
Abstract
Introduction:
This study was designed to develop and evaluate machine learning algorithms for predicting seizure due to acute tramadol poisoning, identifying high-risk patients and facilitating appropriate clinical decision-making.
Methods:
Several characteristics of acute tramadol poisoning cases were collected in the Emergency Department (ED) (2013–2019). After selecting important variables in random forest method, prediction models were developed using the Support Vector Machine (SVM), Naïve Bayes (NB), Artificial Neural Network (ANN) and K-Nearest Neighbor (K-NN) algorithms. Area Under the Curve (AUC) and other diagnostic criteria were used to assess performance of models.
Results:
In 909 patients, 544 (59.8%) experienced seizures. The important predictors of seizure were sex, pulse rate, arterial blood oxygen pressure, blood bicarbonate level and pH. SVM (AUC = 0.68), NB (AUC = 0.71) and ANN (AUC = 0.70) models outperformed k-NN model (AUC = 0.58). NB model had a higher sensitivity and negative predictive value and k-NN model had higher specificity and positive predictive values than other models.
Conclusion:
A perfect prediction model may help improve clinicians’ decision-making and clinical care at EDs in hospitals and medical settings. SVM, ANN and NB models had no significant differences in the performance and accuracy; however, validated logistic regression (LR) was the superior model for predicting seizure due to acute tramadol poisoning.
Introduction
The mortality and morbidity associated with the complications and side-effects of drug poisoning, especially with narcotics and analgesic drugs such as tramadol, are still a major challenge across the globe. 1,2
Tramadol is a potent analgesic drug with an easy availability that is excessively prescribed and has a euphoric effect. There is an increased prevalence of tramadol poisoning in the Middle East and Iran. 3 –5 Seizure, which is defined as a sudden, uncontrolled electrical disturbance in the brain that causes changes in behavior, sensory perception or motor activity, is an important and common neurological effect of tramadol poisoning reported in 15–30% of the cases as generalized tonic-clonic seizure, occurring as a result of the inhibition of the Gamma Aminobutyric Acid (GABA) receptors and serotonin toxicity. 6,7 Several studies have shown that approximately 2–5% of the general population will experience at least one non-febrile seizure in their lifetime that may result from medication or drug use and that causes death in nearly 2% of the cases. 8,9 Previous investigations have demonstrated that delays in the diagnosis and prognosis of seizure causes greater morbidity and mortality in poisoned patients. Therefore, predicting seizure in acute tramadol poisoning may help clinicians identify high-risk patients and take appropriate and timely action to reduce the complications. 10 –14
Machine learning (ML) is an alternative analytic method for managing complex interactions in big data, discovering nonlinear interactions between a number of predictors, and generating actionable predictions in clinical settings. ML algorithms focus on prediction models that learn from available data directly and automatically and are highly flexible methods requiring penalization to prevent overfitting. 15,16 Recently, many studies have reported the application of Machine Learning algorithms in activities from fraud detection to cancer genomics. 17 –20 Nonetheless, these studies have been confined to small sample sizes and narrow clinical and socio-demographic risk factors. Although one study showed a prediction model for tramadol poisoning using Logistic Regression (LR), no studies have yet examined the use of ML models for predicting this poisoning in large populations of adult patients in Emergency Departments (EDs). 21 The common ML models that can forecast clinical outcomes include k-Nearest Neighbor (k-NN), Naïve Bayes (NB), Support Vector Machine (SVM) and Artificial Neural Network (ANN).
The K-NN algorithm is easy and simple method which has few hyper-parameters to tune. However, k should be wisely selected and computation analysis could be large when sample size is large. The Naïve Bayes method is much faster than KNN. Unlike K-NN, the Naive Bayes method is a parametric method. SVM could handle outliers better than K-NN in all conditions. In addition, SVM performs better with more variables and less training data. However, ANN model is used in larger number of variables and lesser training data. In order to achieve a good accuracy, the large training data is needed in the neural network method. Moreover, there are too many hyper-parameters in neural network to tune modeling in training data. 22 –27
The primary goal of this study was to develop ML algorithms using routinely available data to accurately predict seizure caused by acute tramadol poisoning. The secondary goals included the comparison of the predictive performance of these models and the selection of superior algorithms to provide the knowledge and tools needed for improving the ability to predict seizure.
The proposed study will thus apply machine learning to develop prediction algorithms that can more accurately identify patients at high risk of seizure with tramadol poisoning using data sources that are readily available in health care systems.
Methods
Study design and setting
This project is a cross-sectional, single-center study of routinely-collected data. The reporting guideline from the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis statement (TRIPOD) was used in the study for the development and validation of a prediction model of seizure. The ethics committee of Shahid Beheshti University of Medical Sciences approved the study (IR.SBMU.PHNS.REC.1398.110).
Study population and data sources
This research was conducted on all the patients with acute tramadol poisoning admitted to Baharloo Hospital (a poisoning referral center) in Tehran, Iran, from September 2015 to November 2019. The patients with tramadol poisoning confirmed by laboratory tests were included in the study (900 patients). The patients with an age less than 15 years, a history of renal, cardiovascular, hepatic, and respiratory disorders, epilepsy, co-ingestion of other drugs, recent seizure history, pregnancy and missing data in their clinical records were excluded from the study. Data were extracted from the patients’ electronic clinical records and the information they had given at the time of their admission to the ED using a pre-made checklist designed by two trained researchers who were blinded to the findings of the study.
Predictors
The extracted data included: Demographic variables: Age, sex, ingested dose, manner of poisoning, history of addiction, and interval between consumption and seizure Clinical variables: Systolic and diastolic blood pressure, Glasgow Coma Scale (GCS) score, Pulse Rate (PR), and Respiratory Rate (RR) Paraclinical variables: Arterial blood oxygen pressure (PO2), partial pressure of carbon dioxide (PCO2), blood oxygen saturation (O2 sat), blood bicarbonate level, platelet count, hemoglobin level (Hb), white blood cell count (WBC), blood sugar, and blood sodium and potassium levels.
The manner of poisoning was presented as a categorical variable with the values being suicide, accidental, overdose and unknown. History of addiction and sex were binary indicators, and the other predictors were continuous variables.
Clinical outcome
The occurrence of seizure due to acute tramadol poisoning during the first 24 hours after admission to ED was assessed as the clinical outcome of this study. Seizure was diagnosed by clinical symptoms and confirmed with Electroencephalogram (EEG) or Computed Tomography (CT) in suspected patients by an expert physician.
Statistical analysis
A statistical analysis was performed using Stata version 16.1 and R version 3.6.2 software. As for the descriptive statistics, the patients were stratified by the occurrence of seizure (with and without seizure) and their characteristics were also compared. The qualitative data were reported as frequencies and percentages and the quantitative data as mean ± standard deviation. The confidence interval (CI) was 95% and P-values <0.05 indicated statistical significance.
Machine learning algorithms
The study population was randomly split into 70% of the samples (641 patients) as training cohort for presenting a seizure risk algorithm and 30% of the samples (268 patients) as validation cohort in which the algorithms were tested for development of predictive model. Each patient could only appear in either the training or validation cohort. Four machine learning models were developed using the demographic, clinical and paraclinical variables, including (1) the k-Nearest Neighbor (k-NN), (2) the Naïve Bayes (NB), (3) the Support Vector Machine (SVM), and (4) the Artificial Neural Network (ANN). The parameters of each algorithm were tuned so as to accurately predict the seizure risk.
Variable importance
Variable importance was determined by the random forest method. This technique examined the impact of each predictor alone and in interaction with the other predictor variables.
The selection of important variables in the random forest method was based on the Mean Decrease Accuracy (MDA) and the Mean Decrease Gini (MDG). MDA was calculated as the normalized difference between the Out of Bag (OOB) accuracy of the original observation to permuted variable randomly, and MDG was calculated by summing the entire decrease in the Gini impurity at each tree node split. 28 –30 The MDA method was used in the random forest algorithm for selecting importance variables.
Performance of the machine learning algorithms
The performance of the four ML models was evaluated in the validation cohort by: (1) The k-fold cross validation (k = 10) method using the Area Under the Curve (AUC) in the Receiver Operating Characteristic (ROC) analysis, (2) the confusion matrix findings, consisting of sensitivity, specificity, positive predictive value, and negative predictive value, (3) the accuracy of the prediction models, and (4) the net benefit through the decision curve analysis.
As AUC is a threshold-independent measure of discrimination, it was chosen to compare the performance of the four ML models using pairwise comparisons and Bonferroni’s method.
Finally, the superior prediction model was chosen based on the performance of these models for application in clinical decision-making.
Results
Patient characteristics
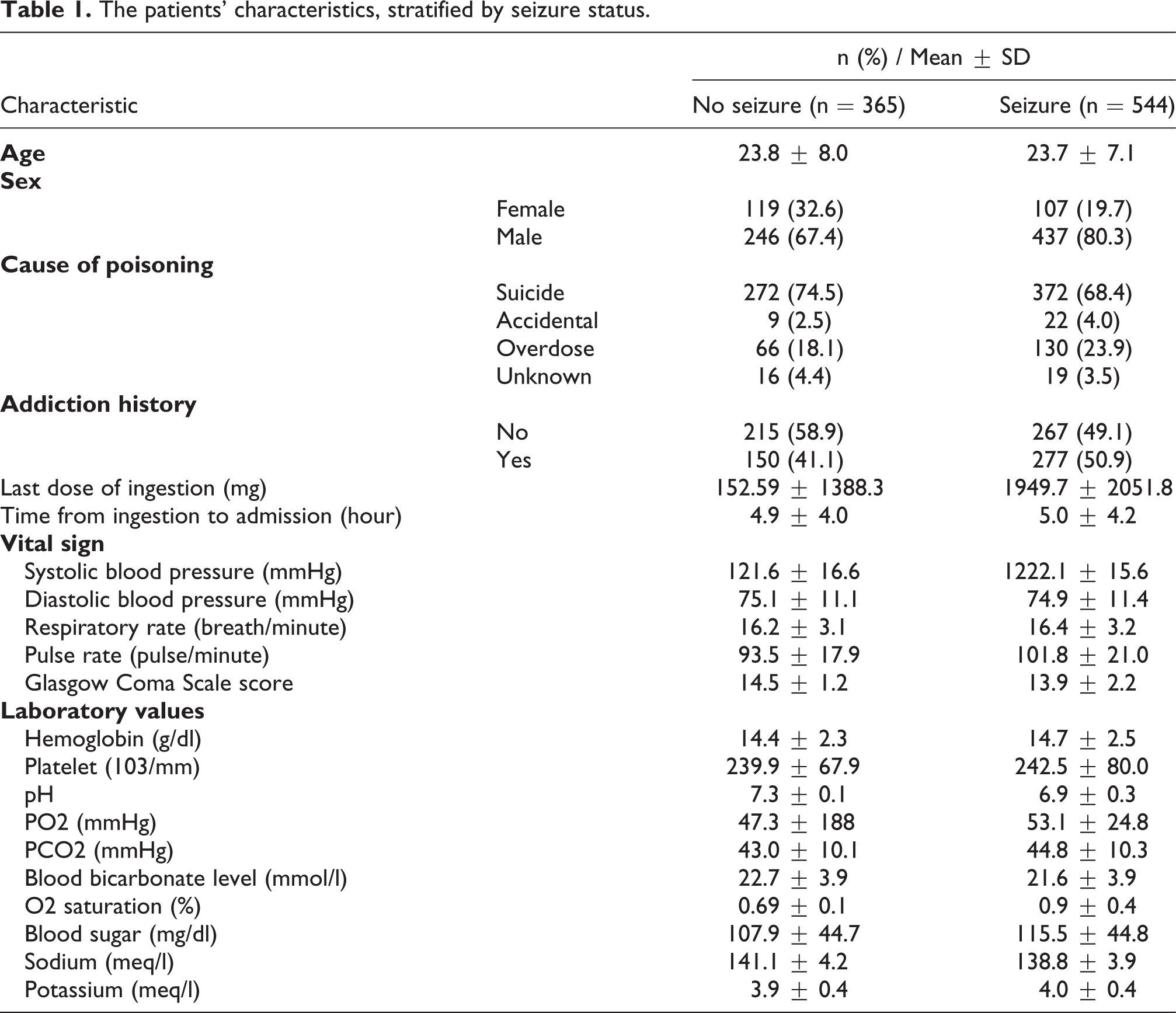
Out of the 909 patients examined, 544 (59.85%) had seizures during the first 24 hours after tramadol consumption. The mean ± SD of age in the seizure and no seizure cases were 23.7 ± 7.1 and 23.8 ± 8.0 years, respectively. Out of the 544 cases with seizure and the 365 cases without seizure, 437 (80.3%) and 246 (67.4%) were male, respectively. Table 1 presents the other characteristics, including the cause of poisoning, addiction history, last dose of ingestion, the time from ingestion to ED admission, vital signs, and laboratory values.
The patients’ characteristics, stratified by seizure status.
Algorithm variable importance
Figure 1 shows variable importance of predictors in the random forest models. The variable importance is a scaled measure to have a maximum value of MDA that consist of PR, blood bicarbonate level (HCO3), pH, PO2, and sex.
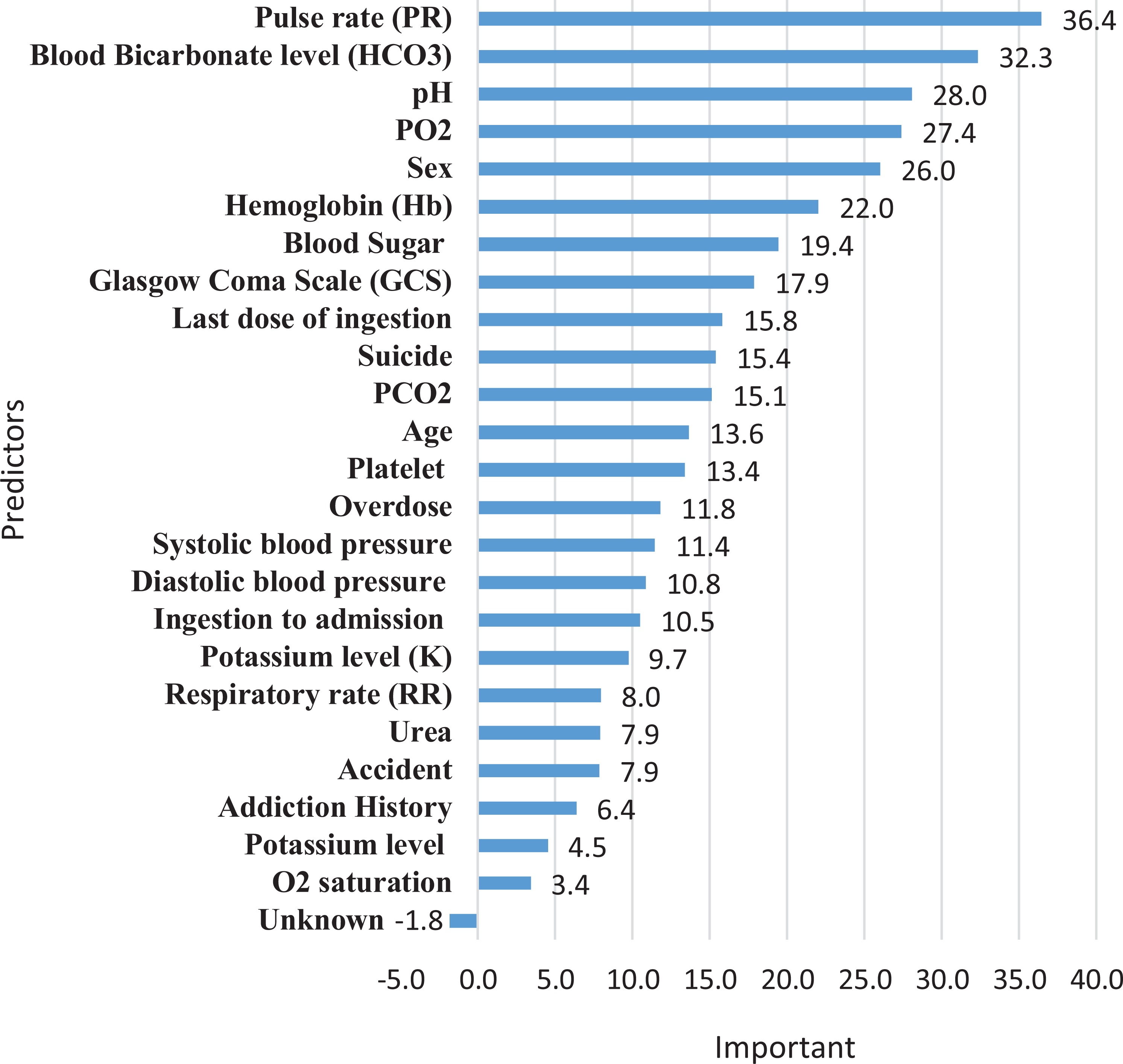
The variable importance of the predictors in the random forest model based on the mean decrease accuracy measure.
Model performance
The Confusion Matrix and the prediction performance of the machine learning models in the validation cohort is shown in Tables 2 and 3. The accuracy of SVM (0.65, 95% CI: 0.59–0.71), NB (0.69, 95% CI: 0.63–0.74), and neural network (0.68, 95% CI: 0.62–0.73) was significantly higher than the No Information Rate (NIR) value (P < 0.001); however, the accuracy of k-NN (0.55, 95% CI: 0.49–0.61) was not significantly different from the NIR value (P = 0.972). The highest sensitivity (0.83) and NPV (0.71) were reported for the NB model and the highest specificity (0.78) and PPV (0.73) for the k-NN model. The AUC of NB (0.71, 95% CI: 0.65–0.78) and neural network (0.71, 95% CI: 0.65–0.77) was significantly higher than the AUC of k-NN (0.68, 95% CI: 0.52–0.64) that was shown in Figure 2.
The Confusion Matrix of the machine learning models in the validation cohort.

The prediction performance of the machine learning models in the validation cohort.

AUC: Area Under the Curve, PPV: Positive Predictive Value, NPV: Negative Predictive Value.
*P-value was measured to compare the accuracy of the No Information Rate (NIR) with that of each machine learning model.

The prediction ability of the machine learning models, including Naïve-Bayes, neural-network and SVM, for predicting seizure in the validation cohort. The receiver-operating-characteristic (ROC) curves.
Discussion
Based on the data of 909 patients, the comparison of the four machine learning algorithms showed no significant difference to predict the occurrence of seizure due to acute tramadol poisoning. The Naïve Bayesian algorithm showed a better performance based on the AUC and accuracy, but a similar research article showed that the logistic regression model is superior for the prediction of seizure. 21 According to the literature review, AUC is an important criterion for evaluating the efficiency of the models. 31,32 Relying on AUC alone, however, may lead to overestimating the advantages of a prediction model, and it is recommended to report other performance criteria as well to present the power performance characteristics of a specific model. Based on the present findings comparing the prediction performance of these ML algorithms, the Naïve Bayesian model had higher sensitivity and NPV, while the k-NN model had a higher specificity and PPV than the other models. The low accuracy and AUC in the k-NN model revealed the superiority of the other ML algorithms over this model for predicting seizure caused by tramadol poisoning.
Several studies have developed prediction models for several types of seizure using important predictive factors and various analysis methods, such as frequency-based methods using EEG signals, the Least Absolute Shrinkage and Selection Operator (LASSO) regression, nonlinear dynamics (chaos), and logistic regression and machine learning models such as k-NN, SVM and the deep learning classifier. 17 –20,33 –35 Nonetheless, the superiority of the application of ML algorithms over conventional logistic regression models to predict seizure remains a controversial assumption. The review of literature did not show any studies that had managed to forecast seizure caused by tramadol poisoning.
As too many features can decrease the accuracy of a prediction model in the machine learning approach, the use of the Random Forest (RF) method to reduce the variables and consider the correlation of feature is outperformed for selection important variables. Many studies similar to the present study have applied the RF method to develop prediction models for clinical outcomes and drug consumption complications. 36 –38
Comparing these ML models with the LR model (AUC = 0.77, sensitivity = 0.8, specificity = 0.6, Positive Predictive Value = 0.71, Negative Predictive Value = 0.64 and accuracy = 0.75) with the same predictors and outcome demonstrated that the LR model has a superior performance in the prediction of seizure caused by tramadol poisoning on the criteria performance with equal number of important variables. 21
The main goal of Emergency Department (ED) triage is to accurately identify high-risk patients to enhance decision-making using the available patient information. Previous studies have reported many related and predictive variables for the occurrence of seizure in acute tramadol poisoning for differentiating high and low-risk patients. Nevertheless, this study showed that the use of demographic, clinical and paraclinical data in ML methods may improve the prediction ability due to the times limitations and the priority of patients in EDs. The selected predictive variables of the four ML models included pulse rate, pH, blood bicarbonate level, pressure of oxygen in blood and sex, which is consistent with the results of other studies. 21,39 –43
Similar to the present research, a previous systematic review showed no performance benefits for ML over LR models to predict various clinical outcomes. 15 The regression logistic model outperformed the others due to its better interpretation model, simple analysis and representation of the model as a nomogram with equal variables. Additionally, LR models can be used for qualitative and semi-quantitative predictors. Log transformation can be used in LR models to transform the nonlinear relationships between the dependent and independent variables into linear relationships with lower restriction conditions and data types. 44,45 Therefore, improvements in methodology and reporting are necessary for investigations that compare prediction modeling.
The strengths of this study include being the first research to predict acute tramadol-poisoning-induced seizure using the routine demographic, clinical and paraclinical information taken from patients and the utilization of ML models. Also, compared to previous studies conducted to predict the risk of opioid use disorder, our models applied fewer important variables to predict seizure caused by tramadol as an opioid drug. Therefore, these models are practically more efficient than previously trained ML algorithms for predicting complication of poisoning.
The potential limitations of this study include the development of prediction algorithms for patients with tramadol poisoning presenting to a medical setting, which means that the findings may not be generalizable to the general population. Also, data were collected from a single medical center, while a multicenter research could improve the efficiency of these models. Nevertheless, the examined center was a referral poisoning center in Tehran, Iran, to which patients with different demographic profiles are often admitted. Second, not all the important patient information, such as EEG reports, were available in the clinical records and hospital electronic system. Hence, the researchers recommend the development of predictive models based on other important available data as well. Third, our models do not provide estimates of errors to predict seizure individually. This limitation can be resolved in future developments of robust prediction models. The fourth limitation was the selection of four rather common ML algorithms from a much larger pool of ML algorithms. Therefore, future studies are recommending to extend other ML algorithms to predict seizure poisoning and compare them with our proposed models.
Conclusion
This study presented the first prognostic algorithm to predict seizure caused by acute tramadol poisoning applying common ML models and using routine demographic, clinical and paraclinical data, and the important predictive variables were selected with the RF method. The support vector machine, neural network and naïve Bayesian models had no significant difference in the AUC and other performance criteria. The k-NN was not an appropriate model for forecasting seizure in tramadol poisoning due to its low accuracy and AUC. In contrast, the validated logistic regression was superior algorithm for predicting seizure in EDs because of its better interpretation and performance model, simple analysis, representation of the model as a decision tool, fit for qualitative and semi-quantitative predictors and possibility of transformation of linear relationships between dependent and independent variables with less restriction conditions and lower data types and ultimately its ability to guide clinicians toward better decision-making and thus improving the quality of care.
Footnotes
Acknowledgements
We express our gratitude to the team involved in the collection of the data at Baharloo Hospital (a poisoning referral center) in Tehran, Iran.
Author contributions
All authors contributed equally to this work. Also, all authors read and approved the final version of the manuscript and met the criteria of authorship based on the recommendations of the international committee of medical journal editors.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.