
Abstract
Transformer models of language represent a step change in our ability to account for cognitive phenomena. Although the specific architecture that has garnered recent interest is quite young, many of its components have antecedents in the cognitive science literature. In this article, we start by providing an introduction to large language models aimed at a general psychological audience. We then highlight some of the antecedents, including the importance of scale, instance-based memory models, paradigmatic association and systematicity, positional encodings of serial order, and the learning of control processes. This article offers an exploration of the relationship between transformer models and their precursors, showing how they can be understood as a next phase in our understanding of cognitive processes.
Transformer-Based Large Language Models
Large language models based on the transformer architecture (Bahdanau et al., 2014; Vaswani et al., 2017) represent a step change in cognitive modeling. For the first time, we have computational models capable of human-level performance on cognitive tasks. The Generative Pretrained Transformer 4 (GPT-4) now surpasses an average human’s performance on various standardized tests, such as the Law School Admission Test (LSAT) and the SAT, and math competitions, including the American Mathematics Competitions and the American Invitational Mathematics Examination (Zhong et al., 2023). In typical cognitive tasks, transformer models perform well. For instance, Webb et al. (2023) conclude that “large language models such as GPT-3 have acquired an emergent ability to find zero-shot 1 solutions to a broad range of analogy problems.” Although there has been critique of the transformers model’s ability to capture some higher-level cognitive tasks (Binz & Schulz, 2022; Chomsky et al., 2023; Han et al., 2022; Mahowald et al., 2023), many of these objections have not been sustained as the models have become larger and training sets have expanded (Han et al., 2024). What the success of transformer models demonstrates is that the information required to learn the control processes and much of the representational substrate of the cognitive system exists in language input and can be extracted using general-purpose learning rules (Piantadosi, 2023). In the next section, we will give a brief overview of the transformer model before discussing its antecedents.
How Does a Transformer Work?
The task of a transformer is to predict the next word given the words that have occurred so far. For instance, given the context “I always found Janice amiable, but not everyone likes”
a good completion might be the word “her.” To create longer responses, the transformer takes its guess at the next word and adds it to the input and then predicts what should come next. It continues generating new words until it predicts that it has reached the end of the response.
Although the immediately preceding words can be helpful in deciding what comes next, often, critical information appears sometime in the past. In the example just given, if one looks only at the immediately preceding words, “not everyone likes,” many possibilities are reasonable: “him,” “it,” “football,” “politicians.” One needs more context in order to narrow down the options. In this case, the important word is “Janice.” But “Janice” appears six words back, and other words that are not useful, such as “amiable” and “everyone,” appear in between. The model needs to ignore these and pay attention to “Janice.”
To isolate the words of interest, the model first constructs a vector for each word in the context (Fig. 1a, yellow boxes). These vectors are constructed by adding an embedding vector that captures the meaning of the word (that is learned during the training phase) to a positional vector that codes when it appears. Then the model takes each word vector and transforms it into a key vector (red boxes) by multiplying it by a matrix of weights. The key vector can be thought of as a set of categories. For “Janice,” it might mean something like “person,” among other things.
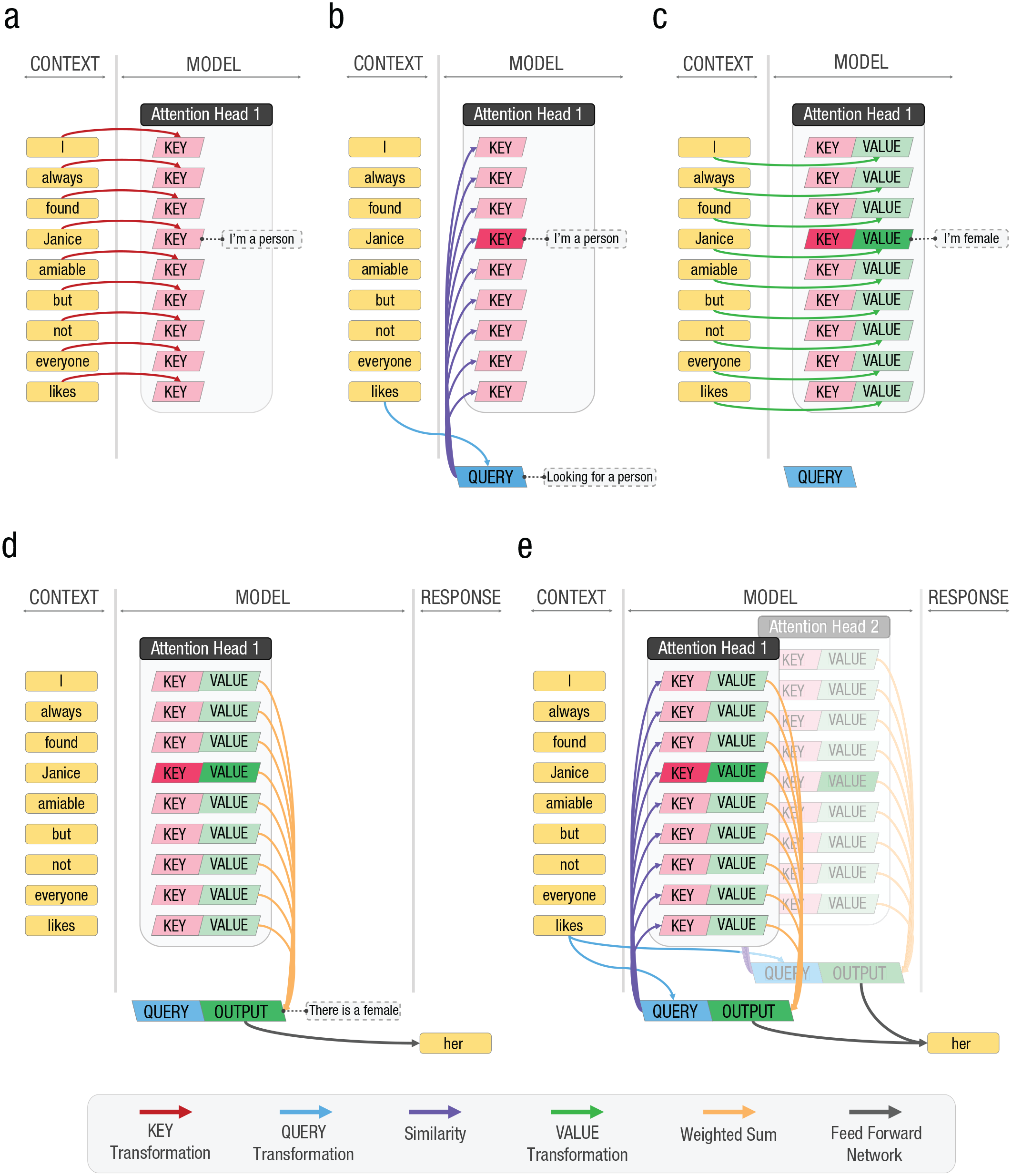
A simplified one-layer transformer architecture exposed to “I always found Janice amiable but not everyone likes.” (a) The model constructs a word vector for each word in the context (yellow). These vectors are constructed by adding a vector that captures the meaning of the word to a positional vector that codes when it appears. Then the model takes each word vector and transforms it into a key vector (red). The key vector can be thought of as a set of categories. For “Janice,” it might mean something like “person,” among other things. (b) Then, the final word of the context—“likes” in this example—is used to generate a query vector (blue). The query vector represents the types of things that are relevant to determining what comes next. In this case, it might include a “person” component. The model then looks for relevant words by comparing the query vector with each of the key vectors (purple arrows). The query vector and the key vector corresponding to “Janice” both contain the “person” component and hence will match. Other words, like “amiable” and “everyone,” do not contain this component and so are ignored. (c) The model takes each word and transforms it into a value vector representing the features of the word, like gender (green). (d) The value vectors of the matching words are added together to create a set of all of the features from the context relevant to producing the next word (orange arrows). (e) This output vector (dark green boxes) is then mapped to the actual word that the model chooses (black arrows). Typically, these operations will be replicated in multiple attention heads to allow attention to isolate different aspects of the context.
Then, the final word of the context—“likes” in this example—is used to generate a query vector (Fig. 1b, blue boxes). The query vector represents the types of things that are relevant to determining what comes next. In this case, it might include a “person” component because people are among the things that can be liked. The model then looks for relevant words by comparing the query vector with each of the key vectors (purple arrows). The query vector and the key vector corresponding to “Janice” both contain the “person” component and hence will match. Other words, like “amiable” and “everyone,” do not contain this component and so are ignored.
While we might consider just returning “Janice” as the next word, that would be slightly odd in this context. We would be more likely to shorten to the pronoun “her.” To do that, however, we need to know that “Janice” is a female. The model takes each word and transforms it into a value vector representing features of the word, like gender (Fig. 1c, green boxes). The value vectors of the matching words are added together to create a set of all of the features from the context relevant to producing the next word (Fig. 1d, orange arrows). This output vector (dark green boxes) is then mapped to the actual word that the model chooses (black arrows).
In the given example, it was the single word “Janice” that was critical. However, it may be that critical information accumulates across multiple words. For instance, if we have the context “Oh, sweet melancholy, dost thou pierce my soul with thy bittersweet”
“lament” might be a better completion than “candy” even though “candy” fits well with bittersweet. In this case, there is no single word that clearly favors “lament.” Rather it is the combined effect of words like “melancholy,” “dost,” “thou,” “pierce,” and “soul” that identifies this as a Shakespearean style of text and suggests that a word like “lament” is more likely than a word like “candy.” The query vector may match many words, in which case the output vector will contain features common to them all. For instance, the query vector might encode the idea of style, and the keys for “melancholy,” “dost,” “thou,” “pierce,” and “soul” might identify them as relevant for determining the style. The value vectors for these words would code the Shakespearean style, which would then become strongly activated in the output vector.
However, we would not want to compromise the model’s ability to isolate specific words in order to have it extract the gist of the context. To allow both to occur, the transformer often includes multiple attention heads (Fig. 1e). Each head uses different query, key, and value transforms, which can be individually configured to focus on different kinds of information. One might be devoted to finding people, while another is looking for words that determine the style. Large models will have many heads. For instance, the GPT-3.5 model uses 96 heads (Li, 2020). All of the output vectors are presented to the final mapping (black arrows) and jointly contribute to the selection of the next word.
The model presented thus far contains only one layer. However, in practice, transformers typically have many layers (96 in the GPT-3.5 architecture; Li, 2020). Instead of predicting the next word directly, the word vectors predicted by one layer become the input word vectors for the next layer—so regardless of the number of layers, there is always a one-to-one correspondence between the input words and the key and value vectors at each layer. A learning algorithm (back-propagation) is used to train all of the query, key, and value transforms as well as the feed-forward networks in each layer by comparing the current predictions of the entire network with the actual next words and adjusting the weights to minimize error.
Although the transformer architecture on which recent advances rely is relatively new, it has many antecedents both in the computer science and cognitive science literature. In this article, we will focus on antecedents from the cognitive modeling literature that may not be widely appreciated.
The Importance of Scale
Transformer models are large in two critical ways: They contain large numbers of parameters (weights) and they are trained on large data sets. For instance, GPT-3 contains 175 billion weights and was trained on 570 GB of text (T. Brown et al., 2020). Srivastava et al. (2022, Fig. 1c) show how performance on the BIG-bench Lite test bank improves with model size. For variants of the PaLM model (Chowdhery et al., 2022), performance rises slowly until the model reaches 1010 parameters but then accelerates, exceeding human performance as the model nears 1012 parameters. Similarly, Touvron et al. (2023) showed that as training sets increase to 1.4 trillion tokens (~ 7 TBs of text), predictive performance is still increasing.
A key observation is that larger models display emergent abilities that do not appear in smaller models (Wei et al., 2022). For instance, capabilities like logical deduction and physical intuition are present only when a model reaches the size of GPT-3.
An early model that demonstrated the importance of scale was latent semantic analysis (LSA; Dumais et al., 1988). LSA was a significant breakthrough in semantic modeling as, for the first time, it was possible to derive semantic representations from a naturally occurring corpus rather than handcrafting representations (Jones et al., 2015). Landauer and Dumais (1997; Landauer et al., 2007) argued that the rapid vocabulary growth that children exhibit could be explained if one assumed that the meaning of a given word was influenced by the appearance of not only itself but all other words. They proposed that scale was required to enable a robust process where the meaning of words is inferred through the complex interplay among their contextual occurrences across large datasets, effectively using the breadth of data to pinpoint the nuance of meanings. Demonstrations of LSA employed models containing nominally hundreds of millions of parameters (although many of these were zero) and naturally occurring corpora that contained tens of millions of words, which was unprecedented at the time. Before LSA, work in cognitive science and artificial intelligence tended to conform to Patrick Winston’s maxim that to learn something new, you need to almost already know it (Winston, 1992). That is, to learn a new concept, you need to already know the concepts on which it relies. LSA demonstrated that was not correct. Rather, concepts could be learned through the simultaneous resolution of large numbers of constraints derived from naturally occurring datasets. This observation sparked the search for simple algorithms that could be applied to large datasets to capture emergent properties, of which the transformer architecture is the most recent example.
Instance-Based Memory Models
A key aspect of the transformer architecture that differentiates it from earlier generations of language models is the use of attention. The ability to systematically bind keys to values and then to retrieve these vectors even if they appeared thousands of tokens into the past seems to be fundamental to the performance of the model.
The term “attention” as used in the transformer literature should not be confused with attention as it appears in the cognitive psychology literature. What the model is really doing is a kind of memory retrieval.
The mathematical operations they perform are very similar to instance-based models of memory, such as Minerva II (Hintzman, 1984, 1986) or retrieving effectively from memory (REM; Shiffrin & Steyvers, 1997).
The correspondence is particularly clear in the case of Minerva II. Minerva II assumes that distinct experiences are retained in memory as vectors of values—one vector for each experience. These vectors encode aspects of the experience, like who was involved, where it took place, or what objects were present. To retrieve memories, a query vector is constructed that encodes the cues. For instance, the query vector might encode the person and place in an effort to recall the objects that were present at the time. The query vector is then compared with each of the vectors in memory. Memory vectors that contain the same person and place will have high similarity values—effectively highlighting them for retrieval. To make these memory vectors stand out even more from the very large number of less relevant vectors, the similarities are raised to the third power. Now those memories that match all of the cues will be much stronger than the other memories even if they match one of the cues. Finally, the memory vectors are multiplied by these strengths and added together to create a vector called the echo that aggregates all of the aspects from memories that are related to the cues, for instance, the objects that were seen in the experiences that involved the given person and place.
In Minerva II, it is assumed that subsequent cognitive operations have access to only the echo vector. That is, the memory system operates not on individual memories but always on aggregates generated as outlined previously. This global matching property explains many of the kinds of memory errors that people make (Clark & Gronlund, 1996) and is shared with several other models (Gillund & Shiffrin, 1984; Humphreys et al., 1989; Murdock, 1982).
The correspondence between Minerva II and the attention mechanism of transformer models is strong. Both models assume that there is a key vector associated with each experience (i.e., word) and that a query vector is compared with each of these to create similarities (in fact both models use the dot product to calculate similarity). Then both models assume an accelerating nonlinearity is applied: In the case of Minerva II, the operation is the cube; in the case of transformer models, it is typically the softmax function—but these functions look very similar over the relevant ranges. Then both models construct the echo (also known as output vector) by taking a sum of the value vectors weighted by the strengths (also known as attention weights). The basic mechanisms are almost identical.
A common complaint about transformer models is that they sometimes produce incorrect answers—so-called hallucinations. In the memory literature, these would be called false memories, and the global matching property (that transformers share with many memory models) was introduced deliberately to produce them (Clark & Gronlund, 1996).
A key bottleneck for transformer models is the calculation of the attention strengths. For each token, the similarity with all other tokens is calculated. As the number of tokens in the context increases, this becomes computationally expensive—putting an effective limit on how far back in time retrieval can extend. An alternative would be to use a composite memory model (Humphreys et al., 1989; Murdock, 1982) in which the key-value mappings are stored in a common-memory vector or matrix rather than as a set of instances, thus removing the computational bottleneck. A model remarkably similar to the transformer architecture, but that uses a composite memory, was proposed by Dennis and Wiles (1993). We are currently working on a version of this architecture, which performs significantly better than equivalently sized transformer models in initial tests. We suspect that there will be further cases where insights from the cognitive literature will lead to improvements in large language models.
Paradigmatic Association and Systematicity
Saussure (1916) introduced the distinction between syntagmatic relations (that exist between words that co-occur, like “cat” and “ball”) and paradigmatic relations (that exist between words that can appear in the same sentential slot, like “cat” and “dog”). The psychological reality of these constructs, possible mechanisms, and the developmental progression have been investigated extensively (R. Brown & Berko, 1960; Entwisle et al., 1964; McNeill, 1963).
These ideas found computational form in the syntagmatic paradigmatic (SP) model (Dennis, 2004, 2005; see also Sloutsky et al., 2017). The SP model assumes separate syntagmatic and paradigmatic memory stores. The paradigmatic store contains key-value vector pairs one for each input token, like transformer models. The keys are derived from syntagmatic retrieval based on the surrounding words and the values are the tokens themselves. During generation, the surrounding words are used to construct a query, which is matched against the keys, and then a weighted retrieval of the values becomes the output—quite similar to how the transformer architecture works.
A key motivation for Dennis (2004, 2005) was the inability of connectionist architectures to capture the systematicity of human thought (Fodor & Pylyshyn, 1988). If someone can understand the sentence “John loves Mary,” they can also understand the sentence “Mary loves John.” Fodor and Pylyshyn (1988) argued that neural networks do not embody these constraints and were therefore inappropriate models of human cognition. They proposed that to capture the underlying structure of sentences, one needed a way to systematically bind roles to fillers and that this mechanism needed to be built into the architecture rather than learned from experience. “John loves Mary” might be represented as {lover=>John, lovee=>Mary}, while “Mary loves John” might be represented as {lover=>Mary, lovee=>John}. The representations of “John,” “Mary,” and “loves” might be learned, but the space of possible bindings is so large that the ability to form each binding could not be learned given the number of examples people experience. Subsequently, Phillips and Halford (1997) confirmed that feed-forward back-propagation networks and simple recurrent networks were not able to systematically generalize to the extent that people do.
Key-value bindings in transformer networks allow for the rapid binding of roles and fillers. A systematic investigation is in order, but it seems likely that the introduction of key-value bindings is the key inductive bias that allows transformers to generalize in combinatorial domains much more efficiently than previous neural architectures—just as the use of paradigmatic associations was the key to the performance of the SP model. While Fodor and Pylyshyn (1988) were thinking of purely symbolic architectures when they brought their critique, the fact that it has taken the introduction of a more structured mechanism in the form of attention/paradigmatic association in order to capture human cognition is a vindication of their concerns.
Positional Encodings of Serial Order
In many languages, word order matters (Dennis, 2007). “John loves Mary” is not the same statement as “Mary loves John.” How people retain the order with which stimuli are presented has been a subject of study since the 1800s (Nipher, 1876). Three approaches have been proposed. The chaining model suggests that associations are formed between successive items and that recalling a sequence involves starting with the first and traversing the chain (Ebbinghaus, 1885/1964). The primacy model suggests that items are stored with descending strengths, and recall proceeds by retrieving the strongest, suppressing it, retrieving the next strongest, suppressing it, and so forth (Page & Norris, 1998). The positional model assumes that there is a separate cue associated with each position within a list, and recall involves applying each position cue in turn and retrieving the item that was associated with it (Henson, 1998). Large language models prior to the transformer can be seen as sophisticated versions of the chaining model in which the prior-context state is used to predict the next item. The transformer architecture removed this context vector and relied exclusively on key-value bindings. Without modification, however, this would have removed its sensitivity to word order. As a consequence, transformers inject a positional cue into the representation of each token, making them akin to traditional positional models.
How one constructs the cues in positional models varies. The approach taken in transformer models is very similar to that employed by the oscillator-based associative recall (OSCAR) model proposed by G. D. Brown et al. (2000; see also Burgess & Hitch, 1999). In OSCAR, a context vector is constructed from units that oscillate at different frequencies. At encoding, the context vector is associated with vectors representing the items to be retained. At retrieval, the oscillators are reset and the context vector is allowed to move forward again. The evolving context vectors are used to retrieve the item vectors one at a time. The oscillators that are changing slowly distinguish between the start and end of the list, while the oscillators that change quickly distinguish between successive items (but not the start and end of the list). Together they form a timing code that captures the position of the item.
In a similar way, transformer models construct a positional code from banks of oscillating units of different frequencies (Dai et al., 2019; Vaswani et al., 2017). In transformer models, the positional vector is typically added to the item vector rather than associated with it. If these item-plus-position vectors were added together as is the case in OSCAR, this approach would not be sufficient to support serial recall. However, in transformer models, the vectors are added into an instance-based memory, which ensures that the binding between the position and item information is maintained. If one were to trial a composite memory model as suggested earlier, care needs to be taken to incorporate positional information in an appropriate fashion.
Learning Control Processes
One of the most impressive and disruptive capacities of transformer models is the ability to learn the control processes that determine what representations are constructed and which operations are applied to manage the flow of information from input stimuli to system responses (e.g., assembling cues to initiate retrieval or selecting responses from information that has been retrieved). Although the cognitive psychology literature has often focused on the modeling of separate tasks, transformers can be applied to different tasks without modification (Riveland & Pouget, 2022). In the cognitive modeling literature, there have been attempts to maintain some consistency of representational substrate. For instance, the global matching models of memory used common-memory representations to account for recognition, cued recall, free recall, and sometimes serial recall (Gillund & Shiffrin, 1984; Hintzman, 1984; Humphreys et al., 1989; Lewandowsky & Murdock, 1989; Murdock, 1982; Raaijmakers & Shiffrin, 1981). Nonetheless, each task involved a separate algorithm. Just as the handcrafting of representations in semantic memory models led to accounts with unreasonably large and hidden degrees of freedom (Jones et al., 2015), the handcrafting of control processes undermines our ability to formally compare models and has backgrounded attempts to understand the commonalities between cognitive capabilities.
There is, however, precedent for attempting to learn control. Dennis (2005) argued for the development of task-independent models that treated the instructions as inputs to a more general model of the cognitive system. As a step toward the development of such a model, he introduced a few-shot learning approach in which the input contains a small number of examples of the task of interest and the model is expected to generalize to new cases of the same task (creating a task virtual machine, as Doug Mewhort [personal communication] referred to it). The SP model highlighted the commonalities between a number of tasks, including sentence processing, semantic categorization and rating, short-term serial recall, and analogical and logical inference and made extensive use of paradigmatic association (key-value pairs) to explain performance. As such, it seems like it might be a particularly fertile place to look for inspiration when trying to understand the emergent properties of transformer models.
The transformer architecture, however, takes the acquisition of control to a new level as it is often the case that no prior examples need to be provided—so-called zero-shot learning. Box 1 shows a conversation with ChatGPT in which it is given a list of words and then asked to recall the list, recognize items from the list, generalize the category of the list items to a new item, and make judgments about the size of the items in the list. In each case, it provides correct responses without being reconfigured for the specific task. The ability of transformers to be applied flexibly to arbitrary tasks and to account for the acquisition of control processes are major advantages over existing cognitive models.
A conversation with ChatGPT demonstrating its ability to address different tasks without modification

Discussion
Whether by causal connection or convergent evolution, many key aspects of transformer models have antecedents in the cognitive science literature. In this article, we have highlighted some of these, including the emergence of new properties with corpus scale, instance-based memory models, paradigmatic association and systematicity, positional encodings of serial order, and the learning of control processes. There are more, including, of course, the use of the back-propagation learning algorithm and the development of hidden unit representations, which is intrinsic to the basic processes of transformers and gained much of its impetus in the cognitive modeling literature (Rumelhart et al., 1986). However, these contributions are more likely to be generally understood, and so we have focused on those components that may not be as universally appreciated.
One cannot help but feel that we are at a major milestone in the development of cognitive models. Yet understanding how transformer models achieve their competence remains a significant challenge. We do not begin from a tabula rasa, however. The existing cognitive modeling literature provides a foundation from which to start, and by highlighting the parallels, we hope to facilitate the process of mining the literature for insight.
Recommended Reading
Contreras Kallens, P., Kristensen-McLachlan, R. D., & Christiansen, M. H. (2023). Large language models demonstrate the potential of statistical learning in language. Cognitive Science, 47(3), Article e13256. A recent article outlining how large language models demonstrate that some form of statistical learning is a viable approach to understanding language.
Piantadosi, S. (2023). (See References). A systematic rebuttal of Chomsky’s arguments about language learnability using large language models as an existance proof.
Rumelhart, D. E., & McClelland, J. L., & PDP Research Group (Eds.). (1986). (See References). An introduction to neural networks and their application in psychology.