
Abstract
Standard visual urine dipstick analysis (UDA) is performed routinely in veterinary medicine; results can be influenced by both the operator and the method. We evaluated the agreement of results for canine and feline urine samples analyzed using a 10-patch dipstick (Multistix10SG; Siemens), both visually under double-anonymized conditions by students and a laboratory technician, and with an automated device (AD; Clinitek Status, Siemens). The mean concordance for semiquantitative urinalysis results between students and the technician and between students and the AD was fair (κ0.21–0.40) in dogs and cats; concordance was moderate between the technician and the AD (κ0.41–0.60) in dogs and good (κ0.61–0.80) in cats. For pH, the mean concordance between students and the technician and between the technician and the AD was good (ρ0.80–0.92) in dogs and cats; concordance was good between students and the AD (ρ0.80–0.92) in dogs and moderate (ρ0.59–0.79) in cats. Repeatability was higher (p < 0.001) for the technician and the AD than for a student. We found good agreement between UDA performed by an experienced operator and an AD in dogs and cats but found low reproducibility and low repeatability for urinalysis performed by an inexperienced operator.
Keywords
Urinalysis is a useful and noninvasive complementary examination in veterinary medicine. 18 When associated with history, physical examination, and bloodwork, it can assist in the differential diagnosis of several medical conditions, especially urinary tract diseases, and it is a powerful tool to assist with the diagnosis of diabetes mellitus.10,12 Moreover, the accurate evaluation of urinary pH alone can provide important information regarding the risk of urolith formation and the acid-base status of the patient.2,7
Urine evaluation using strip reagents is the most commonly used method for assessing several components of urine because of their simple and quick use, and dipsticks are routinely employed in determining and monitoring the health and disease status of both veterinary and human patients.5,12,19,20 However, urine dipsticks have been primarily designed for use in human medicine and validation is warranted before use in veterinary patients.3,6
Visual urine dipstick results can be highly influenced by both reproducibility and repeatability, leading to low diagnostic value of the test, erroneous clinical decision-making, and misdiagnosis.5,20 Reproducibility is “the closeness of the agreement between independent results obtained with the same method on the identical subject(s) (or object, or test material) but under different conditions (different observers, laboratories, etc.).” 13 Applied to a dipstick, reproducibility denotes the variability of results obtained between different observers (inter-observer variability). By contrast, repeatability is “the closeness of the agreement between independent results obtained with the same method on the identical subject(s) (or object or test material), under the same conditions.” 13 Applied to a dipstick, repeatability denotes the variability of results obtained by the same operator reading dipsticks repeatedly from the same sample (intra-observer variability). Operator-dependent errors in visual interpretation of dipsticks may be the result of inaccurate reading and transcription of results, as well as color vision deficiency.3,5,16 Inaccurate reading may be the result of operator inexperience. Lack of mixing urine before testing and lack of standardization of time before reading the patches are the most common operator-dependent errors.4,5
Studies in human medicine have investigated pre-analytical, analytical, and post-analytical errors in urinalysis, and most found that the use of automated urine dipstick readers significantly reduced the error rate encountered during visual dipstick urine evaluation.16,17 Comparative data regarding visual and automated urine dipstick performance in dogs and cats are limited, and results are controversial.2,3,5,6,8 The evidence to date indicates a higher level of agreement between the automated urinalysis results and results obtained by highly trained operators compared to those obtained by inexperienced operators.3,5,6 Moreover, veterinary literature lacks data concerning the intra-observer variability for visual and automated urinalysis in both dogs and cats, and about the inter-observer variability in cats.
Our first aim was to evaluate the reproducibility of point-of-care urinalysis (POCU) results in both dogs and cats obtained by 2 operators with different experience (specifically, trained vs. non-trained operators) and to compare such results with those obtained by an automated device (AD). Our second aim was to evaluate the repeatability of POCU results obtained by operators with different experience and those achieved with an AD. We hypothesized that: 1) high intra-observer and inter-observer variability in visual POCU results exist for both dogs and cats, 2) this variability may depend on the experience of the operator, and 3) this operator-dependent error might be reduced using an AD.
Material and methods
Urine sampling
We performed our prospective double-anonymized observational study at the Veterinary Teaching Hospital of VetAgro Sup (VTHVAS), University of Lyon (France), between January 2017 and June 2018. Urine specimens were collected from both healthy and ill dogs and cats presented to the VTHVAS for medical and surgical treatment, and for vaccination to a lesser extent. Urine sampling was performed regardless of breed, sex, or age. The only inclusion criterion was a urine sample volume of > 1 mL, collected by both free-catch and cystocentesis (the latter performed when indicated by the attending clinician). Urinalysis was performed directly after collection or within 2 h after sampling after storage at 4°C and preservation from exposure to UV light. All owners gave verbal consent when a cystocentesis was required. Given that urinalysis was deemed clinically indicated by the attending clinician for all animals enrolled in our study, approval by an institutional animal care and use committee and signed owner consent were not required.
Visual and automated urinalyses
Urine samples were assayed visually using a 10-patch dipstick (Multistix10SG; Siemens), and automatically using a spectrophotometric AD (Clinitek Status; Siemens). The Clinitek Status has been validated in dogs, and results were compared with reference methods for the determination of variables in canine urine that are routinely assessed in veterinary medicine, including pH, blood, protein, glucose, ketone bodies, and bilirubin. 3 We visually and automatically read each reagent strip according to the recommendations of the manufacturer. Briefly, reagent strips were dipped in urine and then compared with a reference color chart or introduced into the AD within one minute. The AD was run according to the manufacturer’s instructions and checked weekly for calibration.
Dipstick urinalysis was performed for quantitative assessment of pH and semiquantitative assessment of bilirubin (BIL), blood (BLO), glucose (GLU), ketone bodies (KET), nitrites (NIT), protein (PRO), and urobilinogen (URO) in all urine specimens from both dogs and cats. Semiquantitative dipstick assessment of leukocytes (LEU) was only assayed in canine urine samples. Finally, specific gravity was solely assessed by standard refractometry in both dogs and cats, and this variable was not included in the results. The results from quantitative dipstick assessment of pH were graded (5–8.5), with a scale interval of 0.5. Results from semiquantitative dipstick assessment of BIL, BLO, GLU, KET, PRO, and URO were expressed in the 4 standard graduations of test strip results (0–4). Finally, results from semiquantitative dipstick assessment of NIT were expressed as negative (0) or positive (1).
Assessment of inter-observer agreement
To evaluate the inter-rater agreement, visual dipstick urinalysis was performed twice by 2 different operators and once using the AD. Specifically, each urine sample was first assessed by an inexperienced veterinary-school student (randomly chosen), and then by a unique experienced laboratory technician from the clinical pathology laboratory of VTHVAS, unaware of the results of the student urinalysis. Each operator prepared their own dipstick. Inexperienced operators included fourth- and fifth-year veterinary students (130 in the service rotation) who were previously trained in urinalysis (as planned in the 4-y veterinary school course), by showing how to mix the sample before reading, the correct use of the dipstick (urine drip vs. urine dip), the dipstick orientation for reading, and the reading timing. The experienced laboratory technician had 5 y of experience in urinalysis and was trained in standard operating procedures and monitored by an ACVP/ECVP specialist (B. Rannou). Urinalysis with the AD was performed by both experienced (the laboratory technician) and inexperienced (student) operators, after training in the use of the device.
Assessment of intra-observer agreement
To evaluate intra-observer variability, a selected urine sample from one healthy dog was collected by sterile free-catch. The healthy status of the dog was defined as the absence of clinical abnormality reported by both the owner and the attending clinician at the physical examination. A urine sample from this dog was chemically altered with 30% GLU to reach glucosuria, and with 1 mL of post-prandial hemolytic bovine serum to simulate hematuria (i.e., hemolysis), leukocyturia (from LEU present in the bovine serum), and ketonuria (due to KET in the post-prandial bovine serum sample).5,11,15
This altered urine specimen was examined: 1) visually (POCU) by an inexperienced student and the experienced laboratory technician, and 2) automatically by one of the authors (M. Cervone) using the AD. The urinalysis was performed 10 consecutive times by each observer and 10 consecutive times using the AD. To avoid recognition of the tested urine specimen by observers, reagent strips from the altered urine sample were randomly intercalated with reagent strips from other urine samples. To prevent changes in the tested urine specimen related to “aging” of the sample, consecutive measurements were performed within one hour. 9
Statistical analysis
Statistical analysis was performed with R Stat (https://www.r-project.org/); graphics were generated using Prism (GraphPad). For statistical comparison, results from urinalysis performed by the experienced laboratory technician were defined as the gold standard.
Inter-observer agreement (reproducibility) was assessed by calculating the Spearman rank correlation coefficient (ρ) for quantitative variables and the Cohen kappa coefficient (κ) for semiquantitative variables. Correlations were ranked as very good (> 0.93), good (0.80–0.92), moderate (0.59–0.79), and fair (< 0.59) for the Spearman rank correlation coefficient, and as very good (> 0.81), good (0.61–0.80), moderate (0.41–0.60), fair (0.21–0.40), and poor (< 0.20) for the Cohen kappa coefficient.
Intra-observer agreement (repeatability) was evaluated by calculating the CV for both quantitative and semiquantitative results. As the scales of semiquantitative variables were based on different ranges, results were transformed (Table 1), following the manufacturer’s instructions. The Fisher exact test was used for comparison. Results were considered significant at p ≤ 0.05.
Scale transformation for semiquantitative urine dipstick rank variables.
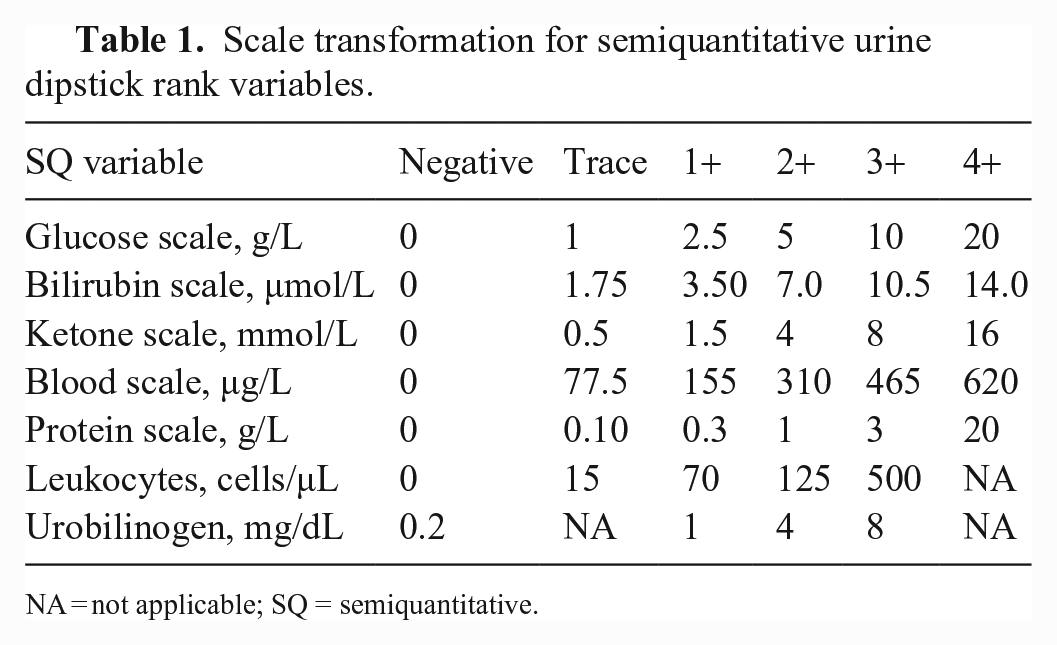
NA = not applicable; SQ = semiquantitative.
Results
Urine sampling
We collected 237 canine urine samples and 80 feline urine samples from both healthy and ill pets. Among canine urine samples, we used 97 (41%) to investigate inter-observer agreement between veterinary-student visual urinalysis (SVU) and laboratory technician visual urinalysis (TVU), 104 (44%) to investigate inter-observer agreement between TVU and automated analysis (AA), and all samples were used to investigate inter-observer agreement between SVU and AA.
Among feline urine samples, we used 33 (41%) to evaluate inter-observer agreement between SVU and TVU, 32 (40%) to evaluate inter-observer agreement between TVU and AA, and 47 (59%) to evaluate inter-observer agreement between SVU and AA.
Assessment of inter-observer agreement
For the quantitative variable (pH), the mean inter-observer agreement between SVU and TVU and between TVU and AA was good in both dogs (ρ = 0.84 and 0.89, respectively) and cats (ρ = 0.85 and 0.88, respectively); between SVU and AA, inter-observer agreement was good in dogs (ρ = 0.82) and moderate in cats (ρ = 0.59; Table 2).
Level of agreement between the urinalysis results from different observers determined by the calculation of the kappa coefficient (κ) for semiquantitative variables and Spearman coefficient (ρ) for pH.
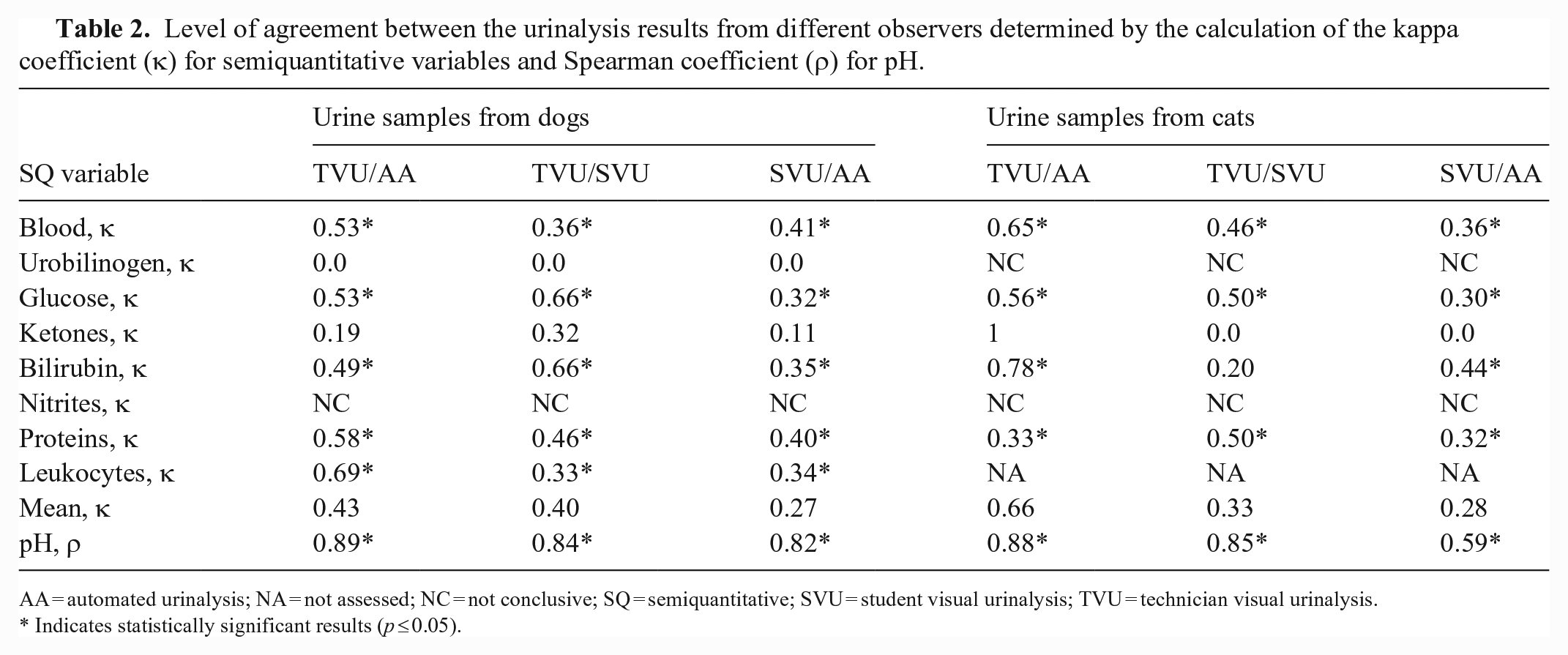
AA = automated urinalysis; NA = not assessed; NC = not conclusive; SQ = semiquantitative; SVU = student visual urinalysis; TVU = technician visual urinalysis.
Indicates statistically significant results (p ≤ 0.05).
Concerning the semiquantitative variables, the mean inter-observer agreement between TVU and SVU was fair (κ = 0.40 and 0.33) for urine samples from dogs and cats, respectively (Table 2). For canine urine samples, a significant fair-to-good correlation was found for all semiquantitative variables, except KET and URO (Fig. 1). For feline urine samples, the inter-observer agreement between TVU and SVU ranged from poor to moderate, with significant correlation for all variables except for KET and BIL (Fig. 2). The agreement could not be statistically evaluated for NIT in dogs and both NIT and URO in cats, because of a very low number of positive samples.
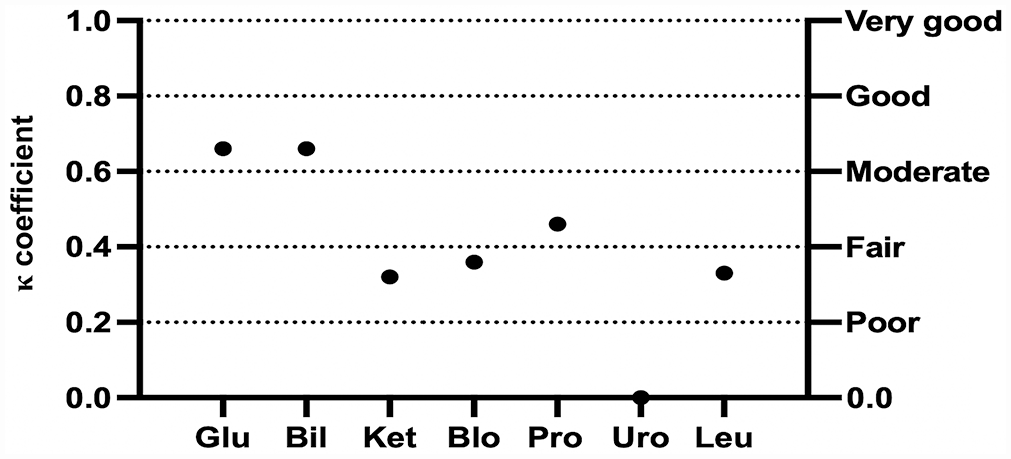
Cohen kappa coefficient (κ) for each semiquantitative urinary variable between the experienced laboratory technician and students for urinalysis results in dogs. Bil = bilirubin; Blo = blood; Glu = glucose; Ket = ketones; Leu = leukocytes; Pro = protein; Uro = urobilinogen.
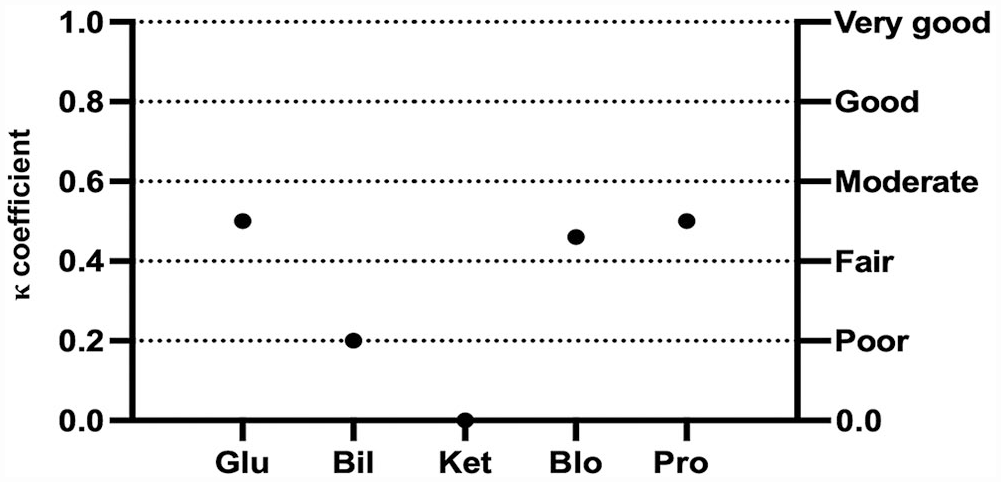
Cohen kappa coefficient (κ) for each semiquantitative urinary variable between the experienced laboratory technician and students for urinalysis results in cats. See Fig. 1 legend for abbreviations.
The mean inter-observer agreement between TVU and AA was moderate (κ = 0.43) for canine urine samples and good (κ = 0.66) for feline urine samples (Table 2). Moderate-to-good correlation was significant in dogs for all semiquantitative variables, except KET and URO (Fig. 3). For feline urine samples, the inter-observer agreement between TVU and AA ranged from fair to very good, with significant correlation for all variables but KET (Fig. 4). However, the dispersion of results was higher in cats. Because of the low number of positive samples, agreement could not be statistically evaluated for NIT in dogs and both NIT and URO in cats.
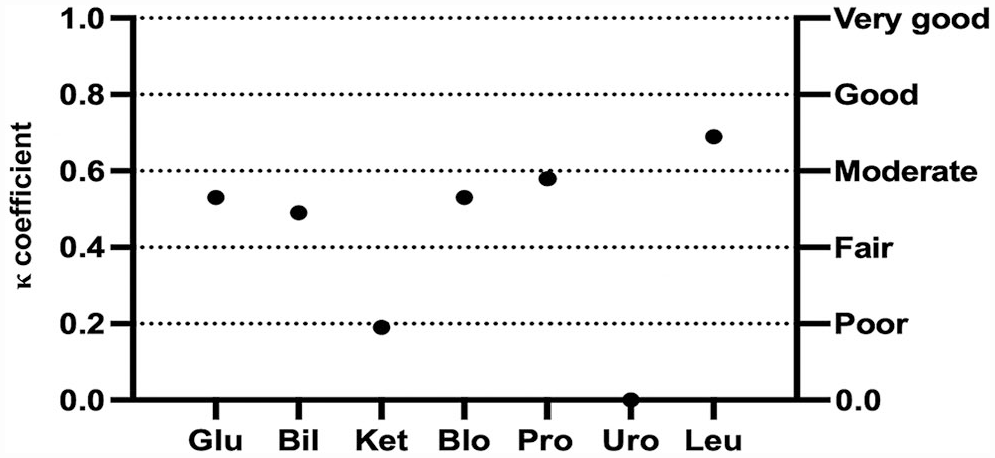
Cohen kappa coefficient (κ) for each semiquantitative urinary variable between the experienced laboratory technician and the automated analyzer for dipstick urinalysis results in dogs. See Fig. 1 legend for abbreviations.
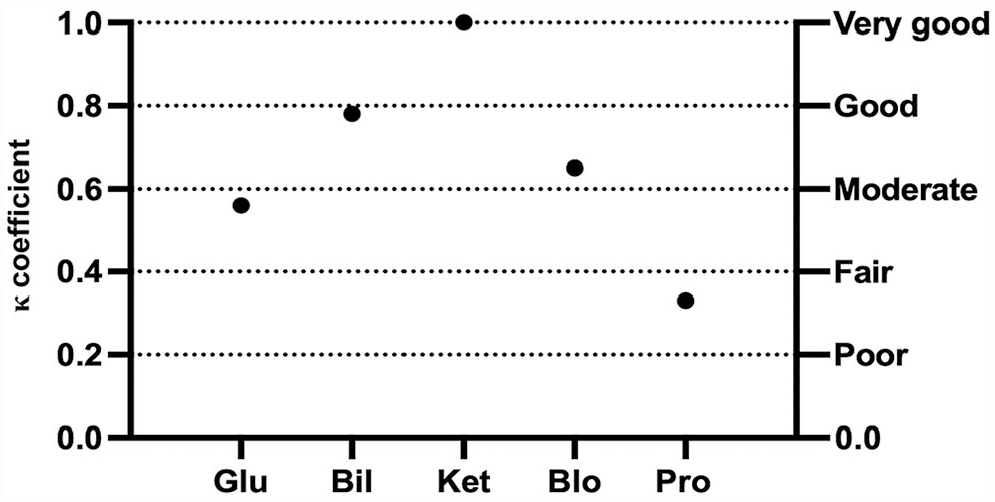
Cohen kappa coefficient (κ) for each semiquantitative urinary variable between the experienced laboratory technician and the automated analyzer for urinalysis results in cats. See Fig. 1 legend for abbreviations.
The mean inter-observer agreement between SVU and AA was fair for both canine and feline urine samples (κ = 0.27 and 0.28, respectively; Table 2). For canine urine samples, poor-to-moderate correlation was significant for all semiquantitative variables, except KET and URO (Fig. 5). For feline urine samples, inter-observer agreement was poor to moderate, with significant correlation for all variables except for KET (Fig. 6). Because of the low number of positive samples, agreement could not be statistically evaluated for NIT in dogs and both NIT and URO in cats.
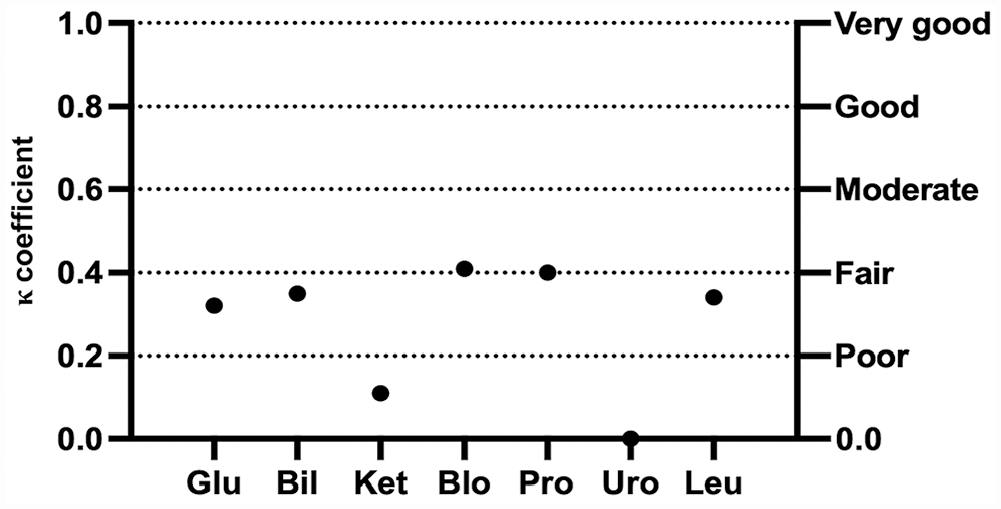
Cohen kappa coefficient (κ) for each semiquantitative urinary variable between students and the automated analyzer for urinalysis results in dogs. See Fig. 1 legend for abbreviations.
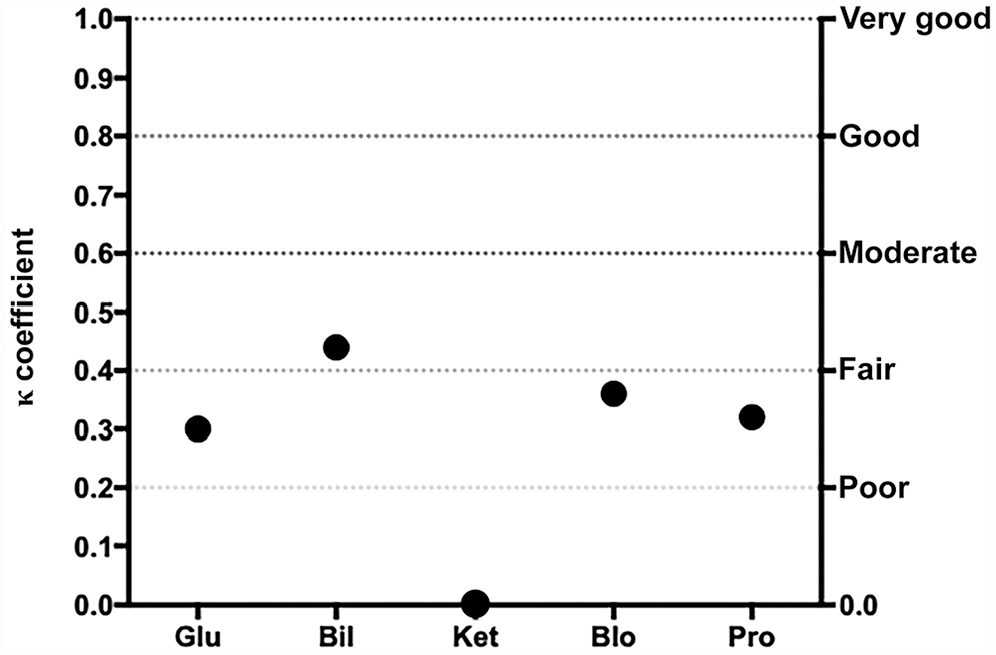
Cohen kappa coefficient (κ) for each semiquantitative urinary variable between students and the automated analyzer for urinalysis results in cats. See Fig. 1 legend for abbreviations.
Assessment of intra-observer agreement
Repeatability was significantly higher (p < 0.001) for TVU (mean CV = 7%) and AA (mean CV = 9%) compared to SVU (mean CV = 48%; Fig. 7). Specifically, for AAs, the CV was 0% for pH, PRO, LEU, and KET, and 27%, 18% and 82% for BIL, BLO, and GLU, respectively (Table 3). For the visual analyses performed by the experienced operator, the CV was 0% for BIL, KET, pH, and LEU, and 33%, 30%, and 9% for GLU, PRO, and BLO, respectively (Table 3). Finally, for the visual analyses performed by the inexperienced operator, the CV was 0% for GLU, and 184%, 88%, 85%, 27%, 10%, and 2% for KET, LEU, PRO, BIL, BLO, and pH, respectively (Table 3). Repeatability for the URO and NIT was not assessed because neither URO nor NIT were present in the urine specimen.
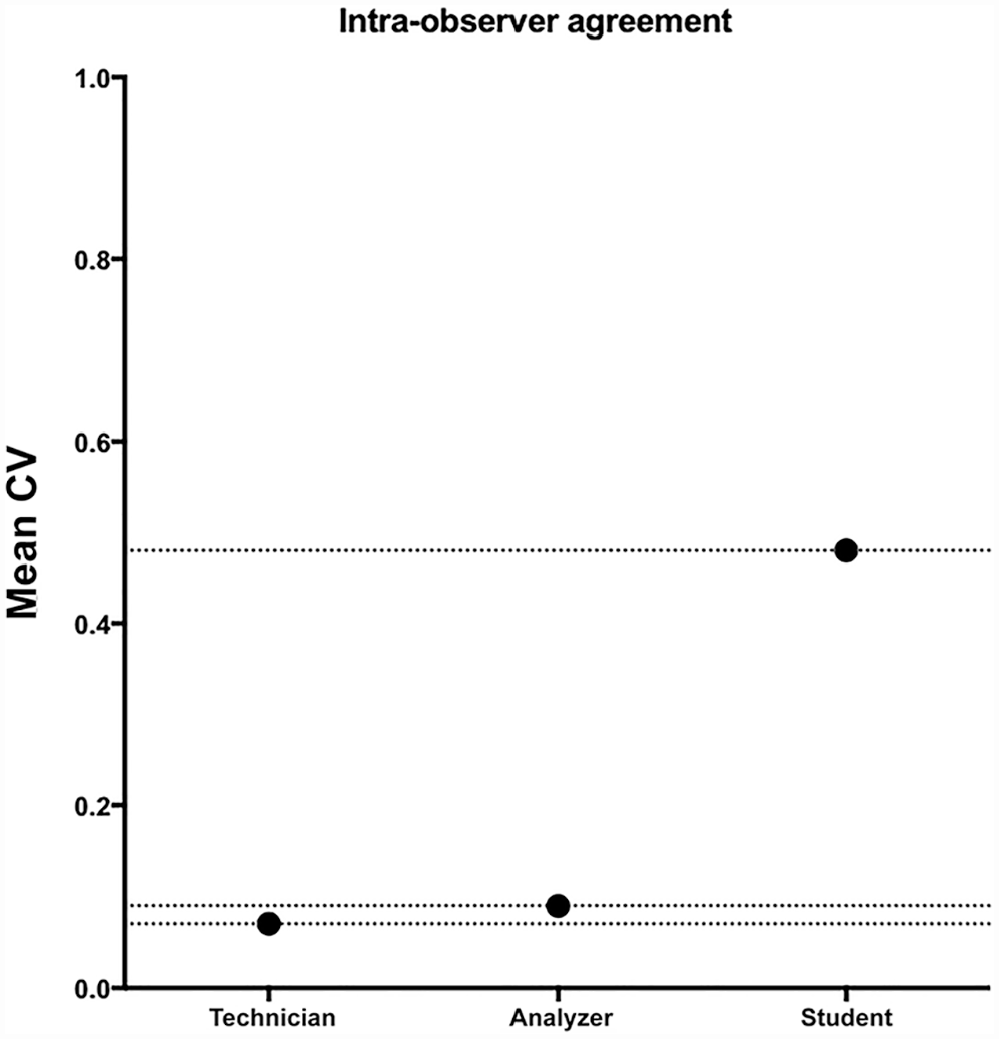
Mean CV for urinalysis results obtained by both experienced and inexperienced operators and the automated device.
Assessment of the repeatability of urinalysis results for semiquantitative variables and pH from different observers determined by the calculation of the CV.
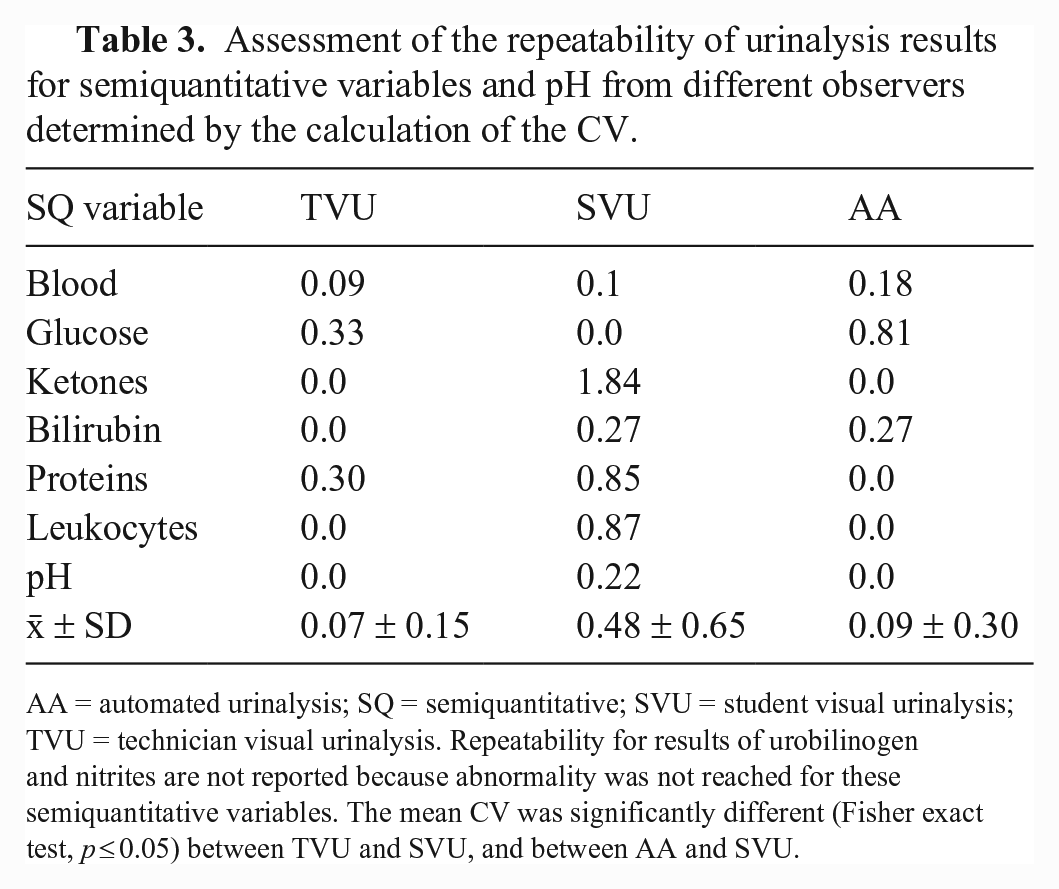
AA = automated urinalysis; SQ = semiquantitative; SVU = student visual urinalysis; TVU = technician visual urinalysis. Repeatability for results of urobilinogen and nitrites are not reported because abnormality was not reached for these semiquantitative variables. The mean CV was significantly different (Fisher exact test, p ≤ 0.05) between TVU and SVU, and between AA and SVU.
Discussion
We prospectively evaluated the reproducibility of visual and automated POCU results in both dogs and cats, and the repeatability of visual and automated POCU results in dogs. For semiquantitative urinary variables, overall low agreement was found between inexperienced operators and both the analyzer and the laboratory technician in both species, indicating that lack of experience could affect POCU results. In contrast, overall moderate-to-good agreement was found between results obtained by the technician and the AD, suggesting that automated urine dipstick reading could be used in veterinary practice to compensate for the absence of well-trained operators.
Concerning the reproducibility of the quantitative variable pH, overall good agreement was found between trained operators, inexperienced operators, and the AD in both dogs and cats, suggesting that the use of an AD for urinary pH assessment does not increase the accuracy of urinalysis for this parameter. The performance of Clinitek Status in cats has not been reported previously, to our knowledge. We found that urinalysis results obtained by a highly trained operator were comparable to those obtained by the AD. Such results could suggest that this device might be useful in cats. However, further studies using reference methods are needed to validate use of the AD in cats.
Discrepancy in urinalysis results between different operators in a veterinary teaching hospital has been reported, 5 and studies have suggested that color vision deficiency could be a reason for variability in visual urinalysis results in an environment with multiple operators.5,14 However, all but one of the published studies about the reproducibility of urinalysis results in companion animals included observers that were not stratified based on their experience.3,5,6 Thus, comparison between results recorded in our study and those from previous publications is challenging.
Concerning semiquantitative results obtained by visual dipstick urinalysis performed by the experienced operator versus inexperienced students, the mean level of agreement was fair for both canine and feline urine samples. Specifically, higher variability was found for BLO, KET, and LEU results in dogs and for BIL in cats, as proved by a lower level of agreement for these parameters after calculation of the Cohen coefficient. This variability was statistically significant for the semiquantitative variables assessed in canine urine samples, and not significant for BIL in cats. The lack of statistical significance for BIL in cats may be a result of the lower number of urine specimens sampled in this species and the even lower number of feline urine samples with bilirubinuria.
Repeatability was unsatisfactory for leukocyturia in dogs when evaluated by an inexperienced student. Indeed, the CV for the student was significantly higher compared to the CV of the highly trained operator and the CV of the AD. However, evaluation of the LEU reagent strip in dogs has limited diagnostic utility because of the high rate of false-negative results. 12 A high CV was also recorded for KET and PRO when the urinalysis was performed by a student. As a whole, our results suggest that accurate recognition of ketonuria, leukocyturia, and proteinuria could be influenced by the experience of the operator and confirm results from previous studies about the variability of urinalysis results in an environment with multiple operators.3,5
In both human and veterinary medical settings, the use of automated dipstick reading methods seems to improve the accuracy and the reliability of urinalysis results.5,17 Accordingly, we found a moderate-to-good mean level of agreement between urinalysis results obtained from the experienced operator (defined as the gold standard in our study) and the AD in both dogs and cats. However, although our results confirm those from studies about the usefulness of automated reading devices in veterinary practice,3,5,6 our results need to be qualified. Indeed, concerning results in dogs, the difference in the mean agreement between SVU/TVU and TVU/AA was low (0.40 and 0.43, respectively), suggesting that the use of an AD did not significantly improve the urinalysis results accuracy. Similarly, the high dispersion of urinalysis results in cats resulted in a wide CI and does not permit strong conclusions. On the other hand, a higher level of agreement was found between the experienced operator and the AD for LEU, PRO, and BLO than between inexperienced operators and the AD, suggesting that automated reading could improve the reliability of urinalysis results for these specific semiquantitative variables. Furthermore, the poor repeatability of urinalysis results obtained by inexperienced operators compared to those obtained both by the experienced operator and the AD supports the hypothesis that the use of an automated method could improve urinalysis diagnostic performance. This is particularly true for the assessment of leukocyturia, proteinuria, ketonuria, and to a lesser extent, hematuria in dogs.
Interestingly, the level of agreement for GLU and BIL in dogs and for PRO in cats was higher between experienced and inexperienced operators than between the experienced operator and the AD. Canine GLU was interpreted differently for 5 of 104 urine samples between TVU and AA, including 2 samples interpreted as having traces (0.5+) of GLU while being negative for GLU, 1 sample interpreted as having mild (1+) glucosuria while being negative for GLU, 1 sample interpreted as having traces of GLU while having mild glucosuria, and 1 sample as having moderate (2+) glucosuria instead of mild glycosuria. Although a better level of agreement was found between TVU and SVU than between TVU and AA for canine GLU, one obvious case of misinterpretation by the student carried more severe consequences as a non-glucosuric urine sample was interpreted as severely glucosuric (maybe as a result of incorrect orientation of the dipstick during the visual reading by the inexperienced observer). Discrepancy between the experienced operator and the AD for canine GLU evaluation could indicate technical error during the urine sample preparation (including lack of urine mixing before dipstick dropping or shorter reading time, as reported previously 5 ), as well as environmental lighting or, less probably, color vision deficiency.5,14 On the other hand, overinterpretation of glucosuria (potentially due to hypersthenuria or pigmenturia) is also possible. Although discrepancy in the severity of glucosuria (i.e., mild vs. moderate) does not hold significant consequence for the patient, results read as glucosuric while being non-glucosuric could lead to a false diagnosis of diabetes mellitus or tubulopathy, with potentially financial consequences for the owner. Moreover, overinterpretation of glycosuria may also lead to unnecessary additional tests, with significant consequences for the dog. 5
For canine BIL, results were different for 31 of 104 samples between the technician and the AA. This was mostly because samples considered to have “traces” or small amounts (1+) of BIL by the AD were classified as non-bilirubinuric by the technician. This could suggest that the AD overinterprets bilirubinuria in dogs or that it is more sensitive to mild bilirubinuria compared to the human eye. However, traces of BIL in urine from healthy dogs are frequently found because canine kidneys synthesize BIL. Therefore, mild bilirubinuria in dogs does not influence either the diagnostic or the therapeutic workup in practice.
For feline PRO, different interpretations arose between TVU and AA for 15 of 32 urine samples, including 1 sample interpreted as having traces of PRO while being negative, 1 sample as having moderate (2+) proteinuria while being negative, 4 samples as having mild-to-moderate proteinuria instead of traces, and 9 samples as having moderate proteinuria instead of mild proteinuria. Although the reasons for such discrepancy could be the same as for canine GLU, the consequences of misdiagnosis of proteinuria at visual urinalysis could be more severe for both the patient and the owner. Assessment of proteinuria by urine dipstick is still used in veterinary practice without performing the more reliable and accurate measurement of urine protein:creatinine ratio. Therefore, both the overinterpretation and the lack of detection of proteinuria by visual urinalysis may negatively influence decision-making and final diagnosis, with significant consequences for the patient and financial implications for the owner.
Concerning the reproducibility of the pH estimate, good agreement was found between all operators and the AD in both dogs and cats. This finding is in contrast with results from other studies, 5 maybe because a calibrated reference bench-top pH meter was not used as a gold standard.
Our study has limitations. Our choice of the experienced technician as a reference method, as opposed to electing the AD, is debatable in a study assessing repeatability and reproducibility (precision). We intended to avoid selecting the AD as the reference method, given that the latter was not entirely validated (the assessment of precision is part of its validation study). Moreover, after discussion with the statistician (J. Cappelle), the statistical tools (correlation) that we used for characterizing the reproducibility (Spearman rank correlation coefficient for quantitative variables; Cohen kappa coefficient for semiquantitative variables) are not impacted by the choice of which of the tested methods is elected as the reference method (observation by the experienced technician; observation by the veterinary students; reading by the AD), given that each method was compared with the 2 others for assessment of correlation. Reproducibility could have been affected by the high number of inexperienced operators that performed the visual dipstick urinalysis, compared to a single experienced operator. Nevertheless, the choice to have multiple inexperienced observers (as opposed to a single one) was elected to mimic what could potentially happen in a veterinary clinic or a veterinary hospital with multiple operators performing urinalysis.
Urinalysis with the AD was performed by both experienced and inexperienced operators, and analyzer operation performed by the inexperienced operators, despite previous training, could be more subject to error. Furthermore, reference methods for the measure of both semiquantitative and quantitative variables (such as the use of a pH meter) were not performed and therefore our study lacks an objective gold standard for the comparison of results. Also, results obtained from feline samples should be interpreted cautiously because of the higher dispersion of results, at least partly because of the smaller number of samples tested. Such limitation is also valuable for canine samples in which ketonuria, nitrituria, and urobilinogenuria were found because of a smaller number of urine samples with such abnormalities. Finally, to assess repeatability for canine urinalysis results, only 10 replicates were performed; a minimum of 20 replicates are advised for short-term repeatability assessment. 1 Also, repeatability was not assessed for feline urinalysis results.
Footnotes
Acknowledgements
We thank Gaelle Barral of the laboratory and animal medical hospital of VetAgro Sup (France) involved in our study, as well as all of the students who participated. We also thank all animals and their owners.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Our study was funded by Siemens Healthcare.