
Abstract
Bias in word embeddings is often measured using bipolar dimensions, constructed as the difference between two anchor centroids. This technique assumes both poles are symmetrical and equally informative. However, normativity literature shows that one category may function as the unmarked norm, with others framed as marked deviations. In race, whiteness typically holds the normative position, and embedding-based race dimensions may inherit the skew. We test this possibility using dimensions constructed from validated African–European name anchors, probed with neutral and valence words. In three embedding models (Wiki-News, South African news, Google News), we assess whether race dimensions favour whiteness as a normative anchor, whether this skew is stronger in culturally specific models (SA, Google), and whether bipolar offsets amplify one pole, given unipolar evidence. Results show that neutral and valence terms cluster nearer to the white pole (most strongly in the Wiki-News model), indicating whiteness as the semantic default. Overshoot favoured Black in Google and Wiki-News, while White overshoot only occurred in the South African model. We argue that this captures racialised variance where the pole with more spread tends to exert greater leverage on the bipolar axis. The study provides quantitative evidence of white-normative anchoring and diagnostics for asymmetric amplification in embedding-based bias measures.
Introduction
“The problem of the twentieth century is the problem of the colour line.”
− W.E.B. Du Bois, The Souls of Black Folk (Du Bois, 2022, p.11).
It is no news that machine learning systems trained on human data inherit and reproduce human-like biases (Caliskan et al., 2017; Durrheim & Quayle, 2025). Recent developments in generative AI have made these biases more visible – for instance, prompting an image model to produce a “software developer” may produce predominantly male figures, while a request for an “elementary school teacher” might return mostly female portrayals. Such outputs are not built into these models by design; rather, they emerge from human activity data on which they are trained.
A common method for detecting biases in word embeddings involves creating bipolar semantic dimensions, defined as the vector difference between the centroid of two sets of anchor words (Arseniev-Koehler & Foster, 2022; Best & Arseniev-Koehler, 2023; Bolukbasi et al., 2016; Boutyline et al., 2023; Boutyline & Johnston, 2023; Durrheim et al., 2023; Garg et al., 2018; Kozlowski et al., 2019; Ohamadike et al., 2025; Taylor & Stoltz, 2021; Van Loon & Freese, 2023). For example, a race dimension might be defined as the difference between the average vector of words associated with “blackness” and that of words associated with “whiteness.” Concepts (e.g., common stereotypes) are then projected onto this dimension to examine race bias.
Researchers and analysts often assume that both poles are symmetrical and equally informative, especially when each side contains the same number of anchor terms. However, normativity literature suggests that one category can act as a normative anchor, while the other is treated as a marked or deviant category. In race contexts, whiteness is often positioned as the unmarked default and non-white categories like blackness are framed in contrast to it and usually found inferior (Brekhus, 1998; Frankenberg, 1993; Henry & Tator, 2006; Keene-Young, 2025; Kirkland, 2013; McDermott & Ferguson, 2022; Morris, 2016; Withers, 2017).
In word embeddings, this skew may occur when the model inherits a cultural default (most commonly whiteness for race dimensions), so the “unmarked” group sits nearer the corpus’s semantic centre while the “marked” group is represented more peripherally. With such asymmetry, bipolar measures may systematically favour the normative pole, which can distort bias measurement and associations, particularly when embeddings are applied in sensitive sociotechnical domains. This phenomenon, here termed normative-pole skew, echoes whiteness scholarship on the cultural dominance of “the norm” and the visibility gap between marked and unmarked groups (Frankenberg, 1993; Henry & Tator, 2006; Keene-Young, 2025; Morris, 2016; Withers, 2017).
One under-recognised mechanism through which such normativity can be produced is frequency. Norms are not only encoded in in what language means, but also in what language repeats: when a group is repeatedly centred in social life, discourse, and institutions, it can come to appear more ordinary, neutral, and default (Brekhus, 1998; Frankenberg, 1993). This is visible in cultural industries such as popular film and television, where persistent overrepresentation makes whiteness appear unmarked and universal (Ramón et al., 2024). It is also mirrored in digital language ecosystems where English dominates large-scale online text and therefore forms a large share of what is available to train “general” models. In this sense, part of normative-pole skew may capture semantic structure where words cluster around a pole that represents the semantic baseline, but part may also be produced by frequency-driven centring in which words become close because they occur frequently in similar contexts.
Our goal, therefore, is to test whether the bipolar measurement instrument absorbs semantic normativity and, in part, examine how much frequency contributes to such normativity. Although this phenomenon has been widely discussed, it has received little quantitative attention and has not been examined in bipolar word-embedding measures of bias. We address this gap using a neutral-target, and valence-based, test across three embedding models: a U.S.-centric Google News model, a South African news model, and a Wiki-News model used as a general-purpose reference.
Our research questions for the study include: 1. Do bipolar race dimensions systematically favour one pole (e.g., European/“whiteness”) as a normative anchor? 2. If skew exists, is it stronger in culturally specific corpora (South African news; US-centric Google News) than in a broad, general reference corpus (Wiki-News)? 3. Does the bipolar score (e.g., Africa–Europe) overshoot one pole, given unipolar evidence (e.g., Africa only)?
By overshoot, we mean pole amplification: when neutral words are projected onto a bipolar axis (e.g., Africa–Europe), one pole can exert disproportionate pull on that axis beyond what its unipolar evidence alone would predict. In simple terms, if you measure how close a word is to, say, the African pole on its own, and then measure it again on the combined Africa–Europe axis, the two should broadly agree. Overshoot occurs when they do not – the bipolar score pushes words further toward one pole than the unipolar evidence. This tends to happen when one pole has greater internal spread in the embedding space, giving the bipolar difference vector more geometric sensitivity in that direction. Overshoot can therefore also be a geometric consequence of normative-pole skew – if a pole is non-normative, it may have more variance, which may result in overshoot.
We hypothesise that neutral and positive terms will skew toward the White side of the race dimension, capturing the normative positioning of whiteness at the semantic centre of the embedding space, while Blackness will be more peripheral and associated with negative valence. This skew is expected to be strongest in culturally specific corpora (Google and South African news), and weaker in the general-purpose Wiki-News model. We further expect that the bipolar dimension will respond to this asymmetry by amplifying one pole, producing overshoot when predicted from unipolar evidence.
To test these, we use established race categories to construct the poles – curated sub-Saharan African/European name sets validated and found most effective for constructing race dimensions in prior work (Ohamadike et al., 2026). We then probed those poles using validated neutral, everyday words (e.g., tools, places, common nouns) and valence-based ones (positive/negative).
Before proceeding, we distinguish between racial bias and normative-pole skew, which are related but conceptually distinct phenomena. Racial bias in embeddings often refers to stereotypical associations between racial groups and evaluative concepts, such as Black terms or names being linked more strongly to negative phenomena than White ones (Caliskan et al., 2017; Ohamadike et al., 2025). Normative-pole skew, by contrast, focuses on pole placement and behaviour. It refers to one pole or group occupying the semantic centre (i.e., the unmarked default) against which the other is measured (Brekhus, 1998; Frankenberg, 1993). Our focus here is mainly on normative-pole skew, specifically whether whiteness operates as the semantic centre of race dimensions.
Literature Review
Normativity
In the social sciences, normativity names the standards that define what counts as ordinary, proper, or acceptable. Norms prescribe what ought to be and, crucially, they furnish reference points against which people, practices, and institutions are judged. Because norms are embedded in organisations, laws, professional guidelines, and everyday routines and social life, they are often experienced as neutral common sense, which makes them powerful (Morris, 2016; Withers, 2017). When a group occupies the “centre” of what is counted as normal, others are positioned as deviations (marked and rendered explainable) while the centre remains unmarked (Feagin, 2020; Frankenberg, 1993).
Two features of normativity are especially relevant for studies of race and for measurement in computational social science. First, norms rarely declare themselves as hierarchies outright. They are instead installed as baselines, standards of evaluation that appear culturally universal (Henry & Tator, 2006; Kirkland, 2013). Second, normativity is reproduced culturally. Withers (2017) shows how cultural repertoires (frames, schemas, tastes, and vocabularies of motive) continually re-inscribe what counts as “normal.” These repertoires animate institutions – school curricula, professional standards, journalistic stylebooks, and even research protocols that end up mirroring the normative centre and treating alternatives as exceptions that must be named and justified.
The analytic payoff of this view is that normativity is observable not only in explicit attitudes but in background assumptions – who must be labelled and who can pass unnamed; what requires explanation and what is presumed obvious; which categories feel “neutral,” and which feel “political.” This is why normative baselines travel so effectively into technical systems that draw their structure from cultural corpora. If the discursive field itself is organised around a centre, then methods that extract semantic regularities from that field will absorb and capture the centre’s gravitational pull.
Whiteness as a Norm
Whiteness studies document how, in many Western and multiracial contexts, whiteness functions as an unmarked, everyday standard (Feagin, 2020; Frankenberg, 1993; Keene-Young, 2025). It operates through the everyday, ordinary practices of social life as a dominant cultural space that sets the yardstick and keeps others on the margin (Frankenberg, 1993). Those inside it need not explain how it works and, in moments of perceived threat, its normativity is often reasserted more explicitly and exclusively (Frankenberg, 1993). As Henry and Tator (2006) put it, white norms and values often become the “normative natural,” the quiet benchmark by which others are measured and usually found inferior. Withers (2017) terms whiteness “a state of normalised white racial domination accomplished through culture,” emphasising that whiteness persists not only through coercive structures but through the ordinariness of cultural practice – evaluative vocabularies of taste, repertoires of civility and respectability, styles of newsworthiness, and common-sense categories of personhood. Lopez (2006) argues that whiteness is maintained by demonising non-white groups and sanctifying whites by contrast. The effect is a strong asymmetry of visibility. Minorities appear in public culture as racialised groups, while whiteness often remains unmarked, just “people,” “families,” “voters,” “Americans” (Kirkland, 2013).
Morris (2016) notes that the potency of white normativity lies in the way it establishes the range of the “properly human,” such that departures from the centre are seen as deficiencies or peculiarities regardless of whether overt claims of racial superiority are voiced. He highlights that white normativity should not be mistaken for a simple, monotonic ranking that always places white people at the top. Rather, it centres whiteness as the “standard of the normal.” Others can be described with both positive and negative stereotypes, yet remain off-centre, subject to interpretive scrutiny that the centre escapes. The “centre of normality” framing explains how even ostensibly flattering stereotypes (e.g., “hard-working,” “family-oriented”) can contribute to marginality – they mark their targets as special cases that require modifiers, while the centre is presumed to need none. In media and institutional life, this unmarkedness produces concrete effects, setting baselines for policy, professional comportment, who is presumed competent, and which histories count as background knowledge rather than “identity” (Morris, 2016; Withers, 2017).
This theoretical frame has methodological consequences. If whiteness functions as a cultural default through its repeated centring, then analytic techniques applied to language models that assume symmetry between “white” and “nonwhite” categories risk importing this asymmetry into the measurement design itself. In such corpora, whiteness’s unmarkedness can reorganise semantic neighbourhoods, including through frequency-driven effects: everyday vocabulary clusters around the normative centre, while marked groups are positioned more peripherally, treated as departures that require labels and explanation.
In such conditions, the appearance of balance in measurement design (e.g., using equal numbers of “white” and “black” anchor terms) may not guarantee a balanced construct, because the corpus itself can encode normative asymmetries that shift the geometric centre of meaning. While most studies of whiteness as the norm have demonstrated this qualitatively (Frankenberg, 1993; Keene-Young, 2025; Kirkland, 2013; Morris, 2016; Withers, 2017), there is little quantitative evidence. This research addresses that gap by analysing bias-detecting dimensions in neural word embeddings and complements existing qualitative scholarship. We detect normative skew by projecting validated neutral terms (and valence ones) onto the black/white race dimension. A skew toward the White pole (negative mean) indicates semantic normativity – that Whiteness functions as an unmarked baseline and neutral vocabulary clusters closer to it.
Implications for Measuring Bias in Word Embeddings
Word embeddings map lexical meaning into geometric space by learning from patterns of co-occurrence. Their strength (absorbing subtle regularities from large corpora) is also a pathway for importing normative structure. A widely used approach to detecting social bias in word embeddings involves constructing bipolar semantic dimensions by subtracting the centroid of one set of anchor words from another and then projecting target terms (e.g., occupations, adjectives) onto that axis (Arseniev-Koehler & Foster, 2022; Best & Arseniev-Koehler, 2023; Bolukbasi et al., 2016; Boutyline et al., 2023; Boutyline & Johnston, 2023; Durrheim et al., 2023; Garg et al., 2018; Kozlowski et al., 2019; Ohamadike et al., 2025; Taylor & Stoltz, 2021; Van Loon & Freese, 2023). Variants of this method underpin influential findings about gender, race, and other biases in vector spaces.
The standard workflow contains two major assumptions. First, it assumes the poles contribute symmetrically to the dimension. The “difference of centroids” (meant to strip both poles of their commonalities, leaving only their differences) is treated as a balanced axis in which both ends are equally informative, equally opposite, and equally distant from the corpus’s ordinary meanings. Word projections onto this dimension are interpreted as evidence of “bias.” Second, it assumes that projecting keywords onto this axis faithfully reveals their association with each pole, rather than with a centre or normative pole that the axis may encode. Both assumptions are less secure, especially in cultural corpora shaped by human activity.
When whiteness functions as an unmarked baseline, it may organise cultural meaning as a centre. In text corpora, that centre can imprint itself on geometric representations of meaning – the assumptions that make whiteness feel “ordinary” or “neutral” become part of the distributional structure that embedding models learn. For this research, two questions on bias measurement design in word embeddings follow from the literature on normativity and unmarkedness. One concerns normative anchoring – whether the bipolar dimension favours one pole as a normative anchor. The other concerns asymmetric amplification – whether the bipolar dimension systematically overshoots one pole relative to what either unipolar pole alone would imply. These questions are methodologically important but underexplored, and our research seeks to address this gap.
Methods
Word Embeddings
The analysis uses three pre-trained word-embedding models representing different cultural contexts. The first is the Google News Word2Vec model trained on approximately 100 billion words scraped from U.S. news outlets (Mikolov et al., 2013), capturing a U.S. centric racial context. The second is the 250-dimensional South African Word2Vec model trained on 1.3 million SA news articles published between 2018 and 2021, collected by Media Monitoring Africa (Mafunda et al., 2022). The model has 123,881 unique words and preprocessing included lowercasing, removing HTML tags, punctuation, and digits, and constructing bigrams and trigrams. The third is a fastText English Wiki-News model trained on 1 million 300-dimensional word vectors from Wikipedia (2017), the UMBC webbase corpus, and the statmt.org news dataset (16B tokens), used here as a general-purpose, relatively neutral reference (Mikolov et al., 2018). These static models mirror social processes (e.g., biases) unfiltered, unlike models (e.g., contextual BERT) that may mask or neutralise bias, although we discuss the implications of our results for contextual models at the end. 1
Race Categories and Dimensions
Race dimensions were constructed using Africa–Europe anchor name sets from previous work (Ohamadike et al., 2026). The analysis used four SSA/European categories – South African, Nigerian, Zimbabwean, and Kenyan names – located across our models (Table S7 in supplementary material). In that earlier study, the effectiveness and generalisability of these race dimensions were evaluated using two statistical metrics: Pairwise Directional Consistency (PairDir) and the PCA-based Axis Coherence Score (ACS).
The anchor sets were also validated with human ratings. Specifically, 26 participants from Global North and Global South institutions rated the association of the names with Africa and Europe. Inter-rater reliability was assessed using Krippendorff’s alpha (α) and intraclass correlation coefficients (ICC), both ranging from 0 to 1, with higher values indicating stronger agreement. Krippendorff’s alpha measures agreement among raters beyond what would be expected by chance; ICC measures how consistently raters distinguish between items relative to total variability. Bootstrapped 95% confidence intervals were reported for alpha, and a two-way absolute agreement ICC model was used. Results showed moderate inter-rater agreement (α = 0.62, 95% CI [0.56, 0.65]; ICC(A, 1) = 0.63, p < 0.001). The authors also correlated the human ratings with embedding-based projections of those names onto an Africa–Europe dimension and found that those SSA/European name categories showed the strongest correlations, indicating they correspond most closely to human understanding of racial meaning.
For this analysis, all anchors were also combined into a collapsed “All Categories” pool to provide a broader Africa–Europe axis. This provides a stronger, more stable race dimension by maximising the number of words in each pole and ensuring the measure captures broader Africa/Europe categories. Pooling is also conceptually justified, as the categories encode similar semantic directions and can function as proxies for one another (Ohamadike et al., 2026). We followed Ohamadike et al. (2026) for our race-category preprocessing, using only capitalised first-letter versions of the names (e.g., Thabo), which were more stable, for analysis in Google and Wiki-News embeddings and lowercase versions for South African news (e.g., thabo), since the model was trained on lowercase words.
The unipolar measure was formed by averaging the word vectors of a single anchor set; for example, the centroids of the African (A) and European (E) anchor sets. To construct the bipolar race dimension, we compute the difference between these centroids:
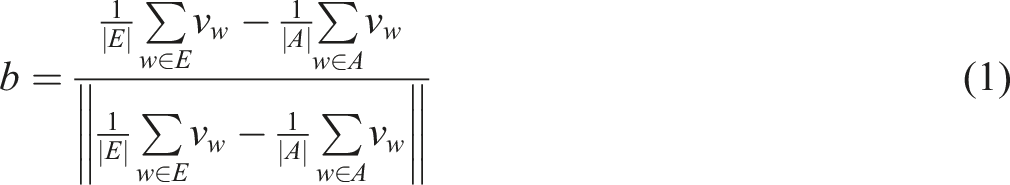
Where
Probe Set (Neutral and Valence Keywords)
The probe set was initially developed by prompting ChatGPT GPT-5 to generate high-frequency keywords drawn from everyday English. This approach is useful for producing a large, diverse candidate pool that would have been difficult to compile manually. We ensured that each target was unique and existed in all three embedding models for cross-corpus comparison. We then removed items with plausible racial associations, particularly from the occupations category (e.g., accountant, waiter). Five raters then independently rated each remaining word on a 1–4 scale (1 = clearly neutral; mostly neutral = 2; 3 = somewhat racially associated; 4 = clearly racially associated) to assess the extent to which each term was neutral or racially associated.
Inter-rater reliability was equally assessed using Krippendorff’s alpha and intraclass correlation coefficients (ICC). Agreement was low (α = −0.03, 95% CI [−0.07, 0.01]; ICC(A, 1) = 0.07, p < 0.01), indicating raters differed considerably in their judgements. Because ratings were aggregated, we used ICC(A,k) (the reliability of the mean of all five raters) as the basis for filtering (ICC(A,k) = 0.26, p < 0.05). Given low inter-rater reliability, we applied a conservative threshold of ≤ 2.0 (mostly neutral or clearly neutral), retaining only words where raters converged on neutrality. This produced 180 validated neutral terms for the analysis (see Table S8 in supplementary material for full list).
Since these words are neutral, have no cultural specificity, and are broadly distributed across topics, they are well-suited to answering our central question: do bipolar race dimensions systematically favour one pole as a normative anchor? Using neutral targets ensures that any asymmetry we detect captures the geometry of the axis and corpus semantics, rather than the idiosyncrasies of racialised keywords. We used only lowercase versions of neutral targets, as they were more frequent in Wiki-News and Google embeddings, and the South African news model was trained entirely in lowercase.
To check the robustness of the findings using the neutral targets (which capture ordinary meaning), we included marked valence (192 positive and 192 negative) keywords from Kurdi et al. (2019). This allows us to test whether the models capture skew beyond what neutrals reveal, and to examine if overshoot follows the same pattern observed with neutral targets.
Measuring Normative-Pole Skew
To assess whether bipolar race dimensions systematically favour one pole, all neutral targets (and negative/positive valence words) were projected onto the SSA/European and pooled race axis. For each model and race category, the mean position of neutrals was calculated along with the share that fell on the black and white sides. We also included 95% confidence intervals, which indicate the range within which the true mean is expected to fall with 95% confidence, based on repeated resampling.
Skew was considered strongest when the mean of the neutral projections fell clearly on one side of the axis (a negative mean indicating a white skew, and a positive mean indicating a black skew), was statistically significant, and when there was a considerable imbalance in how the test words fell on either side of the poles. We also accounted for the effect of frequency on our results by regressing bipolar projection scores on raw frequency and frequency confound 2 for our high-frequency neutral probes and replacing the high-frequency neutral probe set with low-frequency ones.
To assess whether normative skew findings were robust to anchor selection, we conducted a bootstrap sensitivity analysis on the pooled “All Categories” race dimension. For 1,000 iterations, 80% of black and white anchor names were randomly sampled, the bipolar dimension was recomputed, and neutral words were projected onto each resampled axis. Bootstrapped 95% confidence intervals were computed for mean projection across iterations.
To determine whether normative skew is stronger in culturally specific corpora than in a general reference corpus (research question 2), results from the South African and Google News embeddings were compared to those from Wiki-News. Comparisons focused on the mean position of probe sets with confidence intervals and the proportion of neutrals on the white or black side.
Measuring Overshoot
To assess whether bipolar race dimensions amplify one pole, given unipolar evidence, we examined the relationship between neutral and valence (positive and negative) word projections on bipolar axes and on individual pole centroids. For each embedding model and race category, we constructed centroids for the two poles (e.g., Black and White names) and defined the bipolar axis as the normalised difference vector between them (see equation (1)). For the main analysis, each neutral word was then projected both onto this bipolar axis and onto the individual pole centroids, producing one bipolar score and two unipolar scores. For the robustness check using the valence words, we projected the negative and positive words separately onto the bipolar axes and unipolar centroid (see Tables S1–S5 in the supplementary material).
We tested overshoot by estimating separate OLS regressions of the bipolar projection on each unipolar score. For neutral or valence word i, the model took the form:
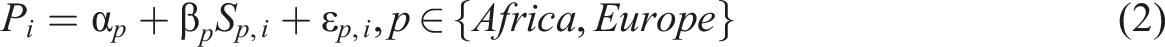
Overshoot was diagnosed by comparing the slopes and R2 values between poles, where R2 captures how much of the variation in bipolar scores is explained by each pole’s unipolar scores, and the slope captures how steeply the bipolar score responds to each pole’s unipolar signal. A large difference implied that the bipolar axis was inordinately shaped by one pole’s unipolar signal. We also examined residual correlations between poles. If the residuals were perfectly correlated (r = 1), both pole-specific regressions leave identical patterns of unexplained variance, meaning their errors fully overlap. Lower correlations suggest more independent predictive contributions, while negative values indicate counter-balancing errors.
Overshoot findings were similarly validated using a bootstrap sensitivity analysis on “All Categories.” For 1,000 iterations, 80% of anchors were randomly sampled, and we recomputed R2 difference between poles and slope imbalance per iteration. We also recorded which pole dominated (higher R2) in each iteration and computed the proportion of samples in which that pole was consistently dominant, as a directional stability diagnostic.
To assess whether overshoot captured word-frequency artefacts, we controlled for log raw frequency and frequency confound in the unipolar–bipolar regression and repeated the analysis using low-frequency neutral probes instead of high-frequency ones.
Results
Normative-Pole Skew
For the first research question on whether bipolar race dimensions systematically favour one pole as a normative anchor, we calculate the mean projection of neutral words onto the bipolar axis. If the race dimension is symmetric, neutral words should distribute evenly around zero (the midpoint between poles). A skew toward the White pole (negative mean) indicates semantic normativity – that Whiteness functions as an unmarked baseline and neutral vocabulary clusters closer to it.
We find that across categories and models, neutral words projected onto the race dimensions largely clustered on the white side (Figure 1). This pattern is most pronounced in the Wiki-News embeddings, where mean position ranges from −0.24 to −0.31 with narrow CIs, and the share of neutral words on the white side is ≥ 0.99 (often 1.00). In other words, the neutral lexical “centre of mass” in the Wiki-News model lies squarely toward the white pole across all race–name sets. Neutral Words on Bipolar Race Dimension. Across models, neutral words cluster on the white side of the race dimensions, with the effect most pronounced in the Wiki-News model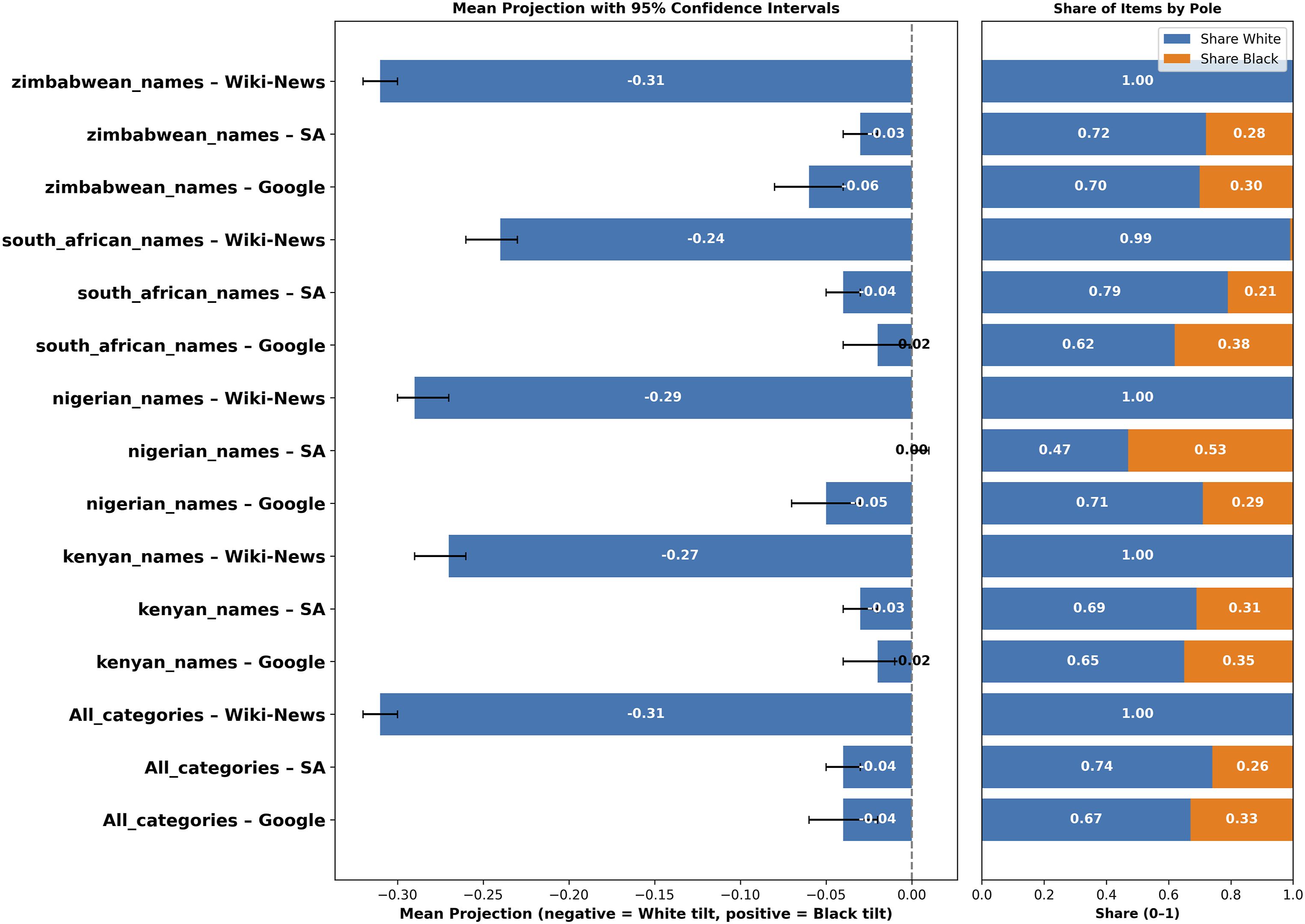
The South African (SA) and Google models also tilt white but with smaller magnitudes. In SA, mean position typically falls around −0.03 to −0.04 with sizable, unambiguous shares on the white side. The one exception is Nigerian/European names in SA, which is essentially centred (0.00) with a nearly 50/50 split between sides. In Google, average tilts are very small, suggesting weaker (but still present) normative anchoring toward the white pole.
For the sub-question (research question 2) on whether skew is stronger in culturally specific corpora (South African news; US-centric Google News) than in a broad, general reference corpus (Wiki-News), the data show the opposite. Skew is strongest in neutral, general-purpose Wiki-News and weaker in the news-trained models. Thus, while all three embeddings show a white-centred geometry, Wiki-News produces the most pronounced normative anchoring toward the white pole.
Robustness checks point in the same direction. When neutral words are projected onto each unipolar reference (e.g., African-only) rather than the bipolar difference, the results mirror the bipolar results (Table S6 in supplementary material). Using valence probes (positive/negative) on bipolar race dimensions also produces similar results (Table S1 in supplementary material). In Wiki-News, positive and negative terms mostly fall on the white side, with positivity almost monopolised by the white side (0.85–0.96); in SA, the white skew is weaker; in Google News, both, especially negatives, tilt towards Black; and overall, whiteness absorbs more positivity than negativity and blackness more negativity than positivity.
Since our neutral probe terms are high frequency and to assess how much frequency contributes to clustering near the white pole, we regressed bipolar projection scores on raw frequency and the frequency confound for our high-frequency neutral probes. As shown in Table S9–S10 in the supplementary material, frequency has small (less than 17% explained variance) but meaningful effects in explaining the neutral projections, particularly in the White pole direction. The strongest frequency effect was observed in the Google News model.
We also replaced our high-frequency neutral probe sets with low-frequency ones generated by ChatGPT GPT-5 and located across our models. The rationale is that if frequency were driving most of the effect, the white normativity observed with high-frequency probes would be expected to reverse. A word is considered low-frequency if its frequency falls at or below the 30th percentile of the candidate pool across all models. Projecting the resulting 189 low-frequency neutral words onto the race dimensions shows Wiki-News still exhibits the strongest evidence of White normativity, with substantially weaker effects in the South African and Google models. Specifically, the SA model shows near-zero bias, and the Google News model shifts modestly toward the Black pole for most categories, echoing earlier findings that frequency has the strongest effect in the Google News model (Figure S1 in supplementary material). Overall, frequency plays a meaningful role in shaping our results, but explains only a small part of it.
Bootstrap sensitivity analysis confirmed that white-normative skew is robust to anchor selection across all three models. Across 1,000 iterations of 80% anchor resampling, white-skew direction was observed in 100% of samples for all models. Confidence intervals excluded zero in all cases: Wiki-News (mean = −0.31, 95% CI [−0.33, −0.29]; SA (mean = −0.04, 95% CI [−0.04, −0.03]); Google (mean = −0.04, 95% CI [−0.05, −0.03]). The pattern mirrors the main results: Wiki-News exhibits by far the strongest and most consistent white-normative skew, with SA and Google showing weaker but robust effects.
Taken together, the results suggest normative-pole skew across the three models and most strongly so in Wiki-News.
Overshoot
OLS Regression Results a
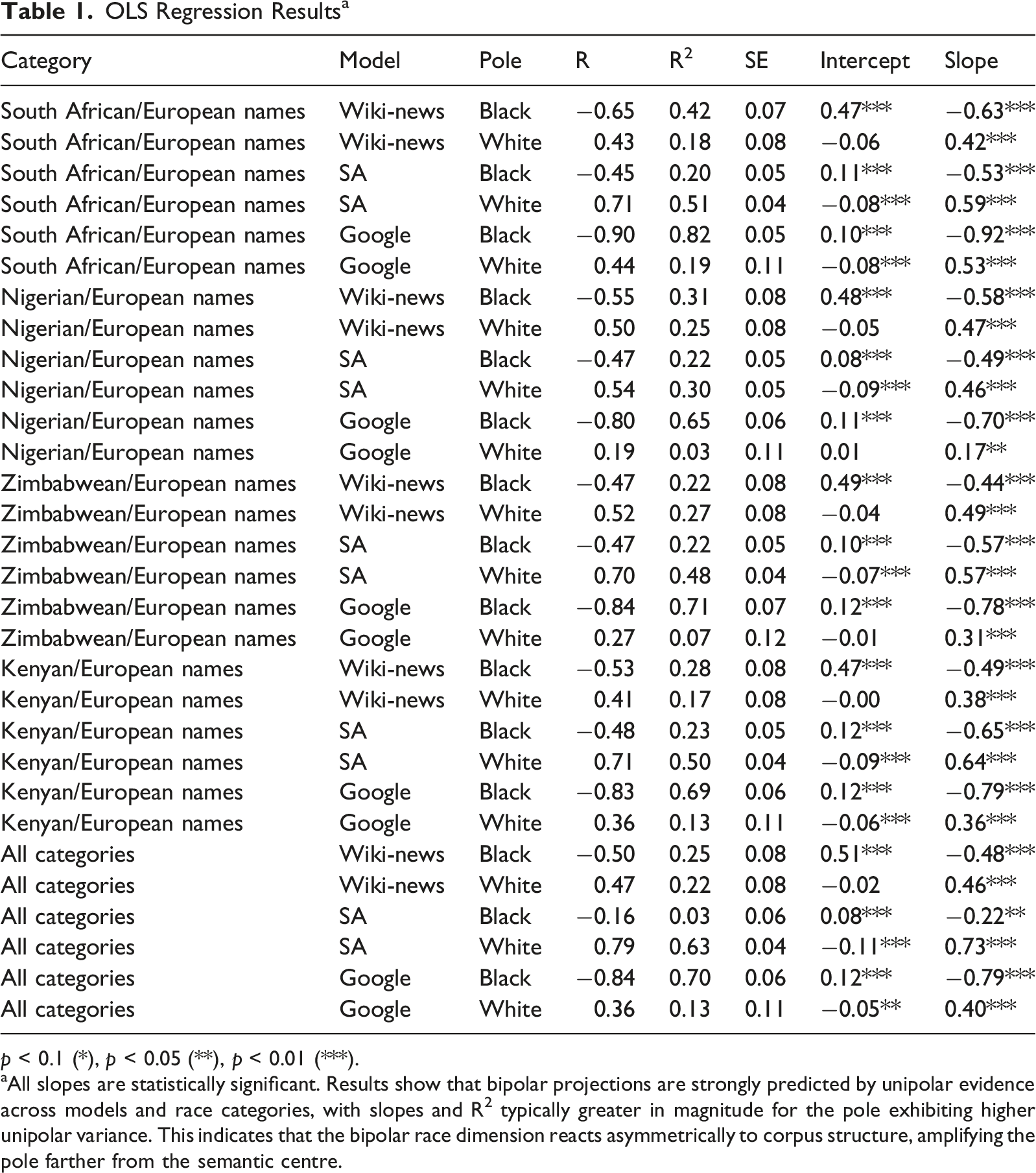
p < 0.1 (*), p < 0.05 (**), p < 0.01 (***).
aAll slopes are statistically significant. Results show that bipolar projections are strongly predicted by unipolar evidence across models and race categories, with slopes and R2 typically greater in magnitude for the pole exhibiting higher unipolar variance. This indicates that the bipolar race dimension reacts asymmetrically to corpus structure, amplifying the pole farther from the semantic centre.
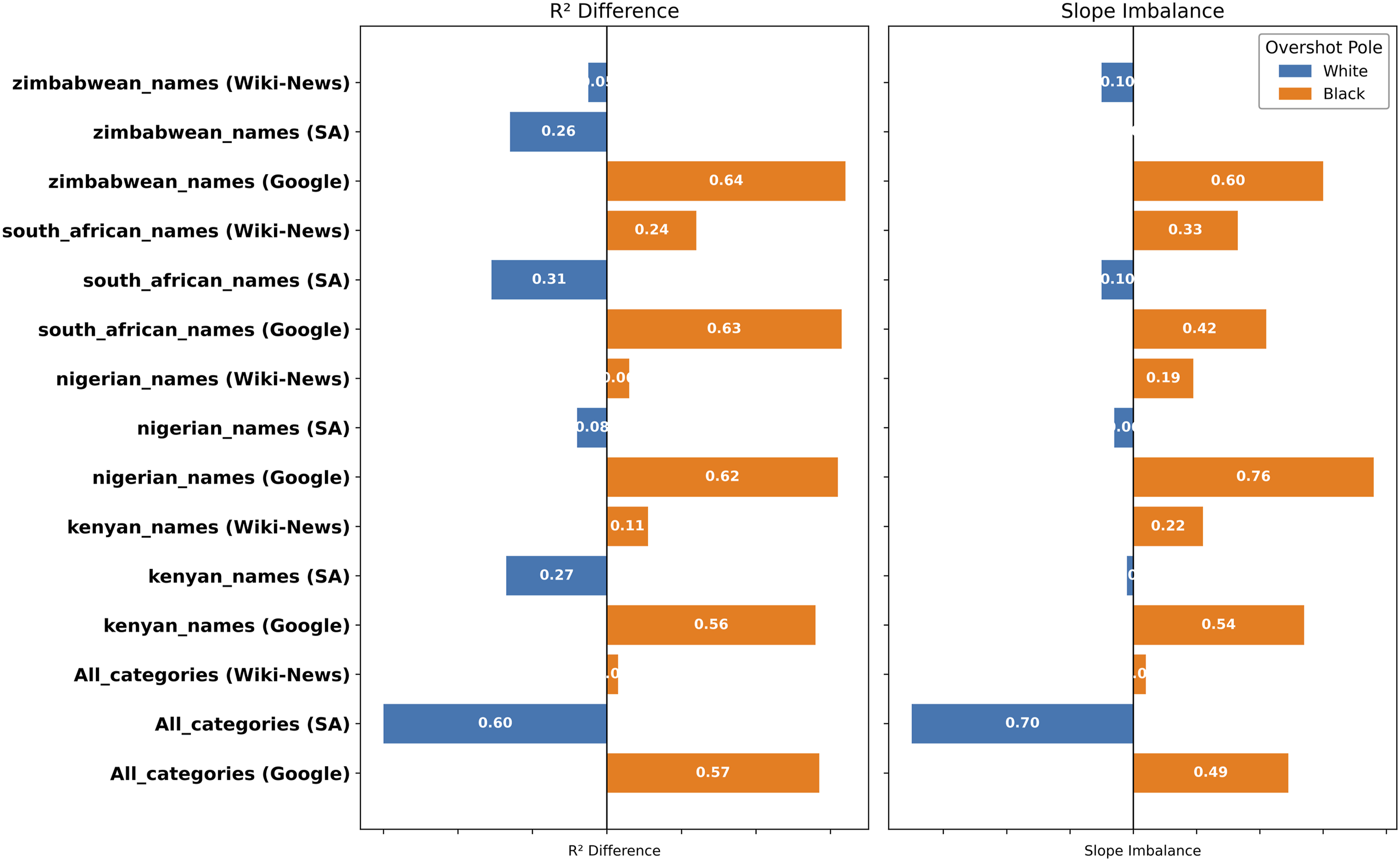
Overshooting analysis from the regression results (Table 1). This quantifies how strongly bipolar projections amplify one pole beyond what unipolar evidence predicts. R2 Difference is the absolute difference between the regression R2 values of the two poles. Slope Imbalance is calculated using 1 – (min/max), so 0 = equal slopes (balanced) and 1 = extreme imbalance. Both are on a 0-1 scale, where higher values indicate greater overshoot. Across models, overshoot corresponds with the pole exhibiting greater unipolar variance – typically the Black pole in the Google and Wiki-News models, and the White pole in the South African model
Overshoot was strongest in Google News (Figure 2). For Nigerian/European names, Black is overshot with a large differential (R2 difference = 0.62; slope-imbalance = 0.76), and similarly for Zimbabwean/European names (0.64; 0.60). Wiki-News also shows Black overshoot, though more moderately compared to Google News. By contrast, White is overshot across the board for neutrals in the SA model, most strongly in All Categories (0.60; 0.70). Put differently, Google shows the strongest Black-overshoot, Wiki-News has a more moderate Black overshoot, and SA shows White-overshoot, especially when race categories are pooled.
In the regression results in Table 1, the slopes are all statistically significant, while several White-pole intercepts in Wiki and Google are not. This suggests that when the White unipolar signal is near zero, the bipolar score is also near zero, but as the unipolar signal grows, the bipolar score rises more sharply for the overshot pole, predominantly Black. Second, the residual correlations between the two pole-specific regressions in Figure 3 are moderate to high in Wiki-News and generally lower in Google. Higher residual concordance in Wiki-News is consistent with its more balanced overshoot profile (the two fits tend to leave similar unexplained variance), whereas Google’s lower concordance corresponds with stronger, pole-asymmetric leverage on the bipolar axis. Residual correlations. This captures how prediction errors for the Black and White poles covary within each model. High correlations, as in Wiki-News, indicate shared unexplained variance. Lower correlations in Google suggest more asymmetric, pole-specific residual patterns
Why does overshoot favour Black in most models but White in SA? In 87% of comparisons across the categories in Figure 2, we found that the pole (Black/White) with the higher unipolar variance is the one that overshoots. We interpret this as racialised variance – neutral terms are more semantically dispersed around the Black pole in Wiki-News and Google, giving the difference vector greater sensitivity to Black-side variation; in the SA model, Black is less peripheral than White (lower unipolar dispersion), so the difference vector is pulled toward White, producing White-overshoot. The same pattern holds when replacing neutral probes with valence (positive/negative) keywords – Black is overshot in most cases, and White is overshot only in the SA model (Tables S2–S5 in supplementary material). This arises from how the bipolar axis inherits geometric sensitivity from the more variable pole. When one pole (e.g., Black) shows greater unipolar variance, this provides the difference vector with more leverage to capture movement in that semantic region (Figure 4). Distribution of neutral word unipolar projections onto the Black and White pole centroids across three embedding models (All Categories). Each violin shows the spread of neutral word projections onto a single pole’s centroid vector. Wider violins indicate greater dispersion of neutral words around that pole in embedding space. Standard deviations (SD) are annotated per pole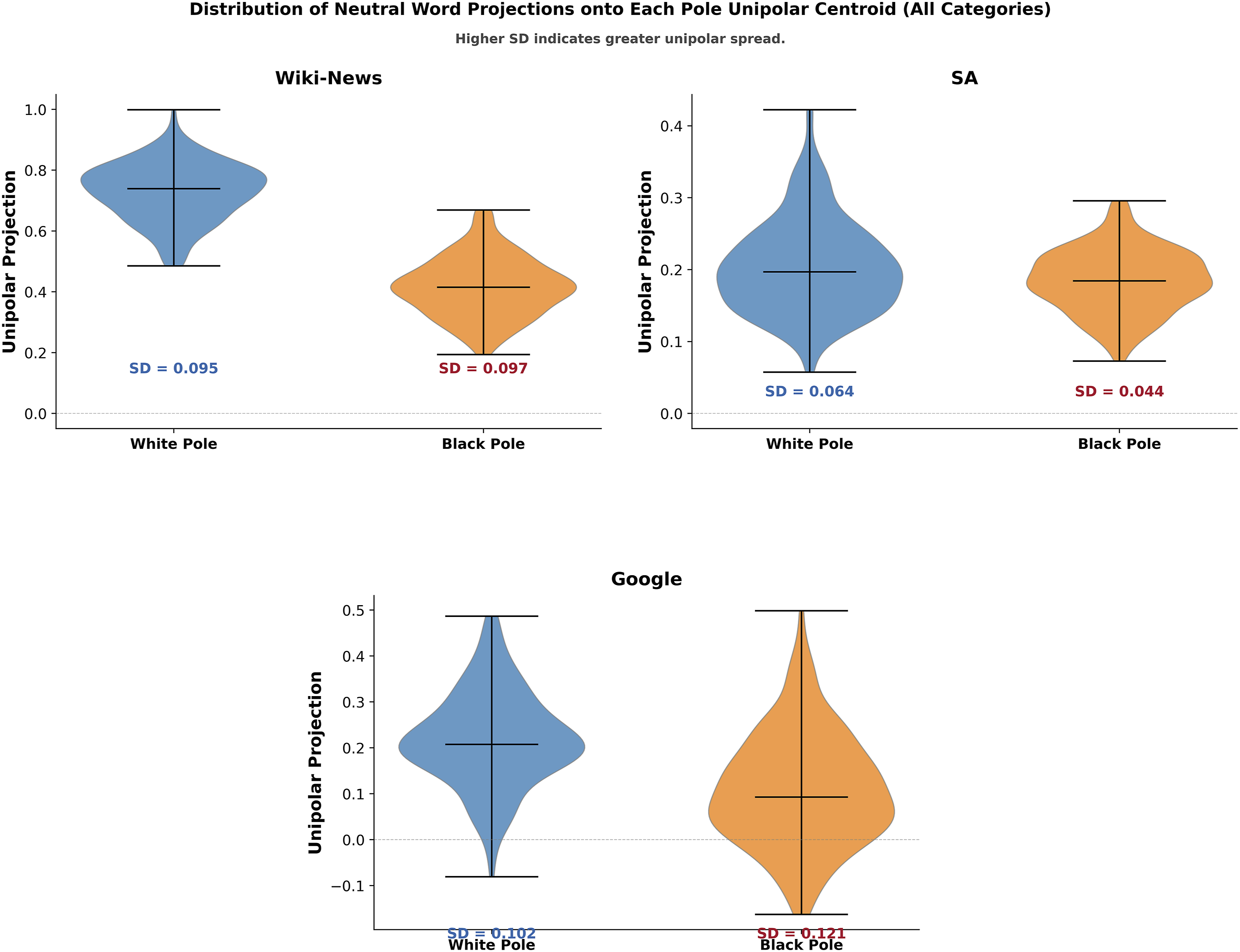
Figure 4 shows the distribution of neutral word projections onto each pole’s unipolar centroid for “All categories.” In Wiki-News and Google, the Black pole has greater spread than the White pole, consistent with Black overshoot in those models. In the SA model, the White pole is more dispersed than the Black pole, consistent with White overshoot. This supports our argument that the pole around which neutral words are more dispersed in unipolar space is often the pole the bipolar axis amplifies. 3
To check whether overshoot patterns reflected word-frequency artefacts in the embeddings, we controlled for log raw frequency and the frequency confound (which accounts for anchor-frequency effects) of high-frequency neutral terms. As shown in Table S11-S12 in the supplementary material, the unipolar results remain consistent after controlling for frequency, indicating that bipolar scores generally overshoot the Black pole, except in the SA model, where only White-pole overshoot occurred. We also replaced the high-frequency probes with low-frequency ones. The low-frequency overshooting analysis shows the Google News model continues to overshoot the Black pole, while the South African and Wiki-News models show more category-dependent behaviour (Table S13 in the supplementary material). The latter indicates that overshoot tends to capture corpus-specific differences in how racial anchors structure bipolar semantic space. Overall, frequency tends to contribute strongly to overshoot asymmetries only when using the low-frequency neutral probe sets.
Bootstrap sensitivity analysis of overshoot confirmed that directional findings were stable across anchor subsets for SA and Google, but more variable for Wiki-News. In the SA model, White was the dominant overshot pole in 100% of 1,000 bootstrap samples, with large and stable R2 differences (mean = 0.58, 95% CI [0.46, 0.68]) and slope imbalance (mean = 0.64, 95% CI [0.39, 0.86]). In Google, Black dominated in 100% of samples, with substantial R2 differences (mean = 0.53, 95% CI [0.39, 0.64]) and slope imbalance (mean = 0.45, 95% CI [0.29, 0.59]). Wiki-News showed weaker and less consistent overshoot: Black was the dominant pole in only 59% of samples, with considerably smaller R2 differences (mean = 0.07, 95% CI [0.003, 0.19]) and slope imbalance (mean = 0.10, 95% CI [0.005, 0.29]), suggesting that Wiki-News overshoot direction is sensitive to anchor composition. 4 These results confirm that overshoot is a robust, direction-stable phenomenon in SA and Google, while weaker in Wiki-News.
In sum, the bipolar axis behaves asymmetrically – given unipolar evidence, it tends to amplify the pole on the periphery of the embedding space, which in our case is the pole around which neutral and valence words are more variable. In our data, that typically means an overshoot of Black (Google, Wiki-News) and, in a corpus where Black is less peripheral, an overshoot of White (SA).
Conclusion
This study investigated whether embedding-based race dimensions encode normative-pole skew, whether such skew is stronger in context-specific than general-purpose models, and whether the bipolar score amplifies one pole, given unipolar evidence (overshoot). The analysis used validated SSA–European anchor sets and neutral and valence probes across three embeddings (Wiki-News, South African news, Google News).
First, we found positional asymmetry. Neutral and valence words cluster nearer the white pole across models, most strongly in Wiki-News. In other words, whiteness appears as the unmarked semantic centre of gravity. In geometric terms, the white centroid often sits closer to the corpus’s “neutral” region, while Black centroids are farther out, so unlabelled, everyday vocabulary and even marked valence ones project white by default. This is a form of architectural normativity – the measurement instrument itself (the difference-of-centroids vector commonly used in bias detection, for example, Arseniev-Koehler & Foster, 2022; Best & Arseniev-Koehler, 2023; Bolukbasi et al., 2016; Boutyline et al., 2023; Boutyline & Johnston, 2023; Durrheim et al., 2023; Garg et al., 2018; Kozlowski et al., 2019; Ohamadike et al., 2025; Taylor & Stoltz, 2021; Van Loon & Freese, 2023) may inherit the corpus’s assumptions about the centre and the periphery rather than revealing only explicit racial associations. Notably, skew is strongest in the general-purpose Wiki-News model and weaker in Google (US-centric) and SA news embeddings, suggesting that broad reference corpora may concentrate normative defaults more tightly than domain-specific ones.
Second, we showed through regression analysis that bipolar dimensions can amplify one pole relative to what its unipolar signal would imply. Across most category–model pairs, the bipolar and unipolar projection of neutral and valence words and the corresponding regression analysis overshot the Black pole (strongest in Google News), whereas White pole overshoot only occurred in the SA model. We argue that this asymmetry captures the dispersion of neutral probe terms in unipolar space. Specifically, overshoot occurs when neutral probes are more widely dispersed around one pole than the other; in such cases, the bipolar construction tends to amplify that more variable pole, given unipolar evidence. In 87% of the race-category comparisons in our analysis, the overshot pole was also the pole around which neutral probes showed greater unipolar variance.
Across models, we also found that frequency contributes to white normativity, especially in the Google News model, but it only explains a small part of it. In other words, when a group is repeatedly centred in social life, discourse, and institutions, it can come to appear more ordinary, neutral, and default (Brekhus, 1998; Frankenberg, 1993). Frequency also influenced overshoot patterns, but the core results remained consistent after controlling for high-frequency probes: bipolar scores generally overshot the Black pole, whereas results varied with low-frequency probes.
Intuitively, if the semantic centre lies nearer whiteness (positional skew), with neutral (and valence) meanings more spread out around Black, the bipolar difference vector becomes more responsive to movement on the Black-side or the Black pole’s variance structure; hence, overshoot. White overshoot only occurred in the SA model, where Black is less peripheral. By way of analogy, the pattern mirrors a seesaw; the fulcrum (the semantic centre) is closer to the white side, but the greater spread on the black side exerts more leverage that affects the entire seesaw’s movement. This also corresponds with sociocultural and normativity literature, where the unmarked category is the quiet benchmark (Henry & Tator, 2006; Kirkland, 2013), while the marked or deviant category upsets the status quo precisely because it stands in contrast to the normative centre. The results demonstrate how structural asymmetries in the embedding’s geometry can translate into unequal representational leverage across racial poles.
These findings connect to the sociological account of whiteness as a norm. Prior work has described whiteness as the norm, a taken-for-granted baseline that renders others legible as marked departures (Frankenberg, 1993; Henry & Tator, 2006; Morris, 2016; Withers, 2017). Our results provide quantitative evidence that this baseline is not merely cultural but also geometric in distributional semantics, where the White pole occupies the representational centre, and the bipolar instrument often captures that centre in both placement (RQ1) and behaviour (RQ3).
Methodologically, the results show that unipolar and bipolar measures do not measure the same thing and are not interchangeable. Second, the common assumption that the bipolar measure is a symmetric instrument, particularly when anchor sets are equal in size, is not supported by our results. Our analysis shows the instrument may inherit skew from the corpus itself, overshooting toward the pole with greater unipolar variance. So the method is not straightforwardly “biased,” but it is sensitive to asymmetries in how poles are represented in the corpus, which may distort what the bipolar score actually measures. Our study also complements a literature that has been primarily descriptive and provides tests for normative-pole skew and asymmetric amplification in static embeddings.
Contrary to our hypothesis, the broad general-purpose corpus exhibited the strongest white-normative skew. This likely captures representational differences across corpora. The Wiki-News embedding is trained on a relatively small corpus, which may limit the representation of Black-associated content. Further, Wikipedia articles, included in the training corpora, tend to be written from predominantly Western perspectives, partly because Wikipedia’s contributor base is 80.3% white (Davis, 2025), which may further reduce the representation of Black experience and meaning. This challenges the assumption that broad-coverage corpora are normatively neutral.
It also points to the importance of corpus construction. More representative training data across cultures and linguistic communities may reduce normativity by limiting the semantic and frequency-based centring of a single pole. Conversely, smaller or less diverse corpora, especially those produced from predominantly Western sources, may intensify it, as our Wiki-News findings suggest.
Taken together, our framework is best understood as a diagnostic complement to existing embedding bias measures. Measures such as WEAT (Caliskan et al., 2017) quantify whether a concept associates more strongly with one pole than another, but also assume both poles are symmetrical. Our method tests whether that assumption holds. A significant WEAT score indicates differential association but does not reveal whether that differential is driven by genuine associations in the corpus, normative skew that makes any valence-neutral word seem more white-associated by default, which may result in overshooting the more variable pole.
Future work could extend these tests to other bias-detecting semantic dimensions (e.g., gender, social class), to multilingual settings, and to contextual embeddings. Our study focuses on static word embeddings, even though most current NLP systems use contextualised embeddings, where meaning shifts with sentence context. We expect normative-pole skew to persist in such models for three reasons. First, many Transformer models are trained on large web corpora that likely reproduce similar normative patterns. Second, contextualised representations are often aggregated into static summaries for bias analysis, which may preserve or even sharpen skew. Third, models trained on less-representative text are likely to encode whiteness-as-norm even if that structure appears differently across architectures such as BERT and GPT. Our unipolar–bipolar framework can be extended to contextualised embeddings, but doing so would require context-sensitive probing and layer-wise analysis. We leave detailed empirical tests for future work, but believe our framework offers a starting point for such tests.
Supplemental Material
Supplemental material - Whose Centre Holds? White Normativity in Race Dimensions Across Word Embeddings
Supplemental material for Whose Centre Holds? White Normativity in Race Dimensions Across Word Embeddings by Nnaemeka Ohamadike, Kevin Durrheim, Mpho Primus in Social Science Computer Review
Footnotes
Acknowledgements
We appreciate the valuable input from the team members of the People Opinion Networks (PONs) project.
Ethical Considerations
This study used secondary text data and anonymised human rating data collected under institutional ethical procedures, with no personally identifiable information reported.
Consent to Participate
All participants in the human rating task provided informed consent prior to participation.
Author contributions
NO analysed the data, conceptualised and wrote the paper. KD and MP designed the study and provided guidance. All authors contributed to, reviewed, and approved the paper.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by funding from the National Research Foundation of South Africa (Grant UID: 137755), the South African Centre for Digital Language Resources (SADiLaR) (Grant OR-AAALV), and the University of Johannesburg. We also gratefully acknowledge the Swiss National Science Foundation for their financial support of this research (grant number: 10001AL_205032).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Our analyses draw on three publicly available word-embedding models: the Google News embedding (https://code.google.com/archive/p/word2vec/) (Mikolov et al., 2013), the English Wiki-News FastText embedding (https://fasttext.cc/docs/en/english-vectors.html) (Mikolov et al., 2018), and a South African News embedding (https://doi.org/10.6084/m9.figshare.18933728) (Mafunda et al., 2022).
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.