users and people with SCD related to empathy and emotion management (mainly Down’s syndrome and autism spectrum disorders). These data can establish a more valuable ground truth about empathic interactions with avatars and would allow the training of learning algorithms to identify empathic and non-empathic behaviors.
In terms of future work, in order to maximize the human–avatar interaction, we are including an aspect of emotion recognition so as to gather a more precise reaction from the avatar to the facial expressions of the user. This will be accomplished using active shape models and support vector machines that have proven to yield good results. 17
Footnotes
Acknowledgements
This work was conducted in the context of UBIHEALTH project under International Research Staff Exchange Schema (MC-IRSES 316337).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partially supported by FONDECYT (Chile), grant no. 1150252.