
Abstract
This article proposes a four-layer media-materialist method for interpreting AI-generated images as cultural-computational artefacts that bear archaeologically readable traces of their production conditions. Drawing on media materialism’s focus on technological processes rather than content alone, the method analyses dataset (training materials), model (computational processing), interface (user mediation), and prompt (linguistic inscription) as interdependent layers that encode distinct biases and constraints into visual outputs. Through detailed analysis of two major training datasets – the human-curated Wikipedia-based Image-Text Dataset and the algorithmically scored LAION-Aesthetics – and sample image analyses, the method reveals how cultural assumptions become statistically compressed into archetypal arrangements. Abstract prompts like ‘intellectual rigor’ materialise through embedded echoes of academic masculinity, complete with books, globes, and contemplative poses, while platform interfaces create aesthetic path dependencies that systematically shape creative possibilities. The method works both diagnostically (with known metadata) and archaeologically (when original prompts are unknown), demonstrating how visual traces can be read backwards to understand the infrastructural pressures that shaped an image’s generation. This media-materialist approach treats AI images as both medium and artefact, revealing how centuries of visual culture become probabilistically recombined through computational inference. The framework exposes how training data biases, model architectures, interface designs, and prompt conventions collaborate to produce images that appear spontaneous but are actually shaped by layered technological and cultural constraints. Rather than dismissing AI outputs as meaningless ‘slop’ or celebrating them as creative breakthroughs, the method provides systematic tools for reading these synthetic images as cultural documents that encode the material conditions of algorithmic production, offering essential literacy for navigating an increasingly synthetic media landscape.
Keywords
As I scroll through the folder of AI-generated images that I’ve saved from almost three years of experimentation, I’m struck by the diversity of quality, resolution, and content. Early experiments resemble low-resolution computer graphics or experimental art, and as time progresses the outputs become sharper and clearer; they also become more purposeful, in the sense that I generated them as placeholder images, for instance, or concept sketches, visual aids, icons, or backgrounds. A majority are hugely colourful and expressive, with bright and dynamic contrasts in hue and tone. And of course, there are those images I’ve saved because they’re charmingly or disturbingly warped, glitched, or broken. Accounting for this chaos and diversity of images is difficult when looking at outputs in isolation. But with the attendant knowledge of the platforms, prompts, processing parameters, and curation decisions involved – as well as the purposes for which I generated each image, whether professional, creative, or experimental – patterns, motivations, and systematic biases emerge.
Outside of my hard drive, AI-generated images proliferate across social platforms and content farms, weaponised for engagement, virality, and monetisation. These are at once posthuman artefacts and representational images that sit at the threshold between data and aesthetics, slop and signal (for a sociological reading of AI image aesthetics as aesthetic alienation, see Smith and Southerton, 2025). If we are indeed entering the Slopocene, what matters is not whether these images are ‘art’, but how they are made – and what they make visible (Binns, 2025). Traditional media analysis should not be discounted – it is readily able to identify what formal and compositional elements are present. But as Grant Bollmer writes, ‘When we only examine meaning, what a medium is and does is limited to human perception and experience’ (Bollmer, 2019, p. 2). With AI-generated images, formal analysis alone cannot account completely for the generative and probabilistic operations that underpin these non-indexical artefacts (i.e. images generated from scratch, rather than from photochemical or digital capture of a subject). A holistic examination requires attending to these images’ material conditions: the datasets, models, interfaces, and prompts that shape their generation.
Recent scholarship has begun developing methods adequate to this task. Eryk Salvaggio treats AI images as ‘infographics’ of their datasets, proposing analysis grounded in both formal visual methods and data auditing (Salvaggio, 2023: 84). Antonio Somaini argues that AI media require new paradigms because of their unique ‘intertwining between human and nonhuman agencies’, positioning algorithmic imagery as processual artefacts that reconfigure perception itself (Somaini, 2023: 76). Shane Denson identifies ‘a broadly aesthetic reconfiguration of agency’ at work, arguing that AI media operate on viewers viscerally, at pre-subjective levels (Denson, 2023: 148; for complementary analyses of AI visual style and platform aesthetics, see also Laba, 2024; Meyer, 2025; Thomson et al., 2026). All point toward the need for methods that attend to both computational processes and embodied effects.
Media materialism offers the analytical purchase this kind of analysis requires. Drawing on Friedrich Kittler’s attention to technological ‘circuits’ and ‘schematism of perceptibility’ rather than content alone (Kittler, 1999: xl-xli), media materialism considers the mechanisms and materials of media systems while affording attention to temporal, spatial, and ecological dimensions. As an example, Jussi Parikka’s ‘geology of media’ traces the material substrates of digital culture (Parikka, 2015: 3), removing traditional distinctions between media and content, focussing instead on the processes and entanglements of technology and culture. As an instrument of cultural analysis, media materialism has proven useful in exploring cinema, television, and audio media in relation to its infrastructural and ecological enmeshments (Cubitt, 2004; Pâquet and Moss-Wellington, 2025; von Mossner, 2024). Applied to AI images, this approach treats them as both medium and artefact: cultural objects shaped by machinic production but embedded in broader semiotic and infrastructural networks.
As an analytical orientation, media materialism does not prescribe a standardised protocol but rather a set of interpretive commitments: to attend to material processes over surface content, to trace infrastructural logics through their cultural effects, and to read outputs as symptoms of the systems that produced them. As Herzogenrath (2015) argues, ‘the material qualities of a medium… are its information’ (5) – a proposition that, applied to AI images, means the generative infrastructure is not merely context but content. It is in this tradition – where interpretive rigour is valued over procedural replicability – that the following method is situated.
The method
This article proposes a four-part method for critically analysing AI-generated images, grounded in a media-materialist approach. The method considers how generative systems function in order to interpret how their layered operations shape the outputs we see. The method treats AI-generated media as cultural-computational artefacts – traces of data, models, interfaces, and prompts sedimented into visual form, each carrying interpretable traces of the systems that shaped them.
Each section focuses on one layer of generative mediation: • • • •
These layers are interdependent: prompts operate through interfaces, interfaces activate models, and models are conditioned by data. But each site introduces distinct biases, affordances, and modes of agency. Together, they form an analytical framework for reading AI images as outputs shaped by infrastructural logics. This scaffold invites us to pose questions like: • What is well-resolved in the image? What is hazy or glitched? What might this tell us about the contents of the model’s training data? • Where do we see signs of compression, or ‘uncertainty’ about composition or style? What might this tell us about how the model operates with conflicting or divergent instructions? • If we know what prompt was used to generate the image, can we connect the language used to figures present in the output? If we don’t know the prompt, could we speculate as to what words may have been included?
Two sample images are used as illustrative cases at the end of each section. These analyses show how the mechanisms of generation, be they code- or cloud-based, mathematical, computational, or even human, leave traces in AI-generated images that are legible and explainable.
Data
Datasets are socio-technical constructs that serve as the raw material from which AI images and videos are shaped. These are selected, curated collections of cultural material, often built by scraping the open internet – a process that routinely raises questions of rights, privacy, and intellectual property, and that has demonstrably breached them in significant cases. Datasets are curated with attention and consideration to – or conscious dismissal of – questions around creative labour and cultural appropriation, and these curatorial choices are themselves ethical decisions with material consequences. Note that while datasets determine what material is available, they do not dictate how that material will be transformed or rendered: that is the role of the model. For this method, though, datasets are the first site where social, technical, and cultural hierarchies of representation take shape.
For analysts of AI media, datasets become crucial objects of study. They are the index material from which the model then ‘represents’ a simulated subject, as prompted by the user. Thus, examining datasets and what they contain or omit, offers insights into the tropes, conventions, and assumptions – visual, stylistic, and cultural – on which these models operate.
Datasets for image generation consist of many low-resolution images with accompanying metadata, usually a short text caption or description. These image-text pairs are called embeddings (Musiol, 2024: 54). In every dataset, there are certain subjects or concepts that are represented to a greater degree than others. If a dataset comprises images from social media, for example, there may be more photos of humans, animals, and scenery, than of other subjects, given the social (and algorithmic) capital of those images in that context. By contrast, a dataset trained on public domain images may privilege older photographic styles, conventions, or aesthetics. The more common a particular concept or subject, the stronger the relationship between concepts in the ML system; image generation models will also sometimes amplify these relationships, increasing representational bias (Chinchure et al., 2025; Seshadri et al., 2024).
Each dataset dictates what outcomes are possible from the model. If the dataset is limited or biased, the generator’s capacity will be affected. Similarly, datasets are collated under particular social or cultural conditions, or by companies or groups with specific interests in mind; the dataset and the tools trained on it will, in turn, incorporate and perpetuate those limitations. As Salvaggio notes, ‘Machines are programmed in ways that inscribe and communicate the unconscious assumptions of human data-gatherers, who embed these assumptions into human-assembled datasets’ (Salvaggio, 2023: 84).
Dataset comparison of LAION-Aesthetics and Wikipedia-based Image-Text dataset (WIT).
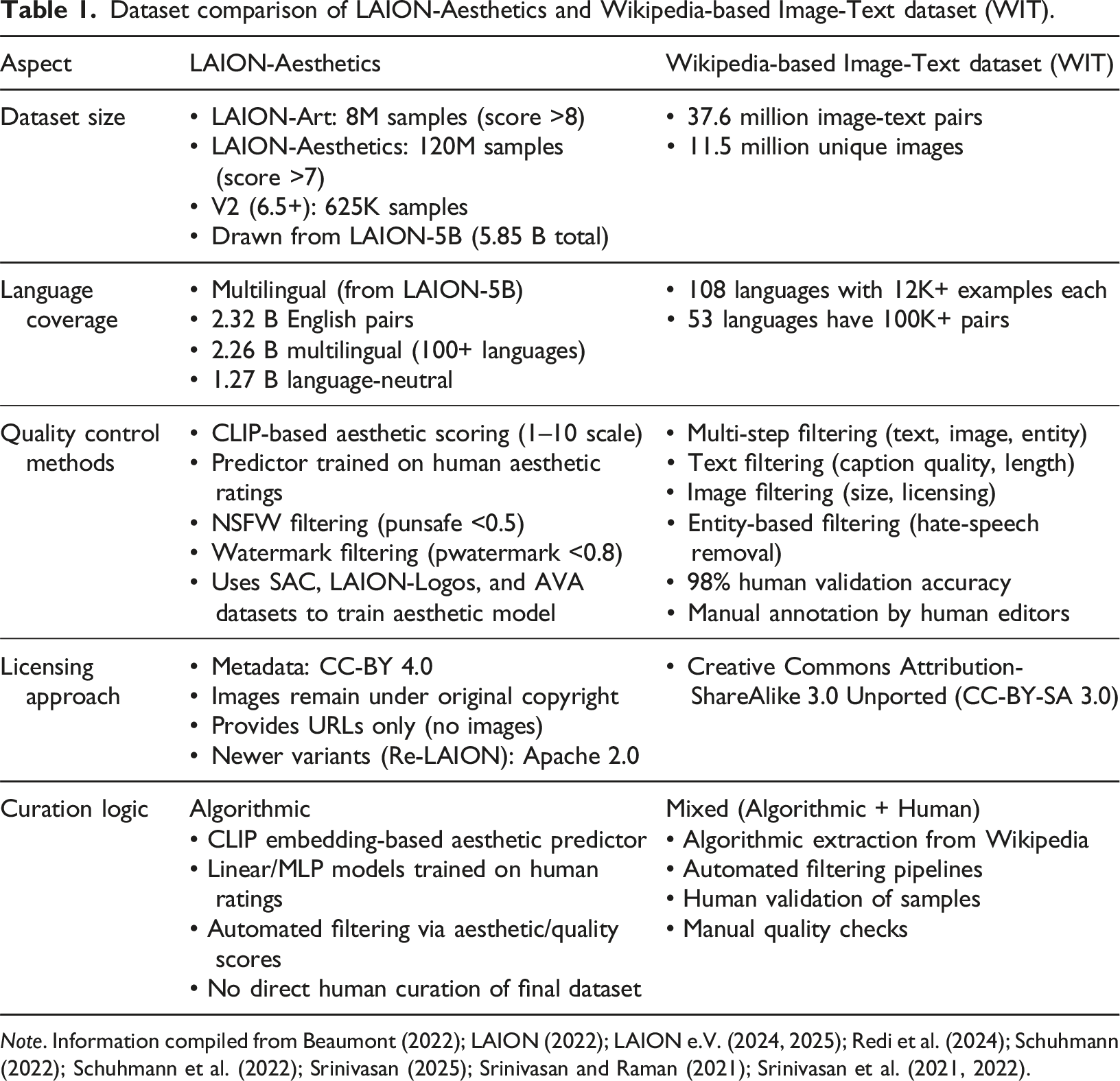
Note. Information compiled from Beaumont (2022); LAION (2022); LAION e.V. (2024, 2025); Redi et al. (2024); Schuhmann (2022); Schuhmann et al. (2022); Srinivasan (2025); Srinivasan and Raman (2021); Srinivasan et al. (2021, 2022).
Wikipedia is a constantly evolving, publicly curated reference tool, with over 65 million articles across its various language editions. There is an assumed or implied integrity and quality to this information, given Wikipedia’s already rigorous verification and correction systems. Many articles feature images, and a team with support from Google Research saw the opportunity to harvest rich metadata around those images. Using the ‘standard’ Wiki template as a guide, a crawler extracted image, caption, page title, and page description into a dataset. Once gathered, the data went through a series of basic automated quality checks: text length, generic alt-text, image format, image location (i.e. primary reference images vs supplementary gallery images), image size, and licensing (e.g. Creative Commons only).
Unlike other datasets, WIT allows for multiple text embeddings/annotations per image: this allows for more contextual information to be associated with a given image. WIT is also much more multilingual than other datasets: ‘Nearly half of the 100+ languages, contain 100K+ unique image-text tuples and 100K+ unique images’. (Srinivasan et al., 2021: 2446) As a final verification step, over 4000 random samples were sent to humans to assess in terms of accuracy of text in relation to the image presented (Srinivasan et al., 2021: 2447).
A standard sample of the WIT dataset (Figure 1) shows a mixture of image types: historical and modern images, maps, symbols, and illustrations. The images are all of reasonable quality. The linguistic inclusiveness of the dataset is present in the spread of imagery – any random sample of images features multiple languages. In that vein, the language also often suggests what is of interest to that particular demographic: exhibits from a railway museum featured on a page of museums in the Donetsk region in Russia; the main road leading into a tiny municipality in the Basque region of Spain; an image of a Bavarian weather-church, a special kind of defended or battle church, on the Dutch Wikipedia page for same. Sample images from the WIT dataset.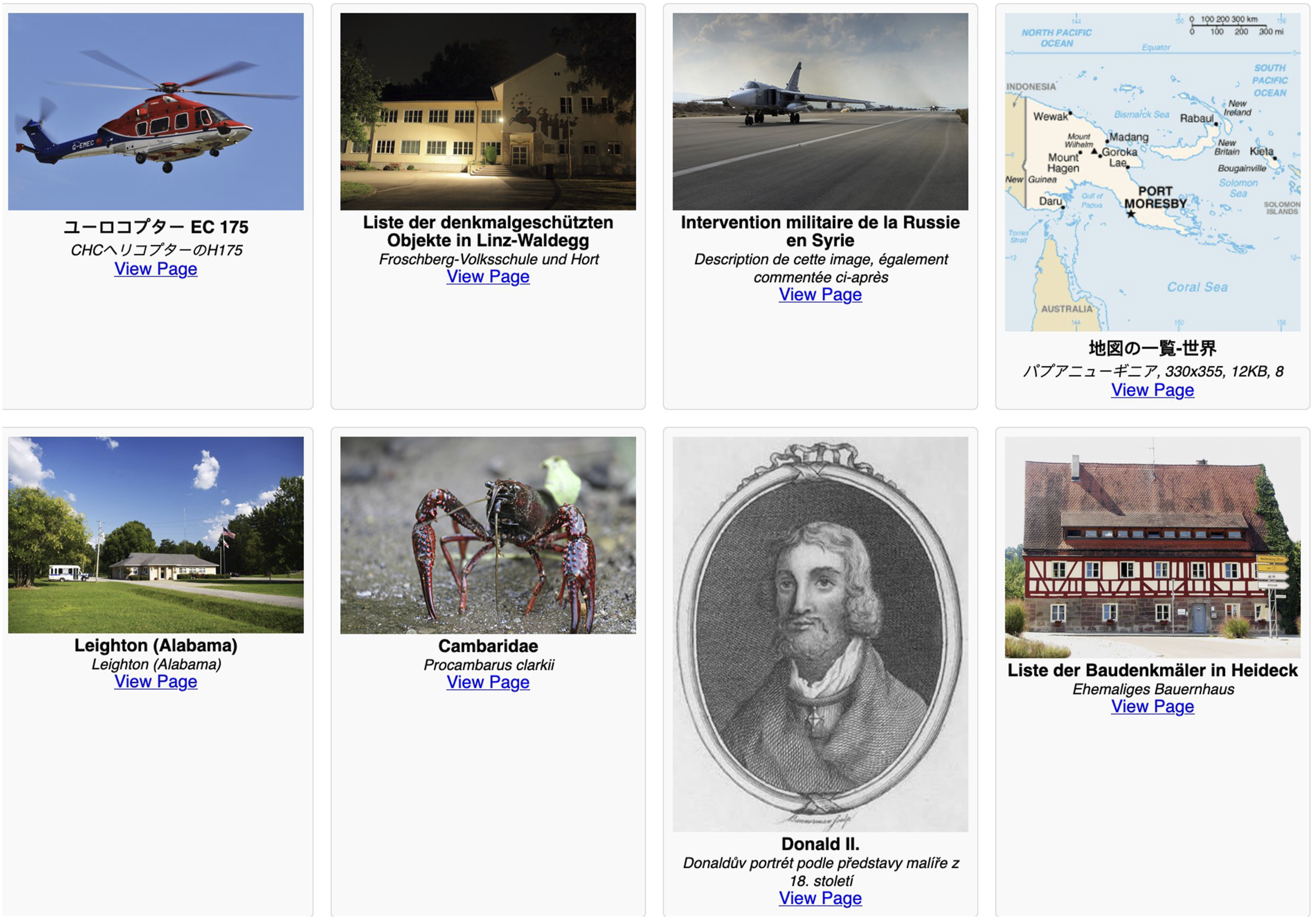
The metadata present in the dataset gives appropriate context to the images even when divorced from the Wikipedia-style layout. Most of these images have a functional, observational, descriptive quality: they are clear images of an item, person, or place. The exceptions are either maps, flags, illustrations of a concept, or examples of types of design or cultural phenomena. The functional nature of the images is reflected in the filtering of the data: the connection between textual information and the images must be strong: for WIT, contextual alignment in the metadata is key. The contents of WIT all adhere to Wikipedia’s image use policy, which prohibits the upload of copyrighted media, unless in exceptional circumstances. This means that many of WIT’s images are freely licensed. WIT has been used to train and fine-tune a variety of multimodal models including Google’s Gemma and OpenAI’s CLIP. The objective, curated nature of the dataset is palpable when browsing through it: it is clear why WIT has been deployed for specialised fine-tuning applications in scientific fields like biomedicine and robotics; its multilingual features have also made it appealing for cross-cultural developers.
As a contrast to WIT’s aligned and curated nature, LAION-Aesthetics is an algorithmically generated dataset based on a semi-subjective framework of what is deemed to be artistically valuable or aesthetically interesting or pleasing. According to the LAION website: ‘[W]e trained several lightweight models that predict the rating people gave when they were asked “How much do you like this image on a scale from 1 to 10?”’ (LAION, 2022) Two decisions are important to note here: firstly, that the predictor models were trained on synthetic images (generated by, among others, Stable Diffusion, itself originally trained on the LAION 5B dataset); secondly, that these model-generated predictions were not then verified by actual humans. Once the models had been ‘trained’, they were simply deployed on 8-million and 120-million sample subsets of LAION 5B to generate the first version of LAION-Aesthetics.
Where WIT is considered, careful, curated, LAION-Aesthetics is a chaotic hodgepodge of various styles, subjects, formats, and techniques – see Figure 2. The images are of varying quality: some are studio photographs, others slightly blurry or grainy, others still are digital fabrications or graphic design elements. Many images are watermarked, and several are captured from copyrighted works such as films, television shows, or video games. Sample images from the LAION-Aesthetic dataset.
While the subject matter of WIT is diverse, there is still a functional coherence to the images: they all represent a particular object, subject, or concept. There is no such coherence in LAION-Aesthetic. This is made even clearer by the metadata of the latter, which offers only whatever filename or text description is part of the embedding, as well as the ‘Aesthetic’ rating out of 10. Different subsets contain different rating ranges; the subset examined for this work consisted of just over 625,000 images with a predicted score of 6.5 or higher. Rating images is subjective by its nature, and programming a model to predict human ratings is arbitrary: an image of a glass match holder has an aesthetic score of 7.24, whereas the highest-rated image in the slice I analysed was a bride-themed doll with a score of 9.53.
The original LAION dataset was used to train the Stable Diffusion image generator, a foundational model for AI media generation (Rombach et al., 2022: 7; Salvaggio, 2024). Subsequent versions of Stable Diffusion were fine-tuned on LAION-Aesthetics, among other datasets (LAION, 2022). The results of this fine-tuning are media generation platforms such as Leonardo.Ai or Midjourney – powerful, multi-purpose tools, but tools trained, in part, on algorithmically defined markers of taste, quality, and accuracy – often derived from mixed-quality, unlicensed media. Meyer (2025: 8) describes this dynamic as a ‘recursive algorithmization of taste’: a feedback loop in which algorithmically predicted user preferences shape the training data that will determine future outputs, compounding aesthetic narrowing at every iteration. This can skew outputs toward polished, professionally styled compositions, or toward dominant visual tropes – especially those centred on idealised human figures common in advertising and mainstream media.
The dynamics at play with both WIT and LAION-Aesthetics suggest a set of questions that can guide analysis of AI-generated media: • What kinds of source material underpin this image? • Whose aesthetics are being amplified? • What feels missing or overrepresented? • Does the image reflect curatorial structure – or algorithmic residue? • What does the curation logic of this image’s likely dataset suggest about whose labour and cultural materials were used to produce it?
Such questions help link the visible surface of AI media to its unseen infrastructural foundations. Importantly, these infrastructural foundations are not politically neutral. The contrast between WIT and LAION-Aesthetics is also a contrast in ethical orientation: WIT’s reliance on open licensing and human editorial oversight reflects, at minimum, an attempt to respect existing rights frameworks, however imperfectly. LAION-Aesthetics, by contrast, aggregates unlicensed material at scale, including images scraped from artists, photographers, and cultural producers without consent or compensation – part of what Crawford and Joler (2019) describe as a new form of extractivism that reaches into ‘the deepest layers of human cognitive and affective being’ (117). The aesthetic biases encoded in these datasets are thus inseparable from the labour conditions of their construction: when a model defaults to masculine figures of intellectual authority, or idealised bodies drawn from advertising, it is not merely reflecting statistical frequency – it is reproducing the cultural dominance of those whose work was most available, most scraped, and most weighted. Dataset bias, in this light, is not only a technical problem to be corrected but also an ethical condition to be read – one that this method is designed to make visible.
For instance, the sample image ‘intellectual rigour’ (Figure 3), presents a male figure at a desk, poring over his work, head in his hand. The figure is surrounded by items like a globe, a skull, glasses, and an apple. The image is depicted as an oil painting, its composition considered, posed, and portrait-like. In terms of the underlying dataset, the model draws on scans or photographs of oil paintings, as well as professional portraiture, for its stylistic flavour and the arrangement of its subject. Without any guidance around gender presentation, the model defaults to a masculine subject, suggesting that data clustered around concepts like ‘intellect’ or ‘academia’ is dominated by images of men. Intellectual authority, then, is here perpetuated through consistent and repeating iconographic patterns within the training dataset. An image generated in Midjourney using the prompt ‘intellectual rigor’.
These datasets do not merely feed the machine; they establish parameters around visual vocabularies, defining a representational field. Before any prompt is typed or any model deployed, it is the dataset that shapes what becomes expressible, seeable, and synthesisable. In generative AI, the politics of representation begins not with the image, but with the base images and textual metadata that determine its representational possibilities.
Model
Datasets determine what is available to be generated. Models then define how that material will be re-configured and re-presented as visual media. The model is far from passive: it is an active transformer, working through latent compression, probability, and both textual and visual inference.
The cultural logics inscribed in datasets – whether WIT’s encyclopaedic curation or LAION-Aesthetics’ algorithmic taste – do not remain static once fed into generative models. While the dataset fixes a representational field, the model transforms that field through probabilistic recombination to control how these cultural patterns will be recalled and recombined. AI models do not ‘decide’ what data they have to work from, nor do they determine how users will access or guide these transformations. As a result, they are frequently described as black boxes. But this opacity is not inherent – it often stems from complexity, scale, and deliberate design choices. As Seaver (2017) argues, algorithms feel opaque not because they are unknowable, but because they are both technically complex and enact layered, culturally situated practices of human decision-making (4-5). Bucher (2016) also critiques the black box metaphor, suggesting that this framing can distract from more productive questions about how algorithms operate, become visible, and shape experience (93-4). To this end, the ‘opacity’ of these systems is often a byproduct of what Burrell (2016) identifies as a ‘mismatch between mathematical optimization’ and the ‘demands of human scale reasoning’ (3). This gap ensures that opacity ‘endures in spite of’ technical simplification, creating a space for an ‘algorithmic imaginary’ (Bucher, 2017) where the model’s probabilistic guessing is mistaken for human-like intent. As Pasquale (2015) notes, maintaining this state serves a strategic purpose: it protects ‘proprietary algorithms’ from scrutiny (4), facilitating a ‘one-way mirror’ where the user’s inputs are transparently harvested even as the model’s internal ‘scaffolding’ remains obscured. These scholars collectively gesture toward interpretive and ethnographic methods that attend to the socio-technical conditions in which algorithms are developed and deployed. A media-materialist reading adopts such a stance – tracking not only what algorithms do, but how they come to be known, felt, and contested through their outputs and interfaces.
Models also privilege certain inputs over others – particularly where one type of image is more prevalent in the dataset. The model attempts to find patterns that match the user’s input, generating the best possible representation of those patterns. This process unfolds not in a symbolic space but in a latent one – a compressed multidimensional environment where learnt patterns, styles, and associations are encoded as distances and vectors, and where representation becomes a matter of proximity rather than precision.
The image-text combinations that constitute training data for datasets such as LAION-Aesthetics are called embeddings; generative models learn statistical associations between visual patterns and linguistic descriptions, building a latent map of the training material. These associations are not ‘comprehension’ in any meaningful sense, but rather a clustering of various patterns and modes (Nichol et al., 2022: 1; Burgess et al., 2024).
The map – the mysterious ‘latent space’ – is not a mirror of reality or cultural knowledge; it does not reflect the collective creativity or imaginary of humanity, as some suggest. It is rather a terrain of probability: abstract but not unknowable. Concepts and terms exist here as mathematical relationships: ‘cat’ might be connected to ‘whiskers’ or ‘witch’, ‘tree’ to ‘green’ or ‘leaf’, based on how often they exist alongside one another in the dataset. Similar concepts are mapped closer to one another; unfamiliar, underrepresented material is positioned further from the centre of generative power – or probability (Kulkarni et al., 2023: 19). The model does not retrieve an image from memory or draw from a library: it mixes the user’s prompt with its statistical map of training data, interpolating patterns to generate a synthetic output that aligns with the probabilities of what it has previously seen.
To generate an image, diffusion models begin with random noise and iteratively subtract it – effectively ‘guessing’ the image through denoising, a recursive process of removing entropy to reveal a latent signal guided by a prompt or image embedding (Rombach et al., 2022; Podell et al., 2023: 7). The model starts not with a subject, but a probability field, shaping patterns through learnt associations until something plausible and contextually appropriate emerges. Probability, not realism, is the model’s guiding logic: it produces outputs that are statistically plausible rather than semantically or narratively ‘true’; this is why visually coherent outputs can still result from unclear or nonsensical prompts. A similar logic governs AI video generation, where the model produces a sequence of frames that simulate motion through consistent probabilistic variation – not through true narrative, cinematic, or spatial understanding in a human sense (Blattmann et al., 2023: 3).
What emerges from this process is not a depiction of an entity with a real-world equivalent, but rather a synthetic approximation: a ‘best guess’ filtered through layers of statistical reasoning, aesthetic bias, and learnt constraints. Even in polished outputs, traces of the model remain. These might take the form of recurring compositional structures, a subtle uniformity in lighting or colour palette, or the smoothing out of visual anomalies. Just as film grain or VHS distortion once signalled medium specificity, generative models also leave behind aesthetic fingerprints: computational residues of their generative operations.
While latent space is mathematically defined, it also functions as a cultural medium – shaped by the material conditions of training data, computational resources, and model design (Somaini, 2024: 56-7). From a media materialist perspective, these systems are charged. They are operational image engines: machines that generate synthetic vision through probabilistic inference, infrastructural constraint, and aesthetic patterning. In this way, as Antonio Somaini (2024) writes, latent spaces are ‘spaces of possibilities but also of impossibilities’ (57).
The model itself – its codebase, architecture, and latent mappings – is a medium in its own right. It sets the conditions for what can appear, and how appearance is structured. These internal logics may not always be visible, but they manifest in outputs – especially at the edges of coherence. When prompts are ambiguous, when styles or references collide, or when relevant training data is sparse, outputs may fracture: hands melt, limbs multiply, perspective buckles. In newer systems, these breakdowns are often smoothed over – replaced by subtler signs of constraint, like compositional sameness or aesthetic flattening. These glitches – be they overt or subtle – are symptoms of a system under constraint, revealing how computation produces its own visual politics. To read these outputs critically is to consider not only what the model shows but also how and why – and where its representational scaffolding begins to fail.
These visual patterns, compositional tendencies, and aesthetic choices invite us to read with the model by attending to its visual logic, defaults, and constraints. • What feels familiar, repeated, or smoothed over – and what might this tell us about the statistical weight of particular visual types in the training data? • Where do we see signs of compression, averaging, or style convergence – and where does the model’s representational scaffolding begin to fail? • What kinds of bodies, gestures, or aesthetics seem absent, implausible, or consistently underdeveloped – and what does their absence reveal about the limits of the latent space? • What aesthetic fingerprints – recurring compositional structures, lighting tendencies, textural defaults – suggest the model’s learnt constraints rather than user intent?
When considering the model’s impact on the output – as opposed to that of the training data – one might look less at the array or diversity of features, but rather at how well those features are presented, resolved, or composed within the image. In Figure 4, for example, the high-resolution skin texture, fabric details, and atmospheric depth of field indicate a model tuned for photorealistic or cinematic rendering. The image is composed with a male figure to the left, female figure to the right, and the moon at the centre top of the image: this triangular composition indicates the model’s capacity for conventional arrangements. The clear branding of the laptop shows that if the model is rendering a computer in a professional setting, or operated by a professional figure, brand clarity is a default signal or cluster within the data. Finally, the successful fusion of different genres – corporate portrait or stock image, gothic romance, and fantasy illustration or painting – suggests a flexible and adaptable latent space with the ability to combine disparate clusters of concepts, conventions, and styles. Image generated in Leonardo.Ai with unknown prompt.
Reading these computational signatures reveals how models function not as neutral tools but as active participants in shaping what forms of visual representation become culturally available. Yet for the majority of users, these model operations remain invisible, experienced only through the interfaces that structure interaction with generative systems.
Interface
As Cramer and Fuller (2008) observe, interfaces are ‘the point of juncture between different bodies, hardware, software, users, and what they connect to or are part of. Interfaces describe, hide, and condition the asymmetry between the elements conjoined’ (150). Interfaces are thus an infrastructural assemblage and site of power negotiation, rather than just a graphical overlay. Johanna Drucker’s (2013) notion of distributed materiality reinforces this view: material conditions in digital systems emerge from the interrelation of layered components, like bandwidth, processing, storage, memory, interface design (5). The interface, then, is thus another layer of the genAI socio-technical assemblage that structures how users can access and manipulate model capacities.
If the dataset defines what can be generated, and the model defines how it is rendered, the interface determines how those capacities are exposed, limited, or made actionable to the user. As Flusser (2011) suggests, the technical apparatus does not merely facilitate image production but actively imposes internal logics that structure both creation and interpretation (43-4). In generative AI systems, the interface formats desire, intention, and creative agency, framing what is permissible, encouraging certain aesthetic forms over others, and distributing power unevenly through its design conventions and defaults.
Galloway (2012) writes that the interface functions as protocol – a set of rules and structures that make interaction possible while also delimiting it (106). In this view, the interface is where control and freedom blur: it opens a space of action, but only within tightly encoded rules of behaviour. Similarly, Lori Emerson (2014) offers that interfaces constrain as much as they enable; they are material architectures of symbolic possibility, shaping the kind of writing or image-making that can occur within a given system. What seems like ‘user-friendly’ design often encodes a set of normative assumptions about what creativity should look like.
The interface, then, as Galloway continues, is a site of ‘agitation’ or generative friction between mediatic layers (31). Interfaces are not just conduits from user to system: they produce the conditions under which interaction becomes meaningful, legible, and productive. As Cramer and Fuller (2008) suggest, interfaces ‘describe, hide, and condition the asymmetry between the elements conjoined’ (150). A seemingly simple slider or dropdown menu – whether marked ‘chaos’, ‘contrast’, or ‘artistic’ – conceals a vast substrate of trained weights, model parameters, and system assumptions. What appears intuitive is often deeply encoded.
As Kaiser (2023: 4) argues, ‘the interface is more than an object or a thing. It is a moment in time where the histories, ideas, and assumptions underlying a particular technology meet the user’s ideas about themselves’. In this meeting point, the interface becomes a site of subject formation – it mediates not only between systems and inputs but between users and the cultural narratives they inhabit. Interface design encodes and presents assumptions about authorship, aesthetic taste, technical competence, and cultural legitimacy. It influences how users imagine their own agency, what forms of creative labour they take up, and which outputs feel ‘correct’, ‘beautiful’, or ‘on trend’.
While open-source and developer-level tools offer divergent affordances and perhaps greater transparency and user control, this analysis focuses on commercial platforms where aesthetic, ideological, and infrastructural assumptions become most normalised. Interfaces like those of Leonardo.Ai and Midjourney are not just gateways to model capabilities; they are sites where normative expectations about creativity, authorship, and control are encoded and enacted. What these interfaces invite, obscure, or automate is not incidental – it is central to how generative media is shaped at the level of form, labour, and purpose.
Leonardo.Ai exemplifies a control panel logic: a densely featured dashboard-style interface offering sliders, toggles, drop-downs, and visual previews (see Figure 5). It presents the user with fine-grained control over model selection, prompt weightings, style presets, guidance scales, and resolution parameters. The interface casts the user as a director, technician, or image engineer – someone who should master the system’s knobs and dials in order to refine its output. This logic echoes legacy creative software like Photoshop or Final Cut: environments of craft premised on technical mastery and iterative precision. As such, Leonardo’s interface supports an aesthetic of polished, high-resolution, commercially viable images, often optimised for branding, concept art, or photorealism. Its interface suggests that better outcomes are a matter of correct tuning: that refinement, not surprise, is the goal. The image creation interface in Leonardo.Ai.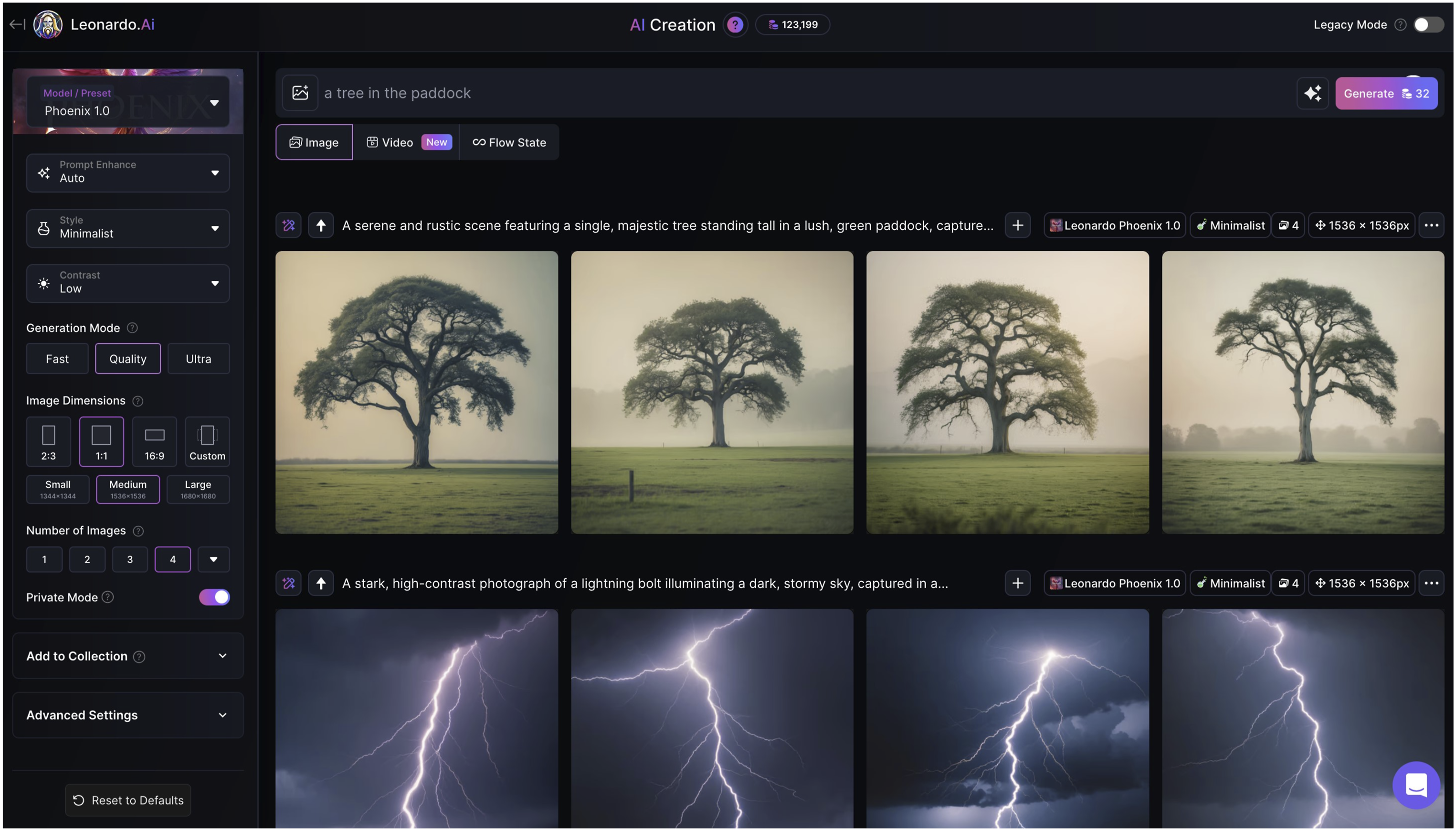
Midjourney, by contrast, adopts what might be called a social prompting logic, via two interface options. Firstly, its original Discord-based interface strips away the visual dashboard entirely, situating prompting within chat threads. Parameter control is largely hidden: stylization, dimensions, and seed values exist but are not foregrounded. Midjourney’s web user interface is similarly minimal (see Figure 6): a text box asks, ‘What will you imagine?’ There are no fine controls visible at first. The text box sits above an endless feed of images and videos that tempt the user with the possibilities of the tool. Both interfaces position the user less as controller and more as explorer, operating in a space where surprise, remix, and serendipity are aesthetic virtues. This orientation is reflected in outputs that consistently exceed literal prompt interpretation: painterly, stylised, sometimes surreal images with a strong model ‘voice’ and less user-overwriting. The ‘stylization’ setting is the core parameter here: this slider controls a spectrum, with strict prompt adherence at one end, and the application of the Midjourney aesthetic at the other. If we interpret the Midjourney ‘aesthetic’ to be a creative reinterpretation of the prompt, then setting stylization to zero should result in a more restrained representation. Its defaults are powerful and persistent, subtly steering output without demanding – or even allowing – fine-grained intervention. Even without ‘stylization’, the outputs bear the platform’s interpretive signature, transforming prompts into legible visual archetypes and compositions via Midjourney’s learnt aesthetic logic. Midjourney’s web interface.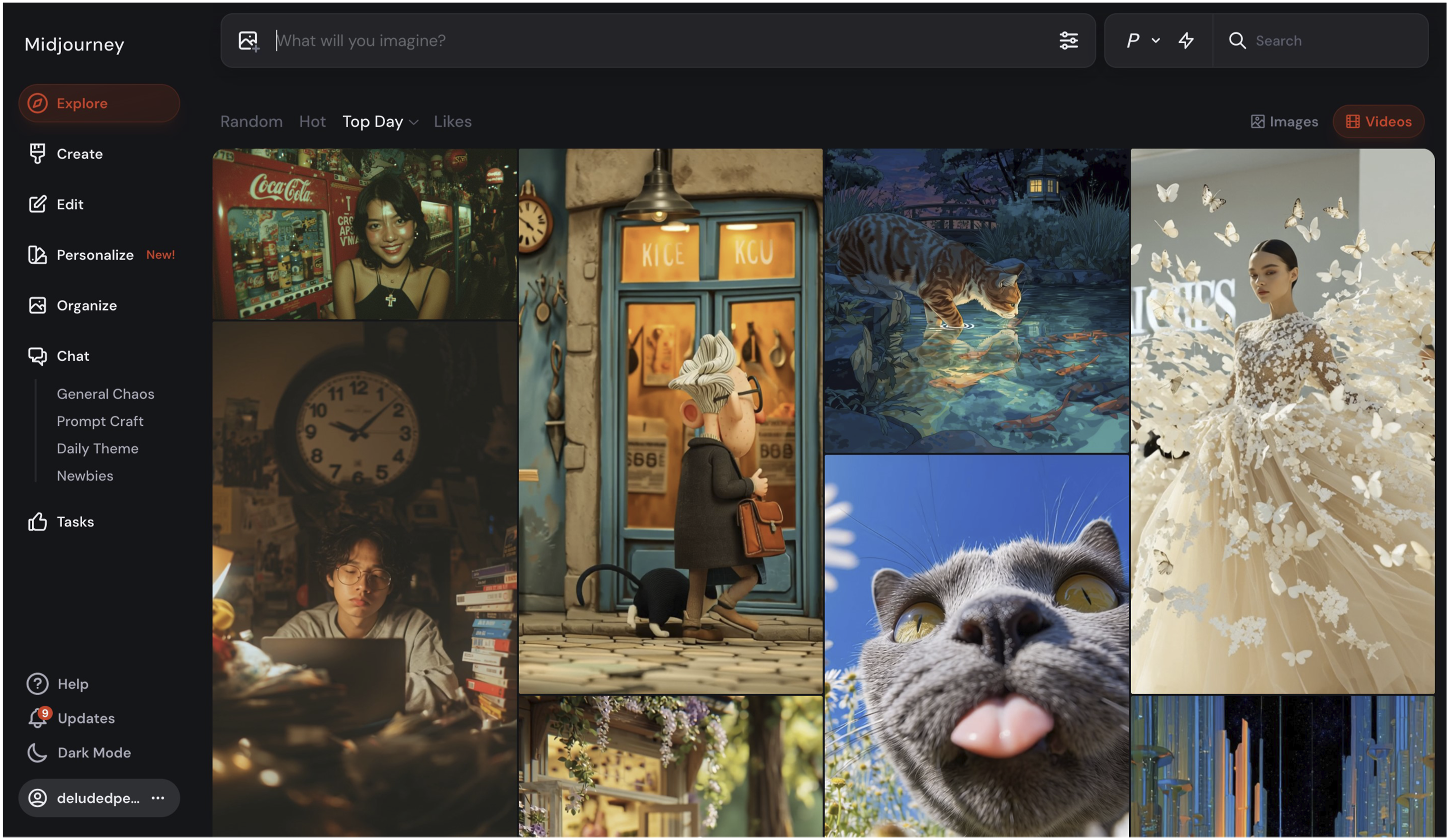
As Cramer and Fuller (2008) observe, engagement with a software interface often begins with a sense of expanded creative agency, but this quickly gives way to a recognition of limitation: the boundaries of what the system will allow or reward (150-1). This dynamic is clearest in the operation of style presets, prompt templates, and default parameter settings, which quietly structure what kinds of outputs seem natural or expected. In platforms like Leonardo.Ai, visual choices are often presented within the interface itself: sliders that foreground ‘photorealism’ or ‘cinematic lighting’, model presets labelled with genres or moods, prompt enhancement toggles that reword user input to align with internal stylistic norms. These features appear as options, but they function as soft constraints: suggestions become standards, and defaults become aesthetic law. In Midjourney, this aesthetic funnelling is less visible but no less effective – its minimal interface conceals powerful model defaults that shape colour palettes, composition, and visual mood, regardless of user intent. In both cases, creative freedom is not eliminated but contoured – made efficient, platform-compatible, and socially shareable.
This creates what might be called an aesthetic path dependency: the interface establishes a narrow channel through which creativity flows, and repeated use deepens the groove. What emerges is not endless possibility, but a patterned ecosystem of platform aesthetics: images that are recognisably ‘Leonardo’ or ‘AI-generated’ more broadly. The interface, then, leaves its trace on the image not just through its affordances, but through the constraints it naturalises. These constraints are technical, to be sure, but they are also cultural and ideological, shaping how creativity is imagined, valued, and reproduced within computational systems. What Meyer (2025) identifies as platform realism – a dominant aesthetic logic privileging legibility, plausibility, and familiarity – is visible here in the narrowing of creative possibility toward the recognisable and shareable. Thomson et al. (2026) extend this analysis to show how platform affordances, from UI sliders to default style presets, operationalise this logic at the level of user interaction, making platform realism not just an aesthetic condition but a designed one.
These constraints are not only aesthetic in their effects. Content moderation policies, safety filters, and platform-level decisions about what can and cannot be generated are interface-level choices with significant cultural consequences: they determine whose bodies are representable, which aesthetics are normalised, and what kinds of imagery are flagged as unsafe or undesirable. These decisions are made by platform developers and encoded silently into the interface – invisible to the user but operative in every generation. The path dependency, then, is not just stylistic; it is political. Certain subjects, aesthetics, and cultural perspectives are systematically routed around, not because the model cannot generate them, but because the interface will not allow it.
Ultimately, interfaces operate as epistemological frames: they determine what is revealed to the user about the underlying system, and what remains hidden. They structure the range of creative choices both technically and culturally – shaping what feels intuitive, valid, or rewarding. The contrasts between Leonardo and Midjourney are not just stylistic; they are symptomatic of different regimes of mediation, each encoding divergent values around authorship, labour, and the politics of machine-assisted creativity. Reading AI images critically, then, requires attention not just to the visible content but to the epistemic conditions of its production – to the role of the interface in shaping what is produced.
As with dataset and model, this section ends with a methodological proposition: what does it mean to read an image through its interface? What would it look like to treat compositional cues, stylistic defaults, or aesthetic regularities not just as artefacts of the model, but also as the consequence of interface conditioning? • What visual tendencies seem overrepresented – and might these be a result of interface presets or default style parameters? • Does the composition reflect a logic of shareability, technical refinement, or commercial purpose – and what interface behaviours encourage or reward these outcomes? What forms of creative labour does the interface presuppose or demand – precision and specification, or exploration and iteration? And what does this imply about whose creative practice the platform is designed to serve? • Is there evidence of prompt enhancement, parameter manipulation, or model selection – or do default aesthetics dominate regardless of user input? • What kind of user is implied in the image’s visual logic – and what does the interface suppress, normalise, or make invisible in producing that user?
As mentioned at the end of the previous section, the technical polish and coherence of the gothic laptop forest throne image (Figure 4) indicate an advanced and capable generation model. In terms of the interface, too, the systematic precision suggests generation using a professional dashboard, where users can specify and finely tweak rather than explore or experiment: this is exactly Leonardo.Ai’s interface design. The image’s polish and upscaling suggest features preferred by commercial or power users: batch generation, collections, private mode for IP management. In essence, nothing in this image appears accidental, emergent, or default-reliant: this reflects an interface that demands specification rather than open-endedness or conversational iteration.
These are not questions of intention alone. They are material questions – ways of tracing how interface mediates between imagination and infrastructure, and how that mediation becomes visible in the surface of the media itself. The interface cannot determine cultural connotations, but it can and does position and construct the user as a particular kind of creative agent – be it experimental explorer or a precise technical director – and the resulting images can indicate which type. Thus do we come to the most immediate site of human-AI negotiation: the prompt. Where the dataset, model, and interface establish the infrastructural conditions of generation, the prompt is where human intention is most clearly directed at the output – a distinct but interdependent variable.
Prompt
Prompts in genAI function as probabilistic activations, nudging the model toward likely visual outputs based on latent statistical patterns rather than operating as deterministic commands. They express user intent within the constraints set by data, model, and interface. Prompts shape activation but cannot control the latent associations or platform defaults that guide interpretation. Thus, prompting becomes more negotiation than control: a semiotic exchange between human ambiguity and machinic patterning.
At the heart of this is a problem of translation. Human language is culturally situated, metaphorical, and affective; machine logic is formal, literal, and associative. As Andrejevic (2020) argues, the ‘fantasy of automated media’ is to bypass the vagaries of human expression altogether – to make language operational, stripped of its excess, irony, or contradiction (134). But that fantasy runs up against a medium – natural language – that is, as Friedman (2023) observes, ‘not considered a rigorous method for communication of knowledge that includes the attributes of reliability and permanence’ (687). Language is messy, idiomatic, rhetorical, and shaped both historically and locally: it was never designed to be parsed by machines.
This mismatch defines the epistemic instability of prompting. Users are asked to specify what they often do not yet fully know – using an expressive medium poorly suited to algorithmic parsing – into a system trained to detect regularity, not nuance. As the co-enunciation framework suggests, the prompt is not simply a textual directive; it is a semiotic event shaped as much by what the system is predisposed to recognise as by what the user intends to express. Or, as Somaini (2023) puts it: ‘what is visible is strictly correlated with what is sayable’ (106). The prompt becomes a threshold where visibility itself is delimited by the legibility of language within machinic regimes. Yet this instability can also be productive – what McCormack et al. (2023) call the ‘resistance of the medium’ that give generative systems their creative potential (208).
In text-to-image generation, prompts do not translate into images through symbolic reasoning or semantic comprehension. Instead, they activate latent associations – statistical relationships between words and images contained in the model’s training data. As McCormack et al. (2023) argue, these systems interpret prompts literally, not metaphorically (199). Concepts such as ‘elegance’, ‘productivity’, or ‘creativity’ are not read as abstract values, but mapped onto visual conventions: corporate stock photography, lifestyle aesthetics, and genre tropes.
This literalism exposes a deeper issue: the image reflects not just what was prompted, but what the model associates with the prompt – often overfitting to cultural stereotypes. For instance, a phrase like ‘creative productivity’ might yield a businessman standing in a forest, a surreal synthesis of nature and commerce that mirrors the training corpus more than the user’s intention. These associations are not only culturally biased but also computationally sedimented: certain kinds of imagery – like white faces, corporate office spaces, or cinematic lighting – are overrepresented in large-scale training datasets scraped from the web. As a result, the model’s understanding of a prompt is shaped less by its semantic richness than by the frequency and prominence of particular visual types in its learnt corpus.
Somaini (2023) offers a media-historical angle on this phenomenon: prompts, he argues, ‘re-mediate previous visual media’ through their invocation of ‘material supports, devices, and operations (e.g. “DVD screengrab”)’ (102). This means that text inputs become cues for media memory retrieval, not conceptual expression. The prompt is less a command than a suggestive invocation, filtered through the visual sediment of the dataset.
Prompting, then, becomes a form of cultural interpretation by proxy – the model guesses at the world, and the prompt is its clue. But what it ‘knows’ is its dataset, a discrete and incomplete representation – a ‘slice’ – of visual culture. Unexpected or undesirable outcomes, then, do not necessarily reflect the prompt’s expressive deficit, but rather the statistical structure of the latent space that the prompt activates.
The prompt’s analytical status within this framework warrants brief clarification. As a layer, it is parallel to dataset, model, and interface – each site introduces distinct constraints, affordances, and modes of agency, and the prompt is no different. But operationally, the prompt is where those layers converge and collide. It is the site where user intention meets the design structures imposed by the model provider: where the interface’s prescribed mediation encounters the user’s act of inscription. That encounter may be productive, generative, or confrontational – but it is never neutral. The interface conditions what can be expressed; the prompt is where the user negotiates those conditions, consciously or not.
While prompting is often imagined as a neutral act of linguistic input, in practice it is shaped profoundly by the platform through which it is performed. Interface design, model tuning, and user community conventions all help produce what we might call platform-specific prompt grammars: semi-formal systems for communicating with generative models that emerge over time, combining technical constraints with cultural habits.
Prompting in Leonardo.Ai follows a layered, hierarchical structure, starting with style or medium, followed by subject, composition, and modifiers. A prompt like ‘cinematic, lady, hoodie, backpack, futuristic city at night, neon lights’ reflects this logic: a modular structure tuned for reproducibility and control. Model presets or prompt enhancers reinforce this grammar, encouraging a kind of procedural authorship in which creativity is expressed through precise calibration (Santos, 2024).
Midjourney, by contrast, invites a more improvisational approach. While originally accessed only via Discord, its web interface now offers more accessible prompting features – but its aesthetic defaults and social logic remain intact. Technical settings are minimised by default, and prompts still function like open-ended invocations. Users lean on rhythm and tone rather than formal structure, composing list-like phrases that often verge on free verse. Syntax features like ‘::’ (weighting) or ‘--ar’ (aspect ratio) act as aesthetic nudges rather than strict parameters. Prompting becomes a discursive or performative act – a means of exploring stylistic resonance within a socially shared, visually responsive environment.
In both cases, prompting is less about expressing pure intention than about learning a grammar – an interface literacy that shapes not just what is generated, but what can be imagined as generatable.
Prompting, however framed, is a deeply compromised endeavour, whose limits are not technical but linguistic. As McCormack et al. (2023) argue, the creative act often resists ‘ex ante description’ – that is, it cannot be fully articulated before it emerges (199). In traditional creative practice, meaning and form evolve iteratively, through a feedback loop between intention and material. But in prompt-based generation, the user must describe in advance what has not yet taken shape, and do so using a tool – natural language – that lacks the precision required for computational execution.
This produces a paradox: the user is asked to control a system that demands not just intention but foreknowledge – you must already know what you want and how to phrase it in a way the model will interpret appropriately. As a result, prompting privileges output over process. There is no visible trace of iteration, no accumulated history of revisions – just a stream of outputs, each severed from the process that led to it.
Moreover, prompt labour is easily reproducible and transferable. Unlike embodied or tacit knowledge in traditional artistic practices, prompt ‘skills’ can be copied and pasted. Prompt-sharing flattens authorship and renders the act of creation interchangeable (not to mention monetisable, as indicated by the emergence of prompt marketplaces). As the co-enunciation perspective suggests, the prompt becomes a semiotic compression of desire – a condensed signal to be decoded by the machine, but stripped of processual depth.
Even when the prompt is hidden or lost, AI-generated images still bear traces of the conditions of their generation. Prompts, platform grammars, and model biases leave residues – aesthetic and compositional traces that are archaeologically readable. These images are not just outputs; they are material negotiations, shaped by interface defaults, platform ideologies, and linguistic framings. This forensic approach is a kind of prompt archaeology, a process of working backwards from visual traces to speculate about the linguistic parameters that shaped an image’s generation.
At a visual level, generative images often exhibit compositional regularities – centrally placed subjects, artificial depth-of-field, strong directional lighting – shaped by stylistic prompts like ‘cinematic’, ‘portrait’, or ‘anime’. These features act as echoes of instructions, however partial or improvised. More subtly, promptable terms reproduce cultural tropes present in training data: ‘elegant’ defaults to white femininity; ‘professional’ conjures suits, corporate architecture. Such defaults are not just aesthetic; they expose deeper limits on what can be visualised. What can be prompted becomes what can be seen – a narrowing of expression within culturally and computationally bounded regimes of legibility. Prompts and interfaces, thus, are interdependent but have particular affordances and limitations. Where interfaces structure agency, they cannot delineate or determine cultural meaning or interpretation; and where prompts express user intent, they cannot always override latent biases or interface defaults.
In this light, we can treat the AI image as a semiotic trace of its generative conditions – an artefact where prompt, model, and aesthetic defaults coalesce. To critically engage with such images requires more than surface interpretation; it means reading them for the infrastructural and ideological pressures they sediment. This includes asking: • What visual patterns suggest prompt conventions, community reuse, or platform grammar – and what do these reveal about the negotiation between user intention and system defaults? • What kinds of language might be behind these images? • Where does the image appear overdetermined – or surprisingly off-script? • How might unexpected outputs or semantic misfires redirect the original prompt intention? • What types of content or perspectives seem excluded or resisted? • How does the image materialise platform defaults or aesthetic ideologies?
The prompt activates cultural conventions that the model then uses to choose what content is brought into the image and how it is staged. In Figure 3, for instance, the phrase ‘intellectual rigor’ contains no clear subject, and yet the model produces a complete, concrete representation of a scene. The root term ‘intellect’ likely triggers statistical associations around books, libraries, contemplation, that are historically masculine-coded. The word ‘rigor’ is likely close to severity, sternness, solitary struggle, proof: it could also be that the model interprets ‘rigor’ through its connections to ‘mortis’, so mortality, death, hence the memento mori figures of the skull and globe. Without a clear subject, the model defaults to literal deployment of symbols and figures. However, this prompt and image also demonstrate how much cultural interpretation and curation the model performs: for this phrase, there are decades, centuries of cultural precedent, so the latent space develops a complete mise-en-scène. Here the prompt acts not as the origin of these conventions but as their trigger; the linguistic switch that activates their expression.
The questions and sample analysis here contribute to a broader interpretive vocabulary – one capable of reading AI-generated images not just for what they depict, but for how they encode system-level constraints, cultural assumptions, and user intentions across different platforms. These residual traces are not limited to prompt formulation, but emerge across the entire generative stack – dataset, model, and interface – as each component shapes how prompts are parsed and visualised. Attending to these visual cues extends this method’s reach, activating a more comprehensive reading of generative media.
Applying the method
These steps translate the media-materialist method from this article into a practical analytical protocol. This method works both diagnostically (with known metadata) and archaeologically (when original parameters are unknown), adapting to whatever documentation is available while maintaining systemic analytical rigour. (1) Select your image or series of images. (2) Gather known metadata: file name, platform, model name and version, parameters, prompt. (3) Analyse the image formally: content, style, composition, technical qualities, anomalies. (4) Consider the image through the analytical questions posed for each layer: Data, Model, Interface, Prompt. (5) Revisit your responses across all four layers, attending to where analytical threads converge, where they pull against one another, and where one layer’s logic appears to override or complicate another’s. Cross-layer tensions – where dataset assumptions conflict with interface design, or where prompt intent is redirected by model defaults – are often the most analytically revealing moments.
This method is intentionally flexible. Not every layer will yield equal insights for every image, and some analyses may focus more heavily on particular layers depending on available metadata and analytical goals. Likewise, sometimes the analysis may tend more cultural or semiotic, as opposed to more technical: the method is designed to accommodate both preferences. The framework reveals computational and cultural pressures evident in AI outputs, but cannot definitively establish user intention or specific algorithmic processes. Cross-layer contradictions (when dataset logic conflicts with interface design, for example) are often the most revealing analytical moments.
Conclusion
This article has proposed a media-materialist method for interpreting AI-generated images, treating them not as mysterious outputs but as artefacts shaped by layered computational processes. The analyses at the end of each section demonstrate this method working both diagnostically and archaeologically, showing how cultural assumptions are themselves embedded in apparently neutral technical systems. Whether analysing a known prompt like ‘intellectual rigor’ or practicing prompt archaeology on unknown inputs, the method transforms AI images from opaque outputs into interpretable image-objects – revealing how centuries of visual culture become statistically compressed into archetypal arrangements.
Generative AI tools continue to reshape creative industries and cultural production in profound ways. While some applications expand creative possibilities, others constrain them by privileging certain outputs over others, creating what might be called aesthetic path dependencies. The ethical concerns around unlicensed training data and corporate opacity in model design compound these dynamics. As models grow more sophisticated, their outputs risk becoming increasingly homogenised – not because the technology demands it, but because the infrastructures of data, interface, and model training favour certain visual logics while suppressing others.
This method functions as a diagnostic tool for examining what biases and constraints shape generative outputs – revealing how ethical conditions are encoded at every layer of the generative stack, not just in its outputs. The extractivist logic of dataset construction, as Crawford and Joler (2019) identify, does not remain at the infrastructural level: it resurfaces in the visual defaults of models trained on unlicensed cultural labour, and in the interface-level suppression of bodies, aesthetics, and perspectives that platform developers have deemed undesirable. What appears as aesthetic path dependency is also, on closer inspection, a form of cultural gatekeeping – one that operates silently, by design, and at scale. Understanding these layered dynamics is not merely a scholarly concern but a practical one: developing more critical and creative approaches to AI engagement requires first being able to read the systems through which that engagement is mediated.
Yet this analysis also identifies creative opportunities when we attend to these baked-in logics and exclusions. Understanding how these systems work – their defaults and affordances, their blind spots and points of friction – enables more thoughtful and resistant forms of engagement. When prompts fail, when juxtapositions are strange, when friction arises between intention and output, these are not necessarily failures but moments of generative potential. The businessman in the forest, the academic amid symbols of vanitas; these images compel not despite computation, but because of the strangeness introduced by it. There are thus implications here for creative and artistic practice where generative tools and systems are used in conjunction with more conventional methods and materials.
While this article has focused on still images, future work might extend this materialist method to AI-generated video. Unlike static images, AI-generated video introduces a temporal and durational layer – motion, spatial continuity, and the accumulated weight of cinematic and social video conventions – that the model must maintain across frames. This makes visible a distinctive tension between motion coherence and probabilistic frame-to-frame inference, where visual outputs can hover between stock-footage banality and surreal misalignment (see Binns, 2024). These cinematic hallucinations present rich ground for future work, particularly in exploring how diffusion models interpolate not just across static forms but across frames, scenes, genres, and cultural expectations – a speculative horizon that this article gestures toward.
Media materialism offers AI discourse and scholarship a way forward that neither dismisses synthetic media as ‘slop’ nor celebrates it as revolutionary. Instead, it cultivates critical technological literacy, positioning AI-generated images and videos as cultural documents that encode the political, aesthetic, and ideological structures of their making. In an increasingly synthetic media ecology, developing interpretive methods attuned to these structures is not just a scholarly task but a cultural imperative. What circulates as disposable or uncanny may in fact reveal the logics of the systems that produced it. These outputs are not simply errors or aesthetic failures – they are symptoms of systems, marked by history, shaped by data, and rich with interpretive possibility.
Footnotes
Acknowledgements
The author sincerely thanks James Meese, Ramon Lobato, Seán Cubitt, and Mark Gibson for their feedback and support of this work across its extended development.
Ethical considerations
This article does not contain any studies with human or animal participants.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
WIT_browser: built for analysing WIT dataset: https://github.com/DeludedPenguin/WIT_browser. LAION-Slicer: built for analysing a sample of LAION Aesthetics dataset: ![]() .
.