
Abstract
Mobile robots should possess accurate self-localization capabilities in order to be successfully deployed in their environment. A solution to this challenge may be derived from visual odometry (VO), which is responsible for estimating the robot's pose by analysing a sequence of images. The present paper proposes an accurate, computationally-efficient VO algorithm relying solely on stereo vision images as inputs. The contribution of this work is twofold. Firstly, it suggests a non-iterative outlier detection technique capable of efficiently discarding the outliers of matched features. Secondly, it introduces a hierarchical motion estimation approach that produces refinements to the global position and orientation for each successive step. Moreover, for each subordinate module of the proposed VO algorithm, custom non-iterative solutions have been adopted. The accuracy of the proposed system has been evaluated and compared with competent VO methods along DGPS-assessed benchmark routes. Experimental results of relevance to rough terrain routes, including both simulated and real outdoors data, exhibit remarkable accuracy, with positioning errors lower than 2%.
1. Introduction
Mobile robots require highly sophisticated and accurate algorithms to achieve accurate location estimations while moving in unknown environments and possessing no prior knowledge of the scene or the robot's motion [1]. Visual odometry (VO) algorithms are able to provide a solution in this respect, and the development of such effective algorithms has become an active research topic as a result. Compared to standard wheel odometry, VO encapsulates a number of advantages, such as the elimination of errors due to wheel slippage in estimating the camera position and the ability to obtain 3D motion estimations even with non-planar surfaces (where wheel odometry alone can only achieve 2D path estimation). Consequently, VO has become a prerequisite for many practical requirements of robotics technology, such as obstacle avoidance, simultaneous localization and mapping, and even in path-planning. It is only in applications where external disturbances of the camera do not allow for a VO solution that researchers investigate other odometry solutions, such as inertial-based solutions [2, 3]. The majority of VO algorithms utilize feature tracking to estimate the relative incremental motion between successive frames with sufficient spatial overlap. The estimation of the path followed is actually based on the summation of smaller, independent motion estimates. However, incremental egomotion estimation typically involves a certain amount of drift, which grows with the distance travelled, leading to accumulated pose errors as a result. In recent years, sophisticated methods have provided more efficient solutions, resulting in accurate localization systems. As described in [4], the trajectory of a robot can be refined by a computationally intensive iterative optimization technique known as sparse bundle adjustment. The computation time of this method increases with the number of images, and therefore it is only applicable to robots with augmented computational resources. Another method for increasing the efficacy of VO algorithms is loop-closure, as reported in [5]. This relies on the hypothesis that a robot following an arbitrary route will eventually return to a previously visited area, and thus a database containing the salient points of every visited scene should be retained. Once a query image is matched with an image in the database, refinements to the covered path of the robot are applied. This approximation is very efficient when robots operate in indoor environments; however, in the domain of field robotics, where long distances need to be covered, the probability of passing through the same area twice will be low. Moreover, the size of the database grows continuously, resulting in an increased computational burden every time a new query image appears in the field of view (FoV) of the robot. Other approaches in this domain address the issue of the occurrence of cumulative errors in the pose of the robot by integrating information derived from both the onboard visual system and the global positioning system (GPS) [6]. Although the resulting VO framework enjoys more accurate estimations of the trajectory, when the robot operates in outdoor environments, it suffers from uncertain motion estimations in places with poor GPS reception.
The proposed VO algorithm was developed within the SPARTAN (Sparing Robotics Technologies for Autonomous Navigation) project, funded by the European Space Agency (ESA). This project focuses on the hardware implementation of computer vision algorithms suitable for planetary exploration rovers that exhibit limited computational resources, as described in [7]. Therefore, the present paper discusses in detail the developed localization algorithm as part of the SPARTAN vision system, which has been integrated and tested on a custom-made robotic platform. More precisely, this paper also extends the early work presented in [8] by thoroughly presenting the theoretical background of the statistical outlier detection algorithm, by providing a relationship between the robot's velocity and the camera's frame rate (aiming to regulate the outlier detection procedure), and by assessing the proposed algorithm with numerous simulated and real world datasets.
It is apparent that the adopted solution should avoid computationally demanding strategies and aim at the development of an algorithm able to operate in real time, even in robots with limited computational resources. Emphasis was placed on developing custom, non-iterative solutions at each step of the proposed algorithm's execution—the ultimate goal being to achieve solutions implementable for the hardware. The first step in the proposed VO method consists of the detection of the salient landmarks between successive images. We use the Speed-Up Robust Features (SURF) feature detector and matcher [9], which ensures great repeatability and speed in the detection of the features between two consecutive frames with significant spatial overlap. A depth estimate of these features is then obtained by means of an enhanced stereo correspondence algorithm. Our solution is a rapidly executed local stereo algorithm embodying a bidirectional consistency check. The next step consists of a non-iterative outlier detection methodology able to discard both the mismatches between the features and the inserted errors due to the 3D reconstruction procedure. A hierarchical motion estimation technique, which produces robust estimations for the movement of the robot is then adopted, thus providing refinements to the robot's global position and orientation every time a new frame arrives. The resulting overall algorithm requires modest computational effort and can thus be exploited in applications where hardware implementation becomes a necessity. The subordinate modules of the introduced VO algorithm are summarized in Fig. 1.

Block diagram of the proposed VO algorithm
In a nutshell, the contributions of this paper can be summarized as:
The introduction of a non-iterative outlier detection technique suitable for real-time robot applications.
The presentation of a hierarchical motion estimation method producing robust orientation and position estimations while providing refinements to the robot's trajectory at every single step.
The design of the subordinate modules of the proposed VO algorithm in order to maintain the overall computational payload as low as possible.
The rest of the paper is organized as follows: the related work is outlined in Sec. 2; the adopted feature detection and matching technique are presented in Sec. 3.1, while the stereo correspondence algorithm with the 3D reconstruction routines is demonstrated in Sec. 3.2. Sec. 3.3 introduces the outlier detection method and Sec. 3.4 describes the hierarchical motion estimation methodology. In Sec. 4, the experimental validation is presented, followed by the discussion in Sec. 5.
2. Visual Odometry Methods
Recent decades have seen the application of VO methods to a significant number of implementations involving both real-time and offline approaches. Due to the fact that several alternative robotic architectures have been proposed, any attempt to provide a categorization of VO algorithms faces various difficulties. A common separating line among existing techniques is that involving vision, i.e., robots bearing either monocular or stereo vision systems. With regards to systems involving monocular vision, successful results for long-range routes have been presented, exploiting both perspective and omnidirectional cameras, as described in [10, 11] and [12]. However, it is well known that a moving calibrated camera observing a scene can recover the camera geometry and motion only up to a certain scale factor [13]. Due to this fact, VO algorithms implemented for stereo vision exhibit more stable behaviour [14] and, as a result, they have been preferred in the majority of the research conducted in the area [15]. In a stereo VO system, correspondences among points of interest appearing in a stereo rig are computed first in order to produce a disparity map, and then, by exploiting this depth information, 3D points are triangulated and fed into a module to estimate 3D motion [16].
VO frameworks can also be categorized according to the landmark detection method used. For example, in [17], the author adopts the feature tracking-based technique, while in [18] the optical flow method, which is based on local neighbourhood correlation, is utilized. In contrast with the dense optical flow technique, the utilization of a feature tracking method leads to less computationally demanding motion estimation tasks. Moreover, the success of the solely vision-based localization algorithms is, to a large extent, due to the development of robust feature detection and description methods. The most common feature detector is the Harris corner detector [19], while more recently developed feature detection methods, such as SIFT [20], SURF [9] and even CenSurE [21] involve both feature detection and description practices. The mismatches within the tracked features, which result from either erroneous estimations of the feature detection algorithms or poor estimations of the depth during the 3D reconstruction, lead to cumulative errors when employed in an incremental motion estimation. Such limitations have led to multiple outlier detection techniques which aim to cope with this problem [22]. In the work presented in [23], the authors make use of the RANSAC algorithm [24] in a least-square motion estimation routine for the detection of the outliers. This technique has since been adopted in many localization algorithms, such as those described in [25] and [26]. An alternative approach to detecting and removing outliers in such a localization system is that described in [27], where only the salient points possessing a high confidence in the disparity space are retained, thus avoiding the introduction of noise due to mismatches in the stereo correspondence routine.
VO algorithms can be further categorized according to the means utilized in estimating robot motion. The majority of the developed monocular VO techniques rely on the theory of structure from motion (SFM)—the beginnings of which are traced in [28]. Methods exploiting SFM theory calculate - usually under a restriction of error - the relative position and orientation of a set of frames relying on the matched salient points of the respective scenes [29, 30]. In addition, VO algorithms are usually accompanied by a refinement step that results in small corrections to the estimated robot trajectory. One of the most common techniques used is referred to as sparse bundle adjustment. According to this framework, location estimations can become more accurate by retaining a portion of any recent features in an iterative structure [31], thereby making the need for increased computational resources imperative. A rather different approach - also leading to localization refinements - is that based on location recognition, i.e., loop-closure detection. This technique relies on content-based retrieval practices, in order to refine the robot's position estimation when features of a new frame are matched with those already existing in the database [5]. For a more comprehensive and in-depth literature survey of the VO algorithms that have been developed, the reader may refer to [32].
3. Algorithm Description
In this section, the overall description of the proposed methodology is presented. It provides details of the 2D feature detection and matching routine, the 3D vision algorithm and the intermediate filtering steps, the outlier detection and discarding routine, the motion estimation as well as the one-step position refinement of the front end of the proposed algorithm. A detailed schematic depiction of the VO single-frame incremental update is provided in Fig. 2.

Schematic representation of the VO single-frame incremental update approach
3.1. Feature Detection and Matching
One of the most common traits among the VO algorithms is that they employ a feature detection methodology which in effect detects the salient points of an image. The most popular such methodologies employed in the localization problem are the SIFT, SURF and Harris corner detectors. The first two detectors are supplemented by their own description and matching algorithms. The Harris corner detection algorithm is a detector only, locating the corners of a scene; a common procedure to match such points with the corresponding points in successive images involves correlating the local neighbourhoods around the detected corners. Among the potential detectors that can be used in the localization algorithms [33], the proposed system here employs SURF, which comprises a scale and rotation invariant detector and a descriptor. This attribute ensures robustness in the motion estimation when the robot's movement involves large motions around or along the optical axis. Moreover, the main reason moving us to choose the SURF algorithm lies in its potential to achieve high repeatability, distinctiveness and robustness, while revealing high computational efficiency, thus allowing significantly faster computation times at the same time. SURF provides a list containing the image coordinates of N matched features in two images. When two consecutive left-reference images of the stereo rig corresponding to the times t and t+1, respectively, are fed into the SURF algorithm, the number N of the features that result depends on a specific threshold. Fig. 3 depicts the SURF features matched across two frames, overlaid on the first one. More analytically, two different scenarios are tested in the same set of successive images: one with a strict SURF threshold and the other with a more tolerant one. Note that in Fig. 3(a), where the threshold is exacting, no mismatches occur, as compared with Fig. 3(b) where the threshold is loose and, as a consequence, several mismatches can be found. In the proposed VO algorithm, a very stringent threshold is utilized, ensuring that the algorithm returns features that are robust enough, thus decreasing the occurrence of mismatches.
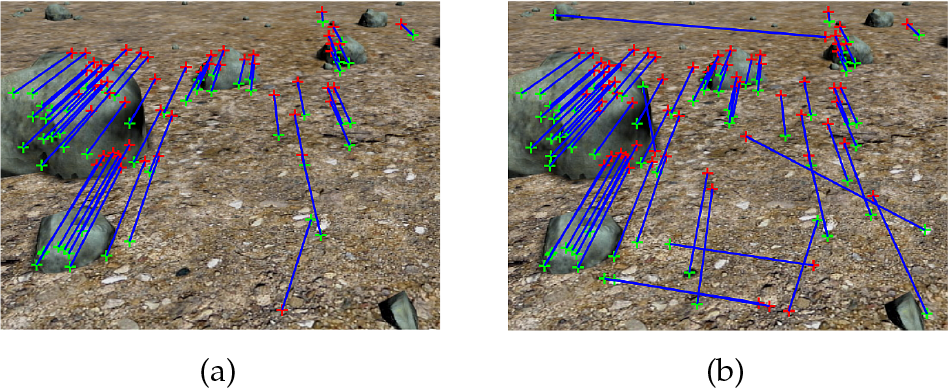
Tracked features for two consecutive images using a) a strict threshold and b) a tolerant threshold. The red and green crosses denote the position of features on the current and the next captured images, respectively, while the blue lines indicate the obtained correspondences.
3.2. 3D Vision Module
The next step in the proposed algorithm comprises the 3D reconstruction module, in which the 2D points previously extracted are now transformed into 3D points, i.e., the image coordinates are converted into a world coordinate system. This procedure comprises two different steps: the first one is the depth estimation of the scene utilizing a stereo correspondence algorithm such that every salient point obtains a disparity value, while the second one is the triangulation of the 3D points, taking advantage of the previously estimated disparity values. The calculated 3D points correspond to the salient landmarks of the scene expressed in world coordinates.
3.2.1. Stereo Algorithm
Depth estimation constitutes the cornerstone of VO algorithms. The third dimension, i.e., the depth of the depicted objects, can be obtained either by stereo vision setups, structured light devices, RGB-D cameras, 3D laser scanners or time-of-flight sensors, etc. By calculating the depth of the depicted objects and given the geometry of the vision system, a 3D point cloud of the scene can be computed easily. However, in the domain of field robotics, the utilization of stereo vision systems for depth perception seems to be the most reliable solution, since the aforementioned devices are sensitive owing to different illumination conditions. Therefore, for the proposed VO algorithm, we assume a stereo rig and, in order to avoid the aforementioned drawbacks, a specially designed stereo correspondence algorithm is employed [34]. The efficiency of the stereo algorithm was extensively tested both in simulated and in real-world navigation instances, as with the example depicted in Fig. 4. Under this method, the initially captured images are processed in order to extract the edges in the depicted scene, and the output of the edge detection procedure is then superimposed onto the initial ones, providing them with the most striking features and textured surfaces. The matching cost aggregation step consists of a sophisticated Gaussian-weighted sum of absolute differences (SAD). Moreover, the disparity selection step is a simple winner-takes-all choice, as the absence of any iteratively updated selection process significantly reduces the computational payload of the overall algorithm. The final step comprises a bidirectional consistency check where the selected disparity values are only approved if they are consistent, irrespective of which image is the reference and which is the target, resulting to the rejection of false correspondences. Furthermore, the precision of the final disparity values is set at a quarter pixel level as a result of a parabola curve-fitting procedure.

A stereo image pair (a), (b) and the resulting disparity map (c), where the colours closer to red indicate larger disparity values (small distances) while the colours closer to blue indicate smaller disparity values (large distances). Dark blue indicates a lack of any disparity value for a particular pixel.
Building upon this stereo algorithm, the proposed method utilizes the same algorithmic process; however, it calculates the disparity values alone for the pixels that correspond to the detected feature points in the image plane (instead of all the pixels in the scene). The advantage of this method is the reduced computational burden for the stereo algorithm, resulting in a very sparse disparity map and computing reliable disparity values for the points of interest only. Consequently, this method is able to provide depth estimations for the most prominent points in a scene, retaining a frame rate suitable for real-time robotics applications.
3.2.2. 3D Reconstruction
Making use of the depth information calculated as the disparity, the positions of the detected features onto the image plane are then expressed in 3D world coordinates. More specifically, pixels expressed in camera coordinates

where z is the depth value of a feature depicted in
At this stage, it should be mentioned that the accuracy of the 3D reconstruction module is of great importance to the VO algorithm. The aforementioned 3D transformation strongly depends on the accuracy of the stereo process (i.e., any erroneous estimations of the depth will lead to incoherent estimations of the 3D coordinates of the features). The accuracy of the resulting disparity map depends on the range resolution, which is the minimal change in range that the stereo vision system can differentiate [35]. The function that calculates the range l (in metres) within which the resolution is better than or equal to a desired value s (in metres) is as follows

where b is the baseline in metres, w is the horizontal image resolution in pixels, F is the camera's FoV in radians and c is the disparity accuracy in pixels. In general, the resolution deteriorates with distance and, therefore, the resolution accuracy decreases for the objects located far from the stereo camera. Apparently, the further a salient point is from the camera, the more erroneous the resulting depth estimations will be. In order to avoid the inclusion of erroneously estimated 3D points in the motion estimation step, a couple of different alternatives can be used. The first one involves the omission of those features corresponding to pixels with a disparity value smaller than a predefined threshold, depending on the range resolution that the current stereo geometry provides. The second alternative involves the adoption of a specific architecture for the stereo camera placement, whereby the latter should be tilted at a certain angle, ensuring that the 3D reconstructed features fall within the optimal disparity range [36]. Such an approach has been adopted during the construction of our robotic platform - the localization stereo camera is a Bumblebee2, placed 30 cm above the ground with a tilt of 31.55°. The existence of a tilted setup limits the largest observed distance, and as a result improves the obtained accuracy. However, the proposed methodology does not depend on a specific value of the tilt angle and can operate with any other value instead.
3.3. Outliers Detection
The feature detection, matching and 3D reconstruction modules result in several hundred pairs of features for two arbitrarily chosen consecutive frames. However, these matched features can include quite a few outliers, arising due to two different reasons: one stems from erroneous estimations of the depth values during the stereo correspondence procedure (thus inheriting errors from the 3D reconstruction module), while the other is due to the feature matching algorithm itself (i.e., SURF), which introduces mismatches as described in Sec. 3.1. As a result, an outlier detection and removal step on the matched features prior to the motion estimation procedure needs to be applied. The outlier detection method described in this work is specifically designed to exploit the dense sampling of the imaging device while the robot is in motion, thus allowing real-time robot navigation. Let us assume that the robot observes a specific point

Substituting the rotation and translation matrices in the previous equation, the following equation system is obtained,
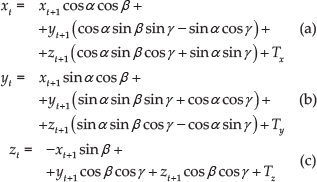
where α, β and γ are the
For cases where the stereo camera acquires images at a high frame rate while the robot moves at regular speed, the changes in the pose of the robot for two consequent observations at times t to

where
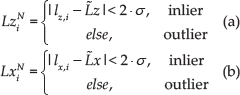
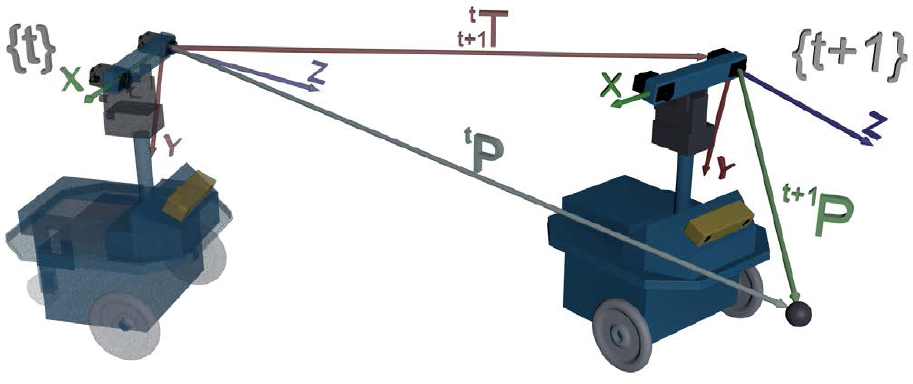
The stereo camera coordinate system
In Eqs. 5,

The robot moving forwards: a) corresponding matches on the
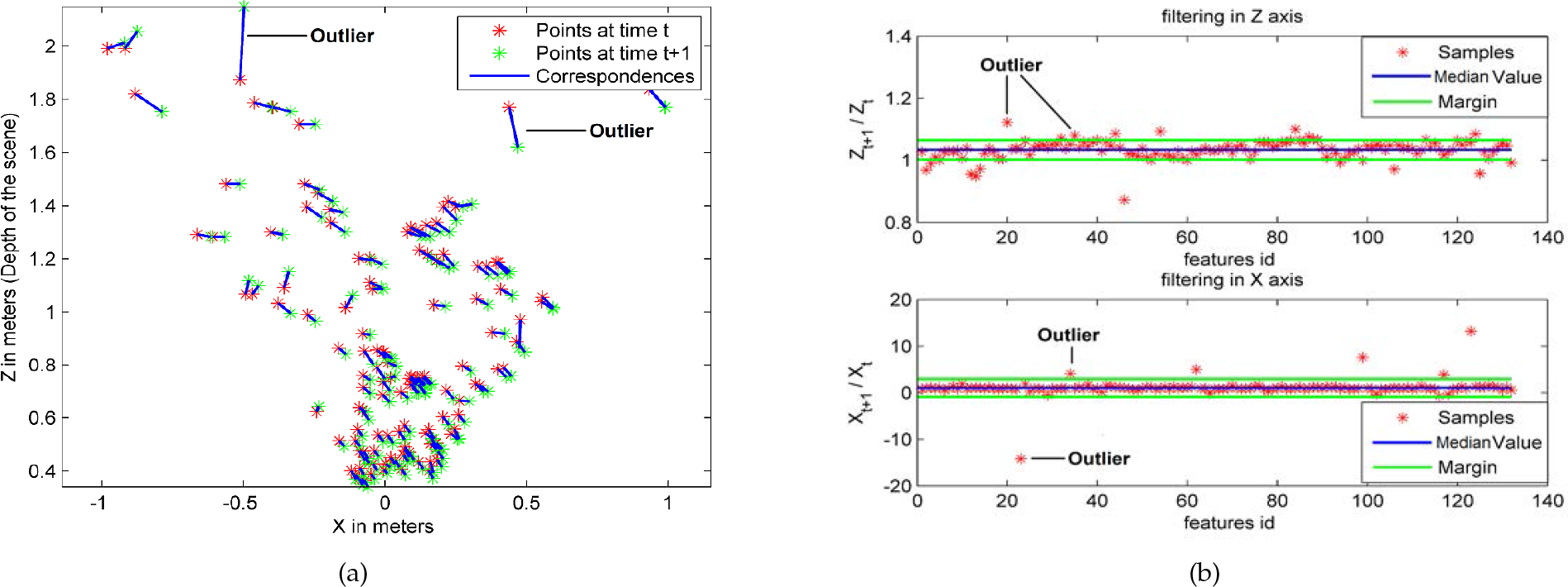
The robot undergoing a turn around its vertical axis: a) corresponding matches on the
It becomes obvious that the efficiency of the proposed framework in detecting the outliers is greatly affected by the displacement of the robot between two feature measurements (i.e., two successive frames), requiring the robot's motion to be as smooth as possible. In such cases, there is a great deal of overlap between successive frames and the numerous available common features to be extracted. However, in applications where the speed of the robot is substantial, the distances travelled by the robot between successive frames can increase significantly. In such cases, the majority of the matched features will lie in the background of the scene, where the range resolution of the depth estimation is diminished (see Sec. 3.2.1), resulting in increased outlier numbers due to inaccurate depth estimations. This phenomenon can be counterbalanced by increasing the frame rate of the stereo camera, although this leads to increased data sampling notwithstanding the real-time frame rate restrictions in the operation of the VO algorithm. Hence, a need arises to determine a function that is able to relate the robot's linear velocity with the stereo camera's frame rate. The linear velocity is derived by differentiating Eq. 3 giving Eq. 7,

where

By using the expansion described in [37], the term
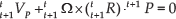
Assuming small angular differentiations β, the rotation matrix
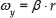
Substituting Eq. 10 into Eq. 9 and applying the requisite transformations, it can be shown that the robot's velocity can be expressed as a linear function encompassing the frame rate as follows:

Eq. 11 shows that there is indeed a linear relationship between the linear velocity of the mobile robot and the feature sampling rate. Therefore, in order to retain the efficiency of the proposed outlier detection method when the robot moves at higher velocities, the frame rate should be increased accordingly and, moreover, it should be ensured that the entire procedure is followed within the same circle. The efficiency of the proposed outlier detection method increases significantly when the robot's position change within successive frames is not significant.
3.4. Incremental Motion Estimation
The motion estimation module comprises the calculation of a transformation that maps the matched 3D reconstructed features between two successive time instances. In this module, only those correspondences that have passed the outlier detection procedure are utilized. Let us consider the resulting two 3D point clouds that correspond to times t and
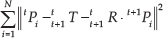
where N is the number of features used.
Additionally, the issues of computing

In Eq. 13,

Thus, the first step in this motion estimation procedure is to find the rotation matrix

where

Instantaneous rotation estimations for 650 frames corresponding to a straight route: a) rotation estimations with (red) or without (blue) the outlier detection method enabled, and b) motion estimation with the outlier detection enabled (red) with the effect of the position refinement module superimposed on it (green)
The mean error together with the standard deviation for the examined sequence of frames is summarized in Table 1. It can be seen that the mean values for the two separate cases are close to each other; however, the standard deviation in the case where the motion estimation makes use of the outliers detection method is decreased, leading to more accurate location estimations as the cumulative error increases more slowly with time.
Mean error and standard deviation for the rotation angle estimation

3.5. One-step Position Refinement
The position refinement module provides corrections to the location estimations of the robot. The purpose of this module is to improve the estimations that come from the motion estimation procedure, suppressing the computational cost at low levels. The proposed methodology provides refinements to the initially estimated 3D rotational angles. This correction is embodied in the accumulated rotation (i.e., from the starting point up to the current point). The position refinement procedure takes place in each successive frame and is applied to the already estimated rotational variables.
The output of the motion estimation is a rotation

where
The contribution of the position refinement module is illustrated in Fig. 8(b). It can be seen that, compared to the case where the outlier detection module is made use of alone, the variations in the rotation angle for a straight route are even lower. As indicated in Table 1, the mean error in the rotation angle for the straight route is close to zero, and the standard deviation is lower than with the other two cases. The utilization of the outlier detection module is crucial for the performance of the motion estimation procedure, while the position refinement procedure provides more accurate location estimations. Therefore, in this work, the trajectory of the robot is computed hierarchically, first calculating an initial transformation between the 3D point clouds of two successive frames, and then applying this transformation in the first 3D point cloud with the aim of producing refinements to the location estimations.
4. Experimental Validation
The performance of the proposed VO algorithm has been evaluated with simulated as well as real-world data. The simulated data were generated by 3D Studio Max, while the real-world data consist of two robot acquired-trajectories; the first one was recorded using the prototypes platform described in this work, and the second one is a part of the New College dataset. During these experiments, the proposed outlier detection procedure is compared with the RANSAC-Homography outlier detection procedure. Initially, this technique was utilized by [10] for the robot's motion estimation based solely on visual input, whereas a more sophisticated aspect - for the detection of the independent motion in a given scene - has been described in [41]. Besides the outlier detection methodology proposed in this work, RANSAC-Homography has also been made use of and, as a result, two variants of the proposed VO algorithm are obtained and compared. The implementation and the parameterization of the RANSAC-Homography technique is based on the framework that has been described analytically in [42]. The proposed VO algorithm is designed as a lightweight solution to be employed in applications where few computational resources are available, such as in the case of space exploration. The novel part of this algorithm is the outlier detection routine, which is a single-frame operating tool that efficiently reduces the cumulative errors during the robot's successive motion estimates. Therefore, concerning the experimental comparison, we felt that it would be reasonable to compare our algorithm with a well-established methodology that also operates in each frame and does not retain the inliers for later optimization during the robot's perambulation. The RANSAC-Homography outlier detection method is a widely employed technique and can be taken as a benchmark for evaluating the accuracy of the proposed method. Given a set of computed salient features in the scene - which are matched considering a proximity measurement and a similarity measurement - the steps for this outlier detection method can be summarized as follows:
A random sample of four correspondences is selected and the homography H is computed.
The Euclidean distance for each putative correspondence is calculated.
The number of the inliers which are consistent with the homography H and which have Euclidean distances smaller than a predefined threshold are computed.
The steps 1–3 are repeated K times, where K is determined adaptively, and where the homography transformation that is satisfied by the majority of the features is detected.
The features that satisfy the homography detected in step 4 are considered as inliers and the rest of them are discarded as outliers.
In this experimental procedure, the parameters of the RANSAC-Homography outlier detection technique have been carefully selected under the RANSAC method to perform optimally. First of all, a strict Euclidean distance threshold for the consideration of the inliers has been selected to be constantly 0.05 m, within the normalized range of [0, 1]m. The reason for this selection is mainly to counterbalance as much as possible the discretization of the disparity image space, with the aim of capturing the transformations stemming from correspondences several metres away from the stereo camera. The number of iterations K was determined adaptively and the iterations cease when the number of the remaining outliers is greater than 30, thus ensuring robustness in the estimation of the transformation. However, in order to avoid the noisy cases where the algorithm converges too quickly (less than 100 iterations), the experiment is repeated by randomly permuting the order of correspondences, and the RANSAC is initialized again. Although RANSAC performs very well when applied to data with few outliers, it regularly fails to find an optimal model when the number of inliers is less than 50% of the utilized data. This is the case where the robot performs quick turns and where the correctly matched features decrease in number, while noise due to blurred images is also introduced. On the other hand, the proposed method depends on fewer parameters and it does not seek an sufficient subset of inliers to converge on an optimal model, although it discards the outliers separately and then the remaining features are utilized to compute the transformation.
Obviously, the computational burden of the RANSAC method increases with the number of iterations K, while the estimation of the homography H at every step also constitutes a demanding procedure. On the other hand, the outlier detection method proposed in the present paper consists of a simple statistical filtering procedure with the computational cost depending only on the number of detected feature pairs in two successive frames.
4.1. Simulated Data

Stereo pair sample from the simulated Dataset 1

Experimental validation with the simulated dataset 1: a) trajectory estimation of the proposed VO algorithm superimposed on the ground-truth; b) trajectory estimation of the VO algorithm inclusive of the RANSAC-Homography method superimposed on the ground-truth; c) rotation estimations of all the successive frames for the two different methods compared with the ground-truth; and d) deviations in the Euclidean distance from the ground-truth for every single frame for the two examined methods. Note that in d) the area under each curve is a measure of the cumulative error for each approach.

Stereo pair sample from the simulated Dataset 2

Experimental validation with the simulated Dataset 2: a) trajectory estimation of the proposed VO algorithm superimposed on ground-truth; b) trajectory estimation of the VO algorithm inclusive of the RANSAC-Homography method superimposed on the ground-truth; c) rotation estimations of all the successive frames for the two different methods compared with the ground-truth; and d) the deviations in the Euclidean distance from the ground-truth for every single frame for the two examined methods. Note that in d) the area under each curve is a measure of the cumulative error for each different approach.

Experimental validation with the robot-acquired outdoor dataset: a) the left reference image of a stereo pair, b) the right reference image of a stereo pair, and c) the prototype robot equipped with a differential global positioning system (DGPS) system during its deployment in the field
4.2. Outdoors Data
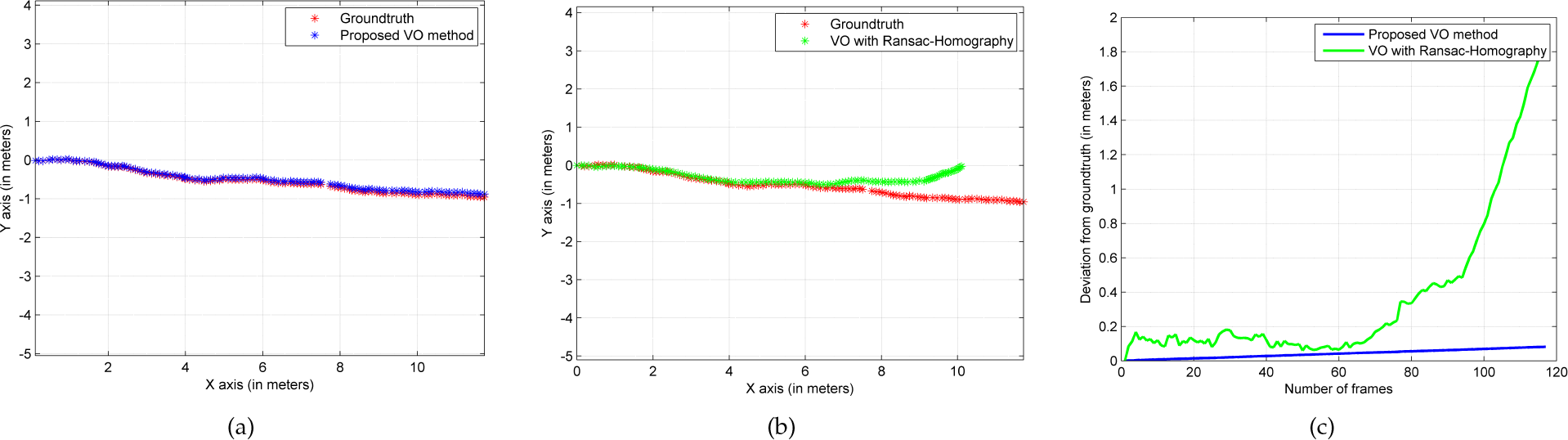
Experimental validation with the robot-acquired outdoor dataset: a) trajectory estimation of the proposed VO algorithm superimposed on the ground-truth; b) trajectory estimation of the VO algorithm inclusive of the RANSAC-Homography method superimposed on the ground-truth; and c) the deviations in the Euclidean distance from the ground-truth for every single frame for the two examined methods. Note that in c) the area under each curve is a measure of the cumulative error for each different approach.

Stereo pair sample and the aerial image from the New College dataset
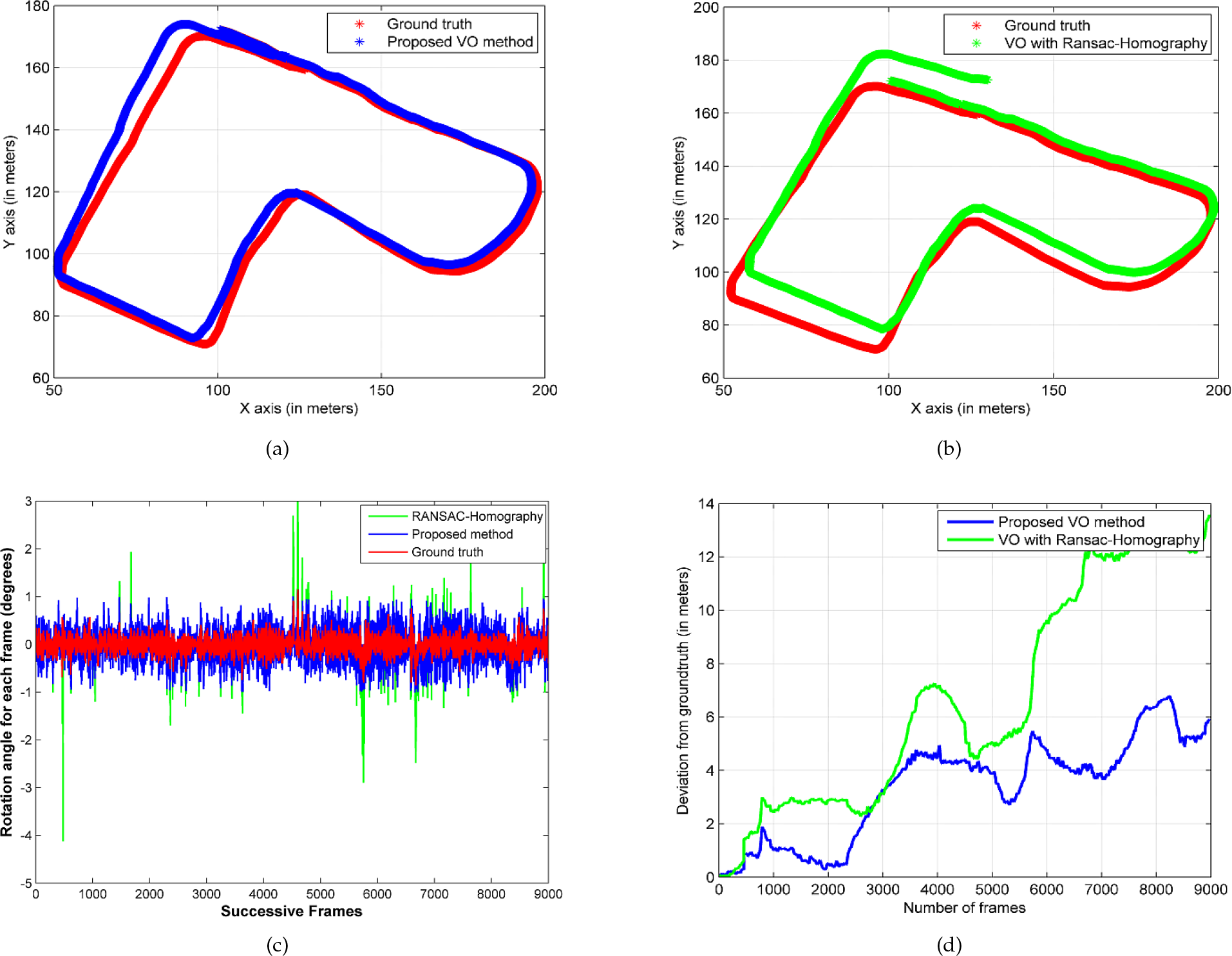
Experimental validation with the outdoor dataset: a) trajectory estimation of the proposed VO algorithm superimposed on the ground-truth; b) trajectory estimation of the VO algorithm inclusive of the RANSAC-Homography method superimposed on the ground-truth; c) rotation estimations of all successive frames for the two different methods compared with the ground-truth; and d) the deviations in terms of the Euclidean distance from the ground-truth for every single frame for the two examined methods. Note that in d) the area under each curve is a measure of the cumulative error for each different approach.

Stereo pair sample of the Atacama Desert Dataset
A subset of this dataset (approximately 96.5 m with a 6 cm distance between successive frames) was selected, where the DGPS data were dense enough, to be used in this work. In particular, we have evaluated our system on the part of this dataset that is accompanied with consistent ground-truth data. The subset considered consists of 1,530 frames corresponding to a 96.5 m route. Although the robot motion is calculated for every frame, the accuracy could be computed only on those frames for which DGPS measurements were available. Figure 18(a) shows that the estimated trajectory closely follows the DGPS ground-truth and performs better than the VO making use of the RANSAC-Homography outlier detection procedure (see Fig. 18(b)). Specifically, the proposed method achieved a 2.2% positioning error, which is better than the 4.6% that the benchmark method achieved. The superiority of the proposed outlier detection algorithm is also exhibited in Fig. 18(c), where the deviations in terms of the Euclidean distance from the ground-truth for every single frame are illustrated for both the examined methods. It should also been mentioned that representative videos that exhibit the performance of our algorithm are available at [46].

Experimental validation with the Atacama Desert dataset: a) trajectory estimation of the proposed VO algorithm superimposed on the ground-truth; b) trajectory estimation of the VO algorithm inclusive of the RANSAC-Homography method superimposed on the ground-truth; and c) the deviations in terms of the Euclidean distance from the ground-truth for every single frame for the two examined methods. Note that in d) the area under each curve is a measure of the cumulative error for each different approach.
4.3. Additional Comparisons

a) The averaged computational time needed for each frame evaluated on both methodologies for all five of the examined datasets; b) the averaged number of inliers retained in frames evaluated by both methodologies for all five of the examined datasets. Note that in both experiments the variance is provided besides the mean value to illustrate any indicative statistical significance of our findings.
5. Discussion
In this work, a computationally efficient stereo VO algorithm was presented. The algorithm is made up of a number of custom-tailored, non-resource consuming modules in order to keep the level of the computational burden low. In the first step, the salient features of the images are detected using the SURF algorithm. The scene's depth information is then acquired by exploiting a stereo correspondence method appropriate to robot applications, followed by the 3D reconstruction of any detected points by means of triangulation. In the next step, a novel statistical-based, non-iterative outlier detection technique was applied in order to discard the outlier features. The retained features were then utilized by the motion estimation module, which is responsible for the calculation of the robot's angular rotation and linear translation in each individual step. For a single step, a position refinement technique is then used at each frame to correct the global orientation of the robot. Due to its simplicity, the localization procedure can be applied in high-frame rate camera systems, ensuring at the same time that rapid robot movements will introduce no faults in its pose computation. This suggests that at very high sampling rates, the proposed outlier detection technique can efficiently discard the outliers. The ability of the introduced outlier detection method to operate efficiently is based on the fact that feature tracking only takes place between salient points with reliable depth estimations. The proposed framework can effectively remove outliers introduced by moving objects, thus maintaining robust behaviour even in cases where people or any other observed object moves. Yet in order to produce a statistically strong set of features, the camera needs to be tilted such that a considerable portion of the stereo pair lies bellow the horizon level.
The proposed VO algorithm was evaluated by means of both simulated and real outdoors data. It was also compared with a VO framework which makes use of a well known outlier detection technique, viz. RANSAC-Homography. The proposed algorithm achieved great accuracy, i.e., approximately a 1% total positioning error distance from the ground-truth, while the aforementioned RANSAC-Homography method was used as a benchmark. Moreover, the continuously varying deviation from the ground-truth is maintained at low levels, suggesting that the proposed VO method maintains its accuracy with long range routes, which can even contain uneven surroundings. Furthermore, the currently proposed VO algorithm was implemented and tested on a custom-made robot platform exhibiting remarkable accuracy during its evaluation using real world outdoor data.
Footnotes
6. Acknowledgements
This paper is the extension of our previous conference paper entitled “Visual Odometry for Autonomous Robot Navigation Through Efficient Outlier Rejection”, initially presented at the IEEE International Conference on Imaging Systems and Techniques, October, 2013.
This paper was supported by the project “Sparing Robotics Technologies for Autonomous Navigation (SPARTAN)” funded by the European Space Agency (ESA/ESTEC). The authors would like to thank Mr. Gianfranco Visentin for his valuable insights and the resources that he provided to our team during the SPARTAN project.