
Abstract
Background
Misdiagnoses of headache disorders are a serious issue. Therefore, we developed an artificial intelligence-based headache diagnosis model using a large questionnaire database in a specialized headache hospital.
Methods
Phase 1: We developed an artificial intelligence model based on a retrospective investigation of 4000 patients (2800 training and 1200 test dataset) diagnosed by headache specialists. Phase 2: The model’s efficacy and accuracy were validated. Five non-headache specialists first diagnosed headaches in 50 patients, who were then re-diagnosed using AI. The ground truth was the diagnosis by headache specialists. The diagnostic performance and concordance rates between headache specialists and non-specialists with or without artificial intelligence were evaluated.
Results
Phase 1: The model’s macro-average accuracy, sensitivity (recall), specificity, precision, and F values were 76.25%, 56.26%, 92.16%, 61.24%, and 56.88%, respectively, for the test dataset. Phase 2: Five non-specialists diagnosed headaches without artificial intelligence with 46% overall accuracy and 0.212 kappa for the ground truth. The statistically improved values with artificial intelligence were 83.20% and 0.678, respectively. Other diagnostic indexes were also improved.
Conclusions
Artificial intelligence improved the non-specialist diagnostic performance. Given the model’s limitations based on the data from a single center and the low diagnostic accuracy for secondary headaches, further data collection and validation are needed.
Keywords
Introduction
Headaches are a widespread public health problem (1). The International Classification of Headache Disorders, 3rd edition (ICHD-3) (2) includes migraine, tension-type headache (TTH), and trigeminal autonomic cephalalgias (TACs) as representative primary headaches. In Japan, migraine prevalence is 4.3–8.4% (3–5), and 29.8–74.2% of patients with migraine headaches reported significant impairment in daily activities (1). Additionally, approximately 15–20% of the Japanese population have TTH, with 22.4–29.2% reporting that it affects their performance (6). Furthermore, approximately 3.5% of patients who visited headache clinics have TACs (7). The prophylactic and acute treatment of headache disorders depends on the type of primary headache disorder and requires a proper diagnosis based on ICHD-3 (8). However, in 2022, there were only 899 headache specialists in Japan for more than 10 million people experiencing migraine, or, one headache specialist for 11,000 individuals with migraine. This lack of headache specialists may lead to diagnostic delays, which can lead to increased risk of chronic migraines, treatment refractoriness, comorbidities, and medication overuse (9–11).
Headache awareness campaigns can increase patients’ awareness regarding the condition (12,13), including the need for doctor consultation. Patients are gradually seeking medical attention; however, there remains only few specialized headache clinics, and primary care doctors are often responsible for the initial consultation regarding headache disorders. Hence, the burden on primary care doctors is enormous. As a result, they are unable to allocate sufficient time to ask detailed questions regarding the patient’s history, and their diagnosis and knowledge of headache treatment are sometimes unsatisfactory, leading to misdiagnosis and patient dissatisfaction. Moreover, since March 2020, the COVID-19 pandemic has increased the need for telemedicine to avoid in-person consultations (14). Online clinics for most diseases officially started in Japan in April 2022 (15). As it is time efficient, telemedicine will continue to grow, particularly among patients with headaches because they are unable to take time off from work to consult doctors during the day on weekdays (12). As telemedicine becomes widespread, it will become even more critical to diagnose headache disorders based solely on medical interviews.
Automated headache diagnosis systems using artificial intelligence (AI) can solve this problem because AI-based diagnosis models can save the time usually taken for a medical interview while improving diagnostic accuracy (16,17). However, reportedly, there are only five models (17–21) that can diagnose primary headache subtypes and have been evaluated in both training and test datasets (22). Furthermore, the efficacy of AI diagnosis models for non-specialist diagnosis performance has not been investigated and must be validated before social implementation. Specifically, no reliable and robust AI-based headache diagnosis models have been proven to improve the diagnostic performance of non-headache specialists.
Therefore, we aimed to develop an AI-based headache diagnosis model using a large questionnaire database in a specialized headache hospital. The primary objective was to prove the model’s efficacy for non-specialist diagnosis performance on headache disorders. Our AI diagnosis model can potentially solve the problem of undertreated and underdiagnosed headache disorders in daily clinical practice by non-specialists.
Materials and methods
Study design
This study consisted of two phases. Phase 1 involved developing an AI diagnosis model based on a retrospective investigation of 4000 patients (2800 training and 1200 test datasets) diagnosed by four headache specialists at Tominaga Hospital Headache Center. The model was developed using the 2800 patient questionnaire datasets with pre-processing, hyperparameter tuning, and cross-validation. We then tested its performance using the 1200 patients’ test dataset. In this phase, the model production was only based on the 2800 training dataset, and the performance was tested using the 1200 dataset, which was not treated in the model production. We then validated the model’s efficacy for accuracy in the 50 new patients in phase 2, separate from the 4000 patients in phase 1. Five non-headache specialists with 1–11 years of experience first diagnosed the headaches of 50 patients and then re-diagnosed them using AI. The ground truth was the diagnosis made by the four headache specialists, and the concordance rates between the headache specialists and non-specialists’ diagnoses with or without the AI model were evaluated (Figure 1).

Study design.
Phase 1: Developing an AI diagnosis model
We retrospectively collected 4000 consecutive patients’ questionnaire sheets and their diagnoses on their first visit to the Tominaga Hospital Headache Center from March 2013 to December 2021. Inclusion criterion was aged ≥15 years. Children <15 years were excluded from this study. From the questionnaire sheet, we retrieved 17 variables: age, sex, height, weight, age at headache onset, headache frequency, headache duration, site of headache, headache characteristics, headache severity, presence of aggravation by exercise, concomitant symptoms, presence of aura, times when the headache is most likely to occur, inducement of headache, use of acute medication, and family history. The patients completed the questionnaire. The items in the questionnaire are listed in Table 1. Four headache specialists in Tominaga Hospital Headache Center finally decided on headache diagnosis after medical examination, appropriate radiological examination, and sufficient discussion. Headache diagnosis was based on the ICHD-3 (2) and was grouped into five categories:
Class 1; migraine and medication-overuse headache (MOH) (ICHD-3 code 1 and 8.2) Class 2; TTH (code 2) Class 3; TACs (code 3) Class 4; other primary headaches (code 4) Class 5; secondary headaches (other codes).
Headache questionnaire sheet.

Ask patients to check or fill out each item on the questionnaire.
Class 1 included codes 1.1, 1.2, and 1.1 + 1.3 but did not include 1.4–1.6. MOH (code 8.2) was not included in Class 5 but in Class 1. Most of class 2 consisted of codes 2.2 and 2.3, with a few 2.1. Class 2 did not contain code 2.4.
The AI-based model used 17 variables in the questionnaire and predicted one of five diagnoses. We used PyCaret (https://pycaret.readthedocs.io/en/latest/index.html) to create the AI-based diagnosis model because it easily performs pre-processing, comparison of algorithms, and hyperparameter tuning. After putting the 4000 patients’ dataset into the PyCaret on Python notebook, PyCaret randomly divided the 4000 patients into training data of 2800 patients and test data of 1200 patients (7:3 ratio) by “get_data” and “setup” commands. The model production is only based on the 2800 training dataset, and the performance was tested using the 1200 dataset. For pre-processing, z-normalization for numerical variables was performed. Using the 2800 training dataset, PyCaret made several predictive models with 10-fold internal cross-validation. The algorithm with the largest c-statistics (area under the curve of the receiver operating characteristic curve; AUC of ROC) was chosen after model comparison by the “compare_models” command among Light Gradient Boosting Machine, Random Forest, Linear Discriminant Analysis, Ridge Classifier, Extra Trees, Gradient Boosting Classifier, Logistic Regression, Ada Boost Classifier, Decision Tree, K Neighbors, Naive Bayes, Dummy Classifier, Support Vector Machine, and Quadratic Discriminant Analysis. The c-statistics were the averages of the 10-fold cross-validation. Hyperparameter tuning was then performed to maximize sensitivity by “create_model,” “tune_model,” and “finalize_model” commands after choosing one of the best models described above. Randomized search cross-validation was applied during hyperparameter tuning with 10 iterations. Finally, the 1200 test dataset, which was still untouched, was predicted using the final tuned model. The accuracy, sensitivity (recall), specificity, precision, F-values (Definition A; macro-average of F values for each class, Definition B; harmonic mean of average recall and precision), and macro c-statistics were used to evaluate the model’s performance. We used SHapley Additive exPlanations (SHAP) values (23) to understand why the AI outputs the patients’ diagnosis. The Python source cord is available in online Supplementary File 1.
Phase 2: Testing the efficacy of the AI diagnosis model
We then validated the efficacy of the AI model for non-specialists in 50 new patients, separate from the 4000 patients, as external validation. The external validation dataset consisted of 50 consecutive patients aged 15 years and older who were in the same hospital where the 4000 patients in phase 1 were in February 2022. We prospectively collected data from the 50 patients with headaches, including questionnaires and diagnoses by the specialists. These data were routinely collected during daily clinical practice. In addition to clinical practice, five non-headache specialists were recruited, and they diagnosed headache in 50 patients solely on the basis of questionnaire sheets, without actually seeing the patients. The details of the five non-headache specialists are described in Table 2. Subsequently, they were re-diagnosed with AI after a rest period of one hour to one week. The ground truth was the diagnosis made by the four headache specialists in clinical practice, and the concordance rates between headache specialists and non-specialists diagnoses with or without the AI model were evaluated. The accuracy, sensitivity (recall), specificity, precision, F-values (definitions A and B), and kappa were evaluated as performance indices. This process, phases 1 and 2, was determined based on the guidelines for developing and reporting machine-learning predictive models (22).
Detail of the five non-headache specialists in phase 2.

Assuming a migraine prevalence of 57.6% in the Tominaga Hospital Headache Center, the permissible kappa was 0.41, and the expected kappa was 0.81. The required sample size was 20. We adjusted the final sample size by accounting for an estimated 2% of patients diagnosed with class 4, other primary headaches (code 4). Hence, we enrolled 50 patients to ensure that they included patients with diagnoses of other primary headaches. Sample size calculation (24) was performed online (https://rdrr.io/cran/irr/man/N.cohen.kappa.html).
Statistical analysis
Variables with a normal distribution are shown as the mean (standard deviation) (25), and those without a normal distribution are shown as the median (interquartile range). Concordance in diagnosis between the model and raters was measured using unweighted Cohen’s kappa statistics; unweighted kappa was selected because the outcomes were nominal variables. Kappa values were interpreted using Cohen’s recommendations (26) as “no agreement” for kappa ≤0, “none to slight agreement” for kappa = 0.01–0.20, “fair agreement” for kappa = 0.21–0.40, “moderate agreement” for kappa = 0.41–0.60, “substantial agreement” for kappa = 0.61–0.80, and “almost perfect agreement” for kappa = 0.81–1.00. The evaluation indices of the AI model and raters were assessed using specialists’ diagnoses as the reference standard (ground truth). The accuracy, sensitivity (recall), specificity, precision, and F-values (definitions A and B) were evaluated to examine whether the AI diagnosis model contributed to the improvement of the diagnostic ability of non-specialists, using the paired t-test for variables with normal distribution and Mann-Whitney U test for those without normal distribution. Statistical significance was defined as one-tailed p < 0.05. We used SPSS 28.0.0 (IBM Corp., Armonk, New York, USA), Python 3.9.0, PyCaret 3.0.0, SHAP 45b85c18, and Matplotlib 3.5.1.
Ethical aspects
The Tominaga Hospital Ethics Committee approved this study (approval number: 120120). The requirement for written informed consent from 4000 patients was waived because of the study’s retrospective nature. Opt-out consent documents were presented on the Tominaga Hospital website (https://www.tominaga.or.jp/about/registration_and_trial/) for patients who did not wish to participate. Written informed consent was obtained from the 50 patients enrolled in the external validation, phase 2. All methods were performed in accordance with the relevant guidelines and regulations of the Declaration of Helsinki. Phase 1, developing an AI-based diagnosis model, was performed under the Strengthening the Reporting of Observational Studies in Epidemiology guidelines (27) Phase 2, external validation of the AI-based model’s efficacy, was performed under the Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis guidelines (28).
Results
Patient characteristics
The diagnoses of the 2800 training and 1200 test data in phase 1 and the 50 test data in phase 2 are summarized in Table 3. There were no missing values. Diagnoses were made by headache specialists in Tominaga Hospital Headache Center; approximately 60% of the patients had migraine or MOH, 16% had TTH, 8% had TACs, 2% had other primary headaches, and 14% had secondary headaches. The mean patient age was approximately 41 years, and 64% of the patients were women. Baseline characteristics were not statistically different.
Patient characteristics.

Abbreviations: TACs, trigeminal autonomic cephalalgia; TTH, tension-type headache; MOH, medication-overuse headache.
Phase 1: Developing an AI diagnosis model and its performance
Using the 2800 training dataset, PyCaret revealed that the light gradient boosting machine classifier (https://lightgbm.readthedocs.io/en/v3.3.2/) had the largest c-statistics of 0.9203 among the several algorithms (online Supplementary File 2). We performed hyperparameter tuning to optimize sensitivity (recall); the results are shown in online Supplementary File 3. The AI model’s performance for the 1200 test data in phase 1 is shown in the confusion matrix (Table 4) and illustrated in Figure 2A. The diagnostic performances for class 1 (migraine and MOH) and class 3 (TACs) were high. The accuracy, sensitivity (recall), specificity, precision, and F value for class 1 were 90.96%, 90.96%, 80.00%, 87.98%, and 89.44%, respectively, and for class 3 were 84.15%, 84.16%, 86.74%, 98.82%, and 85.42%, respectively. Overall, the average accuracy, sensitivity (recall), specificity, precision, and F values (definitions A and B) were 76.25%, 56.26%, 92.16%, 61.24%, 56.88%, and 73.58%, respectively. The ROC for each class and its AUC is shown in Figure 2B. The AUCs for classes 1 and 3 were 0.94 and 0.99. The micro-average AUC of the ROC was 0.95. The SHAP values are shown in Figure 2C. Monthly headache days, age, onset age, nausea, phonophobia, duration; approximately 3 hrs., sex, monthly acute medication intake days, photophobia, neck pain, aggravation by exercise, characteristics; constricting, site; unilateral, numbness in the extremities, family history, onset; morning, site; craniocervical transitional, characteristics; pulsating, characteristics; gouged out, and fatigue were important in that order.
Confusion matrix for Phase 1.

Overall, the average accuracy, sensitivity (recall), specificity, precision, and F values (definitions A and B) were 75.80%, 56.23%, 92.16%, 61.24%, 56.88%, and 73.58%, respectively. Abbreviations: TACs, trigeminal autonomic cephalalgias, TTH, tension-type headache, MOH, medication-overuse headache.
†; the former is Definition A; macro-average of F values for each class, and the latter is Definition B; harmonic mean of average recall and average precision.

AI model performance.
Phase 2: Efficacy of the AI diagnosis model
Apart from the phase 1 treating 2800 training and 1200 test dataset, five non-specialists interpreted the questionnaire sheets of 50 patients and diagnosed one headache disorder from five classes. Without AI, the overall accuracy and kappa for the ground truth were 46.00% and 0.212, respectively. With AI, the parameters statistically improved to 83.20% and 0.678, respectively. Other indices, such as sensitivity, specificity, precision, and F values, also significantly improved. Regarding each class, the sensitivity for class 1, sensitivity and specificity for classes 2 and 3, and specificity for classes 4 and 5 increased (Table 5). The diagnostic agreement using Cohen’s kappa coefficient between the five non-specialists without AI ranged from 0.023 to 0.362, indicating slight agreement. However, those with AI increased to 0.606–0.874, suggesting a substantial agreement. The kappa between the AI and the ground truth by specialists was 0.815 (Table 6).
Indices for diagnostic ability without AI and with AI of five non-specialists in phase 2.

Abbreviations: AI, artificial intelligence; TACs, trigeminal autonomic cephalalgia; TTH, tension-type headache; MOH, medication overuse headache.
*p < 0.05; †, variable with non-normal distribution.
Diagnostic agreement using Cohen’s kappa coefficient between five non-specialists, AI, and ground truth in Phase 2.

Abbreviations: AI, artificial intelligence.
There was disagreement between AI diagnosis and ground truth by headache specialists in six patients, including TACs (class 3), new daily persistent headache (NDPH) (class 4), sinusitis, meningitis, trigeminal neuralgia, and Chiari malformation (class 5). Among those, AI misdiagnosed NDPH as TTH (class 2) and others as migraine (class 1).
Discussion
In phase 1, we developed an AI-based headache diagnosis model using big data of 4000 patients (2800 training and 1200 test datasets). The overall diagnostic performance for the 1200 test dataset was tested; the diagnostic performance for class 1 (migraine and MOH) and class 3 (TACs) were high. Subsequently, in phase 2, we externally validated the efficacy of the AI-based model for non-specialists and found that the diagnostic performance and agreement were significantly improved when supported by AI. Our AI model missed secondary headaches and classified them as migraine or TTH. To our knowledge, this is the first study to report on the effectiveness of a robust AI-based headache diagnostic model.
Use of the AI diagnosis model in clinical settings
Diagnosing headache disorders requires thorough interviews with patients and a comprehensive decision algorithm. Therefore, we tested whether AI could substitute for clinical interviews. The diagnostic performance of our model for class 1 (migraine or MOH) and class 3 (TACs) was high as compared to class 2 (TTH), class 4 (other primary headache disorders), and class 5 (secondary headaches). This may be attributed to the small sample size. In addition, diagnosing secondary headaches requires more detailed information (29), such as neurological examination, radiological imaging, and laboratory tests. Furthermore, the headache specialists had access to the supplementary information regarding diagnoses for the 4000 patients, whereas the AI model only had access to their questionnaire data. The fact that the AI model achieved high diagnostic performance only by learning the medical questionnaire without radiological imaging or laboratory test results suggests the importance of medical interviews in headache clinical practice. On the other hand, only magnetic resonance images (30) and electroencephalography (31) can indicate migraine patients or healthy volunteers, suggesting such information is useful in identifying not only secondary headaches but also primary headaches. The diagnostic performance might have improved if we had used such additional information. Indeed, secondary headaches should be diagnosed based on their clinical course and causative diseases rather than headache features. However, our AI model missed the secondary headaches and classified them as migraine or TTH because the model did not learn such information other than the headache questionnaires.
Therefore, our approach could not completely replace physician-based diagnosis. Nonetheless, this study demonstrated the feasibility of developing an AI-based automated diagnosis method for headache disorders. In addition, our results might be used to inform or assist physicians by pre-screening or to increase the diagnostic accuracy of less specialized care providers. In particular, 100% sensitivity for class 1 (migraine or MOH) diagnosis and 100% sensitivity and specificity for class 3 (TACs) in phase 2 can support primary care doctors in deciding to consult headache specialists regarding probable patients with migraine or TACs. Furthermore, this model can be a powerful tool in clinical practice if secondary headaches are ruled out. On the other hand, one should consider that in settings where secondary headaches cannot be ruled out (e.g., lack of radiological and laboratory testing equipment availability), misdiagnosis is a possibility.
Previous reports on AI-based diagnostic models
Many computer- and broadly AI-based headache diagnosis models have been reported (16) and these diagnostic models should be evaluated in the training and test datasets to avoid overfitting (22). However, only five models (17–21) have met this requirement. Furthermore, external validation using a different cohort should be performed (22) and only two studies (17,20) have performed external validation. In addition, the efficacy of AI diagnosis models for non-specialist diagnosis has not been investigated. Therefore, it remains unclear whether AI-based headache diagnosis models improve the diagnostic performance of non-headache specialists.
The previous five reports (17–21) which met the criteria for developing AI diagnostic models (22) are summarized in Table 7. Yin et al. (19) developed a 2-class classifier using 81 variables to distinguish between migraine and TTH. The accuracy and sensitivity were greater than 90%. They used a case-based reasoning method and a genetic algorithm to calculate the distance between a new case and each case in the case library. The model required a long computing time, and the sample size was less than 1000 patients. Walters and Smitherman (18) developed a 2-class classifier using only four variables to diagnose migraines or other headaches from primary and secondary headaches. They used classical logistic regression with only four variables, holdout testing, and achieved over 90% sensitivity and specificity. However, the model was not a multiple-class classifier because it was a logistic regression model. Vandewiele et al. (20) reported a decision-tree-based 3-class classifier distinguishing migraine, TTH, and TACs from the primary headache disorder cohort. They did not perform tests during the model development. In addition, the validation accuracy was 98%, although only 32 cases were recruited. The 32 cases used for the validation could be simple and were not described in detail. Therefore, the diagnostic performance of this index is questionable. Kwon et al. (21) described a 5-class extreme gradient boosting classifier for diagnosing migraine, TTH, TACs, thunderclap, and epicranial headaches. They used 75 variables and discovered that the diagnostic performance for migraine alone was high. However, the macro-average diagnostic performance was not significantly high, making the 5-class classifier ineffective. Cowan et al. (17) used a decision tree with 135 variables for a 2-class classifier for migraine or other headache disorders. The development process was not described in detail; however, the validation performance was high, with approximately 90% accuracy, sensitivity, and specificity.
Previous reports on AI diagnosis for headache disorders.
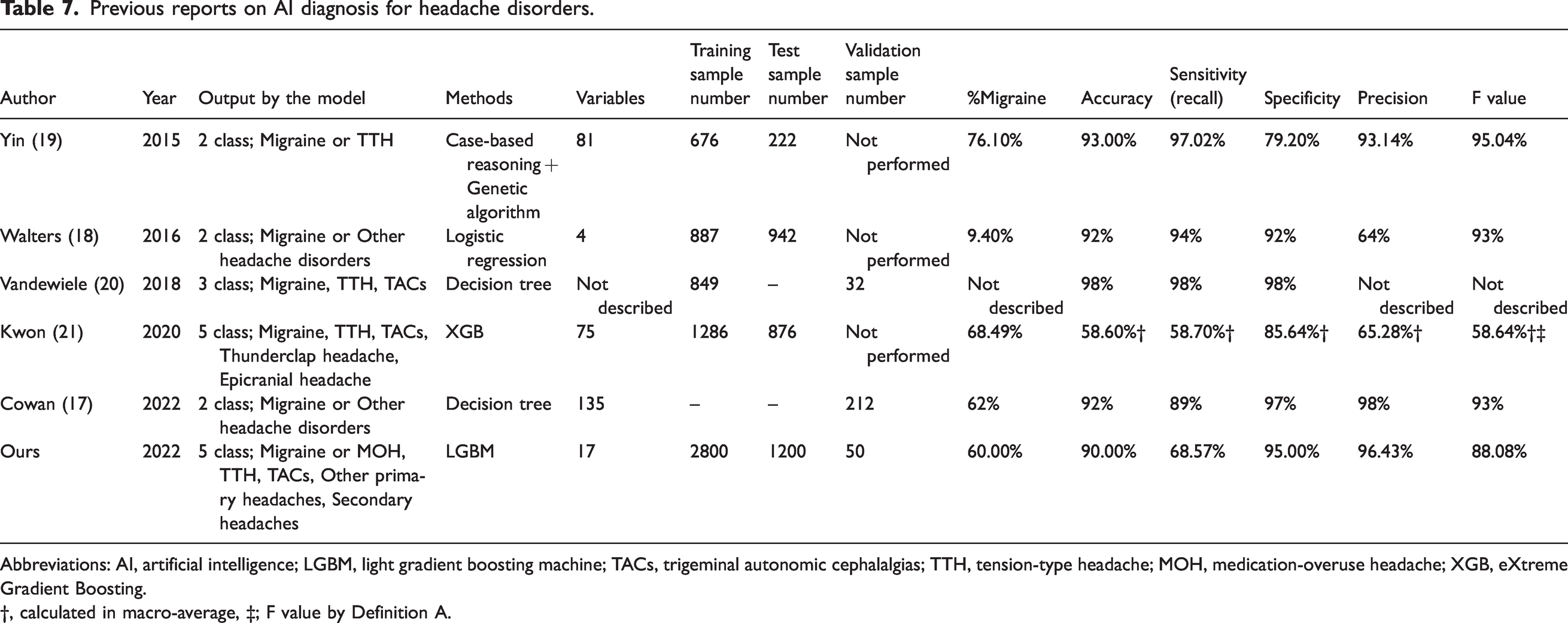
Abbreviations: AI, artificial intelligence; LGBM, light gradient boosting machine; TACs, trigeminal autonomic cephalalgias; TTH, tension-type headache; MOH, medication-overuse headache; XGB, eXtreme Gradient Boosting.
†, calculated in macro-average, ‡; F value by Definition A.
Our model has four distinct advantages. 1) The sample size during AI development was as large as 4000, resulting in high accuracy and robustness. 2) Our model was a 5-class classifier and achieved high diagnostic performance, although categorizing multiple-class classification is more difficult than categorizing 2-class classification. 3) The diagnosis of migraine and TACs can be made with high sensitivity among many class 4 (other primary headaches) and class 5 (secondary headaches) patients, which may act as noise in the computing process. 4) We externally validated the usefulness of diagnostic accuracy for non-specialists. Based on these strengths, our AI diagnosis model can potentially resolve undertreated and underdiagnosed headache disorders in daily clinical practice by non-specialists.
Smartphone applications and AI diagnosis
Recently, smartphone applications for recording headaches have become widespread. Migraine Buddy (Healint, Singapore; https://migrainebuddy.com/) was used with detailed records of headache attacks, as detailed as headache questionnaire sheets. M-sense (Newsenselab GmbH, Berlin, Germany; https://www.m-sense.de/en/), the digital migraine treatment program, can diagnose a single headache attack as migraine or TTH (32). Zutool (BellSystem24, Inc., Tokyo, Japan; https://zutool.jp/) and Tenkitsu Yohou (Weather News, Tokyo, Japan; https://weathernews.jp/s/pain/) provide weather-based headache attack forecasting (33). Of course, these data loggers, as a headache diary, are beneficial for headache self-control. Furthermore, if these digital devices installed our AI diagnosis model, users could self-diagnose their headache disorders, thereby facilitating access to appropriate treatment (17). Furthermore, smartphone applications can collect big real-world data. Therefore, combining smartphone applications with our AI model could aid the development of more accurate diagnostic models in the future.
Limitations
This study has some limitations. First is the lack of generalizability. The results were derived from data obtained from a single outpatient specialized headache hospital. The model primarily learns the diagnostic habits of the specialized headache hospital. It is unknown if the same diagnostic performance can be achieved in general clinics (general practitioners or family doctors) that perform initial headache examinations and clinical practice. Thus, our results need to be validated in an independent cohort study in different situations to show generalizability, such as general clinics, general neurological/neurosurgical, gynecological, and pediatric outpatients. In Japan, only 57.4% of people with migraine consult doctors. The most common settings for lifetime consultation were internist/primary care (34.4%), neurosurgeons (19.9%), headache specialists (7.9%), general neurologists (7.1%), obstetrician/gynecologist (3.0%), and occupational physician (1.8%) (34). Therefore, our model used data of 4000 patients who visited the specialized headache hospital, constituting only 15.0% of migraine patients. The external validation of our models in non-headache specialized hospitals, where people with headache usually visit, should be examined in the future. Furthermore, the burden of headaches is even more serious in foreign countries, especially in developing countries (35), Europe (36) and the United States (37), where the prevalence rates are high. Validation in such countries, with different headache prevalence, headache medical resources, and clinical settings, is also required. Second, because we created this model only from the questionnaire sheets, we lacked information on detailed medication use, comorbidities, or dietary habits, which are factors that can trigger headaches. Apart from headache disorders, we did not acquire information on neurological symptoms, vital signs, or other medical history. Third, we applied conventional machine learning approaches in this study as an AI method. Other recent models include Bayesian statistics, Monte Carlo simulations, and semi-mechanistic modeling. In addition, when combined with other deep learning techniques, such as natural language processing (14), a superior model should be developed. Fourth, in phase 2, there could be a bias in diagnosing the same patients twice within a relatively short time frame. There were no measures made to mitigate this, so the diagnostic performance in phase 2 may have appeared too high. Although reports of the same subject being tested twice by the same examiner exist (38), this bias cannot be completely eliminated due to the nature of the test, which is diagnosed by the same examiner. We will confirm the superiority of our AI model in future external validations to be conducted at other hospitals and clinics. Finally, it is a requirement for a diagnostic tool to have high specificity for secondary headaches to avoid misdiagnosis of potentially life-threatening disorders. In order to rule out secondary headaches, it is desirable to develop an AI-based diagnostic tool that also takes information on the patient’s history, neurological findings, and radiological and laboratory test results.
Conclusions
We developed an AI-based headache diagnosis model using big data of 4000 patients. The diagnostic performance was high, especially for migraine and TACs. Subsequently, we validated the efficacy of the AI-based model for non-specialists. AI significantly improved diagnostic performance and agreement. This AI headache diagnosis model can potentially solve the problem of undertreated and underdiagnosed headache disorders among non-headache specialists. Given the model’s limitations based on the data obtained from a single center and the low accuracy for secondary headaches, further data collection and validation are needed.
Article Highlights
We developed an artificial intelligence-based headache diagnosis model with high performance based on big data of 4000 patients. The model improved non-specialists’ diagnostic performance and inter-rater agreement. The model can potentially resolve undertreated and underdiagnosed headache disorders in daily clinical practice by non-specialists.
Supplemental Material
sj-pdf-1-cep-10.1177_03331024231156925 - Supplemental material for Developing an artificial intelligence-based headache diagnostic model and its utility for non-specialists’ diagnostic accuracy
Supplemental material, sj-pdf-1-cep-10.1177_03331024231156925 for Developing an artificial intelligence-based headache diagnostic model and its utility for non-specialists’ diagnostic accuracy by Masahito Katsuki, Tomokazu Shimazu, Shoji Kikui, Daisuke Danno, Junichi Miyahara, Ryusaku Takeshima, Eriko Takeshima, Yuki Shimazu, Takahiro Nakashima, Mitsuhiro Matsuo and Takao Takeshima in Cephalalgia
Supplemental Material
sj-pdf-2-cep-10.1177_03331024231156925 - Supplemental material for Developing an artificial intelligence-based headache diagnostic model and its utility for non-specialists’ diagnostic accuracy
Supplemental material, sj-pdf-2-cep-10.1177_03331024231156925 for Developing an artificial intelligence-based headache diagnostic model and its utility for non-specialists’ diagnostic accuracy by Masahito Katsuki, Tomokazu Shimazu, Shoji Kikui, Daisuke Danno, Junichi Miyahara, Ryusaku Takeshima, Eriko Takeshima, Yuki Shimazu, Takahiro Nakashima, Mitsuhiro Matsuo and Takao Takeshima in Cephalalgia
Supplemental Material
sj-xlsx-3-cep-10.1177_03331024231156925 - Supplemental material for Developing an artificial intelligence-based headache diagnostic model and its utility for non-specialists’ diagnostic accuracy
Supplemental material, sj-xlsx-3-cep-10.1177_03331024231156925 for Developing an artificial intelligence-based headache diagnostic model and its utility for non-specialists’ diagnostic accuracy by Masahito Katsuki, Tomokazu Shimazu, Shoji Kikui, Daisuke Danno, Junichi Miyahara, Ryusaku Takeshima, Eriko Takeshima, Yuki Shimazu, Takahiro Nakashima, Mitsuhiro Matsuo and Takao Takeshima in Cephalalgia
Footnotes
Acknowledgments
We are thankful to the staff for supporting our work and data acquisition.
Author contributions
MK: drafting the article, statistical analysis, and artificial intelligence. DD, SK, JM, TS, and TT: data acquisition and critical advice about clinical headache practice. TN, YS, MM, RT, and ET: Data acquisition. TS and TT: supervision.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.