
Abstract
A randomized trial of the GRAIL GalleriTM multi-cancer screening test is being planned for the National Health Service in England, and will have 140,000 healthy participants aged 50–79: 70,000 exposed to screening and 70,000 unexposed. The test reportedly detects 50 different cancers and is expected to reduce all-cancer mortality by approximately 25%. Given this effect size—and that cancer deaths constitute a large fraction of all deaths—the trial is sufficiently large to test the effect on all-cause mortality. Because most patients believe cancer screening “saves lives”, the GRAIL/National Health Service collaboration could set the evaluation standard for multi-cancer screening.
Introduction
Liquid biopsies—which detect fragments of cancer DNA in the bloodstream—have been approved by the US Food and Drug Administration to help target therapy in selected patients with breast, lung, ovarian and prostate cancer. Now several companies are preparing to market liquid biopsies to screen for cancers in the general population. Screening for multiple cancers, if effective, could provide evidence that screening does indeed “save lives”—that is, decreases all-cause mortality. Here we consider the case for this endpoint and whether the proposed GRAIL/National Health Service (NHS) England trial has already committed to a sufficiently large sample to power a test of all-cause mortality.
Background
The details of the GRAIL/NHS collaboration are sketchy and have been subject to change. In November 2020, GRAIL announced a pilot of GalleriTM—a blood test for 50 cancers—in 140,000 healthy individuals aged 50–79 within the UK's NHS. 1 In response to an editorial expressing concern about the pilot, the president of GRAIL Europe clarified in early 2021 that the pilot will, in fact, be a randomized trial. 2 Subsequent communications have confirmed a 1 to 1 randomization with a genuine control group: 70,000 are to receive the test, 70,000 are not. 3 The trial is currently recruiting patients. 4
Legitimate concerns have been raised about whether a randomized trial is premature due to the limited published data on test performance and accuracy. 5 While we share these concerns, a trial seems imminent. Furthermore, GRAIL has begun to offer the test to patients in the United States: as part of a partnership with Providence health system 6 and directly to consumers with an out-of-pocket cost of $949 per test. 7 A test deemed ready for routine clinical use should be ready for evaluation in a randomized trial. Thus, given that Galleri is already slipping into medical practice our focus is not on the trial's appropriateness, but the appropriateness of the trial's endpoint.
Case for all-cause mortality
GRAIL's current primary endpoint, late-stage cancer incidence, is problematic. First, it is a surrogate measure of efficacy—and surrogates are often misleading.8,9 While decreased late-stage incidence is evidence that aggressive tumors are being diagnosed earlier, it is not evidence that patients are being helped. Effective screening requires not only earlier detection, but also that therapies initiated earlier confer some benefit over those initiated later. 10 This is most indisputably measured in terms of death. 11 Second, screening with Galleri may have benefits even without a decreasing late-stage incidence—particularly since the assay has relatively poor sensitivity for early-stage cancer. 12 Patients diagnosed with advanced cancer following screening may still be diagnosed earlier (before developing symptoms). Because of earlier detection and intervention they may have fewer painful metastases, require less morbid surgery/reduced doses of chemotherapy, and be less likely to die. Thus, the interpretation of this surrogate is complicated: late-stage incidence may suggest benefit when none exists and may miss benefit that does exist.
Mortality is the most direct measure of screening efficacy. Because Galleri is screening for basically all cancers, an obvious endpoint would be all-cancer mortality. However, this requires a Death Review Committee to decide whether a death is due to cancer or another cause. That gets messy—particularly for deaths that are not directly the consequence of cancer but may be related to diagnostic or therapeutic interventions directed to cancer. 13 All-cause mortality is an unambiguous measure: simply requiring a count of deaths.
All-cause mortality is also the outcome most relevant to patients. Cancer screening is regularly promoted as saving lives, both in public awareness campaigns and medical center advertisements.14,15 Such messages are reflected in the perceptions of our patients: 74% of American adults believe that finding cancer early saves lives most or all of the time. 16 The problem is the disconnect between patient perception and evidence. 17 We owe it to patients to test the hypothesis. A finding of lower all-cause mortality would serve as incontrovertible evidence for enhanced longevity—what is implied by the phrase “saves lives.”
Power calculation for all-cause mortality
The standard argument against using all-cause mortality is straightforward: doing so demands an unfeasibly large sample size. This concern is more persuasive when screening for a single cancer, which is responsible for a small fraction of all deaths. It is less persuasive when screening for 50 cancers, however, as this represents essentially all cancers—which combined are responsible for roughly a third of all deaths. 18
Table 1 outlines a simple effect size calculation using both 10- and 4-year time horizons for all-cause mortality. Screening trials typically require approximately a decade of follow-up for benefit to become apparent. A conservative estimate for the 10-year risk of cancer death for individuals aged 50–79 is 2% or 20 per 1000 (for additional detail, see Supplemental Appendix). GRAIL modeling data shows that adding multi-cancer screening to current practice could reduce the risk of cancer death by ≈25%. 19 If so, the expected 10-year risk in the intervention group would be reduced to 15 per 1000.
Effect size for power calculation using all-cause mortality.
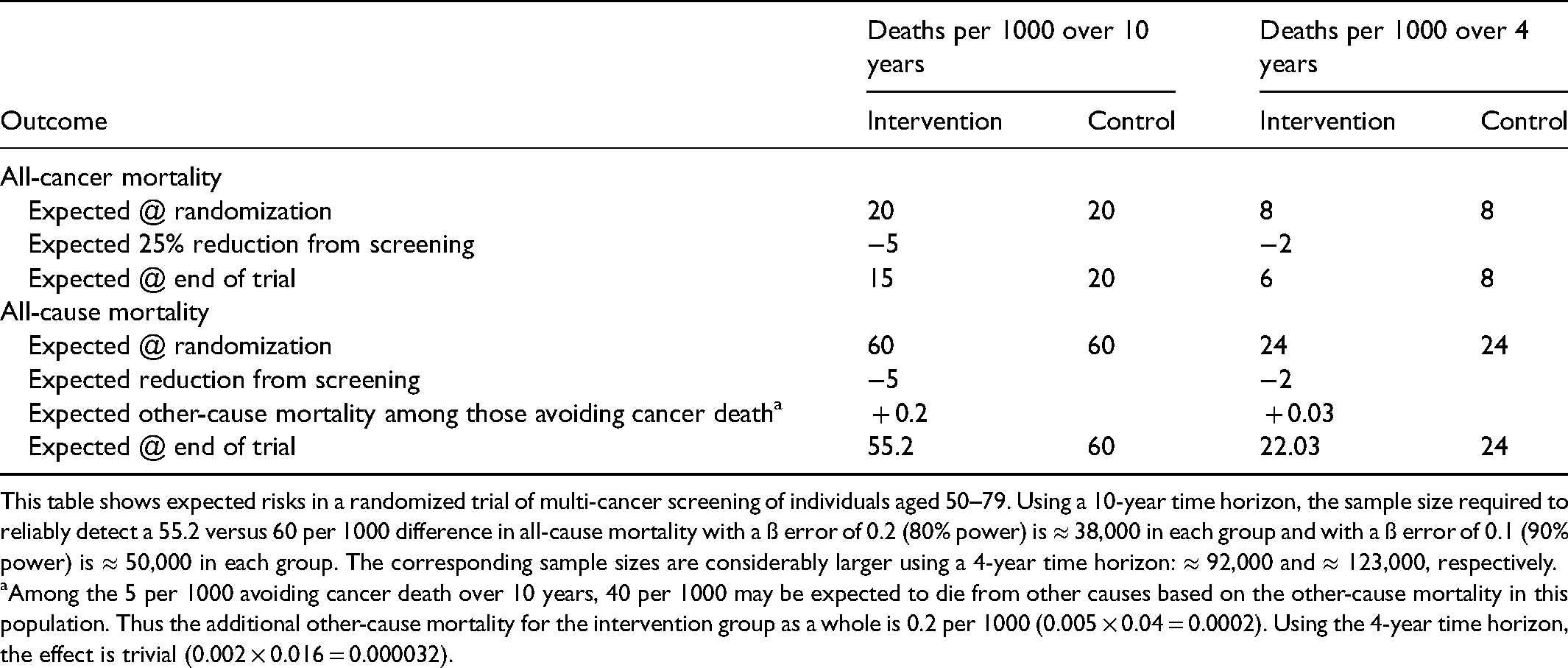
This table shows expected risks in a randomized trial of multi-cancer screening of individuals aged 50–79. Using a 10-year time horizon, the sample size required to reliably detect a 55.2 versus 60 per 1000 difference in all-cause mortality with a ß error of 0.2 (80% power) is ≈ 38,000 in each group and with a ß error of 0.1 (90% power) is ≈ 50,000 in each group. The corresponding sample sizes are considerably larger using a 4-year time horizon: ≈ 92,000 and ≈ 123,000, respectively.
Among the 5 per 1000 avoiding cancer death over 10 years, 40 per 1000 may be expected to die from other causes based on the other-cause mortality in this population. Thus the additional other-cause mortality for the intervention group as a whole is 0.2 per 1000 (0.005 × 0.04 = 0.0002). Using the 4-year time horizon, the effect is trivial (0.002 × 0.016 = 0.000032).
This absolute reduction of 5 cancer deaths per 1000 is applied to all causes of death in the bottom half of Table 1. Allowing for a few more people in the intervention group at risk for other causes of death because they avoided a cancer death (see Table legend), the size of the effect to be reliably detected is the difference between 55.2 and 60 per 1000. A trial with 140,000 people and no loss to follow-up would have power of 97%. The trial could contract to 100,000 people and still achieve a power of 90%. Thus GRAIL has already committed to a trial that is sufficiently large to detect the modeled effect of multi-cancer screening on all-cause mortality.
However, GRAIL's modeled effect size—a 25% relative risk reduction (RRR) in all-cancer mortality—would be a remarkable achievement. Effect sizes in this range are rare in biomedicine 20 (for context, primary prevention with statins is associated with a ≈10% RRR in all-cardiovascular mortality) 21 so there is a reasonable chance that Galleri will fail to reach this mark. Furthermore, there is uncertainty in the base rate of all-cancer mortality among screening participants. Given our conservative estimate, it is likely higher in the general UK population, but may be lower in a screening trial due to healthy volunteer bias. Given these uncertainties we include sensitivity analyses on the expected power to test all-cause mortality given various RRRs in all-cancer mortality and the base rate of cancer death for a trial with 10 years of follow-up (Table 2) and 4 years of follow-up (Table 3).
Sensitivity analysis for 10 years of follow-up: expected power for all-cause mortality given various relative risk reductions (RRR) in all-cancer mortality and base rates of cancer death.
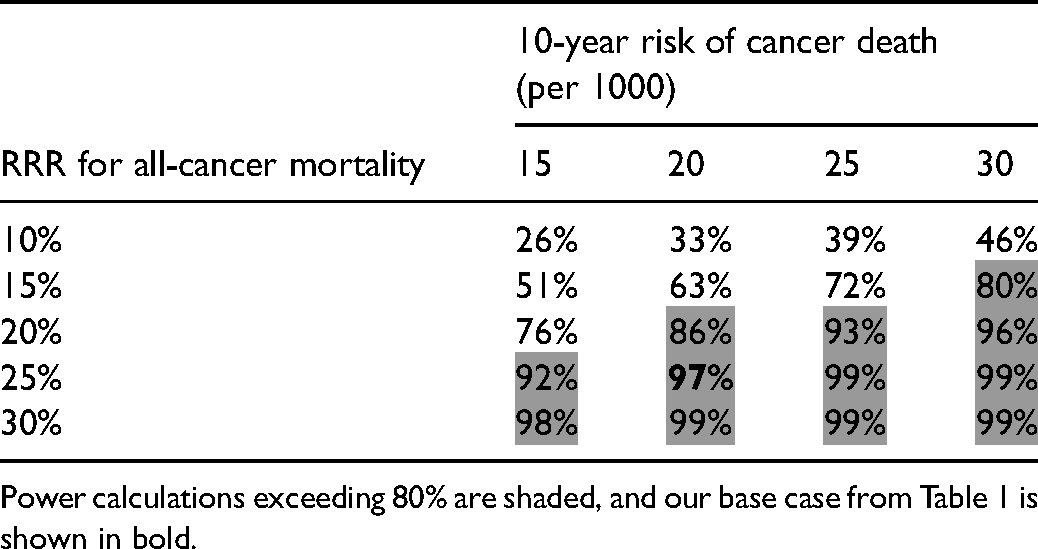
Power calculations exceeding 80% are shaded, and our base case from Table 1 is shown in bold.
Sensitivity analysis for 4 years of follow-up: Expected power for all-cause mortality given various relative risk reductions (RRR) in all-cancer mortality and base rates of cancer death.
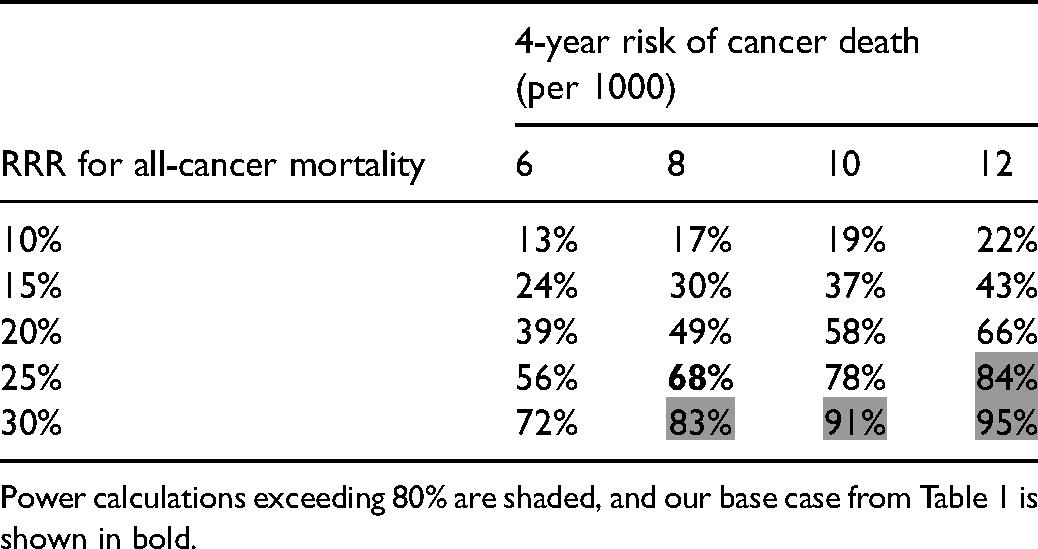
Power calculations exceeding 80% are shaded, and our base case from Table 1 is shown in bold.
Case against all-cause mortality
A trial providing adequate power to test all-cause mortality requires considerable effort. Not only does it require tens of thousands of participants, it also requires that they be followed for a long period of time. Our estimates are based on a decade of follow-up, which is typical for a randomized trial of cancer screening. GRAIL may not want to wait the requisite time to test all-cause mortality. Although details are sketchy, there is some suggestion that the GRAIL/NHS collaboration hopes to conclude the trial by 2024–2025, implying only 4 years of follow-up. Replicating the forgoing sensitivity analysis using a 4-year time horizon shows that such a short follow-up would provide insufficient power to test all-cause mortality (Table 3).
A test of all-cause mortality not only requires considerable effort, it is also a high bar to clear. While successfully clearing the bar would have tremendous promotional and marketing value, it may be too easy to fail from GRAIL's perspective. There are two broad hypotheses for why even an adequately powered trial might not reduce all-cause mortality—despite reducing cancer mortality.
The first is “off target” deaths: deaths related to diagnostic/therapeutic interventions that are engendered by screening, yet are attributed to other causes. Multi-cancer screening will expose more individuals to diagnostic interventions (e.g. lung, liver, and pancreas biopsies) and, if overdiagnosis occurs, more to therapeutic interventions (e.g. chemotherapy, radiation and surgery). All pose some mortality risk, mitigating reductions in all-cause mortality.
The second is the “aging soma” hypothesis: developing an aggressive cancer is a marker of biologic frailty—which impedes not only the ability to respond to clonal expansions of premalignant cells, but also to other diseases (e.g. cardiovascular disease, infections). 22 In other words, individuals at high risk for cancer death are also at high risk for death from other causes. While screening might be expected to lower the former, it would not be expected to lower the latter. If the aging soma hypothesis is correct, the additional other-cause mortality shown in Table 1 (among those avoiding cancer death) could be considerably larger than 0.2 per 1000.
Though the two hypotheses are conceptually distinct, they may be practically impossible to distinguish. And they may be intertwined: a heart attack death following anesthesia and cancer surgery could reflect both treatment death and an aging soma.
However, for patients, the distinction is surely unimportant. They most want to know the answer to a straightforward question: Will screening help extend my life?
Finally, all-cause mortality might not be reduced because cancer mortality is not reduced. The principal appeal of multi-cancer screening is the cumulative benefit that would accrue from screening for many cancers at once. But Galleri may not be effective in screening for 50 cancers, only a small number of them. The resulting small effect could get washed out in a trial of all-cause mortality. However, Galleri is being marketed as a test for 50 cancers and therefore should be tested as such. Extraordinary marketing claims call for more evidence not less.
To be sure, endpoints other than mortality are relevant to patients. The test may affect quality of life and there may be some value of knowing one's prognosis, even if it is immutable. 23 But powering a trial to test all-cause mortality doesn't preclude measurement of these alternative endpoints—which may be enhanced or worsened by screening.
Conclusion
It is important not to presume that multi-cancer screening will confer benefit. However, some GRAIL authors seem to be making this mistake, suggesting that mortality is not an appropriate trial endpoint as it will “delay clinical implementation.” 24 The American experience with bone marrow transplantation for metastatic breast cancer provides a cautionary tale in this regard. For more than a decade an ineffective therapy was widely deployed based on weak research and strong financial incentives. 25 Such established practices that are later proven ineffective (so called “medical reversals”) are common in the general medical 26 and oncology literature. 27 Avoiding such reversals in the future requires the generation of robust medical evidence before clinical implementation. We applaud the GRAIL/NHS decision to perform a randomized trial and hope to persuade them to set the standard for multi-cancer screening by using an all-cause mortality endpoint.
It is entirely possible that an effective multi-cancer screening program could reduce all-cause mortality. But we will never know by settling for surrogate measures: going down the road of demonstrating sensitivity in one study, increased early-stage detection in another, and increased 5-year survival in a third—while screening becomes slowly enmeshed in practice. Once established it will be extraordinarily difficult to address the question: Does multi-cancer screening really save lives? Without a firm understanding of the benefits, it will be very difficult to judge whether the increased testing and treatment (and the associated mental and physical morbidity) that will almost certainly arise from multi-cancer screening is worthwhile—either from an individual or a societal perspective.
Supplemental Material
sj-docx-1-msc-10.1177_09691413211059638 - Supplemental material for All-cause mortality as the primary endpoint for the GRAIL/National Health Service England multi-cancer screening trial
Supplemental material, sj-docx-1-msc-10.1177_09691413211059638 for All-cause mortality as the primary endpoint for the GRAIL/National Health Service England multi-cancer screening trial by David Carr, David M. Kent and H. Gilbert Welch in Journal of Medical Screening
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.