
Abstract
Background:
Gastric cancer remains one of the leading causes of worldwide cancer-specific deaths. Accurately predicting the survival likelihood of gastric cancer patients can inform caregivers to boost patient prognostication and choose the best possible treatment path. This study intends to develop an intelligent system based on machine learning (ML) algorithms for predicting the 5-year survival status in gastric cancer patients.
Methods:
A data set that includes the records of 974 gastric cancer patients retrospectively was used. First, the most important predictors were recognized using the Boruta feature selection algorithm. Five classifiers, including J48 decision tree (DT), support vector machine (SVM) with radial basic function (RBF) kernel, bootstrap aggregating (Bagging), hist gradient boosting (HGB), and adaptive boosting (AdaBoost), were trained for predicting gastric cancer survival. The performance of the used techniques was evaluated with specificity, sensitivity, likelihood ratio, and total accuracy. Finally, the system was developed according to the best model.
Results:
The stage, position, and size of tumor were selected as the 3 top predictors for gastric cancer survival. Among the 6 selected ML algorithms, the HGB classifier with the mean accuracy, mean specificity, mean sensitivity, mean area under the curve, and mean F1-score of 88.37%, 86.24%, 89.72%, 88.11%, and 89.91%, respectively, gained the best performance.
Conclusions:
The ML models can accurately predict the 5-year survival and potentially act as a customized recommender for decision-making in gastric cancer patients. The developed system in our study can improve the quality of treatment, patient safety, and survival rates; it may guide prescribing more personalized medicine.
Introduction
According to global cancer statistics (GLOBOCAN) 2020, gastric cancer ranks fifth for incidence (5.6% of total new cases of cancer, 1089103 people) and fourth for mortality (7.7% of total cancer-related deaths, 768 793 deaths) globally. It is the most commonly diagnosed malignancy and the chief cause of cancer-related mortality in several developing countries. 1 Despite the downward trend during the last decades globally, like many other Asian countries, Iran still has constantly increasing incidence and mortality rates of gastric cancer. According to GLOBOCAN 2020, gastric cancer is the second most common cancer in Iran with 13 191 (11.2%) new cases of total cancer and is first with 79 136 (16.4) deaths of total cancer-related deaths. This rising incidence in Iran is likely due to the recent demographic and epidemiological transitions in its population.2,3
This malignancy imposes heavy costs on the health system and patients’ families. Therefore, prevention and early screening of gastric cancer should be the main priority of the country’s health system programs. 4 The fundamental issue in patients with gastric cancer, as in many other clinical areas, is the multidimensional and ambiguous nature of its diagnosis and treatment processes. 5 The treatment of tumors depends largely on the prognosis judgment that strongly rests on the phase, in which it is detected.6,7 The 5-year relative survival rate is up to 70% for lesions in the early stages and 4% for lesions in the advanced stages.6,8,9 Survival often refers to the likelihood, by which a patient will live 60 months after being diagnosed with cancer. This index is commonly used in medical science to evaluate the effects of surgical and treatment plans. 10 Accurately predicting the survival of gastric cancer patients could help clinicians make better decisions about the diagnosis and treatment process, including the choice of treatment methods, treatment schedule, and follow-up visits, which can increase the patients’ outcomes and contain economic costs.11,12 But calculating survival time in gastric cancer patients by using traditional clinical and statistical methods is faced with limitations and challenges as follows:6,13
The traditional tumor-node-metastasis (TNM) staging system has been useful in stratifying gastric cancer patients; however, mid-stage patients show a variety of prognostic outcomes and there is a critical need to categorize these patients more carefully. 14 Thus, the TNM system is insufficient due to the large differences in survival outcomes. 15 The gastric cancer treatment outcomes are related to many variables, and it is not possible to predict the survival of the disease by using one factor alone because several factors related to the disease, the patient, and the treatment process can affect the survival of cancer patients.16,17 Thus, multivariate analysis tools are needed to find patterns and relationships between multiple variables simultaneously. The multivariate analysis allows to predict the effects that a change in one variable will have on other variables. Multivariate analysis can provide a more accurate picture and understanding of data behaviors which are related to each other.18,19 Multivariate analysis techniques are complex and require a statistical program to perform this analysis. One of the important limitations of multivariate analysis is that it is not always easy for physicians to interpret statistical modeling outputs. In addition, a large sample of data is required to obtain meaningful results for multivariate techniques.8,20 In the past, researchers have used a variety of survival analysis methods to describe the relationship between response variables and a set of independent variables in various fields of medical science. In this context, conventional survival methods such as Cox proportional hazard modeling are still the most common approach for analyzing the relative importance of the predictive variables in the development of the disease.21,22 However, when using this model, some basic assumptions such as the proportionality of risks and the independence of variables affecting the risk rate must be considered. 23
Technical advances in statistics and artificial intelligence (AI) enable computer engineers and health scientists to work closely to improve the prognosis using multifactorial analysis, conventional logistic regression, and Cox analysis.21,24,25 The accuracy of such predictions is significantly higher than the experimental predictions. In addition, research shows that traditional statistical methods do not provide as accurate analyzes as AI. With the implementation of AI, researchers have recently developed models using AI algorithms to predict and diagnose cancer. These methods currently play an important role in increasing the accuracy of predicting cancer vulnerability, recurrence, and survival.19,24,26
Machine learning (ML), as a special concept, is a subset of AI, increasingly used in medicine. This technique is used to build predictive models to extract hidden patterns and uncover unknown correlations from massive historical data. ML has been widely used in improving the prognosis of patients. 27-29 Prognosis is important expertise in clinical practice, especially for physicians who make decisions in complex and ambiguous situations such as caring for cancer patients.12,30 Past research has shown that ML techniques improve the accuracy of predicting cancer vulnerability, relapse, and survival, 3 facets that are essential for early detection and prognosis of cancer. ML can provide good results according to the clinical condition of patients.31-33 By apprehending multifaceted non-linear relationships in the data, the ML technique can increase the prediction performance more than traditional statistical methods. Many studies have applied ML algorithms for predicting cancer survival. Presently, ML can predict breast cancer survivability in the primary stages.34-36 Das et al 37 and Hauser et al 38 have compared selected ML methods to the survival prognosis of patients with leukemia. They have respectively found that the gradient boosting algorithms (BAs) such hist gradient boosting (HGB) with area under the curve (AUC) of 0.779 and XGBoost with AUC of 0.87 achieve the highest performance. Okagbue et al, 39 Kaur et al, 40 and Liu et al 41 have assessed the performance of selected ML-based BAs to predict breast cancer survival. Finally in the reviewed studies, the AdaBoost, HGB, and XGBoost classifiers have achieved the best performance with the AUC of 98.3%, 91.1%, and 83%, respectively. Feng et al’s 42 experimental results showed that the XGBoost method achieved the accuracy of 91.64%, recall of 91.14%, and AUC of 91.35% for neuroblastoma survival prediction.
Given the high prevalence of gastric cancer in Iran and lack of a reliable study to determine risk factors of the disease survival based on ML methods, our study aims to develop an intelligence system regarding the use of novel ML algorithms for the development and validation of gastric cancer survival prediction. The primary outcome indicator is the accuracy of the different models in predicting a 5-year (60 months or 1825 days) survival rate for gastric cancer to provide a better theoretical basis for the application of ML in survival prediction.
Methods
Study design and setting
This is a retrospective study using a data set from Ayatollah Taleghani Hospital in the southwest of Khuzestan Province, Iran. Data related to 1220 patients pathologically confirmed gastric cancer were extracted from the electronic medical record (EMR) database after obtaining appropriate approval from Research Ethical Committee, Abadan University of Medical Sciences. The study methodology complied with the cross-industry standard process for data mining (CRISP-DM). The CRISP method determined 6 phases for a data mining project including business understanding, data understanding, data preparation, modeling, evaluation, and deployment. Figure 1 represents the CRISP-DM research methodology. All the prediction models were developed using Python programming language (3.7). J48 decision tree (DT) and support vector machine (SVM) (with RBF kernel) were implemented using Python library scikit-learn (0.23.2), while bootstrap aggregating (Bagging) classifier, HGB, and adaptive boosting (AdaBoost) were implemented using another specific Python library (see Figure 1).

The framework of the machine learning method based on CRISP-DM.
Data understanding
There is a large number of features collected for the patients with gastric cancer in the EMR database. So, we checked the definition of the features included in the data dictionary section of the database to completely understand the data definitions and choice of proper variables. The criteria for identifying the candidate variables related to gastric cancer for survival prediction were based on consulting with experts’ oncologists and studying the related literature. Patients were only included in the study if all the following criteria were met: (1) patients who were pathologically diagnosed with gastric cancer; (2) the survival status of patients (alive/dead) was available in their records; (3) in terms of the timeframe, we considered patients diagnosed between 2010 and 2017 so as to have adequate follow-up period (5 years or more) after the diagnosis; (4) age of more than or equal to 18 years 43 ; the patients aging under 18 years old should be included in the scope of pediatric exploration; (5) records with missing values of less than 30%.
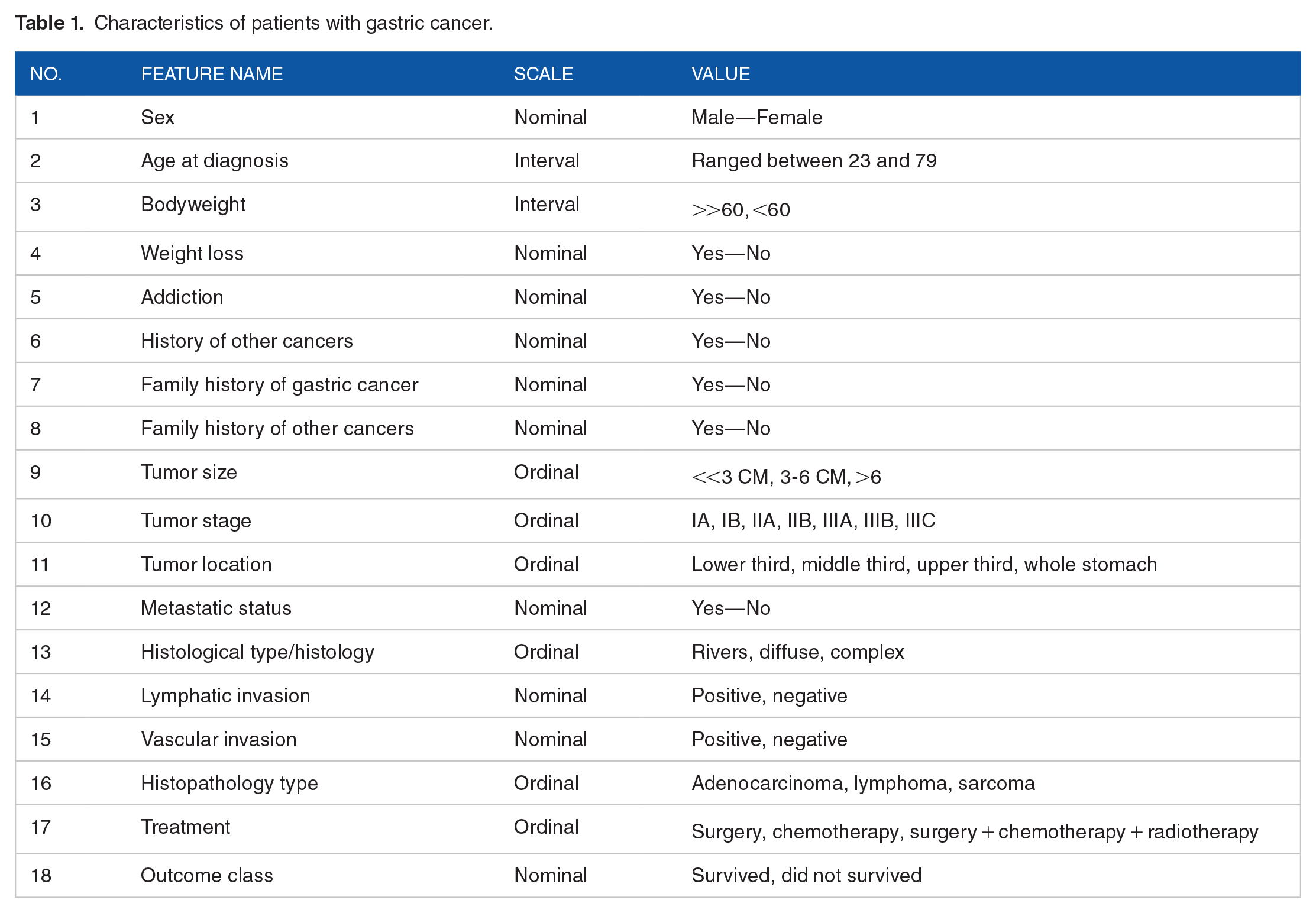
Accordingly, from 1220 patients’ records, 59 records for patients who were aged <18 years old were excluded. In the preprocessing phase, 187 incomplete rows of data (with missing data of greater than 70 %) were removed. After these criteria were applied, a total of 974 patients (399 survived and 575 dead within 5 years) remained for additional analysis. Survival at 5 years was selected as the outcome variable. The following covariates were extracted based on the literature review coupled with experts’ opinions from the EMR database, as depicted in Table 1.
Characteristics of patients with gastric cancer.
Data preparation
Since the raw data with missing values, noisy data, and outliers or inconsistent data will affect ML algorithms’ performance, in our study to improve the performance of prediction models, the preprocessing step was made on the raw data to make it balanced, effective, and noise-free. In this phase, the attribution of missing values means and regression-based techniques were used. The rows with missing values of greater than 70% were removed. The Z-score standardization technique was applied as a data distribution-based data scaling and, for data range-based scaling, the min-max techniques were used. The data set was randomly divided into a training data set (n = 877) and a testing data set (n = 79) with the proportion of 9:1. The procedure of our study is shown in Figure 2.

Gastric cancer patient inclusion diagram (test and training set).
Feature extraction and feature selection
After the data set cleaning and imputation steps, we can extract relevant and important features. For this purpose, in our study, first, the previous literature was studied to extract the candidate features related to predicting survival in the patients with gastric cancer. Then, we adopted the Boruta feature selection algorithm to select the most important variables and, using these selected features, the performance of the ML algorithms was calculated. In this study, we also tested the performances of different ML predictive models for gastric cancer survival prediction on all and selected features.
Development prediction models and evaluation method
To develop the prediction model for predicting survival risk in gastric cancer patients, 5 ML algorithms, including the Bagging classifier, AdaBoost classifier, HGB classifier, SVM (with RBF) and J48, were trained. For the development and validation of ML models, a 10-fold cross-validation method was used to train and test these models over the full and selected features. The final data set was randomly split into training (877 records, 90%) and testing (97 records, 10%) sets using methods in Scikit-learn (as shown in Figure 2). The training set is a piece of data used for model development and hyperparameter tuning (to teach ML models) and the testing set to evaluate the performance of the trained models. Data splitting prevents random data bias and ensures balanced distribution of data in training and testing sets. It is important to note that testing set data, which was used to evaluate the performance of ML algorithms, was never used when training algorithms during the training process.
We experimentally tuned the hyperparameters over the training set based on the cross-validation method.
Once the classification algorithms were implemented over the trained data set, the next phase was to test these trained algorithms over the testing set to assess the performance of classifiers on unseen data. The performance of 5 classification models for predicting survival among gastric cancer patients was evaluated using 5 commonly used performance testing metrics including accuracy, specificity, sensitivity, AUC, and F1-score (Equations 1 to 4). Afterward, the performance of each trained classifier was compared with all other ML algorithms according to the 5 selected performance metrics. Then, the best-performing model was further applied to predict the survival of patients with gastric cancer. The performance evaluation metrics of the classifiers are listed below:
classification accuracy =
classification sensitivity =
classification specificity =
F1-score =
Ethical consideration
Ethical Committee approved the study conducted by Abadan University of Medical Sciences (Ethics code: IR.ABADANUMS.REC.1401.003). To protect the privacy and confidentiality of the patients, we concealed the unique identification information of all the patients in the process of data collection and presentation. It adhered to the principles expressed in Declaration of Helsinki.
Results
Characteristics of patients
Overall, 974 patients with gastric cancer met the prespecified inclusion criteria. Of 974 eligible patients in our study, 648 (66.53%) cases were male and 326 (33.47%) cases were women and the median age of the participants was 57.25 (age of cases ranged from 23 to 79 years old). Of these, 399 (40.96%) cases survived and 575 (59.04%) dead. The detailed descriptions of all the variables are listed in Table 2.
The descriptive statistics of variables of the study after preprocessing.

Variables included in the ML models
The variables that would be important for the prediction of the 5-year survival status of gastric cancer patients were selected from a large number of features for modeling. The Boruta algorithm was used to select important features. The Boruta algorithm selects the most important features based on the random forest (RF) algorithm, which determines all the variables that are either potently or faintly related to the decision features. The 8 features that were selected as the most important predictors by the Boruta algorithm and their scores and ranks are shown in Table 3.
The most important selected variables of survival prediction.

The 8 most important features were tumor stage, tumor site, tumor size, age, metastatic status, type of treatment, lymphatic invasion, and body weight. As shown in Figure 3, tumor stage, tumor site, and tumor size obtained the highest score for the survival prediction among the patients with gastric cancer.
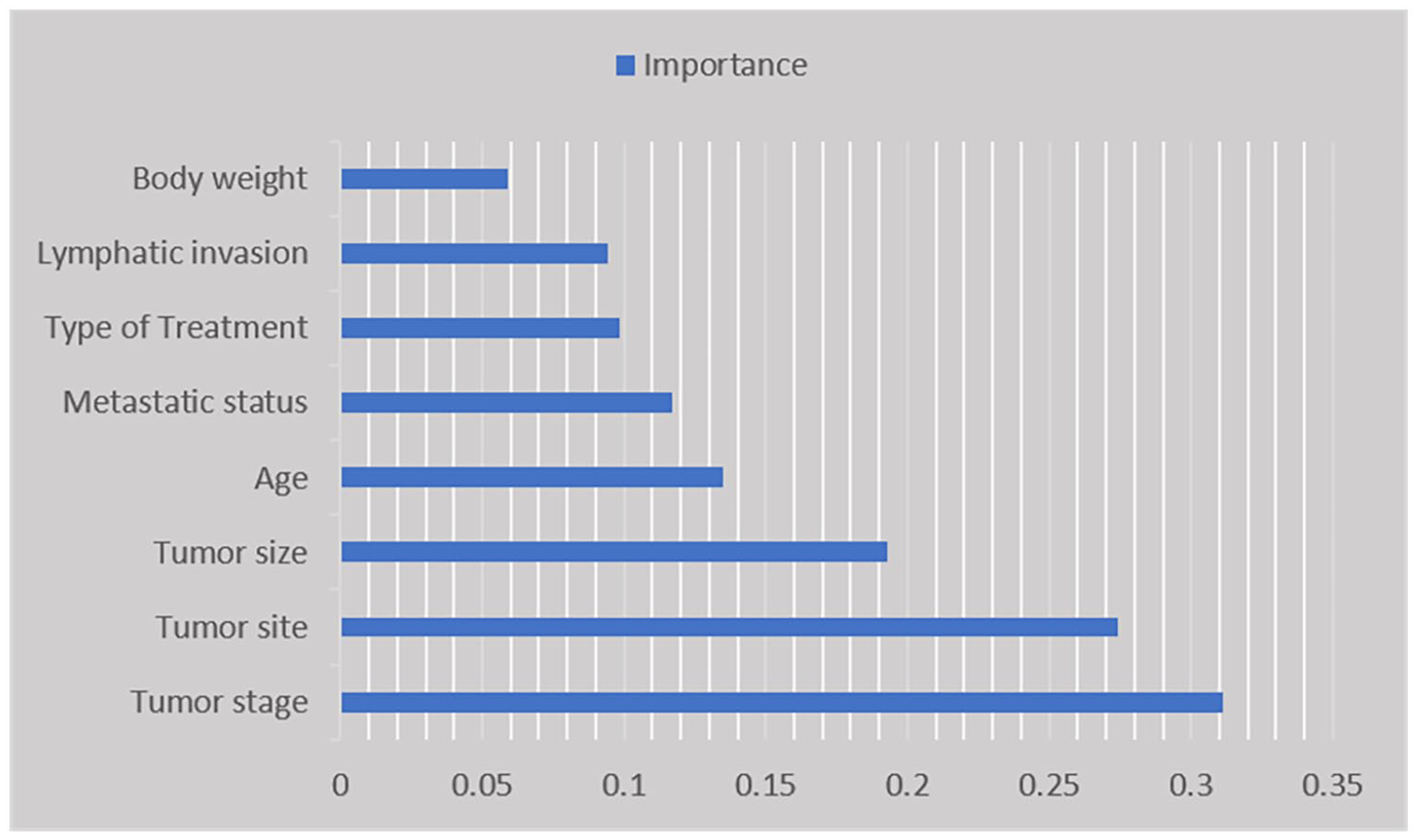
The most important predictors of survival among patients with gastric cancer.
Moreover, between these 8 selected features, body weight and lymphatic invasion had the lowest rank for prediction of gastric cancer survival; additionally, 10 features were not selected for the survival prediction model and were deleted from the data set.
Results of hyperparameters tuning
The performance of prediction models depends on the setting of the hyperparameter. In this study, to select the best model architecture, the Randomized Search CV method was used for parameter tuning and optimization models. Table 4 represents the best hyperparameters selected in this study for feeding into ML algorithms.
Best hyperparameters selected for machine learning algorithms.

Abbreviations: ML, machine learning; SVM, support vector machine; RBF, radial basic function.
Performance of ML models
In this experiment, we first trained 5 ML algorithms (Bagging, SVM, AdaBoost, HGB and J48 DT) over all and selected features. Afterward, we tested these trained algorithms over the testing set. The performances of 5 ML models were tested with a 10-fold cross-validation method using evaluation metrics including the mean of accuracy, sensitivity, specificity, F1-score, and area under the receiver operating characteristic (ROC). Table 5 describes the 10-fold cross-validation performance of the applied ML algorithms when using the full features data set and selected feature.
Overall predictive performance for each ML model to predict survival of gastric cancer.
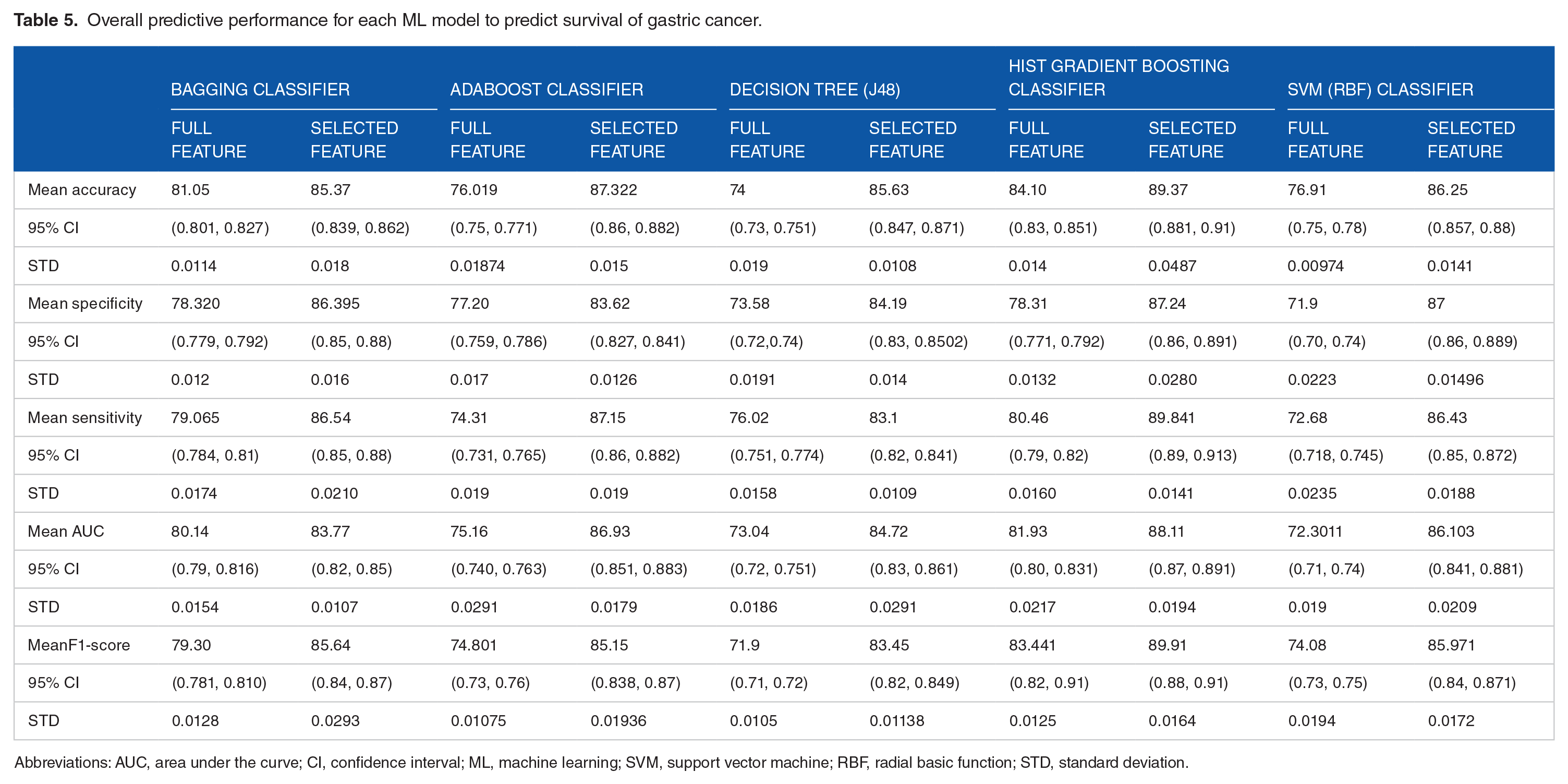
Abbreviations: AUC, area under the curve; CI, confidence interval; ML, machine learning; SVM, support vector machine; RBF, radial basic function; STD, standard deviation.
As indicated in Table 5, the Bagging classifier achieved 85.37 accuracy, 86.395% specificity, 86.54% sensitivity, 83.77% AUC, and 85.64% the F1-score value. The AdaBoost classifier had 87.322% accuracy, 83.62% specificity, 87.15% sensitivity, 86.93% AUC, and 85.15% F1-score value. The J48 DT classifier was given with prediction accuracy of 85.63%, specificity of 84.19%, sensitivity of 83.1%, AUC of 84.72%, and F1-score of 83.45%.
The HGB classifier performance for the prediction of survival among gastric cancer was 88.37% accuracy, 86.24% specificity, 89.72% sensitivity, 88.11% AUC, and 89.91% F1-score value. Finally, the SVM model with RBF kernel had 86.25% accuracy, 87% specificity, 86.43% sensitivity, 86.103% AUC, and 85.971% F1-score (Figure 4).

Comparing machine learning models’ performance on selected features.
As indicated in Figure 4, the best ML model for predicting survival in the patients was with gastric cancer HGB classifier, with mean accuracy value, mean specificity value, mean sensitivity value, mean AUC value, and mean F1-score value of 88.37%, 86.24%, 89.72%, 88.11%, and 89.91%, respectively. Figure 5 depicted the classification report matrix and AUC curve of the HGB model which was selected as the best prediction model in terms of the highest performance metrics. The AdaBoost classifier was the second-best classifier that had the accuracy of 87.322%. The worst ML model’s performance was observed for the Bagging classifier out of 5 prediction models in terms of the average accuracy, sensitivity, specificity, AUC, and F1-measure.
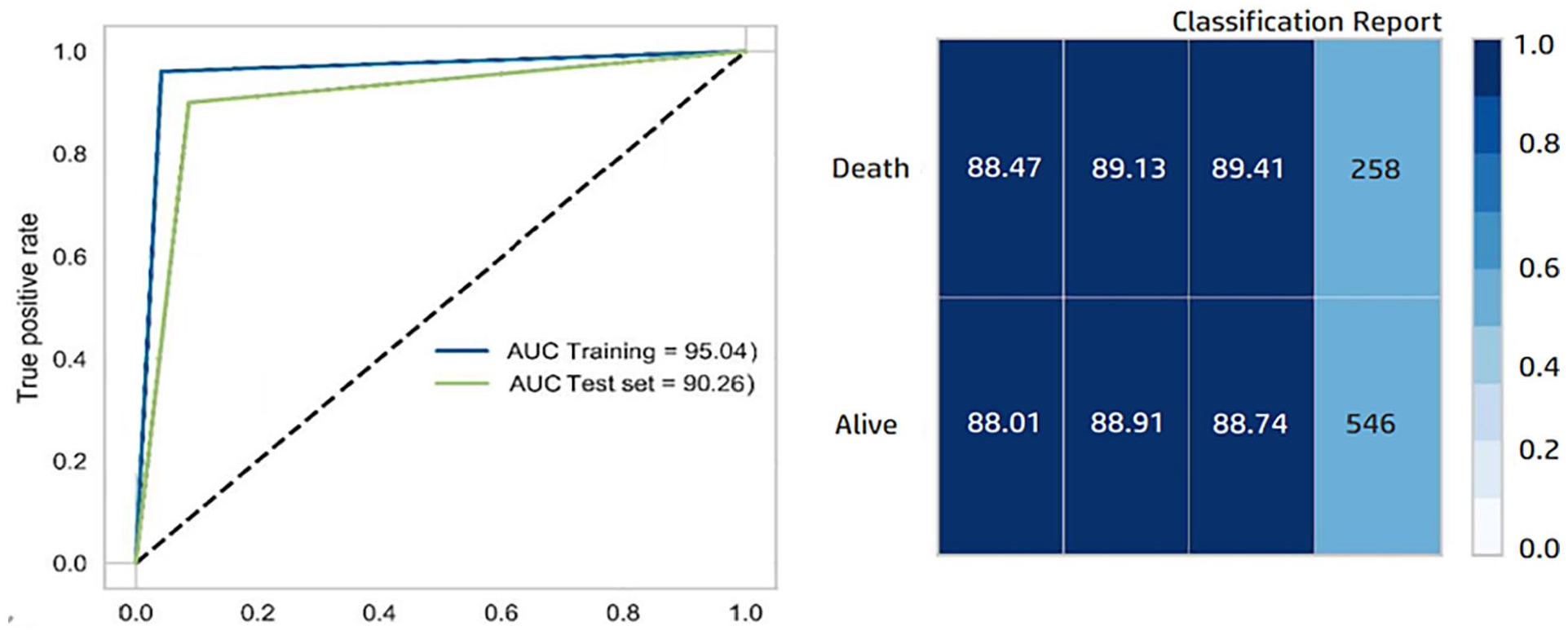
AUC curve and classification report for hist gradient boosting classifier.
System development
Using the best-performing ML model developed from among the 5 models, a windows-based clinical decision support system (CDSS) was designed and implemented between August 2021 and December 2021. The user interface of the gastric cancer survival prediction system was developed by C# programming language. To help medical oncologists’ decision-making and to predict the survival among the patients with gastric cancer, the CDSS was installed at Ayatollah Taleghani Hospital of Abadan city, Iran. Screenshots of the developed CDSS are shown in Figure 6.

Screenshots of CDSS for prediction survival among patients with gastric cancer.
Discussion
Accurate evaluation of the gastric cancer prognosis is of great value in understanding the disease and providing effective treatment for each patient. In the last few decades, the TNM grading system has been the most accepted and used global gastric cancer classification system in the anatomic extent of disease. However, the TNM gastric cancer grading system has led to a substantial difference in the survival of patients with the same tumor stage and similar survival results between distinctive steps.44,45 Presently, TNM staging cannot still meet the individual and precise treatment of patients’ requirements in the health center. The TNM staging system is inherently limited, with large survival variations for same-stage tumors and low accuracy in determining a patient-specific prognosis. Relevant literature has revealed that the recital of making a prognostic model by Cox proportional hazards model 45 and SVM 46 is significantly better than the TNM staging system. However, determining more illustrative variables for precise prediction of prognosis is a crucial problem that needs to be addressed. ML algorithms can be a good alternative for solving this problem. In the present work, the selected ML models were evaluated to predict future gastric cancer survival. Then, a CDSS was developed based on the best model.
So far, several studies have been conducted to compare ML techniques and design optimal and efficient CDSSs for the survival prognosis of the patients with gastric cancer. Liu et al 8 used ML methods in the survival prediction of gastric cancer. Out of 6 models, the light gradients boosting machine (GBM) had the best accuracy and the highest precision rate for survivability analysis. By implementing 6 ML models, Akcay et al 6 concluded that XGBoost with 86% accuracy (95% confidence interval, 0.74-0.97, AUC: 0.86) along with RF is the most successful algorithms for gastric cancer survival and recurrence prediction. Similarly in Bang’s study, 35 among the 18 ML models, the XBoost classifier showed the best performance in early gastric cancer prediction and survivability with the accuracy of 93.4%, precision of 92.6%, recall of 99.0%, and F1 score of 95.7%. Fan et al 36 retrospectively compared 3 ML techniques for the prediction of metastatic, relapse, and patient survival chances in the early stage of gastric cancer. In their study, the AdaBoost model achieved better performance with the AUC of 0.849. Accordingly, Lee et al 47 applied 7 ML methods for a 2-year survival analysis of patients with gastric cancer. They found that the gradient Boosting algorithm (GBA) with the AUC of 0.80 gained the highest performance. In addition, Gao et al 48 implemented the selected ML models for gastric cancer recurrence and survival prediction. Their results showed that the GBA would present optimum performance. Chen et al 49 proposed a gradient-boosting decision tree (GBDT)-based prediction method for projecting the GC clinical deterioration and survival chance. Ultimately, the proposed model attained appropriate performance with 0.89% of AUC. Mirniaharikandehei et al 50 compared 5 gradients boosting machine (GBM) model performance for predicting gastric cancer metastatic risk and patient survivability. The results showed GBM technique combined with a random projection algorithm yielded significantly higher prediction performance (accuracy = 71.2%).
Many clinical predictors influence gastric cancer. In the reviewed studies, after doing feature ranking, the variables such as age,6,35,48,49 gender,36,47,50 body mass index,6,47,50 Karnofsky performance scale,8,48,51 TNM stage,36,47-50 tumor grade,7,8,35,47-50 tumor size,6,7,47,49-51 tumor location,6,7,35,36,48,49 lymphovascular invasion,7,8,47,49,50 active and timely treatment,7,8,36 type of treatment,35,49 disease stage and severity,6,8,35,36,48,49 and weight loss36,47,49 were determined as the most important risk factors affecting gastric cancer survival outcome. Similarly, in our study, feature selection analysis was performed to rank the important set of variables. Among 17 primary variables, 8 variables including tumor stage, tumor site, tumor size, age, metastatic status, type of treatment, lymphatic invasion, and body weight were ultimately selected as the most important variables. These variables were used as input to construct ML models. After implementing the selected classifiers, the HGB with 88.37% accuracy, 86.24% specificity, 89.72% sensitivity, 88.11% AUC, and 89.91% F1 score achieved the highest performance in the survival prognosis of gastric cancer patients.
It is proven that ML technologies will improve health care quality and, consequently, reduce the serious complications and deaths associated with gastric cancer. The developed models in our study can help to better adhere to the best treatment standards. Such models may assist in early and effective diagnosis and accurate survival prediction of gastric cancer cases. Early detection of gastric cancer and active patient triaging help to evade the advanced stages of the disease and increase survival chances. This requirement is more important since numerous risk factors are involved in gastric cancer emergence and development. Therefore, in the present study, initially, the most important effective variables in the survival and the prognosis of patients with gastric cancer were identified using Boruta feature selection.
However, the present study faced several potential limitations and challenges that need to be addressed. These challenges may negatively affect the quality of modeling. The most important limitations in the present study were (1) single-center and small size of the selected data set, (2) retrospective data collection nature and the existence of missing fields and noise, (3) the selected data set lacks some important variables such as history and lifestyle, and (4) we did not use external validation to evaluate the proposed model. Therefore, to improve the quality of modeling and reduce prejudice in future research, more ML algorithms with further variables on multicenter and larger databases should be trained. In addition, it is suggested that the present study be conducted as a prospective to follow-up on the 5-year status of patients and use more external validations to further validate our findings.
Conclusions
Using ML techniques, accurate models can be made based on appropriate algorithms that can guide patient care and treatment, and increase workflow efficiency based on the available big data. Using ML techniques to predict survival in gastric cancer patients is an important opportunity to further improve decision support systems and provide the objective assessment of the comparative benefits of different types of treatment options for each case by determining factors using ML algorithms. The possibility of personalizing the treatment of patients is provided. Further ML studies with a larger number of patients are needed to determine the optimum algorithm and support the decision-making process for personalized treatment.
Footnotes
Acknowledgements
We thank the research deputy of the Abadan University of medical sciences for financially supporting this project. Also, we thank all patients who freely participated in this study.
Declaration of Conflicting Interests:
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding:
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Author Contributions
Availability of Data and Materials
The data sets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Ethics Approval and Consent to Participate
This study is the result of a research project approved by the Research Committee at Abadan University of Medical Sciences (Iran) (ethic code number: IR.ABADANUMS.REC.1401.003). All methods of the present study were performed following the relevant guidelines and regulations of the ethical committee of the Abadan University of Medical Sciences. Participation was voluntary, the consent was verbal, but all participants responded via email or text message to approve their participation. Participants had the right to withdraw from the study at any time without prejudice.
Consent for Publication
Not applicable.