
Abstract
Modern Configurational Comparative Methods (CCMs), such as Qualitative Comparative Analysis (QCA) and Coincidence Analysis (CNA), have gained in popularity among social scientists over the last thirty years. A new CCM called Combinational Regularity Analysis (CORA) has recently joined this family of methods. In this article, we provide a software tutorial for the open-source package
Keywords
Introduction
Configurational Comparative Methods (CCMs) constitute a family of empirical research methods for causal inference that have gained in popularity among social scientists over the last thirty years (Rihoux & Ragin, 2009; Thiem, 2022b). While the inferential foundations of modern CCMs lie within the class of regularity theories of causation (Psillos, 2009), and in particular the INUS Theory (Mackie, 1965, 1980), their mathematical operations are firmly anchored in Boolean algorithms. CCMs can thus be distinguished most clearly from other formalized methods of data analysis by their reliance on the laws of Boolean and Post algebra (Mkrtchyan et al., 2023; Thiem et al., 2016).
For many years, the two most advanced CCMs have been Qualitative Comparative Analysis (QCA; Ragin, 1987, 2000, 2008) and Coincidence Analysis (CNA; Baumgartner, 2009; Baumgartner & Ambühl, 2020). QCA-based studies have long been published in numerous disciplines, mainly business, management and organization studies, political science and sociology (Rihoux et al., 2013; Thiem, 2022b; Wagemann et al., 2016). Although CNA is appreciably more powerful than QCA in its analytical capabilities (Baumgartner & Ambühl, 2020), applications have only begun to appear towards the late 2010s, and almost exclusively in health-related research so far (Whitaker et al., 2020).
A third method called Combinational Regularity Analysis (CORA) has recently joined the fold (Mkrtchyan et al., 2023; Sebechlebská et al., 2023; Thiem et al., 2022, 2024). Most importantly with regard to configurational data analysis, CORA has introduced the possibility to analyze multiple outcomes as well as the conjunctions of these outcomes simultaneously. To this end, CORA generalizes the process of Boolean optimization from the level of single outcomes to entire systems of outcomes. In this way, not only can the causes of individual effects be found, but also the causes of all possible combinations of these effects. For instance, the concept of multi-morbidity, which has assumed increased importance in medical, health and psychological research over the last decade (e.g., King et al., 2018; Suls & Green, 2019), describes the simultaneous presence of multiple diseases in a patient, such as diabetes and depression. A risk factor or combination of risk factors may impact on only one disease at a time, but not the other, or the conjunction of both diseases. In such contexts, CORA represents the only CCM that is able to correctly infer such relations from corresponding data.
A second difference of CORA to QCA and CNA is its in-built option to address the issue of model ambiguity by a data-mining procedure that progresses through tuple-selections of input factors. The idea behind this approach is that any explanatory model that is found with a given number of inputs will, ceteris paribus, also always be found in an analysis with only those inputs involved in this model. More precisely, if CORA cannot identify a fitting model with some set of combinations of inputs, it adds one more input to this set. This approach represents a configurational version of Occam’s Razor, which holds that explanations involving fewer variables are, ceteris paribus, to be preferred over explanations that are more complex (Feldman, 2016). 1
Third, CORA is the only configurational method to date that offers a consistent and effective way of visualizing its solutions. To do so, it draws on logic diagrams (Thiem et al., 2023). Originally, logic diagrams were exclusively used in electrical engineering for representing Boolean functions in general, and switching circuits in particular, but since the early 2000s, they have also become widespread in some subfields of biology (Wang & Buck, 2012). In fact, some prominent researchers in causal inference and artificial intelligence even hold that logic diagrams ”capture …the very essence of causation” (Pearl, 2009, p. 415).
In this article, we provide a software tutorial for the open-source Python package
Software Overview
Overview of Current Software Packages for configurational Data Analysis.
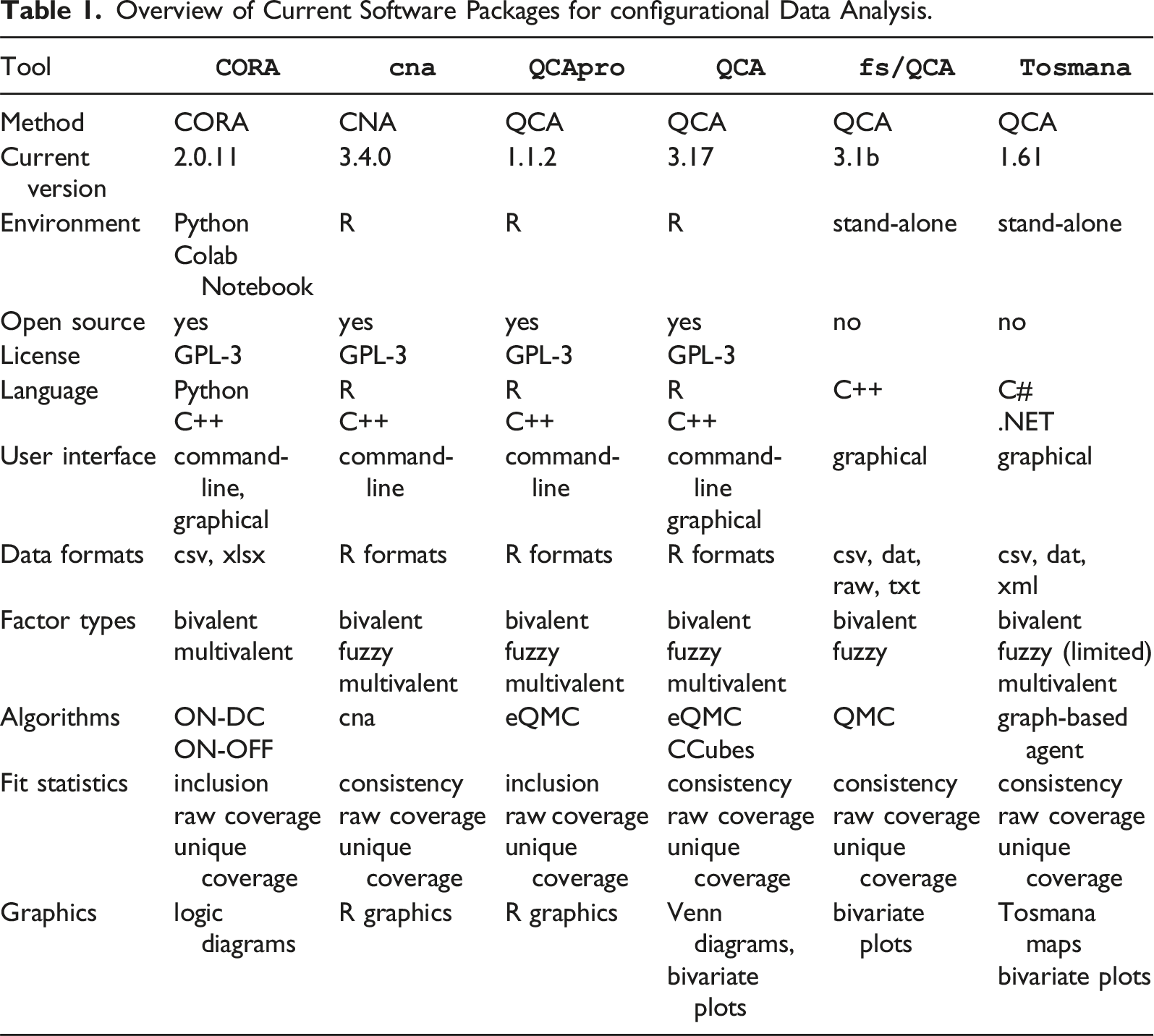
In the family of software packages for configurational data analysis,
With regard to data formats,
Algorithms play an important role in configurational data analysis, as they determine the output and the speed with which that output will be obtained. In CORA, users currently have the choice between two different optimization algorithms, one that optimizes on the basis of positive terms and don’t care terms (ON-DC)—and another that optimizes based on positive and negative terms (ON-OFF). Algorithms of the latter type enjoy significant computational advantages when the set of don’t care-terms is large relative to the set of off-terms. As these two algorithms are equivalent, they will always produce exactly the same solutions. 4
All fit statistics in CORA are conceptually equal to those in QCA or CNA (inclusion and consistency are conceptually identical). However, when dealing with multiple outputs simultaneously, some generalizations are needed that we will explain in more detail further down.
The last difference between CORA and QCA or CNA is its incorporation of logic diagrams. Due to the limited set of logic design symbols required to visualize CORA’s solution and their purpose-tailored layout, logic diagrams are called ”logigrams” in CORA. For producing logigrams,
General Description of
CORA
All components of 
Among the family of software packages for configurational data analysis,
A Colab notebook is a web-integrated development environment that can combine executable code, rich text, pictures, HTML, and LaTeX, among many other components. 6 As Colab notebooks run on Google cloud servers, the power of Google’s hardware, including graphics and tensor processing units, can be utilized. Additional computing power can be bought at different plans. The infrastructure of Colab notebooks is therefore particularly geared towards collaborative projects on data science.
Figure 2 shows the internal structure of The internal structure of 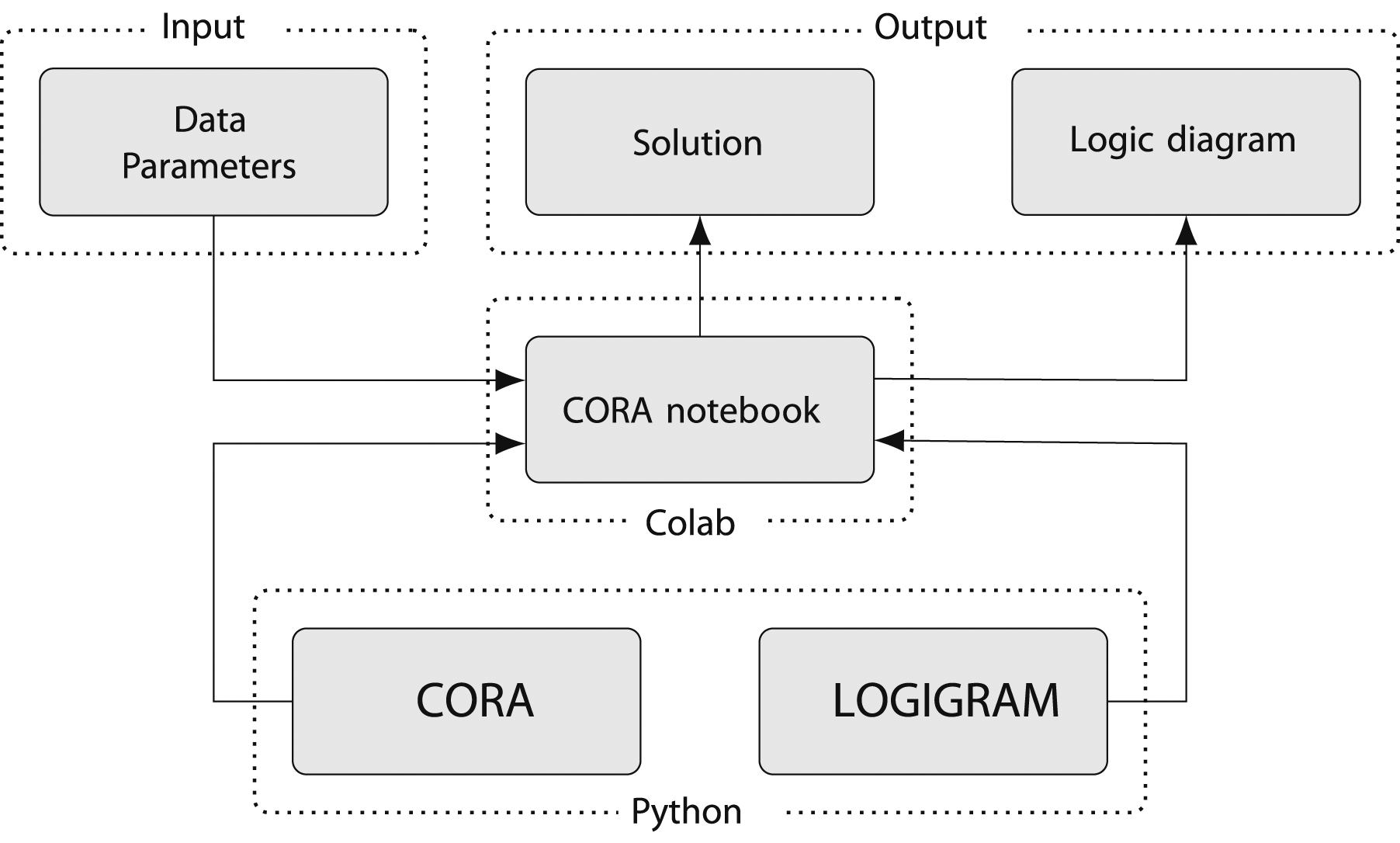
In line with CORA’s reliance on two distinct Python packages, two types of output can be generated: a textual solution, which consists of a (system of) Boolean function(s) expressed in the syntax of propositional logic, and a logigram of a (system of) Boolean function(s).
From Launching 
After having clicked the ”Open in Colab” button, the user is taken to Procedural sections in 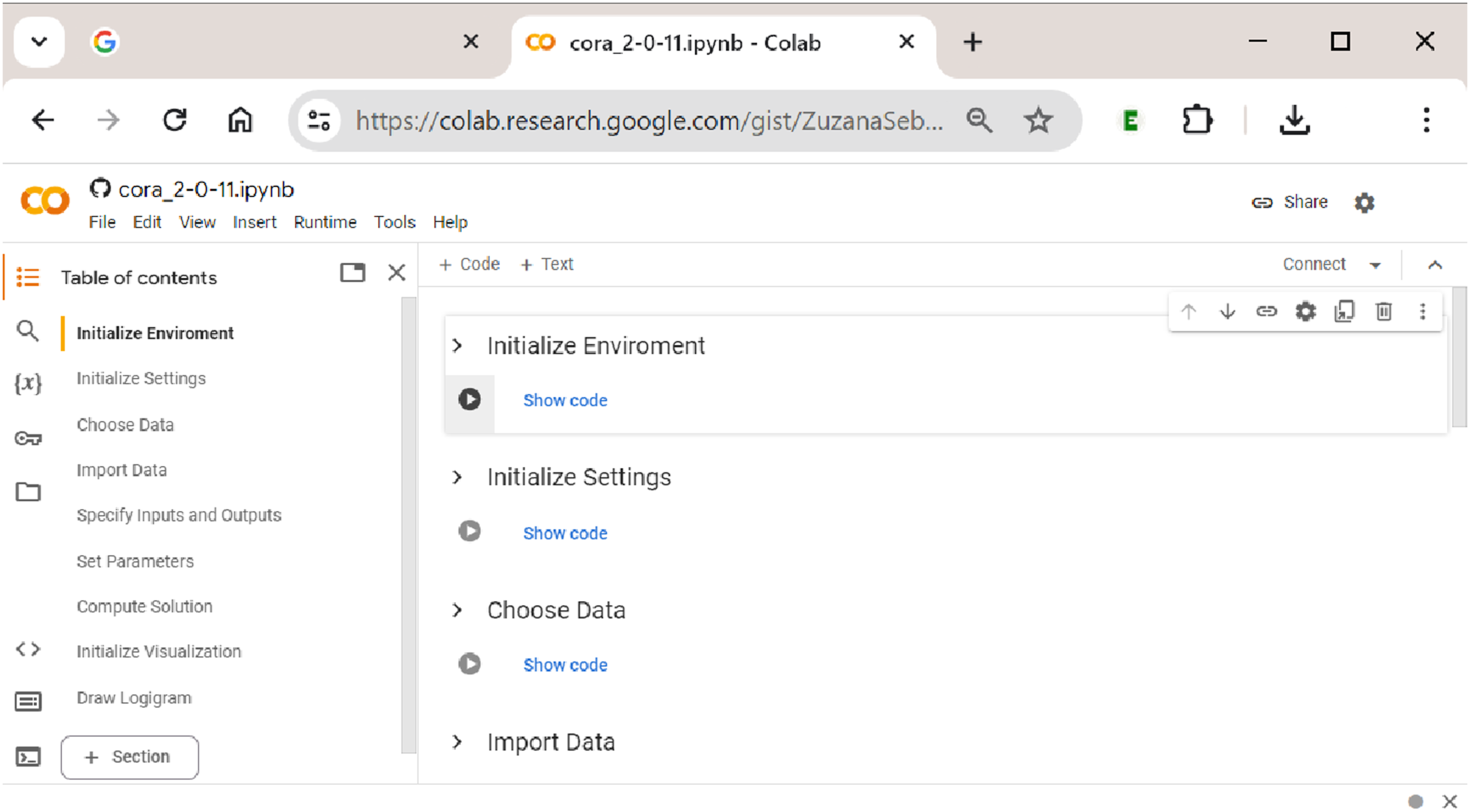
Procedural Sections in
How to Use
CORA
’s Colab Notebook: an Empirical Example
In the following, we demonstrate in a hands-on empirical example how to use Initializing 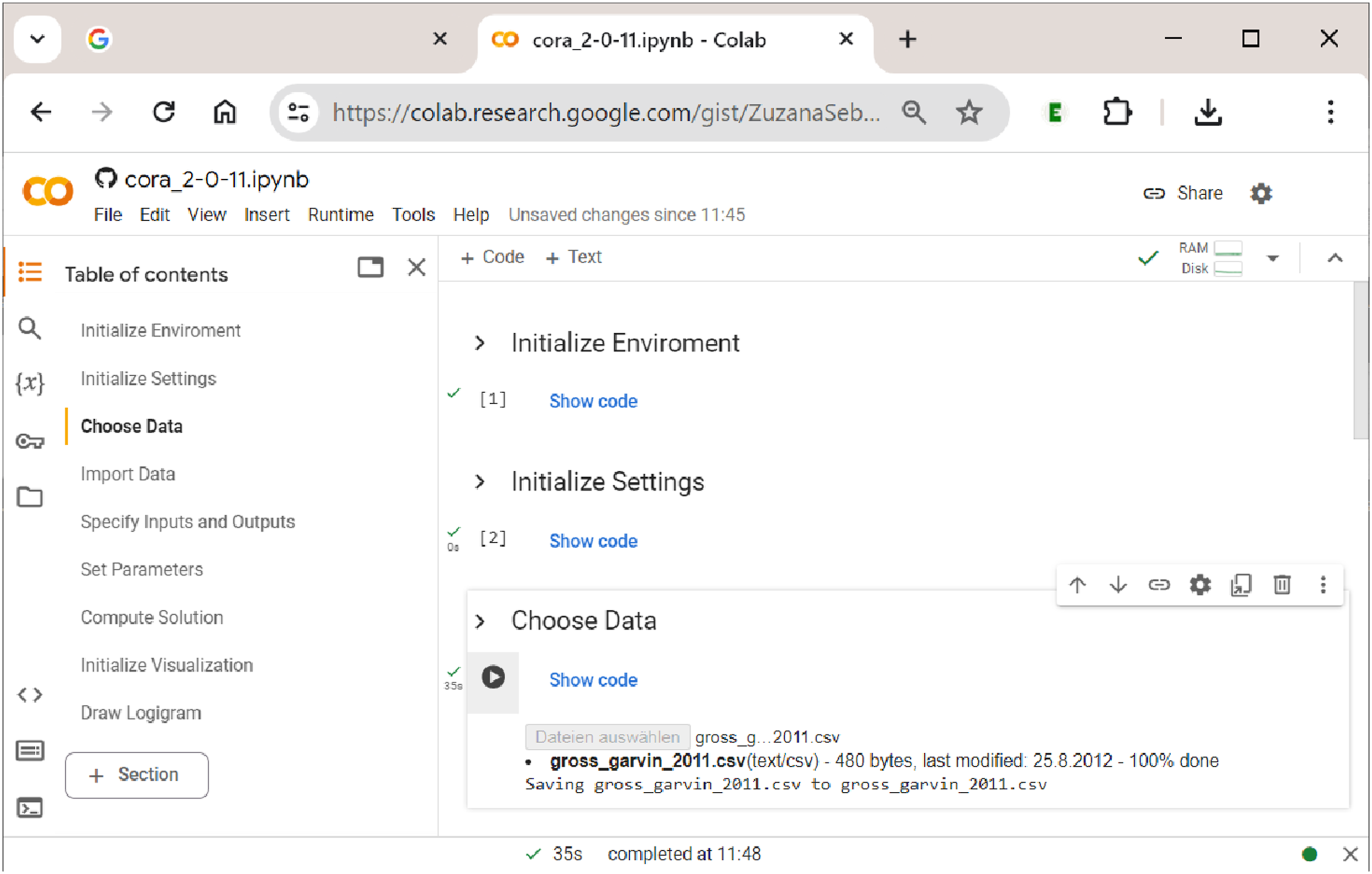
Every time a new session is started, sections 1 (Initialize Environment) and 2 (Initialize Settings) need to be re-run, but within the same session, this is not necessary. If the user wants to only change the data, the inputs or outputs, the analytical parameters or any other component along the way from section 3 (Choose Data) to section 7 (Compute Solution), a re-initialization from the first concerned section is required before the process can be restarted and the section’s output be updated.
Only sections 8 (Initialize Visualization) and 9 (Draw Logigram) can be used without initializing any previous sections because they import and provide the functionality of the
Sections 1–4: Initialization and Data Upload
Every time a new session is started, sections 1 ”Initialize Environment” and 2 ”Initialize Settings” need to be run first. This ensures that the Importing data into 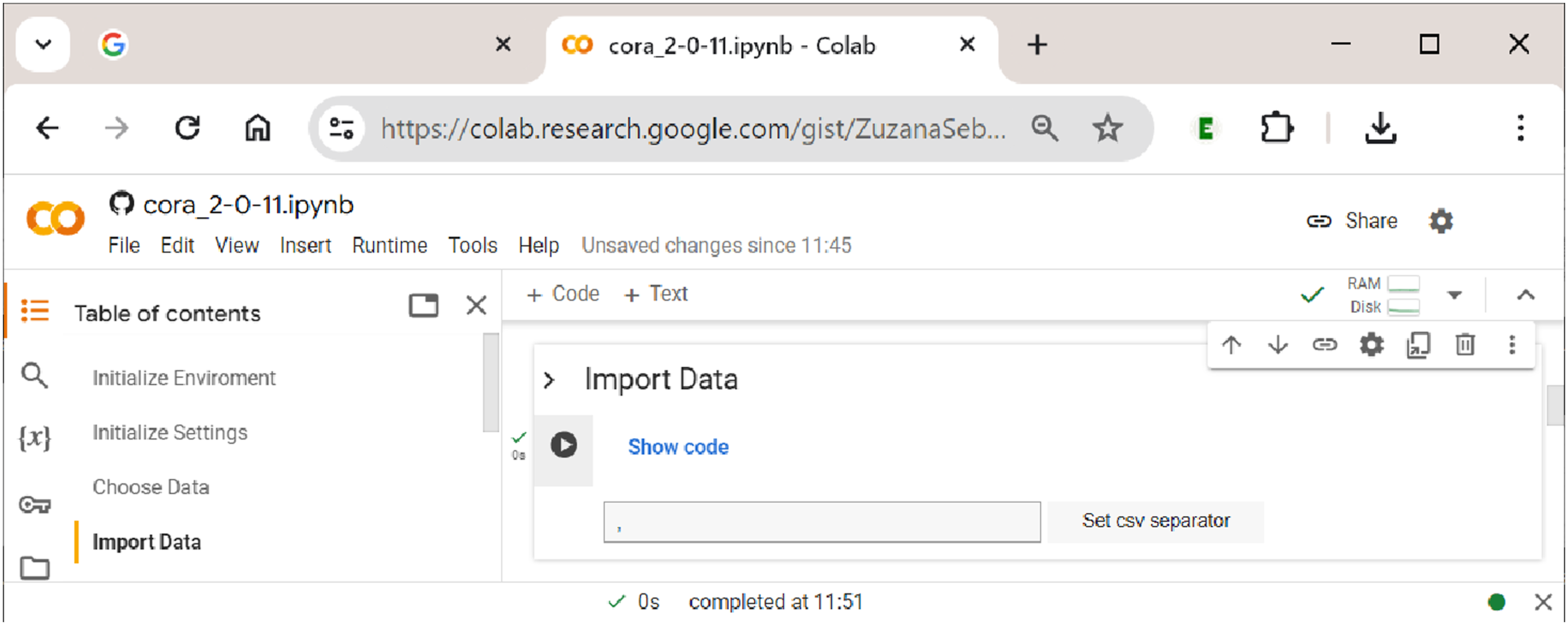
The second step in uploading the data is shown in Figure 7. Here, the separator of the csv file needs to be specified, which is usually a comma (but can sometimes also be a semicolon). By clicking the button ”Set csv separator”, the separator is determined, and the file is properly read into the notebook (if the wrong separator is used, the data will not display as a properly aligned table). Data display in 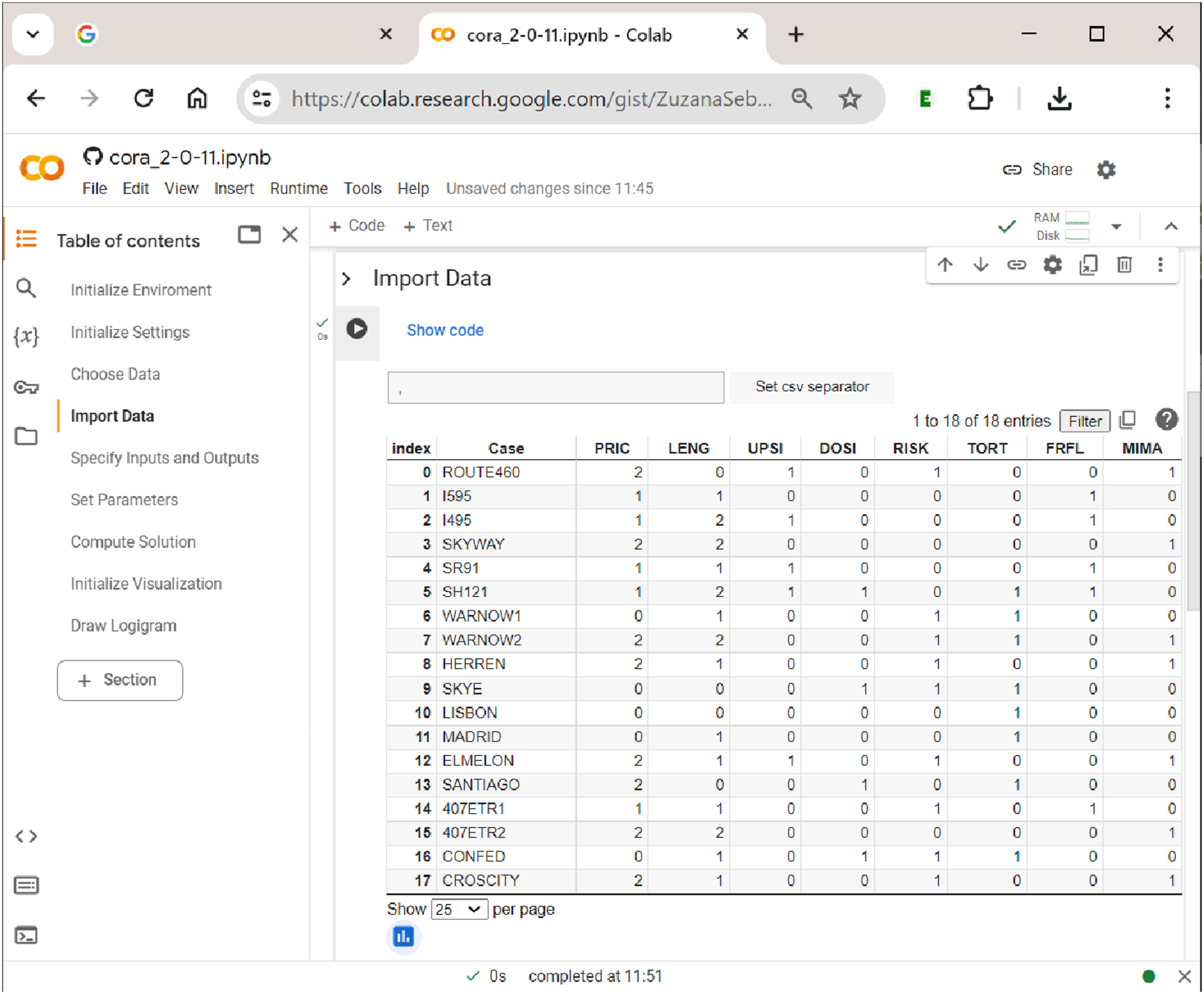
Gross and Garvin (2011) study the effectiveness of public–private partnership contracts for toll roads. To do so, the authors employ multi-value QCA. Their five exogenous factors include the toll rate approach (PRIC; 0 = average cost pricing, 1 = marginal social-cost pricing, and 2 = revenue-maximizing pricing), the concession length (LENG; 0 = variable, 1 = short, and 2 = long), upside revenue sharing (UPSI; 0 = absent and 1 = present), downside risk sharing (DOSI; 0 = absent and 1 = present), and the traffic-demand risk (RISK; 0 = low and 1 = high). Two endogenous factors are related to pricing objectives: achieving an affordable/specific toll rate (TORT: 0 = low, 1 = high) and managing congestion or maximizing throughput (FRFL: 0 = low, 1 = high). Originally, the dataset used by Gross and Garvin (2011) contains three endogenous factors, each of which is analyzed separately with mvQCA, but we use only two here for the sake of keeping the complexity of the simultaneous output analysis with CORA at a purposeful level.
Section 5: Specifying Inputs and Outputs
After having imported the raw data, the fifth section of Specifying inputs and outputs in 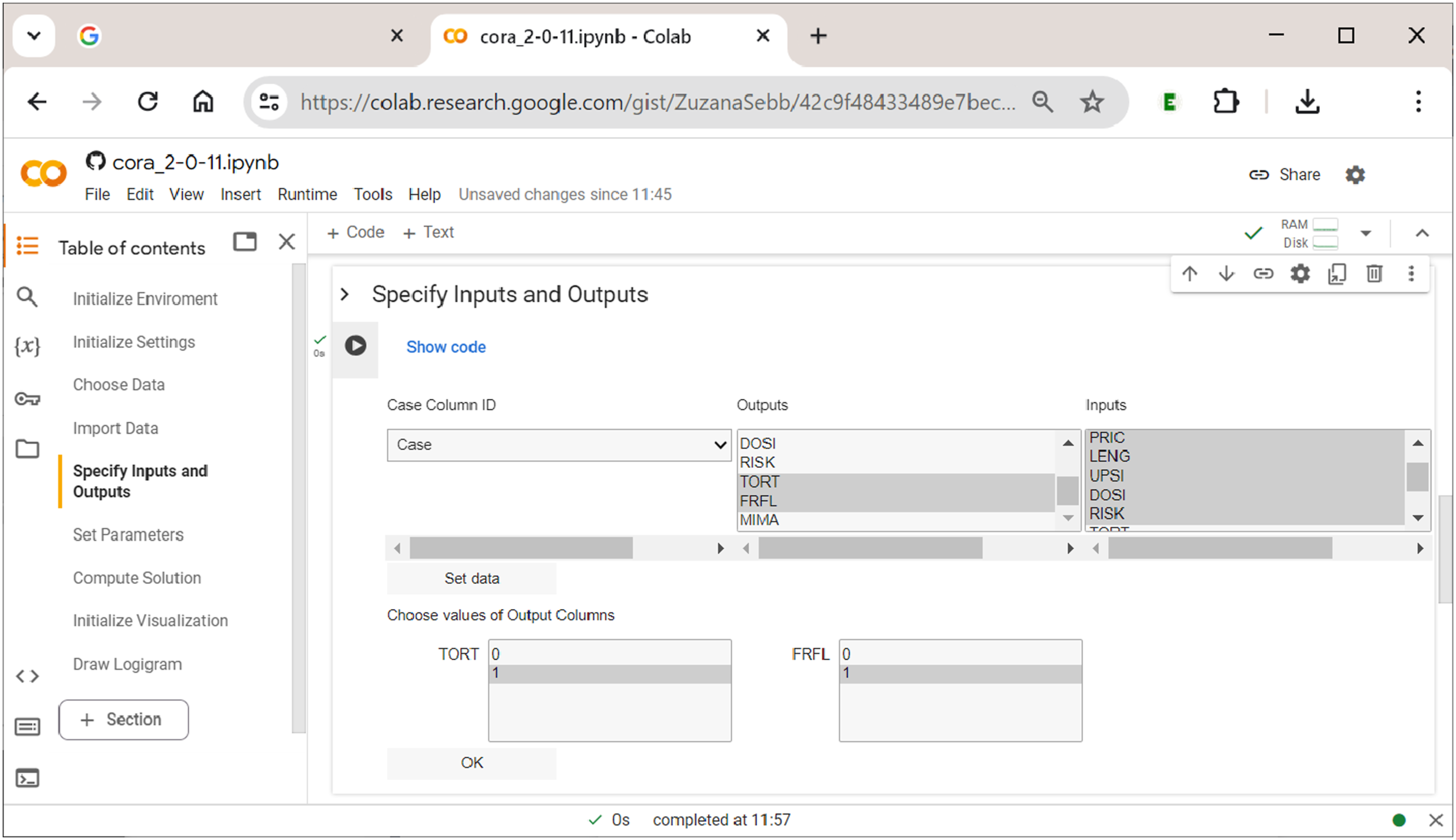
After all required specifications have been provided, a table that shows the re-coded raw data according to the user’s settings is displayed for brief visual cross-checking (not displayed here).
Section 6: Setting the Parameters of the Analysis
In this section, the user sets all parameters of the analysis, chooses the algorithm that will perform the optimization, and pre-processes the data to generate (multi-output) truth tables on which the chosen algorithm will operate. In addition, this section includes the option to use the data-mining feature of CORA. How these options are arranged in Setting the parameters of the analysis.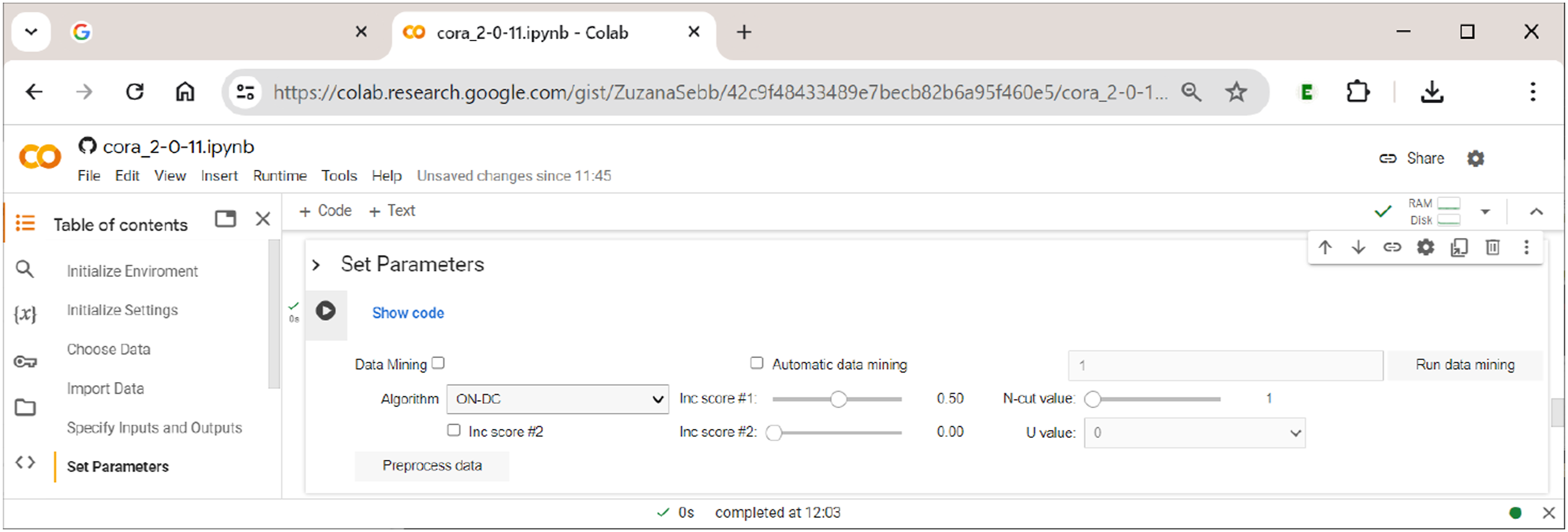
The main analytical parameters for the generation of truth tables largely correspond to those also used in QCA and CNA. They are as follows: • Inc score #1: This score corresponds to what is often called the ”consistency cut-off” in QCA and CNA, and separates positive from negative terms in the truth table (if a term is positive, it means that this term is sufficient for the respective outcome); it should not be below 0.5. Note how this is different from standard practice in QCA, where consistency cut-offs of 0.8 or even higher are often required, which may lead to considerable problems of overfitting (Arel-Bundock, 2022; Baumgartner, 2022). • Inc score #2: This score is a numeric value between 0 and the value of Inc score #1. Terms falling into this range are assigned the value U. In this way, users can quickly test the effect of changing the function value of a term from 1 to 0 or vice versa for certain ranges of inclusion. For example, for inclusion scores between 0.5 (Inc score #2) and 0.6 (Inc score #1), U = 1 has the same effect as setting Inc score #1 to 0.5 without using Inc score #2, whereas U = 0 has the same effect as setting Inc score #1 to 0.6 without using Inc score #2. This simply provides a quicker way to run two separate analyses. • N-cut value: This value is a case frequency cut-off that determines the minimum number of cases below which the term is considered unobserved. • Pre-process data: Pressing this button will generate and print the truth table. Note that it must not be pressed when the intention is to use data-mining, in which case the button ”Run data mining” should be used.
In the current version of
Note that, despite their different approach, both algorithms are completely equivalent and thus produce exactly the same solutions. The fact that both are available in
Configurational data-mining is one of the main distinctive features of CORA. The basic idea behind this approach is that any solution that is found with a given number of inputs, must, ceteris paribus, also always be found in an analysis with only those inputs present in the system. This approach to selecting inputs has first been tested in the context of QCA (Haesebrouck & Thiem, 2018; Lankoski & Thiem, 2020), but CORA is the first CCM to offer an in-built and systematic procedure to analyze all n-tuples of input combinations in a search for feasible tuples of solution-generating inputs. In essence, this feature thus provides a configurational version of Occam’s Razor, which says that explanations that involve fewer variables are, ceteris paribus, to be preferred over explanations that are more complex (Feldman, 2016). For more information on further practical considerations behind this approach, we refer readers to the original presentation of CORA’s methodology in Thiem et al. (2022).
To run data-mining, the user needs to tick the respective checkbox ”Data Mining”, to provide the number of exogenous factors and to indicate the preferred optimization algorithm in the corresponding drop-down menu. Alternatively, by ticking ”Automatic data mining”, the user can let the software search for the minimum size of a factor combination that passes the specified cut-offs (the standard starting value is 1 input). For example, when running (non-automatic) data-mining with tuples of three exogenous factors, The data-mining feature of 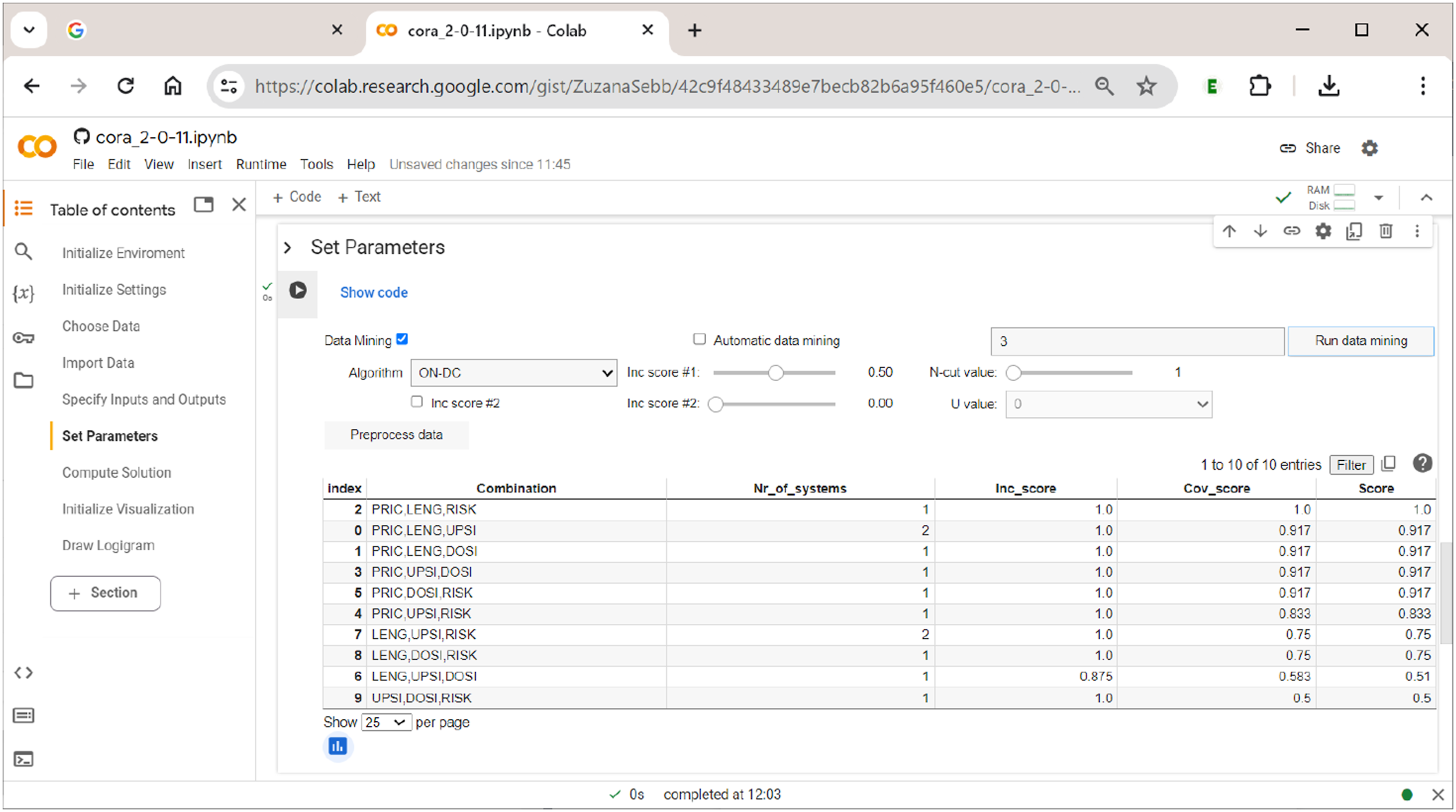
There are ten possible ways to form tuples of three exogenous factors from a set of five exogenous factors. Thus, the table has ten rows (row index counting starts with 0). The respective combinations of factors are given in the column ”Combination”. The column ”Nr_of_systems” shows the number of systems that result under the respective choice of factors. In the column ”Inc_score”, the solution’s inclusion score is given. Its coverage score is shown in the column ”Cov_score”. And finally, the product of the solution’s inclusion and coverage score is listed in the column ”Score”.
In this example, there is one combination of exogenous factors that clearly performs best: the combination of factors PRIC, LENG, and RISK (index #2). Note that this information does not yet provide any information on how these factors and their values are related to each other inside the solution. It just says that, when choosing these factors as inputs, the solution will provide the best fit to the data. In addition, this combination of factors yields only one system, whereas other combinations also yield a single system, yet score lower on data fit, while still others (e.g., PRIC, LENG, and UPSI; index #0) yield two systems and have lower data fit at the same time. Generally speaking, there is an inherent trade-off between these indicators. The larger the size of the combination, the higher the data fit tends to become, but the higher will also be the number of alternative systems fitting the data equally well. It thus makes little practical sense to try and increase data fit by small margins when the price is a significant rise in ambiguity.
After the output table of
For demonstration purposes, however, we continue with all five exogenous factors that have also been part of the analyses of Gross and Garvin (2011) and that we have provided in the section ”Specify Inputs and Outputs” (thus, if data mining is used with the same number of inputs that have been initially provided in the section ”Specify Inputs and Outputs”, there will only be one combination of factors). The corresponding truth table for both outputs TORT and FRFL is shown in Figure 11. A multi-output truth table in 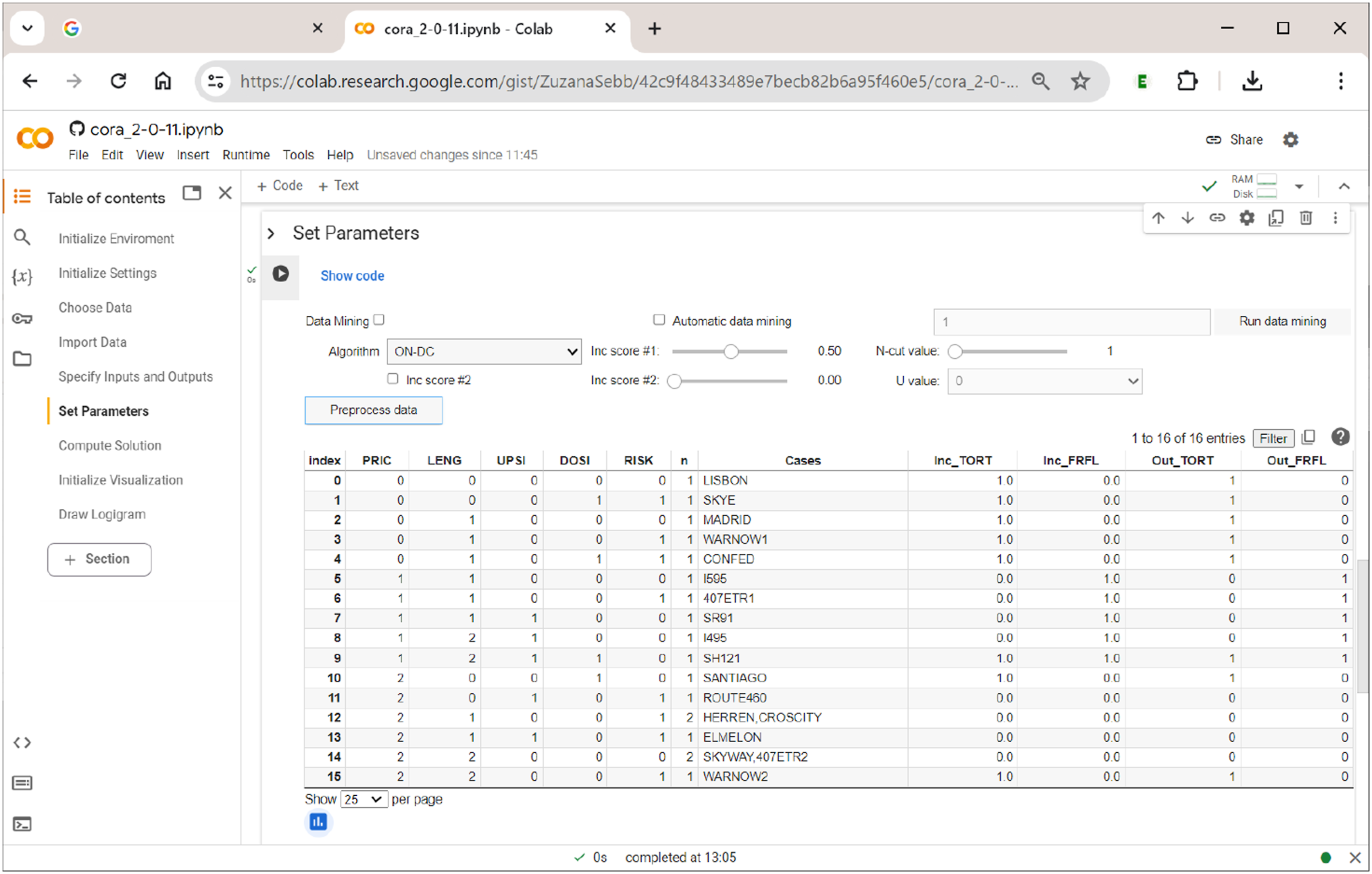
What is unique in CORA with respect to truth tables is that a separate function value is assigned to each output (Out_TORT, Out_FRFL) based on each term’s respective inclusion value (Inc_TORT, Inc_FRFL). With two outputs, there thus exist four different effect constellations: 00 (no outcome present), 10 (only first outcome present), 01 (only second outcome present) and 11 (both outcomes present). Had we also added the authors’ third endogenous factor (MIMA), there would have been eight different effect constellations (000, 001, 010, 100, 110, 101, 011, 111). The complexity of the analysis, and also the demands on the user’s ability to interpret the findings, therefore doubles with each output added. In the case of Gross and Garvin’s data, there is only a single case (Index #9; case SH121) where both outcomes are present. In all other cases, only one is present or none is present.
Section 7: Computing and Interpreting Solutions
In CORA, the solution consists of the set of all irredundant systems (cf. Thiem et al., 2022, p. 8). It is computed in the section ”Compute Solution”. As soon as the ”Run” button of this section is being operated, Computing solutions in 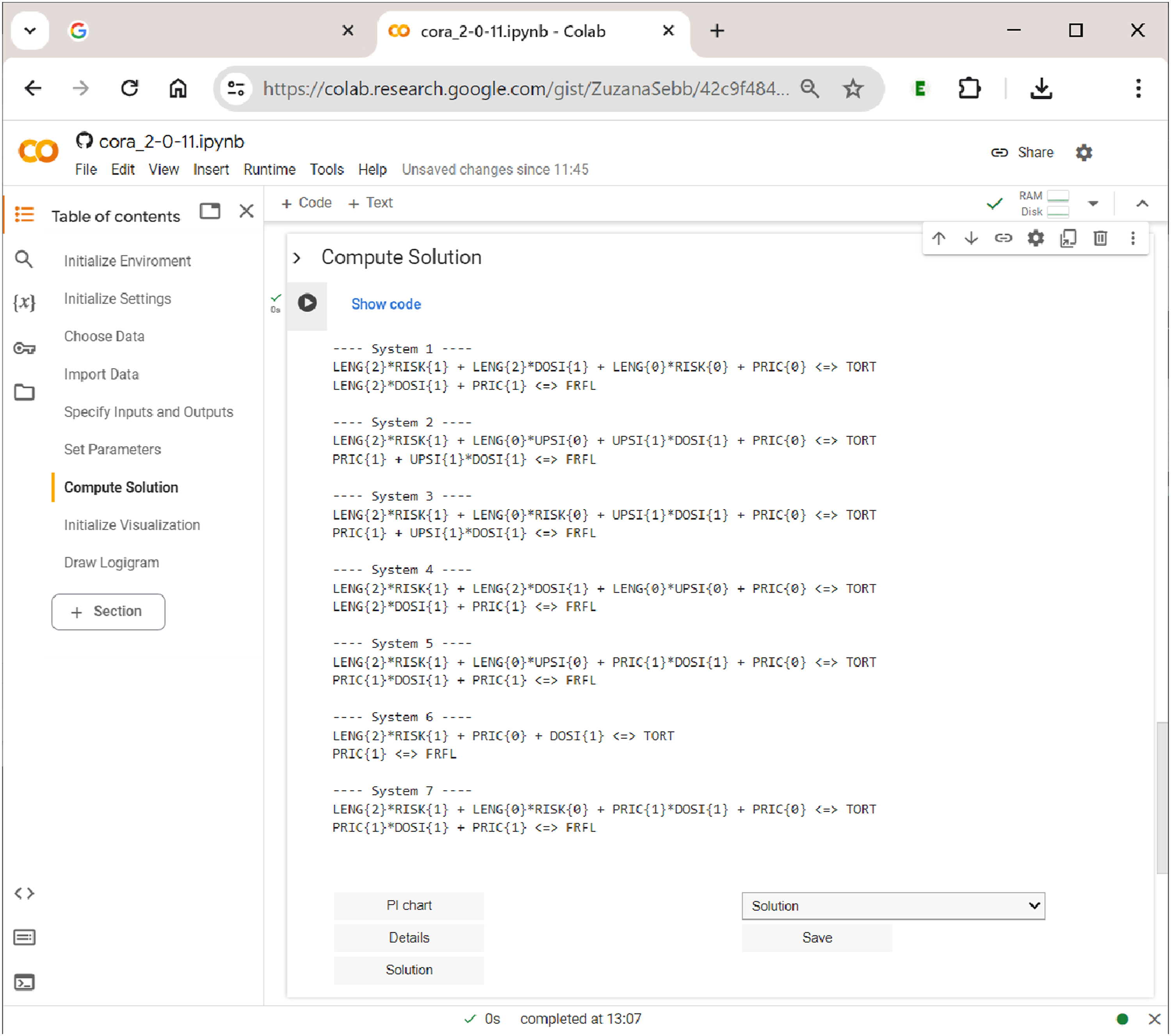
In the case of the analyzed data by Gross and Garvin (2011), the solution consists of seven systems. Analogously to the interpretation of simple models for single outcomes, these systems represent alternative explanations of the same data that fit those data equally well. Sometimes, these systems may be relatively similar to each other, but sometimes, they may also differ fundamentally. A straightforward way to check the degree to which systems are different from each other is to navigate to the dropdown menu above the ”Save” button and choose ”Solution structure”. This will download a Microsoft Excel spreadsheet in which the prime implicants (PIs) are listed across the columns and the outcomes and systems across the rows. A ”1” entry indicates that the PI is a PI for a certain outcome in a certain system. With such an occurrence matrix, users can easily implement their own diagnoses with Excel’s internal filters and functions.
A system returned as part of a solution in CORA must be interpreted in the following way: All PIs that are unique to an outcome represent parts of causal paths to that outcome only, while all PIs that are shared between outcomes represent parts of causal paths to the conjunction of these outcomes only. For instance, in system 1, LENG{2}DOSI{1} is a PI that is shared by TORT and FRFL. That means the former is part of a shared cause of a complex effect that involves both TORT and FRFL. In contrast, for example, PRIC{0} is unique to TORT, while PRIC{1} is unique to FRFL. These PIs thus represent parts of causal paths that lead to the respective outcome in the absence of the other outcome.
However, it is possible that, although the data contain cases showing a conjunction of two or more outcomes, these outcomes need not necessarily form a complex effect with a shared cause. For instance, although case SH121 in Gross and Garvin’s data shows both TORT and FRFL, system 6 provides an explanation in which these two outcomes have nothing to do with each other. Each effect is individually explained by distinct causes. It is one of the major advantages of CORA that the method is able to reveal whether a conjunction of two or more effects is systematically linked to shared causes, or whether this conjunction may merely be a coincidence of two unrelated effects.
Last, but not least, the user has the option to display the PI chart, which is shown in Figure 13. In square brackets, each PI has an index attached which provides the outcomes to which that PI refers. PIs with more than one index number are proper multi-output PIs and thus potential candidates for a shared cause of a complex effect. For example, in Figure 13, three PIs—LENG{2}DOSI{1}, PRIC{1}DOSI{1}, and UPSI{1}DOSI{1}—-are shared between the two outcomes and therefore have the index ” The prime implicant chart in 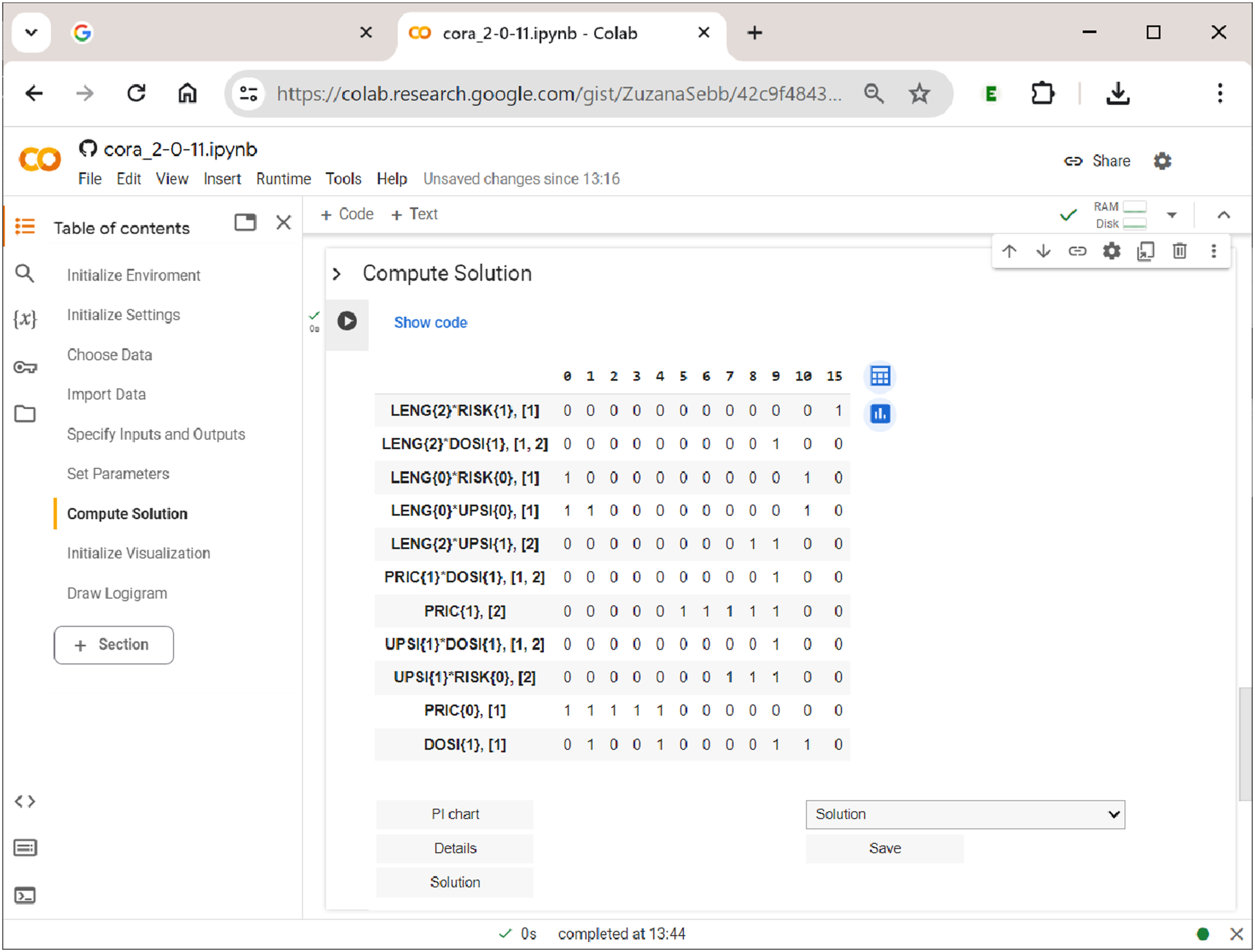
Of interest to the user are also the details of the solution, mainly inclusion and coverage values, both raw and unique. The table of details, which is shown in Figure 14, lists all PIs that have been part of at least one system across the rows, and the different systems across the columns. The first column after the PI column gives the PI’s raw coverage, the second column its inclusion. Below each system, unique coverage values are provided. For PIs that are unique to an outcome, these values are calculated as usual. However, for PIs that have more than one output index, values are calculated with respect to all constellations to which the PI refers. For example, under systems 1 and 4, LENG{2}DOSI{1} is the only shared PI of the complex effect TORT{1}FRFL{1}. For that reason, its unique coverage is 1. The solution details in 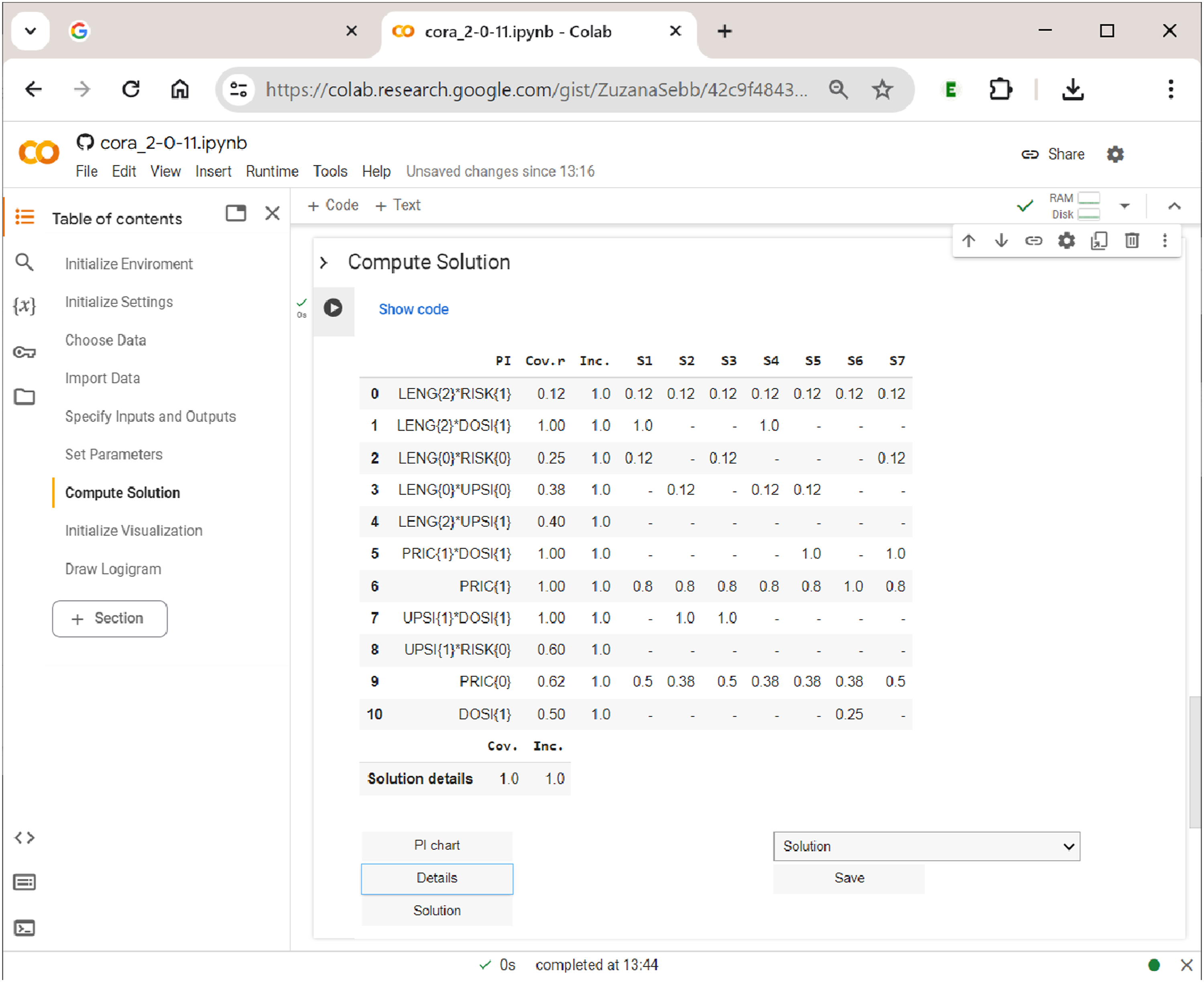
Sections 8–9: Drawing Logigrams
The last part of
Since the
Once the user has opted for the choice of a system from the solution and has picked the desired system, pressing the ”OK” button will generate a plain black-and-white logigram. This can be enhanced with colours for gates. Finally, users can download the respective figure as a png picture file with a specified resolution (default 72 dpi), or as a vector file in svg or pdf format. Figure 15 shows the logigram of the first system (S1) among the seven systems that have resulted from the analysis of Gross and Garvin’s data (cf. Figure 12). Drawing logigrams in 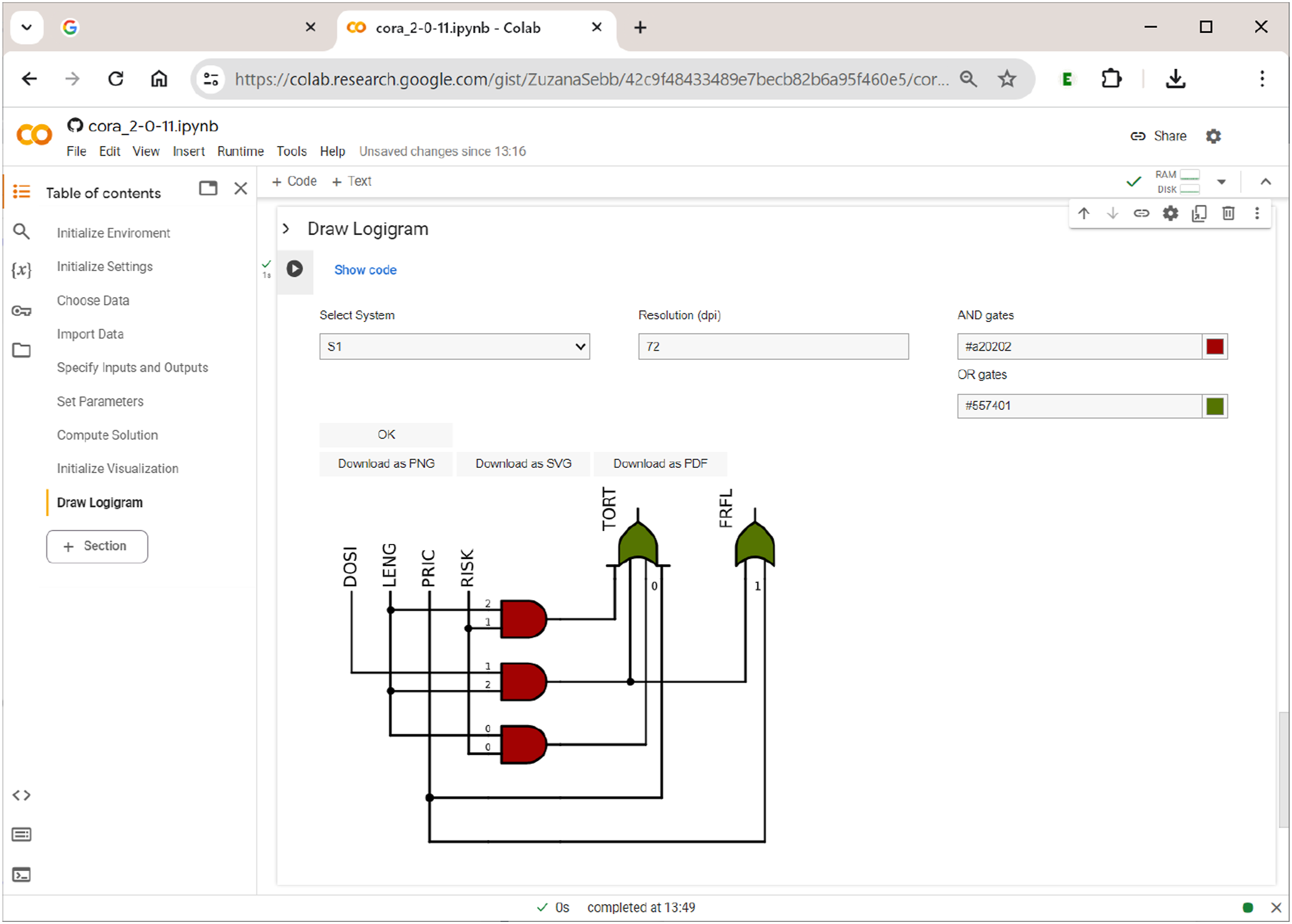
Note that only one system can be rendered as a logigram at a time. If the system to be visualized does not contain conditions or outcomes from multivalent factors, users can choose between case-based notation (e.g., A and a) and prime-based notation (e.g., a and a′).
Conclusions
Modern Configurational Comparative Methods have gained in popularity among social scientists over the last thirty years. Combinational Regularity Analysis (CORA) has recently joined this family of methods. In this article, we have provided a software tutorial for the open-source package
Future versions of
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Swiss National Science Foundation (PP00P1_202676).