
Abstract
Visual generative media represent a novel technology with the potential to mediate public perceptions of political events, conflicts, and wars. Seeking to understand a visual culture in which algorithms become integrated into human processes of memory mediatization, this study addresses representation in AI-generated war imagery. It frames AI image generation as a socio-technical practice at the nexus of humans, machines, and visual culture, challenging Silicon Valley’s prevailing narrative of visual AI as “an engine for the imagination.” Through a case study of AI images generated in response to verbal prompts about Russia’s war against Ukraine, I examine the representational capabilities and limitations of the text-to-image generator Midjourney. The findings suggest homogeneity of visual themes that foreground destruction and fighters, while overlooking broader contextual and cultural aspects of the Russia-Ukraine war, thus generalizing the depiction of this war to that of any war. This study advances the research agenda on critical machine vision as a transdisciplinary challenge situated at the interface of media and cultural studies, computer science, and discourse-analytic approaches to visual communication.
Keywords
Latour (1999): Do you believe in reality? ChatGPT (2023): I’m just a computer program, so I don’t have beliefs or consciousness. I process and generate text based on patterns and information in the data I was trained on. This banality of machine learning is also its power. It’s a generalised numerical compression of questions that matter (McQuillan, 2018). The art of the past no longer exists as it once did. Its authority is lost. In its place there is language of images. What matters now is who uses that language for what purpose (Berger, 2008).
AI-enabled image generators have captured the zeitgeist in the past year, marking a major shift in the landscape of visual communication. This shift began with OpenAI’s breakthrough with DALL·E in January 2021. DALL·E, a linguistic fusion of Salvador Dali and Pixar’s WALL-E, initiated a surge in visual generative media such as Midjourney, Stable Diffusion, Craiyon, and others emerging from labs of private commercial entities and prestigious research institutions. While many produce and share AI-generated images on social media platforms, others engage in spectatorship of the captivating capabilities of AI. Popular media, particularly Wired and magazines like Newsweek, amplifies this fascination, reporting on the advances of text-to-image generation technologies (e.g. Christie’s, 2018; Kelly, 2022) and speculating about their promising future (e.g. Marber, 2023).
The technophilic AI rhetoric echoes the Californian ideology (cf. Barbrook and Cameron, 1996) – the one which provides a contrast to the real world against the ideal vision of the future, framing technological advancement as unavoidable but also as something yet to be achieved. As Forlano (2021) observes, discounting the present for the future helps technology companies and data evangelists conceive of the future as either a solvent to existing social problems or as a tool that will amplify human abilities. In this way, commercial actors conveniently “absolve themselves of responsibilities for the present” (Dourish and Bell, 2011: 22) by placing emphasis on innovation, efficiency, and resolution of societal challenges through the application of cutting-edge technologies. This discursive construction of technology becomes a powerful instrument for charismatic digerati – intellectuals advocating for generative AI – sharing their techno-utopian rhetoric with the public (see e.g. Vincent, 2022). However, such framing obfuscates a significant detail: when people engage in AI image generation, they participate in a social action that is highly homogenized, regimented, and proceduralized.
Throughout much of the history of digital technologies, a prevailing assumption, commonly referred to as “the Lovelace objection,” permeated computer science circles. This notion posited that machines cannot create anything original but only do what they were instructed to do (Abramson, 2008; Gray and Suri, 2019). Now, perhaps for the first time in the human history, a technological tool has transcended its traditional role as a medium, evolving beyond the likes of historical innovations such as the printing press, television, or telephony and producing visual cultural artifacts “on its own.” The current iteration of visual generative models has reached a level that surpasses the average human ability to produce and manipulate images. These models not only generate original visual artifacts (in the computer vision sense) but also outperform previous state-of-the-art methods of image production. While AI-enabled image generators are reportedly used “for fun” at present (Wilson, 2023), it is important to examine their potential trajectory, particularly because there is a looming prospect for AI images to mediate public perceptions of real-world events, including political developments, conflicts, and wars.
This paper has two research objectives. Firstly, I conceptualize AI image generation as a socio-technical practice at the nexus of humans, machines, and visual culture, challenging the dominant commercial narratives of visual AI as a tool for enhancing artistic imagination and visual production skills of human actors. Such an understanding is necessary in the times of accelerated neoliberalism (Tulloch and Johnson, 2021: 923) – an exponential outsourcing of individual choice to algorithms, intelligent assistants, apps, gamed environments, and – in the case of visual generative media – the computational power of deep neural networks. Secondly, through a case study of AI images generated in response to verbal prompts about Russia’s war against Ukraine, I investigate representational capabilities and limitations of the text-to-image generator Midjourney and discuss implications of visual generative media for memorialization of conflicts and wars through what Bucher (2017) terms algorithmic imaginary, or (human) “capacity to imagine, perceive and experience algorithms and what these imaginations make possible” (p. 31). Because the impact of generative media on visual culture cannot be productively studied without addressing algorithmic and machine learning processes, I adopt an analytical focus that encompasses both the social and the technical.
The paper is structured in a way that responds to these two objectives. In the following section, I consider the notion of “machine vision” from the perspective of media and cultural studies, zooming in on several issues surrounding human-machine interaction in the context of mediatization of war, before introducing research questions and the conceptual framework. Next, I address the technical aspect of AI image generation in a way that is accessible to digital media and communication scholars, outline the theoretical framework, and explain how it informs the selection of methods. Lastly, I discuss findings, limitations, and future research directions, focusing on human-machine agency and representational problematics of visual generative media.
Machine vision and memory mediatization
Proliferation of digital technologies has impacted, among many social and cultural practices, the ways in which individuals and communities remember and forget, providing new opportunities to formulate, reinforce, or challenge interpretations of the past (González-Aguilar and Makhortykh, 2022). Mediatized memory is the one which “flows across territorial and social boundaries” (O’Connor, 2022: 635) interwoven with arrangements of cultures, agents, and materialities of production technologies (Lohmeier and Pentzold, 2014). When applied to the context of conflicts and wars, collective memory has traditionally been impacted by conventional media, particular by news photography (Griffin, 2004; Parry, 2010). Human-produced war photography is appreciated as a continuing practice of cultural production within specific historical, cultural, and political circumstances (Parry, 2011), and, as Griffin (2010) argues, a full consideration of any image of war must include an analysis of these conditions. John Berger might also say that war imagery is implicated by how the subject has been seen by other people and that “the specific vision of the image-maker was also recognized as part of the record” (Berger, 2008: 10).
But what is seen in AI-generated war images, and what remains unseen? Generative models bring about changes in agentive nature of technology (Natale and Guzman, 2022) in that AI is increasingly seen as an entity operating in ways too complex for human comprehension, with limited opportunities for human actors to tap into system’s infrastructure. Due to algorithmic opacity of visual generative media, there exists a perpetual tension between the perceptual bias arising from inductive biases in a machine vision system that determine its capability to represent the world (Offert and Bell, 2020: 1333) and the assumed “ways of seeing” – a diverse range of perspectives and realities that the system lacks the capacity to represent. As a result, AI-generated images can reinforce dominant hegemonic narratives in representing collective memory (Makhortykh et al., 2023). Hegemonic AI can act as a “bio-necro-technopolitical machine that serves to maintain the capitalist, colonialist and patriarchal order of the world” (Ricaurte, 2022: 727).
Thus, machine vision differs from human vision in its capacity to mediate collective memory. Cultural meanings in AI images are established through a representation by a technical system which carries someone else’s values and ideologies. Such universality impacts diversity of visual representation, and as Crawford (2021: 98) points out, shapes the epistemic boundaries governing how AI operates and, in that sense, creates the limits of how it can “see” the world. As visual generative media begin percolating through into social structures, it is timely to consider a visual culture in which algorithms become integrated into human processes of memory mediatization. By examining the implications of AI images for collective memory of Russia’s war against Ukraine, this study analyzes representational capacities and visual themes of AI-generated war imagery.
Considering the text-to-image generator Midjourney (https://www.midjourney.com/) as a “proxy for a broader collective consciousness” (Thomas and Thomson, 2023), I examine what is seen and what remains unseen in AI images that represent the Russia-Ukraine war in response to verbal prompts guided by the following research questions: How does Midjourney envisage Russia’s invasion of Ukraine in February 2022? How diverse are the results to RQ1 related to the past event of Russia’s invasion of Ukraine compared to Ukraine’s counteroffensive in July 2023? How does Midjourney imagine Ukraine post-war? I introduce the concept of AI image generation as a socio-technical practice, discussed next, to address these questions.
AI image generation as a socio-technical practice
Central to the approach taken in this paper are the concepts of mythology, technology, and representation. Drawing on Boyd and Crawford (2012: 663), I define AI image generation as a socio-technical practice based on the oscillation of:
i. Mythology: a widespread belief that AIs draw on disembodied processes of machine learning, and as such, they attain a level of authenticity, truth, and epistemic objectivity in the images they generate.
ii. Technology: maximizing the computational capacity of deep neural networks, technology that enables AI image generation, to take verbal prompts as input and use them to generate visual outputs.
iii. Representation: drawing on AI-enabled media to generate images for personal, professional, political, or ideological purposes where the lines between human and machine agencies blur.
Mythology surrounding disembodied machine learning reflects a pervasive assumption that AI yields authenticity and epistemic objectivity. In reality, cultural meanings in AI-generated images are established in a regimented way through operationalized technical systems. These systems as well as their representational capabilities are driven by the interests of commercial actors rather than ordinary people using generative media. Technology involved in the process of co-production is a subclass of algorithms known as deep neural networks which operate in covert ways (Castelvecchi, 2016; Von Eschenbach, 2021). Representation, viewed from the perspective of visual social semiotics, is a discursive process in which a social actor seeks to make a visual representation of a social/political event and uses visual generative media to “translate” a verbal prompt into a visual output. The outcome is AI-generated images that represent the intended events or happenings from a machine vision perspective – the viewpoint that frequently diverges from that of a human actor.
Considerations of mythology, technology, and representation inform the analytical focus of this paper in two ways. Firstly, the technological aspects of visual generative media and the speed at which it develops present us with methodological complexities when studying these socio-technical phenomena. To account for these complexities, I propose to integrate insights from media and cultural studies, computer science, and visual social semiotics. Secondly, there is a dissonance between what is known about the behavior of the system used to generate images and what these images represent. The emergence of visual generative media challenges our understanding of representation – the first key moment in the circuit of culture (cf. Hall, 2013) – reconfiguring the ways in which we make sense of the world outside of our immediate reality. To address the issue of representation, I next outline how image generators work, and endeavor to provide an account of the technical processes in a manner accessible to digital media scholars and a broader readership of this journal.
AI image generation: Mechanisms and critical inquiries
Current AI-enabled image generators draw on text-to-image diffusion models (see e.g. Rombach et al., 2022). Diffusion models represent a subclass of deep neural networks, a type of AI modeled on the human brain. Like the human brain, deep neural networks operate in covert ways (Castelvecchi, 2016), remaining opaque and largely hidden from human comprehension (Von Eschenbach, 2021). As efficiency and performance of diffusion models grow, little remains known about how they learn from themselves and make decisions on the visual outputs when prompted by human agents. The capabilities of diffusion models, as well as specific parameters they identify, remain elusive even to data scientists, with recent calls for a pause in AI development to address growing concerns of algorithmic opacity (Narayan et al., 2023).
Visual generative media have reached remarkable quality outputs in an extremely short period of time since the conference paper Generating Images from Captions with Attention by researchers from the University of Toronto (see Mansimov et al., 2016) presented a model for generating images from captions. Unimpressive as they are by 2024 standards, first AI-generated images served as a testament to the ability of deep neural networks to generate novel scenes not seen during training. This development has set a precedent for technology companies and communities of independent, open-source developers to build text-to-image generators at an exponential rate.
While it may appear that a diffusion model identifies objects from training data through verbal prompts provided by a human agent, or promptor, and then combines the identified objects to form a new image, the generative process is inherently more complex (Figure 1). A novel scene emerges from the latent space of a deep learning model which recognizes complex categories from a network with multiple layers, with earlier layers creating a representation of the raw data and the later layers operating on this representation (Christian, 2021). Thus, AI image generation unfolds through manifest systems, or systems external to human mind (Ehn, 1988: 48). Precisely because such systems are beyond human comprehension, their operational nature may “deepen some humanitarian problematics and introduce new ones of its own” (McQuillan, 2018).

How generative AI models learn and produce visual outputs: (a) training data, (b) deep learning, (c) latent space, (d) generation, and (e) output.
To exemplify, for an image generator to be able to respond to the prompt “War in Ukraine, August 2023” and produce the visual output E in Figure 1, it first needs to be trained on hundreds of millions of images, known as
The next step of image generation model training is
Similar to deep learning,
Lastly, the process of
In sum, AI-enabled image generation is a vastly opaque process of image production through (a) machine identification of the metrics that separate images in the mathematical space of the training dataset, (b) machine-initiated introduction of the variables into a multidimensional space to improve its algorithmic performance and pattern recognition, and (c) subsequent generation of images from verbal prompts introduced by a human agent. Critical questions arise in relation to (i) training datasets and their problematic taxonomies, (ii) black box training and generation, and (iii) production, distribution, and cultural significance of visual outputs. The current study primarily focuses on the latter, seeking to advance our understanding of representation in AI-generated images and their potential implications for memory mediatization in the context of conflicts and wars.
Data and method
The dataset for this study includes a corpus of twelve images generated through the Midjourney model V5.2, released in July 2023. In September 2023, I prompted Midjourney (MJ) to generate images around three points of Russia’s war against Ukraine, anchored in the past, present, and future:
Prompt #1: Day 1, Russia’s invasion of Ukraine, 24 February 2022 (Supplemental Appendix A)
Prompt #2: Day 500, Ukraine’s counteroffensive, 8 July 2023 (Supplemental Appendix B)
Prompt #3: Ukraine, the end of the war with Russia, future (Supplemental Appendix C).
The prompts were deliberately designed to be open-ended, that is, they do not specify any desired visual content by introducing specific object or style descriptors (e.g. image subjects, “in the style of,” etc.). Rather, I was interested in MJ’s visions of two events – Russia’s invasion of Ukraine and Ukraine’s counteroffensive – and one entity (i.e. Ukraine post-war). To leave as much space for MJ’s vision as possible, I only utilized a text prompt functionality of MJ without specifying any technical parameters (Figure 2).

Types and specificity of prompts for generating images with Midjourney (https://docs.midjourney.com/docs/prompts-2).
MJ image generation is hosted on Discord (https://discord.com/). The MJ bot (@midjourney) is added to a Discord server, allowing registered members to generate images from verbal descriptions through the command /imagine. In the MJ V5.2, all registered users could see prompts input by other users, user Discord tags (unique identifiers starting with @), and images that the MJ bot generates. MJ’s Discord server had over fifteen million registered members in September 2023 (a statistic visible to the server members), with monthly subscription plans ranging from $10 to $120 in April 2024. As the only image generator that provides a shared social space during the process of image generation, MJ outpaces other prominent image generators such as DALL·E and Stable Diffusion, reaching its peak in popularity in May 2023 after the release of the MJ model V5.1 (https://docs.midjourney.com/docs/models). However, with the release of DALL·E 3 in September 2023, which offers in-built use of ChatGPT as “a brainstorming partner and refiner of prompts” (OpenAI, 2023), the popularity of DALL·E is swiftly approaching that of Midjourney. Relevant to this study, Ukraine is the eighth country in the world with the most interest in MJ, according to Google Trends (Figure 3).
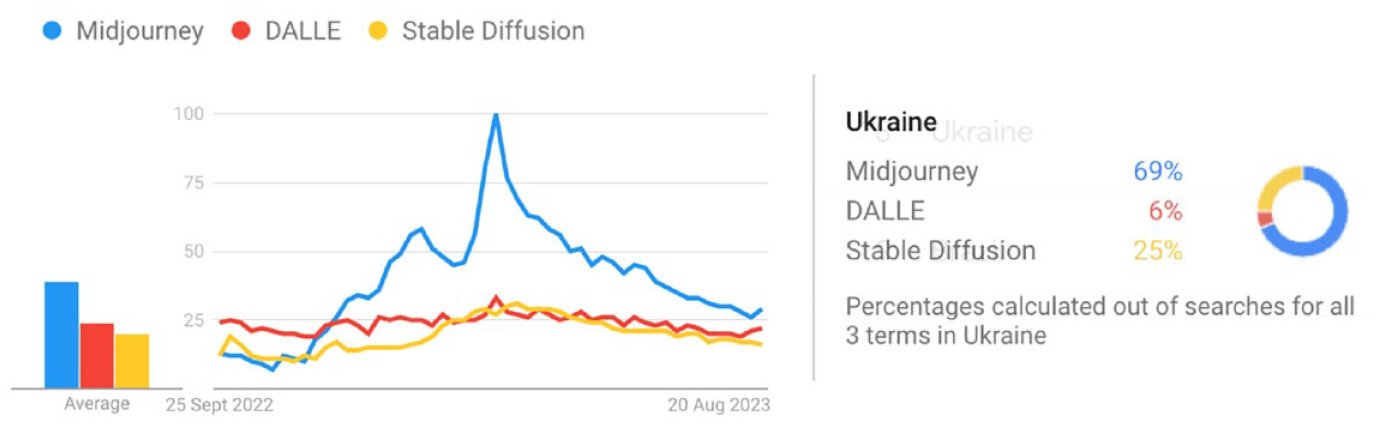
Popularity index of Midjourney, DALL·E, and Stable Diffusion in September 2022–September 2023 (https://trends.google.com/trends): (a) (left) – worldwide; (b) (right) – in Ukraine. 100 = Peak.
A search function on MJ’s website (https://www.midjourney.com/) resembles Pinterest’s “more ideas” feature, enabling users to explore associated prompts and AI images generated by other people. Notably, when other users input more detailed prompts to generate images specifying, for example, artistic style, color, contrast, or mood, MJ’s visual outputs were very similar to my open-ended prompts. Figure 4 shows one such example by comparing the visual output to Prompt #1 “Day 1, Russia’s invasion of Ukraine, 24 February 2022” and the following (highly specific) prompt by a Discord user @polynikez:
A platoon of 21st century Ukrainian infantry, Oil Painting, War Photography, Gamma, Chroma, High Contrast, 3D, 8K, Angry, Powerful, Moody Lighting, Mist, Ray Tracing Reflections, SSAO, in a symbolic style, patrolling the ruined streets of Bakhmut

Homogeneity of visual outputs to open-ended (left) and highly specific (right) verbal prompts.
It is, therefore, noteworthy that regardless of whether prompts are open-ended and generalized or highly specific, the resulting visual outputs often exhibit a striking degree of similarity.
Analysis of the representational discourses of war in the generated corpus of images is grounded in visual social semiotics. I view discourses as semantic constructions of specific aspects of reality that serve the interests of particular social contexts. As Foucault (1977) notes, discourses do not only involve a field of objects (or visual analytics in machine learning) but also “the definition of a legitimate perspective for the agent of knowledge” (p. 199) in a given context. Taking a perspective to the use of visual generative media as the construction of meaning “trains our attention on what meanings are made in AI-generated images, making them ripe for being read as “texts”’ (Thomas and Thomson, 2023).
To understand how AI-generated images position the viewer to relate to image subjects (or represented participants), I first annotated the dataset in relation to three elements of visual composition – gaze, size of the frame, and angle (horizontal and vertical) – drawing on an annotation schema adapted from Kress and Van Leeuwen (2021), as summarized in Figure 5.
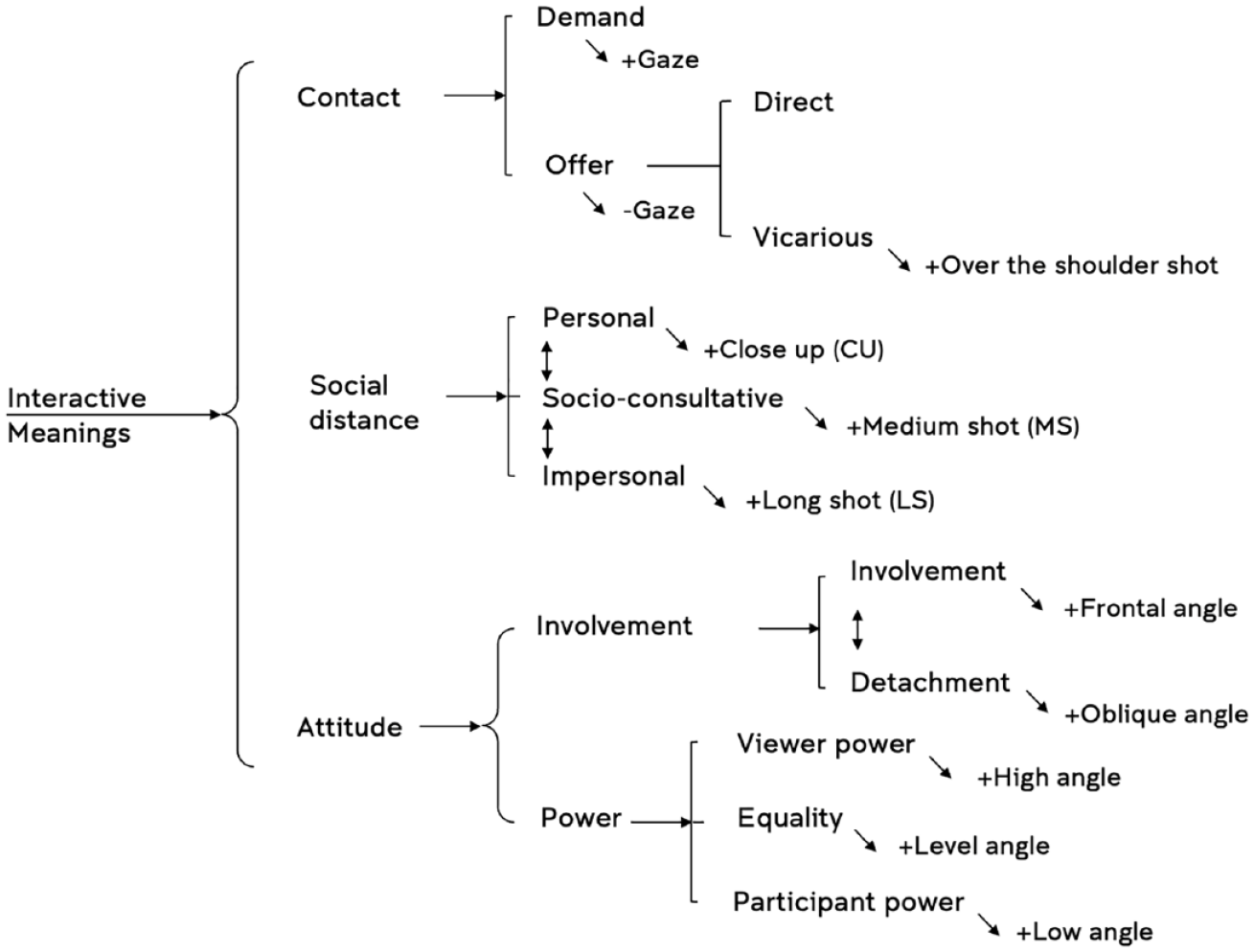
Coding frame for analysis of representation-viewer relationships in AI-generated images. Adapted from Kress and Van Leeuwen (2021: 142).
The coding frame presented in Figure 5 is a system network which maps visual choices in images that position the viewer to relate to image subjects in specific ways. The system network reads from left to right, representing several design choices in relation to gaze (contact), size of the frame (social distance), and angle (attitude).
I explore MJ’s algorithmic imaginary by examining “the site of the image itself” (see Rose, 2016: 32–34) – as a digital media researcher, but also as a promptor. As a promptor, I assume the role of a social actor engaging in the co-creation of visual outputs alongside MJ’s bot on Discord. As a researcher, I operate on the premise that AI-generated images are not straightforward extrapolations from existing generative AI technology, but are to be understood as the “contingent outcome of a series of social, political, and organizational factors” (Woolgar, 2005: 389).
Results: Midjourney bot’s imaginings of the Russia-Ukraine war
All images generated by the MJ bot in response to the three prompts introduced in the previous section featured people, 90.5% of whom were visually represented as male. Female subjects appeared only in images generated for Prompt #3 (“Ukraine post-war”). Findings are presented in Figure 6 which visualizes three clusters of code co-occurrences in the annotated corpus. The codes are located on the map according to their similarity, and the distances between codes represent how similar they are. The statistical data analysis was performed in MAXQDA Analytics Pro 2022 (https://www.maxqda.com/), a software for mixed-method research. A quantitative data analysis tool “Code co-occurrence” embedded in the software was used to uncover which codes occur in the same prompt group and how similar these codes are across the corpus.
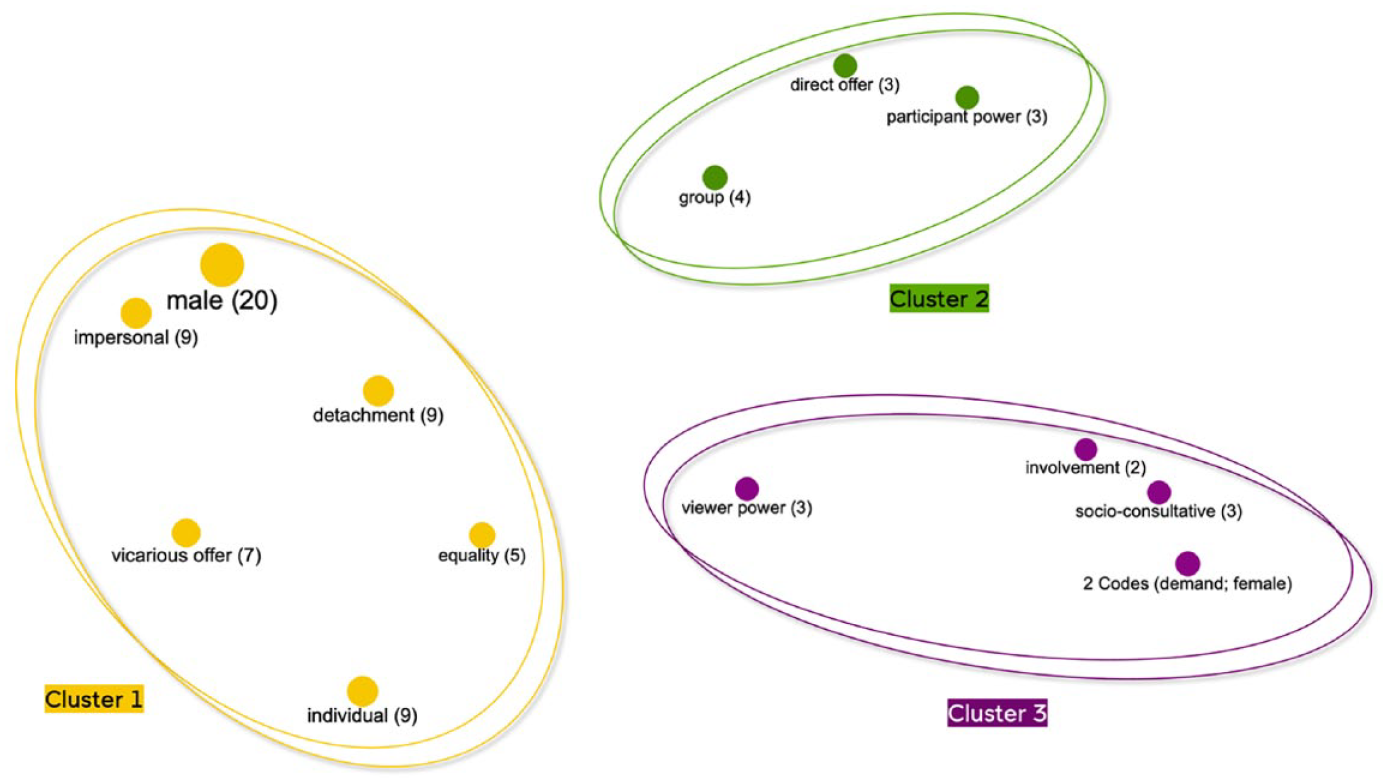
Code co-occurrence model representing three clusters of interactive meanings in the annotated corpus.
Cluster 1, shown in orange in Figure 6, indicates that most AI images featured male subjects presented as individuals through over-the-shoulder shots (vicarious offer) at an impersonal social distance (long shots), angled away from the viewer (detachment), and at an eye level (equal power). This set of visual design choices appeared in 42% of the corpus. In such images, individuals are positioned in the foreground, wearing military uniforms with no identifying insignia and marching through the battlefield filled with smoke, fire, and signs of destruction (e.g. Figure 7). However, these visual choices do not result in warm portraits of the featured individuals, and instead, individuals are homogenized as anonymized soldiers, due to oblique angles, over-the-shoulder shots, and impersonal social distance. Such images do not evoke sympathy or solidarity with the depicted persons, and instead, communicate somberness of a generalized soldier, whom the viewer is invited to follow into the vanishing point of fire and smoke as indices of destruction.

A typical output that combines the most representative visual choices in the annotated corpus.
The most common visual choice from the system of contact was vicarious offer which, together with detachment and impersonal social distance, positions the viewer to metaphorically follow the path of image subject(s) traversing the sights of destruction alongside their comrades. Because of this selection, eight images for both Prompt #1 and Prompt #2 exhibit substantial similarity, differing primarily in their representation of group versus individual subjects. Figure 8 illustrates this further by showing how individuals are presented as a more cohesive group in contrast to Figure 7.

Group representation of soldiers moving across the battlefield.
However, in Figure 8, group unity is not achieved by the means of visual cohesion but rather through a perceptual connection to the contextual factor (i.e. war). In this kind of images, people were depicted at an impersonal social distance and detached from the viewer, that is, they are represented through long shots and at oblique angles. Overall, these sets of visual choices result in constructions of battlefield scenes at an unspecified location where soldiers move through the terrain, with no enemy in sight.
Cluster 2, shown in green in Figure 6, was identified in relation to group depictions, with groups of soldiers represented for observation (direct offer) and from a low angle (participant power). These depictions result in a higher degree of social cohesion realized by the placement of image subjects closer together. Yet again, people in groups appear homogenized, at an impersonal social distance, with hardly discernible individual features (Figure 9).

Group representation that combines visual choices of direct offer and participant power.
Cluster 3, shown in purple in Figure 6, reflects visual choices in AI images generated to Prompt #3 related to Ukraine’s future post-war. This subset is unique in featuring female subjects, appearing as individuals at a socio-consultative distance. They are mostly angled toward the viewer (indicating involvement), make eye contact with the viewer (suggesting demand), and are represented at a high angle (signifying viewer power). In Figure 10, two female subjects make a visual appeal through gaze, “demanding” viewer attention. Salient facial features and grim expressions differentiate these images from the depictions of male subjects. The distinction is particularly evident through the transition from a detached perspective to an engaged frontal angle, a shift from an impersonal to a socio-consultative social distance, and a change from a vicarious offer to a demand.

Individual portraits of female subjects “demanding” viewer attention.
In sum, the analysis reveals homogeneity of visual scenes depicting Russia’s invasion of Ukraine, Ukraine’s counteroffensive, and bleak visions of Ukraine’s future. MJ’s bot appeared to favor representing male subjects as individuals, at oblique angles, through long shots, “over the shoulder” shots, and at level angles (Supplemental Appendix D). These choices result in a particular construction of war scenes emphasizing “the follow me” visual narrative and positioning the viewer as a detached voyeur. Interestingly, the future is female, yet the harsh realities of war are depicted through the lens of male soldiers, as traditionally perceived by society.
Discussion: Visual themes in AI-generated images
Two main visual themes were identified in the annotated corpus: (1) soldiers and fighters (but not injury or death) and (2) destruction and aftermath (but not reconstruction efforts). These include both what is and is not represented in images, in which “the absence of something functions as an active component of a percept” (Arnheim, 1969: 89). Much like the challenge of discerning the causes behind visual absences in Google Photos, which may result from opaque algorithmic recommendations or inherent platform constraints (Brantner et al., 2024: 107), the issue becomes even more complex when applied to AI-generated images due to the mechanisms of deep neural networks discussed earlier.
The most prominent visual theme was that of soldiers and fighters, showing the human side of war. Most often, these kinds of images portray male soldiers moving through the battlefield (Prompts #1–2) or in the moment of contemplation (Prompt #3). Due to the choices of a vicarious offer, detachment, and impersonal social distance, individuals are not portrayed as integrated into the viewer’s world. Instead, such imagery conveys the perspective of an observer positioned to share the soldier’s experiences as an onlooker (Figure 11). Simultaneously, images featuring soldiers do not depict injuries or fatalities, combat, or the enemy, obfuscating the harsh realities of combat.

Positioning of the viewer as a passive onlooker.
The second visual theme was centered around destruction and the aftermath of fighting. This theme is characterized by depictions of explosions, fire, smoke, and rubble which provide a contextual backdrop for the portrayal of soldiers and convey the environmental impact of war. At the same time, these images do not represent displaced civilians or the loss of cultural heritage and artifacts as part of the broader context, thereby generalizing depiction of this war to that of any war.
According to MJ, the future of Ukraine is also marked by infrastructural destruction. The images generated for Prompt #3 do not provide a glimmer of hope amidst devastation, showing no reconstruction efforts. Instead, they showcase male subjects engaged in a passive observation of the ruins (e.g. Figure 11) or female subjects making a visual “demand” through gaze (Figure 10). Overall, all the images encompass destruction and portray individuals in a manner that neither emphasizes their agency nor entices the viewer to develop an emotional connection with those impacted by the war.
Conclusions and future research
AI-enabled image generators represent a novel technology that has the potential to be widely integrated into various social practices and mediate public perceptions of political events, conflicts, and wars. Yet, a more complete understanding of the future(s) of visual generative media and its broader cultural implications remains an elusive task because the cultural and communicative shifts engendered by technological advancements are inexorably linked to the passage of time. Interrogating cultural spaces where the past, present, and future converge beyond the dominant narratives of Silicon Valley is necessary precisely because it lies beneath the surface of our immediate perception.
As visual generative media grow in sophistication, their complexity and opacity pose ethical and practical challenges, particularly in terms of data sourcing and representational capacity. Among these challenges, this paper was mainly concerned with the issue of representation, providing insights into depictions, perspectives, and visual themes in the context of the Russia-Ukraine war. I now return to the notion of AI image generation as a socio-technical practice and discuss several implications and limitations of this study in relation to mythology, technology, and representation in visual generative media.
Mythology
Despite the discursive construction of MJ as “an engine for the imagination,” AI image generation is more than an act of creative expression. In the context of conflict- and war-related imagery, it is a highly regimented and homogenized social action that results in representations that are neither neutral nor objective. Unlike traditional visual production tools, such as Adobe InDesign or Photoshop, text-to-image generators establish cultural meanings through operationalized technical systems, not human-centered design. While it appears that subjectivity is absent because visual outputs emerge from machine learning mechanisms, AI images depict the world based on patterns identified by the system trained on western-centric datasets, not the human actor prompting the system. Biases inherent in such datasets might have generative media far-reaching consequences, shaping societal attitudes as visual generative media sees wider adoption.
Due to the problematic training data and opacity of machine learning processes, AI systems inherit and perpetuate biases and ideologies embedded within their design, influencing the diversity of visual representation. In this study, machine vision of the Russia-Ukraine war was found to be limited, presumably arising from the datasets that shape MJ’s representational capabilities. Since MJ is a proprietary model, information about how recent MJ’s training data is or what impact its general makeup might have on representing conflicts and events unfolding after its training is unavailable. Nevertheless, such a relationship would prove highly significant because generative AI models draw inferences from patterns in datasets they were trained on. The emerging field of critical data set studies (Thylstrup, 2022) offers one promising direction that aims to ensure accountability for individuals and communities in data sets that shape AI models.
Technology
Complexities of machine learning that constitutes the backbone of AI-enabled image generation are also beyond human comprehension, raising further questions about deep learning and latent spaces. Deep learning, involving multilayered models and mathematical metrics, makes image generation even less transparent because associations between variables and the resulting visual outputs remains hidden from the human view. Similarly, the latent space remains poorly understood. Because human promptors can only influence visual outputs through textual prompts, the technical processes are hardly a subject for scrutiny. As the study has briefly demonstrated, the degree of specificity of verbal prompts (Figure 4) does not always lead to a broader representational range. Future research could further address these preliminary observations in relation to representations of Russia’s invasion of Ukraine to images generated for wars and conflicts in general. Such a study could identify whether there are other key features in AIdespictions of war when Russia-Ukraine prompt words are excluded. To understand representational capacity of visual generative media for different representational contexts, critical questions should be raised about training data, the black box of training and generation, and the cultural significance of AI-generated outputs.
Representation
Representation is always bound by cultural and political choices. In AI-generated images, these choices are construed through mathematical models that begin to dominate our social world. Machine visions of the Russia-Ukraine war favor certain perspectives in constructing a particular socio-technical reality, representing male subjects, detachment, impersonal social distance, and oblique angles, which results in generalized portrayals of soldiers as objects for dispassionate scrutiny. Unless the training data is diversified, image generators will continue reiterating prevalent patterns and dominant narratives they were trained on.
The main visual themes of soldiers and fighters and destruction and aftermath contribute to the depiction of a generalized war, removed from the viewer’s world and, for large part, devoid of potential for emotional connection. The two identified visual themes appear to echo dominant visual themes found in studies of news representations of war in the Persian Gulf, Iraq, and Afghanistan (Griffin, 2004; Schwalbe et al., 2008). Similarly, the homogeneity observed in the visual choices in AI-generated images mirrors previous research on war images in traditional mass media (Griffin, 2010; Parry, 2010). This similarity seems to suggest that visual generative models imitate already existing representations in conventional media, and more research of larger corpora is needed to compare human- and machine-made representations of wars.
Therefore, it is necessary to deepen our understanding of visual generative media because a medium is “as much a guild, a profession, a craft, a conglomerate, a corporate entity as it is material means for communicating” (Mitchell, 2005: 213). Media and cultural studies have much to offer in this regard. As Natale and Guzman (2022) highlight in the introduction to the themed issue Reclaiming the Human in Machine Cultures, research of the emerging AI systems and human practices forming around them are “integral to the mission of media and cultural studies” (p. 629), contributing to academic and public debates regarding interactions of humans and machine systems and cultural reconfigurations brought about by such interactions. This study has provided insights into image generation as a socio-technical practice, contributing to scholarship on critical machine vision as an important transdisciplinary challenge situated at the interface of computer science, media and cultural studies, and discourse-analytic approaches to visual communication. Such an interdisciplinary endeavor advances the agenda for critical studies of visual generative media in three ways.
Firstly, accounting for the processes involved in AI image generation – a concern of computer science research – helps to identify potential issues that arise during the various stages of technology development, implementation, and use (refer to Figure 1). Secondly, critical considerations surrounding image generation – a concern of digital media scholarship (broadly defined) – can be addressed by integrating media studies and critical data studies perspectives. Lastly, discourse-analytic approaches, such as visual social semiotics, offer a robust theoretical foundation for addressing meaning-making practices in which AI-generated artifacts are intertwined with their social contexts of use. By studying representations, discourse analysis proves beneficial for considering nuanced sets of choices in AI images. As the study demonstrated, these choices result in specific representations that influence how AI audiences relate to AI-generated content. Three approaches – computer science, media and cultural studies, and discourse analysis – can be applied to studying various aspects of visual generative media. Adopting different frameworks to the new practice of AI image generation presents new perspectives on the production of AI images for various purposes, human-machine agency, and environmental constraints of emerging technologies. This kind of critical work can also inform “ethical and practical considerations through which these technologies are regulated, developed, and used on a global scale” (Natale and Guzman, 2022: 629).
It is, of course, unreasonable to assume that images have the capacity to represent the natural reality objectively. But there is a need to carefully consider just what mechanisms are involved in the construction of our symbolic realities. As socio-technical artifacts, AI-generated images are likely to imbue the many social aspects of our representational practices, and, as Worth (1981: 184) writes, how pictures mean is largely responsible for what pictures mean – a kind of dialog between picture event and reality concerning the very act of structuring that reality. In representing the world, AI-generated images make claims about it, impacting how the world is perceived and remembered.
Supplemental Material
sj-docx-1-mcs-10.1177_01634437241259950 – Supplemental material for Engine for the imagination? Visual generative media and the issue of representation
Supplemental material, sj-docx-1-mcs-10.1177_01634437241259950 for Engine for the imagination? Visual generative media and the issue of representation by Nataliia Laba in Media, Culture & Society
Footnotes
Acknowledgements
I am grateful to Dr Suneel Jethani (University of Technology Sydney) for introducing me to Science and Technology Studies when we first “met” on Twitter during the lockdown in July 2021. Several threads in this paper are ideational extrapolations around data-driven cultures, from our course delivery work in the subjects Digital Media Industries and Data Ethics and Regulation, email conversations, and (not enough) coffees on campus. I also thank the anonymous reviewers for their valuable suggestions on the earlier version of this manuscript submitted for the 74th Annual International Communication Association Conference, Gold Coast, Australia, 20–24 June 2024.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.