
Abstract
Urban origin–destination (OD) data often come from two distinct sources: traditional surveys and global positioning system (GPS)-based records. The former offer rich behavioral detail but are infrequent and costly, while the latter provide continuous coverage but lack semantic context. They often lead to different findings and are rarely examined together, making it difficult to build a consistent understanding of urban travel behavior. To address this gap, we propose a dynamic joint latent factor model that decomposes multi-source OD matrices into shared spatial structures and source-specific temporal dynamics. The model identifies latent movement patterns by jointly factorizing both datasets while allowing each source to retain its unique temporal characteristics. Applied to GPS and survey OD data from Ottawa, Canada, the model achieves strong reconstruction accuracy (
Keywords
Introduction
Origin–destination (OD) matrices are a cornerstone of urban transportation planning. They support critical analyses ranging from travel demand forecasting to infrastructure investment and modal share evaluation ( 1 – 3 ). Traditionally, OD matrices are derived from household travel surveys (HTS), which offer rich demographic and behavioral context ( 4 ). However, these surveys are costly and temporally sparse. In Canadian cities, for instance, they are often conducted only once every 5 years and typically fielded in the fall, which may limit representativeness across seasons and potentially introduce seasonal bias in mode shares and trip patterns ( 4 – 6 ). In recent years, alternative sources such as global positioning system (GPS) traces, mobile phone data, and transit smart cards have emerged, offering continuous and large-scale observations of mobility patterns ( 7 , 8 ). While these new sources offer higher resolution and broader coverage, they often lack the semantic depth and behavioral interpretability of traditional surveys.
This coexistence of multiple OD data sources presents both an opportunity and a challenge. On the one hand, combining data can provide a more complete picture of urban mobility ( 5 , 9 ). On the other hand, OD matrices from different sources often show substantial discrepancies in both spatial and temporal dimensions ( 10 ). These differences are not just random fluctuations but stem from structured biases: surveys may miss short, habitual, or non-home-based trips, while mobile data may exclude trips by users without smartphones or with privacy settings ( 9 ). As a result, transportation planners and researchers often face inconsistent mobility insights depending on which dataset they use, yet these datasets are still commonly analyzed in isolation.
Existing work on multi-source OD analysis has primarily focused on statistically aligning datasets to enhance flow prediction, or on characterizing their divergence using single-value measures. ( 11 – 13 ). For example, Bwambale et al. statistically align HTS with mobile-phone indicators by jointly calibrating trip-generation models, effectively treating residual discrepancies as sampling noise to be minimized ( 12 ). Jing et al. use a context-aware matrix factorization to fuse taxi OD matrices with point-of-interest features, smoothing spatial inconsistencies through external covariates while still viewing cross-source differences as errors to be corrected ( 13 ). Behara et al., in contrast, propose a structural comparison based on Levenshtein distance that quantifies mismatches between OD matrices but remains purely diagnostic and does not offer a generative explanation for where such discrepancies come from ( 11 ). Although these methods provide useful ways to integrate or compare different mobility datasets, they typically treat discrepancies between sources as noise that should be removed. However, many of these differences may reflect real behavioral or structural patterns, and viewing them solely as errors risks overlooking information that is meaningful.
To overcome this issue, recent work has applied low-rank decomposition methods to OD matrices to uncover interpretable spatiotemporal structures ( 14 – 19 ). These methods rely on the assumption that high-dimensional mobility data can be well approximated by a small number of spatial and temporal patterns, which enables the reconstruction of mobility patterns with improved spatial coherence and temporal smoothness ( 20 ). For instance, Du et al. used tensor factorization to extract latent transit flow components from smart-card data, revealing recurrent peak-period travel patterns ( 15 ). Similarly, Li et al. employed probabilistic matrix factorization to uncover hidden ride-hailing demand structures that vary across time and service types ( 16 ). However, these low-rank decomposition approaches primarily aim to interpret latent behavioral structures and uncover recurring mobility patterns within a single dataset, offering limited capacity for detecting inconsistencies across data sources.
Other studies extend low-rank models toward anomaly detection and short-term prediction. ( 14 , 17 – 19 ). These works typically formulate mobility flows as multivariate observations and use probabilistic or tensor-based decompositions to extract latent spatiotemporal structures. For example, Wang et al. represented trajectory data as a fourth-order spatiotemporal tensor (i.e., origin, destination, time of day, and day of week) and used probabilistic Tucker decomposition to detect abnormal behaviors ( 18 ). Cheng et al. used a dynamic-mode-decomposition-based low-rank model to capture temporal patterns in metro OD flows and achieve real-time prediction ( 14 ). Their findings show that such latent representations can reveal anomalous activities, characterize multi-way mobility interactions, and support operational monitoring across urban and maritime contexts. While these approaches offer a powerful lens for understanding OD patterns, they are typically applied to single-source data and are, therefore, unable to identify systematic differences across heterogeneous OD datasets.
To address these limitations, we propose a dynamic joint latent factor model that analyzes multiple OD data sources by decomposing OD flows into several shared latent spatial patterns, each with its own latent time-series pattern by data-source. The shared latent spatial patterns describe how strongly each OD pair contributes to each latent pattern, thereby indicating which OD pairs primarily define the spatial structure of that pattern. For each pattern, the associated time-series factor reflects its magnitude-level changes over time and differs across data sources. For example, one latent pattern may capture the dominant afternoon commuting flows, while another represents morning travel behavior. To link each latent pattern to distinct behavioral groups, we jointly analyzed the spatial patterns and the socio-demographic profiles of origins and destinations, including age composition, household income, vehicle availability, and trip purposes. This enables us to connect socio-demographic variables with the behavioral interpretation of the latent patterns and to demonstrate that each latent pattern highlights distinct aspects of urban activity. In summary, the main contributions of this study are as follows:
The proposed dynamic joint latent factor model decomposes multi-source OD matrices into shared spatial patterns and source-specific temporal dynamics, enabling the extraction of core mobility structures while preserving distinct behavioral signatures across data sources.
The integration of socio-demographic profiles with latent patterns enables a behaviorally grounded interpretation of mobility structures, clarifying the population and income characteristics associated with each pattern.
The proposed framework provides planners with a practical mechanism for reconciling multi-source OD datasets and adjusting demand estimates in areas and population groups prone to systematic underrepresentation, supporting more equitable mobility planning.
The remainder of this paper is organized as follows. The Data Description section introduces the GPS and household survey datasets, describes their spatial and temporal alignment, and outlines the pre-processing steps needed to make the two sources comparable. The Methodology section presents the proposed dynamic joint latent factor model, detailing the factorization structure, temporal transition formulation, and parameter estimation procedure. The Results section reports model’s fitting performance and empirical findings from the Ottawa–Gatineau case study, covering temporal and spatial latent patterns as well as the behavioral contrasts revealed across data sources. The Discussion and Conclusion section discusses the broader implications for OD data fusion, bias diagnosis, and mobility planning, and concludes by outlining future research directions.
Data Description
Data Sources
In this paper, the study area includes both urban Ottawa and Gatineauin, two adjacent cities that form a continuously connected metropolitan region separated by the Ottawa River in Canada. We use two real-world datasets: GPS-based traffic data provided by SMATS Traffic Solutions, a smart transportation data collection and analysis company, and the 2022 Ottawa-Gatineau HTS ( 21 , 22 ). The GPS dataset records vehicle-originated OD flows captured by onboard devices installed in vehicle engines. We extract GPS data from a 4-day period, Monday–Thursday, October 23–26, 2023. In total, the dataset covers 96 continuous hours and includes 1,034,158 trips. In contrast, the HTS data represent a full-day travel pattern compiled from surveys conducted between September 8 and December 7, 2022. Note that the original HTS dataset includes 160,000 sample trips. To correct sampling bias and represent the full population, we apply the weights provided by the HTS data. After applying the appropriate expansion weights, the survey dataset accounts for 1,607,033 trips over a 24 h period.
To enable meaningful comparisons between the two datasets, we align the spatial and temporal resolutions of the datasets by aggregating all flows to traffic analysis zones and to hourly intervals. The region includes 50 zones, resulting in 2,500 possible OD pairs. Since the GPS data capture only motor vehicle trips, the survey data were filtered to include only private vehicle, taxi, and paid ride-share modes, correspondingly. Following pre-processing, the GPS OD matrix has a size of 2,500 × 96, representing OD trip counts across 2,500 zone pairs over 96 hourly intervals, and the HTS matrix has dimensions of 2,500 × 24, reflecting the same spatial coverage over 24 hourly intervals.
Data Analysis
Although both GPS and HTS OD matrices aim to represent travel demand, significant differences arise from their sampling mechanism, temporal resolution, and representation of travel modes. To illustrate this structural mismatch, we examine the relationship between normalized GPS and normalized survey OD flows during two peak periods: 6–10 a.m. (AM peak) and 3–7 p.m. (PM peak), with GPS flows aggregated as a 4-day average for the comparative analyses in this section. As shown in Figure 1, The resulting
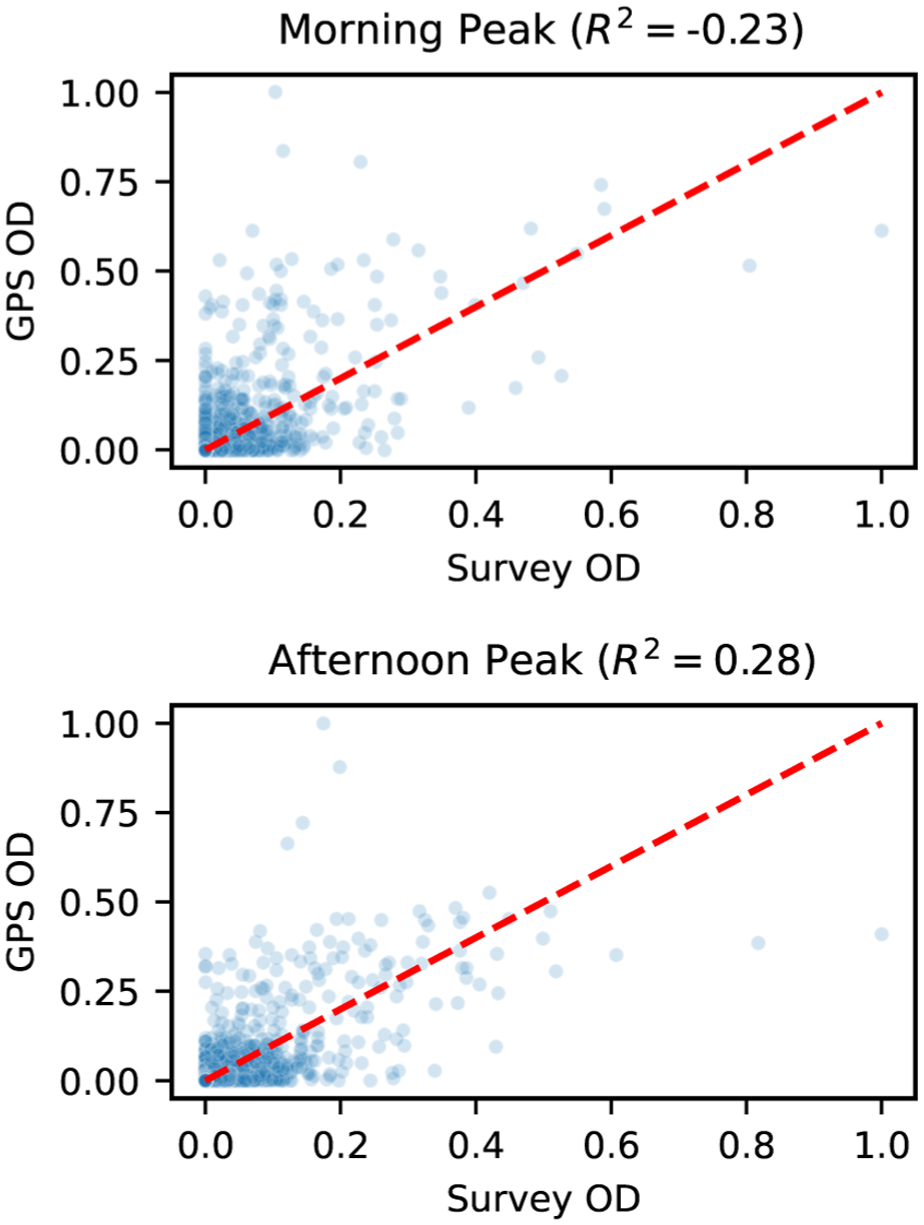
Comparison of global positioning system (GPS) and survey origin–destination (OD) flow for morning (6–10 a.m.) (top) and afternoon (3–7 p.m.) (bottom) periods.
Despite the two datasets differing in scale, they may still exhibit similarity in their underlying spatial structure. To explore this, we compute the Spearman rank correlation between survey and GPS OD flows across five time-of-day periods, which compares the consistency of OD-flow rankings between the two datasets. As summarized in Table 1, the two data sources show strong spatial consistency during commute-dominated daytime periods (6 a.m.–7 p.m.), reflecting common spatial patterns of regular and predictable flows. Evening flows exhibit moderate correspondence (
Spatial Spearman Correlations between Survey-Based and GPS-Derived OD Flows across Time Periods

Note: GPS = global positioning system; OD = origin–destination.
Following common interpretations,
To further examine the structural properties of these OD matrices, we compute the cumulative singular-value spectra of both datasets by singular value decomposition. The results are shown in Figure 2. Over 80% of the energy lies in the first few singular values, and this shows that both GPS and survey OD matrices are strongly low-rank, even with differences in sampling and temporal coverage. This low-rank behavior suggests that the OD matrices can be represented by a few dominant spatial and temporal latent patterns.
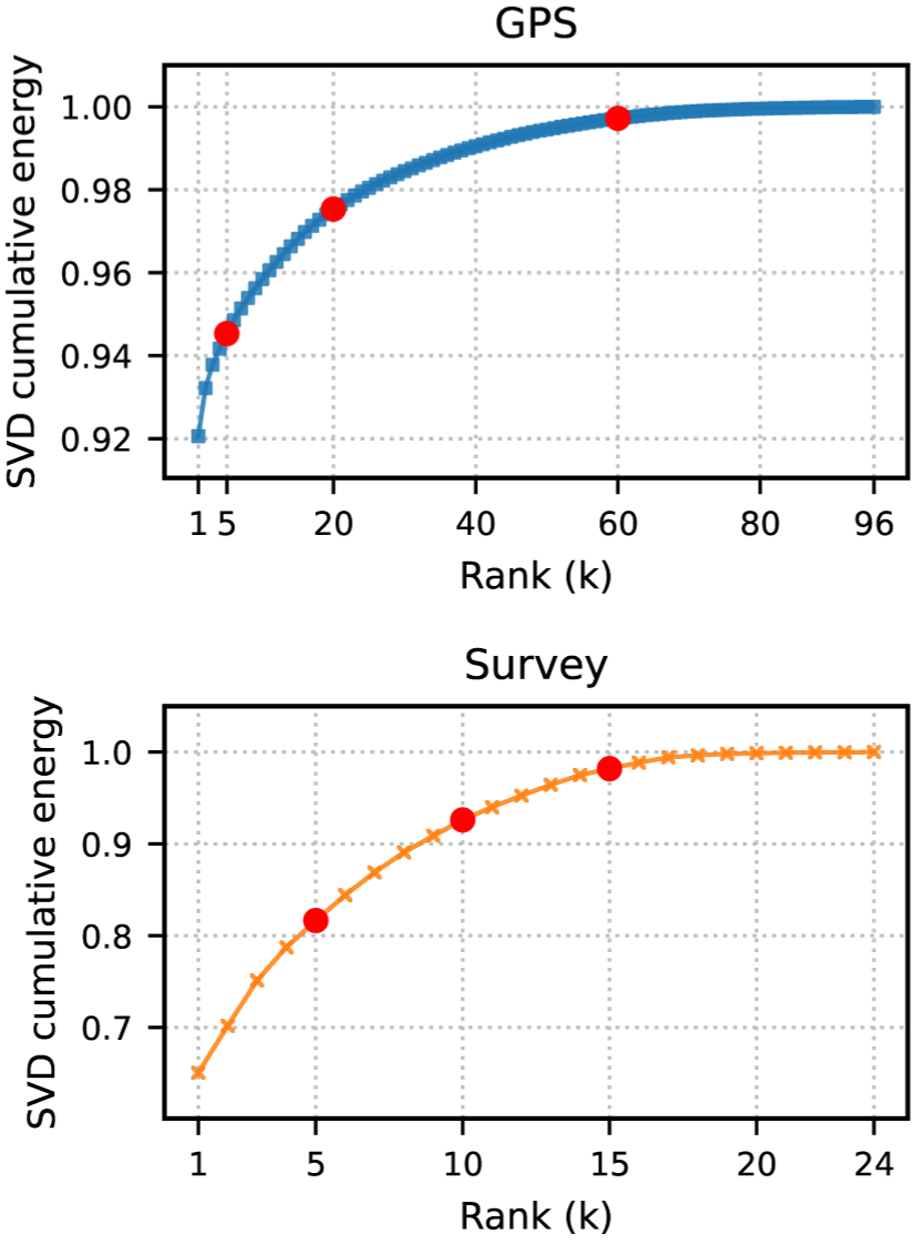
Cumulative singular value decomposition energy of the global positioning system (GPS) origin–destination (OD) matrix (
Taken together, although the GPS and survey OD matrices differ considerably in magnitude, they exhibit a clear spatial correspondence during periods of regular travel demand. This suggests that the two data sources capture similar underlying patterns, while also reflecting source-specific biases. Moreover, the low-rank structure of the OD matrices motivates the use of a joint low-rank model to extract shared spatial patterns while accounting for source-specific temporal variations.
Methodology
To fuse the two heterogeneous data sources, we propose a dynamic joint latent factor model that decomposes each OD matrix into a shared spatial pattern matrix and a temporal pattern matrix. Our previous data analysis shows that the peak-period OD spatial patterns are highly consistent across both datasets, which supports the use of a shared spatial representation. For the temporal patterns, we model the latent temporal factors using a first-order linear dynamical system (LDS), since traffic demand is strongly influenced by its previous state ( 20 , 23 ). Overall, the proposed framework integrates low-rank factorization with state-space modeling, providing a compact and interpretable representation of high-dimensional OD flows ( 24 , 25 ).
Model Formulation
Shared Low-Rank Factorization
We denote the matrices
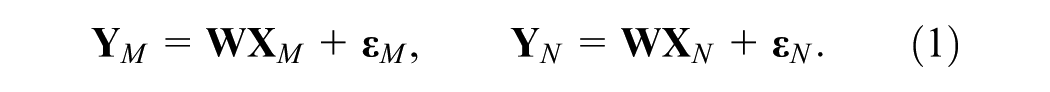
where
This shared low-rank factorization model can also be regarded as an observation model in state-space model setting.
To obtain meaningful spatial patterns and balance the contributions of the two data sources, we first update
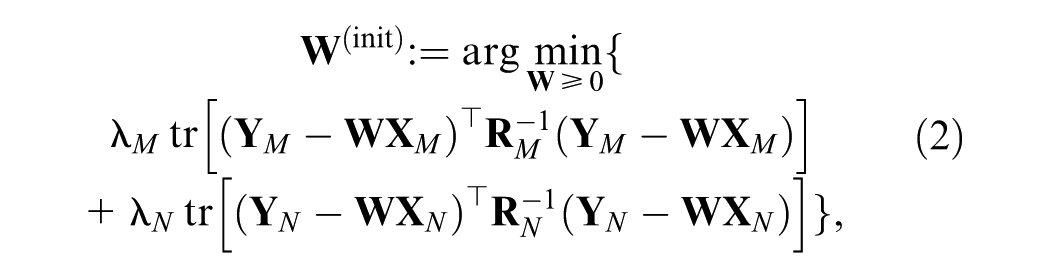
where
The adaptive weights
Starting from the NNLS solution
where
This regularization improves the stability of the learned spatial pattern matrix across different random initializations, while preserving the reconstruction quality obtained from the NNLS initialization. Such stability is essential for interpretability: if different initializations yield substantially different estimates of
Independent Temporal Dynamics
Let

where
In summary, by combining Equations 1 and 3, the model allows the spatial pattern matrix
Latent factor representation of the origin–destination (OD) matrices. Each dataset shares the spatial pattern matrix
Model Inference
We estimate the model parameters using the expectation–maximization (EM) algorithm (
24
,
25
,
27
). The algorithm alternates between estimating the latent variables given the current parameters (E-step) and updating the parameters given the expected latent variables (M-step). In this study, we regard temporal latent matrices
In the E-step, given the current parameter estimates
In the M-step, we update the parameters by maximizing the complete-data log-likelihood with respect to
where
The closed-form updates for
With the updates for
EM estimation for the joint dynamic latent factor model

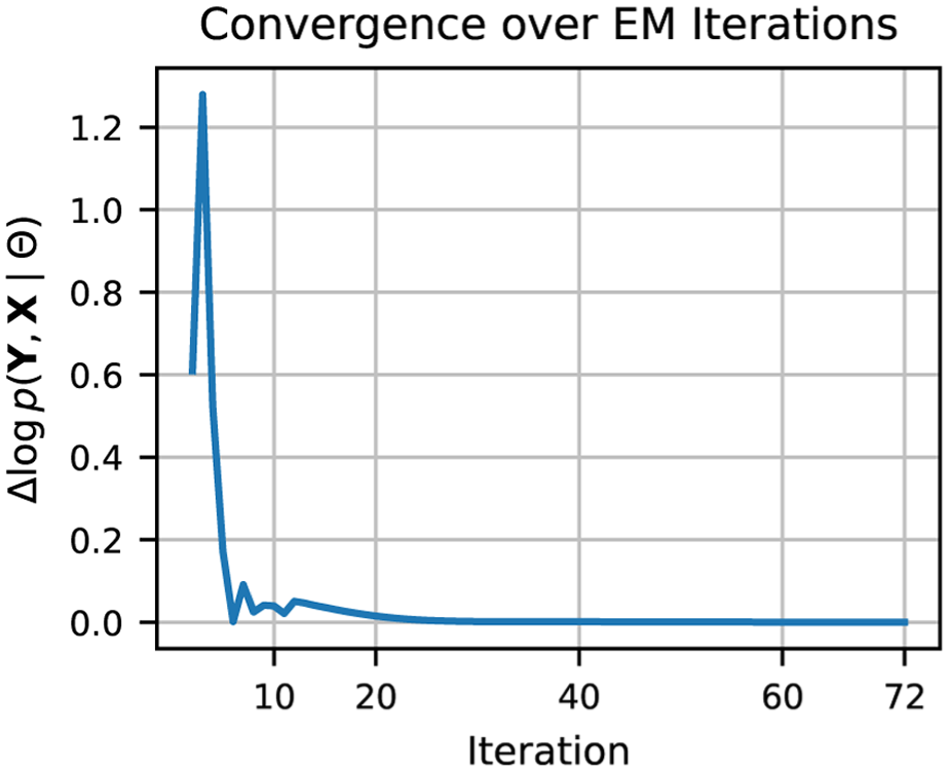
Convergence of the expectation–maximization (EM) algorithm measured by the change in the Q-function (
Results
Model Performance
The proposed joint latent factor model achieves high reconstruction accuracy for both datasets. Figure 5 shows the model’s ability to reconstruct observed OD flows from latent matrices, measured by
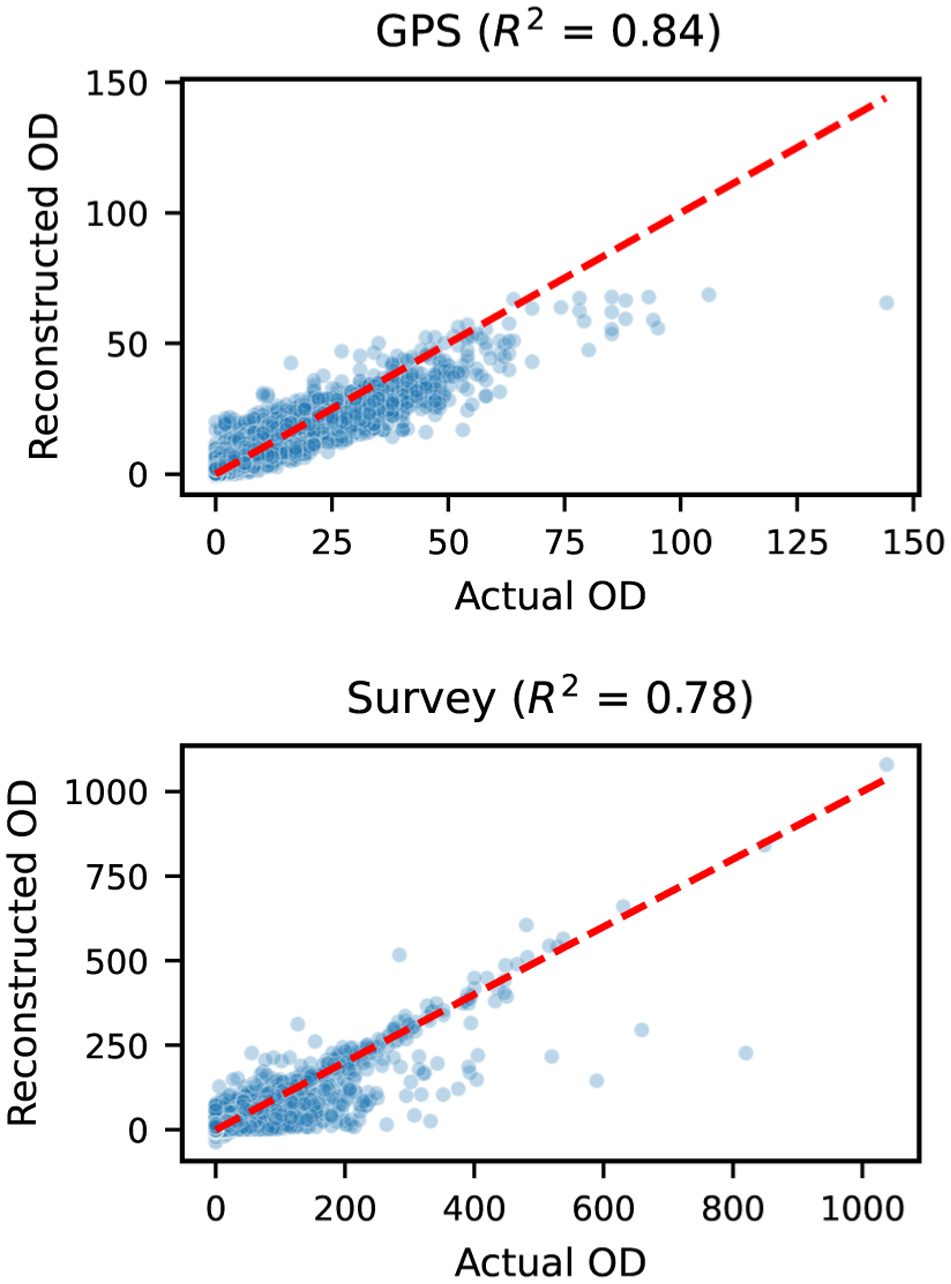
Reconstructed versus actual origin–destination (OD) flows for global positioning system (GPS) (top) and survey (bottom).
Temporal Latent Patterns
To understand the hourly evolution of travel demand in both datasets, we examine the temporal latent patterns matrices
Figure 6 presents the five temporal patterns: the top panel shows GPS factors across 96-hours (four weekdays), and the bottom panel shows the 24-hour weekday profile from the survey. Across both datasets, the dominant factors exhibit clear morning (6–10 a.m.) and afternoon (3–7 p.m.) activity peaks, aligning with well-known commuting patterns. An important structural feature is the contrast between positive and negative magnitudes: positive values indicate hours when a latent pattern contributes more strongly to OD flows, whereas negative values reflect periods when that pattern is relatively suppressed. Furthermore, several patterns display contrasting magnitudes between the morning and afternoon periods in both datasets, suggesting that each pattern captures a different phase of the daily mobility cycle.
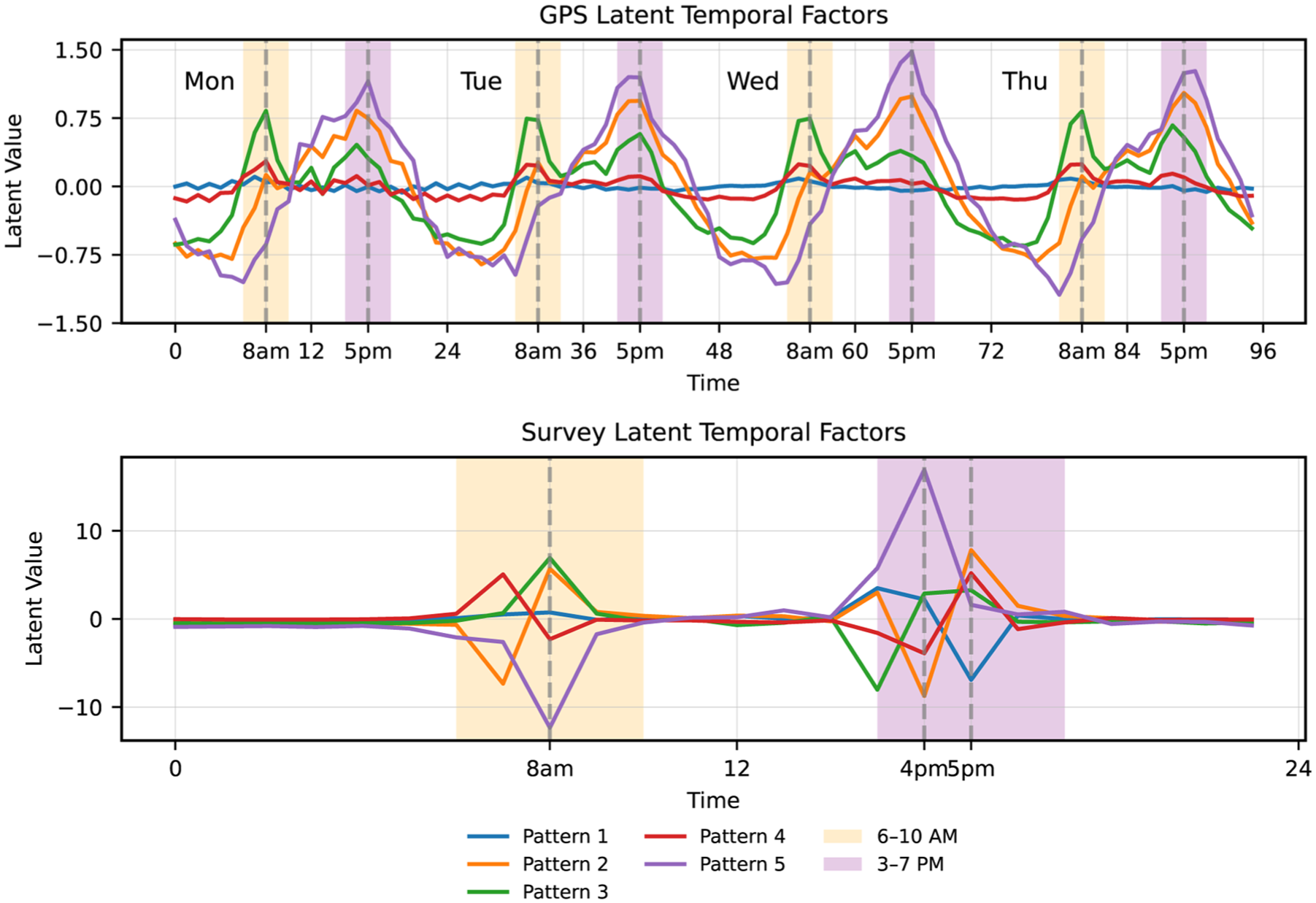
Latent temporal factors learned from global positioning system (GPS) (
A closer comparison at the pattern level reveals clear differences in which latent patterns dominate each peak period. For example, during the morning peak, the GPS data are driven almost entirely by Pattern 3, which reaches the strongest magnitude around 8 a.m., while the other factors show only moderate increases. In contrast, the survey data display a more distributed structure: Patterns 2, 3, and 4 all exhibit positive magnitudes at 8 a.m., indicating that the survey-derived morning peak is jointly supported by multiple factors rather than a single dominant one. The afternoon peak shows greater agreement between the two sources (Patterns 2, 3, and 5). During the afternoon peaking period, Pattern 5 provides the strongly positive magnitude during the 4–6 p.m. time period across both datasets, with Pattern 2 contributing as a secondary component. Thus, while the two datasets share similar timing of peak demand, they differ in how individual latent patterns compose those peaks, particularly in the morning.
Overall, these temporal factors summarize the common daily rhythm of urban travel demand and highlight source-specific differences in smoothness and amplitude. Building on these insights, the next section turns to the spatial dimension to examine how the most influential latent patterns manifest across geographic areas and land-use contexts, where the joint interpretation of
Shared Spatial OD Patterns
In this section, we first analyze the spatial latent pattern matrix
Latent Spatial Structure
The spatial matrix

To ensure comparability across clusters within each mode, these values are normalized into relative shares:
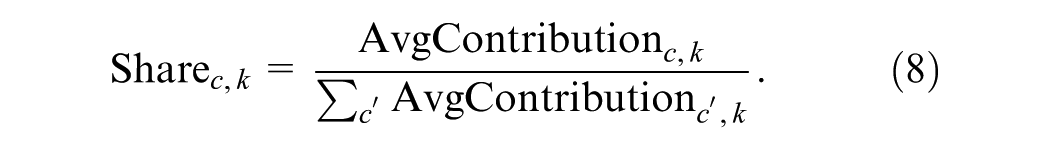
Table 2 reports the contributions by cluster, along with entropy and Gini indices. A full scatterplot of OD-pair magnitudes by cluster and pattern is provided in the Appendix for reference. The results indicate a strong dominance of Cluster 1 and Cluster 2, which together account for more than 50% of total magnitude in each pattern, while smaller clusters contribute diminishing shares. The moderate entropy values (2.5–2.6) and Gini coefficients (0.40–0.43) suggest that each latent pattern is concentrated in a few leading clusters, with the remaining clusters contributing only marginally. This suggests that the patterns are structured around a few dominant spatial clusters OD pairs, rather than being either tightly localized or uniformly dispersed.
Cluster Dominance (% of Mean Magnitude) by Latent Pattern, Entropy, and Gini Index
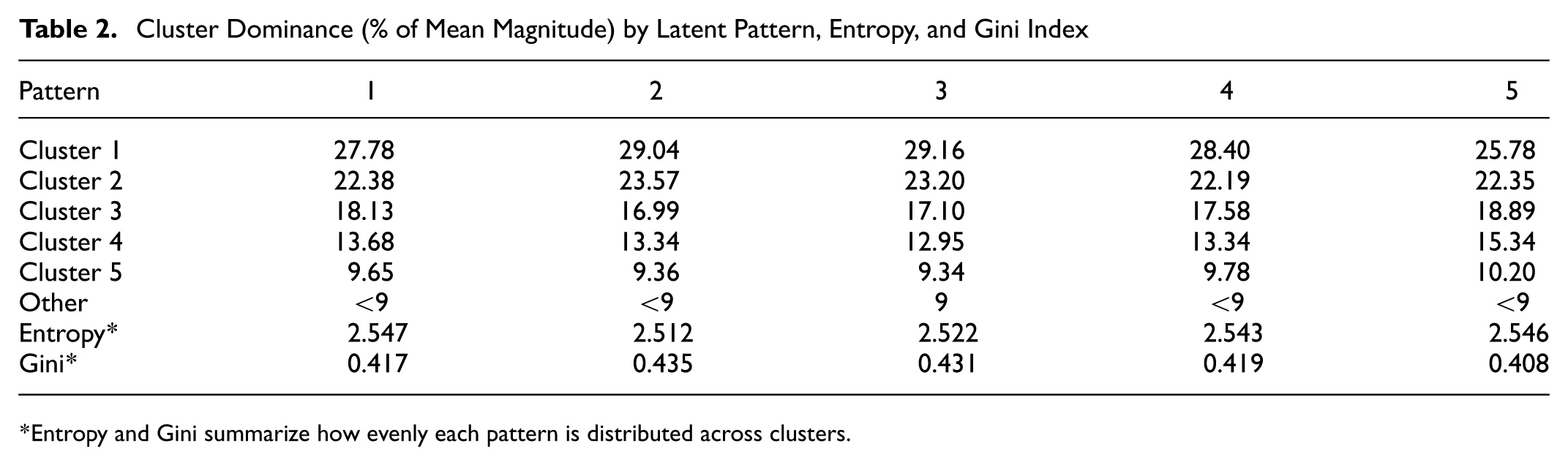
Entropy and Gini summarize how evenly each pattern is distributed across clusters.
Although latent patterns are identified through clustering of OD pairs, trip activity is inherently expressed at the zone level through the origins’ and destinations’ characteristics. Therefore, to examine how these patterns relate to population and land-use characteristics, we aggregate OD flows by origin and destination and analyze zone-level outflows (origin totals) and inflows (destination totals) at the zone level. Figure 7 illustrates the spatial distribution of sending (origin-dominant) and receiving (destination-dominant) zones for Cluster 1, which is most strongly associated with all latent patterns. Across patterns, the maps reveal a clear outer-to-inner structure. Inflow-dominant zones (blue) are concentrated in downtown and south area (i.e., hospital, residential), whereas outflow-dominant zones (yellow) are located mainly in residential and rural fringe areas. Mixed zones (green) appear in several inner-urban neighborhoods and reflect their dual residential and employment functions. Although each pattern highlights different combinations of residential and peripheral areas, they all reflect variations of the same fundamental spatial logic: trips predominantly originate from the outskirts and converge toward central activity hubs.
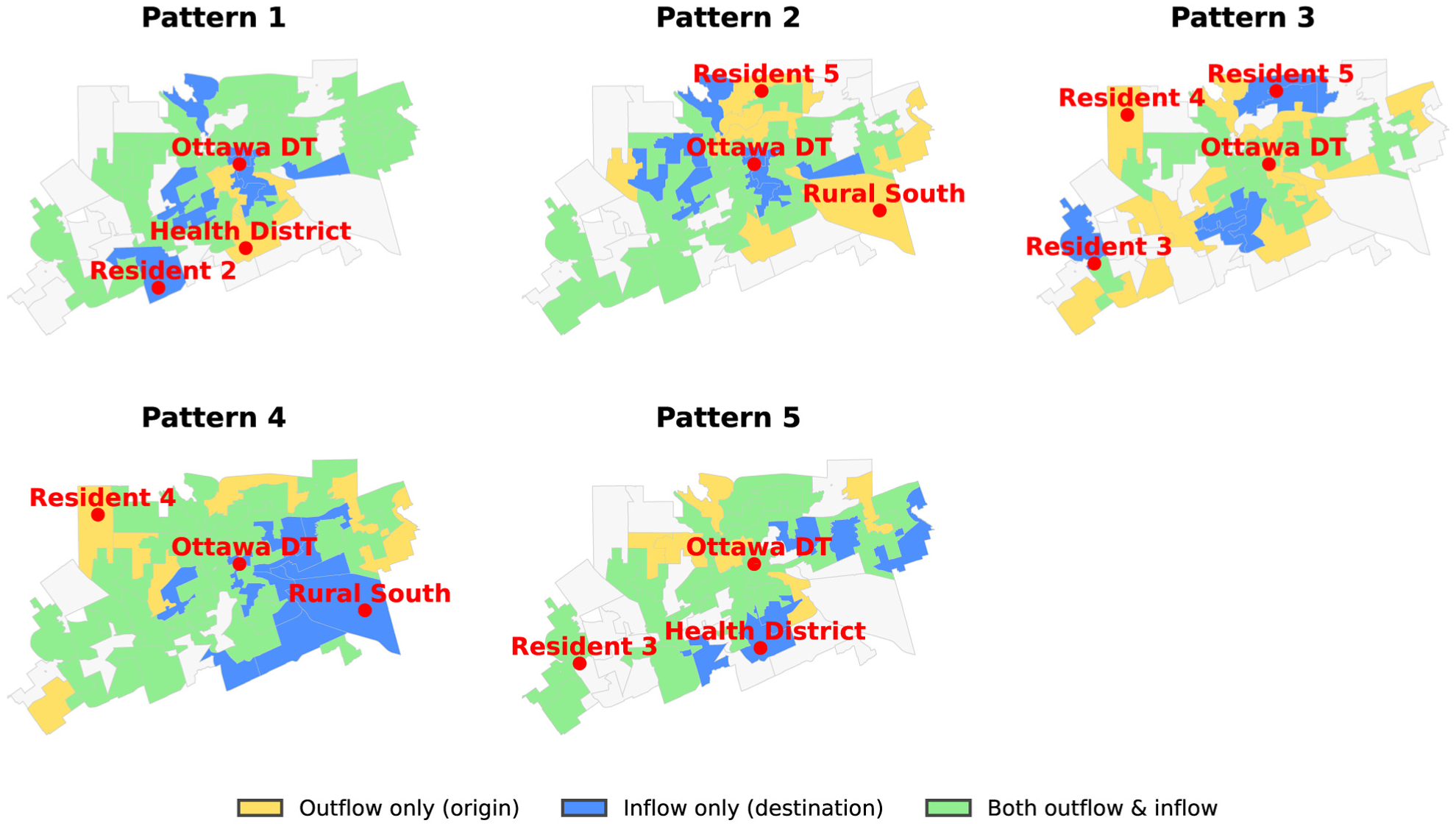
Zone-level (origins) and inflows (destinations) for Cluster 1 across five latent patterns.
Socio-Demographic Analysis
To further interpret the origin (outflow) and destination (inflow) roles implied by the latent patterns, we link them to zone-level socio-demographic profiles. We estimate separate ordinary least squares regressions following standard linear modeling practice ( 30 ). The models are implemented in Python using the scikit-learn library and are fitted separately for outflow and inflow totals in the highest-contributing OD pairs (Clusters 1–3) of each pattern. Table 3 shows that the explanatory variables cover demographic composition, household income, employment characteristics, and household size at both origins and destinations, all of which are commonly linked to commute intensity in urban travel behavior. We retain all coefficients and highlight significant estimates in the table, allowing us to identify the dominant variables associated with the spatial footprint of each latent pattern.
Operational Definitions of Explanatory Variables Used in the Ottawa Case Study

Note: HH = household.
Morning-Peaking Patterns
In the morning period, we focus on Patterns 2 and 3, which show clear morning (AM) contribution in the temporal factors (Figure 6). Figure 8 visualizes these significant coefficients for both survey- and GPS-based OD matrices (survey in blue, GPS in orange), enabling a direct comparison of how the two data sources characterize the outflow and inflow drivers of AM travel patterns. To emphasize the dominant factors of morning travel, our discussion focuses on statistically significant variables, which are shown with darker bars, while non-significant coefficients are displayed with lighter shading for completeness.
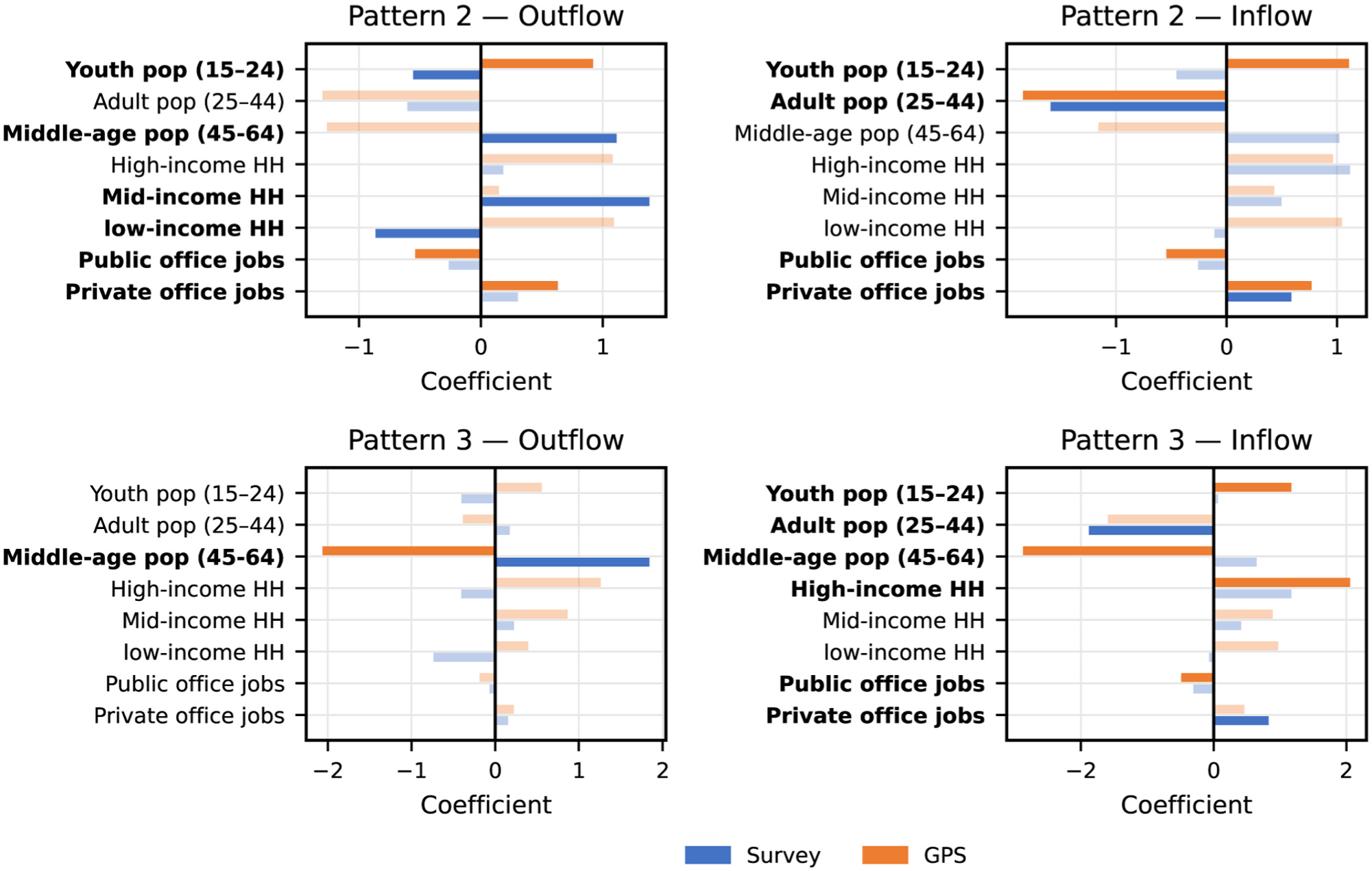
Outflow and inflow by latent pattern during the AM peak. The top-left panel shows Pattern 2 outflow, the top-right panel shows Pattern 2 inflow, the bottom-left panel shows Pattern 3 outflow, and the bottom-right panel shows Pattern 3 inflow. Survey-based coefficients are shown in blue, and GPS-based coefficients are shown in orange.
We first examine Pattern 2, which captures office-oriented morning commuting flows. On the outflow side, the GPS-based model shows stronger associations with younger populations and areas linked to private-office activity, whereas the survey-based model emphasizes middle-aged and mid-income households as the main contributors. This contrast suggests that GPS data are more sensitive to younger commuters working in private-office environments, while the survey better represents middle-aged and mid-income groups that are less prevalent in passive mobile data. On the inflow side, both datasets consistently identify private-office employment as the dominant correlate of morning inflows, while adult population shares are negatively associated with inflows. The GPS results additionally indicate stronger inflows toward youth-dominated zones and weaker associations with public-office areas, extending the demographic contrast observed on the outflow side.
Pattern 3 exhibits weaker and less consistent associations across the two datasets, indicating a more heterogeneous morning travel pattern. On the outflow side, both models emphasize the middle-aged population but with opposite signs: the survey associates middle-aged residents with higher outflows, whereas the GPS model shows a strong negative association. On the inflow side, the GPS-based results reveal a sharper demographic contrast, with positive effects for youth and high-income households and negative effects for middle-aged residents and public-office employment. In contrast, the survey model displays more muted relationships, with only modest demographic effects and a weak association with private-office jobs. Together, these discrepancies suggest that Pattern 3 captures a less stable or more behaviorally diverse form of morning travel that is represented differently by survey and GPS data.
Afternoon-Peaking Patterns
The afternoon analysis examines Patterns 2, 3, and 5, which are the modes with the strongest PM activity in the temporal profiles (Figure 6). As in the morning analysis, we estimate outflow- and inflow-side regressions for each pattern to identify the socio-demographic variables most strongly associated with their OD flows. The corresponding outflow and inflow coefficients for the afternoon patterns are reported in Figure 9.
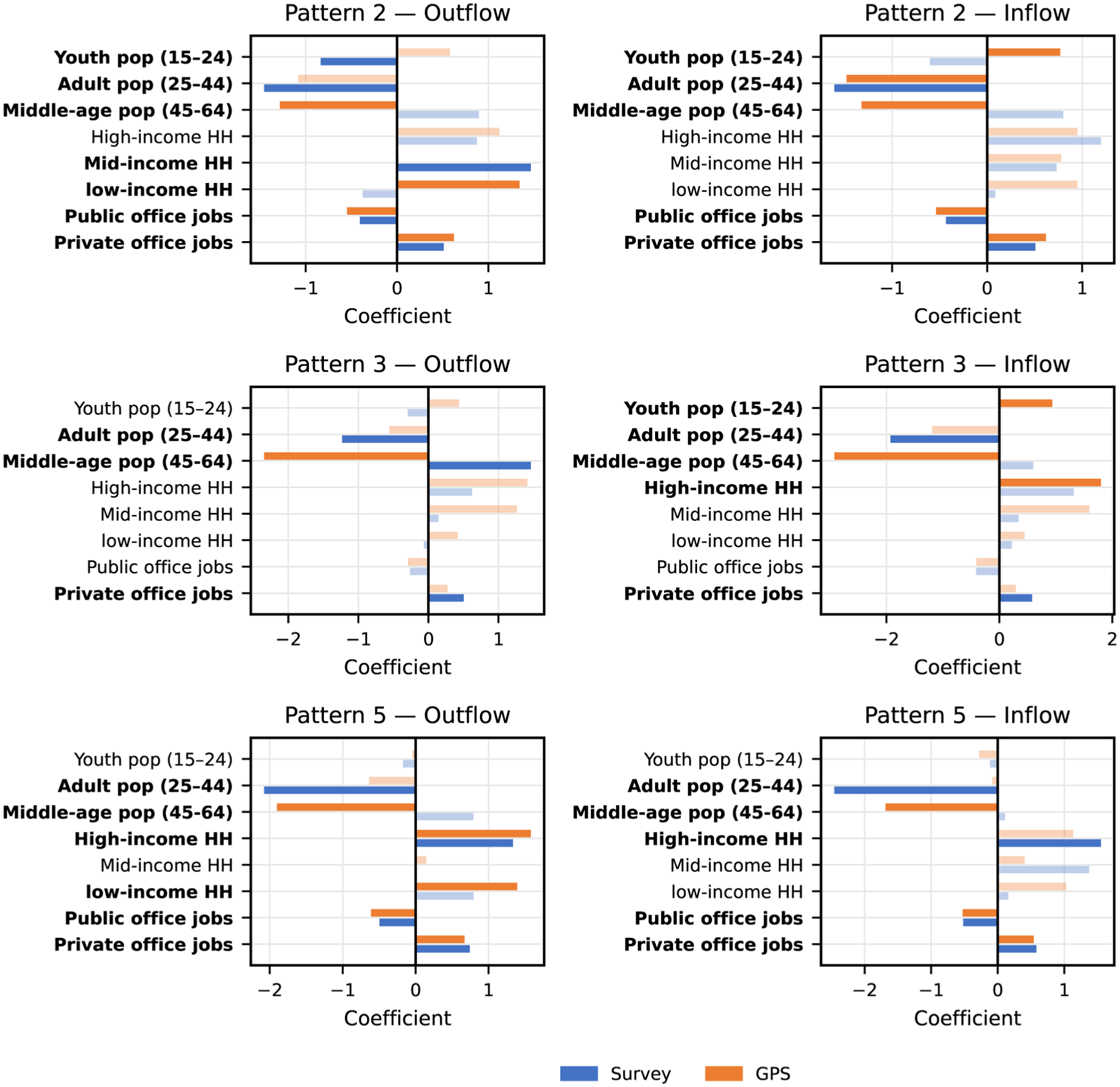
Outflow and inflow by latent pattern during the PM peak. The top-left panel shows Pattern 2 outflow, the top-right panel shows Pattern 2 inflow, the middle-left panel shows Pattern 3 outflow, the middle-right panel shows Pattern 3 inflow, the bottom-left panel shows Pattern 5 outflow, and the bottom-right panel shows Pattern 5 inflow. Survey-based coefficients are shown in blue, and GPS-based coefficients are shown in orange.
Pattern 2 reflects the dominant PM return flow from private-office districts. Both datasets show a consistent employment structure, with private-office areas attracting these flows and public-office areas contributing negatively on both the outflow and inflow sides. The key differences still arise in the socio-demographic signals: GPS associates this pattern with younger and lower-income residents, whereas the survey links it to middle-income, adult households. These contrasts indicate that the two datasets capture different commuter groups participating in the same office-oriented PM return movement. Pattern 3 shows the clearest split between the two datasets. The survey maintains an employment-related return flow with positive contributions from private-office areas and middle-aged populations. In contrast, GPS shows no job-related effects on the outflow side and instead exhibits strong inflows toward youth and high-income zones. This indicates that GPS captures a selective subgroup of younger, higher-income travelers rather than the broader worker flows reflected in the survey.
Pattern 5 represents the second major PM structure and the most income-differentiated mode. Both datasets show a consistent outflow profile: high-income households and private-office employment contribute positively, while public-office areas contribute negatively. On the inflow side, the survey highlights strong pull from high-income and private-office zones, whereas GPS again shows pronounced negative responses for middle-aged populations. Overall, both datasets depict an affluent PM flow connecting higher-income residential areas with office-dominated destinations.
Discussion and Conclusion
This study develops a dynamic joint latent factor model to fuse GPS- and survey-based OD matrices. The model learns a shared spatial structure and separate temporal dynamics for each source. The shared loading matrix reveals consistent OD patterns, while the temporal factors show how these patterns evolve over time. Because surveys provide infrequent behavioral baselines and GPS offers continuous temporal coverage, the framework enables long-term comparison of mobility patterns and systematic monitoring of how OD flows change across years. The method also allows a direct behavioral comparison between vehicle-trace data and self-reported car trips, quantifying where the two sources converge or diverge. However, this analysis is currently restricted to motorized vehicle flows to maintain structural comparability between the datasets. Future work could leverage the framework’s extensibility to incorporate non-motorized modes, providing a more holistic view of multi-modal urban mobility.
With regard to computational scalability, while this study focuses on a mid-sized metropolitan area, the proposed framework is designed to scale to larger regions with hundreds of thousands of OD pairs. Theoretically, the low-rank factorization reduces the effective degrees of freedom from
In the following section, we provide a detailed interpretation of the temporal negative magnitudes and spatial patterns, concluding with a discussion on the implications for urban mobility planning.
Temporal Negative Magnitude Analysis
In the temporal factors
Consequently, this unconstrained temporal structure leads to a subset of reconstructed OD entries taking negative values, as illustrated in Figure 10. These entries account for 18.53% of the GPS-based and 24.32% of the survey-based reconstruction. However, unlike the structural interpretation of negative temporal factors, these reconstructed negatives represent negligible numerical artifacts rather than model instability. Crucially, as the distributions in Figure 10 show, these values are heavily concentrated around zero, and 99% correspond to OD pairs with zero observed flows. This indicates they arise primarily from smoothing effects in sparse regions. While the survey reconstruction exhibits a larger range of negative values, this reflects the high variance and heavy-tailed distribution of survey expansion weights, relative to the total expanded volume of active trips, these fluctuations remain minor. Thus, simple non-negativity clipping is sufficient to ensure valid demand estimates without compromising the model’s accuracy.
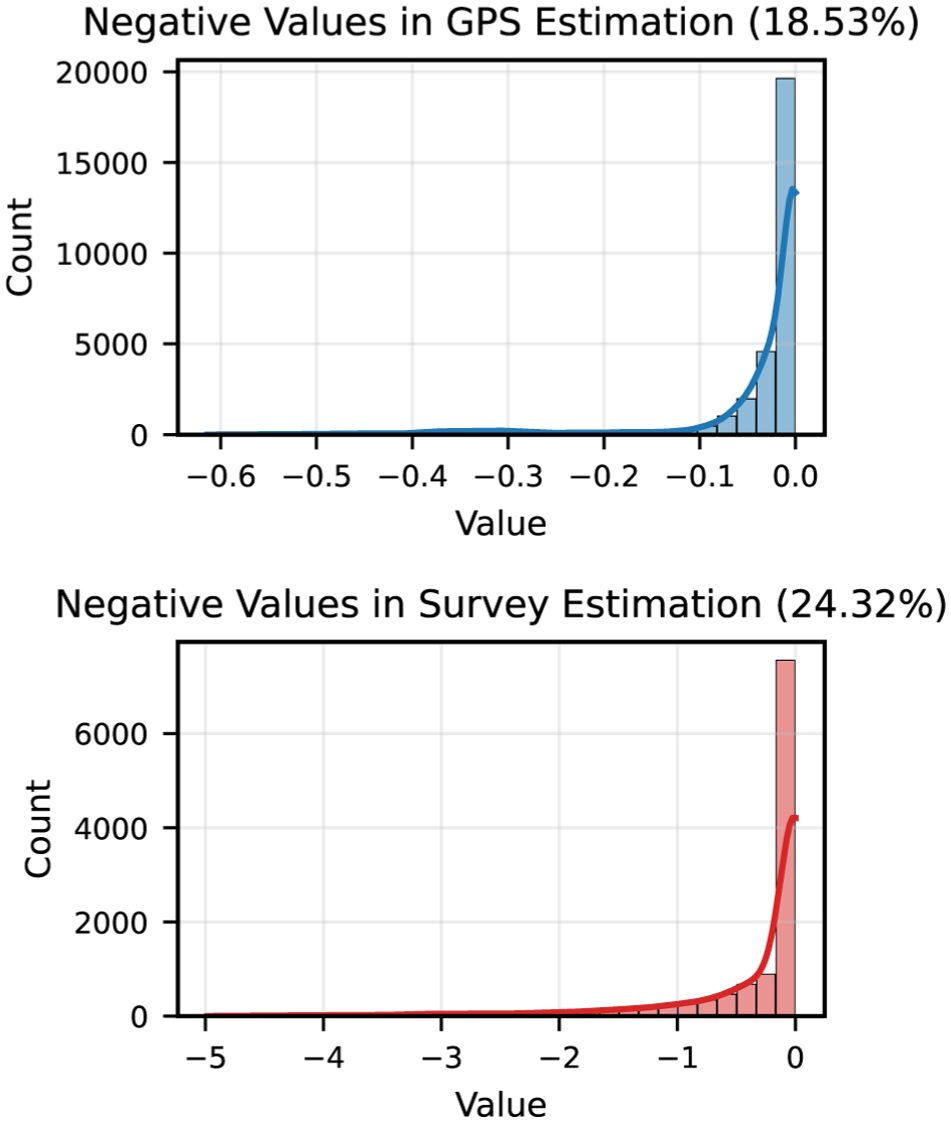
Distribution of negative origin–destination estimates for global positioning system (GPS) data (top) and survey data (bottom).
Spatial Patterns Analysis
Building on the temporal results, the spatial patterns reveal how the latent modes manifest across different parts of the urban region. The morning latent patterns reveal a stable and coherent commuting structure shaped by fixed work schedules and the spatial concentration of employment. Both datasets align closely in identifying the same office-oriented flows, which indicates that morning travel is governed primarily by structural constraints rather than behavioral variation. The differences between GPS and survey signals arise largely from their sampling mechanisms. GPS over-represents groups with higher mobility resources, such as younger and higher-income drivers, whereas the survey reflects a more complete cross-section of the resident workforce. These contrasts therefore reflect differences in population representation rather than differences in the underlying mobility behavior.
The afternoon patterns display greater divergence because afternoon travel is less constrained and more behaviorally heterogeneous. As work schedules loosen and discretionary activities increase, mobility becomes more fragmented across population groups. The GPS data capture this flexibility more sharply, highlighting younger and higher-income travelers whose activity patterns are less regular and more resource-dependent. The survey exhibits smoother gradients and maintains clearer associations with the broader workforce. Patterns 3 and 5 illustrate this dynamic most clearly: GPS responds strongly to youth and high-income zones while showing weaker employment-related effects, whereas the survey continues to reflect flows anchored in office locations and middle-aged workers. These differences show that afternoon modes capture multiple behavioral sub-regimes rather than a single unified flow.
Taken together, the latent patterns reveal that GPS and survey data provide complementary perspectives on urban mobility. GPS captures the flexible and high-intensity component of car travel, while the survey reflects the structural backbone of routine commuting. The joint factor model clarifies when discrepancies arise from sampling bias and when they represent genuine behavioral variation across time periods and traveler groups. These findings emphasize that OD matrix fusion must account for differences across latent mobility regimes.
Implications
From a practical standpoint, these findings offer several implications for mobility planning. The shared spatial factors provide a stable representation of the city’s underlying OD structure, which changes only gradually over time. This stability allows planners to use survey-informed spatial patterns as a behavioral baseline and to track medium- and long-term demand evolution by combining them with continuously collected GPS data. In data-scarce environments where surveys are available only every few years, this approach enables year-to-year and even day-to-day monitoring of travel patterns.
Recognizing the complementary strengths of the two data sources also supports better-informed OD modeling. Survey data provide a reliable basis for representing routine morning commuting, while GPS better captures the flexible and heterogeneous flows that dominate afternoon and discretionary travel. Finally, the interpretability of the latent modes allows planners to link OD patterns to socio-demographic and land-use conditions, enabling targeted corridor planning, demand management, and equity assessments. By integrating these insights, planners can develop OD models that reflect both stable structural patterns and the behavioral diversity present in contemporary urban mobility.
Supplemental Material
sj-pdf-1-trr-10.1177_03611981261444335 – Supplemental material for Joint Latent Analysis of Behavioral Patterns in Multi-Source Origin–Destination Matrices
Supplemental material, sj-pdf-1-trr-10.1177_03611981261444335 for Joint Latent Analysis of Behavioral Patterns in Multi-Source Origin–Destination Matrices by Xiting Zhang, Xudong Wang, Yubo Jiao, Lijun Sun and Luis Miranda-Moreno in Transportation Research Record
Footnotes
Acknowledgements
The authors thank SMATS Traffic Solutions for providing the aggregated GPS data and the City of Ottawa for providing the Household Travel Survey datasets.
Author Contributions
The authors confirm contribution to the paper as follows: study conception and design: X. Zhang, L. Sun, L. Miranda-Moreno; data collection: X. Zhang; analysis and interpretation of results: X. Zhang, X. Wang, Y. Jiao; draft manuscript preparation: X. Zhang, X. Wang. All authors reviewed the results and approved the final version of the manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was made possible through financial support from the Government of Canada and the Fonds de recherche du Québec – Nature et technologies (FQNRT). Specifically, funding from the Government of Canada’s Environmental Damages Fund was provided under its Climate Action and Awareness Fund, while FRQNT contributed through the Programme de recherche en partenariat – Réduction des GES – Mobilité Durable.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.