
Abstract
Introduction
The growing availability of electronic health data provides an opportunity to ascertain diagnosis-specific cases via systematic methods for sample recruitment for clinical research and health services evaluation. We developed and implemented a migraine probability algorithm (MPA) to identify migraine from electronic health records (EHR) in an integrated health plan.
Methods
We identified all migraine outpatient diagnoses and all migraine-specific prescriptions for a five-year period (April 2008–March 2013) from the Kaiser Permanente, Northern California (KPNC) EHR. We developed and evaluated the MPA in two independent samples, and derived prevalence estimates of medically-ascertained migraine in KPNC by age, sex, and race.
Results
The period prevalence of medically-ascertained migraine among KPNC adults during April 2008–March 2013 was 10.3% (women: 15.5%, men: 4.5%). Estimates peaked with age in women but remained flat for men. Prevalence among Asians was half that of whites.
Conclusions
We demonstrate the feasibility of an EHR-based algorithm to identify cases of diagnosed migraine and determine that prevalence patterns by our methods yield results comparable to aggregate estimates of treated migraine based on direct interviews in population-based samples. This inexpensive, easily applied EHR-based algorithm provides a new opportunity for monitoring changes in migraine prevalence and identifying potential participants for research studies.
Introduction
Migraine is a frequently debilitating neurological disorder characterized by headache accompanied by photophobia, phonophobia, nausea, and vomiting (International Classification of Headache Disorders-2 criteria) (1–3). Migraine is ranked among the top 20 causes of disability worldwide (4–6) and is currently one of the leading causes of disease burden for women aged 15–44 years (5). Migraine affects an estimated 11% of the adult population globally (6), with a strong female predominance (7). The one-year period prevalence estimates for migraine headache in the United States (US) are reported to range from 8% to 18% overall, with women affected at approximately three times the rate of men (5,7–10). The prevalence of migraine is similar in boys and girls before the onset of puberty, but after the age of 12, it more commonly affects women, for whom prevalence peaks in the mid-30s to mid-40s (7,8). Previous research in non-integrated health care settings indicated that disparities exist among racial and cultural groups both for diagnosis and treatment of migraine (11–13). In addition, previous studies have demonstrated racial and ethnic variation in pain presentation, as well as communication about pain symptoms (14–16). It is also documented that migraine prevalence varies by country, with European countries reporting the highest rates and African countries the lowest (4,7,17), suggesting possible biologically driven racial as well as cultural differences.
While prior studies have primarily focused on results from population-based surveys and specialty headache clinic data (5), a few have reported prevalence of migraine in health care systems (18,19), but even these estimates are derived from questionnaires. Kolodner et al. used pharmacy and medical claims data to identify migraine sufferers from within a managed care health system in Michigan. When they used the claims to identify migraine by diagnosis or medication use, their statistical model had 92% specificity, but only 36% sensitivity (20). Because they are used for recovering expenses, claims data are subject to misclassification bias that is not inherent in patient electronic health records (EHR) (21,22). The widespread adoption of EHR provides new opportunities for studying the prevalence and life-course of migraine. However, taking full advantage of this new resource requires developing and validating algorithms for quantifying patients' probabilities of migraine and demonstrating that prevalence patterns are in accord with existing studies based on primary data collection.
The primary aims of this study were to develop and validate a migraine probability algorithm (MPA) to assign a diagnostic probability to each patient identified as a potential migraineur and to use this medically-ascertained migraine methodology to estimate the prevalence of diagnosed migraine overall and by pre-specified subgroups. This MPA was developed using readily accessible electronic data, tested with chart review of a patient sample, and validated with a mailed questionnaire to a sample of 1000 potential migraineurs and controls. We then used this information to determine if race/ethnicity variations in diagnosis and treatment exist within this population and to identify higher-risk subgroups.
Methods
Study population
Kaiser Permanente Northern California (KPNC) is a large, integrated health care delivery system providing comprehensive medical care for more than 35% of insured adults in Northern California. The KPNC membership of approximately 3.5 million has substantial racial and ethnic diversity and is highly representative of the surrounding local and statewide populations (23). Information from the 2003 California Health Interview survey (24) indicates that the KPNC membership over-represents African American, Asian, and Pacific Islander racial groups compared with non-KPNC insured and uninsured individuals from the same geographic area, while the proportion of Hispanics in KPNC is comparable to the underlying population of insured but is lower when the uninsured are included. Median income and educational attainment of KPNC members are slightly higher than in the general population but lower than in the general insured population (23). For these reasons, electronic clinical data from KPNC provides an excellent source to examine questions about the prevalence of migraine and the differences in diagnosis and treatment among various population subgroups.
Patient demographics
We used KPNC membership databases to capture patient age and gender. Race/ethnicity, though not completely captured for all members, was compiled from several sources, including the EHR, membership databases, and other administrative databases. For patients with missing race/ethnicity, we imputed racial probabilities using the Bayesian Improved Surname and Geocoding algorithm, which uses census data and surname to impute the probability that the patient belonged to each of six different racial/ethnic groups (25).
Denominators
For calculation of prevalence estimates, we used electronic membership data from the KPNC databases to calculate member-years both for numerators and denominators. We identified all people who were KPNC members at the mid-point of the five-year time interval April 2008–March 2013. Because KPNC tracks membership on a monthly basis and people can enter and leave the health plan throughout this time, we used the number of members at the midpoint of the five-year interval as an approximation to the actual average membership over the interval. For reporting, one-year age strata were combined into 10-year age groups: less than 10, 10–19, 20–29, 30–39, 40–49, 50–59 and 60+ years of age.
Algorithm development
Electronic medical databases including outpatient, pharmacy, and hospitalizations were used in the development of the MPA. Electronic medical databases were searched for the following:
a) Outpatient visits with primary or secondary diagnosis International Classification of Disease, version 9 (ICD9) code consistent with migraine (346.XX). b) Emergency room visits with primary or secondary diagnosis ICD9 code consistent with migraine (346.XX). c) An ICD9 code for migraine in the patient's Significant Health Problem List (SHP). d) All prescriptions filled for migraine-specific abortive medication (i.e. triptans and ergotamine preparations). If the prescription was ordered, but the patient failed to pick up the medication, it was not counted. e) Outpatient visits with primary or secondary diagnosis ICD9 code consistent with cluster headache (339.00, 339.01, 339.02) were recorded, and anyone with this code and no other migraine diagnosis was excluded.
Next, two physicians independently reviewed 30 charts of members who had at least one of the above criteria to classify migraine as “Certain,” “Likely,” “Possible,” or “Unlikely” depending on whether they had been diagnosed by a neurologist and how many diagnoses or prescriptions they had received. The purpose of this step was to use “expert opinion” to broadly classify a large group of patients for more refined algorithm development in the next stage.
Migraine probability algorithm (MPA).

Total MPA score calculation: sum points for all criteria; if score > 100, cap at 101.
SHP: Significant Health Problem.
After a scoring process was finalized, a new random sample of 1000 charts was drawn. For this sample, we stratified by MPA score into the following categories: < 25, 25–49, 50–74, 75–99, 100+. We randomly chose 200, 300, 300, 100, and 100 charts from each stratum, respectively. Then a trained research nurse determined the gold standard of migraine diagnosis by considering all information in each patient's electronic chart, including encounters, procedures, diagnoses, medications, and chart notes to determine if they fulfilled International Headache Society (IHS) criteria for migraine. Blinded to the category of the MPA algorithm, the research nurse categorized each patient as Unlikely, Likely, Certain, or Insufficient information to fulfill IHS criteria of migraine.
We then determined the operating characteristics (positive predictive value (PPV) and sensitivity) for a range of MPA-score cut-points using as the gold standard either Certain or Likely + Certain as described above, and back-calculated the specificity (26). Two-sided 95% confidence intervals (CIs) were estimated with bootstrap methods, using 1000 samples for each estimate (27).
We additionally validated the MPA against an ICHD-2-based migraine classification derived from a self-administered 21-item questionnaire. We sent invitations to a new group of 1000 randomly selected KPNC patients, 800 with evidence of migraine and 200 with no evidence of any type of headache ever during their membership with KPNC to respond to the questionnaire. For this process, we used the American Migraine Prevalence and Prevention Study questionnaire, developed and validated by Lipton et al. (28). We limited the time frame of symptom ascertainment to distinguish headache in the past year, to be consistent with the EHR. A total of 610 surveys were returned: 506 (63%) from patients with some evidence of migraine, and 104 (52%) with no evidence of any type of headache in their EHR. Results from the questionnaire were then used to define our EHR-based gold standard for migraine diagnosis. According to ICHD-2 criteria, a headache was classified as migraine if patient responses indicated that they experienced headaches that were unilateral with pulsating, moderate to severe pain along with one or more of the following: nausea, vomiting, sensitivity to light or sound (photo- or phonophobia). We determined the operating characteristics (negative predictive value (NPV) and sensitivity) for a range of MPA-score cut-points using the gold standard, and specificity was back-calculated (26). Two-sided 95% CIs were estimated with bootstrap methods, using 1000 samples for each estimate (27).
Treatment
Treatment was measured by use of migraine-specific medications recorded in the EHR at any time during the study period.
Statistical analysis
We used standard methods to measure the operating characteristics of the algorithm (26). We used the bootstrap sampling method with 1000 samples to estimate 95% CIs for the PPV, NPV, sensitivity, and specificity. As the epidemiologic portion of the study was largely descriptive, we provide estimates of prevalences with two-sided 95% CIs. All CIs were estimated using a bootstrap sampling method with 1000 samples per estimate (27). For simple comparisons of continuous variables, we used Student's t-test with a two-sided alpha = 0.05. P values are reported from unadjusted analyses. All analyses were performed using SAS 9.3 (Cary, NC).
Results
MPA
The operating characteristics of the MPA against the two gold-standard measures (the 1000-patient chart review by the research nurse and the self-administered questionnaire) are presented below. Using the chart review, we identified those patients with certain medically-ascertained migraine, and we determined the best cut-point of MPA >10, for which we estimated the MPA to have a sensitivity = 85.0% (95% CI = 82.2% to 87.6%) and for the prevalence observed in this study, PPV = 74.3% (95% CI = 71.4% to 77.2%). When we relaxed the gold standard criterion to include the population of those with certain or likely medically-ascertained migraine, the sensitivity dropped slightly to 79.5% (95% CI = 77.0% to 82.0%), with a corresponding increase in the PPV = 92.2% (95% CI = 90.3% to 94.0%). Using back calculation (26), we then estimated specificities for a range of prevalence from 10% to 25%; in all cases the specificity exceeded 90%.
Operating characteristics of the algorithm for the 610 questionnaire respondents.

PPV: positive predictive value; NPV: negative predictive value.
Prevalence estimates
Characteristics of KP population and migraineurs.
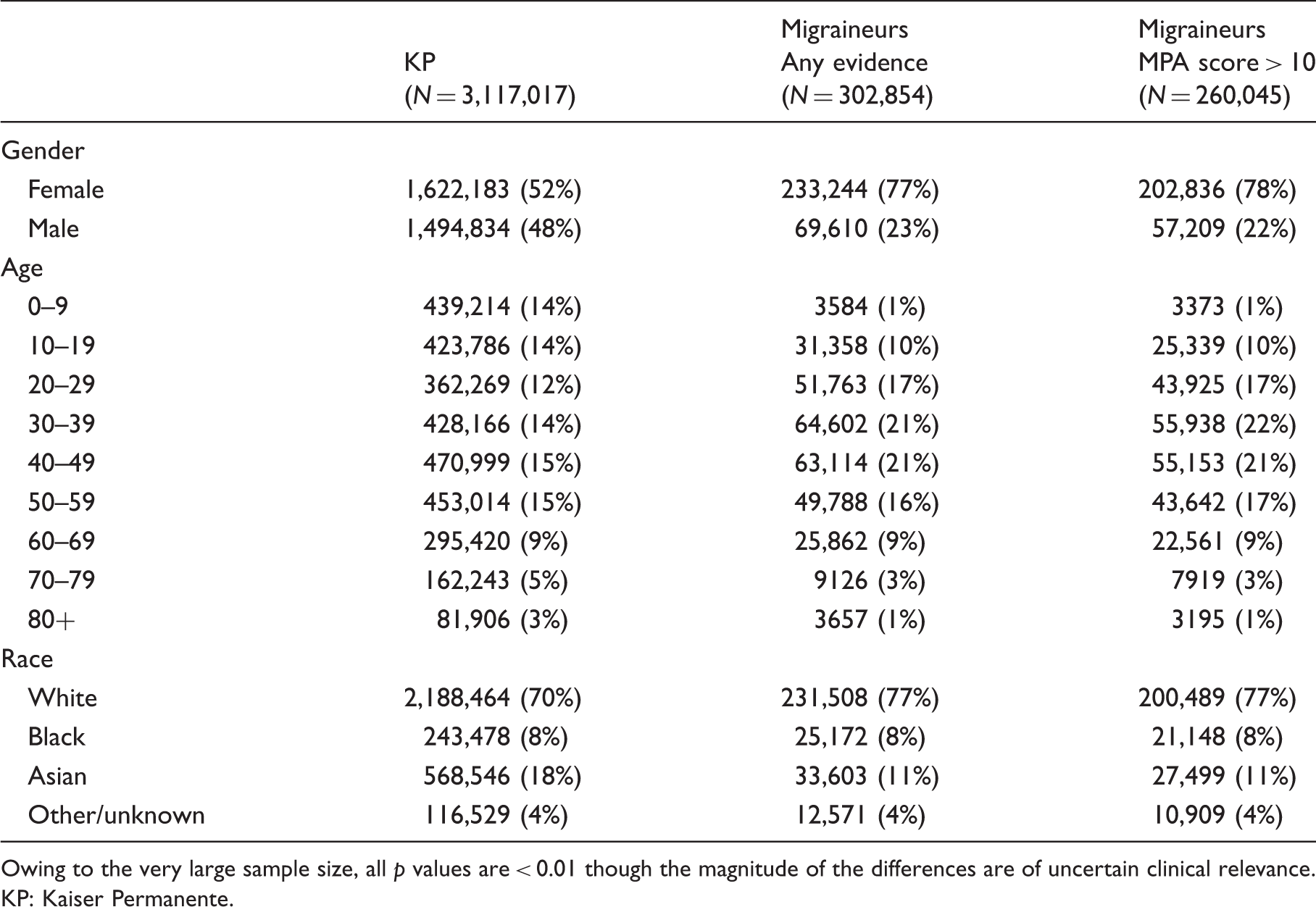
Owing to the very large sample size, all p values are < 0.01 though the magnitude of the differences are of uncertain clinical relevance. KP: Kaiser Permanente.

Prevalence of migraine, migraine probability algorithm (MPA) > 10, during April 2008–March 2013 by age and sex.

Prevalence of migraine, migraine probability algorithm (MPA) > 10, during April 2008–March 2013 by race, age, and sex.
MPA criteria
Relaxing our definition of medically-ascertained migraine to include all patients with any evidence of migraine (MPA greater than or equal to 10), the estimate of overall prevalence of migraine was slightly higher, at 14.4% for women and 4.7% for men. When we restricted our analysis to patients age 18 years and older, the total prevalence using the broader definition of migraine was 11.9% (17.6% for women, 5.4% for men), and using the stricter MPA >10 definition of migraine, prevalence was 10.3% (15.5% for women, 4.5% for men). Our estimate of the prevalence of migraine in children through age 17 was 3.3% (4.0% for females, 2.7% for males). When we further broke this group down to adolescent ages 12–17 and used the MPA > 10 criteria, we estimated the prevalence to be 5.9%.
Treatment
Among those with an MPA score > 10, women were more likely to receive and fill a migraine-specific medication than men (50% vs 42% (p < 0.0001)). Asian women were less likely to receive and fill a prescription for a migraine-specific medication than black or white women (47% vs 50% vs 50%, respectively, p < 0.0001); however, these differences are small and probably not clinically meaningful. Men had similar migraine-specific medication use across all racial groups. Those of other/unknown race had similar prescription patterns to those of whites (Figure 3).
Medication use by race and sex (size of bubble represents size of subgroup).
Discussion
To our knowledge, this is the first study to exclusively use EHR to measure medically-ascertained migraine to estimate migraine prevalence in a large integrated health plan sample. Because migraine could not be ascertained without health plan contact, the proportions reported here are prevalence estimates for “migraine in people who complain of headache” or “diagnosed migraine.” Importantly, the five-year age-specific prevalence estimates followed a very similar pattern as prevalence estimates reported from the American Migraine Prevalence Study (5), as well as aggregate international prevalence rates of migraine (7). The algorithm tested well against chart review and against self-report with strong operating characteristics, 88% sensitivity and >85% estimated specificity, for self-report, in our sample.
Overall, the prevalence of migraine in KPNC followed the same characteristic age curve seen in the literature (5,8,28), with boys and girls experiencing similar prevalence before the onset of puberty, women peaking in the mid-20s to early 30s, and flattening out at approximately age 70. Beginning at puberty, the curve for men is nearly flat, averaging 5%–6%. Because most published prevalence rates do not lump adults and children together, we estimated rates among the adult (age ≥ 18 years) subgroup of the KPNC population. In this group, using the MPA >10 definition of migraine, overall prevalence was 10.3% (15.5% for women, 4.5% for men). These estimates are quite similar to other published estimates (6,7). We then considered the pediatric population subset of adolescents ages 12–17; our prevalence estimate of 5.9% was similar to other published rates for this age group (7,28,29). When compared to the general KPNC population, migraine patients were overrepresented in the middle age groups and differed by racial distribution.
By race, Asians experienced a similar curve by age; however, the peak was much lower (12%) for women, and the flat prevalence for men averaged 2%. Lipton et al. reported that migraine prevalence in the US is highest among European Americans, intermediate among African Americans, and lowest among Asian Americans (30). We found that in addition to the Asians and whites in our population, blacks experienced a similar peak in prevalence (approximately 27% for women at age 30–34), and the averages for blacks over all age groups were similar to those of whites for both genders, a relationship contrary to what is typically found in the literature (28,31). We suggest two plausible explanations for this observation. One possibility is that culturally, blacks may feel more comfortable seeking medical attention for their headaches, increasing the prevalence estimates for this subgroup. Another possible explanation is that the missing race data are not random in the denominator causing a biased estimate of prevalence. If there was a higher percentage of black members for whom race data were missing, then the prevalence estimates for blacks would be less stable.
Medication use is represented in Figure 3 in which the size of the circle represents the size of the particular subgroup, and the percentage of that subgroup receiving a migraine-specific medication is represented on the y-axis. We found that women use more medication than men, but there was little difference in prescription use by race. The racial similarities were somewhat unexpected as it is well documented that cultural differences exist both in pain reporting and in pain treatment (15,32,33), with minority populations tending to report pain less often, and be treated less aggressively. This may also be explained by the standardized coverage for members of KPNC that may minimize lower treatment rates of migraine in ethnic minorities often caused by lack of health care insurance coverage.
The major strength of our study is the large and diverse patient population at KPNC, which surpasses that of any prior study of migraine. Because of the observational nature of our study and the fact that we do not draw our descriptive data from a clinical trial or other primary data-collection design with restrictive eligibility criteria, our descriptive estimates may be more likely to reflect true population-based estimates. In addition, our algorithm uses information readily available in most electronic medical records, ensuring our algorithm is easy to implement and can be widely generalized. Finally, our methods address an issue for which few population-based data exist and have the potential both to improve the clinical outcomes of patients with migraine headache (particularly underserved segments of the population), and to make more efficient use of health-care resources and potentially reduce the costs of migraine care. Furthermore, the development of methods to take advantage of the growing availability of EHR data provides new opportunities for research (both for population-based studies and for identifying individuals for primary data-collection studies, including clinical trials). This report describes the first attempt to develop and validate a systematic method to identify migraine from EHR data.
This study has several limitations. First, though development of our algorithm was designed in such a way as to minimize the number of uncertain diagnoses, we recognize that there are patients who do not manifest criteria for a specific headache subtype, as often encountered in clinical practice. We addressed this concern in two ways: (1) by assigning a probability of diagnosis (not a simple dichotomous attribute) in order to incorporate the inherent uncertainty in any clinical diagnosis; and (2) by beginning the study after implementation of the Kaiser Permanente EHR system, April 2008–March 2013, that provided more comprehensive and accurate data than the earlier medical record database. Second, in validating our algorithm with the mailed questionnaire, we were not able to include individuals with headache diagnoses but not migraine (because of data access issues). This subset would have offered valuable insight into the under-reporting of migraine, and we recommend this group be targeted for future consideration. Third, because we do not have complete race data for either the migraine or total sample, we employed a probability algorithm to impute data on race. Fourth, we may have missed some cases of migraine that were not reported in the EHR, an acknowledged weakness of any study that relies primarily on secondary electronic data. Because less than half of those with migraine actually received this clinical diagnosis (7,34), the prevalence of migraine at KPNC could be as high as 25% among women and 8% among men. Fifth, we are not able to directly measure the specificity of our diagnosis algorithm. Because a patient must complain of a headache in order to have any headache evidence appear in their EHR, there is no way to accurately calculate the rate of false negatives. We were, however, able to estimate the specificity over a range of prevalences (26). Sixth, for the questionnaire validation portion of the study, we restricted our sample to those with evidence of migraine in the previous 12 months and then asked only about the same time period, thereby ensuring a more reliable recall. Caution should be exercised when extrapolating the algorithm to a broader time frame; however, we do not have any reason to believe that the medical records would be more or less accurate over the five-year time period for which we make prevalence estimates.
In addition to the above limitations, there are other sources of potential bias we must point out. Although the response rate was high for the mailed questionnaire, there remained a substantial portion (39%) of individuals for whom we have no questionnaire data. If these individuals differ from the responders in a way that is related to reporting of migraine, then they could potentially bias the results of our validation study. The most likely scenario would be that those with true migraine have a higher response rate. If so, for the case where the algorithm is not predictive of true migraine status, this bias would not increase the predictive appearance of the algorithm. In the alternative case, in which the algorithm is predictive of true migraine status, the assessment of predictive power within score strata could be altered slightly. Using simulation, we investigated various scenarios of this type, and determined that the overall conclusions would not be affected (data not shown). Another source of potential bias stems from the fact that KPNC is a group membership, closed health-care system, and people who become members are not likely to be the same as people who do not choose such membership. Caution should be exercised when applying the results of this study to patients outside of the KPNC health plan membership.
It is important to note that the results, while similar to the reported literature, cannot provide inference beyond the catchment of KPNC and other populations with similar structure and characteristics. In addition, the PPV is prevalence-dependent and is relevant only for our health plan and other populations with a similar prevalence. Finally, for the calculation of the CIs, we used the bootstrap method of re-sampling, therefore, the results represent the properties of the sample, not those of the general population.
Conclusions
We successfully used EHR to capture migraine diagnoses and estimate the prevalence of migraine in the KPNC population. Our results yield similar patterns to those reported in the literature in that the prevalence of diagnosed migraine in KPNC was 2.5–3 times higher in women than men, peaked at the expected age in women but remained flat for men, and was roughly two-thirds that of whites among Asian adults. However, the prevalence of migraine among black adults was unexpectedly similar to that of white adults.
These methods for migraine ascertainment are inexpensive, easy to implement, and have applications and implications that extend well to other institutions and debilitating pain conditions. The results of this study help to advance further research into the epidemiology of migraine using the efficiency of existing electronic medical records, and are generalizable to most health systems with EHR. We now have an efficient and validated method for monitoring the prevalence of migraine overall and among informative subgroups, and we have a straightforward method to identify patients who might be eligible for observational studies and clinical trials.
Article highlights
In order to study the epidemiology of migraine headache, the first step of migraine ascertainment from headache clinics and surveys is costly and difficult when patient contact is not feasible. To simplify the process, we developed an algorithm based on patient data available in electronic medical records. Ours is the first study to exclusively use an electronic health record (EHR) to estimate migraine prevalence in a large integrated health plan sample. The algorithm is based on International Classification of Disease, version 9 (ICD9) diagnosis codes from outpatient clinic and emergency room visits, prescriptions for migraine-specific medications, and significant health problem lists. It was tested with a chart review of a sample of Kaiser Permanente Northern California (KPNC) patients, and validated with a mailed questionnaire to 1000 potential migraineurs. Using the algorithm to identify adult patients with evidence of migraine along with KPNC membership data, we estimate the prevalence of migraine headache reported in a clinic during April 2008–March 2013 to be 15.5% for women and 4.5% for men. These estimates, plus age curves and differences by race, are consistent with those reported in the literature. The algorithm appears to be an efficient and effective use of electronic patient data, appropriate both for population-based studies and for identifying individuals for primary data-collection studies. The algorithm approach has potential for other institutions and debilitating pain conditions.
Footnotes
Funding
This work was supported by the National Institutes of Health (NIH)/National Institute of Neurological Disorders and Stroke (NINDS) (grant number 5R01NS080863-03).
Conflict of interest
None declared.