
Abstract
Nested case-control sampling design is a popular method in a cohort study whose events are often rare. The controls are randomly selected with or without the matching variable fully observed across all cohort samples to control confounding factors. In this article, we propose a new nested case-control sampling design incorporating both extreme case-control design and a resampling technique. This new algorithm has two main advantages with respect to the conventional nested case-control design. First, it inherits the strength of extreme case-control design such that it does not require the risk sets in each event time to be specified. Second, the target number of controls can only be determined by the budget and time constraints and the resampling method allows an under sampling design, which means that the total number of sampled controls can be smaller than the number of cases. A simulation study demonstrated that the proposed algorithm performs well even when we have a smaller number of controls compared with the number of cases. The proposed sampling algorithm is applied to a public data collected for “Thorotrast Study.”
Keywords
Introduction
In practice, the large-scale studies are often limited because of time and budget constraints. One popular cohort-based sampling method that reduces the costs of data collection is the nested case-control (NCC) design that selects a set of controls from the risk sets defined in the cohort and then matches them to cases, respectively. For example, Grant et al 1 considered the NCC design to reduce the cost and time efforts involved in the covariate ascertainment for the Life Span Study and the Adult Health Study cohorts of the Radiation Effects Research Foundation, in Japan. These NCC sample data having a time-to-event outcome are popularly analyzed using the Cox proportional hazards model based on partial likelihood. Many previous studies discuss the more general estimations and asymptotic properties of parameter estimators obtained from the partial likelihood in the NCC design.2–7
In general, the NCC design is only applicable to retrospective studies because censored subjects in control groups can be selected during the sampling process. However, researchers often want to add new covariates to statistical models (eg, epigenetic studies), such as genetic information and blood test results, as a prospective study. In this case, control groups should be observable subjects in the sense that we can obtain other information from the selected controls. One solution is to sample the controls at the end-point of the observation time period, which will generally be available for further data collection. For example, Yao et al 8 considered a new retrospective cohort-based sampling design, called end-point sampling (EPS), to sample the observed controls from a cohort, and then applied the expectation and maximization (EM) method as a parameter estimation. Similarly, Sboner et al 9 considered an extreme case-control (ECC) design with a naive statistical method in which the cases were patients who had died from prostate cancer within 10 years after diagnosis and the controls were patients who survived at least 10 years. Although these EPS or ECC designs were initially implemented to improve the efficiency of the design, we can use this sampling idea to reduce the costs of data collection and to observe additional information from the selected samples.
In this article, we propose a new cost-effective extreme case-control design (CECC) utilizing a resampling technique. First, the total number of controls, say
This manuscript is organized as follows. First, we describe the classical NCC sampling design and our proposed CECC sampling design. We conduct simulation studies to illustrate the relative bias and efficiency of our proposed method in comparison to the classical NCC study design. In the real data example section, we applied our new sampling algorithm to the “Thorotrast Study” data which investigated the relationship between liver cancer occurrence and volume of injected thorotrast.11,12 Finally, the concluding remarks and the limitations of our proposed method are provided.
Methods
Basic setup
Consider a cohort study with a size of
Now assume that we have

We also denote
NCC design
Thomas 2 initially suggested that the NCC design can be implemented by taking control samples from each risk set. The theoretical properties using this NCC design were provided by Goldstein and Langholz 4 and Borgan et al 5 under Cox’s 13 proportional hazard model. A conventional NCC design is as follows
Specify the risk set
Randomly select
Repeat (A) and (B) for all cases.
Note that some individuals can be repeatedly selected for different cases because non-censored individuals cannot be specified as the cases are included in all risk sets. Usually, the number of control subjects at event time points is considered in between

Sampling procedure of NCC design. (A) Nested case-control sampling design. (B) Nested case-control sample with two control subjects.
For the NCC studies, the individual matching of controls to cases can be applied by adjusting the confounding or background covariates at the control-sampling stages. The matching technique in the NCC study can be used when researchers believe that all controls have the same value of specific characteristics as the corresponding case such as age and gender covariates. The procedure of matching the NCC study design is that at each event time, control subjects are randomly sampled from within strata defined by the matching covariates. Let
According to the data type of
Specify the risk set
Randomly select
From the sampling design, there is no variation in exposure status
CECC design using a resampling method
In this article, we propose a new cost-effective ECC design using a resampling technique that allows us to select an arbitrary number of controls
CECC design.

The main difference compared with the classical NCC design is that the new algorithm only uses the final risk set, that is, all of the cases share the same risk set, while the classical NCC design specifies each risk set for each case (see Figure 2). Figure 2A mimics the NCC design similar to Figure 1A, but the final risk set is only considered as the risk set in the new CECC design. Figure 2B describes the control samples selected in the final risk set corresponding to the cases randomly assigned to each stratum on each case-event time point. This new sampling design is similar to the conditional approach of the ECC proposed by Salim et al, 10 apart from the resampling parts.

Sampling procedure of CECC design. (A) Cost-effective extreme case-control sampling design. (B) Cost-effective extreme case-control sampling design with two control subjects.
This new CECC design has some advantages compared with the conventional NCC design: (i) The new algorithm is more cost-effective because the number of selected controls can be smaller than the number of cases and does not have to be a multiple of the number of cases, (ii) it does not need to specify all the risk sets at the sampling stage, and (iii) it does not require censoring information. The advantage (ii) can be applied to practical analysis. Suppose that we are interested in the gene-exposure interaction effects based on cohort samples. We want to apply the NCC design because a gene-association study is expensive or some subjects were lost, and we can get some data from censored subjects. Thus, the proposed method only considers the candidate control subjects as the final risk, and we can then obtain extra bio-markers or genetic information.
For the matching design, we need to separate a given risk set by the matching variable
CECC design matching on

Partial likelihood and parameter estimation
In this article, we implicitly adopt the same assumptions required for the classical NCC designs: (A1) event is rare; (A2) the censoring time is independent of the event time; and (A3) the event time is independent of each other. However, this assumption does not guarantee the consistency in parameter estimation. Thus, we use Salim et al’s 10 partial likelihood to adjust our length-biased samples.
Applying Salim et al’s 10 partial likelihood, the likelihood function according to our length-biased sample is

where

are the adjusting term for sampling bias defined by the fraction of survival times,
Approximating the survival time as the Kaplan-Meier (KM) estimates,
16
the weights

where
Once we plug-in the estimated
Results and Discussions
Simulation study
In this section, we first generated 2000 Monte Carlo (MC) cohorts, each of which consists of individuals of

where the baseline risk rate,
In this simulation study, we consider three estimators:
NCC: estimators obtained from the classical NCC design samples;
CECC: estimators obtained from the CECC design samples with constant
CECCW: estimators obtained from the CECC design samples with the estimated
The CECC estimator does not use the sampling bias adjust term, but it does not require any censoring information for parameter estimation. Thus, we will also discuss if this naive CECC estimator without bias correction can be used in practice when the censoring time is not available or accurate. For estimation of the conditional logistic regression and the KM estimates, we used the R function clogit and ncc built in the R packages ‘survival’ and ‘Epi.’
As the simulation outputs, we report the relative bias (R.Bias), standard errors (SE), and mean squared errors (MSE) of the estimators. Here, R.Bias is defined by

Table 1 presents the MC relative biases, standard errors, and mean squared errors of the NCC, CECC, and CECCW estimators for no matching scenario. The column of “Controls” denotes the total number of controls selected for the NCC sample in each design. For example, in the case of CECC, we first select
Monte Carlo relative biases (R.Bias), standard errors (SE), and mean squared errors (MSE) of estimators from the NCC, CECC, and CECCW without matching.

Abbreviation: NCC, nested case-control.
Table 1 shows that the CECCW estimators have better performance than the CECC estimators, because the bias adjusting terms are represented during the estimation. The CECC estimators produce a larger bias when the length bias is increased as the number of cases is increased from 250 to 500. However, the size of biases is not critical in the sense that we may use the naive CECC estimators in practice when the censored time is not available or accurate. Among three estimators, the CECCW estimators are the most efficient under the same number of controls. This because the CECCW estimators incorporate the cohort information through the estimated survival function. We can also confirm that the proposed method performs well even when the number of sampled controls is smaller than the number of cases. Although we need to pay some efficiency loss due to the size of controls, the biases are well controlled for this under sampling design. This is desirable results as the cost-effective NCC design. The efficiency of the proposed estimators depends on the size of total number of controls selected as the CECC sample.
Similar to Table 1, Table 2 also presents the MC relative biases, standard errors, and mean squared errors of the NCC, CECC, and CECCW estimators for matching scenario. The simulation results presented at Table 2 are almost similar to those of no matching case, which implies that when the matching variable is considered, the proposed method also works well. Thus, in summary, all estimators produce nearly unbiased estimates in this simulation setup. However, the CECCW is slightly more efficient compared with other estimators.
Monte Carlo relative biases (R.Bias), standard errors (SE), and mean squared errors (MSE) of estimators from the NCC, CECC, and CECCW with matching on
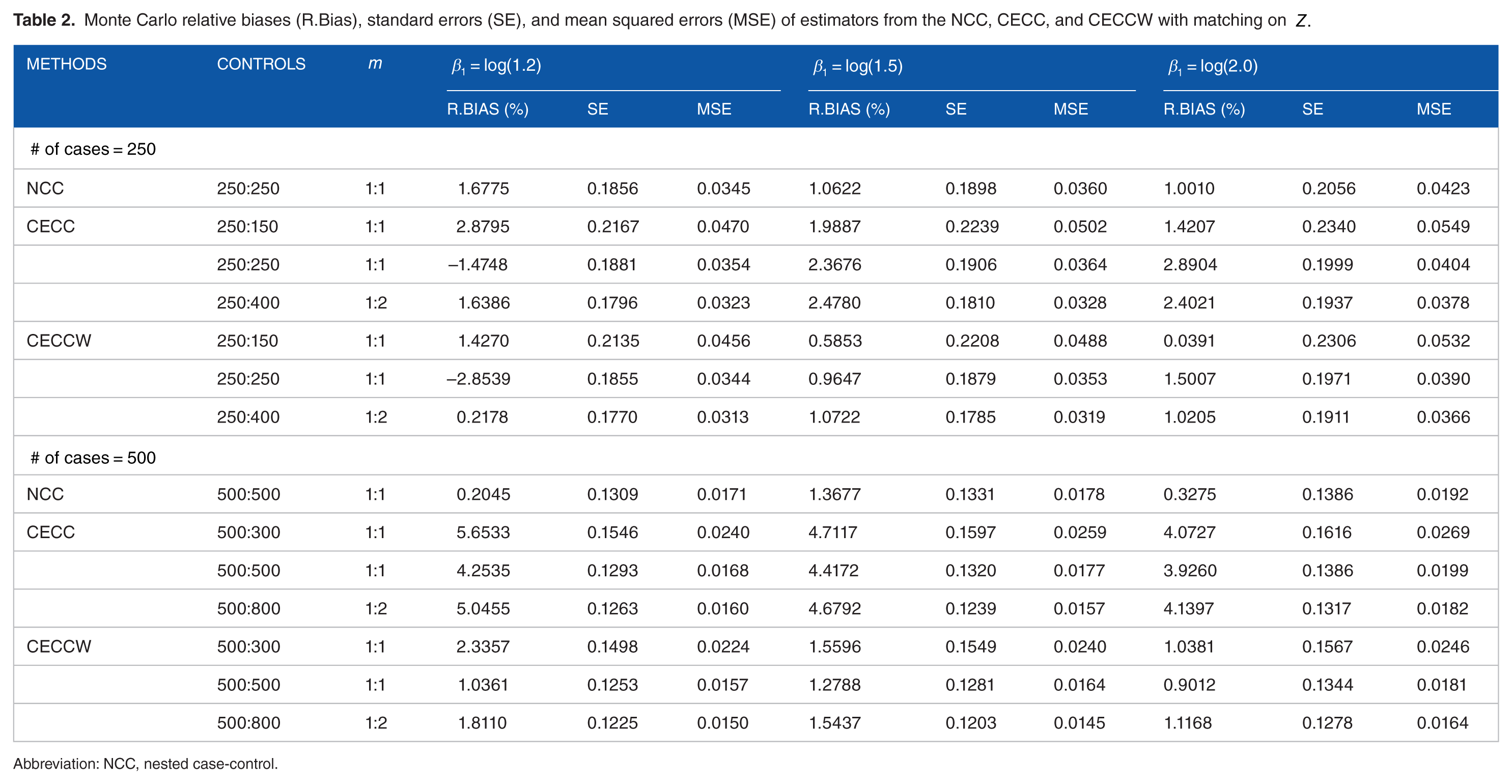
Abbreviation: NCC, nested case-control.
Real data example
Andersson et al11,12 studied the association between chronic α-particle irradiation from Thorotrast and the liver cancer incidence. All of the study subjects took cerebral angiography with or without Thorotrast from 1935 to 1947 or from 1946 to 1963, respectively. The ‘thoro’ data are available from R package ‘Epi.’ The modified data for the NCC and the CECC designs are employed. In particular, we consider both the CECC and the CECCW for this data analysis. For simplicity, we consider the small number of variables and a simple model. The variable is as follows:
Sex: 0 for male and 1 for female.
Event: indicator of liver cancer diagnosis.
Exposure: injected volume of thorotrast in milliliter. Control patients have a 0 in this variable.
Censored: 0—not censored and 1—censored.
Incidence age: age of liver cancer diagnosis.
Exit age: age of exit year from the study including the incidence age.
Birth: birth cohort as 0 for birth date earlier than 1920 year and 1 for birth date later than 1920 year.
Time = Exit age – Incidence age.
Tables 3 and 4 show the total number of observation is 2468. We considered the final exit date, February 20, 1992, for data application. The number of liver cancer cases is 130 and censored observations are 40 and the numbers of male and female are 1291 and 1177. The range of birth date is from January 7, 1868 to February 1, 1958. The number of subjects which was born before January 1, 1920 is 1816, otherwise 652. There are 1479 non-exposed and 989 exposed subjects in this study. The median of the follow-up years is approximate 26 years and the median of the incidence age (years) is 62.32 years old. For the age at injection (year), the median value is 40.35 years old.
Characteristics of study population for Thorotrast data 1.

Characteristics of study population for Thorotrast data 2.
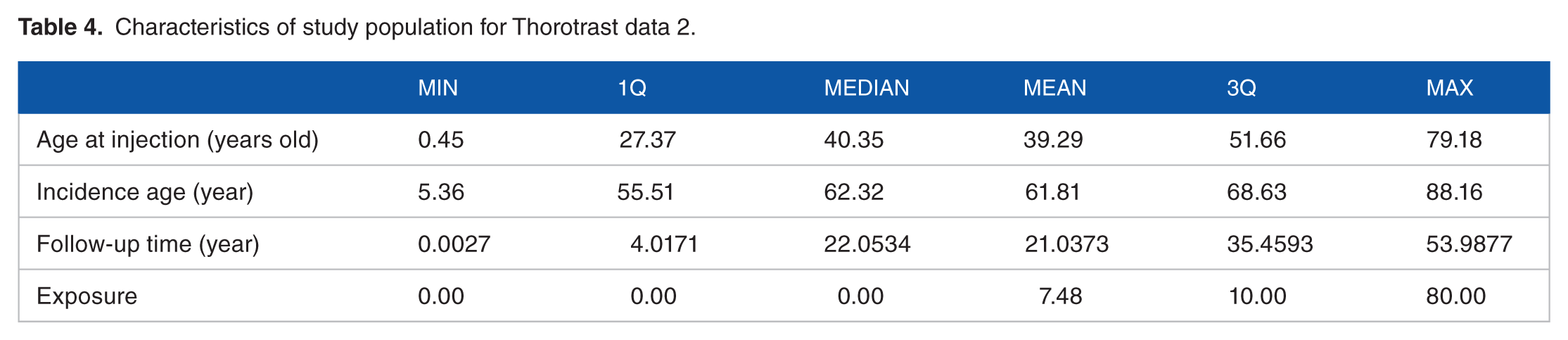
Table 5 provides estimates of exposure
Comparison among the NCC data, and the CECC and the CECCW data from Thorotrast data.

Abbreviation: NCC, nested case-control.
Conclusions
In this article, we propose a new CECC utilizing a resampling idea to make flexibility the choice of the number of control samples. This new procedure provides two advantages compared with the classical NCC sampling design. It allows an under sampling design, which means the number of controls is less than the number of cases. Also, it does not need to specify all risk sets required for the classical NCC design. Considering these advantages, the new algorithm can be applied to the real data analysis when the budget and time constraints are limited to include new measurements. We can use CECCW estimators when the censored times are all available for cohort and use CECC estimators otherwise.
This study is not free from limitations. When the size of the final risk set is very small with respect to the cohort, that is, most units in the cohort have an event or are censored during the observation time; the proposed algorithm may lead to unintended biases during the estimation. This phenomenon is similar to a coverage problem in the sense that the small final risk set can easily fail to cover the whole range of risk sets used for the candidates of controls. Thus, the proposed sampling technique will efficiently work when we have rare events and observation time is relatively short avoiding too many censored units.
Footnotes
Acknowledgements
The authors would like to thank the editor and reviewers for their careful readings and thoughtful comments.
Funding:
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is supported by the National Research Foundation (NRF) of Korea, NRF-2016R1D1A1B03932212 for the author and NRF-2018R1D1A1B07045220 for the second author, respectively.
Declaration of conflicting interests:
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author Contributions
All authors contributed equally to this work.