
Abstract
Social evaluation is fundamental to everyday interactions, yet our understanding has been constrained by fragmented theories and the lack of a scalable method for tracking group attitudes in real time. This paper resolves this methodological gap by introducing and validating a computational framework that empirically synthesizes three major theoretical models (Stereotype Content Model, Dual Perspective Model, and Semantic Differential) within a unified word embedding space. We demonstrate that social evaluation is structured by two core latent dimensions: Warmth-Communion-Evaluation (WCE), capturing affective and moral judgments, and Competence-Agency (CA), reflecting perceptions of ability and effectiveness. To validate its real-world utility, we apply this framework to U.S.-based Twitter posts about Chinese and Japanese individuals before and during the COVID-19 pandemic. Our analysis reveals that while perceptions of competence (CA) remained stable, affective evaluations (WCE) of Chinese individuals declined sharply, a dynamic not observed for Japanese individuals. This work offers a robust, scalable instrument for tracking intergroup attitudes during crises and provides a crucial bridge between social psychological theory and computational social science, enabling the real-time analysis of intergroup dynamics.
Introduction
Social evaluation, the process by which individuals judge others, is a central domain of inquiry for the social sciences. These judgments underpin phenomena ranging from interpersonal interactions to large-scale patterns of social stratification, political polarization, and group-based inequality (Higgins & Bargh, 1987). Within social psychology, decades of research have produced influential theoretical models, (Ellemers et al., 2013; Koch et al., 2021; Yzerbyt, 2016), most notably the Stereotype Content Model (SCM), the Dual Perspective Model (DPM), and the Semantic Differential (SD) framework (Abele & Wojciszke, 2014; Fiske, 2018; Osgood et al., 1975a). These models utilize theoretical constructs like Warmth, Communion, Competence, and Agency to conceptualize social evaluations along distinct dimensions (Koch et al., 2021; Yzerbyt, 2016).
The centrality of these dimensions is not confined to social psychology; their conceptual equivalents are foundational across the social sciences. In sociology, for example, Abbott (2014) work on the system of professions shows that sociological subfields are stratified by public perceptions of both their moral character (a variant of Warmth-Communion) and their technical competence (Competence-Agency). In political science, voter perceptions of candidates often hinge on a trade-off between perceived warmth and competence (Laustsen & Bor, 2017). Similar dimensions also inform the concept of trust in organizational studies, where the level of trust placed by a trustor on a trustee is determined by assessments of the trustee’s Integrity and Benevolence (Warmth-Communion) alongside its Ability (Competence-Agency) (Chang & Tam, 2005; Mayer et al., 1995).
Recent scholarship has identified significant conceptual overlaps across these models’ content dimensions (Abele & Wojciszke, 2014; Kervyn et al., 2013). Abele et al. (2021) and Koch et al. (2021) proposed that, despite differences in terminology and empirical focus, these frameworks can be mapped onto broader “vertical” (Competence-Agency, “getting ahead”) and “horizontal” (Warmth-Communion, “getting along”) dimensions. However, achieving a unified empirical synthesis has been constrained by methodological limitations. Specifically, it remains challenging for researchers to agree on how to objectively specify the similarities and differences between dimensions defined in abstract theoretical terms or those that are conceptually overlapping. Moreover, the field’s reliance on traditional survey methods yields ratings that are small-scale, static, and drawn from non-representative samples, preventing researchers from scaling up or capturing the dynamic nature of social evaluations in real time (Nederhof, 1985; Nicolas et al., 2022).
To bridge the gap, this study utilizes natural language processing and word embedding techniques to empirically analyze the core constructs of the SCM, DPM, and SD within a unified semantic space. Our main research question is whether the separate dimensions of SCM, DPM, and SD can be empirically validated as constituting a unified, latent semantic framework. Our comprehensive validation provides compelling evidence for a two-dimensional structure of social evaluation. The first dimension, Warmth-Communion-Evaluation (WCE), captures affective and moral judgments such as warmth, likability, and trustworthiness. The second, Competence-Agency (CA), reflects perceptions of ability, agency, and effectiveness. To demonstrate the effectiveness of the synthetic framework, we analyze a large dataset of U.S.-based tweets to examine changes in American perceptions of Chinese and Japanese individuals before and during the COVID-19 pandemic. This illustrative analysis demonstrates that our data-driven synthesis is a scalable tool for monitoring real-time intergroup dynamics and offers meaningful insights into how different aspects of prejudice develop during crises.
Background: Theories and Methods
The Dimensionality of Social Evaluation
Extensive research in social psychology has revealed a fundamental principle of human cognition: when we judge other people and groups, we primarily rely on two universal dimensions (Abele & Wojciszke, 2007, 2014; Fiske et al., 2002; Koch et al., 2021). The first dimension captures judgments of friendliness, morality, and trustworthiness, answering questions such as “What are person/group A’s intentions toward person/group B?” The second dimension addresses capability, intelligence, and effectiveness, answering questions such as “Is person/group A able to carry out its intentions?” (Fiske et al., 2007; Kervyn et al., 2012; Yzerbyt & Corneille, 2005). This framework traces back to Asch (1946) “warm-cold” distinction and Rosenberg et al. (1968) multidimensional scale of social and intellectual desirability. These dimensions structure real-world phenomena, from voters weighing a candidate’s relatability versus leadership ability (Walter & Redlawsk, 2019) to consumers judging a corporation’s ethics versus market power (Shea, 2010).
While major theoretical models agree on two primary dimensions, each adopts different concepts: warmth and competence in the Stereotype Content Model (SCM; Fiske et al., 2002), communion and agency in the Dual Perspective Model (DPM; Abele & Wojciszke, 2014), and evaluation and potency in the Semantic Differential (SD) framework (Osgood et al., 1957b). Recent research indeed suggests substantial conceptual and empirical overlap among these content dimensions (Abele et al., 2016; Bruckmüller & Abele, 2013; Kervyn et al., 2013). For instance, studies demonstrate that the modern Warmth-Competence and Communion-Agency dimensions map strongly onto each other, as well as onto the foundational Evaluation-Potency and Social-Intellectual desirability factors (Abele & Wojciszke, 2013; Fiske et al., 2002; Kervyn et al., 2013).
Attempts and Challenges at Integration
Recognizing the clear conceptual overlap, scholars have increasingly sought to integrate these parallel models into a unified framework. Recent systematic reviews have proposed reconciling the different traditions by mapping them onto broader “Big Two” dimensions: a “horizontal” dimension (encompassing Communion, Warmth, and Morality) and a “vertical” dimension (encompassing Agency, Competence, and Status) (Abele et al., 2021; Koch et al., 2021). For instance, Koch et al. (2021) argued that Agency and Competence, while theoretically distinct, often function similarly in practice as they both drive the assessment of professional capability and status. However, translating this theoretical convergence into a single, empirically validated framework has proven difficult due to inherent methodological limitations.
Two fundamental barriers have stalled the empirical synthesis of these models. The first is the challenge of statistical discriminability. While theoretical definitions of “competence” (ability), “agency” (intent), and “potency” (dominance) are distinct, they are semantically proximal. In traditional survey contexts, these constructs often exhibit high multicollinearity, with correlations so strong that they become statistically indistinguishable (Abele et al., 2016). Consequently, designing a survey that asks participants to reliably differentiate between these nuances places an immense cognitive burden on respondents, leading to measurement artifacts rather than true conceptual distinctions. Furthermore, the subjective selection of scale items by researchers can introduce top-down biases, making cross-study comparisons precarious (Fraser et al., 2021; Nicolas et al., 2021).
The second barrier concerns the ecological validity of the data source itself. Traditional methods rely on small or convenience samples (e.g., college students) in artificial settings, which are particularly susceptible to social desirability bias (Nederhof, 1985). This is especially problematic for research on stereotypes and prejudice, where respondents may consciously suppress negative evaluations in surveys. While recent work has successfully employed more diverse and representative samples (e.g., Klysing et al., 2021), surveys remain static snapshots that struggle to capture the dynamic, “organic” nature of social evaluation as it unfolds in real-world discourse. This paper introduces a computational approach designed to augment these established methods. By analyzing unstructured text data, we aim to provide a complementary perspective, capturing spontaneous social evaluations that offer distinct ecological validity compared to structured survey data.
Computational Methods for a Data-Driven Synthesis
Recent advances in Natural Language Processing (NLP) offer a promising avenue to overcome the methodological bottlenecks inherent in traditional survey measures. Specifically, word embedding techniques enable the analysis of social cognition at scale by leveraging vast, naturalistic text corpora. Unlike static survey scales, word embeddings map words into a high-dimensional vector space based on their co-occurrence patterns (Mikolov et al., 2013). In this semantic space, geometric proximity reflects conceptual similarity—words used in comparable contexts (e.g., “doctor” and “nurse”) cluster together, while distinct concepts drift apart. This architecture allows researchers to quantify complex sociological constructs, including cultural schemas (Kozlowski et al., 2019), social biases (Nicolas et al., 2022), and social behavior (Han et al., 2020), as they naturally manifest in language, effectively bypassing the cognitive burdens and top-down constraints of forced-choice questionnaires.
The application of these computational tools to social psychology has evolved through distinct phases. Initial efforts focused on operationalizing social evaluation by expanding sentiment lexicons (Alhothali & Hoey, 2017; Miller, 1995) or constructing computational stereotype dictionaries (Nicolas et al., 2021). Subsequent scholarship showed that the principal axes of these embedding spaces naturally mirror major cultural dimensions (Boutyline & Johnston, 2023; Durrheim et al., 2023) and reveal latent semantic structures (Van Loon & Freese, 2023). More recently, researchers have moved towards substantiating specific theoretical models. For instance, Fraser et al. (2021) and Fraser et al. (2022) used the POLAR framework (Mathew et al., 2020) to successfully map the Warmth and Competence dimensions within embedding spaces. Building on this, Qin and Tam (2023) constructed robust representations for the SCM, DPM, and SD models, confirming that word embeddings can accurately encode these core theoretical constructs. Notably, Qin and Tam (2025) have posited the potential for synthesizing these models, though further integration remains unexplored.
Despite progress in computational methods, existing applications have primarily focused on validating the computational method itself and on showing that embeddings can capture theoretical meaning. To date, no study has used a computational approach to systematically compare the SCM, DPM, and SD models or to empirically test their convergence into a unified dimensional structure. This study bridges the critical gap between theoretical fragmentation and empirical validation in social perception research by using computational approaches. Moving beyond method advancement, we further demonstrate the utility of these approaches through an illustrative application.
By constructing high-dimensional vector representations of six core theoretical dimensions and applying Principal Component Analysis (PCA), we rigorously test whether these distinct dimensions empirically converge into a unified structure. We then validate this framework through an illustrative application, analyzing a large-scale social media dataset to quantify shifts in social perceptions of Chinese and Japanese groups during the COVID-19 pandemic (see Figure 1). Methodological pipeline.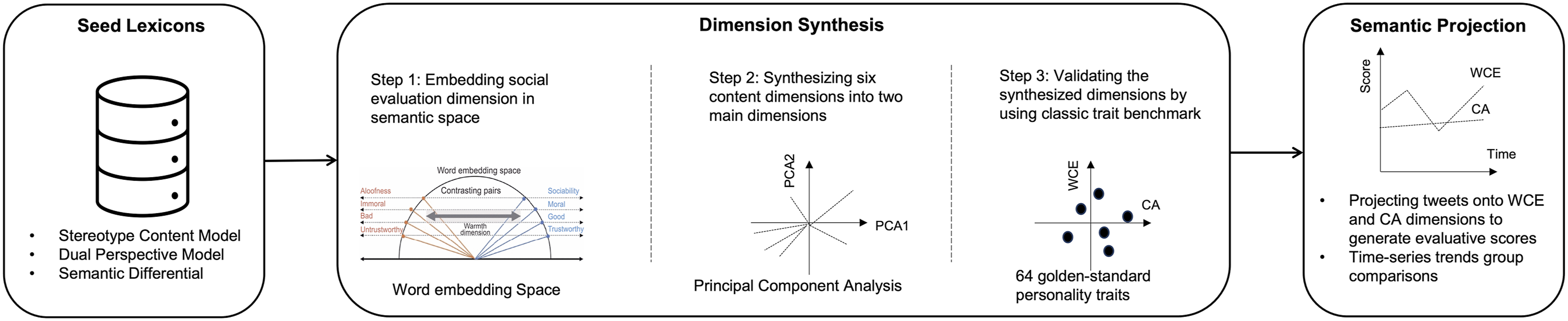
Research Design
The primary objective of this study is to operationalize the dimensions of the SCM, DPM, and SD models within a semantic space and rigorously test their potential for structural integration.
Data for Word Embeddings and Seed Lexicons
We employed the widely used, pre-trained Word2Vec model as our semantic space (Google News, 300 dimensions; Mikolov et al., 2013; Bojanowski et al., 2017; Church, 2017). To represent the theoretical constructs, we selected seed words for six dimensions: warmth, competence (SCM); communion, agency (DPM); and evaluation, potency (SD). These seed lexicons were adapted from foundational literature: the Semantic Differential (Osgood et al., 1957b), the Dual Perspective Model (Pietraszkiewicz et al., 2019), and the Stereotype Content Model (Nicolas et al., 2021). Semantic vectors for each dimension were constructed by averaging the embeddings of their respective seed words. This approach ensures that each vector mathematically encodes the central semantic meaning of its theoretical construct. All word lists were cross-validated against theoretical definitions and are detailed in Appendix A.
Methods for Constructing and Synthesizing Dimensions
The methodological procedure involved two steps to transform theoretical concepts into computable vectors. First, we operationalized the six core dimensions as vectors in a 300-dimensional embedding space. Following Qin and Tam (2025), we averaged the pre-trained word embeddings of the curated seed words. This approach ensures that each vector mathematically encodes the central semantic meaning of its corresponding theoretical construct.
Second, we assessed the potential of dimension synthesis. We examined the relationships among the six dimensions’ vectors using cosine similarity, a standard metric for measuring the angle between vectors. High correlations indicated significant conceptual overlap, prompting the application of Principal Component Analysis (PCA). 1 PCA was used as a dimensionality reduction technique to determine whether the six correlated theoretical variables could be summarized by a simpler, fundamental structure.
Analytical Strategy
Our analytical approach aimed to verify the robustness of the constructed structure through comprehensive testing scenarios and validation criteria. We set two strict standards: (1) explained variance, requiring the first two principal components to account for a significant majority of variability, and (2) interpretable loadings, ensuring the original dimensions cluster in a theoretically consistent manner (e.g., warmth/communion/evaluation grouped together, separate from competence/agency). The common belief in a two-dimensional structure of social evaluation would be contradicted by the evidence if: (a) a single dimension dominated the variance, (b) three or more dimensions were needed to adequately explain the variance, or (c) the loadings across components were incoherent, suggesting that the theoretical models do not align with a unified structure.
To ensure robustness, we implemented this analysis in three scenarios. • Scenario 1: Focused on Warmth (SCM) and Communion (DPM), as well as Competence (SCM) and Agency (DPM), dimensions widely regarded as the core of social perception (Abele & Wojciszke, 2014). • Scenario 2: Broadened the analysis by including the Evaluation and Potency dimensions from the SD model to test robustness against historically distinct models (Kervyn et al., 2013). • Scenario 3: Incorporated the Activity dimension from SD to assess whether a meaningful, distinct dimension emerges or whether its variance would be subsumed by the traditional two-dimensional structure.
Once the synthesized dimensions were empirically established, we focused on assessing their external validity and interpretive clarity. To confirm the semantic validity of our newly synthesized dimensions, we benchmarked them against Rosenberg et al. (1968) classic set of 64 personality trait adjectives. We mapped each trait’s word embedding onto our synthesized dimensions and used classic models to evaluate the semantic coherence and distinctiveness of the newly generated dimensions. Additionally, we identified prototypical word pairs with maximal semantic proximity to each axis to provide intuitive anchors for interpretation.
Results
The empirical evidence regarding the structure of social evaluation’s dimensionality will be presented in three subsections: First, we examine the raw semantic relationships among the six content dimensions. Second, we evaluate the latent structure of these dimensions through dimensionality reduction. Third, we validate and interpret the synthetic framework.
Relationships of Content Dimensions Across Three Models
Analysis of cross-model relationships revealed substantial conceptual alignment between the Stereotype Content Model (SCM) and the Dual Perspective Model (DPM). 2 Specifically, SCM’s warmth dimension closely paralleled DPM’s communion dimension (cosine similarity = 0.78), and SCM’s competence and DPM’s agency dimensions also showed high semantic similarity (cosine similarity = 0.82). These findings indicate that, although developed within distinct theoretical frameworks, the warmth–communion and competence–agency dimensions capture fundamentally similar aspects of social evaluation.
In contrast, the Semantic Differential (SD) model showed a more differentiated pattern: its evaluation dimension was more strongly associated with the warmth and communion cluster. However, the potency dimension was only modestly correlated with competence and agency (cosine similarity ≈0.27) and showed minimal overlap with the warmth and communion cluster (cosine similarity ≈0.11). Although a baseline correlation between positive traits is typical in natural language (the “halo effect”), the distinct pattern of relative similarities, in which warmth aligns much more closely with communion than with competence, indicates distinct conceptual clusters. Figure 2 presents the full similarity matrix. Cosine similarity matrix of social evaluation dimensions.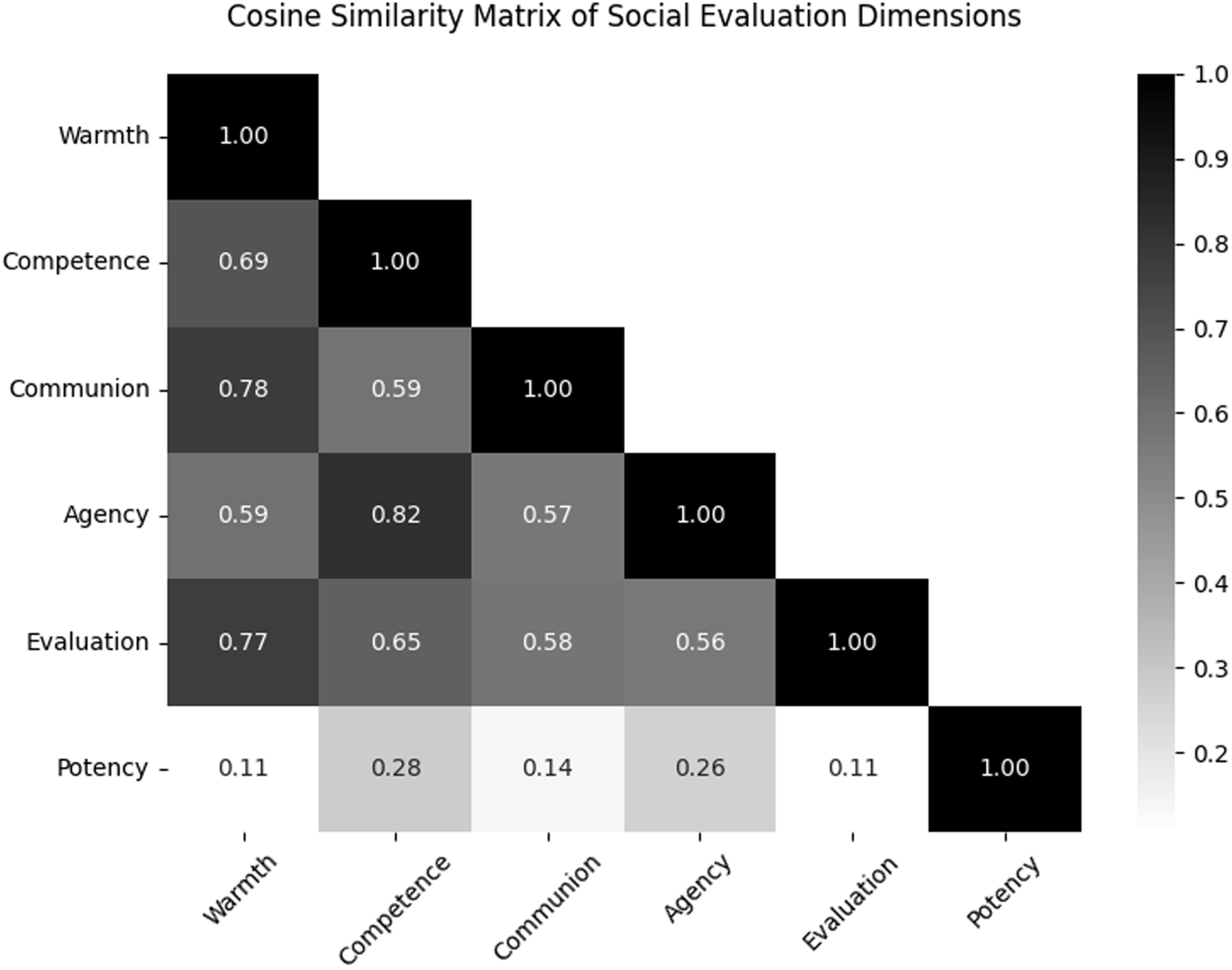
These initial correlations suggest the emergence of two integrated dimensions underlying social evaluations, one encompassing warmth, communion, and evaluation, and the other comprising competence and agency. Crucially, the Potency dimension remains empirically distinct. This distinction is conceptually meaningful and highlights a core feature of social judgment. Both the Warmth/Communion and Agency/Competence clusters are inherently evaluative (Abele et al., 2021; Koch et al., 2021; Yzerbyt & Demoulin, 2010); that is, they are tied to notions of “goodness/badness” in social perception. Being seen as warm and competent is almost universally a positive judgment. In contrast, Potency, which captures power, dominance, and force (e.g., “strong,” “hard,” “dominant”), is valence-neutral. Potency itself is not inherently good or bad; it can be applied toward benevolent ends (a “strong protector”) or malevolent ones (a “dominant tyrant”) (Abele & Hauke, 2020; Hornsey, 2008; Yzerbyt & Cambon, 2017).
Latent Structure of Six Content Dimensions
To formally test the structural integration of these dimensions, we applied Principal Component Analysis (PCA). The first two principal components accounted for 85%, 71%, and 64% of the variance across our three analytic scenarios, respectively, confirming that a two-dimensional solution is highly robust and sufficient to capture the underlying structure of the data.
Figure 3 visualizes these structural relationships. In these plots, the vectors represent the original dimensions, and their alignment with the horizontal (PC1) and vertical (PC2) axes reveals the latent structure. In scenario 1 (Figure 3(a)), which includes only the SCM and DPM dimensions, the analysis recovers the classic structure of social evaluation. The Competence and Agency vectors cluster together, while the Warmth and Communion vectors point in opposite directions along the primary axis of variation (PC1). This demonstrates a clear separation between the competence/agency cluster and the warmth/communion cluster along the main axis of variation. This configuration supports the theoretical alignment of Warmth with Communion and Competence with Agency, reflecting two distinct directions that correspond to the widely recognized two dimensions in social evaluation (Abele & Wojciszke, 2014; Cuddy et al., 2008). On the second principal component (PC2), Warmth and Communion have higher values than Competence and Agency, further emphasizing their dimension priority. Visualization of social evaluation content dimensions in two-dimensional PCA Space.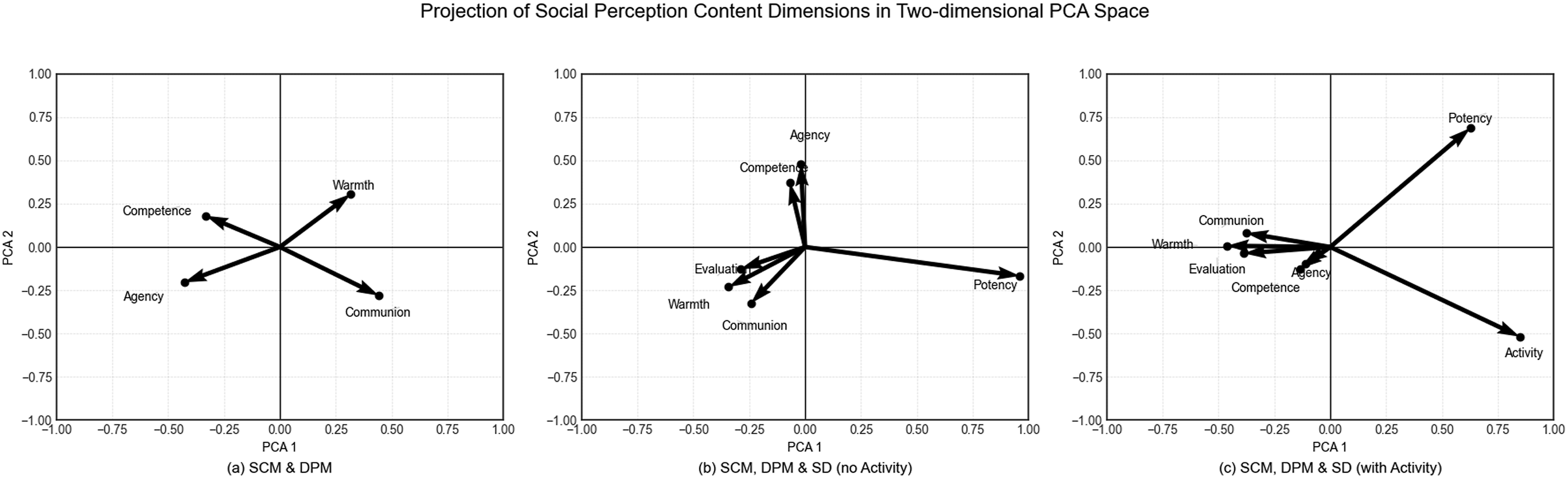
In scenario 2 (Figure 3(b)), we introduce Evaluation and Potency from the SD model to test this structure. The results are striking and provide a clear justification for our synthesized dimensions. The Evaluation vector aligns well with Warmth and Communion, confirming that it taps the same underlying construct and validating our decision to merge them into a single Warmth-Communion-Evaluation (WCE) dimension. At the same time, Competence and Agency now align with the vertical axis (PC 2), confirming their status as a distinct Competence-Agency (CA) dimension (their PC 1 loadings are close to 0). Notably, the Potency vector points in a unique direction, empirically confirming that it does not load onto the primary social evaluation axes (Wojciszke, 1994).
In scenario 3 (Figure 3(c)), adding the Activity dimension provides the definitive structural test. This final model powerfully confirms the uniqueness of Potency and Activity. The two vectors now align to form their own dominant horizontal axis (0.84 and 0.62 on PC1, respectively), while the core social evaluation dimensions (WCE and CA) move as a coherent block onto the vertical axis (PC2). This “axis reorientation” is the most compelling evidence yet: it demonstrates that Potency and Activity constitute a separate, unified dimension, often interpreted as Dynamism (Kervyn et al., 2013), that is empirically distinct from social evaluation. The fact that the WCE and CA dimensions remain tightly clustered, even when displaced by a more dominant component, indicates their strong internal coherence. This finding aligns with long-standing observations that the SD’s Potency and Activity dimensions are conceptually broader than the two dimensions that define contemporary social perception research (Abele & Wojciszke, 2014; Osgood et al., 1957b).
Validation and Interpretation of the Synthetic Framework
These PCA results provide clear, data-driven evidence for our final model. They justify synthesizing Warmth, Communion, and Evaluation into a single WCE dimension and Competence and Agency into a second CA dimension. 3 Furthermore, they provide robust empirical grounds for systematically excluding Potency and Activity, demonstrating that these belong to a distinct, non-evaluative dimension of Dynamism. To validate the semantic integrity of these new dimensions, we compared them with the 64 personality trait adjectives established by Rosenberg et al. (1968). Our computational framework achieved 98% accuracy in predicting these traits, surpassing the original SCM, DPM, and SD models (see Appendix C for full validation details and classification tables).
Top Five Seed Word Pairs for Two Computational Synthesized Content Dimensions

This synthesis does more than simply group terms; it resolves a central, long-standing tension in the literature about the relationship between the SD and SCM/DPM models. Our findings show that the SD’s “Evaluation” dimension is not a separate concept but rather the conceptual core of the Warmth/Communion dimension. This insight provides a direct empirical explanation for a previously puzzling observation: why the “Evaluation” axis often appears to run diagonally across the SCM’s two dimensions in prior studies (Kervyn et al., 2013; Rosenberg et al., 1968). Our framework shows that this is because Evaluation is the primary component of the WCE axis, not an independent factor. Furthermore, the analysis confirms that Potency and Activity form a distinct Dynamism dimension, separate from social evaluation, aligning with their original conceptualization and explaining their limited role in modern social perception models (Osgood et al., 1957b).
The synthetic two-dimensional framework thus resolves previous inconsistencies among the Stereotype Content Model (SCM), Dual Perspective Model (DPM), and Semantic Differential (SD) models. It shows that warmth, communion, and evaluation are not competing dimensions but rather complementary ones. In contrast, competence and agency form a unified and practical dimension. These results not only further theoretical integration but also provide a comprehensive empirical map of how individuals and groups are positioned within social hierarchies. By capturing both the subjective basis of trust and inclusion (Warmth, Communion, and Evaluation - WCE) and the objective basis of agency and achievement (Competence and Agency - CA), the synthetic framework offers new insights into the structure of social evaluation and its implications for status, power, and group dynamics.
Illustrative Application
Having validated the structural integration of the SCM, DPM, and SD models, we now present an empirical demonstration of the framework’s usefulness. In this section, we apply this two-dimensional framework to a dataset of natural observations: tweets mentioning Chinese and Japanese groups before and during the COVID-19 pandemic. We treat the pandemic as a natural experiment to observe changes in social evaluation. We will revisit a research question that has been well studied by a team of Princeton sociologists using different methodologies. Their recently published findings and substantive insights provide us with a convenient benchmark to evaluate the credibility and usefulness of our framework when addressing the same research question with comparable data.
Case Background
Extensive research has documented the rise of anti-Asian (Gover et al., 2020; Tessler et al., 2020) and xenophobic attitudes (Dhanani & Franz, 2021; Cheah et al., 2020; Daniels et al., 2021) in the United States during the pandemic. Crucially, this animosity was often directed specifically at China, driven by narratives blaming the country for the virus’s origin and spread (He et al., 2022; Jaworsky & Qiaoan, 2021; Silver et al., 2020).
Prior studies using surveys (He & Xie, 2022) and sentiment analysis of Twitter data (Cook et al., 2026) have reported a sharp rise in negative attitudes toward the Chinese but not toward the Japanese. These findings offer an opportunity to validate our computational framework’s ability to corroborate the rise in negative evaluations of the Chinese and to provide nuanced insights that prior studies cannot reveal. To distinguish COVID-related stigma from general racial bias, we select Japanese individuals as a control group. Because both groups are categorized as “East Asian” in the U.S., this comparison isolates stigma directed at the Chinese from generalized anti-Asian sentiment (Grimm et al., 2017). Thus, we propose two hypotheses that refine the findings of He and Xie (2022) and Cook et al. (2026).
Drawing on intergroup threat theory, we posit that the COVID-19 pandemic framed the Chinese group as both a symbolic and a realistic threat. Because blame attribution typically focuses on intent and harm (the social/moral dimension) rather than on capability, we predict that changes in American evaluations would be reflected in the Warmth-Communion-Evaluation (WCE) dimension and would differ across otherwise similar East Asian ethnic groups. ⁃ ⁃
Data Source and Pre-processing
We selected the TwiBot-22 dataset (Feng et al., 2022), a large-scale benchmark corpus known for its comprehensive coverage and high-quality annotation. This dataset was chosen for two key reasons. First, its reliable user-type labels allowed us to isolate tweets from human users, a critical step for measuring genuine public perception and filtering out the confounding influence of automated bot accounts. Second, its scale (over 88 million tweets) and network-based sampling provide a broad and ecologically valid snapshot of discourse within interconnected American Twitter communities.
Our data processing followed a multi-step protocol to construct the final analytical corpora. (1) Temporal and User Filtering: We retained only tweets published by human users (excluding bots) between December 1, 2019, and January 1, 2021, covering the pre-pandemic baseline and the first year of the pandemic. (2) Target Group Filtering: We isolated English-language tweets containing the keywords “Chinese” or “Japanese.” (3) Content Cleaning: Syntax rules were applied to exclude non-evaluative content (e.g., URLs or videos only).
This process yielded a final analytical corpus of 17,037 tweets referencing Chinese individuals and a comparative corpus of 4,534 tweets referencing Japanese individuals. Specifically, the analyzed tweets averaged 16 words (16.61 for Japanese-related tweets; 16.41 for Chinese-related tweets). Qualitatively, the content ranged from news sharing and political commentary to personal comments about the pandemic. 4 Further details on the dataset are discussed in Appendix E.
Applying the Framework: Semantic Projection
With the validated synthesized dimensions established in the previous section, we applied them to our dataset of Twitter posts. First, we represented each tweet as a vector by computing the centroid (average) of the embeddings of its constituent words using NLP techniques (tokenization, lowercasing, and stopword removal). This standard approach placed each tweet in the same high-dimensional semantic space as our theoretical dimensions. Next, using linear projection, 5 each tweet was projected onto the validated synthesized dimensions to obtain the theoretical relative scores.
Unlike simple distance measures, our analytical goals require capturing the direction of semantic alignment. As Kozlowski et al. (2019) argue, meaning in a semantic space is defined by the direction of differences between vectors. By projecting a tweet’s vector onto our validated synthesized axis, we measure its “shadow”—the degree to which its meaning aligns with the concepts of warmth and morality. This method, common in computer science (Mathew et al., 2020) and computational sociology (Durrheim et al., 2023), yields continuous scores for each post on dimensions analogous to Warmth-Communion-Evaluation and Competence-Agency. Importantly, this projection effectively pulls the aggregate semantics along two interpretable dimensions, isolating the dominant evaluative “signal” from the statistical “noise” of non-evaluative discourse at a massive scale, enabling subsequent statistical analysis of temporal and group-based shifts in social evaluation.
Statistical Analysis and Findings
To test our hypotheses about temporal shifts and group differences, we aggregated the predicted scores for individual tweets into daily mean scores. This produced a time-series dataset spanning 31 days of pre-pandemic baseline data (December 2019) and 367 days of pandemic-era data. This daily-level aggregation allows us to track macro-level shifts in public opinion while controlling for the high variance of individual tweets.
We employed two distinct statistical tests tailored to the data structure. First, to test the temporal shift (H1), we used Welch’s t-test (unequal-variances t-test) to compare the Pre-COVID and Post-COVID periods. This method was chosen to account for the substantial imbalance in sample sizes between the baseline period (N = 31 days) and the pandemic period (N = 367 days) and to robustly handle potential heterogeneity in variances across these periods.
Second, to test the group difference (H2), we used a Paired Samples t-test to compare American evaluations across the Chinese and Japanese groups. Because both groups were exposed to the same external global events on any given day, pairing the data by date controls for extraneous temporal confounders (e.g., holidays, major non-COVID news events), allowing us to isolate the specific divergence in social evaluation between the two groups.
Divergent Trajectories on the WCE Dimension
As shown in Figure 4(a), American perceptions of the Chinese and Japanese groups along the WCE dimension—which captures warmth, trustworthiness, and moral evaluation—followed distinct trajectories. Predicted Perception Scores via WCE and CA Dimensions (Dec 1, 2019 - Jan 1, 2020).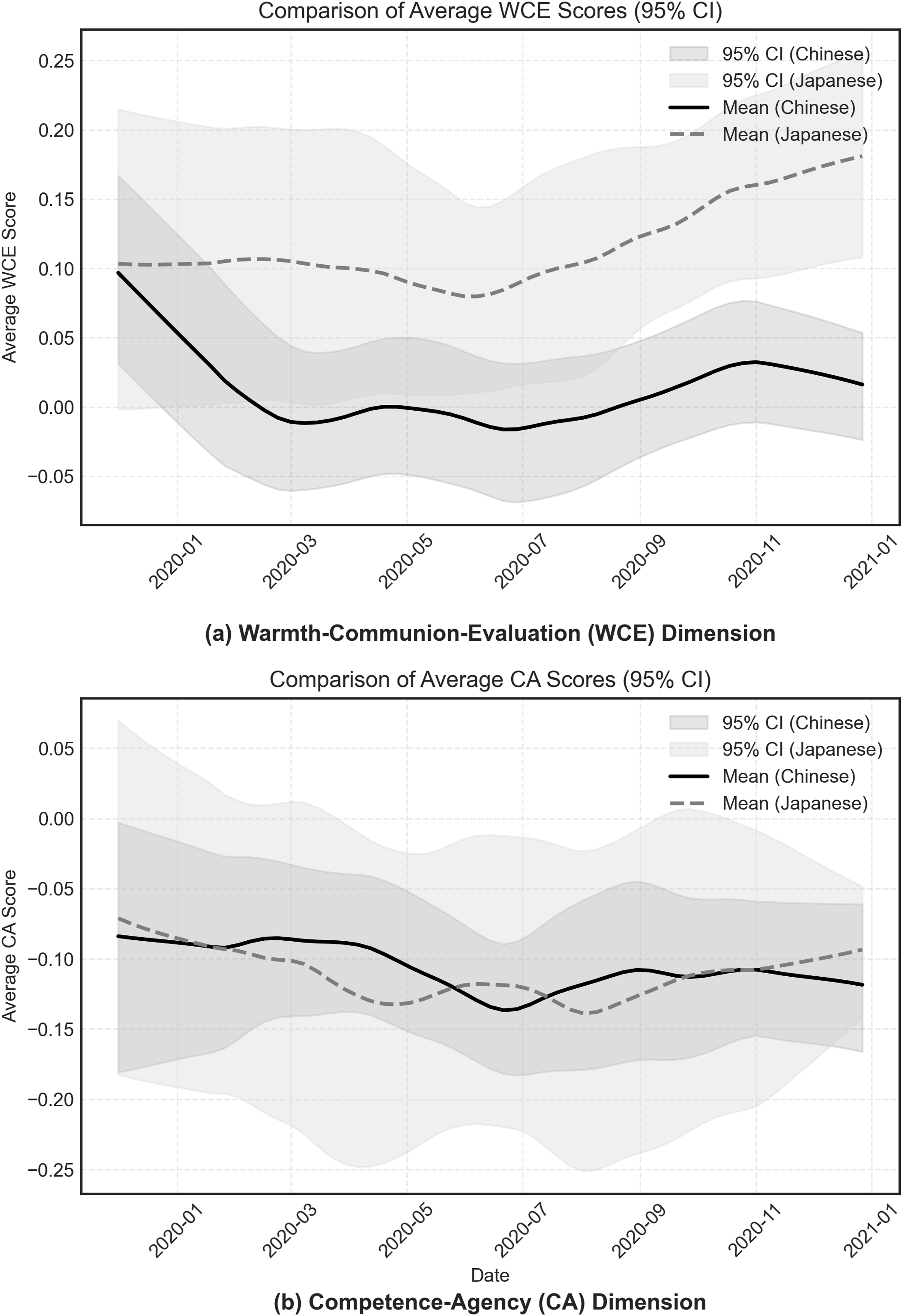
Social Evaluation Changes Before and During COVID-19 (Independent-Samples Welch’s t-test)
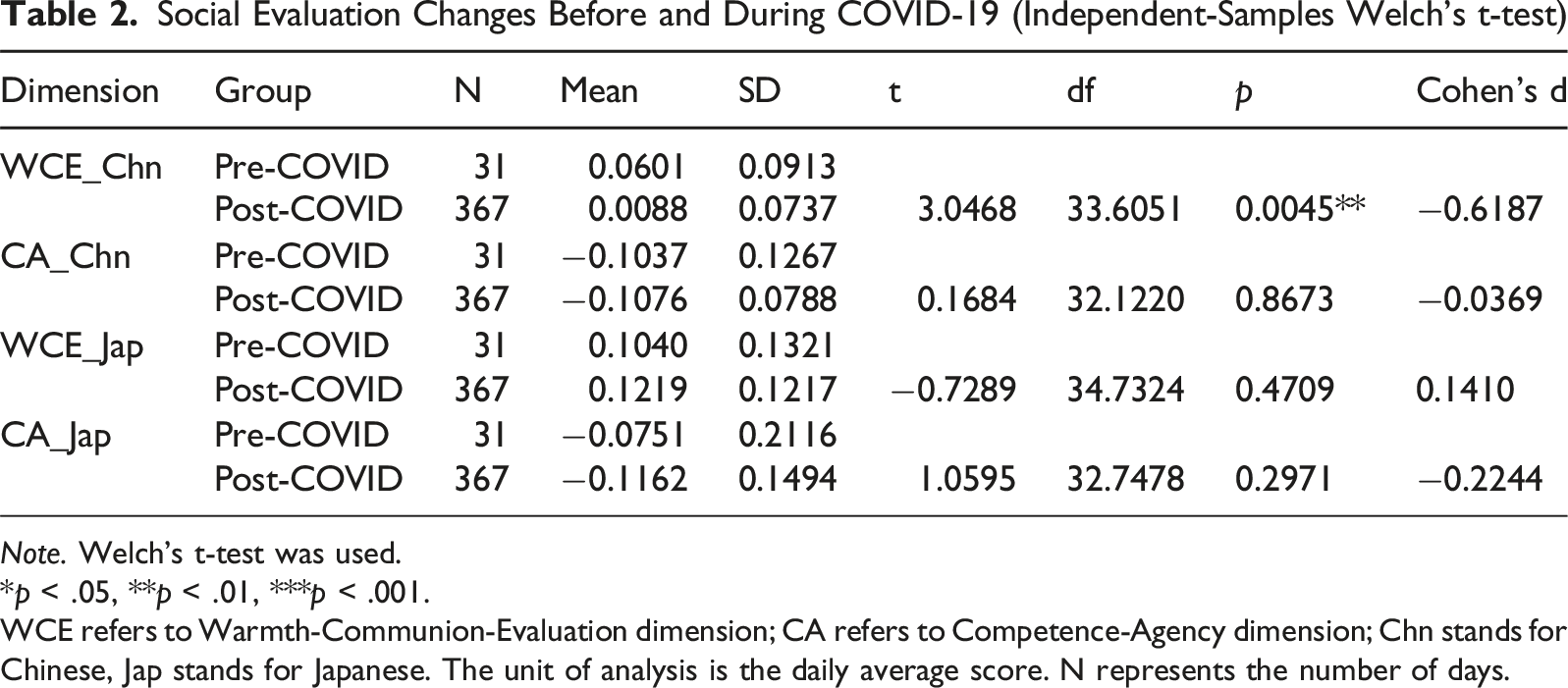
Note. Welch’s t-test was used.
*p < .05, **p < .01, ***p < .001.
WCE refers to Warmth-Communion-Evaluation dimension; CA refers to Competence-Agency dimension; Chn stands for Chinese, Jap stands for Japanese. The unit of analysis is the daily average score. N represents the number of days.
Empirical analysis indicates that this decline was not uniform but concentrated within a specific window from late January to late February 2020. This period coincided with the initial escalation of the crisis, including the lockdown of Wuhan (Jan 23), the WHO’s declaration of a global health emergency (Jan 30), and the U.S. travel ban on visitors from China (Jan 31). Following this precipitous drop, the WCE scores stabilized at a lower level from March onward.
In contrast, WCE scores for the Japanese group were remarkably stable. There was no significant difference between pre- and post-pandemic periods (t = −0.73, p = 0.471, d = 0.14; see Table 2). This stability provides a distinct “control” baseline against which the shift in Chinese evaluations can be measured.
Comparison of Social Evaluation Between Chinese and Japanese (Paired Samples t-test)
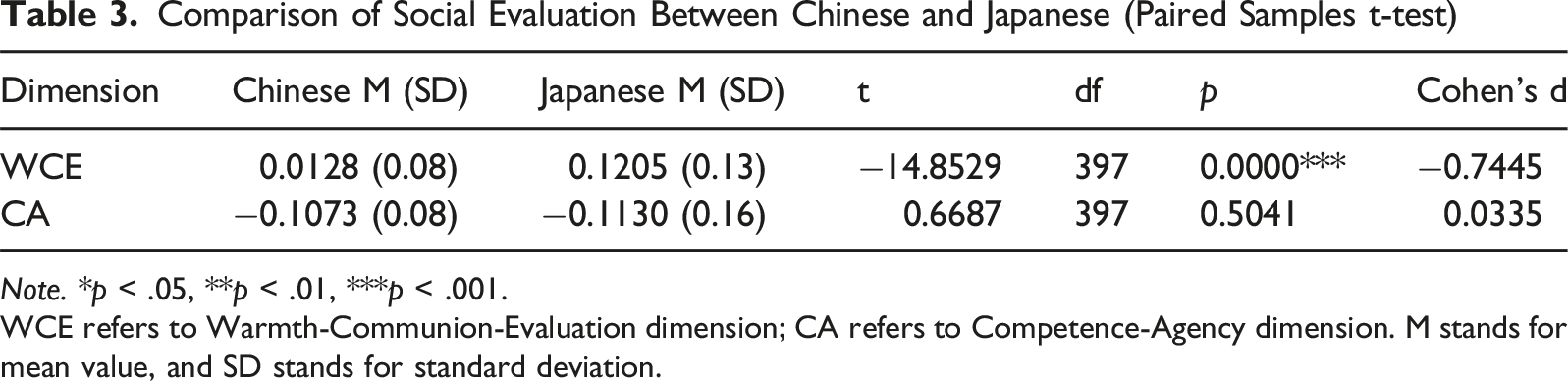
Note. *p < .05, **p < .01, ***p < .001.
WCE refers to Warmth-Communion-Evaluation dimension; CA refers to Competence-Agency dimension. M stands for mean value, and SD stands for standard deviation.
The Resilience of Competence Stereotypes
In contrast to the volatile judgments observed in the WCE dimension, perceptions along the CA (Competence-Agency) dimension remained resilient to the crisis (see Figure 4(b)). Formal statistical tests confirmed this stability across both time and groups. First, regarding longitudinal changes, neither the Chinese group (t = 0.17, p = .867, d = −0.04) nor the Japanese group (t = 1.06, p = .297, d = −0.22) showed any significant shift in CA scores following the pandemic onset (see Table 2). Second, regarding intergroup comparison, no significant difference was found between Chinese and Japanese evaluations in the post-pandemic period (t = 0.67, p = .504, d = 0.03; see Table 3).
These null results are critical to the validity of the computational two-dimensional framework. They show that the negative shift in sentiment toward Chinese individuals was domain-specific: a collapse in perceived morality and trustworthiness (WCE), not a generalized reassessment of capability or agency (CA).
Discussion and Conclusion
This study addressed a long-standing challenge in social perception by developing and validating a unified, data-driven two-dimensional framework. We empirically confirmed that in natural language, the core constructs of major social evaluation theories converge into two robust dimensions: Warmth-Communion-Evaluation (WCE) and Competence-Agency (CA). Our primary contributions are twofold. Methodologically, we provide a validated tool for measuring social evaluations at an unprecedented scale. Theoretically, we offer new insights into the dynamics of crisis-driven stigma. By applying this framework to the COVID-19 pandemic, we found that the surge in anti-Chinese sentiment did not represent a generalized collapse of image. Instead, it manifested as a sharp, domain-specific decline in perceived morality and warmth (WCE), while perceptions of competence (CA) remained resilient.
These results highlight a critical theoretical distinction in how stereotypes function. While judgments of warmth and trustworthiness (WCE) appear fluid and highly responsive to sociopolitical narratives, competence stereotypes are more structural and “sticky”, likely tied to durable perceptions of economic and technological capacity. By decomposing social evaluation into these distinct components, our framework reveals the complex and often contradictory nature of stereotypes: a group can be scapegoated on a moral-social dimension while simultaneously retaining its status on a capability-agency dimension. This null result on the CA dimension is not merely an absence of change; it suggests that the crisis triggered a specific moral panic rather than a reassessment of the group’s agency.
Crucially, our findings provide quantitative evidence against the homogenization of “Asian” identity in American discourse. Although previous studies reported that Americans rated Chinese and Japanese groups similarly before the pandemic (Zou & Cheryan, 2017), our longitudinal analysis captures a rapid, divergent renegotiation of these group boundaries. The stability of American evaluations of Japanese individuals, contrasted with plummeting WCE scores for Chinese individuals, suggests a process of intergroup boundary-drawing (Wimmer, 2013).
As one group became the target of intense moral condemnation, a contrast effect appears to have emerged. In this dynamic, a related but distinct out-group (Japanese) was evaluated more favorably, or at least protected from negative evaluation, to sharpen the boundary around the stigmatized group (Grimm et al., 2017). This empirically validates qualitative and survey-based research on the targeted nature of pandemic racism (Gover et al., 2020; He & Xie, 2022). It demonstrates that the stigma was not an undifferentiated “anti-Asian” prejudice but a precise geopolitical scapegoating (Reny & Barreto, 2022) that followed the contours of specific narratives about the virus’s origin.
Beyond its academic value, this framework serves as a practical diagnostic for monitoring the health of public discourse. The ability to track the WCE dimension in real time provides an early-warning system for public health officials and civic organizations, enabling them to anticipate scapegoating narratives before they become entrenched and cause real-world harm. Furthermore, for digital platforms, this framework suggests a more nuanced approach to content moderation. By distinguishing between dehumanizing attacks on a group’s fundamental trustworthiness (WCE) and critiques of competence (CA), platforms can develop more sophisticated tools to protect vulnerable communities.
In conclusion, by bridging social psychological theory and computational linguistics, this study demonstrates that social perception in the digital age is measurable, multidimensional, and highly dynamic. The computational two-dimensional framework offers a powerful lens through which to view not only the history of the COVID-19 pandemic but also the unfolding future of intergroup relations online.
Limitations, Ethics, and Future Directions
While this study provides a novel synthesis and application, several limitations point to important avenues for future research. First, our empirical analysis relies on Twitter data, which is not representative of the general U.S. population. Because Twitter users tend to be younger, more educated, and more politically engaged than the average citizen, the attitudes expressed in our dataset reflect a specific, albeit highly influential, segment of public discourse. Consequently, these findings should be interpreted as reflecting the digital public sphere rather than as a proxy for universal public opinion. Future research could validate these findings by triangulating social media data with traditional survey methods to assess how online discourse mirrors or diverges from offline sentiment.
Second, our methodology uses static word embeddings, which have inherent technical limitations. These models capture meaning from global patterns of word co-occurrence and struggle to interpret complex linguistic phenomena such as sarcasm, irony, or polysemy. While the sheer volume of data helps mitigate the impact of individual misclassifications, the model cannot reliably distinguish between sincere and sarcastic statements. Future work could address this by employing context-aware language models (e.g., BERT or GPT-based architectures), which are better equipped to handle the nuances of syntax and tone, provided they can be adapted to the specific biases inherent in their training data.
Third, and perhaps most critically, our analysis of the “Chinese” category cannot fully disentangle sentiment directed at the Chinese government (e.g., the CCP) from sentiment directed at Chinese individuals. A decline in the Warmth-Communion-Evaluation dimension may, in some cases, reflect political disapproval rather than purely interpersonal animosity. Although a post hoc frequency analysis of our corpus suggests that this confounding factor is limited: explicit references to political entities (e.g., “CCP,” “Xi,” “Communist”) appeared in less than 2% of the tweets, whereas pandemic-related terms (e.g., “virus,” “COVID”) were dominant. This limitation should also be considered: in times of geopolitical conflict, the boundary between the “state” and the “people” often blurs in public perception. Future work using Named Entity Recognition (NER) could attempt to separate regime-targeted from people-targeted discourse to quantify the extent to which political critique spills over into racialized stigma.
Finally, although our computational approach identifies robust patterns of association, it is descriptive rather than causal. We observe a decline in affective evaluation, but our method does not disentangle the precise influence of media consumption, political rhetoric, or personal experience on this shift. Complementary qualitative or experimental studies are needed to provide a deeper understanding of the causal mechanisms behind the trends we observe.
These limitations are tied to crucial ethical considerations. We acknowledge that social media data and the models trained on it are not neutral; they are artifacts of a society that contains biases. Our framework is designed not to create an “unbiased” model, but to use these signals as a diagnostic tool to measure real-world prejudice. Furthermore, although the data is public, this does not imply consent for research. Our primary ethical mitigation was aggregation: the analysis focuses exclusively on group-level trends, protecting individual privacy while making the invisible dynamics of social evaluation visible and quantifiable.
Supplemental Material
Supplemental material - Computational Evidence for the Two-Dimensional Structure of Social Evaluation: Pandemic-Era Insights From Americans’ Perceptions of Chinese and Japanese on Twitter
Supplemental material for Computational Evidence for the Two-Dimensional Structure of Social Evaluation: Pandemic-Era Insights From Americans’ Perceptions of Chinese and Japanese on Twitter by Xuanlong Qin and Tony Tam in Social Science Computer Review
Footnotes
Acknowledgments
We are grateful for the valuable feedback from anonymous reviewers. We also appreciate the insights provided by Hai Liang, Ling Zhu, and Siqi Han. In particular, we sincerely appreciate the help and comments from Lingyan Tu for the first version. The views expressed herein are our own. A previous version of this article has been presented at the 5th Sociological Forum of International Sociological Association and has won the Nan Lin Student Paper Travel Award at the 25th Annual Conference of International Chinese Sociological Association.
Ethical Considerations
There are no human participants in this article and informed consent is not required.
Author Contributions
Xuanlong Qin: Conceptualized the research questions, developed the methodology, and wrote the primary draft of the manuscript. Tony Tam: Contributed to the theoretical framework, the overall research design, and the revision of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All the data and codes are available on Github (https://github.com/XuanlongQ/Integrating_SCM_SD) and OSF (![]() ).
).
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.