
Abstract
Purpose
Bard by Google, a direct competitor to ChatGPT, was recently released. Understanding the relative performance of these different chatbots can provide important insight into their strengths and weaknesses as well as which roles they are most suited to fill. In this project, we aimed to compare the most recent version of ChatGPT, ChatGPT-4, and Bard by Google, in their ability to accurately respond to radiology board examination practice questions.
Methods
Text-based questions were collected from the 2017-2021 American College of Radiology’s Diagnostic Radiology In-Training (DXIT) examinations. ChatGPT-4 and Bard were queried, and their comparative accuracies, response lengths, and response times were documented. Subspecialty-specific performance was analyzed as well.
Results
318 questions were included in our analysis. ChatGPT answered significantly more accurately than Bard (87.11% vs 70.44%, P < .0001). ChatGPT’s response length was significantly shorter than Bard’s (935.28 ± 440.88 characters vs 1437.52 ± 415.91 characters, P < .0001). ChatGPT’s response time was significantly longer than Bard’s (26.79 ± 3.27 seconds vs 7.55 ± 1.88 seconds, P < .0001). ChatGPT performed superiorly to Bard in neuroradiology, (100.00% vs 86.21%, P = .03), general & physics (85.39% vs 68.54%, P < .001), nuclear medicine (80.00% vs 56.67%, P < .01), pediatric radiology (93.75% vs 68.75%, P = .03), and ultrasound (100.00% vs 63.64%, P < .001). In the remaining subspecialties, there were no significant differences between ChatGPT and Bard’s performance.
Conclusion
ChatGPT displayed superior radiology knowledge compared to Bard. While both chatbots display reasonable radiology knowledge, they should be used with conscious knowledge of their limitations and fallibility. Both chatbots provided incorrect or illogical answer explanations and did not always address the educational content of the question.

Introduction
Artificial intelligence (AI) chatbots have utility in a variety of contexts, and their applications within medicine are a particularly exciting current area of investigation. ChatGPT (Chat Generative Pre-trained Transformer) by OpenAI is currently the most popular chatbot and was released in a preliminary form last year, in November 2022. 1 A direct competitor was recently released by Google, named Bard. 2 Similar to ChatGPT, Bard is an interactive AI chatbot that engages in conversation in response to human input. However, unlike ChatGPT, Bard also has real-time access to the internet and a unique communication model named the Language Model for Dialogue Applications (LaMDA) instead of ChatGPT’s Generative Pre-training Transformer. 3
In recent months, there have been a number of studies published regarding the potential role of ChatGPT in radiology. Potential uses include assistance with report generation, as a study tool for trainees, improving differential diagnoses, data analysis, determining suitable imaging options, and as a source of information for patients. 4-6 Studies earlier this year found that ChatGPT-4 performed better than ChatGPT-3.5 in answering a sample of 150 questions designed to be similar to the Canadian Royal College and American Board of Radiology examinations. 7,8 Given the novelty of Bard by Google, to the best of our knowledge, there are only 2 published articles comparing ChatGPT to Bard, both of which found ChatGPT to be superior. 9,10 In this project, we aimed to compare the most recent version of ChatGPT, ChatGPT-4, and Bard in their ability to accurately respond to radiology board examination questions. Understanding the relative performance of these different chatbots can provide important insight into the strengths and weaknesses of each of these chatbots and which roles they are most suited to fill.
Methods
Questions were collected from the American College of Radiology’s Diagnostic Radiology In-Training (DXIT) examination. 11 The DXIT examination is an annual exam prepared by the ACR used to simulate the American Board of Radiology (ABR) Core exam. The exam is administered in many radiology residency programs internationally and serves as a formative assessment tool for residents in training. The literature suggests that it can serve as a predictor for residents’ future performance on the Canadian Royal College examination or the ABR Core examination. 12,13 DXIT exam questions were collected through a publicly available, open-source flashcard software. 14 Consent was obtained from the ACR to conduct our analysis using these publicly available questions. A 5-year sample of DXIT examination questions, between 2017 and 2021, was used in this study. These questions were categorized by year and by exam subsections including neuroradiology, mammography, general & physics, nuclear medicine, pediatric radiology, interventional radiology, gastrointestinal radiology, genitourinary radiology, cardiac radiology, chest radiology, musculoskeletal radiology, and ultrasound. Questions were entered into each chatbot using the same methodology as described by Gilson et al. (2023). 15 Only text-based questions were included in our analysis.
Data was collected using ChatGPT-4 and Bard on June 11, 2023. Each AI chatbot was reset before entering another question. The primary outcome of this study was the comparative performance of ChatGPT and Bard in answering DXIT questions. The secondary outcomes of this study included the chatbots’ performance in each subspecialty, the length of responses, the response time, and the proportion of questions answered with an explanation. Additionally, 10% of our questions and their respective responses by ChatGPT and Bard were selected for more detailed analysis by 2 radiologists at a tertiary care center (N.L., C.V.P.). Specifically, each response by each chatbot was read in detail and the proportions of responses which contained hallucinations/fabrications, illogical or incorrect answer rationales, or do not accurately address the educational content of the questions, were recorded. Data was collected independently, and conflicts were resolved through discussion. Paired t-tests were used to compare means and chi-squared tests were used to compare proportions. A P-value threshold of .05 was used to determine statistical significance in this study. Microsoft Excel was used for all analyses.
Results
ChatGPT-4 and Bard Response Characteristics and Accuracy in Answering American College of Radiology DXIT Exam Questions.
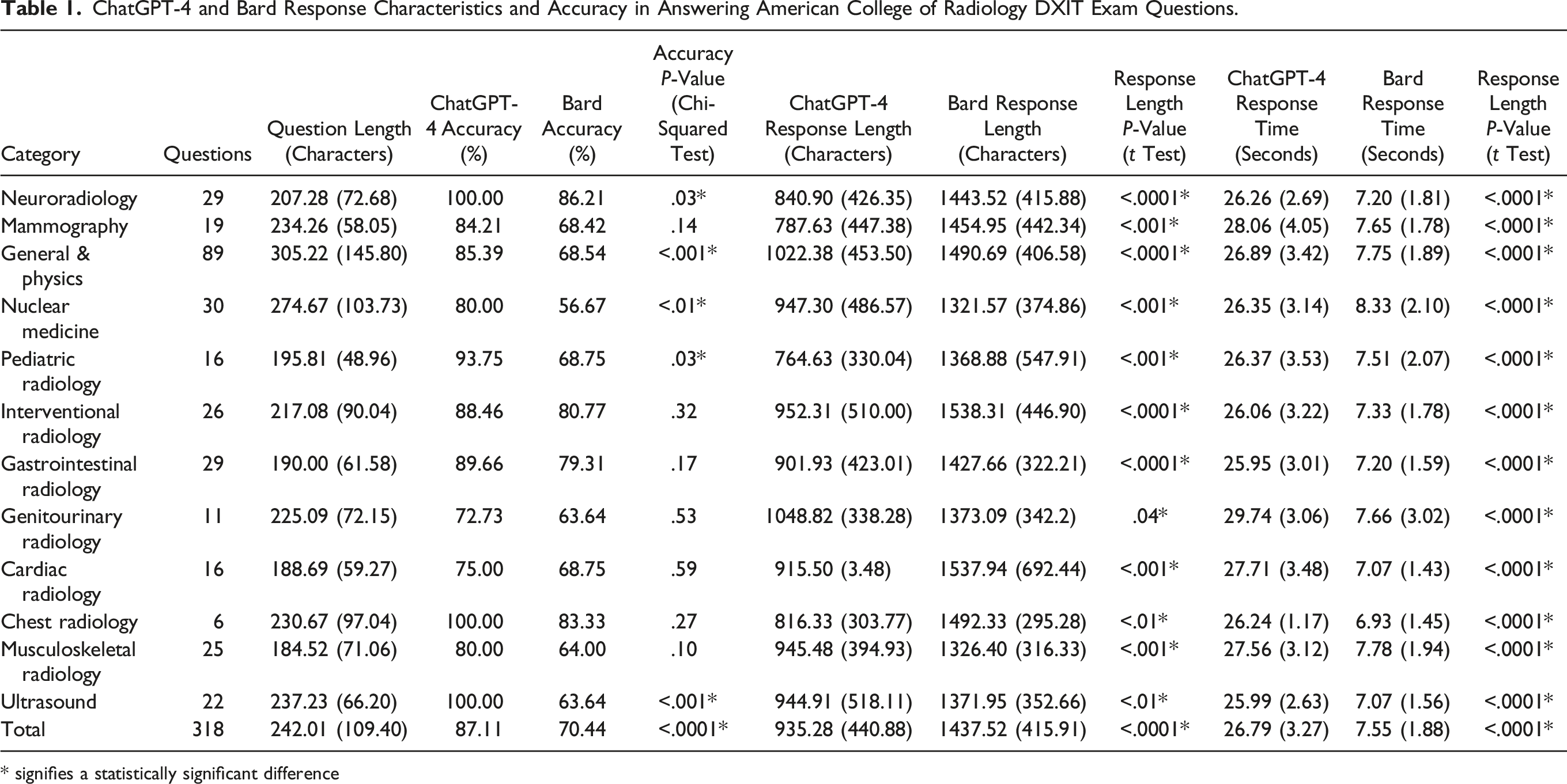
* signifies a statistically significant difference
ChatGPT answered more accurately than Bard (87.11% vs 70.44%, P < .0001). ChatGPT’s response length was shorter than Bard’s (935.28 ± 440.88 characters vs 1437.52 ± 415.91 characters, P < .0001). ChatGPT’s response time was longer than Bard’s (26.79 ± 3.27 seconds vs 7.55 ± 1.88 seconds, P < .0001).
ChatGPT performed superiorly to Bard in neuroradiology, (100.00% vs 86.21%, P = .03), general & physics (85.39% vs 68.54%, P < .001), nuclear medicine (80.00% vs 56.67%, P < .01), pediatric radiology (93.75% vs 68.75%, P = .03), and ultrasound (100.00% vs 63.64%, P < .001). In the remaining subspecialties, there were no differences between the chatbots. In each subspecialty-specific analysis, ChatGPT’s response length was shorter, and its response time was longer (Table 1).
32 questions (10%) were randomly selected for closer analysis by 2 staff radiologists. This analysis revealed that both chatbot responses for these questions did not contain hallucinations or fabrications. 19% of ChatGPT’s responses contained illogical and/or incorrect answer rationales. 6% of ChatGPT’s responses did not accurately address the educational content of the question. An example is provided in Figure 1. 38% of Bard’s responses contained illogical and/or incorrect answer rationales. 9% of Bard’s responses did not accurately address the educational content of the question. Sample ChatGPT response demonstrating a correct answer with an answer rationale that does not accurately address the educational content of the question.
Discussion
Overall, ChatGPT performed superiorly to Bard in responding to DXIT exam questions. There were several differences between these chatbots in their accuracy and response characteristics. Both chatbots consistently provided explanations for their responses, although this was the case regardless of whether the answer was correct or incorrect. Bard generally provided lengthier responses, but answered quicker, possibly due to lower rates of usage currently. While performance varied for both chatbots across subspecialties, a similar trend to the primary analysis was established, with ChatGPT performing superiorly. Possibly, ChatGPT-4 performed superiorly to Bard as there is variation in their respective training data as well as the strength of their models in answering medical questions. Recently published studies suggest that ChatGPT outperforms Bard in answering lung cancer questions and neurosurgery oral boards preparation questions, which is consistent with our analysis. 9,10
ChatGPT-4 and Bard both display reasonable radiology knowledge. The role of AI in radiology spans many domains including image interpretation, tumour staging, report generation, workflow improvements, medical writing, and research. 4,16-18 However, at this stage, human input remains vital in ensuring quality and optimal patient outcomes. 19 Although AI chatbots continue to be updated, with multimodal input anticipated to arrive later this year, currently, their role is more limited. Specifically, AI chatbots' primary role currently is likely as a study tool for trainees or as an information resource for patients, and even then, their role may be limited. As illustrated in Figure 1, a chatbot may provide the correct answer, but the explanation may not appropriately address the educational content of the question. Similarly, our analysis of the quality of answers suggested that both chatbots also occasionally provided illogical or incorrect answer rationales. This can be particularly deceptive for trainees or patients who may be fooled by the confidence with which AI chatbots communicate. As a result, the way in which trainees are educated and assessed will also need to adapt. 20,21 Particularly, an increasingly large focus should be placed on higher-level thinking questions as outlined in Bloom’s taxonomy. 22 It is also important to educate radiologists and radiology trainees about the strengths and weaknesses of AI in radiology, a topic that they are currently underexposed to. 23,24
There are drawbacks to AI chatbots and their potential role in radiology. As mentioned previously, the rationale chatbots provide for their answers can serve as a useful tool for trainees and patients looking to gain knowledge, but a significant downside arises when erroneous responses are justified with confidence. Particularly, for a patient or trainee who does not have the prerequisite knowledge or experience, it would be easy to be led astray by the responses from these chatbots. Particularly in a field such as radiology, and more broadly medicine, the dangers of inaccuracy can be devastating. Furthermore, ChatGPT and Bard are designed to provide unique responses, even to the same prompts, suggesting that there may be times when questions may be answered correctly or incorrectly depending on the content of previous conversations with the chatbot. AI chatbots also have a tendency to make assumptions when insufficient information is provided which can have significant repercussions in the context of medical care. 25 Hallucinations, omissions, and errors have all been documented with the use of ChatGPT. 26,27 Our analysis of a subset of chatbot responses demonstrated that both chatbots contain errors in their answer explanations and do not always address the intended educational content of the question, with Bard performing worse than ChatGPT. Without a comprehensive understanding of the nuances and subtlety in radiology, AI chatbots should be used with caution. Lastly, thorough investigation into the safety and efficacy of AI technology both prior to adoption and after adoption is vital. A study by van Leeuwen et al. (2021) showed that of 100 AI products, only 36 had peer-reviewed evidence regarding efficacy. 28
Limitations of our study include the following. Only text-based questions were included in our analysis which is not reflective of radiology as a field that is inherently image based. Further, this led to disproportionate subspecialty representation. For example, there was an increased representation of questions from the general & physics subsection and decreased representation from the chest radiology subsection. That being said, by focusing on text-based questions, our study provides specific insights into AI chatbots’ radiology knowledge, which is separate from interpretation skills. In the future, multimodal input is anticipated for both these chatbots, and a repeat assessment and that point will provide important insights. Another limitation of our study is that given the sample size, there may be selection bias in the questions included in this study. A lack of long-term evaluation of these chatbots precludes an understanding of the reliability, consistency, and potential improvements of these chatbots. As the precise data used as training input for ChatGPT and Bard is unknown, it is possible that the publicly available dataset of DXIT questions we used may have been included in the chatbot training process. In a separate project, we found that in some cases, these chatbots cited the specific resource the question was based on (ACR appropriateness criteria), but nevertheless, still provided an incorrect answer. 29 On the other hand, further improvements in chatbot performance may be possible if more radiology specific content is provided as part of the training process in future updates to these models.
In conclusion, our study highlights some key differences between ChatGPT and Bard in radiology knowledge. Chatbot assumptions, confidence in response explanations, and are important factors to consider when choosing the optimal chatbot. Furthermore, future investigations into direct comparisons between AI chatbot performance and radiologist or radiology trainees’ performance would be useful. As AI chatbots, and more broadly AI models, continue to develop and learn, continual reassessment of their strengths, weakness, and role in radiology is warranted.
Supplemental Material
Supplemental Material - Comparative Performance of ChatGPT and Bard in a Text-Based Radiology Knowledge Assessment
Supplemental Material for Comparative Performance of ChatGPT and Bard in a Text-Based Radiology Knowledge Assessment by Nikhil S. Patil, Ryan Huang, Christian B. van der Pol, and Natasha Larocque in Canadian Association of Radiologists Journal.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.