
Abstract
Multivariate imputation using chained equations is a popular algorithm for imputing missing data that entails specifying multivariable models through conditional distributions. Two standard imputation methods for imputing missing continuous variables are parametric imputation using a linear model and predictive mean matching. The default methods for imputing missing categorical variables are parametric imputation using multinomial logistic regression and ordinal logistic regression for imputing nominal and ordinal categorical variables, respectively. There is a paucity of research into the relative computational burden and the quality of statistical inferences when using predictive mean matching versus parametric imputation for imputing missing non-binary categorical variables. We used simulations to compare the performance of predictive mean matching with that of multinomial logistic regression and ordinal logistic regression for imputing categorical variables when the analysis model of scientific interest was a logistic or linear regression model. We varied the sample size (N = 500, 1000, 2500, and 5000), the rate of missing data (5%–50% in increments of 5%), and the number of levels of the categorical variable (3, 4, 5, and 6). In general, the performance of predictive mean matching compared very favorably to that of multinomial or ordinal logistic regression for imputing categorical variables when the analysis model was a logistic or linear regression model. This was true across a range of scenarios defined by sample size and the rate of missing data. Furthermore, the use of predictive mean matching was substantially faster, by a factor of 2–6. In conclusion, predictive mean matching can be used to impute categorical variables. The use of predictive mean matching to impute missing non-binary categorical variables substantially reduces computer processing time when conducting multiple imputation.
Background
Multiple imputation (MI) is a statistical method for addressing missing data. 1 It involves the creation of M (M > 1) complete datasets, in which missing values have been replaced by plausible values generated using an imputation model. A separate statistical analysis is then conducted in each of the M complete datasets, and the results are pooled across the M complete datasets. The foundation of MI is an algorithm for generating plausible values to replace missing observations.
Fully conditional specification (FCS) is an MI algorithm that specifies multivariable models through conditional distributions (e.g. for a continuous variable that is subject to missingness [e.g. weight], the distribution of weight conditional on other variables [e.g. age, sex, education, etc.] is determined using a linear regression model using the other variables as predictors). A popular algorithm for implementing FCS is the MI using chained equations (MICE) algorithm, in which each variable is imputed conditional on all other variables.2–5 Thus, linear regression can be used for imputing continuous variables (e.g. weight), logistic regression can be used for imputing binary variables (e.g. presence or absence of diabetes), a multinomial logistic regression model can be used for imputing missing nominal (or unordered) categorical variables (e.g. race), and an ordinal logistic regression model can be used for imputing missing ordinal (or ordered) categorical variables (e.g. cancer stage). We refer to this approach as parametric imputation, as the imputed values are generated from a parametric statistical model.
The algorithm for parametric imputation for missing nominal categorical data using a multinomial logistic regression model can be described as follows (see Algorithm 3.3 in the cited reference) 2 : first, using subjects with complete data, one estimates the regression coefficients for the multinomial logistic regression model that is being used as the imputation model. The parameters of the multinomial logistic regression model and its variance-covariance matrix are estimated using iteratively reweighted least squares (IRLS). Second, one draws a set of regression coefficients for the imputation model from the posterior distribution of regression coefficients using the quantities obtained in the first step. Third, for each subject for whom the categorical variable is missing, one estimates Pr(Z = j), for j = 1, …, K (where Z denotes the K-level categorical variable that is being imputed), using the regression coefficients obtained in the second step and the set of predictor variables in the imputation model, followed by a random draw from the categories based on the subject's K probabilities. Before fitting the model, the data are augmented, as suggested by White et al., 6 to avoid problems with perfect separation. A similar approach imputes ordinal variables using ordinal logistic regression under the additional assumption that the categories are ordered.
When variables are continuous, predictive mean matching (PMM) is a fast and robust alternative to parametric imputation using a linear model. 2 For a subject with missing data on a given variable, PMM identifies those subjects with no missing data on that variable whose linear predictors (computed using the regression coefficients from the fitted imputation model) are close to the linear predictor of the given subject (created using the regression coefficients sampled from the appropriate posterior distribution). Of those subjects who are close, one subject is selected at random, and the observed value of the given variable for that randomly selected subject is used as the imputed value of the variable for the subject with missing data.
It was recently shown that PMM could also be used to impute missing binary variables by treating the binary variable as a continuous variable and that inferences obtained about the coefficients of the analysis model when using PMM were essentially identical to inferences obtained when using a conventional logistic regression model as the imputation model. 7 Using PMM to impute incomplete binary variables was about three times faster than parametric imputation using a logistic regression model. Computation time is related to the estimation method. PMM fits an imputation model using ordinary least squares regression. The regression coefficients and their variance-covariance matrix can be estimated using closed-form expressions. In contrast, imputation using logistic regression fits the imputation model using IRLS, an iterative procedure. Thus, the estimation of the regression coefficients and the associated variance-covariance matrix takes more processing time for the logistic imputation model than for the linear imputation model. Due to the iterative nature of FCS, the reduction in processing time when using PMM rather than logistic regression can be substantial.
The mice package for the R statistical programming language is one of the most frequently used software packages for implementing MI. The default imputation models for ordinal and nominal categorical variables are ordinal logistic regression and multinomial logistic regression, respectively. While van Buuren and Groothuis-Oudshoorn suggested that PMM could be a faster alternative to multinomial logistic regression for imputing nominal categorical variables, they provided no evidence on the performance of using PMM for this purpose.5 Indeed, there is a paucity of information on the relative performance of PMM compared with multinomial logistic regression and ordinal logistic regression for imputing categorical variables.
The mice version 3.16.4 package added new functionality for using PMM to impute ordinal and nominal categorical variables. Before 3.16.4, PMM with categorical data employed the internal integer codes of categorical variables as the dependent variable in the imputation model. With ordinal variables, these levels are monotonically related to the order of the categories, which approaches the numerical case when the inter-category distances can be considered constant. However, for nominal variables, the integer codes are in alphabetic order by default and have no sensible interpretation. The new functionality quantifies the categories by optimizing the canonical correlation between the dummy-coded version of the incomplete variable and the predictors of the imputation model. 8
The quantification process works as follows. Let
The quantification method transforms the relationships in the imputation model into a linear framework, facilitating the association between the incomplete variable and its predictors. Since the transformation is derived from the subset of observed outcomes, it inherently assumes a MAR mechanism. While the imputed values always retain the original category order, the quantification method allows for a different internal ordering within the imputation model. If a strict ordinal structure is required, this flexibility can be constrained using monotone regression. However, enforcing monotonicity may introduce additional noise in the imputations.
After quantification, the imputation model is fitted, and the predicted values from that model are used to measure the similarity of predictive matches. Apart from being faster, the method is expected to be insensitive to the order of categories of nominal variables and to avoid problems related to perfect prediction. However, the relative quality of the inferences about the regression coefficients of the analysis model is not known.
Nominal categorical variables are common when describing individuals’ demographic characteristics, with examples including race (e.g. White, Black, Asian, and Other), marital status (e.g. never married, married, widowed, and divorced), and job category. Nominal categorical variables occur frequently in medical and epidemiological research, with examples including blood type and smoking status (e.g. current smoker vs. recent smoker vs. former smoker vs. never smoker). Similarly, ordinal categorical variables are common (e.g. cancer stage or symptom severity). Given the abundance of nominal and ordinal categorical variables and the high rates of missing data across all research disciplines, it is imperative to determine the optimal method for imputing incomplete categorical data.
Given the importance of nominal and ordinal categorical variables across a wide range of research disciplines, we sought to answer two questions: first, what is the relative difference in computational efficiency between PMM and multinomial and ordinal logistic regression when imputing missing nominal and ordinal categorical variables. Second, to compare the quality of statistical inferences between using PMM and multinomial logistic regression for imputing nominal categorical data, and between using PMM and ordinal logistic regression for imputing ordinal categorical data. As a test case, we considered scenarios in which the analysis model of scientific interest is either a logistic regression model or a linear regression model, and a categorical explanatory or predictor variable is subject to missingness. The article is structured as follows. In Section 2, we provide an empirical case study comparing the performance of PMM with multinomial logistic regression for imputing a nominal categorical variable (smoking history) in a large sample of patients hospitalized with acute myocardial infarction (AMI or heart attack). Section 3 describes the design of a complex series of Monte Carlo simulations to address the study objectives. The design of the Monte Carlo simulations was informed by empirical analyses conducted in patients hospitalized with AMI. In Section 4, we report the results of these simulations. Finally, in Section 5, we summarize our findings and place them in the context of the existing literature.
Case study—Individuals hospitalized with AMI
We provide a case study to compare the performance of PMM with that of multinomial logistic regression for imputing a nominal categorical variable when the analysis model of scientific interest is a multivariable logistic regression model. The scientific question is, in patients hospitalized with an AMI, what is the independent association between an individual's smoking history (categorized as current smoker, former smoker, recent smoker, and never smoker) and the risk of death within one year of hospital admission after adjusting for demographic and presentation characteristics, vital signs on presentation, classic cardiac risk factors, comorbid conditions, and laboratory tests.
Data
We used data on 11,506 patients hospitalized for AMI at 102 hospitals in Ontario, Canada, between 1 April 1999 and 31 March 2001. These data were collected as part of the Enhanced Feedback for Effective Cardiac Treatment study, an initiative designed to improve the quality of cardiac care in Ontario. 12 Data were collected on demographic characteristics (age and sex); presentation characteristics (cardiogenic shock and acute congestive heart failure/pulmonary edema); vital signs on presentation (systolic blood pressure, diastolic blood pressure, heart rate, and respiratory rate); classic cardiac risk factors (diabetes, hypertension, smoking history, dyslipidemia, and family history of coronary artery disease); comorbid conditions (cerebrovascular disease [i.e. stroke], angina, cancer, dementia, peptic ulcer disease, previous AMI, asthma, depression, peripheral vascular disease, previous revascularization, congestive heart failure, hyperthyroidism, and aortic stenosis); and laboratory tests (hemoglobin, white blood count, sodium, potassium, glucose, urea, and creatinine). Age, the four vital signs on presentation, and the seven laboratory tests were continuous. Smoking history was a four-level nominal categorical variable: never smoker versus current smoker versus recent smoker, versus former smoker. The remaining variables were binary variables. In the current case study, the outcome was a binary variable denoting death within one year of hospital admission. Two thousand three hundred and eight (20.0%) individuals died within one year of hospital admission.
Forty-five percent of individuals had missing data on at least one of the variables listed above. Except for age and sex (which were available from provincial registries), all variables were subject to missingness. Smoking history was missing for 14.6% of subjects. Of those with an observed smoking history variable, 3320 (33.8%) were never smokers, 3729 (38.0%) were current smokers, 2579 (26.3%) were former smokers, and 194 (2.0%) were recent smokers.
Statistical analyses
The analysis model of scientific interest was a logistic regression model in which the binary variable denoting death within one year of hospital admission was regressed on all the other variables listed above.
We used MI to create 45 complete datasets (the number of complete datasets was set equal to the percentage of subjects with any missing data 3 ). PMM was used to impute the missing continuous and binary variables, while multinomial logistic regression was used to impute missing values of smoking history, which was a nominal four-level categorical variable. For each variable that was subject to missingness, the imputation model included all the other variables listed above, including the binary outcome for the scientific model of interest. 3
In each of the 45 complete datasets, we regressed the binary outcome variable denoting death within one year of hospital admission on all the other variables listed above using a logistic regression model. For each variable, the estimated regression coefficients and associated standard errors were pooled across the 45 complete datasets using Rubin's rules.
We then repeated the entire process using PMM to impute all variables that were subject to missingness, including the four-level nominal categorical variable denoting smoking history.
R code for the analyses conducted in this case study is available in the first author's GitHub repository [https://github.com/peter-austin/2025-SMMR-PMM_imputing_categorical_variables].
Results
Creating the 45 complete datasets required 52.0 min when using multinomial logistic regression to impute smoking history and 22.9 min when using PMM to impute smoking history (using slurm jobs limited to 1 CPU and 4 GB of memory on a grid of compute servers [8 vCPUs – Intel Xeon CPU E5-2643 v3 at 3.40 GHz, 128GB per node], running RedHat 7). Thus, the use of multinomial logistic regression required ∼2.3 times more time than did PMM.
After using multinomial logistic regression to impute smoking history, the pooled prevalence of the four levels of smoking history across the 45 complete datasets were 35.2% (never smoker), 36.3% (current smoker), 26.6% (former smoker), and 1.9% (recent smoker). Identical estimates of the pooled prevalences were obtained when using PMM to impute smoking history. Thus, using PMM instead of multinomial regression did not change the estimated prevalence of each of the four categories of smoking history.
The estimated odds ratios (obtained by exponentiating the pooled estimates of the regression coefficients) and their associated 95% confidence intervals for all the variables in the logistic regression model are reported in Table 1. In our discussion of the results, we focus on the estimated odds ratios for smoking history. When using multinomial logistic regression to impute smoking history, the estimated odds ratio for being a current smoker at the time of hospital admission was 1.177 (95% CI: 0.999–1.386). Thus, being a current smoker at the time of hospital admission was associated with a 17.7% increase in the odds of death within one year compared with those who had never smoked. The estimated odds ratio for being a former smoker was 0.991 (95% CI: 0.846–1.161). Thus, being a former smoker was associated with a 0.9% decrease in the odds of death within one year compared with those who had never smoked. The estimated odds ratio for being a recent smoker was 1.200 (95% CI: 0.743–1.941). Thus, being a recent smoker was associated with a 20.0% increase in the odds of death within one year compared to those who had never smoked. All three 95% confidence intervals contained the null value; thus, none of these estimated relative changes in the odds of death were statistically significantly different from the null. When using PMM to impute smoking history, the estimated odds ratio for being a current smoker at the time of hospital admission was 1.193 (95% CI: 1.004–1.416). Thus, being a current smoker at the time of hospital admission was associated with a 19.3% increase in the odds of death within one year compared with those who had never smoked. The estimated odds ratio for being a former smoker was 1.042 (95% CI: 0.892–1.218). Thus, being a former smoker was associated with a 4.2% increase in the odds of death within one year compared with those who had never smoked. The estimated odds ratio for being a recent smoker was 1.259 (95% CI: 0.780–2.031). Thus, being a recent smoker was associated with a 25.9% increase in the odds of death within one year compared to those who had never smoked. The 95% confidence intervals for two of the levels of smoking history included the null value. While the estimated odds ratios were not identical between the two imputation approaches, the estimated odds ratios and their associated 95% confidence intervals were qualitatively similar between the two imputation approaches.
Estimated odds ratios and 95% confidence intervals for patient characteristics in the case study.
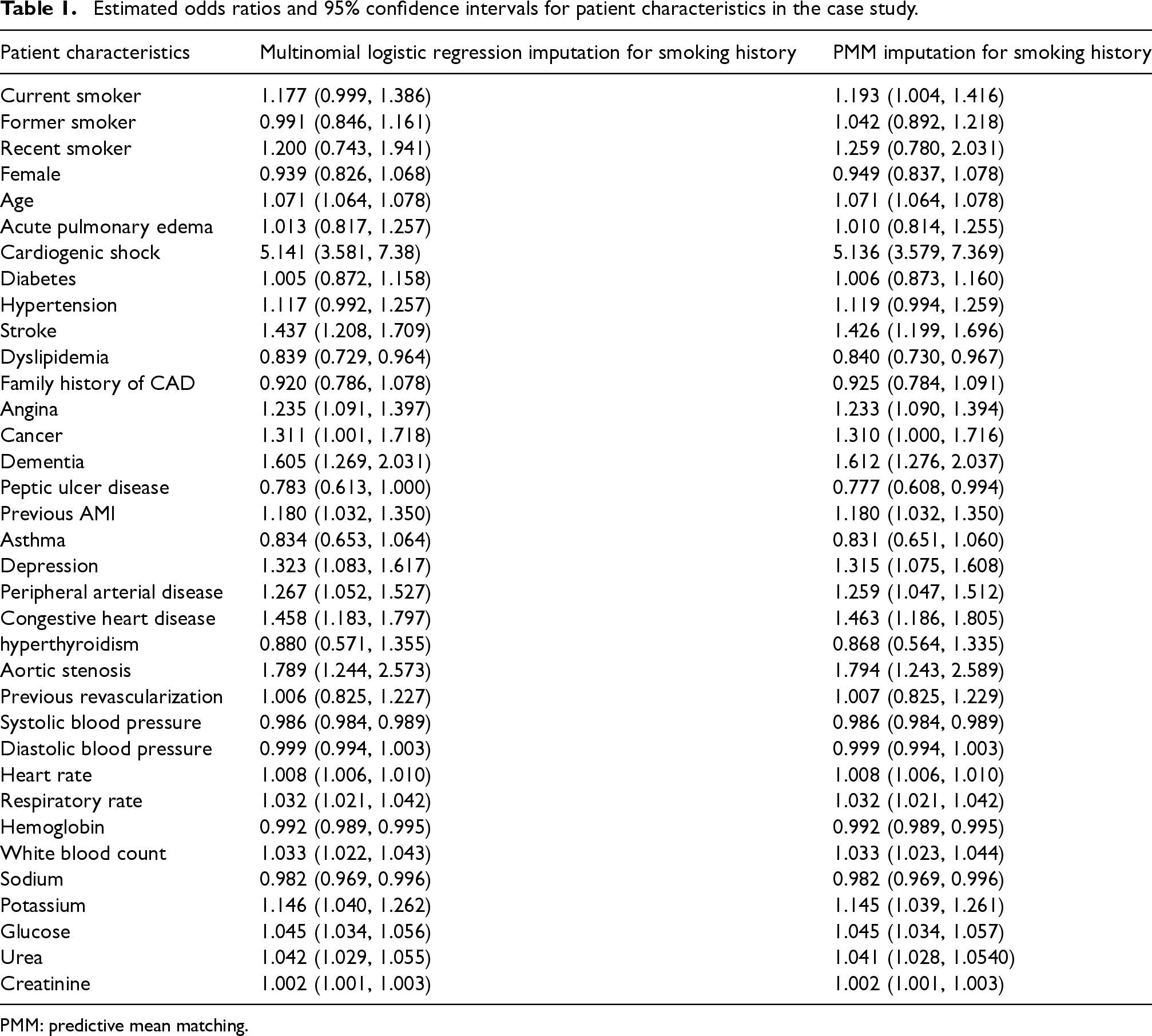
Estimated odds ratios and 95% confidence intervals for patient characteristics in the case study.
PMM: predictive mean matching.
In summary, using PMM to impute missing categorical variables required less than half the time required by multinomial logistic regression. Furthermore, inferences about the association between smoking history and the risk of one-year death were qualitatively similar across the two imputation approaches.
We conducted a series of complex Monte Carlo simulations to compare the performance between PMM and multinomial logistic regression for imputing nominal categorical data, and between PMM and ordinal logistic regression for imputing ordinal categorical data. We evaluated the performance of each method in settings in which the analysis model of scientific interest was either a multivariable logistic regression model or a multivariable linear regression model. The design of the Monte Carlo simulations was informed by empirical analyses conducted on the data on patients hospitalized for AMI described in Section 2.1. Thus, the simulated data arereflective of the complexities of medical data observed in clinical research.
Factors in the Monte Carlo simulations
We allowed three factors to vary in our simulations: Nsample (the size of the random sample drawn from the super-population), pmissing (the rate of missing data), and K (the number of levels of the categorical variable that was subject to missingness). The first took four values: 500, 1000, 2500, and 5000. The second took 10 values: from 5% to 50% in increments of 5%. The third took four levels: from 3 to 6 in increments of one. We used a full factorial design and thus considered 160 different scenarios. In each scenario, we simulated a super-population of size 1,000,000 from which a random sample of size Nsample was sampled in each of the 1000 iterations of the simulations.
Empirical analyses in the case study to obtain parameters for the data-generating process
Analysis model is a multivariable logistic regression model
We made the decision to simulate nine baseline variables in addition to the K-level categorical variable of interest. This number of baseline covariates would reflect clinically realistic settings, but not be so large as to make the simulations overly computationally burdensome. Using the 45 complete datasets created above, when multinomial logistic regression was used to impute smoking history, we used logistic regression to regress the binary variable denoting death within one year on the variables listed above, with the exception that smoking history was excluded from the set of predictor variables. We selected nine of the variables that had amongst the strongest relationship with one-year mortality: age, systolic blood pressure, heart rate, respiratory rate, glucose, white blood count, urea, creatinine, and hemoglobin. We will simulate nine variables whose multivariate distribution will be similar to that observed for these nine variables in the case study data.
We fit a reduced logistic regression model in each of the 45 complete datasets in which one-year mortality was regressed on these nine predictor variables. For each individual, we determined the linear predictor based on these nine predictor variables. In each complete dataset, we determined the polyserial correlation between the linear predictor and the nominal categorical variable denoting smoking history. We used Rubin's rules to pool the estimated polyserial correlation coefficient across the 45 complete datasets. The estimated polyserial correlation was equal to −0.097. We also used Rubin's rules to pool the intercept and the nine estimated regression coefficients across the 45 complete datasets. Let
We estimated the mean of each of the nine variables in each of the 45 complete datasets and pooled the resultant means across the 45 complete datasets using Rubin's rules. Similarly, we computed the variance-covariance matrix of the nine variables in each of the 45 complete datasets and pooled the 45 variance-covariance matrices using Rubin's rules. Let
In each of the 45 complete datasets, we fit a logistic regression model in which the binary variable denoting death within one year was regressed on the nine variables and the four-level variable denoting smoking history. The estimated regression coefficients were pooled across the 45 complete datasets using Rubin's rules. Let
Finally, in each of the 45 complete datasets, we fit a logistic regression model in which a binary variable denoting whether smoking history had been missing for that individual (prior to imputation) was regressed on the nine continuous variables and the binary outcome of the scientific model (one-year mortality). The estimated regression coefficients were pooled across the 45 complete datasets using Rubin's Rules. Let
Analysis model is a multivariable linear regression model
We modified the empirical analyses described in Section 3.2.1 to estimate parameters for a data-generating process for simulations in which the analysis model of scientific interest was a multivariable linear regression model. We replaced the binary outcome (death within one year) for the analysis model with a continuous outcome: systolic blood pressure at hospital discharge. For these empirical analyses, we restricted the analytic sample to those 10,368 patients who were discharged alive from the hospital (as only these patients will have a discharge systolic blood pressure). For consistency with the previous empirical analyses, we used the same 10 predictor variables as in Section 3.2.1.
We created 45 complete datasets using multinomial logistic regression to impute smoking history. We fit a linear regression model in each of the 45 complete datasets in which discharge systolic blood pressure was regressed on these nine predictor variables. For each individual, we determined the linear predictor based on these nine predictor variables. In each complete dataset, we determined the polyserial correlation between the linear predictor and the nominal categorical variable denoting smoking history. We used Rubin's rules to pool the estimated polyserial correlation coefficient across the 45 complete datasets. The estimated polyserial correlation was equal to −0.080. We also used Rubin's rules to pool the intercept and the nine estimated regression coefficients across the 45 complete datasets. Let
In each of the 45 complete datasets, we fit a linear regression model in which discharge systolic blood pressure was regressed on the nine variables and the four-level nominal variable denoting smoking history. The estimated regression coefficients were pooled across the 45 complete datasets using Rubin's Rules. Let
Finally, as in Section 3.2.1, we estimated the regression coefficients for the missing data model for smoking history. The pooled estimate of the regression coefficients was
Monte Carlo simulations: Simulating a super-population
Simulations with a binary outcome for the analysis model
We constructed a vector of 10 means,
For a large super-population consisting of 1,000,000 individuals, we generated 10 continuous variables from a multivariate normal distribution with mean
For the settings in which Z was nominal, we then randomly permuted the labels for this variable so that any implicit ordering in the variable due to the use of the normal distribution was removed (e.g. a random permutation was used so that the labels were changed as follows: 1 → 4; 2 → 5; 3 → 3, 4 → 2; 5 → 1).
We then generated a binary outcome Y for each subject in the super-population. To do so, we applied an outcomes model to each individual in the super-population and computed the probability of the occurrence of the binary outcome. We then simulated a binary outcome from a Bernoulli distribution with this subject-specific parameter. We used the following outcomes logistic models, each of which is specific to a given value of K:

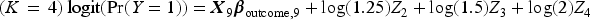
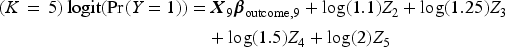
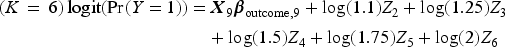
We then fit the outcomes model in the simulated super-population by regressing the simulated binary outcome on the 10 simulated explanatory variables. The estimated regression coefficients will be considered the “true” values of the regression coefficients to which the coefficients estimated below will be compared.
We then induced missing data in the simulated super-population. We assumed that there was only one missing data pattern: Z, the K-level categorical variable, was subject to missingness, while nine continuous variables (X1 through X9) and Y (the binary outcome variable) were not subject to missingness. We set the data to missing such that the prevalence of missing data in the super-population was equal to the desired prevalence
The above data-generating process was for simulating data such that Z was a nominal K-level categorical variable. We used a similar data-generating process for simulating data such that Z was an ordinal K-level categorical variable. Only two modifications were made: (i) we generated data such that Spearman's rank correlation (rather than using the polyserial correlation) between the linear predictor comprised of the first nine continuous variables and the K-level ordinal categorical variable was equal to −0.097; (ii) we did not randomly permute the labels of the K-level categorical variable, but retained the ordering implicit in the categorization of the underlying normal distribution.
Simulations with a continuous outcome for the analysis model
These simulations were similar to those described above, with the following modifications. Instead of using a logistic regression model to simulate binary outcomes, we used a linear model to simulate continuous outcomes. We used the following outcomes linear regression models, each of which is specific to a given value of K:
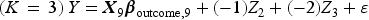
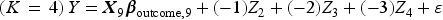
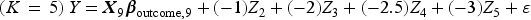
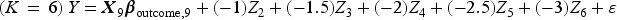
Monte Carlo simulations: Statistical analyses
We drew a random sample of size Nsample without replacement from the super-population. We used the MICE algorithm to impute missing data in the random sample. When the categorical variable was treated as a nominal categorical variable, it was imputed using multinomial logistic regression. When the categorical variable was treated as an ordinal categorical variable, it was imputed using ordinal logistic regression. In either case, the imputation model used all other variables: X1 through X9 (the continuous explanatory variable for the analysis model) and Y (the binary or continuous outcome for the analysis model). The number of multiply imputed datasets was set equal to the percentage of subjects with missing data in the given sample. 3 In each of the imputed datasets, we fitted the analysis model, either a logistic regression model or a linear regression model with X1 through X9 and Z. The estimated regression coefficients and standard errors were pooled across the imputed datasets using Rubin's rules. Ninety-five percent confidence intervals were computed for each estimated regression coefficient using normal-theory methods. Confidence intervals were constructed using Barnard and Rubin's small-sample degrees of freedom. 13 This process was repeated 1000 times.
The imputation models consisted of multinomial logistic regression models and ordinal logistic regression models. We then replaced both imputation models with PMM. In all instances when using PMM, we used PMM with Type 1 matching. 14 The size of the donor pool of potential matches was fixed at 5.
Performance measures
Five metrics were used to assess the performance of the imputation methods: (i) the percent relative bias of the estimated regression coefficient for each of the explanatory variables in the analysis model; (ii) the percent relative error in the estimated standard error of the estimated regression coefficients; (iii) the empirical coverage rates of estimated 95% confidence intervals; (iv) mean squared error (MSE); (v) the percent relative increase precision in the estimated regression coefficients when using PMM compared to when using multinomial or ordinal logistic regression. This latter method compares the empirical standard error when using PMM with the empirical standard error when using multinomial or ordinal logistic regression.
Percent relative bias was computed as
Statistical software
The simulations were conducted using the R statistical programming language (version 3.6.3). MI using the MICE algorithm was implemented using the mice function from the mice package (version 3.16.16). Simulation results were summarized using the rsimsum package (version 0.13.0). 16
Results of Monte Carlo simulations
We first provide a detailed description of the results for the settings in which the analysis model was a multivariable logistic regression model. We then provide a briefer summary of results for the settings in which the analysis model was a multivariable linear regression model.
Analysis model was a logistic regression model
We report our results first for when the categorical variable was a nominal categorical variable and then for when the categorical variable was an ordinal categorical variable. Within each subsection, we report the results for each value of K separately. We focus on inferences about the regression coefficients associated with K–1 levels of the K-level categorical variable and not on X1 through X9.
Nominal categorical variable
The simulations took 331.9 h (13.8 days) when using multinomial logistic regression to impute the K-level categorical variable and 78.1 h (3.3 days) when using PMM. Thus, the use of multinomial logistic regression required ∼4.2 times more time than the use of PMM.
Three-level categorical variable (K = 3)
Results for the 40 scenarios with K = 3 are reported in Figure 1, which consists of five panels, one for each of the performance metrics. Each panel consists of a series of line plots, with the percent of missing data on the horizontal axis and the performance metric on the vertical axis. Results for the two imputation methods are reported using different colors (red for multinomial logistic regression and blue for PMM), while the variable for which results are reported (the K–1 dummy variables necessary to represent Z; as described above,
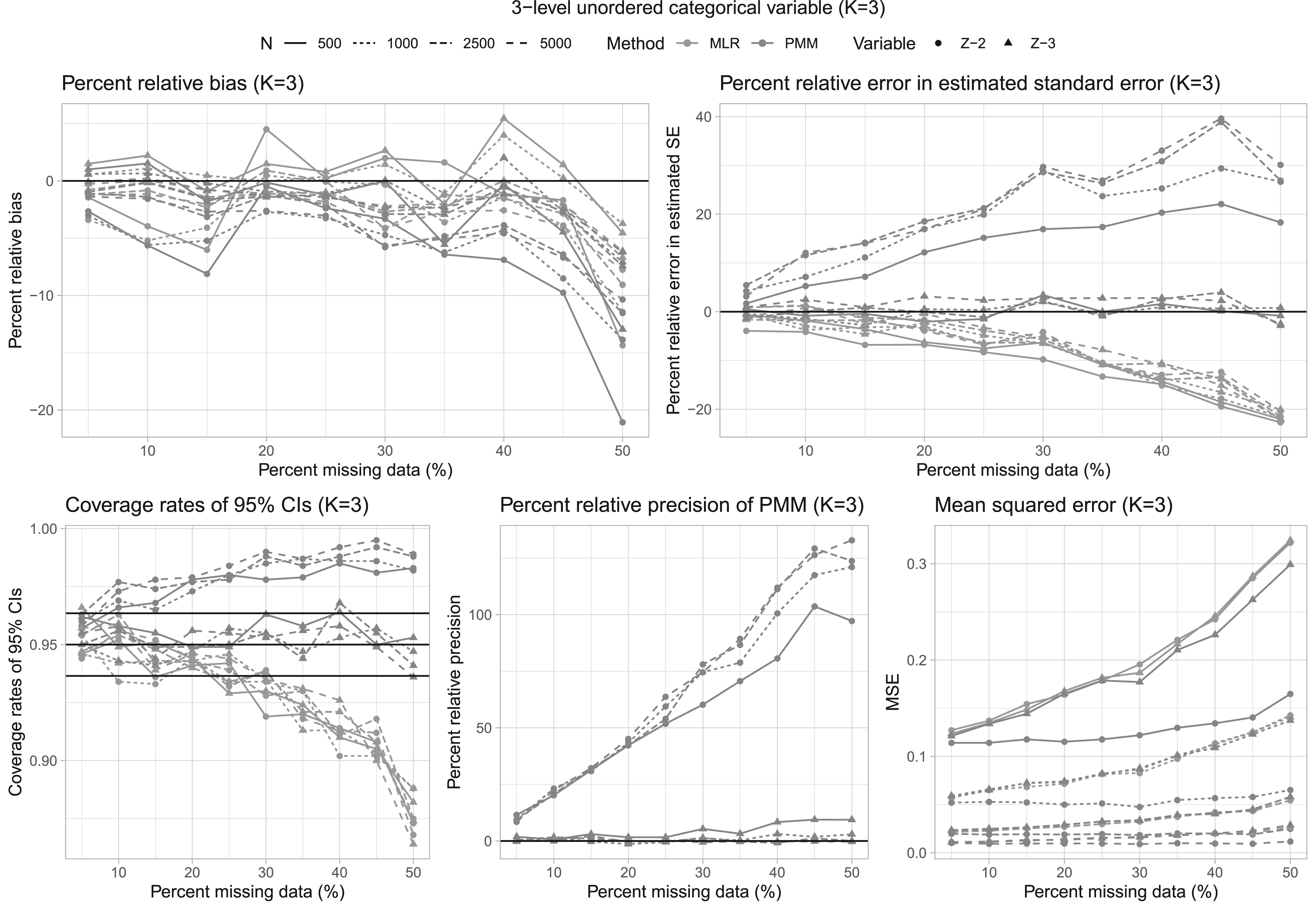
Three-level unordered categorical variable (K = 3).
Results are also summarized in Figure 2 using boxplots. This figure has 20 panels, one for each combination of performance metric and value of K. There is one row for each of the performance metrics and one column for each of the values of K. For four of the performance metrics (percent relative bias, percent relative error in estimated standard error, empirical coverage rates of 95% confidence intervals, and MSE), we report side-by-side boxplots comparing the distribution of the performance metric across the different estimates. For K = 3, 4, 5, and 6, there are 80, 120, 160, and 200 different estimates. For K = 3, there were 80 estimated regression coefficients (40 scenarios [4 sample sizes × 10 prevalences of missing data] × two regression coefficients [the two dummy variables required to represent Z]) (with a similar calculation for the other values of K). For the fourth performance metric, percent relative precision, we report only a single boxplot for PMM, since this metric implicitly incorporates a comparison with multinomial logistic regression.
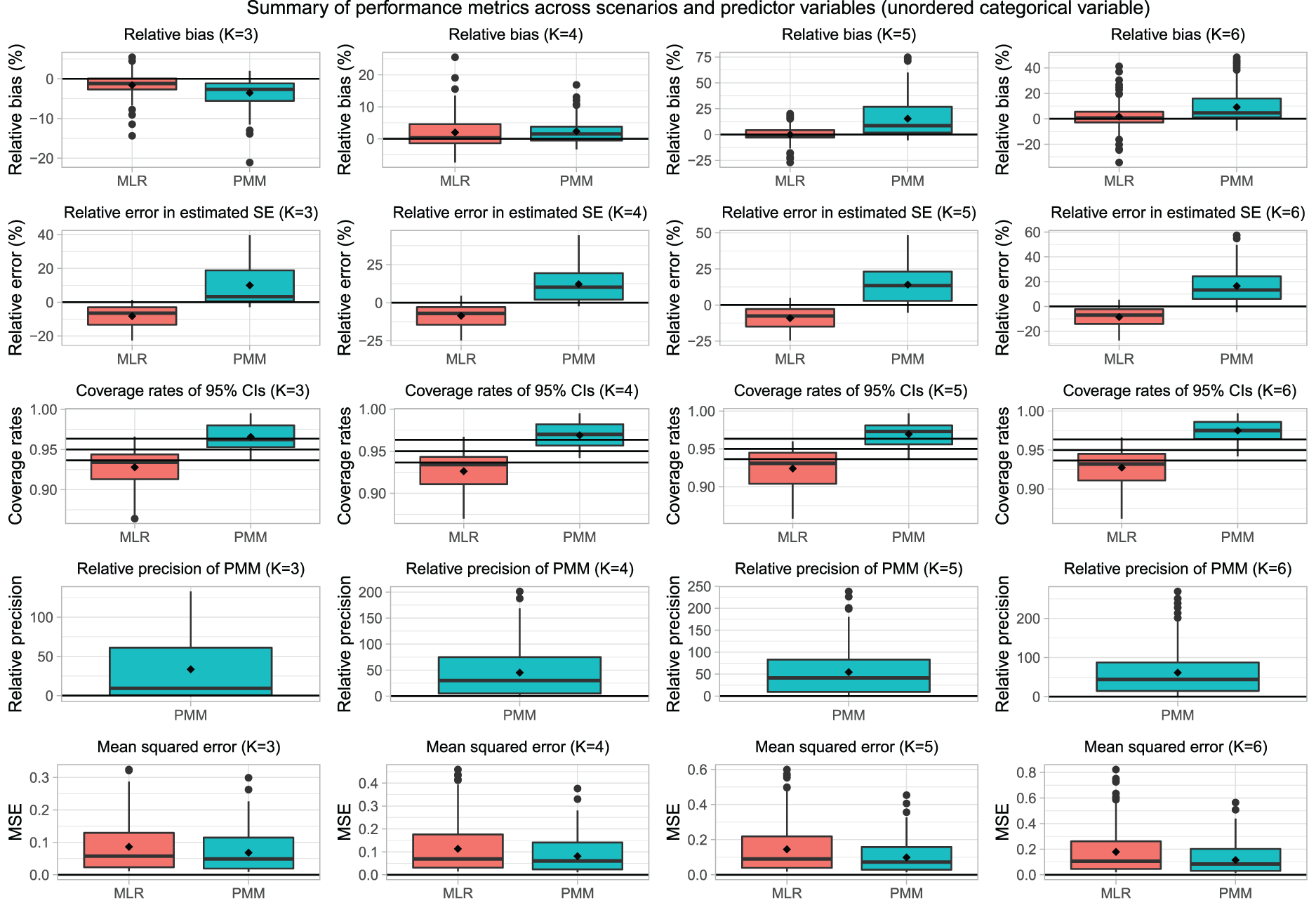
Summary of performance metrics across scenarios and predictor variables (unordered categorical variable).
The percent relative bias is reported in the top left panel of Figure 1. We have superimposed a horizontal line on this panel denoting a 0% relative bias (i.e. unbiased estimation of the regression coefficient). Bias tended to be minimal, with percent relative bias ranging from approximately −20% to ∼5%. The distribution of percent relative bias across the 80 estimated is reported in Figure 2. The two boxplots illustrate that, in general, the use of multinomial logistic regression tended to result in estimates with a negligibly lower percent relative bias. Overall, relative bias was negligible for both methods.
The percent relative error in the estimated standard errors is reported in the top right panel of Figure 1. We have superimposed a horizontal line on this panel denoting a relative percent error of zero (i.e. unbiased estimation of the standard error). Differences between the two imputation methods were more pronounced for the percent relative error in estimated standard errors than they were for the percent relative bias in estimated regression coefficients. When using PMM, the estimated standard errors for
The empirical coverage rates of estimated 95% confidence intervals are reported in the lower left panel of Figure 1. We have superimposed horizontal lines on this panel denoting empirical coverage rates of 0.9365, 0.95, and 0.9635. As noted above, empirical type I error rates that are < 0.9365 or > 0.9635 are statistically significantly different from the advertised rate of 95%. The use of PMM tended to result in estimated 95% confidence intervals whose empirical coverage rates were either not statistically significantly different from the advertised rate or that were conservative (i.e. whose empirical coverage rate was higher than the advertised rate). In contrast to this, the use of multinomial logistic regression often resulted in estimated 95% confidence intervals whose empirical coverage rates were lower than the advertised rate when the rate of missing data was high. The distribution of empirical coverage rates across the 80 estimated regression coefficients is reported using side-by-side boxplots in Figure 2. In general, the use of PMM tended to result in confidence intervals that did not differ from the advertised rate or that were conservative. In contrast to this, in ∼50% of the comparisons, multinomial logistic regression resulted in confidence intervals whose empirical coverage rates were lower than advertised.
The relative percent increase in precision for PMM compared to multinomial logistic regression is reported in the bottom middle panel of Figure 1. We have superimposed a horizontal line on this panel denoting a relative percent increase in precision of zero. The use of PMM tended to result in estimates of the regression coefficient for
The MSE of the estimated regression coefficients are reported in the lower right panel of Figure 1. In general, the MSE of the estimate obtained using PMM tended to be approximately the same as or lower than that of the estimate obtained using multinomial logistic regression. The distribution of MSE across the 80 estimated regression coefficients is reported using side-by-side boxplots in Figure 2. The boxplots confirm the above observation that the MSE when using PMM tended to be slightly lower than when using multinomial logistic regression.
Results for the 40 scenarios with K = 4 are reported in Figure 3, which has a similar structure to that of Figure 1, while the distribution of percent relative bias across 120 estimated regression coefficients is reported using side-by-side boxplots in Figure 2. Overall, the two imputation methods displayed similar relative bias across the 120 estimated regression coefficients.
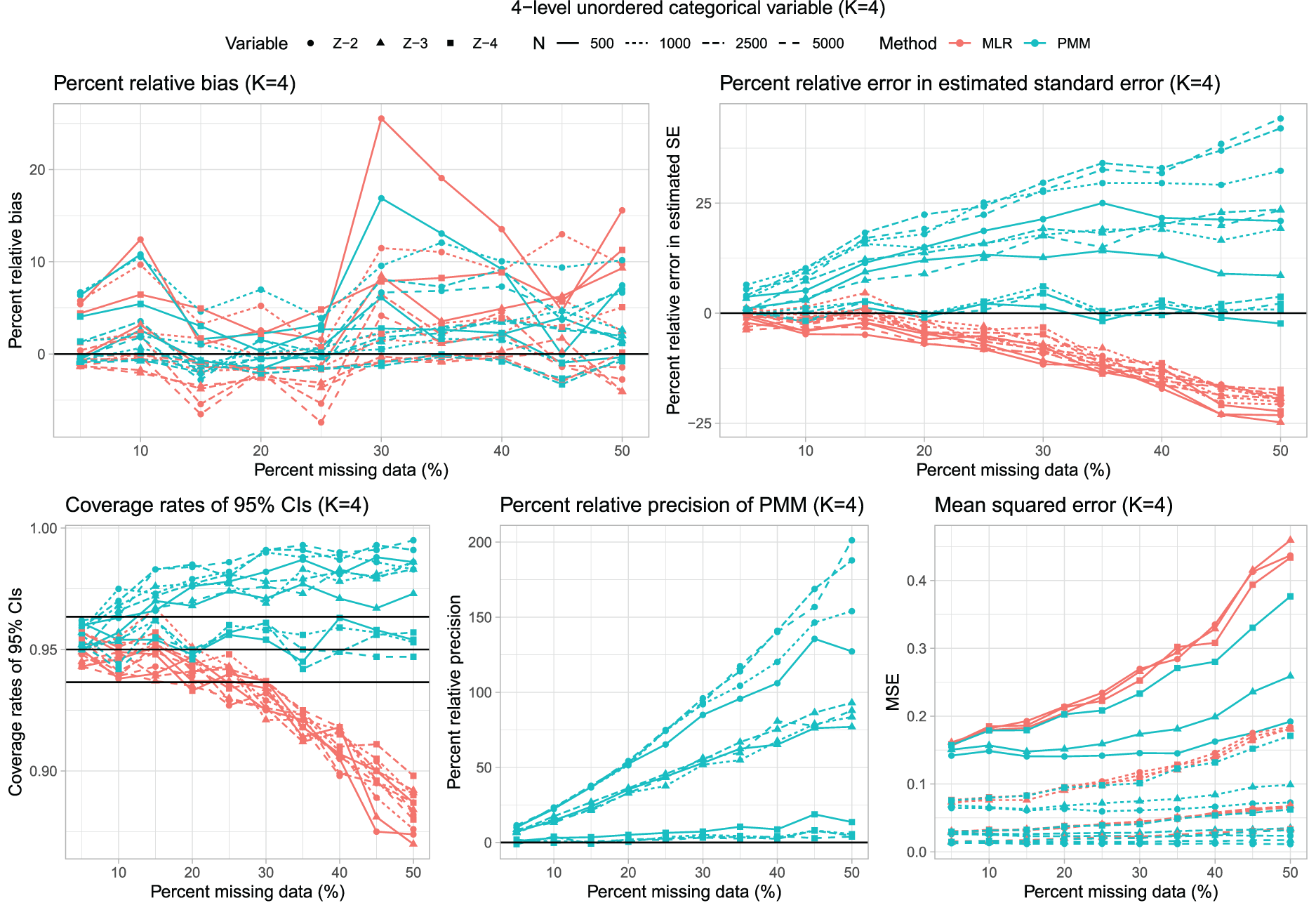
Four-level unordered categorical variable (K = 4).
The percent relative error in the estimated standard error were comparable to those observed for K = 3. The distribution of percent relative bias in the estimated standard error across the 120 estimated regression coefficients is reported in Figure 2. On average, the use of PMM resulted in a modest positive bias in the estimation of the standard error, while the use of multinomial logistic regression tended to result in minor underestimation of the standard error.
As with K = 3, the use of multinomial logistic regression often resulted in estimated confidence intervals whose empirical coverages were lower than advertised when the rate of missing data was high. This did not occur when using PMM. The distribution of empirical coverage rates across the 120 estimated regression coefficients is reported using side-by-side boxplots in Figure 2. The use of multinomial logistic regression resulted in confidence intervals whose empirical coverage rates were lower than the advertised rate in ∼50% of the instances, while this did not occur when using PMM.
The use of PMM tended to result in estimated regression coefficients that were estimated more precisely (Figure 2). Similarly, the use of PMM tended to result in estimates with lower MSE compared to when using multinomial logistic regression.
Results for scenarios with K = 5 are reported in Figure 4, which has a similar structure to that of Figures 1 and 3. In general, the use of multinomial logistic regression tended to result in estimated regression coefficients with a lower percent relative bias (Figure 2).
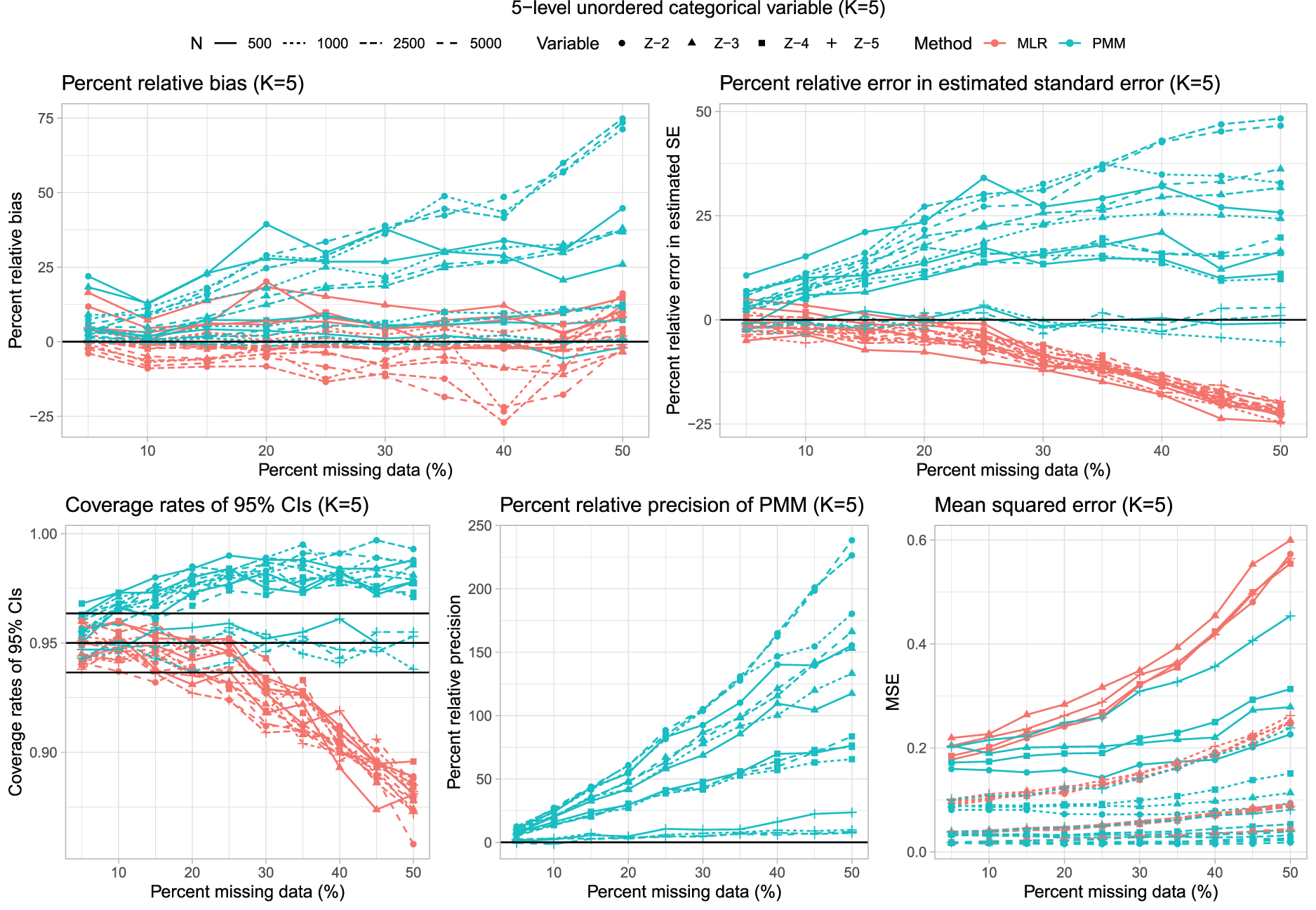
Five-level unordered categorical variable (K = 5).
The percent relative error in the estimated standard error was comparable to those observed for K = 3 and K = 4. In particular, the use of multinomial logistic regression tended to result in underestimation of the standard error when the rate of missing data was moderate to high. The distribution of percent relative error in the estimated standard error across the 160 estimated regression coefficients is reported in Figure 2. In general, the use of multinomial logistic regression tended to result in estimates that underestimated the standard deviation of the sampling distribution of the regression coefficients, while the use of PMM tended to result in estimates that overestimated the standard deviation of the sampling distribution. However, the absolute magnitude of the percent relative error tended to be smaller when using multinomial logistic regression compared to using PMM.
As with K = 3 and K = 4, multinomial logistic regression often resulted in estimated confidence intervals whose empirical coverages were lower than advertised when the rate of missing data was high. The distribution of the empirical coverage rates across the 160 estimated regression coefficients is reported in Figure 2. The use of multinomial logistic regression tended to result in confidence intervals whose empirical coverages were significantly lower than the advertised rate more frequently than did the use of PMM.
The use of PMM tended to result in estimated regression coefficients that were estimated more precisely (i.e. that had a smaller empirical standard error) compared to when multinomial logistic regression was used (Figure 2). Similarly, the use of PMM tended to result in estimated regression coefficients that had lower MSE compared to when multinomial logistic regression was used.
Results for scenarios with K = 6 are reported in Figure 5, which has a structure similar to Figures 1, 3 and 4. The distribution of percent relative bias across the 200 estimated regression coefficients is reported using side-by-side boxplots in Figure 2. The use of PMM tended to result in estimates with modestly more bias than when using multinomial logistic regression.
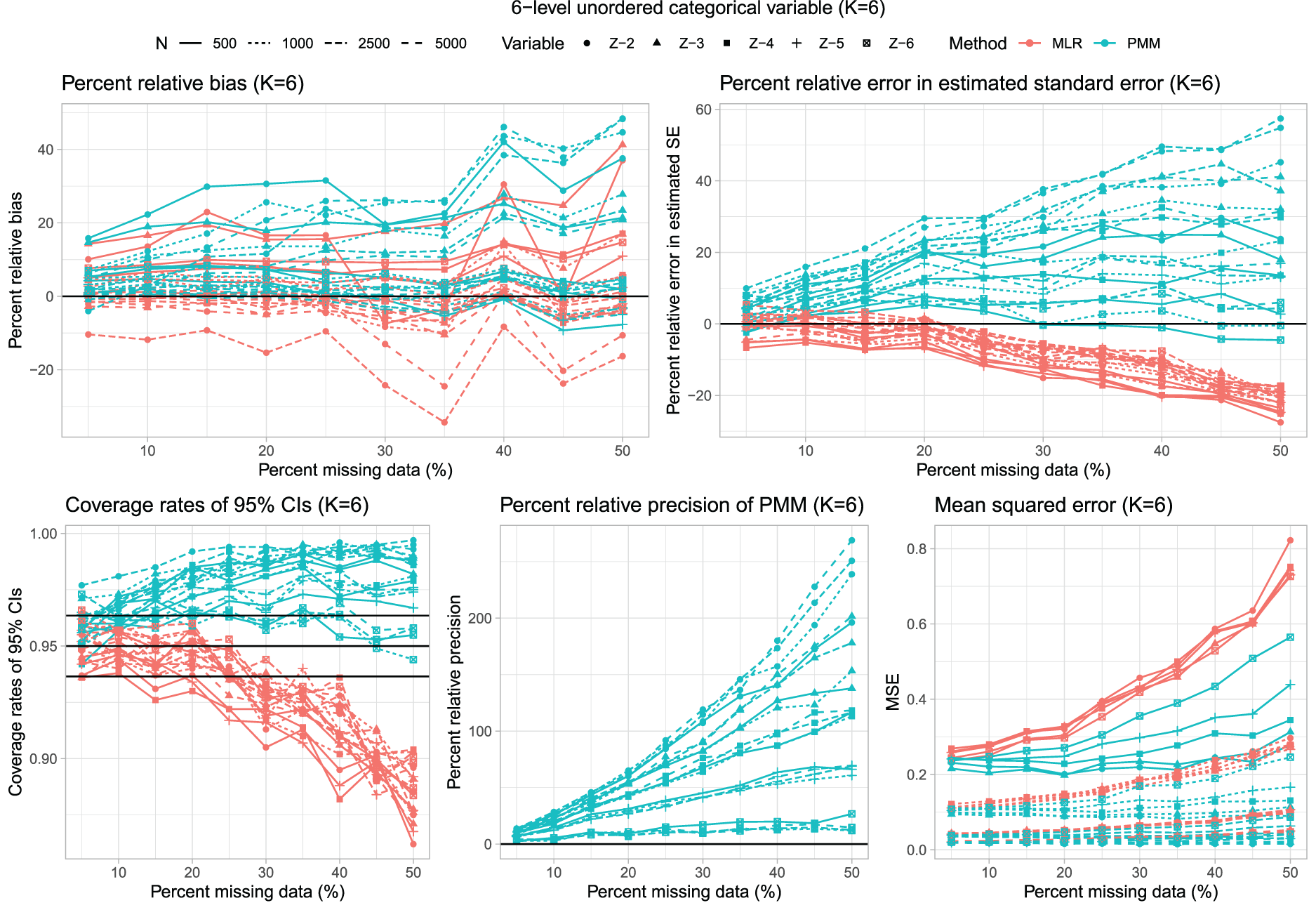
Six-level unordered categorical variable (K = 6).
Multinomial logistic regression tended to result in modest underestimation of the standard error when the rate of missing data was moderate to high. In contrast to this, the use of PMM tended to result in estimates of standard errors that were biased upwards.
As with K = 3, K = 4, and K = 5, the use of multinomial logistic regression often resulted in estimated confidence intervals whose empirical coverages were lower than advertised when the rate of missing data was high. This did not occur when using PMM. In examining the side-by-side boxplots in Figure 2, one observes that in ∼50% of the instances, the use of multinomial logistic regression resulted in estimated confidence intervals whose empirical coverages were statistically significantly lower than advertised.
Finally, as with the other values of K, the use of PMM tended to result in estimated regression coefficients that had smaller empirical standard errors. Similarly, the use of PMM tended to result in estimates with lower MSE compared to when multinomial logistic regression was used.
The simulations took 352.6 h (14.7 days) when using ordinal logistic regression to impute the K-level categorical variable and 100.7 h (4.2 days) when using PMM. Thus, the use of ordinal logistic regression required ∼3.5 times more time than the use of PMM.
Results for ordinal categorical variables are reported in Figures 6 to 10, which have structures identical to those of Figures 1 to 5. We briefly summarize the results, focusing on Figure 7, which uses boxplots to summarize the distribution of the performance metrics across the different combinations of scenarios and estimated regression coefficients.
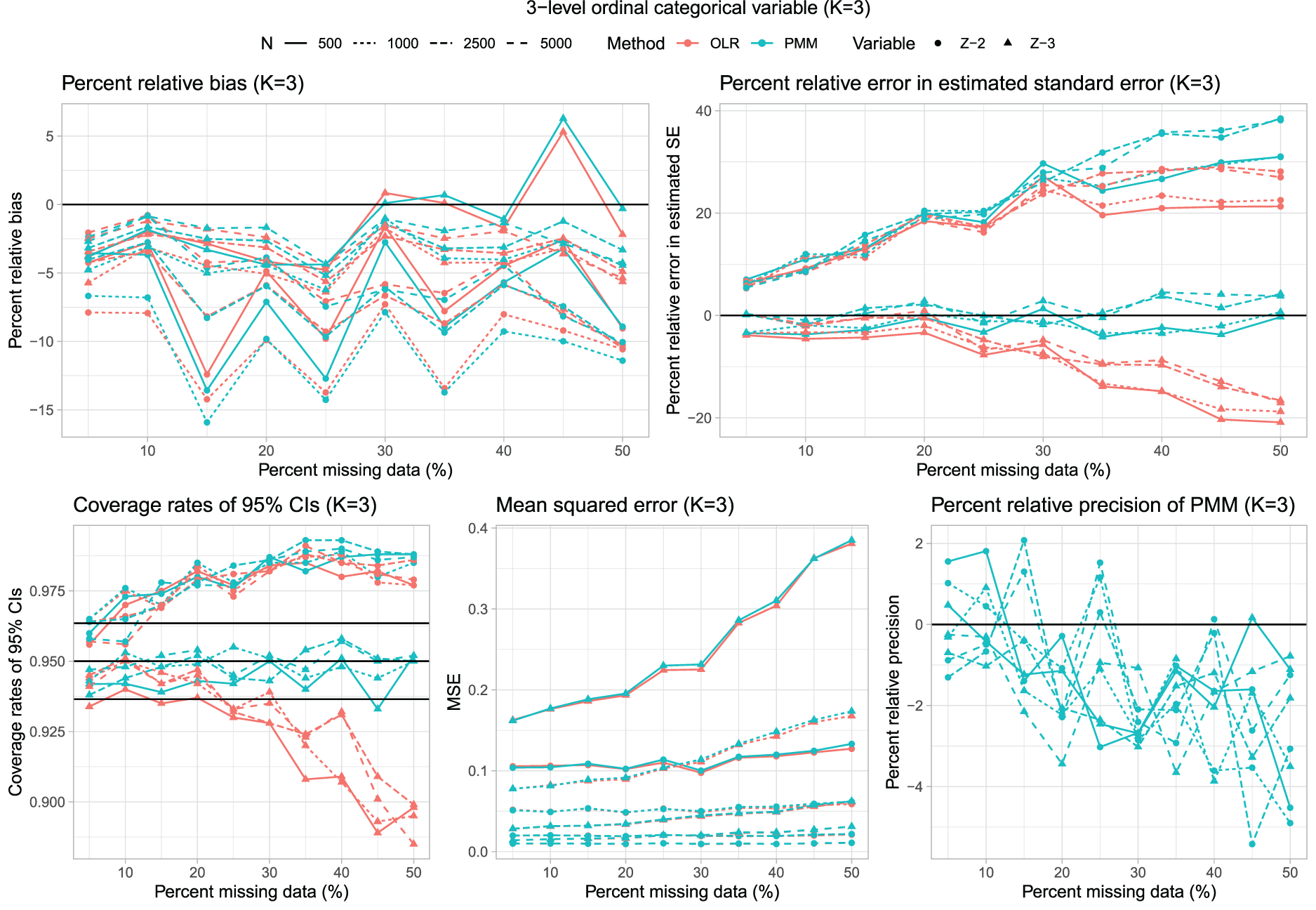
Three-level ordinal categorical variable (K = 3).
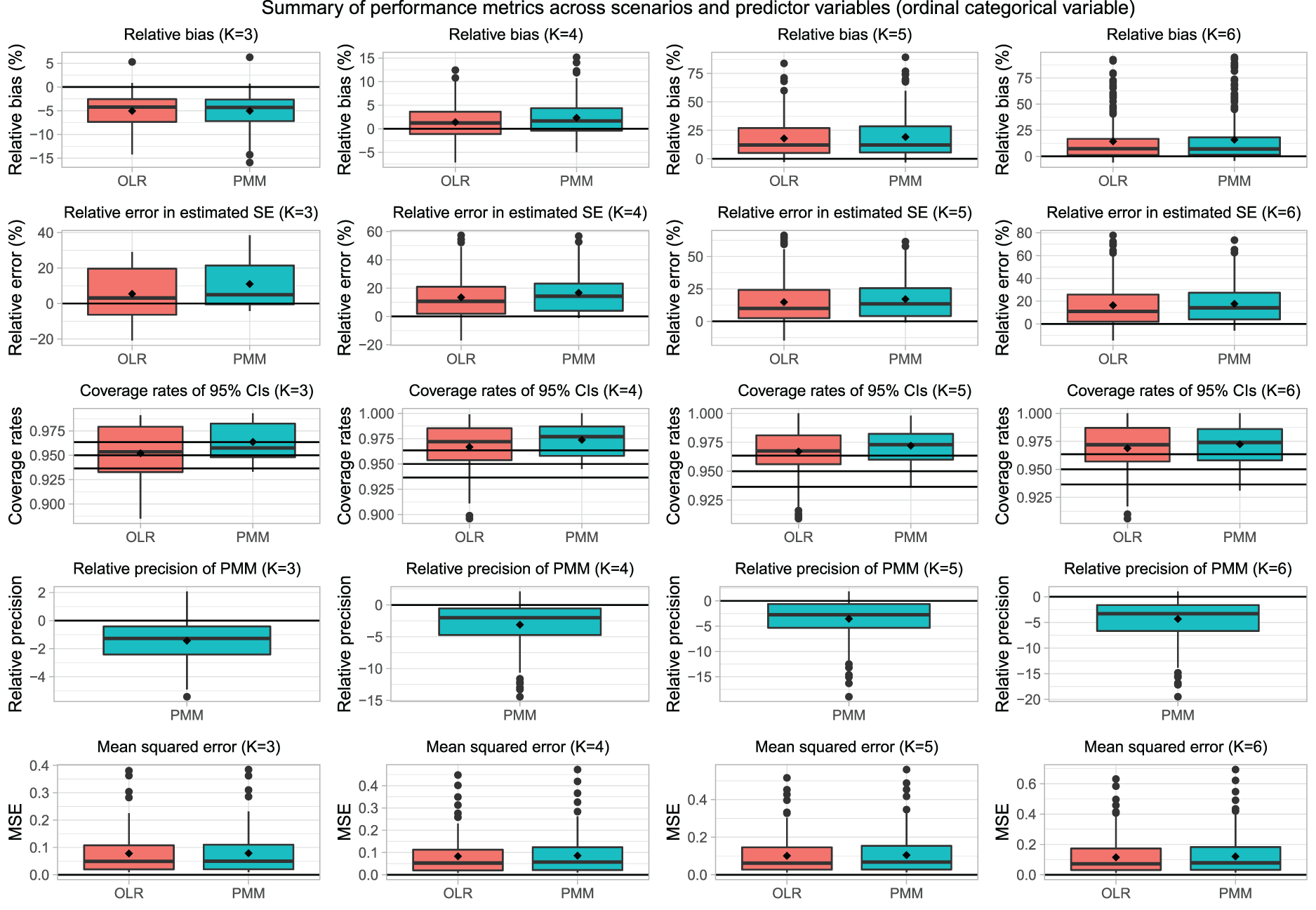
Summary of performance metrics across scenarios and predictor variables (ordinal categorical variable).
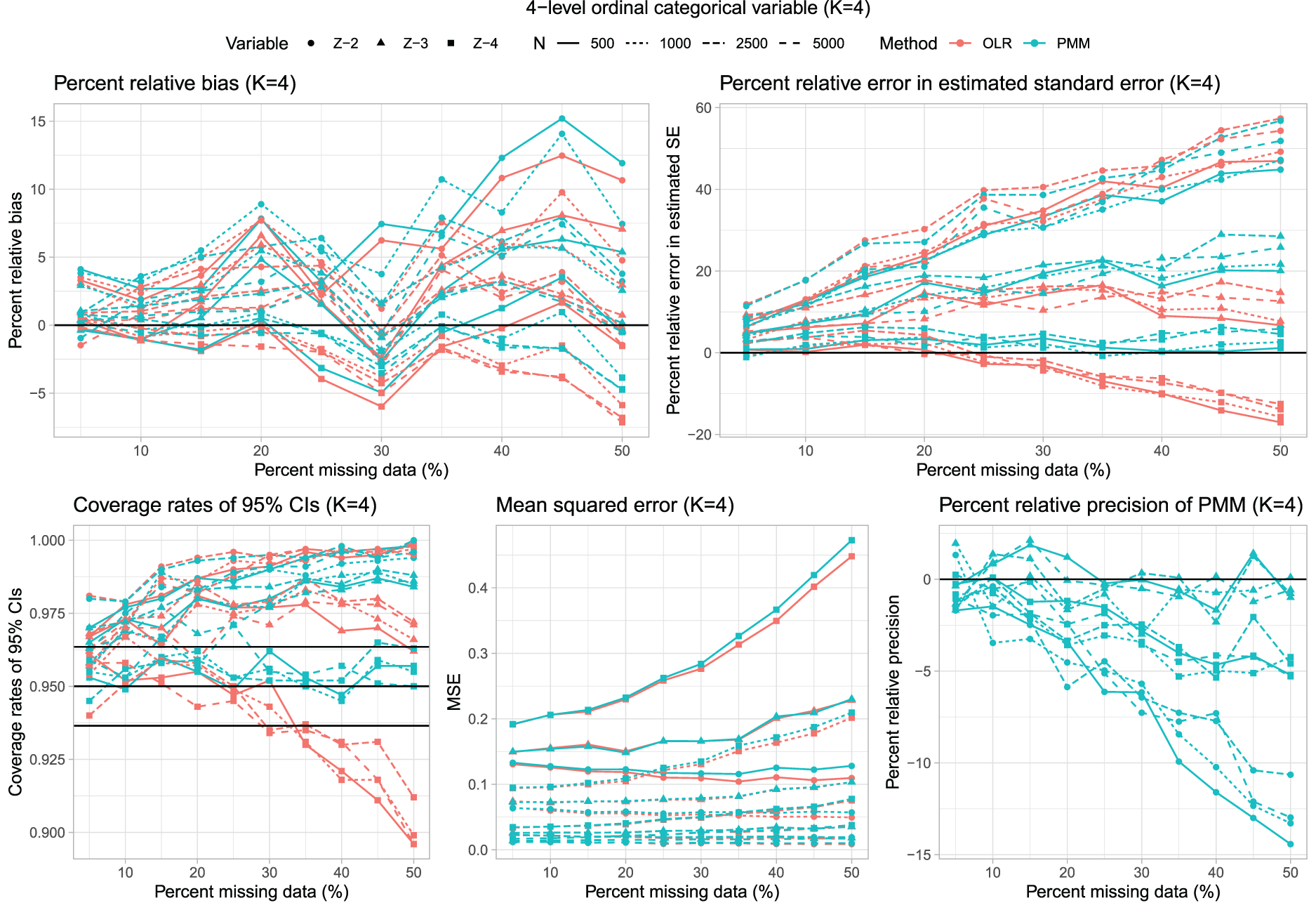
Four-level ordinal categorical variable (K = 4).
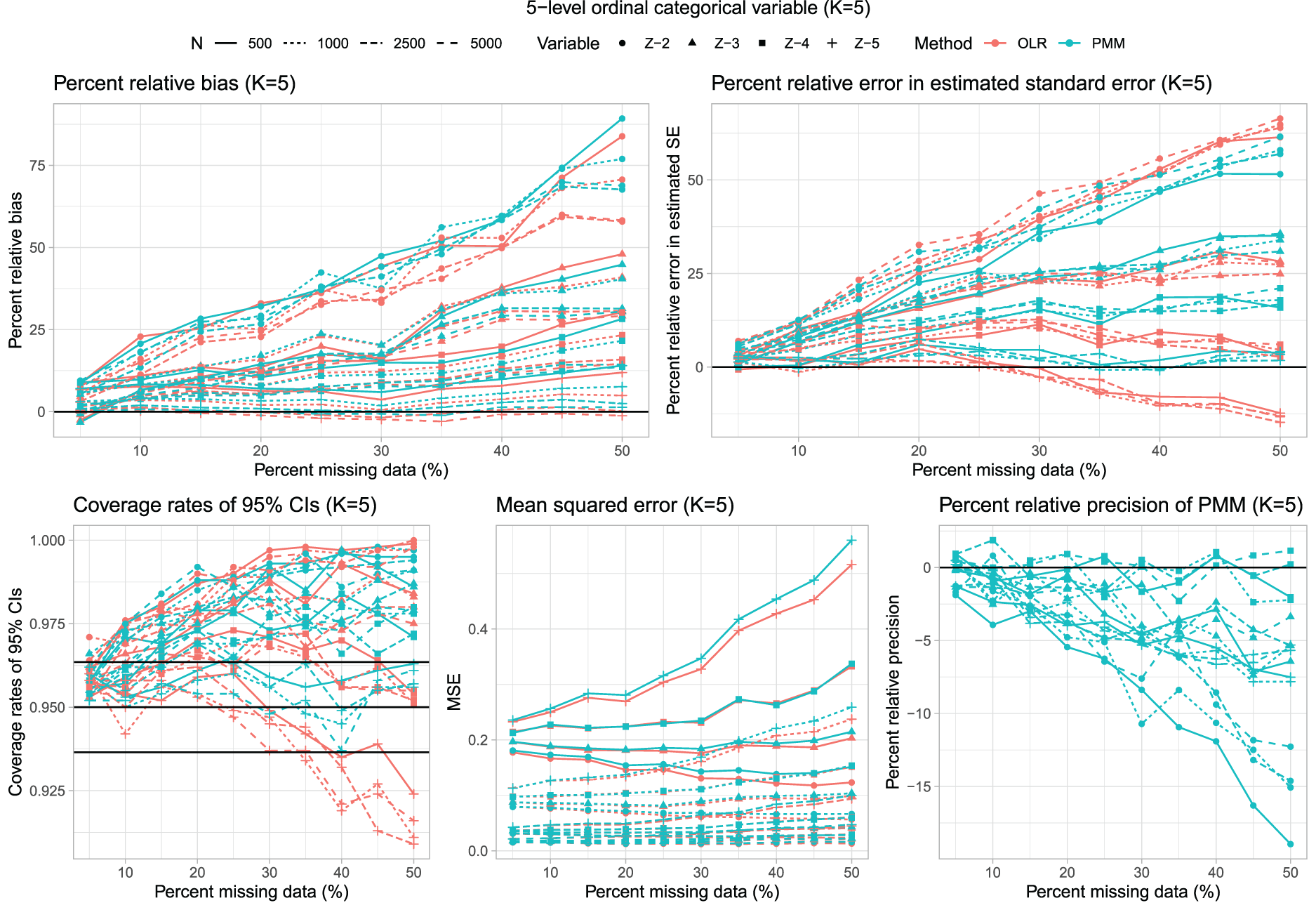
Five-level ordinal categorical variable (K = 5).
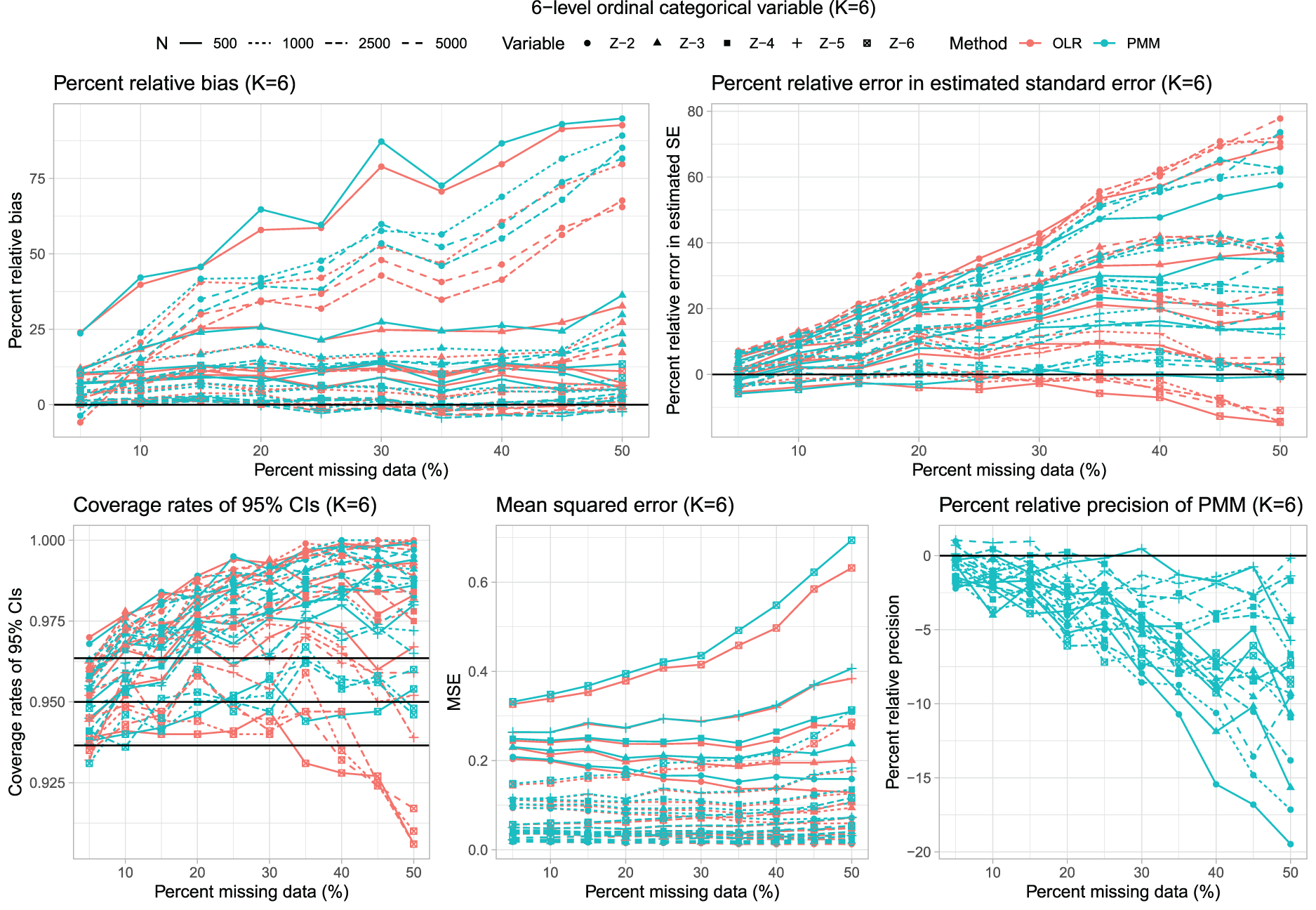
Six-level ordinal categorical variable (K = 6).
When assessed using the percent relative bias in the estimated regression coefficients, differences between the use of ordinal logistic regression and PMM tended to be minimal. On average, differences between the two methods were negligible. Similarly, differences between ordinal logistic regression and PMM when estimating standard errors of the estimated regression coefficients tended, on average, to be minimal.
The use of ordinal logistic regression resulted in estimated 95% confidence intervals whose empirical coverages were statistically significantly lower than the advertised rate in a modest number of scenarios. In contrast to this, in almost all the scenarios, the use of PMM resulted in 95% confidence intervals whose empirical coverage rates were either not significantly different from the advertised rate or that were conservative (i.e. higher than the advertised rate).
In contrast to what was observed with the nominal categorical variable, the use of PMM resulted in estimated regression coefficients that were less precise than those obtained when using ordinal logistic regression. However, the decrease in imprecision tended to be negligible to modest in most scenarios. Finally, the choice of imputation algorithm tended to have a negligible impact on the MSE of the estimated regression coefficients.
When the categorical variable was nominal, the simulations took 323.6 h (13.5 days) when using multinomial logistic regression to impute the K-level categorical variable and 62.5 h (2.6 days) when using PMM. Thus, the use of multinomial logistic regression required ∼5.2 times more time than the use of PMM. When the categorical variable was ordinal, the simulations took 355.2 h (14.8 days) when using multinomial logistic regression to impute the K-level categorical variable and 59.4 h (2.5 days) when using PMM. Thus, the use of multinomial logistic regression required ∼6 times more time than the use of PMM.
The results of the simulations are summarized in Supplemental Figures A1 to A10. These 10 figures have a structure identical to those of Figures 1 to 10. Overall, the results on the quality of statistical inferences were similar to those observed in the settings in which the analysis model was a logistic regression model.
Discussion
We evaluated the performance of PMM in comparison to multinomial logistic regression (for imputing nominal categorical variables) and ordinal logistic regression (for imputing ordinal categorical variables). Performance was assessed in settings where the analysis model was either a logistic or a linear regression model. Overall, PMM performed comparably, or even favorably, to both logistic and ordinal regression in terms of inference quality, while requiring substantially less computational time. Across simulation scenarios, PMM was about 3 to 6 times faster than parametric models, highlighting its practical advantage for large-scale or high-dimensional applications.
One reason for PMM's superior speed is that it avoids the problem of perfect prediction, which often complicates logistic regression models and may require artificially adding regularization records. Instead of relying on iterative likelihood maximization, PMM uses ordinary least squares within a linear modeling framework, which is simpler and faster to compute. Moreover, the mice package implementation of PMM leverages optimized C routines for efficiently generating donor-based imputations.
The strong performance of PMM for imputing missing categorical data can be attributed to the similarity between the linear predictors used in linear and logistic regression models, particularly in the central part of the outcome distribution. PMM handles categorical variables by applying an optimal scaling transformation that assigns numeric values to each category, effectively converting the outcome into a quasi-continuous variable. For ordinal variables, this transformation can be constrained to follow a monotonic pattern that respects the category order, which may enhance stability when the ordinal structure is correctly specified. However, imposing such constraints risks introducing systematic bias if the assumed order is incorrect. To avoid this, we recommend not enforcing monotonicity by default. A practical benefit of this choice is that PMM remains invariant to the ordering of categories.
From a practical standpoint, PMM emerges as a competitive and pragmatic default for the imputation of categorical variables. Not only does it match the inferential performance of parametric alternatives, but it also completes imputations in roughly one-third to one-sixth of the time. Its non-parametric nature also allows it to capture certain kinds of nonlinearity that standard logistic models may fail to capture.
Nonetheless, caution is warranted in specific settings. PMM can be less stable in regions with sparse outcome data, such as tails or gaps, where the behavior of the linear predictor becomes erratic. For applications requiring robust extrapolation or precise modeling of extremes, parametric models are preferable. Additionally, some categorical structures may not linearize well. In such cases, extending the approach to allow for multiple orthogonal quantifications of the outcome (i.e. using a multivariate representation) may improve robustness and capture complex patterns.
The current study is subject to certain limitations. First, our study relied on Monte Carlo simulations. Consequently, our findings are dependent on the data-generating process that was used. It is possible that PMM may have inferior performance compared to the use of multinomial or ordinal logistic regression in other settings. We suggest that our methods be replicated in other settings to examine the generalizability of our findings. Second, we did not include an examination of the complete case estimator, which is often included in studies examining the performance of MI-based estimators. The rationale for this omission was that we were motivated by examining whether PMM could be used instead of multinomial or ordinal logistic regression for imputing missing categorical variables. We were not interested in comparing how each imputation method compared with the use of a complete case analysis.
In conclusion, PMM offers a fast, flexible, and statistically sound alternative to conventional multinomial and ordinal regression models for imputing categorical data. Its combination of computational efficiency and favorable inferential properties makes it a strong candidate for default use in the mice framework and other MI workflows.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802251362642 - Supplemental material for Imputation of incomplete ordinal and nominal data by predictive mean matching
Supplemental material, sj-pdf-1-smm-10.1177_09622802251362642 for Imputation of incomplete ordinal and nominal data by predictive mean matching by Peter C Austin and Stef van Buuren in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
ICES is an independent, non-profit research institute funded by an annual grant from the Ontario Ministry of Health (MOH) and the Ministry of Long-Term Care (MLTC). As a prescribed entity under Ontario's privacy legislation, ICES is authorized to collect and use health care data for the purposes of health system analysis, evaluation, and decision support. Secure access to these data is governed by policies and procedures that are approved by the Information and Privacy Commissioner of Ontario. This study was supported by ICES, which is funded by an annual grant from the Ontario Ministry of Health (MOH) and the Ministry of Long-Term Care (MLTC). This study also received funding from the Canadian Institutes of Health Research (CIHR) (PJT 166161). This document used data adapted from the Statistics Canada Postal CodeOM Conversion File, which is based on data licensed from Canada Post Corporation, and/or data adapted from the Ontario Ministry of Health Postal Code Conversion File, which contains data copied under license from ©Canada Post Corporation and Statistics Canada. Parts of this material are based on data and/or information compiled and provided by CIHI and the Ontario Ministry of Health. The analyses, conclusions, opinions, and statements expressed herein are solely those of the authors and do not reflect those of the funding or data sources; no endorsement is intended or should be inferred. The dataset from this study is held securely in coded form at ICES. While legal data sharing agreements between ICES and data providers (e.g. healthcare organizations and government) prohibit ICES from making the dataset publicly available, access may be granted to those who meet pre-specified criteria for confidential access, available at ![]() (email: das@ices.on.ca).
(email: das@ices.on.ca).
Supplementary material
Supplementary material for this paper is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.