
Abstract
Patient-reported outcomes (PROs) that aim to measure patients’ subjective attitudes towards their health or health-related conditions in various fields have been increasingly used in randomised controlled trials (RCTs). PRO data is likely to be bounded, discrete, and skewed. Although various statistical methods are available for the analysis of PROs in RCT settings, there is no consensus on what statistical methods are the most appropriate for use. This study aims to use simulation methods to compare the performance (in terms of bias, empirical standard error, coverage of the confidence interval, Type I error, and power) of three different statistical methods, multiple linear regression (MLR), Tobit regression (Tobit), and median regression (Median), to estimate a range of predefined treatment effects for a PRO in a two-arm balanced RCT. We assumed there was an underlying latent continuous outcome that the PRO was measuring, but the actual scores observed were equally spaced and discrete. This study found that MLR was associated with little bias of the estimated treatment effect, small standard errors, and appropriate coverage of the confidence interval under most scenarios. Tobit performed worse than MLR for analysing PROs with a small number of levels, but it had better performance when analysing PROs with more discrete values. Median showed extremely large bias and errors, associated with low power and coverage for most scenarios especially when the number of possible discrete values was small. We recommend MLR as a simple and universal statistical method for the analysis of PROs in RCT settings.
Keywords
Background
Patient-reported outcomes (PROs) are widely used to measure patients’ subjective attitudes towards their health or health-related conditions.1,2 PROs enable health researchers to measure, analyse and compare clinical outcomes from the patient's perspective, providing clinical effectiveness outcomes in clinical trials and evidence to support decision making in health technology assessment. There has been an overall increasing trend in using PROs as clinical outcomes in the United Kingdom's publicly funded randomised controlled trials (RCTs). 3
RCTs are regarded as the gold standard for evaluating the effectiveness of health interventions.4,5 The randomisation process in a well-designed RCT can reduce selection and allocation bias, and inform the causality of the treatment on responses. 6 These traits of RCTs can simplify the data analysis of PROs. PROs produce numerical scores and generate distributions that are typically bounded, discrete, and skewed, which complicates the decision on what statistical methods to use for analysis. An inappropriate analysis can result in unreliable estimates and fail to provide accurate and robust results for decision-making on the use of health interventions.
An estimand is a detailed description of what treatment effect a trial is trying to focus on. It illustrates what the numerical result found in the trial will represent.7,8 An estimand is composed of five connected attributes: the population, the treatments to compare, the outcome or endpoint, how to account for intercurrent events, and a population-level summary measure of how the outcome between the different treatment conditions will be compared. 9
PROs in RCTs are frequently analysed with statistical methods that are part of the family of general linear models, particularly linear regression, analysis of covariance, and linear mixed models, 3 where the population summary measure of how the outcome between the different randomised groups will be compared is the difference in group means. There are several alternative statistical methods to general linear models for analysing PRO, some of which have a similar estimand (e.g. bootstrapping, 10 Tobit regression, 11 and quantile regression, 12 where the population-level summary measure is a difference in means or medians); while other models (e.g. ordinal logistic regression 13 and beta-binomial regression 14 ) have a different estimand (where the population-level summary measure is an odds ratio).
However, as each method has its own model assumptions, estimation procedures, and estimands, it is still unknown which method is the most appropriate to analyse PROs, particularly in RCT settings.
Existing guidelines that have been published by government organisations, such as the Food and Drug Administration (FDA), 15 and academic groups such as the Standard Protocol Items: Recommendations for Interventional Trials-PRO extension (SPIRIT-PRO) 16 and the Consolidated Standards of Reporting Trials Statement-PRO extension (CONSORT-PRO) 17 to standardise the use of PROs, mainly focused on the reporting of PROs or on the process of PRO development such as what health dimensions to cover, what items to include, and how feasible, valid, and reliable the PROs are. In terms of the statistical analysis of PROs, they provide guidance on what components to report and consider such as the targeted dimensions, the specification of the primary endpoint, and the statistical approaches to dealing with the missing data, but no guidance on what specific statistical methods should be considered to analyse PROs under different scenarios are provided.
As the ‘truth’ is unknown for real-world datasets, 18 simulation analysis is used as a common approach to the evaluation of different statistical methods under various predefined scenarios, through which, investigation on how close the estimates produced by these methods are to the predefined ‘truth’, and whether the performance of these methods remain robust when analysing different dimension scores of PROs and when model assumptions are violated can be carried out. The existing literature, especially simulation studies, mainly focus on the application of different statistical methods for analysing health utility scores,11,19–24 while there is a lack of research in statistical methods for analysing PRO dimension scores.
This study aims to apply simulation analysis for the evaluation of different statistical methods for estimating the treatment effect of latent continuous PRO dimension scores with equally spaced discrete scoring under a two-arm balanced RCT, considering multiple scenarios. Since we believe the PRO is an underlying continuous variable then, using the estimand framework, an appropriate population-level summary measure for the treatment effect is a difference in measures of central tendency such as means or medians between the randomised groups. Therefore, the statistical methods for comparison in this study are multiple linear regression (MLR), Tobit regression (Tobit), and Median regression (Median), which generate mean or median estimates. Other statistical methods, for analysing PROs such as ordinal logistic regression and beta-binomial regression, estimate odds ratios or differences in proportions as the population-level summary measure of the treatment effect, and are therefore a different estimand and outside the scope of this study.
The rest of the paper is composed of the design of the simulation analysis; the comparison of model performance of targeted statistical methods in various scenarios; and discussion and recommendations on what statistical methods to use for the analysis of PRO dimension scores in RCT settings.
Methods
This section describes the techniques to conduct simulation analysis for the comparison of the accuracy and robustness of three statistical methods, i.e., MLR, Tobit, and Median. Multiple scenarios for PRO data with 4, 10, and 26 possible discrete values or scores (i.e. levels) were simulated using a random-data generator from a Normal distribution, followed by discretisation techniques that rescored the Normally distributed data into different numbers of possible discrete values. The ‘ADEMP’ strategy proposed by Morris et al., 25 which abbreviates the initials of aims, data-generating mechanism (DGM), estimands, methods, and performance measure, was adapted to develop this section.
Aims
This study aimed to evaluate the ability of MLR, Tobit, and Median to estimate the predefined treatment effects of latent continuous PROs with equally spaced discrete scores, also called the predefined ‘truth’, under a range of scenarios in balanced two-arm RCT settings.
Data-generating mechanism
Multiple DGMs were proposed to ensure the coverage of different scenarios, by varying the number of observations (i.e. sample size) and predefined treatment effects, and by considering PRO scores with different number of possible discrete values, such that each DGM provides us with empirical results for a specific scenario. 25
The Short Form 36 Health Survey (SF-36) was used as the representative of PROs in this study as it is one of the most used PROs in publicly funded RCTs in the UK.
3
The SF-36 is a multidimensional PRO that consists of 36 items on different discretised scales, which generates eight health dimension scores that are composed of two or more exclusive items and one additional item that measures health transition compared to the past.
26
Modifications of the original SF-36 are developed, and the original version was chosen as the reference to generate simulated datasets since it contains more variability in the number of possible values that a dimension score can have. Similar DGMs were used to construct simulated datasets for three dimensions with different discrete values, including role limitation-emotional (RE)
Possible discrete values of the three dimensions in SF-36 (RE, BP, and MH).

Possible discrete values of the three dimensions in SF-36 (RE, BP, and MH).
The Normal distribution, denoted by
We also adapted a variation of predefined treatment effect (
Parameter specification for five DGMs using Normal distribution.

DGM: data-generating mechanism; SD: standard deviation.
An issue of generating data from the Normal distribution is that the simulated dimension scores may go beyond the boundaries of 0 and 100 for the SF-36 BP score. The following strategy was used to deal with this issue. Firstly, simulated scores exceeding the lower and upper bounds were rounded to the values at boundaries, i.e. 0 or 100, and secondly, the values on the continuous scale were discretised onto an equally spaced discrete scale between 0 and 100. The discretisation techniques were determined by the number of possible discrete values of the simulated dimension score (Table 3). For example, RE scores with four possible values will be discretised into 0, 33.3, 66.6, or 100. A simulated continuous score of 10.5 would be discretised onto a value of 0 under level 4, a value of 11.1 under level 10, and a value of 12 under level 26.
Discretisation techniques for the three dimensions in SF-36 (RE, BP, MH).
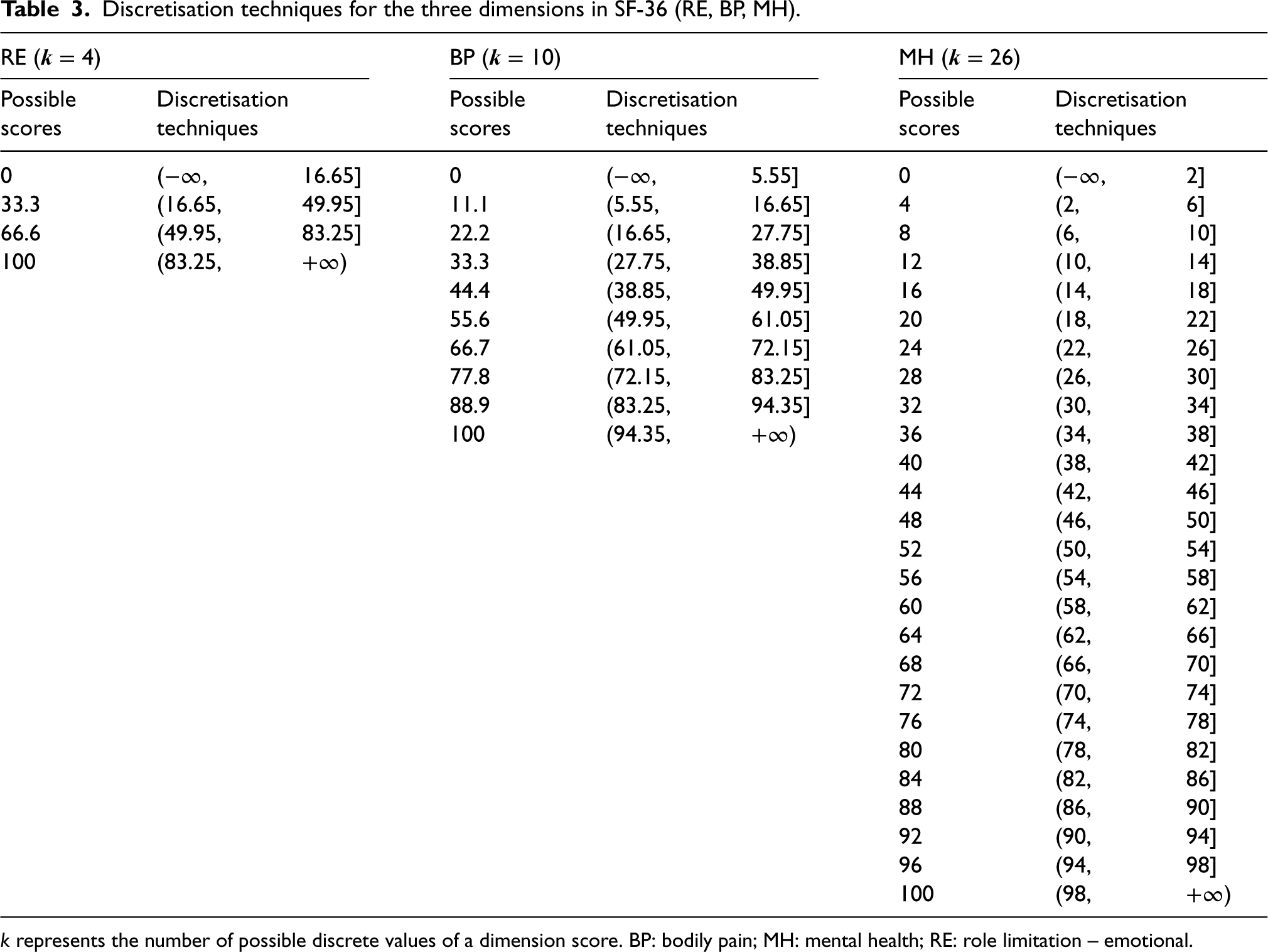
The number of observations, i.e. sample size, of each simulated dataset, was set at 100, 200, 400, 800, 1200, and 1600, using evidence from 114 identified trials that used PROs as primary clinical outcomes. 3 The sample sizes of these trials ranged from 65 up to 7677, with the 5th, 50th, and 95th percentile of 102, 387, and 1084, respectively. Given the right-skewed distribution of their sample size, the sample sizes of 1600 and 100 were used as the maximum and the minimum number of observations in each simulated dataset, respectively. Assuming two balanced arms in an RCT, half of the sample was assigned to the treatment group and the other half to the control group for each simulated dataset.
The number of repetitions was set at 5000 for all scenarios, since with 5000 number of simulations, the Monte Carlo standard error 25 of the estimate, such as the coverage of 95% confidence interval (CI) estimates, is approximately 0.003, leading to approximate 95% CI for the coverage of 0.944–0.956, which is believed as a sufficient level of precision for the coverage performance measure.
For this simulation analysis of the treatment effect in a PRO score at a specific post-randomisation between two randomised groups, four of the elements of the estimands framework (i.e. population, treatments, outcomes, and how to account for intercurrent events) were unchanged, but the fifth the population-level summary measure was the treatment effect between two parallel treatment arms measured by the means for MLR and Tobit, and medians for Median, which was also broadly the same if we assume both means and medians are measures of location or central tendency and the summary measure is a difference in measures of location or central tendency.
Methods of analysis
In MLR, the relationship between the mean of each PRO score and the linear predictor is described using the following equation:
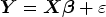
Median is a special case of quantile regression when the quantile level is set at the 50th. It estimates the conditional median of the response variable and does not assume a particular parametric distribution for the response. Median has a similar equation as MLR, but it depicts the relationship between the median of dimension scores, denoted by 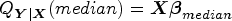
Tobit regression is an extension of MLR that estimates the mean. It describes the relationship between the latent variable and the linear predictor. It is a case of censored regression that assumes the boundaries of the dependent variable are due to censoring, that is, the mean of latent PRO scores, denoted by 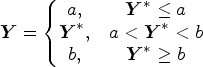
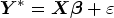
Since the DGMs were simulated under the RCT settings, no other
Performance measures
The main performance measures were bias, coverage of the 95% CI, empirical standard error (EmpSE), mean squared error (MSE), Type I error under the null hypothesis of no treatment effect (DGM 1), and power under the alternative hypothesis of a variety of predefined non-zero treatment effects (DGM 2–5). The estimated treatment effect from each statistical method is denoted using
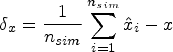
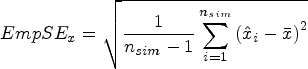
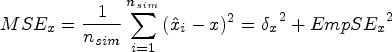
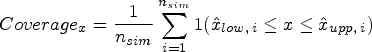
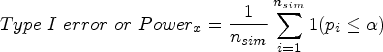
Exploratory analysis will be carried out, mainly by graphs for each DGM, estimand, number of observations, and statistical method. 25 The statistical package Stata/MP 17.0 was used for simulation analysis and MATLAB R2023a was used for data visualisation. The seeds and streams for the random-number generator were set the same in Stata to ensure that the exact same set of Normal distributions were used to produce scores for these three dimensions.
Results
This section reports the characteristics of the simulated datasets and evaluates the performance of three statistical methods (i.e. MLR, Tobit, and Median) for analysing latent continuous PROs with equally based scores in balanced two-arm RCT settings under multiple scenarios.
Characteristics of the simulated datasets
Following the five proposed DGMs, each simulation generated one simulated dataset assuming an underlying latent Normal distribution to randomly generate the outcome. The base case (DGM 1) has a mean of 50 and SD of 22. The simulated latent Normally distributed scores were then ‘discretised’ into an outcome with a discrete number of levels or scores (e.g. 4, 10, and 26 levels). Under each level, the mean PRO score in the control group was the same for all DGMs, but the mean PRO score in the treatment group varied by the five predefined treatment effects. With 5000 simulations and six sets of sample sizes (i.e. 100, 200, 400, 800, 1200, and 1600) per simulation, a total number of 30,000 simulated datasets (= 5000 simulations × 6 sets of sample sizes) were produced under each level, generating 2,700,000 estimates in total (= 30,000 simulated datasets × 6 methods × 5 DGMs × 3 levels).
Figure 1 presents example distributions of five DGMs for three different levels using scores generated from the same latent Normal distribution, with the observed average treatment effect and SDs marked in brackets. The example dataset used a sample size of 400 since it is the closest to the median sample size of the 114 identified trials in our review. 3
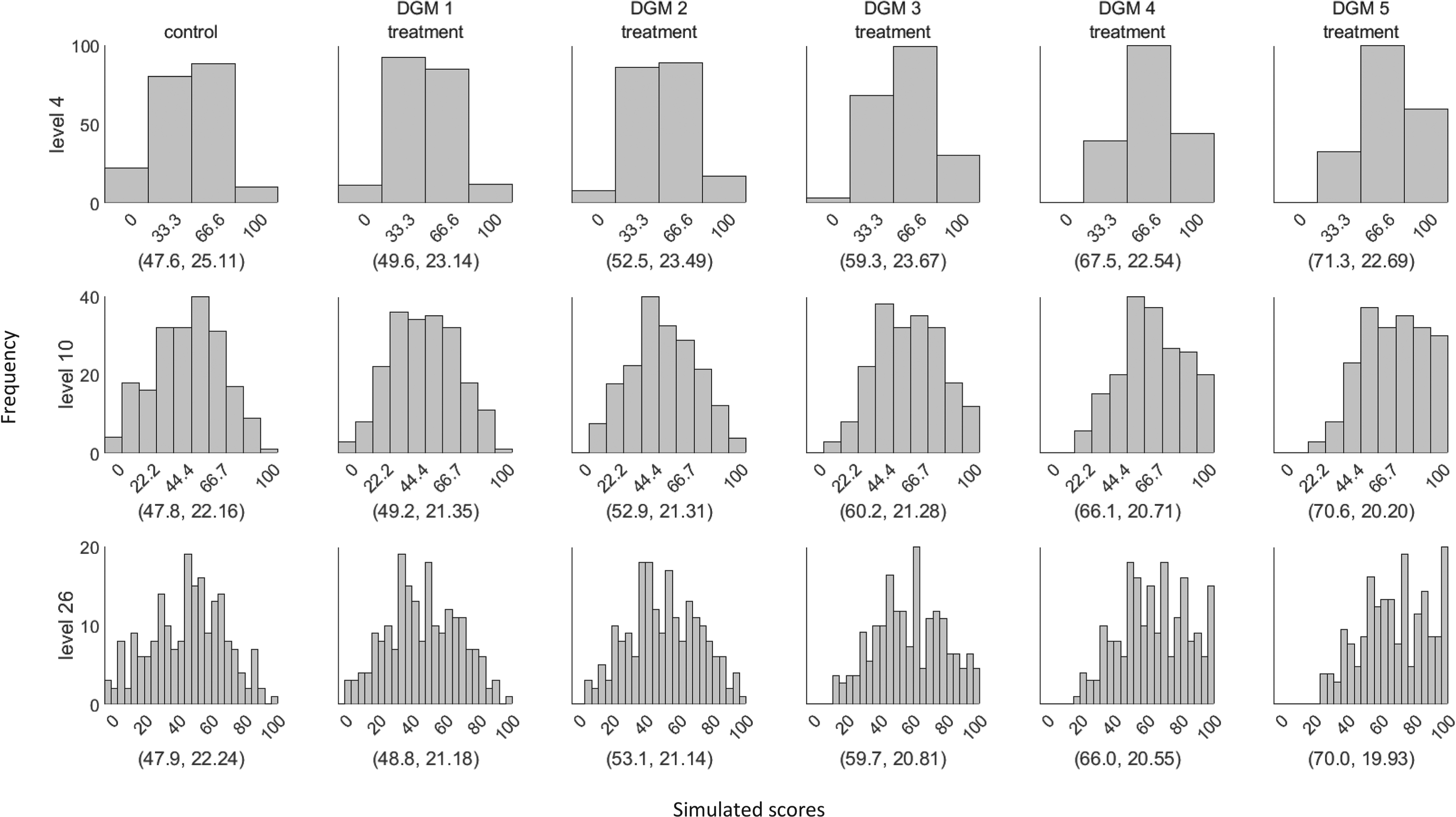
Example distributions of the simulated dataset using the five data-generating mechanisms (DGMs) for three different levels (sample size = 400). The values in the bracket represent the mean and standard deviation of the displayed distribution. The first column represents the score distribution of the control group. DGM 1–5 represents the score distributions of the treatment group using the predefined treatment effect of 0, 4.4, 11, 17.6, and 22.
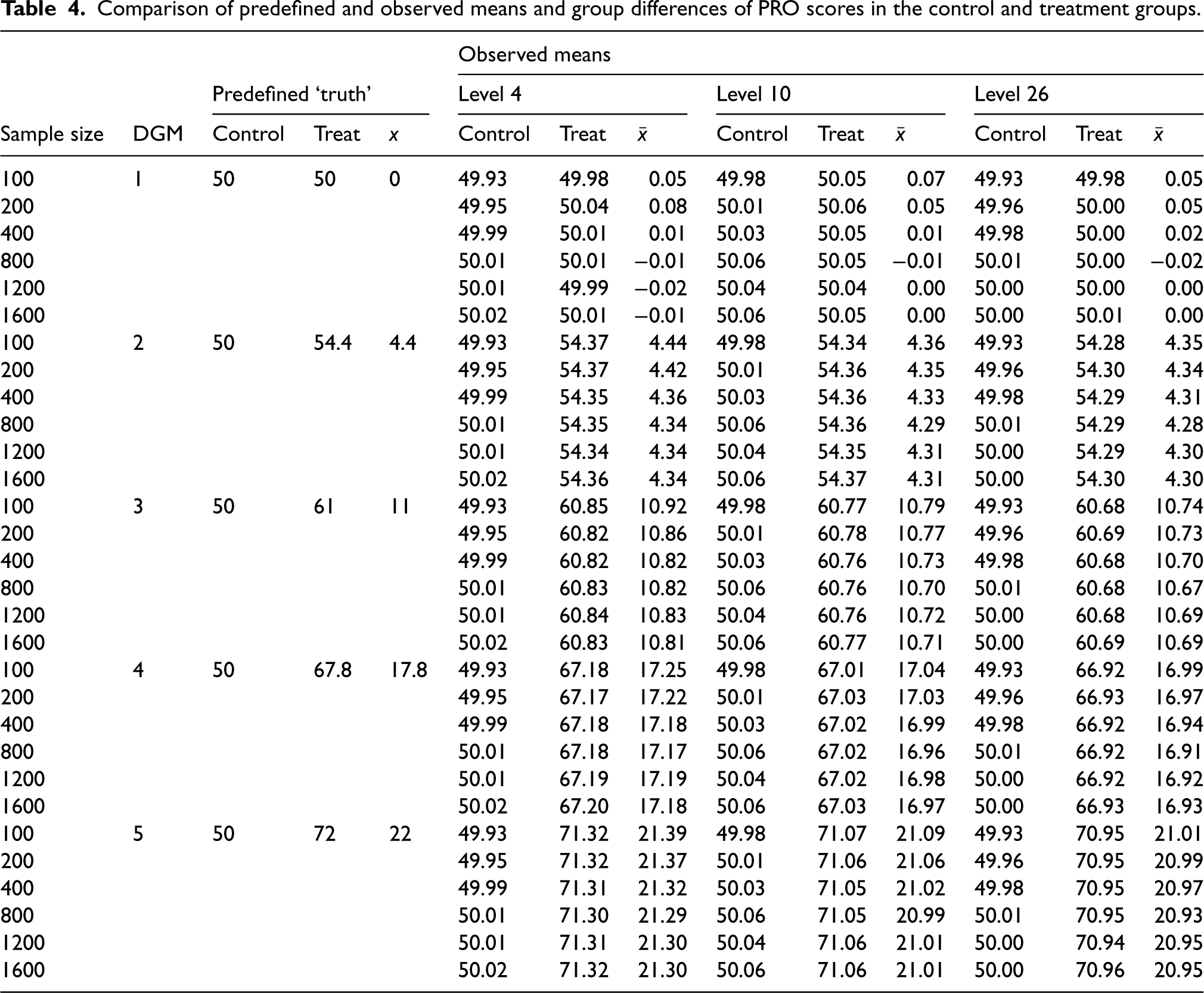
Table 4 shows the predefined and the observed means of the simulated PRO scores in the control and treatment groups, and the observed group differences. Table 5 presents the mean estimates from three different statistical methods under the five DGMs for each level using all observed estimates. Estimates for these methods under each DGM tended to decrease with an increase in the number of possible discrete scores, except for Median. For example, under DGM 5 where the treatment effect is predefined as 22-point on the original latent Normally distributed PRO scale, the average treatment effect in MLR is 21.33 for level 4, 21.03 for level 10, and 20.97 for level 26. Except for the Median, non-convergence was not seen for the other included methods. Median produced around 0.1% missing values when analysing level 4.
Comparison of predefined and observed means and group differences of PRO scores in the control and treatment groups.
Estimates of treatment effect from three statistical methods under five DGMs for three different levels.
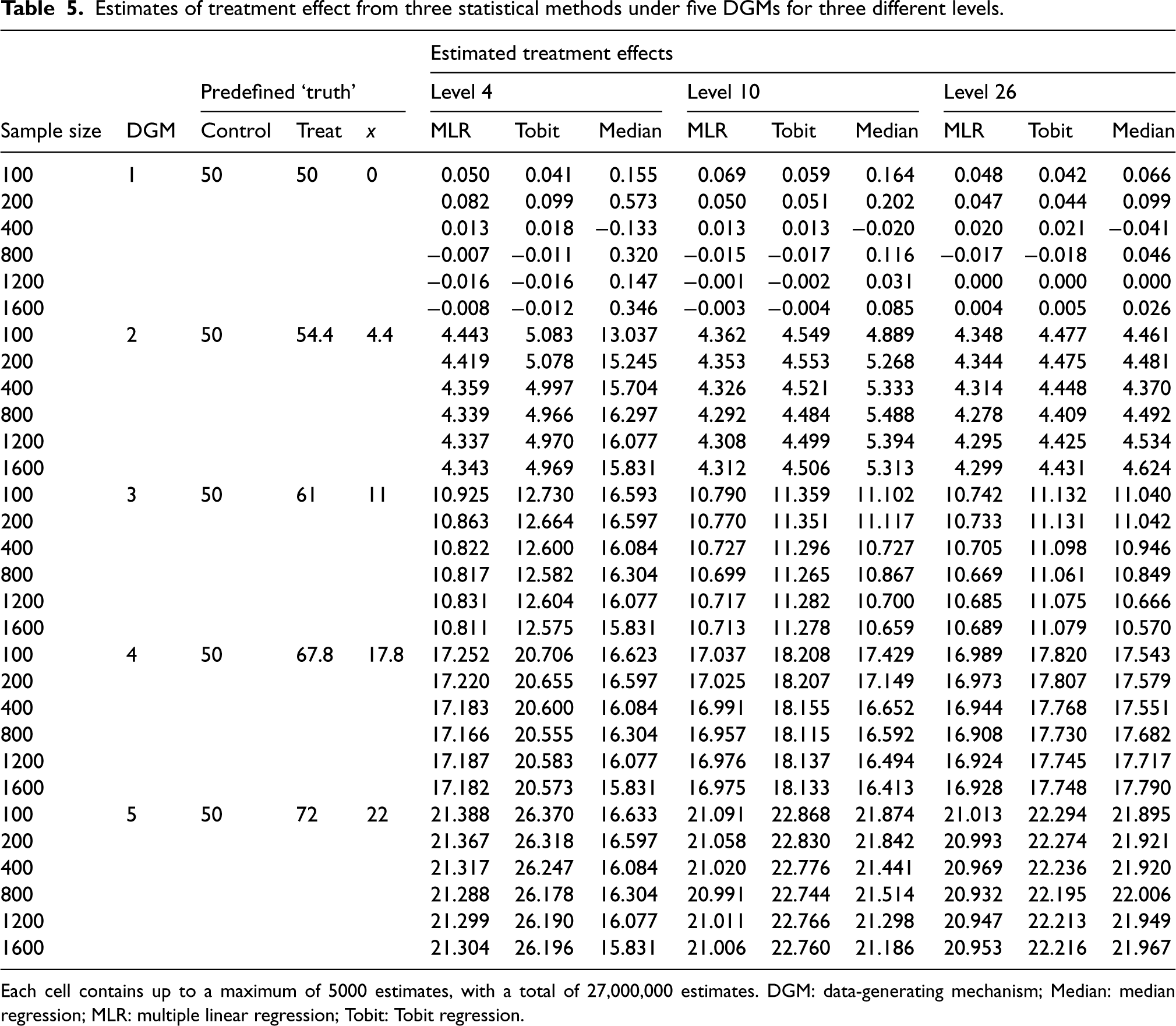
Each cell contains up to a maximum of 5000 estimates, with a total of 27,000,000 estimates. DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
Figure 2 presents the distributions of the estimated treatment effects (
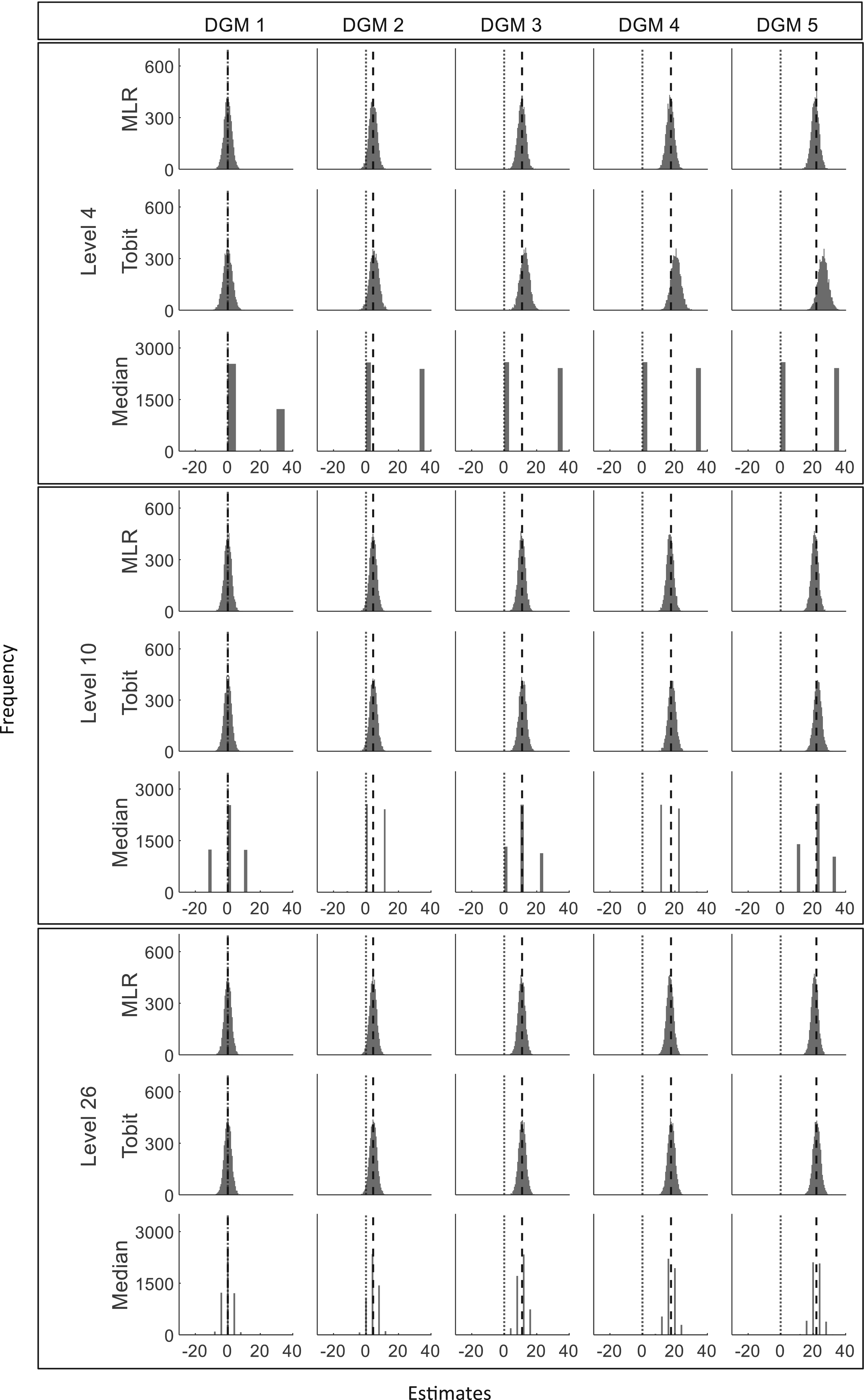
Histograms of estimates from three statistical methods for three different levels (sample size = 400). DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression. Note that different scales for the y-axis are used for MLR/Tobit and Median. The vertical dotted line represents estimates of 0 and the dashed line represents the predefined ‘truth’ of 0, 4.4, 11, 17.6, and 22 under five DGMs.
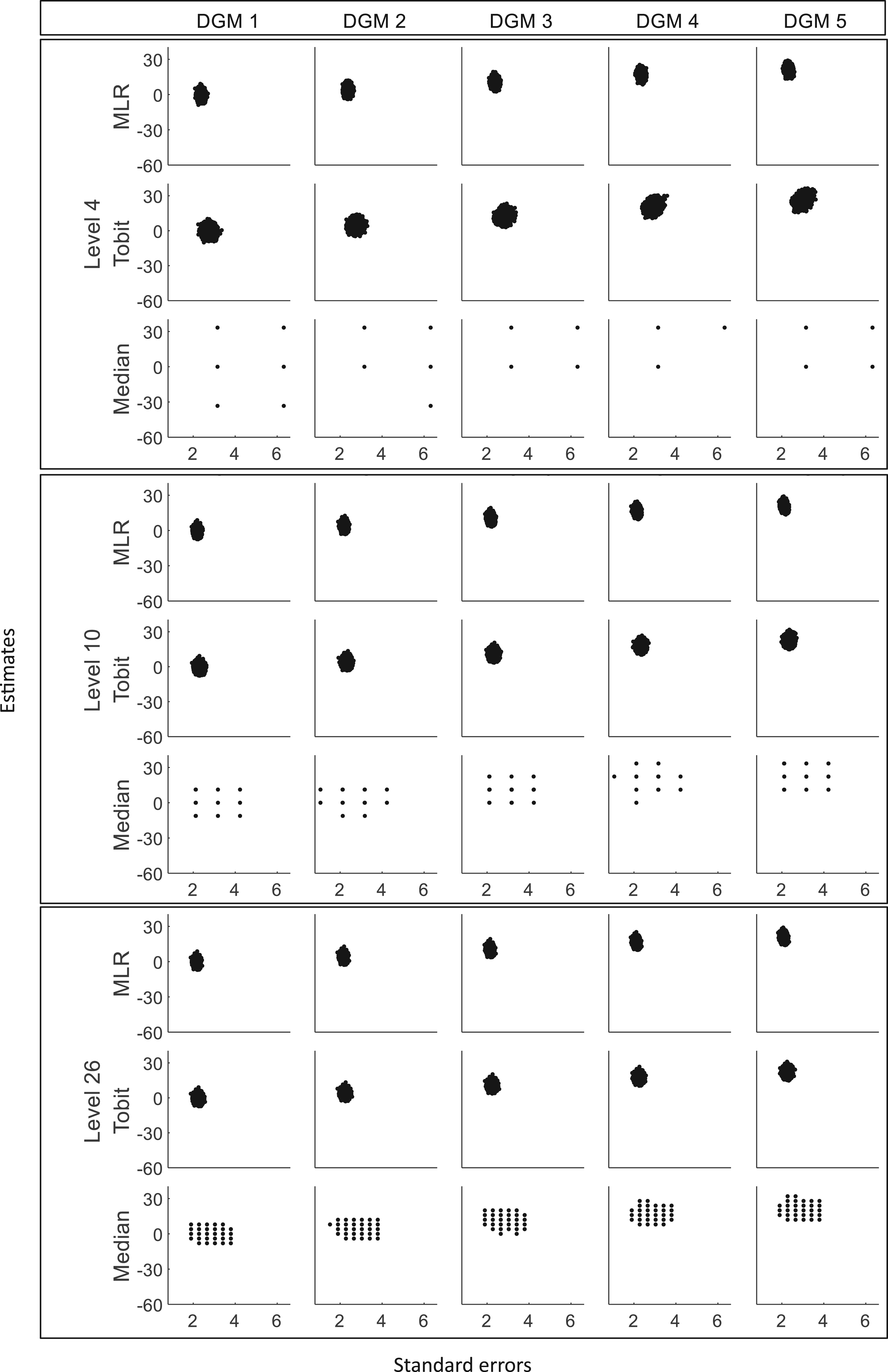
Scatterplots of estimates against standard errors for three different levels (sample size = 400). DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
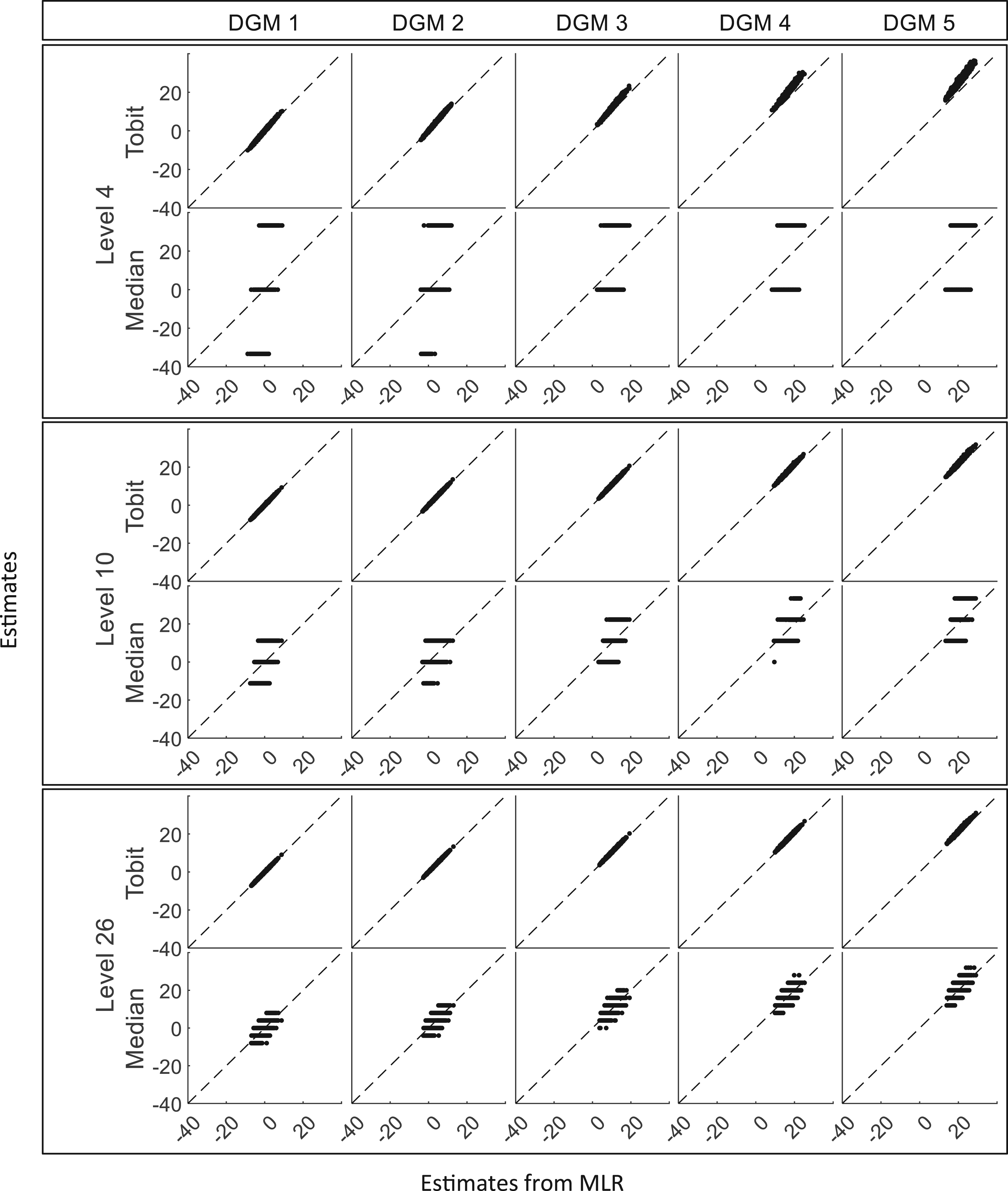
Scatterplots of estimates from Tobit and Median against estimates from MLR for three different levels (sample size = 400). DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
The key performance measures include the bias that measures the accuracy of these statistical methods for estimating the true treatment effect, the coverage of 95% CI for including the true treatment effect, MSE, EmpSE, and the power or Type I error that measures the precision or the robustness of these methods.
Figure 5 presents the change in bias of these three methods under the null hypothesis (DGM 1) and the alternative hypothesis (DGM 2–5). When the predefined ‘truth’ is zero, these methods were able to produce estimates close to the predefined ‘truth’. Their estimates fluctuated and gradually converged to the dashed line (bias = 0) with the increase in sample sizes. Median presented a larger bias than other methods, especially for PROs with a small number of levels. When analysing a small number of levels, especially level 4, Tobit tended to overestimate the treatment effect, and MLR tended to underestimate the treatment effect, but Tobit was more biased than MLR. However, when analysing a higher number of levels, the bias from Tobit became smaller than MLR.
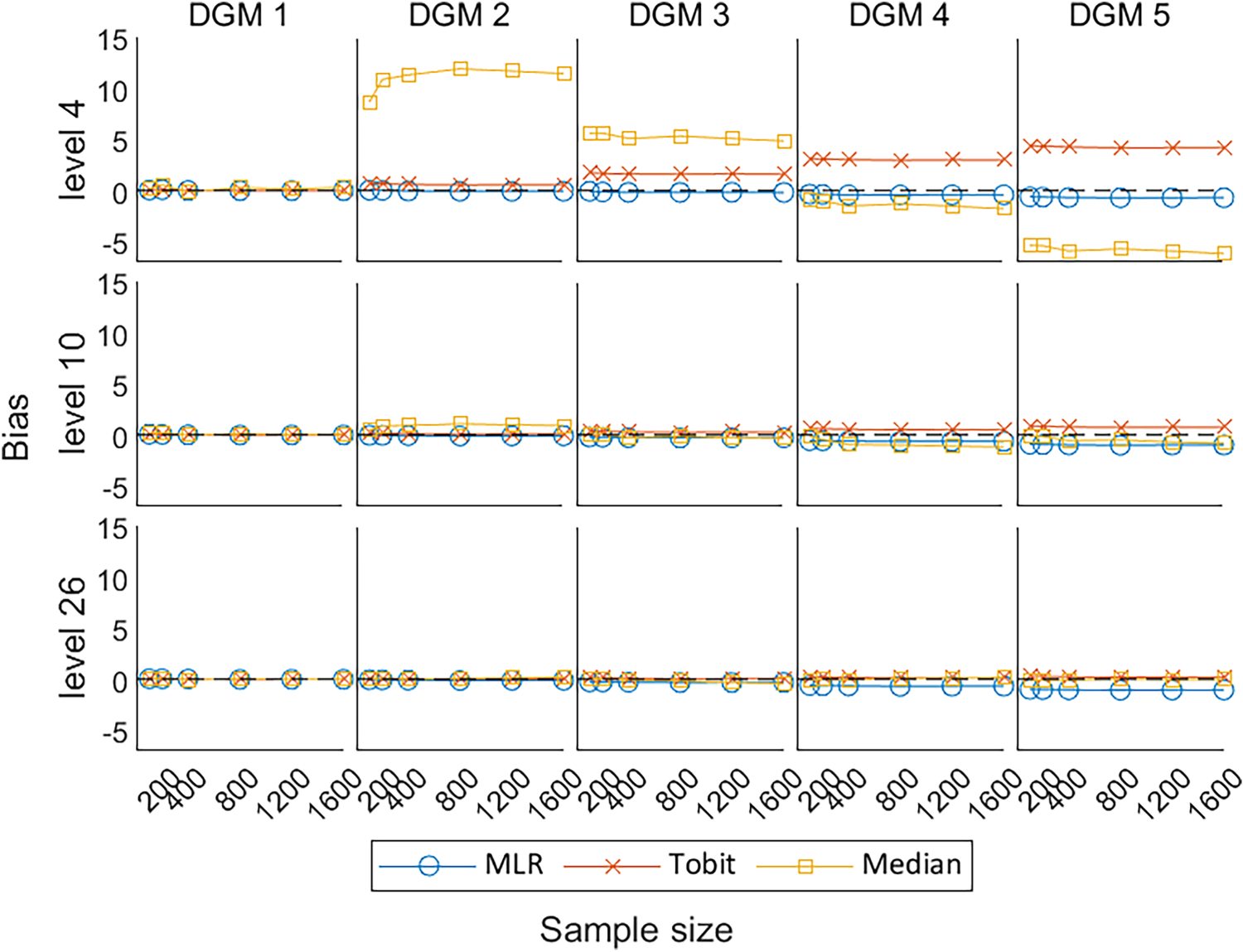
Line plots of bias for the three methods with the change of sample sizes for three different levels. DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
As shown in Figure 6, the EmpSE for MLR and Tobit remained similar under different scenarios, except that Tobit was associated with slightly higher EmpSE, i.e., less precision to the average estimates, when the number of levels is small. This indicates that Tobit was less precise than MLR for PROs with a small number of levels (i.e. level 4). Median tended to have less EmpSE and converge to the trend for MLR and Tobit, when analysing PROs with more number of discrete values (i.e. levels 10 and 26). Although the EmpSE of Median dropped dramatically with the increase in the number of levels, Median had the worst precision in comparison with MLR, and Tobit in all scenarios.
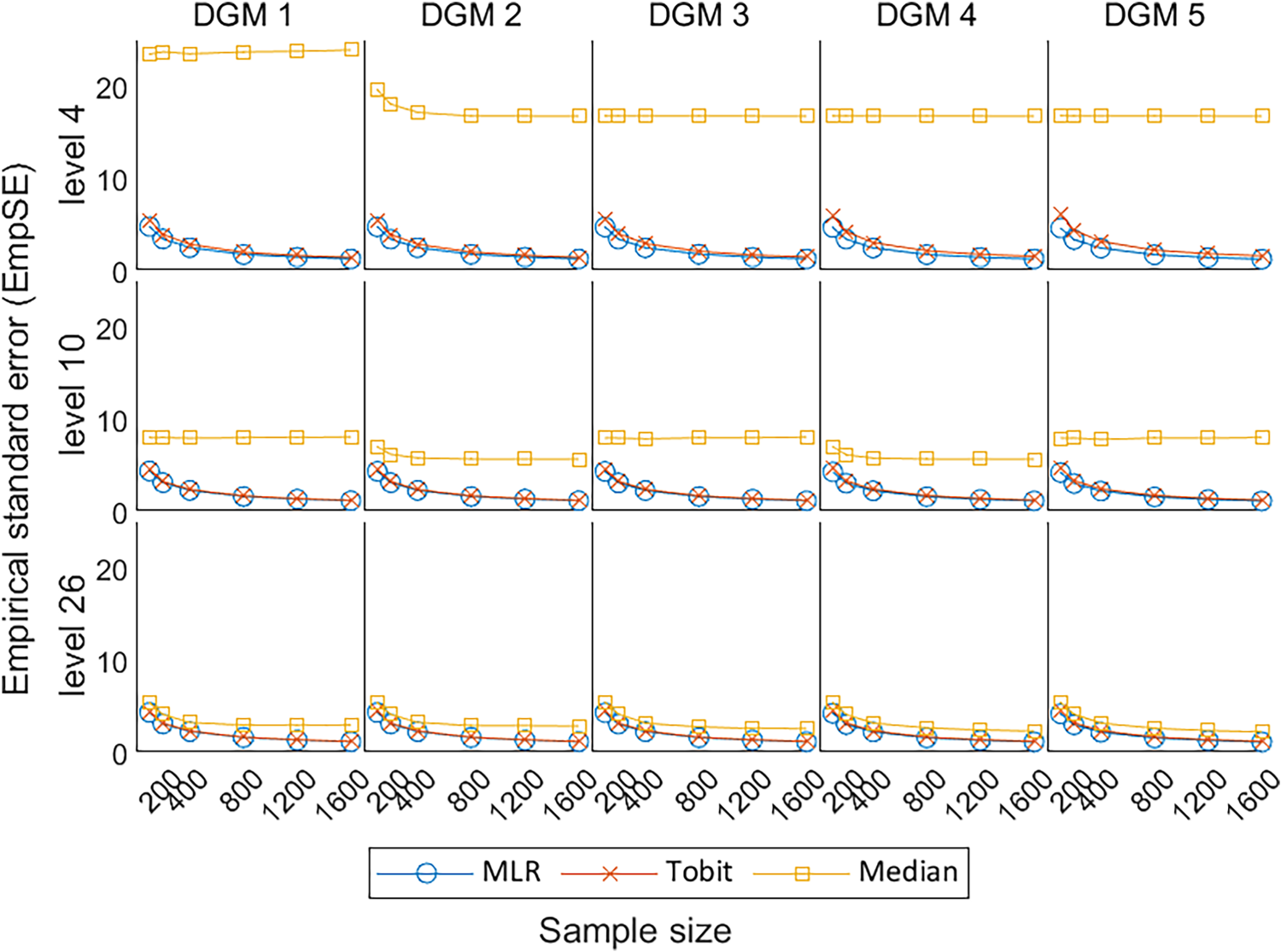
Line plots of EmpSE for the three methods with the change of sample sizes for three different levels. EmpSE: empirical standard error; DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
Under the null hypothesis, the MSE estimated by the MLR and Tobit are similar to each other, decreasing with the increase in sample size, and converges to the dashed line representing MSE = 0; whereas Median presents comparatively high MSE (Figure 7). Under the alternative hypotheses, MLR and Tobit show similar trends, with Tobit having a slightly larger MSE for level 4 but a smaller MSE for level 26 when the predefined ‘truth’ was large (i.e. under DGM 4 and 5). This indicates that Tobit was less precise than MLR for a small number of levels (i.e. level 4), but more precise than MLR for a large number of levels (i.e. level 26). Despite the MSE of Median decreasing dramatically with the increase in the number of levels, Median had the worst precision in comparison with MLR and Tobit in all scenarios.
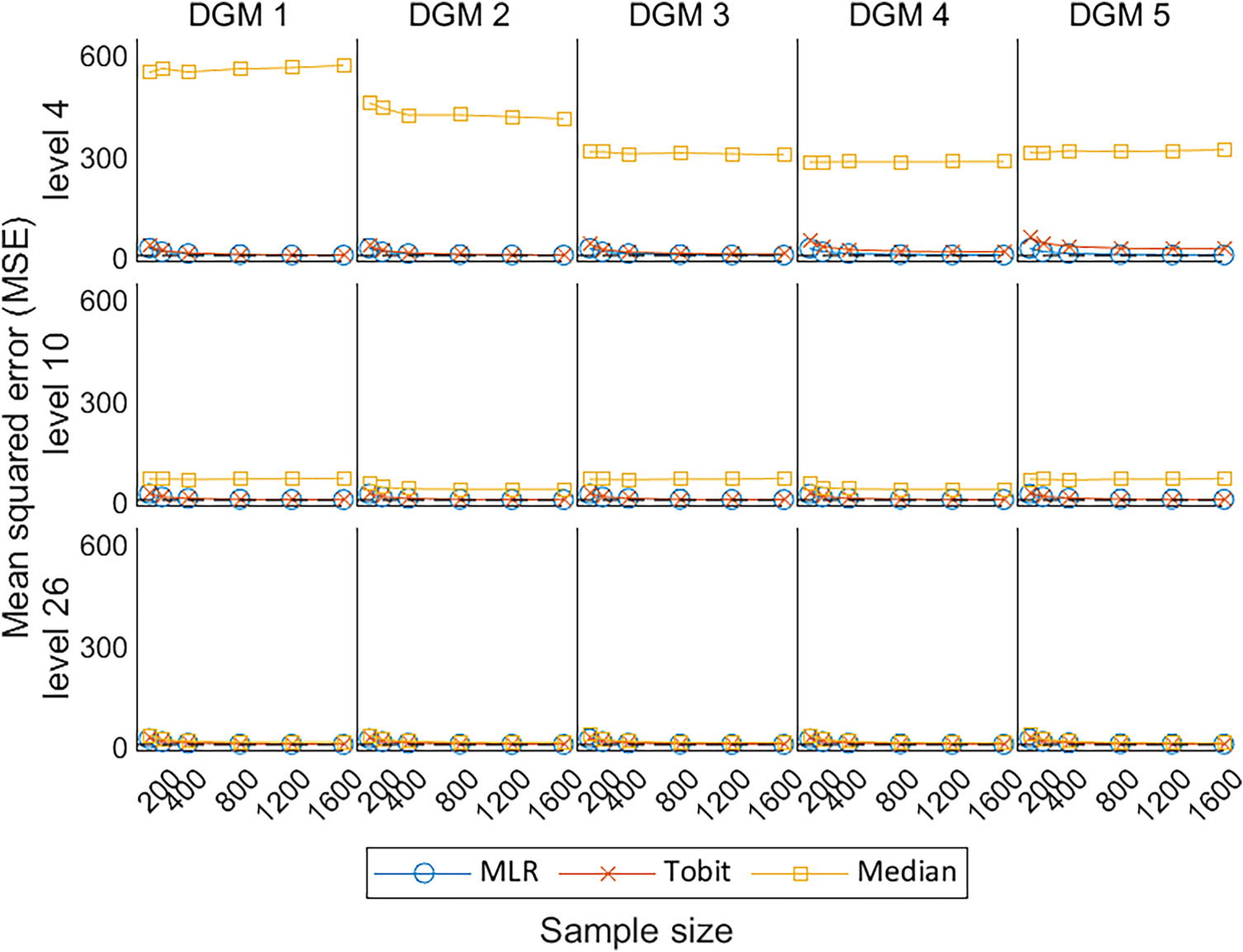
Line plots of MSE for the three methods with the change of sample sizes for three different levels. MSE: mean squared error; DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
Figure 8 shows the coverage of 95% CI for
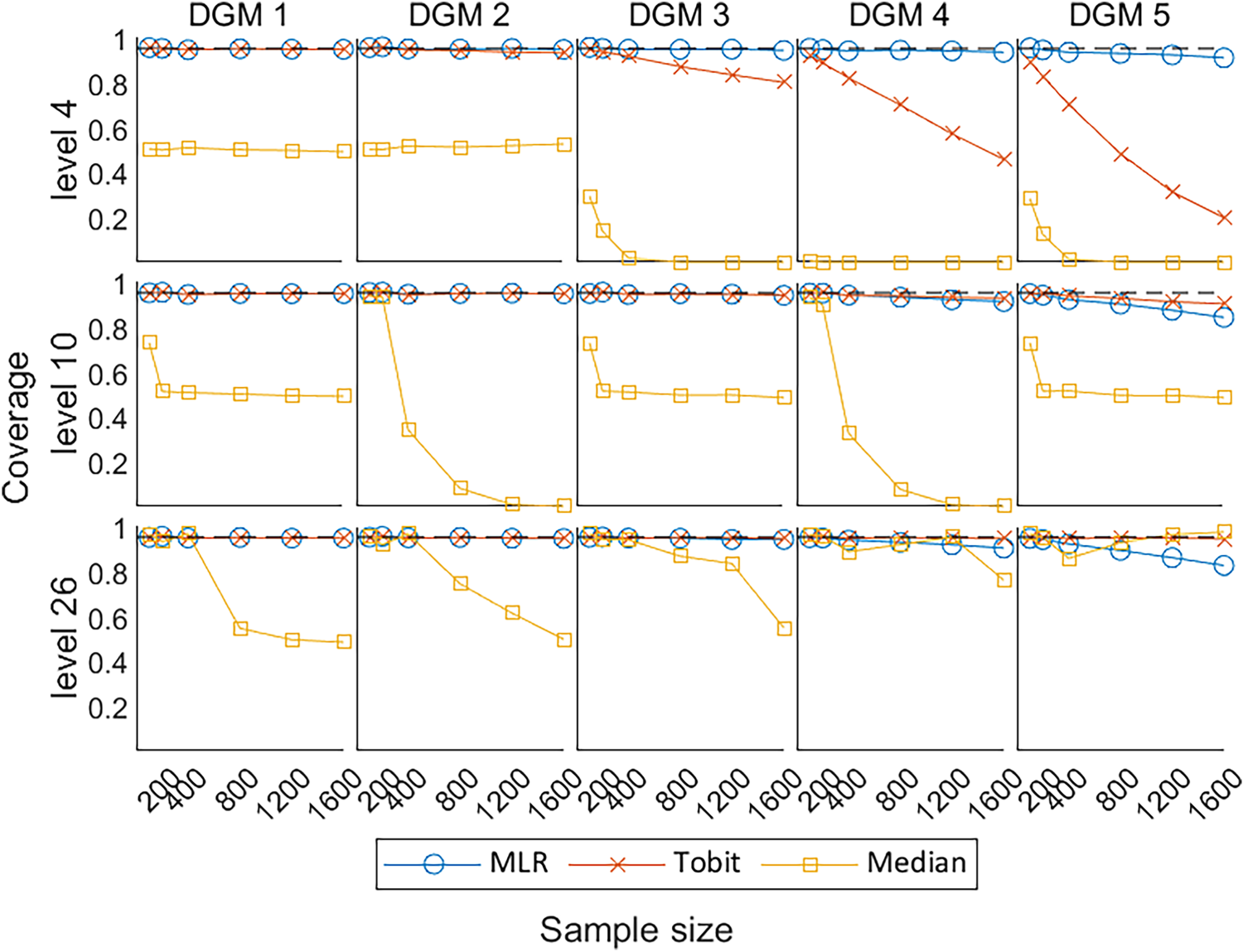
Line plots of coverage of 95% CIs with the change of sample sizes for three different levels. CIs: confidence intervals; DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
Figure 9 shows the Type I error under the null hypothesis of no treatment effect (DGM 1) and power under the alternative hypothesis of a variety of predefined non-zero treatment effects (DGM 2–5) for
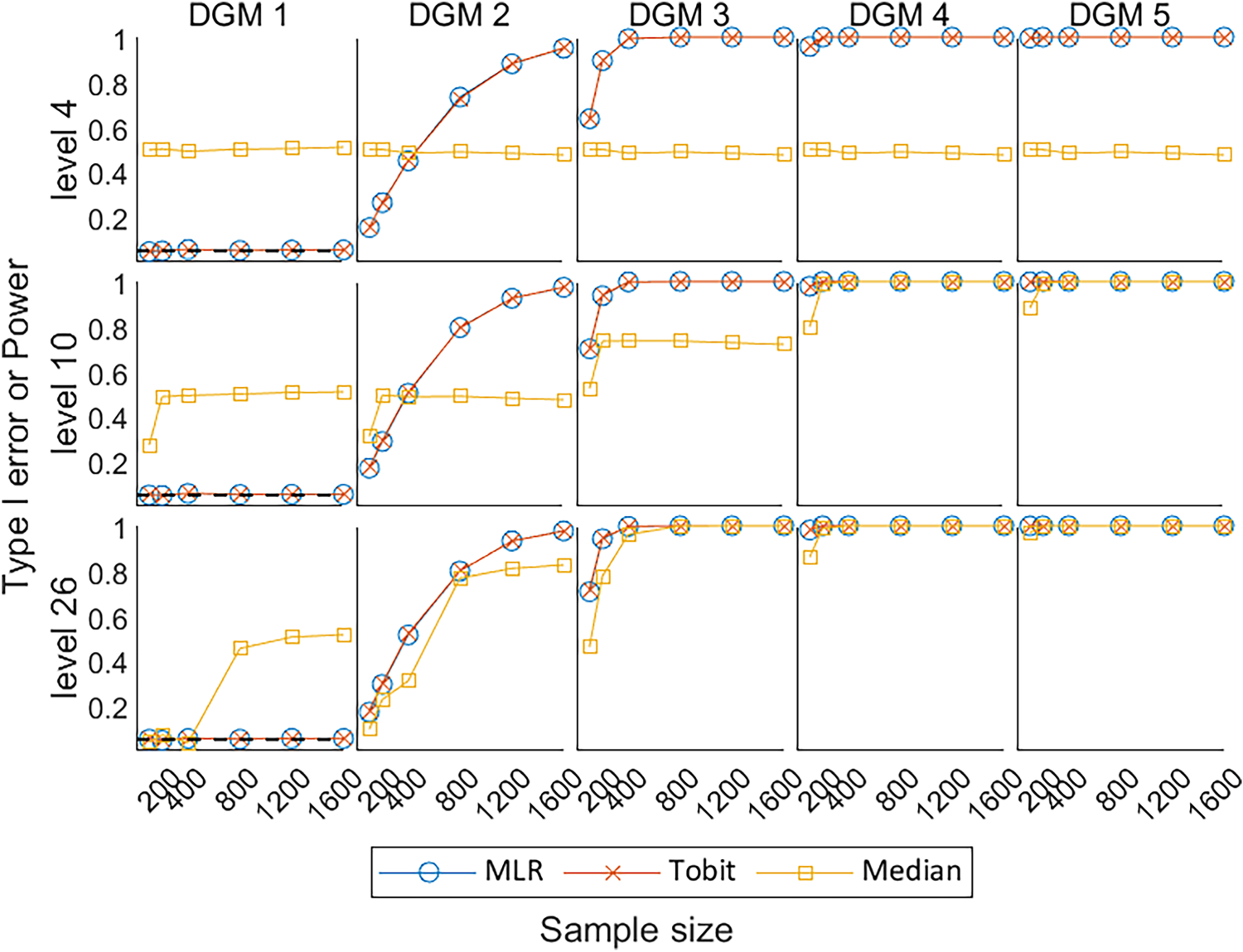
Line plots of Type I error under the null hypothesis (DGM 1) and power under the alternative hypothesis (DGM 2–5) with the change of sample sizes for three different levels. DGM: data-generating mechanism; Median: median regression; MLR: multiple linear regression; Tobit: Tobit regression.
This article compared the model performances of three statistical methods (i.e. MLR, Tobit, and Median) in estimating the predefined treatment effects of PROs with different number of discrete values (i.e. levels 4, 10, and 26) under a range of scenarios in RCT settings, using Monte Carlo simulation methods.
The key performance measures of the three statistical methods were compared, i.e. bias, coverage, EmpSE, MSE, Type I error, and power. MLR performed better than other methods when analysing simulated PRO datasets in RCT settings with a wide range of possible dimension levels. It was associated with little bias in the estimate, small EmpSE, and appropriate coverage of 95% CI compared to Median and Tobit under most scenarios. Tobit had a slightly smaller bias with its coverage of 95% CI closer to the 0.95 reference line than MLR when the predefined treatment effect was large (i.e. DGM 5) for levels 10 and 26. However, it had a larger bias and worse coverage than MLR when the number of possible discrete values was small (i.e. level 4). Median showed extremely large bias and errors, associated with low power and coverage compared to other statistical methods for most scenarios, especially under level 4.
MLR is recommended as the universal statistical method for the analysis of latent continuous PRO dimension scores with equally spaced scoring in balanced two-arm RCT settings. This recommendation is a trade-off on various aspects of the model performance in the simulation analysis and technical details of these methods, and we believe that the same statistical method is preferred for the analysis of all dimension scores in a multidimensional PRO such as SF-36 if applicable. MLR is also recommended by other studies that compared different sets of statistical methods for PRO analysis.20,33,34 From a medical statistician's point of view, MLR requires no transformation of the response variable, it produces point estimates that are based on the untransformed scale of measurement and are easy to interpret, and is a robust method when faced with the violation of model assumptions,35,36 particularly when the population mean and difference in population means between the randomised groups is an appropriate population-level summary measure of the treatment effect. From a health economist's point of view, the mean treatment effect in a PRO is commonly used for the calculation of incremental cost-effectiveness ratio, which represents the additional cost of one unit increase in a PRO to inform the results of a cost-effectiveness analysis, compared to other population-level summary measures such as medians or odds ratios. 37
Tobit is recommended to analyse PROs when the treatment effect is believed to be very large and when the PRO is less discrete (i.e. at least 10 levels). Tobit is known to be consistent and efficient under the Normality assumption of residuals and homoscedasticity.11,38 When analysing a small number of levels, especially level 4, Tobit tended to overestimate the treatment effect, and MLR tended to underestimate the treatment effect, but Tobit produced more biased estimates than MLR. The undercoverage of Tobit under level 4 can result from bias, heteroscedasticity, or non-Normality. 20 Tobit had better model performance for the analysis of PRO data with more possible values (i.e. levels 10 and 26), which is evident by previous studies.11,38 It is worth noting that the application of Tobit requires an additional premise that the PRO scores exceeding the lower and upper limits are believed to be meaningful.
Censored least absolute deviations (CLAD) regression that generates latent median estimates can be used as a substitute for Tobit regression when analysing a PRO with a ceiling effect. Austin (2002) compared Tobit, Median, and CLAD for analysing health utility index (HUI) scores 19 in a large sample, of 14,460 subjects, from a non-randomised cross-sectional design, and found that Median and CLAD tend to produce estimates with similar patterns and their estimates tend to be shrunk to zero compared to MLR and Tobit regression. They found conflicting evidence of the effect of a binary outcome (gender) and the PRO and because this was an empirical study, the true effect (of gender) was unknown. Austin 19 recommended the use of CLAD for its low predictive accuracy in practice and its robustness to heteroscedasticity and non-Normality of errors theory. This differs from our recommendations, as our focus is to generate simulated datasets of continuous latent PROs with equally spaced scoring to compare statistical methods that generate means or medians as the population-level summary measure for the purpose of estimating robust and reliable treatment effect estimates instead of making predictions. In an empirical analysis comparing several statistical methods (including CLAD) for the analysis of PROs using three RCTs, we found that the CLAD, as a censored form of Median, was not computationally efficient and took extra time to run compared to other methods. This is because it requires compulsory bootstrapping techniques to estimate the standard errors and hence an additional stage to calculate the p-values and CIs, which would complicate the simulation with an extra layer of resampling.
Although Median, a non-parametric statistical method, theoretically makes no assumption about the distributions of the outcome variable, it has been found to fail when the outcome variable is discrete. 39 Some degree of smoothness should be artificially imposed to apply quantile regression to ordered data, such as adding uniformly distributed noise to the ordered data. 40 This explains why the simple median regression produced unsatisfactory estimates in striped patterns with poor performance when analysing the small number of possible levels in the empirical analysis and the simulation analysis.
Previous studies11,19,20,23 have compared various statistical methods for the analysis of different types of PROs, but these studies focused on various groups of methods, proposed different DGMs, and made inconsistent recommendations on what statistical methods are more appropriate to use.
We agree with Bottomley et al. 41 that establishing predefined criteria to assess statistical methods used in PRO analysis is crucial for making scientifically informed choices. The choice of statistical methods for analysing PROs depends on multiple factors, including the nature of the outcome variable, the adherence of the data to the method assumptions, and the criteria set for method evaluation by different stakeholders. The study design and the research question are the fundamental factors and can influence the selection of a statistical method, for example, whether the PRO is believed to be measuring an underlying latent variable, and whether the underlying latent variable is believed to be fundamentally continuous or discrete; whether the study design requires the adjustment for clustering, time effects, or unbalanced data; and whether the PRO analysis is to be used for making predictions, estimating a treatment effect, or measuring influencing factors. These factors vary study-by-study and need to be carefully considered when researchers are making the decision on what statistical methods to use.
This study compared three commonly used or proposed statistical methods for the analysis of PROs under multiple scenarios, with a thorough comparison of the performance measures of these included methods. The recommendation of this paper is based on the technical details of these methods, and their performance in the simulation analysis, with the aim of estimating the treatment effect of the latent continuous PROs with equally spaced discrete scores ranging from 0 to 100 under a two-arm balanced design RCT. The outcomes can be extrapolated to other popular PROs similar to SF-36 that focus on functions in the domains of health assessed, such as the European Organization for the Research and Treatment of Cancer Quality of Life Questionnaire (EORTC QLQ-C30), 42 Beck Depression Inventory (BDI), 43 and Hospital Anxiety and Depression Scale (HADS). 44
However, the appropriateness of recommending MLR or Tobit to analyse extremely skewed distribution with ceiling effects needs to be investigated further. The extreme skewness and ceiling effects are commonly seen in preference-based PROs that typically apply weights based on patients’ preferences through attached algorithms to generate health utility scores such as Short Form 6-Dimensions (SF-6D), 45 Health Utilities Index (HUI), 46 and EuroQol-5 Dimension (EQ-5D). 47 When the PRO scores are extremely skewed with ceiling effects, the proportions or odds ratios might be a better population-level summary measure of the treatment effect in RCTs, than differences in measures of central locations such as means or medians. In these circumstances, the use of MLR or Tobit that produces mean estimates may be flawed. Utilising the estimand framework, statistical methods such as the beta-binomial or ordinal regression have a different estimand (where the population-level summary measure is an odds ratio rather than a difference in means) to MLR and Tobit, and compare the outcomes between treatment groups in a different way. Methodological research has been published to deal with the analysis of health utility scores.11,19–24 We believe that it is interesting to discover to what extent of the skewness may alter the recommendation of using MLR to analyse PRO dimension scores, but this is outside the scope of this study.
This simulation study has the following limitations:
First, this simulation study considered 90 scenarios, i.e. five predefined treatment effects to produce PRO scores under three different numbers of levels (i.e. 4, 10, and 26), using six different sample sizes. These scenarios are not able to represent all possible distributions of PRO that would appear in an RCT setting. However, the selection of these parameters was evidence-based, and the same set of parameters were used to compare performance measures across PRO data with different levels. Second, the dilemma of this study is finding the appropriate distribution with predefined parameters that can depict the distribution of SF-36 dimension scores, which is typically bounded, skewed, and discrete. The use of Normal distribution assuming an underlying latent variable to generate simulated datasets may favour MLR and Tobit.
25
Alternatively, other distributions could be used to produce the simulated datasets,23,48 for example, the use of beta-binomial distribution to generate PRO data is seen in the simulation analysis comparing two approaches to achieve the beta-binomial regression by Najera-Zuloaga et al.,
48
but potentially it would favour the beta-binomial regression instead and produce an odds ratio as the population-level summary measure. This is outside the scope of our study. The Normal distribution is preferred to other distributions in this simulation analysis not only due to its simplicity and extensive applicability,
49
but also because we believe that the PRO is inherently continuous with no boundaries. Third, for the treatment effect we assumed a simple ‘location shift’ on the underlying latent continuous normally distributed PRO, i.e. the underlying distribution for the outcome is ‘shifted’ to the right so the mean of the new distribution is 4.4, 11, 17.8, or 22-points higher with the mean and the SD of the Normal distribution was set fixed for all scenarios. Again, this assumption may favour statistical methods that assume the outcome is continuous. If the mean was set at a higher value, the location shift would be more influenced by the ceiling effect given the current set of predefined treatment effects, i.e. there would be more values censored at the upper bound, and thus setting the mean at a higher value will make the observed treatment effects farther from the predefined value. If the mean was set at a lower value, there would be more space to move up on the scale, such that the location shift would be less influenced by the ceiling effect given the current set of predefined treatment effects, i.e. the observed treatment effects would be closer to the predefined treatment effects. In addition to the ‘location shift’, there could also be a change in the shape of the distribution. For example, when simulating from Normal distributions, the SD could be different in the two groups due to the effect of treatment. However, this simulation study only considered the simple scenario where the SD of two groups was assumed the same. The discretisation procedure is the only factor that may change the shape of the simulated PROs in this simulation besides the ceiling effect. Fourth, discretisation techniques were required in this study to simulate the discrete characteristics of the PRO data. The simulated datasets in this analysis were discretised into equally spaced values, such that whether the conclusion from this simulation is generalisable to non-equally spaced PROs needs to be further investigated. However, there is no standard way to discretise the PRO data. Also, the discretisation of the Normally distributed latent PRO into 4, 10, or 26 levels or discrete values may mean that all the statistical methods produce a slightly biased estimate of the true treatment effect as the observed differences in mean scores from the simulations show. Therefore, this discretisation procedure makes it impossible to observe the exact predefined treatment effect of 4.4, 11, 17.8, and 22 points on the underlying Normally distributed scale, except when the predefined treatment effect is set at zero under the null hypothesis.
Furthermore, this study considered a limited number of statistical methods that produce means or medians and excludes methods that produce estimates of log odds ratio such as ordinal logistic regression or beta-binomial regression. This is because the population-level summary measures of these methods are by nature different, for example, MLR produces estimates of differences in means while beta-binomial regression produces estimates in odds ratio, and strictly speaking, these methods with different population-level summary measures are not comparable. As the focus of this study is to compare statistical methods for the analysis of latent continuous PROs, with the target population-level summary measure of central tendency i.e. means or medians, some statistical methods are naturally excluded as outside the scope of our study, and the model performance of these methods for analysing PROs need to be further explored.
This article focused on a simple situation where there is a single baseline and a single post-randomisation assessment of an outcome, and compared the statistical methods that are suitable for such an analysis. Other factors that can affect the accuracy and robustness of the analysis of PRO scores, such as measurement error or missing data, are not considered. For future research, there exists an opportunity to explore statistical methods for correlated responses, strategies to deal with missing values, and techniques to estimate the clustering effect for the analysis of PROs. In addition, other distributions such as the beta distribution or beta-binomial distribution can be considered to generate the simulated dataset to investigate whether the model performance of each statistical method may change.
Conclusions
This article compared three common statistical methods for the analysis of PRO data using Monte Carlo methods in various scenarios. Considering a single baseline and a single post-randomisation assessment of an outcome, MLR shows better performance than Tobit and Median in most scenarios, and we suggest using it as the universal statistical method for the analysis of latent continuous PROs with equally spaced scoring in balanced two-arm RCT settings, especially when one statistical method is preferred to analyse multiple dimension scores, and Tobit is recommended as an alternative method if the treatment effect is believed very large. Future work involves the exploration of statistical methods for analysing PROs in more complex scenarios.
Footnotes
Acknowledgements
This work was completed during YQ's PhD study which was jointly sponsored by the University of Sheffield and the China Scholarship Council (grant number 201908890049). SJW, RMJ, and LF received funding across various projects from the National Institute for Health and Care Research (NIHR). SJW was an NIHR Senior Investigator supported by the NIHR (NF-SI-0617-10012) for this research project. The views expressed in this publication are those of the authors and not necessarily those of the China Scholarship Council, NIHR, NHS, or the UK Department of Health and Social Care. These organisations had no role in the study design; in the collection, analysis, and interpretation of the data; in the writing of the report; or in the decision to submit the paper for publication.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the China Scholarship Council, University of Sheffield, National Institute for Health and Care Research (grant number 201908890049, NF-SI-0617-10012).