
Abstract
Manual plan evaluation faces reliability and scalability challenges. This research benchmarks human evaluations against a large language model (LLM) using a multi-agent approach and/or retrieval-augmented generation (RAG) to automate complex content analysis tasks. We find that LLMs generally perform comparably with humans, with most errors arising from overimplication and limited domain knowledge. The multi-agent approach substantially enhances LLM’s performance, reducing common machine errors by over 50 percent. Integrating such LLM tools with human oversight will likely become the new norm for content analysis, and this study demonstrates how to leverage artificial intelligence’s (AI) efficiency and precision alongside humans’ contextual understanding and domain expertise.
Keywords
Introduction
Plan evaluation is a well-established component of the planning discipline. It is because plans are considered the printed currency of the profession; they not only represent the outcome of the plan-making process but also serve as key inputs for informing local decision-making (Krizek, Forsyth, and Slotterback 2009; Levy, Hirt and Dawkins 2009; Norton 2008). Therefore, many argue that plans should be frequently evaluated against evolving plan quality principles to reflect the latest knowledge in urban planning and to foster continuous learning and improvement in professional practice (Berke and Godschalk 2009; Guyadeen 2018). However, conducting plan evaluations more routinely and at a larger scale has proven increasingly challenging.
The reasons are twofold. First, the rapid growth of digital plans, driven by regular updates to conventional plans (e.g., comprehensive and hazard mitigation plans) and the increasing development of new plans (e.g., climate adaptation and heat action plans) to address emerging urban issues, has led to an overwhelming volume of planning documents (Batty 2022; Fu, Li and Zhai 2023). This is evidenced by recent large-scale studies such as Reckien et al. (2018) and Salvia et al. (2021), both of which evaluated hundreds of climate plans from European Union (EU) cities and relied heavily on large, coordinated teams of human coders.
Secondly, plan quality evaluation is a highly labor-intensive task, often requiring two or more human coders to analyze lengthy and technical planning documents to produce reliable results (Bracken 2014; Krippendorff 2018; Stevens, Lyles and Berke 2014). Despite efforts to ensure consistency in manual plan evaluation, intercoder reliability remains a challenge, such as ongoing debates about appropriate reporting measures and frequent omissions of such metrics that make it difficult to assess the robustness and reproducibility of findings in plan evaluation studies (Stevens, Lyles and Berke 2014). This inconsistency reflects both methodological limitations and practical constraints, including the time-intensive nature of training and calibrating multiple coders. Hence, routinely evaluating a large number of plans can be both challenging and cost-prohibitive for many researchers and practitioners.
In this context, the rapid development of artificial intelligence (AI) technology, particularly in the form of large language models (LLMs), offers transformative potential to automate plan evaluation, addressing many of the abovementioned challenges posed by traditional, labor-intensive manual content analysis methods (Cugurullo et al. 2024; Fu et al. 2025b; Sanchez et al. 2023). However, existing LLMs cannot yet replace humans in plan evaluations due to their inherent limitations, including hallucinations, 1 a lack of domain-specific knowledge, insufficient contextual understanding, challenges in long-text reasoning, and non-deterministic outputs. These limitations significantly undermine their reliability and adoption in urban planning, a concern shared by many other fields (Liu et al. 2023).
Improving these areas has been a focal point for ongoing research in the AI community to enhance LLMs’ performance and reliability. While there are several mainstream approaches to mitigate LLMs’ existing limitations, retrieval-augmented generation (RAG) and multi-agent frameworks are among the most promising (Gao et al. 2023; Han et al. 2024a). 2 Specifically, RAG enables LLMs to dynamically retrieve the most relevant information from long-context documents in real time, enhancing accuracy and contextual relevance. In contrast, the multi-agent approach simulates human teamwork by allowing multiple specialized agents to collaborate on complex tasks, which improves task decomposition and therefore overall performance. Despite the promises, no study has examined these novel approaches’ effectiveness in the context of urban planning, particularly for plan evaluation that requires robust reasoning, complex domain knowledge, and nuanced contextual understanding.
This research addresses this gap by systematically evaluating the performance of LLMs enhanced with RAG and multi-agent frameworks in automating plan evaluation. Using a recent study by Keith et al. (2023) that analyzed networks of plans for cities’ resilience to extreme heat, we replicate their methodology to benchmark the performance of these advanced LLM techniques against traditional manual content analysis. The key reasons for selecting this study, including its detailed coding protocols, diverse reasoning tasks, and focus on a network of plans for holistic LLM testing, are further detailed in the methodology section. Our takeaway findings reveal that while multi-agent frameworks significantly enhance LLM performance, RAG can unexpectedly degrade task accuracy. This study sheds light on the potential of LLMs with novel enhancement techniques in automating content analysis and highlights the importance of the human-in-the-loop approach for reliable and effective AI adoption in urban planning research and practice.
Background
The rapid accumulation of digital data poses a critical challenge for manual content analysis methods in processing large volumes of data efficiently and effectively. Such data may include formal sources such as governmental plans, reports, policies, and stakeholder feedback, as well as informal sources like social media and newspapers (Hu et al. 2019; Lore, Harten and Boeing 2024). Timely analysis of these data provides essential evidence for planning and decision-making, helping localities address rapidly changing urban challenges with prompt responses and swift turnarounds (Batty 2013; Kitchin 2014).
Natural language processing (NLP), a subfield of AI encompassing LLMs that focuses on enabling machines to understand and generate human natural language (Chowdhary 2020), has emerged as a promising research area in urban planning (Fu 2024). In the pre-LLM era, researchers primarily applied conventional NLP techniques like topic modeling and sentiment analysis to a variety of urban textual data, including planning documents (Brinkley and Stahmer 2024), public feedback (Fu et al. 2025a; Kim et al. 2021), and council meeting minutes (Lesnikowski et al. 2019). While these traditional methods are effective for mining the inherent patterns of human language, they lack the ability to simulate higher order reasoning or contextual understanding. As a result, their applicability is often limited in more complex tasks, such as those involving nuanced content analysis.
Since the premiere of ChatGPT, LLMs have risen to prominence for their advanced ability to simulate human reasoning and “understand” natural language, unmatched by the capabilities of conventional NLP techniques (Fu et al. 2025b; Hu et al. 2023; Liu et al. 2023; Zhong et al. 2023). It should be noted that while existing LLMs have demonstrated impressive reasoning capabilities, they are considered “a kind of meta-mimicry,” or in simple terms, they generate responses that mimic human reasoning without necessarily understanding or truly solving the problems (Mitchell 2025). Despite their promises, LLMs are still at a nascent stage and therefore subject to multiple inherent methodological limitations hindering their reliability (Chang et al. 2024; Zhao et al. 2023).
RAG and multi-agent frameworks are among the most promising methods in addressing LLMs’ primary limitations (Gao et al. 2023; Han et al. 2024a). 3 RAG is uniquely advantageous compared with other domain-adaptation methods because it offers a scalable and adaptable solution to dynamically retrieve the most relevant information from long-context documents in real time, improving the model’s outputs so that they are accurate and contextually relevant (Gao et al. 2023). Unlike other static methods, such as prompt engineering and fine-tuning, which require manual curation and lack the flexibility and adaptability needed for complex or large-scale language processing tasks like plan evaluation, RAG provides a versatile and efficient alternative. Multi-agent frameworks, on the other hand, emulate human teamwork by enabling multiple specialized agents to collaborate, thereby enhancing performance on complex tasks (Han et al. 2024b; Talebirad and Nadiri 2023). Together, these approaches enable LLMs to mitigate key limitations, such as insufficient domain knowledge, hallucinations and long-context reasoning challenges, by mimicking human behaviors like consulting external knowledge (RAG) and working collaboratively to enhance efficiency and reliability (multi-agent frameworks), without requiring domain-specific prompts or datasets.
Nevertheless, the advancing capabilities of LLMs and their versatility now enable researchers to explore their use in almost any conceivable case and at all scales, holding promising potential to transform urban analytics for urban planning and many other fields. Therefore, exploring how to harness the latest developments of LLMs and for what purposes remains at the frontiers of these disciplines.
Plan Evaluation
Plan evaluation appears to be a natural application for these advancements due to the complexity of reasoning required in evaluating plans and its important role in urban planning literature. Plan evaluation is defined as the “systematic assessment of plans, planning processes, and outcomes compared with explicit standards or indicators” (Laurian et al. 2010, 741). It allows planners to assess prior strategies, identify strengths and weaknesses, and improve future plan-making efforts (Berke and Godschalk 2009; Brinkley and Wagner 2024; Guyadeen and Seasons 2016). In recent decades, the evaluation of plan quality has remained an active area of research (Berke and Godschalk 2009; Guyadeen and Seasons 2016; Lyles and Stevens 2014). Unlike other plan evaluation research that focuses on planning processes or implementation outcomes, plan quality studies primarily center on the content of the plans themselves, using various conceptual dimensions and well-defined coding protocols to assess them against predefined criteria (Berke et al., [1995] 2006; Berke and Godschalk 2009; Khakee 2000; Talen 1996). As Berke et al. (2012) argued, this approach offers a robust framework for identifying the strengths and deficiencies of planning documents, thereby providing the necessary evidence for advancing the development of higher quality, more impactful plans, as well as the profession.
In recent years, LLMs have demonstrated remarkable capabilities in understanding and analyzing textual materials, enabling them to support tasks such as content analysis, document summarization, and policy evaluation (Fu et al. 2024; Liu et al. 2024; Zhong et al. 2023). By leveraging LLMs’ advanced capabilities, researchers and practitioners can potentially overcome traditional challenges in plan evaluation, including the lack of routine studies, scalability issues, and inefficiencies. For example, Fu, Wang, and Li (2024) used ChatGPT (GPT-3.5 Turbo) to evaluate ten climate change plans, comparing its performance with manual content analysis. While existing studies generally find that LLMs significantly outperform traditional NLP techniques in simulating human reasoning and conducting text mining, they are not yet as effective as human analysts. The study also highlighted challenges in relying solely on ChatGPT, including difficulties with planning-specific jargon and limitations in interpreting nuanced planning contexts. Thus, it is crucial to continue exploring ways to enhance the performance of LLMs in domain-specific applications by incorporating the latest developments in AI, aiming to mitigate or even overcome these limitations and fully realize their potential in plan evaluation and content analysis research.
Methodology
This study explores and compares two novel techniques, RAG and the multi-agent framework, coupled with a state-of-the-art LLM (GPT-4o), against manual content analysis for evaluating plans. We followed the steps outlined by Keith et al. (2023) for plan evaluation and employed Baltimore’s network of plans as identified in their study for our research sample. The reasons for choosing this study are threefold: first, this plan evaluation study involves multiple complex reasoning tasks, including evaluating relevance, categorization based on criteria, and grading, which allow us to test the LLM’s capability in various textual analysis tasks. Second, their work focused on a network of plans rather than a single type of plan, as is common in most plan evaluation studies, enabling us to test the validity of LLMs across different plan types. Third, this recent study published in the Journal of Planning Education and Research provides detailed instructions and coding protocols that enable us to easily reproduce the evaluation using both AI and manual content analysis. In summary, we chose to replicate this study with the aim of testing the LLM’s transferable versatility and applicability.
Manual Content Analysis
We first downloaded the network of plans in the City of Baltimore by searching online for the respective plan names given in Keith et al. (2023). It should be noted that the City of Baltimore was randomly selected from the pool of sample cities in the study to ensure the feasibility of this research and to keep costs manageable. Specifically, the research sample includes four different types of plans, namely “City of Baltimore Comprehensive Master Plan 2006,” “Baltimore Sustainability Plan 2019,” “Baltimore Climate Action Plan 2012,” and “City of Baltimore Disaster Preparedness and planning Project (DP3) 2018.” These plans are quite representative because they include both conventional plans (comprehensive plans and hazard mitigation plans) and emerging plans (sustainability plans and climate action plans). They also cover a wide range of topics with varying lengths, structures, and contexts (Table 1).
Summary of Research Sample.

To generate the manual evaluation results, we followed the steps specified in Keith et al. (2023). As illustrated in Figure 1A, this involved three tasks: extracting policies for inclusion, categorizing the included policies, and grading the policies based on their potential impacts. We also involved two coders to undertake the above content analysis tasks to ensure the reliability of our manual results (Krippendorff 2018).
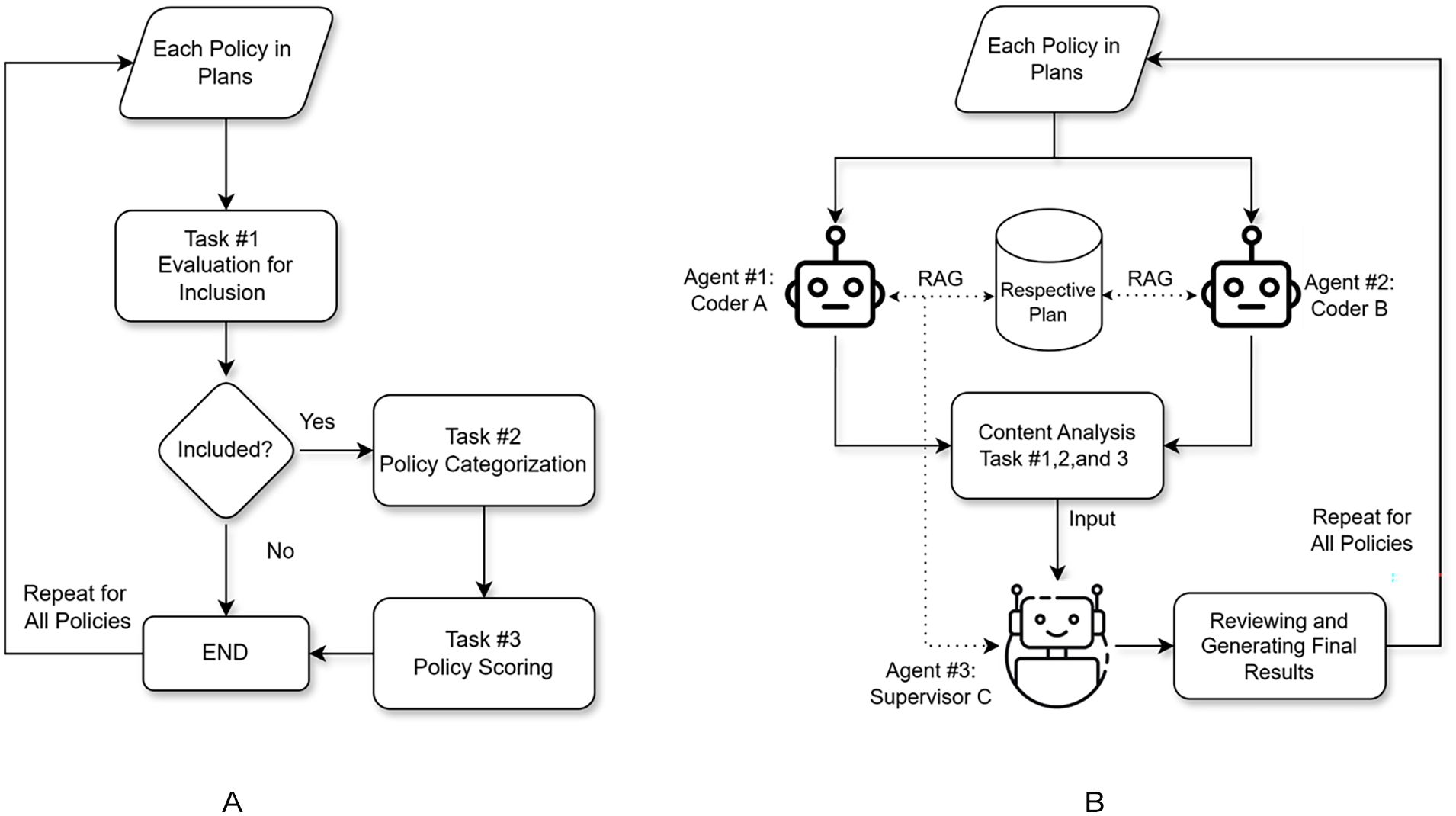
Content analysis flowchart: (A) manual and (B) machine automated with RAG and multi-agent framework.
Specifically, (task 1) we first extracted and evaluated the policies based on their relevance to heat risk (i.e., either potentially increasing or decreasing the urban heat island effect) and actionability (i.e., having a recognizable policy tool for implementation). 4 Both coders independently analyzed the content of the plans to extract qualified policies, then compared their results to identify discrepancies, and finally discussed them to reach a consensus before moving to the next task. Next, (task 2) the two coders independently evaluated the included policies against the established heat mitigation strategy categories (found in Table A2 of the Supplementary Material of Keith et al. 2023), repeating the same consensus-building process. Finally, (task 3) we followed the same process to score the policies based on their likely impact on urban heat, with policies helping to mitigate heat assigned “1,” “–1” for worsening, “0” for neutral, and “U” for unknown. Before reconciling the results, we also computed the percentage agreements between the two coders for the above three content analysis tasks, which were 83, 92, and 97 percent, respectively. All percentages were above the acceptable level of 80 percent for plan evaluation studies, suggesting reasonable intercoder reliability and validity of the manual results (Stevens, Lyles and Berke 2014).
Automating Content Analysis Using LLMs
We used the state-of-the-art LLM, OpenAI’s GPT-4o, accessed via its API platform, to automate the manual content analysis procedures outlined above within a Python programming environment. As shown in Table 2, we explored in total four ways of leveraging LLM for evaluating plans, including using the LLM only by itself (LLMO), the LLM with RAG (RAG), the multi-agent LLM (MA LLM), and the multi-agent LLM with RAG (MA RAG). This allowed us to explore the effectiveness of these novel techniques, both individually and in combination, in advancing LLMs’ capabilities for content analysis tasks.
Descriptions of the Four LLM Approaches.
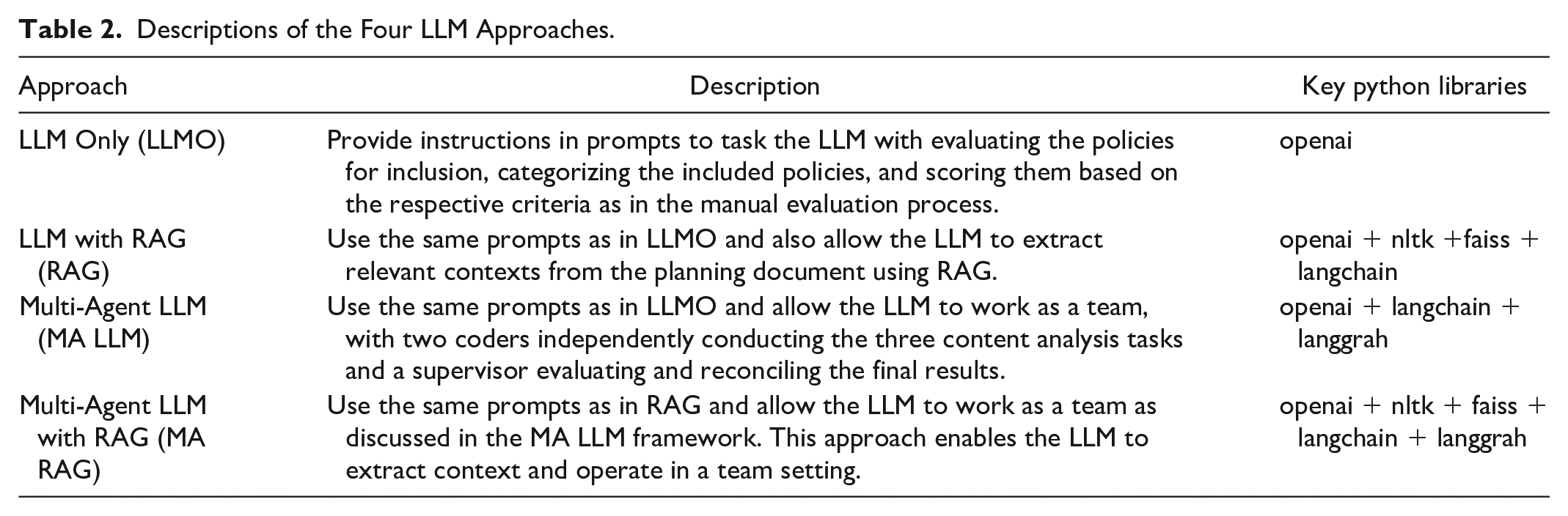
In brief, for the most basic approach, LLMO, we directly used the LLM, GPT-4o, to evaluate the sample plans by following the same steps as in manual content analysis. As illustrated in Figure 1B, RAG involves linking the LLM to the actual planning documents, enabling it to retrieve the most relevant information regarding the policies being evaluated, whereas MA LLM emulates teamwork, which allows a single LLM to take on different roles and collaborate to carry out the complex tasks involved in plan evaluation. The fourth approach, MA RAG, seeks to leverage the strengths of both methods by combining RAG with multi-agent frameworks. It should be noted that the temperature 5 was set to zero in all approaches to minimize randomness and ensure consistency in the AI-generated outputs. The prompts for the three different tasks were iteratively tested and finalized in the LLMO approach, and these exact same prompts were then used in other approaches to ensure comparability across the differing approaches. Technical details about these methods can be found in Supplemental Appendix A, including the four different approaches, respective prompts, and source codes. This ensures that cutting-edge planners can adapt and implement these techniques in their own work.
Performance Evaluation
To evaluate and compare how well each technique performs in automating the content analysis tasks, we applied the commonly used percentage agreement as the primary measure largely because of its simplicity and ease of interpretation. Percentage agreements were used to measure the performance of different techniques across two dimensions: (1) consistency and (2) accuracy. It is important to note that each technique was run five times to assess how consistently they produced outcomes since LLMs are nondeterministic models, with each run yielding slightly different results. The multiple runs would help calibrate how consistently a technique can produce reliable results. For details, please refer to the Supplemental Material, which documents both the human evaluation results and the outputs from AI across all runs.
The consistency score for each technique was calculated based on the average percentage agreement between all ten possible pairs from the five runs. For the accuracy score, we calculated the average percentage agreements between each of the five runs and our manual results, considered as the “ground truth” here. In short, the consistency score denotes how consistently a technique can perform, and the accuracy score denotes how well a technique can produce reliable results comparable with those from human manual evaluation. It should also be noted that we computed the accuracy scores for the second and third tasks (i.e., categorization and policy scoring) based only on the policies that were agreed upon by both the machine and human evaluators. This is because the machine might falsely include a non-qualified policy, and its categorization and policy scoring results cannot be benchmarked against human results. Additionally, we also conducted one-way analysis of variance (ANOVA) tests followed by Tukey’s HSD tests to statistically compare the performance in terms of both consistency and accuracy between the different models. The detailed results can be found in Supplemental Appendix B.
Besides assessing consistency and accuracy, we also scrutinized what might have contributed to the discrepancies between the results generated by machine and human evaluation. This was possible because we purposefully asked the LLM to provide reasons for all the tasks so that we could later evaluate its simulated reasoning and the evidence given to unveil any underlying patterns or biases. To this end, we could identify specific areas where the machine’s logic diverged from human judgment.
Our approach for coding the errors involved a systematic process to identify and categorize such discrepancies. First, we compared the AI-generated results with the human manual results which is also treated as the “ground truth.” We then scrutinized these discrepancies and analyzed the underlying reasons for the errors through inductive coding, allowing patterns to emerge from the data. Lastly, we conducted a thematic analysis by grouping similar errors together, identifying common patterns, and therefore deriving the respective error categories. The detailed analysis allowed us to pinpoint the exact factors contributing to discrepancies, such as differences in contextual understanding, or interpretation of nuanced information. This thorough approach not only highlighted the strengths and limitations of the LLM but also provided valuable insights for improving its performance and alignment with human evaluative standards.
Results
Benchmarking LLM in Plan Evaluation
Overall, as shown in Figure 2, the LLM generally performed well in evaluating plans by providing consistent outputs as well as accurate answers in line with human manual evaluations over the five different runs. Summary statistics for the performance scores by task and model are provided in Supplemental Appendix B. When comparing the different techniques, MALLM performed the best in terms of both consistency (mean: 0.96) and accuracy (mean: 0.91), both of which exceed the acceptable percentage agreement of 0.80 by large margins, suggesting very high intercoder reliability (Stevens, Lyles and Berke 2014). This is followed by MARAG, with an average consistency score of 0.94 and an accuracy score of 0.86. LLMO and RAG were less reliable, with average consistency scores of 0.92 and 0.91, and accuracy scores of 0.79 and 0.81, respectively. When we used these high-level results for the ANOVA and Tukey’s HSD tests (Supplemental Appendix C), we found that the multi-agent framework could significantly improve both the consistency and accuracy of the LLM’s results in plan evaluation (p < .05), whereas the RAG might have no or negative influence on the LLM’s performance in this case (p < .05).
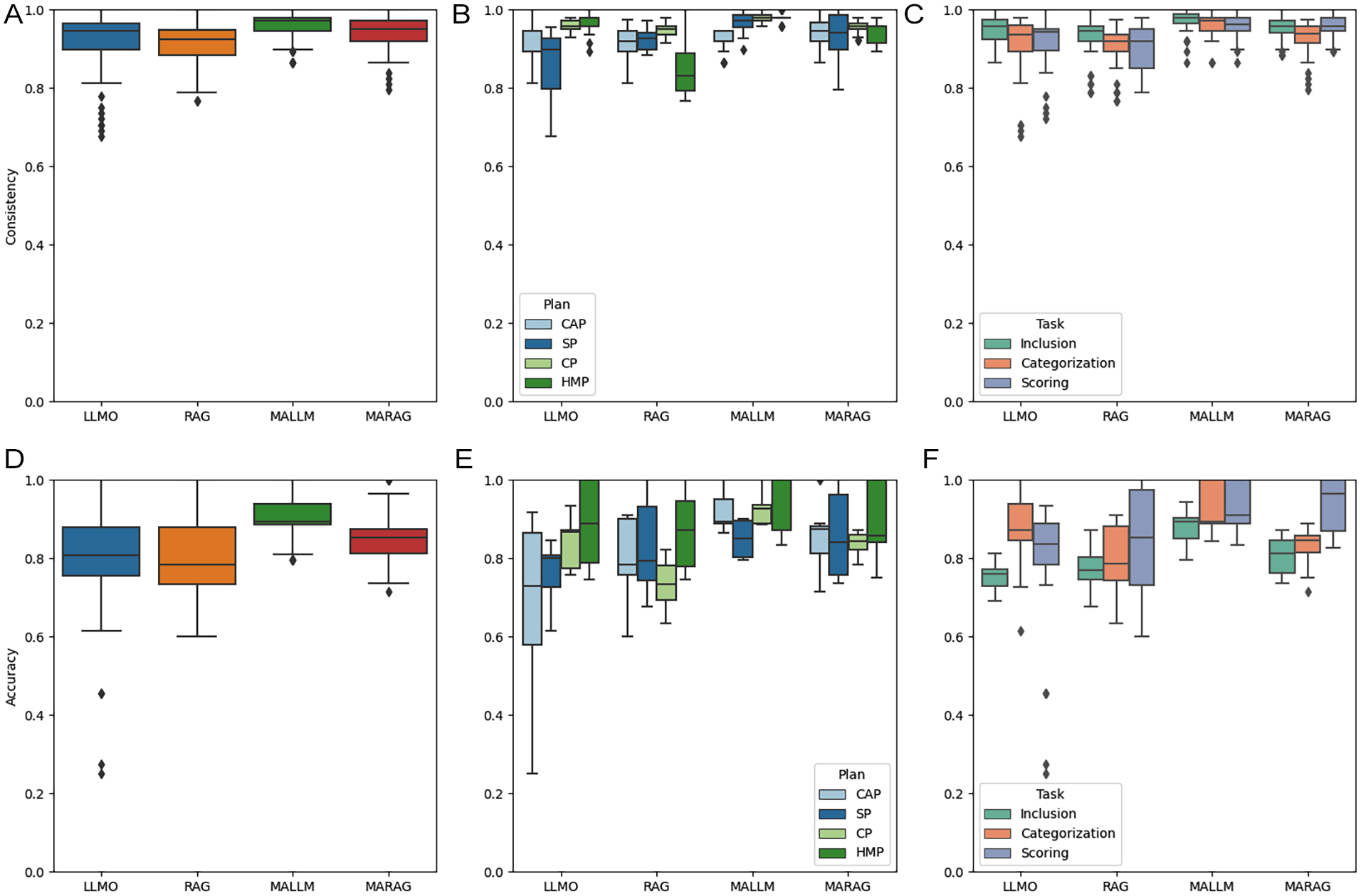
Boxplots of performance for consistency (A), (B), (C) and accuracy (D), (E), (F) using different LLM methods.
Additionally, a technique that can be applied at scale heavily relies on its robustness, often indicated by its performance range and lower bounds (LB) across different contexts. Using the LLM only (LLMO) exhibited the worst robustness, with the widest range and the lowest floor score for both consistency and accuracy. When comparing its performance by the plans and different tasks involved, we found that LLMO did not perform consistently when evaluating the SP (range: 0.69–0.96), categorizing (LB: 0.69), and evaluating policy scores (LB: 0.72). The LLM by itself also performed very poorly in terms of accuracy, particularly for evaluating the climate action plan (range: 0.25–0.92), conducting policy categorization (LB: 0.25), and evaluation (LB: 0.62). Thus, these results suggest that using the LLM by itself is not robust in content analysis, which aligns with a previous study that used ChatGPT, the earlier version of GPT-3.5 Turbo, to evaluate ten climate change plans and found an average accuracy score of 0.68 (Fu, Wang and Li 2024).
When augmenting the LLM, we found that the multi-agent framework significantly improved its performance and robustness, while RAG had no effect or an adverse effect. Specifically, while MALLM and MARAG yielded better performance and robustness compared with LLMO, incorporating RAG with LLM made no significant difference. When compared with MALLM, MARAG degraded the overall performance (p < .05) across almost all plans and tasks.
Uncovering LLM’s Discrepancies
In the following, we first explore the discrepancy patterns for each of the three distinct tasks. Task 1 requires a model to evaluate a policy against the given criteria, whereas task 2 involves labeling based on categories, and task 3 requires marking a policy based on its effects. These varying requirements underscore the importance of understanding how the specific nature of each task impacts the model’s performance and contributes to discrepancies. We then compare these error patterns across the different tasks using the varying LLM techniques to further investigate how they influence the types and frequencies of errors. Table 3 summarizes the error distribution across the different tasks using the four LLM techniques, highlighting the variability in error patterns as well as the strengths and limitations of each technique. The values represent the total number of errors, summed across the five runs, and categorized into four primary error types. It is important to note, despite the differences among the tasks, our inductive error pattern analysis uncovers four common types of errors: overimplication, logical inconsistencies, lack of expertise, and contextual errors. The following analyzes these errors for the respective tasks by examining the rationale and supporting evidence provided by the LLM and identifying the specific errors associated with each technique.
Error Distribution across Different Tasks and Methods.
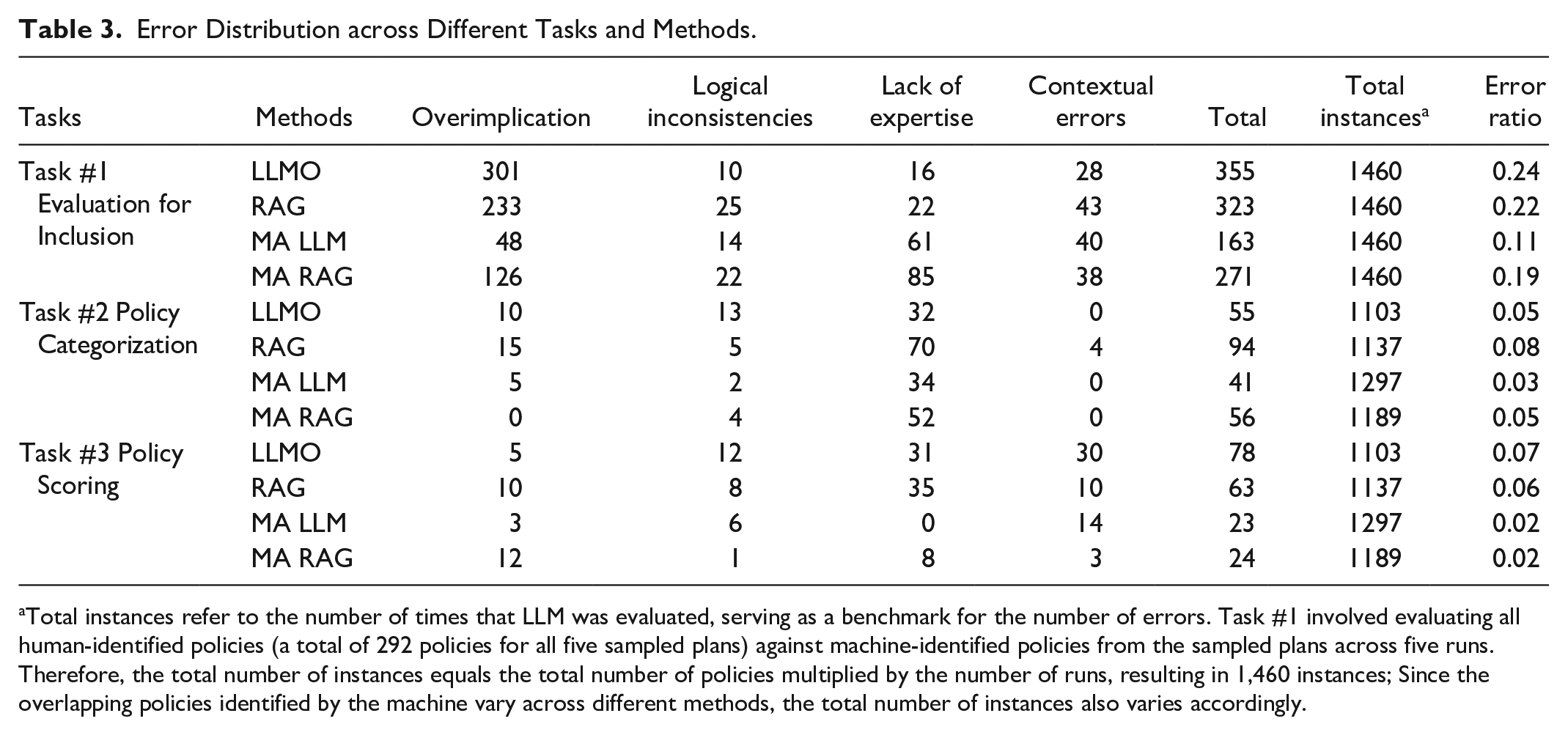
Total instances refer to the number of times that LLM was evaluated, serving as a benchmark for the number of errors. Task #1 involved evaluating all human-identified policies (a total of 292 policies for all five sampled plans) against machine-identified policies from the sampled plans across five runs. Therefore, the total number of instances equals the total number of policies multiplied by the number of runs, resulting in 1,460 instances; Since the overlapping policies identified by the machine vary across different methods, the total number of instances also varies accordingly.
Evaluation for Inclusion
As shown in Table 3, overimplication is the most dominant error for the first task, accounting for 708 of 1112 total errors (64%), regardless of the applied technique, which is followed by lack of expertise (17%), contextual errors (13%), and logical inconsistencies (6%). The predominant error pattern of overimplication suggests that LLMs tend to overextend their simulated reasoning to arrive at exaggerated conclusions. Using the representative examples presented in Table 4, when assessing the policy “Eliminate homelessness,” the LLM overimplied by assuming that incorporating greening solutions into housing and shelter would also mitigate urban heat island effects. This exemplifies a common source of error, where the machine often overimplies by identifying policies as relevant to urban heat island effects, whereas humans reasonably excluded such policies without making unsubstantiated assumptions.
Examples of Error Reasons for Task #1 Evaluation for Inclusion.
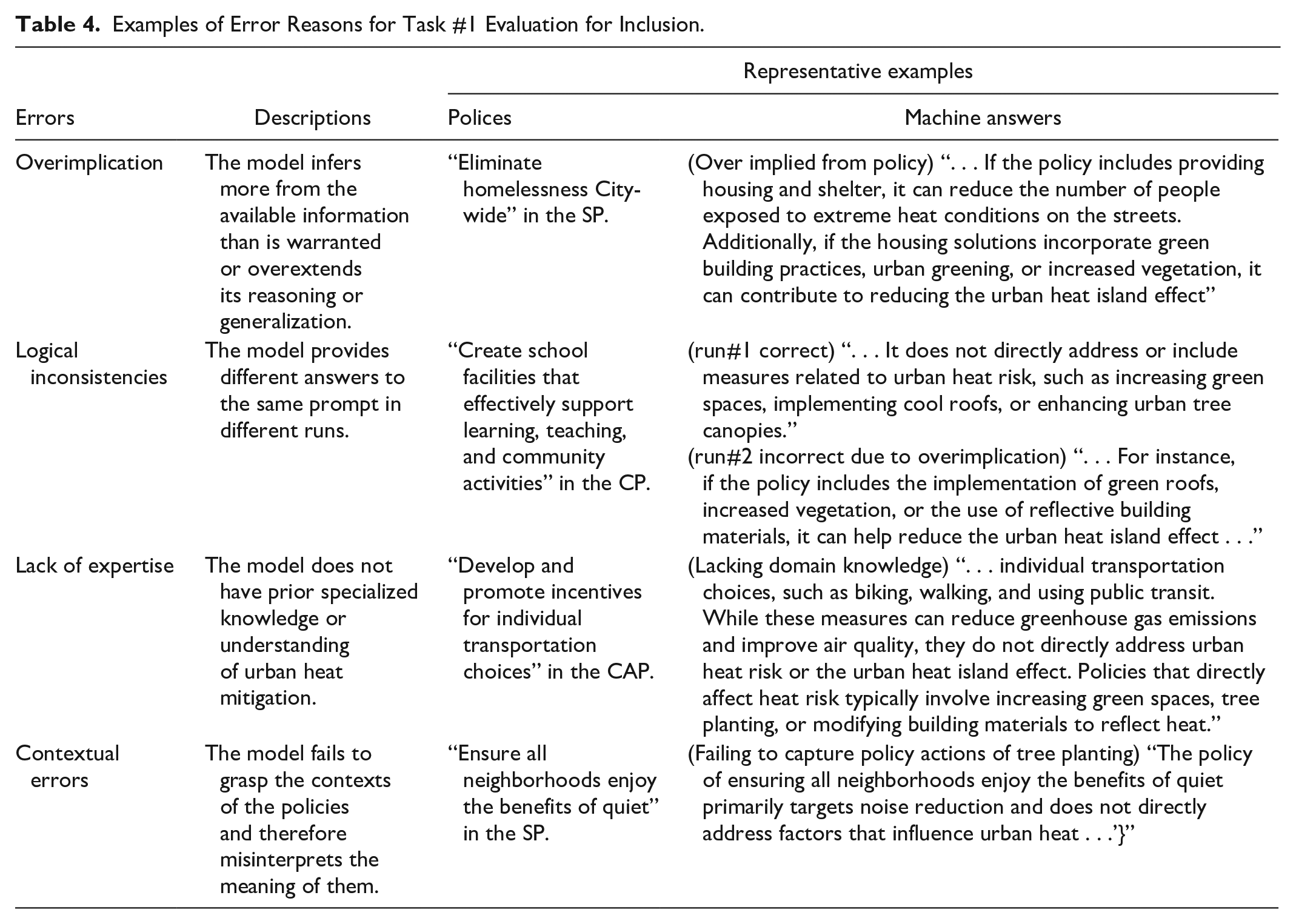
Another machine error is that the LLM sometimes incorrectly analyzed policy relevance due to a lack of domain knowledge—in this case, extreme heat mitigation—and limited contextual understanding of the policies. For example, the LLM considered the policy “Develop and promote . . . individual transportation choices” as irrelevant to extreme heat because it did not involve green spaces, tree planting, or building materials. This largely reflects the LLM’s understanding of relevant heat mitigation strategies. However, according to the sampled study (Keith et al. 2023), promoting public transportation options that reduce private vehicle ridership and associated waste heat is considered a heat mitigation strategy.
Additionally, the LLM struggled to correctly analyze policy relevance when the policy was provided by itself without sufficient context or additional descriptions. For example, when evaluating the policy “Ensure all neighborhoods enjoy the benefits of quiet,” the LLM considered it irrelevant. This assessment was not incorrect when considering the text alone, but in fact, the plan included actions under this policy that emphasized the need for tree planting, a critical heat mitigation strategy that the LLM failed to recognize due to its lack of contextual awareness. This highlights the model’s challenges in interpreting implicit connections and contextual details, which are essential for conducting a more nuanced and comprehensive analysis in plan evaluation.
In other cases, LLMs can fail to provide consistent answers across multiple runs, that is, identifying a policy as relevant in some runs yet irrelevant in others. For instance, when evaluating the policy “Create school facilities” (Table 4), the LLM considered the policy irrelevant to urban heat risk in one run but relevant in another run, assuming the policy could include green roofs. While the error patterns within logical inconsistencies were similar to the LLM’s overall error patterns, we categorized this separately due to the nondeterministic nature of LLM models. In addition to the overimplication example above, other errors within this category resemble those found in the other categories described below.
Policy Categorization
When labeling the respective relevant policies into given heat mitigation categories, the LLM primarily made errors in assigning policies to the most appropriate category (i.e., lack of expertise; 76%), particularly in cases where several of the established policy categories were closely related. Although we provided the LLM with the established heat mitigation categories and their detailed definitions (developed by Keith et al. 2023), it was unable to categorize them in the exact same way as humans. However, we, along with the authors of the sampled research (Keith et al. 2023, 5), acknowledge that the policy categories are not mutually exclusive, as many policies could reasonably fit into multiple heat mitigation strategies. Hence, the majority of such errors are associated with mislabeling between closely related categories such as “land conservation,” “green stormwater infrastructure,” “urban forestry,” “vegetated parks and open space,” and “water features” categories.
For example, when categorizing the policy “Expedite housing renovations, demolitions, and greening efforts to increase the number of thriving, safe neighborhoods,” the LLM categorized it as “vegetated parks and open space” because (machine-generated response) the policy includes actions such as strategic demolitions, transferring vacant properties for rehabilitation, and increasing code enforcement. . . (which) align with the subcategory of ‘vegetated parks and open space’ as they aim to create and maintain green spaces, improve environmental conditions, and enhance the overall livability of neighborhoods.
However, we labeled this policy as “urban forestry” because it was more focused on planting trees at granular neighborhood scales in an urban setting rather than the other category that emphasized the larger scale network of green spaces.
Other errors followed a similar pattern, where the LLM labels a policy under a category that was close to but different from the human-labeled category. Such nuanced reasoning highlights the importance of context-specific interpretation and understanding the intent behind policy actions, a capability that general-purpose LLMs generally lack. We also admit that in some of these error cases, policies could be reasonably labeled into multiple categories. If we were to relax the constraint of assigning a single distinct category as correct, the LLM’s performance would then be quite promising.
Policy Scoring
When evaluating the policies for their impacts on urban heat risks, the LLM suffers from the same error patterns as previously discussed. Scoring a policy for its potential impacts on extreme heat risk involves similar reasoning and thinking as in the first task of analyzing the policy’s relevance to urban heat islands but includes an additional step of scoring based on criteria (e.g., 1 for policies that can mitigate heat risk).
Scrutinizing the actual errors, we found that most of them were associated with a lack of expertise and contextual errors, including those from logical inconsistencies. For example, “creating mixed-use neighborhoods to increase access to goods and services” is a policy that can increase the density of development for a more compact city and reduce the need for driving, both of which can contribute to the mitigation of urban heat risk. However, the LLM failed to reason this way, stating that “mixed-use neighborhoods focus on accessibility and convenience, with no direct impact on urban heat” due to a lack of expertise on this topic.
Another common error stemmed from a lack of contextual understanding. For example, when evaluating the policy “encourage changes to road maintenance and construction materials based on anticipated changes in climate,” the LLM often provided the answer as unknown, arguing that the policy fails to provide “specific details on the types of materials and methods to be used” and is therefore unable to determine the direction of the impact on urban heat. Similarly, as in other tasks, the LLM often did not have access to the planning document, except for when RAG was implemented, so it is understandable when it questions the lack of details in arriving at decisive conclusions. However, incorporating RAG does not necessarily appear to improve overall performance in this study, and we aim to shed light on the reasons by comparing the various LLM techniques used and their respective error patterns in the subsequent section.
Comparing across LLM Techniques
In this section, we aim to further contextualize the results with examples and better explain the differing performance levels between the LLM techniques as discussed above. In summary, there is almost no statistically significant difference between using the LLM only (LLMO) and using the LLM with RAG (RAG) across the tasks for both consistency and accuracy (Table 3 and Supplemental Appendix C). Incorporating the multi-agent framework with LLM (MALLM) improves its performance as compared with LLMO and RAG also almost across the board, but when the multi-agent framework is combined with RAG (MARAG) it can degrade the LLM’s performance. This is partially counterintuitive, as we assume that incorporating RAG can improve the LLM’s performance by allowing the model to access and incorporate relevant information from the planning document, thereby enhancing the accuracy and relevance of the generated responses.
By inspecting the errors from using RAG, we realize that the additional context provided by RAG does not necessarily improve the LLM’s understanding of the policy and can often worsen its ability to generate correct answers due to the noise introduced by the additional texts. For example, when evaluating the policy “Meet the goals of Baltimore’s noise ordinance by reducing overall noise levels” in the sustainability plan, both RAG and MARAG falsely identified this policy as relevant to urban heat island effects (task 1) by highlighting the action of tree planting as part of this policy. However, this tree planting action is actually part of the subsequent policy, not the one both indicated. This error is a clear example of the methodological limitation of RAG, which relies on retrieving and integrating text chunks that may introduce irrelevant or misleading information. Such errors are particularly pronounced for plans similar to the sustainability plan, which has a policy section with all policies in one place. Hence, when setting up the RAG system, this plan is split into text chunks, and the policy chunks will likely include multiple policies. As a result, when retrieving the most relevant chunks, they will still contain irrelevant or even misleading information (as exemplified above), leading to inaccurate answers.
When comparing the answers between MALLM and LLMO, we found that the multi-agent framework generally improves the LLM’s performance primarily in two ways. First, the multi-agent framework significantly improves the LLM’s ability to “reason” by reducing errors mainly in overimplication. For example, the LLMO overimplied by identifying the policy “Leverage CIP resources in targeted areas using the neighborhood plans” in the comprehensive plan as relevant to urban heat island effects. The provided explanation was that “CIP projects could include the development of green spaces, tree planting, and the installation of cool roofs or reflective pavements, all of which can help mitigate the urban heat island effect.” In comparison, both the two agents and the supervisor in the MALLM correctly identified this policy as being irrelevant because it “fails to explicitly mention any measures that directly affect urban heat risk. Therefore, it is not clear that this policy would directly impact the urban heat effect.” The reasons behind the change in the model’s behavior with the incorporation of the multi-agent framework are currently unclear, since both the LLM and MALLM used almost identical prompts and LLM models. Future research could further explore this mechanism.
The second way MALLM improves performance is by reducing instances of logical inconsistencies. This is achieved by involving multiple agents working collaboratively in a team setting, as evidenced by the significantly enhanced consistency over multiple runs compared with all other methods (p < .05).
Discussion and Conclusion
Key Takeaway Findings
This study explores and demonstrates how LLMs can be used to automate content analysis tasks by replicating a published plan evaluation study that involves complex content analysis tasks, domain-specific understanding, and a variety of planning documents. To the best of our knowledge, this is the first study to investigate whether, and to what extent, different cutting-edge augmentation techniques can improve LLM’s performance in comparison with manual results.
Our research offers several key findings: first, benchmarking different LLM techniques, including LLM only, LLM and RAG, multi-agent LLM, and multi-agent RAG, against manual content analysis shows that LLMs, particularly when integrated with a multi-agent framework, demonstrate great potential for automating plan evaluation tasks. In this study, which involved three content analysis tasks applied to four different planning documents across five runs, the multi-agent framework improved the baseline LLM’s performance by 4.3 percent (from 0.92 to 0.96) in model consistency and by 13.8 percent (from 0.80 to 0.91) in result accuracy. Notably, the multi-agent framework reduced the common errors of using the LLM only by over 50 percent (from 126 to 58 total errors).
Given that an acceptable percentage agreement of at least 0.8 is commonly accepted in the plan evaluation literature (Stevens, Lyles and Berke 2014), our results suggest that the multi-agent LLM surpasses this threshold in both consistency and accuracy. Overall, our findings indicate that the multi-agent LLM approach offers clear improvements in sophisticated plan evaluation tasks over single-agent methods previously explored (Fu, Wang and Li 2024) and highlight the potential of multi-agent frameworks to enhance the reliability and applicability of LLMs in future planning research and practice.
While our benchmarking results show high intercoder reliability between manual and machine evaluations, we argue that AI techniques should not fully replace humans in such analysis. However, we advocate for the routine inclusion of AI as a companion coder in future studies, because such techniques can significantly improve the replicability and robustness of human-generated results, even when best practices are followed. This is particularly valuable when the content analysis involves evaluating complex documents with highly sophisticated protocols often in plan evaluation studies that can challenge human coders, leading to errors or omissions of key information (Loh and Kim 2021). Admittedly, our sample size is relatively small, but this was a deliberate decision to balance an appropriate sample size and diversity with the practical feasibility of the research (i.e., analyzing four distinct methods, each with five runs on complex text analysis tasks). Future research should build on this pilot work by incorporating larger and more diverse datasets to further test and explore the rapidly advancing capabilities of LLMs in content analysis across different contexts, tasks, and materials, thereby continuing to benchmark their general applicability and reliability.
Additionally, incorporating RAG did not consistently improve the LLM’s performance and, in many cases, introduced additional noise that undermined input quality and output accuracy (i.e., garbage in, garbage out). Our error analysis suggests that this is largely due to the technical limitations of the RAG methodology, which involves truncating plans into text chunks and retrieving the most relevant chunks based on text embedding. Although designed to enhance contextual understanding, this process often introduces irrelevant or even misleading information, such as policies and actions immediately before or after the target content within the same text chunk. When these chunks with noise are retrieved and fed to the LLM for analysis, they distort contextual interpretation and degrade overall performance. This finding also resonates with Loh and Kim’s (2021) finding that trained and untrained human coders introduced different structural biases when evaluating plans, like how RAG can introduce external “expertise” that may lead to unwanted biases in LLM outputs. Future research should focus on improving the relevance and precision of retrieved information to reduce noise and fully realize the potential of this approach.
Last, our detailed error pattern analysis reveals that LLMs, even advanced models like GTP-4o, are subject to common errors such as overimplication, logical inconsistencies, and contextual misunderstandings. These errors provide the needed evidence for future research directions to further improve the model’s overall performance. For example, future research may refine prompts to minimize overimplication, apply a multi-agent framework to increase result agreement and reduce inconsistencies, use more advanced RAG methods (e.g., combining RAG and knowledge graph) to improve contextual understanding, and/or fine-tuning models for domain-specific tasks. While these strategies have the potential to reduce errors, their actual effectiveness remains uncertain. Additionally, LLMs are rapidly advancing with frequent updates, but existing models such as ChatGPT remain black-box algorithms, making it difficult to fully understand or predict their internal reasoning mechanisms and processes. This opacity, combined with the linguistic drift—the evolving behavior of the model over time as it is continuously updated (Chen, Zaharia and Zou 2024)—raises ongoing concerns regarding consistency and reproducibility that are critical for research tasks such as content analysis in plan evaluation.
Implications for Plan Evaluation
The promising results of this research hold transformative potential for plan evaluation research and the broader plan quality literature, which has long faced criticism for its fragmented research landscape, sporadic focus, and limited scalability (Berke and Godschalk 2009). When applied properly, LLMs can improve existing plan evaluation research by enabling consistent, scalable, and efficient content analyses across larger datasets and with greater frequency.
LLMs can reduce the time and resources required for manual analysis and uncover patterns and insights that might otherwise be overlooked by human evaluators, particularly in larger samples involving complex coding protocols (Loh and Kim 2021). They also hold the potential to bridge gaps in the literature by enabling comparative plan evaluation studies across regions, plan types, and languages, thereby fostering co-learning and knowledge co-production on a global scale (Reckien et al. 2018; Salvia et al. 2021; Sietsma, Ford and Minx 2024). For instance, LLMs could support cross-country analyses of specific types of plans (e.g., heat action plans) and facilitate international comparisons, tasks that were previously highly challenging for human coders alone. It is also important to note that plans are often stored by individual localities or jurisdictional entities, rendering the collection of plans for such comparative studies an extremely onerous task. Data infrastructure like the Adaptation Clearinghouse (Georgetown Climate Center, n.d.) and the California General Plan Database (Poirier et al. 2024) are needed to enable broader access to planning documents and facilitate large-scale plan evaluation research.
Despite the promising results, challenges and limitations remain in the adoption of LLMs in both planning research and practice. A primary concern is the inherent nondeterministic nature of LLMs, which leads to performance variability across runs and may undermine trust in their use. While we acknowledge the need for deterministic results and reproducibility for LLMs to be reliable and trustworthy, it is also important to note that human coders rarely produce identical results even when best practices are followed, especially as tasks become more complex and time-consuming. However, as long as intercoder reliability reaches a certain acceptable level, the results are generally considered reliable.
We contend that the best practice for reproducing content analysis tasks, particularly for complex plan evaluation studies, is to integrate AI alongside human coders. AI excels at processing large volumes of data efficiently, is capable of simulating reasoning over complex texts involving sophisticated tasks, but it often lacks the specialized knowledge required to interpret nuanced meanings and apply domain-specific contextual judgments like human experts that are critical for rigorous content analysis. While human coders are often considered the gold standard for content analysis due to their contextual understanding and domain expertise, they are also subject to several limitations, including biases, difficulty capturing details in complex documents, and an increased likelihood of errors due to fatigue (Kleinheksel et al. 2020; Loh and Kim 2021; Potter and Levine-Donnerstein 1999). Prior research has shown that even with efforts to improve intercoder reliability, human coders can introduce inconsistencies and biases into manual labeling and coding, particularly in tasks requiring sophisticated subjective judgment and interpretation (Fu, Wang and Li 2024; Loh and Kim 2021; Lore, Harten and Boeing 2024). In our study, for example, policies that could fit into multiple categories often led to differing interpretations between human coders, requiring further discussions to reach agreement.
A combined approach harnesses the strengths of both AI and human expertise, significantly enhancing the replicability and robustness of the analysis. AI can efficiently handle repetitive and tedious tasks, reducing the cognitive load on human coders and minimizing errors due to fatigue or oversight. Meanwhile, human coders provide the contextual understanding and domain-specific knowledge that AI currently lacks. Together, this synergy enables higher accuracy and consistency in content analysis, ensuring that the results are both reliable and trustworthy.
Finally, it is crucial to clarify the role of human involvement in plan evaluation when incorporating LLMs and other automated tools. At this stage, human input remains indispensable for guiding plan evaluations toward topics of interest and developing theory-based evaluation protocols. Human efforts are also vital for fostering community engagement in the evaluation process (Brinkley and Wagner 2024). To improve efficiency and reduce costs, planners might consider integrating human coding with the support of LLMs. LLMs can serve as a secondary coder (Fu, Wang and Li 2024), assisting with content analysis while human coders oversee the process, especially by reviewing and resolving discrepancies between human and LLM-generated results to ensure accuracy. When working with a large volume of plans, planners might begin with a subsample to assess the performance variance of LLMs across different tasks or coding items. Based on this assessment, coding tasks could be allocated according to LLM performance. For example, LLMs could handle relatively simple items where they demonstrate high accuracy within the subsample, while human coders focus on more complex or nuanced items that require higher levels of contextual understanding and judgment.
In the context of integrated human-AI collaboration, there is a growing need for future planners to develop hybrid competencies that combine traditional skills (e.g., theoretical grounding, content analysis), with emerging technical proficiencies in LLMs. Planning education needs to be adapted by introducing training on foundational knowledge of AI tools such as LLMs as well as their effective use, including prompt engineering and basic coding skills. This hybrid skill set will better equip future planners to navigate the evolving professional landscape of planning practice, where emerging technology increasingly complements traditional methodologies.
Supplemental Material
sj-docx-1-jpe-10.1177_0739456X251372082 – Supplemental material for Automating Plan Evaluation Using Agentic Large Language Models
Supplemental material, sj-docx-1-jpe-10.1177_0739456X251372082 for Automating Plan Evaluation Using Agentic Large Language Models by Xinyu Fu and Chaosu Li in Journal of Planning Education and Research
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.