
Abstract
In this paper, a new direct computational approach to dense 3D reconstruction in autonomous driving is proposed to simultaneously estimate the depth and the camera motion for the motion stereo problem. A traditional Structure from Motion framework is utilized to establish geometric constrains for our variational model. The architecture is mainly composed of the texture constancy constraint, one-order motion smoothness constraint, a second-order depth regularize constraint and a soft constraint. The texture constancy constraint can improve the robustness against illumination changes. One-order motion smoothness constraint can reduce the noise in estimation of dense correspondence. The depth regularize constraint is used to handle inherent ambiguities and guarantee a smooth or piecewise smooth surface, and the soft constraint can provide a dense correspondence as initial estimation of the camera matrix to improve the robustness future. Compared to the traditional dense Structure from Motion approaches and popular stereo approaches, our monocular depth estimation results are more accurate and more robust. Even in contrast to the popular depth from single image networks, our variational approach still has good performance in estimation of monocular depth and camera motion.
Introduction
Structure from Motion (SfM) is a crucial challenge in computer vision for a long time. Most existing state-of-the-art systems are regarded to be involving several consecutive processing steps. An important goal of these pipes is the estimation of the structure and relative motion for consecutive image pairs. There are some intrinsic limitations in current implementations of this step. For example, it is common sense to estimate the camera motion before recovering the structure of the scene by means of dense correspondence matching. Therefore, erroneous estimation of camera motion can lead to incorrect depth prediction. In addition, the lower-level process that the camera motion is estimated from sparse correspondences matching is prone to outliers and in-effective in non-textured areas. Finally, all current existing SfM approaches are not applicable to the situation of small camera translation as it is difficult to integrate priors knowledge to obtain the rational solutions in those degenerate cases. SfM estimated in a small baseline setting is regarded unreliable due to bas-relief ambiguity and a large amount of rotation between two cameras is required for accurate reconstruction.
Presently, most work on estimation of depth and motion from image pairs follows Marr and Poggio’s computational vision framework1,2 which was biologically inspired by human vision, and therefore consists of two processes of feature detection (acting as the correspondence role) and 3D reconstruction from matched features. Longuet-Higgins 1 presented the first algorithm for reconstructing 3D scene from two views where the first process of correspondence was assumed to have been solved and only the second process of 3D reconstruction was investigated. State-of-the-art systems3,4 are utilized for reconstructions of large scenes including big cities. They consist of a series of methods, starting with descriptor detecting and matching for searching sparse correspondences between image pairs, followed by solving the essential matrix to recover the camera motion. Before applying bundle adjustment to jointly optimize camera motions and structure of multiple images, the estimated accuracy mainly relies on the quality of the initial camera motion and structure between image pairs. Dense depth maps can be obtained by exploiting the epipolar geometry constraint after recovery of camera motion and sparse 3D point cloud. Such a divide-and-conquer strategy has been commonly adopted in computer vision community and a branch of multi-view geometry has been developed. Unlike above approaches, LSD-SLAM 5 considers multiple consecutive images from a short temporal window by jointly optimizing semi-dense correspondences and depth maps. DTAM 6 can estimate camera poses reliably by matching against dense depth maps. However, it still relies on classic structure and motion methods as an external depth initialization. Lately, CNN based optical flow methods7–10 have been proposed and show their good performances. These methods also can provide a dense correspondence to estimate the camera matrix for further 3D reconstruction.
Recently, SfM and optical flow (dense correspondences) share many connections. Estimation of Depth and camera pose from dense correspondence search has been presented by Valgaerts et al. 11 with the epipolar constraint as an extra term into the objective function to build a direct link between optical flow and SfM problem. Lately, Aubry et al. 12 presented a joint photometric and geometric variational model which focused on variational camera calibration to estimate camera extrinsics and dense correspondence for reconstruction. Other related work investigated in the framework of variational optimization include.13,14 In Becker et al., 13 the depth and camera motion were estimated by utilizing probabilistic inference in a video sequence. In Bagnato et al., 14 the depth and camera motion were alternately optimized for omnidirectional image sequences. Roxas and Oishi 15 proposed to separately optimize the camera extrinsics and 3D structure in existing SfM methods by adding the epipolar geometry as a soft constraint and refining the dense correspondence. However, all above referenced approaches are brue and two-stages for depth estimation. Therefore, extra error would be introduced into further recovering 3D structure by the incorrect camera motion estimation.
Meanwhile, Dense 3D reconstruction using motion stereo vision has been a hotspot research subject. Several methods have been proposed in successfully solving the 3D reconstruction problem.16–19 Stühmer et al. 16 presented a TV-L1 minimization framework to handling the correspondence problem. Graber et al. 17 solved the smoothness problem based on minimal-surface smoothness regularization. Galliani et al. 18 proposed a multi-view PatchMatch Stereo approach with an additional 3D integration step. Recently, many depth estimation from single image networks20–28 have been presented to estimate the monocular depth for automatic drive and have showed their good performances. However, they all need extra information, that is, view synthesis or stereo images as the supervisory signal. Meanwhile, those methods are not suitable for multi-view 3D model reconstruction.
In this paper, we propose a new direct computational approach to solve dense 3D reconstruction problem that includes computation of depth, estimation of dense correspondences, and the camera motions between image pairs. Here, the “direct” means that the intermediate process of feature detection or correspondence is not needed in the proposed approach. Instead, as a “by-product”, the correspondence task is accomplished in the process of depth estimation. Specially, the admission solution for the depth is restricted in smooth surfaces, in order to overcome the ill-posedness of the binocular depth estimation where the depth in 3D space is to be inversely recovered from 2D images. The camera motion and dense 3D structure are estimated by minimizing an variational objective function. Different from Hu and Chen 29 the texture constancy constraint, one-order motion smoothness constraint, a second-order depth regularize constraint, and a soft constraint are integrated in the objective function in the proposed method. The texture constancy constraint can improve the robustness of our method to illumination change. one-order motion smoothness constraint can smooth the calculated optical flow field and reduce the noise in estimation of dense correspondence. The depth regularize constraint is used to guarantee a smooth or piecewise smooth surface, and the soft constraint can provide a dense correspondence as initial estimate of the camera matrix. This work can effectively addresses the dense reconstruction problem, and as a result, improves the quality of depth prediction and camera motion estimation. In summary, we show a variational model for jointly estimating of depth, camera motion which effectively breaks through Marr and Poggio’s biologically inspired framework on computational vision. The experimental results show that the proposed approach can work well even on complex scene.
The rest of the paper is organized as follows. In section II and III, basic concepts and the direct variational approach are reviewed. The Implementation about occlusion handling and ambiguity and numerical solution are presented in section IV. Experimental results and conclusion are given in section V and VI.
Basic concepts
Let us start by defining image pairs of a static scene
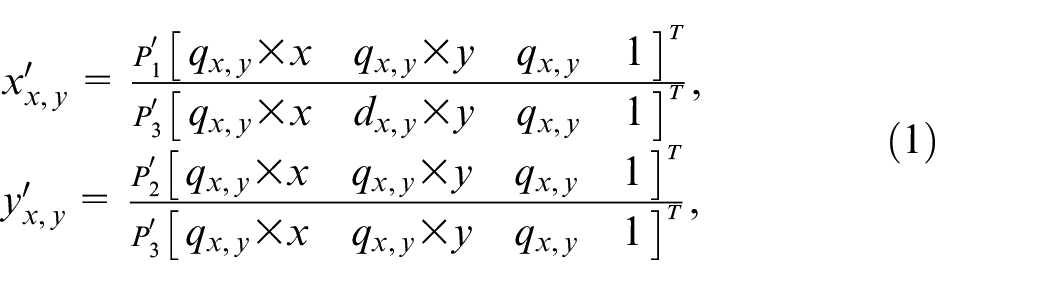
where
For a concise representation, as the cameras are calibrated, suppose camera matrix
Framework overview
Dense correspondence constraint
The brightness constancy assumption states that the intensity of a pixel keeps constant in two views when the object or camera moves. The brightness constancy constraint has been used in most of optical flow approaches. It is usually expressed as
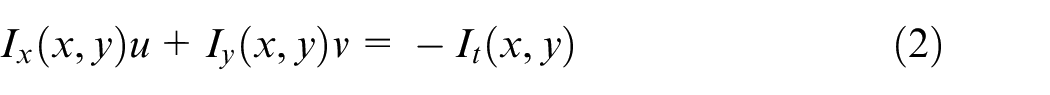
where
Recently, image textures based on different types of descriptors, such as the histogram of oriented gradient, 30 the modified local directional pattern, 31 and the census signature 32 have been successfully embedded in the optical flow estimation. The image textures are robust against illumination changes. Afterwards, the variational model has been modified to utilize the texture constancy assumption based on the extracted features. In our paper, the framework of dense correspondences which contains the texture constraint based on the histogram of oriented gradient 32 and a one-order motion smoothness constraint is formulated as:
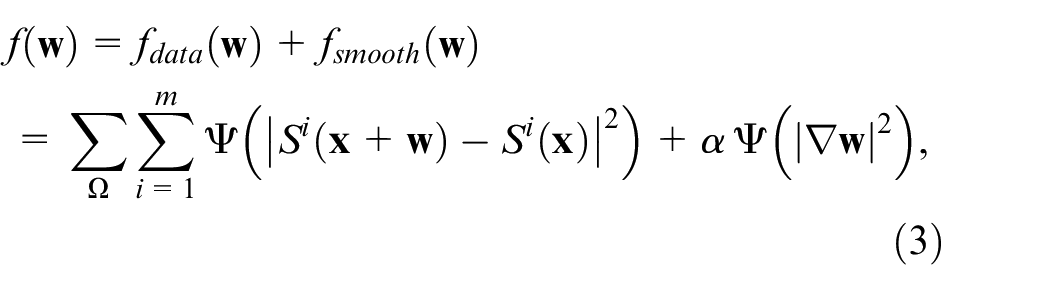
where m states the number of color channels,
Second-order depth regularization
It is a common sense that the second-order smoothness prior as depth constraint is more suitable for scenes with complex geometric characteristics to deal with ambiguity at object boundaries. Considering slanted surfaces in the reconstruction, we take advantage of the second-order depth regularization which allows to model linear depth changes
33
instead of using a first-order depth constraint that inherently favors fronto-parallel surfaces. Then, a stair effect for slated or highly curved surfaces is generated:
The triple-clique
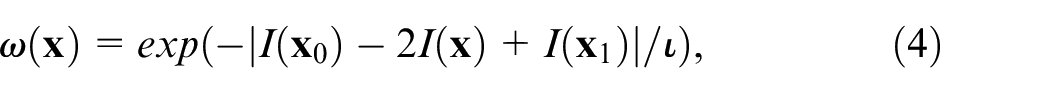
where
This second-order depth smoothness prior can help to capture richer features of local structure and permit planar surfaces.
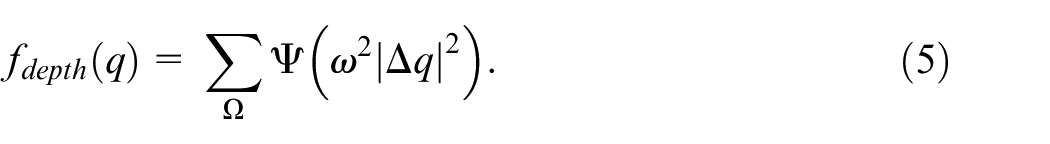
In order to overcome the tendency for large depths, the following regularization term is used:
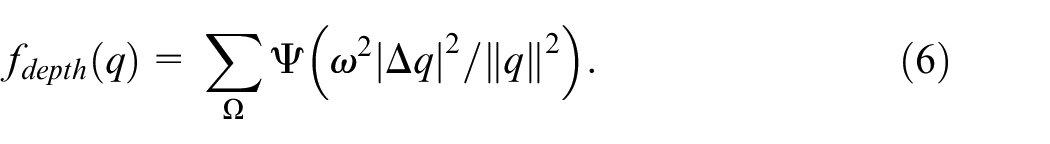
Soft regularization
As descriptor matching is a discrete technique that can not provide subpixel accuracy in optical flow estimation, to further improve the accuracy of depth estimation and the robustness in complex scene, we would like to combine some excellent optical flow matching with the variational model in its coarse-to-fine optimization.
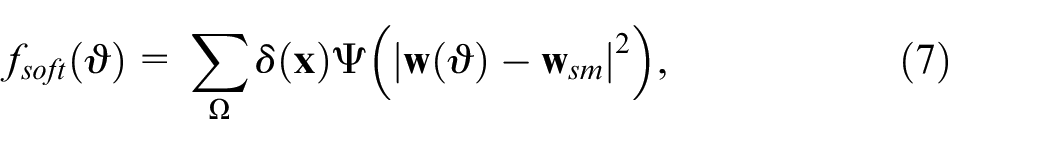

where
Variational model
Above all, the flow field
As described above, we propose to impose a soft constraint on the optical flow and a second-order smoothness constraint directly on the depth. Therefore, the following objective function is used:
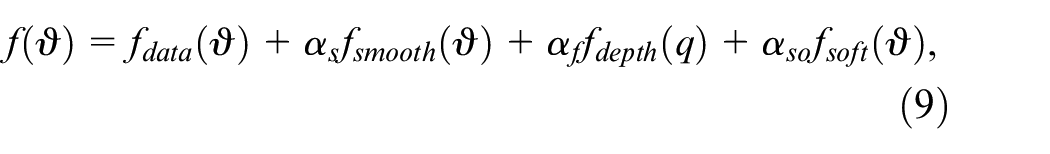
where the depth parameter q and the camera matrix
Implementation
Occluded handling
Occlusion estimation is a universally known and long-standing difficult issue that 3D reconstruction has been entangled with. Accurate priori knowledge of occluded regions is crucial for reliable 3D reconstruction. Yet, estimating accurate 3D reconstruction, conversely, is required for localizing occlusions reliably as it causes severe distortion around occlusion. Checking the left-right motion consistency in a subsequent post-processing step and extrapolating flow into inconsistent regions also helps resolving the motion mismatch in the occluded area. Occlusion is a challenging issue for our proposed method as 3D structure can’t be rebuilt for occluded parts. Here, our occlusion detection is based on the forward-backward consistency assumption. 35 It means that we hope the forward flow should be equal to the inverse of the backward flow at the corresponding pixel in the second view for non-occluded pixels. If the mismatch between the two flows is too large, the pixels can be marked as occluded. Thus, occlusion in the forward direction can be set to be one wherever the constraint is violated, and zero otherwise.
The occlusion in the forward direction can be defined as:
The occlusion in the backward direction can be defined as the same way. In all of our experiments,
With the forward-backward consistency constraint, the pixels satisfy the bi-directional flow consistency are forced to be visible. Otherwise, they are identified as occlusions.
Update of projection matrix in the coarse-to-fine framework
In the coarse-to-fine optimizing stage for our approach, with a ratio
Ambiguities
As for depth estimation, in Euclidean/similarity reconstruction, there still exist two types of inherent ambiguities: scale ambiguity and bas-relief ambiguity. Regardless of calibrated or un-calibrated cameras, the scale of the reconstructed scene can’t be determined due to the scale ambiguity. That is, when the translation vector between two cameras scales k times and the scene scales k times, no change on two views is resulted in.
Mathematically, the objective function does not change when inherent ambiguities happen. Supposing
In addition to the scale ambiguity, the bas-relief ambiguity happens, when the rotation angle between two cameras is small enough and consequently the focal length can’t be reliably estimated in such settings. The effect of bas-relief ambiguity becomes clearer in a simplified model, where two parallel cameras are
Changing to the default camera representation, where the first camera projection matrix is
Scale ambiguity and bas-relief ambiguity are actually two particular sub-classes of projective ambiguities, with a projective transformation of
Sensitiveness to noise due to bas-relief ambiguity
In addition, the SfM estimation in a small-baseline setting is regarded unreliable due to the bas-relief ambiguity, 36 Here, it should be stressed that the unreliability in SfM does not mean the bas-relief ambiguity itself, but the sensitiveness to the inaccuracy in correspondence or estimated disparity when the bas-relief ambiguity happens. The ambiguities happen because some factor, for example the scale or the focal length, can’t be visually determined, and consequently, the 3D reconstruction can be done up to a subclass of projective transformations.
The difficulty with the bas-relief ambiguity lies in the sensitiveness to the correspondences in accuracy in SfM when the bas-relief ambiguity (approximately) happens. Specifically, the inaccuracy in depth estimation due to the error in estimated disparity is approximately proportional to the square of the depth when the bas-relief ambiguity happens, as can be verified by the fact that the angular disparity approximately decreased with the square of the observation distance. Consequently, sparse SfM in a small baseline setting is still a challenge for existing algorithms, let alone propagation-based dense 37 or quasi-dense SfM. 38 Moreover, the resulted sensitiveness due to bas-relief ambiguity is aggravated by the current separate-manner SfM, to bas-relief ambiguity is aggravated by the current separate-manner SfM, where the depth estimation can be regarded as being separately accomplished feature by feature.
On the other hand, such sensitiveness to noise in a small-baseline SfM can be suppressed to a great degree in the proposed approach. As a result of the regularization technique, the depth estimation in the proposed approach is implemented, not in a separate one-by-one manner, but in a locally con- strained way with its neighbors. Thus, noise in a single pixel or even in a local patch does not lead to unpredictable error. In addition, the advantage of the proposed approach can also be demonstrated in a complex scene, where a satisfactory 3D reconstruction is produced except around occlusions.
A new interpretation in nonlinear LS
Note that each term of the objective function (9) is convex. Above all, the objective function (9) can be rewrite as:
wherein

The objective function (12) is optimized by employing an iterative algorithm in nonlinear LS. We define an integral L which meet the standard form of the Euler-Lagrange constraint in calculus of variations as below. (Omitting the camera matrix parameter
According to the Euler-Lagrange equation, for reaching an extreme value, the objective function (14) must meet:

Particularly, the Euler-Lagrangian equation (15) is:
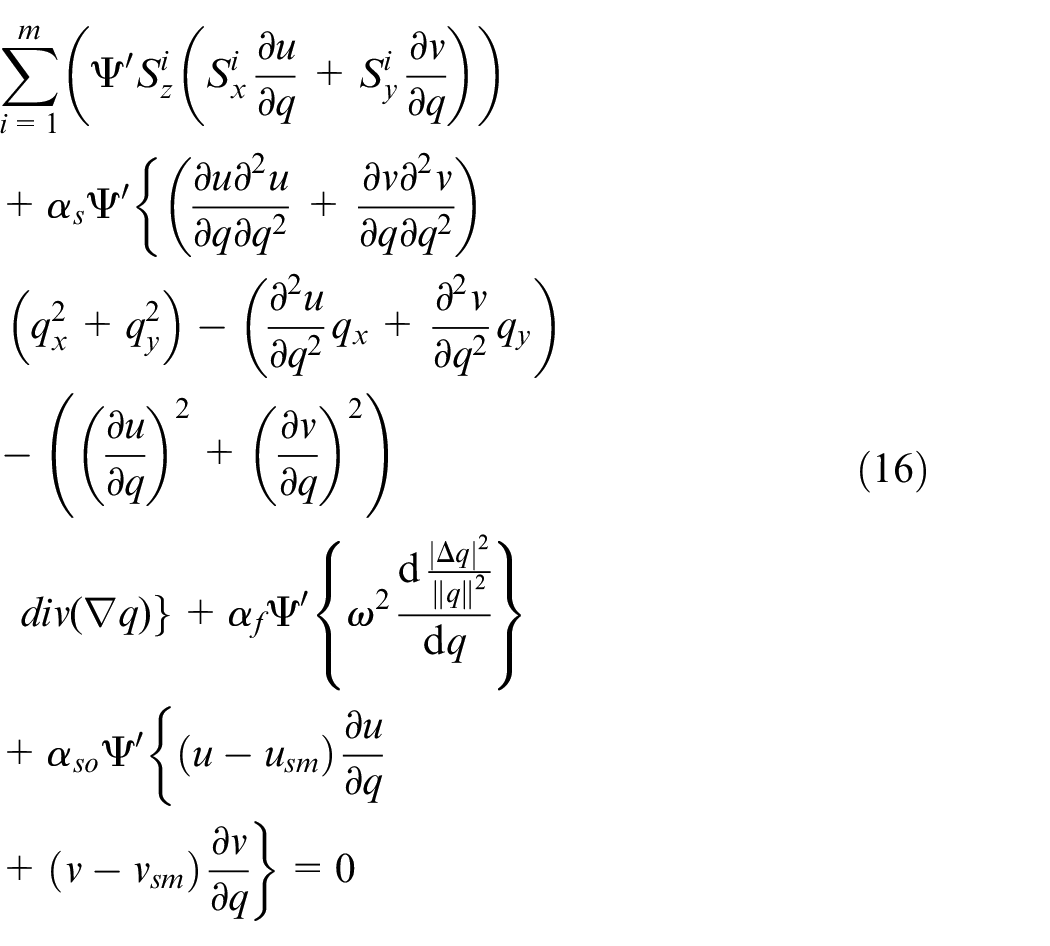
where the symbolic expressions are used as:
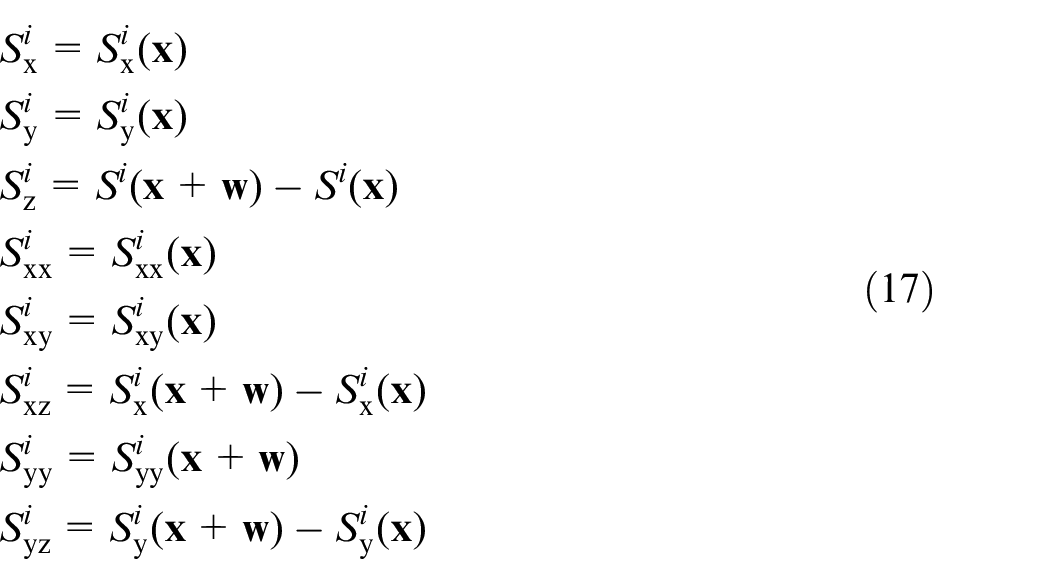
Meanwhile, according to the theorem that the derivative of the extrenum is zero, the objective function (12) meets:

that is,
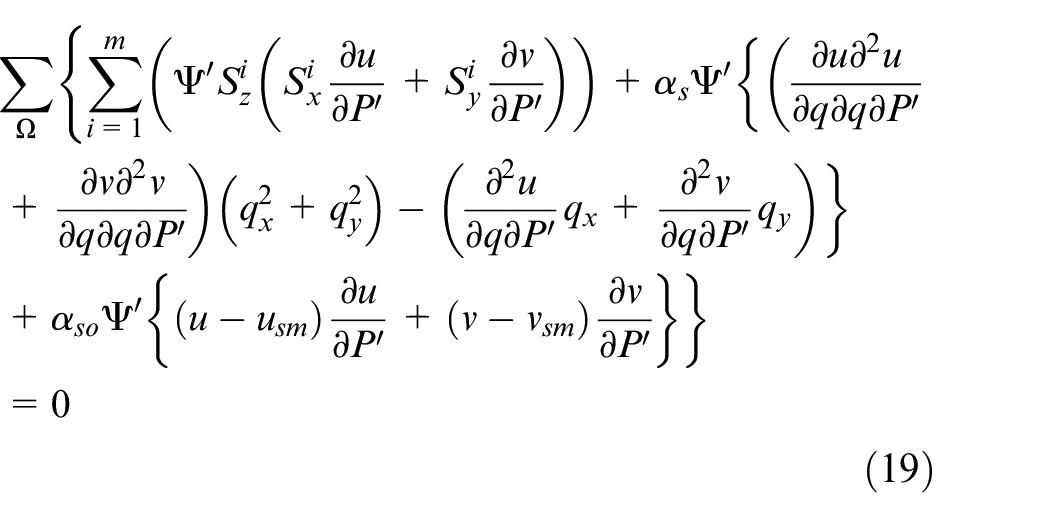
To this end,
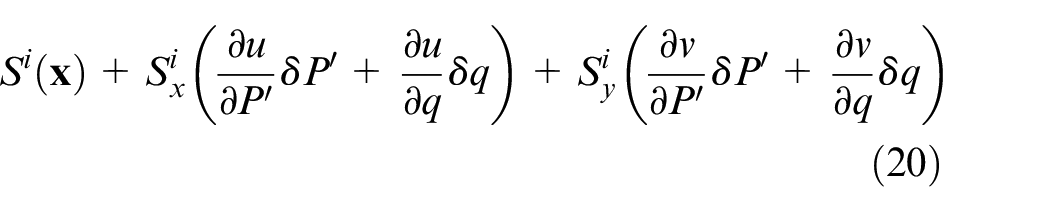
where

Then,

In this way, calculation on each iteration turns into solving

Results and comparison
In this paper, we mainly focus on solving the reconstruction problem for two images. Although there are many existing multiview methods which can provide more accurate reconstruction results have been proposed, we leave the extension to the multi-view problem for future work.
To evaluate the performance of our algorithm, we make use of three public datasets: the KITTI dataset,
39
Strecha dataset
40
and the official KITTI visual odometry split. Meanwhile, the forward-backward consistency assumption
35
is taken to using for occlusion handling. For all experiments on KITTI dataset, the same parameters are set as :
KITTI dataset
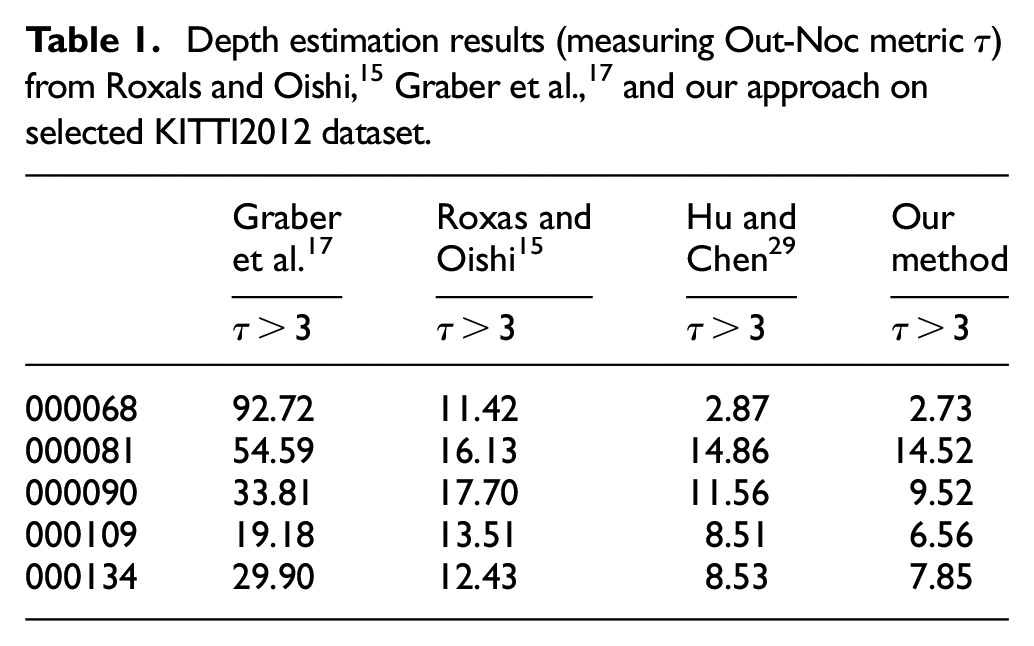
Here, the KITTI dataset
39
is used to evaluate the reconstruction performance by comparing the depths with Roxas and Oishi
15
and Graber et al.
17
using estimated pose. the qualitative depth results are shown in Figure 1 for sample images in terms of the estimated camera pose. The color-coding marks and visualizes outliers (

Depth (normalized color), optical flow and their Out-Noc results on the KITTI2012 for our approach using estimated pose. From top to bottom: 000068, 000081, 000090, 000109, and 000134.
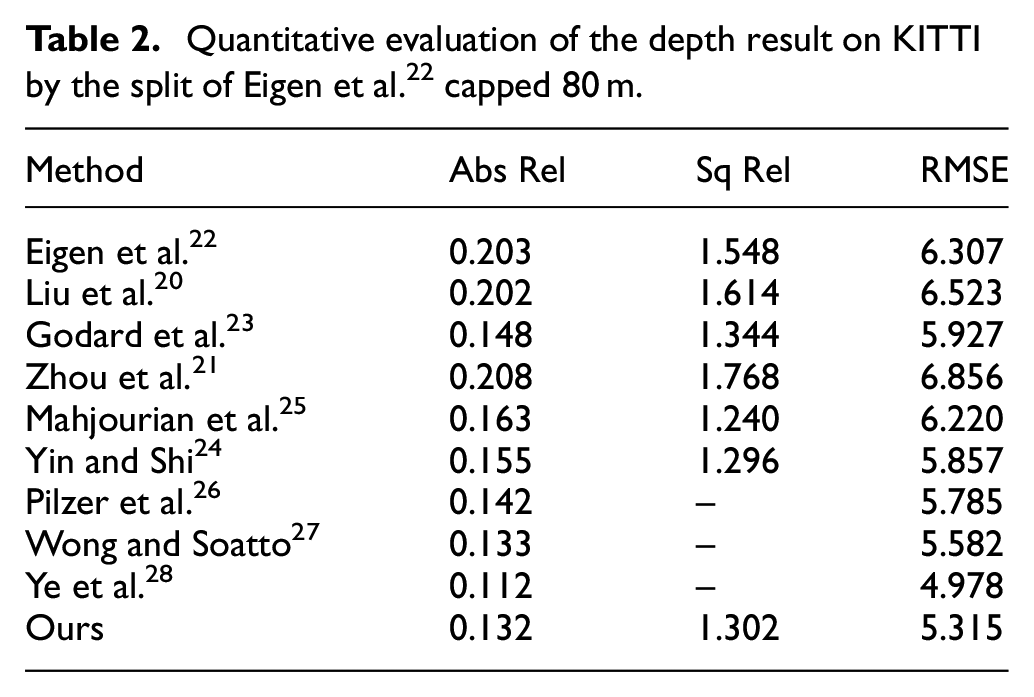
Quantitative evaluation of the depth result on KITTI by the split of Eigen et al. 22 capped 80 m.
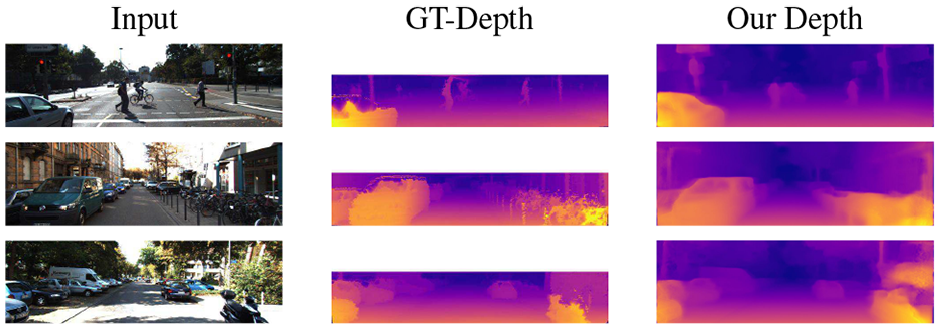
Qualitative results on the KITTI Eigen Split. The ground truth velodyne depth being very sparse, we interpolate it for visualization purpose.
To evaluate the dense correspondences, our simulation results of optical flow estimation on KITTI2012 are compared with the publicly available implementation DeepFlow,
9
FlowNet2,
34
and Roxas and Oishi.
15
We compare the computed optical flow with previous traditional methods by EPE in Table 3. The estimated visualize results are shown in Figure 1 as same as the depth color coding results by measuring the percentage of erroneous pixels (
AEE (average endpoint error) on the KITTI2012 dataset comparison of the optical flow results.

Strecha dataset
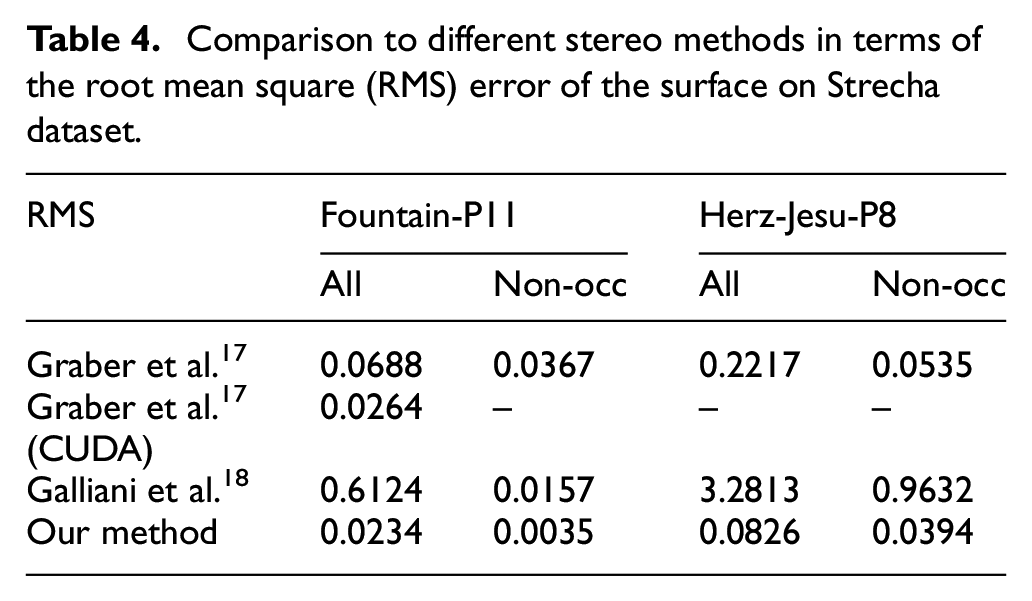
Our approach also are applicable to model reconstruction, we use two consecutive frames of Fountain-P11 and the Herz-jesu-P8 subdataset in the strecha dataset 40 with the approximate ground truth 3D model captured with laser radar system (LIDAR). Since the recovery of fine details heavily depends on the sharpness of the involved images, we downsample the initial slightly blurred frames to halve its resolution before rebuilding the scenes from only two views for our experiment.
We compare our reconstruction results with two recent proposed stereo approaches which can be applied to arbitrary camera settings. The variational method of Graber et al. with a surface smoothness constraint has a significant improvement on the performance compared to stand TV-regularization. The basic approach of Galliani et al. which is considered as the multi-view variant of PatchMatch Stereo would omit the additional 3D integration step in our experiment because the depth map only need to be evaluated from the reference camera. Qualitative results for the Fountain-P11 and the Herz-Jesu-P8 images are depicted in Figure 3. For the Fountain-P11 dataset, we can see that the corresponding reconstruction of Gallinai et al. can’t generate fine details and contains many significant outliers in occlusion areas. The method of Graber et al. recovers a more detailed reconstruction with considerate noise. Compared with these two stereo approaches, the reconstruction of our approach is quite accurate in depth estimation. While flat surfaces are almost noise free in non-occlusion areas, details of the fountain and the wall are more pronounced. Also, the results of Herz-Jesu-P8 dataset is also visually appealing. The quantitative numbers of the results on the strecha dataset are shown in Table 4. It reveals that the RMS errors of our approach are significantly lower than those of the above two stereo methods both for the Fountain-P11 and the Herz-Jesu-P8 images.

Comparison to different stereo methods in terms of the root mean square (RMS) error of the surface on Strecha dataset.
Pose estimation
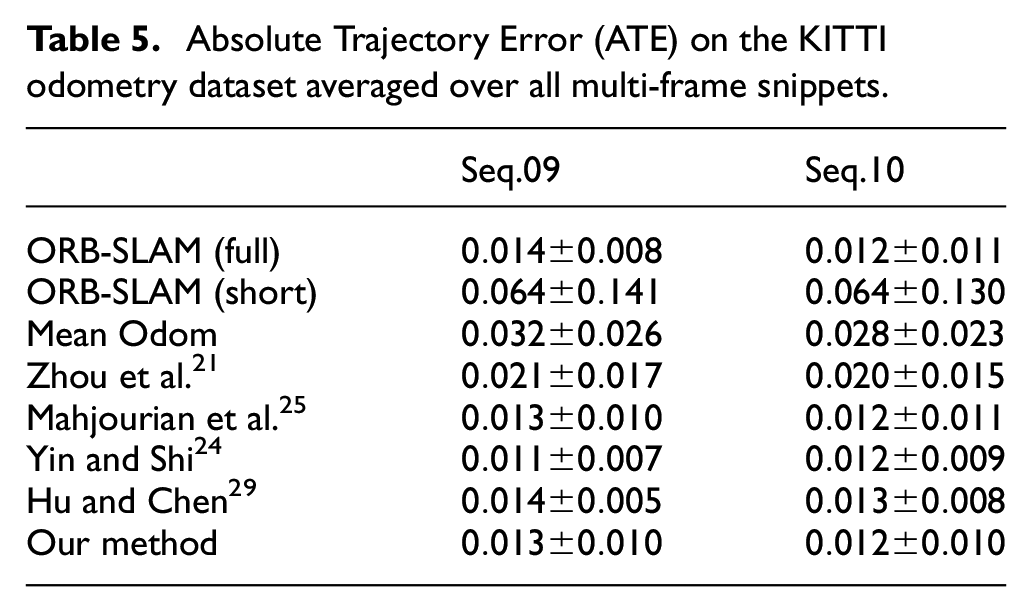
In this paper, sequences 09–10 of the official KITTI odometry split are applied to our algorithm to evaluate the performance of our approach in camera pose estimation. The common 5-point Absolute Trajectory Error (ATE)20–25 metric measures local agreement between the estimated trajectories and the respective ground truth. Moreover, we compare our method with a traditional representative SLAM framework: ORB-SLAM. 42 It involves global optimization steps such as loop closure detection and bundle adjustment. As shown in Table 5, our method significantly outperforms the unsupervised methods by Liu et al., 20 Zhou et al., 21 Eigen et al., 22 Godard et al., 23 and Hu and Chen, 29 but falls short of Yin and Shi 24 and Mahjourian et al. 25
Absolute Trajectory Error (ATE) on the KITTI odometry dataset averaged over all multi-frame snippets.
Conclusion
In this paper, a direct dense 3D reconstruction approach is proposed by jointly employing the framework of multi-view geometry and the regularization strategies involving the texture constancy constraint, one-order motion smoothness constraint, depth regularize constraint and soft constraint. The texture constancy constraint is conducive to improve the robustness against illumination changes. One-order motion smoothness constraint is used to guarantee smooth dense correspondences. The depth regularize constraint is taken to handle inherent ambiguities problem, and the soft constraint can provide a more accurate dense correspondence to improve the robustness future. The results showed our approach have a good performance in depth estimation. It matches or outperforms the excellence variational depth estimation methods and state-of-the-art CNN models. We also achieved comparable results with existing variational and learning-based camera pose estimation methods. Our approach is still limited by the occlusion problem and cannot account for large illumination change. In future work, we will focus on these problems to create a more robust and accurate system that can handle occlusion problem and be applied to more complex scenes.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.