
Abstract
High-throughput screening data repositories, such as PubChem, represent valuable resources for the development of small-molecule chemical probes and can serve as entry points for drug discovery programs. Although the loose data format offered by PubChem allows for great flexibility, important annotations, such as the assay format and technologies employed, are not explicitly indexed. The authors have previously developed a BioAssay Ontology (BAO) and curated more than 350 assays with standardized BAO terms. Here they describe the use of BAO annotations to analyze a large set of assays that employ luciferase- and β-lactamase–based technologies. They identified promiscuous chemotypes pertaining to different subcategories of assays and specific mechanisms by which these chemotypes interfere in reporter gene assays. Results show that the data in PubChem can be used to identify promiscuous compounds that interfere nonspecifically with particular technologies. Furthermore, they show that BAO is a valuable toolset for the identification of related assays and for the systematic generation of insights that are beyond the scope of individual assays or screening campaigns.
Keywords
Introduction
T
In an effort to find novel entry points for drug discovery programs, countless HTS campaigns comprising large commercial and proprietary compound libraries have produced massive data sets, primarily in pharmaceutical companies. The National Institutes of Health (NIH) Molecular Libraries Roadmap Initiative 2 and the availability of more affordable “out-of-the-box” screening systems and reagents have facilitated a dissemination of HTS capabilities into academic institutes and universities, where they are now relatively common and available to researchers.
HTS data sets, which consist of experimental results and assay metadata, are typically stored in data warehouses using relational database schemas.3,4 The fast pace of innovation in assay designs and detection technologies, as well as the increasing complexity of the biological targets under investigation, poses challenges to “static” database schemas to capture and manage the diversity of screening experiments and their outcomes. To optimize the value of HTS efforts beyond any individual HTS campaign and to facilitate more informed decision making as compounds progress in the value chain, systematic knowledge management is receiving increased attention from informatics organizations. 5 In this context, a formal, well-structured, knowledge-based, and extensible description of biological assays is required. Expert biocuration to organize and annotate existing data is also a critical component of any HTS knowledge management solution.
PubChem is a public repository of HTS assay descriptions, small-molecule compounds, and HTS results (which we refer to as endpoints).6,7 Originally put in place as part of the Molecular Libraries Program (MLP), it serves to host data generated at the MLP centers as well as that from other NIH-funded projects. As of September 2010, there were more than 2100 bioassays from the MLP deposited in PubChem. In addition to PubChem, there are several other publicly available sources of screening data, including ChEMBL, 8 which contains structure–activity relationship (SAR) data curated from the medicinal chemistry literature; the Psychoactive Drug Screening Program (PDSP)9,10; and ChemBank.11,12 In addition, private resources, such as Collaborative Drug Discovery (CDD),13,14 also make large screening data sets publicly accessible.
Despite recommendations from industry and government work groups, there is currently no agreed-upon standard for the representation of HTS assay data. Such a representation is vital for researchers to meaningfully interpret and compare diverse assay results. 15 Because HTS data repositories lack detailed annotations using standardized terms, seemingly trivial queries such as “list the biochemical vs. cell-based assays” or “list assays that use a luciferase reporter construct” are not possible. In addition, the lack of a formal description of biological assays hinders the integration of HTS data from different sources as well as with other life science databases (e.g., biological pathways).
PubChem’s already large and diverse set of deposited assay results along with several other accessible screening data repositories form a large corpus of data that can serve as a starting point to develop a systematic categorization of HTS assays. The exponential growth of public data repositories indicates that we are only beginning to explore the space of possible assay designs. The development of a clearly structured and standardized formal description of concepts that are relevant to interpreting HTS results is therefore very timely.
In this report, we demonstrate how such a formalized terminology can facilitate analyses across multiple diverse assays to identify promiscuous compounds. These compounds are traditionally problematic for HTS, and it is desirable to identify them as early as possible in a campaign. Compound promiscuity can be related to assay design, detection technology, or interaction with biological targets, and often the specific mechanisms of action are not fully understood. There have been attempts at the identification of compound classes that can interfere with specific assay technologies, but these studies usually focused on a small number of biological assays and did not make use of the large numbers of data sets currently available.16,17 Here we attempt for the first time to identify promiscuous behavior on a large scale using a curated data set that allowed us to interrogate compound behavior across certain assay categories and subcategories.
Methods
PubChem local mirror database and chemical structures
A local relational mirror of the PubChem bioassay database was created using in-house scripts and a public version of the MySQL database. The details of this database, schema, population and update processes, implementation, and code are reported elsewhere. 18 Briefly, the database consisted of several tables, including assay details (such as AID, assay name, description, project category, protocol), panel assay specifications, result definitions (such as IC50, percentage inhibition, or any other observed measurement or statistics), result data (with PubChem Activity Outcome and Score and the most important results, such as IC50, and qualifiers such as <, >, =), cross-references (links of assays to other National Center for Biotechnology Information (NCBI) databases such as protein or nucleotide target, PubMed, taxonomy), and relationships (links between different assays, links to other NCBI Entrez databases, and links between targets and their sequences). The system used the PubChem FTP site to access XML assay descriptions and CSV assay data and the NCBI Entrez Utilities (eUtils) to access additional information (including if an assay had changed) to keep the mirror database current. The database included a structure table only as a placeholder. Chemical structures corresponding to the assay data were downloaded by substance IDs (SIDs) directly from PubChem as SDFiles using the batch download facility.
PubChem assay annotation and assay clustering
PubChem assays were annotated manually using the mirror database described above, which was fetched from PubChem in April 2010 with 2299 assays by AID. In total, 172 assays had no data at all (on-hold assays). There were 194 summary assays, of which 136 had no substances or activity data. These assays were not considered for annotation. There were 105 assays with no activity outcome method (which is usually assigned as screening, confirmatory, other, or summary)—these are from Ambit Biosciences, Developmental Therapeutics Program/National Cancer Institute, and Structural Genomics Consortium. From the screening centers of the NIH Molecular Libraries Probe Center Network (MLPCN) and the former Molecular Libraries Screening Center Network (MLSCN) were 1498 assays—not including assays without data (on hold) and summary assays.
To aid the manual annotation process, all assays were clustered based on the assay title, description, protocol, and source. Several assays (other than on-hold or summary assays) did not have a protocol or only a minimal description, but all had information about the source. To cluster the assays, first for each assay a text fingerprint was generated from all words used in title, description, protocol, and source after stemming (to consolidate different grammatical forms) using the Pipeline Pilot 8.0 (Accelrys, San Diego, CA)
19
text analytics component collection. The text fingerprints (TXFP_Custom) encode for each individual assay the presence and absence of word tokens from the global corpus of assays. The assay “documents” were then clustered based on the fingerprints using the Tanimoto similarity metric and setting the average cluster size to five members. The clustering method is a relocation technique based on maximum dissimilarity partitioning implemented in the Pipeline Pilot text analytics collection. A total of 460 clusters were generated. This method grouped together similar assays very effectively—for example, all assays of the same screening campaign by center or assays with the same procedure or assay design (e.g., many National Center for Chemical Genomics [NCGC] toxicity assays); as expected, clusters usually included assays from the same source. The method also grouped together related assays with minimal annotations (such as many of the NCI or Chembank assays), summary assays, or assays that were on hold. Two hundred ninety-nine clusters were generated from the 1498 MLPCN and MLSCN assays that had data deposited and were not summary assays. To illustrate the similarity relationships of these assays, we generated a minimum spanning tree (MST) based on the pairwise (Tanimoto) similarities of the assays computed from their text fingerprints (the same similarities that were used for clustering above). The MST was computed using an in-house protocol implementing Kruskal’s algorithm. The MST was visualized in Cytoscape
20
and is shown in
Following cluster preprocessing, assays were then manually annotated by assay format, design, technology, and the other BioAssay Ontology (BAO) categories. The BAO schema with classes, individuals, relationships, and their definitions can be downloaded from our Web site, and BAO can also be visualized there. 21 For the limited analysis presented here, we focused specifically on assays based on designs to detect luminescence from the luciferase-catalyzed conversion of luciferin substrates 22 and assays employing β-lactamase-based technology. 23
Luciferase-assays were classified into five subcategories: reporter gene, viability, adenosine triphosphate (ATP)–coupled, luciferin-coupled, and luciferase enzyme activity assays. Briefly, luciferase reporter gene assays use the luciferase gene downstream of a promoter of interest. The amount of luciferase expressed is quantified by the intensity of light (luminescence) produced in the presence of substrates, ATP, and luciferin. Viability assays estimate the proportion of living cells in an assay by measurement of ATP content in a luciferase-catalyzed reaction. ATP-coupled assays measure the residual amount of ATP (e.g., after a kinase reaction) by a coupled luciferase reaction. Luciferin-coupled assays measure the amount of luciferin generated after detoxification by cytochrome P450 enzyme activity. Luciferase enzyme activity assays quantify the luciferase enzyme activity by the amount of light produced in a biochemical reaction. β-Lactamase technology is used in either reporter gene or enzyme activity assays.
PubChem Promiscuity Index (PCIdx)
The PubChem Promiscuity Index (PCIdx) of a substance (by SID) was defined as the number of assays in which this substance is active divided by the number of assays in which it was tested (equation (1), where N is the assay count for the substance).
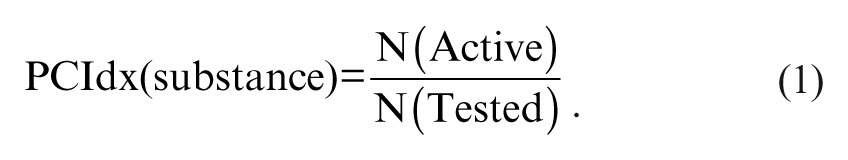
To define active, we used the PubChem activity outcome, which is one of the required fields to be uploaded by the assay depositor. Activity outcome categorizes tested samples as active, inactive, inconclusive, or unspecified. PubChem does not have rules when to apply the outcome category “active,” which is defined (subjectively) by the depositor. Therefore, active can have different meanings across different assays. This is clearly not the best way of comparing compounds in a large number of assays, and it would be much better to standardize the most important endpoints across all assays. However, currently, activity outcome is one of the only two required endpoints (the other one is activity score—also subjectively depositor defined) and therefore the only way to quickly identify “active” compounds.
To compute PCIdx for each compound, all assays in which it was tested and the corresponding activity outcomes were determined by querying the PubChem mirror database above. PCIdx was calculated according to equation (1), separately for single-concentration assays (PubChem activity outcome method “screening”) and concentration–response assays (activity outcome method “confirmatory”). Only assays of a certain category were considered—for example, all luciferase technology assays or a certain subset thereof, such as viability assays or luciferase enzyme inhibition assays.
Because the significance of the PCIdx measure increases with more tested assays, we visualized compounds’ promiscuities by plotting PCIdx over the number of assays tested while indicating the number of active assays by a color code (cf.
Fig. 1
and
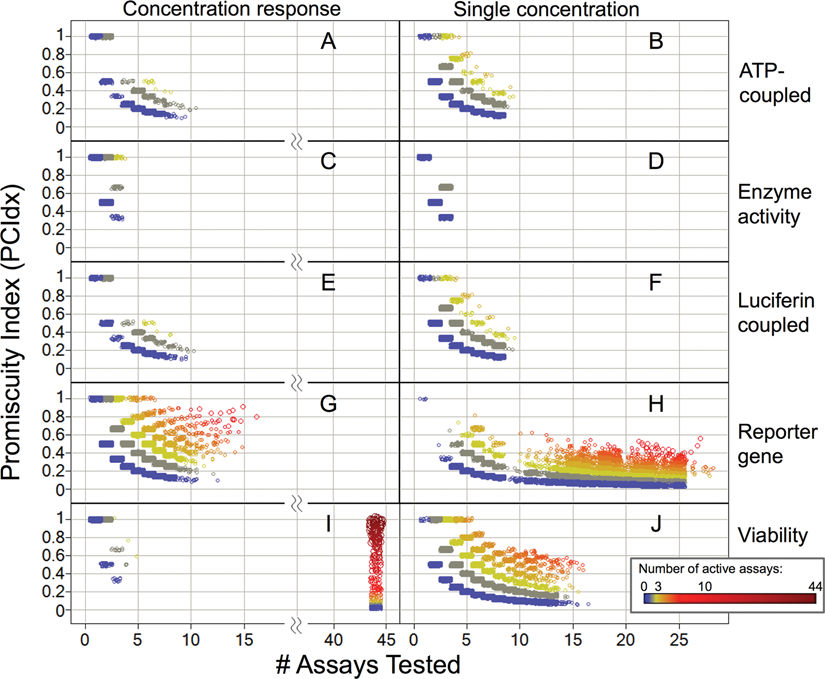
Compound promiscuity by luciferase assay technologies. For each compound, the Promiscuity Index versus number of tested assays is depicted. (
Figure 1
,
Data Clustering
Data in
Figure 2
(corresponding to
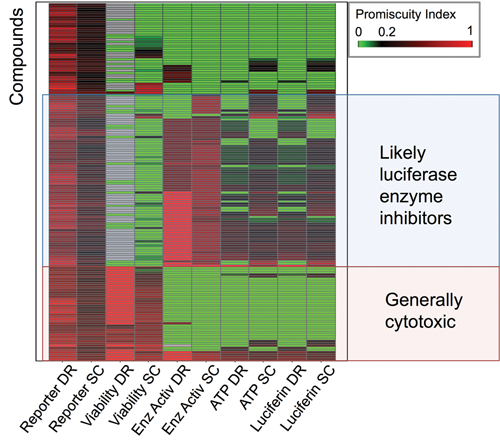
Heat map of 161 most promiscuous compounds in luciferase reporter gene assays, which are active in at least five concentration–response and five single-concentration (luciferase reporter) assays. DR, dose response; SC, single concentration. Shown are the promiscuity indices of all compounds in the different luciferase assay categories for both concentration–response and single-concentration assays, respectively, clustered by their PubChem Promiscuity Index (PCIdx) profiles. Two groups of promiscuous reporter gene compounds were apparent, suggesting the mechanism for reporter gene assay promiscuity: one in which compounds were also active in viability assays (red) and the other where compounds were also active in luciferase enzyme assays (blue). Compare
Chemical Structure Clustering
Chemical structures were clustered by maximum common substructure using ChemAxon Library maximum common substructure (MCS). 25
Chemical Structure Similarities
Compound pairwise similarities and the similarity matrix were computed using extended connectivity atom-type fingerprints of length 4 (ECFP4) 26 and the Tanimoto metric implemented in Pipeline Pilot 8. 19
Results
BioAssay Ontology and assay annotations
We have developed an ontology (BAO) 21 to facilitate analyses of screening results from large and diverse sets of biological assays spanning multiple technologies and originating from different sources. The BAO project seeks to develop a formal, extensible, knowledge-based description of biological assays by making use of descriptive logic-based features of the Web Ontology Language (OWL). Expert curation is an important component of the BAO project, and we have been systematically annotating sets of PubChem bioassays with BAO terms describing assay concepts. The BAO project will also provide software tools to query and explore data sets in the context of the ontology.
The BioAssay Ontology describes several concepts related to biological screening, including Perturbagen, Target, Format, Assay Design, Detection Technology, and Endpoint, including endpoint data manipulation. Perturbagens deposited in PubChem and the other screening data sources mentioned above are mostly small molecules but can include various other perturbing agents that are screened in an assay. We refer to targets as “Meta Target” describing not just protein targets but also pathways, biological processes or events, and so on targeted by the assay. Format describes the biological or chemical features common to each test condition in the assay and includes biochemical, cell based, organism based, and variations thereof. Assay Design describes the assay methodology and implementation of how the perturbation of the biological system is translated into a detectable signal. Detection Technology relates to the physical method and technical details to detect and record a signal. Endpoints are the final HTS results as they are usually published (such as IC50, percentage inhibition, etc.). Endpoint data manipulation specifies how the raw signal(s) is transformed into reported endpoints (i.e., normalization, correction, etc.). BAO also captures other assay properties such as assay purpose and how assays are related in campaigns. BAO is also designed to handle multiplexed assays. All main BAO components include multiple levels of subclasses and specification classes, which are linked via object–property relationships forming a knowledge representation. The details of the development and description of BAO will be reported elsewhere. The BAO schema with classes, individuals, and relationships can be downloaded from our Web site. 21 BAO classes, their subsumption hierarchies, and class definitions can also be visualized directly on the BAO Web site. 21
We annotated a set of more than 350 PubChem assays and grouped them into related classes by assay design and detection technology. Specifically, we focused on widely used HTS assay technologies that employ luciferase- and β-lactamase–based reporters.
22
By analyzing the outcomes of related assays, we could readily identify compounds of interest, for example, those that were promiscuously active in one or multiple classes of assays. The luciferase assays were annotated and classified into subcategories that relate to assay design (described in Methods). To efficiently annotate assays and to facilitate data analysis across all PubChem assays, we created a local mirror of the PubChem database. This database stores assay descriptions and endpoints in a relational format and can be queried easily using SQL. Mirrored assays were then manually annotated with BAO terms after interpreting the textual descriptions available in PubChem. To aid in the assay annotation process, we clustered the assays based on text fingerprints derived from the free text in assay title, description, protocol, and source (see methods).
Analysis of luciferase technology assays
Using the local relational database created from data as of April 2010, we identified a total of 257 assays using a design based on the luciferase-induced conversion of luciferin substrates that results in the emission of light.
22
Specifically, we annotated the following types of luciferase technology assays: reporter gene assays (105), cell viability assays (through detection of ATP, 82), ATP-coupled assays (other than viability assays, 35), luciferin-coupled assays (23), and enzyme (biochemical) activity assays (12). A histogram of assay types is shown in
Using the luciferase assay annotations, we computed promiscuity statistics for each compound that was tested in any of the luciferase assays. We developed a Pipeline Pilot (Accelrys) protocol that queries the relational database to determine how many different assays (of a luciferase technology category) each compound was tested in and in how many it was found active. This was done separately for single-concentration and concentration–response assays. To define active and inactive, we used the PubChem activity outcome endpoint. Although this is a subjective, “local” definition (each depositor can define active and inactive for each assay independently), we found it a useful first approximation. We calculated a PCIdx for each category as the quotient of the number of luciferase assays in which a substance was reported as active and the number of assays in which it was tested (see Methods, equation (1)). The larger the ratio of active luciferase assays to assays tested, the higher a compound’s promiscuity PCIdx. However, the significance of this promiscuity measure increases with the number of assays tested. We therefore visualized promiscuity by a scatter plot of PCIdx and the number of assays tested while also indicating the number of active assays (of each category) by color.
Figure 1
shows compound promiscuities for the different luciferase technology categories for single-concentration and concentration–response assays (87 615 data points shown overall). It shows a large number of promiscuous compounds identified from viability and reporter gene assays, which we decided to investigate in greater detail.
The majority of viability assays were concentration–response series deposited by the NCGC. Figure 3 shows the most promiscuous cytotoxic compounds (by SID) identified by these assays. We have previously demonstrated that such data can be useful to model acute animal toxicity. 27 All of the compounds shown have been tested in 44 concentration–response assays and were categorized as active in more than 95% of them. For example, the toxicity of digitonin (SID 17389047) is related to its lipid (membrane) solubilizing properties. Most of the compounds are chemically reactive, which is likely the cause of their toxicity. Crystal violet (hexamethyl-p-rosaniline chloride; SID 17389869) and methylene blue (SID 17388909) are redox-active and electrophilic dyes, respectively. 17388695 and 17389115 are surfactants (phase transfer reagents), 17389451 is a reactive dihydroxyanthraquinone, 17389124 is used as a pesticide, and 17389974 is an alkylator.
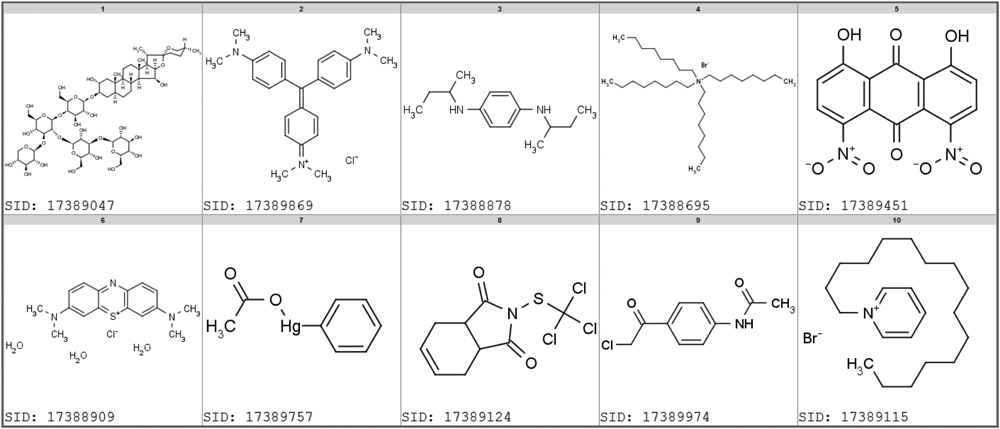
Examples of highly promiscuous (cytotoxic) compounds in luciferase viability assays. All compounds have a promiscuity index between 0.95 and 1.0, were tested in 44 assays, and are active in at least 42 assays.
Although luciferase is often used in viability assays, its most common application is in reporter gene assays. To investigate promiscuous compounds in this category, we retrieved all substances that were active in at least five single-concentration and five concentration–response luciferase reporter gene assays.
Figure 2
illustrates the PCIdx of the 161 compounds in each of the luciferase assay categories for dose–response (DR) and single-concentration (SC) assays after hierarchical clustering (see Methods). There are two major clusters of compounds. In one group, the compounds were also highly promiscuous across viability assays. This could be expected because broadly cytotoxic compounds should also show up as actives in luciferase reporter gene assays. Importantly, this pattern was immediately revealed by our analysis method, which used activity outcomes across all assays of each category in which a compound had been tested. In the other group, compounds also showed promiscuity in the category of luciferase enzyme inhibition assays. It is therefore likely that the mechanism responsible for their promiscuity across reporter gene assays is inhibition of the luciferase enzyme. Most of those compounds also showed high promiscuity indices in the other categories of luciferase assays.
Figure 4 and Table 1 illustrate example chemical structures of both categories of highly promiscuous reporter gene compounds. The first row in Figure 4 and the first five entries in Table 1 show selected compounds that likely act via inhibiting luciferase enzyme. They represent five different chemical classes, including the benzoyl-aryl-urea (SID 3717070) or the 3,5-disubstituted-1,2,4-triazole (SID 865680) scaffolds. 16 The second row of Figure 4 and entries 6 to 10 in Table 1 show cytotoxic compounds that were broadly active across cell proliferation assays. They include reactive compounds such as electron-deficient vinyl chloride (SID 24817234) and Michael acceptor (SID 845529), as well as daunorubicin (SID 855534), which is a DNA intercalator used as a chemotherapeutic.
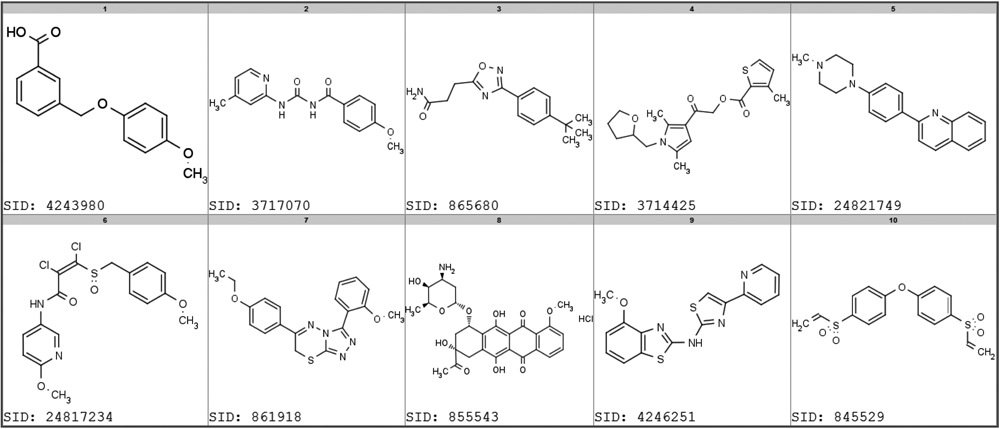
Selected examples of promiscuous compounds in luciferase reporter gene assays of two categories. Top row compounds were also active in luciferase enzyme inhibition assays. Bottom row compounds were active in viability assays. Refer to Table 1 for details.
Promiscuity Indices (PCIdx) and Number of Assays Tested and Found Active for Selected Promiscuous Compounds in Luciferase Reporter Gene Assays
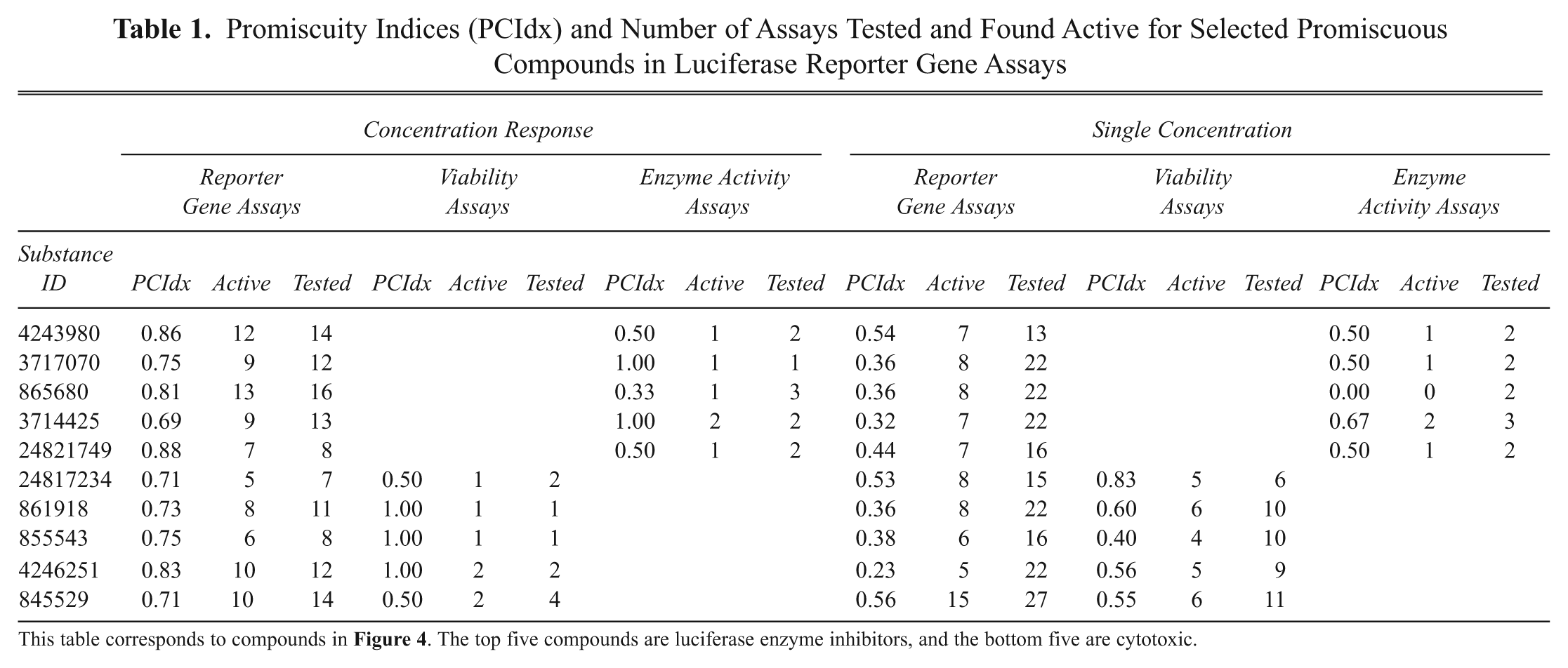
This table corresponds to compounds in Figure 4 . The top five compounds are luciferase enzyme inhibitors, and the bottom five are cytotoxic.
β-lactamase versus luciferase reporter gene assays
Another widely used assay reporter technology relies on β-lactamase.
23
Most of the implementations use fluorescence resonance energy transfer (FRET) substrates, resulting in a fluorescence shift upon hydrolysis of the β-lactam.
28
As of April 2010, we annotated 92 β-lactamase assays, 74 of which were reporter gene assays (
For further analysis, we selected compounds with a PCIdx of at least 0.5 and that have been tested in at least 10 reporter gene assays (for single-concentration or concentration–response assays). These compounds were clustered by MCS. Some of the most promiscuous clusters are shown in
Figure 5
by their MCS scaffolds.
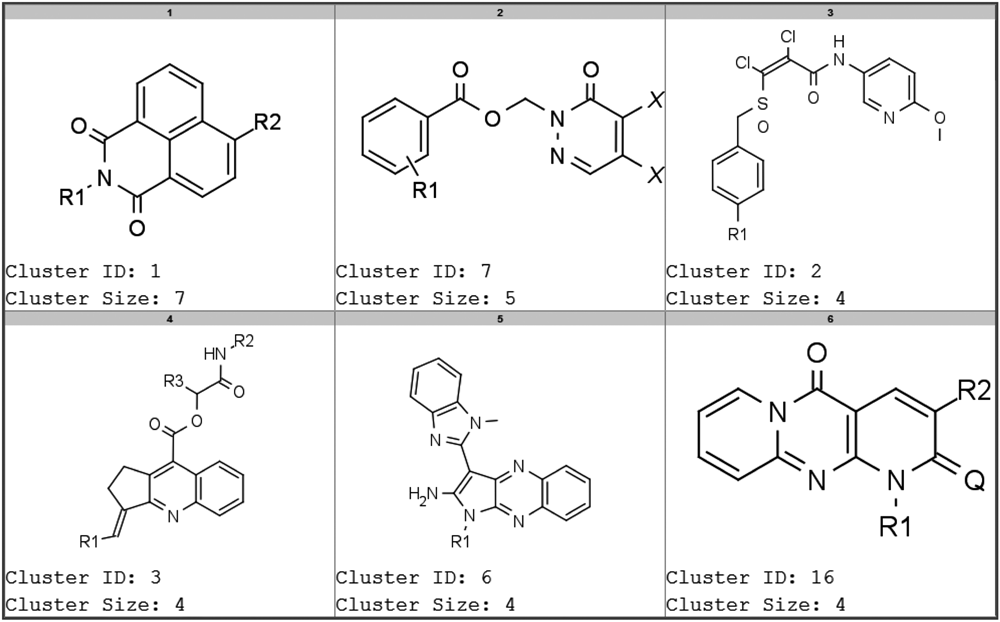
Representative chemical scaffolds of the most promiscuous compounds in β-lactamase reporter gene assays (see
To further investigate how the promiscuity mechanisms were distinct among luciferase and β-lactamase reporter gene assays, we pairwise compared all highly promiscuous compounds across the two technologies—specifically, 102 compounds that were active against the majority of luciferase reporter gene assays versus 97 compounds active against the majority of β-lactamase reporter gene assays. Compounds were selected with PCIdx ≥0.5 and tested in at least 10 assays of their respective reporter technology.
Figure 6
shows the similarity histogram of the maximum similar compound among one group for each compound in the other group (see Methods). The complete similarity matrix and the histogram of all pairwise similarities are provided in
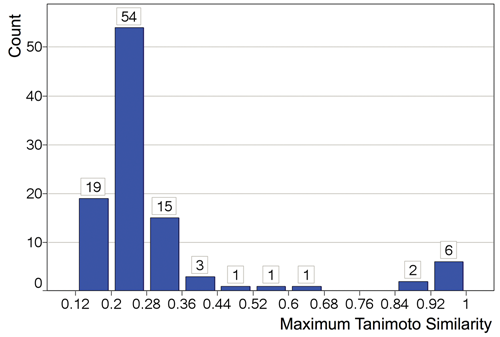
Histogram of the maximum pairwise Tanimoto similarities of each of the 102 most promiscuous luciferase reporter gene compounds compared with the 97 most promiscuous β-lactamase reporter gene compounds. Tanimoto similarities were computed using ECFP4 fingerprints. Most promiscuous compounds were defined as those with a promiscuity index (PCIdx) ≥0.5 and that were tested in at least 10 assays. See
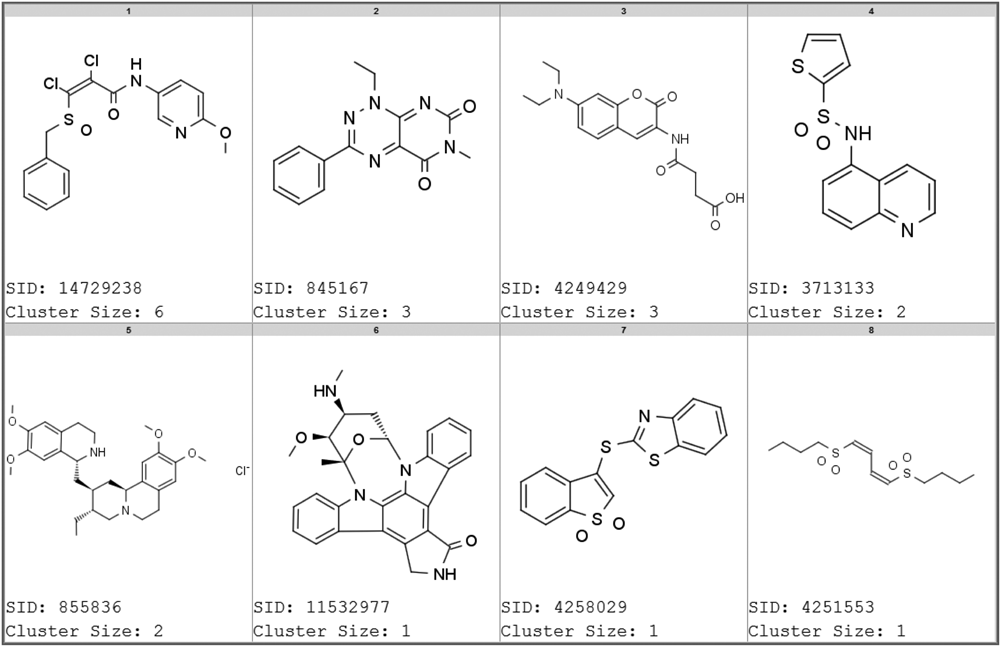
Compounds representing structural classes that show promiscuous activity across luciferase and β-lactamase reporter gene assays.
Discussion
The BioAssay Ontology is the first public effort to develop a formal knowledge-based description of HTS assays and screening outcomes. 21 The value of large public data repositories such as PubChem will ultimately be determined by how well researchers are able to use the information to extract knowledge as a starting point for new research and drug development. Their usefulness will largely be determined by two factors: (1) the content and quality of data in the repository and (2) the ability to retrieve relevant results. The ability to identify, aggregate, and analyze data from various assays that are related to a project of interest is particularly important. BAO primarily addresses this second aspect, but it will also help to analyze data quality by identifying redundancies and related data. While developing BAO, we have annotated more than 350 PubChem assays to organize them by concepts that are relevant to interpret HTS results. Specifically, we investigated assays based on designs that use the luciferase-catalyzed conversion of luciferin substrates, resulting in luminescence and assays detecting β-lactamase via FRET substrates. In contrast to previous reports that focused mostly on individual screening campaigns, BAO has enabled a systematic analysis of many related assays to generate results that could not be obtained from individual screens. Our promiscuity analyses also demonstrated clearly that there is valuable information in the PubChem repository beyond individual screening campaigns and that the BAO descriptions can facilitate the extraction of new knowledge from large numbers of related data sets.
Among assays employing luciferase technologies, we identified five subcategories: reporter gene assays, viability assays, ATP-coupled and luciferin-coupled enzyme activity, and biochemical luciferase enzyme activity (
The majority of the annotated luciferase assays belong to the category of reporter gene assays. We identified the most promiscuous compounds in both single-concentration and concentration–response assays, based on the promiscuity index and the number of luciferase reporter gene assays in which a compound was screened. The identified chemotypes are of interest because it is likely that they will be identified in future luciferase reporter gene assays. The fact that many of the most promiscuous luciferase reporter gene compounds have been tested in concentration–response assays indicates that they were selected as interesting hits from primary assays. On the basis of our observations, researchers would be well advised to exclude these compounds from follow-up studies because they act via a mechanism that is related to the assay technology and not the biological target of interest. Calculated promiscuities of these compounds in the different subtypes of assays that use luciferase in their design suggested two likely mechanisms of action. One was related to cell viability/toxicity and the other to inhibition of the luciferase enzyme. We have shown specific examples for both cases (
Figs. 2
,
4
;
Table 1
; and
We then performed a similar promiscuity analysis for β-lactamase reporter gene assays to identify chemotypes that were nonspecifically active in this category of assays (
Fig. 5
;
Pairwise comparison of the most promiscuous compounds in luciferase-versus β-lactamase reporter gene assays showed that, with a few exceptions, their chemical spaces do not overlap (
Fig. 6
;
In summary, we have systematically analyzed data from a large number of assays in PubChem to identify compounds that are promiscuously active in assays of specific designs and technologies and via distinct mechanisms of action. Such an analysis is only possible with the detailed annotations that we made based on the BioAssay Ontology, the first reported ontology to formally describe HTS assays and assay outcomes. There are many advantages of a formal description of bioassays and standardized annotations of data sets such as those in PubChem. Here we demonstrated that analyses across many assays are facilitated by standardized annotations such as those produced by BAO and that the results can provide insights that cannot be obtained by analyzing individual data sets. This is particularly relevant for relatively noisy primary HTS results. Analysis across many assays of the same type can also be expected to be more robust than analyses focused on individual data sets. Although HTS data contain false positives and false negatives, the BAO approach does not rely on each individual result data points but requires only that the ensemble of results reflects the correct trend (i.e., the fraction of the experiments of a certain category in which a compound is found active).
Although undesirable and reactive chemical functionalities that are prone to cause false positives in HTS have been reported in the past, 31 the definition of undesired chemical substructures to a large extent depends on the specific assay technologies and biological targets; for example, in some applications, covalent modifiers may be acceptable or even desired, but in others, they have to be excluded. BAO provides a means to identify undesirable chemical substructures in a data-driven manner specific to the assay technologies or biological meta-targets that are covered by BAO. With the type of analysis presented here, it would thus be possible to identify undesirable chemotypes that are specifically relevant to a given discovery project.
We would not recommend to a priori remove from a screening library all compounds that show promiscuity but rather flag them, because such compounds can still be of interest for certain targets and orthogonal assay designs, and detection technologies are prone to structurally different artifacts (as we have shown for luciferase and β-lactamase reporter gene assays). By the same token, certain chemotypes may cause artifacts across a large number of assay technologies and biological targets, and these could be removed to improve a screening collection. This will require more comprehensive analyses. We are currently annotating more assays from PubChem and will perform similar analyses for various other categories. The curation effort is time-consuming and not an effective long-term strategy to standardize data. Although a certain amount of curation will likely be required to consolidate terminology, it would be desirable to add BAO-type annotations at the stage of assay deposition and to make these annotations available in the primary data sources such as PubChem. BAO is available from our Web site. 21
As the number of available data sets increases, the type of analyses presented here would have to be repeated periodically to comprehensively and accurately identify promiscuous compounds of a certain category. However, this is a straightforward undertaking, given standardized assay annotations and endpoints. Using BAO annotations and standardized endpoints, we are also currently working on developing predictive classifiers from quantitative outcomes of luciferase assays. Such classifiers could then be used to automatically flag potentially promiscuous compounds.
The BAO software under development 21 will facilitate the query, exploration, and downloading of curated HTS data by BAO terms and thus will also facilitate the identification of promiscuous compounds for specific assay technologies.
Footnotes
Acknowledgements
The work presented here was supported by NIH grant RC2 HG005668. We acknowledge resources from the Center for Computational Science of the University of Miami. Vance Lemmon holds the Walter G. Ross Distinguished Chair in Developmental Neuroscience.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.