
Abstract
Purpose:
Patients may seek online information to better understand medical imaging procedures. The purpose of this study was to assess the accuracy of information provided by 2 popular artificial intelligence (AI) chatbots pertaining to common imaging scenarios’ risks, benefits, and alternatives.
Methods:
Fourteen imaging-related scenarios pertaining to computed tomography (CT) or magnetic resonance imaging (MRI) were used. Factors including the use of intravenous contrast, the presence of renal disease, and whether the patient was pregnant were included in the analysis. For each scenario, 3 prompts for outlining the (1) risks, (2) benefits, and (3) alternative imaging choices or potential implications of not using contrast were inputted into ChatGPT and Bard. A grading rubric and a 5-point Likert scale was used by 2 independent reviewers to grade responses. Prompt variability and chatbot context dependency were also assessed.
Results:
ChatGPT’s performance was superior to Bard’s in accurately responding to prompts per Likert grading (4.36 ± 0.63 vs 3.25 ± 1.03 seconds, P < .0001). There was substantial agreement between independent reviewer grading for ChatGPT (κ = 0.621) and Bard (κ = 0.684). Response text length was not statistically different between ChatGPT and Bard (2087 ± 256 characters vs 2162 ± 369 characters, P = .24). Response time was longer for ChatGPT (34 ± 2 vs 8 ± 1 seconds, P < .0001).
Conclusions:
ChatGPT performed superior to Bard at outlining risks, benefits, and alternatives to common imaging scenarios. Generally, context dependency and prompt variability did not change chatbot response content. Due to the lack of detailed scientific reasoning and inability to provide patient-specific information, both AI chatbots have limitations as a patient information resource.
Introduction
Understanding the risks and benefits of medical imaging is an important component of informed consent. Similarly, informed consent in imaging is particularly relevant in situations where intravenous iodinated or gadolinium-based contrast is used, for example in patients with chronic renal disease or patients who are pregnant.1,2 Additionally, patients and physicians are often concerned about ionizing radiation exposure, especially for pregnant and pediatric patients.3-5
The widespread adoption of computed tomography (CT) has raised concerns about an increased incidence of radiation exposure-related cancers. 5 Additionally the risk of allergic reaction to iodinated contrast, and the much debated entity of contrast-induced nephropathy, are important to consider when weighing the risks and benefits of performing a contrast-enhanced CT.6-8 Magnetic resonance imaging (MRI) does not expose patients to ionizing radiation, but the level of risk associated with gadolinium-based contrast agent deposition remains topical. 9 The association of gadolinium-based contrast agents with nephrogenic systemic fibrosis is likely not as strong as once suggested, especially using more modern and stable molecular structures such as macrocyclic ionic agents. 10 The clinical impact of gadolinium deposition in the brain remains unestablished. 11 The decision to administer gadolinium, and gadolinium agent type, should be a consideration when imaging patients on dialysis, with acute kidney injury, or a low estimated glomerular filtration rate (eGFR, <30 mL/min/1.73 m2) for which the American College of Radiology (ACR) Group I agents are absolutely contraindicated.9,12-16
With the advent of artificial intelligence (AI) chatbots, powered by large language models (LLMs), it may be possible for patients and healthcare professionals to use these resources to educate themselves of the risks and benefits of different imaging techniques. Recently released, ChatGPT by OpenAI and Bard by Google, are currently, 2 of the most popular AI chatbots available for public. These chatbots function by offering a simple user interface where users can type in prompts and receive responses from the chatbot in a conversational fashion. The underlying large language model is a form of artificial intelligence trained on an extremely large corpus of text-based data including books, forums, news articles, and other writing on the internet. The purpose of this study was to assess the accuracy of information provided by 2 popular artificial intelligence (AI) chatbots pertaining to common clinical imaging scenarios’ risks, benefits, and alternatives.
Methods
Chatbot Prompts
Research ethics board approval was not sought as no human or animal subjects were included in this study. The following clinical scenarios were queried in this study: (1) administration of CT iodinated intravenous contrast in the setting of normal renal function, (2) CT intravenous contrast with chronic renal disease (eGFR <30 mL/min/1.73 m2, (3) CT intravenous contrast in a pregnant patient, (4) CT pulmonary angiography in a pregnant patient, (5) CT pulmonary angiography in a non-pregnant patient, (6) CT abdomen/pelvis exam in a pregnant patient to assess for acute appendicitis, (7) CT abdomen/pelvis exam in a non-pregnant patient to assess for acute appendicitis, (8) MRI gadolinium-based intravenous contrast with chronic renal disease (eGFR <30 mL/min/1.73 m2, (9) MRI gadolinium-based intravenous contrast with normal renal function, (10) MRI gadolinium-based intravenous contrast in a pregnant patient, (11) MRI brain in a pregnant patient, (12) MRI brain in a non-pregnant patient, (13) MRI abdomen/pelvis in a pregnant patient to assess for acute appendicitis, and (14) MRI abdomen/pelvis in a non-pregnant patient to assess for acute appendicitis. These scenarios were selected as they represent common clinical/imaging scenarios for which the potential risks and benefits may be unknown to patients.
For each clinical scenario, 3 AI chatbot prompts were used as follows (with the example scenario of a CT pulmonary angiography in a pregnant patient):
1. Please describe the potential risks of CT pulmonary angiography in a pregnant patient.
2. Please describe the potential benefits of CT pulmonary angiography in a pregnant patient.
3. Please describe alternatives to CT pulmonary angiography in a pregnant patient.
Note that for scenarios pertaining specifically to contrast use (and not a type of imaging), prompt 3 as outlined above was replaced with a prompt in the format “Please describe potential implications of not using intravenous iodinated CT contrast in a patient with an eGFR less than 30.” A complete list of the clinical scenarios, prompts, AI chatbot responses, and average reviewer grading are provided in Supplemental Table 1. Each AI chatbot was reset before entering the next prompt. Response length in characters and response time in seconds were recorded. Response time was quantified by measuring the time interval between the prompt being sent and the final word of the AI chatbot’s response, using a digital stopwatch. Data was collected in June 2023. ChatGPT-4 and the most up-to-date version of Bard at the time were used.
Expert Evaluation
An expert consensus grading rubric outlining the key points that should be raised were determined a priori by 2 independent staff radiologists at a tertiary care centre (N.L., C.V.P.; staff radiologists with 2 and 6 years of experience, respectively) and were used as a reference during the grading process. This grading rubric is available in Supplemental Table 2. The AI chatbot responses were anonymized prior to distribution to 2 independent reviewers (J.Y., S.C.; third- and fourth-year radiology residents, respectively). A response that mentioned a single potentially harmful claim, but was otherwise perfect, would receive a score of 1. The following 5-point Likert scale was used:
1. Very poor (incorrect and potentially harmful)
2. Poor (significant omissions or incorrect claims)
3. Moderate (satisfactory with some questionable or minor incorrect statements)
4. Good (minimal or inconsequential errors)
5. Excellent (complete and no errors/false claims)
Prompt Variability and Context Dependency Analyses
Two subgroup analyses were conducted. First, a prompt variability analysis was conducted. Four imaging scenarios mapping to a total of 12 prompts were selected: (1) CT intravenous contrast with chronic renal disease (eGFR < 30), (2) CT pulmonary angiography exam in a pregnant patient, (3) MRI contrast (gadolinium) in a pregnant patient, and (4) MRI abdomen/pelvis in a non-pregnant patient to assess for acute appendicitis. For each of the original 12 prompts, 3 additional prompts were created and inputted into the AI chatbots. An online AI paraphrasing and rewording tool was used to create a new prompt of casual or neutral tone of voice. 17 The second additional prompt was manually written to mimic a patient asking the chatbot a question. Lastly, a third prompt was written to mimic a physician requesting information by adding the phrase: “I am a physician and would appreciate any scholarly sources, citations, or references to clinical guidelines” to the end of the original prompt. These prompts, LLM responses, and grades are provided in Supplemental Table 3.
Second, a context dependency analysis was conducted. The same 42 prompts were used for each of ChatGPT and Bard, but instead of resetting the chatbot after each response, prompts were consecutively inputted. For both the prompt variability and context dependency analyses, there were 2 independent reviewers (J.Y., S.C.; third- and fourth-year radiology residents respectively), and the final score constituted an average of the 2 grades.
Statistical Analysis
Means were compared using paired t-tests. To compare proportions, chi-squared tests were performed. Cohen’s kappa coefficient was used to calculate inter-rater reliability. For statistical significance, a P-value of .05 was employed. Microsoft Excel was used to conduct analysis.
Results
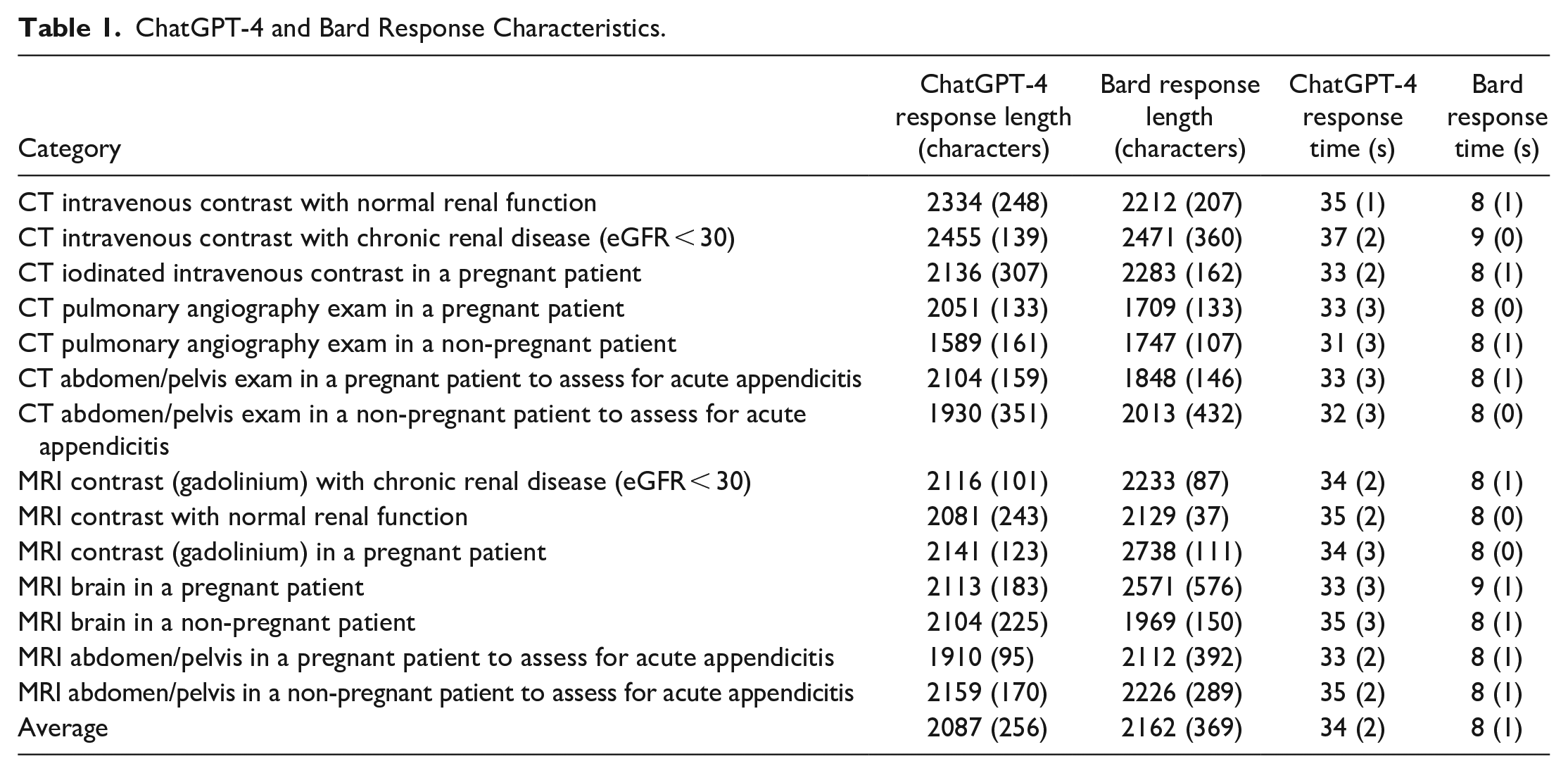
Overall, there were 42 prompts with an average prompt length of 103.71 ± 19.53 characters. Response length was not statistically different between ChatGPT (2087 ± 256 characters) and Bard (2162 ± 369 characters, P = .24). Response time was longer for ChatGPT (34 ± 2.5 seconds) than Bard (8.1 ± 0.6 seconds, P < .0001).
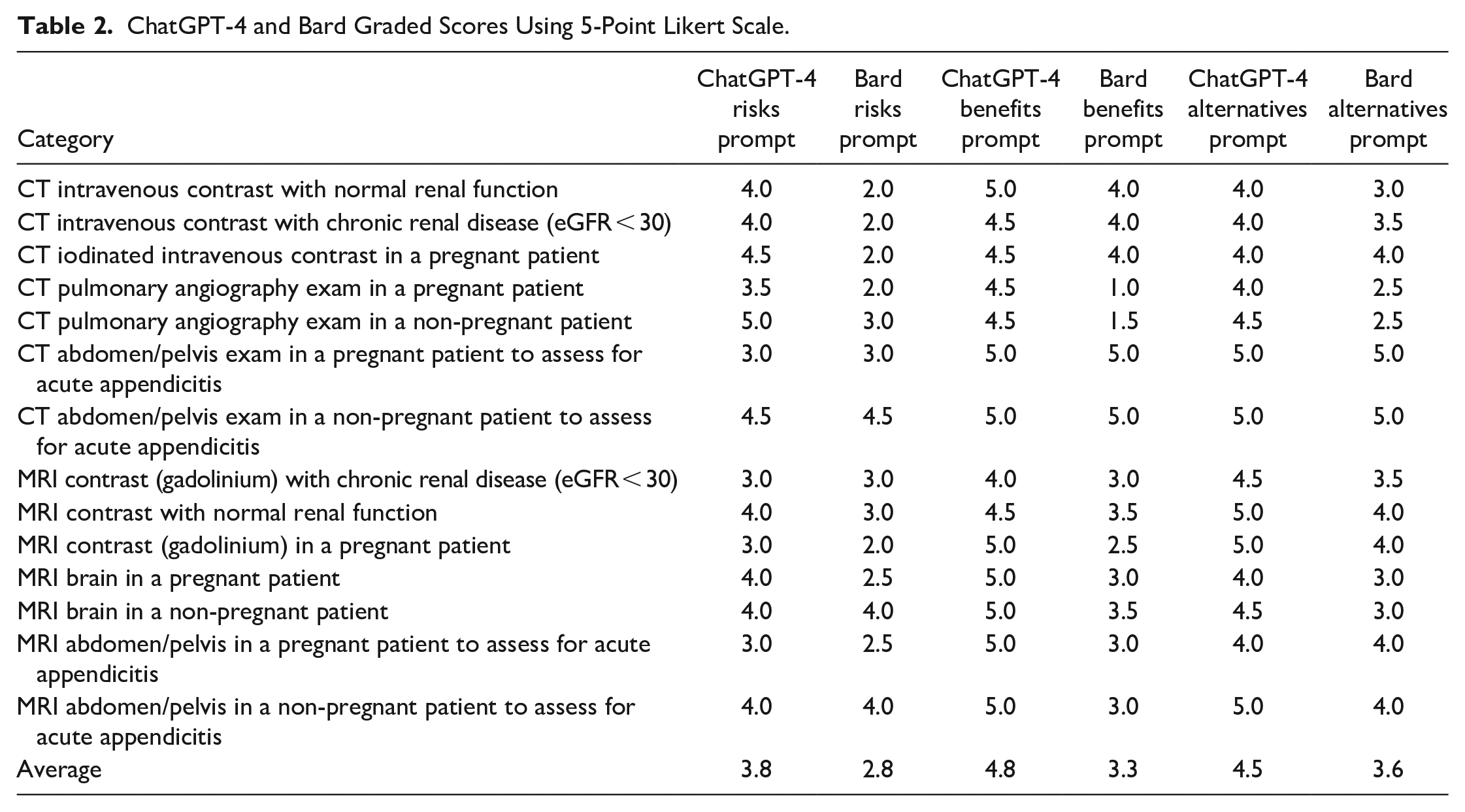
There was substantial agreement between the 2 reviewers per the criteria outlined by Landis and Koch. 18 The ChatGPT grading Cohen’s kappa coefficient was 0.621, and the Bard grading Cohen’s kappa coefficient was 0.684. The average reviewer grades were 4.36 ± 0.63 for ChatGPT responses and 3.25 ± 1.03 for Bard responses. ChatGPT responses were graded higher than Bard responses (P < .0001). Table 1 outlines ChatGPT and Bard response characteristics while Table 2 summarizes the Likert grading for each imaging clinical scenario. Supplemental Table 1 provides a list of prompts, ChatGPT and Bard responses, and the average reviewer grading for each response.
ChatGPT-4 and Bard Response Characteristics.
ChatGPT-4 and Bard Graded Scores Using 5-Point Likert Scale.
In comparison with the original responses, the prompts rephrased by AI to a casual or neutral tone of voice, were graded to be better based on the 5-point Likert grading scores (ChatGPT: 4.29 for original responses vs 4.58, Bard: 2.88 for original responses vs 3.96). Of the responses in this analysis, 75% of the ChatGPT responses and 42% of the Bard responses received a mean Likert grading of within 0.5 of the original responses. In comparison with the original responses, the prompts emulating patient questions were graded to be better based on the 5-point Likert grading scores (ChatGPT: 4.29 for original responses vs 4.33, Bard: 2.88 for original responses vs 3.38). Of the responses in this analysis, 75% of the ChatGPT responses and 50% of the Bard responses received a mean Likert grading of within 0.5 of the original responses.
In comparison with the original responses, the responses for the context dependency analysis received a mean Likert grading that was similar for ChatGPT (4.36 for original responses vs 4.35) and better for Bard (3.73 for original responses vs 3.25). Eighty-one percent of ChatGPT and 62% of responses received a mean Likert grade of within 0.5 compared to the original response grading. Qualitatively, in the majority of cases, both chatbots provided responses with similar content and rationales in the prompt variability and context dependency analysis responses when compared with the original responses.
When requested to provide physician-catered information, ChatGPT did include relevant scholarly sources in all its responses whereas Bard did not, often mentioning sources that were not currently available online. The responses qualitatively increased in complexity and increased frequency of medical terminology use, however, neither chatbot incorporated in-text citations in their responses. In comparison with the original responses, the responses for the physician user rewording received a mean Likert grading that was better for ChatGPT (4.29 for original responses vs 4.38) and Bard (2.88 for original responses vs 3.41). Seventy-five percent of ChatGPT and 42% of responses received a mean Likert grade of within 0.5 compared to the original response grading.
Here, we provide an example of a Very Poor chatbot response (1/5 Likert grading) in response to the prompt: “Please describe the potential benefits of CT pulmonary angiography in a pregnant patient.” Bard’s response includes the following phrase: “The type of CTPA: Not all CTPAs require intravenous iodinated contrast. If your doctor does not think that the benefits of intravenous contrast outweigh the risks, you may be able to have a CTPA without contrast.” This is an example of incorrect information that is misleading and potentially harmful, as CTPA requires intravenous contrast. In contrast, ChatGPT’s response to the same prompt correctly mentioned both criteria in the grading rubric of (1) confident diagnosis or exclusion of pulmonary embolism and (2) possible detection of other intra-thoracic pathology, without the inaccurate claims made by Bard. This response received a mean Likert grade of 5/5. Notably, the response also included extraneous information such as “Alternative imaging methods, such as ventilation-perfusion scans or Doppler ultrasound of the legs, may be appropriate depending on the clinical scenario and the patient’s risk factors,” however, extraneous information did not result in downgrading in this study.
Discussion
Our study found that ChatGPT performed superior to Bard in outlining the risks, benefits, and alternatives to common imaging scenarios when compared to expert radiologists. Both chatbots displayed conversational responses without medical jargon and generally accurately described the risks and benefits of CT and MR imaging. Similarly, the chatbots accurately described the risks and benefits of CT intravenous iodinated contrast, MRI gadolinium-based intravenous contrast, and imaging in pregnant patients. Based on the results of our study, these AI chatbots may be a reasonable and accessible source of basic information for patients. However, these chatbots do not appear to give higher-level descriptions catered toward physicians or healthcare professionals. The limited previous investigations in the literature comparing ChatGPT and Bard show consistent findings, with ChatGPT generally performing superior to Bard.19-22 Furthermore, even for patients, chatbot responses may be misleading without sufficient context and background information. As such, the involvement of a certified healthcare practitioner remains imperative.
If there is not continual update of these AI models the concept of data drift may lead to a decrease in performance. Currently, there are few articles discussing this concept in the literature.23,24 Particularly, in medical contexts, AI chatbots trained on outdated data could have more adverse consequences. One study suggests that retraining periods of a couple of months or using several 1000 patients may be adequate for machine learning models predicting sepsis. 25 Furthermore, ChatGPT does not currently have real-time internet access suggesting that without frequent updates it may quickly provide outdated information. As patients may receive inaccurate or incomplete information from an AI chatbot, it remains essential for physicians to provide an opportunity for patients to ask questions and to assess the patient’s understanding of their diagnoses, management, and any potential procedures.
Although the prompts did not supply specific patient information, a pertinent drawback of AI chatbots was highlighted as the chatbots made assumptions about indications for the study, presence or absence of contrast, and patient characteristics such as age, sex, and comorbidities. Notably, while the training data is not publicly available, there is potential for biases present in the training data to influence AI chatbots’ responses, for example, in making assumption of patient characteristics. AI chatbots such as ChatGPT and Bard, currently, are unable to provide personalized recommendations or ask for further information and thus are not well suited for medical applications where such assumptions may be wrong and negatively affect outcome. 26 Furthermore, patient confidentiality and medicolegal issues may prevent the early widespread adoption of AI chatbots in a medical context.27,28 Both chatbots consistently provided extraneous information that was not directly related to answering the prompt. For patients, this may be confusing or cause unnecessary anxiety. Providing additional information did not result in a downgrading of responses in our study.
Our prompt variability analysis revealed that varying the structure and vernacular of a prompt while maintaining the content of the prompt, can lead to different AI chatbot responses. Prompt engineering may be an important skill in obtaining optimal medical information for patient education and further investigation in this domain is warranted. 29 This is further illustrated for our physician-based prompts where the prompts were designed to request for scholarly sources. In general, this led to an increase in the grading of the responses. However, an important deficiency was highlighted with Bard as in all of these responses, Bard did not provide relevant scholarly resources and in multiple cases provided a reference to a source that did not exist online currently. It is possible that the source was previously available and used to train the LLM, but subsequently taken down or updated. For example, in its response to the prompt about benefits of MRI in a pregnant patient, Bard references the “Royal College of Obstetricians and Gynaecologists (RCOG). Green-top Guideline No. 58: MRI in Pregnancy,” however this is not currently available online and it is unclear whether it was previously available online. Green-top Guideline No.58 currently references “Vulval Skin Disorders, management” and there is no Green-top Guideline titled with MRI.30,31 Previously, it has also been shown that an LLM referring to the American College of Radiology Appropriateness Criteria to justify its response, can do so and still provide the incorrect information. 22 These deficiencies are important as incorrect information can lead to an inaccurate perception of the risks related to their medical imaging. In contrast, ChatGPT did provide relevant resources correctly for all of its responses to these prompts.
Our context dependency analysis also provides evidence that real world use of chatbots may yield unique results, since patients will not be likely to reset the chatbot after each prompt. With many studies published on the use of AI chatbots within medicine, it remains essential to understand the limitation that chatbot use in a research setting may not reflect real world use. Nevertheless, the results were similar even with chatbot context dependency in this study. For both the prompt variability and context dependency analyses, ChatGPT appeared to display less variability than Bard.
Limitations of this study are described herein. CT and MRI exams, their respective intravenous contrast agents, and patients who are pregnant were only included in this analysis and the results do not necessarily generalize to all imaging scenarios. The prompts did not mention which risks should be discussed and did not provide sample patient characteristics which may have assisted the chatbots provide more specific recommendations and information. The limited sample size with regards to the prompts and topics may lead to sampling bias. Our prompts related to decreased renal function were limited to stage 4 and 5 kidney disease and did not include responses pertaining to lesser degrees of renal dysfunction (ie, eGFR between 30 and 60 mL/min/1.73 m2). Large language models should be evaluated formally for medical use through a randomized controlled trial or observational study for conclusions on their clinical utility to be drawn. Lastly, chatbots can provide different responses for the same or similar prompts which is an inherent limitation in our study. For example, in a testing phase, there was an instance where an AI chatbot suggested that ventilation/perfusion scans do not expose the patient to radiation, which is factually incorrect. However, during our formal data collection for this study, no such response was elicited. Further studies investigating AI chatbots variability in response content is warranted.
In conclusion, ChatGPT and Bard generally provide accurate information regarding the risks, benefits, and alternatives in our provided CT and MRI scenarios. They did however not provide detailed, scientific reasoning, and are currently unable to provide patient-specific information. ChatGPT performed superiorly in our study, however neither LLM was felt to be evolved enough, at this time, for clinical adoption. Future investigation into the role of AI chatbots to aid decision making around diagnostic imaging is indicated as LLMs continue to grow more sophisticated and evolved.
Supplemental Material
sj-xlsx-1-caj-10.1177_08465371231220561 – Supplemental material for Artificial Intelligence Chatbots’ Understanding of the Risks and Benefits of Computed Tomography and Magnetic Resonance Imaging Scenarios
Supplemental material, sj-xlsx-1-caj-10.1177_08465371231220561 for Artificial Intelligence Chatbots’ Understanding of the Risks and Benefits of Computed Tomography and Magnetic Resonance Imaging Scenarios by Nikhil S. Patil, Ryan S. Huang, Scott Caterine, Jason Yao, Natasha Larocque, Christian B. van der Pol and Euan Stubbs in Canadian Association of Radiologists Journal
Supplemental Material
sj-xlsx-2-caj-10.1177_08465371231220561 – Supplemental material for Artificial Intelligence Chatbots’ Understanding of the Risks and Benefits of Computed Tomography and Magnetic Resonance Imaging Scenarios
Supplemental material, sj-xlsx-2-caj-10.1177_08465371231220561 for Artificial Intelligence Chatbots’ Understanding of the Risks and Benefits of Computed Tomography and Magnetic Resonance Imaging Scenarios by Nikhil S. Patil, Ryan S. Huang, Scott Caterine, Jason Yao, Natasha Larocque, Christian B. van der Pol and Euan Stubbs in Canadian Association of Radiologists Journal
Supplemental Material
sj-xlsx-3-caj-10.1177_08465371231220561 – Supplemental material for Artificial Intelligence Chatbots’ Understanding of the Risks and Benefits of Computed Tomography and Magnetic Resonance Imaging Scenarios
Supplemental material, sj-xlsx-3-caj-10.1177_08465371231220561 for Artificial Intelligence Chatbots’ Understanding of the Risks and Benefits of Computed Tomography and Magnetic Resonance Imaging Scenarios by Nikhil S. Patil, Ryan S. Huang, Scott Caterine, Jason Yao, Natasha Larocque, Christian B. van der Pol and Euan Stubbs in Canadian Association of Radiologists Journal
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.