
Abstract
Background
Large language models (LLMs) may reduce the burden associated with performing systematic reviews by prescreening abstracts from a literature search for eligibility for inclusion in full-text review.
Methods
We developed an iterative, LLM-based workflow for screening abstracts: after manual specification of eligibility criteria and seed examples, an ensemble of five LLMs deliberates through a Delphi process to classify a batch of abstracts; these labels are used to train a logistic regression model that ranks the remaining abstracts and identifies a new batch of abstracts for LLM escalation until all abstracts are labelled by the LLM or probability thresholds. We tested our workflow on abstracts screened in three published systematic reviews in psychiatry. Our primary endpoint was the recall metric, and secondary endpoint was the work saved over sampling at 95% recall metric (WSS@95%).
Results
In a dataset on autism biomarkers, 1,655 (35%) of 4,745 retrieved abstracts were judged to be relevant by the original authors. The Delphi–LLM workflow correctly identified 1,605 (97.0%) of these 1,655 abstracts (precision = 54.2%, WSS@95% = 38.1%). The performance metrics were better than non-LLM approaches (recall ≤ 91%, WSS@95 ≤ 26%), and, overall, balanced these metrics optimally compared to single-LLM agents (recall = 84.9–99.9%, WSS@95% = 16.7–39.8%). The recall and work saved metrics were similarly reliable and among the top in two low-prevalence datasets on an attention-deficit hyperactivity disorder treatment review (10% of 2,891 relevant) and a posttraumatic stress disorder trajectory review (7% of 4,453 relevant). For these two datasets, recall was 100.0% and 96.4%, and the WSS@95% was 17.3% and 18.5%, respectively.
Conclusions
We presented the design and validation of a novel abstract screening workflow that centres around a Delphi-style aggregation process to harness the strengths of five open-source LLMs that can be run on consumer-level workstations. This multi-LLM workflow showed acceptable and reliable performance for use as an automated prescreening method to facilitate systematic reviews.
Plain Language Summary Title
A new algorithm to debate a team of AI language models for improving the screening process of article abstracts in psychiatry.
Large language models (LLMs) can now understand and write complex scientific texts. Systematic reviews, which demand significant time and resources, can greatly benefit from the use of LLMs, which can process thousands of articles much faster and cheaper than human researchers.
We built an automated workflow inspired by the Delphi method, where five different LLMs communicate with each other to reach a consensus decision on the relevance of a given abstract for a specific systematic review. In essence, the five-LLM Delphi ensemble serves as a teacher model that processes a small batch of difficult abstracts, which are also used to train a student classifier model that can clear similar abstracts. This two-stage cycle repeats until all abstracts are labelled, either by the LLM–Delphi teacher ensemble, or by the student classifier.
We tested this workflow on three systematic reviews in psychiatry. In the first review containing 4,745 abstracts, the original authors determined 1,655 (35%) to be truly relevant. The workflow automatically determined 62% of the dataset as relevant and 38% as irrelevant, saving significant labour. The positively labelled abstracts contained 97% of the truly relevant abstracts, demonstrating the workflow’s competence (i.e., recall). The workflow showed similarly high recall (96–100%) but reduced labour savings (17–18%) in the other two reviews, which contained a lower proportion of relevant abstracts (i.e., 7% of 4,453 total in one, and 10% of 2,891 in another). Overall, the five-LLM model produced a more well-rounded and reliably excellent performance compared to using just a single-LLM model as the teacher, and better performance compared to not using LLMs to label the difficult cases.
The entire workflow can run on a consumer-grade computer without sending data to costly cloud-based models. By achieving high recall ability and substantial labour savings, this approach could make systematic reviews faster and cheaper to conduct.
Introduction
Large language models (LLMs) are enabling the automation of routine tasks. However, their adoption in medical research remains limited by high stakes and stringent standards required for clinical knowledge.1,2 Systematic reviews have been a popular target for LLM-enhanced automation, 3 as they require substantial time and effort: publishing a review takes an average of 67 weeks 4 ; conducting a meta-analysis takes an average of 1,139 h 5 or nearly $140,000. These immense upfront costs significantly delay the translation of evidence into clinical practice.
The abstract screening phase represents a major, error-prone workload in systematic reviews. Even with independent assessment and tie-breaking consensus, risk of rater fatigue and decalibration over time is not negligible. Recent reviews have estimated interrater reliability to range between 0.6 and 0.9 for human or machine-learning-assisted reviews. 6 Different rater groups can also yield different decisions, even after consensus. Acknowledging these reliability issues justifies setting realistic recall targets for automated workflows, while benefiting from the labour savings and standardization that LLM automation offers.
Psychiatric systematic reviews pose unique complexities that challenge LLM automation: (1) terminology often changes over time, leading to a mixed usage of legacy terms, which require domain expertise from reviewers; (2) diagnostic criteria and instruments are heterogeneous in their application, hindering their usage as keyword cues for constructing reliable prompts 7 ; and (3) nuanced confounding mechanisms in sample selection can invalidate the eligibility of certain studies, even if anchoring keywords are present in the abstract. These require an in-depth understanding of medical terms and clinical practice, which general-purpose LLMs likely cannot provide without adaptation, fine-tuning, or human-in-the-loop verification.
Recently, several studies have reported methods for creating systematic reviews more efficiently.3,8–18 These studies have reported promising early results achieving high recall, precision, and specificity metrics. Xu et al. reported the aggregated performance of cloud-based LLM screeners at 79% recall, 47% precision, and 97% specificity. 19 However, while the latest LLM-based screening tools (commonly using a single state-of-the-art LLM) provide a rich knowledge base and their responses are generally accurate when given detailed instructions, hallucinations still occur, which can undermine trust. In abstract screening, hallucination can lead to misidentification of study components or overextension of details, directly causing false positives and negatives. Thus, the low precision in LLM-based screening and the manner in which responses are generated present viable targets for improvement.
In this context, the Delphi method, 20 a widely used technique for achieving informed consensus among experts, provides an attractive framework for improving LLM-based abstract screening. It involves the anonymous collection and sharing of viewpoints, requiring all contributors to independently assess the merits of all opinions and revise decisions in an informed, iterative manner. The anonymous nature of data collection also encourages the elicitation of dissenting opinions, which can be powerful in detecting fallacies. Using five LLM agents from different architectures to enrich and reassess a common prompt should minimize the detrimental impact of any one model's hallucination or training biases. The standardization of communication offered by the Delphi method can also improve face validity and explainability by allowing researchers to audit the evolution of discussions beyond aggregate statistics.
In this paper, we describe an LLM-based workflow for selecting relevant abstracts, where a simple classification model is iteratively trained by the decisions of an ensemble of five LLMs deliberating through a Delphi-based consensus process. We hypothesized that if the workflow can capture at least 95% of the researcher-identified relevant abstracts while meaningfully reducing the number of abstracts to be screened, it could be valuable for integration into routine usage.
Methods
Datasets
The workflow was first validated using the systematic review by Parellada et al. 21 on nonsyndromic autism spectrum disorder (ASD) biomarkers, which was chosen as it published complete abstract-stage screening data in its supplements. After removing 10 duplicates and 10 random seed example abstracts, 4,745 remained for validation. In this dataset, 1,660 abstracts (35%) were labelled relevant by the authors for full-text review.
For secondary validation, two additional psychiatry datasets were reconstructed from widely referenced systematic review-screening datasets, chosen due to their size and availability of abstract-stage labelling. The first was a Cochrane review from Storebø et al. 22 on attention-deficit hyperactivity disorder (ADHD) treatment from the 2019 CLEF-TAR competition, 23 yielding a dataset of 2,901 abstracts, of which 283 were relevant (10%). The second was a review from van de Schoot et al. 24 on posttraumatic stress disorder (PTSD) trajectories, which was part of the SYNERGY dataset25,26 with additional abstract-level labels published by the authors. 24 This dataset yielded 4,463 abstracts, of which 311 were relevant (7%). Unlike the complete ASD dataset, however, these additional datasets were reconstructed post hoc by third parties and thus could not capture the entire corpus that the original authors screened (capturing 22% and 72% of the original total records, respectively). Nevertheless, their inclusion in the few widely used screening dataset repositories makes them ideal for contextualizing the results with past and future investigations on screening algorithms.
Abstract Filtering Workflow Description
In this iterative workflow, the LLM–Delphi ensemble (the “teacher”) labels a batch of abstracts, and these decisions continually retrain a “student” classifier model to accelerate screening (Figure 1 and Supplemental Appendix 1). The workflow begins with the manual specification (Supplemental Appendices 2–4) of the eligibility criteria, their query-style paraphrases, and identifying five positive and five negative abstracts. First, a model (SPECTER v2 from Allen AI) 27 converts the text of each title and abstract into a set of 768 numeric features called embeddings. These embeddings are adapted to the eligibility criteria by using the five manual query paraphrases and the seed examples. Unlabelled abstracts are then clustered to sample a small batch of up to 50 abstracts that are most diverse in their embedding, which is a proxy of their content. This diversified batch is sent to an ensemble of five LLMs (Gemma 3 8B, Qwen 3 8B, Granite 3.2 8B, Llama 3.1 8B, and Ministral 2410 8B),28–32 which deliberate over each abstract in a five-round Delphi procedure until ≥75% consensus is reached. This batch of LLM–Delphi decisions is used to train a logistic regression model, which produces a probability score for all remaining abstracts. If an abstract's relevance probability is above 90% or below 10%, it is labelled by the classifier's probability-based threshold. Otherwise, it remains in the unlabelled pool, potentially to be sampled into the LLM-processing batch or labelled by the probability threshold as the classifier's output improves over new training iterations. A limited safety-net mechanism vetoes any LLM- or probability-threshold-based decisions that markedly contradict the embedding-based similarity to the eligibility criteria in order to reduce hallucinations and random errors. The cycle continues until all abstracts are labelled either through the LLM- or threshold-based mechanisms.

Schematic diagram of the abstract filtering workflow described in this study. In essence, an LLM ensemble deliberates over a difficult abstract with a classifier probability near 0.5. These LLM decisions accumulate a labelled set of abstracts which iteratively trains a logistic regression classifier model. The classifier then updates its weights and re-ranks the abstracts, escalating a new batch of abstracts for LLM processing, and automatically labelling ones which have cleared the probability thresholds for inclusion or exclusion. The cycle repeats until all abstracts are labelled either by the LLM–Delphi ensemble model, or the probability threshold. LLM = large language model; LLM–Delphi = multiround, multimodel LLM ensemble used as a quasi-gold-standard “teacher”; SPECTER2 = citation-relatedness document embedding model used to compute document embeddings and query centroid; log-reg = logistic-regression classifier; K-means = K-means clustering used for diversity sampling; SR = systematic review.
LLM–Delphi Comparison to Single-LLM and Non-LLM Workflows
The LLM–Delphi workflow was compared with simpler screening workflows using a single-LLM teacher or no LLMs. All other applicable settings (e.g., SPECTER embedding features, prompt, logistic regression student classifier, escalation logic, and safety-net settings) remained identical.
In the non-LLM tests, there was no iterative teacher–student retraining. Instead, these benchmark workflows used only a starting set of randomly selected five positive and five negative examples, their base SPECTER embedding, and one of three established semisupervised clustering methods consisting of (1) label spreading, (2) contrastive learning, and (3) query-based tuning of the base embeddings in addition to contrastive learning. Label spreading propagates labels from the seed abstracts to unlabelled abstracts based on their proximity in the 768-dimensional embedding space. Contrastive learning manipulates the embedding space to best differentiate the positive and negative seed abstracts, then labelling the rest by proximity in this manipulated space. The query-based method adds another layer to the contrastive method by further adapting the base embedding with the eligibility criteria queries (as was done with the LLM-based methods). These three comparative methods produce a continuous probability score for each abstract, which was dichotomized at the threshold that achieved the same number of positive labels as the LLM–Delphi approach (i.e., the screening budget) to calculate performance metrics. The starting set of 10 seed examples was bootstrap resampled 100 times to establish confidence intervals, including one run with the same starting seed examples (i.e., run #100) as the LLM agent experiments.
Statistical Analysis
Performance of the various non-LLM, single-LLM, and LLM–Delphi workflows was reported with standard metrics, including precision, recall, descriptive counts of positive and negative classifications, as well as the Work Saved over Sampling at Recall = 95% metric (WSS@95%). The primary metric was recall, which is the proportion of relevant abstracts detected as relevant by the screening model. The precision metric contrasts recall by quantifying what proportion of the abstracts that the model identified as relevant was truly relevant as per the human rating. This metric relates to the amount of unnecessary work that must be done to manually screen and exclude any false positive identification from the model's output, which is of lower priority than recall for document screening. A more informative metric of this work saving metric, the WSS@95%, was considered the secondary metric, which measures how much more of the abstract corpus can be automatically excluded by a rank-producing model while still retaining 95% of the true positives, compared to unaided evaluation.33,34 The WSS@95% is affected by both the precision and recall, providing a precision-like metric while fixing the recall at a high 95% threshold, which allows for standardized comparison across models. All analyses were performed in Python.
Results
Performance metrics of the LLM–Delphi ensemble workflow, as well as the single-LLM and non-LLM methods, are visualized as figures and provided in detailed tabulations in Supplemental Appendices 6 and 7.
Classification Performance
Primary validation dataset
On the ASD dataset, the workflow screened all 4,745 abstracts in approximately 20 h, or 96 iterations. Of the 1,655 abstracts identified as positive by the original review's authors, the LLM–Delphi model achieved 97.0% recall and 54.2% precision (Figures 2 and 3, and Supplemental Appendix 6). These metrics translate to a further 38.1% reduction in manual screening compared to unaided sequential evaluation, at the same benchmark of 95% recall (i.e., WSS@95%). The model missed 50 of the original 1,655 researcher-identified abstracts. Eventually, 48 of these 50 abstracts were excluded at the full-text review, which ultimately yielded 264 abstracts.

Venn diagram of the abstract filtering workflow in assessing abstracts for inclusion, compared to the original systematic review researchers’ selection. Of the 4,745 abstracts screened by Parellada et al. (“ASD” dataset diagram on the left), our automated workflow selected 2,961 as potentially positive (62.4%). This filtered set captured 97.0% of the abstracts filtered in by the researchers at their abstract-only screening stage (N = 1,605/1,655), and 99.2% of the articles (n = 262/264) which were eventually included after full-text review with the expanded eligibility criteria of the systematic review. This performance equates to reducing the workload by 34.6% at the observed 97.0% recall compared to unaided evaluation (i.e., WSS@97% metric), or 38.1% at the simulated 95% recall standard (WSS@95%). In the two secondary validation datasets reconstructed from the reviews of Storebø et al. and van de Schoot et al., the recall metric was similar (100.0% and 96.4%), but the work saved metrics were lower (17.3% and 18.5% WSS@95%, respectively), owing to the differences in the eligibility criteria sensitivity and the prevalence of relevant articles in these reviews. ADHD = attention-deficit hyperactivity disorder (Storebø et al. dataset); ASD = autism spectrum disorder (Parellada et al. dataset); LLM = large language model; PTSD = posttraumatic stress disorder (van de Schoot dataset); WSS@95% = work saved over sampling at recall = 95%.

Summary visualization of the main performance metrics for the Delphi–LLM, single-LLM, and the best non-LLM study workflow designs. The top right quadrant represents the best performance. The vertical axis represents the standard recall metric, i.e., the proportion of relevant abstracts detected by the model. Horizontal axis represents the work saved metric, calculated from the continuous probability scores produced by the screening methods, standardized at the conventional 95% recall threshold. The coloured cross marks represent the average of the five single-LLM results, with length of bars representing the standard error of the mean. Data presented in this figure appears in Supplemental Appendices 6 and 7 in more detailed tabular formats. ADHD = attention-deficit hyperactivity disorder (Storebø et al. dataset); ASD = autism spectrum disorder (Parellada et al. dataset); LLM = large language model; PTSD = posttraumatic stress disorder (van de Schoot et al. dataset); WSS@95% = work saved over sampling at recall = 95%.
The LLM–Delphi model outperformed alternative approaches that did not utilize the LLM teacher component, which achieved 84–91% recall (Figure 4, right). When comparing the performance of each of the five LLMs individually as single-LLM agents integrated into the same student–teacher workflow, the performance profiles varied widely, highlighting their diverse attributes (Figure 3 and Supplemental Appendix 6). The recall of the five LLMs ranged from 84.9% to 99.9% (median 98.4%), precision from 37.1% to 65.9% (median 50.0%), and WSS@95% from 16.7% to 39.8% (median 36.4%).
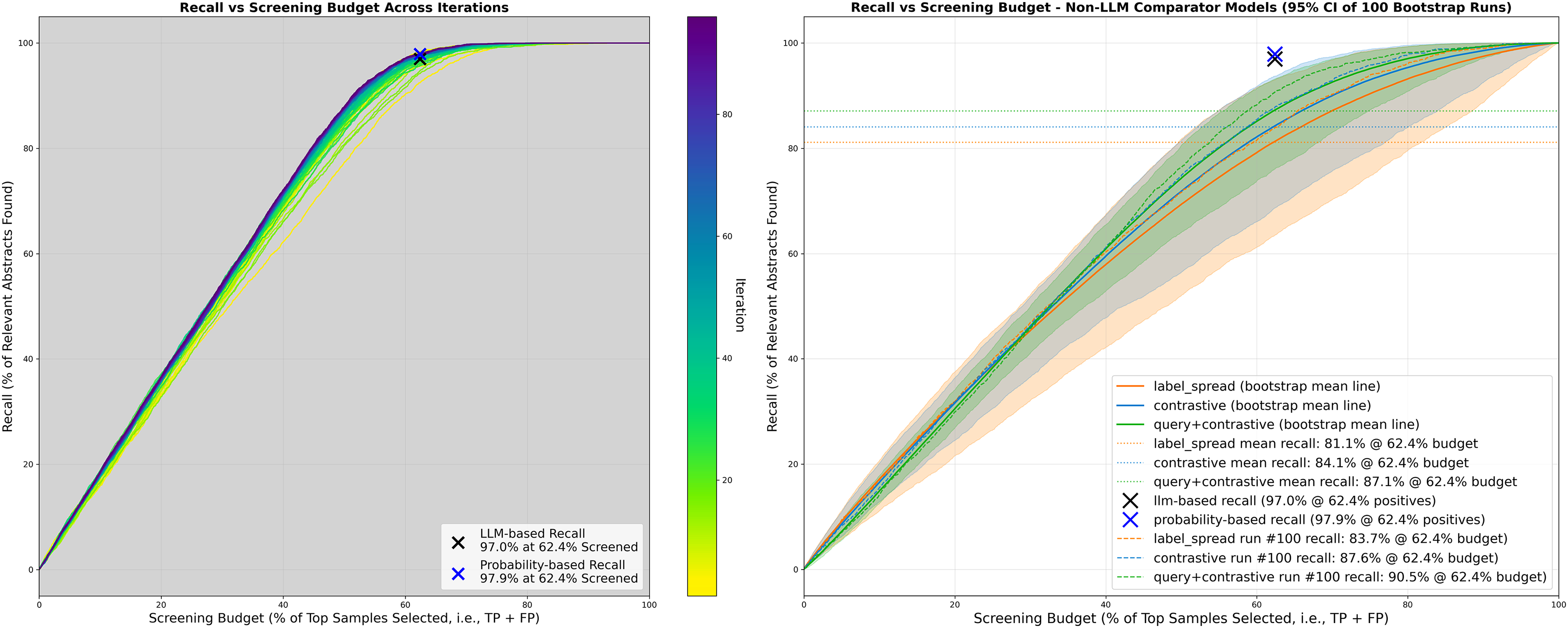
Representation of the recall vs. screening budget performance profiles on the ASD dataset, for the LLM–Delphi-based model over training iterations (left panel) and traditional embedding methods not utilizing the LLMs (right panel). The probability produced by the LLM-trained classifier model improves steadily over the iterations (darker shades in left panel) as the LLM–Delphi ensemble contributes more labelled cases to train the classifier model. Right panel shows performance profile confidence intervals of three non-LLM comparator methods, which achieved a mean of 81–87% recall at the same screening budget of 62.4% as the LLM-based model (top 2,961/4,745 selected as positive by model). Similar plots for the ADHD and PTSD datasets are included in Supplemental Appendices 8 and 9. Detailed results on the non-LLM models are presented in Supplemental Appendix 6. ASD = autism spectrum disorder (Parellada et al. dataset); LLM = large language model; ADHD = attention-deficit hyperactivity disorder (Storebø et al. dataset); PTSD = posttraumatic stress disorder (van de Schoot et al. dataset); WSS@95% = work saved over sampling at recall = 95%.
Secondary validation datasets
In the ADHD review, 22 the authors labelled all abstracts containing potentially relevant information on methylphenidate's efficacy or side effects in a wide variety of study designs. In subsequent stages, two separate reviews were written from the screened corpus, one on the efficacy and adverse events of the drug in randomized control trials against placebo, and one on adverse events in all other research designs, requiring the abstract screening prompt and queries to capture both domains. This caused the screening to favour sensitivity, and consequently the results yielded a perfect 100% recall but a reduced efficiency gain, with WSS@95% at 17.3%. One single-LLM experiment had notably less sensitive performance (blue outlier in Figure 3), yielding suboptimal recall at 70.9%. Consequently, the best single-LLM run (Gemma 3 12B) outperformed the Delphi–LLM by not only matching its recall but also improving on its WSS@95% (19.0% vs. 17.3%). The best non-LLM method (query adapted, contrastive learning method, blue star marker in Figure 3 and Supplemental Appendix 7) missed two relevant articles compared to the Delphi–LLM method, yielding a 99.3% recall, but provided greater efficiency gain at the 95% recall standard (20.4% vs. 17.3%). Overall, Delphi aggregation provided a reliable sensitivity-leaning performance profile as instructed, with comparable efficiency to the top experiments.
In the PTSD review, 24 the authors labelled abstracts relevant for full-text screening if the study evaluated longitudinal data pertaining to PTSD or other acute stress-related conditions. In later full-text review stages, a more restrictive PTSD study population and specific longitudinal analysis criteria were applied. The LLM prompt therefore needed a sensitive profile to capture a broad domain of longitudinal research on psychological traumatic stress symptoms, while excluding cross-sectional, neurobiological and physical trauma literature. The LLM–Delphi method detected 96.4% of the relevant abstracts, missing 11/306, providing 18.5% work saved (Figure 3 and Supplemental Appendix 6). The Ministral model outperformed the LLM–Delphi in both recall (98.4%, missing 5/306) and 18.8% work saved. The best non-LLM model showed lower recall and WSS@95% (91.5% and 15.1%, Supplemental Appendix 7).
In addition to the binary include/exclude labels, the student classifier of the workflow also produces an evolving probability score (Figure 5) deriving from the abstract's 768-dimensional embedding. This continuous score allows researchers to rank the abstracts by their probability of relevance and stop screening when the rate of new eligible abstracts wanes. The point of diminishing returns was reached at approximately 60% in the ASD dataset (Figure 4, left). This probability-ranking-based method yielded a higher recall rate of 97.9% (i.e., detecting 15 more of the 50 missed by the binary classification) at the same 62.4% screening budget. Intuitively, the probability-based ranking should perform better than the original dichotomous ranking (which is done on-the-fly with no revision), since the classifier improves over time as the training sample accumulates. However, this advantage was not observed in the ADHD (one more missed compared to the original perfect recall; Supplemental Appendix 8) and PTSD datasets (eight more missed than the original 11 false negatives; Supplemental Appendix 9).

Progression of the abstract filtering process over the course of iterations. Abstracts are processed through one of the two mechanisms: explicit consideration and decision by LLM–Delphi method, or a probability score produced by a classification model trained by the LLM–Delphi-produced labels. Over the course of 96 iterations, the LLM–Delphi ensemble processed the abstracts at a decreasing rate from up to 41 abstracts per iteration. This gradually expands the training set, which makes the classification model better able to differentiate the relevant and irrelevant abstracts over time, with the probability occasionally pushing past the inclusion and exclusion a priori thresholds. Approximately half (56%) of the abstracts were processed by the LLM–Delphi method, and the other half by the classifier model. Coloured circles represent the final labelling of an abstract at the iteration in which it was decided by either of these mechanisms. LLM = large language model.
Delphi Progression
In the ASD dataset, the diversity sampling component escalated up to 41 abstracts per iteration from the boundary group for LLM–Delphi discussions. Approximately 56% (n = 2,634/4,745) of the total abstracts were escalated for LLM labelling, while the remainder was labelled by the classifier based on the probability threshold (Figure 5). Of the 2,634 LLM-escalated abstracts, 2,058 (78%) reached consensus in round one (58% unanimous, 42% with ≥75% agreement). Of the remaining 576 (22%) proceeding to the subsequent rounds, 72% were eventually correctly classified, 23% were false positives, and 5% were false negatives. The Delphi discussion records simulated human experts, with LLMs regularly citing prior justification statements and showing patterns of acquiescence or disagreement that conformed to the LLM-ensemble's conclusion.
Missed Abstracts
Examination of the Delphi records for the 50 false negatives from the ASD dataset suggested three misclassification themes. The most common reason (26/50) was the overemphasis of keywords related to genetic or metabolic biomarkers. These details triggered the LLMs to falsely interpret the study's population as syndromic types of ASD, despite the investigational nature of the biomarkers and the study's broad relevance to autism in general. The second common theme (17/50) was the failed detection of a nonsyndromic ASD subgroup that was either explicitly compared or studied together as a general autism cohort. The two consequential false negatives35,36 ultimately included among the 264 abstracts for full-text data extraction were also of this type. The rest (7/50) were misclassified as reviews rather than primary research.
Discussion
We developed an innovative multiagent workflow for abstract screening that combines LLMs, text-embeddings, and probabilistic modelling in a Delphi-based design. This explainable, LLM-in-the-loop process achieved very high recall (96.4–100%) and reduced the screening workload by 17.3–38.1% (WSS@95%) across diverse datasets. Performance varied by knowledge domain and class prevalence—the high-prevalence (35%) biomarker review showed greater efficiency gains compared to low-prevalence reviews on pharmaceutical intervention and longitudinal observation research (10%, 7%). Although occasionally outperformed by specific single-LLM or non-LLM methods, the LLM–Delphi hybrid method consistently placed towards the highest recall and WSS@95%, providing a reliable and well-rounded choice that compensates for the weaknesses and hallucination risks of single-pass model workflows.
Contextualizing our findings within recent LLM-based screening studies is challenging due to differences in datasets and prompt engineering objectives. Recent works utilizing cloud-based GPT-4 models reported diverse performance profiles ranging from 76% to 100% in recall, and 94% to 100% specificity.12–16 While our recall-focused screening objective achieved equivalent or better recall (96.4–100%), specificity (14.9–56.1%) was consequently lower. Ultimately, this reflects the trade-off between detection and labour savings where the former must take precedence, though further optimizations to our workflow's prompt and architecture may improve efficiency with minimal loss in recall.
Missed abstracts can have profound implications in domains where the stakes are high and research evidence is scarce. Post-hoc review revealed some hallucination errors such as LLMs overextending trivial text in the abstract. Nevertheless, these misclassifications and the trail of Delphi records can illuminate practical recommendations for future abstract writing. Many of the observed errors may have been prevented if abstracts provided a more standardized and balanced description of results, rather than overemphasizing novel findings or contextualization. The misinterpretation of abstracts with negative findings (which may lack typical numeric cues) as narrative reviews or commentaries is also concerning, as this will exacerbate publication bias if these negative results systematically fail to pass through automated screening algorithms.
Prompt engineering and workflow optimizations benefit from a psychiatry-specific context that is obvious to clinicians but poorly encoded in small, general-purpose LLMs. Including a concise clinical background in the prompt (e.g., how an illness is typically defined, types of treatment) may help the LLM infer why a study was conducted and whether it represents primary research. Brief glossaries of legacy terms (e.g., Asperger's cf. Pervasive Developmental Disorder - Not Otherwise Specified), target and off-label use of common clinical instruments, common brand name alternatives to generic drug names, and general description of the target condition are also key areas where a field expert can bridge gaps in the LLM's generic knowledge. Finally, training datasets of LLMs can perpetuate existing societal factors that have led to detrimental associations, clinical prejudices, and underrepresentation of research in vulnerable populations.37,38 Explicitly mentioning relevant pitfalls in the prompt and involving a diverse model selection in the Delphi ensemble may help mitigate these issues. It can also be useful to add challenges in the domain's medical practice that shape how its research is done (e.g., recruitment and adherence difficulties, funding constraints, and societal biases that affect diagnosis, treatment effectiveness, and outcomes). Providing this context can help the LLM understand the utility of exploratory pilot studies that may be underpowered for the typical statistical investigation but emphasize feasibility, access, or implementation outcomes.
Future studies evaluating multi-LLM workflows must investigate the impact of Delphi-style consensus against alternative methods, such as simple majority voting, Condorcet voting, approval rating, and adversarial schemes. In the current study, the low number of ensemble members made the simple majority threshold (3-to-2) too close to the Delphi threshold to adequately power such a comparison. Purposive study designs with much larger ensembles and more nuanced (at least three-level) decision choices will be needed to accentuate the divergence between Delphi, majority, and other modern voting schemes. Moreover, the performance and feasibility of fully automated LLM-based approaches also must be compared against the established human-in-the-loop screening tools such as ASReview, AbstractR, Rayyan, and DistillerSR. These active-learning tools are computationally efficient, and the human labeller helps them maintain strong anchoring to the eligibility criteria, which is an advantage against our workflow's potential for self-reinforcing LLM hallucinations in longer automated runs. On the other hand, the LLM workflow's output may offer improved standardization and explainability by providing detailed audit trails of reasoning from the Delphi procedure. Since both the human- and LLM-in-the-loop approaches can achieve near-perfect recall, future comparative studies will require a large number of high-quality datasets and holistic outcome considerations to fully address the challenges of clinical adoption.
The chief limitation of our study is the validation of the workflow on a limited number of systematic review datasets. Eligibility criteria for highly specialized domains may be more difficult for generic LLMs. These may necessitate a staged screening approach as with the three datasets tested in this study.
Strengths of our study include the development of a novel method on consumer-level computer hardware. The models integrated into the workflow are all open-source, and the entire workflow can run on a private, local workstation with a single 16 GB GPU without relying on cloud-based solutions. The small size of these tested LLMs also makes them amenable to fine-tuning on domain-specific knowledge, further improving their capability. However, since human-labelled datasets can still contain occasional labelling inconsistencies or rely on heuristics or privileged information not explicit in the abstract, expecting 100% recall may be impractical, even with the best models and workflows. Nevertheless, given the rapid improvements in LLMs and the accessibility of computing hardware to adapt them into practical applications, we believe the Delphi-based methodology will have an immediate positive impact.
Conclusions
We developed an innovative multiagent workflow utilizing LLMs, Delphi-style response aggregation, text-embedding, and probabilistic modelling for conducting abstract screening. The workflow achieved 96.4–100% recall while also substantially lowering the number of abstracts to manually screen (WSS@95%: 17.2–38.1%). The Delphi-based design also showed a more balanced performance profile compared to the five LLMs individually. Our workflow is optimized for privacy-focused local deployment avoiding costly cloud-based solutions. As a preranking or prescreening step, it can save substantial time while providing excellent recall and reasoning trails. The Delphi technique therefore provides an attractive method for building multiagent workflows in scientific literature reviews.
Supplemental Material
sj-docx-1-cpa-10.1177_07067437261445767 - Supplemental material for Novel Abstract Screening Algorithm Using Delphi-Inspired Large Language Model Consensus for Systematic Reviews in Psychiatry: Nouvel algorithme de sélection des résumés utilisant un consensus issu d’un grand modèle de langage inspiré de la méthode Delphi pour les revues systématiques en psychiatrie
Supplemental material, sj-docx-1-cpa-10.1177_07067437261445767 for Novel Abstract Screening Algorithm Using Delphi-Inspired Large Language Model Consensus for Systematic Reviews in Psychiatry: Nouvel algorithme de sélection des résumés utilisant un consensus issu d’un grand modèle de langage inspiré de la méthode Delphi pour les revues systématiques en psychiatrie by Mirkamal Tolend, Ramzi Halabi, Kousai Ghaouari, Yvonne C.Y. Lau, Martin Alda, Arend Hintze, Benoit H. Mulsant and Abigail Ortiz in The Canadian Journal of Psychiatry
Footnotes
Author Contributions
MT conceptualized and designed the abstract screening workflow, implemented the code, and performed the analysis.
MT and AO drafted the manuscript text and MT prepared the figures.
All authors (MT, RH, KG, YCYL, MA, AH, BHM, and AO) contributed intellectual input to the design of the workflow and revised the manuscript for important critical feedback.
All authors (MT, RH, KG, YCYL, MA, AH, BHM, and AO) read and approved the final manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Considerations
Ethical approval was not applicable because the research only used publicly available data and did not involve human subjects.
Funding
The authors received no financial support for the research and/or authorship of this article. Open access publication cost was supported by UT Southwestern.
Data Availability Statement
The dataset of abstracts and their ground truth labels are available in the Supplemental materials of the systematic reviews by Parellada et al. (accessible at: https://doi.org/10.1176/appi.ajp.2110099), Storebø et al.’s CLEF-TAR dataset (https://github.com/CLEF-TAR/tar), and van de Schoot et al. (https://osf.io/vk4be/overview and ![]() ). Codebase of the abstract screening workflow is not publicly available at this time due to ongoing intellectual property considerations. However, we provide details of the workflow logic, configurations, and LLM prompts in the methods, schematic figure, and supplements to facilitate independent reproduction.
). Codebase of the abstract screening workflow is not publicly available at this time due to ongoing intellectual property considerations. However, we provide details of the workflow logic, configurations, and LLM prompts in the methods, schematic figure, and supplements to facilitate independent reproduction.
ORCID iDs
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.