
Abstract
Visual motion estimation is a well-studied challenge in autonomous navigation. Recent work has focused on addressing multimotion estimation in highly dynamic environments. These environments not only comprise multiple, complex motions but also tend to exhibit significant occlusion. Estimating third-party motions simultaneously with the sensor egomotion is difficult because an object’s observed motion consists of both its true motion and the sensor motion. Most previous works in multimotion estimation simplify this problem by relying on appearance-based object detection or application-specific motion constraints. These approaches are effective in specific applications and environments but do not generalize well to the full multimotion estimation problem (MEP). This paper presents Multimotion Visual Odometry (MVO), a multimotion estimation pipeline that estimates the full SE(3) trajectory of every motion in the scene, including the sensor egomotion, without relying on appearance-based information. MVO extends the traditional visual odometry (VO) pipeline with multimotion segmentation and tracking techniques. It uses physically founded motion priors to extrapolate motions through temporary occlusions and identify the reappearance of motions through motion closure. Evaluations on real-world data from the Oxford Multimotion Dataset (OMD) and the KITTI Vision Benchmark Suite demonstrate that MVO achieves good estimation accuracy compared to similar approaches and is applicable to a variety of multimotion estimation challenges.
Keywords
1. Introduction
Autonomous robotic platforms are being deployed in an increasingly diverse range of applications. Many platforms and algorithms are highly specialized to operate in specific environments, but the ability to safely navigate diverse and complex dynamic environments is becoming more important.
A principle objective of robotic navigation systems is determining the egomotion of a dynamic robot relative to its environment, usually using a mounted sensor. Visual odometry (VO) is a technique for finding the egomotion of a camera by isolating the static parts of a scene and estimating the motion relative to those regions (Moravec, 1980). The segmentation of static portions of the scene is itself an important focus of visual navigation research (e.g., Fraundorfer and Scaramuzza, 2012; Nistér, 2004), but much less research has focused on also analyzing the dynamic regions of the scene that the segmentation rejects.
Third-party dynamic motions are more difficult to estimate than the sensor egomotion because their observed motions comprise both their arbitrary real-world motions and the sensor egomotion. This multimotion estimation problem (MEP) is often simplified by constraining motions according to kinematic assumptions (e.g., Sabzevari and Scaramuzza, 2016), or by first isolating and estimating the sensor egomotion and then compensating for it to estimate the remaining third-party motions in the scene (e.g., Jaimez et al., 2017). These techniques can be successful in specific applications, but few generalized approaches have been proposed to address the full MEP.
Third-party motions are also difficult to track because highly dynamic scenes often include significant occlusions. Occlusions can be defined as any time there are insufficient measurements of part of a scene. They are either direct, when an object is partially or fully obscured, or indirect, due to sensor limitations or algorithmic failure. Multiobject tracking (MOT) techniques can successfully track multiple dynamic objects through full and partial occlusions, but they are often constrained by application-specific object detectors and simplistic motion models (e.g., Milan et al., 2016; Mitzel et al., 2010). Consistently estimating multiple independent motions in the presence of occlusions is necessary for autonomous navigation in complex, dynamic environments.
This paper presents Multimotion Visual Odometry (MVO), a multimotion estimation pipeline that prioritizes motion over appearance. It emphasizes the importance of understanding how things are moving in the environment before understanding what they are. MVO addresses the MEP by applying multilabeling techniques to the traditional VO pipeline using only a rigid-motion assumption. It simultaneously estimates the full SE(3) trajectory of every motion in a scene, including the sensor egomotion, without making any a priori assumptions about object number, appearance, or motion (Figure 1). The pipeline is adaptable to a variety of motion priors and achieves robust motion-based tracking through occlusion via motion closure. Motion trajectories estimated by MVO for sequences from the KITTI (top, Geiger et al., 2012) and OMD (bottom, Judd and Gammell 2019a) datasets. The KITTI segment involves an autonomous driving scenario in a residential environment where the car-mounted camera follows a van and a cyclist. The OMD segment includes four independently swinging blocks observed by a handheld camera. In both sequences, the SE(3) trajectories of the camera egomotion and third-party motions are estimated simultaneously without prior knowledge of their number, appearance, or nature.
The rest of the paper is organized as follows. Section 2 explores the details of the MEP and the current approaches for addressing it. Section 3 describes how the MVO pipeline extends traditional VO techniques to multimotion estimation. Section 4 demonstrates how different types of state estimators and motion priors can be used within the MVO pipeline. Section 5 discusses how to address the challenges involved in implementing MVO as a sliding-window estimator, particularly with respect to occlusions. Sections 6 and 7 evaluate and discuss the performance of the MVO pipeline quantitatively and qualitatively using the Oxford Multimotion Dataset (OMD; Judd and Gammell, 2019a) and the KITTI Vision Benchmark Suite (Geiger et al., 2012).
This paper is a continuation of ideas that were first presented at the Joint Industry and Robotics CDTs Symposium (Judd et al., 2018) and the Long-term Human Motion Prediction Workshop (Judd and Gammell, 2019b) and were published in Judd et al. (2018a), Judd (2019) and Judd and Gammell (2020). It makes the following specific contributions: • Presents a unified and updated version of MVO that is adaptable to a variety of trajectory representations and estimation techniques. • Incorporates a continuous SE(3) white-noise-on jerk (WNOJ) prior into the estimator, extends it for geocentric third-party estimation, and examines its advantages and limitations in the context of the MEP, along with the previously presented discrete and white-noise-on-acceleration (WNOA) models. • Details the challenges of full-batch and sliding-window implementations of MVO, including handling temporary occlusions. • Compares pose-only, pose-velocity, and pose-velocity-acceleration estimators both quantitatively on indoor experiments (OMD) and qualitatively in the real world (KITTI).
2. Background
Dynamic environments consist of the static background, a moving observer (i.e., sensor), and one or more independent, third-party motions. The observed motions include both the objects’ real-world motion and the sensor egomotion, so the static scene appears to move with the inverse of the egomotion trajectory.
Fully addressing this, MEP requires both segmentation, i.e., clustering points according to their movement between observations, and estimation, i.e., calculating the motion of a cluster of points. The interdependence of these tasks creates a chicken-and-egg problem: the motion trajectories must be estimated from groups of points, but the segmentation of those groups depends on the available motion estimates.
This interdependence is addressed in single-motion VO systems by using heuristics (e.g., number of features) to select the egomotion and ignore the other motions in the scene (Section 2.1). Appearance-based tracking techniques are often used to track multiple dynamic objects, but currently do not accurately estimate the underlying motion of generic objects (Section 2.2). These heuristic- and appearance-based techniques are not readily extensible to general multimotion estimation problems and analyzing multiple independently moving bodies remains a challenging problem for state-of-the-art vision systems (Section 2.3).
2.1. Egomotion estimation
VO estimates the motion of a camera relative to its static environment (i.e., egomotion) and has a long history in robotics starting with the motion-estimation pipeline presented by Moravec (1980). The camera egomotion is calculated from a stream of images by assuming it corresponds to the dominant motion in the scene.
The egomotion is estimated by first isolating regions of the scene that move according to the dominant motion and assuming they are static. Those regions are then used to estimate the egomotion trajectory relative to those static points and the rest of the scene is usually ignored as noise.
Recent developments in VO focus on improving the static segmentation (Nistér, 2004; Sabzevari and Scaramuzza 2016). The estimation can also be improved by using more advanced estimation techniques, such as dense or direct estimation methods (Engel et al., 2017; Valgaerts et al., 2012) and continuous SE(3) motion priors (Anderson and Barfoot, 2015; Tang et al., 2019). These techniques make the egomotion estimation more robust and accurate, but few methods extend them to also analyze the dynamic parts of the scene that VO rejects.
2.2. Multiobject tracking (MOT)
MOT techniques are often used in tandem with VO to track multiple dynamic objects over time, usually through a tracking-by-detection paradigm (Milan et al., 2016). They use appearance-based object detectors to find instances of specific object classes in each frame. They then seek to accurately associate present and past detections to form simple
MOT algorithms often track objects through occlusions by modeling object interactions (Yang et al., 2011) or employing simple motion models to extrapolate object positions (Mitzel et al., 2010). These techniques are limited by the object representations used by the target detectors and tend to be constrained to simple motion models that do not adequately represent the motion of an object. Fully addressing the MEP requires applying more expressive motion estimation techniques, such as those used to estimate egomotion, to the other third-party motions in a scene.
2.3. Multimotion estimation
In contrast to MOT, multimotion estimation focuses on the motions in the scene rather than the objects that generate them. This involves both segmenting observed points into independent rigid objects and estimating the SE(3) trajectories of those objects. Several multimotion estimation approaches have been developed using techniques such as scene flow clustering, simultaneous localization and mapping (SLAM) frameworks, and energy-minimization, but none has fully addressed the general MEP.
Lenz et al. (2011) use sparse scene flow to detect and track multiple dynamic objects from a dynamic, vehicle-mounted camera. The approach operates on stereo image pairs and clusters sparse points based on their scene flow. These clusters are then used to track objects through
Menze and Geiger (2015) instead model the world as piecewise-planar superpixels. The approach simultaneously calculates both scene flow and the homographies defining the motion of the planes in the scene, which are modeled as full SE(3) motions. Similarly, Quiroga et al. (2014) and Jaimez et al. (2017) define optimization frameworks that estimate scene flow by modeling the underlying motions as full SE(3) motions. This formulation is more robust to rotations but it complicates the MEP by introducing additional constraints to estimate the pixel-wise velocity of every point in the scene. Each of these techniques also relies on accurate RGB-D sensing and an independent egomotion estimation pipeline, which can lead to errors when large portions of the scene are moving.
Wang et al. (2007) extend the traditional SLAM formulation to include MOT techniques in their SLAMMOT framework using lidar sensors and monocular and stereo cameras (Lin and Wang, 2010). The traditional SLAM state, consisting of the SE(3) sensor pose and a static map of the environment, is extended to include the range, bearing, and linear velocity of any tracked objects in the scene. Like most 3D MOT algorithms, SLAMMOT only estimates the
Rather than tracking 3D bounding boxes, Huang et al. (2019) estimate bulk point motions in ClusterSLAM, a multibody dynamic SLAM backend that was extended to a full multimotion estimation pipeline in ClusterVO (Huang et al., 2020). The pipeline clusters tracked 3D points according to their bulk motion but relies on a semantic object detector to inform its data association and tracking. Visual Direct Object aware SLAM (VDO-SLAM; Henein et al., 2020; Zhang et al., 2020a; 2020b) also extends the SLAM formulation to estimate the full SE(3) pose of other objects in the scene, but uses an external instance segmentation algorithm to segment the image into its constituent objects first. DynaSLAM II (Bescos et al., 2021) similarly uses front-end instance segmentation to guide feature matching and segmentation before estimating the SE(3) trajectory of each tracked object. ClusterVO, VDO-SLAM, and DynaSLAM II are able to estimate the motion of each object more accurately than techniques that only track bounding boxes, but they are reliant on significant front-end preprocessing, which limits their applicability to the general MEP. In contrast, DymSLAM (Wang et al., 2020) is a SLAM framework without any significant front-end processing. It uses spectral clustering to segment dynamic motions and estimate their SE(3) motions but primarily focuses on dense scene reconstruction which is separate from the MEP.
Instead of building on the traditional SLAM framework, Isack and Boykov (2012) demonstrate an energy-based multimodel-fitting framework that can be used to segment motions in a frame-to-frame manner. Roussos et al. (2012) use this framework to simultaneously estimate depth maps and object motions from a monocular camera while also performing object tracking. The technique minimizes a complex cost function involving photometric consistency, geometric smoothness in depth, spatial smoothness in image space, and a minimum-description-length term that promotes a compact solution. The approach proceeds in an offline, full-batch manner and its additional focus on dense reconstruction, combined with its initialization requirements, make it ill-suited for MEP applications.
Other techniques use RGB-D sensors to segment and estimate motions while also performing suitable tracking for object reconstruction. Rünz and Agapito (2017) use an RGB-D camera to segment and track targets while simultaneously fusing 3D object models. The technique combines motion segmentation with object instance segmentation, which relies on predefined class-based object detectors. Rünz et al. (2018) extend this work to real-time processing by improving the efficiency of the semantic segmentation, and Xu et al. (2019) define a similar system using a volumetric representation, rather than surface normals. These techniques represent significant progress in addressing the MEP, with the added ability to fuse 3D models of the tracked objects, but they are reliant on high-quality, dense depth sensing and they are limited in the number of active models they can reasonably process.
Qiu et al. (2019) and Eckenhoff et al. (2019) address the MEP using monocular cameras. Monocular observations are underconstrained and a separate scale parameter must be estimated using the inertial measurement unit (IMU). This scale parameter is valid for the egomotion of the camera, but estimating the scale for third-party motions is difficult and leads to several degenerate cases, such as when the object and camera motions are colinear. The performance of these techniques is impressive given the limitations of the sensors, but they are not broadly applicable to the general MEP.
In contrast to these approaches, MVO fully addresses the MEP in an online manner using only a rigid-motion assumption. The pipeline estimates the full SE(3) trajectory of every motion in a complex, dynamic scene without any a priori information about object number, appearance, or motion. It also operates directly on sparse 3D points and is therefore applicable to a variety of 3D sensors. MVO can incorporate physically founded SE(3) motion priors to extrapolate motions accurately through occlusions and achieves motion-based tracking through a motion closure procedure.
3. Simultaneous SE(3) estimation and segmentation
Fully addressing the MEP requires both motion estimation and segmentation. Motion estimation involves calculating the motion of a set of points. Motion segmentation involves clustering points according to their movement.
The interdependence of estimation and segmentation leads to a chicken-and-egg problem: the motion trajectories must be estimated from groups of points, but the segmentation of those groups depends on the available motion estimates. In single-motion VO systems this is addressed by using heuristics (e.g., number of features) to select the egomotion and ignore the other motions in the scene. These heuristics are not readily extensible to multimotion estimation problems and analyzing multiple independently moving bodies remains a challenging problem for state-of-the-art vision systems.
MVO addresses the MEP by casting motion segmentation as a multilabeling problem where a label represents a motion trajectory. It iteratively segments and estimates motions using these labels in an alternating fashion until the segmentation converges. The set of motion labels adapts to the motions in the scene without making any a priori assumptions about object number, appearance, or motion.
MVO does not use any assumptions or heuristics to identify the static background until after the segmentation converges, so each motion is estimated as if it corresponds to the true egomotion. After the segmentation converges, the true egomotion is selected and used to reestimate the true third-party motions in a geocentric frame (Section 4).
The pipeline operates directly on tracked 3D observations, i.e., tracklets, from a 3D sensor. It iteratively generates labels and segments those observations according to their motion (Figure 2). The tracklets are embedded in a graph structure that forms the basis of the motion segmentation (Section 3.2). New labels are proposed when the motion of tracklets assigned to a given label may be more accurately explained by multiple trajectories (Section 3.3). Motion labels are assigned to each tracklet by minimizing a cost functional that incorporates reprojection residual, graph smoothness, and model complexity (Section 3.4). Tracklets whose motions are not well explained by any other label are assigned to an outlier label and redundant and oversegmented labels are then merged (Section 3.4.4). Once the segmentation converges, the final labels are then sanitized and any remaining outliers are rejected (Section 3.5). Initial versions of these ideas were first presented in Judd et al. (2018a, 2018b), and they are further developed here. An illustration of the stereo MVO pipeline, which extends the standard VO pipeline by replacing the egomotion estimator with a multimotion estimator. MVO operates on 3D tracklets and generates the SE(3) trajectory for every motion in the scene, including the sensor egomotion. The pipeline builds a neighborhood graph based on how rigidly pairs of points move over time and iteratively splits and estimates new labels using the graph. It assigns labels based on an energy functional and merges labels that can be considered redundant until convergence. Once the segmentation converges, the labels are sanitized and a batch estimation produces the geocentric SE(3) trajectories, employing motion closure to determine if newly discovered motions can be explained by the reappearance of an occluded object.
3.1. Notation
A sequence of observations of a point, j, relative to a moving sensor frame, Illustrations of the MEP showing the motion of frames through time (left) and the relative point observations (right). Two independent third-party motions, 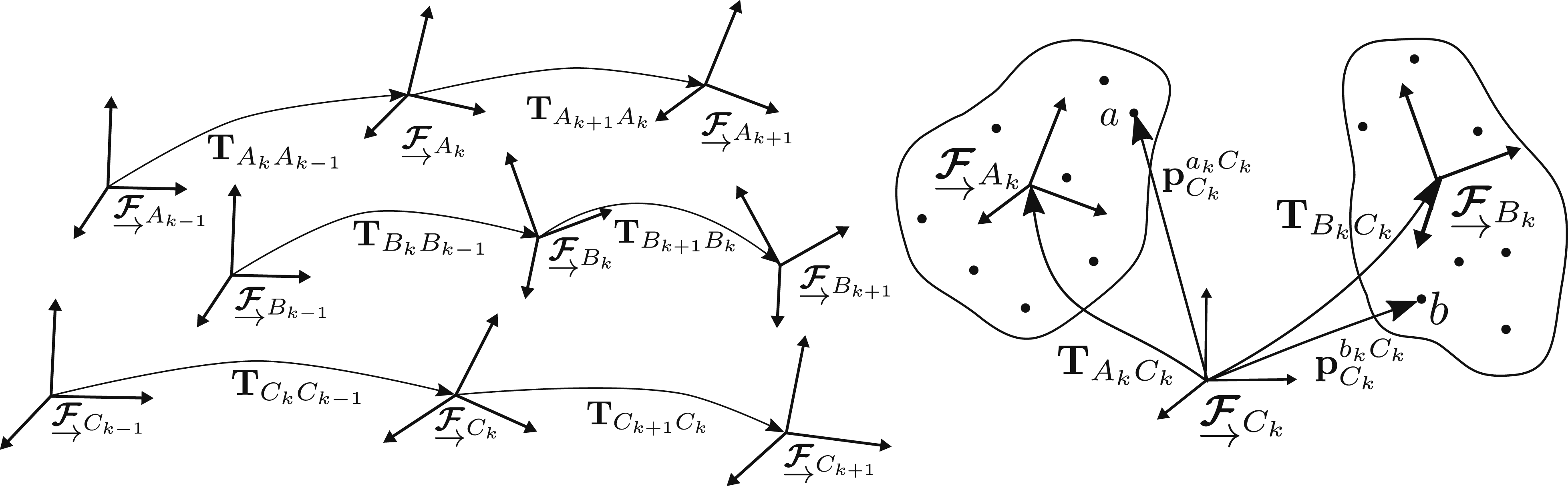
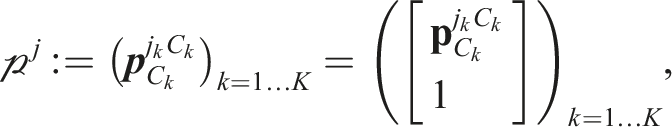
A transform,
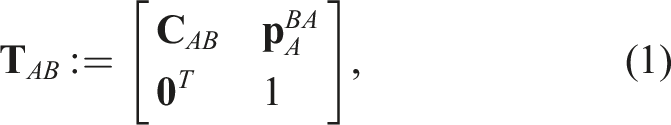

The motion trajectory,
The set of tracklets visible in a scene,
3.2. Graph construction
The multilabeling is performed on a graph that represents each tracklet as a vertex. The graph,
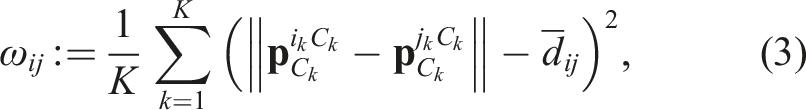
The graph consists of vertices for all tracklets and the k least-costly edges from each vertex. This k-nearest neighbors graph is unlikely to connect independently moving pairs of tracklets so it reasonably and efficiently approximates the rigid-body assumption. Its connectivity forms the basis for label generation (Section 3.3) and assignment (Section 3.4), and an over- or under-connected graph can lead to an under- or overfit solution, respectively.
3.3. Label proposal
The motions in the scene are segmented by assigning tracklets to a finite set of motion labels,
A potential new label, ℓ′, is generated for each fully-disjoint component of the subgraph,
3.3.1. Estimating new labels
Each label is estimated as if it corresponds to the static portion of the scene using standard egomotion techniques. The new egomotion hypothesis,
The frame-to-frame RANSAC procedure estimates the observed motion between pairs of consecutive frames,
The translational component is calculated by
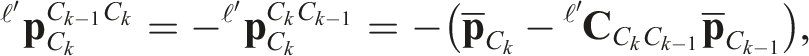
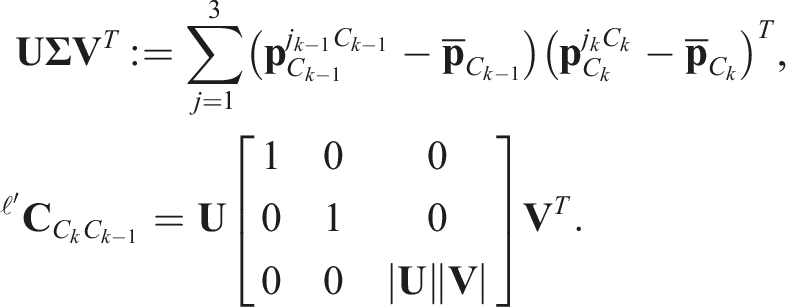
The calculated transform is evaluated by the number of inlier tracklets with reprojection residuals,
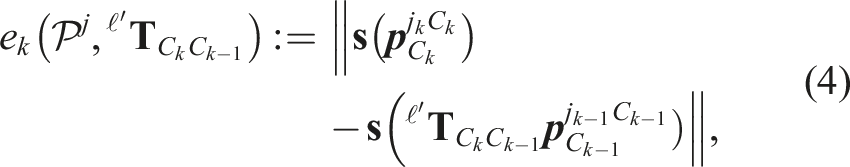
The process of sampling, estimation, and evaluation is iterated a chosen number of times, NRSAC, and the transform with the most inliers is kept. This process is repeated independently for each pair of consecutive frames in the estimation window to generate a new trajectory for the label.
This frame-to-frame procedure is used to propose a new trajectory for each extant label. Any tracklets found to be outliers of the newly estimated trajectories are appended to the outlier label,
3.4. Label assignment
Casting the MEP as a multilabeling problem involves assigning each tracklet,

The residual and smoothness portions of the energy are minimized using the convex relaxation algorithm (CORAL; Amayo et al., 2018), a multimodel-fitting algorithm that relaxes discrete labeling to allow for efficient parallelization on GPGPU devices. This “soft” labeling assigns each tracklet a score for how applicable each label is to the observed data. The score is in the continuous range [0,1] and the scores for each tracklet across all labels sum to 1. The soft labels are discretized by taking the strongest label for each point. Points with ambiguous soft labels (e.g., less than 0.5) are labeled as outliers to avoid mislabeling points. The total energy is finally minimized by merging similar labels to avoid oversegmentation and overfitting (Section 3.4.4).
3.4.1. Residual cost
The residual term
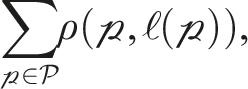
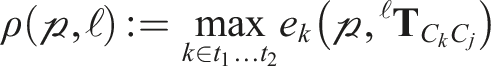
The residual cost of the outlier label,
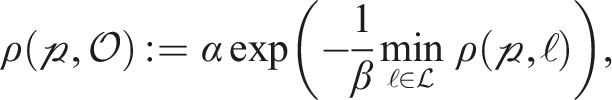
3.4.2. Smoothness cost
The smoothness term
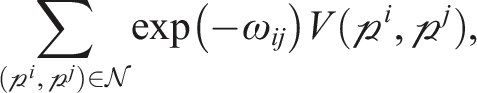
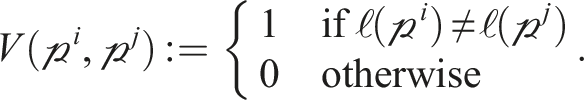
3.4.3. Complexity cost
The complexity term
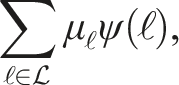
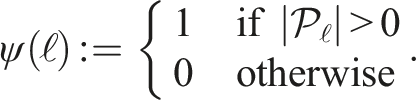
The cost of using a label, μ
ℓ
, is an open design decision. All motion labels can be assigned the same cost or label costs can be designed to encourage common motions and penalize kinematically complex motions if prior information about the environment is known, such as the sensor platform or third-party kinematics. A privileged “playbook” of likely motions can also be included in the label set as default options and assigned low costs. The label cost,
3.4.4. Label merging
Label merging reduces the total energy in (5) by addressing the model complexity term. Two labels, ℓ and ℓ ′, are merged if relabeling all tracklets from one label,
The label splitting, assignment, and merging stages (Sections 3.3 and 3.4) are iterated until the labels converge or a maximum number of iterations, Nconv, have been reached. Label convergence can be defined relative to various criteria, such as the total energy, the change in energy, or the change in the labeling.
3.5. Label sanitization
Once the label set has converged, the final segmentation is refined to remove noisy tracklets before the final estimation. Individual tracklets whose residual error is greater than the threshold, eth, are relabeled as outliers, regardless of the potential change in energy. Likewise, any label with fewer than a minimum number of support tracklets, Nth, or that exists for fewer than a minimum number of frames, Kth, is removed and its tracklets are relabeled as outliers. These thresholds remove spurious labels describing small sets of tracklets or brief bulk motions and must be at least 3 points and 2 frames, respectively. This label sanitization provides a consistent final set of tracklets for the batch estimation of each motion.
4. Batch SE(3) estimation
The SE(3) trajectories of the sensor and each object in the scene are estimated from the segmented tracklets. Batch trajectory estimation techniques traditionally calculate the motion of a sensor relative to a set of points assuming they are static. This is appropriate for egomotion estimation (Section 4.1), but third-party trajectory estimation requires extending these techniques to include the geocentric (i.e., quasi-inertial) frame defined by the egomotion estimation (Section 4.2).
Initially, each segmented motion represents an egomotion trajectory hypothesis,
These geocentric trajectories can be estimated without making any assumptions about the object or sensor motion other than rigid motion. The estimation can be made more robust by using more expressive motion models that constrain the trajectories to the real-world kinematics of the scene. Examples of generalized, physically founded SE(3) motion models include the WNOA prior described by Anderson and Barfoot (2015) and the WNOJ prior described by Tang et al. (2019). The WNOA prior extends the pose-only trajectory state to also include velocity and the WNOJ prior extends it to include both velocity and acceleration.
The applicability of any motion model depends on how well it matches the motions in an environment. The pose-only estimator (Sections 4.1.1 and 4.2.1) can estimate complex rigid motions but can also generate physically implausible motions. The pose-velocity (Sections 4.1.2 and 4.2.2) and pose-velocity-acceleration (Sections 4.1.3 and 4.2.3) estimators penalize deviation from a constant body-centric velocity or acceleration, respectively. They are generally applicable because objects tend to move smoothly through their environment, but they are not robust to motions that deviate significantly from these assumptions. Each estimator brings advantages and disadvantages in the context of the MEP, and this investigation shows how MVO can leverage different estimators in different applications (Sections 6 and 7).
4.1. Egomotion estimation
The egomotion label, C, may be selected by a variety of heuristics. It can be chosen as the label with the largest support, as in VO, or with the most similar motion to the previous egomotion estimate. This can be combined with external sensors or application-specific heuristics, such as attention masks that prioritize parts of the field of view that usually contain static background objects, to robustly identify the true egomotion label.
Once identified, the point measurements in the egomotion label are assumed to be static. The trajectory is therefore estimated relative to a geocentric frame and inertial motion priors can be used in the estimation.
4.1.1. Pose-only estimator
A discrete single-motion bundle adjustment (e.g., Barfoot, 2017) defines the egomotion state,
Each observation,
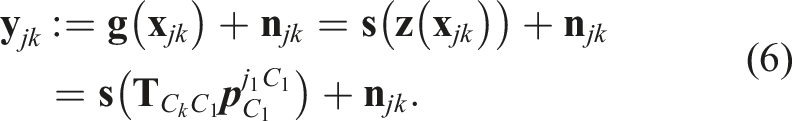
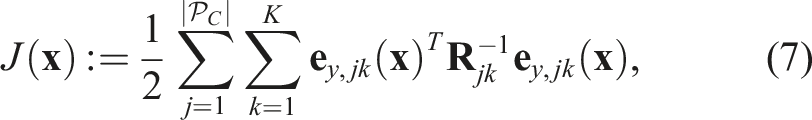
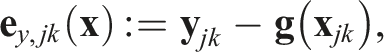
This cost is linearized about an operating point,
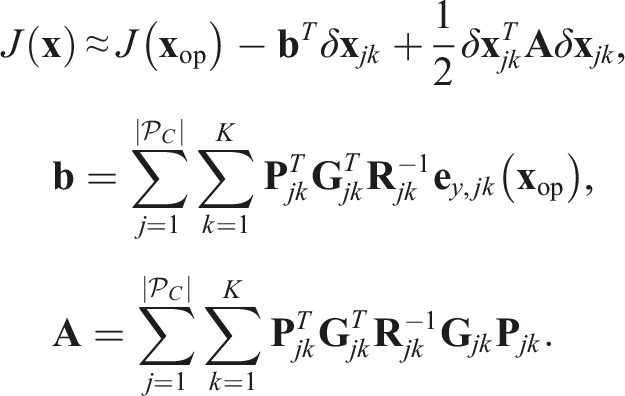
The Jacobian,
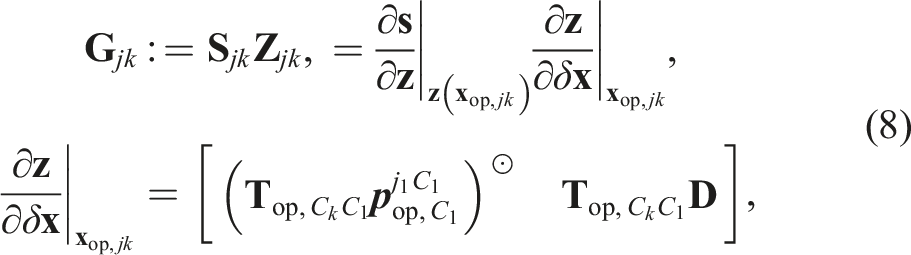
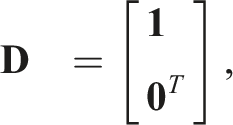
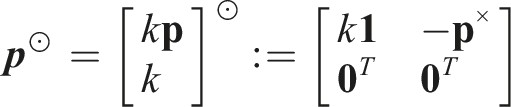
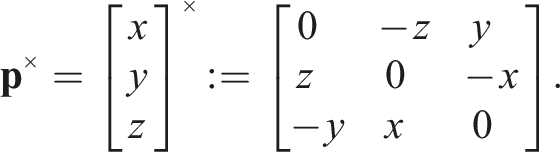
The state perturbation, δ
The optimal perturbation, δ
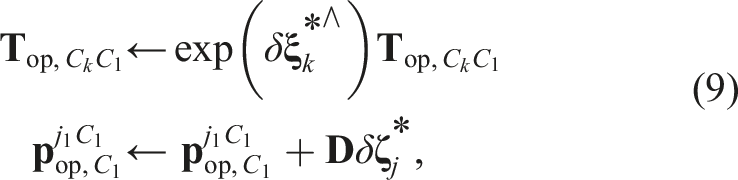
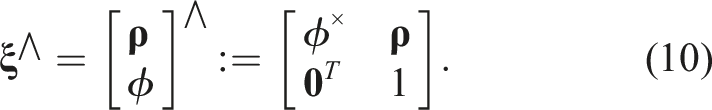
The cost function is then relinearized about the updated operating point and the process iterates until convergence. Convergence is user defined and can be a threshold on the number of iterations, the total cost, the change in cost, the magnitude of the update, or other criteria.
4.1.2. Pose-velocity estimator
The pose-only estimator is applicable to any rigid-body motion, but is not constrained to physically plausible motions. This can be mitigated by constraining the trajectory to a locally constant velocity.
The pose-velocity estimator employs an SE(3) WNOA prior (Anderson and Barfoot, 2015),
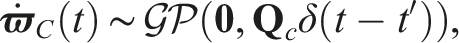
The pose-velocity estimator state,
The prior is characterized by the transition function,
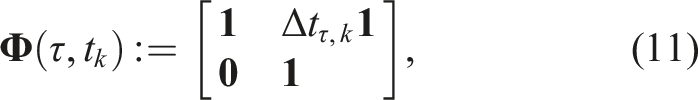
The transition function propagates the local prior state,
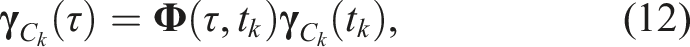
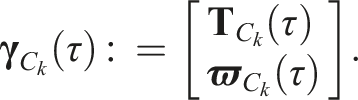
The least-squares estimate is found by minimizing the combined objective function,

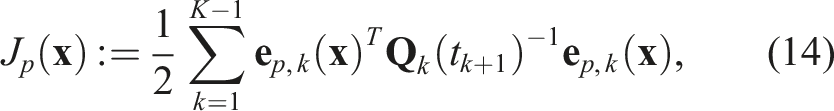
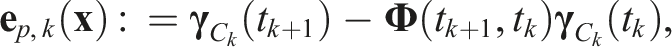
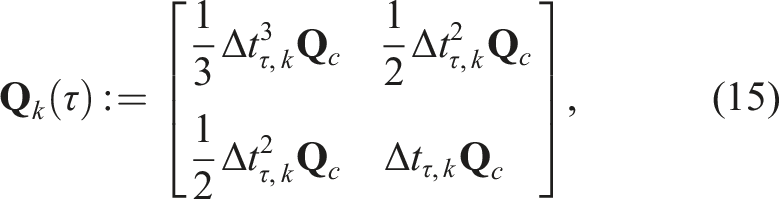
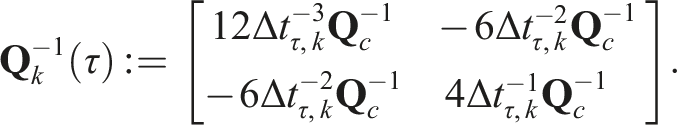
The total cost is minimized by linearizing the error about an operating point,
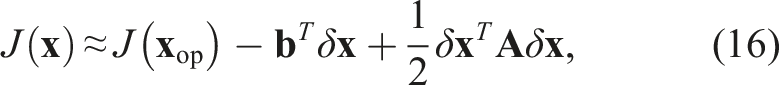
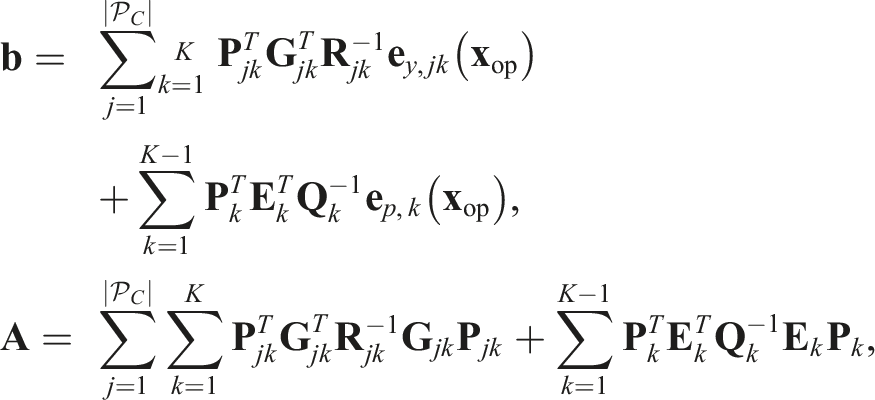
The Jacobian of the measurement model,
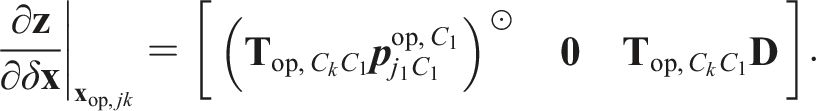
The Jacobian of the prior error function,
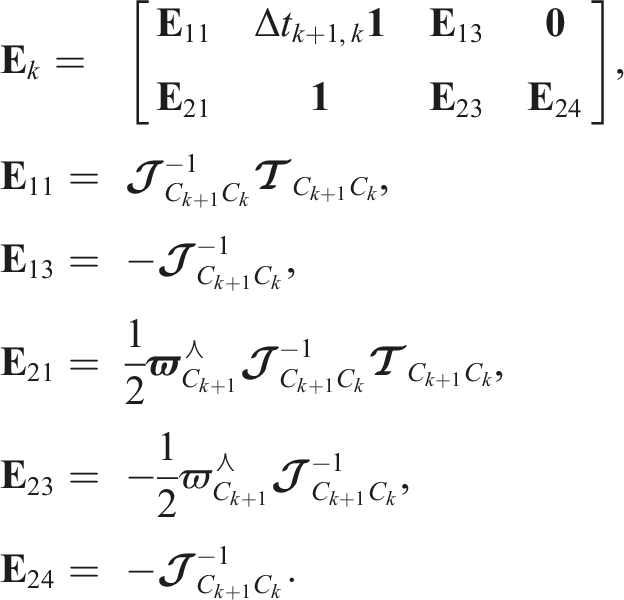
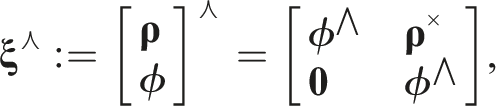
The adjoint of
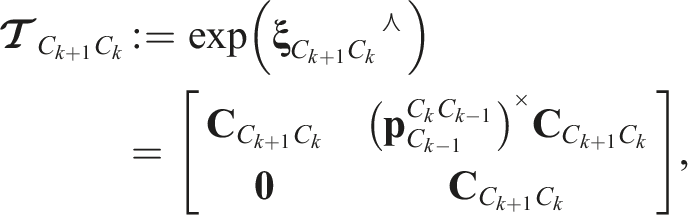
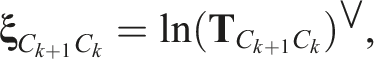
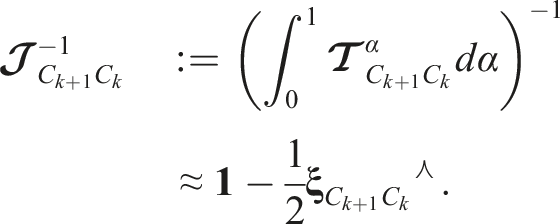
The operating point is perturbed according to the transform perturbations,
The optimal perturbation, δ
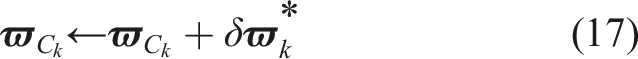
The cost function is then relinearized about the updated operating point and the process iterates until a user-defined convergence criterion.
4.1.3. Pose-velocity-acceleration estimator
The WNOA prior incentivizes locally-constant velocity, i.e., zero acceleration, which yields more physically plausible velocities, but is less accurate for motions with nonconstant velocity. This limitation is particularly important for objects that change direction, and a prior that can model nonzero accelerations is more representative of real-world motions.
The WNOJ prior models the trajectory jerk as a continuous zero-mean, white noise Gaussian process (Tang et al., 2019),
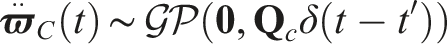
The pose-velocity-acceleration estimator state,
The estimator proceeds analogously to the pose-velocity estimator using the same combined objective function in (13) with an expanded state transition function,
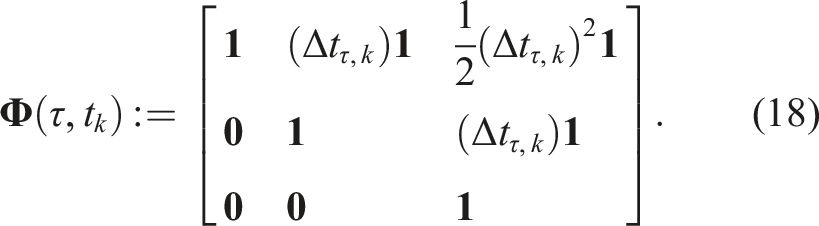
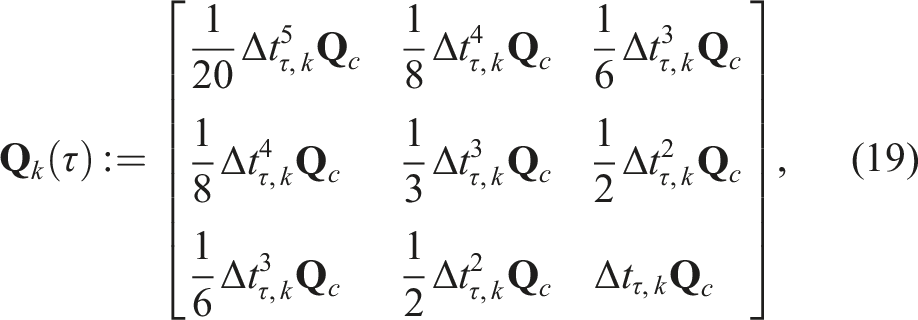
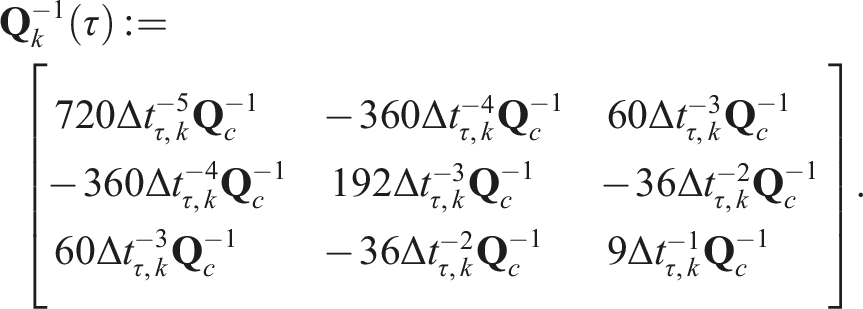
The total cost is again minimized by linearizing the error about an operating point,
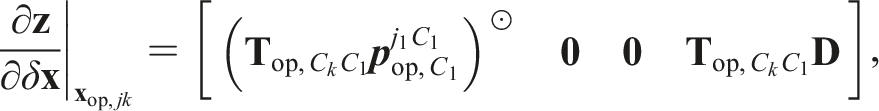
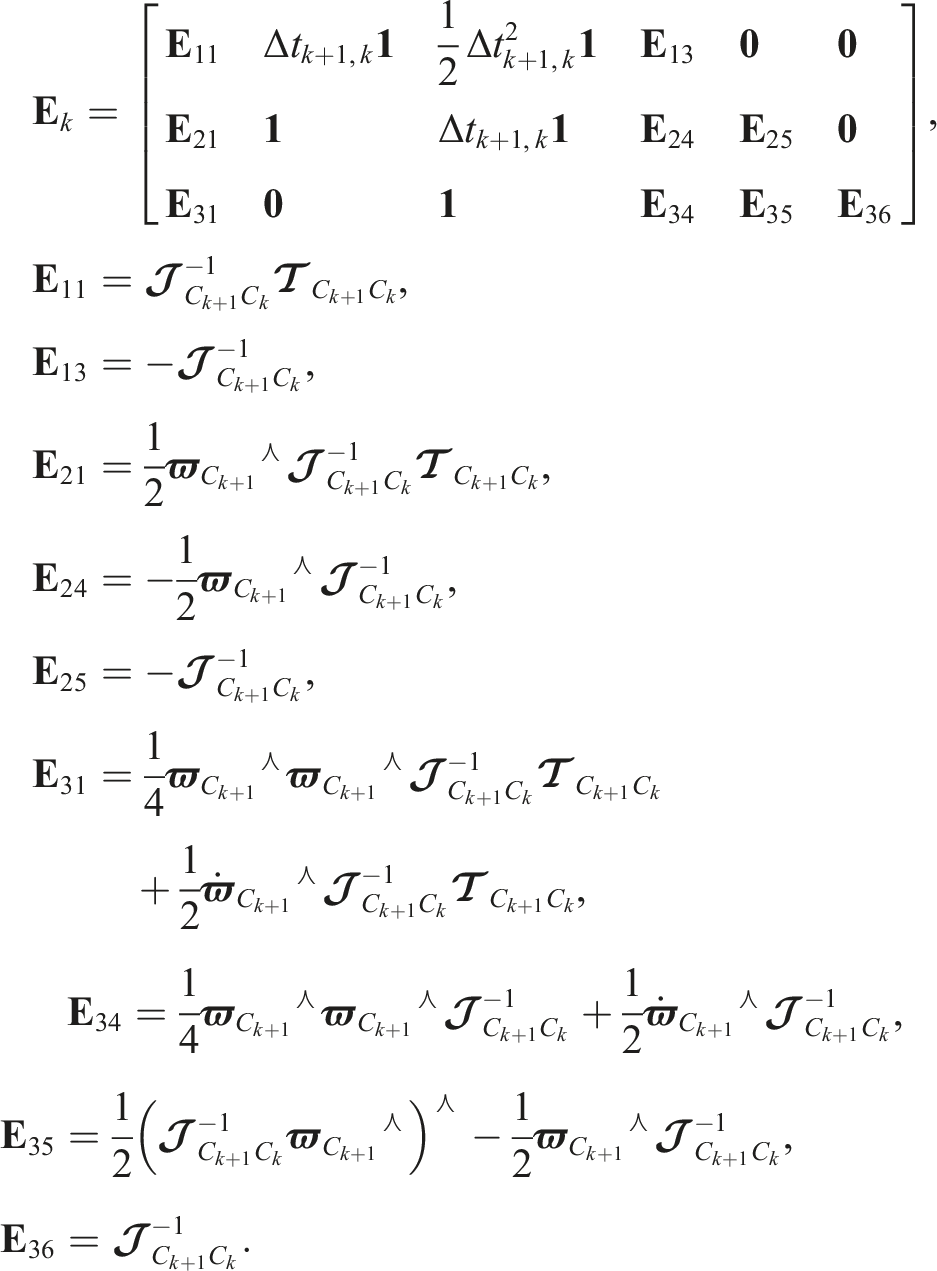
The operating point is perturbed according to the transform perturbations,
The optimal perturbation, δ
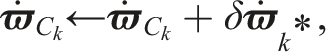
4.2. Geocentric third-party estimation
Egomotion estimation techniques must be adapted to estimate the geocentric trajectories of dynamic objects that invalidate the static tracklet assumption. Initial versions of the ideas in Sections 4.2.1 and 4.2.2 were first published in Judd et al. (2018a) and Judd and Gammell (2020), respectively, and they are further developed here. The ideas in Section 4.2.3 are presented here for the first time.
Pose-only estimates (Section 4.1.1) in an egocentric frame can be directly converted to a geocentric frame (Section 4.2.1). Inertial priors, such as the WNOA (Section 4.1.2) and WNOJ (Section 4.1.3) priors, are more complicated because bodies moving with a constant motion relative to a common inertial reference frame do not have constant motion relative to each other. Applying these motion priors to third-party trajectories requires rederiving the motion model in (6) and its associated Jacobians in (8) (Sections 4.2.2 and 4.2.3).
4.2.1. Pose-only estimator
SE(3) transforms initially estimated using egomotion estimation techniques (Section 4.1.1) represent egomotion hypotheses calculated from the assumption that observed points are static. When the tracklets are moving, these estimates are the inverse of the objects’ motion relative to the sensor, i.e., the inverse of their egocentric motion.
Egomotion hypothesis trajectories,
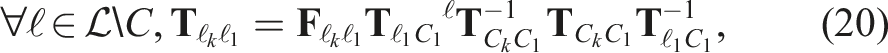
The initial sensor-to-object transform,
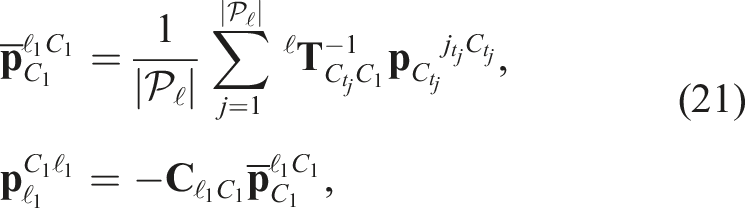
Note that the egomotion estimate is only needed to convert third-party motions from the egocentric to geocentric frames and all motions are batch estimated first as egomotion hypotheses (Section 4.1.1) before identifying the egomotion label. This means motion-based heuristics and other application-specific information can be used to identify the egomotion before converting the remaining third-party motions to geocentric estimates.
4.2.2. Pose-velocity estimator
The WNOA prior is defined in an inertial frame, so third-party motions are estimated after identifying the egomotion. The techniques used to estimate the egomotion (Section 4.1.2) must be adapted to estimate third-party motions in a geocentric frame.
The transform model,
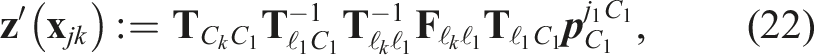
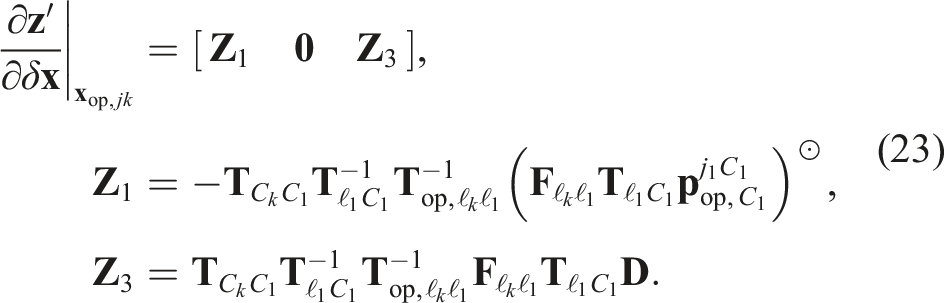
The prior cost is the same as in (14). The linearized cost in (16) is then used to estimate the geocentric trajectory of every third-party motion in the scene.
Note that the egomotion must be estimated before the third-party motions, so motion-based heuristics cannot be used to help identify the egomotion label as in pose-only estimation.
4.2.3. Pose-velocity-acceleration estimator
The WNOJ prior is also defined in an inertial frame and is adapted using a similar procedure to the pose-velocity estimator (Section 4.2.2).
The transform model,
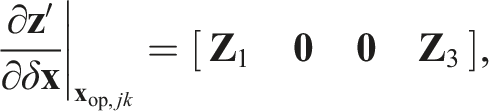
Note again that the egomotion must be estimated before the third-party motions and therefore motion-based heuristics cannot be used to identify the egomotion label.
5. Sliding-window multimotion estimation
Sections 3 and 4 present a full-batch implementation of MVO. Full-batch estimation requires all observations of a given data segment at once but makes motion segmentation and estimation more accurate because motions are more distinct over longer periods of time. It can also reason about temporary occlusions after they occur, making it easier to determine when an object becomes occluded or unoccluded, as well as track motions through those occlusions. Full-batch estimation is computationally expensive and is often used in offline estimation systems.
MVO can also be implemented as an online sliding-window pipeline that processes data as it is observed and is less computationally expensive than a full-batch implementation. Sliding-window estimation uses smaller batches of the K-most-recent observation frames, and maintaining consistent trajectories over consecutive batches presents several challenges.
Motion segmentation is more difficult in a sliding-window pipeline because independent motions are often less distinct over short timescales. Motions must be associated across estimation windows to maintain label consistency because motions in separate windows are not guaranteed to be assigned the same label (Section 5.1). Unlike full-batch estimation, sliding-window estimation must reason about temporary occlusions as they occur. This requires motions to be extrapolated from, and interpolated between, direct observations (Section 5.2). Detecting when an object becomes unoccluded requires determining when a newly segmented motion is actually the reappearance of a previously occluded motion, i.e., motion closure (Section 5.3). Initial versions of these ideas were first presented in Judd and Gammell (2019b) and Judd and Gammell (2020), and they are further developed and fully detailed for the first time here.
5.1. Label consistency
Sliding-window estimation requires consistently tracking motions across multiple windows. This involves associating motions in consecutive estimation windows to form a single trajectory over the entirety of the data.
Each new window associates currently estimated motion labels, ℓ
k
, with previously estimated motion labels,
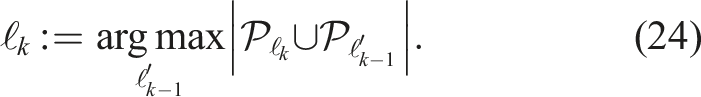
The labeling and estimates from the current window are used to initialize the segmentation and egomotion hypotheses in the next window. Any current tracklets that also exist in the next window retain their labels, and the current trajectory estimates are extrapolated forward to the next time stamp to initialize the label set. This is done by extrapolating the geocentric estimates,
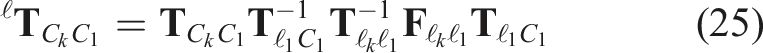
5.2. Extrapolation and interpolation
Unobserved motions can be estimated by modeling the expected motions of previous observations. This is less accurate than direct estimation, but can extend existing motions to initialize the next set of motion estimates as well as estimate motions through temporary occlusions. The accuracy of these estimates depends on the fidelity of the motion model to the true motion of the object, and inferring the motion of an object between two states, i.e., interpolation, is more accurate than from a single state, i.e., extrapolation.
Pose extrapolation and interpolation require an estimate of the change in pose over time, i.e., the velocity. In the pose-only estimator (Sections 4.1.1 and 4.2.1), the velocity is discretely calculated from the relative transform between the final two poses,
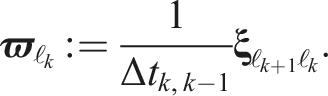
The pose-velocity-acceleration estimator also directly estimates the body-centric acceleration, which can be used for extrapolation and interpolation. This term is zero for the pose-only and pose-velocity estimators, i.e., constant-velocity extrapolation.
5.2.1. Extrapolation
The local state,
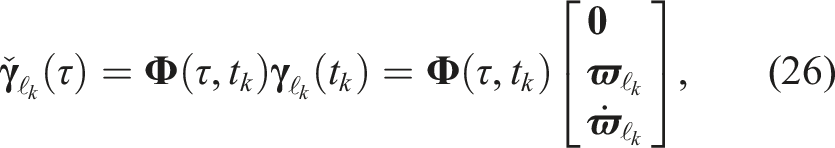
The extrapolated local state is transformed to the global pose, velocity, and acceleration state via
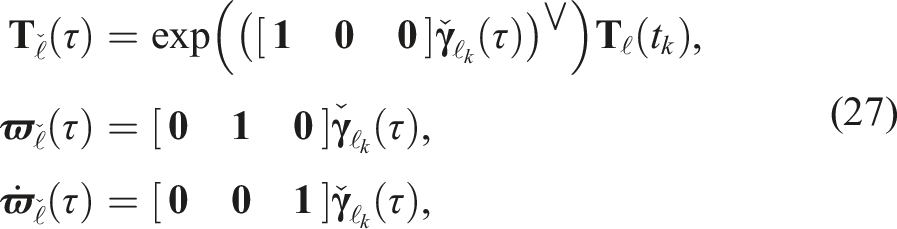
Estimates can be extrapolated forward or backward in time. The extrapolation accuracy will degrade over time, especially if the true motion exhibits significant changes in velocity or acceleration.
5.2.2. Interpolation
When the unobserved states are constrained by direct estimates on both sides, they can be estimated through interpolation. This is useful when tracking is resumed after an occlusion. The accuracy of the previously extrapolated estimates is improved because interpolation considers the directly observed data both before and after the occlusion.
The pose-only state is linearly interpolated to an intermediate time, t
j
< τ < t
k
, via
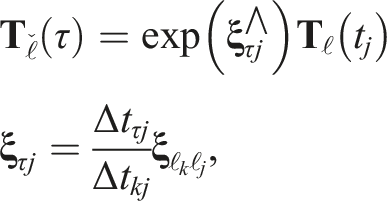
The pose-velocity and pose-velocity-acceleration states are interpolated (Anderson and Barfoot, 2015; Tang et al., 2019) via
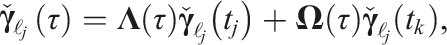
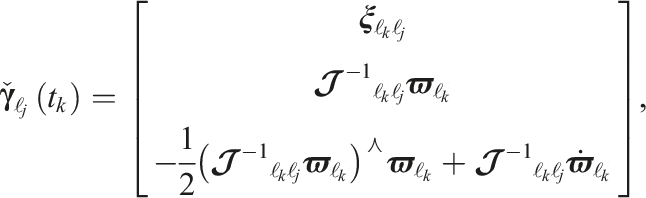
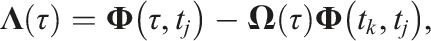
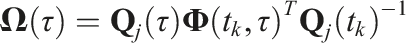
The block covariance matrix,
Calculating the interpolation involves estimates both before and after the occlusion. This requires recognizing when a newly discovered motion can be explained by the reappearance of a previously occluded object, i.e., motion closure (Section 5.3).
5.3. Motion closure
Online, sliding-window estimation requires actively recognizing when objects become occluded and unoccluded. While most existing tracking techniques address occlusions with appearance-based object detectors and simple motion models, MVO tracks arbitrary objects through occlusions using motion-based tracking metrics (Figure 4). This motion closure recognizes when a motion becomes unoccluded (Section 5.3.1), corrects the extrapolated pose using information from the new trajectory (Section 5.3.2), and updates the previously extrapolated estimates through interpolation (Section 5.3.3). A demonstration of the motion closure procedure showing trajectory estimates produced before (left), during (center), and after (right) an occlusion in the 
5.3.1. Recognizing previously occluded motions
Motions are reacquired by comparing a newly discovered motion, ℓ′, to an extrapolated previously observed motion,
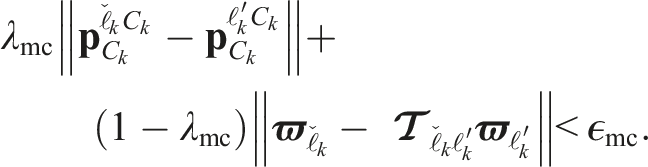
The position of the newly discovered motion,
The body-centric velocity of the newly discovered motion,
This newly closed trajectory is then used to correct the extrapolated pose (Section 5.3.2).
5.3.2. Correcting occluded states
The newly closed motion is adjusted to create a consistent, smooth trajectory. Information from both the extrapolated and newly discovered trajectories is used to correct the extrapolated states from the start of the occlusion to the time of closure, t k .
The final corrected pose,
The translation component of the correction transform,
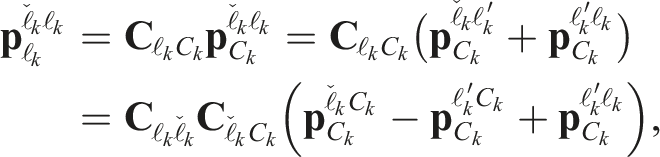
The extrapolated camera-to-object rotation,
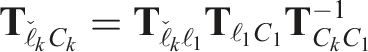
The rotation component of the correction transform,
5.3.3. Updating closed trajectories
The previously estimated trajectory is updated to incorporate the motion closure. The correction transform,
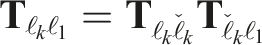
The states after the closure, τ > t
k
, are reestimated directly from measurements relative to the corrected pose,
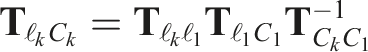
6. Evaluation
The performance of MVO is evaluated on real-world stereo data from the OMD (Judd and Gammell, 2019a) and the KITTI dataset (Geiger et al., 2012). It is evaluated both quantitatively and qualitatively and the accuracy of the different estimators is discussed. MVO is also compared to VDO-SLAM (Zhang et al., 2020b), a dynamic SLAM system that also estimates the SE(3) motion of all objects in the scene, which has reported better performance than CubeSLAM (Yang and Scherer, 2019) and ClusterVO (Huang et al., 2020).
Before evaluation, each estimated trajectory must first be calibrated to the ground-truth trajectory frame (Section 6.1). The accuracy of MVO and VDO-SLAM are evaluated using two metrics that give different context to their performance (Section 6.2).
The OMD contains several challenging multimotion scenes with ground-truth trajectory data for each motion in the scene. The
The KITTI dataset is a driving dataset that includes ground-truth GPS/INS data for the sensor platform, but no third-party motion data. While it does not allow for the same quantitative evaluation as the OMD, it is a commonly used benchmark for evaluating navigation algorithms and the segments
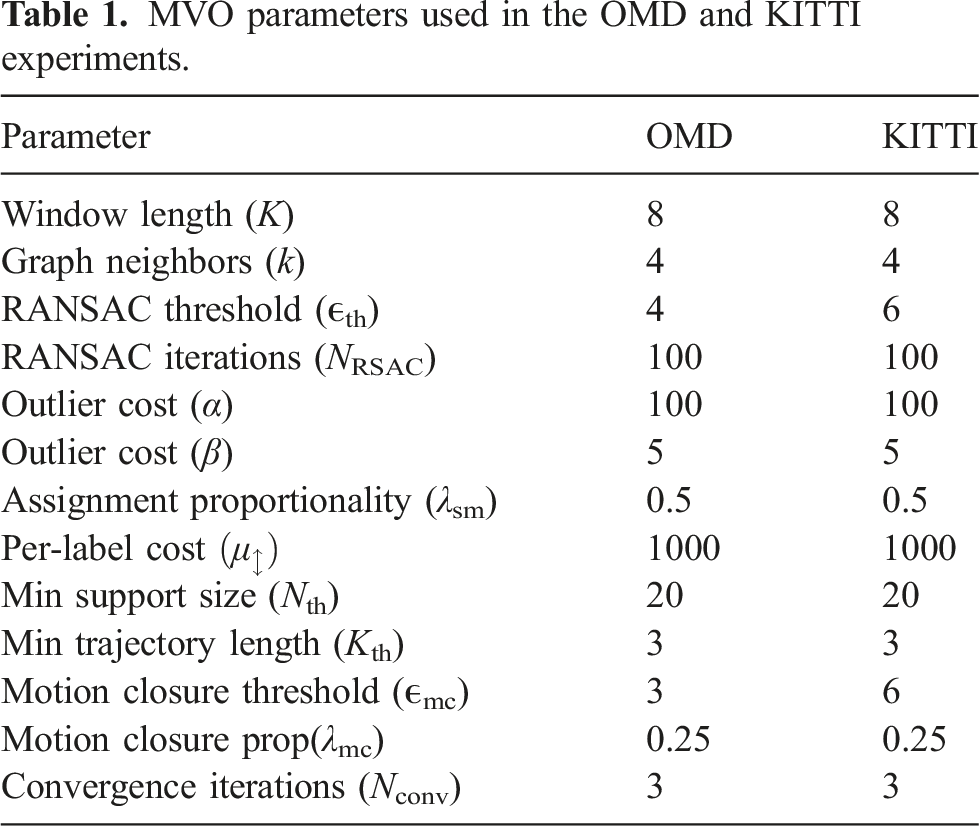
MVO parameters used in the OMD and KITTI experiments.
6.1. Error calibration
Calculating the error between an estimate and the ground truth at a time, t k , requires calibrating the trajectories at some earlier reference time, t j < t k . This makes the calibration dependent on the chosen reference time.
The calibration depends on the initial transform between the estimated and ground truth object frames,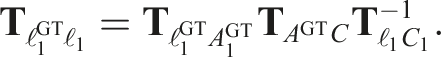
The calibration at any future time is given by propagating the initial calibration forward,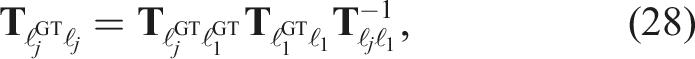
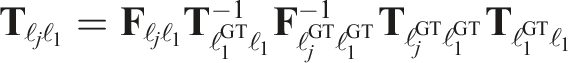
6.2. Error metrics
The accuracy of the estimation techniques is assessed using two SE(3) error metrics. Global odometric error measures the estimation accuracy of the entire trajectory to a given point. Relative RMS error measures the error over consecutive time steps. Both errors provide useful context for quantifying the accuracy of the trajectory estimation.
Each metric is defined using the error between the estimated motion, 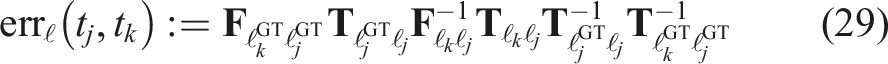
6.2.1. Global error
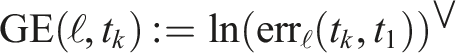
Maximum translational and roll-pitch-yaw errors for each MVO estimator and VDO-SLAM for the
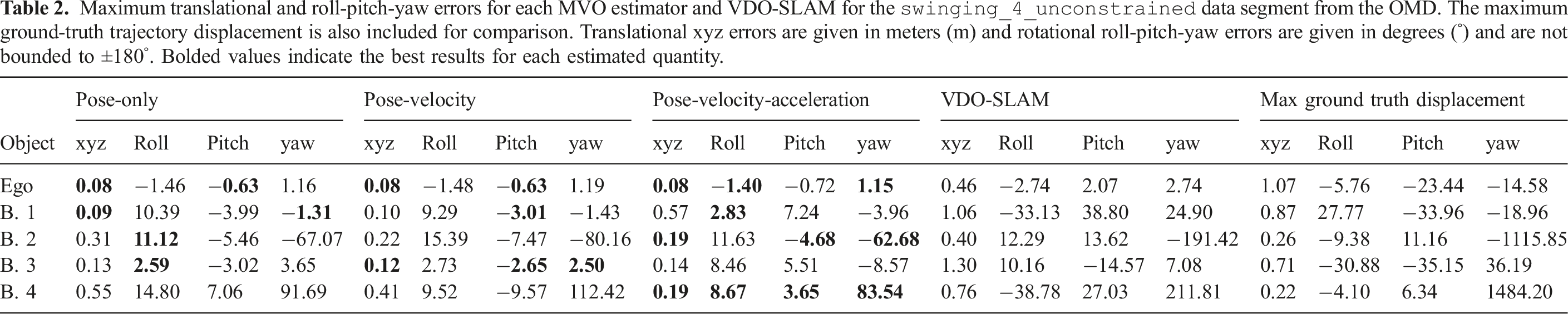
Maximum translational and roll-pitch-yaw errors for each MVO estimator for the
Total ground-truth translational and roll-pitch-yaw path length for the
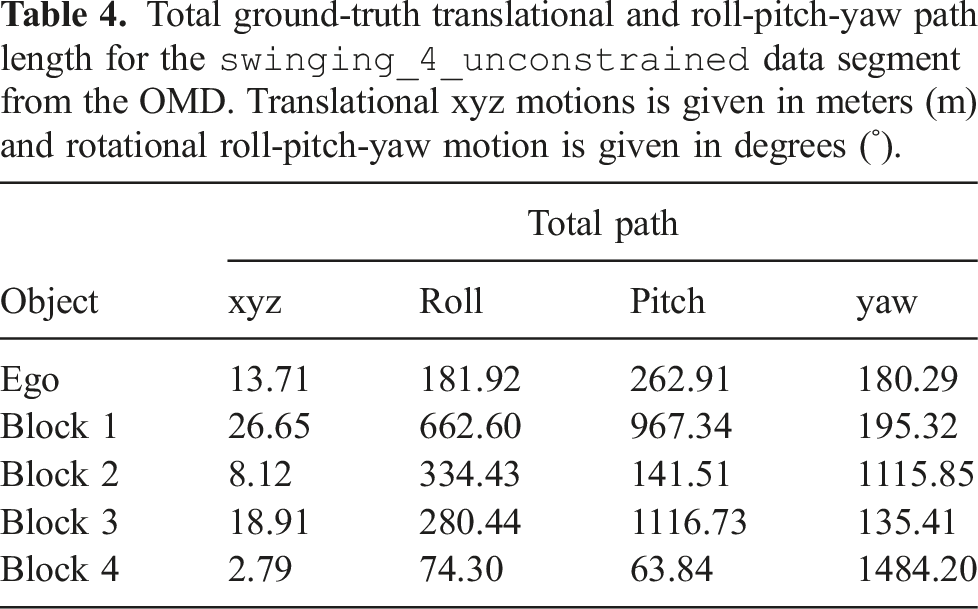
Total ground-truth translational and roll-pitch-yaw path length for the
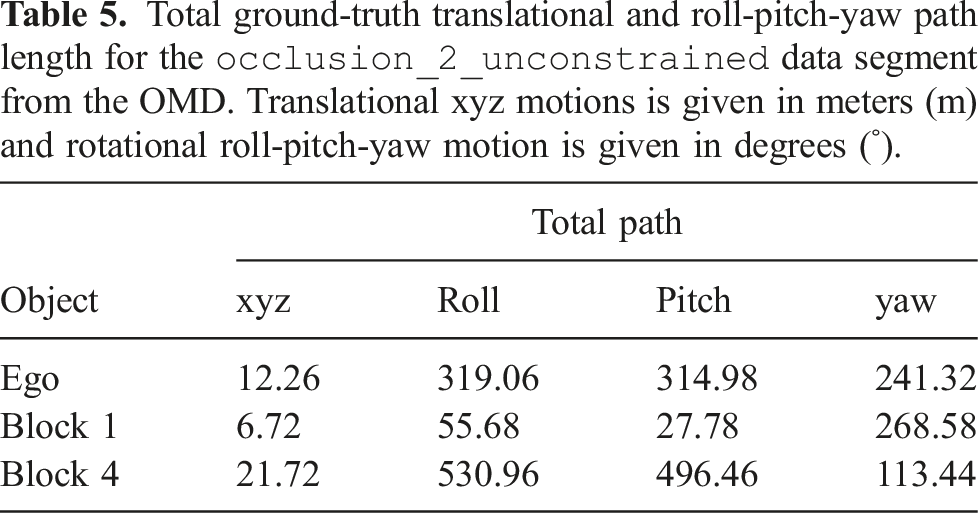
Total ground-truth translational and roll-pitch-yaw path length for the
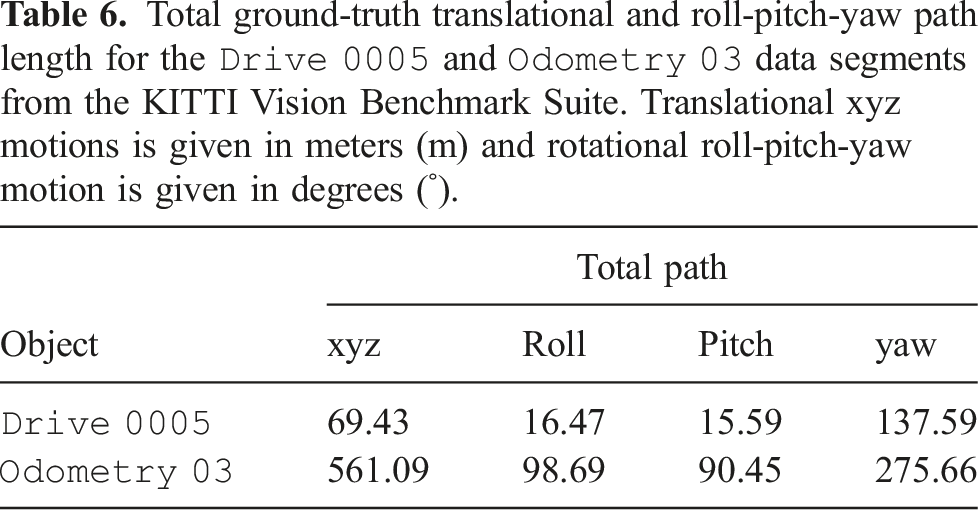
Maximum translational and roll-pitch-yaw errors for each MVO estimator and VDO-SLAM for the egomotion in the

6.2.2. Relative error
The global error is sensitive to the time at which an error occurs. An estimation error that occurs at the beginning of a trajectory results in significantly more global error than an equivalent error occurring at the end of the trajectory. In contrast, the relative error measures how much the estimated transform between consecutive time stamps deviates from the ground truth. The translational and rotational root-mean-square (RMS) relative errors are given by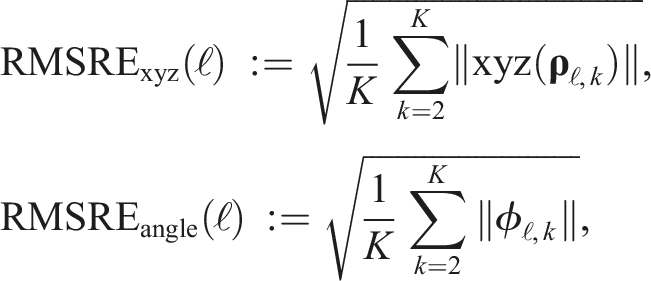
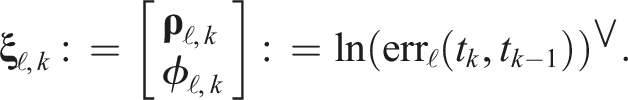
RMS (and maximum) relative translational and axis-angle errors for each MVO estimator and VDO-SLAM for the
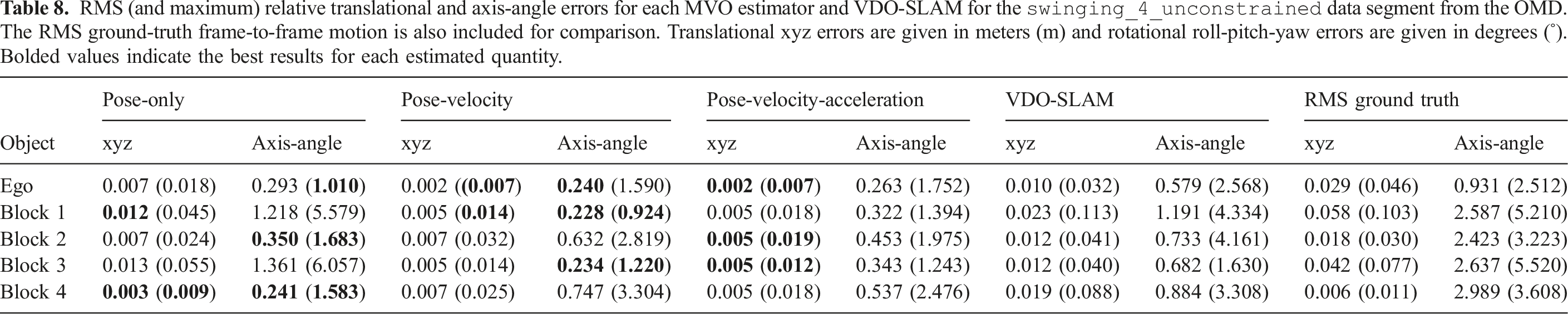
RMS (and maximum) relative translational and axis-angle errors for each MVO estimator for the
RMS (and maximum) relative translational and axis-angle errors for each MVO estimator and VDO-SLAM for the

Both global and relative errors are decomposed into their translational (i.e., xyz) and rotational (i.e., roll-pitch-yaw) components. All errors are reported for geocentric trajectory estimates, so a portion of the error for each motion is due to error in the camera motion estimate.
VDO-SLAM third-party motion estimates were provided as calibrated relative motions. These transforms are recalibrated and combined to match the global transform representation of MVO for evaluation.
6.3. Multimotion estimation
The Motion segmentation (top) and trajectories (bottom) produced by MVO using the pose-velocity estimator for the 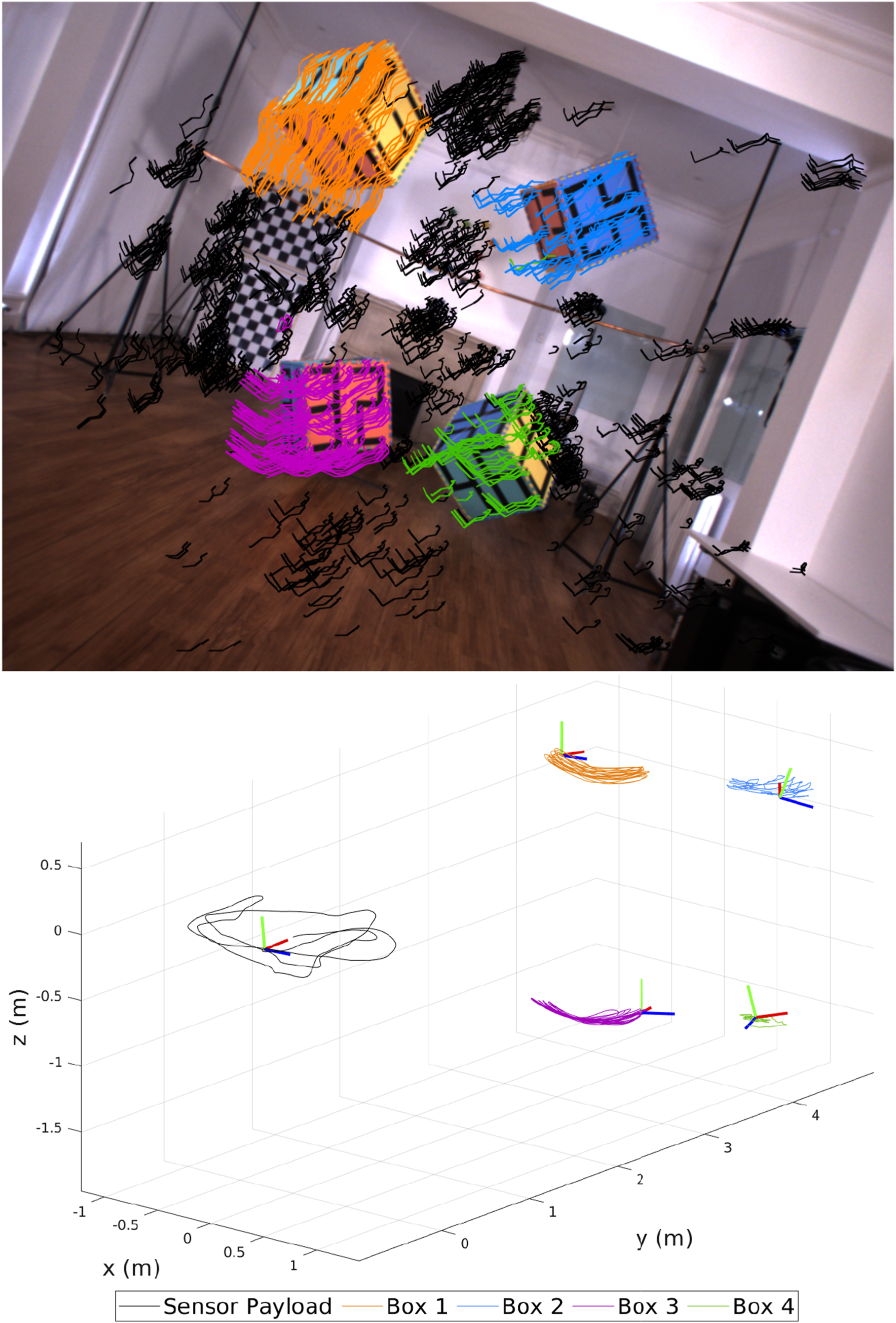
Two of the blocks, Block 1 (top left) and Block 3 (bottom left), have minimal rotation and swing primarily along the ground-truth world y- and x-axis, respectively. The other two blocks, Block 2 (top right) and Block 4 (bottom right), rotate significantly about the positive ground-truth body z-axis. Block 4 rotates counter-clockwise and Block 2 rotates clockwise while also swinging, which creates a complex motion.
6.4. Tracking through occlusion
The Motion segmentation (top) and trajectories (bottom) produced by MVO using the pose-velocity estimator for the 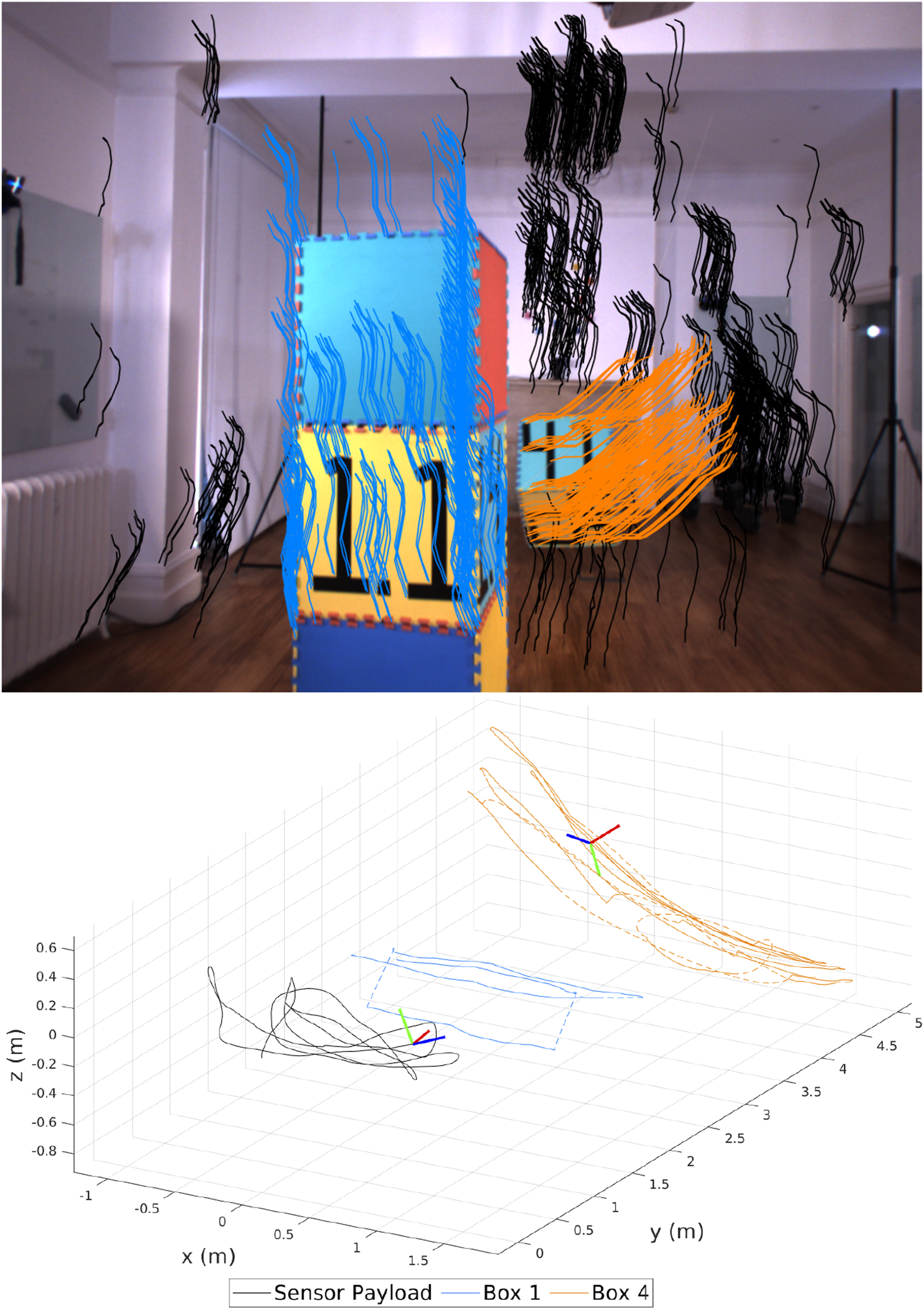
The sliding block tower is partially occluded multiple times when it partially leaves the field of view of the camera, further complicating the estimation. It also occasionally stops moving and becomes part of the static background, which is a form of indirect occlusion in motion-based tracking. VDO-SLAM was not evaluated on this segment because it is not designed for this level of occlusion.
6.5. Urban driving
The KITTI Vision Benchmark Suite (Geiger et al., 2012) is a collection of datasets and benchmarks dedicated to autonomous driving scenarios. The suite contains data and evaluation metrics for object detection and tracking, depth and flow calculations, and VO. The datasets and benchmarks within KITTI are widely used to develop and evaluate computer vision techniques, but it does not contain any ground-truth third-party trajectory data. This makes it less suitable for quantitatively evaluating multimotion estimation algorithms; however, it is still a useful qualitative tool for evaluation in a real-world scenario.
The KITTI Motion segmentation (top) and trajectories (bottom) produced by MVO using the pose-velocity estimator for the 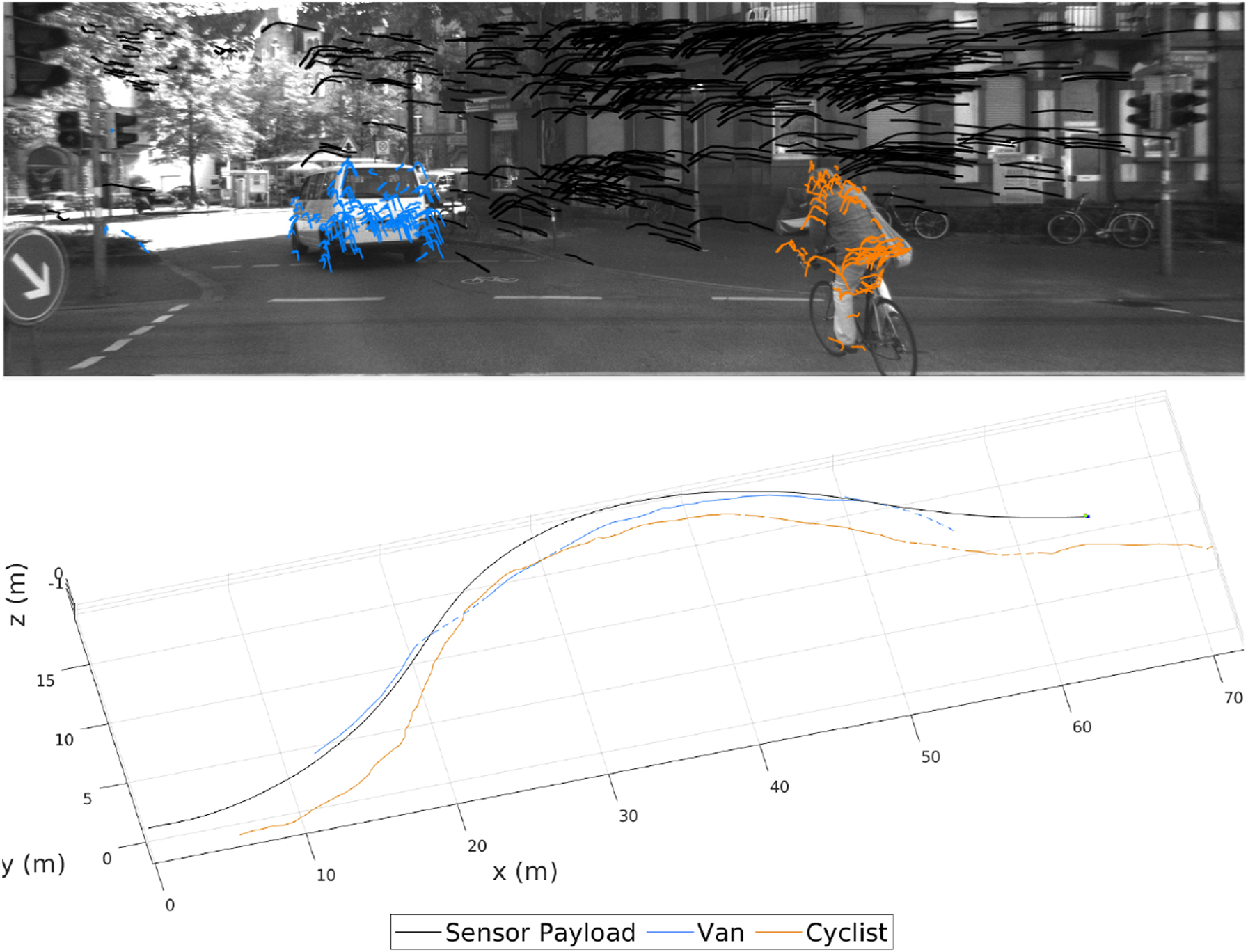
The KITTI
7. Discussion
Qualitative and quantitative evaluations show that MVO consistently estimates ego- and third-party motions, even in the presence of temporary occlusions. MVO demonstrates good estimation and tracking accuracy on the evaluated toy problems and a real-world driving scenario without relying on appearance-based detectors or preprocessing segmentation stages.
MVO uses sparse feature tracking which does not require prior knowledge about object appearance but has known limitations (Section 7.1). The distribution of features on each object affects the estimation of its motion, and small or distant objects can be difficult to segment and estimate. Similarly, MVO demonstrates that motion-based tracking through occlusions is a reliable way to address the MEP without making appearance-based assumptions, but accurately estimating the rotation of a previously occluded object without modeling its shape is challenging. Some of the limitations of MVO are inherent to the estimators it employs, each bringing its own advantages and disadvantages (Section 7.2). Despite its limitations, MVO outperforms VDO-SLAM in both egomotion and third-party trajectory estimation accuracy (Section 7.3).
7.1. Limitations of sparse approaches
MVO is a sparse, feature-based approach and therefore its estimation accuracy depends on the distribution of features on each dynamic object. This distribution affects the nature of the estimated motion, the observed shape of the object, and the motion extrapolation during occlusions.
Features are only observed on object surfaces facing the sensor, which makes it difficult to estimate certain types of motions, such as translations along the optical axis and rotations not around the optical axis. For example, Block 2 and Block 4 in the The translational and rotational errors estimated by MVO for the camera (a) and the swinging blocks (b)–(e) for a 500-frame section of the The translational and rotational errors estimated by MVO for the camera (a) and the swinging blocks (b)–(e) for a 500-frame section of the The translational and rotational errors estimated by MVO for the camera (a) and the swinging blocks (b)–(e) for a 500-frame section of the 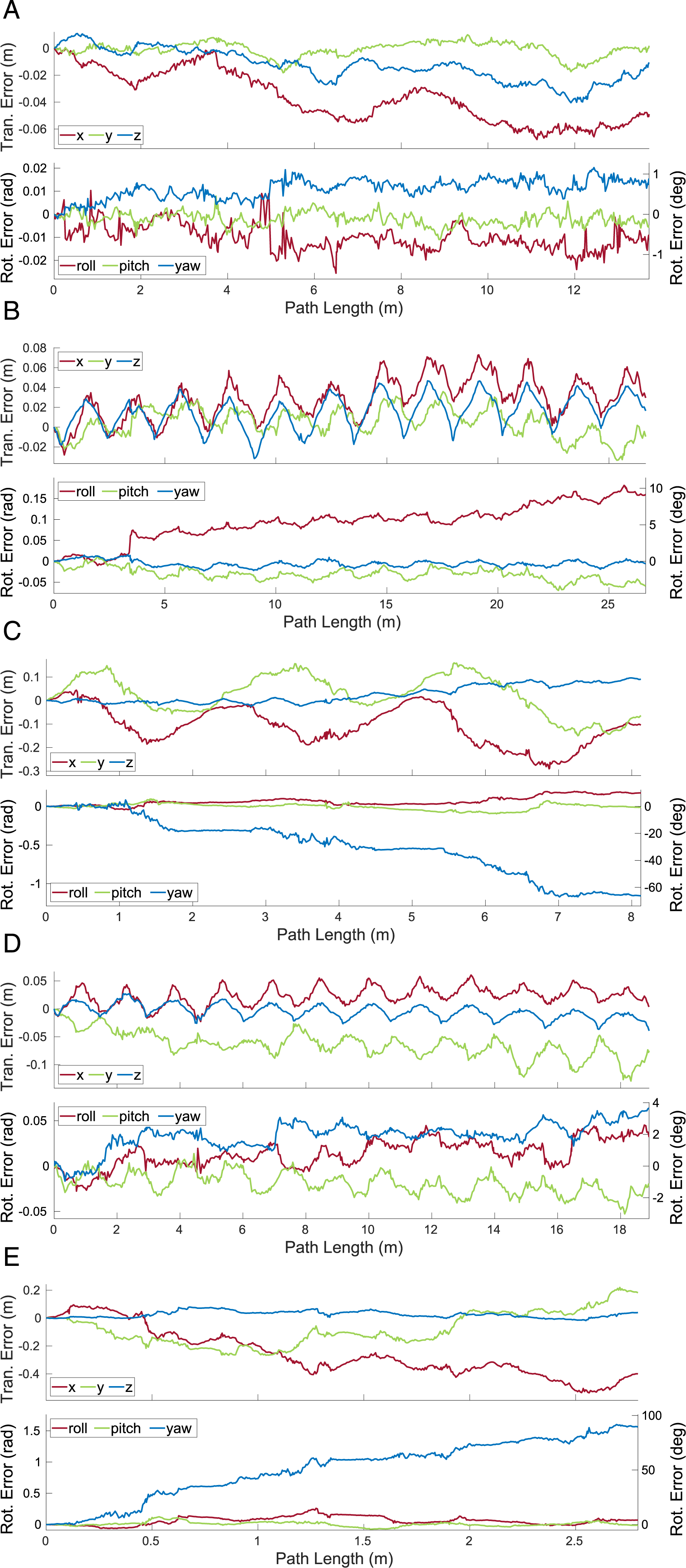
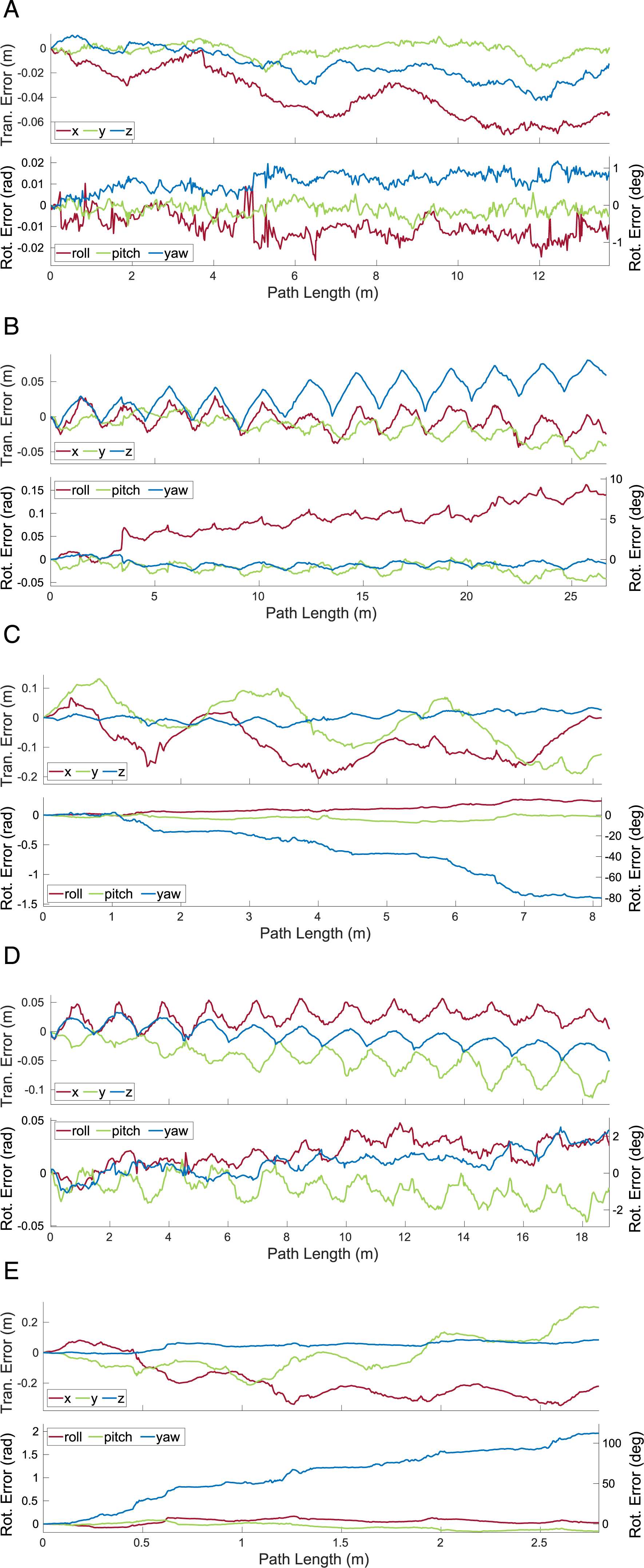
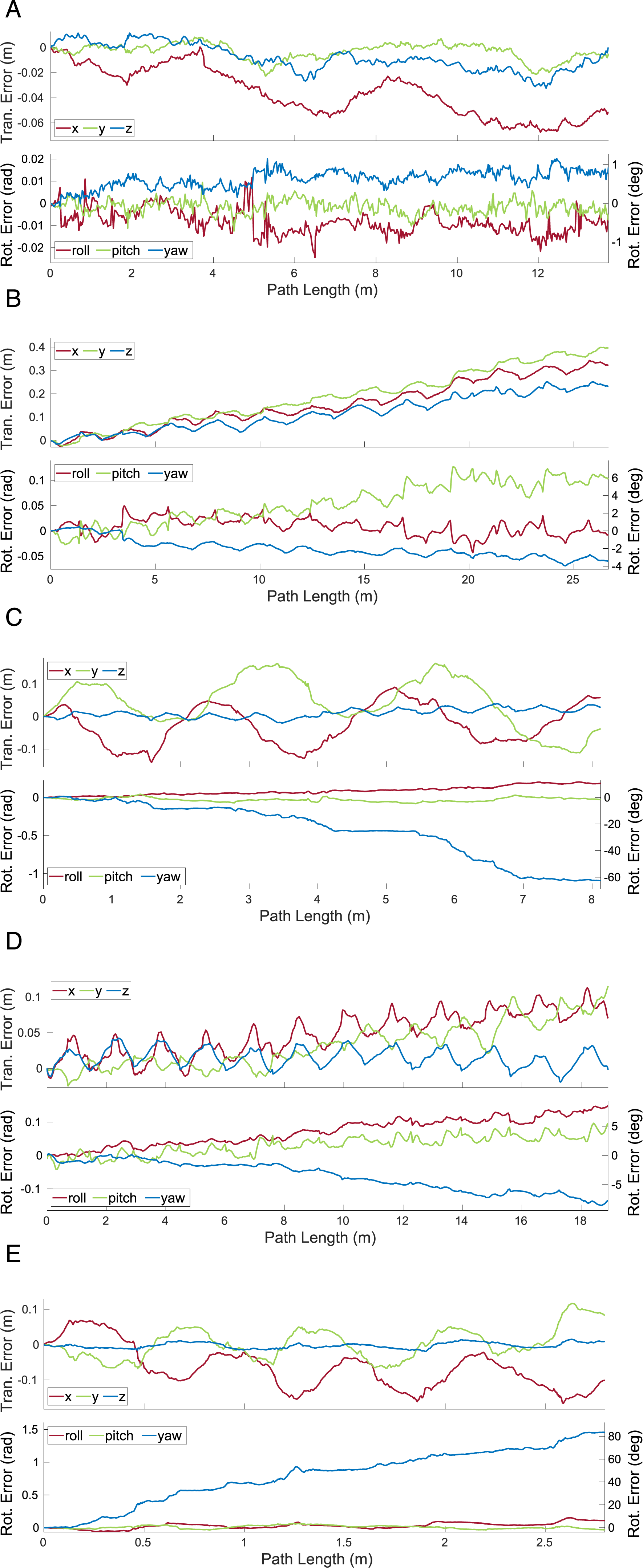
The observable shape (and centroid) of an object also changes over time as it and the sensor move. This shifts the observable features on the object and the geocentric trajectory estimate, which degrades the interpolated estimates. This is often most evident before and after an occlusion, as seen in the estimates for the block tower in the
The transition into occlusion itself presents estimation challenges. As the object becomes more occluded, the number of tracked features decreases and the quality of the segmentation and estimation degrades. This is evident in the egomotion and block tower estimates for the \The translational and rotational errors estimated by MVO for the camera (a), the block tower (b), and the swinging block (c) for a 500-frame section of the The translational and rotational errors estimated by MVO for the camera (a), the block tower (b), and the swinging block (c) for a 500-frame section of the The translational and rotational errors estimated by MVO for the camera (a), the block tower (b), and the swinging block (c) for a 500-frame section of the 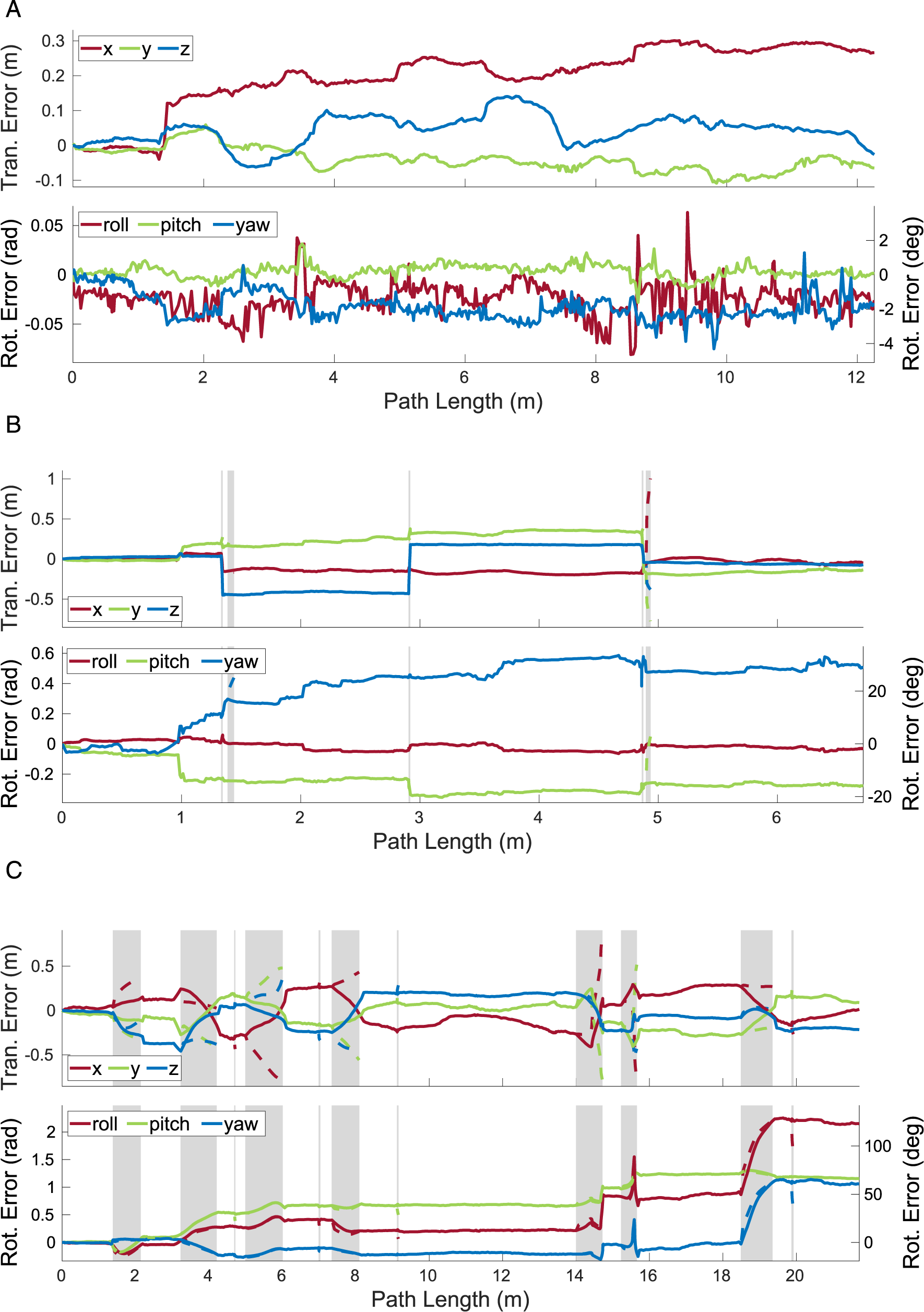
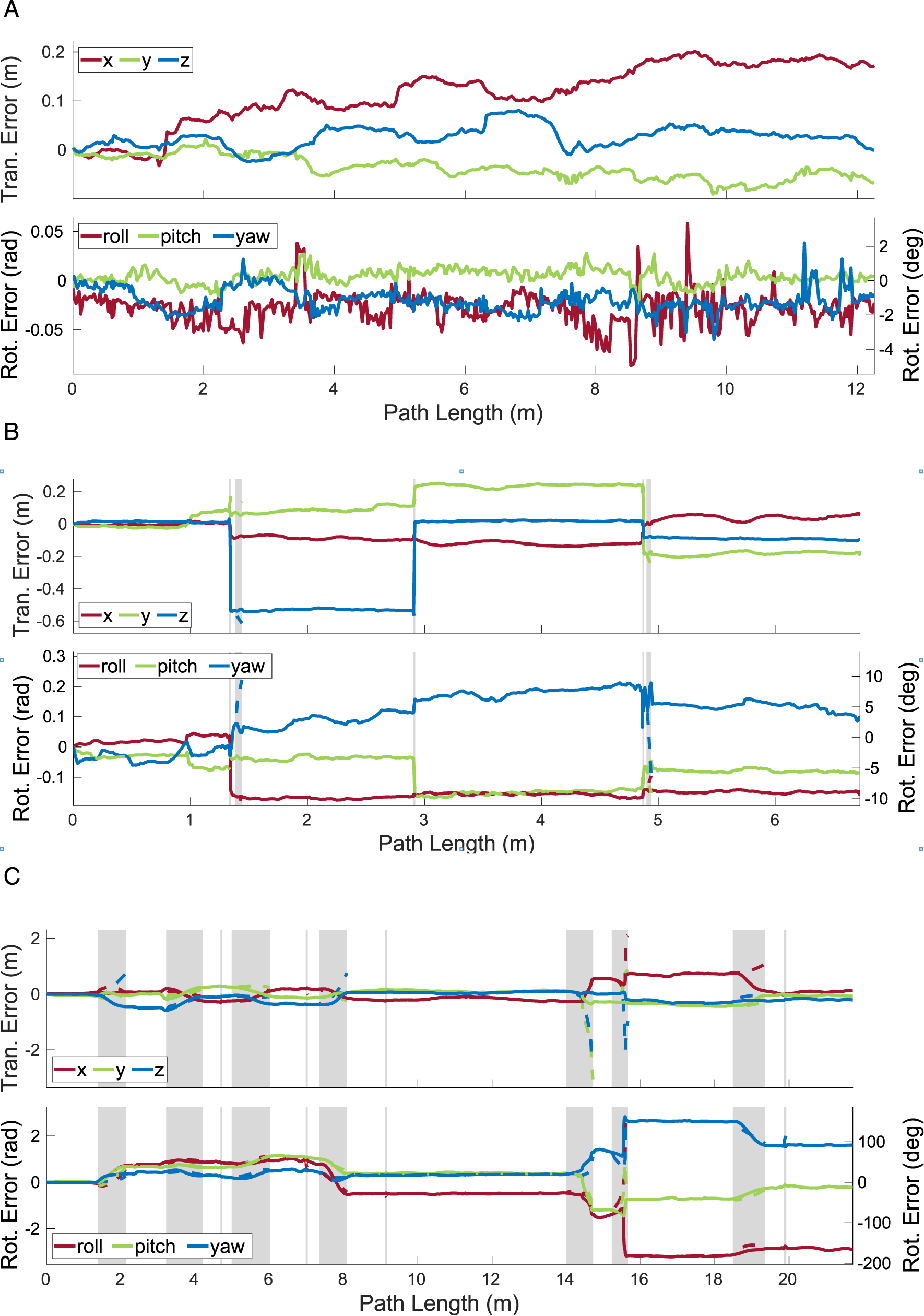
The transition into occlusion also makes extrapolation harder because the erroneous estimates before an occlusion are extrapolated forward and make motion closure more difficult. This is evident in the swinging block estimates for the
7.2. Estimator comparison
MVO is a direct extension of VO to the MEP and can therefore leverage significant developments in egomotion estimation. This includes different SE(3) estimation techniques, such as the discrete, WNOA, and WNOJ motion models presented here. The associated estimators have advantages and disadvantages in MVO.
The pose-only estimator is the most general of those discussed in this paper. Its lack of motion prior makes it simple, but it can estimate physically implausible motions (e.g., discrete jumps) and it is not as robust to occlusions. The pose-velocity and pose-velocity-acceleration estimators constrain the trajectory estimate with a WNOA and WNOJ prior, respectively. This makes estimation more complex but penalizes physically implausible motions and allows for more accurate extrapolation and interpolation through occlusions. The WNOA prior assumes a locally constant velocity that is appropriate for many real-world situations but does not accurately model motions with large changes in direction. The WNOJ prior assumes a locally constant acceleration that is applicable to more real-world situations, including objects with large changes in direction; however, it often does not sufficiently constrain its estimates to accurately extrapolate motions for long periods of time.
7.2.1. Swinging blocks segment
All estimators performed similarly well in the
7.2.2. Occlusion segment
The estimators perform differently in the presence of occlusions, as seen in the
The pose-only estimator performed reasonably well for directly observed motions but did not perform well on occlusions (Figure 11 and Tables 3, 5 and 9). This is because its linear extrapolation and interpolation are sensitive to estimation noise, which often increases as an object becomes occluded (Section 7.1). The egomotion estimate is also affected by the sliding block transitioning between being stationary and dynamic more than the other estimators because of the lack of motion prior.
The pose-velocity estimator performed well for the entire segment and was the best at extrapolating occluded motions (Figure 12 and Tables 3, 5 and 9). Its locally constant-velocity assumption reasonably models many motions and allows for gradual changes in direction when directly observed. When changes in motion are not observed (i.e., during occlusion), the extrapolation can be inaccurate and motion closure may fail. This is expected because a WNOA prior only allows for small changes in velocity between consecutive frames, so it distributes large changes in motion over longer periods of time.
The pose-velocity-acceleration estimator was the best at interpolating occluded motions, but occasionally underconstrained its extrapolated estimates (Figure 13 and Tables 3, 5 and 9). Its locally constant-acceleration assumption directly models changes in velocity, even during occlusion. This more expressive prior results in better interpolations after motion closure than the WNOA prior but is less robust when extrapolating motions. This is because even small nonzero accelerations are extrapolated to significant motions over a moderate-length occlusion, as evidenced by the high extrapolation error for the swinging block.
All estimators had high rotational error after occlusion because motion closure does not correct the extrapolated rotation (Section 5.3). This results in similar maximum rotation errors when extrapolating and interpolating (Tables 2, 3 and 7). Accurately recognizing the relative rotation of an object after an occlusion is difficult without modeling the appearance or structure of the object. This may be achieved by tracking the visual features of the object or by building a model of its structure.
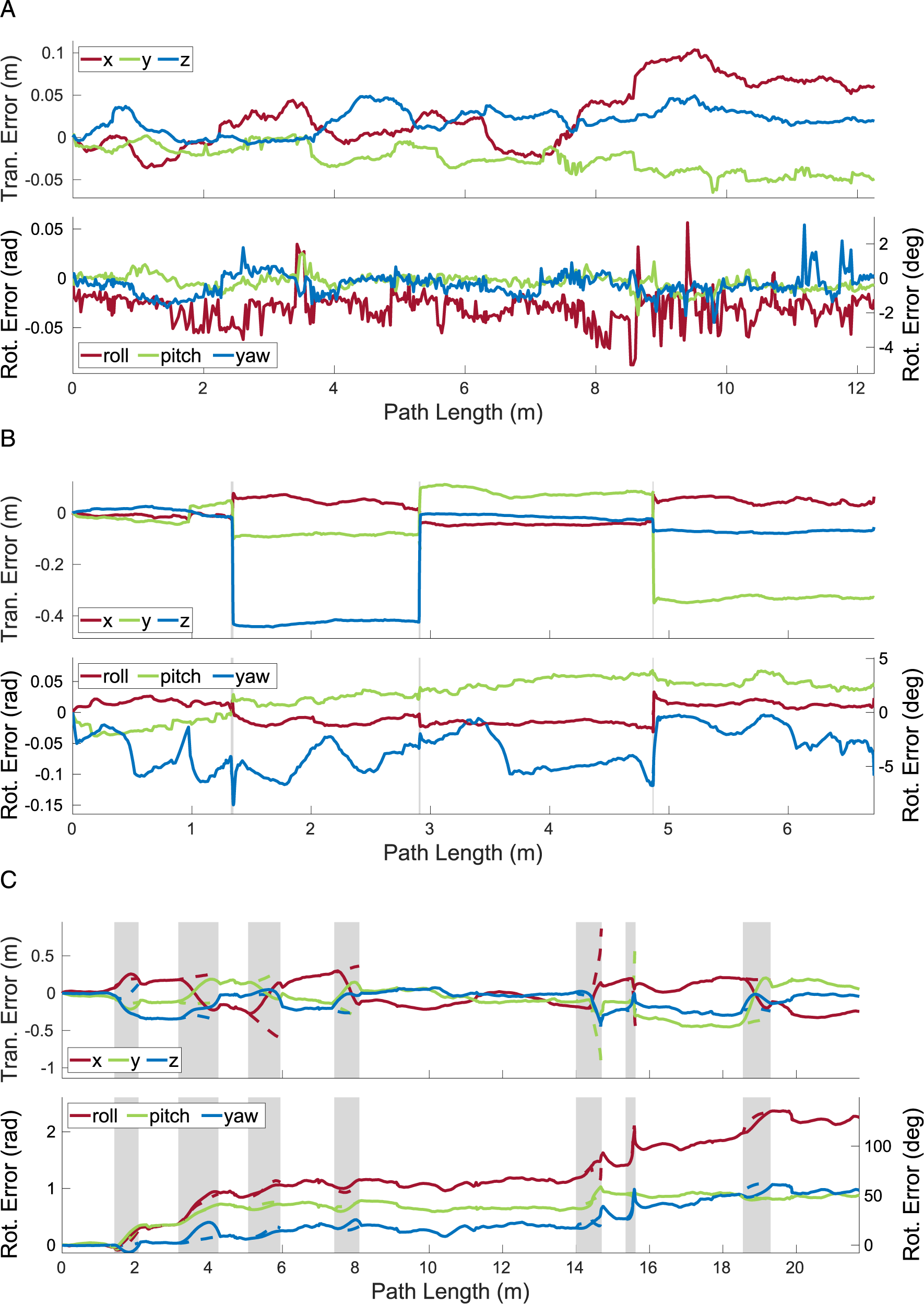
7.2.3. KITTI segments
MVO consistently estimates the motions of the camera and the cyclist throughout the
The egomotion estimation error for the different estimators and VDO-SLAM on the The translational and rotational errors estimated by MVO for the camera for the full 154-frame The translational and rotational errors estimated by MVO for the camera for the full 800-frame 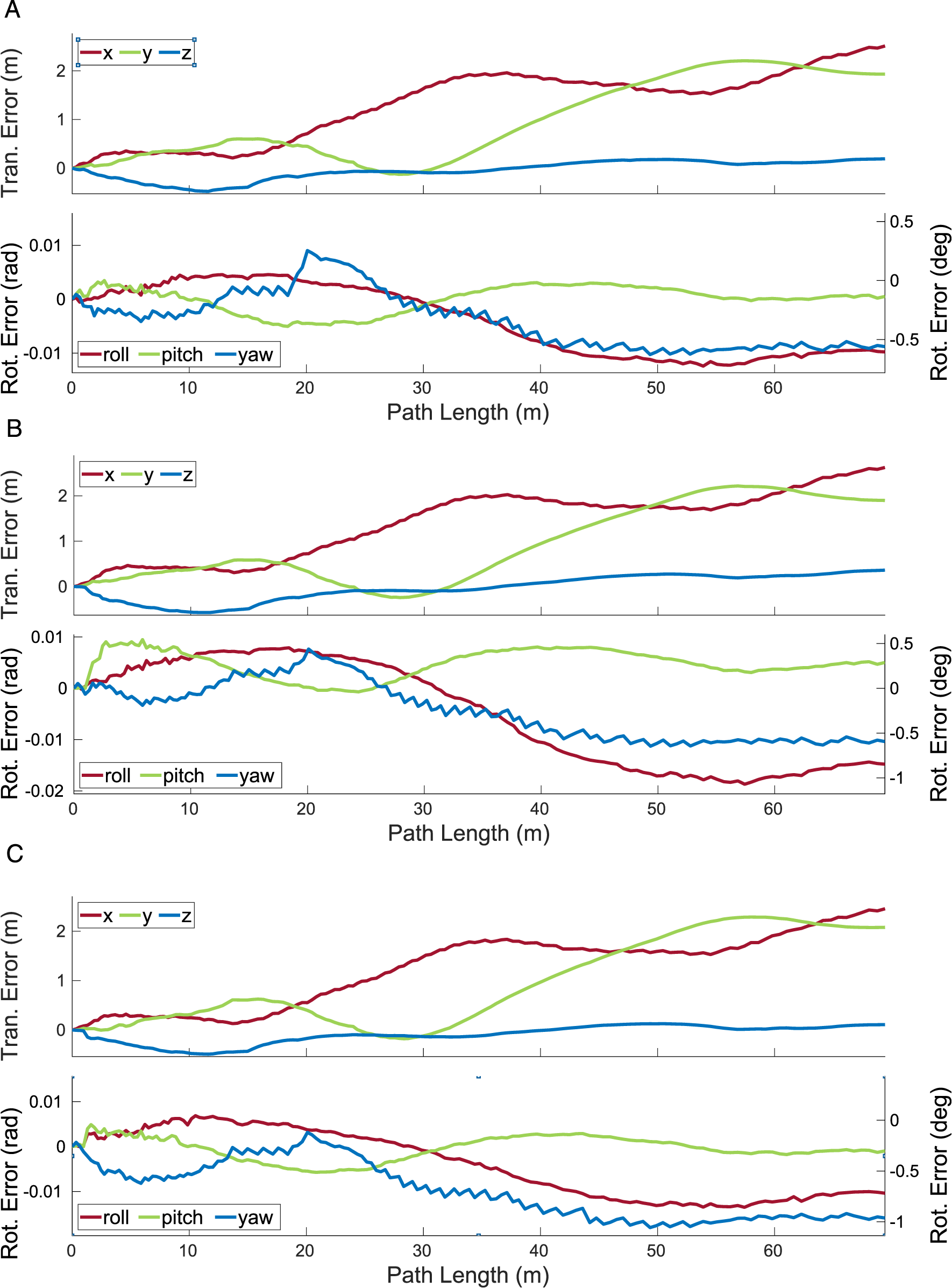
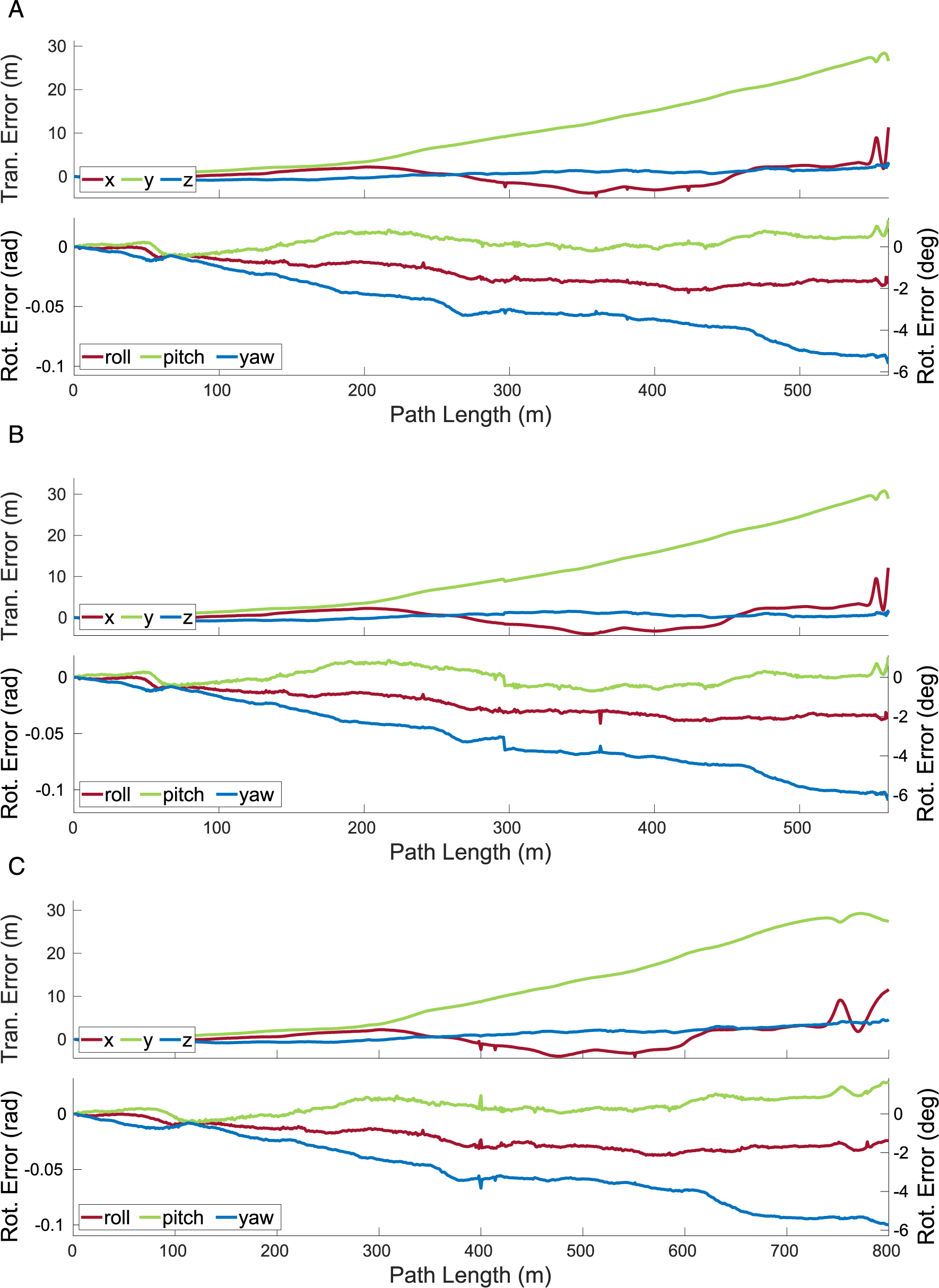
The decision of which estimator to use in any given application can be dependent on the requirements and characteristics of the situation. Based on the performance demonstrated on these segments, the WNOA is likely the most reliable prior for the general MEP. The WNOJ prior proved most accurate for interpolation, and it could likely be combined with the WNOA estimator for improved performance in cases with significant occlusion of nonconstant motions.
7.3. MVO comparison
MVO and VDO-SLAM demonstrate similar tracking performance, but MVO outperforms VDO-SLAM for metric estimation of both ego- and third-party motions for the
VDO-SLAM prioritizes estimating relative object motions in outdoor scenes with minimal rotation, such as autonomous driving scenarios, and is not designed for significant occlusion, so it is not evaluated on
Unlike VDO-SLAM, MVO is reliant on motion, so objects that temporarily move similarly may be given the same label, such as when the sliding block tower becomes stationary (Section 6.4). Extrapolating lost motions even when they are similar to existing motions allows temporarily similar motions to be resegmented once they diverge, providing a form of motion permanence. This allows the block tower to be successfully tracked through motion-based occlusions, but MVO still had higher egomotion errors in the
MVO and VDO-SLAM qualitatively demonstrate a similar ability to track both the cyclist and van in the
8. Conclusion
This paper presents MVO as an extension of the traditional VO pipeline to address the MEP. It uses multilabeling techniques to simultaneously segment and estimate all rigid motions in a scene. A variety of motion-based trajectory states are explored, and their effect on the ability to estimate independent SE(3) motions and track them through occlusions is discussed.
A stereo implementation of MVO is evaluated both quantitatively and qualitatively using the OMD (Judd and Gammell, 2019a) and the KITTI Vision Benchmark Suite (Geiger et al., 2012). MVO achieves egomotion estimation accuracy comparable to similarly defined egomotion-only VO systems, and it outperforms an appearance-based multimotion system (Zhang et al., 2020b) in addressing the MEP.
The pipeline operates directly on tracked 3D points and is agnostic to the type of sensor that generates them, so a variety of sensors and corresponding estimators can be employed in MVO (Judd, 2019). MVO also relies exclusively on motion-based estimation and tracking techniques. Future work will include extending MVO to other sensors, such as LiDAR and event cameras, parallelizing the batch estimation in order to run at real time, and introducing application-specific, appearance-based techniques to improve performance in specific environments.
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Supplemental Material
Footnotes
Appendix
Acknowledgments
We would like to thank Paul Amayo for providing his implementation of CORAL and the authors of VDO-SLAM for providing their results and discussing them. We would also like to thank the editorial board for considering this manuscript and our reviewers for their time and constructive criticism.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by UK Research and Innovation and EPSRC through Robotics and Artificial Intelligence for Nuclear (RAIN) [EP/R026084/1], ACE-OPS: From Autonomy to Cognitive assistance in Emergency OPerationS [EP/S030832/1], and the Autonomous Intelligent Machines and Systems (AIMS) Centre for Doctoral Training (CDT) [EP/S024050/1].
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.