
Abstract
High-throughput screening (HTS) has achieved a dominant role in drug discovery over the past 2 decades. The goal of HTS is to identify active compounds (hits) by screening large numbers of diverse chemical compounds against selected targets and/or cellular phenotypes. The HTS process consists of multiple automated steps involving compound handling, liquid transfers, and assay signal capture, all of which unavoidably contribute to systematic variation in the screening data. The challenge is to distinguish biologically active compounds from assay variability. Traditional plate controls-based and non-controls-based statistical methods have been widely used for HTS data processing and active identification by both the pharmaceutical industry and academic sectors. More recently, improved robust statistical methods have been introduced, reducing the impact of systematic row/column effects in HTS data. To apply such robust methods effectively and properly, we need to understand their necessity and functionality. Data from 6 HTS case histories are presented to illustrate that robust statistical methods may sometimes be misleading and can result in more, rather than less, false positives or false negatives. In practice, no single method is the best hit detection method for every HTS data set. However, to aid the selection of the most appropriate HTS data-processing and active identification methods, the authors developed a 3-step statistical decision methodology. Step 1 is to determine the most appropriate HTS data-processing method and establish criteria for quality control review and active identification from 3-day assay signal window and DMSO validation tests. Step 2 is to perform a multilevel statistical and graphical review of the screening data to exclude data that fall outside the quality control criteria. Step 3 is to apply the established active criterion to the quality-assured data to identify the active compounds.
Introduction
H
In an ideal HTS assay, the behavior of active compounds would be completely distinct from that of inactive compounds, the maximum (MAX) and minimum (MIN) control values would be highly reproducible and widely separated from each other, and there would be no false positives or false negatives. 12-16 In practice, all HTS assays contain both random and systematic variability that contribute to the “noise” associated with the experimental data. 1,3,5,7,8,12-15 Sources of random variability include variability in biological activity (true activity) and random errors that arise from occasional technical or procedural failures. 12-16 In addition, there are many potential sources of systematic variability, including differences between reagent lots, buffer preparations, compound concentration, and consumable materials (microplates, pipette tips); defective signal capture by detection instruments (e.g., nonnormalized photomultiplier tubes); uneven temperature or evaporation equilibration across plates; and failed compound or reagent transfer. 12-16 The consequences of a high false-positive rate will depend on the time and resources that will be required to identify and eliminate these compounds during the follow-up hit characterization effort. False-negative results are more serious because they represent potential lead candidates that were missed in the screen and consequently never selected for follow-up studies. The compound collection may also contribute to systematic variability and false positives, promiscuously interfering with assay formats due to physical properties such as color, fluorescence, and aggregation or by reacting chemically with target proteins or assay reagents. 2,17-20 For example, Michael acceptors may modulate activity through the alkylation of critical cysteine or amino groups of target proteins, and redox cycling compounds generate H2O2 in reducing environments that may indirectly inhibit the activity of target proteins susceptible to oxidation. 2,17
There are typically 3 major steps in any strategy to identify active compounds from a primary HTS campaign: (1) the development and validation of a quality-assured assay compatible with HTS, (2) data processing and quality control (QC) review of the screening data, and (3) analysis of quality-assured HTS data to identify actives. 2-10,15,17 Assay quality plays a major role in determining the hit confirmation rate, 15,16 and specific criteria for the exclusion or inclusion of HTS assay data will typically be established during the assay development and validation phases of an HTS campaign. Some of the critical objectives of assay development are to maximize the assay signal window, minimize or control assay variability, estimate statistical variability of the assay, and select a threshold to distinguish actives from inactive compounds. 2-10,17 The HTS community has developed and established automated data analysis methods to process data, provide measures for QC review, and select active compounds. 12-15,21,22 Traditionally, HTS data are preprocessed for analysis by 1 of 2 methods, plate controls-based normalization methods (e.g., percent inhibition) or non-controls-based statistical methods (e.g., Z score). Both approaches have been widely used to QC HTS data and to identify hits. 12,13 More recently, advanced statistical methods such as B scores and BZ scores have been introduced for robust hit identification that reduce the impact of systematic row/ column effects in HTS data. 13,23 Given the enormous variety and complexity of targets, assay formats, and data outputs, it is hardly surprising that none of the data-processing and analysis procedures provides a universal hit selection method for HTS. 12,13 Here, we describe a practical 3-step process to guide the selection of the most appropriate data-processing method for a particular HTS assay and to select active compounds. The process begins with a rigorous statistical analysis of HTS assay development and validation data and incorporates multiple-level statistical and graphical QC review of the primary screening data. Finally, we present an analysis of the unbiased application of 5 different processing and hit identification methods to the data from 6 HTS campaigns.
Materials and Methods
Experimental data
As part of the National Institutes of Health (NIH) Roadmap Initiative, the Pittsburgh Molecular Screening Library Center (PMLSC) was 1 of 10 pilot phase (2005-2009) centers of the Molecular Libraries Screening Center Network (MLSCN) established to provide the academic community broader access to HTS technology and capabilities. 24,25 By the third year of the MLSCN pilot phase, the NIH had amassed a screening library of ~220,000 chemically diverse small molecules that were distributed to the centers for HTS campaigns. The assay descriptions and results from all MLSCN-sponsored HTS campaigns are published to the PubChem database and are publically accessible via their respective assay identifier numbers (AIDs; Suppl. Table S1). 26 All 6 HTS assays used in the present study were developed and implemented in a 384-well plate format with the same layout for plate controls and compounds (Suppl. Fig. S1). The controls were located in columns 1, 2, 23, and 24 of the plate with 32 MAX control wells distributed at the 4 plate corners, 24 MIN control wells in the middle of the 2 sides of the plate, and eight 50% inhibition controls at 1 side. The distributed locations for both the MIN and MAX controls minimized the edge-related variability, and locating the 50% inhibition controls at 1 side provided a means to identify plate orientation. We used assay development and validation data from the 6 of the PMLSC HTS campaigns (Suppl. Table S1) conducted in the first (65K library), second (97K library), and third (200K library) years of the pilot phase of the MLSCN to demonstrate the application of the 3-step statistical methodology described in this article.
HTS data-processing and hit identification methods
In this report, we compare 5 HTS data-processing and hit identification methods, which are either widely used or newly introduced. The 5 methods include controls-based percent inhibition/activation, 12,13 Z score, 12,13 median absolute deviation (MAD) score, 12 B score, 12,13 and BZ score. 23 The details of each method are described in detail in the supplementary text.
Statistical indices to direct selection of HTS data-processing and hit identification methods
We developed decision criteria based on statistical indices derived from 2 experimental data sets generated during our HTS assay development and validation process to allow us to select the most appropriate data-processing and hit identification methods for an HTS assay.
Statistical analysis of 3-day assay signal window variability data
In practice, the robustness and reproducibility of the assay signal window are arguably the most critical features of an HTS assay. 4,8,12,13,15,22 We employed a procedure to rigorously measure and evaluate the signal windows of our assays by capturing data from 2 full plates each of the MAX and MIN controls tested in 3 independent experiments conducted on separate days. The reproducibility and variability of the 3-day assay signals and window were evaluated within the assay plate itself (intraplate), from plate to plate (interplate), and from day to day. 3-5,8,22
The Z′ factor is one of the most widely accepted statistical coefficients that is used to assess the quality of HTS assays, 15 and we used the data to calculate Z′ factors for each of the 3 days.
We also calculated the signal-to-background ratio (S/B), another commonly used parameter employed to estimate the separation or range of an assay signal window, 15,22 for each of the 3 days.
The percent coefficient of variation (%CV) is a normalized measure of the dispersion of a probability distribution. We calculated the %CVs for the 2 full plates of MAX and MIN control signals for each day.
The definitions of Z′ factor, S/B, and %CV are described in detail in the supplementary text.
Statistical analysis of the 3-day DMSO validation data
The 3-day, 5-plate DMSO validation experiments mimic 3 independent days of screening operations where DMSO is substituted for compounds. In a random diversity screen, it is assumed that the majority of the compounds will be inactive, 12 and the 3-day DMSO validation data therefore represent a measure of the variability of inactive compounds in the HTS assay. We analyzed the 3-day DMSO validation data by performing a normality evaluation and analysis of variance (ANOVA) to identify row/column effects or other positional biases.
Normality analysis
The normplot functionality of Matlab (Mathworks, Inc., Natick, MA) was used to generate normal probability plots of the DMSO validation data and to evaluate the normality of the measurements. A normal probability plot presents the sample data superimposed on the line joining the first and third quartiles of each column (a robust linear fit of the sample order statistics). The x-axis values are the data measurements. In the normal probability plot, when samples approximately follow straight lines through the first and third quartiles of the samples, an assumption of normality is reasonable. Otherwise, if the points between the first and third quartiles curve away from the line, an assumption of normality is false.
Two-way ANOVA of columns/rows effects
The anova2 functionality of Matlab was used to perform the 2-way ANOVA of the DMSO validation data by comparing the means of columns and rows of data in the matrix X, where each data point represented an independent sample containing mutually independent observations. The function returns the columns’ and rows’ p-values under the null hypothesis that all samples in matrix X are drawn from populations with the same mean. If the columns’ or rows’ p-value is less than 0.01, it casts doubt on the null hypothesis and suggests that at least 1 sample mean is significantly different from the other sample means. The row/column matrixes of the 15 DMSO validation plates for each assay were loaded into Matlab, and the anova2 function was applied to each plate data matrix. If the columns’ p-value of a plate was <0.01, probabilistically (1 out of 100 times), 2 or more columns of that plate were statistically different (i.e., column effects existed on that plate). Similarly, if the rows’ p-value of a plate was <0.01, probabilistically (1 out of 100 times), 2 or more rows of that plate were statistically different (i.e., row effects existed on that plate).
If the DMSO data are not normally distributed, the 2-way ANOVA is not a valid means of evaluating the column/row effects, but a qualitative decision could be made from a graphical inspection of the data (plate heat map and plate scatter plot vs. rows or columns). The evaluation of the normality and column/row effects is useful to help select an appropriate hit identification method. For example, if the ANOVA of DMSO data exhibits a statistically normal distribution with significant row and/or column position effects, a B score hit identification method is recommended over a Z score method. 12,13
Multilevel quality control review of HTS data
For QC purposes, HTS data are typically reviewed at 3 levels: at the plate, operations run, and overall screen performance levels. 2-10,17 We used a variety of data visualization tools such as heat maps, scatter plots, and results frequency distribution plots together with plate controls-based Z′ factors and S/B ratios for the QC of HTS data. 2,3,5-10,17 We also incorporated non-controls-based QC parameters such as plate median and robust %CV for the QC of HTS data. 14,27 The robust %CV is calculated through the median and MAD of the normalized sample values that reduce plate row and column positional effects by fitting the 2-way median polish algorithm. The median of the sample values on a plate is more resistant to outliers and provides a better representation of any trends in plate-to-plate measurements. 13,14 In a primary screen, the majority of samples are inactive, whereas a few outliers are either true or false (random errors) actives. Since the mean and standard deviation of all samples can be skewed by the unusual values of active compounds, we calculated the plate robust %CV to take into consideration any plate row and column position effects, which may unexpectedly increase the sample variability, and small numbers of actives or random errors that act like outliers. For QC purposes, we passed all HTS plates with robust %CVs <20%.
Results and Discussion
Statistical analysis of HTS assay development and validation data
During the assay development phase, all 6 of the HTS assay case histories considered here (Suppl. Table S1) were subjected to the 3-day assay signal window test described above, and derived average Z factors, %CVs of MAX and MIN control signals, and S/B ratios are presented in Table 1 . The 3-day Z-factors for all 6 assays were >0.5, indicating that they were high-quality assays that should be compatible with HTS. 15 The 3-day %CVs of the MAX controls for all 6 assays were all <15%, well below the 20% threshold for the maximum acceptable dispersion of the probability distribution of the assay control data. 22 Similarly, the 3-day %CVs of the MIN controls for 5 of the 6 assays were also <15%. Only the 3-day %CVs of the MIN controls for the WNV NS2B-NS3 assay (47.7 ± 15.6) exceeded the 20% threshold. The Cdc25B, WNV NS2B-NS3, PLK-1, PKD, and RT-RNaseH assays all exhibited 3-day average S/B ratios >3.5-fold, whereas the PLK-1 PBD assay 3-day average S/B ratio was only 3.06 ± 0.7-fold. The combination of Z′ factors >0.5 together with low %CVs in both control populations and average S/B ratios >3.5-fold all indicated that a controls-based data-processing and active identification strategy would be most suitable for the Cdc25B, PLK-1, PKD, and RT-RNaseH assays. In contrast, the relatively narrow 3-fold signal window of the PLK-1 PBD assay and the very large (%CV = 47%) variation observed in the MIN control population of the WNV NS2B-NS3 assay would seem to be better suited to non-controls-based statistical data-processing and hit identification methods.
Three-Day Assay Signal Window Statistical Indices Summary
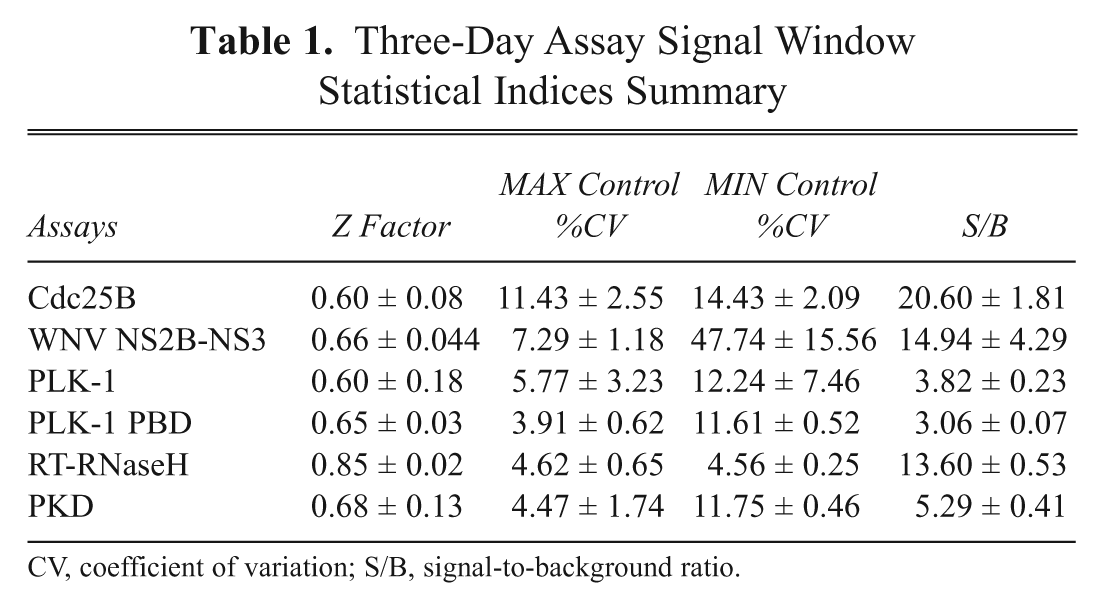
CV, coefficient of variation; S/B, signal-to-background ratio.
The Z score statistical method is only valid for normal distribution measurements. 12,13,15,21,22 The graphical normal probability plots for the DMSO validation data for the 6 assays are presented in Figure 1 . Superimposed on the DMSO sample data is a line representing the robust linear fit of the sample order statistics for a normal distribution. The 15 plates of DMSO validation data for all 6 HTS assays closely approximated a normal distribution line ( Fig. 1 ), and a 2-way ANOVA performed by rows and columns indicated that none of these assays exhibited significant (p > 0.01) row or column effects. The same statistical indices described above were also generated from the DMSO validation plate controls (Suppl. Table S2). Consistent with the 3-day assay signal window data ( Table 1 ), the Cdc25B, PLK-1, PKD, and RT-RNaseH assays all performed well during the 3-day DMSO validation test, and their plate controls exhibited robust and reproducible Z′ factors and S/B ratios (Suppl. Table S2). In addition, for all 4 of these assays, the %CVs of the MAX and MIN controls were consistently <20%, confirming that they were well behaved (Suppl. Table S2). Using an active criterion of ≥50% inhibition/activation for these 4 assays, the PLK-1 and PKD assays exhibited false-positive rates of 0.19% and 0.12%, respectively, in the 4800 DMSO wells tested (Suppl. Table S2). For the PLK-1 PBD assay, however, the average S/B ratio collapsed from 3-fold ( Table 1 ) to ~2-fold, the corresponding plate Z′ factors were only acceptable on day 3 of the test, and based on an active criterion of ≥50% inhibition, the assay exhibited a false-positive rate of 0.17% (Suppl. Table S2). The average %CVs of the PLK-1 PBD MAX and MIN controls were <20%, indicating that the assay was reasonably well behaved (Suppl. Table S2). Although the majority of the WNV NS2B-NS3 assay plate Z′ factors were acceptable during the 15-plate DMSO validation test, the average S/B ratio had collapsed from ~15-fold ( Table 1 ) to ~3-fold, and based on an active criterion of ≥50% inhibition, the assay produced the highest false-positive rate of 0.52% (Suppl. Table S2). The large variation observed in the WNV NS2B-NS3 MIN plate control data during the 3-day assay signal window test ( Table 1 ) was also apparent during the DMSO validation test and contributed to the lower Z′ factors, the collapse in the S/B ratio, and the high false-positive rate (Suppl. Table S2).

Normal probability plots of the 3-day, 5-plate DMSO validation data: (
Figure 2 illustrates how the multiple statistical indices calculated from the 3-day assay signal window ( Table 1 ) and DMSO validation tests ( Fig. 1 and Suppl. Table S2) may be applied to aid the selection of the most suitable data-processing method for HTS data. Controls-based percent inhibition/ activation normalization methods are sensitive to variability in plate controls when the numbers of replicates are limited and also when the magnitude of the assay signal window is small. 12,13,15,22 In contrast to the 2 full plates of MAX and MIN plate controls (n = 768) of the 3-day assay signal window determinations ( Table 1 ), the 384-well HTS plate format used in the DMSO validation test and HTS only provides a limited number of control wells (24 MIN controls, 32 MAX controls, and 320 compound wells; Suppl. Fig. S1). Nevertheless the cumulative statistical indices from the 3-day assay signal window and DMSO validation studies indicated that a controls-based data-processing and active identification strategy would be suitable for the Cdc25B, PLK-1, PKD, and RT-RNaseH assays ( Fig. 1 , Table 1 , and Suppl. Table S2); the MAX and MIN control %CVs were both <20%, the S/B ratio was >3.5-fold, the DMSO validation data closely approximated a normal distribution, and no significant row or column biases were detected. In contrast, the statistical indices for the PLK-1 PBD and WNV NS2B-NS3 assays indicated that they would be better suited to non-controls-based Z score statistical data-processing and active identification methods. Although the DMSO validation data closely approximated a normal distribution ( Fig. 1 ) and no significant row or column biases were detected, the WNV NS2B-NS3 and PLK-1 PBD assays violated 1 or more of the 3 other statistical indices ( Table 1 and Suppl. Table S2). The WNV NS2B-NS3 assay exhibited MIN control %CVs >20%, and for the PLK-1 PBD assay, the S/B ratio was consistently ≤3-fold. Robust hit identification methods such as B scores and BZ scores can reduce the impact of systematic row/column/edge effects in HTS data, 13,23 but since none of the HTS assays exhibited significant row/column biases in either test, these methods would not have been selected. Indeed, it would be our recommendation that any assay that exhibits significant row/column biases in these tests should be suspended until the source of the systematic error has been identified and corrected. The value of such robust methods resides in their ability to rescue HTS data on occasions when a systematic positional bias such as a row/column/edge effect may have occurred in a large HTS data set. Rather than failing the affected plates and rescreening them, the retrospective application of these data analysis methods may serve as an alternative that allows the data to be used and actives identified.

Work flow to aid selection of high-throughput screening (HTS) data-processing methods, establish quality control criteria, and select actives. CV, coefficient of variation; false +ve, false positive; S/B, signal-to-background ratio.
Multiple-level statistical and graphical quality control review of HTS data
Although measured signals from HTS operations are determined accurately, the issue is that artifacts contributing to the measurements lead to false conclusions (inappropriate positives or negatives). 12-14 Nonrandom systematic variability from technical or procedural failures can often be detected through the application of appropriate statistical and graphical QC procedures at the plate, operations run, and overall HTS performance levels. 2-10,13,14,17 A thorough QC review and analysis of the HTS data are therefore critical to the correct identification of actives/hits. To illustrate the utility of a multilevel QC process, we present data from one of three 150-plate days of screening operations from the PKD HTS campaign of 197,000 compounds.
Plate-level QC
The scatter plot ( Fig. 3A ) data visualization of the percent inhibition from a single assay plate randomly selected in the PKD HTS campaign (AID:797) indicated that the assay was well behaved, and there was a robust assay signal window between the MAX and MIN plate controls and that the majority of compounds were inactive and exhibited activity levels that coincided with the DMSO controls. The corresponding heat map of the percent inhibition data encoded by continuous color changes from white (low) to black (high) revealed no discernible systematic patterns within the data ( Fig. 3B ). The Z′ factor for the plate presented was 0.62, the S/B ratio was 3.2-fold, and a single active compound (well E13, 95% inhibition) was readily apparent in both the scatter plot and heat map data visualizations ( Fig. 3 ).

Primary high-throughput screening (HTS) data quality control review. (
Screening operations run QC
A scatter plot of the plate Z′ factors versus plate order from a 150-plate day of operations in the PKD HTS is presented in
Figure 4A
. The average Z′ factor across all 150 plates was 0.44 ± 0.24. The negative Z′ factor values for 3 of the plates (121, 122, and 125) were clearly outliers and indicated that the plate control data for these 3 plates were of poor quality and that they should be failed and scheduled for retesting. When the number of plate controls is limited and the assay has a narrow assay signal range, the Z′ factor is very sensitive to variability in the control data,
15
and the use of Z′ factors alone may be a poor choice for assessing the quality of an HTS assay.
Figure 4B
depicts the plate median raw data value for all 320 samples on the plate versus plate order for the same 150 plates presented in
Figure 4A
.
Figure 4B
clearly illustrates that the 150 plates screened on this day were batch processed in 3 × 50-plate batches, which was not apparent from the Z′ factor scatter plot (
Fig. 4A
). The average median raw data value for all plates was 334.7 ± 18.0, and the plate medians of plates 122 and 125 were >3 standard deviations below the mean of the plate medians. The median values for plates 122 and 125 clearly departed from the general trend of the plate medians in the third batch of plates processed (
Fig. 4B
).
Figure 4C
is a scatter plot of the plate robust %CV versus plate order for the same 150 plates presented in

High-throughput screening (HTS) operations data quality control review. (
To further illustrate the important contribution of data visualizations to the QC review process, we present trellis views of heat maps ( Fig. 5A ) and scatter plots ( Figure 5B ) for 15 of the same 150 assay plates from the PKD HTS presented in Figure 4 . Columns 1, 2, 23, and 24 on each plate contained the MAX and MIN plate controls that produced consistent color patterns in the heat maps ( Fig. 5A ) and a robust assay signal window in the scatter plots ( Fig. 5B ). Even a brief glance reveals that the sample data from 5 of the plates (PMLSC1071 to PMLSC1075) exhibit significantly different patterns as compared to the rest of the plates in both the heat map and scatter plot representations ( Fig. 5 ). PMLSC plates 1071, 1072, and 1075 exhibit quite high variability in their MAX and MIN plate controls data and negative Z′ factor values ( Fig. 4A ). There was less variability in the controls on plates 1073 and 1074, but the systematic errors in the sample data for both of these plates were readily apparent in the heat map and scatter plot representations ( Fig. 5 ), even though they produced Z′ factors of 0.38 and 0.31, respectively. An underlying assumption of controls-based data-processing methods is that the behavior of control samples truly reflects the performance of the test samples. In practice, however, several factors may compromise the validity of the control-based assumption and the accuracy of any QC conclusions: (1) as discussed above, limitations in both the number and position of control well replicates relative to the number and placement of samples on the plate can lead to large differences between the QC parameters calculated from controls and the actual behavior of the samples; (2) plate controls are often stored differently than the compound samples and/or may be added to assay plates by a different automated process; and (3) temporal or spatial plate effects and artifacts from compound properties may also not be apparent in the plate controls. For these reasons, we strongly recommend the use of both statistical and graphical QC procedures to review and pass/fail all HTS data.
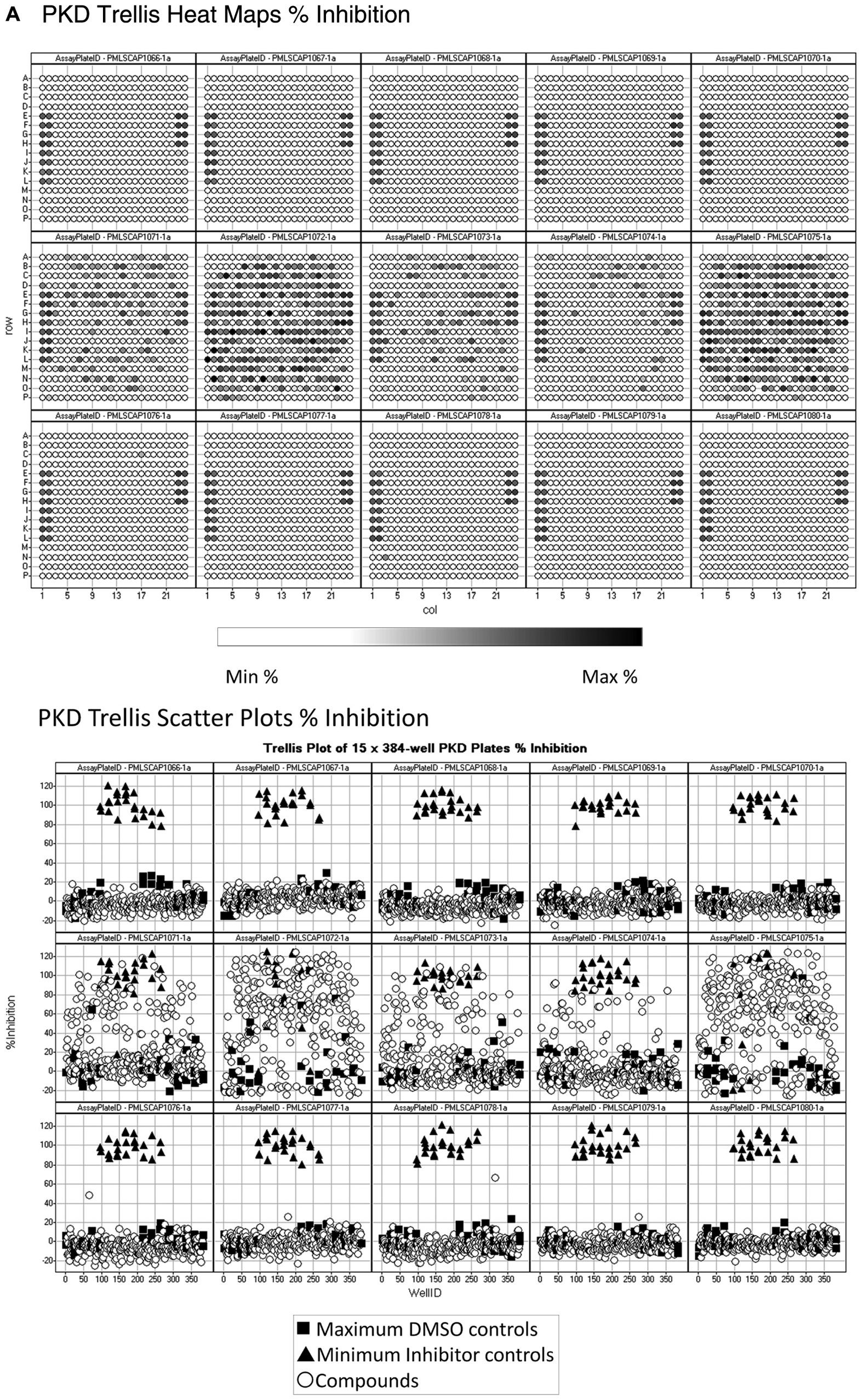
Trellis heat map and scatter plot high-throughput screening (HTS) operations data quality control review. (
HTS campaign QC
In Figure 6 , we directly compare the plate Z′ factor statistical coefficient, a widely used indicator of HTS assay quality, 12,13 to the robust %CVs for the assay plates that passed the QC review from our 6 HTS campaigns.
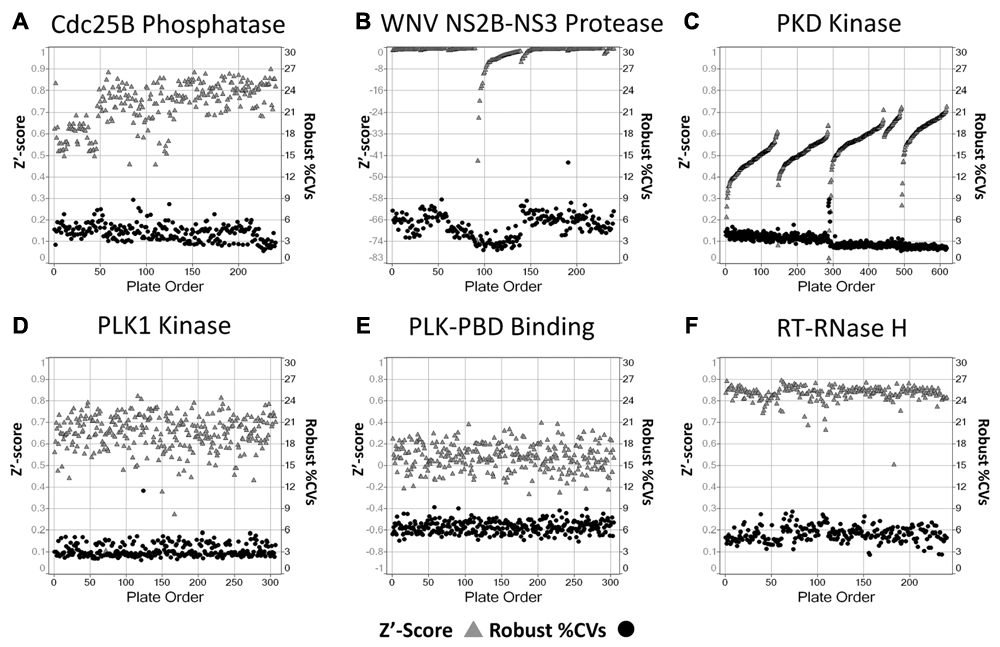
High-throughput screening (HTS) campaign-level data quality control review. Plate Z′ factors and plate robust % coefficients of variation (%CVs). Scatter plots of the plate Z′ factors (solid triangles, left y-axis) and plate robust %CVs (filled circles, right y-axis) versus plate order for the 6 HTS campaigns. Individual plate Z′ factors were calculated from the 32 MAX and 24 MIN control wells on each plate. (
Overall, the Cdc25B assay performed extremely well during the HTS campaign, and the plate controls provided a robust percent inhibition assay signal window and produced average plate Z′ factors and S/B ratios of 0.74 ± 0.1 and 64.4 ± 27-fold, respectively (
Fig. 6A
and Suppl. Table S3).
6
The compound wells of the plates in the Cdc25B HTS exhibited an average robust %CV of 4.4% ± 1.2% for the whole campaign (
Fig. 6A
and Suppl. Table S3), consistent with high-quality HTS data. A similar analysis of the data from 5 days of operations for the PKD kinase screening campaign revealed that the assay also performed very well in HTS (
Fig. 6C
)
10
with a reproducible controls-based percent inhibition assay signal window that produced average Z′ factors and S/B ratios of 0.55 ± 0.1 and 3.22 ± 0.22-fold, respectively (Suppl. Table S3). For each of the 5 PKD operations runs (
Fig. 6C
), the plate Z′ factors improved with plate order, indicating that there was a systematic enhancement of the assay signal window over time. It may be that as the screening run progressed, later plates benefitted from longer incubation times after certain additions during the HTS process or that starting reagents exhibited a time-dependent increase in activity as they sat in reservoirs over the duration of the run. In any case, the observed trend was an increase in assay quality (improved Z′ factors), and the compound wells of the plates in the PKD HTS exhibited an average robust %CV of 3.09% ± 0.83% for the campaign, also consistent with high-quality HTS data (
Fig. 6C
and Suppl. Table S3). The same was also true for the PLK-1 kinase HTS campaign (
Fig. 6D
), where the plate controls again provided a good percent inhibition assay signal window and produced average Z′ factors and S/B ratios of 0.66 ± 0.09 and 4.65 ± 0.38-fold, respectively (Suppl. Table S3). In addition, the compound wells of the plates in the PLK-1 HTS exhibited an average robust %CV of 3.31% ± 0.96% for the whole campaign (
Fig. 6D
and Suppl. Table S3), indicative of high-quality HTS data. The RT-RNaseH assay also performed extremely well in HTS, and the plate controls provided a robust assay percent activation signal window with average Z′ factors and S/B ratios of 0.84 ± 0.04 and 10.89 ± 1.09-fold, respectively (
Fig. 6F
and Suppl. Table S3). The high quality of the RT-RNaseH HTS data was also indicated by the average robust %CV of 5.56% ± 1.06% for the campaign (
Fig. 6F
and Suppl. Table S3). In agreement with the data from the 3-day assay signal window and DMSO validation tests (
Table 1
and Suppl. Table S2), the HTS performance data indicate that the plate controls for the Cdc25B, PKD, PLK-1, and RT-RNaseH assays exhibited very low variability and produced signal windows with relatively large and stable dynamic ranges. The average plate Z′ factors for all 4 HTS campaigns were >0.5, and the compound-derived average robust %CVs were <10%, indicating that both run-level parameters reflected the quality of the HTS data (
For the WNV NS2B-NS3 HTS campaign, however, the large variation observed in the MIN plate control data during the 3-day assay signal window and DMSO validation tests ( Table 2 and Suppl. Table S2) was also apparent throughout the screen and resulted in negative Z′ factor performance data for all of the HTS plates ( Fig. 6B and Suppl. Table S3). In contrast, the average robust %CV for the compounds in the WNV NS2B-NS3 HTS campaign was 5.28% ± 1.71%, indicating that despite the poor Z′ factor coefficients of the plate controls, the HTS compound data were of good quality ( Fig. 6B ). 5 In the PLK-1 PBD campaign, a significant number of the plates also exhibited negative Z′ factors that contributed to a low overall average Z′ factor of 0.10 ± 0.12 for the screen ( Fig. 6E and Suppl. Table S3). The narrow dynamic range of the PLK-1 PBD assay observed in the 3-day assay signal window and DMSO validation tests ( Table 1 and Suppl. Table S2) was also apparent in the screen where the plate controls only produced an average S/B ratio of 2.14 ± 0.1-fold (Suppl. Table S3). Despite the very narrow assay signal window and the apparent low plate Z′ factors, the compound wells of the PLK-1 PBD plates exhibited an average robust %CV of 6.55% ± 0.83%, consistent with high-quality HTS data ( Fig. 6E and Suppl. Table S3).
In Silico Comparison of High-Throughput Screening (HTS) Data-Processing and Hit Identification Methods
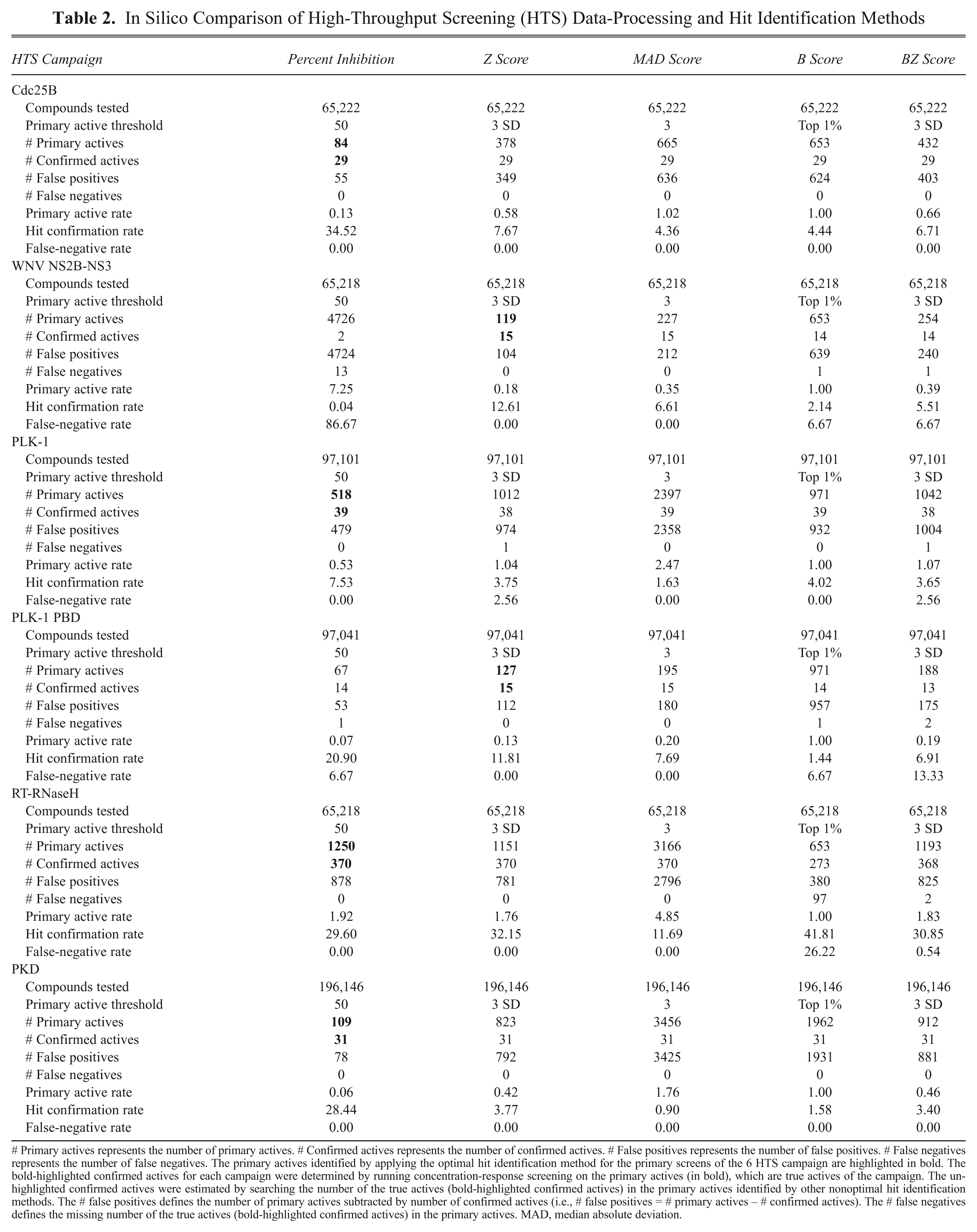
# Primary actives represents the number of primary actives. # Confirmed actives represents the number of confirmed actives. # False positives represents the number of false positives. # False negatives represents the number of false negatives. The primary actives identified by applying the optimal hit identification method for the primary screens of the 6 HTS campaign are highlighted in bold. The bold-highlighted confirmed actives for each campaign were determined by running concentration-response screening on the primary actives (in bold), which are true actives of the campaign. The un-highlighted confirmed actives were estimated by searching the number of the true actives (bold-highlighted confirmed actives) in the primary actives identified by other nonoptimal hit identification methods. The # false positives defines the number of primary actives subtracted by number of confirmed actives (i.e., # false positives = # primary actives – # confirmed actives). The # false negatives defines the missing number of the true actives (bold-highlighted confirmed actives) in the primary actives. MAD, median absolute deviation.
Active identification determined by an optimal active identification method
To be consistent in our comparison of the 5 different data-processing and active identification methods, we applied the following terms to assess the performance of the methods:
The primary active rate 16 defines the ratio of the total number of primary actives to the number of total tested compounds in a primary screen (i.e., primary active rate = [100 * number of actives]/number of tested compounds).
The hit confirmation rate 16 defines the ratio of the number of confirmed actives to the total number of primary actives selected in a primary HTS screen (i.e., hit confirmation rate = number of confirmed actives * 100/number of primary HTS actives). Primary HTS actives were confirmed as hits in concentration-response assays.
The false-positive rate 16 defines the ratio of the number of primary HTS actives that failed to be confirmed in concentration-response assays (i.e., false-positive rate = [number of primary HTS actives – number of confirmed hits] * 100/number of primary HTS actives).
The false-negative rate 16 defines the ratio of the number of the actives missed in primary actives to the number of confirmed actives (i.e., false-negative rate = number of missed actives * 100/number of confirmed actives).
To compare the 5 data-processing and hit identification methods, we estimated false-positive and false-negative rates based on the number of actives that were actually confirmed in concentration-response screening of the 6 campaigns ( Table 2 ). A good data-processing and active identification method should provide a lower primary active rate, a higher hit confirmation rate, and a lower false-negative rate. We applied each of the 5 methods to the committed quality-assured HTS data measurements acquired in the 6 campaigns ( Table 2 ). The active thresholds for the 5 methods, the number of primary actives identified, the corresponding active rate, and the number of hits confirmed in concentration-response assays, together with the estimated numbers of false positives and negatives, are presented ( Table 2 ).
Our analysis indicates that the controls-based percent inhibition method clearly provided the lowest primary HTS active rate and the highest hit confirmation rates for the Cdc25B, PLK-1, and PKD HTS campaigns ( Table 2 ). For all 3 of these screens, the other data-processing and active identification methods would have produced a significantly higher primary HTS active rate with correspondingly more false positives and lower hit confirmation rates. In the WNV NS2B-NS3 campaign, however, a plate controls-based percent inhibition method would have produced a primary HTS active rate (7.25%) that was much too high, and 13 of the 15 confirmed hits would have been missed because they would not have met the active criterion in the primary screen ( Table 2 ). For the WNV NS2B-NS3 screen, the Z score statistical method provided the lowest primary HTS active rate (0.18%) and the highest hit confirmation rate (12.6%). For the WNV NS2B-NS3 data set, the MAD score, B score, and BZ score methods all provided higher primary HTS active rates with correspondingly more false positives and lower hit confirmation rates than the Z score method ( Table 2 ). The Z score statistical method was also optimal for the PLK-1 PBD campaign, where the other methods produced significantly higher primary HTS active rates, more false positives, and lower hit confirmation rates ( Table 2 ). Both the plate controls-based percent inhibition and the Z score statistical methods provided comparable primary HTS active and hit confirmation rates for the RT-RNaseH HTS data set. In this instance, the MAD score method would have provided a much higher primary HTS active rate with more false positives and a lower hit confirmation rate ( Table 2 ). Although the B score method actually provided the highest active confirmation rate for the RT-RNaseH HTS data set with the lowest primary HTS active and false-positive rates, it also produced a false-negative rate of 26% that would be unacceptable ( Table 2 ). These data suggest that although the use of advanced robust statistical methods such as B scores may help to reduce the impact of systematic row/column biases in HTS data, care must be exercised to ensure that they are effectively and properly used.
The 5 hit identification methods described in this article can all be used to normalize plate-to-plate variability. 12,13,23 By definition, the Z score data-processing method makes a normal distributional assumption of the assay measurements. 12,13 Since the mean and standard deviation are influenced by statistical outliers, Z score methods are not resistant to statistical outliers. In contrast, the MAD score and B score methods are nonparametric with minimal distributional assumptions for the measurements and are subsequently resistant to the presence of statistical outliers. The BZ score does not assume normal distribution for the measurements but makes normal distributional assumptions for calculated B scores. 23 With the B score method, imbedding a 2-way median polish removes systematic row and/or column effects that has the potential to provide 3 main advantages: (1) minimal distributional assumptions, (2) a reduction of measurement bias to positional effects, and (3) resistance to statistical outliers. 12,13 However, setting the limit of actives identified by the B score is often contingent on personal preference (e.g., top 1%). 13
Conclusions
Many factors beyond biological activity affect HTS data quality. Identifying systematic errors and taking steps to reduce and/or control their impact is critical for identifying actives in primary HTS data. No single data-processing and active identification method is optimal for all HTS data sets. To aid the selection of the most appropriate HTS data-processing and active identification method, we have developed a 3-step statistical decision methodology ( Fig. 2 ). Step 1 is to conduct the 3-day assay signal window and DMSO validation tests and, on the basis of the statistical indices determined from these data, to select the most appropriate HTS data-processing method and to establish criteria for QC review and active identification. Step 2 is to perform a multilevel statistical and graphical quality control review of the screening data to exclude data that fall outside the QC criteria. Step 3 is to apply the established active criterion to the quality-assured data to identify the actives. When used in conjunction with the optimal data-processing method selected in step 1 and applied systematically to every HTS run, the multiple-level statistical and graphical QC methods provide a better way to accurately evaluate the quality of HTS screen data and improve hit confirmation rates.
Footnotes
Acknowledgements
We thank Caleb Foster, Sunita Shinde, Jennifer Phillips, John Skoko, and Stephanie Leimgruber for their excellent work in the development and implementation of the 6 HTS campaigns used in this article. We also acknowledge the many screen leaders and researchers at Eli Lilly’s Research Triangle Park global assay development and HTS facility (Sphinx) who contributed to the genesis of the practical methodologies described herein (![]() ). The work reported here was supported by National Institutes of Health grants U54 MH074411, X01 MH077605, X01 MH077601, X01 MH078959, X01 MH76330, X01 MH078944, and R03 DA024898; a National Cancer Institute grant CA078093; and a grant from the Commonwealth of Pennsylvania (DOH-SAP4100027294).
). The work reported here was supported by National Institutes of Health grants U54 MH074411, X01 MH077605, X01 MH077601, X01 MH078959, X01 MH76330, X01 MH078944, and R03 DA024898; a National Cancer Institute grant CA078093; and a grant from the Commonwealth of Pennsylvania (DOH-SAP4100027294).
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.