
Abstract
Background
This narrative review establishes the current state of the art of machine learning approaches for prediction of migraine attacks. Related concepts are highlighted including the identification of triggers or premonitory symptoms and methods for evaluating prediction models. Existing efforts at machine learning prediction of individual migraine headaches and attacks are reviewed in detail. Challenges in this task are discussed.
Results
A variety of input data and modeling approaches have been used. It is consistently found that individualized models provide better results compared to a generalized model and achievable performance varies considerably between individuals. Patient needs should be assessed to discover what a valuable prediction looks like. The field should develop common standards for evaluating migraine prediction algorithms.
Conclusions/Interpretations
While the problem is far from solved there is great potential and reason to believe that feasible solutions that improve the quality of life of those with migraine are within our grasp.
This is a visual representation of the abstract.
Introduction
In addition to other symptoms, migraine is most commonly characterized by painful episodic headache attacks. Part of the burden of migraine comes from the unpredictable nature of these attacks. This uncertainty can create negative impacts on work, social and personal lives as well as stigma for people with migraine (1,2). In addition, recent research suggests that treatment with migraine-specific medications in the earliest stages of the migraine attack (the premonitory phase) (3) may be most effective or even prevent the headache and further symptoms from developing (4–7). For those without the ability to identify their attacks in the premonitory phase this early treatment is not possible. For this reason, and others, the prediction of migraine attacks is of great interest to the migraine world.
This narrative review will discuss machine learning-based efforts at predicting individual migraine attacks. We conducted a comprehensive search using the Arizona State University Library's main discovery tool, which is powered by Ex Libris's Central Discovery Index for the terms “migraine prediction” and “migraine forecast”. This tool aggregates metadata from a wide range of scholarly resources from thousands of publishers, aggregators, and open-access repositories. All returned abstracts were reviewed to identify important themes and examples. Machine learning efforts in related migraine topics, such diagnosis and treatment response prediction are not discussed.
We begin by briefly reviewing research topics serving as the foundation of migraine attack prediction research: the ability of people to identify migraine triggers and/or premonitory symptoms and findings of physiological changes associated with the premonitory phase of migraine. We then establish the current state of machine learning for prediction of individual migraine attacks by reviewing important publications followed by synthesizing this information in a discussion of the challenges associated with migraine attack prediction and recommendations for future work.
Migraine attack prediction precursors
Several areas of research suggest that prediction of migraine attacks may be possible: 1) patient reported premonitory symptoms; 2) reports of migraine triggers; and 3) physiological changes which occur between migraine phases.
Self-prediction
Research suggests that there is a portion of individuals with migraine who can predict their next migraine attack with some reliability.
In a study (8), which enrolled patients with migraine who reported non-headache symptoms that they believed predicted headache in two of three attacks, the participants correctly predicted attacks in 72% of diary entries reporting premonitory features. The generalizability of these results is limited as some with migraine do not ever experience premonitory symptoms and those that do may not experience them before each attack. In a second study (9) patients recorded what they believed to be premonitory symptoms. The study found that premonitory symptoms had a very high positive predictive value (PPV) 85.1%, meaning that when premonitory symptoms were experienced, they were almost always followed by an attack. However, only 35.3% of participants were able to predict 50% or more of their attacks and premonitory symptoms were reported a priori in only 27.5% of attacks. An additional study (1) found that only 4% of the study participants were able to correctly predict the day of their next migraine attack. The importance of developing migraine attack prediction models derives from the inability of many people with migraine to reliably predict their attacks.
Triggers
Triggers are events which increase the probability of the start of a migraine attack within a relatively short period of time (10).
Stress and specific foods (11) are often discussed as triggers but many others have been identified. For example, occupational noise and vibration (12), particularly in combination, are associated with headache and eyestrain. Poor quality sleep (13) is predictive of both migraine and non-migraine headache. Many individual studies and several reviews exist on this topic (14–18).
Working with triggers can be difficult because of the wide variety of reported triggers and inconsistency in their impact. For example, Hoffmann et al. (19) noted that a correlation between weather and migraine attacks existed but only in a subset of the study participants.
It can also be difficult to resolve whether some purported triggers (e.g., thirst) are true triggers vs premonitory symptoms (15,20,21). For other potential triggers (e.g., weather) (19,22) the relationship is clear. It is also difficult to understand and measure trigger potency or to be precise in measuring a trigger “dose” (20).
Physiological changes
There are many known physiological changes associated with changes in the migraine phase.
For example, there have been findings associated with changes in phase of the migraine cycle in electroencephalography (EEG)(23,24), including home administered EEG (25), Event Related Potentials (26), Contingent Negative Variation (27), pain thresholds and pain adaptation (28,29) and surface electromyography (EMG) (30). Valuable reviews of Contingent Negative Variation in migraine (31), EEG in the migraine cycle (32) and neuroimaging changes associated with the preictal or premonitory phase of migraine (33) provide important background on these topics.
Not every physiological signal that shows phase-based differences in a group-based analysis is useful for predicting attacks for an individual. Creating models and evaluating models that perform well for individuals may be more challenging than population level analysis (34). Additionally, some approaches, such as MRI, are not practical for daily migraine attack prediction given current technological limitations. However, as technology develops (e.g., home EEG) (25) opportunities expand. For continuous monitoring body worn sensors like fitness watches are a practical and common choice. Machine learning is a particularly valuable tool when working with this kind of data because of its ability to handle large amounts of data.
Evaluating migraine predictions
Several of the models that are reviewed in detail below make predictions of whether or not the subject will experience a headache on the day following data collection. However other models approach it as a continuous monitoring task, with a goal of issuing warnings as attacks develop. These models are trying, sometimes in combination with other data, to detect the physiological changes which signal that the subject is in the premonitory phase of a migraine. Predictions can be made to cover timespans of different lengths (35) and performance of the model can vary depending on the timespan used (36). Comparisons should be made between models reporting similar temporal properties.
In addition to standard metrics for evaluating binary classification (Area Under the Curve (AUC), Positive Predictive Value (PPV), sensitivity, etc.) (37) there are multiple additional measures of forecast quality (38). A highly calibrated model shows high consistency between the distributions of forecasts and the observations. The frequency of an event happening for a specific predicted probability will be close to that predicted probability if the model is calibrated. A model which only gives a probability of headache that is similar to the individual's long run probability of a headache is of limited utility (39). For example, if a person had headaches on 21/28 days each month a model which predicted a 75% chance of headache every day would be calibrated but not helpful. A model with good sharpness makes predictions with more concentrated probability distributions i.e., individual predicted probabilities are high when events happen and low when events do not happen (40). A model that is both calibrated and sharp will make prediction probabilities that average to the average rate of events with variability between the high and low probability days. The Brier score measures the accuracy of probabilistic prediction and is comprised of uncertainty, reliability and resolution components.
Patients may have different risk tolerances or prefer different metrics for assessment depending on the actions they will take in response to the information. One may prefer false positive notifications over false negatives to feel prepared, but this would be problematic if the goal is to use the warning to treat the attack prior to headache.
Generally, all of the individual's data should only be included in either the training set or the test set (Figure 1). However, the most successful migraine attack prediction models are individualized models which are trained only on one person's data and must be evaluated on that same person's data (Figure 2). The test data should be from events separate from the events used in the training and ideally the later events should be used for the test set to mimic real world conditions where there may be seasonal or cyclical changes. In practical application a standard procedure for developing individualized models will be needed, and testing should include the development of individualized models for entirely new individuals from start to finish.

Data collection.

Predictive models.
Machine learning migraine prediction
We will now review relevant publications that used machine learning to make predictions of individual migraine attacks. It is important to note that across the literature, though authors most often use the term “migraine attack” to describe their outcome of interest, they operationalize it differently. Holsteen et al. (41) use the term “new-onset migraine headaches,” requiring that the episode meets relaxed ICHD criteria and that no migraine occurred in the preceding 24 h. In contrast, Houle and colleagues (39) define an attack as any head pain in the study's migraine population. Pagan et al. (36) is the only study reviewed that shifts focus from next-day attacks to “symptomatic crises.” These and other important facets of the studies are highlighted in Table 1. Figure 3 presents a conceptual framework for research on migraine attack prediction. Several indices which are associated with increased risk of attacks have been developed (26,30) but do not make individual predictions so are not covered in detail in this review.

Framework for research on predicting individual migraine attacks/headaches.
Important facets of relevant migraine attack prediction works and highlighted results.

OOS: Out of sample, PPV: Positive Predictive Value, TPR: True Positive Rate, AUC: Area Under the Curve.
Pagan et al. (2015)
Pagan et al. (36) created individual models for predicting migraine attacks based on data collected from a body worn sensor network using a state space algorithm: N4SID.
Data was collected from two female patients; one young (Patient A) with aura who was not under medical treatment and one middle aged patient with migraine without aura and who was not receiving preventive therapy (Patient B). This study focused on the hemodynamic changes (heartrate, electrodermal activity, skin temperature and peripheral capillary oxygen saturation (SpO2)) collected from two sensors. Patients wore the sensor network near-continuously for four to six weeks. In contrast to the other works discussed here, the focus in Pagan et al.’s study is on forecasting “symptomatic crises” as they arise rather than next day attacks. No differentiation between migraine and non-migraine headaches is made.
A symptomatic pain curve was generated for each attack by querying the patient about the increase or decrease in their pain level at regular intervals throughout the attack. This curve was estimated with two semi-Gaussian curves, the first modeling the pain from beginning to maximum pain and the second modeling pain from maximum to cessation.
The data prior to the onset of pain were used to train the models. It was preprocessed to recover missing data and divided into samples of one minute duration. After this the gathered data was divided into train (75% of migraine episodes) and test (25%) sets. For each attack a total of 200 different models were fit and the best model for that attack was chosen. A fit metric was used to evaluate the accuracy: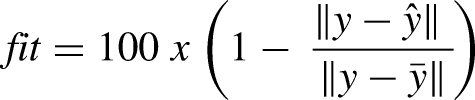
Where y is the modeled symptomatic curve and
The best model from each attack was compared to the chosen models from other attacks using cross validation. In the validation step additional processes were implemented to limit false positive results. From the validated models the top 1/3 of models were chosen to compile the final model. When used in application each of the top 1/3 of models is run and their predictions averaged to get the prediction.
Models with subsets of three features were also examined
Results showed there is considerable variability between migraine attacks even within the same person. Fit for the best models for Patient A ranged from 71.3% to 85.2%. Optimum performance may depend on the person; in this study the fit of Patient B's models were consistently higher, and the possible prediction horizon was longer than for Patient A even though Patient A had more training data available.
The original model fits were for a 30-min prediction horizon. Experiments to extend that horizon showed acceptable fit at an average of 25 min for Patient A and 47 min for Patient B.
They provided binary classification metrics on the test set but did not give a specific number of asymptomatic intervals included . The PPV was 100% for both patients with all of the tested models but the true positive rate (TPR)varied with a maximum of 67% for Patient A and 90% for Patient B; meaning the models did not identify any false attacks but also did not identify all true attacks. Because there were no false attacks this model could be used in prompting the early use of treatment prior to the headache.
This study addressed missing data and limiting false positives; important practical considerations. The sensor network was not practical for everyday use as it consisted of multiple electrodes attached to the chest and arm.
A second approach to the problem with this data, Grammatical Evolution (42), reported the ability to accurately detect an attack 20 min prior to headache onset. In one patient 100% of the test samples were correctly identified and for the other participant the PPV was 75%, the TPR was 60% and the True Negative Rate (TNR) was 80%. Grammatical Evolution is a variation of a genetic algorithm. In genetic algorithms improved solutions to a problem “evolve” by iteratively combining starting solutions.
An additional analysis (43) further extended the work to maximize the prediction horizon. It examined the tradeoff between conservative short-term models and less accurate prediction with longer horizons. The authors determined that 40 min is the limit of prediction horizon for their approach. At 40 min Patient A had a fit of 78.8% for the four-input model. Patient B’s fit was 97.2%.
A further abstract from 2022 (44) reported that, in a sample of n = 10, personalized models were able to predict 23/24 attacks 120 min prior to the pain appearing using an artificial recurrent neural network long short-term memory approach. The short nature of the abstract prevents presentation of detailed information.
Houle et al. 2017
This study (39), using data from the Headache Prediction Study (HAPRED), followed several other publications by the lead author on the application of time series analysis to migraine (45,46).
This study used the daily stress inventory and current headache state in a generalized linear mixed-effects model to forecast headache attack over the next 24 h following the daily evening headache diary entry. An attack was defined as any headache pain greater than zero.
This study enrolled participants with episodic migraine with or without aura, greater than two headache attacks and 4–14 headache days per month. Exclusion criteria included recent changes to the headache pattern, the presence of medication overuse headache, secondary headache disorder, substance abuse and recent psychiatric hospitalization.
From 95 participants 4625 diary days were collected using an electronic diary. Participants had headaches on 38.5% of days.
This approach used a generalized linear mixed-effects forecast model. This random effects model is a single model which allows tuning for each individual by allowing individual intercepts. Authors tested several models including combinations of the average headache frequency, current headache state, and stress features.
All models were evaluated using the BIC and AUC calculated on all training samples. The best model, identified by BIC, used only patient headache frequency, current headache state and the Average Intensity Rating of the stress instrument as inputs. Leave-one-out-cross-validation (LOOCV) on the final model reported Brier score of 0.200 and AUC of 0.65. The model had good calibration between forecasted probabilities and observed frequencies but only had low levels of sharpness meaning it predicted the same average headache frequency, but the individual predictions were not very specific.
The benefits of this modeling approach are that it is insensitive to missing data and it is a single model which is tailored to each individual.
In this work there was no out-of-sample evaluation. LOOCV is preferable to many other approaches but can still overestimate performance. Setting aside all data from a few people could have given an approximation of how the model would perform for new patients. This was addressed in a second analysis.
The secondary analysis of this dataset (47) used a Bayesian approach (vs “traditional” frequentist.) Bayesian analysis allows for the use of priors (prior probability distributions) in modeling. The prior is information, such as expert subjective opinion, from outside the dataset that is included in the model. In situations where models are re-estimated (updated) as more data is acquired these priors can give the model a head start at achieving a good fit earlier on (“warm up”). Their simulation work showed that use of a prior based on self-reported headache frequency over the last month improved early model performance compared to models without a prior. This effect decreased as more data was collected and the other models improved.
Siirtola et al. 2018
The next study (48) was based on the observation that sleep problems and migraine are connected.
The authors used wrist worn sensors (Empatica E4) which provided acceleration, galvanic skin response, blood volume pulse, heart rate, heart rate variability and skin temperature to predict next-day self-defined migraine attacks using quadratic discriminant analysis and linear discriminant analysis.
Only data from the sleep period was used due to poor quality of signals during the day, hypothesized to be due to movement. The sleep phase was manually identified by the investigators. The determination of whether a day was a migraine day or not was based on participant's headache diary. It is not clear if all headache days were labeled as migraine days or if some were filtered out for not being migraine.
Of seven participants five were female. Two had aura symptoms and most did not use preventive medications. 200 days of data were collected.
The authors compared quadratic discriminant analysis (QDA) and linear discriminant analysis (LDA) approaches to making both generalized and personalized classifiers. They introduced noise to avoid overfitting and used sequential forward selection to choose features.
To increase sample size, features were developed which were the differences between all night-before-a-migraine-day (NM) and night-before-a-non-migraine-day (NN) pairs and all NN/NN pairs. From these differences they calculated 110 features such as the mean of the temperature over the nighttime period.
To test the individual models two NM samples were selected from each subject for inclusion in the test set. All features derived from a chosen NM were included entirely within the test set; however, it is not specified that all data derived from NNs included in the test set were only within the test set. Including features derived from the same NNs in both training and test could potentially lead to inflated performance.
The personalized models performed better than the user-independent models and QDA performed better than LDA. Even among the individual QDA models there was significant range in performance between study participants. Accuracy ranged from 60% to 95%and specificity from 30% to 95%. In short, the prediction model worked well for some participants but not others. The specificity (ability to identify days without a migraine) of 30.0% or 42.5% as described for two study participants would not be useful for treating migraine before it begins.
This is another study which highlights the benefits of individualized models and shows how some people's headaches appear easier to predict than others. The authors’ discussion of the difficulties of working with unbalanced data is valuable. They also highlight the difficulties in correctly labeling days as migraine (vs headache) based on self-report in diaries.
Holsteen et al. 2020
This study (41) attempted to forecast next-day new migraine attack based on exposure to trigger factors and participant self-prediction using a multivariable multilevel logistic regression. Enrollment criteria included 2–10 headaches per month, with a maximum of 15 headache days per month. Those who changed medication within the first 30 days of the study were excluded from analysis.
A relaxed version of ICHD criteria was used to label headaches as migraine. New migraine attack days were days where no migraine was present in the past 24 h. The final data set included 178 participants and 1870 migraine attacks.
Multiple lag-based features were developed from the collected data. They first fit trigger category-specific models and used these results as a variable selection to create the final model. Trigger categories included sleep, stress, caffeine/alcohol and weather. They also considered a grouped-lasso penalized logistic regression model.
Variables predictive of next-day new migraine included decrease in caffeine consumption, self-predicted probability of a headache, stress and menstruation onset.
They reported a within-person cross-validated C-statistic of 0.56. Authors suggested the model was overfitted and concluded that attacks were not predictable based on the information they considered.
The authors argued that predicting new migraine attacks (vs days) should be the standard, but predicting new migraine attacks is a more difficult task than predicting migraine days. They also differentiated between headache and migraine days, finding that 80% of headache days in this study were migraine days. This differentiation is important if the goal is to use attack prediction to direct early medication use.
The study cohort was geographically dispersed, a positive for generalizability. They also address predictor susceptibility to measurement error and presented and argued for the superiority of within-person discrimination statistics compared to an overall C-statistic. The supplemental material provides a valuable discussion of several technical issues including measurement error, discrete hazards of an attack and timing of measurements. They also discussed the importance of examining multiple evaluation metrics (calibration in the large, weak calibration) when evaluating a model.
Stubberud et al. 2023
In this 2023 study (49) participants completed a biofeedback session (Cerebri app) and headache diary once per day to predict next day attacks using machine learning. There was no differentiation between migraine and non-migraine headaches. In addition to the presence or absence of headache the diary also collected headache premonitory symptoms and information on medication use and sleep. Skin temperature, heart rate and surface EMG data was collected during the biofeedback session from the electromyography sensor and combination thermistor and photoplethysmography sensors.
Inclusion criteria included 2–8 attacks per month and experience with an iPhone. The study included 18 individuals. Three hundred and eighty-eight diary days were collected and 295 were used.
Several machine learning model approaches (logistic regression, Support Vector Machine (SVM), Gradient Boosting Machine (GBM) (37) )were tried with the best performing model being a random forest model.
This group split the data into the training, validation and tests so that all data from one individual was in either the training, validation or test sets. Failing to do so is data leakage and can lead to significant performance overestimation.
For the random forest model, described as the best model, reported test AUC, accuracy, sensitivity and specificity were 0.62, 0.56, 0.0 and 1.0 respectively. This would mean that none of the headache days and all of the non-headache days were correctly predicted i.e., all predictions were that there would be no headache the next day. Test AUC of the gradient boosting model was 0.62 (accuracy: 0.62, sensitivity: 0.21, specificity: 0.95).
The authors note that having a headache today was strong predictor of having a headache the next day underscoring the point made by Holsteen et al. (41) about the utility of predicting new headache attacks vs headache days. This study was notable for its use of a large number of prediction variables and strong testing approach.
The authors suggest that AUC > 0.8 is necessary for forecasting to prevent medication overuse headache due to false positives. This would depend on the medications being used as not all medications cause medication overuse headaches.
Kapustynska et al. 2024
This study (50) used overnight data from wrist-worn Empatica Embrace sensors to predict attacks the next day using machine learning. No distinction was made between migraine and non-migraine headaches. Enrollment criteria required at least four migraine attacks per month. Those with a diagnosis of chronic and/or hemiplegic migraine, who used a preventive migraine treatment or other drug with an effect on the autonomic nervous system or other diagnosis of chronic pain were excluded. Ten people were enrolled, nine participants did not have aura. They had experienced migraine for between five and 29 years.
The authors examined multiple machine learning models including SVM, random forests and XGBoost. The authors found both individual models and a general model and reported accuracy, precision, recall and F-1 score of 0.806, 0.638, 0.595 and 0.607 respectively for the XGBoost general model with a five-minute analysis frame. Results for the best model for each individual for each analysis frame length were reported and variable. Reported F1s for the five-minute analysis frame ranged from 0.494 to 0.829.
To expand the dataset they divided the data from each night into windows they termed “analysis frames”. From each frame they extracted multiple features. They examined multiple analysis frame durations and found that a 5-min analysis frame gave the best performance. However, data from the same night are likely to be highly correlated, not independent, and if data from one night were allowed to be present across multiple folds of a cross-fold validation it would be a form of data leakage and likely inflate model performance.
A second form of data leakage could potentially occur in the preprocessing step where the data is normalized by dividing by the difference between the minimum and maximum of the signal of interest. Including any of the data from the test set in calculating the maximum or minimum used in normalization of the entire set is potential data leakage. The authors are notable for reporting their process in sufficient detail to make these observations possible.
Limitations
As reflected in the publications to date there are a number of challenges in predicting migraine attacks.
For approaches which identify the premonitory phase to predict headache a fundamental question is how far in advance of the headache does the premonitory phase begin? The duration and even existence of these phases may differ between individuals (48). It is conceivable that a migraine headache may not follow every premonitory phase resulting in a mismatch between the physiological approach to attack prediction (identifying the premonitory phase) and predicting completed attacks.
There are technology related challenges specific to wearables-driven prediction. Continuous physiological monitoring (36,48,50) generates massive amounts of data on the order of 1MB of data per hour for one person (36). When commercial or consumer grade equipment is used it is possible for the manufacturer to alter the algorithms or discontinue the sensors (51) at any time, potentially decreasing model performance. There are no examples of algorithms which have been demonstrated to be equipment agnostic.
Most efforts have not distinguished between migraine and non-migraine headache. Although the majority of headaches for those with migraine may be migraine headaches (41) correct identification of migraine headaches/migraine attacks may still be a concern when the application is early acute treatment, depending on the treatment and headache frequency.
Studies’ inclusion and exclusion criteria for enrollment shape training and test data and limit the works’ generalizability to the wider population. Studies are often limited to a specific geographic area (49,50). Limitations such a minimum and maximum headache/migraine frequency, presence or absence of aura, use of preventive medications or use of other medications limit generalizability in some cases (e.g., excluding chronic migraine) significantly.
To our knowledge no existing studies have tested data for a sufficient timespan to adjust for potential seasonal changes (41,47) or demonstrated prediction in real time. We do not know how warnings will impact participants’ perception of their headaches and migraine. It is conceivable for example that the stress of anticipating a predicted migraine attack could change the likelihood of developing one. The burdens on the participants, particularly if the study requires multiple forms of daily activity from the participant, may make long-term studies challenging. Participant compliance with wearing a sensor device can be low and is complicated by limitations such as battery life and failed connection to the receiving device (51). Collecting and processing data and making predictions in real time requires different infrastructure than performing the same tasks asynchronously. This infrastructure is not as easily available or researcher-friendly.
Several of the models predict next-day attacks based on overnight data. Treatment of individuals who wake with headache in evaluating the performance has not been addressed. There is limited utility to telling a person who woke up with a headache they will have a headache that day. Being alerted of a migraine attack or headache happening later that day would be very beneficial in general but the timing would need to be more specific for these to be useful for early treatment.
Future considerations
In many regions deployment of prediction models may require the approval of the appropriate governing body (United States Food and Drug Administration, European Medicines Agency, United Kingdom Medicines and Healthcare Product Regulatory Agency, Health Canada, etc.). These agencies commonly require that products be interpretable. The ability of the user to understand why a model makes the decisions that it does can increase user comfort with the model and help them understand instances when a model should not be applied. For example, if a generalized model developed on a cohort of healthy adults were to reveal that overnight maximum heart rate is an important predictor of next-day migraine attack we could surmise that the model may perform less well on individuals whose heart rates differ from the norm such as high-performance athletes or people on beta blockers or opioids. In a blackbox model this limitation would not be visible. Interpretability can also help assuage fears about bias in models but it is important to note that variables of concern need not be explicitly included in order for that information to be available to the model (52).
The models described in detail in this manuscript and the features used have been highly interpretable.
A promising area of advanced research is the development of digital twin models (53)—virtual representations of individuals constructed from integrated systems of models capable of simulation and prediction. These models are tied to the object they represent through continuous, bidirectional data exchange, enabling real-time updates and feedback. While the application of digital twins to migraine remains a long-term objective due to the current limited understanding of migraine-specific biomarkers and existing technological constraints, research on predictive modeling provides a foundational step toward their eventual realization.
Discussion
Taken together efforts to date suggest that personalized models are more promising than a general model that works for all individuals with migraine. It is perhaps most efficient and practical to develop models which are tuned to the individual but which can take advantage of group data (47). Widespread implementation of individualized models would require an automated process for developing those models.
When reviewing models, it is important to understand the heterogeneity of the training and test populations to understand how the model will generalize. It is important to establish that models perform better than existing methods e.g., chance based on long run frequency, population odds.
Murphy (38) differentiates between the
Patient needs regarding attack forecasting have not been assessed and this should happen to understand the range of performance that they would find acceptable. Much of the attention on this problem relates to its ability to enable early acute treatment but anecdotally patients are interested in solutions with a longer timeframe as well, in order to plan their day. The range of acceptable tradeoff between accuracy and prediction horizon should be assessed. As the field continues to develop it is important to carefully evaluate proposed models. It is not enough to report group AUC or accuracy; additional metrics need to be provided. Turner and colleagues (20) emphasized the need for high precision and calibration with models that are clinically actionable in the individual's home environment. Data leakage is a problem across machine learning in healthcare. Preventing it and accurately evaluating models in this context may be especially difficult. Correspondingly details on the data handling should be reported.
An ideal solution will produce predictions or forecasts that are precise and sensitive. They will not give false warnings and will warn of all oncoming attacks. They will work across the entire population regardless of age, sex, presence of aura, preventive medication use or other variables. They will give sufficient warning to allow for intervention whether that intervention is early treatment with an acute medication or general preparation for the day ahead. They will be robust to unusual occurrences such as illness or change in climate or season. However, this is likely an impossible standard. A reasonable solution should meet patient expectations for performance and their individual needs and risk tolerance. It may be that attack forecasting is only possible in a subset of patients and there may be limits to the horizon it can be predicted over.
Communication and collaboration will be the key to developing tools that provide real value to people with migraine. Implementing standardized methodologies, ensuring robust validation processes and thorough reporting will be crucial in translating research advancements into patient-centered, reliable, real-world solutions.
Promising existing research and ongoing innovations in technology, pharmacology and machine learning make this a critical time to address the important problem of migraine attack prediction. While the exact form of the ultimate solution remains to be seen, it is clear we are poised to make significant advances. With progress comes the promise of significantly improving quality of life, restoring control and reducing the burden of migraine.
Key findings
Existing results show the potential to predict migraine attacks and improve the quality of life of those with migraine.
Several studied report that individualized models perform better than a generalized model.
The difficulty of making accurate predictions appears to vary across individuals.
Footnotes
Data availability statement
The data used for this article may be obtained from the author with a reasonable request.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.