
Abstract
Framing is considered an important theoretical perspective for analyzing the influence of media information. Despite the explicit inclusion of visual elements within established frame definitions, visuals have long been marginalized in framing research. Based on a systematic review of 552 articles addressing visual framing, this article closely investigates 72 empirical studies on visual/multimodal framing effects. Drawing on framing as a multidimensional process, we discuss how existing studies have examined the sensory, affective, cognitive, and behavioral dimensions of impact. We explain the rising importance of visual communication and multimodality and conclude with implications for mass communication and visual journalism.
In the ever-evolving landscape of media communication, framing research has become a critical lens through which the shaping and interpretation of mediated information can be understood (see D’Angelo et al., 2019). Framing, conceptualized here as a multidimensional model of media effects, provides a framework for exploring how media influence perception, cognition, and behavior. The process involves several stages that unfold during exposure to and reception of mediated messages. Recognizing a transformative shift in both the representation of media information and framing research traditions, this systematic literature review focuses on the effects of visual framing in multimodal media environments. Incorporating multimodality, which reflects changes in the way information is presented and consumed, becomes essential to a comprehensive understanding and analysis of framing processes. Having conceptualized framing as a multidimensional model of media effects, our investigation begins by elucidating the significance of multimodality in framing processes, setting the stage for the examination of modality-specific properties of images and visual frames. This foundational step seems critical for addressing the evolving nature of media communication and the challenges posed by the multimodal media landscape.
Motivated by the growing body of research on visual and multimodal framing, our systematic review aims to consolidate and synthesize the scattered state of knowledge in media and communication studies. We approach this research with two central questions:
In the following sections, we describe our methodological approach and coding scheme and present overarching findings related to visual framing as a field of research. We then systematically categorize and analyze studies of visual framing effects, dissecting findings based on the sensory, affective, cognitive, and behavioral dimensions of multimodal framing. We conclude with a discussion of challenges for future research in mediated communication. Our systematic exploration not only synthesizes existing knowledge but also lays the groundwork for advancing the discourse on visual framing effects in the dynamic realm of multimodal media environments.
Framing as a Multidimensional Process of Media Effects
A frame is defined as “a central organizing idea or story line that provides meaning to an unfolding strip of events” (Gamson & Modigliani, 1987, p. 143), which affords interpretation by establishing connections between interpretable units of visual, textual, and auditory information. According to Entman (1993), “to frame is to select some aspects of a perceived reality and make them more salient in a communicating text” (p. 52). The underlying idea is that in media contexts, certain aspects of reality are selectively emphasized, providing the recipients with interpretative patterns that both support and influence information processing. Frames therefore not only define a problem and identify its cause, but also make moral judgments and suggest possible solutions (Entman, 1993). By framing issues and events in a particular way, the media can influence public opinion in favor of or against certain political, economic, and social trends (de Vreese, 2003).
As a model of media effects, framing operates by encouraging active selection and meaning-making. It encompasses the fundamental principle of simplifying complexity in the process of perception and processing, which is present in nearly all forms of communication (Geise & Baden, 2015). Given this premise, framing can be understood as a multidimensional process consisting of various intertwined subprocesses, including (1) sensory, (2) affective, (3) cognitive, and (4) behavioral dimensions of influence.
Before discussing these dimensions in more detail, it is important to explain why we have chosen to focus on sensory, affective, cognitive, and behavioral dimensions in the study of visual and multimodal framing effects. As outlined below, these dimensions represent key aspects of human response to visual framing in multimodal media settings and provide a nuanced understanding of framing effects. The first, the sensory dimension, addresses how visual stimuli engage sensory modalities, providing insight into immediate, physiological responses and laying the foundation for subsequent cognitive and affective processes. The second, the affective dimension, is concerned with the emotional responses elicited by visual framing. It is crucial because emotions play a central role in shaping attitudes, preferences, and decision-making. The third, the cognitive dimension, examines how visual frames affect cognitive functions, helping to unravel the mental mechanisms at play that influence the understanding, knowledge construction, and information processing guided by frames. And finally, the behavioral dimension, addresses observable actions and reactions that result from visual framing, thus providing a tangible link between framing processes and real-world outcomes that inform practical applications. Taken together, these dimensions provide a comprehensive view of how individuals engage with and respond to visual and multimodal framing. Further and systematic exploration of these dimensions will provide a nuanced assessment of the impact of visual framing on various facets of human response and behavior. It will therefore also enrich our understanding of the complex processes involved and inform practical applications in the development of communication strategies and the design of media messages.
As illustrated in Figure 1, this process begins with (a) the sensory perception of a media frame, which captures the recipient’s attention and directs focus to the multimodal media information, simultaneously initiating the processing phase. This step involves directing visual attention, stimulating associated physiological responses, and selectively perceiving the communication stimuli offered (Geise & Baden, 2015). At the same time, it is accompanied by interrelated cognitive evaluation stages (Seo & Dillard, 2019b), including the spontaneous assessment of the personal relevance of the information provided, which subsequently influences the continuation or interruption of visual attention (Dahmen, 2012; Smith et al., 2021). In addition, an evaluation of the emotional tone, an initial risk assessment, an evaluation of the controllability of the underlying information, and an attribution of responsibility may follow (Kühne & Schemer, 2015). According to appraisal theories (e.g., cognitive appraisal theory), (b) emotions arise from these evaluations (Lazarus, 1991; Scherer, 2005). For example, if the media information is deemed relevant, a frame that emphasizes the perpetrators of a problem may evoke anger, while a frame that focuses on the victims may evoke sadness (Kühne, 2013). As information processing continues, the emotions activated at this stage can then influence subsequent (c) “higher-level” cognitions, which are understood as (elaborated) mental propositions or units of knowledge about an object or topic (Ajzen & Fishbein, 1980), such as the formation of judgments, opinions, or behavioral intentions. These behavioral intentions can then lead to (d) behaviors or changes in behavior, which to some extent are aftereffects of framing.
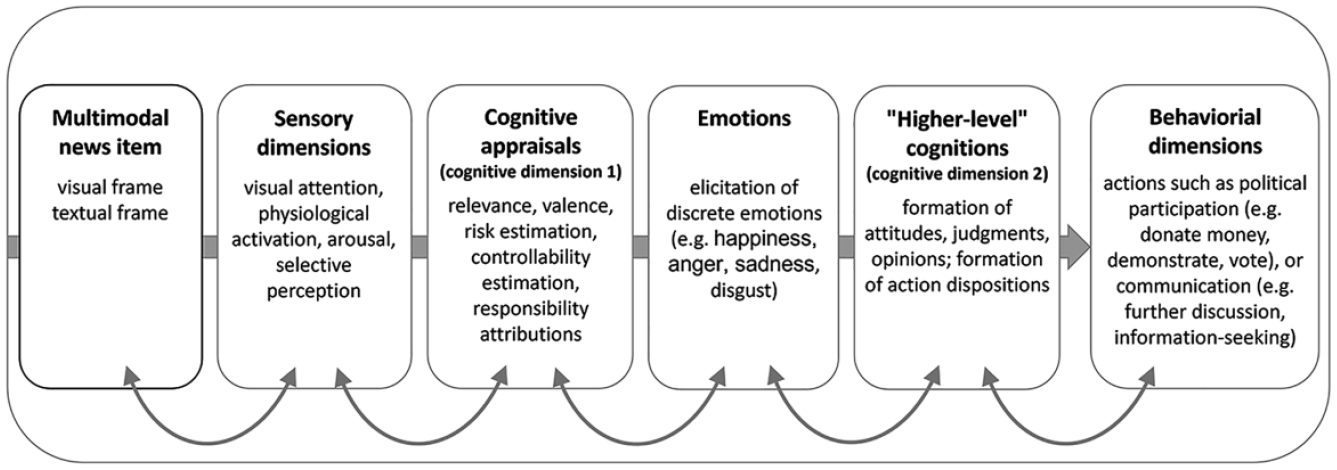
Framing as a Multi-Dimensional Process.
It is important to note that the assumption of chronologically sequential framing subprocesses provides only a partial explanation for the complexity of human information processing. These subprocesses not only overlap but also interact (e.g., visual attention and relevance judgments). Nevertheless, distinguishing between them provides analytical value by making us aware of the specific subprocesses and subdimensions that are interwoven in the framing process. In addition, it suggests avenues for empirical research on different framing effects from this process-oriented perspective by providing concepts for methodological operationalization.
Framing in Multimodal Media Environments
Despite its integrative potential, framing has long been studied primarily in textual contexts (D’Angelo et al., 2019; Geise & Baden, 2015). The initial focus on linguistic frames is not self-explanatory, as many of the established conceptions of framing explicitly include visuals as framing devices. For example, in his early theoretical reflection, Gitlin (1980, p. 7) defined media frames as “persistent patterns of perception, interpretation, and presentation, selection, emphasis, and exclusion by which symbol handlers routinely organize discourse, whether verbal or visual.” Gamson and Modigliani (1987) have also explicitly referred to visual images—together with metaphors, exemplars, catchphrases, and depictions—as five symbolic devices in a frame package (see also Borah, 2011; Tankard, 2001; de Vreese, 2005).
Because contemporary media environments are rife with multimodality (Wessler et al., 2016), images were put “back into the frame” (Geise & Baden, 2015), and research has devoted more interest to the visual and multimodal aspects of framing. In many media contexts, visual and textual messages appear together, and recipients receive and process them contemporaneously. Such offerings are multimodal because they are—according to the definition of multimodality—characterized by a “communicative interaction of meaning encoded in different modalities (e.g., sound, image, text)” (Geise & Baden, 2015, p. 4; Kress & Van Leeuwen, 2021). The concept of multimodality not only addresses the multifaceted interplay of information embedded in different modalities, but also acknowledges the fact that each modality offers mode-specific communicative potentials, functions, and limitations (Kress & Van Leeuwen, 2021).
To further elucidate the concept of visual framing in multimodal media contexts and explore its implications, we will use news articles as a representative example of how textual and visual elements work together to construct multimodal media representations. Within a multimodal news article, visual frames (typically conveyed by a press photograph, occasionally by a picture spread or short videos) coalesce with textual frames (typically including the headline, subhead, caption, and article text) to create a distinctive multimodal media unit (e.g., Rodarte et al., 2023; Xu & Löffelholz, 2021). According to framing theory, both the visual and the textual frames in news articles have the capacity to emphasize specific interpretations and evaluations of news events, shaping how recipients perceive and process the information and influencing their understanding, categorization, and evaluation of the reported events.
News images and article text serve as archetypal tools in multimodal framing, allowing news creators to shape their audience’s view of the world (Caple, 2017). Multimodal framing emerges as a particularly appropriate theoretical framework as it allows for the simultaneous consideration of the different elements of visual, textual, and auditory communication (Geise, 2017; Geise & Baden, 2015; Geise & Coleman, 2015). This is important because each modality brings its own specific features to the communication process (Kress & Van Leeuwen, 2021). These attributes need to be recognized in their own right, but also for their interplay with each other (Powell et al., 2015), potentially creating additional layers of meaning beyond the scope of a single modality. This includes the possibility that visual and textual frames, as autonomous modes of communication, may not only complement and reinforce each other’s messages but also present conflicting interpretations. For example, in a news story that uses both images and text, “the text may convey one set of meanings and the images another” (Kress & Van Leeuwen, 2021, p. 41). Nevertheless, from an information-processing perspective, both the visual and textual “information packages” provide elements that readers must synthesize to decipher the central meaning or framework(s) of a news piece (Geise & Baden, 2015). This being said, visual framing effects then occur when elements within an image, the image itself, or a collection of images endorse a certain meaning or interpretation of the depicted content and are adopted by certain recipients (Geise, 2017). From the perspective of perception and emotion psychology as well as visual communication and media effect research, a number of mechanisms come into play that suggest a particular impact potential of visual frames (e.g., Coleman, 2010; Fahmy et al., 2014; Geise & Baden, 2015; Messaris & Abraham, 2001). These mechanisms, resulting from the specific “logic” of the visual mode, are summarized below.
Modality-Specific Properties of Images and Visual Frames
Although images have been neglected in framing research in the past, they form part of the routine of journalism practice and mass communication in which photojournalists and editors select news images that highlight certain points of view, convey a certain interpretation of the news, or imply a moral judgment (Coleman, 2010; Entman, 1993). As Messaris and Abraham (2001) have pointed out, journalists employ various visual framing strategies, such as “choosing one view over another when examining a photograph, cropping and altering the resulting image in different ways, and/or choosing to display one image out of many taken at the same time and place” (p. 217).
Various journalistic framing strategies lead to different representations of visual frames in news media. Following this idea, Rodriguez and Dimitrova (2011) proposed an often-cited framework for understanding the four levels of visual framing. The denotative level refers to the different subjects and objects portrayed in the visuals. The stylistic-semiotic level delves into the conventions involved in visual representation, such as the positioning of the camera shot. The connotative level attends to not only the depiction but also the implicit symbols and cues of an interpretative nature. The ideological level uncovers the intentionality and the latent discourse through visual framing and reflects the ideas and power relationship behind the visual portrayals of perceived realities. Due to modality-specific properties, the processing and reception of visuals take place differently compared with other modalities of communication, particularly texts.
First and foremost, visual communication operates on a different associative logic than the linear, argumentative reasoning of textual communication (Messaris, 2003). While text reading follows a “sequential processing system,” the perception of visual information relies on a “parallel system” that utilizes heuristic information processing (Paivio, 1991). Images, particularly photographs, serve as integral communicative units that present a time-bound, condensed, concrete, and vivid representation of the subject matter. This condensed format efficiently encapsulates a wealth of detailed information in a coherent, easily understood framework that closely resembles the intended representation. As a result, images are perceived holistically, almost automatically, and with less conscious cognitive effort (Rodriguez & Dimitrova, 2011). Visuals are thus mostly quickly processed, easily accessed, and readily understood (Coleman, 2010). Kress and van Leeuwen (2021) attribute this to the fact that visual communication has a distinct semiotic quality in that it encodes and decodes information as tangible representations rather than transforming it into abstract signs. Accordingly, the perception of visual images depends on the recognition of similarity relations between the image and its subject, without the need for prior familiarity with specific representational conventions (Messaris & Abraham, 2001). This indexical quality imbues images with a sense of testimony, enhancing their credibility and establishing their “potential value as evidence” (Messaris, 1998, p. 130). In addition, images command a higher level of attention and salience, resulting in rapid and often prolonged mental anchoring even with peripheral exposure (Messaris, 2003; Paivio, 1991). Images, therefore, are not merely particularly intrusive in low-involvement situations, such as quickly scanning news stories; the heuristic processing of visuals was also shown to bias systematic information processing (Chaiken & Maheswaran, 1994; Tversky & Kahneman, 1974).
Given these modality-specific characteristics, visuals, especially photographs and videos, are more prone to elicit framing effects. Using their associative and heuristic logic, images quickly establish a visual frame that is particularly salient and rarely questioned by viewers. Because visual images carry a sense of authenticity similar to real-life experiences, they can lead viewers to implicitly believe that they are closer to the truth than other modes of communication (Messaris & Abraham, 2001). Visual frames, therefore, have the ability to convey meanings that might be more resistant to the audience if conveyed through words alone (Messaris & Abraham, 2001, p. 215). In these settings, visually suggested patterns of interpretation serve to simplify message comprehension by reducing complexity, inadvertently influencing how recipients interpret and evaluate the information. As a result, visual communication is often considered more “effective” than text-only communication (Kress & van Leeuwen, 2006).
In addition, visuals usually activate higher levels of attention and generate stronger psychological arousal, which is often referred to as the “picture superiority effect” (Childers & Houston, 1984). From this perspective, pictorial information was found to have a superior influence, even when the information is incidental and not mentioned in textual content at all (Gibson & Zillmann, 2000). Research has accordingly shown that visual frames can effectively shape their interpretation of textual information by triggering specific cognitive patterns (Gibson & Zillmann, 2000), potentially exerting a superior influence on message perception and interpretation (Geise, 2017; Geise & Baden, 2015; Powell et al., 2015). Therefore, in a typical multimodal news article, a strong image paired with text is expected to capture visual attention, evoke emotions, and shape citizens’ perceptions of political issues and individuals (Grabe & Bucy, 2009; Graber, 1996; Powell et al., 2018).
Visual Framing in Multimodal Media Environments: A Research Overview
The scientific discourse on framing has led to an immense body of research over the past decades. Due to the increasing importance of images in multimodal media environments, in the past two decades, research has been devoted more intensively to the analysis of visual frames. Instead of regarding framing as a “fractured paradigm,” the state of research seems quite dispersed, which is reflected, on the one hand, in a great diversity of phenomena studied as visual frames, and, on the contrary, in a variety of disciplinary approaches. In this circumstance, a systematic literature review helps to get a renewed overview of the existing research field. Based on the theoretical framework described above, this review can provide further insight into how existing studies have addressed sensory, affective, cognitive, and behavioral dimensions when examining visual framing effects in multimodal media environments.
In answering these research questions, our systematic review contributes to the advancement of multimodal framing research by synthesizing and critically analyzing a substantial body of existing studies. By comprehensively examining the available literature, this review provides a holistic understanding of the current state of knowledge in the field and helps to identify specific knowledge gaps in the existing communication literature. In addition, the review provides methodological insights by evaluating common methodological practices, challenges, as well as less frequently used but insightful approaches, thus guiding future researchers in designing future studies on multimodal framing.
Method
Literature Search
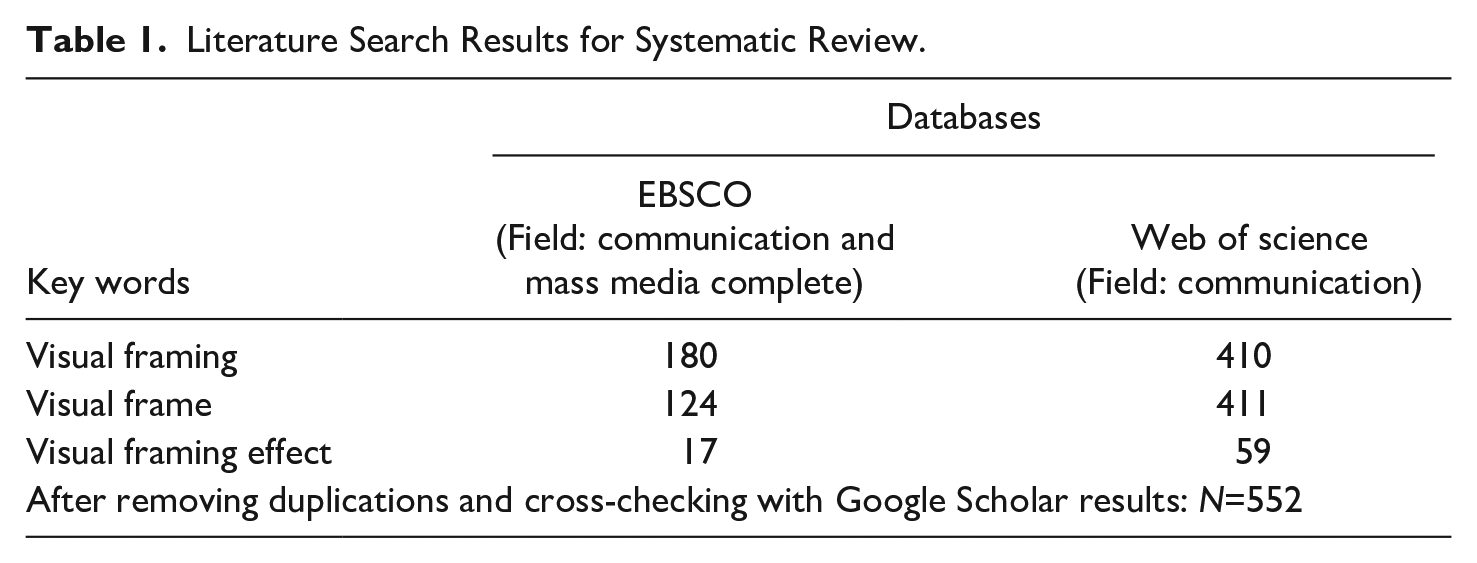
Adhering to the established systematic review protocol (Moher et al., 2009), two reputable scientific databases, namely EBSCO (Communication and Mass Media Complete) and Web of Science (category: Communication), were chosen to conduct the literature search. Google Scholar was used to verify and supplement the search results with additional articles. The scope of the literature search is communication scholarship in general. There was no pre-defined time frame, as this study intended to collect all relevant publications that were available in the databases. In line with previous studies (Bock, 2020; Brantner et al., 2012) that evaluated visual framing research published prior to 2017, this review employed three specific search terms: “visual framing,” “visual frame,” and “visual framing effect.” The scope of the publications reviewed included journal articles, review articles, and book reviews.
Table 1 shows the results of the literature search on September 1, 2023. The first content research addressing visual frames in news media could be dated back to 1979, while the earliest study dealing with visual framing effects was published in 1980. After removing duplicate records and cross-checking with Google Scholar search results, 552 publications were identified for the systematic review. It should be noted that this systematic review takes a broader understanding of visual framing. That is, publications were included for review as long as they examined messages from legacy media (i.e., newspapers, magazines, and television), online news sites, social media, movies, advertisements, political campaign materials, books, or spatially immersive media (e.g., virtual reality).
Literature Search Results for Systematic Review.
Coding Scheme
The codebook consists of formal and content variables. Formal variables include year of publication, authors’ names, country (where the first author affiliated), title of publication, source, and types of publication (including empirical study, theoretical or methodological essay, and book review).
Content variables include fields of communication research (including six subfields such as communicator research, content research, media effects or audience research); research methods (including observation, interviews, surveys, discourse analysis, content analysis, eye-tracking, computational methods, mixed), and analysis units (including text, photograph, cartoon or artistic illustration, data visualization, multimodal unit such as textual-visual news, audiovisual news). Drawing on the abovementioned theoretical differentiation, four variables were specifically developed for understanding how existing studies have empirically examined the multidimensional process in visual/multimodal framing effects. We dichotomously (1/0) coded the variables: sensory, affective, cognitive, and/or behavioral dimensions of framing. Moreover, based on the levels of visual framing (Rodriguez & Dimitrova, 2011), studies were coded dichotomously (1/0) by which level(s) they address the visual analysis, including denotative, stylistic, connotative, and/or ideological levels.
Intercoder Reliability Test
Intercoder reliability was assessed using a random sample of 10% (N= 50) from collected articles. Two independent coders reached very satisfactory results with all variables ranging from Krippendorff’s α=0.94 to α=0.99. On average, the overall reliability result was α=0.97.
Results
Visual Framing as a Research Field
Between 1979 and 2023, a total number of 552 articles referred to visual framing as indicated by the applied keywords. Of these, 465 empirical studies (84%) account for the majority of publications, followed by 69 theoretical or methodological essays (13%) and 18 book reviews (3%).
From 1979 to 2005, the number of publications was less than ten articles per year, implying a low level of attention to visual framing research. This finding is consistent with Matthes’ (2009) review of framing literature during the period 1990-2005, which revealed only 5% of studies included visuals in their analysis. After 2005, the number of publications rapidly increased and has multiplied year after year since 2015. Brantner et al. (2012) presented the first paper with a qualitative review of 29 visual framing studies. They also concluded that around 2010 the theory-building of visual framing was still under establishment. The increasing popularity of visual framing research was also found by a previous review article (Bock, 2020).
Looking at the fields of research, the vast majority of studies analyzed visual frames as part of media content (n=259, 47%). Media effects were examined in 72 articles (13%), followed by 45 studies about the medium (8%) such as digital platforms, journalistic drones, and virtual reality. There were 79 studies applying a communicator perspective (14%); but the least investigated field was audience research (n=33, 6%). In addition, 15 publications (3%) combined more than two research fields.
Visual framing scholars focus on a number of recurring themes, which is consistent with existing review articles (Bock, 2020; Brantner et al., 2012). The most popular topics were war, conflict and crisis (n=82, 15%), photojournalism practices and advertising (n=81, 15%), presidential election and political campaign (n=67, 12%), identity and stereotype (n=63, 11%), social movement and protest (n=40, 7%), and health-related issues (n=40, 7%).
Regarding research methods, more studies followed a quantitative approach (n=217, 47%) than a qualitative one (n=205, 44%). The most frequently used methods were critical discourse analysis (n=177, 38%) and content analysis (n=137, 30%). Survey (or survey-based experiment) was less used (n=66, 14%). The least used methods were: interview (n=17, 4%), observation (n=8, 2%), eye-tracking (n=10, 2%), computer-assisted analysis (n=4), and focus group (n=3).
Interestingly, the review shows that the vast majority of studies treated multimodal media offerings—such as textual-visual news, audiovisual reports, or news video clips—as the unit (or stimulus) of analysis (n=258, 56%). Visual framing research, therefore, rarely considers visuals in isolation, but seriously acknowledges that visuals are usually embedded in textual or linguistic contexts.
Quite a number of studies were primarily dedicated to the visual level and then mostly used photographs as units of analysis (n=132, 28%). Cartoons or artistic illustrations (n=23, 5%) and data visualization (n=7, 2%) were analyzed rather rarely. In 15 visual framing studies (3%), the text was the primary unit, for example, the capture of news images or videos, or headlines in the newspaper layout. Ten studies (2%) referred to more than two units of analysis, and 20 articles (4%) used other units such as performance, exhibition, and virtual environment.
Studies on Visual Framing Effects
Drawing on framing as a multidimensional process, this review further identified 72 empirical studies that were specifically dedicated to visual/multimodal framing effects. Figure 2 illustrates the number of studies that examine the sensory, affective, cognitive, and behavioral dimensions of the framing process. The areas where the ellipses overlap represent studies that have examined more than one dimension. Most studies measured how visual/multimodal news influenced cognition (n=65, 90%). A considerable number of studies have also evaluated the affective effects of visual/multimodal frames (n=28, 39%). Only 14 studies (19%) examined the sensory dimension in visual/multimodal framing effects. Only 4 studies (6%) measured the behaviors triggered by visual/multimodal frames. The sub-sections below provide a closer overview of these empirical studies (see Appendix for an overview of studies categorized by dimensions).
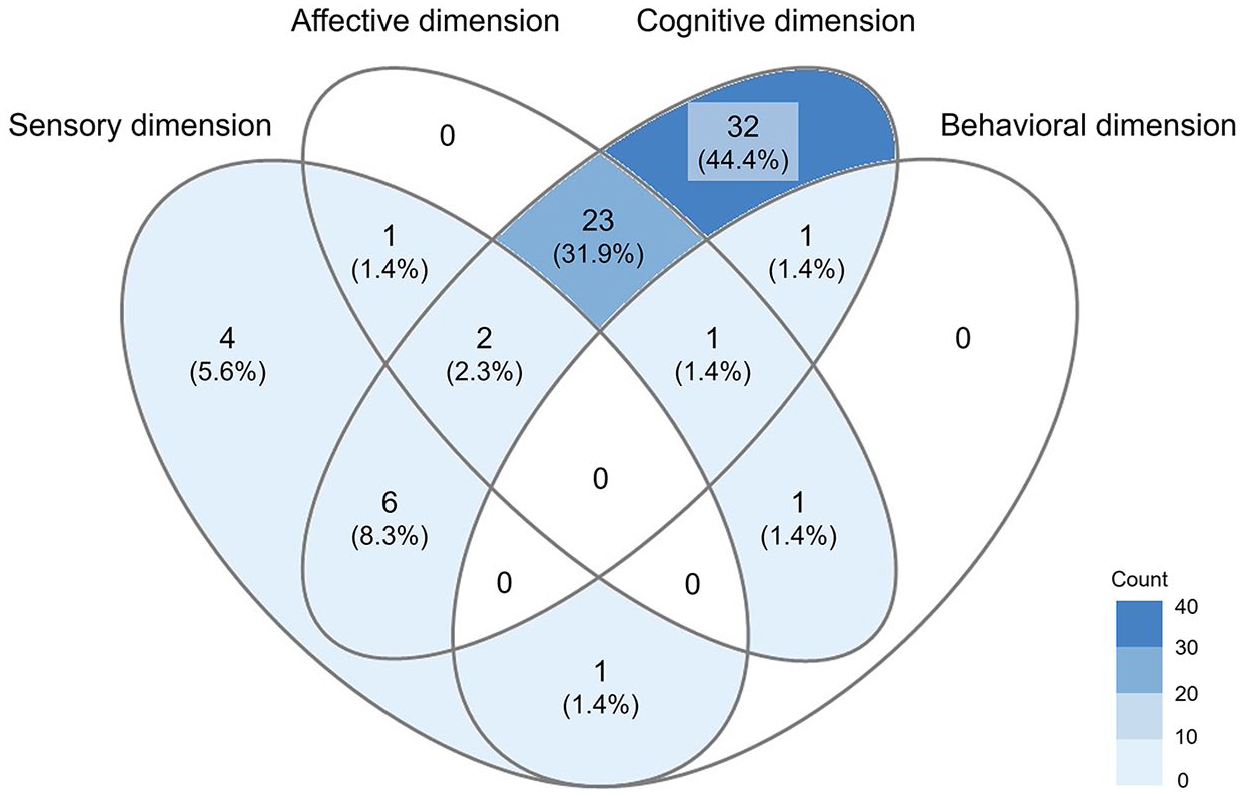
Venn Diagram of Multi-Dimensions in Studies on Visual Framing Effects.
Sensory Dimensions of Visual Framing in Multimodal Media Environments
Since the vast majority of framing research focuses on post-receptive observations of cognitive framing effects, this review found only 14 articles examining the immediate sensory perception as part of visual/multimodal frame processing. Only four of them (Bucher & Schumacher, 2006; Geiger & Reeves, 1993; Smith et al., 2021; Vázquez et al., 2021) measured sensory perception alone, while other studies combined the examination of sensory aspects with affective (Gómez-Carmona et al., 2021) or cognitive dimensions (Dahmen, 2015; Segesten et al., 2022).
Eye-tracking was used as an efficient tool to capture sensory perception. However, researchers also explored other methods. Early studies on TV news recorded participants’ visual attention using reaction times to a secondary task as the measure (Geiger & Reeves, 1993). Researchers from neuroscience applied brain-imaging detection to capture the visual scene encoding in long-term memory for TV commercials (Rossiter et al., 2001).
Eye-tracking studies reported mixed-results regarding dwell time spent on textual and visual modality, but most scholars observed that recipients spent more time reading textual captions or stories than viewing images (Bucher & Schumacher, 2006; Lee & Ho, 2018; Smith et al., 2021; Vázquez et al., 2021). However, compared with textual messages, visual frames generate more and quicker attention in the reception process. In multimodal messages, “eye-catching” images are regularly the first elements that attract sight and draw it to the accompanying texts (Bucher & Schumacher, 2006; Vázquez et al., 2021), often creating a first impression of the communicated content (Rodgers & Thorson, 2000). Visual frames, therefore, reduce selectivity and potentially cause a stronger physiological activation during the first stages of sensory reception.
Most scholars share the finding that recipients perceive multiple modalities, such as visual images and texts in news, together and complementary to each other—and generate meaning from this nested process of multimodal communication (Geise & Baden, 2015). Bucher and Schumacher (2006), for example, demonstrated that recipients read headlines for a more detailed description of the news picture and actively included this information in their subsequent interpretation of the textual information. This supports the idea that visual and textual information should not be studied in isolation, but in their multimodal interaction.
While news frames are predicted to cause a change in the allocation of visual attention and thus control sensory perception, different types of frames are expected to drive visual attention differently (Smith et al., 2021). In an early eye-tracking study, Dahmen (2012) showed that divergent types of visual frames lead to different sensory responses to identical news texts. Recipients viewed emotionalizing photographs longer compared with the neutral ones. The altered intensity of visual perception also influenced the intensity with which recipients further engaged with the multimodal content at subsequent processing stages (Dahmen, 2012).
The effects on sensory perception, however, are also dependent on prior attitudes of the recipients. Gómez-Carmona et al. (2021) examined the moderating role of issue concern. Participants with high concern for the environment viewed related media frames faster, more focused, and more often. Using mobile eye-tracking technology, Ohme et al. (2022) compared visual attention devoted to news screened on a mobile versus a desktop computer. They found that visual attention did not differ significantly between devices, but memorization of political information was lower, when news posts were seen on a smartphone.
2. Affective Dimensions of Visual Framing in Multimodal Media Environments
Affective dimensions of visual framing have been empirically analyzed but in a limited number of studies (n=28). Analogous to the fact that framing research predominantly focuses on mental processes and models of memory-based judgment formation, none of these studies investigated emotional responses to frames alone, but mostly together with cognitive effects.
Methodologically, affective dimensions of visual framing are mostly examined with the help of standardized, post-receptive survey items (n=27; e.g., Coleman & Banning, 2006; Fung, 2019; Henderson et al., 2022; Iyer et al., 2014; Krause & Bucy, 2018; Parrott et al., 2019). Only a few authors use qualitative approaches, such as focus groups (e.g., Midberry, 2020). No study in this review applied physiological or process-related behavioral measures (such as facial expression) to examine emotional framing effects.
When examining the affective dimensions of framing effects, popular themes include war, conflict, and crisis (n=7), health messages (n=7), migrants or refugees (n=3), environmental issues (n=3), and advertising (n=3). Across these topics, the examined studies show that (a) visual/multimodal frames often lead to emotional effects in viewers, which (b) in turn, affect the subsequent processing of information, such as cognitive framing effects (e.g., Powell et al., 2015; Seo & Dillard, 2019a).
Comparing the affective impact of monomodal versus multimodal news items, Pfau et al. (2006) found that photographs plus captions elicited greater emotional responses (such as puzzlement, anger, and sadness) and reduced political support, than those conveyed via text alone. Later studies (e.g., Iyer et al., 2014; Powell et al., 2015) also showed that particularly visual frames can trigger specific emotions such as pity, fear, or anger that further shape the evaluation of political issues.
Throughout, research reveals that different frame types lead to divergent emotional responses. For example, Brantner et al. (2011) examined the effects of visual frames on the evaluation of news texts about the Gaza conflict. They found that divergent visual frames (victims vs. politicians) led to divergent affective evaluations of the identical news text. Similarly, Parrott et al. (2019) examined affective effects induced by news photos with either a human-interest frame (“immigrants as everyday people”) or a political frame (showcasing politicians). While the political frame increased negative emotions and led to negative attitudes, the human-interest frame fostered positive emotions and attitudes. Midberry et al. (2022) investigated how frames influence discrete empathy, behavioral intentions, and efficacy in reaction to visual solutions journalism. They found that textual frames yielded lower levels of sadness, anger, and disgust than frames with problem-centered images. In contrast, it was image pairs showing both problems and solutions that elicited the highest emotional response, including hope, compassion, and empathy.
Examining the emotional dimensions of framing also reveals that emotions develop along the previous attitudes of the viewers. Krause and Bucy (2018) analyzed how people affectively evaluate, interpret, and make sense of differentially framed images of fracking. Findings demonstrated that valence responses were heightened when individuals processed visual frames that aligned with their existing level of issue agreement. Fracking supporters were more positive toward economic benefit frames while fracking opponents expressed significantly more negative thoughts in response to environmental risk framing (Krause and Bucy, 2018).
3. Cognitive Dimensions of Visual Framing in Multimodal Media Environments
Because theory suggests that particularly visual frames influence information processing and shape cognition (Geise & Baden, 2015), cognitive effects are addressed in almost all identified studies (90%, n=65). The recurring contexts are political campaigns or elections (n=13), advertising (n=11), war and conflict (n=8), health issues (n=9), environmental issues (n=6), and social movements and protests (n=5).
From a methodological perspective, scholars primarily used standardized survey items to measure cognitive effects (n=58), mostly subsequent to the reception of frames (e.g., Dan & Arendt, 2021; Hameleers et al., 2020; Jeon et al., 2019). Here again, qualitative approaches are rarely applied, although they can deepen the understanding of framing processes. For instance, Weber et al. (2022) used a combination of an experimental study and retrospective follow-up interviews to gain deeper insights into the decision-making process of recipients when confronted with virtual reality images versus traditional text formats. Bode (2021) used a discourse analysis of viewer comments on social media and regarded them as indicators of cognitions related to viewers’ understanding of deep fakes.
Researchers have paid attention to a wide range of cognitions that are influenced by the visual/multimodal presentation of messages. Many studies conclude that the visual frame sets the direction and interpretive horizon in which the accompanying linguistic information is evaluated. In an early study, Zillmann et al. (1999) demonstrated that visual frames shape the evaluation and interpretation according to the frames set. The finding has been replicated in follow-up studies (e.g., Gibson & Zillmann, 2000). Arpan et al. (2006) also found that conflict-oriented protest images produced more negative evaluations than peaceful, positively framed images and, in turn, shaped viewers’ further evaluations of protests. The framing effects of visual representation on the evaluation of political actors were shown by Coleman and Banning (2006). Reception of visually framed TV news influenced the perception of the two covered candidates in a corresponding direction.
While framing theory predicts that visual frames exhibit lower cognitive reflection, higher recall performance, and superior memorability (Messaris & Abraham, 2001; Rodriguez & Dimitrova, 2011), there is limited research on visual framing effects in the context of memorization and information retrieval (Rossiter et al., 2001), learning (Ohme et al., 2022), or decision-making (Weber et al., 2022).
To explore frame-dependent effects on recipients’ cognition, researchers mainly manipulated the visual depiction in news images (n=54, 83%; e.g., Bolsen et al., 2019; Lee & Ho, 2018; Sontag, 2018), while effects of stylistic formats were less studied (n=13; e.g., Schindler et al., 2017; von Sikorski, 2018). Nonetheless, a few studies show that stylistic frames can also influence cognitions: visual cues to ideology embedded in political images, for example, were found to affect citizens’ evaluations of political actors (Dan & Arendt, 2021; von Sikorski, 2022).
Only a handful of studies examined the symbolic/connotative aspect of visual content, such as semiotic icons in health messages (Lazard et al., 2017), visual grammar in cartoons (Abdel-Raheem, 2017), or subtle ideological cues in political communication (Dan & Arendt, 2021). Lazard et al. (2017) compared the effects of a symbolic, indexical, and iconic image on the perceived severity and effectiveness of different diseases. Findings suggest that symbolic icons may be most effective for diseases that are not easily visualized otherwise (such as addiction), but iconic and indexical icons, which mostly represent an object’s likenesses, seemed more effective for health effects attributable to specific symptoms.
While most studies demonstrated framing effects triggered by the visual frame, some studies argued that the accompanying text predisposes the meaning of the visual content (e.g., Domke et al., 2002; Pfau et al., 2006). More recent studies, however, imply that interactions between visual and textual frames are complex and need to be differentiated across effect dimensions (e.g., Hameleers et al., 2020). In one of the few “explicit” multimodal framing studies, Powell et al. (2015) compared the effects of a monomodal visual, a monomodal textual, and a multimodal frame on sub-Saharan conflict. In the monomodal conditions, they found stronger effects of visual frames on recipients’ salience perception and attention allocation, while the text frame more strongly shaped cognitive elaboration of the topic. In the multimodal setting, the text frame increased approval of military intervention independent of the media frame, while the visual frame had a stronger effect on recipients’ willingness to engage personally, independent of news texts (Powell et al., 2015). Boomgaarden et al. (2016) support the idea that the textual frame has a stronger influence on the cognitive elaboration of the competence of political candidates than the visual one; for the more affective evaluation dimension of personal integrity, visual and textual frames showed a mutually reinforcing effect. Thus, Boomgaarden et al. (2016) conclude that future studies should more closely investigate which impact dimensions and aspects of political judgment formation are activated more by visual frames and which by textual frames.
4. Behavioral Dimensions of Visual Framing in Multimodal Media Environments
Although framing theory suggests that visual frames are particularly strong drivers of frame-related actions (Entman, 1993; Grabe & Bucy, 2009), behavior as an outcome of framing has only scarcely been studied. In the systematic review sample, only four articles measured the behavioral outcomes triggered by visual/multimodal frames (e.g., Meng, 2019; Powell et al., 2021; Ryan, 2012; Weber et al., 2022).
Using eye-tracking to investigate how visual signaling elements in software documentation influenced task accuracy and completion, Meng (2019) showed that participants working with visual tutorials executed assigned tasks more correctly and successfully. To study the selection and avoidance of political news, Powell et al. (2021) simulated a realistic social media environment where participants could select news items about politics, sports, or entertainment. When people selected political posts, they measured issue agreement and discrete emotions. Once selected, multimodal political news aroused stronger emotions and led to higher issue agreement than text messages, regardless of an article’s attitude congruence. Nevertheless, when compared with news presented solely in text, multimodal articles tended to encourage selective exposure and news avoidance rather than mitigating these tendencies.
Intending to investigate the effect of immersive VR imagery on voting behavior, Weber et al. (2022) simulated a voting decision in an experimental survey. Results show that participants exposed to the VR format cast more YES votes regardless of the pro or con arguments of the content presented; the virtual presentation therefore increased people’s decision-making and related actions substantially.
One understandable reason that actions—understood as individual observable responses in a given situation—are examined in so few studies is that they are very difficult to capture, especially when they do not immediately follow reception. Aiming to resolve this dilemma, a number of studies used action dispositions and behavioral intention as indicators of a person’s attitude and readiness to perform a given behavior later (Warshaw & Davis, 1985). For instance, Powell et al. (2015) claimed that it “remains unclear” how graphic visuals affect “public opinion and behavior” (p. 997), but then measured the intentions to discuss, to donate, to sign a petition, and to protest as proxies of frame-related actions. The measurement of behavioral intentions as framing outcomes involves a variety of different concepts, including the tendency of information seeking (Midberry et al., 2022), willingness to participate or act politically (Geise et al., 2021; Olesen, 2018; Shih & Lin, 2017; von Sikorski & Knoll, 2019), likelihood of further social media engagement (Midberry et al., 2022; Mourão & Brown, 2022), behavioral attainment to certain medical treatments (Fung, 2019; Kang & Lin, 2015; Sontag, 2018), or purchase intentions (Chang, 2012).
Challenges for Research and Mediated Communication
Contemporary media communication inherently involves multiple modes (Wessler et al., 2016). While many studies have focused on analyzing multimodal framing from the perspectives of framing theory and visual framing, our systematic literature review reveals a recent shift toward considering multimodal layers as units of analysis. Scholars have demonstrated the powerful influence of framing effects in both visual representations and verbal descriptions across a range of topics. They have emphasized that textual and visual frames have distinct effects, but it is primarily the interplay of multimodal elements that shape recipients’ perceptions and interpretations. However, the multimodal relationship between image and text has primarily been explored by testing different combinations of frames (e.g., multimodal vs. monomodal) or abstract categories (e.g., congruence vs. incongruence). This is a critical area for future research to delve into and further examine the dynamic interactions between textual and visual elements within the multimodal framing process.
While visual communication scholars have already discussed other ways in which modes interact, including illustration, complementation, argumentation, extension, and reinforcement, future research should more closely examine the resulting types of potential interactions between elements in multimodal messages. In addition, as our overview illuminates, visual framing researchers so far have shown relatively little interest in the effects of connotative and ideological visual cues. Yet, due to the unique characteristics of visual images, symbolic representations, latent stereotypes, and ideological intentions seem more likely to induce framing effects—and their influence seems particularly crucial in times of increasing polarization and propaganda, war, and crises.
Our systematic review also provides exciting methodological insights that can be harnessed for further framing research. For example, we found that although cognitive framing dimensions are investigated in almost all studies, qualitative methods that could more deeply account for framing effects at the level of interpretation and evaluation performance are rarely used. Our overview also shows that the affective dimensions of visual framing have rarely been empirically analyzed—and if so, then with the help of standardized, post-receptive survey items. This offers an exciting starting point for future research, especially if studies focus on affective framing effects using physiological or computer-based observation methods. Finally, our review reveals that behavior as an outcome of framing has only scarcely been studied. This research gap also offers potential for further research, especially as framing theory suggests that visual frames are particularly strong drivers of frame-related actions (Entman, 1993; Grabe & Bucy, 2009).
In examining the effects of multimodal arrangements, research has long emphasized that individuals are not passive recipients, but actively select and interpret information from different modalities in messages, experience emotions, make judgments, and process information based on their existing knowledge and attitudes. This has implications for visual journalism and mass communication, as it may be a challenge for (photo)journalists, news editors, and other visual and multimodal content creators to consider the perspective of recipients. Furthermore, how people create, interpret, and respond to visual content in the media is also influenced by socio-political and cultural differences. Our systematic review found that the majority of visual framing studies have been conducted in Anglo-American or European-centric contexts. Further research is imperative to mitigate knowledge biases. This is not only important from a scientific perspective but also from a practical one. Visual journalists and framing scholars need to understand how cross-national or intercultural similarities in visual/multimodal framing effects are driven by shared values or mass communication and media production practices. Conversely, they should also recognize how contextual factors can lead to divergent interpretations of a multimodal media frame.
As our research review shows, the concept of visual and multimodal framing has gained importance not only in journalism studies, but also in areas of mass communication such as political communication, health communication, public relations, and advertising. Adopting a multimodal perspective is beneficial for both media researchers and practitioners, as it helps to identify the diverse preferences and needs of news audiences, harness the strengths of different communication tools, and contribute to the creation of more effective and engaging content in multimodal media environments.
On the one hand, media professionals need to consider how to effectively structure media content to capture viewers’ attention, convey emotional content, and facilitate recipients’ comprehension and interpretation. On the contrary, showing that visual content is of immense importance throughout the entire reception process, research findings highlight a significant responsibility for media practitioners in creating, selecting, checking, combining, and contextualizing these images. However, every representational process involves a “translation or conversion of some kind; a process of inscription, transcription, and/or fabrication whereby the phenomenon or concept is captured, transformed, or even re-created” (Pauwels, 2006, pp. 4–5), and visual communication is also thus embedded in multimodal news framing. Visual producers must be aware of the potential impact—across sensory, emotional, cognitive, and behavioral dimensions. This adds complexity and challenge to the process of multimodal media communication, but it also underscores the tremendous influence of images in media. Their use goes way beyond illustrative purposes. As part of multimodal media framing, images are prominent, they are relevant, and they are fundamental, but they should be used with thoughtful consideration.
Footnotes
Appendix
Overview of Empirical Studies on Visual/ Multimodal Framing Effects.

Data Availability
Supplemental materials (codebook, codesheet, list of publications) are available from the corresponding author, upon reasonable request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.