
Abstract
High-quality observations of the real world are crucial for a variety of applications, including producing 3D printed replicas of small-scale scenes and conducting inspections of large-scale infrastructure. These 3D observations are commonly obtained by combining multiple sensor measurements from different views. Guiding the selection of suitable views is known as the Next Best View (NBV) planning problem. Most NBV approaches reason about measurements using rigid data structures (e.g., surface meshes or voxel grids). This simplifies next best view selection but can be computationally expensive, reduces real-world fidelity and couples the selection of a next best view with the final data processing. This paper presents the Surface Edge Explorer (SEE), a NBV approach that selects new observations directly from previous sensor measurements without requiring rigid data structures. SEE uses measurement density to propose next best views that increase coverage of insufficiently observed surfaces while avoiding potential occlusions. Statistical results from simulated experiments show that SEE can attain similar or better surface coverage with less observation time and travel distance than evaluated volumetric approaches on both small- and large-scale scenes. Real-world experiments demonstrate SEE autonomously observing a deer statue using a 3D sensor affixed to a robotic arm.
Keywords
1. Introduction
Capturing high-fidelity observations of the real world is crucial for performing accurate analysis. High-accuracy scanners attached to industrial robots can be used to compare the structure of manufactured parts with ground-truth production models for quality control. Observations obtained from surveying large-scale outdoor structures, typically with an aerial platform, can be used for infrastructure inspection or to preserve edifices of historical significance. For example, observations of the Notre-Dame de Paris and the ancient city of Palmyra are being used to aid their respective reconstruction efforts.
Obtaining high-quality 3D observations is a challenge regardless of their final purpose. A scene (i.e., a bounded region of space) is observed by combining individual 3D measurements of surfaces obtained from multiple different positions. An observation is complete when there is sufficient measurement coverage on all visible surfaces. The final surface coverage achieved depends on the sensor capabilities, the scene structure and the views from which measurements are obtained. These views can be chosen by a human operator, but empirically selecting views is often undesirable or impossible.
Algorithmic view selection mitigates human uncertainty by intelligently choosing views. This challenge of planning a next view that can provide the best improvement in a scene observation is known as the Next Best View (NBV) planning problem. It was first explored by Connolly (1985).
NBV approaches can be broadly categorised by their sources of information. Model-based approaches require prior scene information to plan views (e.g., to compare a manufactured part with its production model) and cannot generalise to unknown scenes. Model-free approaches do not require a priori scene information and plan next best views from the current observation state.
The state of an observation is encoded with a scene representation. Most model-free NBV planning approaches use structured representations. These impose an external structure onto the scene. Volumetric representations segment the scene volume into a 3D voxel grid. Surface representations create a connected mesh from subsampled sensor measurements. These representations aggregate multiple measurements into each element of their structure. This simplifies selecting next best views but is computationally expensive and reduces observation fidelity (e.g., measurements from a partial surface may be sufficient for a voxel to be considered observed or a mesh to be connected without preserving surface details). Increasing the structural resolution (e.g., voxel number or mesh density) captures more detail but also increases computational costs. High resolution voxel grids and denser meshes are more computationally expensive to raycast and update.
NBV approaches with unstructured pointcloud representations do not impose external structures onto the scene and reason directly about sensor measurements. This maintains full fidelity and does not require restrictive assumptions about the scene structure but does require NBV approaches to reason about sensor measurements. Approaches with pointcloud representations aim to obtain coverage of scene surfaces rather than volumes of space by capturing new measurements that incrementally expanded an observation over connected surfaces.
The Surface Edge Explorer (SEE) proposes next best views directly from measurement density and is therefore referred to as a ‘measurement-direct’ approach. It identifies surfaces with low measurement density and proposes views to capture additional measurements. These views can be refined to avoid occlusions and improve visibility of their target surfaces. A next best view is chosen from these proposals to obtain a significant improvement in scene coverage while moving a short distance. New measurements from this view are then added to the observation and new views are incrementally captured until a minimum measurement density is obtained from the entire scene. The efficiency of this method allows SEE to obtain complete observations with short travel distances and observation times compared to state-of-the-art volumetric approaches.
The observation performance of SEE is evaluated with both simulated and real-world experiments. The simulation experiments provide a quantitative comparison of SEE with state-of-the-art volumetric approaches on both small- and large-scale scenes. In one simulation, small-scale tabletop models are observed using an RGB-D camera attached to a robotic arm. In another simulation, large-scale building models are observed with a LiDAR mounted on an aerial platform. SEE consistently outperforms the evaluated volumetric approaches in these simulation experiments by obtaining similar or better surface coverage while travelling shorter distances and requiring less observation time.
Real-world experiments demonstrate the same observation performance on a physical robotic platform (Figure 1). The platform is comprised of a turntable, onto which observation targets are placed, and a UR10 robot arm with an Intel RealSense L515 affixed to the end effector. It was specifically designed to evaluate NBV approaches and is not intended to be comparable with commercial 3D scanners. The observation target used for the real-world experiments was a deer statue, known as the Oxford Deer. Results from these real-world experiments show that SEE can obtain high-quality observations of the Oxford Deer with similar performance to the simulations, despite sensor noise (Figure 2). A photograph of the UR10 platform. An object (e.g., the Oxford Deer) is placed on a turntable (white) and captured by an Intel RealSense L515 on the UR10 end effector. SEE jointly directs the turntable and UR10 to observe the object. A pointcloud of the Oxford Deer captured by SEE using the UR10 platform.

1.1. Statement of contributions
This paper presents a definitive version of SEE and evaluates its observation capabilities in simulation and the real world. SEE and its density-based pointcloud representation were first presented in Border et al. (2017) and extended in Border et al. (2018), Border (2019) and Border and Gammell (2020). This paper makes the following specific contributions: • Presents a definitive version of SEE that unifies previously published work and extends it to improve performance. These extensions include computing suitable parameters online instead of using user-specified values and a more robust method for determining the correct direction of surface normals. • Uses realistic simulations of both small- and large-scale scenes to compare the observation performance of SEE with state-of-the-art volumetric approaches. The results demonstrate that SEE can capture highly complete scene observations using less travel distance and observation time than the volumetric approaches. • Presents the first evaluation of SEE working with a fully autonomous real-world system. This illustrates that SEE can efficiently obtain high-quality observations of a real-world object using a 3D sensor.
2. Related work
This section presents an overview of the NBV planning problem (Section 2.1) and a review of relevant literature on model-free approaches. Different strategies for categorising NBV planning approaches have been presented in survey papers (Karaszewski et al., 2016a; Scott et al., 2003; Tarabanis et al., 1995; Zeng et al., 2020). This paper adopts the classification scheme used by Scott et al. (2003) to discuss approaches based on their scene representation.
Approaches using volumetric representations are reviewed in Section 2.2, those with surface representations are discussed in Section 2.3 and approaches that utilise a combination of multiple representations are considered in Section 2.4. A new class of pointcloud representations, which includes the density representation used by SEE, is introduced in Section 2.5.
2.1. The next best view planning problem
The challenge of NBV planning is proposing and selecting views from which a scene can be efficiently observed. The quality of an observation can be quantified by its accuracy (i.e., how closely the captured data resembles the actual scene) and completeness (i.e., what proportion of the scene has been observed). Observation accuracy primarily depends on the sensor capabilities but can be improved by considering the scene texture and geometry. The completeness of an observation is determined by the coverage obtained from captured views. The efficiency of a NBV approach is quantified by the time and travel distance required to obtain an observation.
Approaches to the NBV planning problem select views by evaluating information obtained from previous views and in some cases a priori scene information. The general NBV problem can be formally expressed as a function,
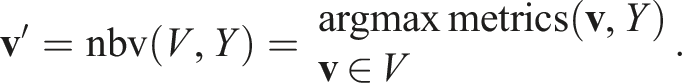
Each captured view improves the scene information available for selecting subsequent next best views. The representation chosen to encode this information is a defining characteristic of NBV algorithms. Volumetric representations segment the scene volume into a three-dimensional voxel grid (Figure 3(a)). Surface representations connect sensor measurements to create a surface mesh (Figure 3(b)). Some NBV planning approaches also encode scene information using a combination of these volumetric and surface representations. Pointcloud representations, such as the density representation presented in this paper, do not impose an external structure on the scene or assume any connectivity between sensor measurements (Figure 3(c)). Illustrations of (a) a volumetric scene representation (i.e., a voxel grid), (b) a surface representation (i.e., a connected mesh) and (c) the density-based pointcloud representation presented in this paper. A resolution parameter, r, defines the voxel size for a volumetric representation, the maximum edge length for a surface representation or the search radius for the density representation.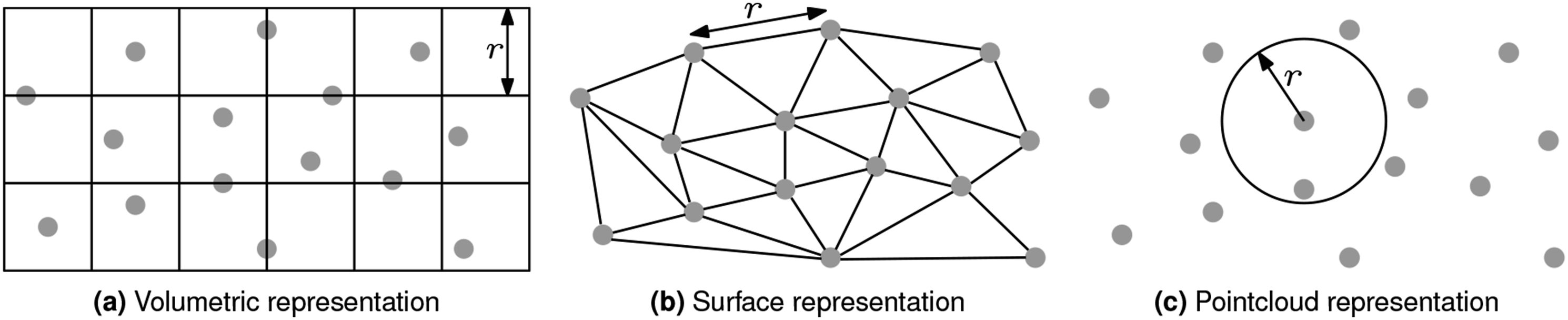
The NBV selection metrics used by an approach are largely determined by its representation. Approaches with volumetric representations typically aim to achieve the greatest reduction in the volume of unobserved space. Approaches with surface representations usually aim to expand the extent of their mesh and reduce surface uncertainty. Approaches with pointcloud representations commonly aim to improve the coverage and density of captured measurements. Almost every approach also considers the travel cost incurred to reach a view.
2.2. Volumetric representations
NBV planning approaches most commonly use a volumetric representation for encoding scene information. This representation divides the scene volume into three-dimensional cells known as voxels. A state associated with each voxel encodes information on its observation status and occupancy. The visibility of voxels from a set of potential views is evaluated by raycasting the voxel grid from each view and recording the states of voxels intersected by the rays. A value for each view is determined from the intersected voxel states.
Approaches using a volumetric representation can be broadly separated into three categories based on their method for proposing views. Many approaches use a predefined set of views chosen from a surface (e.g., a sphere or hemisphere) encompassing the scene (Section 2.2.1). Some approaches use path planning methods to propose views within free space regions of the scene (Section 2.2.2). Other approaches propose views using scene information obtained from the occupancy and observation states of voxels (Section 2.2.3).
2.2.1. Selecting views from a predefined set
Volumetric approaches that select views from a predefined set are primarily differentiated by how they use the measurement information encoded in their voxel representation.
Connolly (1985) coined the term next best view in formative work which presents the first approaches to the NBV problem. Voxels are classified by their occupancy and observation states. Next best views are selected to capture the most unobserved voxels. Papadopoulos-Orfanos and Schmitt (1997); Wong et al. (1999) use the same voxel classifications and view selection metric but different view proposal sets (e.g., using the centres of empty voxels). These approaches prioritise capturing unobserved voxels and consider occlusions from occupied voxels but do not classify occluded voxels or evaluate observation quality.
Several approaches extend this work by classifying occluded voxels and considering observation quality. Banta et al. (2000) introduce an occluded classification for voxels that lie within a viewing frustum but are obscured by occupied voxels. Massios and Fisher (1998); Vasquez-Gomez et al. (2009, 2014) present approaches that combine an occluded voxel classification with view selection metrics that consider observation quality. These approaches obtain better measurements by explicitly considering occlusions and observation quality but the use of binary voxel occupancy states can result in scene regions being sparsely covered by captured measurements.
Some limitations of binary voxel states can be addressed with a probabilistic voxel representation. This defines voxel occupancy as the likelihood that a voxel should contain sensor measurements. NBV approaches using this representation select next best views with Information Gain (IG) metrics, which quantify view value as the expected information available from voxels. Potthast and Sukhatme (2014); Isler et al. (2016); Delmerico et al. (2018) present IG-based view selection metrics that consider the occupancy probability, visibility and distance of voxels from a view. Abduldayem et al. (2017); Almadhoun et al. (2019) use knowledge of the scene geometry to predict voxel occupancy.
Krainin et al. (2011) create an implicit Truncated Signed Distance Field (TSDF) surface (Curless and Levoy 1996) and select views to reduce its uncertainty. Hou et al. (2019) improve upon the accuracy of independent per-voxel occupancy probabilities by jointly estimating occupancy probabilities for the entire voxel grid. Lauri et al. (2019, 2020) jointly maximise an IG metric between multiple sensors while reducing unnecessary overlap between their views. These probabilistic approaches are able to obtain observations with more consistent scene coverage by encoding more detailed measurement information in voxels, but are still limited by the voxel grid resolution.
Some recent works (Mendoza et al., 2020; Pan et al., 2022, 2023; Wang et al., 2019) have applied learning methods to the NBV problem by training networks to select next best views from a predefined set. These approaches can obtain highly complete observations of scenes with geometry similar to the training sets but do not necessarily generalise to scenes with unseen geometry.
Many volumetric approaches that choose views from a predefined set are capable of obtaining observations with high coverage of the scene volume; however, the completeness of these observations depends on the distribution of the predefined views since high coverage of the scene volume does not ensure good surface visibility.
2.2.2. Sampling views with path planning
Other volumetric approaches use sampling-based planning techniques to generate views in the free space of a scene. Views are proposed at the sampled states and evaluated when selecting a next best view.
Some approaches sample views from the entire scene volume. This enables them to obtain high global scene coverage but it is computationally expensive to raycast a large number of views. Potthast and Sukhatme (2011) use the Probabilistic Roadmap (PRM; Kavraki et al., 1996) planner. Yoder and Scherer (2016) use the SPARTAN planner (Cover et al., 2013).
Many approaches (Bircher et al., 2016, 2018; Respall et al., 2021; Vasquez-Gomez et al., 2017, 2018) reduce the cost of raycasting views by limiting their view sampling to a local region around the current sensor position (e.g., using Rapidly-exploring Random Trees (RRT) or RRT*; LaValle 1998; Karaman and Frazzoli 2011). Observations captured by these approaches can be highly complete in local scene regions but do not typically obtain good global coverage.
Recent approaches introduce methods to obtain high global scene coverage with a reduced computational cost. Selin et al. (2019) extend Bircher et al. (2016, 2018) by preserving high-value views between sampling iterations and evaluating view value with an efficient sparse raycasting method. Schmid et al. (2019) use RRT* to expand a single exploration tree when sampling new views and use a TSDF map representation to consider observation quality when selecting views. Schmid et al. (2022a) extend this work by training a neural network to learn a voxel confidence metric for selecting views. Dang et al. (2019) build both local and global exploration graphs by sampling views with a Rapidly-exploring Random Graph (RRG) algorithm (Karaman and Frazzoli 2009). Xu et al. (2021) propose an incremental PRM-based algorithm for sampling views. Cao et al. (2023) train a reinforcement learning network to select a next best view from a set of views uniformly sampled in free space.
Volumetric approaches that sample view proposals using path planning techniques can typically obtain greater scene coverage than those using a predefined set of views. The sampled views have better visibility of scene surfaces since they are distributed throughout the scene volume instead of around it. A limitation is the computational cost of raycasting a large number of sampled views, which is an important consideration when choosing a feasible sampling density.
2.2.3. Proposing views using scene information
Volumetric approaches that use the current voxel states to propose views can capture high-quality observations with greater efficiency than other volumetric methods as higher quality views are proposed and fewer views need to be considered.
Some approaches simply propose views in unoccupied voxels (Daudelin and Campbell 2017; Palomeras et al., 2019; Potthast and Sukhatme 2014). These are unlikely to obtain higher quality observations as they do not consider the observed scene geometry when proposing views but may achieve lower computation times by evaluating fewer views.
The highest quality observations are captured when views are proposed using the observed scene geometry. Volumetric approaches can achieve this by proposing views to capture surface frontier voxels (i.e., occupied voxels with unobserved neighbours) or exploration frontier voxels (i.e., unoccupied voxels with unobserved neighbours). Some approaches (Monica and Aleotti 2018a; Hardouin et al. 2020a, 2020b) identify clusters of surface frontier voxels, compute a normal for each cluster and generate a view along each normal. Kompis et al. (2021) compute a normal for each surface frontier voxel and generate multiple views around each normal. Batinovic et al. (2021) use a mean-shift clustering approach to identify views that lie at the centre of exploration frontier clusters. These approaches typically select a next best view to capture the most frontier voxels while moving the least distance.
Some recent approaches (Ren and Qureshi 2023; Schmid et al., 2022b; Zacchini et al., 2023) use learning methods to generate views based on scene information. They learn to propose views in free space that are likely to improve coverage of the scene by training on views generated by an existing sampling algorithm (Ren and Qureshi 2023; Schmid et al., 2022b) or by learning a scene-specific view distribution online from the current observation state (Ren and Qureshi 2023; Zacchini et al., 2023). These approaches demonstrate promising results in comparison with traditional volumetric methods for proposing views.
Volumetric approaches that use the current voxel states to propose views can obtain higher quality observations with greater efficiency than other volumetric methods. Computational cost is reduced as only views proposed to improve an observation are evaluated with raycasting.
2.3. Surface representations
Approaches with surface representations approximate the scene geometry by creating a connected mesh from sensor measurements. This mesh can provide high-fidelity information about the scene structure for proposing views, selecting a next best view and evaluating observation quality.
Many surface approaches require multiple data capture stages to obtain complete scene observations. An initial observation creates a course mesh from sparse measurements by following a preplanned or human-directed view trajectory. This initial mesh is then refined by integrating measurements from a second NBV-planning-directed observation.
Reed and Allen (2000) select next best views to observe occluded surfaces in a mesh representation. This improves the measurement density on surfaces with irregular geometry and refines the initial mesh observation. Hollinger et al. (2012) model uncertainty in the initial mesh using Gaussian process implicit surfaces and select next best views to reduce the uncertainty. Roberts et al. (2017) propose views by independently sampling sets of view positions and orientations. The value of each view is defined by the visibility of vertices in the initial mesh and a view trajectory is planned to maximise the additive value of each view visited. Peng and Isler (2019) account for the scene geometry when proposing views by sampling them from a manifold encompassing the scene, which is produced by moving each vertex in the initial mesh a given distance along its surface normal and computing a convex hull.
All these two-stage approaches are able to capture high-quality observations by using knowledge of the scene geometry obtained from the initial survey, but requiring an extra capture stage increases the overall observation time.
Some surface-based approaches do not require a multistage observation. Khalfaoui et al. (2013) classifies the visibility of surfaces in its current mesh based on the angles between their normals and the sensor pose. Views are chosen to observe surfaces with poor visibility. Lim et al. (2023) present a NBV approach for Multi View Stereo (MVS) reconstruction that selects views from a predefined set to provide the best coverage of surface landmarks.
Surface approaches can typically capture higher quality scene observations than volumetric approaches by considering the scene geometry when proposing and selecting views; however, requiring multiple observation stages increases the overall capture time and creating a mesh from dense sensor measurements is often computationally expensive.
2.4. Combined representations
Approaches with combined representations aim to leverage the advantages of multiple representation types and mitigate their limitations. Most combine volumetric and surface representations to utilise information on both voxel observation states and the scene geometry.
Kriegel et al. (2012, 2015) present a combined approach with a probabilistic voxel grid by extending earlier work using a surface representation (Kriegel et al., 2011). Views are proposed to extend the boundaries of a surface mesh and are assigned an IG value from the voxel grid.
Song and Jo (2018) and Song et al. (2020) extend earlier work on a volumetric approach (Song and Jo 2017) with a surface representation. The surface representation is obtained by creating a Poisson reconstruction (Kazhdan et al., 2006) from a TSDF extracted from the voxel grid. A trajectory is planned between views sampled with RRT* to observe uncertain surfaces in the reconstruction and exploration frontier voxels. Song et al. (2021) present a similar approach for online MVS reconstruction.
Low and Lastra (2006) represent scene observations with a combination of voxels and surface patches. Their approach aims to obtain a minimum measurement density within each occupied voxel. Measurements in voxels with insufficient density are connected to define surface patches. Views are proposed to observe these patches and a next best view is selected to observe the patch with the greatest potential increase in measurement density.
Karaszewski et al. (2016b) present a multistage combined approach. The first stage, originally presented by Karaszewski et al. (2012), uses a volumetric representation with a density-based measurement classification to propose and select views of scene regions with insufficient measurements. A Poisson surface reconstruction is created from this initial observation and then refined by capturing more views.
Dierenbach et al. (2016) use the Growing Neural Gas (GNG) algorithm (Fritzke 1994) to learn a model of the scene geometry from sensor measurements. This model defines a graph of connected nodes which partition the scene volume into a Voronoi tessellation, where each node lies at the centre of a Voronoi cell. Views are proposed to observe each cell and a next best view is selected to observe the cell with the lowest measurement density.
Monica and Aleotti (2018b) present an approach with a surfel representation. Surfels that lie on the boundary between unobserved and unoccupied voxels are classified as frontels. Next best views are selected to observe the set of visible frontels with the greatest surface area.
Ran et al. (2023) present an approach that uses a novel Neural Radiance Field (NeRF)-based representation and estimates the neural uncertainty of implicit surface points. Views are sampled by RRT* and next best views are chosen to reduce the neural uncertainty.
Approaches with combined representations can obtain more complete and accurate scene observations than other approaches by leveraging the advantages of multiple representations; however, a greater computational cost is typically incurred for maintaining several representations.
2.5. Pointcloud representations
Many of the limitations associated with structured scene representations can be overcome by using an unstructured pointcloud representation. These directly represent the observation state using sensor measurements instead of encoding scene information in an external structure. They do not reduce the fidelity of scene information and avoid some of the computational costs (e.g., raycasting) incurred by maintaining an external structure.
SEE is the first NBV approach to use a fully unstructured representation, to the best of our knowledge, but other approaches have since been presented. Peralta et al. (2020); Zeng et al. (2020) train neural networks to select views from a predefined set that can obtain the greatest improvements in surface coverage. Arce et al. (2020) present a multistage approach with a density-based measurement classification similar to SEE. Williams et al. (2020) use the Hidden Point Removal (HPR) algorithm (Katz 2015) to identify point-based frontiers on the boundaries of visible surfaces.
SEE is a measurement-direct NBV approach with a density-based pointcloud representation. All scene information is directly associated with sensor measurements and therefore SEE avoids the computational cost of maintaining an external structure (i.e., a voxel grid or surface mesh). The computational cost of updating the density representation scales with the number of measurements captured and processed at the discrete views chosen by SEE rather than the scene volume or the resolution of an external structure.
Measurements are processed when they are added to the observation and are only reprocessed if they have insufficient density and lie within the classification neighbourhood of newly added measurements. Visibility and occlusion checking is only required for the small subset of points used to propose views for extending an observation, instead of for every added measurement as is typically required for volumetric approaches.
The fidelity of scene information is not constrained by a structural resolution since captured measurements are individually classified based on the density of neighbouring points instead of being aggregated into a single set of values for each unit of the external structure (e.g., a voxel). SEE leverages this detailed knowledge to identify scene regions that require further observation, propose views that avoid occlusions and select next best views that can obtain the best improvements in surface coverage. This enables it to observe scenes with less observation time and often higher completion than structured approaches.
3. The surface edge explorer
This paper presents SEE, a NBV planning approach with a density-based pointcloud representation. SEE aims to obtain complete scene observations by capturing a minimum measurement density from all visible surfaces. Sensor measurements are individually classified by the number of neighbouring points within a resolution radius (Section 3.1). Measurements with a minimum number of neighbours are core points and those without are outlier points. Outliers with core neighbours become frontier points, which in the context of this work represent a boundary in the captured measurements between fully and partially observed surfaces.
This density-based classification of measurements is used to identify the boundaries between sufficiently and insufficiently observed surfaces (Section 3.2). Views are then proposed to observe the frontier points that define these boundaries (Section 3.3). Known occlusions are handled proactively by detecting occluding points before a view is obtained and proposing an alternative unoccluded view (Section 3.4). The visibility of surfaces from views is quantified by encoding the shared visibility of frontier points from views in a graphical representation (Section 3.5). Next best views are chosen from this graph to obtain significant improvements in surface coverage while reducing travel distance (Section 3.6). If a target frontier point is not observed from a view – typically due to an unknown occlusion or surface discontinuity – then it is reactively adjusted to avoid the obstruction (Section 3.7). Views are captured until there are no frontiers remaining (Section 3.8).

Algorithm 1 presents an overview of SEE. The observation parameters, Γsee, are set using user-specified values and the sensor properties, Γsensor (Line 4). New measurements are iteratively obtained and processed to select a next best view (Line 5). A set of new measurements, P′, is captured from a sensor at the current view,

3.1. Computing suitable parameters
The configuration parameters of SEE.
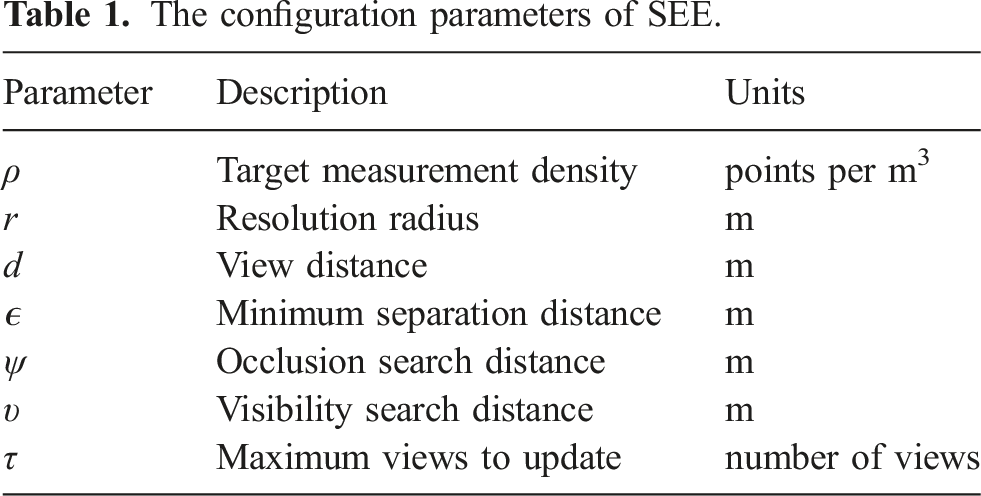
The target measurement density, ρ, determines how many measurements need to be captured from scene surfaces. It should be set sufficiently high to attain the desired level of structural detail from a scene. The resolution radius, r, defines the scale at which the measurement density is evaluated. This should be large enough to handle measurement noise robustly (i.e., most noisy measurements that deviate from true surfaces should be encompassed within the resolution radius to prevent them from being classified as frontier points) while still retaining surface features and computational efficiency.
The view distance, d, sets the range at which a sensor observes the scene. It should be set so that sufficient frontier points can be identified from captured measurements. If the view distance is too large, the measurements will be sparsely distributed over scene surfaces and may all be outlier points. When the sensor is too close, the measurements will be densely distributed over surfaces and may all be core points. A method is presented to compute a suitable distance from the measurement density and sensor properties (Alg. 2, Line 10). The minimum separation distance, ϵ, between measurements is used to reduce memory consumption and computational cost. It should be set small enough that it does not affect point classification.
Algorithm 2 presents the calculation of these parameters from the sensor resolution, ωx and ωy, and field-of-view, θx and θy. If the user specifies a value for the target density but not the resolution radius then it is computed such that the resulting volume will contain three points at the target density (Lines 3–5). If the resolution radius and view distance parameters are set, but the target density is not, then it is calculated from the sensor properties to equal the density of sensor measurements that could be captured from the largest observable surface area at the specified view distance (Lines 6–8). If the target density and resolution radius are set but not the view distance then it is computed such that the measurement density captured from the largest observable surface would be equal to the target density (Lines 9–11).
If the minimum separation distance is not specified then a suitable value is computed from the target density and resolution radius (Lines 12–14). The final parameter, kmin, is not user-configurable and defines the number of points that need to exist in an r-radius sphere with density ρ (Line 15).
The remaining user-specified parameters tune the practical performance of SEE. The occlusion search distance, ψ, is the radius around a frontier point that is searched for occluding points. It should ideally be equal to the view distance to capture all occluding points but can be reduced to limit computational cost. The visibility search distance, υ, is the radius around the sight line of a view that is searched for occluding points. It should be large enough that an unoccluded view is able to successfully observe new measurements around its associated frontier. The maximum views to update, τ, defines the number of neighbouring views that are processed when handling occlusions and updating the frontier visibility graph. It should be as high as possible without incurring a significant computational cost.
3.2. Processing sensor measurements
Sensor measurements are classified based on the number of neighbouring points within the resolution radius (Figure 4). Measurements with more neighbours than the target density are classified as core points and those without are outlier points. Outlier points with core neighbours are frontier points. These frontiers define a boundary between sufficiently and insufficiently observed surfaces. An illustration of the density-based classification used by SEE (Alg. 3). Measurements with a sufficient number of neighbours, kmin, in an r-radius are classified as core (black) while those without are outliers (white). Outlier measurements with core neighbours are frontiers (grey).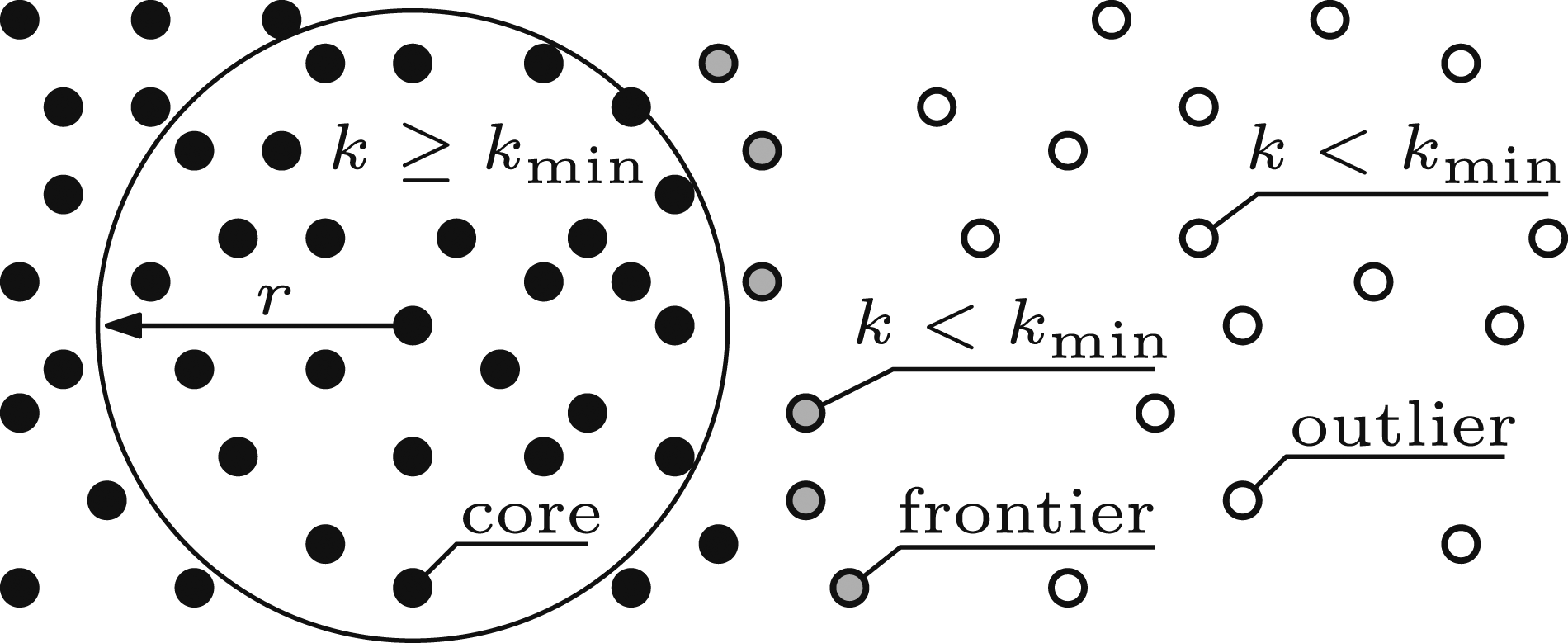
New sensor measurements are added to the SEE pointcloud and assigned a classification. This density-based classification is based on Density-Based Spatial Clustering of Applications with Noise (DBSCAN; Ester et al., 1996). Sensor measurements, 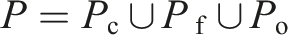
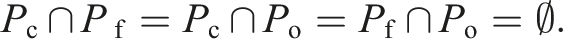
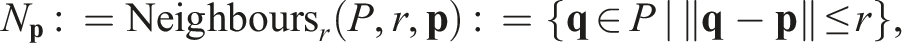
A point is classified as core if it has at least kmin neighbours,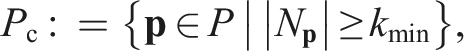
A point is classified as a frontier if it has fewer than kmin neighbours, some of which are core points,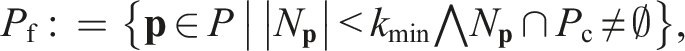
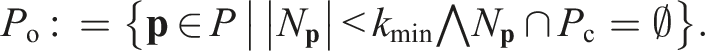

Algorithm 3 presents the classification of new measurements. Each point in the new measurement set,
If a point in the queue is not a core point then it is (re)classified based on the new measurements (Lines 8–10). Points with insufficient neighbours to be core are (re)classified as frontier points if they have core neighbours or become outliers (Lines 11–19). Points with sufficient neighbours are (re)classified as core points (Lines 20–27). If an unprocessed point is (re)classified as a core point then its neighbours are added to the (re)classification queue and it is marked as processed (Lines 28–31). The classification procedure completes when all new measurements and those in the (re)classification queue are processed.
Classifying sensor measurements based on the density of neighbouring points distinguishes a boundary between scene regions that are completely observed (i.e., consist only of core points) from those that require additional measurements (i.e., contain frontier and outlier points). The frontier points identified along this boundary are used to propose views for extending the coverage of completely observed surfaces.
3.3. Proposing views
Observation coverage is improved by capturing measurements from surfaces around frontier points. Views are proposed to observe the frontiers by estimating the local surface geometry from an eigendecomposition of measurements within their r-radius neighbourhoods. The surface geometry is described by a set of orthogonal vectors (Section 3.3.1). They represent the local surface normal, a boundary between complete and incomplete surfaces and the direction of partial observation (i.e., a frontier vector). The outwards facing normal direction is determined by evaluating the visibility of vectors pointing in both potential directions (Section 3.3.2).
Each view, An illustration of a view proposal (Alg. 4). A view, 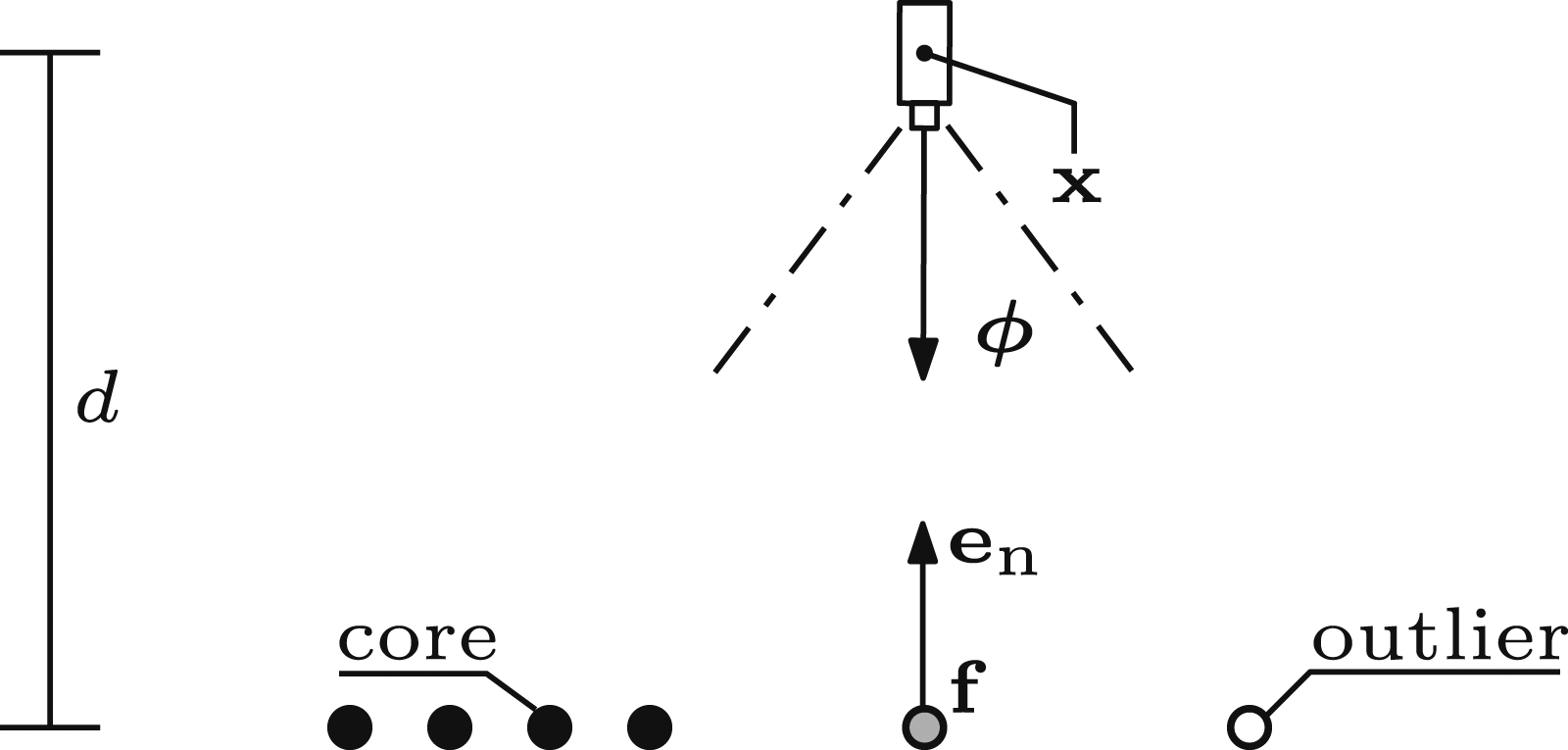
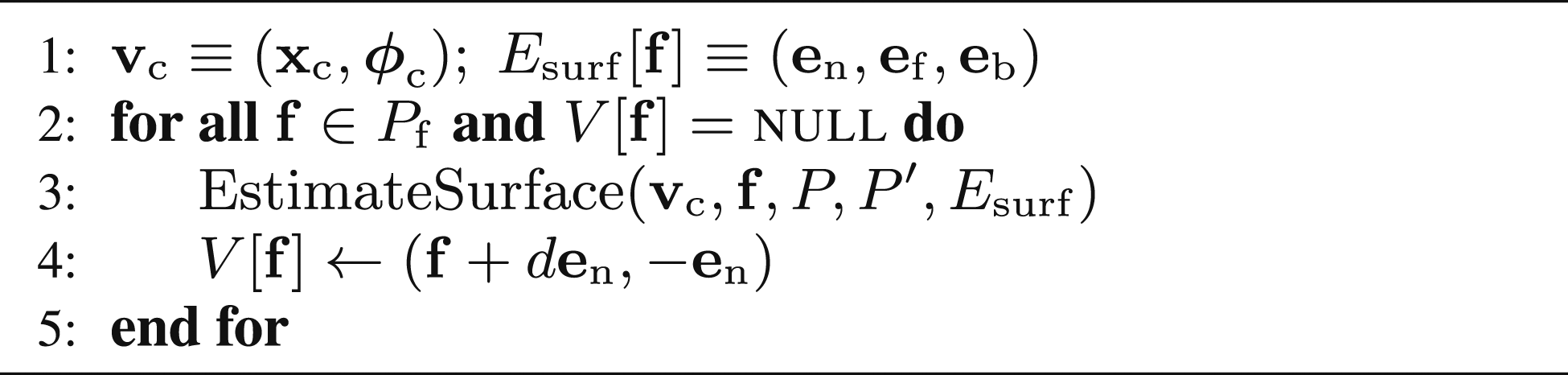
Algorithm 4 presents the generation of a view proposal for each new frontier point,
3.3.1. Estimating the surface geometry
The surface geometry around a frontier point is estimated by an eigendecomposition of the neighbouring measurements within an r-radius. This produces a planar estimate defined by three orthogonal vectors, each of which describes one component of the local surface geometry (Figure 6). An illustration of the orthogonal vectors that represent the local surface geometry (Alg. 5). The normal vector, 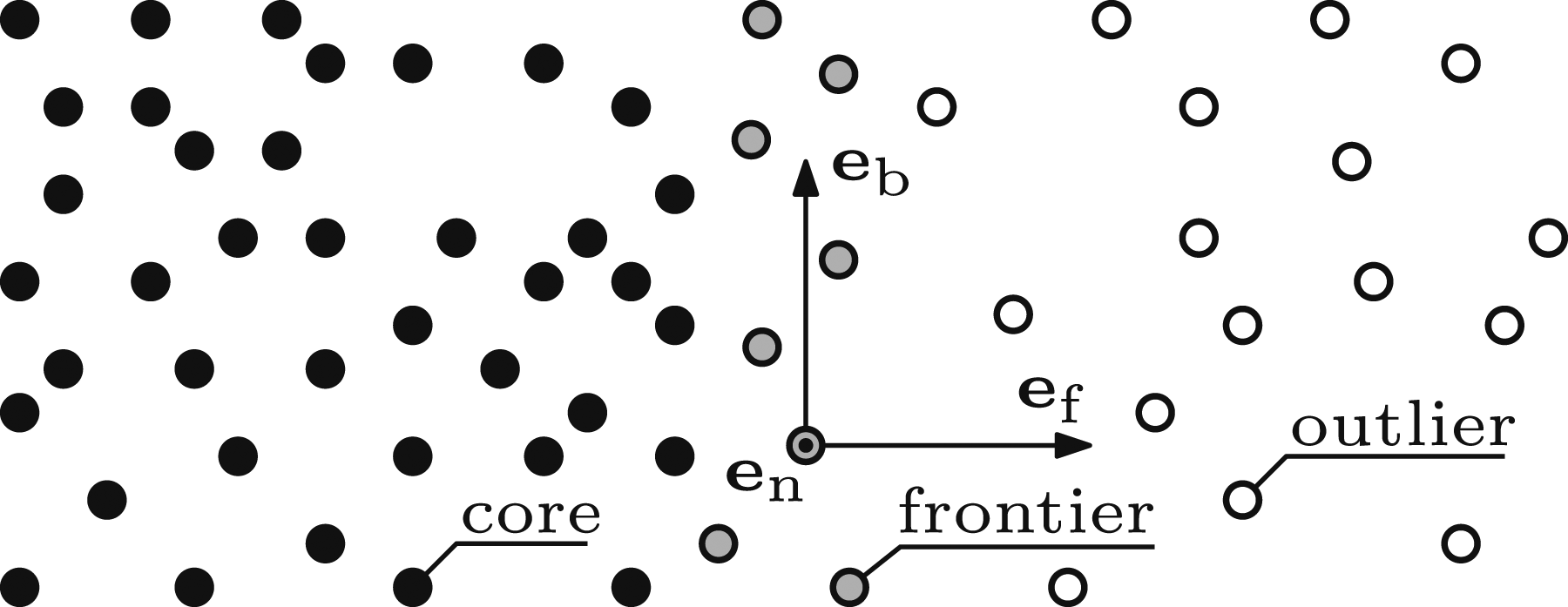
Algorithm 5 presents the estimation of local surface geometry. A planar estimate of the local geometry around a frontier point,
Each eigenvector describes one component of the estimated surface geometry. The normal vector,
The normal vector,
The frontier vector,
The boundary vector,

3.3.2. Determining the correct normal direction
The views proposed to observe frontier points are defined by their associated surface normals. These normals must point outwards from the surface in order to obtain valid views.
The direction of a normal can often be defined as pointing towards the current view. This technique works well when the current view is close to the surface normal but can fail when it observes the surface at an acute angle. In this scenario, the sightline and surface normal are nearly perpendicular and measurement noise can corrupt the identification of the outwards facing normal direction.
A more robust method to determine the outwards facing normal direction is to evaluate the visibility of both potential vectors from the current view (Figure 7). The normal direction pointing outwards from the surface will not be occluded by measurements while the other direction will be. An illustration of how the correct normal direction is determined (Alg. 6). Normal vectors pointing in opposite directions, 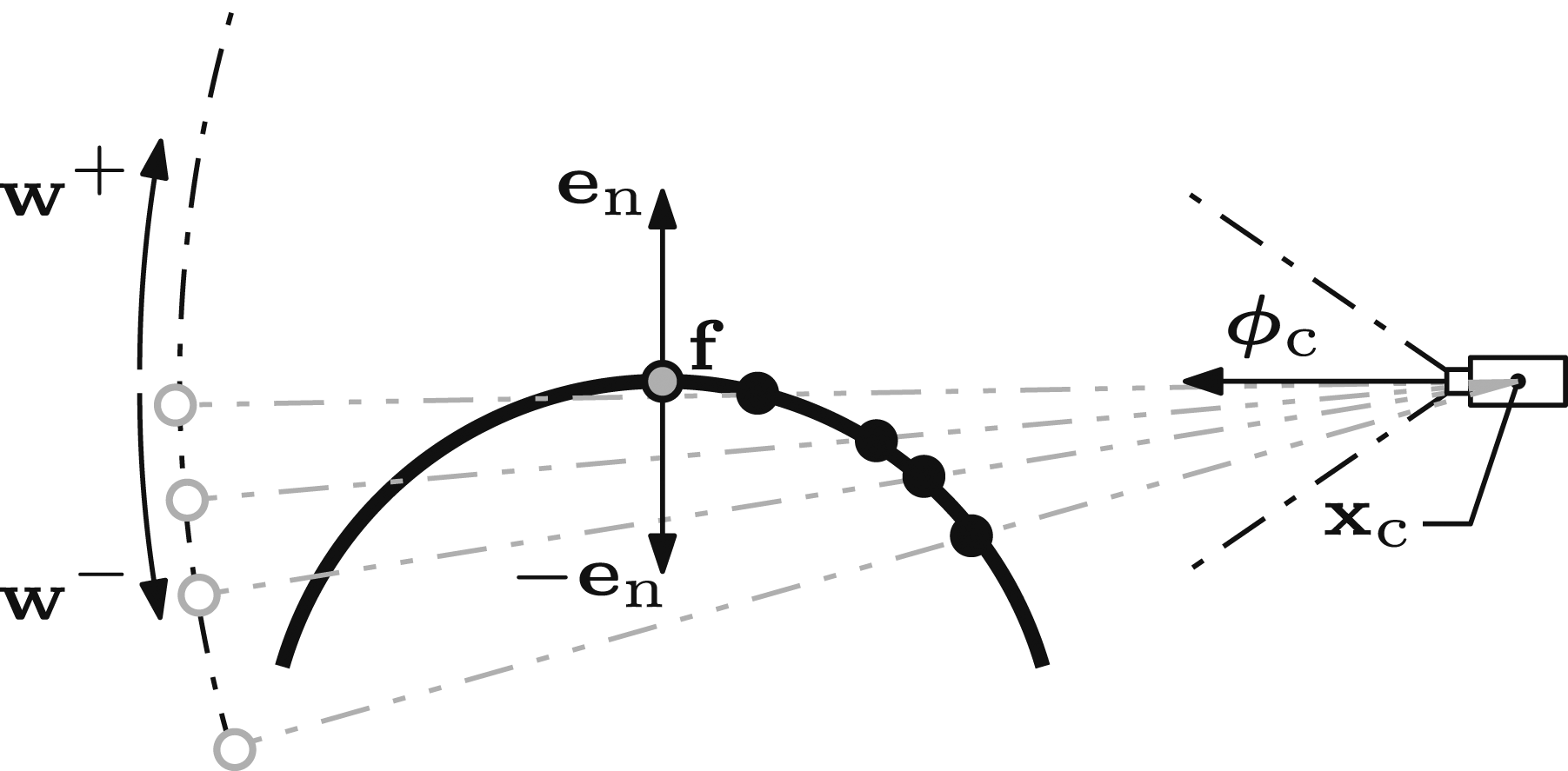
The visibility of the two potential normal vectors from the current view is evaluated by sampling points along each vector, starting at the frontier point and checking for an unoccluded sight line. The visibility of points is evaluated in both directions until the first unoccluded point is found. Its corresponding vector defines the outwards facing normal.
The visibility of points is evaluated by projecting them onto the surface of a unit sphere centred on the current view, a method inspired by HPR (Katz 2015). Measurements captured from the current view that are closer to the view than the normal vectors are also projected. This projection preserves the relative orientation of points to the view while normalising the distance. Projected points with similar sight lines are close to each other on the sphere surface and a point is considered occluded if projected sensor measurements exist within a specified radius.

Algorithm 6 presents the calculation of the outwards facing normal direction. Sampled points along each vector,
In each iteration, the sampled points are moved along their respective vectors by the visibility search distance, υ (Lines 5–6). New measurements that are closer to the current view than the sampled points are projected onto the surface of a unit sphere centred on the current view position,
This method is able to reliably determine the outwards facing normal direction for the estimated surface around a frontier point. It improves observation efficiency by identifying the correct direction from which to propose a view and reduces the number of failed views attempted.
3.4. Refining views
Proposed views can only observe their target frontier points if they are unoccluded. Occlusions are handled proactively by identifying occluded views before they are visited (Section 3.4.1). These occluded views are refined to alternative unoccluded views (Section 3.4.2).
Algorithm 7 presents the proactive identification of known occlusions and the resulting view refinement. The τ-nearest views,
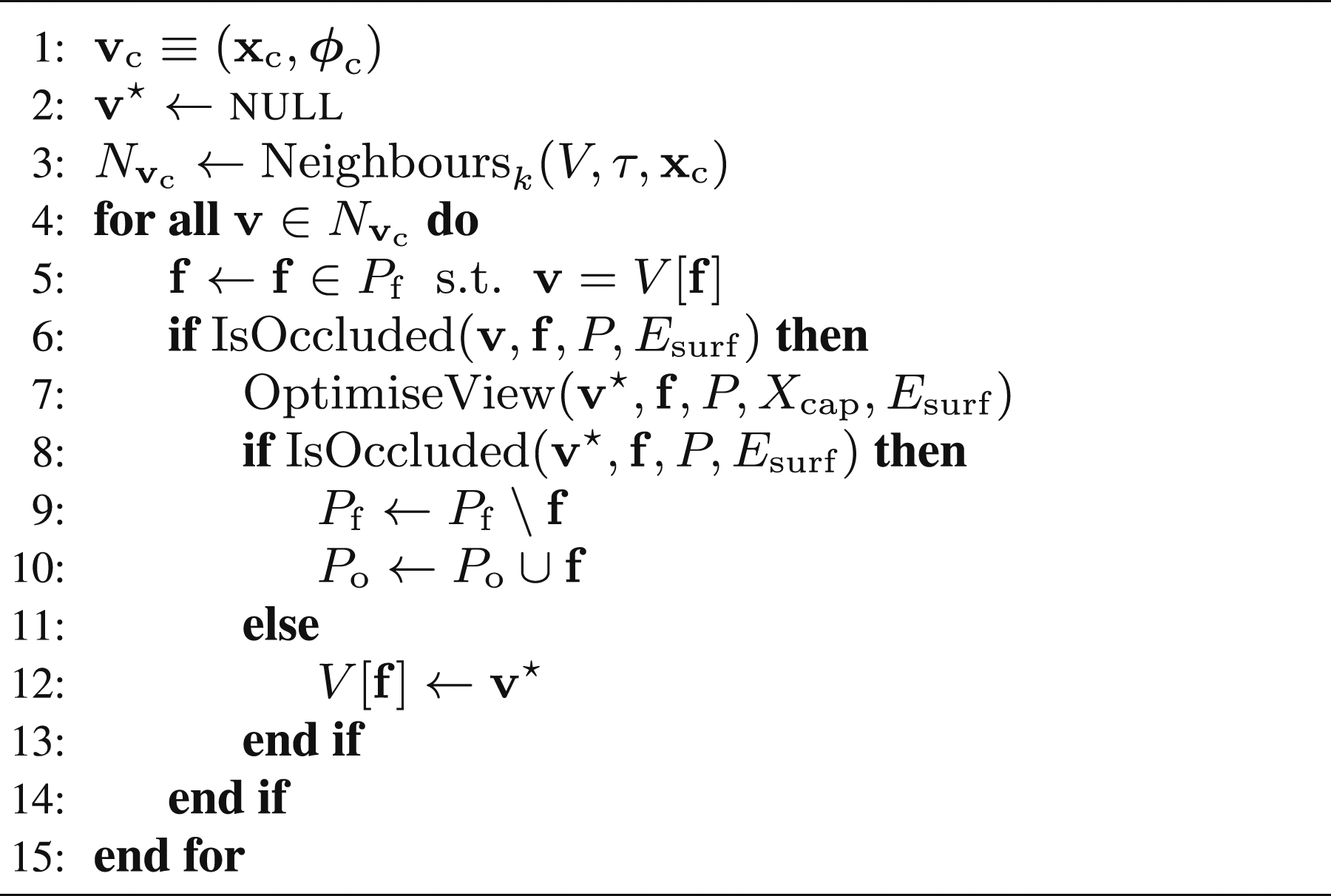
3.4.1. Detecting occlusions
A frontier point is occluded if measurements exist within the visibility search distance, ν, of the sight line from the target view. Occluding measurements are found by searching the υ-radius neighbourhoods of points sampled along the sight line (Figure 8). A frontier is visible from a view if no occluding measurements are found. An illustration of detecting occlusions between a frontier point and its associated view (Alg. 8). Measurements (black dots) within a set distance of the sight line are assumed to represent occluding surfaces. They are found by performing a υ-radius search around discrete points (grey circles), 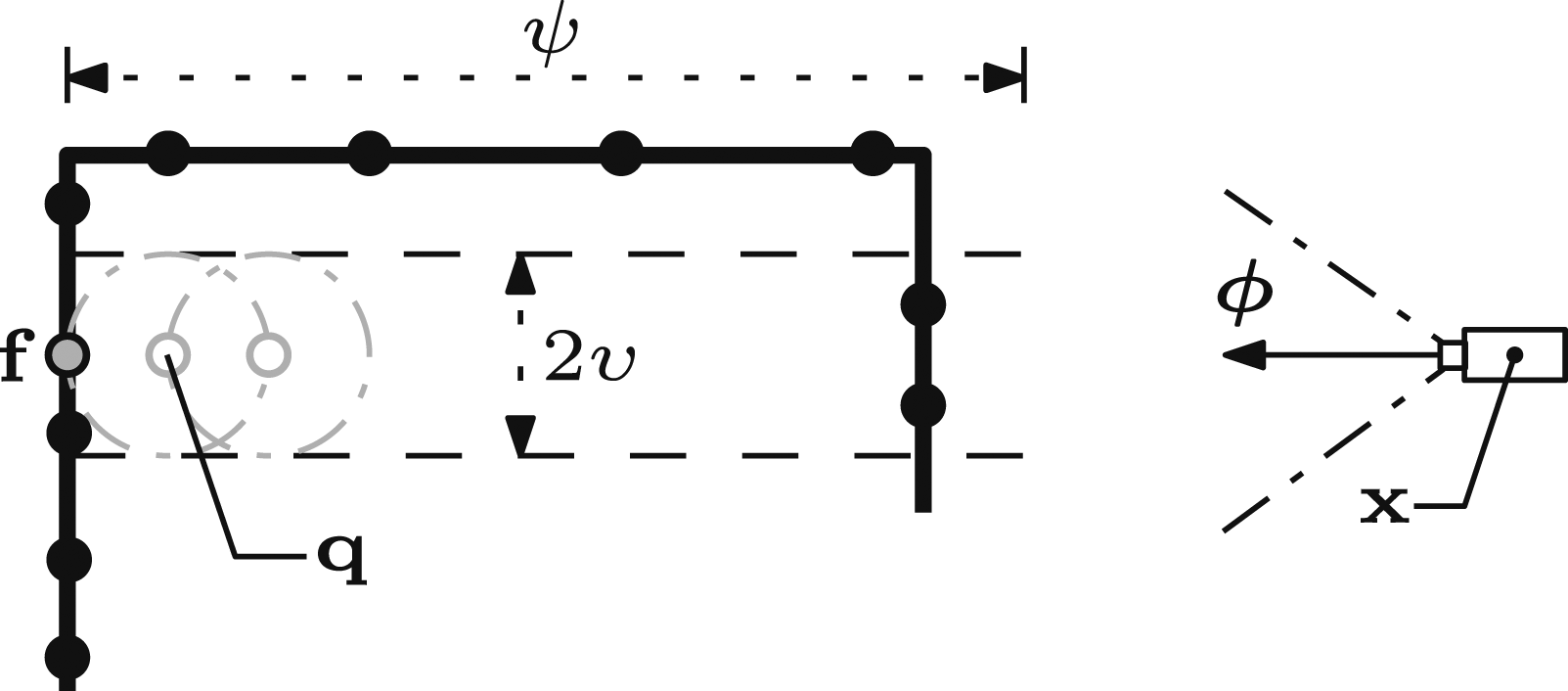
Algorithm 8 presents the method for occlusion detection between a frontier point and a view. Points are sampled along the sight line at an υ-interval, starting at an offset from the frontier, ζ, and ending at the occlusion search distance, ψ (Lines 3–5). The υ-radius neighbourhood around every sampled point is searched for occluding measurements (Line 6). The view is occluded if the union of the search result sets, N
The search for occluding measurements starts at an offset from the frontier to account for measurement noise. A suitable offset is identified by searching along the local surface normal until the first region of free space is found.
Algorithm 9 presents the calculation of this offset. Points are incrementally sampled along the normal vector at an υ-interval, starting at the frontier point, until the υ-radius neighbourhood around the newest sampled point is empty or the occlusion search distance is reached (Lines 2–6).
Proactively detecting known occlusions improves observation efficiency by reducing the number of unsuccessful views. This method also aids in the selection of next best views that can observe more frontiers by quantifying the shared visibility of frontiers between views.
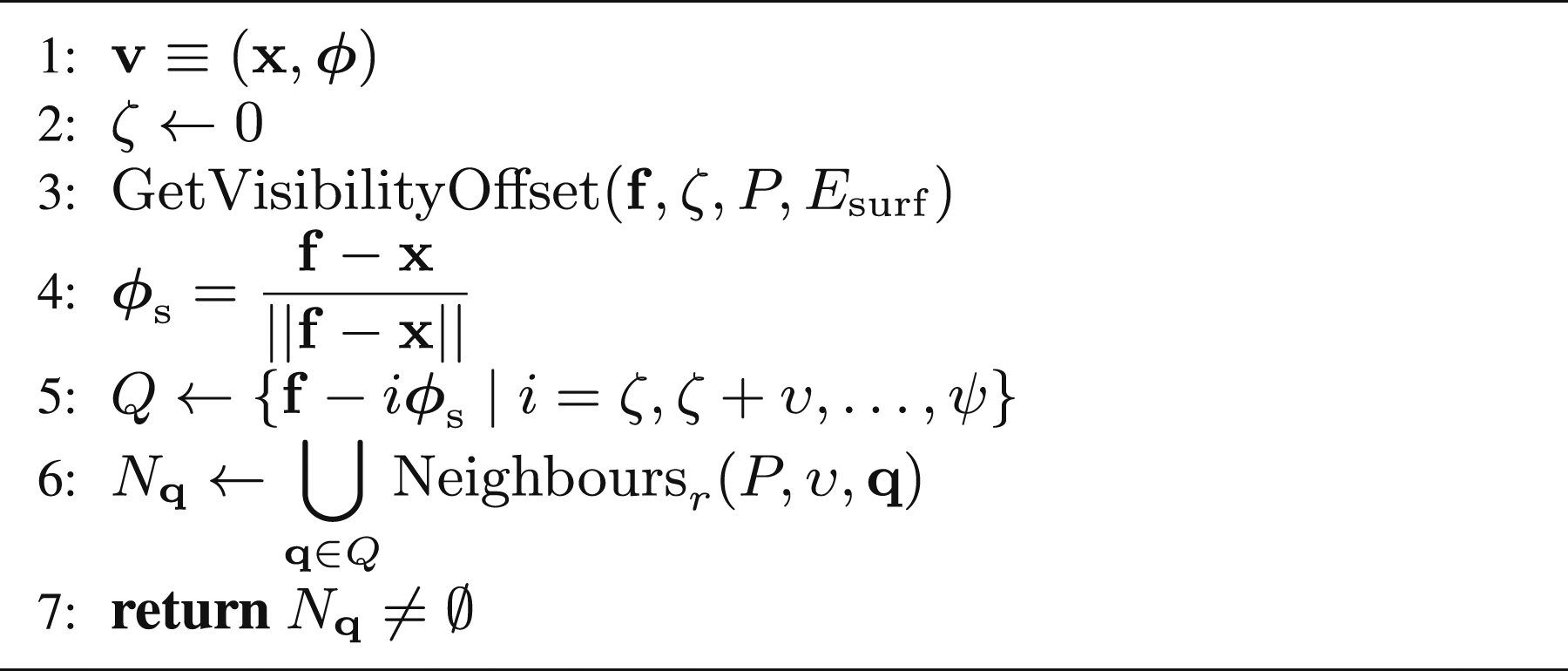
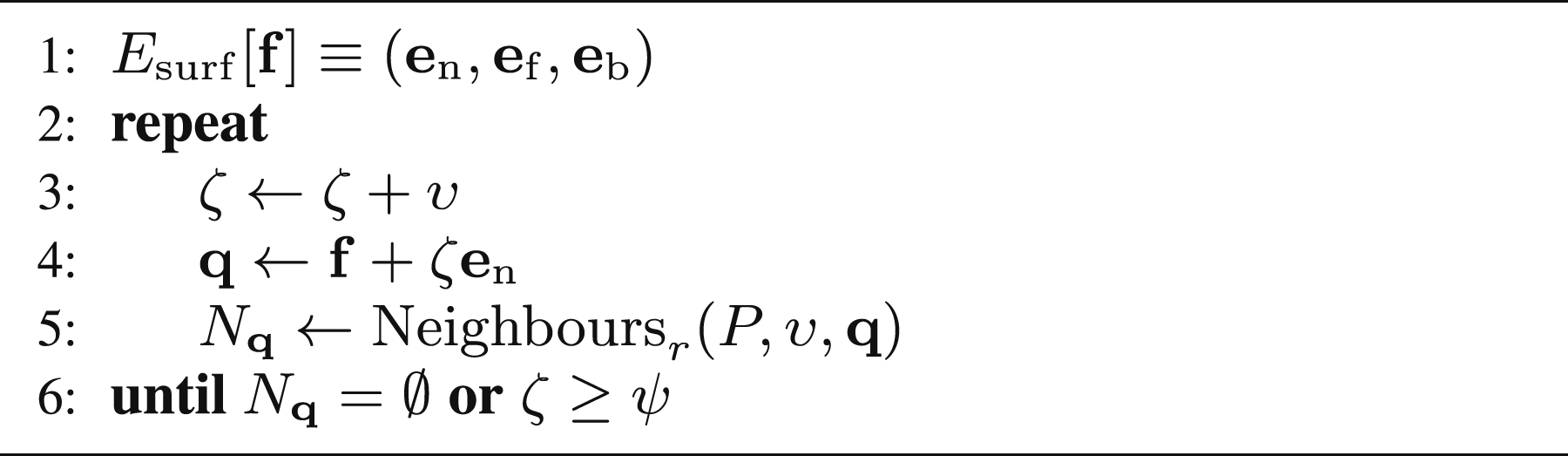
3.4.2. Proposing an unoccluded view
Occluded views are updated to an unoccluded view by finding the sight line to their frontier point that has the greatest separation from any occluding measurements. This sight line provides the best chance that the frontier will be successfully observed.
A frontier point is occluded when measurements exist along the sight line between it and the proposed view. A frontier’s visibility from different views can be found by projecting possibly occluding measurements onto a unit sphere (Figure 9), using the same method discussed in Section 3.3.2. The sphere centre may be slightly offset from the frontier to account for measurement noise. The projection preserves the direction of occluding measurements while placing them on a uniform manifold for efficient processing. A 2D illustration of the spherical projection used to find an unoccluded sight line of a target frontier point (grey dot), 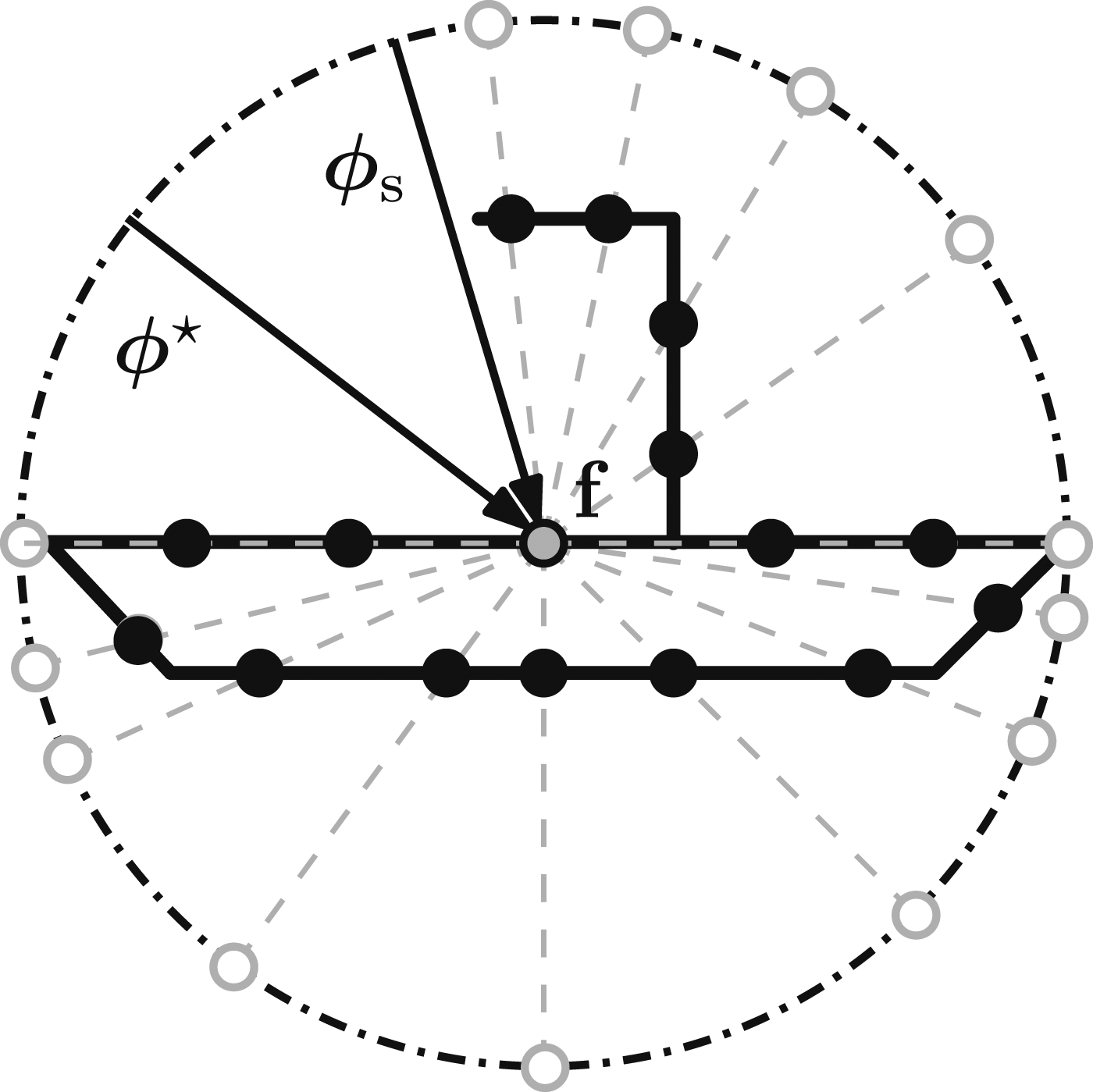
An unoccluded view of the frontier point is found by solving a maximin optimisation problem on the spherical projection. This maximises the minimum distance between the processed view and any of the projected points. The maximin problem solution is the antipole (Drezner and Wesolowsky 1983) of the complementary minimax problem solution (Patel and Chidambaram 2002).
The minimax solution is the centre of the smallest spherical cap that contains the projected points. This cap is defined by a plane intersecting the sphere and is found by optimising the plane normal and its distance from the sphere centre. The minimax solution is the intersection point of the plane normal with the sphere.
The specific optimisation method depends on the distribution of projected points. If they are spread over more than a hemisphere then the smallest containing cap is found by minimising the distance of the plane from the sphere centre. If the projected points lie on less than a hemisphere then the smallest containing cap is found by maximising the distance of the plane from the sphere centre.

Algorithm 10 presents the calculation of an unoccluded view using this maximin optimisation strategy. The projection centre of the sphere,
If the projected points lie on less than a hemisphere then the full sphere optimisation converges to a plane bisecting the sphere (i.e., e⋆ = 0) and a hemispherical optimisation is performed (Lines 9–10). The distance of a plane intersecting the sphere from its centre is maximised while ensuring the plane normal satisfies the optimisation constraints and the projected points all lie on the same side of the plane. The plane normal is initialised to the direction of the capturing view orientation as this is known to be unoccluded. The optimised view orientation points in the same direction as the optimised normal (Line 11). After the view optimisation is complete the optimised view position,
This optimisation is guaranteed to find a view of a frontier point that is free from known occlusions if one exists. Refining proposed views with it improves the efficiency of scene observations by increasing the chance that a frontier point will be successfully observed from its associated view.
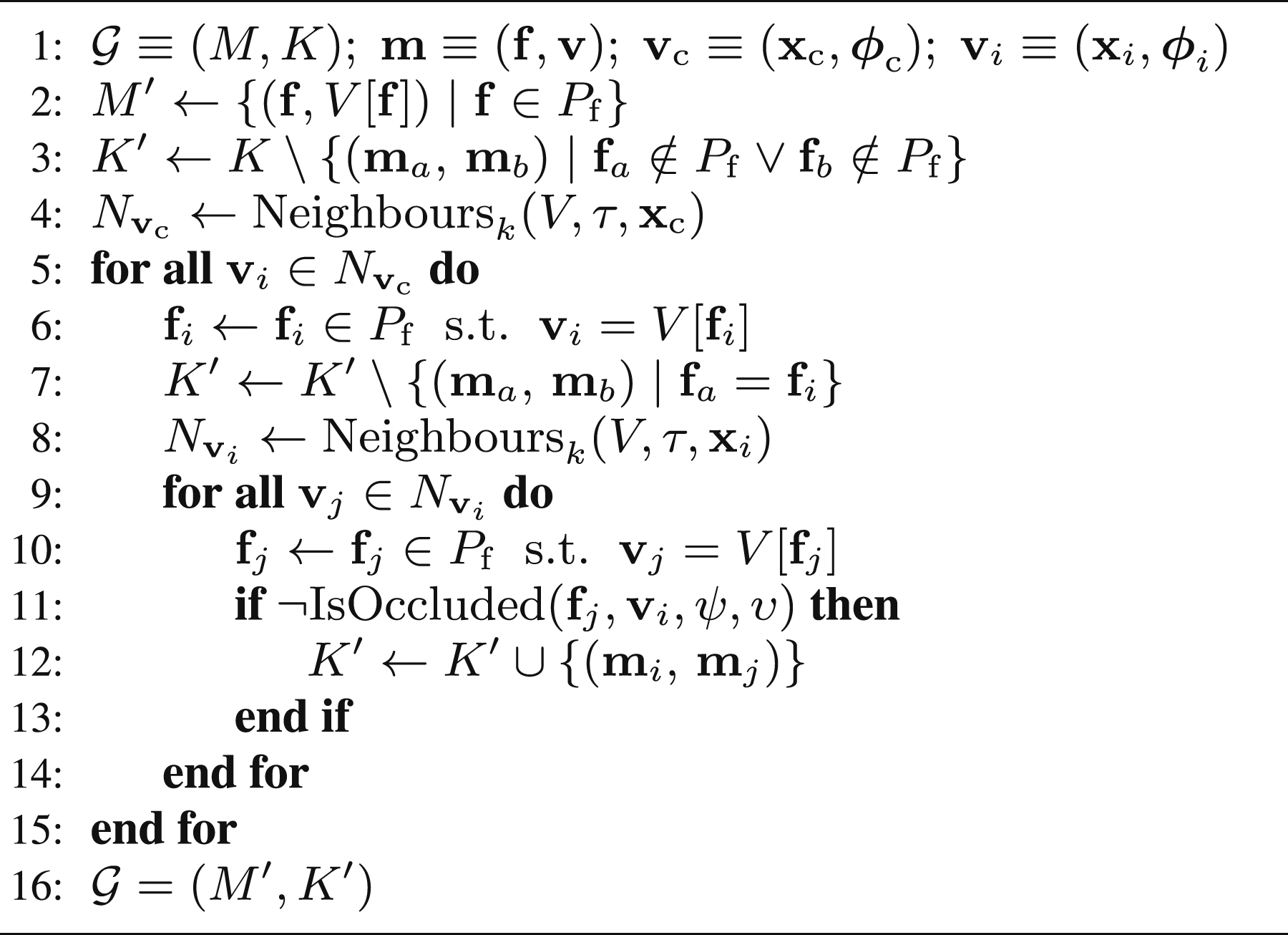
3.5. Quantifying views
The best views are those that capture the most new surface coverage. SEE quantifies the predicted coverage from a proposed view as the number of visible frontier points. The visibility of frontiers from views is encoded in a directed frontier visibility graph that connects each frontier to the views from which it can be observed. It is used to select next best views that can obtain large increases in surface coverage.
The frontier visibility graph, An illustration of the frontier visibility graph (Alg. 11). The connectivity between frontier-view pairs (grey dots and sensors) is represented with directed edges (grey arrows). An edge from a parent to a child denotes that the child frontier point is visible from the parent view proposal.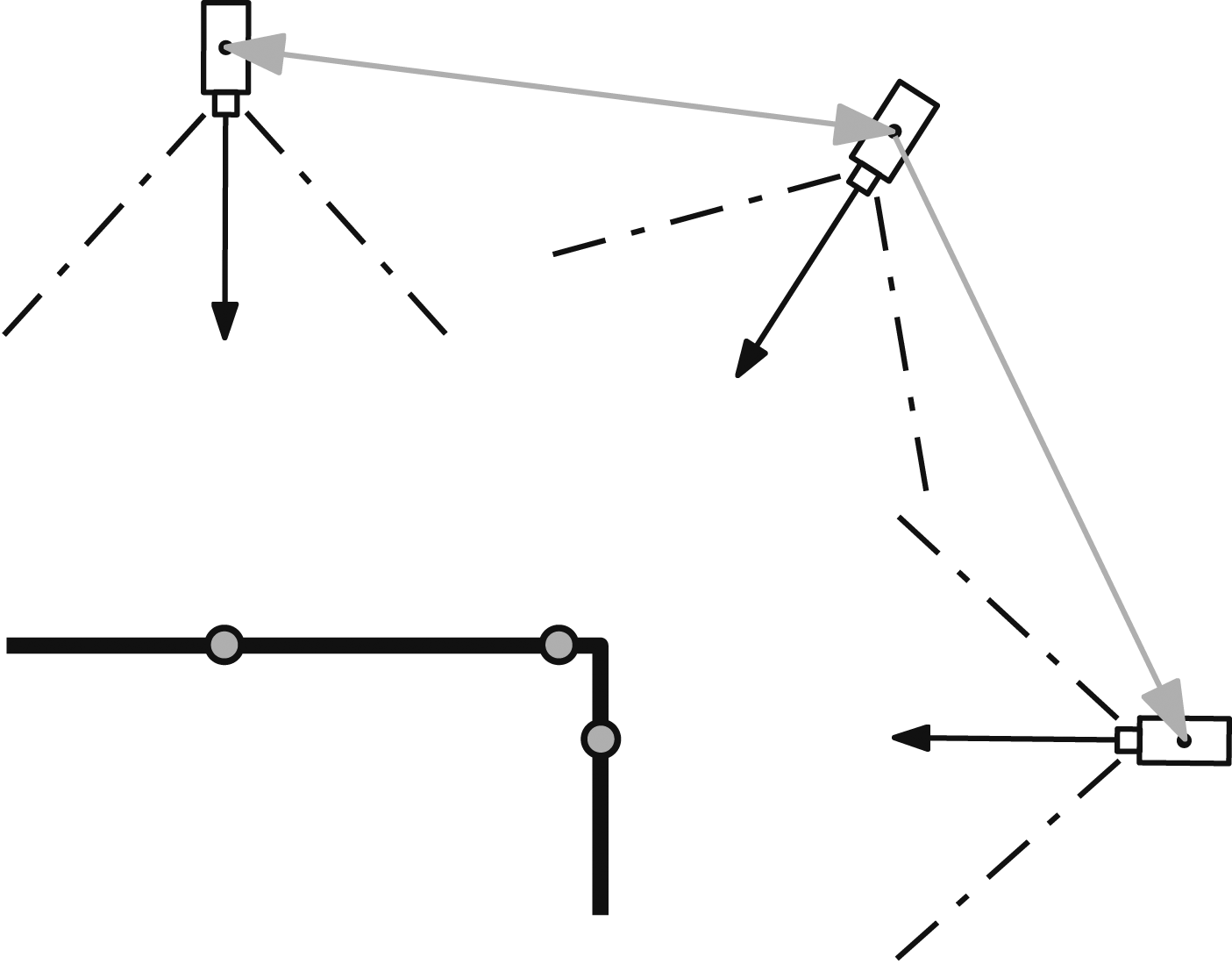
Algorithm 11 presents the calculation of the frontier visibility graph. The vertices, M′, are a new set of frontier-view pairs created from the view proposal set, V (Line 2). A new edge set, K′, is created from the existing edge set, K, by removing edges between vertices that have been reclassified as core points (Line 3). Only the set of frontier-view pairs corresponding with the τ-nearest view proposals,
Each frontier-view pair,
The frontier visibility graph quantifies views that should obtain large increases in surface coverage. This information is used by the next best view selection metric to choose views that can capture an efficient scene observation.
3.6. Selecting a next best view
Next best views are selected to improve a scene observation while reducing the acquisition cost. SEE selects views with the most visible frontier points relative to their distance from the current sensor position. This ratio penalises views far from the current sensor position that cannot observe more frontiers than closer views. Euclidean distance may differ significantly from the actual travel distance of the sensor on some platforms, but SEE is platform agnostic and it therefore provides the best available estimate of travel cost between sensor positions.
This greedy view selection behaviour may select a distant view with many visible frontier points that then requires the sensor to return to capture closer surfaces. This problem is avoided by requiring the chosen view to have visibility of the frontier point associated with the closest view proposal (Figure 11). The closest view can have a very small travel distance so it is only selected when it has visibility of at least as many frontiers as any other potential view. An illustration of the next best view selection metric (Alg. 12). Vertices (grey circles) in the frontier visibility graph represent frontier-view pairs and are connected with directed edges denoting visibility (black arrows). The sensor represents the current view, 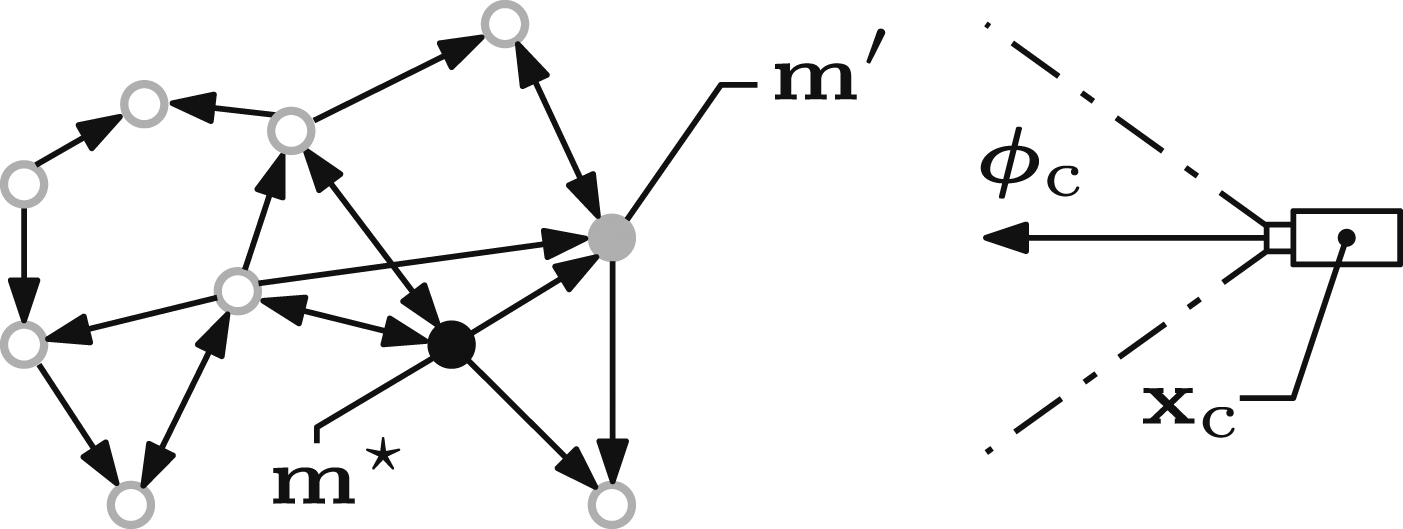
Algorithm 12 presents the selection of next best views. The closest view proposal,
This next best view selection metric chooses views that can capture significant improvements in scene coverage while travelling short distances. It enables SEE to obtain observations with a low travel distances by capturing local surfaces before travelling to larger unobserved regions.
3.7. Handling failed views
Views do not always successfully observe their associated frontiers. A view is considered failed if its associated frontier is not reclassified as a core point after processing the newly captured measurements. This occurs when part of the local surface is not visible, either due to occlusions or surface discontinuities (e.g., corners). These failed views must be adjusted to successfully observe their target frontiers.
A new view is proposed by using the captured measurements to compute an adjustment for the failed view. This adjustment aims to avoid occlusions and surface discontinuities by reducing the separation distance between the frontier and the mean of the captured measurements. It is calculated from translations along, and rotations around, the local surface geometry vectors (Figure 12). An illustration of a view adjustment around a surface discontinuity (Alg. 13). The frontier point, 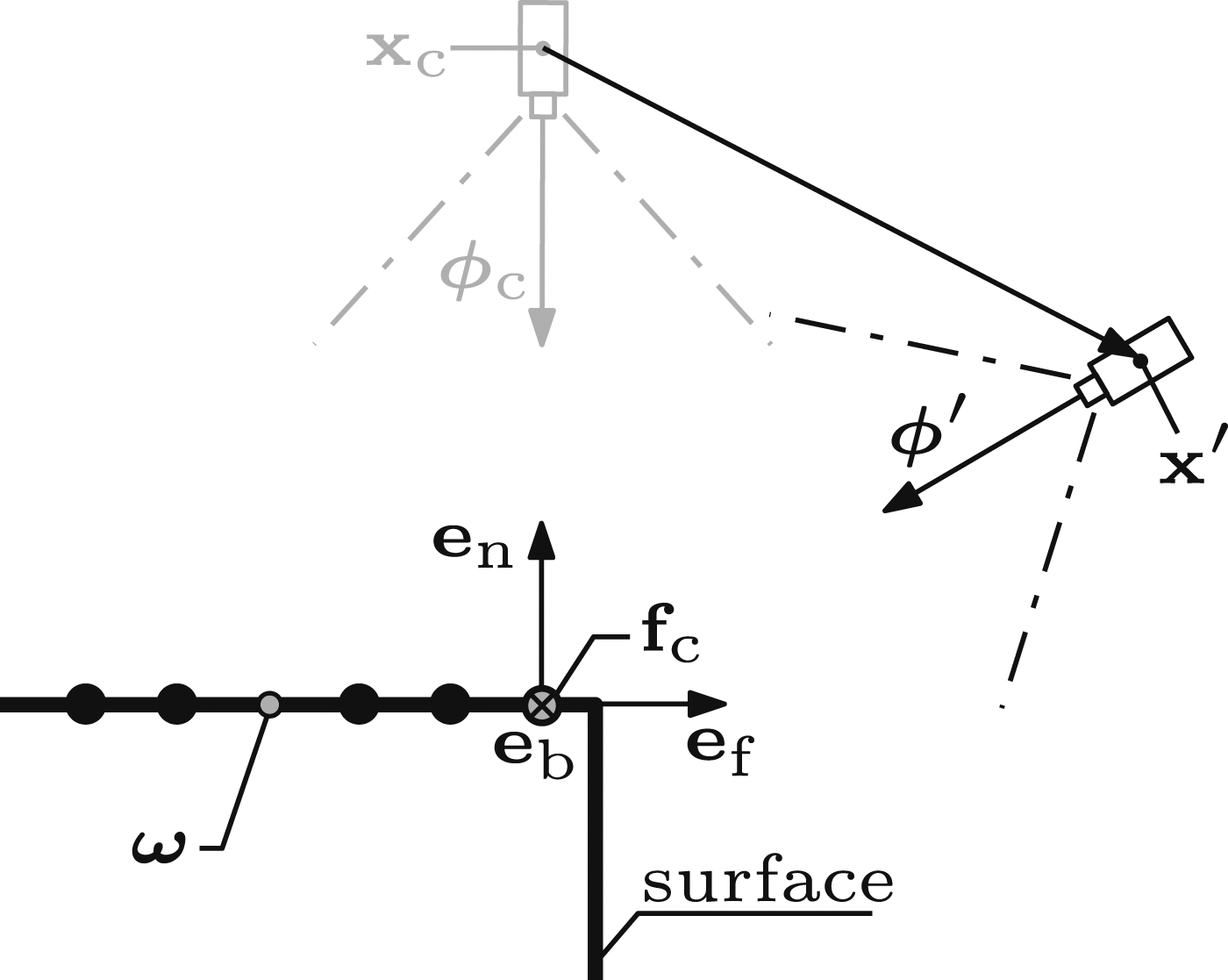
The view adjustment is repeated until the target frontier is successfully observed or a termination criterion is reached. When the separation between the frontier point and the mean of the captured measurements stops decreasing the adjusted view is reinitialised to the position from which the frontier point was first captured, as this is known to be unoccluded. This new view is again adjusted until the frontier is successfully observed or the process is terminated. If this process also fails then the frontier is reclassified as an outlier.
Algorithm 13 presents the view adjustment procedure. The adjustment parameters are initialised if this is the first time the view has been adjusted (Lines 3–7). Individual adjustments are calculated using a scaling factor, A[

The view adjustment is performed in a coordinate frame,
The translational adjustments,
The rotational adjustments, 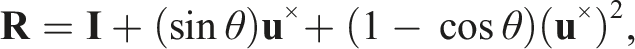
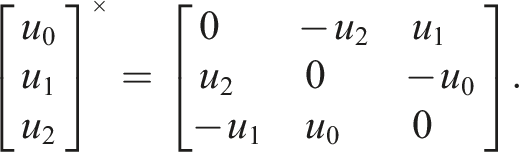
The adjusted view orientation,
A view adjustment is terminated when the separation distance stops decreasing. If the adjustment started from the initial view proposed then the new view orientation,
The new position,
This reactive adjustment of failed views enables scene coverage to be extended beyond surface discontinuities and previously unseen occluding surfaces. It enables SEE to obtain highly complete observations by capturing measurements from surfaces with restricted visibility.
3.8. Completing an observation
A scene observation completes when there are no remaining frontiers and all measurements are classified as either core or outlier points. The extent of a scene observation can be bounded by discarding all points outside of a given volume.
4. Simulation experiments
The simulation experiments compare the observation performance of SEE with several volumetric NBV planning approaches on numerous models of varying size and geometric complexity. All of the evaluated approaches were tuned to capture the highest surface coverage using the least views and have a worst case computation time of less than 10 seconds per view. The volumetric approaches and other versions of SEE have been evaluated on some of the models in previous work (Border 2019; Border et al., 2018; Border and Gammell 2020; Delmerico et al., 2018) but these results are not directly comparable due to differences in the model sizes, simulated platforms, simulated sensors and parameters (e.g., the view distance). These changes were necessary as the experiments in this paper were designed to simulate realistic platforms with limited observation time budgets.
SEE is compared with seven volumetric NBV planning approaches: Average Entropy (AE; Kriegel et al., 2015), Area Factor (AF; Vasquez-Gomez et al., 2014), Occlusion Aware (OA; Delmerico et al., 2018), Proximity Count (PC; Delmerico et al., 2018), Rear Side Entropy (RSE; Delmerico et al., 2018), Rear Side Voxel (RSV; Delmerico et al., 2018) and Unobserved Voxel (UV; Delmerico et al., 2018). The implementations of these volumetric approaches are provided by Delmerico et al. (2018).
Experiments were performed with six small-scale models: Newell Teapot (Newell 1976), Stanford Bunny (Turk and Levoy 1994), Stanford Dragon (Curless and Levoy 1996), Stanford Armadillo (Krishnamurthy and Levoy 1996), Happy Buddha (Curless and Levoy 1996) and Helix (Burkardt 2012) and three large-scale models: Statue of Liberty (Fisher 2014), Radcliffe Camera (Boronczyk 2016) and Notre-Dame de Paris (FabShop 2014). The algorithms were run for 100 independent experiments on each model.
The small models were observed in a robot arm simulation environment. This consisted of a UR10 robot arm with an RGB-D camera attached to the end effector and a turntable (Figure 13). The turntable centre and UR10 base are separated by 0.75 m. The turntable has a diameter of 0.8 m, so the small models are scaled to fit within a 0.8 × 0.8 × 0.6 m bounding box. The maximum model height is 0.6 m so that views above a model are reachable by the end effector. The UR10 simulation environment used in the experiments in Section 4. An object (dark grey) is placed on the turntable (light grey) and measurements are captured with an RGB-D camera attached to the UR10 end effector.
The large models were observed in an aerial simulation environment. Measurements are captured by a LiDAR (i.e., a similar configuration to Hovermap; Hudson et al., 2022) mounted onto the underside of a quadrotor with a two-axis gimbal. The large models are placed at the origin on a virtual ground plane and scaled to fit within a 40 × 40 × 40 m box. The quadrotor is able to reach any collision-free view position and the two-axis gimbal can position the LiDAR at any view orientation in the hemisphere below the quadrotor.
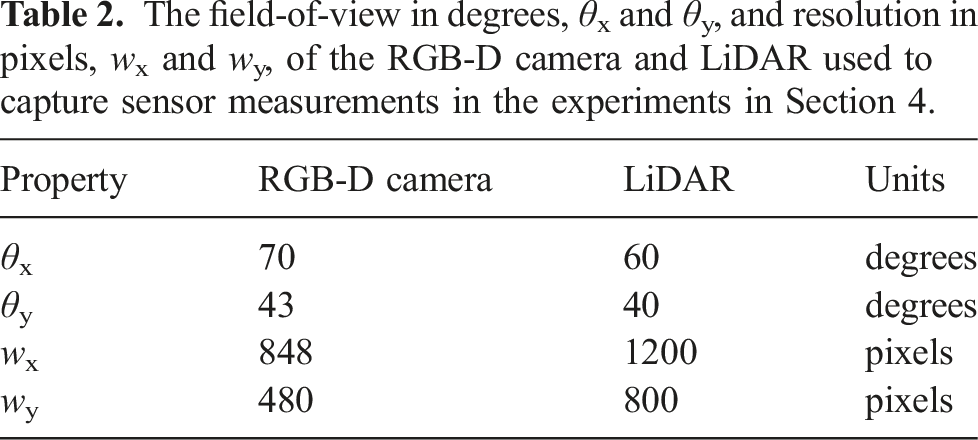
The field-of-view in degrees, θx and θy, and resolution in pixels, wx and wy, of the RGB-D camera and LiDAR used to capture sensor measurements in the experiments in Section 4.
Collision-free paths between views are planned with Adaptively Informed Trees (AIT*; Strub and Gammell 2020, 2022), using the Open Motion Planning Library (OMPL; Sucan et al., 2012), and executed with MoveIt (Coleman et al., 2014). The platform-specific reachability of each next best view is evaluated before planning a path and any unreachable view is adjusted to a reachable view based on platform-specific constraints. If the path planning to a view fails then the NBV algorithm is forced to select a different view.
SEE selects next best views until its completion criterion is satisfied. The volumetric approaches use a view limit termination criterion that is set by the user. For each model, the volumetric algorithms are limited to the largest number of views taken by SEE for any run on the model. This provides a fair comparison with SEE by ensuring they have sufficient views to achieve highly complete observations of the models.
View proposals for the volumetric approaches are sampled from a surface encompassing the scene, in this case a hemisphere, as presented by Vasquez-Gomez et al. (2014) and Delmerico et al. (2018). Kriegel et al. (2015) does not sample views from an encompassing view surface but we use the implementation provided by Delmerico et al. (2018) which does. The radius of the view hemisphere is set to the sum of the view distance, d, and a surface offset equal to the mean distance of points in the model from the origin. The number of views sampled from the hemisphere is 2.4 times the view limit, as presented by Delmerico et al. (2018).
4.1. Performance metrics
The observation performance of each approach is quantified by the surface coverage obtained, travel distance required and time used when capturing an observation. These values are averaged across the 100 independent experiments performed on each model with each approach.
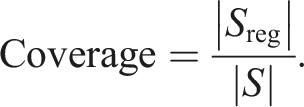
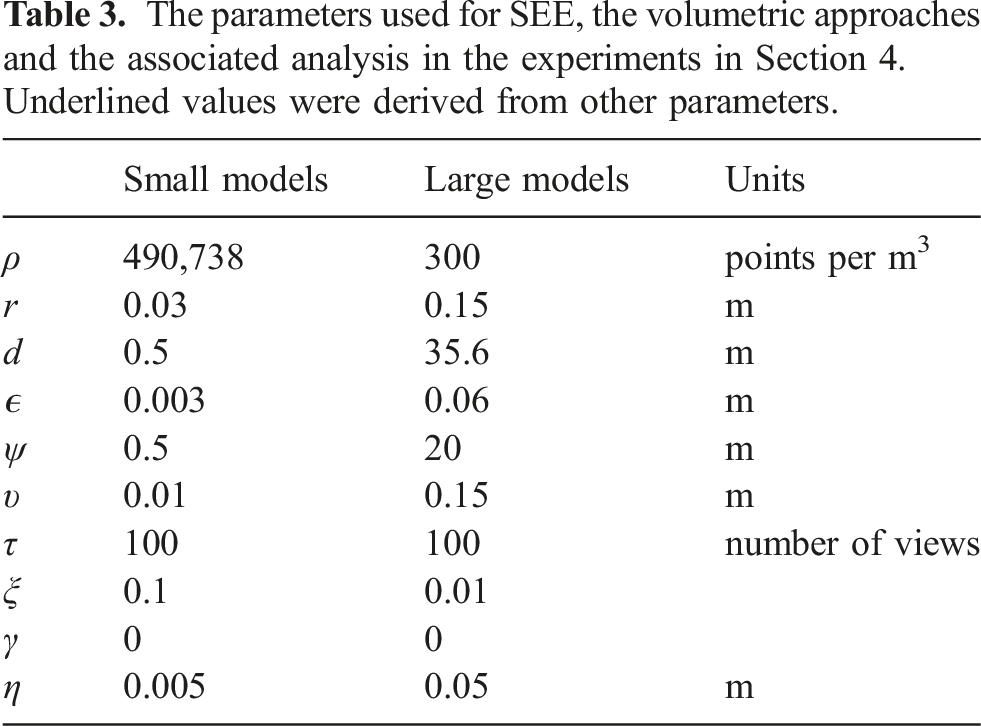
The parameters used for SEE, the volumetric approaches and the associated analysis in the experiments in Section 4. Underlined values were derived from other parameters.
The sensor travel distance is measured as the summed lengths of the paths travelled by the sensor between views. The total observation time is the time required to process new sensor measurements, select a next best view, plan a collision-free path to the chosen view and move the sensor from its current position to the next best view.
4.2. Algorithm parameters
Table 3 presents the parameters used by SEE and the evaluated volumetric approaches to observe the small- and large-scale scene models. The minimum separation distance between sensor measurements used by SEE, ϵ, is also applied to the volumetric approaches to reduce memory consumption and computational cost for all the evaluated approaches and ensure a fair comparison.
4.2.1. Small models
The target measurement density, ρ, for SEE on the small models is computed from the resolution radius, view distance and sensor properties (Alg. 2, Line 4). The resolution radius, r, is set large enough to robustly handle measurement noise and is also used as the voxel size for the volumetric approaches. The view distance, d, is chosen to be far enough that a significant proportion of the scene is visible from each view while remaining reachable by the UR10. The occlusion search distance, ψ, is set equal to the view distance so that all known occlusions can be identified. The visibility search distance, υ, is set slightly smaller than the resolution radius so that frontier points on narrow concave surfaces (e.g., between the folded segments of the Stanford Dragon) can be accurately evaluated. The view update limit, τ, is chosen to process a large number of proposed views while maintaining a reasonable computational cost. The values of these parameters are presented in Table 3.
The raycasting resolution parameter, ξ, sets the fraction of the sensor resolution that is raycast by volumetric approaches to calculate the IG value of view proposals. It is chosen to be small enough to attain a worst case computation time of less than 10 seconds per view without unduly impacting the observation performance. The travel cost weight, γ, for the volumetric approaches is set to zero so that they obtain the highest surface coverage possible within the specified view limit.
4.2.2. Large models
The target density for SEE on the large models is set to capture small surface details. The resolution radius is chosen to be large enough to accurately estimate the local surface geometry and is again also used as the voxel size for the volumetric approaches. The view distance is computed from these parameters and the sensor properties (Alg. 2, Line 6). The occlusion search distance is set to half the model size to reduce the computational cost. The visibility search distance is set to the resolution radius as this is sufficiently small to determine the visibility of frontier points on concave surfaces in the large models (e.g., the balconies on the Radcliffe Camera). The view update limit is set as large as possible while maintaining a reasonable computational cost. The values of these parameters are presented in Table 3.
The raycasting resolution for the volumetric approaches is chosen to attain a worst case computation time of less than 10 seconds per view and their travel cost weight is set to zero for the highest surface coverage.
4.3. Discussion
The results (Figures 14–16) show that a measurement-direct NBV approach with a pointcloud representation captures highly complete scene observations with greater efficiency than structured volumetric approaches. SEE achieves similar or better surface coverage than the volumetric approaches on every tested model while using shorter travel distances and less observation time. For the maximum number of views taken, SEE captures equivalent or greater surface coverage per view, unit of travel distance and unit of observation time than the volumetric approaches on every model. A comparison of SEE and the evaluated volumetric approaches in the UR10 simulation environment for 100 experiments on the Newell Teapot, Stanford Bunny and Stanford Dragon. The graphs show, from top to bottom, the mean surface coverage relative to the number of views, the mean surface coverage relative to travel distance and the mean surface coverage relative to observation time. The mean surface coverage axes start at 40% to highlight the algorithm performance at completion. The error bars denote one standard deviation around the mean. The table shows each algorithm’s mean surface coverage, distance travelled and observation time over all 100 experiments on each model for 50%, 75% and 100% of the maximum views taken, respectively, with the best value highlighted in bold. A comparison of SEE and the evaluated volumetric approaches in the UR10 simulation environment for 100 experiments on the Stanford Armadillo, Happy Buddha and Helix. The graphs show, from top to bottom, the mean surface coverage relative to the number of views, the mean surface coverage relative to travel distance and the mean surface coverage relative to observation time. The mean surface coverage axes start at 40% to highlight the algorithm performance at completion. The error bars denote one standard deviation around the mean. The table shows each algorithm’s mean surface coverage, distance travelled and observation time over all 100 experiments on each model for 50%, 75% and 100% of the maximum views taken, respectively, with the best value highlighted in bold. A comparison of SEE and the evaluated volumetric approaches in the UAV simulation environment for 100 experiments on the Statue of Liberty, Radcliffe Camera and Notre-Dame de Paris. The graphs show, from top to bottom, the mean surface coverage relative to the number of views, the mean surface coverage relative to travel distance and the mean surface coverage relative to observation time. The mean surface coverage axes start at 40% to highlight the algorithm performance at completion. The error bars denote one standard deviation around the mean. The table shows each algorithm’s mean surface coverage, distance travelled and observation time over all 100 experiments on each model for 50%, 75% and 100% of the maximum views taken, respectively, with the best value highlighted in bold.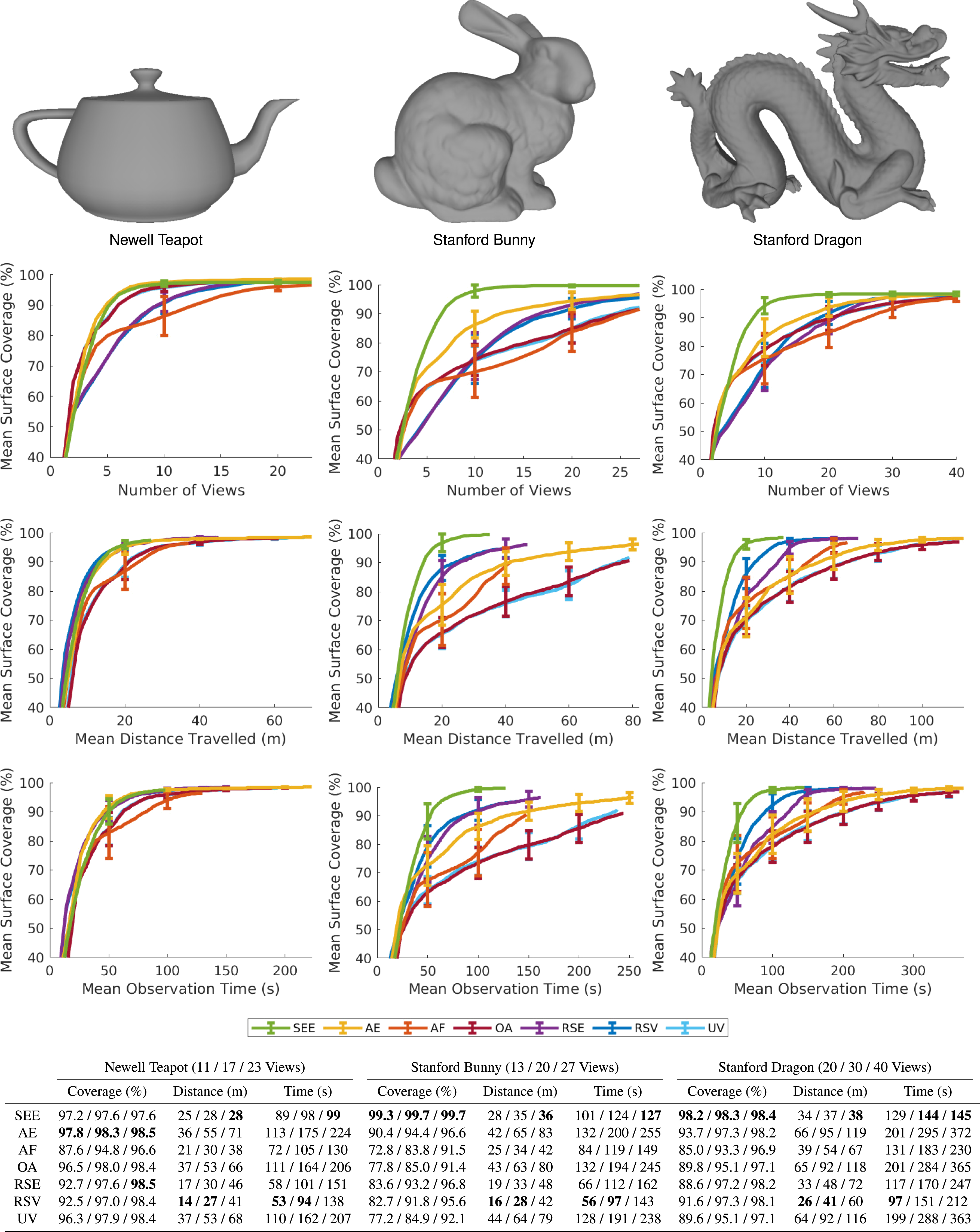
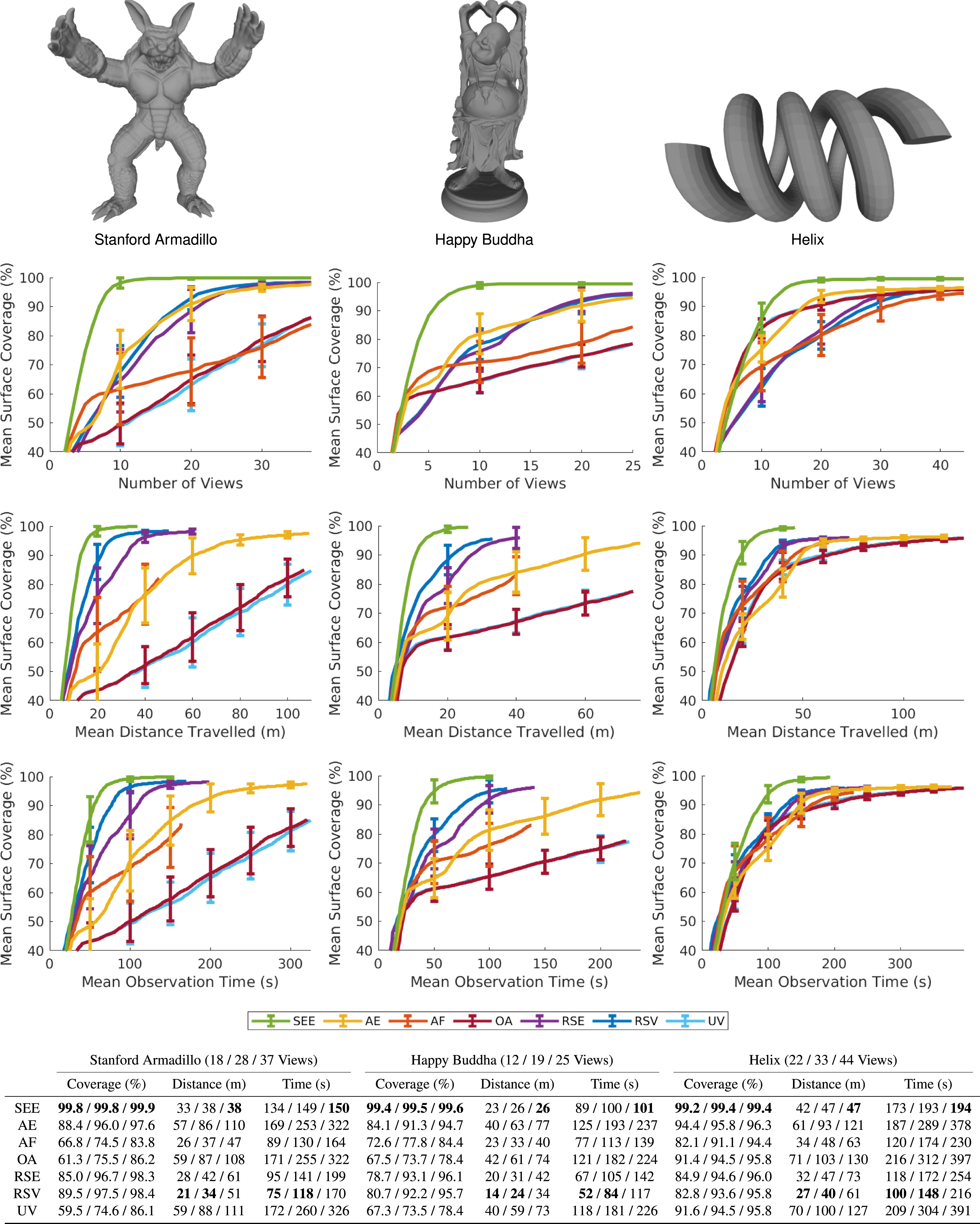
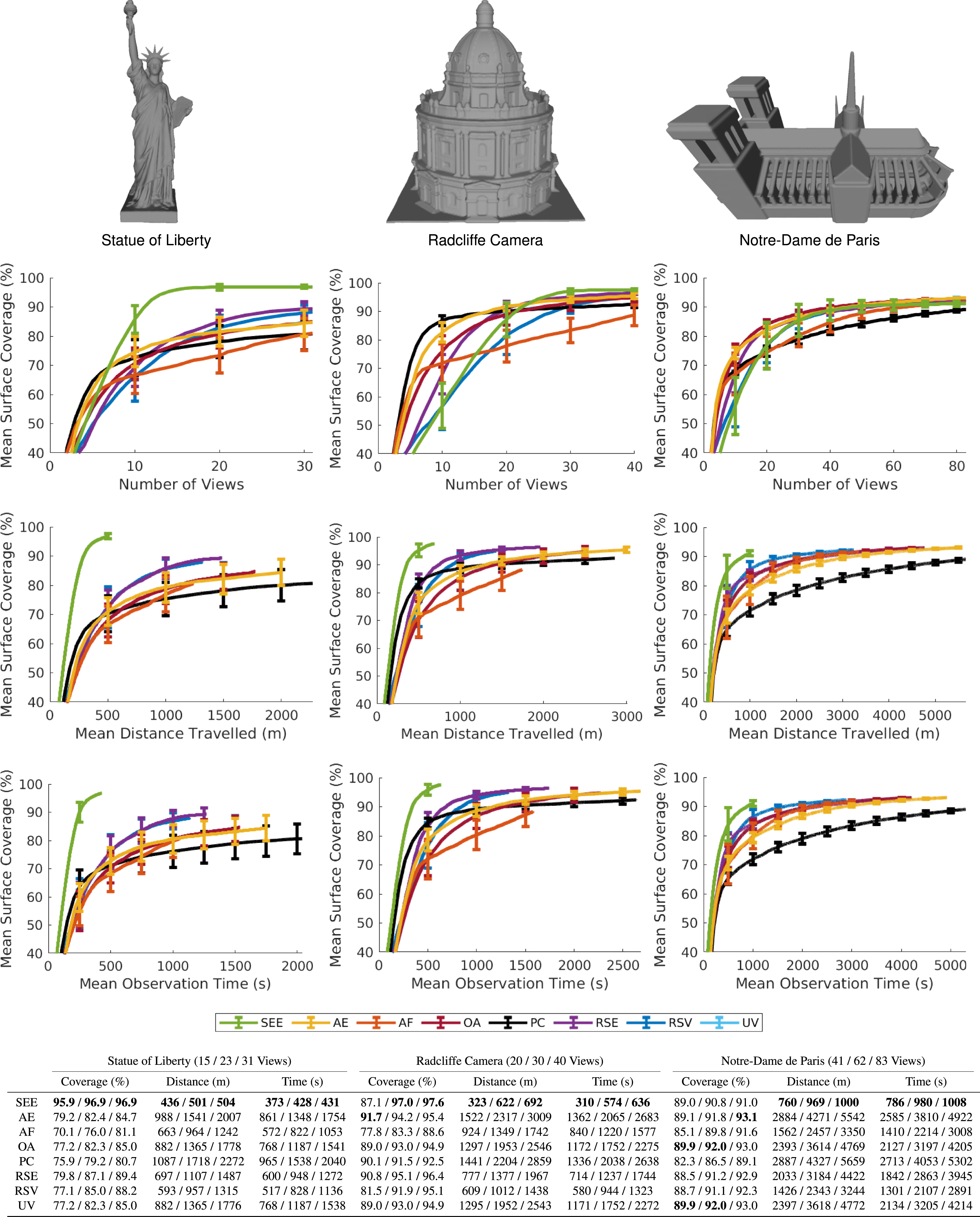
When considering 50% and 75% of the number of views taken, SEE captures equivalent or greater surface coverage per view than all of the volumetric approaches on every model except one. The surface coverage obtained per unit of distance and observation time is greater than all of the volumetric approaches on the large models and most of them on the small models. The following sections discuss the performance of SEE on individual small (Section 4.3.1) and large (Section 4.3.2) models, and review limitations of the volumetric approaches (Section 4.3.3).
4.3.1. Small models
SEE captures similar or better surface coverage than all of the volumetric approaches on every small model using less travel distance and a shorter observation time. It also attains equivalent or greater surface coverage per view than all of the volumetric approaches on every model for 50%, 75% and 100% of the maximum number of views taken.
SEE obtains higher surface coverage than all of the volumetric approaches on every small model except for the Newell Teapot. It achieves marginally lower surface coverage on the Newell Teapot but requires a shorter travel distance and less observation time to do so. This is because sensor noise causes the intersections between the teapot body and the handle to be prematurely classified as fully observed.
SEE achieves greater surface coverage per unit of travel distance and observation time than all of the volumetric approaches on every small model when considering the maximum number of views taken. For 75% of the maximum views taken, SEE achieves equivalent or greater surface coverage per unit of travel distance and observation time than all but one volumetric approach on every model except the Stanford Bunny and Stanford Armadillo, where RSV achieves a greater surface coverage per unit of travel distance. For 50% of the maximum views taken, SEE achieves equivalent or greater surface coverage per unit of travel distance and observation time than most of the volumetric approaches on every model, except for RSE and RSV which achieve greater coverage relative to both metrics.
This demonstrates that these volumetric approaches are initially able to attain greater surface coverage in less time and distance than SEE but that their progress slows as they approach a complete observation since they require more time and distance to capture measurements from surfaces that are challenging to observe (e.g., between the folds of the Dragon and inside the Helix), resulting in a worse overall observation efficiency than SEE.
4.3.2. Large models
SEE obtains similar or better surface coverage than all of the evaluated volumetric approaches on every large model using less travel distance and observation time. It also attains equivalent or greater surface coverage per unit of travel distance and unit of observation time than all of the volumetric approaches on every model, for 50%, 75% and 100% of the maximum views taken.
SEE obtains equivalent or greater surface coverage per view than every volumetric approach on every model for 75% and 100% of the maximum views taken. For 50% of the maximum views taken it attains equivalent or greater surface coverage per view than every volumetric approach on every model except for the Radcliffe Camera, where SEE captures slightly less coverage per view than all of the volumetric approaches except for AF and RSV. This demonstrates that while some of the volumetric approaches are initially able to observe more of the model with fewer views their progress again slows as they approach a complete observation since they struggle to capture some challenging surfaces (e.g., inside the balconies) and are less efficient than SEE overall.
SEE achieves higher surface coverage than all of the volumetric approaches on every large model except for the Notre-Dame de Paris, where it performs marginally worse than all of the volumetric approaches except PC. This is because it took SEE more observation time to plan and capture views of the flying buttresses without successfully increasing surface coverage underneath these uniquely challenging features; however, SEE still observes the Notre-Dame de Paris using a shorter travel distance and a lower observation time than all of the volumetric approaches.
4.3.3. Volumetric limitations
The results demonstrate that the final surface coverage of the volumetric approaches depends upon the surface area of a model relative to the volume of its bounding box. This variation is most noticeable for the AF, OA, UV and PC approaches, which perform significantly worse on models with high surface-to-volume ratios, either locally (e.g., Stanford Bunny ears and Stanford Armadillo limbs) or globally (e.g., the Happy Buddha and Statue of Liberty). These algorithms prioritise voxels that are visible from a previous view, which limits the final surface coverage of objects not easily observed with overlapping views. The PC algorithm is the most affected as it only prioritises occluded voxels. This made a fair evaluation on the small models unfeasible due to the small viewing frustum of the simulated sensor.
SEE consistently observes all of the models more efficiently than the evaluated volumetric approaches. It obtains equivalent or better observations of every model using shorter travel distances and lower observation times. SEE achieves this by proposing and selecting views that typically obtain greater improvements in surface coverage per unit of distance travelled, particularly for surfaces that are challenging to observe. The surface coverage obtained per unit of observation time is also frequently higher due to the proactive handling of known occlusions.
5. Real-world experiments
SEE was deployed on a UR10 robotic arm to evaluate its real-world performance by observing a deer statue, the Oxford Deer, for 20 independent experiments. The statistically significant results demonstrate that SEE performs well observing an object with varied texture, geometry and self-occlusions using a real platform. It is able to capture high-quality observations of the Oxford Deer despite the complex measurement noise associated with a real sensor, which can vary with the view orientation, surface geometry and texture.
The field-of-view in degrees, θx and θy, and resolution in pixels, wx and wy, of the Intel RealSense L515 used in the experiments in Section 5.

The observation pipeline was extended to handle the noise of a real-world system. Collision-free paths between views were planned with AIT* and executed by MoveIt. The sensor pose was then held steady for 5 s before capturing measurements to ensure stability. A radius-based outlier filter was applied to captured measurements to mitigate sensor noise. This filter removed measurements with fewer than 170 neighbours in a 3 cm radius as they were typically the result of sensor noise. The filtered measurements were then aligned to the SEE pointcloud using ICP (Besl and McKay 1992).
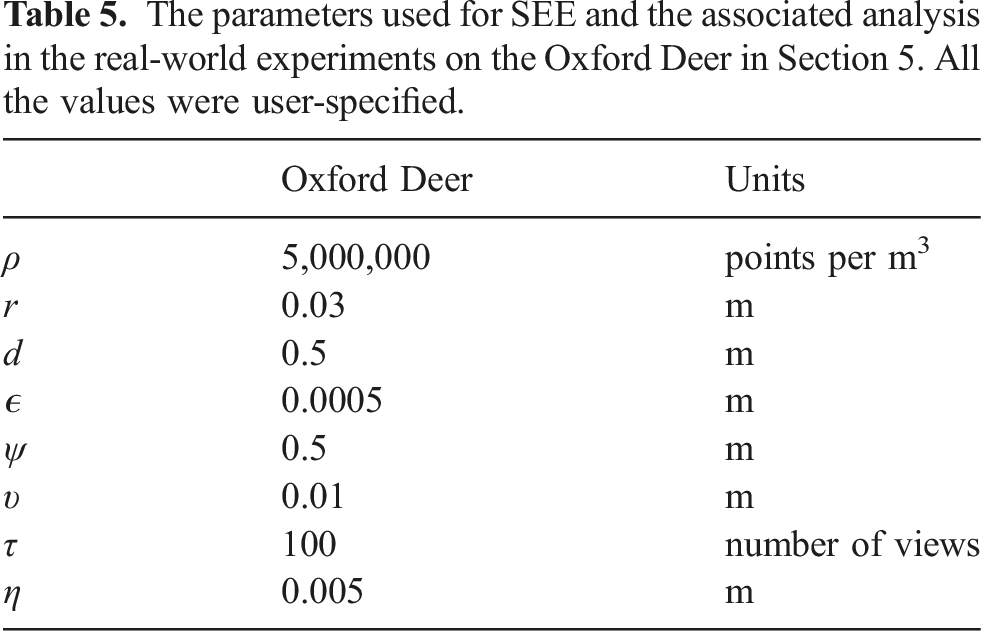
The parameters used for SEE and the associated analysis in the real-world experiments on the Oxford Deer in Section 5. All the values were user-specified.
The real-world performance of SEE is evaluated quantitatively and qualitatively (Figure 17). Its performance is quantified by surface coverage, view count, travel distance, NBV planning time, path planning time, movement time, measurement time and total observation time. Since there is no ground truth, the surface coverage of each experiment is calculated as a percentage of the final SEE pointcloud. The view count, travel distance, NBV planning time, path planning time and movement time metrics are calculated using the methods presented in Section 4.1. The measurement time combines the sensor steadying time with the time required for noise filtering and applying ICP. The total observation time includes all operations from capturing the first view until SEE finishes an observation. The qualitative performance of SEE is illustrated by the final pointcloud and a mesh reconstruction generated with Open3D (Zhou et al., 2018) for a representative experiment taking the median number of views (Figure 17, top). A demonstration of SEE on the UR10 platform for 20 independent experiments observing the Oxford Deer. The images show, from left to right, a photograph of the Oxford Deer, the coloured pointcloud obtained by SEE for a representative run and a greyscale mesh generated from that pointcloud using Open3D, respectively. The graphs show, from left to right, the mean surface coverage relative to the number of views, distance travelled and computation time, respectively. The error bars denote one standard deviation around the mean. The surface coverage is computed relative to the final pointcloud since no ground truth is available. The table shows the final mean number of views captured, distance travelled, NBV planning time, path planning time, movement time, measurement time and total observation time over all 20 experiments.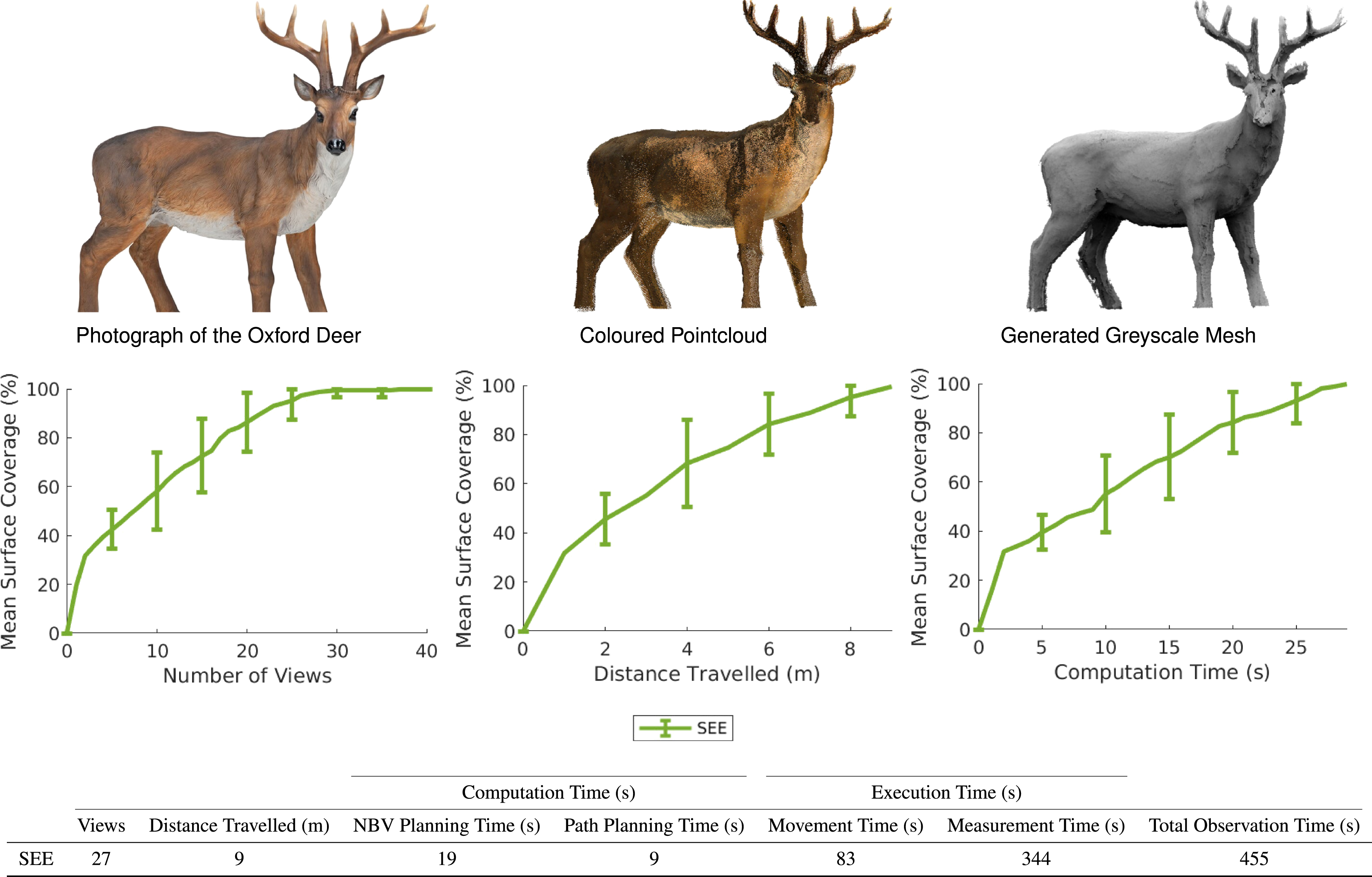
The quantitative results show that SEE was as or more efficient in the real world than in simulation. The Oxford Deer required a similar number of views and movement time to the small model simulation experiments. It required less travel distance as AIT* found paths that prioritised rotating the turntable over moving the end effector by sampling more goal poses. These paths were simpler, took less planning time to find and resulted in shorter end effector travel distances. The total observation time is greater since it measures the overall time elapsed between capturing the initial view and SEE completing an observation. This includes measurement time, which was not quantified for the simulation experiments.
The qualitative results show that SEE captured complete and largely accurate observations of the Oxford Deer, despite the presence of sensor noise. The coloured pointcloud (Figure 17, top centre) has high fidelity. This results in a mesh reconstruction (Figure 17, top right) that is also highly complete and accurate, except for some noise around the face, antlers and hind legs. These quantitative and qualitative results show that SEE is suitable for real robotic scenarios.
Further real world demonstrations of SEE working with different sensor platforms (e.g., a handheld Velodyne VLP-16 LiDAR or Intel RealSense D435 camera and an Ouster OS1-64 LiDAR mounted on aerial platform) in environments with varying size and complexity (e.g., small indoor scenes to large industrial buildings) are presented in Border (2019) and Border et al. (2023).
6. Conclusion
NBV planning is key to obtaining 3D scene observations. NBV approaches determine where sensor measurements should be captured, with the aim of efficiently obtaining a complete observation. Most existing approaches represent observations by aggregating measurements into an external scene structure. These rigid structures can be easily evaluated but often limit the fidelity of information and can be computationally expensive to maintain. This paper presents a NBV approach that aims to overcome these limitations by using a density-based pointcloud representation.
SEE is a measurement-direct NBV approach that makes view planning decisions directly from sensor measurements to capture a minimum measurement density. Fully and partially observed surfaces are identified by individually classifying each measurement based on the density of neighbouring measurements. Measurements that lie on the boundary between these regions are classified as frontiers. Views are proposed to capture new measurements around these frontier points. These views are initially generated by considering the local surface geometry but can be refined to proactively avoid known occlusions. Observation efficiency is prioritised by choosing next best views to capture the most frontier points while moving short distances. If a view is unsuccessful then it is reactively adjusted to avoid a previously unknown occlusion or surface discontinuity. SEE completes an observation when all frontier points have been observed or are deemed unobservable.
Simulation experiments comparing SEE with volumetric NBV approaches demonstrate the superior observation performance of this measurement-direct NBV approach. SEE is able to obtain highly complete observations of both small- and large-scale scene models while travelling shorter distances and requiring less observation time than the evaluated volumetric approaches. Real-world experiments conducted with a robot arm show that SEE performs equally well in the real world. SEE captured high-quality observations of a deer statue using a UR10 arm with an Intel RealSense L515 sensor. Work has since demonstrated its utility on an aerial platform capable of autonomously mapping buildings (Border et al., 2023).
An open-source implementation of SEE is available at https://robotic-esp.com/code/see.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Acknowledgements
The authors would like to thank Wayne Tubby and the Hardware Engineering team at the Oxford Robotics Institute (ORI) for building the UR10 platform used for the real-world experiments.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by UK Research and Innovation and EPSRC through Robotics and Artificial Intelligence for Nuclear (RAIN) [EP/R026084/1], ACE-OPS: From Autonomy to Cognitive assistance in Emergency OPerationS [EP/S030832/1], and the Autonomous Intelligent Machines and Systems (AIMS) Centre for Doctoral Training (CDT) [EP/S024050/1].
Supplemental Material
Supplemental material for this article is available online.
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.