
Abstract
In recent years, proponents of configurational comparative methods (CCMs) have advanced various dimensions of robustness as instrumental to model selection. But these robustness considerations have not led to computable robustness measures, and they have typically been applied to the analysis of real-life data with unknown underlying causal structures, rendering it impossible to determine exactly how they influence the correctness of selected models. This article develops a computable criterion of fit-robustness, which quantifies the degree to which a CCM model agrees with other models inferred from the same data under systematically varied threshold settings of fit parameters. Based on two extended series of inverse search trials on data simulated from known causal structures, the article moreover provides a precise assessment of the degree to which fit-robustness scoring is conducive to finding a correct causal model and how it compares to other approaches of model selection.
Keywords
Introduction
Different methods of causal data analysis tend to track different features of causal structures, exploit different markers in empirical data for their inference to causation, or define causation along the lines of different theories of causation. These differences must be taken into account when benchmarking the issued models. This holds notably for model robustness. What it means for a model to be robust depends on what the corresponding method’s aims and purposes are. More concretely, the models of a method aiming, say, to quantify effect sizes on the population level must meet different robustness criteria than the models of a method aiming to capture difference-making relations on the case level. It follows that different criteria are needed for different methods. While some methodological frameworks have long traditions of robustness benchmarking, others do not. A framework of the latter type is the one of configurational comparative methods (CCMs; see, e.g., Baumgartner and Ambühl 2020; Cronqvist and Berg-Schlosser 2009; Ragin 2008; Thiem 2014b), where discussions about robustness have begun only recently. The goal of this article is to contribute to the ongoing development of robustness benchmarks custom-built for the aims and purposes of CCMs.
The most widely employed robustness measures are the ones of causal discovery methods using statistical techniques. Such methods, as regression analysis (e.g., Gelman and Hill 2007) or Bayes-nets methods (e.g., Spirtes, Glymour, and Scheines 2000), rely on probabilistic or counterfactual theories of causation (e.g., Lewis 1973; Suppes 1970), they track causal dependencies between random variables (e.g. “X is a cause of Y”), and, most importantly, their models are built to reflect average or marginal effect sizes or net effects in the whole data. Their models count as robust only if they remain invariant across repeated re-analyses of the data under subsampling, measurement error introduction, or variation of tuning parameters. CCMs, by contrast, rely on regularity theories of causation (e.g., Mackie 1974), they track causal dependencies between specific values of variables (e.g., “X=
Nonetheless, some authors have recently benchmarked CCM models against statistical robustness standards (e.g., Hug 2013; Krogslund, Choi, and Poertner 2015). The results are seemingly devastating for CCMs, as their models typically do not meet these standards to an acceptable degree. But that finding, rather than yielding a meaningful estimate of the robustness of CCM models and demonstrating their unreliability, as Hug (2013) and Krogslund et al. (2015) submit, merely exhibits that a robustness measure rewarding invariance is at cross purposes with CCMs.
A lot of variance in CCM models is completely benign. It simply reflects varying amounts of inferentially exploited difference-making evidence without implying any inconsistent causal conclusions. Two different models are in no disagreement if the causal claims entailed by them stand in a subset relation, that is, if one of them is a submodel of the other. In that case, the submodel merely recovers the data-generating structure less completely than the supermodel. But given the massive fragmentation of data commonly analyzed by CCMs, CCMs cannot normally be expected to uncover data-generating structures in their entirety anyway. Importantly, CCM models only make claims about causal relevance, not about causal irrelevance. If a factor value X=
However, not all variance in CCM models is of the benign kind. For example, it regularly happens that data entail many different models that are not submodels of one another, giving rise to model ambiguities (Baumgartner and Thiem 2017). Criteria are needed that select among such unrelated models. Or, maximizing the two core parameters of model fit, namely, consistency and coverage, tends to induce CCMs to expand resulting models by irrelevant factor values, prompting overfitting and corresponding false positives (see the section Overfitting; Arel-Bundock 2019). Strategies are needed to avoid that pitfall. Hence, there is a need for distinguishing benign from non-benign model variance and, more generally, for complementing existing criteria of model selection by additional constraints. Robustness standards—properly adapted to the purposes of CCMs—are straightforward candidates to fill that bill.
Indeed, in recent years, proponents of CCMs have advanced various dimensions of robustness as instrumental to model selection (e.g., Cooper and Glaesser 2016; Schneider and Wagemann 2012:
This article develops a computable criterion of fit-robustness that is tailor-made for CCMs by measuring the degree to which a model’s causal ascriptions overlap with the causal ascriptions of other models inferred from the same data under systematically varied fit thresholds. More specifically, our operationalization of robustness involves two steps: First, the set of all models
This article is organized as follows. The second section reviews the conceptual preliminaries of our argument. In the third section, we demonstrate the need for complementing existing criteria of model selection by a robustness criterion, whose details are presented in the fourth section. The fifth section benchmarks that criterion under a range of discovery conditions. We conclude in the sixth section. The Online Supplementary Material provides detailed R-scripts that supply an explicit R function operationalizing our robustness scoring and allow for replicating our benchmark tests along with all other calculations of this article.
Preliminaries
We begin by introducing the notation and the relevant concepts used in our ensuing discussion. CCMs study Boolean dependence relations between variables taking on specific values. In the CCM literature, variables are typically referred to as factors. Factors represent categorical properties that partition sets of units of observation (cases) either into two sets, in case of binary properties, or into more than two (but finitely many) sets, in case of multi-value properties. Factors representing binary properties can be crisp-set (
For simplicity of exposition, we will subsequently illustrate our robustness account with examples featuring binary factors only. This allows us to conveniently abbreviate the explicit “Factor
Based on the implication operator, the notions of sufficiency and necessity are defined, which are the two Boolean dependence relations exploited by CCMs: X is sufficient for Y if, and only if (iff),
CNA models can be atomic or complex, representing single-outcome and multi-outcome structures, respectively. An atomic model has the form
Since configurational data
To clarify the causal interpretation of CNA models, consider the following complex exemplar:
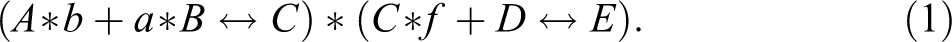
Functionally put, (1) claims that the presence of A in conjunction with the absence of B (i.e., b) as well as a in conjunction with B are two alternative minimally sufficient conditions of C (relative to the chosen consistency threshold) and that
Importantly, CNA models are to be interpreted relative to the data

(2) identifies A and B as alternative direct causes of C and indirect causes of E, moreover C and D are claimed to be alternative direct causes of E. All of this also follows from (1). The causal claims entailed by (2) thus constitute a subset of the claims entailed by (1), meaning that (2) is a submodel of (1). As the submodel relation will be of core relevance for our ensuing argument, we define it in all explicitness here.
Submodel Relation
A CCM model all factor values causally relevant according to all factor values contained in two different disjuncts in all factor values contained in the same conjunct in if
If
Overfitting
Numerous authors (e.g., Braumoeller 2015; Krogslund et al. 2015; Lucas and Szatrowski 2014) have argued that CCMs have a dangerous tendency to incorporate causally irrelevant factors in their models, thereby committing too many false positive errors. Representatives of CCMs (e.g., Baumgartner and Thiem 2020; Rohlfing 2015; Thiem and Baumgartner 2016) have found various flaws and overgeneralizations in these arguments and have shown that CCMs work reliably for data conforming to the high-quality standards imposed by CCMs, in particular, the homogeneity of the unmeasured causal background. 5 Still, the fact remains that CCMs run a serious false positive risk when these quality standards are not met (Arel-Bundock 2019; Baumgartner and Ambühl 2020), in particular, when the data comprise cases incompatible with the data-generating causal structure over the set of measured factors, meaning cases that, subject to that structure, should not exist. Such case incompatibilities can have different sources, for instance, measurement error or confounding. For brevity, we will subsequently often simply say that case incompatibilities are due to noise.
Of course, noise has a negative effect on the output quality of any method, but for CCMs, this effect is especially high when the data have small sample size and the analyst is maximizing the model fit, that is, consistency and coverage. To illustrate this problem, consider the data in Table 1A, which have been simulated from the very simple causal structure in (3) and one added irrelevant factor D.

More specifically, Table 1A is the result of, first, collecting one case instantiating each of the 16 configurations of the factors A, B, C, D, and E compatible with (3) and, second, replacing one case in these clean and complete data by a case that is incompatible with (3). The incompatible case,
Effect of Random Error.
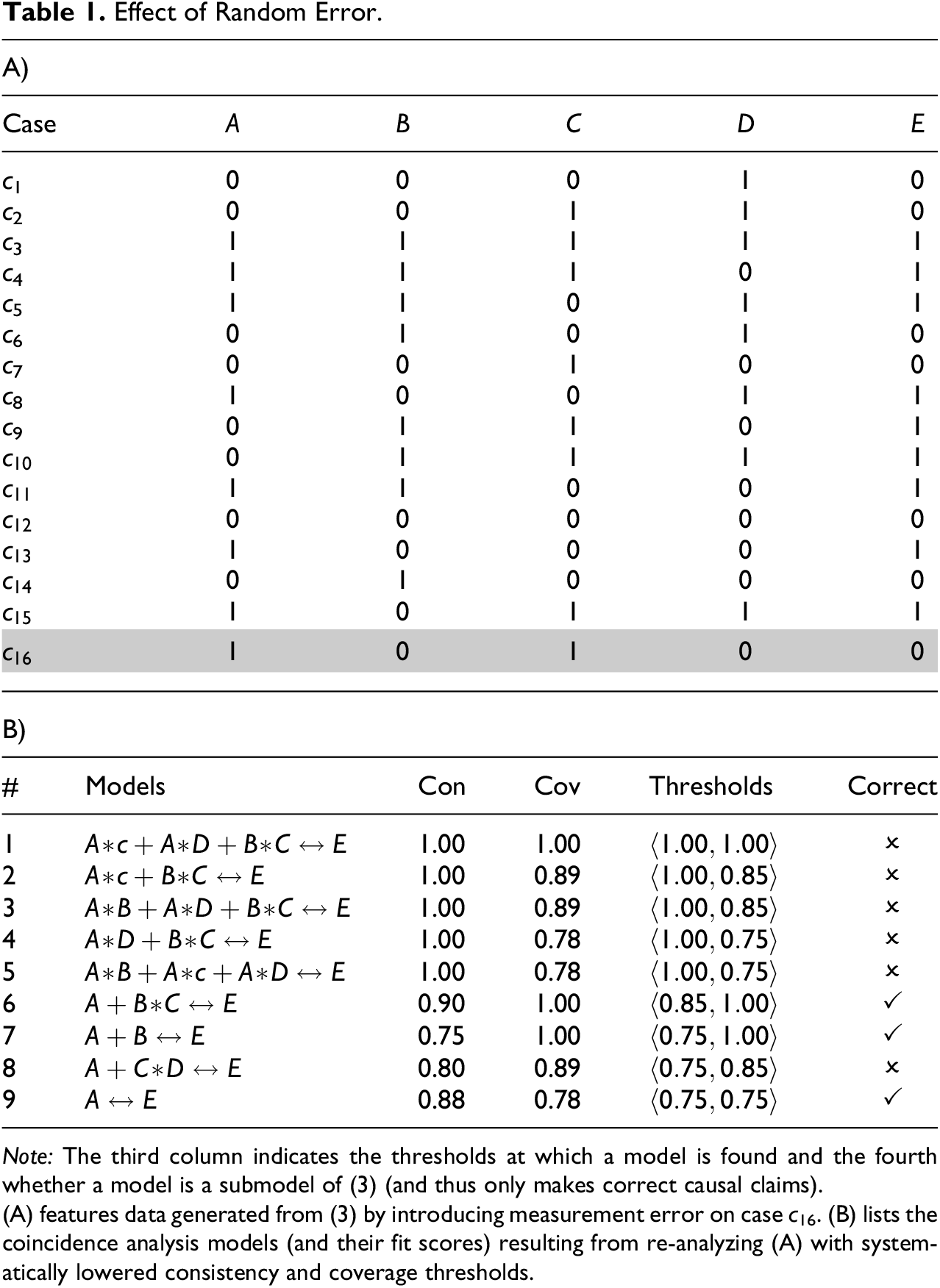
Note: The third column indicates the thresholds at which a model is found and the fourth whether a model is a submodel of (3) (and thus only makes correct causal claims).
(A) features data generated from (3) by introducing measurement error on case c 16. (B) lists the coincidence analysis models (and their fit scores) resulting from re-analyzing (A) with systematically lowered consistency and coverage thresholds.
Case
Although not recovered at
That CCMs fall prey to overfitting in the presence of only one single incompatible case is not some rare idiosyncrasy of Table 1A; rather, it is a commonplace phenomenon in small sample sizes.
7
For CNA, the prevalence of overfitting can be demonstrated using the function
The results are plotted in Figure 1. It can easily be seen that they are damning for small sample sizes. At the base frequency of one case per compatible configuration, a single incompatible case leads to false positives due to overfitting in 38 percent of the trials. An incompatibility share of 12.5 percent, that is, two incompatible cases at
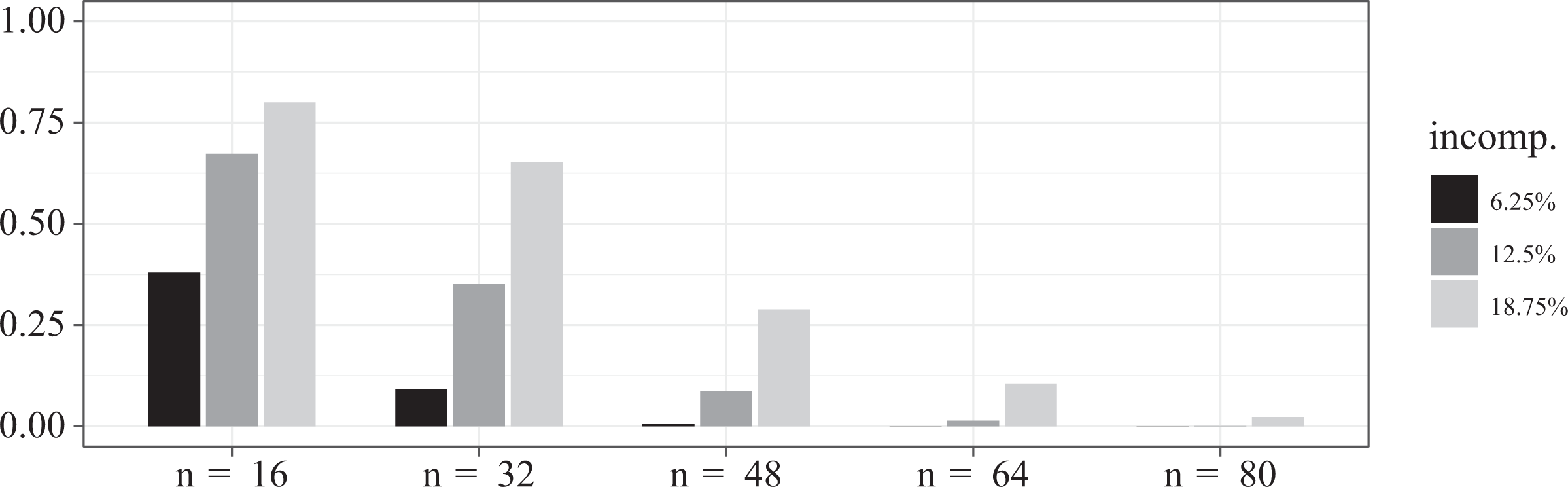
Overfitting ratios when processing data simulated from the target structure (3) with increasing sample sizes and increasing shares of randomly drawn incompatible cases. Each overfitting ratio is a mean over 1,000 executions of a trial.
The obvious conclusion to draw is that when analyzing small-sized noisy data, maximizing consistency and coverage is not a reliable strategy of model selection. This finding conflicts with certain methodological recommendations in the CCM literature. Ragin (2008:46), for instance, suggests that “[i]n general, consistency scores should be as close to 1.0 (perfect consistency) as possible”; or Schneider and Wagemann (2012:128) recommend that consistency thresholds be placed the higher, the lower the number of cases under investigation. However, in actual CCM practice, fit thresholds are often simply set to non-maximal bounds given by conventions, typically some values between 0.85 and 0.75; and in the example of Table 1A, such a conventional threshold placement avoids the overfitting problem. At
Overall, in noisy discovery contexts, CCM model fit (just as model fit in other frameworks) should neither be maximized, to avoid overfitting, nor minimized, to avoid underfitting. Hence, the question arises how to identify threshold settings yielding models that are as revealing as possible about the ground truth without inducing false positives. In simulations, where the data-generating structure is presupposed, that question is easily answerable by re-analyzing the data at varying threshold settings and identifying the setting at which the (known) ground truth is recovered. But, of course, real-life discovery contexts are characterized by the data-generating structure being unknown, which makes it impossible to determine which among all tested threshold settings actually recovers the truth. To alleviate that problem, the next section introduces a criterion of fit-robustness that helps to identify the models that can be trusted among all the models returned by CCMs within the range of acceptable threshold settings.
Robustness
Searching for robust models to avoid over- and underfitting is an approach that comes easily to mind. But, as we have seen in the introduction, we cannot simply draw on statistical robustness measures rewarding model invariance under varying re-analyses of the data. Instead, we propose to understand the robustness of a CCM model in terms of the degree to which its causal attributions are contained in and contain the causal attributions of all the other models obtained from a series of data re-analyses under varying consistency and coverage settings. Rather than rewarding invariance, robustness in that sense rewards those models that are most closely interrelated with the other models from that re-analysis series and it punishes models making idiosyncratic causal attributions.
Before we flesh out that sketch, let us clarify the aims and limitations of our proposal. Robustness testing is a heuristic for model selection in noisy discovery contexts. If there is enough noise, especially if it is patterned or biased, any method will misfire sooner or later. But CCMs, as we have seen in the previous section, are particularly vulnerable through even mild degrees of noise. The purpose of a robustness measure for CCMs must be to reduce that vulnerability, without being expected to erase it altogether or to work equally well in all noise scenarios; it is only one tool for vulnerability reduction among others. In that light, the aim of our proposal shall be to improve the overall model quality in the presence of randomly distributed noise. The robustness measure sketched above can be expected to achieve that purpose because if measurement error is not biased and there is no systematic confounding (and there is not so much noise that CCMs abstain from drawing inferences altogether), the signal stemming from actual causal dependencies will, on average, be stronger in the data than spurious associations due to noise. In consequence, elements of the ground truth will be included in many models obtained at varying threshold settings, whereas spurious factor values will only be included in models inferred at specific consistency and coverage thresholds. That may not hold in biased and patterned noise scenarios. Thus, the next section will put the performance of our approach to the test under both random and non-random noise.
We now render our robustness measure precise on the basis of the submodel relation introduced in the section Preliminaries, which directly mirrors containment relations among causal attributions of CCM models. If two models are related in terms of the submodel relation, at most one of them makes causal attributions not made by the other one, such that the model with fewer attributions remains silent about the other model’s additional attributions. By contrast, if two models are not related by the submodel relation, they both entail some causal attributions not entailed by the other model. That is, the more sub- and supermodels a model
This approach requires first producing a set
Fit-robustness (FR)
Given a set of models
Before we illustrate (FR)-based robustness scoring with a concrete example, two features of (FR) must be emphasized. First, (FR) provides a notion of robustness that is relative to a re-analysis type
Second, (FR) strikes a balance between overly complex and overly simple models. To show this, we use the number of exogenous factor values in a model as measure of its complexity. If
Let us now look at a concrete example of (FR)-based robustness scoring. To this end, we revisit the nine models inferred from Table 1A by performing the re-analysis type
Relisting of the Models in Table 1B.
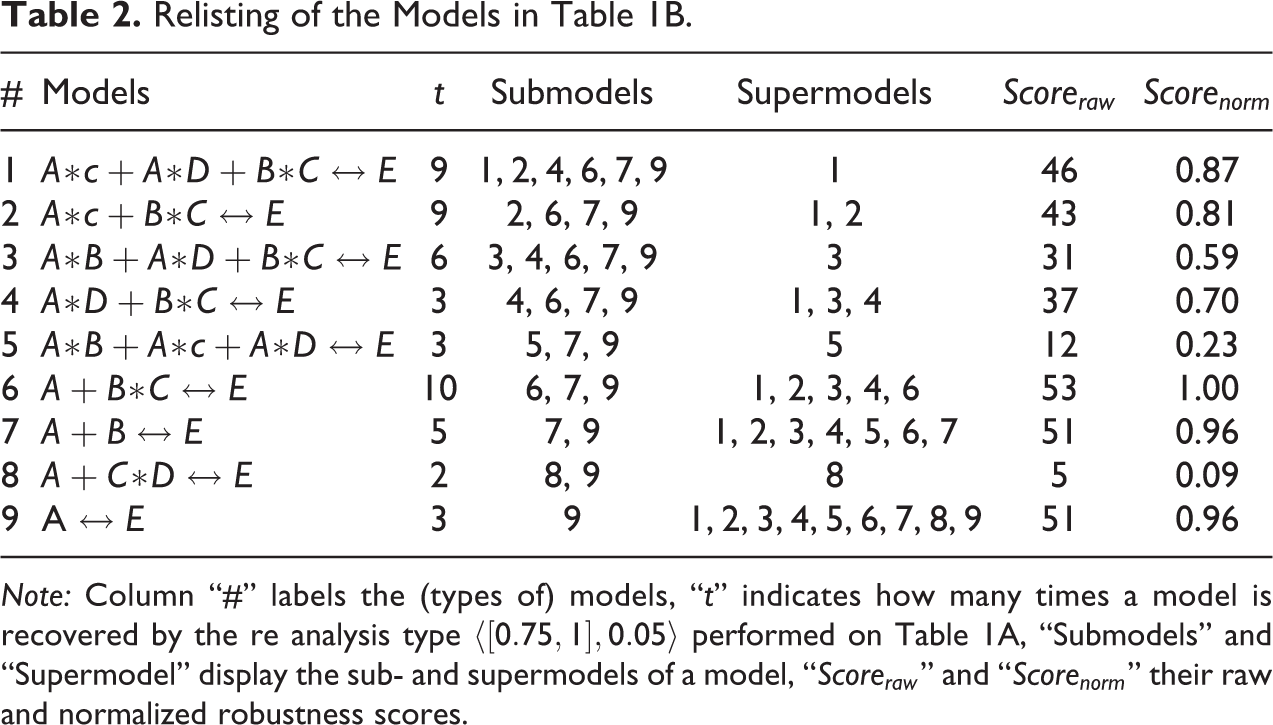
Note: Column “#” labels the (types of) models, “t” indicates how many times a model is recovered by the re analysis type
The columns “Submodels” and “Supermodels” of Table 2 exhibit which models in
To see how these scores are calculated, consider model 4. It has model 6 as a submodel, of which there are 10 instances in
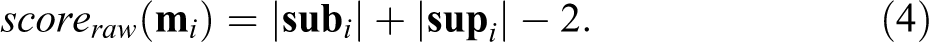
It is evident that, depending on the data and the performed re-analysis type,
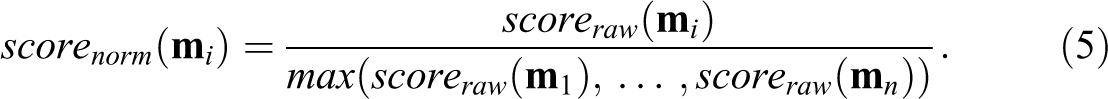
The overall fit-robustness scoring for our example has various notable features. First, model 1, which has the highest consistency and coverage (cf. Table 1B), does not have the highest (FR) score, meaning that (FR) scores do not align with fit. In other words, (FR) is an additional criterion of model selection over and above consistency and coverage. Second, the (FR) score is independent of model complexity. There are complex and simple models with high as well as with low (FR) scores, which corroborates that (FR) has no built-in preference for more or less complex/informative models. Third, the frequency at which a model is returned, while important, is not the sole determinant of the (FR) score and may not even be the decisive one. In the re-analysis series of our example, model 6 is the most frequent one, being returned in 10 of the 36 analyses, and also has the highest (FR) score. But it is clear that frequency alone is not driving the results: The second most frequent models, 1 and 2, are both returned nine times and lose in (FR) score to model 7, returned five times, and to model 9, returned only three times. Fourth, all three models with highest fit-robustness—6, 7, and 9—avoid causal fallacies, as all their causal claims are correct according to the ground truth (3). That means true causal dependencies receive higher (FR) scores than spurious ones. What is more, the highest scoring model, model 6, exactly corresponds to the causal structure (3) used to simulate the data in Table 1A. Thus, (FR) succeeds in selecting the ground truth among all generated models, thereby avoiding both under- and overfitting.
Plainly, though, this example was purposefully selected to introduce and illustrate (FR) on a simple test case. What is needed next is an assessment of whether (FR) achieves its intended purpose when applied to examples not selected for introductory purposes and simplicity, that is, to randomly drawn examples. This is the topic of the next section.
Benchmarking
We extensively benchmarked (FR)-based robustness scoring to determine, first, whether it indeed improves the overall quality of CCM models in discovery contexts featuring random noise and, second, how it fares in contexts with non-random noise. This section reports our results. We first discuss the general setup of our tests and then detail the specifics and results of the tests with random and non-random noise, respectively. We executed all tests both on crisp-set and fuzzy-set data. For brevity, our subsequent discussion focuses on the crisp-set tests, which, overall, turned out to be less favorable to (FR)-based robustness scoring. The results of the fuzzy-set tests are presented in the Online Appendix. The Online Supplementary Material moreover supplies separate replication scripts for all tests.
General Test Setup
To determine whether selecting models based on high (FR) scores improves or diminishes the overall model quality, we contrast it with standard model selection approaches. More specifically, we process data by means of CNA and select sets
To determine the quality of the selected models in
We test the model sets
It is a frequent phenomenon in all methodological frameworks that empirical data underdetermine their own causal modeling to the effect that multiple models account for them equally well (e.g., Baumgartner and Thiem 2017; Eberhardt 2013; Spirtes et al. 2000:59-72). In cases of such ambiguities, CCMs output all data-fitting models (and leave the disambiguation up to the analyst). It follows that, if a CCM issues multiple models, it is not thereby implying that all of these models correspond to the ground truth but only that (at least) one of them does, and that—based on the available evidence—it is undetermined which one exactly. The same holds if one of FRscore, MaxFit, Conv8.0, or Conv0.75 selects multiple models, that is, if
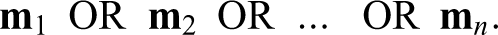
A disjunction is true iff at least one disjunct is true; and conversely, it is false iff all disjuncts are false. Hence, in order for a set of models
In light of that specification of fallacy-freeness, our second benchmark criterion is straightforwardly clarified. It focuses on non-empty sets
Finally, our third benchmark criterion addresses the fact that the correctness of a model does not entail anything about its informativeness. In other words, of two different models that are both submodels of the ground truth
Random Noise
In a first series of tests, we compare the performance of FRscore, MaxFit, Conv0.8, and Conv0.75 on the above benchmarks when the analyzed data feature randomly distributed noise, meaning randomly drawn cases incompatible with the ground truth. That performance depends on various parameters, such as the complexity of the ground truth, the sample size, or the noise ratio. To vary these parameters (to some degree), we set up 12 different test types simulating data
The 12 Test Types of the Random Noise Series.

One particular test trial, that is, one instance of a test type, consists in a data set simulated according to the parameters of that type being sequentially processed by FRscore, MaxFit, Conv0.8, and Conv0.75. The resulting four sets of selected models are then benchmarked for fallacy-freeness, correctness, and completeness. To get a statistically reliable performance assessment, we run 1,000 trials of each test type, yielding a total of
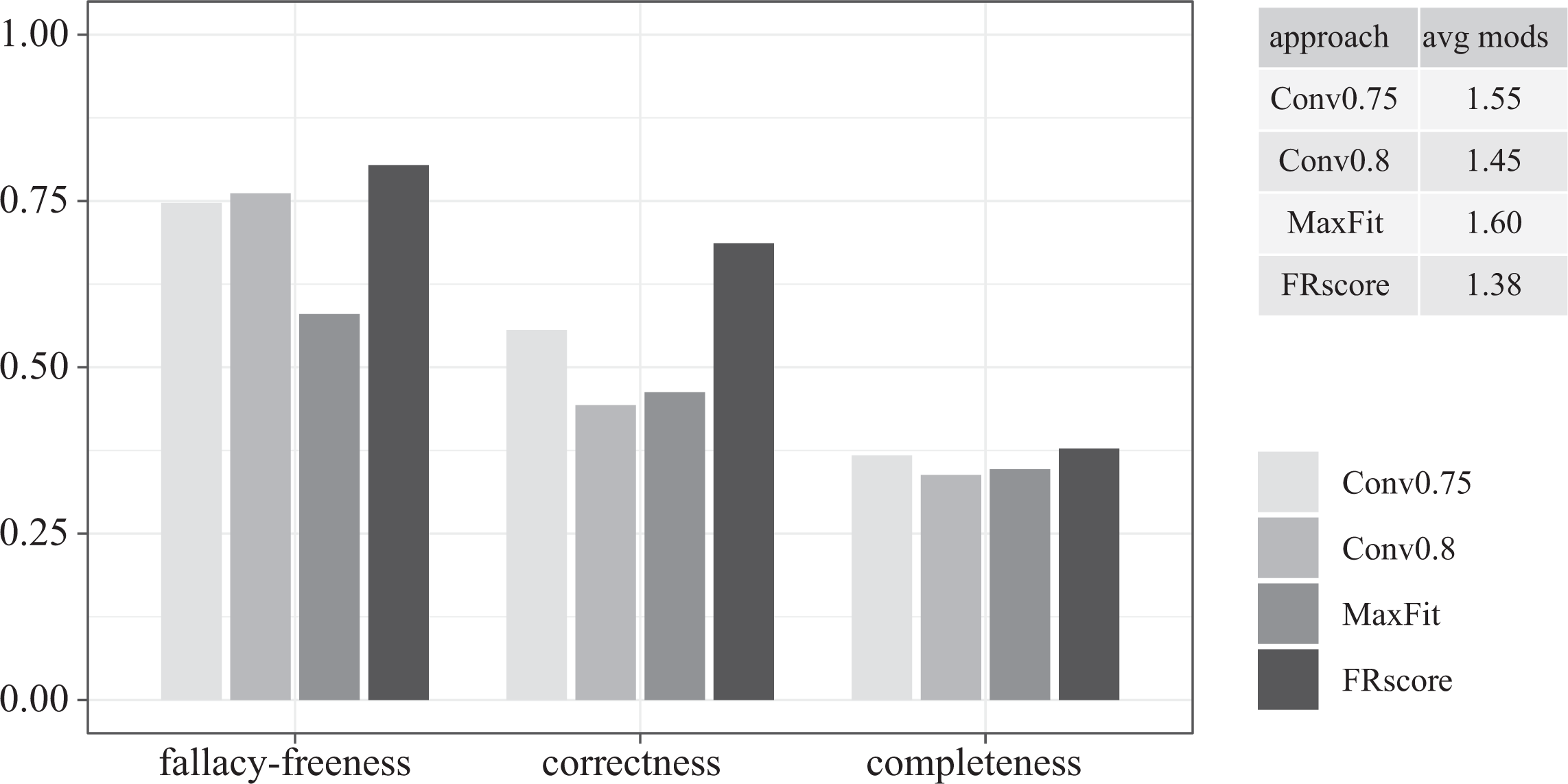
Benchmark scores averaged over all 12,000 trials of the random-noise test series. The top-right table provides the average number of models per trial selected by an approach.
These averaged results show that, across all different
To set these results into proper perspective, the three bar charts in Figure 3 break them down by the parameters varied in our 12 test types. The first chart shows that FRscore scores highest on correctness at all noise ratios—by a particularly large margin in high noise scenarios. While Conv0.75 and Conv0.8 reach decent scores on fallacy-freeness even in the tests with 25 percent incompatible cases, they only find a correct model in, respectively, 20 percent and 12 percent of the trials, meaning that they mostly issue no model at all, whereas FRscore still recovers a correct model in 40 percent of the trials. At the same time, the most cautious approach, Conv0.8, which typically abstains from drawing any causal inferences when processing the most noisy data, avoids causal fallacies in 73 percent of the trials, while FRscore only reaches 69 percent on fallacy-freeness. That is, in the tests with 25 percent incompatible cases, FRscore comes with a slightly higher false positive risk than Conv0.8, which, however, is counterbalanced by a more than three times higher prospect of actually being rewarded by the recovery of a correct model. While Conv0.8 has an advantage on completeness in the tests with only 5 percent noise, the models selected by FRscore are the most complete ones in all other tests.
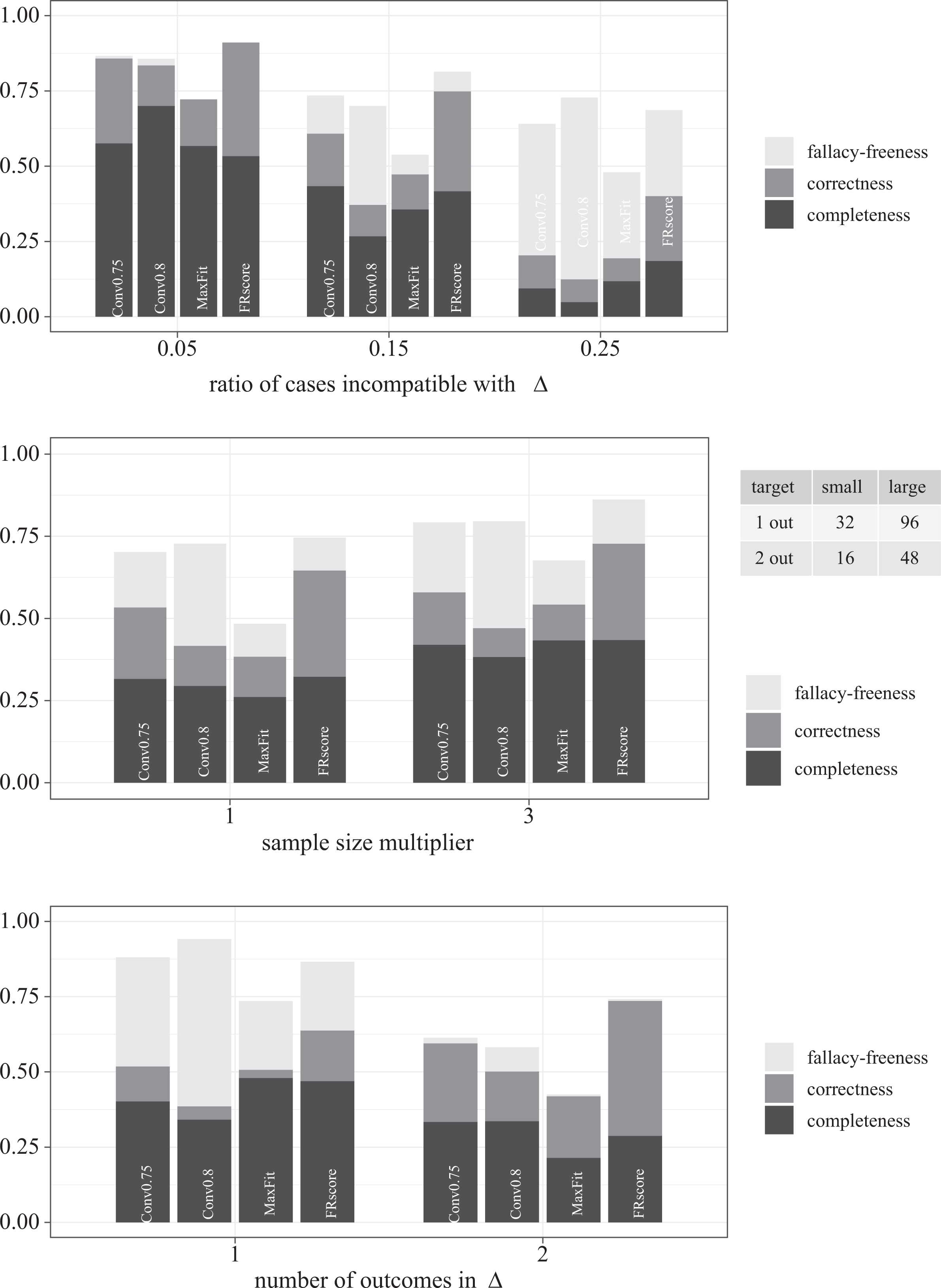
Benchmark scores broken down by the ratio of cases incompatible with
The second chart in Figure 3 shows a similar edge of FRscore over the other approaches as regard to correctness in all sample sizes. As is to be expected, all benchmark scores are better in the larger sample sizes. MaxFit is by far the most unreliable approach, in particular, in small-sized data: While Conv0.75, Conv0.8, and FRscore avoid causal fallacies in over 70 percent of the trials, MaxFit misfires in half of the trials. Finally, the third chart in Figure 3 plots the benchmarks against the complexity of
Non-random Noise
Of course, cases incompatible with the data-generating structure may not be equally probable. Certain types of measurement error may more frequently occur than others or unmeasured variation of latent causes may confound the data with a bias. In order to also assess the performance of FRscore in non-random noise scenarios, we compare it with MaxFit, Conv0.8, and Conv0.75 in a second series of three additional classes of tests. Tests in class I are set up analogously to our previous tests, that is, ground truths
The Seven Test Types of the Non-random Noise Series.

Tests of classes II and III are set up differently. They do not simulate noise due to measurement error but noise induced by an uncontrolled variation in latent causes. Instead of replacing cases in ideal data with incompatible ones, we now draw ground truths and generate ideal data from which we then eliminate columns corresponding to causally relevant factors. Tests in classes II and III differ in the severity of the resulting data confounding. In class II, ground truths are built from the factors in
As before, we run 1,000 trials of each test type. The bar charts in Figure 4 plot the benchmark scores averaged over all trials in each test class. The main finding is that FRscore only has a clear edge over the other selection approaches in the tests of class I. While the systematicity of the measurement error drags down the overall performance of CNA significantly (as it would for any method), it still holds that FRscore selects a correct model in 50 percent of the trials, which is about twice as much as the other approaches. Moreover, its models are most complete—although at a low level of 15 percent—and it likewise avoids causal fallacies most frequently (54 percent). But the low scores of all approaches on the fallacy-freeness benchmark exhibit that systematic measurement error is not reliably detected by CNA, which, as a result, misfires where it should abstain from drawing any causal inference.
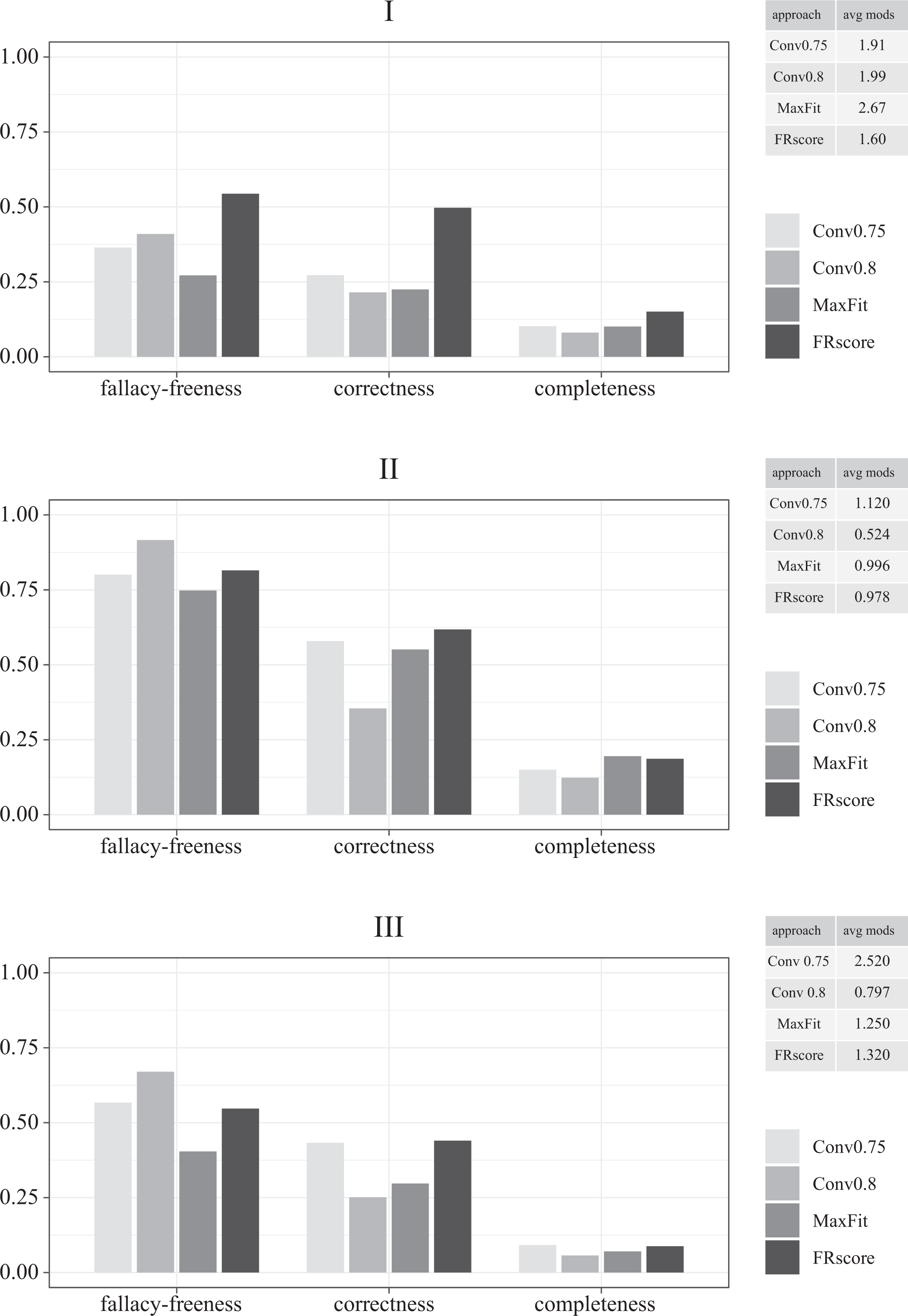
Benchmark scores averaged over all trials in classes I (top), II (middle), and III (bottom) of the non-random-noise series.
This changes in the tests of class II. Conv0.8 reliably detects noise induced by a variation of latent causes and avoids causal fallacies in 92 percent of the trials—mostly by abstaining from drawing an inference. Although beaten by Conv0.8 on fallacy-freeness, FRscore (62 percent) scores better than the other approaches on correctness. When it comes to completeness, MaxFit scores highest (20 percent). The results in the tests of class III are similar, albeit at a significantly lower level. When a common cause of two observed factors is unmeasured, Conv0.8 avoids fallacies in 67 percent of the trials. But also in these tests, FRscore scores highest on correctness (44 percent). While Conv0.75 (43 percent) recovers almost as many correct models as FRscore, it outputs nearly twice as many models per trial. Finally, there is a tie between Conv0.75 and FRscore on the completeness benchmark, both recovering 9 percent of the ground truth, on average. The Online Appendix provides additional plots breaking down those average scores by the varied parameters.
Overall, while FRscore performs best on all benchmarks in the tests of class I, it only scores higher than the other selection approaches on the correctness benchmark in classes II and III. If there are varying latent causes, there is a certain danger that FRscore is not cautious enough and produces false positives that could be avoided by a more cautious selection approach as Conv0.8.
Conclusion
This article has shown that maximizing consistency and coverage thresholds in configurational causal modeling is a highly unreliable practice, even in the presence of only mild degrees of noise. Maximizing model fit induces CCMs to overfit at unacceptably high rates, which various critics of CCMs have justifiably pointed out. The non-maximal threshold settings that have evolved by convention over the years alleviate the overfitting danger considerably—however, at the price of recovering data-generating structures less completely than would be possible based on the available evidence (i.e., underfitting) or of abstaining from drawing causal inferences altogether. Overall, there is a clear need for complementing standard criteria of model fit by further criteria of model selection.
To this end, we developed a criterion of fit-robustness which measures the degree to which a model overlaps in its causal ascriptions with other models inferred from re-analyzing data at systematically varied consistency and coverage thresholds. The more overlap, the higher the (FR) score. We argued that, contrary to robustness measures customary in statistical methods, which reward model invariance, (FR) does justice to the fact that CCMs are expressly built to mirror cross-case variation. (FR) allows for ample variation among output models, as long as they are sub- or supermodels of one another and, hence, do not make idiosyncratic causal ascriptions.
Contrary to recent robustness considerations in the methodological literature on CCMs, (FR) is straightforwardly computable based on the submodel relation, and we implemented it as an explicit R function. We extensively benchmarked model selection based on (FR) in two test series, one with random and one with non-random noise, comparing it to standard approaches of model selection. If noise is randomly distributed, (FR) scoring reduces the false positive risk by 5 to 22 percentage points, depending on the alternative approach it is contrasted with, and it increases the chances that a correct model—which is as complete about the ground truth as possible—is actually returned by 13 to 25 points. To top it off, this maximization of correctness coupled with a minimization of the false positive risk is achieved while only issuing 1.38 models per trial, which amounts to the lowest ambiguity ratio of all selection approaches. Hence, if there is reason to assume that noise is randomly distributed, selecting CCM models based on the measure of fit-robustness developed in this article is unequivocally recommendable.
By contrast, in discovery contexts featuring non-randomly distributed noise, for example, induced by systematic measurement error or confounding, the overall performance of CCMs is so severely hampered that using a standard selection approach, which cautiously abstains from drawing any causal inferences if noise ratios are too high, might be the safer bet. But even in non-random noise scenarios, analysts willing to take a risk are well advised to select models based on the robustness measure developed in this article because, although it does not minimize the false positive risk, it still maximizes the chances of actually finding a correct model.
Supplemental Material
Supplemental Material, sj-zip-1-smr-10.1177_0049124120986200 - Robustness and Model Selection in Configurational Causal Modeling
Supplemental Material, sj-zip-1-smr-10.1177_0049124120986200 for Robustness and Model Selection in Configurational Causal Modeling by Veli-Pekka Parkkinen and Michael Baumgartner in Sociological Methods & Research
Footnotes
Acknowledgments
The authors would like to thank the audience at CLMPTS 2019 in Prague, where an early version of this article was presented, as well as two anonymous referees for their helpful comments and suggestions. They also wish to thank the Toppforsk program of the University of Bergen and the Trond Mohn Foundation for financial support.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors received funding from the Trond Mohn Foundation, grant ID 811866.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.