
Abstract
Background and Objective
Osteoporotic fractures significantly impact individuals's quality of life and exert substantial pressure on the social pension system. This study aims to develop prediction models for osteoporotic fracture and uncover potential risk factors based on Electronic Health Records (EHR).
Methods
Data of patients with osteoporosis were extracted from the EHR of Xinhua Hospital (July 2012–October 2017). Demographic and clinical features were used to develop prediction models based on 12 independent machine learning (ML) algorithms and 3 hybrid ML models. To facilitate a nuanced interpretation of the results, a comprehensive importance score was conceived, incorporating various perspectives to effectively discern and mine critical features from the data.
Results
A total of 8530 patients with osteoporosis were included for analysis, of which 1090 cases (12.8%) were fracture patients. The hybrid model that synergistically combines the Support Vector Machine (SVM) and XGBoost algorithms demonstrated the best predictive performance in terms of accuracy and precision (above 90%) among all benchmark models. Blood Calcium, Alkaline phosphatase (ALP), C-reactive Protein (CRP), Apolipoprotein A/B ratio and High-density lipoprotein cholesterol (HDL-C) were statistically found to be associated with osteoporotic fracture.
Conclusions
The hybrid machine learning model can be a reliable tool for predicting the risk of fracture in patients with osteoporosis. It is expected to assist clinicians in identifying high-risk fracture patients and implementing early interventions.
Introduction
Osteoporosis, a metabolic bone disease characterized by a decrease in the amount of bone tissue per unit volume, is prone to fracture due to a variety of reasons such as bone density and bone quality decline, bone microstructure damage, and increased bone fragility.1–3 Osteoporosis is highly prevalent among the elderly, afflicting 36% of the older population in China, 4 and significantly increases the likelihood of experiencing fragile fractures (medically recognized as osteoporotic fractures), which poses substantial challenges to the public health system5,6 and invariably lead to a diminished quality of life and a reduction in life expectancy of those patients. 3
Despite the widespread occurrence and severe consequences of osteoporotic fractures, the rates of diagnosis and treatment for these patients in China are disappointingly low. 2 The subtle onset of bone density loss, which often shows no clear symptoms initially, complicates early intervention efforts. Based on this, many patients realize their diminished bone density only when addressing unrelated health concerns. Thus, leveraging existing clinical data from Electronic Health Records (EHR) may aid in early diagnosis and timely intervention. These records, compiled during each patient check-up, encompass a wide range of information including demographics, medical history, and vital signs. 7 The FRAX tool, 8 developed by the World Health Organization, is widely utilized to date for assessing fracture risk. Nevertheless, its application is confined to specific demographic groups (e.g. ages 40–90), and it falls short of identifying emerging risk factors.
Machine learning (ML) strategies have the potential to bolster clinical decision-making processes by facilitating accurate and efficient early predictions of osteoporotic fractures. For example, Atkinson et al. assessed fracture risk using GBM models based on bone images. 9 Vincenzo et al. used several machine learning models to predict fracture risk according to genotypes. 10 Chen et al. developed a hybrid deep learning model to predict the risk of fracture for diabetics. 11 Even without desired information like bone mineral density (BMD), these models can potentially reveal indicators of fracture risk, offering valuable insights for preventive healthcare initiatives. However, there has been no model established based on EHR data for Chinese elderly patients with osteoporosis, especially those older than 90 years old.
The purpose of this study was to develop prediction models for osteoporotic fracture and uncover potential risk factors based on EHR. 12 independent ML algorithms plus 3 hybrid ML models were applied to develop prediction models for osteoporosis patients based on EHR from the Chinese elderly. Moreover, we confirmed that the hybrid XGBoost and SVM model had the best predictive performance in terms of accuracy and precision (above 90%) among all models, and 20 important features according to the comprehensive importance score which represents high-risk factors for fractures were interpreted from a clinical point of view. These findings offer valuable novel insights into the prediction of fractures in patients with osteoporosis.
Material and methods
Patients and data
We obtained the EHR of outpatients and inpatients in Xinhua Hospital, which consists of diagnosis data, medical records, vital signs, inspection index, medication history, and so on. There are a total of 14418 patients in this dataset. The workflow of our study is shown in Figure 1.

The flow chart of this study.
Inclusion criteria and exclusion criteria
We initially selected patients over the age of 60 with osteoporosis as subjects, totaling 8530 individuals. The selection criteria were based on patients with the International Classification of Diseases (ICD)-10 code M81.9 in their Electronic Health Records (EHR). Besides, we referred to the guideline definitions to identify and include patients who potentially met the diagnostic criteria for osteoporosis and excluded patients with fractures caused by trauma. 12 Patients who had osteoporotic fractures were marked as 1, and others as 0. In our database, the average time from the initial check-up to the occurrence of fractures in patients with osteoporotic fractures was 109 days, with the longest time being 5 years. Additionally, abnormal records are removed from the dataset caused by input errors, such as systolic blood pressure >300 mmHg, age of menopause <30, height <30 cm, etc. The flowchart of data extraction is shown in Figure 2.

The flowchart of patient selection.
In terms of feature selection, we obtained patients’ age and gender as well as medical histories of smoking, drinking, and fractures. From inspection data, parameters of blood and urine tests were obtained, such as blood Calcium, blood glucose, urine, and so on. We obtained patients’ height, weight, and blood pressure from vital signs data. From doctor's order and medication data, we obtained the patient's medication status and medication history, such as glucocorticoids, aromatase inhibitors, thyroid hormones, proton pump inhibitors, and other medicines that might affect bone metabolism. From symptom data, we obtained information about arthralgia, weight loss, and puffiness. From bone density data, we collected the bone density of patients’ lumbar spine1∼4.
We started by incorporating all possible features to mine the potential risk factors of the elderly with osteoporosis and then neglected features with too few non-null values. As a result, 146 factors were obtained which can be divided into six categories, including demographic data, medical history, inspection data, illness, medicine, and symptoms. Next, we formulated the task of identifying old osteoporosis patients for their risk of fracture as a binary classification problem by training machine learning models with these features.
Variable selection
The raw data went through a data-wrangling pipeline including missing value handling and unbalanced label processing.
Missing data is a common occurrence in clinical research, where the value of the variables of interest is not measured or recorded for all subjects in the sample. 13 Our dataset exhibits a high rate of missing data, necessitating the establishment of an appropriate data handling criterion. Deleting all records with missing values would render the dataset extremely small, while imputing all missing values would result in most values being inferred, rendering the analysis results unreliable. XGBoost, with its capability to automatically handle missing values, was applied for the pilot study. The experiment demonstrated that the model exhibits optimal generalization capabilities when records with a feature missing rate exceeding 55% are deleted. After eliminating records where the missing rate of any feature exceeded 55%, a total of 1913 samples were obtained for subsequent training.
Several methods were used to deal with the missing values, including layered average filling, missMDA, 14 and random forest regression. 15 XGBoost was applied to compare the results of the three filling methods, and Area Under Curve (AUC) was used as a measure. Results are shown in Figure 3 that random forest regression filling performs the best out of the three.

Receiver operating characteristic curve of three filling methods.
The effect of random forest regression filling (blue) was better than missMDA (green) and average filling method (pink).
The labels in our dataset are extremely unbalanced which can lead to poor predictive performance. One efficient and flexible strategy for solving this problem is to employ sampling techniques before training a classification learning model. 16 We randomly split the dataset into training set and testing set, and then only performed oversampling and undersampling methods to the training set, leaving the testing set unprocessed. In general, a combination of oversampling and undersampling of the majority class yields better classifier performance. Once again, XGBoost was applied here to evaluate several sampling methods. Results are shown in Figure 4 that the combination of the SMOTE and Tomek links outperforms the rest.

Comparison of several sampling methods’ performance.
Statistical analysis
We conducted descriptive statistical analysis and significance testing on the dataset to ascertain if there were any statistically significant differences between the fracture and non-fracture groups’ indicators. We categorized the characteristics into two groups: categorical and numerical variables. For characteristics meeting the criteria for parametric testing, we used the chi-square test and the t-test. Otherwise, we applied non-parametric tests. Further details are presented in Table 1.
Characteristics of the study cohort.

Models
The task of identifying fracture risk is formulated as a classification problem by training machine models with features collected from real-world data. The structure of this hybrid model is presented in Figure 5. XGBoost was used for the feature transformation and SVM was used as the classifier to predict fracture risks.

Hybrid model structure diagram of XGBoost and SVM.
Results
The data set was divided into training set and testing set at a ratio of 4:1. We oversampled the training set by adapting Synthetic Minority Oversampling Technique (SMOTE) to generate the minor class, and then undersample it by Tomek links to avoid overfitting. We repeated the experiment 100 times to get the average metrics score. The results of each model are shown in Table 2.
Model performance metrics.

We formulated a strategy to identify critical factors for fracture, which integrates the significance scores from four perspectives: weight, the number of times a feature is used to split the data across all trees; gain, the average gain across all splits the feature is used in; cover, the average coverage across all splits the feature is used in; SHAP (SHapley Additive exPlanations). The feature importance scores of each metrics are shown in Figures 6 and 7.

The feature importance score is computed by three methods. (a) the feature importance score of weight; (b) the feature importance score of gain; (c) the feature importance score of cover.
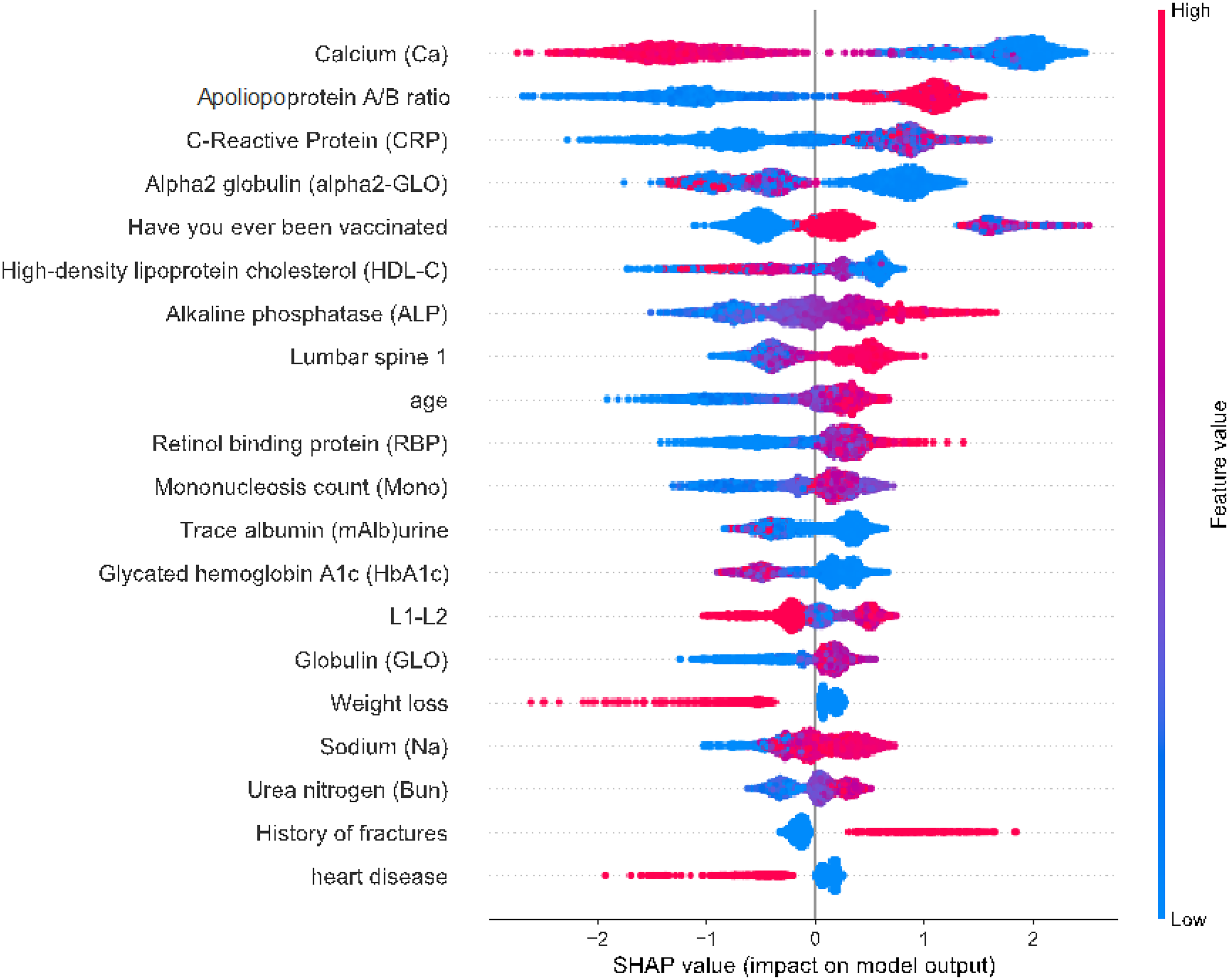
SHAP diagram of important features.
To get the comprehensive feature importance score, we first normalized the values obtained by the four methods. In this way, all values are scaled between 0 and 1.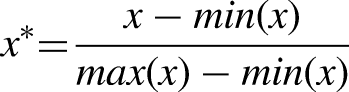
Then, these four scores are linearly combined to generate the comprehensive feature importance score.
Optimal coefficients are determined by evaluating various combinations. For each combination, a composite feature importance score was generated and ranked, isolating the top 20 features. These features were then fed into the model to determine accuracy, precision, recall, and F1-score.
Our model achieved the best results when coefficients for cover and gain were set at 0.3, and weight and SHAP were set at 0.2. The top-ranked features, in order, were Calcium (Ca)-blood, Apolipoprotein A/B ratio-blood, Weight loss, C Reactive Protein (CRP)-blood, Vaccination history, High-density lipoprotein cholesterol (HDL-C)-blood, Alpha2globulin (alpha2-GLO)-blood, Alkaline phosphatase (ALP)-blood, Heart disease, Retinol binding protein (RBP)-blood, Smoking history, Sodium (Na)-blood, Bilirubin (BIL)-blood, Weight, Alkaline granulocyte count-blood, DXA value of Lumbar spine 1, White blood cell esterase-urine, Insulin (2 h)-blood, Age, and DXA value of L1-L2.
For comparison, all features were input into the model, but only the top 20 features as obtained above are illustrated in Figure 8. When using only these 20 features, the model was able to achieve a superior classification effect. This suggests that these 20 features are predictive of fractures in elderly patients with osteoporosis, and thus could be considered risk factors for fracture.

Top 20 important features and comparison between 20 features and all features. (a) top 20 features ranked by comprehensive feature importance score; (b) the predictive performance of the top 20 features and all features. The top features achieved better results than inputting all features.
Discussion
In the realm of medical applications where high dimensionality and limited data are common phenomena, high prediction accuracy and model stability are crucial, and the fusion of XGBoost and SVM into a hybrid model presents several advantages. The hybridization of the two models could enhance accuracy by capitalizing on the different aspects of the data each model excels at capturing. The amalgamation could amplify the models’ inherent robustness, given XGBoost's aptitude for handling noise and outliers, and SVM's resistance to overfitting when appropriately kernelized and regularized. Additionally, the combination model can efficiently manage imbalanced data, a frequent concern in medical scenarios as well, by adjusting the weights on minority classes in XGBoost and leveraging techniques such as SMOTE in SVM. Moreover, the hybrid model can provide a level of interpretability via the XGBoost component by examining the significance of the features, offering valuable insights into which factors are driving predictions. With XGBoost's capacity for capturing complex non-linear relationships and SVM's proficiency in binary and multiclass classification problems being particularly notable, both XGBoost and SVM have demonstrated superior performance across diverse tasks. 17
Our comprehensive feature importance score considered four aspects of information to mine the top 20 important features (shown in Figure 8). These features play important roles in this model, which could be viewed as the risk factors for fracture. Some of the features 18 found during this study are well known to be associated with osteoporosis or even fractures, such as smoking history, 19 weight loss, 20 DXA value of Lumbar spine 1, weight, age, sodium-blood and DXA value of L1-L2. 8 Several factors were not well demonstrated in prior studies. They appeared to be related to osteoporosis, which should be focused on, such as (i) bone metabolite: Calcium-blood and Alkaline phosphatase (ALP)-blood, (ii) inflammatory response markers: C reactive protein-blood, and (iii) indicators of lipid metabolism: Apolipoprotein A/B ratio-blood and High-density lipoprotein cholesterol (HDL-C)-blood. The detailed SHAP diagram is shown in Figure 9.

The SHAP value of Calcium-blood, Alkaline phosphatase-blood, C-Reactive Protein-blood, Apolipoprotein A/B ratio, and High-density lipoprotein cholesterol.
Our model predicted that calcium (Ca)-blood may be a high-risk factor for fracture. Even though 99% of the body's calcium is stored in the bones with the remaining 1% in the blood, calcium-blood is much easier to measure than calcium-bone; therefore, it is a routine laboratory test for patients with osteoporosis. For patients with primary osteoporosis, their blood calcium values are usually within the reference range. As we all know 21 that blood calcium and parathyroid hormone levels have reciprocal regulatory effects, such as decreasing concentrations of blood calcium ions, secondary secretion of increased parathyroid hormone by parathyroid chief cells, stimulation of osteoclast proliferation, inhibition of osteoblast activity, and resulting osteoporosis. A recent study 22 suggested that patients with osteoporosis have significantly lower serum calcium than controls. Likewise in our model, when blood calcium levels decrease, the predicted probability of fracture increases.
Alkaline phosphatase (ALP) is a hydrolase enzyme responsible for removing phosphate groups from many molecules, including nucleotides, proteins, and alkaloids. 23 It belongs to bone formation markers among bone turnover biochemical markers and can react to osteoblast activity and bone formation status. ALP plays an important role in the differential diagnosis of several skeletal disorders, determination of bone turnover types, monitoring treatment adherence, and evaluation of drug efficacy, 24 and the levels of ALP are usually normal or mildly elevated in patients with primary osteoporosis. A recent study has also shown that the activity of serum total ALP >129 U/L is used as an indicator for osteoporosis in males, 25 consistent with what our model predicts.
C-reactive protein (CRP) participates in the immune response, 26 which is a non-specific and high-sensitivity inflammatory biomarker. The inflammatory processes are involved in a wide variety of physical health problems and systemic chronic inflammation often increases with age. 27 Meanwhile, studies28,29 also show that older individuals have higher circulating levels of cytokines, chemokines, acute phase proteins, and greater expression of genes involved in inflammation. Moreover, systemic chronic inflammation is persistent and ultimately causes collateral damage to tissues and organs over time, such as by inducing osteoporosis. In addition to age, physical inactivity was found to be directly associated with increased anabolic resistance, increased CRP levels, and increased levels of proinflammatory cytokines in healthy individuals. 30 These effects, in turn, promote several inflammation-related pathophysiologic alterations, including osteoporosis.31,32 Furthermore, several studies even showed that increased CRP was linked to an increased fracture rate due to osteoporosis.33,34
The association between lipid and bone metabolism has become an increasing focus of interest in recent years. 35 A study by Dennison et al. 36 investigating the correlation between BMD and lipid profiles, observed that total spine BMD was inversely correlated with levels of apoA but positively associated with levels of apoB in males and females, which agrees with our model results. However, regarding HDL-C, our model's trends don’t appear to match exactly what has been reported. On the one hand, Ackert-Bicknell et al. proved that there is sufficient evidence to conclude that bone metabolism and HDL-C are genetically linked, and HDL-C can interact directly with osteoblasts and osteoclasts. 37 Yamaguchi et al. 38 investigated the correlation between plasma lipid levels and BMD and found that low levels of HDL-C were associated with an increased risk of vertebral fracture (similar to those predicted by our model). Nevertheless, another study reported the opposite result. 36 On the other hand, Hsu et al. 39 conducted a study that aimed to analyze the association between plasma lipid profile and BMD, bone mineral content, and osteoporotic fractures in 7137 Chinese males, and 4585 premenopausal and 2248 postmenopausal females. No significant correlation between whole-body bone mineral content and levels of HDL-C was detected. Similarly, another study showed no association between HDL-C and BMD. 40 Several factors may be responsible for these discrepancies. Firstly, the differences in non-modifiable characteristics of the subjects, including age, sex, and medication history may have introduced bias. Secondly, the differences in modifiable characteristics, including cigarette and alcohol consumption, or physical activity among the study subjects may also have led to bias. Apart from these reasons, the use of different models may have affected the results. Therefore, the relationship between lipid profile and bone metabolism warrants further investigation.
To the best of our knowledge, some of the remaining factors predicted by our model, such as heart disease, 18 Retinol binding protein (RBP)-blood, 41 and Bilirubin (BIL)-blood,42,43 also seem to have some relationship with fractures and future work is suggested to focus more on these indicators.
Several limitations of our work need to be mentioned here. Firstly, the retrospective and observational nature of our study. Although we incorporated various clinical features in an attempt to make prospective predictions, it is more accurate to describe this work as essentially retrospective (i.e. focused on the discrimination or detection of an event that has already occurred). Secondly, given that the raw data is imbalanced, we have performed oversampling and undersampling of the training set, which might lead to deviation from the true value. Thirdly, the patient's data came from a single center in China. Therefore, further research with large samples and multiple centers is necessary to validate our model's performance.
Conclusions
To sum up, the hybrid model incorporating XGBoost and SVM has demonstrated utility as a predictive tool for assessing fracture risk in elderly patients. Furthermore, our study has identified several risk factors for fracture, providing valuable new insights for elderly patients with osteoporosis in clinical practice.
Footnotes
Acknowledgments
We extend our gratitude to all those who provided valuable insights and recommendations for this work.
Contributorship
The experiments are designed by Xf G and Aj X, and performed by Mh L, Zc M, and Jw R. Data analysis is conducted by XW, Yl C and Mh L. Mh L, XW, Xd X, and Aj X drafted the manuscript.
Conflicting interests
The authors declare that there is no conflict of interest.
Ethical approval
All procedures followed complied with the ethical standards of the responsible committee on human experimentation (institutional and national) and the Helsinki Declaration of 1975, as revised in 2000(5). Informed consent was obtained from all patients included in the study.
Funding
This work was funded by the National Key R&D Program of China (2020YFC2005502), the National Natural Science Foundation of China (82072142), and the Science and Technology Commission of Shanghai Municipality (Project No. 19401900500).
Guarantor
Aj X.