
Abstract
Identifying policy topics from lengthy text documents such as official reports is an important analytical task for policy evaluation purposes; yet it is a time-consuming process if done manually. Advanced Natural Language Processing (NLP) models such as Bidirectional Encoder Representations from Transformers (BERT) model and other emerging Large Language Models (LLMs) have demonstrated the capability to capture semantic meanings within sentences. However, BERT-based models require substantial expert-labelled training data for fine-tuning for optimal performance, whereas off-the-shelf LLMs provide greater flexibility but tend to overgeneralise. This paper aims to (1) demonstrate three NLP/LLMs methods (fine-tuned BERT, with 10,000 manually labelled sentences; standard GPT-4o; and GPT-4o with in-context learning, with five example sentences provided for each policy domain) for identifying planning policies from planning documents at sentence level and (2) assess the accuracy of NLP/LLMs in policy identification, using 2,000 manually identified results by planning experts as the benchmark. Our results demonstrate that policy identification can be performed effectively and accurately when in-domain labelled training data is available, achieving a high out-of-sample accuracy of 92.50%. However, the time and labor cost of manual labelling is significant. In cases where in-domain training data is lacking, LLMs can still achieve a notable accuracy of 72.50%, which improves to 87.75% when given a small number of examples and 89.00% with role-prompting that guides the model to act as an urban planning research expert. We applied this method to analyse policy priority across 1,026 official government annual reports for both the national level and across 113 prefecture-level cities in China between 2011 and 2019. We found significant divergence between national and local planning policies and cross-city heterogeneity in planning policies.
Introduction
Planning documents encompass a wide range of policy domains, including transport, land use, and public services. These documents outline plans and decision-making at national and local levels, with many essential decisions directly impacting citizens’ lives. Reading and evaluating these documents provide valuable insights that help planners and policymakers ensure policies meet objectives, identify areas for improvement, and guide future planning decisions. However, the sheer volume, length, and often redundant nature of planning documents make evaluation challenging. For instance, a typical government annual report in China is around 12,500 words, and many general plans in the UK span hundreds of pages long, as such they are rarely read in full. The task becomes even more challenging as planners need to analyse past reports while processing new information to stay aligned with national and international best practices. To address these challenges, identifying policy domains accurately and efficiently within planning documents is essential. This allows planners to filter relevant content, conduct in-depth analysis, and compare policies systematically, enhancing the decision-making process.
Traditional methods, such as manual content analysis, require human reviewers (often experts in their field) to read and label documents. This process is not only time-consuming but also subjective, making it prone to biases and errors. In recent years, advanced natural language processing (NLP) models, such as Bidirectional Encoder Representations from Transformers (BERT) and other emerging large language models (LLMs), have demonstrated the ability to capture semantic meanings in text. However, concerns have risen regarding the reliability of the results for these models (Fu et al., 2023). BERT-based models typically require substantial expert-labelled training data for fine-tuning to achieve optimal performance, while off-the-shelf LLMs offer greater flexibility but risk overgeneralising. LLMs with in-context learning, which incorporate subject-specific examples, can further enhance performance for context-dependent tasks. Thus, for the policy identification task, planners and policymakers face two major challenges: (1) how to use NLP/LLMs tools to identify planning policies from lengthy documents and (2) how to assess and compare the accuracy of these tools.
This paper addresses the challenges by (1) introducing an approach for identifying planning policies from planning documents at the sentence level, using three NLP/LLMs methods (fine-tuned BERT, with 10,000 manually labelled sentences; standard GPT-4; and GPT-4o with in-context learning, with five example sentences provided for each policy domain) and (2) assessing the accuracy of NLP/LLMs when applied to policy identification purposes, compared with manually identification results. We applied these methods to analyse policy priorities across 1,026 official government annual reports for both national government and 113 cities in China between 2011 and 2019. The whole dataset includes 0.69 million sentences in total.
This paper makes two contributions to existing literature. Firstly, we introduced an analytical framework for policy identification that integrates human expertise with algorithmic processing by categorising sentences into predefined policy domains. Secondly, our findings demonstrate a high level of accuracy when applying NLP and LLMs to facilitate the policy identification task. Our results demonstrate that: (1) policy identification can be performed effectively and accurately when in-domain labelled training data is available, for example, using fine-tuned BERT we achieved out-of-sample accuracy of 92.50%; (2) even without a large base of in-domain training data, LLMs (GPT-4o) can still achieve an accuracy of 72.50% in zero-shot learning, 87.75% accuracy is achieved when provided with just five examples for few-shot learning, and further improved to 89.00% with role-prompting that guides the model to act as an urban planning research expert; and (3) aggregating sentence-level predictions, such as calculating the ratio of policy-relevant sentences to total document length, enables a comparative analysis of policy emphasis across governmental levels and functions.
The remainder of this paper is structured as follows: Section 2 provides background information on conventional methods and NLP/LLMs approaches. Section 3 outlines the data and methodologies used in this study. Section 4 presents the model results, followed by a discussion in Section 5. Section 6 provides the conclusion.
Literature review
Conventional approach for policy identification
The conventional approach to identifying topics relies on qualitative content analysis, where experts manually review urban plans to infer topics or themes. However, due to the reliance of human-expert input, this method is subjective and therefore prone to biases and errors (Compton et al., 2012; Krippendorff, 2018; Stevens et al., 2014). Reducing bias requires multiple expert reviews, making the process time-consuming and costly. An alternative quantitative approach is the dictionary (lexicon-based) method, where researchers specify a set of terms related to the topic or domain of interest, allowing each document to be represented by the frequency of matched terms. This approach has been widely used (Bao and Liu, 2022; Liu et al., 2021; Wang et al., 2024a), but it fails to capture contextual meaning and this challenge is particularly pronounced in urban planning, where terms can have ambiguous meanings depending on the context. For instance, the term ‘park’ might refer to a car park in a transportation context but refer to greenspace for leisure in an environmental context. Such ambiguities highlight the difficulty of capturing nuanced meanings through word-based analysis alone.
Moving beyond conventional dictionary approaches, numerous studies have attempted to employ algorithms to automatically detect topics within texts, with topic modelling being a widely adopted method. Topic modelling automates the identification of latent topics and the associated words within a corpus. For example, Fang and Ewing (2020) apply topic modelling to identify the main themes across 30 years of publications in planning and planning-related journals. Brinkley and Stahmer (2021) employ topic modelling to identify areas of emphasis across 461 city-level General Plans in California. Fu et al. (2022) compare topic modelling with manual content analysis regarding the extraction of key topics from planning documents. The authors found that topic modelling automatically and quickly extracts the main topics from large documents, although at the expense of omitting topics is deemed less important. Manual content analysis is more precise but add considerable labor and time costs.
A significant limitation of the unsupervised algorithms, such as topic modelling, is to reliably generate objective and interpretable topic labels (i.e., policy domains). Consequently, a single topic may encompass numerous keywords, which can also appear across multiple topics, leading to varied interpretations of the outputs. While these unsupervised learning methods are entirely data-driven – allowing researchers to explore corpus content without extensive prior knowledge – they may fall short when linking topics to specific and meaningful planning concepts or domains. This is further complicated by the model sensitivity to pre-processing and modelling choices. Therefore, a practical application of topic models is to serve as an initial filter to eliminate clearly unrelated content, after which more targeted methods can be employed to measure specific concepts within the remaining data. For example, Angelico et al. (2022) adopted this strategy to identify relevant tweets for assessing inflation expectations.
The use of advanced NLP and LLMs for policy identification
Supervised learning based on human automation
Unlike unsupervised learning, which relies solely on algorithmic processing, supervised learning integrates human insights by using expert-labelled data to train models. This approach aligns with contextual specificity and user intended requirements. A common method involves fine-tuning pre-trained language models like BERT, where a classifier head is added (specialised layer for classification tasks). Fine-tuning leverages human-labelled training data to update the model, enabling it to accurately predict labels and effectively scale human insights across a larger dataset. BERT achieves state-of-the-art performance on most standard NLP benchmarks and can be further improved for text classification through fine-tuning techniques. Real-world applications demonstrate the effectiveness of these techniques, such as categorizing hospitality reviews based on service quality and ambiance (Botunac et al., 2024) or analysing corporate climate goals and actions (Cenci et al., 2023). While these techniques are powerful, they require substantial labelled data for fine-tuning to achieve state-of-the-art results (Edwards and Camacho-Collados, 2024), which can introduce additional labor costs compared to using larger, pre-trained language models without task-specific adaptation. Human-labelled data also serves as a benchmark for evaluating dictionary performance and guiding term selection, further enhancing model accuracy and application (Jiang et al., 2024).
Large language models (LLMs)
In recent years, with access to extensive training data, larger model sizes, and increased computational resources, LLMs have been developed and deployed rapidly, especially since the public release of ChatGPT in late 2022. Unlike earlier NLP methods requiring extensive fine-tuning, modern LLMs (such as ChatGPT) generalize across tasks with minimal additional training, reducing the need for manual intervention. The surge in public and investor interest has accelerated advancements, with major tech firms and startups competing to develop the most advanced models. As a result of the fast-paced and iterative technological improvements, LLMs now can perform a wide array of language-related tasks with little or no task-specific data. Numerous recent studies explore their use in processing lengthy documents across various fields, including urban planning (Fu et al., 2023), economics (Gueta et al., 2024), and law (Trautmann, 2023; Wei et al., 2023). These efforts aim to process diverse data sources, such as government reports, survey responses, semi-structured interviews, website comments, and legal documents.
Despite their remarkable proficiency in processing textual information, concerns regarding the reliability and accuracy of LLMs remain largely unaddressed. In urban planning, Fu et al. (2023) concludes that ChatGPT cannot replace human experts when assessing plans. Therefore, in addressing the needs of planners and policymakers, NLP and LLMs tools are essential for alleviating the heavy workload and helping reduce subjective biases and errors. However, two critical questions persist: (1) How can tasks be effectively refined, and LLMs integrated with human expertise to enhance both reliability and accuracy? (2) Can the outputs of NLP and LLMs tools be considered trustworthy for decision-making?
Data and methods
Data source
Documents in this study, which form the corpus of textual data for national and local government annual reports, are sourced from official government websites. In China, both national and local governments are required to present annual reports at the beginning of each year, detailing the previous year’s performance and outlining plans for the year ahead. These reports serve as pivotal documents, reflecting government decisions and strategies, and are made publicly available on official websites to promote transparency and communication with the public. The consistent style and structure of the reports provide a valuable dataset for cross-city comparisons. The average length of the annual report is approximately 12,500 Chinese characters, making it a significant undertaking for experts to read and comprehend the entire document. Each report typically includes three sections: an introduction, a review of the past year, and a plan for the upcoming year. For this study, which focuses on the planning context, we specifically analyse the third section – the plan for the upcoming year as outlined at the time of the report. In cases where a few cities do not adhere to this three-section format, we manually select the relevant planning and forward-looking section for analysis.
The compiled dataset consists of 0.69 million sentences, covering both national government and 113 prefectural-level cities in China from 2011 to 2019. The selection of cities in the dataset was based on the availability of official reports. Our study period encompasses two Five-Year Plan periods in China: the 12th Five-Year Plan (2011–2015) and the 13th Five-Year Plan (2016–2020). In China, Five-Year Plans serve as national master plans, setting the comprehensive development strategy and guiding priorities over each 5-year period. The endpoint of our sample is set at 2019 to ensure consistent comparisons of planning strategies before the COVID-19 pandemic.
Policy domain identification
To benchmark three NLP/LLM methods against human performance in policy domain identification, we first created a comprehensive dataset by manually annotating 10,000 randomly selected sentences. This serves two purposes: (1) identifying policy domains and (2) creating a ground truth dataset for training and validation process. Details on each model are provided in the following subsections.
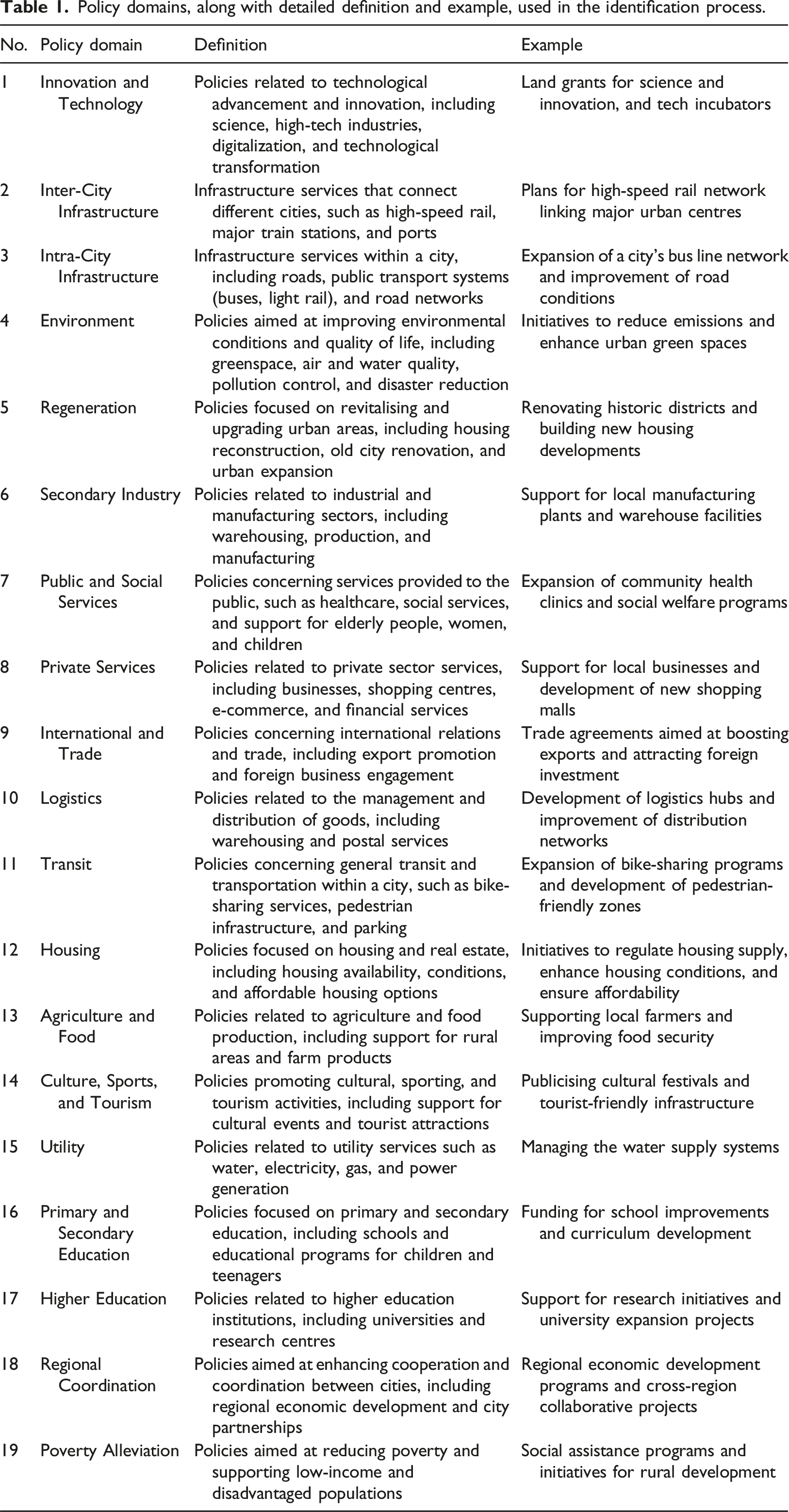
Policy domains, along with detailed definition and example, used in the identification process.
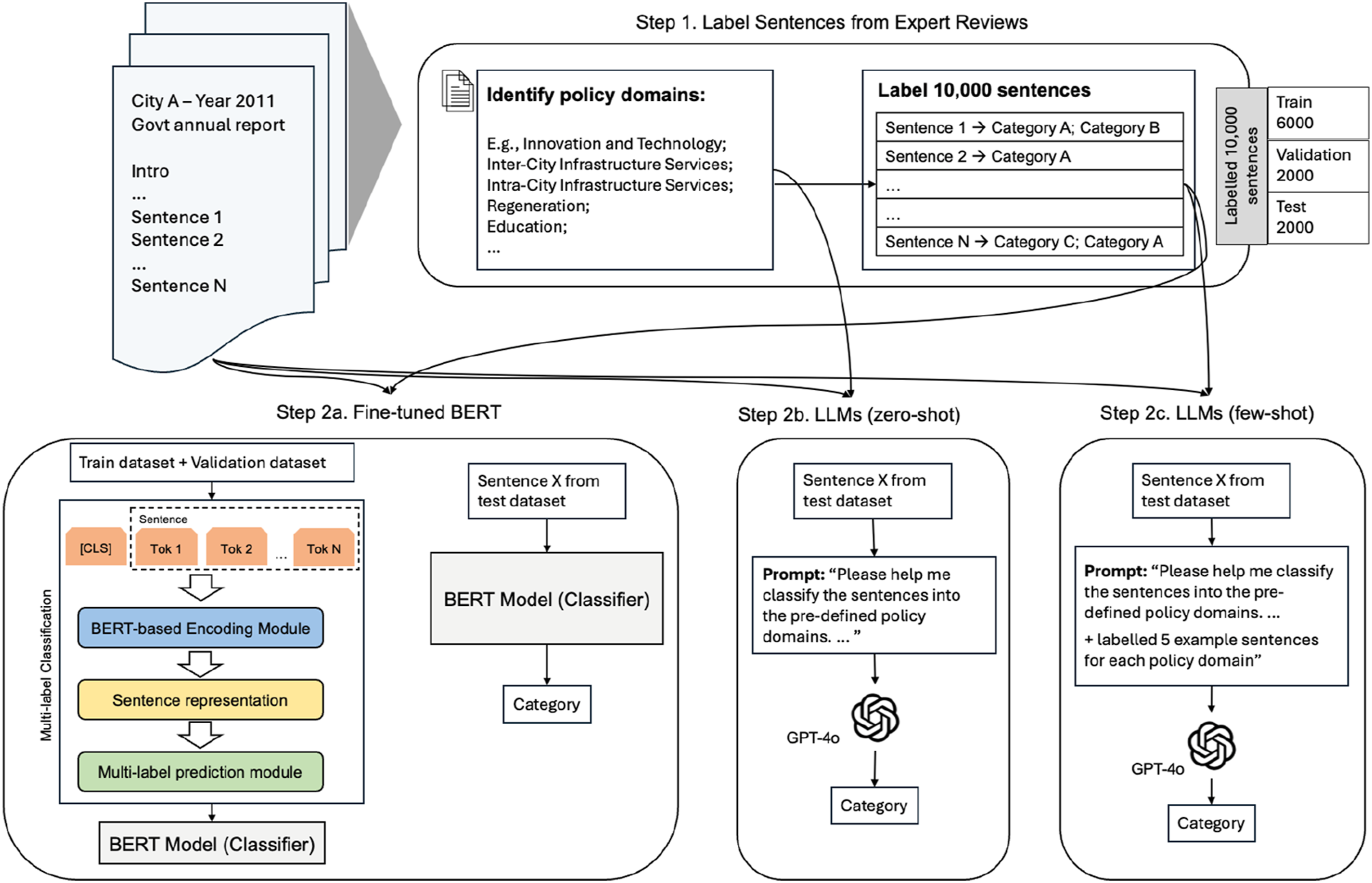
Overall analytical framework.
Fine-tuned BERT model
Next, we train a BERT-based classifier to categorise each sentence into the relevant policy domain(s) based on its semantic meaning. We utilised 6,000 expert-coded sentences as the training input, which will enable the model to learn from diverse examples; 2,000 expert-coded sentences for validation to tune model parameters and mitigate overfitting; and 2,000 expert-coded sentences for the test set to evaluate the model performance. Our multi-label classification model is designed to capture sentences that may simultaneously be classified into multiple policy domains, unlike traditional classifiers that only address one domain per sentence. For example, the sentence ‘Supporting reforms in school education, medical care, social security.’ encompasses multiple domains per our definition in Table 1, including Primary and Secondary Education, Public and Social Services. Since the policy documents are published in Chinese, we use BERT-in-Chinese 1 as the base model, which has been pre-trained on the Chinese language.
Off-the-shelf large language model using GPT-4o (zero-shot)
For the LLM workstream, we leverage GPT-4o (the latest version of Generative Pre-trained Transformer four omni developed by OpenAI in May 2024), to perform policy topic identification task. The implementation was straightforward, consisting of two steps: (1) establishing API access to the GPT-4o server and (2) defining the prompt for policy identification and generating output. We employed the off-the-shelf GPT-4o model with zero-shot learning to evaluate its ability to perform tasks without any training data, relying solely on its pre-existing knowledge. We set the temperature parameter to 0 to ensure output consistency and minimize result randomness, which aligns with the approach used in the recent study (Fu et al., 2023). To evaluate the model’s performance, we used a test set of 2,000 expert-coded sentences, consistent with the dataset used for the fine-tuned BERT model. To ensure the results were in a format suitable for direct comparison without requiring additional processing, we instructed the model, via the prompt, to identify policy domains without providing explanations. This approach addresses ChatGPT’s tendency to produce conversational responses that require additional manual processing to extract relevant information.
Large language model using GPT-4o with in-context learning (few-shot)
We further enhanced our approach by incorporating in-context learning into this step, which integrates a few labelled examples directly into the prompt to guide the generative process of LLMs. Unlike fine-tuning, which involves modifying a model’s parameters and weights through additional training, in-context learning requires no parameter adjustment, making it less resource-intensive (Edwards and Camacho-Collados, 2024). Fine-tuning LLMs is not the focus of this study, as the proprietary model used requires minimal setup and lacks practical applicability for urban planners. Furthermore, we did not use the open-weight LLaMa 3.1 model due to its limited language support, which excludes Chinese, making it unsuitable for this study.
In this step, we included 100 randomly selected sentences in total from the training dataset as examples in the prompt. Considering the cross-classification, the number of examples was determined to ensure at least five example sentences per class while staying within prompt size limit (Chandra et al., 2024). Due to the upper limit on prompt size, we could not utilise all 10,000 labelled sentences, nor was it the intent of LLMs to handle exhaustive expert-annotated data incorporation. To evaluate model performance, we used a test set of 2,000 expert-coded sentences, consistent with the datasets used for the fine-tuned BERT model and the LLMs in the zero-shot setting.
Prompt used in GPT-based models.

Evaluation framework for trustworthiness
Evaluation metrics include accuracy, precision, recall, and F1-score are employed to evaluate the model performance, which are standard evaluation metrics for multi-label classification (Faraji et al., 2024). A brief description about these evaluation metrics are given below, aligning with the earlier study by (Madjarov et al., 2012). For each sentence in the multi-label classifier, a vector of 19 binary values is generated to correspond to the 19 pre-defined policy domains. Identification of each policy domain is turned into a successive series of binary classification problems. Each binary value can be assigned as positive or negative (1 or 0) showing that sentence either belonging or not belonging in a given policy domain. At the output of the classifier, each sentence will have a vector that has a length of 19 binary values. To benchmark the performance of the evaluation metrics, ground-truth binary values are provided through repeated expert review. Comparing to the ground-truth state of each binary value, the modelled binary outcome can be evaluated through one of four states as below. True Positive (TP) is assigned when the modelled outcome is positive and identical to the ground-truth. True Negative (TN) is assigned when the modelled outcome is negative and identical to the ground-truth. False Positive (FP) is assigned when the modelled outcome is positive and opposite to the ground-truth. False Negative (FN) is assigned when the modelled outcome is negative and opposite to the ground-truth.
In the evaluation procedure, we create a matrix of 2,000 by 19, corresponding to the 2,000 manually labelled sentences reserved in the test set along the rows and 19 pre-defined policy domains as columns. As these sentences have a ground-truth state manually labelled by multiple experts, the evaluation procedure can produce a comprehensive set of metrics as follows: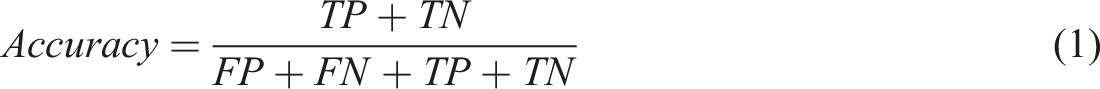
Accuracy is defined as the proportion of correct predictions (both True Positive and True Negative) within the total number of sentences in the test set, with higher values indicating that the model has a high rate of accuracy in the modelled outcomes. Accuracy reflects the likelihood that the model will produce the correct result, as identified by multiple human experts.
Precision measures the proportion of correctly predicted Positive results (True Positive) within the total number of predicted Positive results (False Positive + True Positive). Higher values for precision indicate the model is able to produce consistent results, potentially helping to rule out overfitting (i.e., the number of False Positives is penalised).
Recall measures the proportion of correctly predicted Positive results (True Positive) within the total number of ground-truth Positive results (False Negative + True Positive). Higher values for recall is also a reflection of high accuracy, but focused on the subset of Positive identifications – these identifications are particularly important for our research questions, as we are interested in which policy domains are correctly identified for each sentence.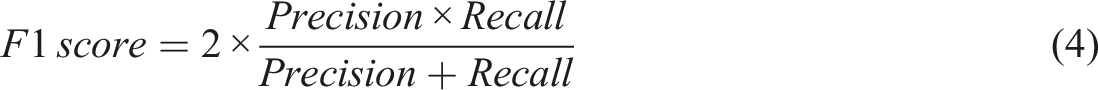
F1-score is the harmonic mean of precision and recall, that a higher F1-score indicates a better balance between precision and recall. In the typical multi-label classification model, these metrics are adopted by calculating the metrics for each policy domain, and then taking the average over all the domains.
For multi-label classification, evaluation metrics can be calculated using macro-averaging or micro-averaging. Macro-averaging treats all classes equally by calculating metrics independently for each class and then averaging the results. In contrast, micro-averaging computes a single average metric by aggregating contributions from all classes, giving more weight to classes with more examples. Micro-averaging is often preferred when dealing with imbalanced datasets, where certain classes have significantly more examples than others. Therefore, the micro-averaged Precision, Recall, and F1-score are calculated in this study, which is in line with the method in relevant study (Al-Smadi, 2024).
Results
Comparison of model performance
Comparison of model performance using evaluation metrics defined above.
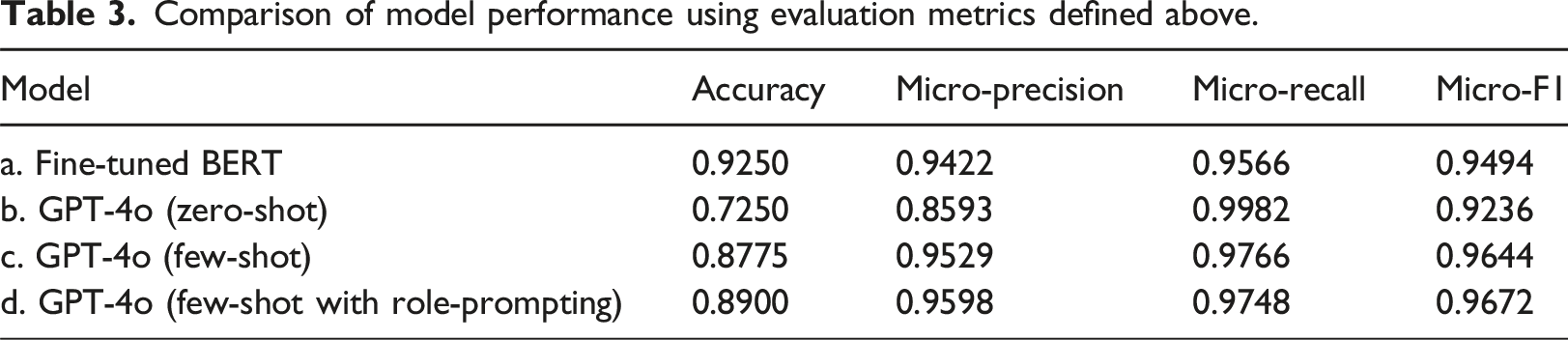
In contrast, GPT-4o in zero-shot mode achieved an accuracy of 72.50%, demonstrating a satisfactory level of accuracy in identifying the key topics within planning documents. This can be done without the need for experts to manually label data while still relying on human input to predefine policy domains and create a limited set of categories, ensuring the downstream task is specified in a clear and structured manner. When utilising a few-shot approach, where five examples were provided for each category, GPT-4o achieved an accuracy of 87.75%, showing a clear improvement from the zero-shot setting. When incorporating role-prompting – instructing LLM to act as a research expert in urban planning – the accuracy further increased to 89.00%. The difference between few-shot (87.75%) and few-shot with role-prompting (89.00%) is modest but indicates that domain-specific instructions can slightly enhance performance. The Micro-Precision (0.9598), Micro-Recall (0.9748), and Micro-F1 score (0.9672) for GPT-4o in the few-shot setting were the highest among the four models, surpassing the fine-tuned BERT model. We evaluate prompt sensitivity by testing four alternative prompts with GPT-4o (few-shot with role-prompting). Overall the models achieved an average accuracy of 88.63% with a 0.0040 standard deviation. Compared to the baseline GPT-4o (few-shot with role-prompting) performance, the alternative prompts performed similarly, demonstrating stability which likely stems from the prompt specificity and the consistent structure of the source data which are government annual reports. Details on the prompts and model performance statistics are in Tables S2 and S3 in Supplementary Materials. Overall, the results align with the earlier findings of (Zhong et al., 2023), which demonstrated that GPT with few-shot learning achieves performance comparable to fine-tuned BERT in single-sentence classification tasks, through their study specifically in the context of sentiment analysis.
Examples of misclassified sentences that have no policy domain relevance.
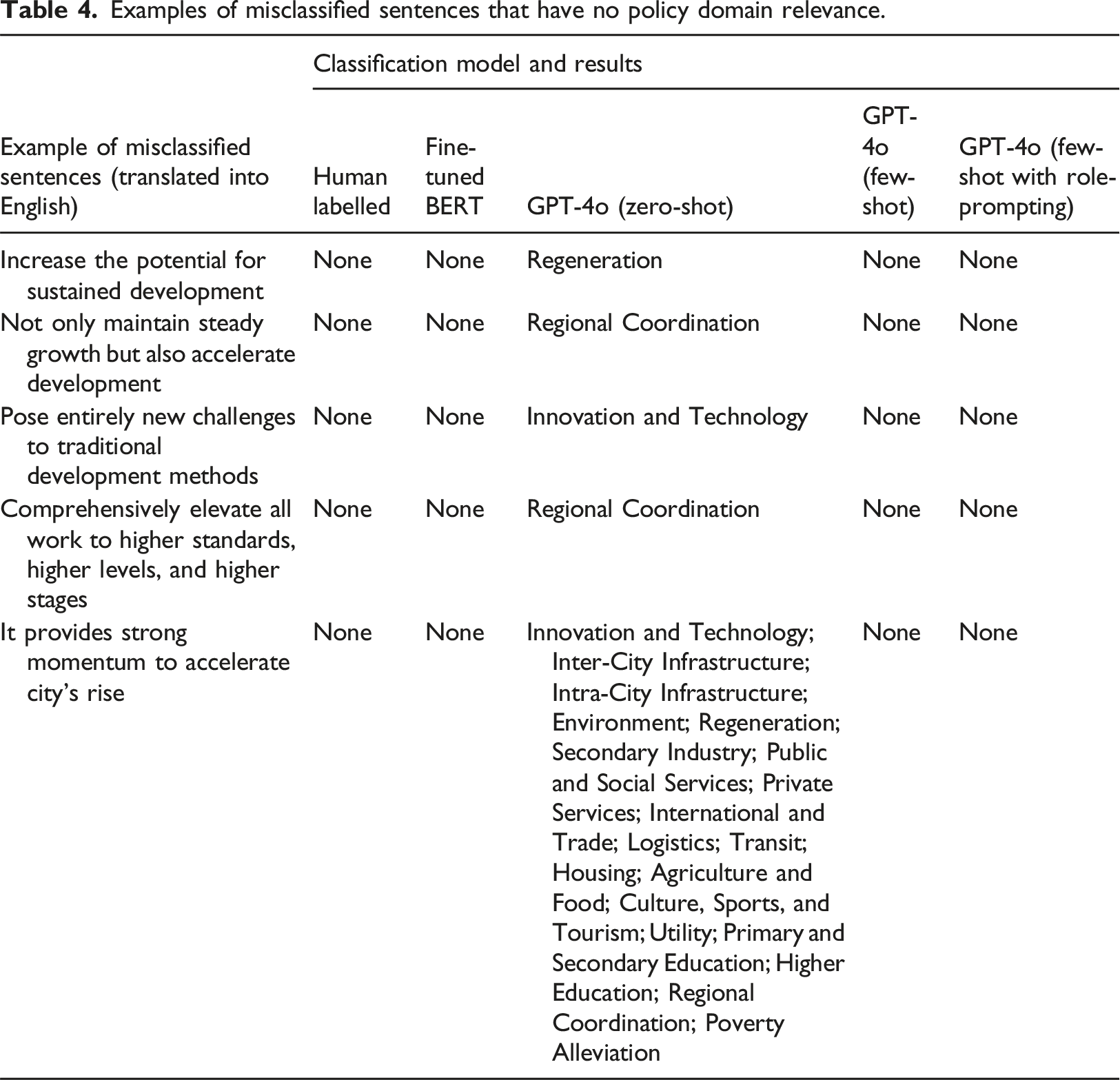
In terms of labelling time, the few-shot GPT-4o model, which reaches a rate of accuracy comparable to fine-tuned BERT, requires only 95 sentences for labelling. Time cost of the few-shot learning method is approximately
Example result of justification from GPT-4o.

Which policies do local planning decisionmakers focus on over time?
Given the completion of manual labelling undertaken in our project and its high level of accuracy, we apply the fine-tuned BERT model to the full dataset consisting of 0.69 million sentences, for both national government and 113 cities in China between 2011 and 2019. The attention value for each policy domain is determined by dividing the number of sentences related to that policy domain by the total number of sentences in the document. This case study is an application of using NLP and LLMs to identify policy domains and track the evolving priority of policy domains across cities over a decade.
Figure 2 visualises the transition of policy priority for cities aggregated based on state-defined tiers
2
across two periods: Period 1 (2011–2015) and Period 2 (2016–2019). For each city tier, the overall patterns between the national plan and local plans are similar, suggesting strong alignment on average between local and central governments. At national government level Public and Social Services and Environment are consistently prioritised across the two periods. In Period 2, we observe a national policy focus shift from Agriculture and Food toward Innovation and Technology. While local governments are broadly aligned with the plan of the central government, there are also distinct policy priorities across the city tiers: Tier-1 prioritised Innovation and Technology, significantly higher than the national focus, as the largest cities agglomerated both human and physical capital to drive the economic transition. Tier-2 cities showed greater focus on Inter-city Infrastructure as regional connectivity are crucial for people and commerce to easily access these regional sub-centres (including most provincial capitals). Tier-3 cities prioritise Agriculture and Food and Poverty Alleviation as employment opportunities in these less developed cities are closely linked to the primary industry, which is also linked to the increasing policy focus on Environment. This strong emphasis may reflect changing incentives for local officials given the new inclusion of environmental protection in the cadre evaluation system, the personnel management system used to assess the performance of government officials in China (Qi et al., 2021; Yang and Zhou, 2024). Box plot of policy priority by domain across Period 1 (2011–2015) and Period 2 (2016–2019) for three tiers of Chinese cities.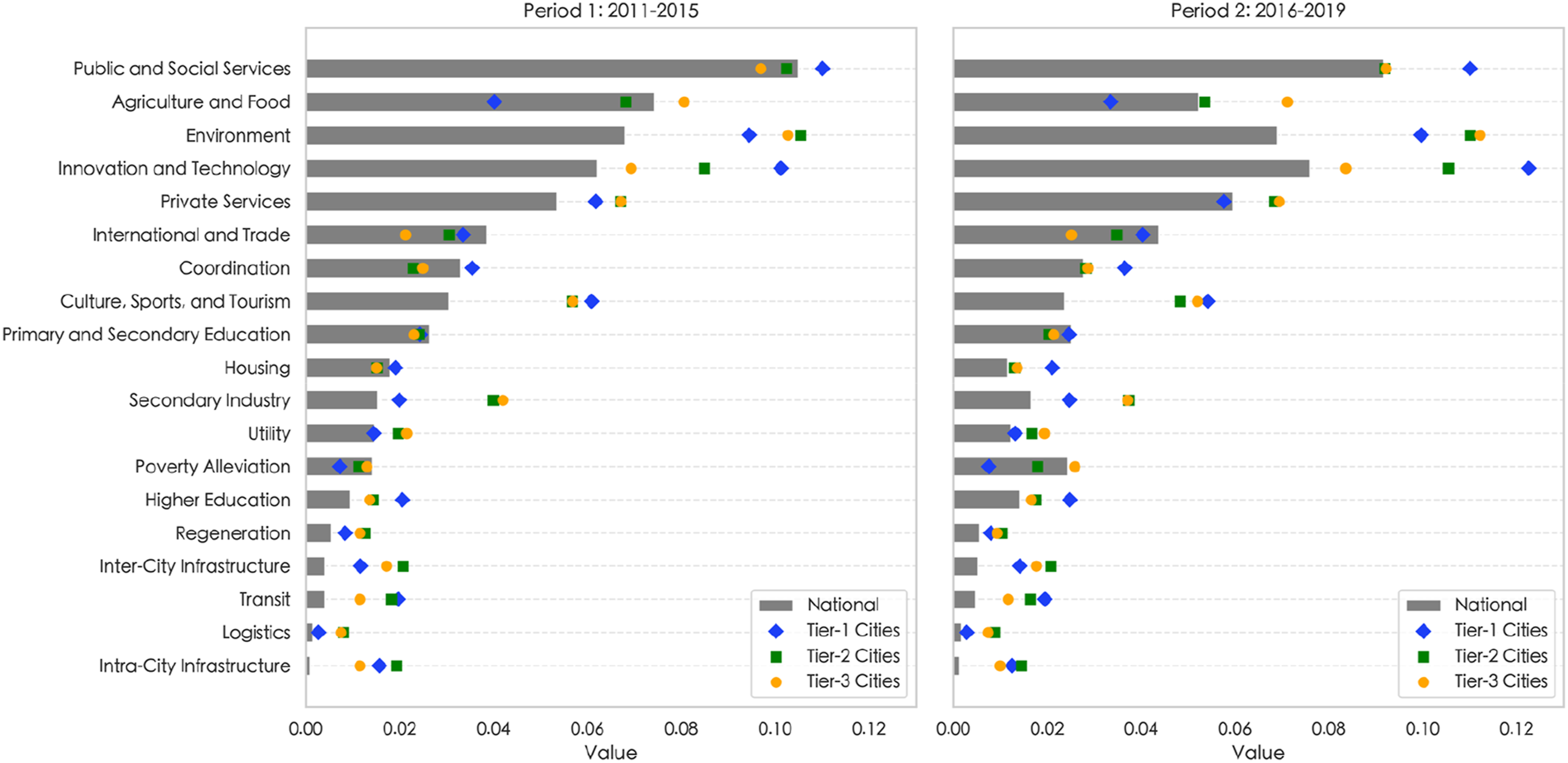
Discussion
The study evaluates the potential of using NLP/LLMs techniques for policy identification and offers three key insights. First, the policy identification task can be effectively addressed using NLP/LLMs methods, but human expertise remains fundamental and indispensable to the process. In our 2,000-sentences test dataset, the fine-tuned BERT model achieved 92.50% accuracy with 10,000 labelled examples. GPT-based models improved significantly with contextual examples, increasing from 72.50% (zero-shot) to 87.75% (few-shot with five examples per domain) and 89.00% with role-prompting as an urban planning research expert. Zero-shot prompts, despite no example needed, require careful design to clarify objectives. Additionally, the structured format of government annual reports likely enhances model performance, providing a consistent dataset for cross-city comparison. Noted that, despite rigorous cross-checking for the manual annotation, the ground-truth dataset is not free from subjectivity and human judgement. Our study aims to assess how well NLP/LLM techniques replicate human decision-making. The accuracy and evaluation metrics measure the extent to which models align with human performance. Given the inevitability of human annotation errors (Fu et al., 2023), our findings regarding GPT-4o’s strong zero-shot performance suggests that it has the potential in assisting human annotators in refining policy classifications in future research. A hybrid approach – combining LLM capabilities with human oversight – could inform and support human annotation and enhance model performance.
Second, regarding large-scale applications, there are two key constraints: fine-tuned BERT models require extensive labelled data, which is labor-intensive, while GPT-based models could reduce this effort but incur high financial costs. In our study, processing 2,000 sentences using GPT-4o (with few-shots, role-prompting) cost USD21.25 (at the rate applicable on Oct 11, 2024). Scaling this to analyse 113 cities over 9 years (0.69 million sentences) would cost approximately USD7,331.25, making large-scale analysis financially challenging. To address this issue, our findings confirm that GPT-4o’s acceptable accuracy with limited examples using role-prompting could enable integration with a fine-tuned BERT model. Specifically, GPT-4o (few-shot, role-prompting) could be used to label a training dataset (e.g., 10,000 sentences for ∼USD106.25), assess its accuracy, and then fine-tune BERT for large-scale processing. This aligns with recent studies on the potential of distilling LLMs into BERT models (Palo et al., 2024). Future research could continue to further explore the efficiency of this process, considering the specific user needs.
Third, the study highlights the transformative potential of NLP and LLMs in evaluating and analysing policy plans. By leveraging sentence-level classification outputs, we introduce a method for measuring policy emphasis and government priority through semantic analysis of official reports. For example, calculating the ratio of sentences classified into respective domains to the total document length allows for the quantification and comparison of policy emphasis across different reports. Unlike traditional keyword-based methods, such as word frequency analysis, this approach addresses two major limitations: it transcends word-level analysis by capturing meaning within larger context windows, and it reduces ambiguity in planning contexts. In future research it is possible to combine the sentence-based analysis with Retrieval Augmented Generation (RAG) to enable the LLMs to provide evidence of how each classification was generated by querying specific sentences and documents utilised in the generation process.
Conclusion
This paper explores the potential of using NLP and LLMs for the policy identification task through sentence classification. Our study contributes to the literature by (1) introducing a sentence-level approach for identifying planning policies from lengthy planning documents, using three NLP/LLMs methods (fine-tuned BERT, with 10,000 manually labelled sentences; standard GPT-4o with zero shot learning; and GPT-4o with few-shot in-context learning and role-prompting); and (2) evaluating the accuracy of recent NLP/LLMs for policy identification.
We make three novel empirical observations as our key findings. Firstly, we demonstrate that policy identification can be performed effectively when substantial in-domain labelled training data is available, achieving a high out-of-sample accuracy of 92.50%. Secondly, in cases where in-domain training data is lacking, LLMs can still achieve a notable accuracy of 72.50%, which improves to 87.75% with just five examples per class, and further increases to 89.00% when incorporating role-prompting as urban planning expert. Finally, by aggregating sentence-level predictions by calculating the amounts of sentences identified within each policy domain as a proportion of the total number of sentences in the document, we demonstrate a quantitative approach that enables a comparative analysis of policy priority across cities over the years.
Although our study is based on the Chinese context, the findings and methodologies have broader applicability for research. Firstly, our analytical approach provides a solid foundation for policy identification that could guide future planners and researchers in the urban planning field. This foundation is essential for advancing research in urban planning. Second, our study highlights the potential heterogeneity among cities of different population sizes and levels of economic development, illustrating the need for targeted planning policy priorities.
Regarding research limitations, despite our best efforts, a notable constraint is the limited exploration of optimal prompts to enhance LLM-based model performance. This limitation stems from the primary focus of our study, which was to demonstrate methods for applying NLP/LLMs to policy identification tasks. While few-shot learning with role-prompting (e.g., assigning the model as an urban planner) improved performance, further prompt engineering research could enhance effectiveness in similar applications. Additionally, ethical concerns require further investigation, particularly regarding data privacy, security, and the environmental impact of models like GPT-4o. The computational demands of LLMs, including energy consumption and carbon emissions, must be considered for their responsible integration into urban planning workflows.
Overall, while large language models like GPT-4o hold significant potential for quantitative analysis, their deployment must be carefully managed to ensure they complement rather than replace human expertise. Future research could explore the use of NLP in planning contexts to gather more detailed information, such as specific policy actions and timelines, addressing both near-term concerns (e.g., when actions will occur) and long-term considerations (e.g., how to improve citizen wellbeing). The potential impact of central-local policy alignment on local development outcomes could also be explored in future studies.
Supplemental Material
Supplemental Material - Natural language processing for planning policy identification: A benchmarking study using 113 Chinese cities between 2011 and 2019
Supplemental Material for Natural language processing for planning policy identification: A benchmarking study using 113 Chinese cities between 2011 and 2019 by Tianyuan Wang, Jerry Chen, Zhenyun Deng, and Li Wan in Environment and Planning B: Urban Analytics and City Science
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Tianyuan Wang is supported by the PhD student scholarship from both the Cambridge Commonwealth, European and International Trust, and the China Scholarship Council. Dr Jerry Chen is supported by the Isaac Newton Trust Academic Career Development Fellowship and the Queens' College Stamps Scholarship. Dr Li Wan was supported by The Ove Arup Foundation for the Digital Cities for Change Programme research grant (RG89525), and the Cambridge Centre for Smart Infrastructure and Constuction, which is funded by Innovate UK and EPSRC grants (EP/N021614/1, EP/I019308/1 and EP/K000314/1).
Data Availability Statement
Data are available upon reasonable request from the corresponding author.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.