
Abstract
Background
A previously developed risk prediction model needs to be validated before being used in a new population. The finite size of the validation sample entails that there is uncertainty around model performance. We apply value-of-information (VoI) methodology to quantify the consequence of uncertainty in terms of net benefit (NB).
Methods
We define the expected value of perfect information (EVPI) for model validation as the expected loss in NB due to not confidently knowing which of the alternative decisions confers the highest NB. We propose bootstrap-based and asymptotic methods for EVPI computations and conduct simulation studies to compare their performance. In a case study, we use the non-US subsets of a clinical trial as the development sample for predicting mortality after myocardial infarction and calculate the validation EVPI for the US subsample.
Results
The computation methods generated similar EVPI values in simulation studies. EVPI generally declined with larger samples. In the case study, at the prespecified threshold of 0.02, the best decision with current information would be to use the model, with an incremental NB of 0.0020 over treating all. At this threshold, the EVPI was 0.0005 (relative EVPI = 25%). When scaled to the annual number of heart attacks in the US, the expected NB loss due to uncertainty was equal to 400 true positives or 19,600 false positives, indicating the value of further model validation.
Conclusion
VoI methods can be applied to the NB calculated during external validation of clinical prediction models. While uncertainty does not directly affect the clinical implications of NB findings, validation EVPI provides an objective perspective to the need for further validation and can be reported alongside NB in external validation studies.
Highlights
External validation is a critical step when transporting a risk prediction model to a new setting, but the finite size of the validation sample creates uncertainty about the performance of the model.
In decision theory, such uncertainty is associated with loss of net benefit because it can prevent one from identifying whether the use of the model is beneficial over alternative strategies.
We define the expected value of perfect information for external validation as the expected loss in net benefit by not confidently knowing if the use of the model is net beneficial.
The adoption of a model for a new population should be based on its expected net benefit; independently, value-of-information methods can be used to decide whether further validation studies are warranted.
Keywords
When transporting a risk prediction model from one population to a new, plausibly related population, differences in settings, time, or place might affect its performance. This entails validating the model in an independent sample obtained from the new population. 1 During such external validation, model performance is typically examined in terms of calibration, discrimination, and net benefit (NB). 2 Calibration refers to the degree that predicted and actual risks agree and is typically evaluated using calibration plots. 3 Discrimination quantifies the degree by which the model can separate low-risk from high-risk individuals and is classically quantified through the c-statistic. 2 The NB is a decision-theoretic metric that considers the benefits and harms associated with risk stratification and is calculated via decision curve analysis. 4 Due to its deep roots in decision theory as well as its ease of calculation, the NB approach has become a widely used tool for the evaluation of prediction models.
Given the finite size of the external validation sample, the assessment of the performance of a risk prediction model is accompanied by uncertainty. This is typically approached as a statistical inference problem (e.g., by presenting error bands around the calibration plot or 95% confidence interval [CI] around the c-statistic). Recent work on power and sample size calculations for external validation studies propose targeting prespecified standard errors on mean calibration, calibration slope, c-statistic, and NB. 5 However, the use of standard inferential methods to express the uncertainty of a decision-theoretic measure is questionable.6,7
As risk prediction models are ultimately used to inform patient management, uncertainty in their performance can be assessed in terms of its impact on the outcomes of medical decisions. From this perspective, the finite size of the validation sample can lead to incorrect conclusions, for example, recommending the use of the model where in fact the best strategy is to treat all eligible patients. Thus, conclusions based on a finite validation sample can be associated with loss of clinical utility. Value-of-information (VoI) analysis is a set of concepts and methods rooted in decision theory that aims at quantifying the expected loss due to uncertainty in decisions, which can in turn inform the value of future research toward reducing uncertainty. 8 In a recent work, we applied VoI analysis to the development phase of risk prediction models. 9 We defined the expected value of perfect information (EVPI) for model development as the expected loss in NB due to uncertainty in the coefficients of a prediction model developed based on a finite sample. In this article, we extend such a concept from the development to the validation phase and propose the validation EVPI as the expected loss in clinical utility due to uncertainty about the NB of the model in a new population inferred from a finite validation sample.
Context
We focus on a previously developed risk prediction model for a binary outcome that is now undergoing external validation in a new target population. We have access to a representative sample of
We focus on the primary goal of validation: whether the decision to use a prespecified model in this population provides clinical utility. We are interested in evaluating the expected loss in clinical utility due to the finiteness of the validation sample and the potential incorrect decision that such uncertainty might lead to (e.g., recommending to use the model whereas the most efficient decision is to treat all). We note that sometimes the investigator is not just interested in this pursuit but also whether the model needs updating in this population to improve its performance. The VoI analysis for such model revision is closely connected to the previously discussed development EVPI 9 and hence is not the focus of this paper.
The measure of clinical utility that we will focus on is NB.
4
In brief, to turn a continuous predicted risk to a binary classification (e.g., low versus high risk) to inform a treatment decision, a decision maker needs to specify a context-specific risk threshold
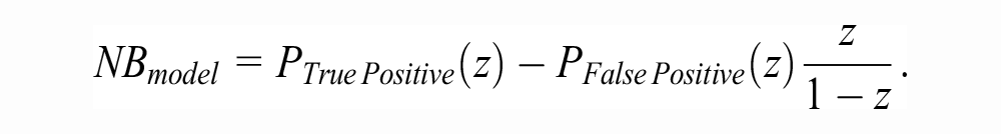
For brevity, we drop the notation that indicates the left side is dependent on
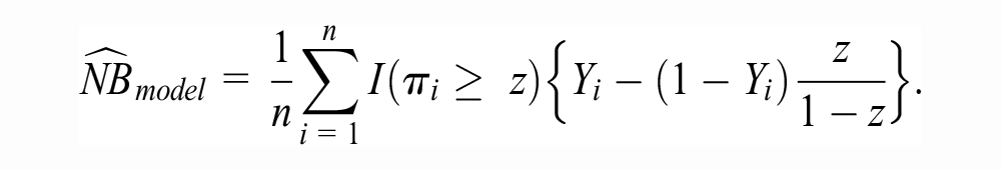
The strategy of using the model for patient management competes with at least 2 “default” strategies: treating no one and treating all. The NB of the former is zero by definition. The NB of treating all is
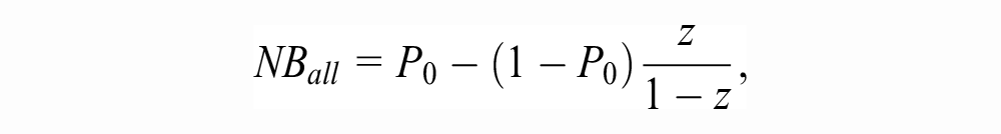
where
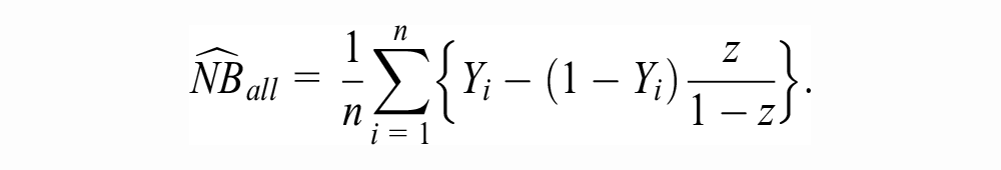
As is implicit in NB calculations, we assume the decision maker is risk-neutral and the only source of evidence is the validation sample at hand. Under such assumptions, the model is recommended if the sample value of its incremental utility over the default decisions,
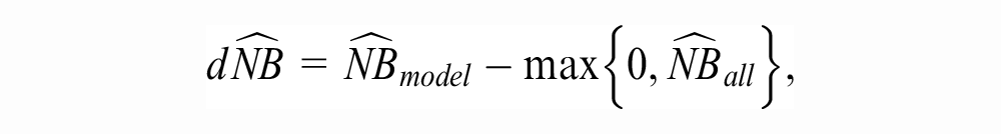
is positive.
Motivating Example: Prediction of Mortality after Acute Myocardial Infarction (AMI)
Identifying the risk of immediate mortality after an AMI can enable stratification of more aggressive treatments for high-risk individuals. GUSTO-I was a large clinical trial of multiple thrombolytic strategies for AMI. 11 This data set has frequently been used to study methodological aspects of developing or validating risk prediction models.12–14 In line with a previous study, we used the non-US sample of GUSTO-I (n = 17,796) as a sample from the development population to fit a prediction model for 30-day post-AMI mortality12,15. We are interested in externally validating this model for the US population and thus used the US sample (n = 23,034) for external validation. Such a validation sample is larger than typical sizes of samples in most practical contexts. To make a case for our developments, we assume that we have access to data for only 500 patients; we will later use the entire sample to study how EVPI changes with sample size. We randomly selected, without replacement, 500 individuals from the US sample to create such an exemplary validation data set. Because of the strict trial protocol, the US and non-US samples can be more similar than the development and validation samples in a typical external validation study. However, in simulation studies, we create more divergent simulated samples to study how EVPI behaves. Thirty-day mortality was 7.0% in the non-US sample, 6.8% in the entire US sample, and 8.6% in the validation sample. As in previous case studies using these data, 9 our primary threshold of risk interest is 0.02, above which more aggressive thrombolytic treatments are justified. All analyses were conducted in the R statistical programming environment. 16 Ethics approval was not required because the anonymized data are publicly available for research.
Our candidate risk prediction model is similar to the previously developed ones using this data set. 9 We did not apply any shrinkage given the large development sample. The final model for 30-day post-AMI mortality based on applying logistic regression to the entire development sample was
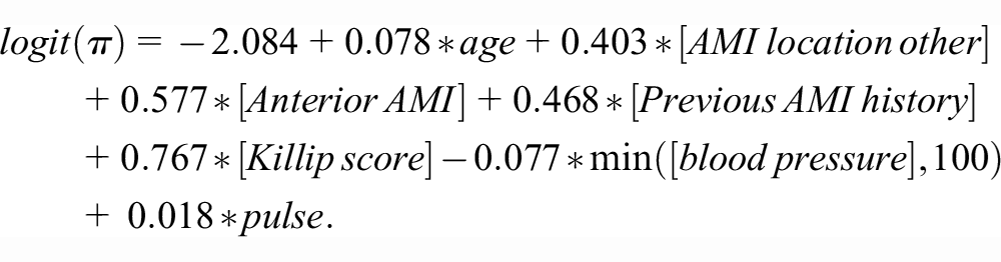
The c-statistic of this model is 0.847 in the validation sample. Figure 1 shows the decision curve depicting the empirical NB of the model (
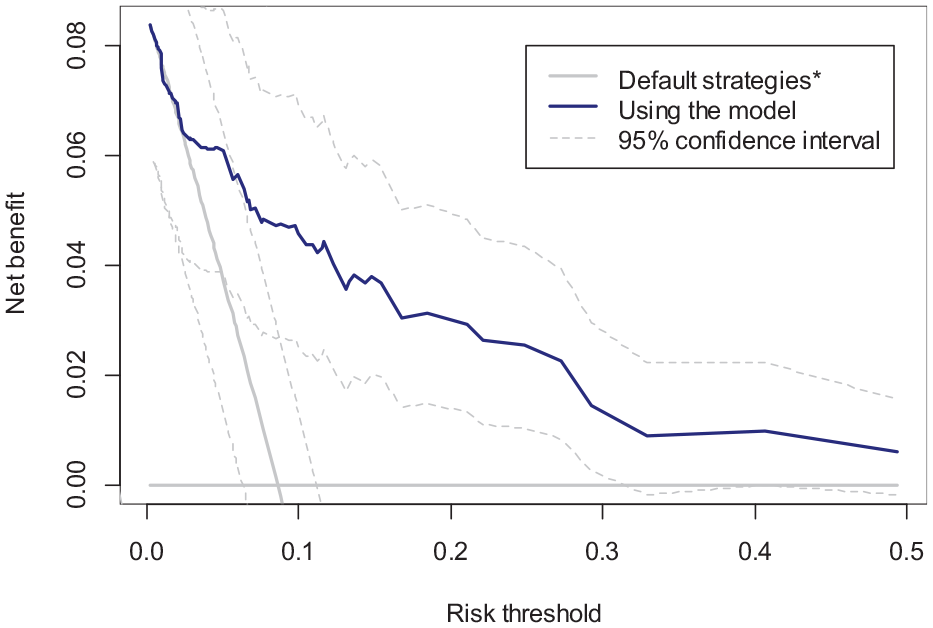
Decision curve (NB) of the candidate model (solid blue), treating all (gray oblique line), and treating none (gray horizontal line) in the validation sample.
The gain in NB by using the model over the default strategies can be presented either in terms of change in the number of true positives while holding the number of false positives constant or vice versa. 4 Here, the difference of 0.0020 means that for every 1,000 treatment decisions, the use of the model will result in an expected gain of 2 true positives. Because a 0.02 threshold implies an exchange rate of 49 between false and true positives, this can also be interpreted as the use of the model resulting in, on average, 2 more true positives × 49 = 98 fewer false positives (i.e., fewer unnecessary treatments) per 1,000 decisions.
However, due to the finite validation sample, a
A Bayesian Approach toward Interpreting Uncertainties around NB
The conventional bootstrap is akin to assigning a random weight to each observation, with weights drawn from a scaled multinomial distribution. Rubin proposed the Bayesian bootstrap, in which weights are instead generated from a Dirichlet distribution. 18 They showed that a summary statistic derived from such a bootstrapped sample can be interpreted as a random draw from the posterior distribution of the corresponding population parameter given the sample and a noninformative prior on the underlying data-generating mechanism. 18 The similarity of the weighting scheme and numerical results between the ordinary and Bayesian bootstrap has resulted in the former being also interpreted in a Bayesian view, as in the approximate Bayesian bootstrap method for the imputation of missing data 19 or in VoI analysis of cost-effectiveness trials. 20
Such Bayesian interpretation of the bootstrap enables us to make probabilistic statements about the true NBs. For example, we can count the proportion of bootstraps in which the NB of the model is higher than the NB of the default strategies. This quantity, proposed by Wynants et al.
21
and termed P(useful), will be the posterior probability that the model-based treatment is truly the strategy with highest NB in the target population. Figure 2 depicts the bootstrap distribution of
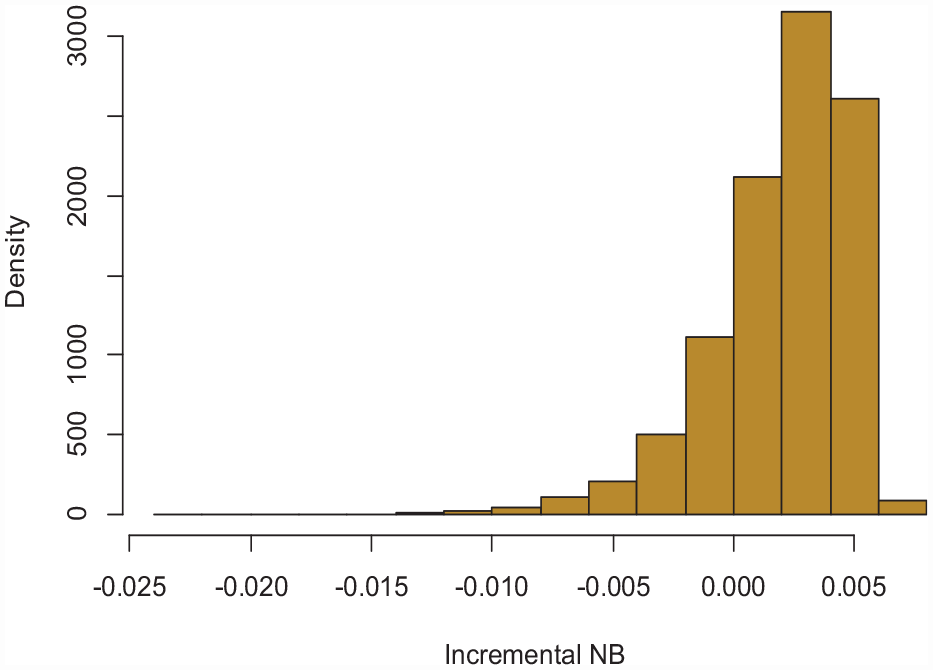
Histogram of the incremental NB of the model (dNB) based on 10,000 bootstraps.
EVPI
A P(useful) < 1 indicates the possibility that our model, despite having the highest expected NB in this validation sample, might not truly be better than the default strategies (
Stepwise Calculations for the Expected Gain with Perfect Information for the Case Study a
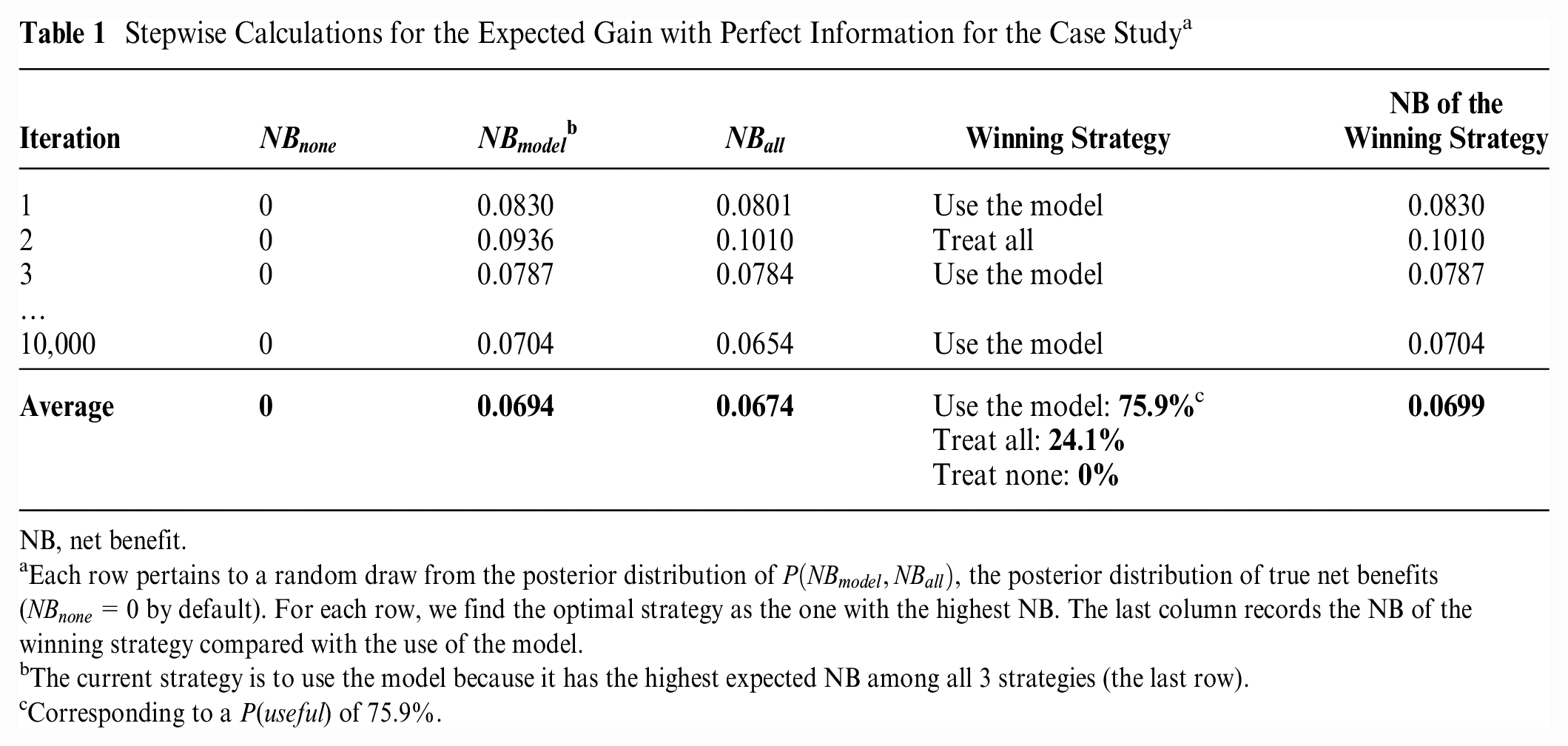
NB, net benefit.
Each row pertains to a random draw from the posterior distribution of
The current strategy is to use the model because it has the highest expected NB among all 3 strategies (the last row).
Corresponding to a P(useful) of 75.9%.
Across the bootstraps, the average of
Formalizing the above derivations, we quantify the EVPI by contrasting the expected NBs of the decision-making process under 2 scenarios of current information (estimating NBs with uncertainty in the sample) and perfect information (knowing the true NBs). With the validation sample at hand, the best we can do is to choose the strategy with the highest expected NB, an approach that confers an expected NB of
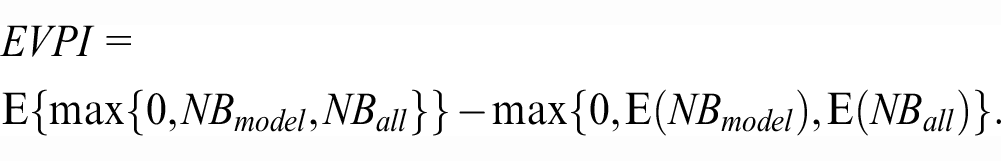
How Can We Interpret the EVPI?
EVPI is a nonnegative scalar quantity in the same units as the NB of risk prediction models, with higher EVPI values indicating higher expected NB loss due to uncertainty. Given that the EVPI is in NB units, the consequence of uncertainty can be presented in the same way as the results of the decision curve analysis. An EVPI of 0.0005 indicates that removing uncertainty about which strategy is the most beneficial is associated with an expected gain of 0.5 in true positives or avoiding an expected 24.5 false positives (unnecessary treatments), for every 1,000 treatment decisions.
Theoretically, any EVPI > 0 indicates the potential value of future validation studies. However, a very low positive EVPI value would indicate a low yield from such a study. A given value of EVPI cannot be declared low or high without considering the decision context. The EVPI measures the expected NB loss per treatment decision due to uncertainty, a loss that is potentially avoidable by performing more validation studies. The true magnitude of this avoidable loss is affected by the number of times the decision of interest is being made in the target population. For example, more than 800,000 AMIs occur every year in the United States, 22 and a guideline panel in charge of making a national-level recommendation for AMI treatment can consider our candidate model potentially applicable to all such events. In this case, the impact of validation uncertainty is equal to missing the proper intervention in 400 true-positive cases (patients with AMI who will die within 30 d) or imposing unnecessary treatments to 19,600 false-positive cases (patients who will survive) per year. Given such consequences, procuring more samples to reduce this avoidable loss seems justifiable.
An alternative way to contextualize an EVPI value, applicable when the model has the highest expected NB in the validation sample, is the previously proposed relative EVPI. 9 The relative EVPI compares the expected NB gain with perfect information with the expected NB gain due to use of the model with current information. In our case study, the incremental NB of the model over the next best decision (treating all) is 0.0020. With perfect information, we expect to gain an extra NB of 0.0005. Thus, we can gain, on average, 0.0025/0.0020 = 1.25, or 25% more efficiency by removing validation uncertainty. Such relative EVPI can thus be defined as 9
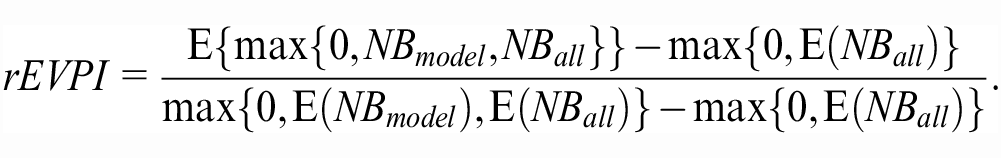
Computation Algorithms
(Bayesian) bootstrapping
As explained earlier, a Bayesian interpretation of the bootstrap enables us to use this method readily for EVPI calculations. In this scheme, we interpret
Bootstrap-Based EVPI Computation


The R code in the table can be downloaded from https://github.com/resplab/papercode/tree/main/voipred_ex/StylizedExamples.
In calculating the expected NB under current information, we propose to estimate
Asymptotic approach based on central limit theorem
Marsh et al.
24
proposed an asymptotic Wald-type inferential method for NB based on deriving the first 2 moments of the sample distribution of the scaled
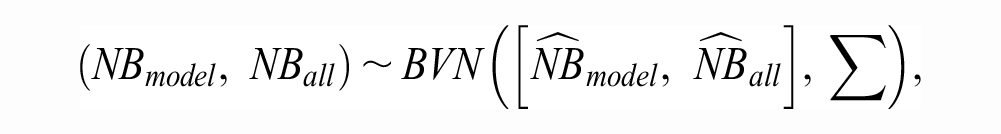
with covariance matrix
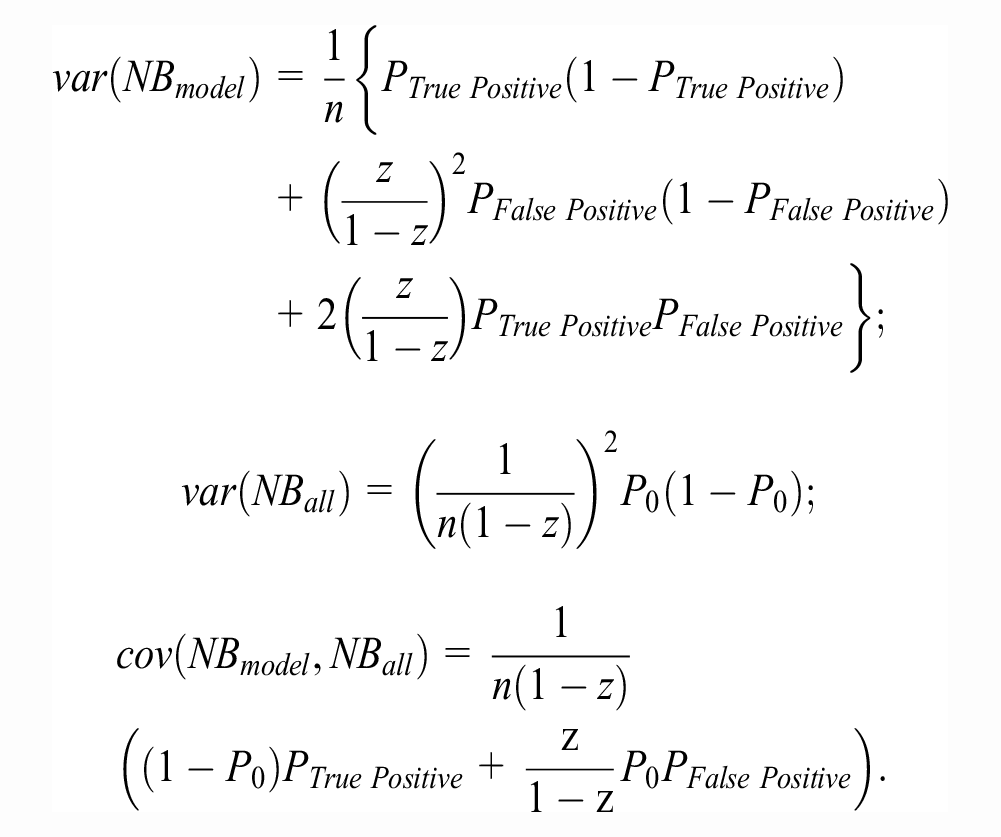
In estimating the above quantities,
Asymptotic Method for EVPI Eomputation


The calc_NB_moments and mu_max_trunc_bvn functions are available in the predtools R package. The development version can be installed from Github (https://github.com/resplab/predtools). The R code in the table can be downloaded from https://github.com/resplab/papercode/tree/main/voipred_ex/StylizedExamples.
One limitation of this closed-form solution is that it cannot currently be extended to situations in which more than 1 prediction model is considered, as the corresponding truncated
Figure 3 demonstrates the EVPI values calculated using the Bayesian bootstrap (solid red), ordinary bootstrap (dashed blue), and asymptotic (dotted orange) methods across the (0–0.1) threshold (higher thresholds were considered clinically irrelevant). The asymptotic method for EVPI calculations resulted in an EVPI of 0.0004 at the 0.02 threshold for our case study, while the bootstrap methods both generated an EVPI of 0.0005.
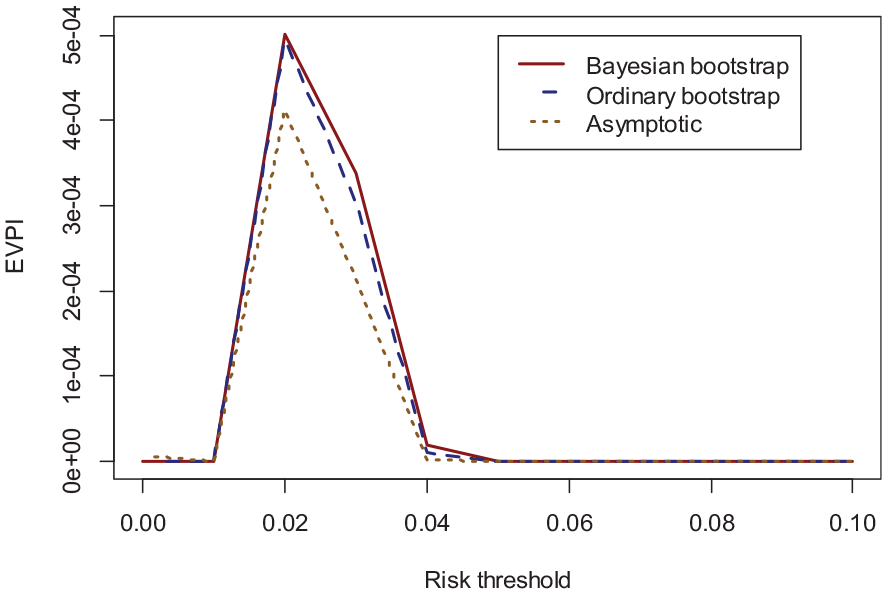
Validation EVPI for the case study as a function of thresholds* for the Bayesian bootstrap (solid red), ordinary bootstrap (dashed blue), and asymptotic method (dotted orange).
Brief Simulation Studies
We conducted proof-of-concept simulations, the purpose of which were 2-fold: to evaluate the consistency of computing EVPI using the proposed algorithms and to study how the EVPI changes with validation sample size.
In the first set of simulations, we considered a simple continuous predictor
Figure 4 provides the results, which are the average of 10,000 simulations. The 3 computation algorithms generated nearly identical results. As expected, the EVPI declined with larger sample sizes, with an expected pattern of diminishing gains with large samples.
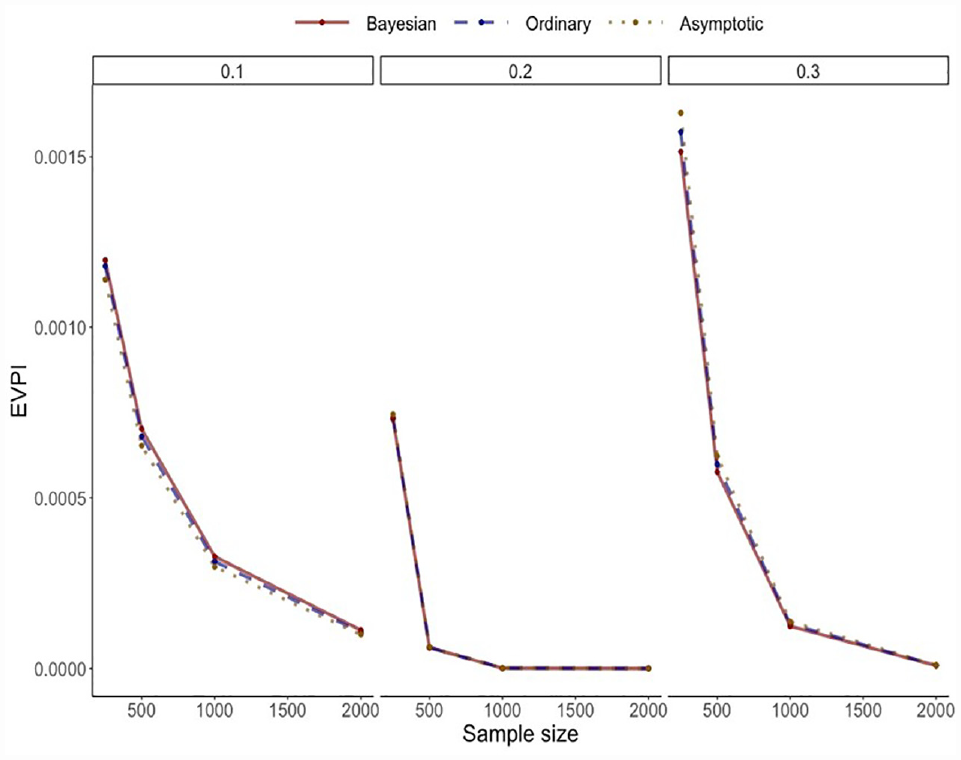
Results of the simulation study for the simple model.
Supplementary Material Section 1 provides the results of related simulation scenarios in which the prediction model was changed in different ways (change in discrimination via adding an error term to predictions, and change in calibration by perturbing the model intercept). The results demonstrate the particularly strong effect of model miscalibration on EVPI values, with striking nonlinearities between EVPI and model calibration that varied by the risk threshold. On the other hand, there was generally an inverse association between c-statistic and EVPI (detailed explanations are provided in Supplementary Material).
The second set of simulations was related to the case study. We simulated larger validation samples by using an increasingly larger subset of the US sample of GUSTO-I as the external validation data set. We repeatedly (1,000 times) drew samples without replacement from the entire validation sample, starting from n = 250 and doubling it in each step to the maximum size (23,034). We investigated the EVPI at 4 thresholds of 0.01, 0.02, 0.05, and 0.10. Figure 5 provides the results on how EVPI changes as a function of sample size for the GUSTO-I study.
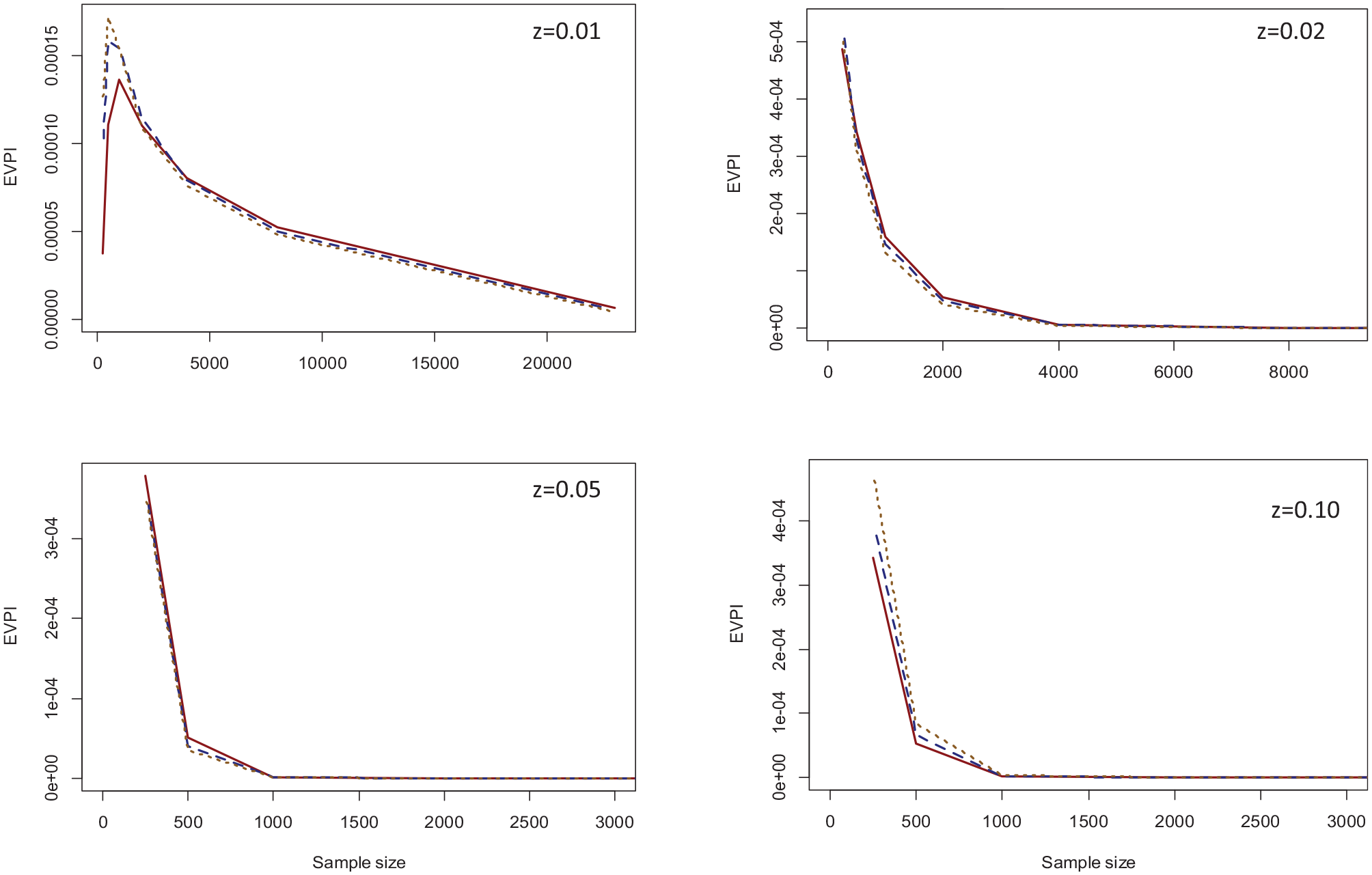
EVPI values across the range of sample sizes for the three computation methods and threshold values of 0.01 (top left), 0.02 (top right), 0.05 (bottom left), and 0.10 (bottom-right). Solid red: Bayesian bootstrap; dashed blue: ordinary bootstrap; dotted orange: asymptotic method.*
Again, all 3 methods generated similar results. For all thresholds except z = 0.01, the EVPI declined with increasing sample size, with the decline being very steep for higher threshold values that were close to outcome prevalence (0.05 and 0.10). With the full validation sample, the EVPI was 0.000005 for z = 0.01 and 0 for other thresholds. The only nonintuitive finding was for z = 0.01 at small sample sizes, where the EVPI increased when the sample size increased from 250 to 500 for all 3 computation methods and from 500 to 1,000 for the Bayesian bootstrap method. Of note, the 0.01 threshold is significantly lower than outcome prevalence. Only 13% of observations in the original validation sample had a predicted probability below this threshold, and none had an event. Because of this, the sample variance of
Discussion
In this work, we defined the validation EVPI as the expected loss in NB due to the finiteness of an external validation sample and the associated risk of incorrectly identifying the optimal strategy. We developed algorithms based on bootstrapping and asymptotic methods for EVPI computation. In proof-of-concept simulation studies, we showed EVPI calculation algorithms generated consistent results, and EVPI generally behaved as expected, in that with more information (larger sample size) it declined, but very large sample sizes were associated with diminishing gain. Simulations showed that validation EVPI was particularly sensitive to model calibration. We interpreted the EVPI in a clinical example for predicting risk of mortality after heart attack. An R implementation of the proposed method is provided in the predtools package (https://github.com/resplab/predtools/).
Decision curve analysis has been considered a breakthrough in predictive analytics as it enables the estimation of decision-theoretic metric (NB) for risk prediction models. However, whether and how to quantify uncertainty around DCA remains controversial.6,7 Principles of decision theory stipulate that for a risk-neutral decision maker and in the absence of (substantial) irrecoverable costs associated with a change in practice, the decision whether to adopt a model for clinical practice should be based on its expected NB in comparison with the expected NB of the default decisions, irrespective of uncertainty. 27 From this perspective, uncertainty around NB informs whether, independently of the decision concerning the adoption of the model, future validation is required. 27 Given the interpretability of EVPI, we propose presenting EVPI values in decision curve analysis.
We proposed interpreting the EVPI based on scaling it to the population, as well as comparing it to the NB gain associated with the use of the model. In cost-effectiveness analysis where the payoffs can be converted to net monetary benefit, VoI metrics are typically in monetary units. 28 Thus, when scaled to the population, VoI metrics can be compared with the budget of research to objectively inform whether future empirical studies are justifiable. 28 However, such calculations involve considering all relevant costs and health consequences of competing strategies over a sufficiently long time horizon, an approach that most often warrants decision-analytic modeling. 29 A main appeal of the NB approach in risk prediction is that it uses the information in the validation sample, without having to obtain often jurisdiction-specific evidence or making assumptions on long-term consequences of interventions. While we advocate for such full decision modeling in its due course (e.g., after an impact study has quantified the resource use associated with implementing the model at point of care), the EVPI proposed here involves much fewer assumptions and generates results that can be interpreted alongside the results of decision curve analysis. As such, it has the potential to become a standard component of validation studies and provide general guidance on the impact of uncertainty due to the finite validation sample.
Our previously proposed development EVPI captures the expected NB loss due to the distance between the correct (strongly calibrated) model and a candidate model developed using a finite sample.
9
Its computation requires modeling
There are several directions for future research in applying VoI to clinical prediction models. Dedicated simulation studies are required to compare more deeply the performance of the EVPI computation methods. A distinct area of future research is to develop a framework for expected value of sample information (EVSI) analysis for development and validation of prediction models. While EVPI puts an upper bound on the expected NB gain with more information, EVSI represents the expected gain in NB associated with an empirical study of a given specification (e.g., sample size) and can thus more specifically guide future research. Further, treatment benefit models that predict an individual’s response to a specific treatment are gaining momentum in predictive analytics,30,31 and VoI methods that estimate the expected gain with further development or validation of such models should be developed.
The proposed validation EVPI is applicable to the decision curve analysis for a typical external validation study in which a prespecified model is evaluated in a single new population. A broader context is multicenter studies, in which hierarchical Bayesian methods can be used to model differences among settings.13,21 An important decision in such settings is whether to use 1 global model across all settings or whether setting-specific models should be developed 32 . The finite sample results in NB loss in from different sources: uncertainty in the structure and coefficient of setting-specific models (related to development VoI) and uncertainty in the decision to use global versus setting-specific models (related to validation VoI). In such hierarchical settings, the expected NB loss quantity therefore has elements of both development and validation EVPI, and its development should be pursued separately.
Uncertainty is a fact of life during all stages of predictive analytics including development, validation, implementation, and revision of clinical prediction models. Such uncertainty is conventionally quantified and communicated using classical inferential metrics. VoI combines the probability of incorrect decisions due to uncertainty with the expected loss in clinical utility into a single measure and therefore provides a complete picture of the consequences of uncertainty. 8 VoI metrics, now available for the development and validation phases of risk prediction modeling, have the potential to provide actionable insight on the need for further evidence across the life cycle of predictive algorithms.
Supplemental Material
sj-pdf-1-mdm-10.1177_0272989X231178317 – Supplemental material for Value-of-Information Analysis for External Validation of Risk Prediction Models
Supplemental material, sj-pdf-1-mdm-10.1177_0272989X231178317 for Value-of-Information Analysis for External Validation of Risk Prediction Models by Mohsen Sadatsafavi, Tae Yoon Lee, Laure Wynants, Andrew J Vickers and Paul Gustafson in Medical Decision Making
Footnotes
Acknowledgements
The authors would like to thank the reviewers of Medical Decision Making for their insight and many helpful comments and suggestions.
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Financial support for this study was provided in part by the Canadian Institutes of Health Research with a Team Grant to the University of British Columbia (PHT 178432), and by the National Institutes of Health/National Cancer Institute (NIH/NCI) with a Cancer Center Support Grant to Memorial Sloan Kettering Cancer Center (P30 CA008748). The funding agreements ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.