
Abstract
Evaluation is a practice with increasing global demand. However, an understanding of who wants to learn evaluation and their learning needs related to evaluator competencies is relatively unexplored. This article describes a research effort designed to address those needs using an evaluator competency self-assessment. Despite their validity challenges, self-assessments can yield valuable information for a variety of audiences. Respondents and their organisations can use this method to understand evaluation capacity strengths and needs and create professional development plans. For those conducting evaluation capacity building in or for organisations, and those developing formal evaluation education programs, self-assessment results can provide a road map for planning, development and delivery. This article describes the process of developing and piloting the Learn Evaluation Assessment Portal, an evaluator competency self-assessment tool, with the Australian Evaluation Society. The article reflects on the lessons learnt from the development and testing of the tool and will be valuable for a range of stakeholders from practitioners to commissioners and in particular Voluntary Organisations of Professional Evaluators which are committed to developing evaluation capacity and are working towards professionalisation of the field.
Keywords
• Evaluators are on a continuous path of professional development. • Information about strengths and development areas can enable focussed professional development. • Publicly available, free instruments for evaluators to assess their competency are rare.
• Documents the value and challenges of self-assessment in the field of evaluation. • Consolidates and presents an updated set of principles for good self-assessment instruments for evaluators. • Details the process of developing a publicly available online self-assessment tool for evaluators that can be adapted to any Voluntary Organisation of Professional Evaluators.What we already know
The original contribution the article makes to theory and/or practice
Introduction
Evaluation is a practise that is increasingly in demand in Australia and globally. The Australian Centre for Evaluation, for example, has been established to ‘put evaluation evidence at the heart of policy design and decision making’ (Department of the Treasury, 2023). How to educate evaluators is an increasingly hot topic; the subject of multiple recent special issues and peer-reviewed articles across the evaluation literature (e.g., Chouinard & LaVelle, 2021; Kallemeyn et al., 2022; LaVelle et al., 2023). However, an understanding of who wants to learn evaluation and their learning needs related to evaluator competencies is relatively unexplored. This article explores a research effort designed to address those needs.
In this article, we present the design (Phase 1) and testing (Phase 2) of an evaluator self-assessment instrument, the Learn Evaluation Assessment Portal (LEAP), developed by the authors. The research team was formed through collaborative work for the International Society for Evaluation Education (https://www.isee-evaled.com/) which identified a gap in research on evaluation learners – particularly knowledge of their backgrounds and existing competencies. The team decided that an online self-assessment would simultaneously provide data for our research and provide a critical service to evaluation learners and their organisations. Despite the recognised issues with self-assessment, the team saw this technique as the most useful short-term method of gathering data on evaluators.
The pilot of LEAP involved a partnership between the researchers, Matilda Tech, who designed and hosted the Portal, and the Australian Evaluation Society Pathways Committee Competencies Working Group (AES Working Group). The research team designed the initial instrument, and then the two groups collaborated over three years to refine and test it. The University of Melbourne Centre for Program Evaluation and the Australian Evaluation Society (AES) provided financial support to Matilda Tech to develop and launch the self-assessment platform using the AES Evaluators’ Professional Learning Competencies (AES Professional Learning Committee, 2013). These will be referred to as the AES Competencies from this point forward. The updates to the competencies required for them to be suitable for self-assessment are discussed in Gullickson et al. (2024a, this issue).
The LEAP study was primarily a Methodological Study which Mouton (2022) describes as ‘aimed at developing new methods such as questionnaires, scales and tests of data collection and sometimes also validating a newly developed instrument through a pilot study’ (p.159). The article focuses on the design considerations and piloting of the self-assessment instrument only, not the competencies used in the tool.
We began our work with the following three criteria for a successful instrument: (a) it had to provide a service to the individuals who completed it; (b) where possible, it should provide a service to the respondents’ Voluntary Organisations for Professional Evaluation or organisation; and (c) it had to contribute to the knowledge base on evaluation learners and learning, therefore, articles and the final anonymised data should be made publicly available. The research team was committed to ensuring we were not conducting extractive research that did not directly benefit those who participated, as has often been the case (Cram et al., 2018; Smith, 2021), and that we upheld the principle of reciprocity (Australasian Evaluation Society, 2013). These criteria enabled us to focus on building a high-quality assessment tool that provided mutual benefit to participants and researchers. The development of the tool occurred during the COVID-19 pandemic and so we used online events for pilot testing.
Conceptual framework
During the conceptualisation and design phase of LEAP, we looked at the literature to understand the benefits and challenges of self-assessment generally and consider how those would apply to a tool developed for the field of evaluation. We also focussed on case studies where self-assessment had been used in evaluation or related fields to discover principles, ideas, and functionality for LEAP. In this section, we summarise our findings related to those areas.
Benefits
Self-assessments provide several benefits related to learning. They establish the grounds for what knowledge and skill is considered important in a specific context; can contribute to the development of performance standards for a field; and assist with the development of learning pathways for individuals (Dellai et al., 2009; Jahan et al., 2011; Stufflebeam & Wingate, 2005). Self-assessments can therefore contribute significantly to promoting a learning environment. These contributions are now discussed in more detail.
Firstly, the content of a self-assessment, by its very nature, establishes the grounds for what knowledge and skill is considered important in a particular context. What is included has been deemed important enough for the opportunity cost of assessment. In the field of evaluation, evaluator competencies have emerged over the last 20 years as one way to articulate the parameters of what knowledge and skills are considered important in the field. At the time of this publication, the research team found 25 sets of evaluator competencies from across the world, which have similar core components but also varied context specific components. The discussion around the development and adequacy of those competency sets is discussed briefly in Gullickson et al. (2024a, this issue).
A second benefit of self-assessments is that they often require the setting of performance standards. Articulated standards create a shared understanding of what can be expected from different levels of expertise. For instance, a novice to the field can focus on acquiring surface knowledge (e.g. describe the parameters of experimental designs), whereas an expert should be able to integrate and apply that knowledge (e.g. design and conduct an experimental design that is fit for the context and the relevant evaluation questions). This has not yet been a strong focus of current evaluation competency frameworks and further research is required to develop performance standards for the field. The development of LEAP and its resulting data can contribute to the development of performance standards for the field of evaluation.
The creation of standards also links to the third benefit: creating a pathway for learning. Diaz et al. (2020) describe the process of the setting of standards as ‘a road map for those who develop evaluation capacity building programs for CE [Credentialed Evaluator] educators and other non-formal educators’ (p. 8). With the parameters of knowledge and skills, and the performance standards in place, taking a self-assessment can facilitate a process for recognising individual strengths and specific areas for development. Self-assessment, consequently, allows for focused instruction (Honken, 2013) and prioritisation of training needs. The combination of parameters, performance standards, and self-rating can be a powerful contribution to the promotion of a learning environment – the fourth benefit.
The fact that self-assessment, although problematic, was shown to be highly suitable for learning, confirmed our initial research idea – to develop a self-assessment tool for the key purpose of supporting evaluation learners and contributing to a greater understanding of the competencies and standards required for the field. We noted the important challenges of carrying out self-assessments, and these are discussed in the next section.
Challenges
Many of the challenges and limitations of self-assessments to assess knowledge and competence (Lichtenberg et al., 2007; Sitzmann, et al., 2010) stem from the nature of expertise – that it develops with time and experience, and that it is a prerequisite of accurate self-assessment. Persky and Robinson (2017) indicate that ‘experts develop through years of experience and by progressing from novice, advanced beginner, proficient, competent, and finally expert’ (p. 72). Expertise is also not necessarily transferable – ‘each time individuals acquire a new skill, they start at the novice stage where they need to learn the facts and the rules for determining action’ (Honken, 2013, p. 5). Dreyfus and Dreyfus (2005) distinguish between ‘crude skills and “subtle skills”’ (p. 788). Crude skills, like walking, can be done without conscious thought, have a larger margin for error, and allow for time to make corrections. Subtle skills, like music and surgery, require intense concentration with little time for reflection or deliberation while using the skill, and instead require acting swiftly with little or no time to correct mistakes. This distinction has implications for the kinds of skills we try and assess, particularly in the field of evaluation.
The conundrum of self-assessments is that they are developed to help inform people from novice to expert about their abilities in particular domains, but as Kruger and Dunning (1999) argue, the skills that produce competence in a particular domain are often the very same skills necessary to evaluate competence in that domain. Persky and Robinson (2017) indicate that ‘due to a high level of understanding of how they know what they know and what they do not know, experts have greater metacognitive awareness than novices. This awareness allows experts to be “sensitive to task demands (e.g. time, effort, resources needed)”’ (p. 78) which results in more realistic assessments of their expertise. Kruger and Dunning (1999) highlighted the fact that people overestimate their abilities particularly due their incompetence which ‘robs them of the metacognitive ability to realize it’ (p. 1121). Therefore, ‘incompetent individuals lack what cognitive psychologists term metacognition (Everson & Tobias, 1998), metamemory (Klin et al., 1997), meta comprehension (Maki et al., 1994), or self-monitoring skills (Chi et al., 1982; Kruger & Dunning, 1999, p. 1121). As a result, they claim that “unaccomplished individuals”’ (p. 1122) do not possess the metacognitive skills necessary for accurate self-assessments. This results in novices inflating their self-appraisals and experts under-rating their expertise; what has become known as the ‘Dunning-Kruger effect’. This ‘under-rating’ of expertise can also result in what Stufflebeam and Wingate (2005) label as ‘ceiling effects’ for evaluation ‘elders’ (p. 552). An individual’s views of self can also influence their ratings depending on whether they see themselves as able or not in the area being assessed (Ehrlinger & Dunning, 2003).
Case studies
At the time the researchers were exploring self-assessment, four evaluation related examples existed. The researchers reviewed these studies to see how they dealt with some of the practical elements of developing and implementing self-assessment for evaluators. Following the review of literature and the case studies, the team generated a set of principles for best practice in the development of self-assessments for evaluation which are presented at the end of this section.
Materials development training and support program (Stufflebeam & Wingate, 2005)
Stufflebeam and Wingate (2005) describe a study that was carried out ‘to assess learning gains in the 1999 to 2004 Project MTS (Materials Development, Training, and Support Services) Summer Evaluation Institutes at The Evaluation Center at Western Michigan University’ (p. 545). The Institutes were three-week evaluation capacity building programs; the self-assessment was used to replace a traditional pretest-post-test and focused on course content. The instrument the researchers developed was called the ‘Self-Assessment of Program Evaluation Expertise’ and was reviewed by 15 prominent evaluators. The self-assessment was completed by three different cohorts – (a) a group of nationally recognised evaluators, (b) participants in the 1999 Institute and (c) participants in the 2000 to 2004 Institutes.
Extract from rating scale example. Source: Stufflebeam and Wingate (2005, p. 549).

They found that self-assessment met their needs in gauging knowledge, skills and application of skills without direct assessment which would not have been feasible, particularly as a pre-test. They also discovered that self-assessment of general competencies was sufficient to indicate learning gains across various types of content instruction over the life of the Institute.
Stufflebeam and Wingate (2005) describe some of the lessons learnt in developing their self-assessment. They found the instrument must include: (a) a brief discussion of the purpose, domain, and caveats on the cover page; (b) simple, streamlined instructions and wording; (c) clear items; and (d) defined anchor points for the rating scale. The defined anchor points are necessary to accommodate the complexity of representing expertise in a rating scale, and the complexity of the competencies being rated with that scale. ‘Typical quality ratings of poor, good, fair, and excellent are general and subject to idiosyncratic interpretation’ (Stufflebeam & Wingate, 2005, p. 558). The requirement of participants to interpret scales will be exacerbated by the Dunning-Kruger effect, so the ratings must make the distinctions between each level clear. In addition, the scale should be the same across items and domains so respondents can compare their ratings across the various domains. The authors developed a personal report together with the anonymous aggregated result from the self-assessment. They found this practice reduced likelihood that people will over-rate their expertise to impress others and allowed participants to see how their expertise related to that of the group.
Essential competencies for program evaluators (Ghere et al., 2006)
Ghere et al. (2006) produced a two-hour professional development unit for reflecting on the Essential Competencies for Program Evaluators. The self-assessment activity used a three-page pen and paper rating sheet which included all competencies grouped by domain. Participants were asked to rate themselves on a 7-point expertise scale across the competencies (Figure 1). The authors did not provide information about the origin of the rating scale. They, like Stufflebeam and Wingate, felt that the ratings should be only known to the individual. Rating scale from Ghere et al. (2006).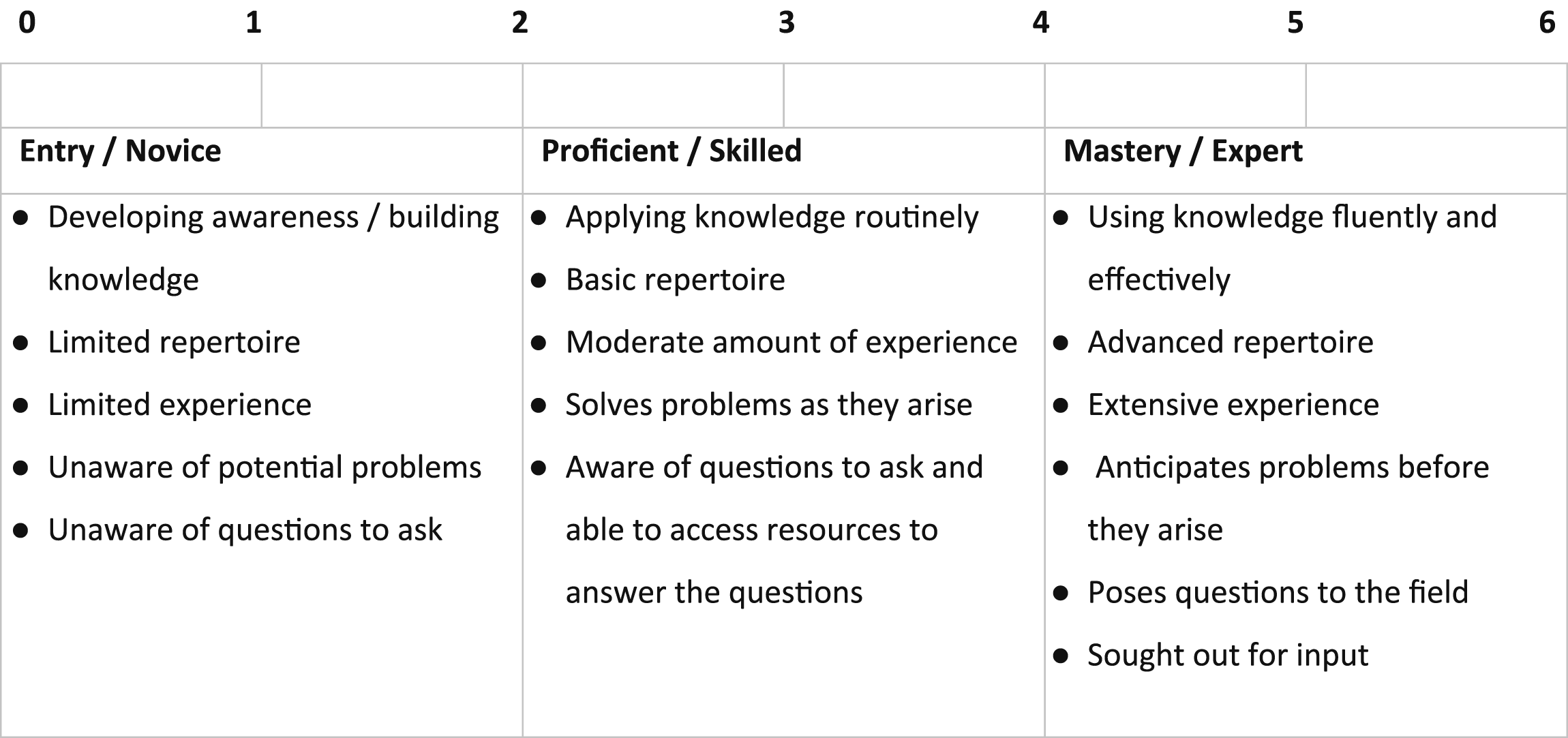
The Magenta Book (Her Majesty’s Treasury, 2020)
Her Majesty’s Treasury (United Kingdom) developed the Magenta Book in 2011 and updated it in 2020 (HM Treasury, 2020c) to provide guidance on evaluation for the United Kingdom Central Government. Alongside the Magenta Book they produced the Government Analytical Evaluation Capabilities Framework (HM Treasury, 2020a) which ‘…describes the skills, attitudes and practices which enable effective and high-quality Government evaluations’ (p. 3). They also produced a self-assessment tool: an excel spreadsheet with a list of competencies by domain in one tab; a collated results tab with scores in charts by domain and by domain and competency; and an action plan tab which was not linked to the results (HM Treasury, 2020b). For the tool they used a shortened version of the full framework, and no information was provided about how they chose which statements to include. The worksheet is not downloadable, so no data set on overall competency ratings is automatically generated by those who complete it. Competency statements are rated using the following scale: 1. No knowledge or experience; 2. Basic or limited knowledge or experience; 3. Working knowledge and practical experience; 3. Detailed knowledge and significant experience; and 4. Expert knowledge and experience. No information was provided about the basis of the rating scale, and there is no information on lessons learnt from the process, but we reviewed it as a case study due to the value of examining its evaluation content domains. It is also the only self-assessment instrument the research team found that was developed by a government agency.
Social Value (UK)
Social Value developed an online self-assessment tool which practitioners and organisations can use to assess themselves against the Seven Principles of Social Value developed by Social Value UK (Social Value International, n. d.). Whilst values are a key consideration for evaluators, this self-assessment tool does not utilise any other evaluation competencies. Users complete the assessment by selecting from a set of six tailored statements under each Principle, which best describe their practice or project. For example, for Principle #1 (Involve Stakeholders), users are asked to select the most applicable statement from ‘Stakeholders are not involved at any stage [of the measurement]’ to ‘Representatives from each stakeholder group are involved [in all aspects of measurement]’. The results of the self-assessment are provided as scores under each Principle and displayed online as a spider chart and can be downloaded. Users can also benchmark their scores against averages for their country, their industry, the age of their organisation/program and the turnover of their organisation/program. A set of generic suggestions for improvement under each Principle are also provided.
Summary
Principles for good self-assessment instruments.
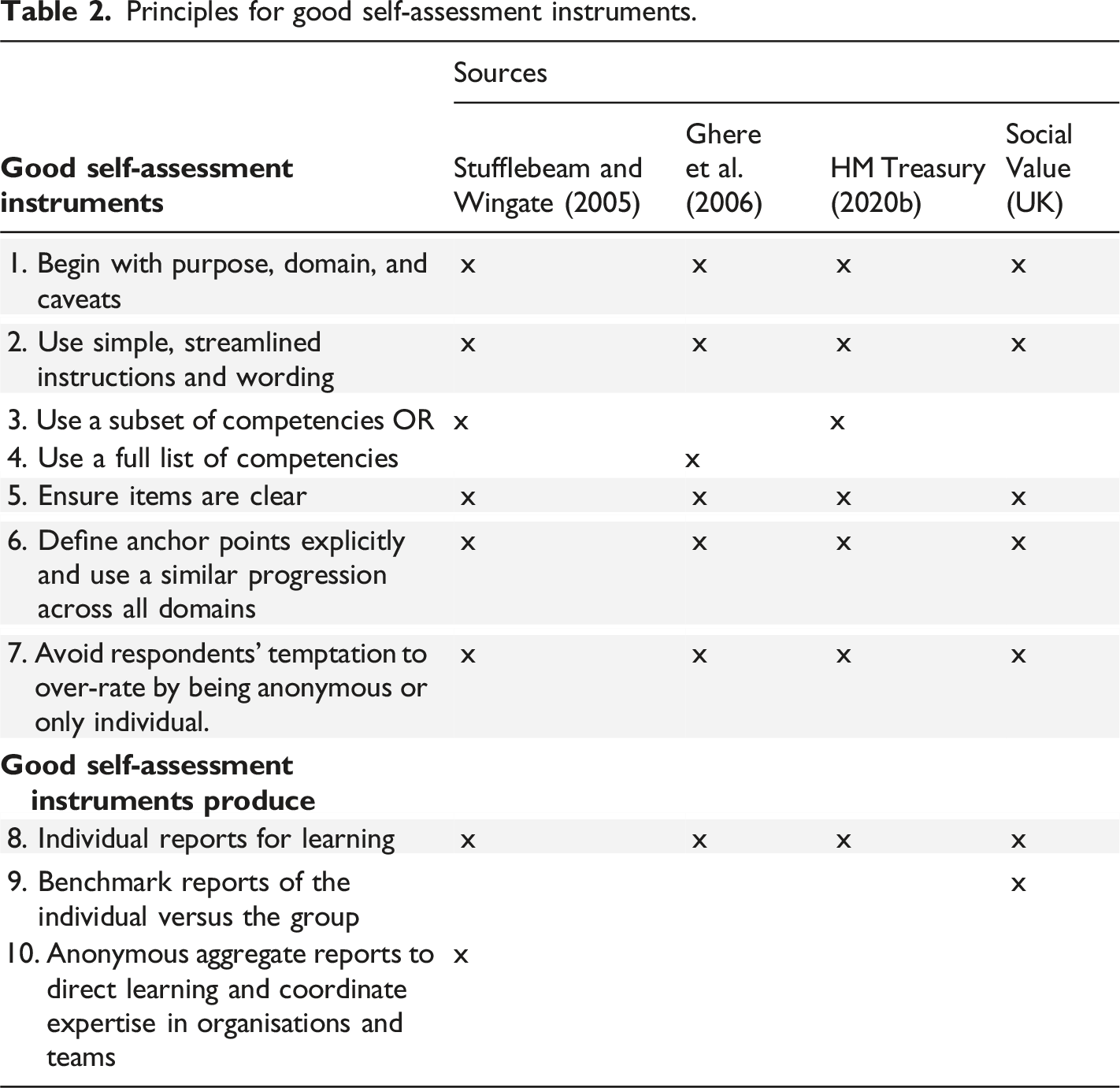
Whilst all the case studies provided information on the purpose and target group for their self-assessments, not all of them discussed the structure or provided detailed information on the rating scales or lessons learnt. Stufflebeam and Wingate (2005) and Ghere et al. (2006) used written instruments, whilst Her Majesty’s Treasury (HM Treasury, 2020b) systematised the self-assessment with a shortened list of competencies and an electronic tool (Excel). While these two approaches (paper and Excel) were effective for individual reflection, the researchers involved in those studies missed the opportunity to create an aggregate data set that could inform evaluation education efforts more broadly. The Social Value (UK) tool (Social Value International, n. d.) took that step and added benchmarking. Creating an aggregate data set was a key need for the LEAP and formed the basis of the design of an online tool with the good self-assessment parameters provided in the case studies.
Research design and questions
The next step in the research was to design, develop and pilot test the self-assessment. That work was split into two phases with aligned research questions: 1. Phase 1 (design): How can we design a self-assessment that meets the needs of individuals, organisations, and our research team? 2. Phase 2 (pilot testing): a. Will there be interest in taking a self-assessment on evaluator competencies? b. Will people judge that it is worth their time to complete? c. Can doing the self-assessment expand people’s frame of reference around what is required for an evaluator to know and be able to do? d. Can this self-assessment tool assist evaluators at any level of expertise in identifying areas for professional development? e. How can we improve the LEAP to make the self-assessment more effective and user friendly?
The methods, findings and discussion are presented in the following sections.
Methodology and methods
An overview of the LEAP study is presented in Figure 2. The research team used the review of the literature to understand the strengths and limitations of self-assessments and case studies to understand their principles for assessment development and resulting products. In this section we describe the methods for developing and pilot testing LEAP. Purposes and methods of study.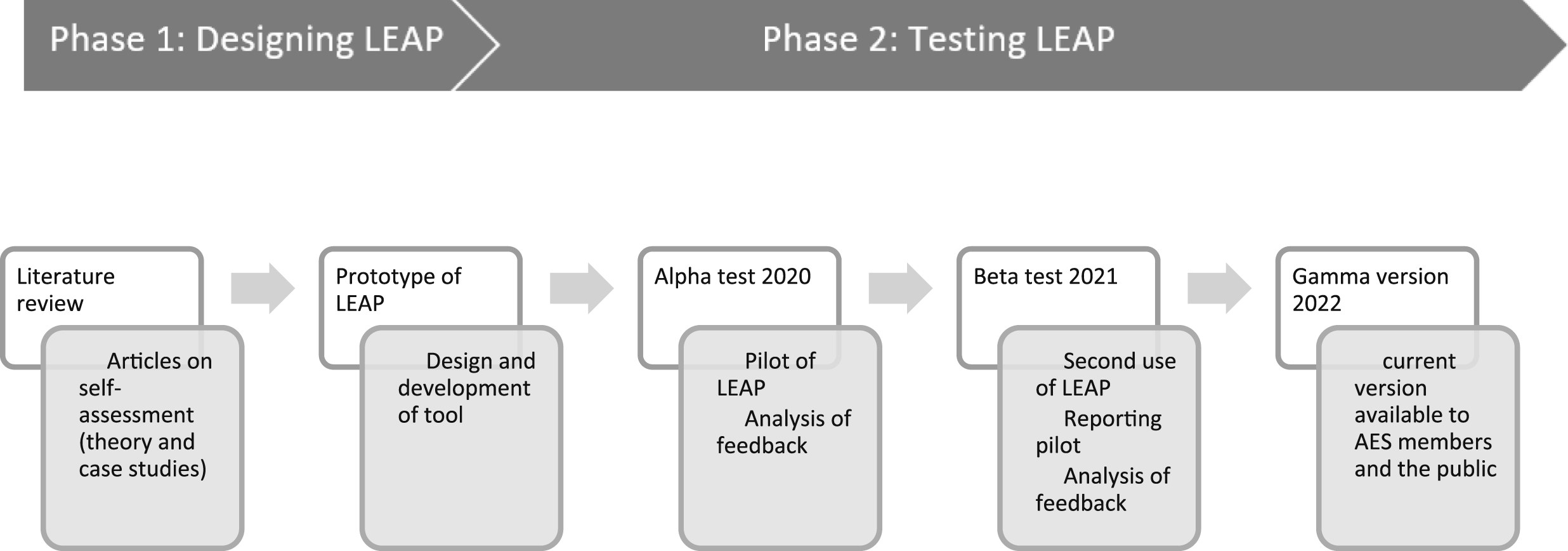
Phase 1: Instrument development
The researchers used the information from the literature review to inform design choices for the instrument and then in collaboration with the AES Working Group and the team at Matilda Tech developed LEAP using the AES Competencies. This required revisions to the competency framework described in Gullickson et al. (2024, this issue). The researchers’ design choices are described in the findings section.
Phase 2: Pilot testing
In Phase 2 of the study, the researchers in collaboration with the AES Working Group piloted LEAP and then carried out analysis of the qualitative feedback from participants to make changes, a common component of Methodological Studies. Due to COVID-19, in September 2020 and 2021, the AES replaced its annual conference with free online events: FestEVAL. The AES Working Group and the research team led four sessions (two each year) to refine the self-assessment and reports using crowdsourcing. The following sections provide further details on the aims and methods for the alpha and beta tests.
2020 alpha test
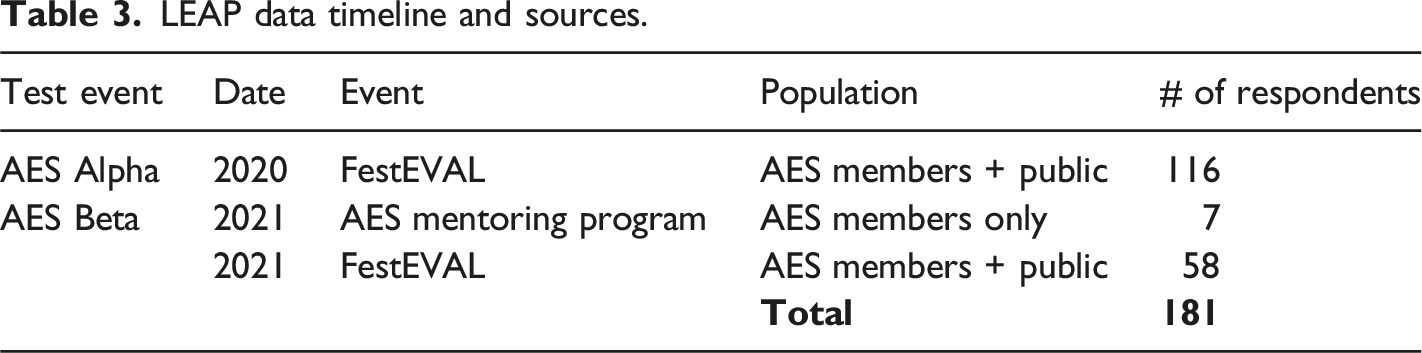
In 2020, the draft instrument was alpha tested on the online platform (Gullickson et al., 2020a, 2020b). The alpha test consisted of two sessions. The first session had 120 participants and 90 of those participants engaged in the live test and feedback session. Provision was made for completing the self-assessment after the session. The presenters used Rogers (2003) diffusion of innovation model to position the alpha test as a raw instrument that would be best tested by innovators. This was apparently successful framing, as and by the time the self-assessment closed, 116 people had completed the task.
The researchers asked participants in the piloting process to provide feedback on their experience of using LEAP and the use of the AES competency items which were embedded in the tool for the self-assessment process. Feedback was provided through three sources: emails (4) to the researchers, messages (226) from the chat function of the online meeting hosted by AES and messages (8) from a comment function in the tool itself. The feedback was placed into ATLAS.ti (computer-assisted qualitative data analysis software) and inductively coded by the researchers. The AES Working Group analysed the demographic data and produced heat maps of the expertise distribution across the domains and individual competencies. In the second session, the AES Working Group representatives shared and discussed the demographics and competency findings (see Gullickson et al., 2024a, this issue). All data was analysed and integrated into the 2021 beta tests. In the period between the alpha and beta tests, the research team and the AES Working Group developed the individual and organisation level report formats which were included in the beta testing.
2021 beta tests
In 2021, the AES group mentoring project and AES FestEVAL 2021 provided beta testers. Seven participants in the mentoring project took it as a pre-test; fifty-eight completed at FestEVAL. In the first 2021 FestEVAL session, the working group and the research group presented the feedback from the alpha test and how it had been addressed (Wildschut et al., 2021). In the second FestEVAL session, the respondents examined and commented on the content and format of the individual and organisation level reports (Gullickson et al., 2021). Feedback from FestEVAL 2021 was used to make minor changes to the self-assessment competencies and demographic items, and to modify the report format. The revised instrument (version gamma) was then launched publicly on learnevaluation.org for use at AES’ annual in person conference in Adelaide in 2022 (Gullickson & Siddiqi, 2022).
Sample
LEAP data timeline and sources.
Ethics
Our motivation for this project was research on evaluation learners. Using a self-assessment survey with individual and organisation level reports provided reciprocal value for participants and us in keeping with the AES Ethical Guidelines (Australasian Evaluation Society, 2013). Reciprocity was the research team’s first ethical consideration related to the project.
The learnevaluation.org self-assessment portal (LEAP) and associated research is part of an ongoing research project on evaluation learners, located at the University of Mississippi. Before the research team conducted a preliminary study at the 2019 American Evaluation Association conference, the project was reviewed by the University of Mississippi Human Ethics Institutional Review Board. The Board determined the research did not meet the regulatory definition of human subjects research at 45 C.F.R. 46.102, which characterises this as eligible for exemption as ‘any disclosure of the human subjects’ responses outside the research would not reasonably place the subjects at risk of criminal or civil liability or be damaging to the subjects’ financial standing, employability, educational advancement, or reputation’ (Protection of Human Subjects, 46.104, 2018). This aligns with the NHMRC Guidelines related to evaluation and quality control (National Health and Medical Research Council, 2014).
At FestEVAL 2020, the AES Working Group and research team verbally briefed session participants about the use of their portal data and feedback via the Zoom chat. Comments from the Zoom feedback shared below have been de-identified as per the verbal briefing. In response to the large number of participants in the session, the researchers developed a retrospective consent process for the LEAP data. The AES Working Group approved the process and the University of Mississippi Human Ethics Institutional Review Board reviewed it again under the existing research project with no change to their determination. Therefore, when alpha test participants logged in to view their individual report, they were asked to provide consent to use their self-assessment data in publications. Based on alpha test feedback, the research team added a privacy statement which is now embedded in the Portal registration process. Only employees of the technology company (Matilda Tech) running the portal can see identified data; the research team and any organisation level users can see only de-identified data unless special arrangements have been made with the learnevaluation.org team and Matilda Tech.
Findings
Our literature review informed design of the LEAP, and crowdsourcing through the alpha and beta tests enabled us to refine and test the instrument and reports. In this section we describe the design considerations and how they were enacted, the findings from the qualitative data analysis of participant feedback, and the report design and testing.
Phase 1: Designing the LEAP
In Phase 1, we focused on the question: How can we design a self-assessment that meets the needs of individuals, organisations, and our research team? In this section we discuss the key design considerations, including how we used lessons learnt from the case studies. The section is ordered based on the principles presented in Table 2. In terms of overall process, the research team first created the basic self-assessment tool and then worked with the AES Working Group on the competencies that were used in the LEAP.
Principle 1: State purpose and domain
In 2019, when we began the process of developing the self-assessment instrument, there were 25 evaluator competency sets globally. Since we intended our tool to be internationally applicable, we considered looking across all the competency lists from the various Voluntary Organisations for Professional Evaluation and creating our own, shorter list (with commonalities) to use in the self-assessment. However, we agreed with the literature that there was value in the contextual nature of each of the evaluator competency sets (AES Professional Learning Committee, 2013; Aotearoa New Zealand Evaluation Association, 2011; Stevahn et al., 2005). Keeping in mind our key criteria of benefit to those who took the self-assessment, we thought learners would want to self-assess on a competency set relevant to the contexts in which they worked. As a result, we decided to provide functionality for any set of competencies to be used in the tool in the future. We included a statement at the beginning of the tool describing the purpose of the self-assessment and that we would be using the AES Competencies for the current version.
Principle 2: Use simple, streamlined instructions and wording
Developing the LEAP for use in an online platform meant we had to consider text and layout for both phone and computer. We chose to use minimal text at the start, clear navigation and progression visuals, and a caveat about the length of the survey (Figure 3). Competency domains were presented one domain per page with rating scale and descriptions above. Due to the length of the competency statements, we told respondents the survey was best suited to completing on a computer. First page of the LEAP alpha test.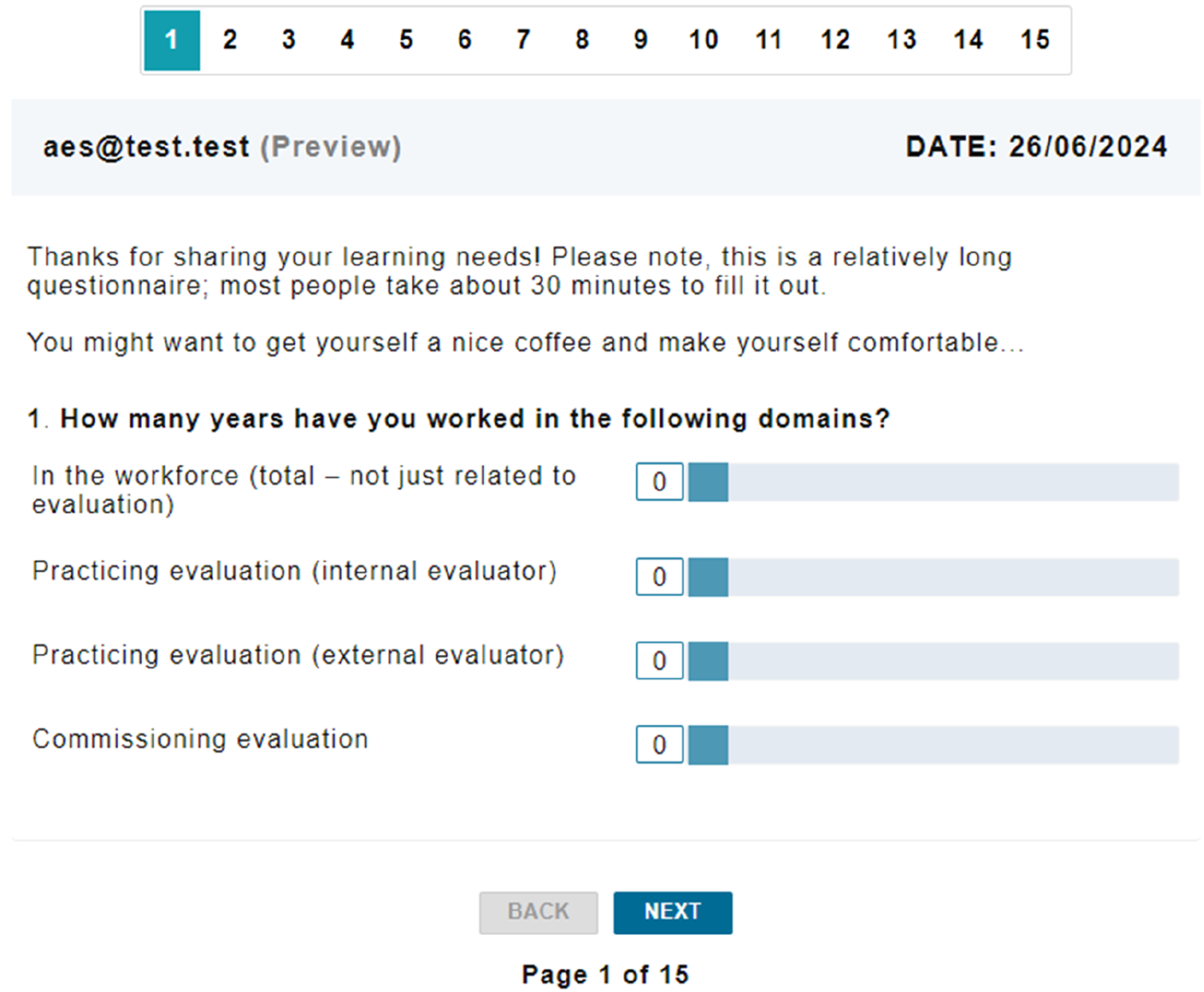
Principles 3 & 4: Choose full or reduced set of competencies
We decided to include the full set of AES competencies as the researchers and the AES Working Group agreed domain level ratings would be too general to be useful for the intended purposes of the self-assessment. We considered asking participants to rate the importance of the competencies to generate a shorter list for future self-assessments but based on the diversity inherent in evaluation, we decided against this. Those who practice evaluation come from a variety of backgrounds and operate with a range of evaluation definitions that inform their practice (Gullickson, 2020). Therefore, if we asked people to rate competencies on their importance, we believed we were likely to get equal ratings across all, or lower ratings of competencies they didn’t use based on their operating definition of evaluation.
Principle 5: Ensure items are clear
Most items were based on the domains and competency statements from the AES Evaluators’ Professional Learning Competency Framework. The original framework, launched in 2013, was deliberately designed not to meet measurement requirements, so the statements needed to be revised to suit self-assessment. The process to address this need is described in Gullickson et al. (2024, this issue). The measurement ready statements were then entered into the LEAP.
Principle 6: Clear and justified rating scale
2020 Alpha Test Expertise rating scale adapted from Dreyfus and Dreyfus (2005).

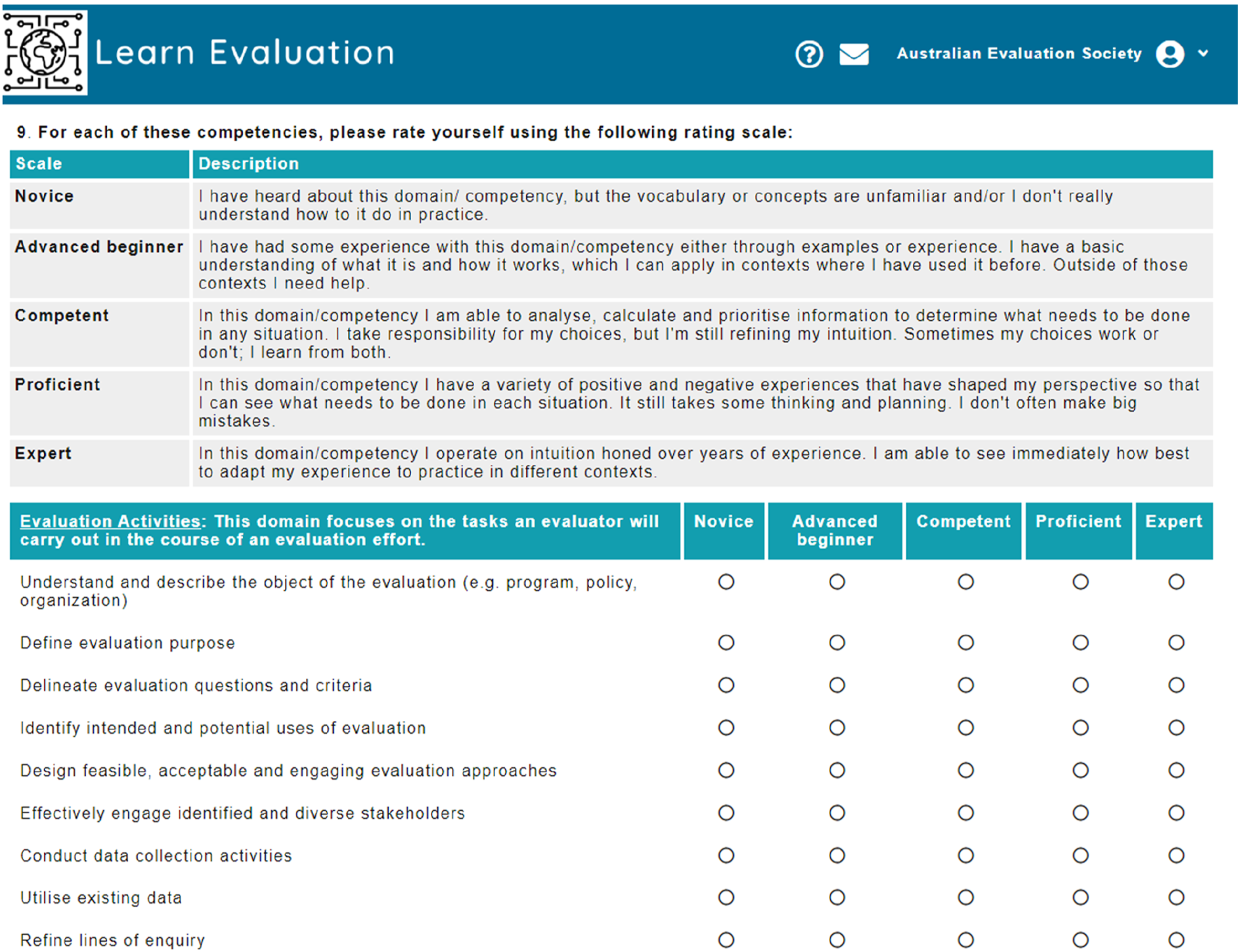
Example Domain rating page from alpha test.
At the end of the self-assessment, we asked a few more questions related to the respondents’ learning. We then used a matrix item and asked them to indicate their preferred type and mode of learning. We believed that the use of the rating scale together with open-ended questions at the end of LEAP would provide the required data on evaluators’ competencies and learning needs.
Principle 7: Avoid respondents’ temptation to over-rate by being anonymous or individual
On registration to LEAP Individuals were informed that they would be able to see their report, but any data shared in the public domain would be anonymised and aggregated.
Principles 8–10: Individual reports for learning/Benchmark reports of the individual versus the group/Anonymous aggregate reports to direct learning and coordinate expertise in organisations and teams
The nature of the reports produced by LEAP were addressed in the Phase 2 beta test as individual and aggregate reports were discussed with AES members and then embedded in the LEAP. Funding limitations meant benchmarking was not possible in these first iterations.
Demographic considerations
None of the self-assessments we reviewed discussed collecting demographic information on their respondents. Since this was an important element of our research, we considered carefully which demographic items were important to help us understand learners and their needs. We asked a range of workforce related questions at the start of the tool and then basic demographics at the end. We asked participants if there was anything else they would like to tell us about their evaluation learning needs (open text) and any feedback they had about using LEAP and challenges experienced.
Phase 1 summary
In the design of the platform, we addressed the lessons learnt from the literature. LEAP began with the purpose, domain and caveats on the opening page. We worked with AES to ensure simple, streamlined instructions and wording, and the AES team revised the competency list to increase clarity. We used an adapted Dreyfus and Dreyfus (2005) rating scale for explicitly defined anchor points across all domains. Individuals set up personal accounts to take the self-assessment and received individual reports for learning; any reports created used only anonymous aggregate information. We were ready to test the LEAP with the AES.
Phase 2: Testing the LEAP
LEAP went through two tests – the alpha test at FestEVAL in 2020 and the beta test in 2021 – to produce the gamma version in 2022. Most of the data collection, analysis and revision to the platform happened through the alpha test in 2020. Therefore, the remainder of this article focuses on the methods and findings from that event, with occasional mention of additional information from the 2021 testing.
Alpha test 2020
Alpha test findings
The initial data analysis done by the AES Pathways Committee members, the self-assessment response data and feedback were handed over to the LEAP team for further analysis and interpretation. Some of the feedback was related to specific questions in the tool and allowed the researchers to address each question specifically, whilst other comments were related to the AES competencies which would require a reformulation for the tool. An overview of the breakdown by topic of these messages and emails is shown in Figure 5. Amount of feedback by category.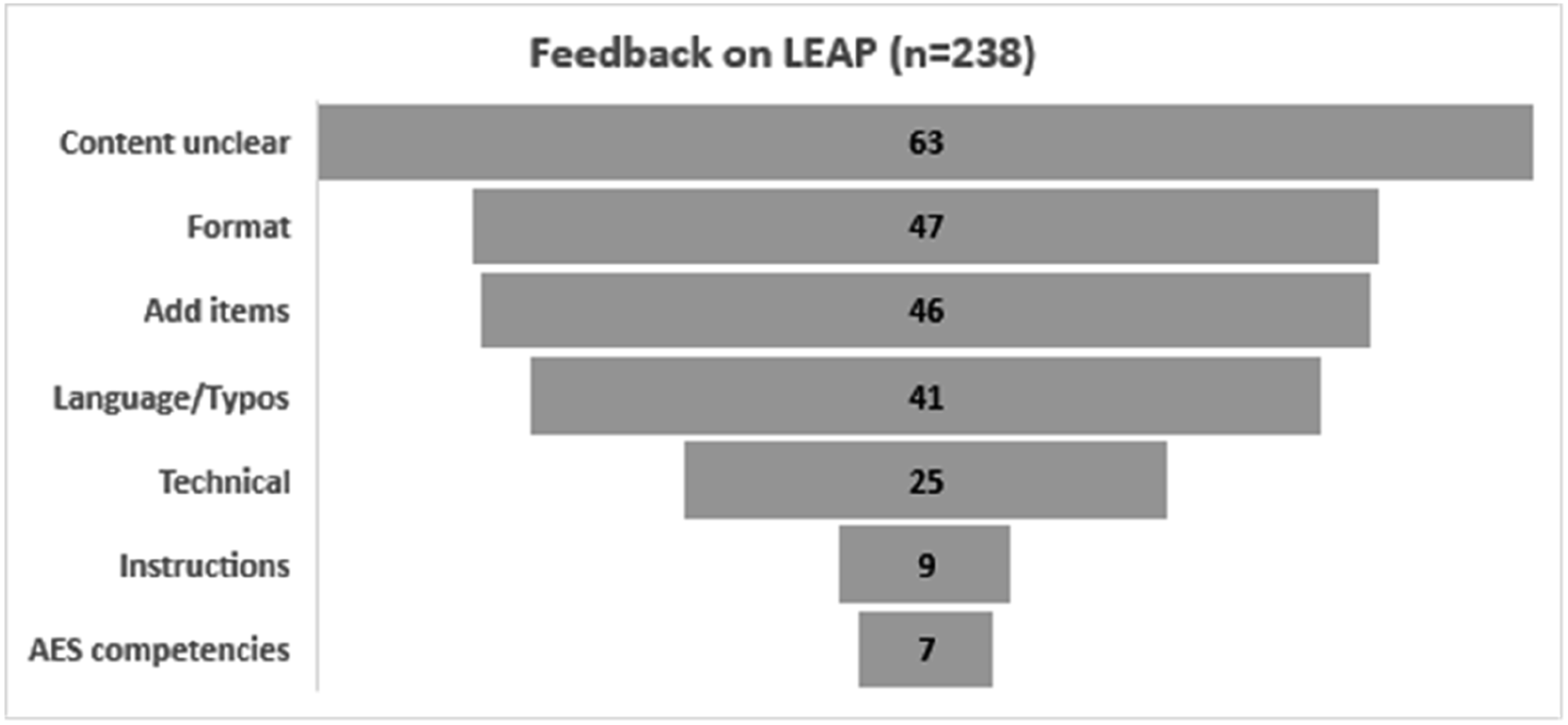
Many of the messages – content unclear (63), add items (46) and AES competencies (7) – were related to the AES competencies and their formulation. Those shortcomings are addressed in Gullickson et al. (2024a, this issue). However, there were also clear recommendations for the improved formatting of the tool (46), technical (25) and instructions (9). The feedback related to the process of the pilot is discussed first and then we move on to the revision implications for the LEAP tool.
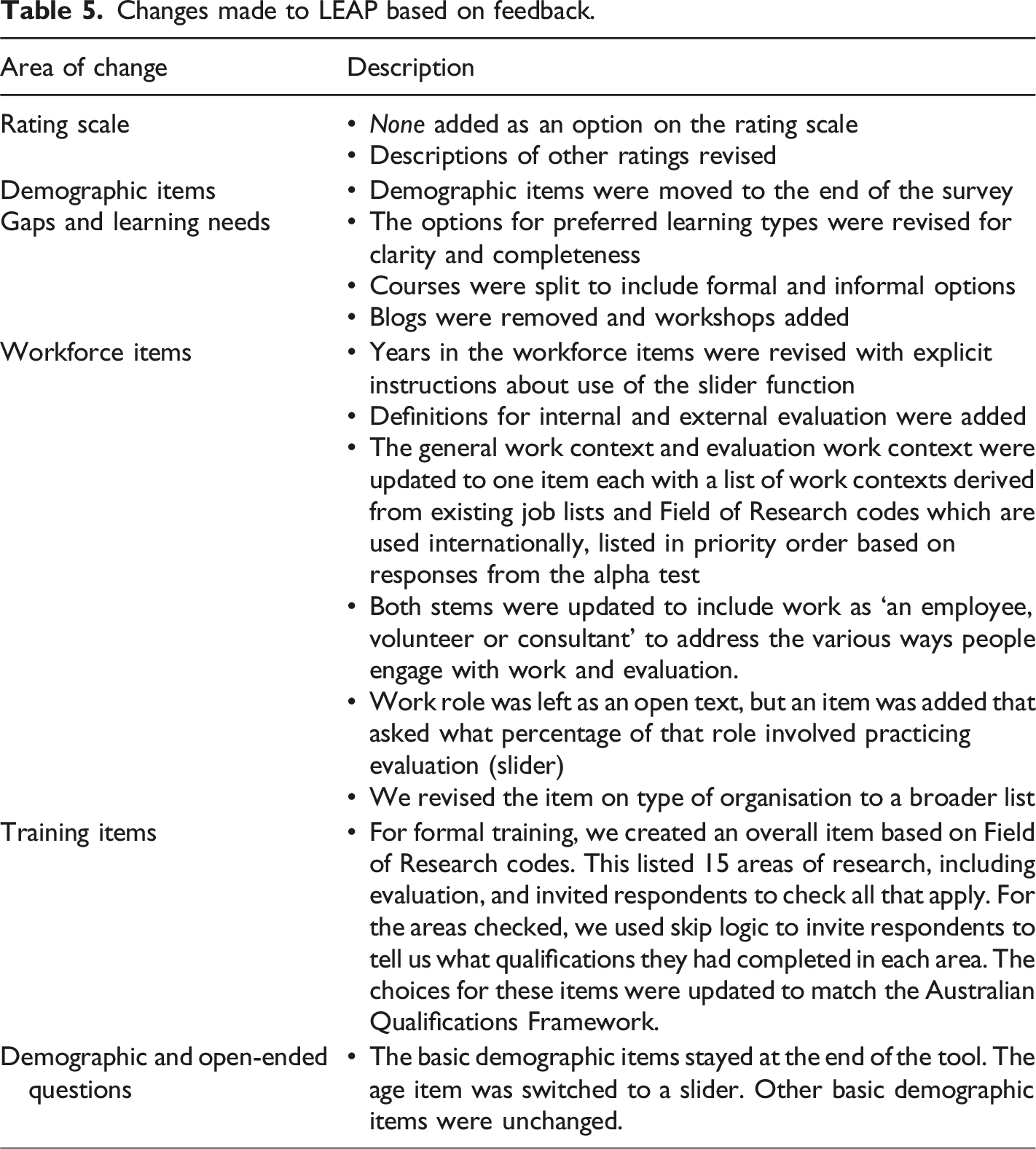
Improvements made to LEAP
Changes made to LEAP based on feedback.
Beta test 2021: Testing the report
The individual and organisational reports were designed to address Principle 8: Individual reports for learning, and Principle 10: Anonymous aggregate reports to direct learning and coordinate expertise in organisations and teams. The reports were shared and tested at AES FestEval 2021 (Gullickson et al., 2021) and then updated based on user feedback. The individual and organisational reports used strengths-based language and the same colour scheme to indicate domains/competencies where ratings were competent or above, or not yet competent. The organisation level report was based on all the Beta test responses collected via the AES link to the LEAP. The first page of the reports summarised the ratings by domain organised from highest to lowest (Figure 6 – individual). Example individual report page 1: Overall Summary.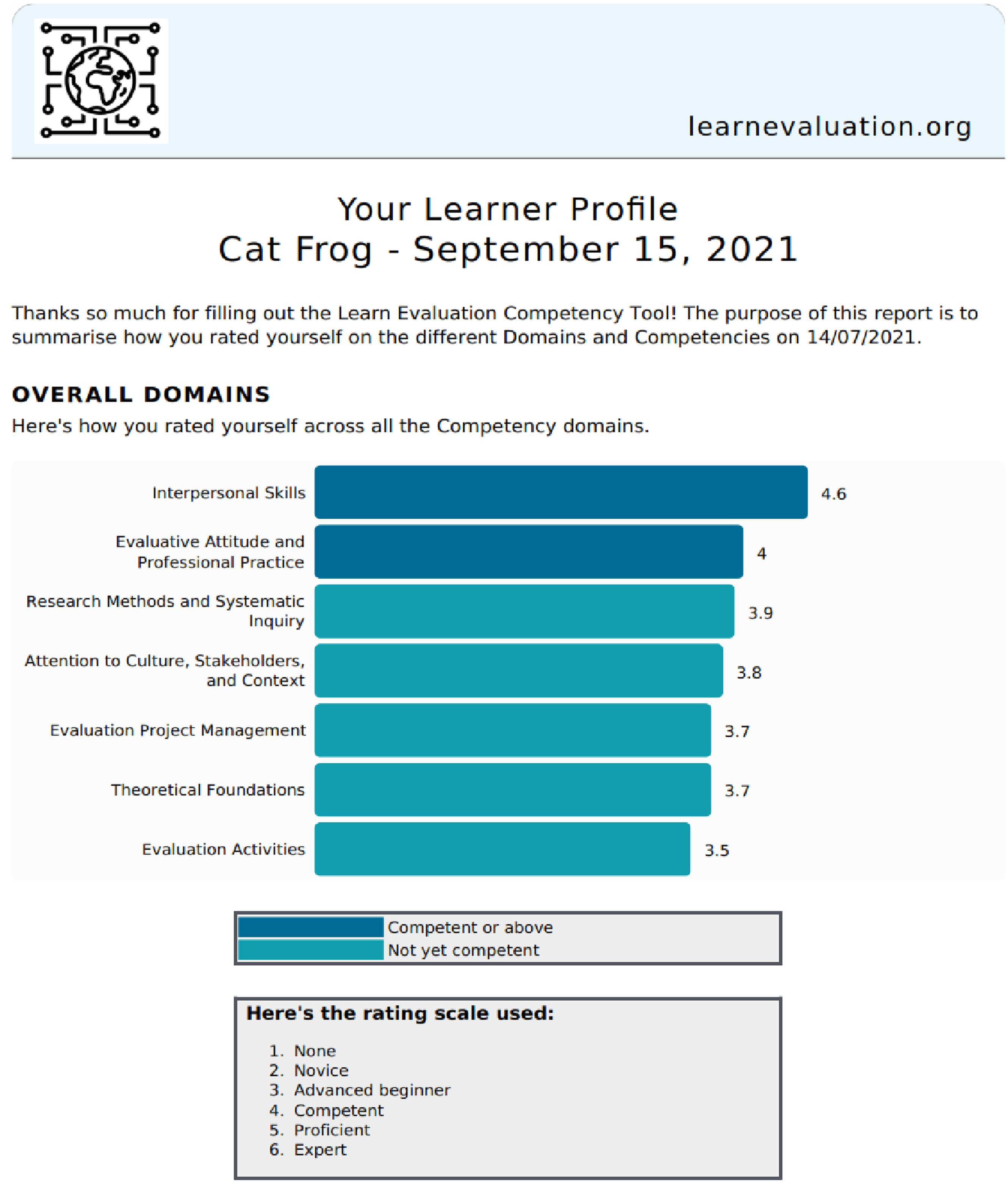
Top and lowest rated competencies were flagged as key strengths and areas for improvement. On the following pages, the ratings were listed for each competency grouped by domain (Figure 7). Example individual report page 2: Strengths and opportunities.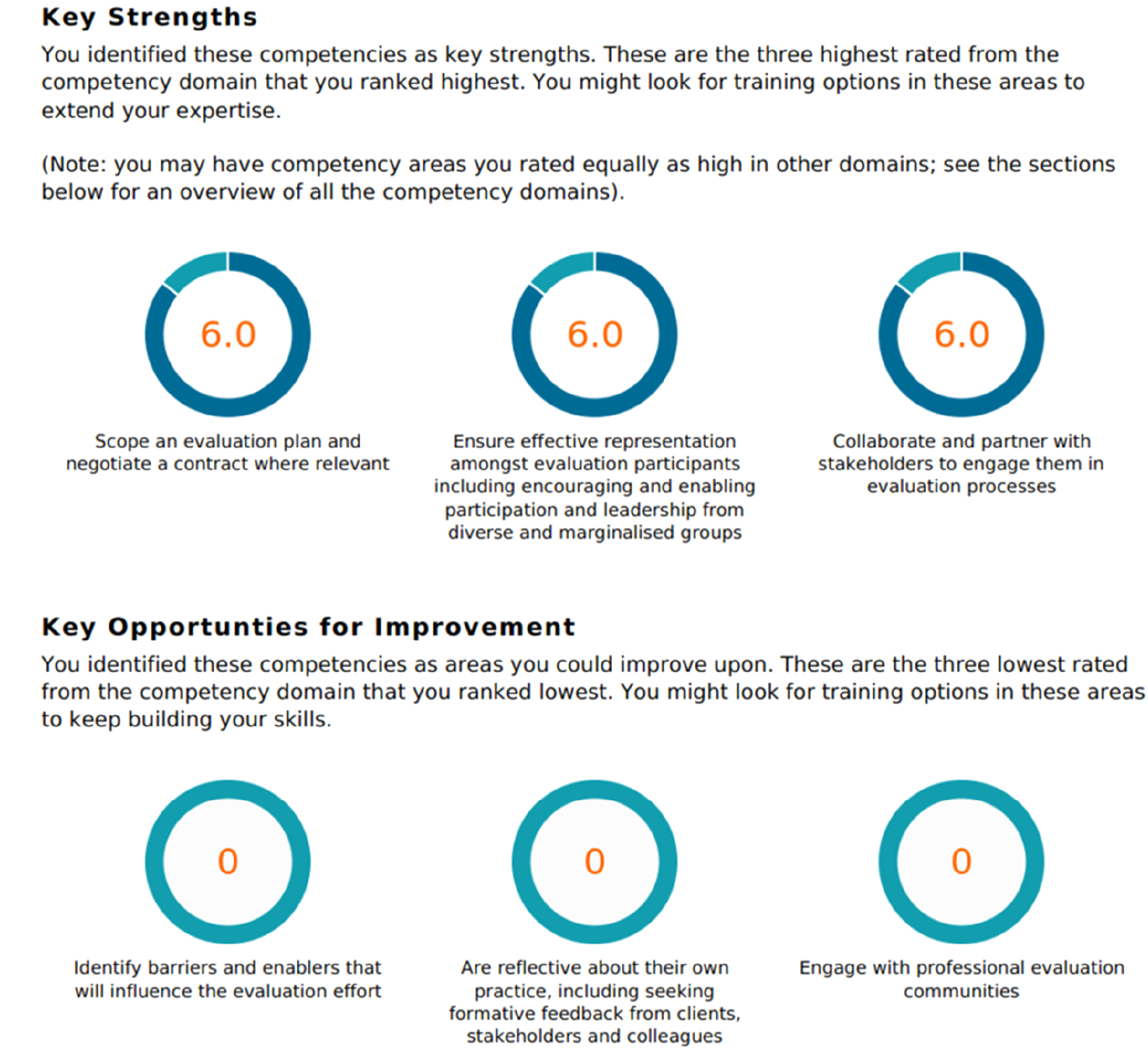
A key difference in the organisation level report was the inclusion of heat maps for the domains overall, and for competencies within domains (Figure 8). The use of heat maps rather than statistical reporting was a deliberate choice to keep the reporting as simple as possible for all users and to make it easier for respondents to benchmark their ratings against the group. AES Organisation report excerpt with heat map colouring.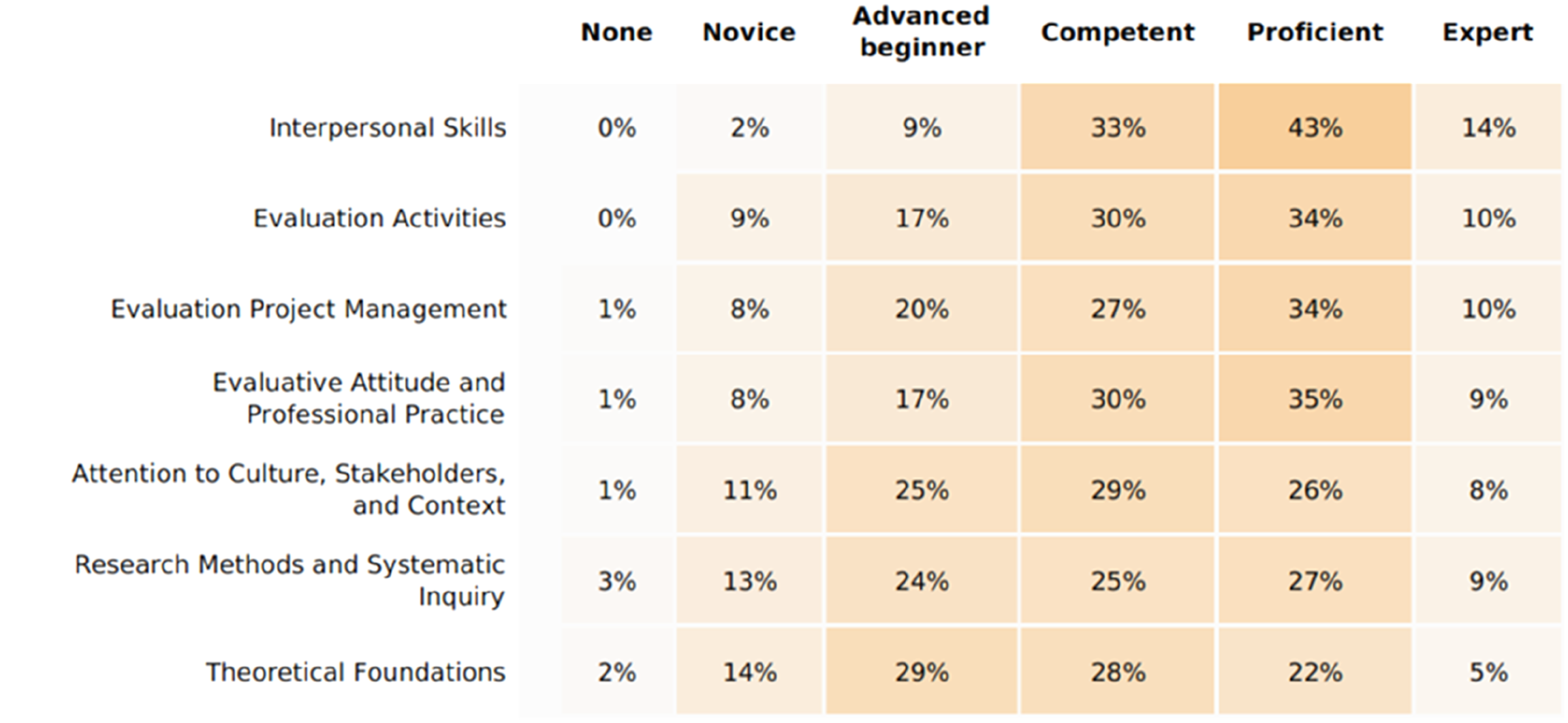
Response to LEAP by participants
This section discusses the findings of the analysis of feedback provided by participants. The feedback provided aligned closely to the benefits and challenges related to self-assessment which were identified in the earlier discussion of the literature review.
Benefits of self-assessment raised by participants
The positive comments from the analysis of the alpha test were aligned with the benefits related to learning which were highlighted in the literature review. Participants in the pilot acknowledged the value of a process which allowed them to recognise individual strengths and areas for development. It takes time to go through the questions rating competencies, but I like it because it compels us to self-reflect and be more specific in identifying needs/gaps each of us needs to address.
Eighteen comments related to key areas for professional development were identified by those participating in the alpha test. These comments focussed on the following needs: research methods; fundamentals of evaluation; quantitative data collection; quantitative analysis methods; knowledge of indigenous evaluation methods; evaluation for policy makers and resources for learning. Participants also claimed that mentoring was critical to their learning as evaluation capacity building opportunities were limited in their organisations and indicated that learning communities should be set up for emerging evaluators. One of my main challenges is the low level of capability in my organisation at every level so I do not have an accessible brains trust. I am very active in seeking out mentoring opportunities and tapping into other professional forums, e.g., communities of practice, AES courses, but I feel my learning is stunted by the fact I have to work more or less in isolation.
Challenges of self-assessment raised by participants
The participants raised three key challenges to carrying out the self-assessment.
Self-reporting
Sixteen of the responses were aligned to challenges regarding self-assessment discussed earlier in this article and relate primarily to the Dunning-Kruger effect. I wonder if there is scope for bias because it is a subjective self-assessment. An evaluation of capacity within my organisation showed that a lot of people thought they were very knowledgeable and capable when it came to evaluation. As the resident ‘expert’ this does not appear to be the case in my interactions with my colleagues.
Lack of internationally accepted standards
Two responses also referred to the lack of ‘benchmark’ or ‘standards’ for the various levels of evaluators (from novice to expert). Challenging to consider what the benchmark might be for the discipline, especially considering it does vary considerably across a variety of domains (NFP, government, private etc). It is tricky to self-assess many of these competencies as I am not so sure on where the ‘bar’ is set and how I would compare to the bar and to my peers
These challenges were also raised in the literature and will remain a challenge for evaluator self-assessments until international benchmarks are developed.
Timing of the self-assessment
One of the participants raised the issue of timing of the self-assessment. … my take on all these is different since the pandemic, and likely won’t change any time soon, but might. Hard to predict and I would have put in different answers in January
While the issue of timing is not particular to self-assessments instruments per se, timing of completion of self-assessments does need to be considered. In earlier discussion of other case studies, Stufflebeam and Wingate (2005) indicated that they timed their self-assessments to act as a pre-test-post-test within the timeframe of a course.
We now discuss our responses to the findings and updates to the instrument. Changes to the AES competencies that occurred due to the feedback on tests of the LEAP are discussed in Gullickson et al. (2024a, this issue).
Discussion
The research study involved two phases which focussed on the design and pilot testing of LEAP.
Phase 1 (design)
Self-assessments come with limitations and benefits. Accuracy is the main limitation of self-assessments, related to the nature of the knowledge and skills being assessed, and the metacognitive ability of the person doing the assessment. Crude skills are easier to assess than subtle skills; experts will rate themselves lower, non-experts will rate themselves higher. However, self-assessments provide benefits by setting boundaries for important knowledge and skills, and contributing to the development of performance standards and learning pathways. The researchers and the AES Pathways Working Group found this combination tenable: the benefits addressed key needs in evaluation, and the limitations could be managed with a caveat statement in the tool that self-assessments should not be used as summative reports of ability unless they are triangulated with direct methods of assessing skills and knowledge.
LEAP’s performance on the characteristics for good self-assessment instruments.

Phase 2 (pilot testing)
Phase 2 findings by research question.

Engagement with the free online self-assessment has produced benefits for the AES other organisations, one of which is described in this issue (Gullickson et al., 2024b, this issue). It has also laid the foundation for collaboration with further organisations; the South African Monitoring and Evaluation Association (SAMEA) will launch their competencies in the LEAP in late 2024. The free online platform is accessible to the public. Together with the organisational portals, the research team continues its overarching goal to learn more about those who want to learn evaluation.
Future research
Several future research questions emerged from this study. Some research questions are related to the development of competency sets we use in in self-assessment tools – such as ‘How can we identify the domains that differentiate evaluators and generate measures that are useful?’; ‘How might we distinguish between “crude” and “subtle” skills within evaluation competencies?’. Others relate to the user of self-assessments tools themselves – such as ‘Is a rough idea of competence or competency sets good enough?’; ‘How do we allow for benchmarking in self-assessments?’ Some of these research questions will be tackled in the next iteration of LEAP but we also hope that evaluation researchers will partner with us as we work towards understanding more about evaluation learners and their need for professional development pathways.
Conclusion
The co-design and development of LEAP through the partnership between AES and the researchers provided learning opportunities for all those involved. Reflection by evaluators regarding their strengths and weaknesses and their preferred modes of learning allows for the development of appropriate learning pathways for participants by AES. The research also contributed to making evaluator competencies more measurable and provided valuable data for the research team on the competencies of evaluation learners and the development. The authors believe that the further development of and research on using the LEAP will contribute significantly to the use of self-assessments internationally as a formal process for assessing the expertise of practitioners. The collaboration in development and refinement of LEAP has created a platform that can provide benefit to learners and their organisations beyond just the AES and can continue to generate data for research on evaluation learners.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.